
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Microbiol. , 15 July 2021
Sec. Evolutionary and Genomic Microbiology
Volume 12 - 2021 | https://doi.org/10.3389/fmicb.2021.670336
 Danielle Peterson1
Danielle Peterson1 Kevin S. Bonham1
Kevin S. Bonham1 Sophie Rowland1
Sophie Rowland1 Cassandra W. Pattanayak2 RESONANCE Consortium
Cassandra W. Pattanayak2 RESONANCE Consortium Vanja Klepac-Ceraj1*
Vanja Klepac-Ceraj1*The colonization of the human gut microbiome begins at birth, and over time, these microbial communities become increasingly complex. Most of what we currently know about the human microbiome, especially in early stages of development, was described using culture-independent sequencing methods that allow us to identify the taxonomic composition of microbial communities using genomic techniques, such as amplicon or shotgun metagenomic sequencing. Each method has distinct tradeoffs, but there has not been a direct comparison of the utility of these methods in stool samples from very young children, which have different features than those of adults. We compared the effects of profiling the human infant gut microbiome with 16S rRNA amplicon vs. shotgun metagenomic sequencing techniques in 338 fecal samples; younger than 15, 15–30, and older than 30 months of age. We demonstrate that observed changes in alpha-diversity and beta-diversity with age occur to similar extents using both profiling methods. We also show that 16S rRNA profiling identified a larger number of genera and we find several genera that are missed or underrepresented by each profiling method. We present the link between alpha diversity and shotgun metagenomic sequencing depth for children of different ages. These findings provide a guide for selecting an appropriate method and sequencing depth for the three studied age groups.
There is increasing evidence that changes in activity and diversity of the gut microorganisms are associated with the development of diseases and conditions such as type II diabetes (Hartstra et al., 2015; Lambeth et al., 2015), cancer (Marchesi et al., 2011; Bultman, 2014), and even depression (Foster and McVey Neufeld, 2013). Assessing the taxonomic diversity of gut microbes is a key first step toward understanding how those microbes may affect host health. Most of what is currently known about the gut microbiome has been derived using culture-independent profiling methods such as next-generation sequencing (Lozupone et al., 2012; Ji and Nielsen, 2015; Malla et al., 2019). The two most widely used culture-independent methods are amplicon sequencing, a method that amplifies variable regions of a highly conserved bacterial gene such as the 16S rRNA gene, and shotgun metagenomic sequencing, an approach that sequences all of the DNA present in a sample. While each of these methods have unique advantages, the tradeoffs of these methods in young children in the context of sequencing depth and coverage remain largely unexplored.
Profiling microbial communities using 16S rRNA genes is a straightforward and cost-effective method to profile the taxonomic composition of a microbial community, but it has limited taxonomic resolution due to the conservation of the target gene and length of amplicon product. The reliance on the 16S rRNA gene also means that we have limited ability to profile non-bacterial members of the gut microbial community such as Archaea and Eukarya. Furthermore, the 16S rRNA gene does not provide us with the functional capacity of the microbe, despite there being tools that attempt to estimate it (Douglas et al., 2020; Wemheuer et al., 2020). In addition, the amplification step used to enrich for the rRNA gene can introduce sequence artifacts (PCR errors) and subsequently, bias in quantifying taxa in the resulting taxonomic profiles (Acinas et al., 2005; Tremblay et al., 2015). For instance, the choice of primers that bind to the 16S rRNA gene during amplification or the presence of introns have been shown to have a great effect on microbiome community characterization (Salman et al., 2012; Tremblay et al., 2015; Chen et al., 2019). However, despite the need for a PCR amplification step, this type of profiling requires a relatively low number (∼50,000) of sequenced reads per sample to maximize identification of rare taxa and is generally cheaper than shotgun metagenomic sequencing. Amplified sequences are computationally binned and identified typically using either operational taxonomic unit (OTU) clustering, a method which clusters sequences based on percent sequence similarity, and more recently, methods such as amplicon sequence variant (ASV) identification (Callahan et al., 2016), or sub-operational taxonomic unit (sOTU) (Amir et al., 2017), methods which identify unique sequences and remove low quality reads and sequence artifacts, by using a probabilistic model to assess the probability that a rare sequence is a true biological variant. In general, OTU-based approaches overestimate alpha diversity (Nearing et al., 2018). In addition, the identification of OTUs, ASVs, or sOTUs is database-independent and can therefore be used to identify novel microbes in previously unsampled environments (Callahan et al., 2017). In our study, we use the DADA2 pipeline (Callahan et al., 2017), which aims to resolve OTUs to the genus, and sometimes species level. However, many taxa often cannot be resolved because the V4–V5 doesn’t provide enough nucleotide variability to resolve different taxa.
Shotgun metagenomics indiscriminately sequences all the DNA material in a sample, and therefore typically requires more sequenced reads per sample to find unique taxonomic identifiers (Zaheer et al., 2018). This need for increased sequencing depth carries a higher cost (Comeau et al., 2017), but yields information on many genes rather than only one. This substantially increases resolution in taxonomic assignments–metagenomic profiling often provides species-level assignment where amplicon sequencing is restricted to identifying genera (Ranjan et al., 2016) and has the additional benefit of providing direct evidence of gene functional variation in strains present. Moreover, because shotgun metagenomics does not rely on the characterization of a gene that is uniquely present in microbes to assign taxonomy, it can be used to investigate non-microbial parts of the microbiome (e.g., fungi, viruses, and micro-eukaryotes) that do not have the 16S rRNA gene. These reads can be used to assign taxonomy using different methods: comparison of marker genes (Segata et al., 2012; Tovo et al., 2020), species-specific k-mer comparison (Wood et al., 2019), and assembly followed by whole genome alignment (Couronne et al., 2003). Metagenomic reads may also be used to generate assemblies from multiple metagenomic studies, yielding higher resolution assemblies that provide further insight into microbial diversity (Wilkins et al., 2019). However, despite these advantages, metagenome taxonomic profiling typically relies heavily on reference databases, which can make it challenging to identify novel microbes without computationally expensive assembly, and can make it more susceptible to false positives (Peabody et al., 2015; Gonzalez et al., 2016; McIntyre et al., 2017).
The ability to draw conclusions about taxonomy from microbiome sequencing data depends not only on the sequencing method, but also on sequencing depth: how many times on average a given piece of DNA is likely to be sequenced given a fixed read length and the assumption that all regions of a genome are equally likely to be sequenced (Sims et al., 2014). If it were possible to achieve the resolution of shotgun metagenomics at a lower cost, we could sequence more deeply, identify less abundant taxa, obtain information about the functional potential of the microbiota, and learn more about the microbial diversity within and between samples (Pereira-Marques et al., 2019). However, deeper sequencing is more expensive. A few studies have investigated the potential for reduced metagenomic sequencing (Hillmann et al., 2018; Zaheer et al., 2018), but there has not been substantial research analyzing the reduced sequencing depth for investigation of the gut microbiomes in young infants and children. The gut microbial communities of children are potentially good candidates for experimentation with shallower sequencing depths because their communities have lower gut microbial diversity until their microbiomes stabilize and become more adult-like around 2–3 years of age (Palmer et al., 2007; Yatsunenko et al., 2012; Stewart et al., 2018; Radjabzadeh et al., 2020).
Both profiling methods have been utilized in children (Vatanen et al., 2016; Ravi et al., 2018), and the known tradeoffs between amplicon and metagenomic sequencing have been previously explored in soil (Brumfield et al., 2020) and plant environments (Regalado et al., 2020), as well as in human adult microbiomes (Eloe-Fadrosh et al., 2016; Ranjan et al., 2016; Laudadio et al., 2018). To date, no one has directly investigated the relative tradeoffs between 16S rRNA amplicon sequencing and metagenomic sequencing at different sequencing depths in the gut microbiomes of infants and young children (Sinha et al., 2017; Laudadio et al., 2018; Jayasinghe et al., 2020). In this study, we compared paired 16S rRNA vs. metagenomic sequencing gut microbiome datasets from a cohort of young children broken into 3 age brackets: less than 15, 15–30, and over 30 months. Specifically, we investigated taxa that were only identified by one method or the other and the effect of sequencing depth on diversity measurements of children in different ages. Ultimately, we show that decreasing shotgun-metagenomic sequencing depth in children less than 30 months can adequately characterize the infant gut microbiome.
Samples for this study came from a subset of 338 children (Supplementary Figure 1) in the RESONANCE Cohort (Providence, RI), an accelerated-longitudinal study of healthy children ages 0–12 years. The RESONANCE cohort is part of the Environmental influences on Child Health Outcomes (ECHO) Program (Forrest et al., 2018; Gillman and Blaisdell, 2018), which aims to investigate the effects of environmental factors on childhood health and development. Children with known major risk factors for developmental abnormalities at enrollment were excluded from the study. Approval for the study was granted by the local Institutional Review Board at Rhode Island Hospital and IRB Authorization Agreement was established between Rhode Island Hospital, Brandeis University and Wellesley College. All experiments adhered to the regulation of the review board. Written informed consent was obtained from all parents or legal guardians of enrolled participants.
One stool sample per child (n = 338) was collected by parents in OMR-200 tubes (OMNIgene GUT, DNA Genotek, Ottawa, ON, Canada), stored on ice, and brought within 24 h to the lab in RI where they were immediately frozen at −80°C. Stool samples were not collected if the infant had taken antibiotics within the last 2 weeks. Samples were transported to Wellesley College (Wellesley, MA, United States) on dry ice for further processing.
Nucleic acids were extracted from a 200 μL aliquot of fecal slurry using the RNeasy PowerMicrobiome kit automated on the QIAcube (Qiagen, Germantown, MD, United States), according to the manufacturer’s protocol, excluding the DNA degradation steps. The samples were subjected to bead beating using the Qiagen PowerLyzer 24 Homogenizer (Qiagen, Germantown, MD, United States) at 2500 speed for 45 s. The samples were transferred to the QIAcube to complete the protocol, and extracted DNA was eluted in a final volume of 100 μL. DNA extracts were stored at −80°C until sequenced.
Samples were sequenced at the Integrated Microbiome Resource (IMR) (Dalhousie University, Halifax, NS, Canada; Comeau et al., 2017). To sequence metagenomes, a pooled library was prepared using the Illumina Nextera Flex Kit for MiSeq and NextSeq (a PCR-based library preparation procedure) from 1 ng of each sample where samples were enzymatically sheared and tagged with adaptors, PCR amplified while adding barcodes, purified using columns or beads, and normalized using Illumina beads or manually. Samples were then pooled onto a plate and sequenced on the Illumina NextSeq 550 platform using 150 + 150 bp paired-end “high output” chemistry, generating ∼400 million raw reads and ∼120 Gb of sequence (NCBI BioProject PRJNA695570).
For sequencing 16S rRNA gene amplicons, the V4–V5 region of the 16S ribosomal RNA gene was sequenced according to the protocol described by Comeau et al. (2017). Briefly, the V4–V5 region was amplified once using the Phusion High-Fidelity DNA polymerase (Thermo Fisher Scientific, Waltham, MA, United States) and universal bacterial primers 515FB: 5′-GTGYCAGCMGCCGCGGTAA-3′ and 926R: 5′-CCGYCAATTYMTTTRAGTTT-3′ (Parada et al., 2016; Walters et al., 2016). These primers had appropriate Illumina adapters and error-correcting barcodes unique to each sample to allow up to 380 samples to be simultaneously run per single flow cell. After being pooled into a single library and quantified fluorometrically, samples were cleaned up and normalized using the high-throughput Charm Biotech Just-a-Plate 96-well Normalization Kit (Charm Biotech, Cape Girardeau, MO, United States). The normalized samples were sequenced on the Illumina MiSeq platform (Illumina, San Diego, CA, United States) using 300 + 300 bp paired-end V3 chemistry, producing on average 55,000 raw reads per sample (Comeau et al., 2017).
Reads profiled using the 16S rRNA gene were analyzed using the Quantitative Insights in Microbial Ecology 2 (QIIME2), v 2021.2.0 (Bolyen et al., 2019) and we used a modified protocol developed by Comeau et al. (2017). Briefly, primers flanking V4–V5 for the RESONANCE cohort or V4 for the DIABIMMUNE cohort were removed from Fastq reads using the cutadapt v 3.2 QIIME2 plugin (Martin, 2011). Fastq reads were then filtered, trimmed and merged in DADA2 (Callahan et al., 2016) to generate a table of ASVs. A multiple-sequence alignment was created using MAFFT, and FastTree was used to create an unrooted phylogenetic tree, both with default values (Price et al., 2010). A root was added to the tree at the midpoint of the largest tip-to-tip distance in the tree. Taxonomy was assigned to the ASVs using a Naïve-Bayes classifier compared against a SILVA v 138.99 reference database trained on the 515–926 region of the 16S rRNA gene (Bokulich et al., 2018). Rarefaction curves showed that the majority of samples reached asymptote, indicating sequencing depth was appropriate for analyses (mean reads per sample ∼39k).
Metagenomic data were analyzed using bioBakery workflows with all necessary dependencies and default parameters (McIver et al., 2018). Briefly, KneadData v 0.7.10 was used to trim and filter raw sequence reads, and to separate human and 16S ribosomal gene reads from bacterial sequences. Samples that passed quality control were taxonomically profiled to the species level using MetaPhlAn v 3.0.7, which uses alignment to a reference database of “marker genes” to identify taxonomic composition (Beghini et al., 2020).
Statistical analyses were carried out in R (4.0.3). vegan (v 2.5-6) was used for all alpha-diversity calculations: Shannon diversity index (Shannon, 1948) (alpha diversity measurement of evenness and richness); evenness (homogeneous the distribution of taxa counts) and richness (number of taxa in a community). Pairwise Bray-Curtis dissimilarity was used to assess beta-diversity, or the overall variation between each sample (Bray and Curtis, 1957). The Bray-Curtis dissimilarity metric compares two communities based on the number or relative abundance of each taxon present in at least one of the communities. When we calculated these values, we assumed that the set of dissimilarities calculated across a group was independent, even when the same child was paired to other children multiple times. These distance matrices were used for principal coordinates analysis (PCoA) to create ordinations. The two principal components that explained the most variation were used to create biplots (Supplementary Figure 2).
Univariate comparisons were performed in two-sample two-tailed t-tests when we could assume normality, and Wilcoxon Signed Rank tests when we could not. P-values of less than 0.05 [or the equivalent after Benjamini-Hochberg false discovery rate correction (Benjamini and Hochberg, 1995)] were considered statistically significant. Mixed-effects linear models in lme4 were used to analyze data from subsampling results, to account for the fact that multiple subsamples were generated from each sample. Shannon ∼1.58 + 5.21 × 10–4 × read depth–3.79 × 10–1 × less than 15 months–4.38 × 10–2 × older than 30 months–1.50 × 10–4 × read depth: less than 15 months–1.56 × 10–4 × read depth: older than 30 months.
A genus was classified as being unique to a particular profiling method if reads were only assigned to it through one method. For any reference-based approach, one will always be limited by the quality of the reference database used. Taxa that could not be resolved down to the genus level (taxonomic assignments containing the phrases “unclassified,” “unidentified,” “group,” or “uncultured”) were removed prior to calculating relative abundance diversity, and all downstream metrics. Genera that only occurred in one but not the other method were classified as uniquely identified by 16S rRNA profiling or shotgun metagenomics. We found the intersection of genera by identifying microbes that were found at least once by both methods.
We used Wilcoxon Signed Rank tests to compare the abundances of microbes that were found by both methods. This analysis was limited by the direct comparison of relative abundances instead of direct counts. Because 16S rRNA profiling was able to identify more taxa at the genus level, this meant that the relative abundances of its organisms were systematically lower.
TestPrime 1.0 (Ludwig et al., 2004; Klindworth et al., 2013) was used to perform in silico PCR to investigate how well certain primer pairs align to microbes in the SILVA database. We entered our forward and reverse primers (515FB and 926R) into the TestPrime web tool provided by SILVA (Quast et al., 2013) to analyze the percent primer coverage of microbes found only with metagenomic sequencing, but not by amplicon sequencing. Coverage is defined as the percentage of matches for a particular taxonomic group [# of matches/(total # of mismatches + matches)]. The primers described in section “16S rRNA Gene Amplicon Processing and Analysis” were compared to sequences found within the SSU r138.1 SILVA database. A single nucleotide mismatch between each primer and 16S rRNA gene sequence was considered a mismatch for that organism. Once the percent coverage was calculated, we compared the average coverage of microbes uniquely found by shotgun metagenomics, 16S rRNA profiling, or both methods. Some genera identified uniquely by shotgun metagenomics were not as identified as hits to the primer, despite being in the SILVA database. Their alignment was manually entered to be 0% for downstream analysis.
The union of all genera that were identified by either 16S rRNA gene or shotgun metagenomic sequencing was used to generate a phylogenetic common tree using TimeTree (Kumar et al., 2017), a software that visualizes taxa and produces Newick files. In addition to these genera, Thermus aquaticus was added as an outgroup, as it is a deeply branching bacterium not commonly found in the human gut microbiome. This tree was visualized using the Interactive Tree of Life (iTOL) v 5.5.1 (Letunic and Bork, 2019), along with metadata that described which profiling method (either 16S, shotgun metagenomics, or both) was able to identify the genus (Letunic and Bork, 2007, 2019). For taxa that were unidentified by a particular profiling method, we investigated whether or not that taxon was present in the missing database. The phylogenetic tree notes taxa that would be impossible to be identified by that method, as they were not present in the relevant database.
We investigated the results of decreasing read depth on alpha and beta-diversity by resampling shotgun metagenomic reads from a subset of children within the RESONANCE cohort that had deeply sequenced metagenomes (average 7,209,871 ± 2,562,647 reads). Metagenomic reads from 30 children were selected and 10k, 100k, 250k, 500k, 750k, and 1M reads were randomly sampled (with replacement) from each child’s reads. Each child was resampled at each depth four times for the analysis involving RESONANCE subjects.
To investigate whether these observations were generally applicable to other childhood cohorts, we performed the same subsampling analysis on the DIABIMMUNE cohort (Simre et al., 2016). Only a single sample for each depth was obtained for DIABIMMUNE subjects due to the substantially higher number of original samples. DIABIMMUNE subjects were subsampled at depths of 100k, 250k, 500k, 750k, 1M, and 10M reads. All children were separated by developmental stage (less than 15 months: n = 389; between 15 and 30 months, n = 340; over 30 months, n = 46). Reads were reassigned taxonomy using MetaPhlAn (see section “Comparing Missing and Underrepresented Genera in 16S rRNA to Shotgun Metagenomics Datasets”) and diversity was recalculated. The majority of these samples subsampled at 10,000 reads had no identifiable taxa and were excluded from downstream analysis.
First, we directly compared taxonomic profiles generated by shotgun metagenomic or amplicon sequencing to assess their ability to detect poorly characterized or low abundance taxa. On average, the proportion of microbes resolved to the genus level in a sample was 95.84% (SD = 4.71%) when profiled by shotgun metagenomic sequencing and 88.78% (SD = 11.53%) when profiled by 16S rRNA sequencing. As expected, regardless of the profiling method, the observed alpha (within-sample) diversity of the gut microbiome of children increased in the first 30 months of life (Welch’s t-test, p-value < 0.001). Given that we observed that children’s microbiomes grow increasingly complex and diverse, we hypothesized that any differences in the ability of the profiling methods to identify less-abundant taxa would only be magnified with age. Consistent with this hypothesis, we found that profiles created from shotgun metagenomics data had systematically lower alpha diversity than profiles from 16S rRNA sequencing at the genus level across all developmental stages (Figure 1A). The mean of these differences between paired profiles increased as the children age, with the largest differences observed in children less than 15 months (mean of the differences = 0.14, paired t-test, p-value < 0.001). This suggests that the paired differences between 16S rRNA and shotgun metagenomics profiling in capturing alpha diversity are greatest in the youngest children; because of the lower taxon richness (fewer microbial taxa), any differences in taxonomic identification will be amplified.
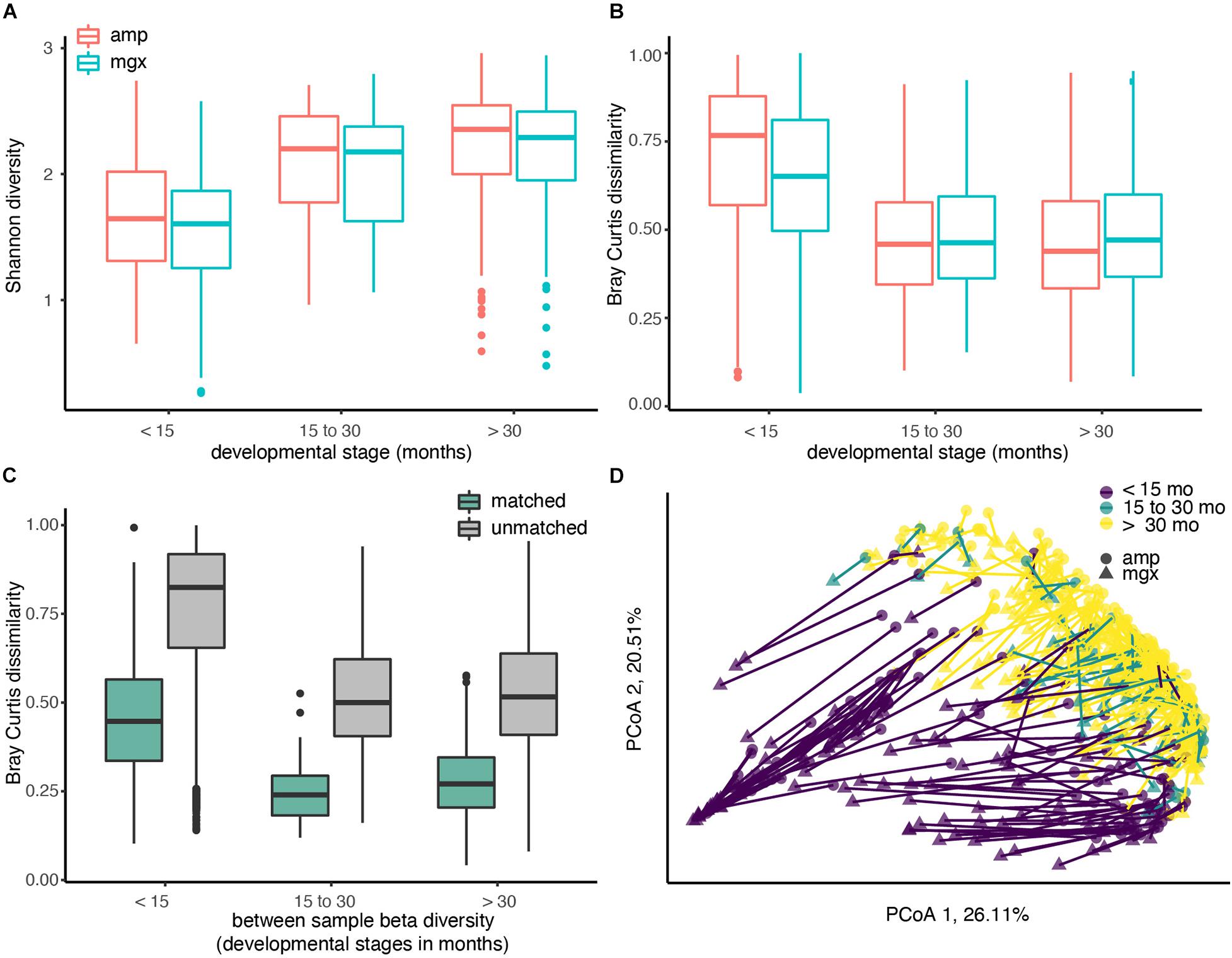
Figure 1. Diversity of the child gut microbiome differs by age, regardless of profiling method. Microbiome communities from 338 children were sequenced using 16S rRNA (abbreviated “amp”) and shotgun metagenomic (abbreviated “mgx”) profiling. (A) Alpha diversity was calculated using the Shannon diversity index for each child. Boxplots are grouped by age and colored by profiling method. (B) Beta-diversity was quantified using pair-wise Bray-Curtis dissimilarities between all children within the same profiling method and developmental stage. (C) Bray-Curtis dissimilarities between 16S and metagenomic profiles for matched samples (from same fecal sample), 16S and metagenomic profiles among unmatched samples (from different fecal samples). (D) Beta-diversity was visualized using Principal Coordinate analysis (PCoA). The first two principal coordinate axes, which together explain 46.62% of variation, are shown. Each dot represents one taxonomic profile, with lines connecting profiles from the same sample. Colors represent developmental stages and shape represent profiling methods.
We next examined between-sample, or beta, diversity within each of the three age groups to determine if age or profiling method were associated with large between-sample differences. Overall, we found that profiling method could account for 5.64% of the Bray-Curtis dissimilarities in the data (PERMANOVA, R2 = 0.05643, p-value < 0.001). Comparisons of beta diversity within children of the three groups indicated the similarity between gut microbiome communities increased with age in both profiling methods. Regardless of which method was used, Bray-Curtis dissimilarity, a pairwise measure of beta diversity between two communities, was the smallest between children over the age of 30 months (Figure 1B).
After observing differences in the two profiling methods among young children, we next compared profiles generated from the different methods for the same fecal sample. If data from shotgun metagenomics and 16S rRNA gene profiling both produced exactly the same gut microbial profiles, we would expect that profiles from the same child’s fecal sample would have a Bray-Curtis dissimilarity of ∼0. This perfect correspondence between methods is not likely, but at a minimum, we would expect to see that the Bray-Curtis dissimilarity among profiles constructed from the same stool sample would be smaller than the dissimilarity between two profiles from two random children. As hypothesized, the average Bray-Curtis dissimilarity among paired samples was much lower than that of unpaired samples (Figure 1C; mean difference = 0.531, Welch’s t-test, p-value < 0.001). The largest differences in the paired profiles were found in children less than 15 months (Figures 1C,D).
To further investigate the cause of the largest discrepancies in diversity between the two profiling methods, we looked at biases in taxonomic representation at different taxonomic levels. At all taxonomic levels, except the species level, 16S rRNA amplicon profiling identifies more taxa (Figure 2A). We found that 66 families were found by both methods, while 223 and 4 were uniquely identified by 16S rRNA and shotgun metagenomic profiling, respectively. At the genus level, of 560 genera identified across all samples, only 145 genera (25.9%) were identified with both amplicon and shotgun metagenomic sequencing. Amplicon sequencing of 16S rRNA gene identified 375 genera not found by metagenomic profiling including Erythrobacter, Fusibacter, Flavobacterium, Pseudomonas, and Sulfitobacter, while only 40 genera were uniquely found using shotgun metagenomic sequencing, such as Enterobacter, Escherichia, Klebsiella, Pediococcus, and Salmonella (Figure 2B and Supplementary Figure 3). At the species level, 16S rRNA amplicon profiling was able to resolve 146 taxa to the species level, though on average only 22.01% of the relative abundance of samples could be classified to a species, while shotgun metagenomics was able to identify 317 unique species, representing 95.18% of samples on average (Table 1). We decided to focus on comparing taxonomic differences at the genus level, as that is the most specific taxonomic level in which we are able to meaningfully compare the two methods.
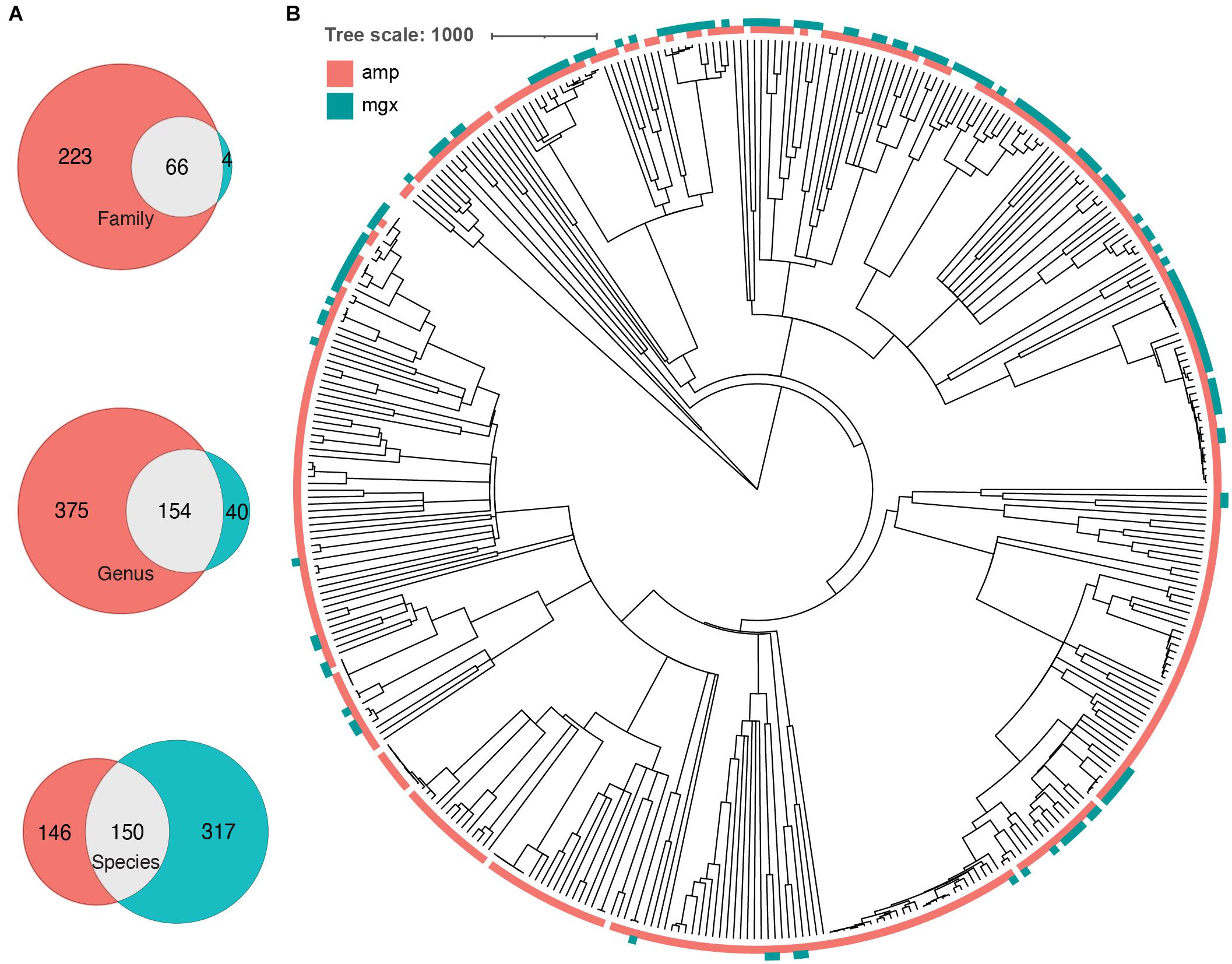
Figure 2. Some phylogenetic clustering of taxa by profiling method. (A) Venn diagrams indicating the number of taxa that were found by 16S (peach), shotgun metagenomics (cyan), or both (gray) methods. Number of overlapping and unique taxa were calculated on the family, genus, and species level. (B) A common phylogenetic tree was generated from all taxa identified by both 16S rRNA gene (amp) and shotgun metagenomic sequencing (mgx). Colors indicate which method was able to identify taxa (peach = identified by 16S, cyan = identified by shotgun metagenomics).
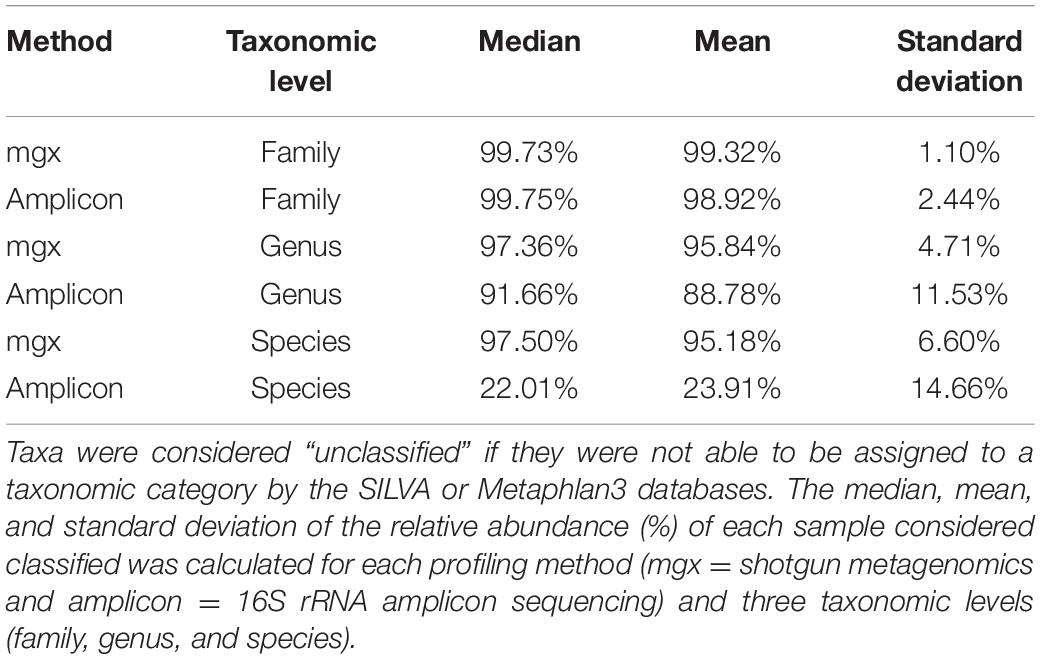
Table 1. 16S rRNA profiling resolves more taxa down to the family level, but fewer to the species level.
After identifying genera that were found by only one of the two methods, we next investigated whether there were any taxa that were systematically found at higher levels in one method vs. the other. We found that Butyricicoccus was observed to have a significantly higher relative abundance in 16S rRNA profiles compared to samples profiled with shotgun metagenomics (Wilcoxon signed rank test for this and all microbes, p-value < 0.001) (Supplementary Table 1). Similarly, Romboutsia (p-value < 0.001) and Sutterella (p-value < 0.001) were found to have a higher relative abundance when detected by 16S rRNA amplicon sequencing. In contrast, genera such as Bifidobacterium (p-value < 0.001), Eggerthella (p-value < 0.001), and Klebsiella (p-value < 0.001) systematically had higher relative abundance when detected by shotgun metagenomic techniques. These differences may be due to multiple factors, including reduced primer efficiency amplification step during 16S rRNA sequencing. To investigate whether these discrepancies are generally true of other pediatric cohorts, we re-analyzed the metagenomes and amplicon sequencing from DIABIMMUNE, a longitudinal study of children from 3 Scandanavian countries that are at risk for type-I diabetes (Simre et al., 2016). Though this study used different primers for amplicon sequencing, we observed similar trends–taxonomic profiles from metagenomic sequencing identified fewer unique families (68 vs. 9) and genera (151 vs. 47), but more unique species (111 vs. 384).
After comparing two different profiling methods, we investigated the effect of reducing metagenomic sequencing depth on observed alpha diversity among the three developmental groups. We selected samples from a sub-group of 30 children (10 from each developmental stage) that were initially sequenced at the highest depth (mean 7.2 million reads; SD = 2.6 million reads) and performed random resampling of shotgun metagenomic reads at varying depths (100k, 250k, 500k, 750k, and 1M reads). We then recalculated alpha diversity metrics (evenness, richness, and Shannon) for each community of re-sampled reads after assigning taxonomy using MetaPhlAn. Figure 3A shows the relationship between the evenness, richness, and sequencing depth across all the resamplings we performed. Regardless of the starting community’s diversity, as sequencing depth increased, observed sample richness and evenness also increased (Supplementary Figure 3). For example, samples that were only profiled with 100k reads had a mean Shannon Index of 1.35, whereas those sampled at 1M reads had mean Shannon Index of 1.89 (Figure 3B).
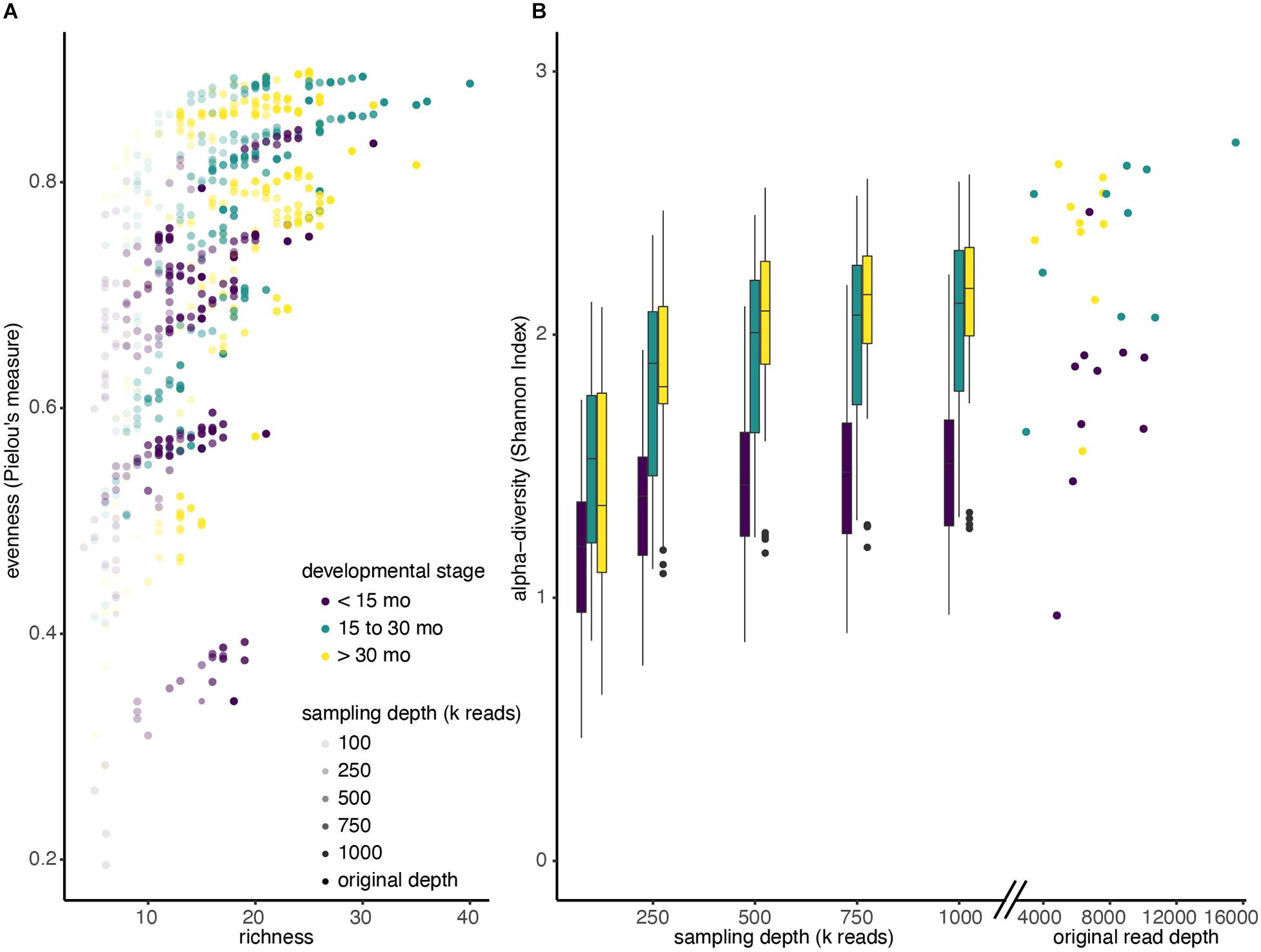
Figure 3. Alpha diversity increases with sequencing depth. (A) Shotgun metagenomic reads from 30 deeply sequenced samples were resampled four times at each different sequencing depths (100k; 250k; 500k; 750k; 1M reads). Reads were reassigned taxonomy using MetaPhlAn and diversity was recalculated. Each dot represents a single resampled community. (B) Boxplots of Shannon diversity among all samples at each re-sampling depth, colored by developmental stage. Scatter plot indicates Shannon diversity of original samples.
In addition, we observed that increasing sequencing depth affected children of different ages differently. Not only did children younger than 15 months have a lower median Shannon Index when we ignore sampling depth (<15 months median: 1.42, >15 months median: 1.99), the Shannon Index increases more slowly with sampling depth in kids under 15 months. In particular, a mixed effects linear model showed that the slope of the Shannon Index on sampling depth is significantly lower for children under 15 months, compared to those between 15 and 30 months (p < 0.001), and the slope is significantly lower for children between 15 and 30 months compared to those greater than 30 months (Figure 3B; p < 0.001).
While the stepwise increase in alpha diversity with sampling depth is statistically significant for children less than 15 months (p < 0.001), the increase in observed alpha diversity is substantially smaller than typical effect sizes in childhood microbiome studies. For instance, a recent meta-analyses of other studies that investigated alpha diversity of children that were and were not breastfed observed average differences in Shannon Index to be 0.34 (95% Confidence Interval: [0.20, 0.48]) (Ho et al., 2018), but increasing sequencing depth from 500k reads to 1M reads only increased this metric by 0.06 (Table 2 and Supplementary Table 2).
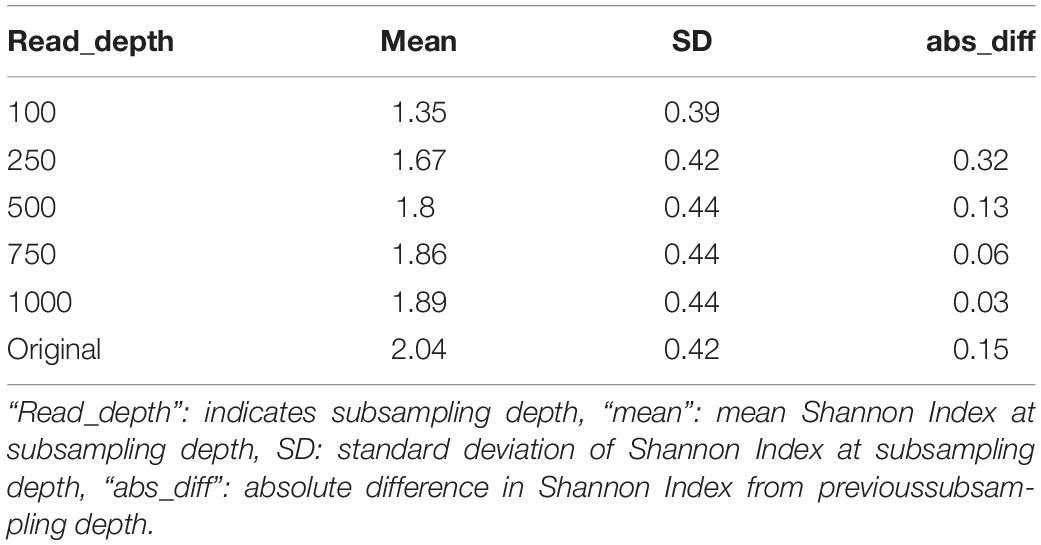
Table 2. Average Shannon index values among children less than 15 months at different subsampling depths in the RESONANCE data-set.
To investigate whether these observations were generally applicable to other childhood cohorts, we performed the same subsampling analysis on the DIABIMMUNE cohort (Simre et al., 2016) (Supplementary Figure 4). Consistent with the findings from the RESONANCE cohort, lower sequencing depth decreases the Shannon Index for all age groups (Mixed effects linear model, p < 0.001), and the benefits of deeper sequencing are most pronounced in older kids, as observed alpha diversity increases more quickly as additional reads are added for older children (Supplementary Table 3, p < 0.001). In addition, for both cohorts, the benefits of additional sequencing on observed diversity in children under 15 months substantially decrease over 500 000 reads.
Increasing interest in the human microbiome, especially during early child development, raises the urgency of selecting appropriate methods for interrogating taxonomic and functional composition of human-associated communities. Given that shotgun metagenomic sequencing is capable of providing higher taxonomic resolution as well as information about gene functional potential, it is clearly preferable to amplicon sequencing when working with high biomass samples such as stool and when cost is not an issue. However, the higher cost of sequencing to provide sufficient sequencing depth for shotgun metagenomics is relevant when resources are constrained. Because infant microbiomes are substantially less diverse than adult microbiomes, we reasoned that lower sequencing depth (and therefore lower cost) may enable comparable taxonomic resolution to amplicon sequencing at a similar cost.
We, therefore, set out to analyze a group of child stool samples sequenced with both methods and profiled with commonly used taxonomic-assignment tools so that direct comparisons could be made. As expected, microbial communities from younger children (less than 15 months old) were substantially less diverse than communities from older children, and both amplicon and shotgun metagenomic sequencing with ∼1.2 Gb per sample were able to capture comparable taxonomic diversity at the genus level across all age groups. It is important to note that metagenomic sequencing generally captures more diversity due to its species-level resolution (Ranjan et al., 2016), but we restricted our analysis to the genus level in order to make the most direct comparison to amplicon sequencing. While restricting our analysis to the genus level allowed us to most appropriately compare the two profiling methods, shotgun metagenomic profiling has many strengths not highlighted by this comparison, including characterization at the species, strain, or functional level.
Interestingly, though the observed diversity overall was comparable between methods, the actual taxonomic profiles generated by each method had substantial differences, particularly in the youngest children. For example, some particularly important genera in young children such as Bifidobacterium and Enterobacter were under-represented in amplicon sequencing profiles. Because shotgun metagenomic sequencing does not include an amplification step and therefore avoids issues of amplification bias, it is likely to be more accurate, though further investigation with synthetic or in silico communities may be necessary to determine which method provides the most accurate profiles in this population. In contexts where we may be interested in taxa such as Bifidobacterium longum infantis, which is critical for breaking down human milk oligosaccharides and often identified by the presence of these milk-digesting genes (LoCascio et al., 2010; Zabel et al., 2019), shotgun metagenomics may be the best method. Not only does 16S rRNA amplicon sequencing under-represent the prevalence of this microbe, but shotgun metagenomics can also provide more comprehensive functional information (Franzosa et al., 2015).
While shallower sequencing may enable investigators to observe comparable diversity, there are substantial differences in the identities of taxa profiled. Like other groups (Rausch et al., 2019), we showed that 16S rRNA gene amplicon and shotgun metagenomic sequencing each missed some taxa, but more genera were identified overall by 16S rRNA gene profiling, at least in the RESONANCE cohort. This finding was also supported in the DIABIMMUNE cohort, where 197 genera were identified with 16S rRNA profiling, while only 40 were uniquely found with shotgun metagenomics. Interestingly, we also show that the largest discrepancies between the two profiling methods were found in the youngest kids. This is likely due in part to the low diversity of these samples, since the loss of one genus in a profile with few genera may have a larger impact on dissimilarity metrics. Another possible explanation is the large fraction of many samples in young children (as much as 40% relative abundance) that could not be resolved to the genus level (see section “Alpha Diversity Increases With Age in Both 16S rRNA Gene- and Metagenomic-Profiled Samples”) with amplicon sequencing. As unresolved taxa were excluded from our alpha diversity analysis, the true diversity could be much higher or lower than we observe in those samples.
Some of the discrepancies we observed were due to technical differences in sequencing methods. For example, some taxa found exclusively through 16S rRNA gene profiling were not found in the MetaPhlAn database, including 16 genera that did not have reference genomes available. All of the genera found uniquely by shotgun metagenomics were present in the SILVA database, but their 16S rRNA gene sequences may not have perfectly complemented the primers we used. Though 16S rRNA PCR primers are often referred to as “universal,” there is considerable sequence diversity in the 16S rRNA gene, even in the most conserved regions and among bacteria of the same species (Větrovský and Baldrian, 2013). Using TestPrime 1.0, we identified several genera that had very low alignment with our primers, such as Solobacterium (2.2% alignment) and Pediococcus (1.3%) and 10 genera that were present in the SILVA database and identified using shotgun metagenomics, but were not found to be hits with our primers. We also explored if certain clusters of taxa were more systematically unidentified by a particular profiling method. For example, several genera identified uniquely by shotgun metagenomic profiling had lower primer coverage compared to the genera identified by 16S rRNA amplicon profiling (Supplementary Figure 5). Other taxa were only identified using 16S amplicon profiling (Figure 2B; ex. clade containing Ruegeria, Planktotalea, Planktomarina, and Sulfitobacter).
Given that both profiling methods exhibited some biases against certain taxa, future study designs should carefully consider which method is most appropriate to their research question, and further investigation using communities where the ground truth of composition is known should be pursued to interrogate whether these differences are systematic. For instance, studies investigating taxa that are not easily identified with 16S rRNA analysis or functional capacity of microbes should utilize shotgun metagenomics. However, studies collecting samples from many children and that do not require as granular taxonomic resolution may save money by using 16S rRNA profiling. In addition to uncertainty about the true composition of these samples’ communities, our study was also limited in scope to a single 16S rRNA gene primer pair for amplification, a single sequencing read length for shotgun sequencing, and a single computational pipeline for taxonomic profiling each sequencing method. There are several different approaches for both the sequencing (Martínez et al., 2014; Driscoll et al., 2017; Rausch et al., 2019) and profiling step (Almeida et al., 2018; Ye et al., 2019), each of which is likely to have its own biases. We chose to compare widely used and accessible methods to compare for investigation of child microbiomes, but further investigation to select the best combination of methods may be warranted. Finally, advances in sequencing technology [e.g., long-read sequencing of 16S rRNA genes (Karst et al., 2020)], changes to reference databases and improved taxonomic assignment methods may affect the performance and relative tradeoffs in the future.
Understanding the advantages associated with different methods of investigating the human microbiome will allow others in the field to use the most cost-effective methods to explore the relationship between the gut microbiome and human health. Most research is limited by financial resources, which impacts the number of controls, replicates, samples we can analyze, and the depth to which we can characterize each sample. Better insight into how we can sequence more efficiently will allow us to use these finite resources more effectively. Hopefully, this will allow us to devote resources where they will be best utilized (e.g., deep sequencing for older children with higher alpha diversity) and reduce them where they are not necessary.
Given the importance of the first 30 months of one’s life in shaping future health outcomes (Bokulich et al., 2016; Tamburini et al., 2016; Yang et al., 2016), it is crucial that we understand how to efficiently characterize developing microbiomes. By identifying the most effective methods for investigating the microbiomes of children at different stages of development, we can reduce sequencing costs and reduce bias in results. This will ultimately increase the quality of the research by ensuring that resources are appropriately expended. Altogether, understanding the links between the infant gut microbiome and child development will allow us to better predict how early life environmental exposures or health decisions can mediate the gut microbiome’s effects on health later in life.
Sean C. L. Deoni, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Viren D’Sa, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Muriel Bruchhage, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Alexandra Volpe, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Jennifer Beauchemin, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Caroline Wallace, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; John Rogers, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Rosa Cano, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Jessica Fernandes, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Elizabeth Walsh, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Brittany Rhodes, Department of Pediatrics, Warren Alpert Medical School at Brown University, Providence, RI, United States; Matthew Huentelman, The Translational Genomics Research Institute, Neurogenomics Division, Phoenix, AZ, United States; Candace Lewis, The Translational Genomics Research Institute, Neurogenomics Division, Phoenix, AZ, United States; Matthew D. De Both, The Translational Genomics Research Institute, Neurogenomics Division, Phoenix, AZ, United States; Marcus A. Naymik, The Translational Genomics Research Institute, Neurogenomics Division, Phoenix, AZ, United States; Susan Carnell, Department of Psychiatry and Behavioral Sciences, Johns Hopkins University School of Medicine, Baltimore, MD, United States; Elena Jansen, Department of Psychiatry and Behavioral Sciences, Johns Hopkins University School of Medicine, Baltimore, MD, United States; Jennifer R. Sadler, Department of Psychiatry and Behavioral Sciences, Johns Hopkins University School of Medicine, Baltimore, MD, United States; Gita Thapaliya, Department of Psychiatry and Behavioral Sciences, Johns Hopkins University School of Medicine, Baltimore, MD, United States; Kevin Bonham, Department of Biological Sciences, Wellesley College, Wellesley, MA, United States; Monique LeBourgeois, Department of Integrative Physiology, University of Colorado, Boulder, CO, United States; Hans Georg Mueller, Department of Statistics, University of California, Davis, CA, United States; Jane-Ling Wang, Department of Statistics, University of California, Davis, Davis, CA, United States; Changbo Zhu, Department of Statistics, University of California, Davis, Davis, CA, United States; Yaqing Chen, Department of Statistics, University of California, Davis, Davis, CA, United States; Joseph Braun, School of Public Health, Brown University, RI, United States.
Raw and processed data is available through SRA (NCBI BioProject PRJNA695570) and at OSF.io (Peterson et al., 2021).
The studies involving human participants were reviewed and approved by Lifespan–Rhode Island Hospital. Written informed consent to participate in this study was provided by the participants’ legal guardian/next of kin.
DP, VK-C, and KB designed the study. SR processed the samples. DP and KB designed and wrote the code and analyzed the data. CP contributed to data analyses and statistical methods. All authors wrote, edited, and finalized the manuscript and approved the manuscript’s final version.
The project was funded by the NIH UG3 OD023313 (VK-C).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We thank families participating in the RESONANCE cohort. We also thank Maureen Coleman and Steven Biller for reviewing the manuscript and providing helpful comments, and Christopher Loiselle and Jennifer Beauchemin for assistance with biospecimen and metadata collection.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmicb.2021.670336/full#supplementary-material
Supplementary Figure 1 | RESONANCE: a cohort of healthy children between ages 2 months and 4 years. Histogram showing distribution of ages across developmental stages. Both 16S rRNA gene data and metagenome profiles were obtained for 338 stool samples (one sample per child and timepoint). n = 104 for children <15 months, n = 41 for children 15–30 months, and n = 193 for children >30 months. Color indicates developmental stage.
Supplementary Figure 2 | Cumulative percent of variation explained by first 100 principal components. Barplot of the cumulative sum of the percentage explained by the first 100 principal components used to create Figure 1D. The first 10 principal components explained 88.55% of the total variation in Bray-Curtis dissimilarity within the dataset.
Supplementary Figure 3 | A common phylogenetic tree was generated from all taxa identified by both 16S rRNA gene (amp) and shotgun metagenomic sequencing (mgx). Colors indicate which method was able to identify taxa (peach = identified by 16S, cyan = identified by shotgun metagenomics). Labels at tree tips indicate genera from Figure 2B.
Supplementary Figure 4 | Species richness increases with sampling depth within each age group. (A) Boxplots of species richness among all samples at each sampling depth, colored and grouped by developmental stage. (B) Boxplots of species richness among all samples at each re-sampling depth, separated by sampling depth.
Supplementary Figure 5 | Alpha diversity decreases with sequencing depth in DIABIMMUNE dataset. (A) Shotgun metagenomic reads from 804 deeply sequenced samples were resampled times at six different sequencing depths (100k; 250k; 500k; 750k; 1M, and 10M reads). Reads from both cohorts were reassigned taxonomy using MetaPhlAn and diversity was recalculated. Each dot represents a single resampled community. (B) Boxplots of Shannon diversity among all samples at each re-sampling depth, colored by developmental stage. Scatter plot indicates Shannon diversity of original samples.
Supplementary Figure 6 | Genera found by 16S rRNA amplicon sequencing have significantly higher primer coverage. TestPrime 1.0 was used to calculate the percent primer coverage of the primers used in our study for amplicon sequencing. We compared the percent coverage for microbes found uniquely by 16S rRNA sequencing, both methods, and shotgun metagenomic sequencing. A pairwise Wilcoxon test found that primer coverage for microbes found uniquely by amplicon sequencing is significantly higher than that in the genera found uniquely by shotgun metagenomics (p < 0.05).
Supplementary Table 1 | Genera systematically over-represented with either profiling method. The Wilcoxon signed-rank test was used to compare the relative abundances of a particular genera, calculated from 16S and shotgun metagenomics profiling. “Diff” is the average relative abundance difference for a particular genera (mean 16S rRNA gene relative abundance–mean shotgun metagenomics relative abundance) “P.adjust” is the p-value after Benjamini-Hochberg correction. The table presents genera with significant differences (adjusted p-value < 0.05), indicating genera that had higher average relative abundances when profiled by 16S rRNA or shotgun metagenomics. “Method” indicates the profiling method where the genus was more abundant.
Supplementary Table 2 | Output of linear model used to predict Shannon Index based on read depth and developmental stage in RESONANCE dataset. lme4 was used to construct a Mixed effects linear model to analyze data from the RESONANCE subsampling results. “Estimates” reports the estimated coefficients for the intercept of the fitted line and each variable (read depth, developmental stage) or interaction of variables.
Supplementary Table 3 | Output of linear model used to predict Shannon Index based on read depth and developmental stage in DIABIMMUNE dataset. lme4 was used to construct a Mixed effects linear model to analyze data from the DIABIMMUNE subsampling results. “Estimates” reports the estimated coefficients for the intercept of the fitted line and each variable (read depth, developmental stage) or interaction of variables.
Acinas, S. G., Sarma-Rupavtarm, R., Klepac-Ceraj, V., and Polz, M. F. (2005). Pcr-induced sequence artifacts and bias: insights from comparison of two 16s rrna clone libraries constructed from the same sample. Appl. Environ. Microbiol. 71, 8966–8969. doi: 10.1128/aem.71.12.8966-8969.2005
Almeida, A., Mitchell, A. L., Tarkowska, A., and Finn, R. D. (2018). Benchmarking taxonomic assignments based on 16S rRNA gene profiling of the microbiota from commonly sampled environments. GigaScience 7: giy054.
Amir, A., McDonald, D., Navas-Molina, J. A., Kopylova, E., Morton, J. T., Xu, Z. Z., et al. (2017). Deblur rapidly resolves single-nucleotide community sequence patterns. MSystems 2:e00191–16.
Beghini, F., McIver, L. J., Blanco-Míguez, A., Dubois, L., Asnicar, F., Maharjan, S., et al. (2020). Integrating taxonomic, functional, and strain-level profiling of diverse microbial communities with bioBakery 3. BioRxiv [Preprint]. doi: 10.1101/2020.11.19.388223
Benjamini, Y., and Hochberg, Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B Methodol. 57, 289–300.
Bokulich, N. A., Chung, J., Battaglia, T., Henderson, N., Jay, M., Li, H., et al. (2016). Antibiotics, birth mode, and diet shape microbiome maturation during early life. Sci. Transl. Med. 8:343ra82. doi: 10.1126/scitranslmed.aad7121
Bokulich, N. A., Kaehler, B. D., Rideout, J. R., Dillon, M., Bolyen, E., Knight, R., et al. (2018). Optimizing taxonomic classification of marker-gene amplicon sequences with QIIME 2’s q2-feature-classifier plugin. Microbiome 6:90.
Bolyen, E., Rideout, J. R., Dillon, M. R., Bokulich, N. A., Abnet, C. C., Al-Ghalith, G. A., et al. (2019). Reproducible, interactive, scalable and extensible microbiome data science using QIIME 2. Nat. Biotechnol. 37, 852–857.
Bray, J. R., and Curtis, J. T. (1957). An ordination of the upland forest communities of southern wisconsin. Ecol. Monogr. 27, 325–349. doi: 10.2307/1942268
Brumfield, K. D., Huq, A., Colwell, R. R., Olds, J. L., and Leddy, M. B. (2020). Microbial resolution of whole genome shotgun and 16S amplicon metagenomic sequencing using publicly available NEON data. PLoS One 15:e0228899. doi: 10.1371/journal.pone.0228899
Bultman, S. J. (2014). Emerging roles of the microbiome in cancer. Carcinogenesis 35, 249–255. doi: 10.1093/carcin/bgt392
Callahan, B. J., McMurdie, P. J., and Holmes, S. P. (2017). Exact sequence variants should replace operational taxonomic units in marker-gene data analysis. ISME J. 11, 2639–2643. doi: 10.1038/ismej.2017.119
Callahan, B. J., McMurdie, P. J., Rosen, M. J., Han, A. W., Johnson, A. J. A., and Holmes, S. P. (2016). DADA2: high resolution sample inference from illumina amplicon data. Nat. Methods 13, 581–583. doi: 10.1038/nmeth.3869
Chen, Z., Hui, P. C., Hui, M., Yeoh, Y. K., Wong, P. Y., Chan, M. C. W., et al. (2019). Impact of preservation method and 16S rRNA hypervariable region on gut microbiota profiling. MSystems 4:e00271–18.
Comeau, A. M., Douglas, G. M., and Langille, M. G. I. (2017). Microbiome helper: a custom and streamlined workflow for microbiome research. MSystems 2:e00127–16.
Couronne, O., Poliakov, A., Bray, N., Ishkhanov, T., Ryaboy, D., Rubin, E., et al. (2003). Strategies and tools for whole-genome alignments. Genome Res. 13, 73–80. doi: 10.1101/gr.762503
Douglas, G. M., Maffei, V. J., Zaneveld, J. R., Yurgel, S. N., Brown, J. R., Taylor, C. M., et al. (2020). PICRUSt2 for prediction of metagenome functions. Nat. Biotechnol. 38, 685–688. doi: 10.1038/s41587-020-0548-6
Driscoll, C. B., Otten, T. G., Brown, N. M., and Dreher, T. W. (2017). Towards long-read metagenomics: complete assembly of three novel genomes from bacteria dependent on a diazotrophic cyanobacterium in a freshwater lake co-culture. Stand. Genomic Sci. 12:9.
Eloe-Fadrosh, E. A., Ivanova, N. N., Woyke, T., and Kyrpides, N. C. (2016). Metagenomics uncovers gaps in amplicon-based detection of microbial diversity. Nat. Microbiol. 1:15032.
Forrest, C. B., Blackwell, C. K., and Camargo, C. A. (2018). Advancing the science of children’s positive health in the NIH environmental influences on child health outcomes (ECHO) research program. J. Pediatr. 196, 298–300. doi: 10.1016/j.jpeds.2018.02.004
Foster, J. A., and McVey Neufeld, K.-A. (2013). Gut–brain axis: how the microbiome influences anxiety and depression. Trends Neurosci. 36, 305–312. doi: 10.1016/j.tins.2013.01.005
Franzosa, E. A., Hsu, T., Sirota-Madi, A., Shafquat, A., Abu-Ali, G., Morgan, X. C., et al. (2015). Sequencing and beyond: integrating molecular “omics” for microbial community profiling. Nat. Rev. Microbiol. 13, 360–372. doi: 10.1038/nrmicro3451
Gillman, M. W., and Blaisdell, C. J. (2018). Environmental influences on child health outcomes, a research program of the NIH. Curr. Opin. Pediatr. 30, 260–262. doi: 10.1097/MOP.0000000000000600
Gonzalez, A., Vázquez-Baeza, Y., Pettengill, J. B., Ottesen, A., McDonald, D., and Knight, R. (2016). Avoiding pandemic fears in the subway and conquering the platypus. MSystems 1:e00050–16.
Hartstra, A. V., Bouter, K. E. C., Bäckhed, F., and Nieuwdorp, M. (2015). Insights into the role of the microbiome in obesity and type 2 diabetes. Diabetes Care 38, 159–165. doi: 10.2337/dc14-0769
Hillmann, B., Al-Ghalith, G. A., Shields-Cutler, R. R., Zhu, Q., Gohl, D. M., Beckman, K. B., et al. (2018). Evaluating the information content of shallow shotgun metagenomics. mSystems 3:e00069-18.
Ho, N. T., Li, F., Lee-Sarwar, K. A., Tun, H. M., Brown, B. P., Pannaraj, P. S., et al. (2018). Meta-analysis of effects of exclusive breastfeeding on infant gut microbiota across populations. Nat. Commun. 9:4169.
Jayasinghe, T. N., Vatanen, T., Chiavaroli, V., Jayan, S., McKenzie, E. J., Adriaenssens, E., et al. (2020). Differences in compositions of gut bacterial populations and bacteriophages in 5-11 year-olds born preterm compared to full term. Front. Cell. Infect. Microbiol. 10:276. doi: 10.3389/fcimb.2020.00276
Ji, B., and Nielsen, J. (2015). From next-generation sequencing to systematic modeling of the gut microbiome. Front. Genet. 6:219. doi: 10.3389/fgene.2015.00219
Karst, S. M., Ziels, R. M., Kirkegaard, R. H., Sørensen, E. A., McDonald, D., Zhu, Q., et al. (2020). Enabling high-accuracy long-read amplicon sequences using unique molecular identifiers with nanopore or pacbio sequencing. BioRxiv [Preprint]. doi: 10.1101/645903
Klindworth, A., Pruesse, E., Schweer, T., Peplies, J., Quast, C., Horn, M., et al. (2013). Evaluation of general 16S ribosomal RNA gene PCR primers for classical and next-generation sequencing-based diversity studies. Nucleic Acids Res. 41:e1. doi: 10.1093/nar/gks808
Kumar, S., Stecher, G., Suleski, M., and Hedges, S. B. (2017). TimeTree: a resource for timelines, timetrees, and divergence times. Mol. Biol. Evol. 34, 1812–1819. doi: 10.1093/molbev/msx116
Lambeth, S. M., Carson, T., Lowe, J., Ramaraj, T., Leff, J. W., Luo, L., et al. (2015). Composition, diversity and abundance of gut microbiome in prediabetes and type 2 diabetes. J. Diabetes Obes. 2, 1–7.
Laudadio, I., Fulci, V., Palone, F., Stronati, L., Cucchiara, S., and Carissimi, C. (2018). Quantitative assessment of shotgun metagenomics and 16S rDNA amplicon sequencing in the study of human gut microbiome. OMICS 22, 248–254. doi: 10.1089/omi.2018.0013
Letunic, I., and Bork, P. (2007). Interactive Tree Of Life (iTOL): an online tool for phylogenetic tree display and annotation. Bioinformatics 23, 127–128. doi: 10.1093/bioinformatics/btl529
Letunic, I., and Bork, P. (2019). Interactive Tree Of Life (iTOL) v4: recent updates and new developments. Nucleic Acids Res. 47, W256–W259.
LoCascio, R. G., Desai, P., Sela, D. A., Weimer, B., and Mills, D. A. (2010). Broad conservation of milk utilization genes in bifidobacterium longum subsp. infantis as revealed by comparative genomic hybridization. Appl. Environ. Microbiol. 76, 7373–7381. doi: 10.1128/aem.00675-10
Lozupone, C. A., Stombaugh, J. I., Gordon, J. I., Jansson, J. K., and Knight, R. (2012). Diversity, stability and resilience of the human gut microbiota. Nature 489, 220–230. doi: 10.1038/nature11550
Ludwig, W., Strunk, O., Westram, R., Richter, L., Meier, H., and Yadhukumar, et al. (2004). ARB: a software environment for sequence data. Nucleic Acids Res. 32, 1363–1371. doi: 10.1093/nar/gkh293
Malla, M. A., Dubey, A., Kumar, A., Yadav, S., Hashem, A., and Abd Allah, E. F. (2019). Exploring the human microbiome: the potential future role of next-generation sequencing in disease diagnosis and treatment. Front. Immunol. 9:2868. doi: 10.3389/fimmu.2018.02868
Marchesi, J. R., Dutilh, B. E., Hall, N., Peters, W. H. M., Roelofs, R., Boleij, A., et al. (2011). Towards the human colorectal cancer microbiome. PLoS One 6:e20447. doi: 10.1371/journal.pone.0020447
Martin, M. (2011). Cutadapt removes adapter sequences from high-throughput sequencing reads. EMBnet. J. 17, 10–12.
Martínez, M. A., Romero, H., and Perotti, N. I. (2014). Two amplicon sequencing strategies revealed different facets of the prokaryotic community associated with the anaerobic treatment of vinasses from ethanol distilleries. Bioresour. Technol. 153, 388–392. doi: 10.1016/j.biortech.2013.12.030
McIntyre, A. B. R., Ounit, R., Afshinnekoo, E., Prill, R. J., Hénaff, E., Alexander, N., et al. (2017). Comprehensive benchmarking and ensemble approaches for metagenomic classifiers. Genome Biol. 18:182.
McIver, L. J., Abu-Ali, G., Franzosa, E. A., Schwager, R., Morgan, X. C., Waldron, L., et al. (2018). bioBakery: a meta’omic analysis environment. Bioinformatics 34, 1235–1237. doi: 10.1093/bioinformatics/btx754
Nearing, J. T., Douglas, G. M., Comeau, A. M., and Langille, M. G. I. (2018). Denoising the denoisers: an independent evaluation of microbiome sequence error-correction approaches. PeerJ 6:e5364. doi: 10.7717/peerj.5364
Palmer, C., Bik, E. M., DiGiulio, D. B., Relman, D. A., and Brown, P. O. (2007). Development of the human infant intestinal microbiota. PLoS Biol. 5:e177. doi: 10.1371/journal.pbio.0050177
Parada, A. E., Needham, D. M., and Fuhrman, J. A. (2016). Every base matters: assessing small subunit rRNA primers for marine microbiomes with mock communities, time series and global field samples. Environ. Microbiol. 18, 1403–1414. doi: 10.1111/1462-2920.13023
Peabody, M. A., Van Rossum, T., Lo, R., and Brinkman, F. S. L. (2015). Evaluation of shotgun metagenomics sequence classification methods using in silico and in vitro simulated communities. BMC Bioinformatics 16:363. doi: 10.1186/s12859-015-0788-5
Pereira-Marques, J., Hout, A., Ferreira, R. M., Weber, M., Pinto-Ribeiro, I., van Doorn, L.-J., et al. (2019). Impact of Host DNA and sequencing depth on the taxonomic resolution of whole metagenome sequencing for microbiome analysis. Front. Microbiol. 10:1277. doi: 10.3389/fmicb.2019.01277
Peterson, D., Bonham, K., and Klepac-Ceraj, V. (2021). Open Science Framework. Available online at: https://osf.io/f4dbj/. doi: 10.17605/OSF.IO/F4DBJ
Price, M. N., Dehal, P. S., and Arkin, A. P. (2010). FastTree 2–approximately maximum-likelihood trees for large alignments. PLoS One 5:e9490. doi: 10.1371/journal.pone.0009490
Quast, C., Pruesse, E., Yilmaz, P., Gerken, J., Schweer, T., Yarza, P., et al. (2013). The SILVA ribosomal RNA gene database project: improved data processing and web-based tools. Nucleic Acids Res. 41, D590–D596. doi: 10.1093/nar/gks1219
Radjabzadeh, D., Boer, C. G., Beth, S. A., van der Wal, P., Kiefte-De Jong, J. C., Jansen, M. A. E., et al. (2020). Diversity, compositional and functional differences between gut microbiota of children and adults. Sci. Rep. 10:1040.
Ranjan, R., Rani, A., Metwally, A., McGee, H. S., and Perkins, D. L. (2016). Analysis of the microbiome: advantages of whole genome shotgun versus 16S amplicon sequencing. Biochem. Biophys. Res. Commun. 469, 967–977. doi: 10.1016/j.bbrc.2015.12.083
Rausch, P., Rühlemann, M., Hermes, B. M., Doms, S., Dagan, T., Dierking, K., et al. (2019). Comparative analysis of amplicon and metagenomic sequencing methods reveals key features in the evolution of animal metaorganisms. Microbiome 7:133.
Ravi, A., Avershina, E., Angell, I. L., Ludvigsen, J., Manohar, P., Padmanaban, S., et al. (2018). Comparison of reduced metagenome and 16S rRNA gene sequencing for determination of genetic diversity and mother-child overlap of the gut associated microbiota. J. Microbiol. Methods 149, 44–52. doi: 10.1016/j.mimet.2018.02.016
Regalado, J., Lundberg, D. S., Deusch, O., Kersten, S., Karasov, T., Poersch, K., et al. (2020). Combining whole-genome shotgun sequencing and rRNA gene amplicon analyses to improve detection of microbe–microbe interaction networks in plant leaves. ISME J. 14, 2116–2130. doi: 10.1038/s41396-020-0665-8
Salman, V., Amann, R., Shub, D. A., and Schulz-Vogt, H. N. (2012). Multiple self-splicing introns in the 16S rRNA genes of giant sulfur bacteria. Proc. Natl. Acad. Sci. U.S.A. 109, 4203–4208. doi: 10.1073/pnas.1120192109
Segata, N., Waldron, L., Ballarini, A., Narasimhan, V., Jousson, O., and Huttenhower, C. (2012). Metagenomic microbial community profiling using unique clade-specific marker genes. Nat. Methods 9, 811–814. doi: 10.1038/nmeth.2066
Simre, K., Uibo, O., Peet, A., Tillmann, V., Kool, P., Hämäläinen, A.-M., et al. (2016). Exploring the risk factors for differences in the cumulative incidence of coeliac disease in two neighboring countries: the prospective diabimmune study. Dig. Liver Dis. 48, 1296–1301. doi: 10.1016/j.dld.2016.06.029
Sims, D., Sudbery, I., Ilott, N. E., Heger, A., and Ponting, C. P. (2014). Sequencing depth and coverage: key considerations in genomic analyses. Nat. Rev. Genet. 15, 121–132. doi: 10.1038/nrg3642
Sinha, R., Abu-Ali, G., Vogtmann, E., Fodor, A. A., Ren, B., Amir, A., et al. (2017). Assessment of variation in microbial community amplicon sequencing by the Microbiome Quality Control (MBQC) project consortium. Nat. Biotechnol. 35, 1077–1086. doi: 10.1038/nbt.3981
Stewart, C. J., Ajami, N. J., O’Brien, J. L., Hutchinson, D. S., Smith, D. P., Wong, M. C., et al. (2018). Temporal development of the gut microbiome in early childhood from the teddy study. Nature 562, 583–588.
Tamburini, S., Shen, N., Wu, H. C., and Clemente, J. C. (2016). The microbiome in early life: implications for health outcomes. Nat. Med. 22, 713–722. doi: 10.1038/nm.4142
Tovo, A., Menzel, P., Krogh, A., Cosentino Lagomarsino, M., and Suweis, S. (2020). Taxonomic classification method for metagenomics based on core protein families with Core-Kaiju. Nucleic Acids Res. 48:e93. doi: 10.1093/nar/gkaa568
Tremblay, J., Singh, K., Fern, A., Kirton, E. S., He, S., Woyke, T., et al. (2015). Primer and platform effects on 16S rRNA tag sequencing. Front. Microbiol. 6:771. doi: 10.3389/fmicb.2015.00771
Vatanen, T., Kostic, A. D., d’Hennezel, E., Siljander, H., Franzosa, E. A., Yassour, M., et al. (2016). Variation in microbiome LPS immunogenicity contributes to autoimmunity in humans. Cell 165, 842–853. doi: 10.1016/j.cell.2016.04.007
Větrovský, T., and Baldrian, P. (2013). The variability of the 16S rRNA gene in bacterial genomes and its consequences for bacterial community analyses. PLoS One 8:e57923. doi: 10.1371/journal.pone.0057923
Walters, W., Hyde, E. R., Berg-Lyons, D., Ackermann, G., Humphrey, G., Parada, A., et al. (2016). Improved bacterial 16S rRNA gene (v4 and v4-5) and fungal internal transcribed spacer marker gene primers for microbial community surveys. MSystems 1:e00009–15. doi: 10.1128/mSystems.00009-15
Wemheuer, F., Taylor, J. A., Daniel, R., Johnston, E., Meinicke, P., Thomas, T., et al. (2020). Tax4Fun2: prediction of habitat-specific functional profiles and functional redundancy based on 16S rRNA gene sequences. Environ. Microbiome 15:11.
Wilkins, L. G. E., Ettinger, C. L., Jospin, G., and Eisen, J. A. (2019). Metagenome-assembled genomes provide new insight into the microbial diversity of two thermal pools in Kamchatka, Russia. Sci. Rep. 9:3059. doi: 10.1038/s41598-019-39576-6
Wood, D. E., Lu, J., and Langmead, B. (2019). Improved metagenomic analysis with Kraken 2. Genome Biol. 20:257.
Yang, I., Corwin, E. J., Brennan, P. A., Jordan, S., Murphy, J. R., and Dunlop, A. (2016). The infant microbiome: implications for infant health and neurocognitive development. Nurs. Res. 65, 76–88. doi: 10.1097/nnr.0000000000000133
Yatsunenko, T., Rey, F. E., Manary, M. J., Trehan, I., Dominguez-Bello, M. G., Contreras, M., et al. (2012). Human gut microbiome viewed across age and geography. Nature 486, 222–227. doi: 10.1038/nature11053
Ye, S. H., Siddle, K. J., Park, D. J., and Sabeti, P. C. (2019). Benchmarking metagenomics tools for taxonomic classification. Cell 178, 779–794. doi: 10.1016/j.cell.2019.07.010
Zabel, B., Yde, C. C., Roos, P., Marcussen, J., Jensen, H. M., Salli, K., et al. (2019). Novel genes and metabolite trends in bifidobacterium longum subsp. infantis bi-26 metabolism of human milk oligosaccharide 2’-fucosyllactose. Sci. Rep. 9:7983.
Keywords: 16S rRNA gene, metagenome, pediatric cohort, gut microbiome, sequencing depth, amplicon sequencing
Citation: Peterson D, Bonham KS, Rowland S, Pattanayak CW, RESONANCE Consortium and Klepac-Ceraj V (2021) Comparative Analysis of 16S rRNA Gene and Metagenome Sequencing in Pediatric Gut Microbiomes. Front. Microbiol. 12:670336. doi: 10.3389/fmicb.2021.670336
Received: 21 February 2021; Accepted: 28 May 2021;
Published: 15 July 2021.
Edited by:
Yasir Muhammad, King Abdulaziz University, Saudi ArabiaReviewed by:
Stephen Nayfach, Lawrence Berkeley National Laboratory, United StatesCopyright © 2021 Peterson, Bonham, Rowland, Pattanayak, RESONANCE Consortium and Klepac-Ceraj. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Vanja Klepac-Ceraj, dmtsZXBhY2NAd2VsbGVzbGV5LmVkdQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.