 Neema Jamshidi
Neema Jamshidi Anu Raghunathan
Anu Raghunathan
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
TECHNOLOGY REPORT article
Front. Microbiol. , 06 October 2015
Sec. Infectious Agents and Disease
Volume 6 - 2015 | https://doi.org/10.3389/fmicb.2015.01032
This article is part of the Research Topic Computational Systems Biology of Pathogen-Host Interactions View all 15 articles
Constraint-based models have become popular methods for systems biology as they enable the integration of complex, disparate datasets in a biologically cohesive framework that also supports the description of biological processes in terms of basic physicochemical constraints and relationships. The scope, scale, and application of genome scale models have grown from single cell bacteria to multi-cellular interaction modeling; host-pathogen modeling represents one of these examples at the current horizon of constraint-based methods. There are now a small number of examples of host-pathogen constraint-based models in the literature, however there has not yet been a definitive description of the methodology required for the functional integration of genome scale models in order to generate simulation capable host-pathogen models. Herein we outline a systematic procedure to produce functional host-pathogen models, highlighting steps which require debugging and iterative revisions in order to successfully build a functional model. The construction of such models will enable the exploration of host-pathogen interactions by leveraging the growing wealth of omic data in order to better understand mechanism of infection and identify novel therapeutic strategies.
Rudolph Virchow, a nineteenth century co-founder of pathology is credited with describing pathology as “physiology with obstacles” and specifying a “diseased state” as a quantitative deviation from normal function as a result of internal and external (i.e., environmental) influences (Virchow, 1958). Infections of a host by a pathogen can lead to acute and chronic pathological conditions. The process of infection by a pathogen can be viewed as a pathological process resulting from environmental stresses. These causal influences by the pathogen, onto the host, define the capabilities of the host and its pathogen can be expressed as constraints on the metabolic capabilities of the host and pathogen (Figure 1).
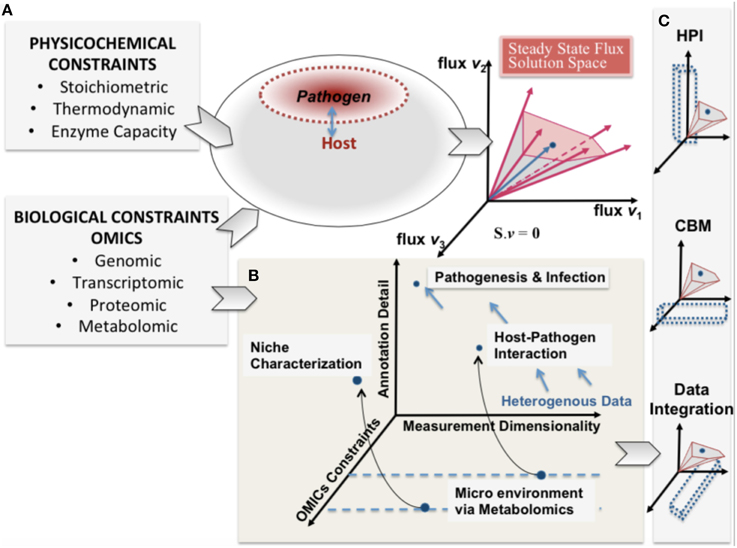
Figure 1. A conceptual representation of integrating constraint-based modeling and omic data. The heterogeneity of omic data (biological constraints) and their integration is represented in parallel with the phenotypic solution space of the high dimensional host-pathogen model derived from physicochemical constraints. The degree of constraints represented will depend on the measurement capability and also define a reference set of behaviors that are feasible. (A) enumerates the heterogeneity of constraints for both host and pathogen and the resultant mathematically feasible and the potential biologically relevant solution space. In (B) pathogenesis and infection are shown from the perspective of 3 dimensions (i) omics constraints (also determined by experimental constraints) (ii) Annotation detail (based on existing legacy data) and (iii) the measurement dimensionality (also defining dimensionality of data). (C) shows that understanding host-pathogen interaction would be possible at multiple scales by integrating heterogeneous data/measurements and constraint-based modeling algorithms. The opportunity afforded by the legacies of high throughput omics experimentation and systems-level mathematical models would help understand the emergent host-pathogen interaction.
The continued development of high-throughput technologies are enabling profiling of multi-cellular and multi-organism environments (Gawronski et al., 2009; Han et al., 2010; Pacchiarotta et al., 2012; McAdam et al., 2014). Such advances enable the detailed measurement of molecular changes occurring in host-pathogen interactions (Kim and Weiss, 2008; Stavrinides et al., 2008; Beste et al., 2013; Le Chevalier et al., 2014; Schoen et al., 2014; Chang et al., 2015; Henningham et al., 2015; Yao and Rock, 2015). Generation of these large datasets, in the context of the complexity of pathogenesis, highlight the need for systems based approaches for integration into a cohesive biologically interpretable framework (Durmus et al., 2015). Constraint-based modeling is an ideal approach for a systematic, integrated analysis of these data. The approach is based on well-defined stoichiometric biochemical transformations (including mass balance, reaction capacity, and directionality) and gene-protein-reaction (GPR) relationships allow mapping and integration of multiple, disparate data types. These methods can incorporate heterogeneous data-types that represent all hierarchies in the reductionist causal chain of an organism, thus enabling prediction of emergent properties (Figure 1). Additionally, constraint-based models circumvent the problem of over fitting data, which often plagues strictly statistical based methods. There exist a number of freely available tutorials and implementation tools and packages enabling the use of reconstructions for modeling, analysis, and simulation in the literature (Schellenberger et al., 2011; Liao et al., 2012; Ebrahim et al., 2013; Sadhukhan and Raghunathan, 2014; Palsson, 2015).
Constraint-based modeling in metabolism has its roots in microbial organisms, but has progressively grown in the past decades to describe complex multi-cellular organisms and various processes (Reed and Palsson, 2003; Mo et al., 2007; Feist et al., 2009; Karlsson et al., 2011; Osterlund et al., 2012). There has been a continual, systematic growth and progression of constraint-based models which initially began as the formulation of a core biochemical network as a linear optimization problem (Papoutsakis, 1984; Fell and Small, 1986; Varma et al., 1993). Further incorporation of additional layers of biological information through GPRs, thermodynamic constraints, and various high throughput data have increased the scope of the models beyond small species metabolism, to multi-cellular, multi-compartmental organisms (Duarte et al., 2007; Mo et al., 2007; Herrgård et al., 2008; Lewis et al., 2010; Ahn et al., 2011; Bordbar et al., 2011; Chang et al., 2011; Saha et al., 2011; Mintz-Oron et al., 2012; Seaver et al., 2012; Wang et al., 2012; Pornputtapong et al., 2015). This evolution in the field has been accompanied by a growth in associated methodologies (Lewis et al., 2012) and new discoveries (Ellis et al., 2009; Ahn et al., 2011; Frezza et al., 2011; Thomas et al., 2014; Väremo et al., 2015). The importance of metabolism in understanding the process of infections and host pathogen relationships is increasingly being recognized (Han et al., 2010; Kafsack and Llinás, 2010; Pacchiarotta et al., 2012; Beste et al., 2013; Mcconville, 2014; Schoen et al., 2014; Yao and Rock, 2015). The cellular environment and repertoire of available metabolites is critical in characterizing and understanding how a pathogen interacts with and infects the host and constraint-based approaches can provide value insight into mechanisms of resistance and potentially new drug treatment targets (Chavali et al., 2008; Huthmacher et al., 2010; Bazzani et al., 2012; Kim et al., 2013; Shoaie and Nielsen, 2014; Tymoshenko et al., 2015).
In the “evolutionary tree” of constraint-based models, host-pathogen models lie between multi-cellular models, pathogen modeling, and new constraints/data integration approaches. There are now numerous exciting frontiers in the growth of these models, including the scope, incorporation of physicochemical constraints, multi-tissue, and multi-organism models (Cakir et al., 2006; Kümmel et al., 2006a,b; Beg et al., 2007; Duarte et al., 2007; Mo et al., 2007; Herrgård et al., 2008; Lewis et al., 2010; Ahn et al., 2011; Bordbar et al., 2011; Chang et al., 2011; Saha et al., 2011; Metris et al., 2012; Mintz-Oron et al., 2012; Seaver et al., 2012; Wang et al., 2012; Pornputtapong et al., 2015). Some of the challenges regarding model integration will be shared with related areas of multi-cellular constraint-based modeling, such as modeling microbial communities (Stolyar et al., 2007; Karlsson et al., 2011; Shoaie and Nielsen, 2014) and the development of new methods characterizing the interaction between cellular interactions between different species (Harcombe et al., 2014). Notable differences between host pathogen modeling and microbial community modeling include the specification of cellular objectives and constraints as well as differences in spatial compartmentalization (microbial community modeling will generally involve interaction through a shared extracellular space, whereas host pathogen models may interact through additional compartments; see below). We confine the scope of this work to focus on host-pathogen constraint-based modeling that entails the explicit integration of two genome-scale (or cell scale) constraint-based models. The purpose of this article is to describe a systematic methodology leading to successful integration of constraint-based host-pathogen models. Although there have been a relatively small number of actual host-pathogen (hp) models reconstructed to date, the existing studies have produced interesting results and have taken steps toward elucidating the pathway forward for future investigations (Raghunathan et al., 2009, 2010; Bordbar et al., 2010; Sadhukhan and Raghunathan, 2014).
The extracellular environment has an influential effect on the phenotype state and behavior of cells, thus pathogens have different biochemical phenotypes when inside the host versus outside the host and that the host cells will be affected in some manner by the pathogen and vice-versa. Many current experimental techniques enable characterization of these different states (Deatherage Kaiser et al., 2013). The generation of such data results in the technical challenge of simultaneous interpretation and analysis of genomic, proteomic, and/or metabolomics data of two independent, yet interacting organisms. The ability to derive meaningful interpretations of such data requires a computational setting which enables mapping and integrating data in a coherent format that further allows the data to be analyzed simultaneously, beyond simply looking at correlations or fitting presumed associations to an expected model. The constraint-based modeling framework affords a means to do so.
While there are a seemingly innumerable number of ways that pathogens have evolved to infect and reside their chosen host tissues and organs, in general terms there are few places these organisms can localize: intracellular, extracellular—interstitial, extracellular—intravascular, extracellular—transcellular, and “semi-open” spaces (e.g., the respiratory or alimentary tracts, etc.). In the constraint-based framework, there are three types of compartment based interactions between the host and pathogen (defined by the interaction boundary as defined by the pathogen's cell wall): extracellular, intracellular:cytosolic, intracellular:intra-organelle (Figure 2). Within the intracellular environment, there are multiple compartments that a pathogen may localize and life cycles of pathogens in some organisms reside in different compartments, depending on the stage of infection. These details are organism specific and are addressed on a case-by-case basis.
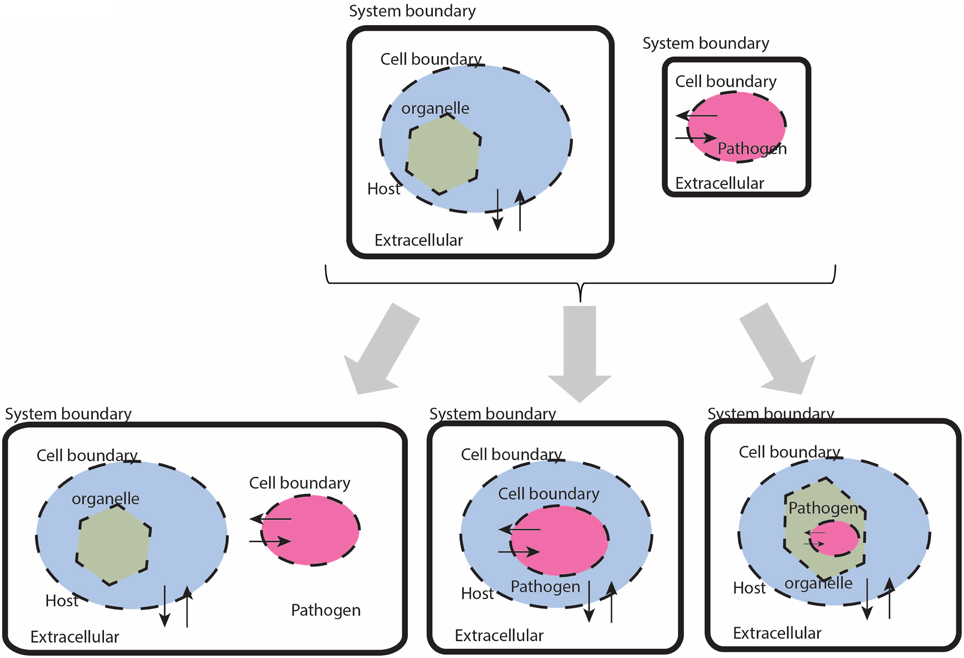
Figure 2. Cartoon based schematic representation of different types of interactions between a host and pathogen model, with special attention to system boundaries. The system boundary is clearly delineated with a solid black line, whereas organism boundaries are dashed lines (the organelle boundary is represented with a thinner black line. Note that with this formulation, individual models will be required to have exchange reactions for every metabolite that has a trans-membrane transporter.
The formulation of metabolic network descriptions in terms of constraint-based modeling and relation optimization methods is rooted in applying the principle of mass conservation and thermodynamic constraints to these networks and has previously been described in detail (Fell and Small, 1986; Varma et al., 1993; Orth et al., 2010; Palsson, 2015). Integration of host-pathogen models requires two curated stoichiometric representations of metabolic networks, for which the minimum requirements are a stoichiometric matrix and a flux vector with upper and lower bounds,
for the host and,
for the pathogen, with Sh ∈ Rmh x nh, Sp ∈ Rmp x np, vh ∈ Rnh, and vp ∈ Rnp (see Notations/Abbreviations).
For host-pathogen modeling, Equations (1) and (2) are not applied under the strict steady state assumption, but rather along the lines of a quasi-homeostatic state for which we enforce mass conservation over a time scale of interest. With this consideration in mind, the calculation of interest is rarely a specific flux point, but rather a group of points reflecting a particular flux state (or a region within the right null space) corresponding to a particular phenotype that can be differentiated from other qualitatively different flux states. Identification of such regions often may not require the specification of a metabolic objective function, in which case non-objective based methods, such as sampling, may be appropriate (Savinell and Palsson, 1992; Barrett et al., 2006; Schellenberger and Palsson, 2009; Bordel et al., 2010).
Pre-existing curated, functional models are a necessary but not sufficient requirement for building an hp model. Even if two models are well posed, integration of the two may result in discrepancies as a result of multiple factors including,
• Error ranges in experimentally derived values (such as biomass components).
• Incorporation of data from different experimental conditions that may not be consistent with one another from a mass balance or thermodynamic perspective.
• Limitations in biological scope of each respective model.
• Lack of knowledge about the true or underlying biological objectives.
Additional, important considerations to be made when transitioning from the analysis of an isolated pathogen to a host-pathogen model include, simulating different conditions with different data sets, simulating the same species under different states versus different species under similar conditions, and specification of the conditions in which gene lethality knockout/knockdown studies or drug sensitivity screens are performed and their applicability to host-pathogen infectious states. These issues highlight the need for a systematic methodology for integrating host-pathogen models. Constraint-based host-pathogen modeling can be viewed as a generalizable, systematic, multi-tiered process with iterative sub-steps (Figure 3). Each step includes multiple sub-steps that require simulations or calculations to be performed, often in an iterative fashion. A systematic approach for building and testing the models during the integration process will help make the debugging process more transparent and the more directed identification of potential problems.

Figure 3. A systematic procedure for successful, functional integration of a constraint-based host-pathogen model. Details are described in the main text. The asterisks identify steps that require iterative revisions if the models fail the corresponding test (see *Iteration/revision checkpoints in the main text).
This initial step serves as a “sanity check” to avoid problems during the subsequent integration components of the study. Although current standards for building curated network reconstructions generally require critical quality control/quality assurance steps to avoid spurious behavior from ill-posed models, prior to integration, there are a number of tests that must be completed for each model to confirm the models have been constructed and formulated appropriately.
1.i Check mass balances (“No free lunch”). Well curated models should be free of errors that may lead to violation of mass conservations constraints. However prior to integration, each model should be tested to confirm this, i.e., all uptake exchange reactions should be closed and flux variability analysis (FVA) (Mahadevan and Schilling, 2003) should be performed on the entire model, in order to confirm that there is no net production of any metabolite, when no substrates are available for uptake. In the toy model depicted in Figure 4, it is clear that if the substrates for the host and pathogen are not available (Fe, Ae, and De), then none of the secreted compounds (Be, Xe, Ee, Qe) can be produced.
1.ii Identify boundary points. The simplest approach for identification of the boundary points for a model is through FVA. Although this step can technically be included in the Functionality Test Suite, FVA is such a useful tool for debugging and initial assessment of models, that it is judicious to include this as a mandatory step in the model integration protocol. Under general uptake conditions (that are still biologically and thermodynamically feasible), FVA is performed with subsequent calculation of the flux spans. This assessment will enable the determination of the ranges of all reactions and the potential identification of “closed” reactions, any unbounded reactions, etc.
1.iii Functionality test suite. Prior to integration there should be a pre-defined set of simulation condition(s) and reaction optimizations in order to test and confirm desired functionality of the model (Duarte et al., 2007); this set of reactions comprise the Functionality Test Suite (FTS). The FTS can contain any number of desired tests and simulations to ensure appropriate physiologic behavior of the model, examples include biomass production under different growth conditions, specific gene knockout lethality experiments, inability to growth under specified conditions, or any other appropriate test that would evaluate the physiological/biological characterization of the model or the underlying mathematical definition.
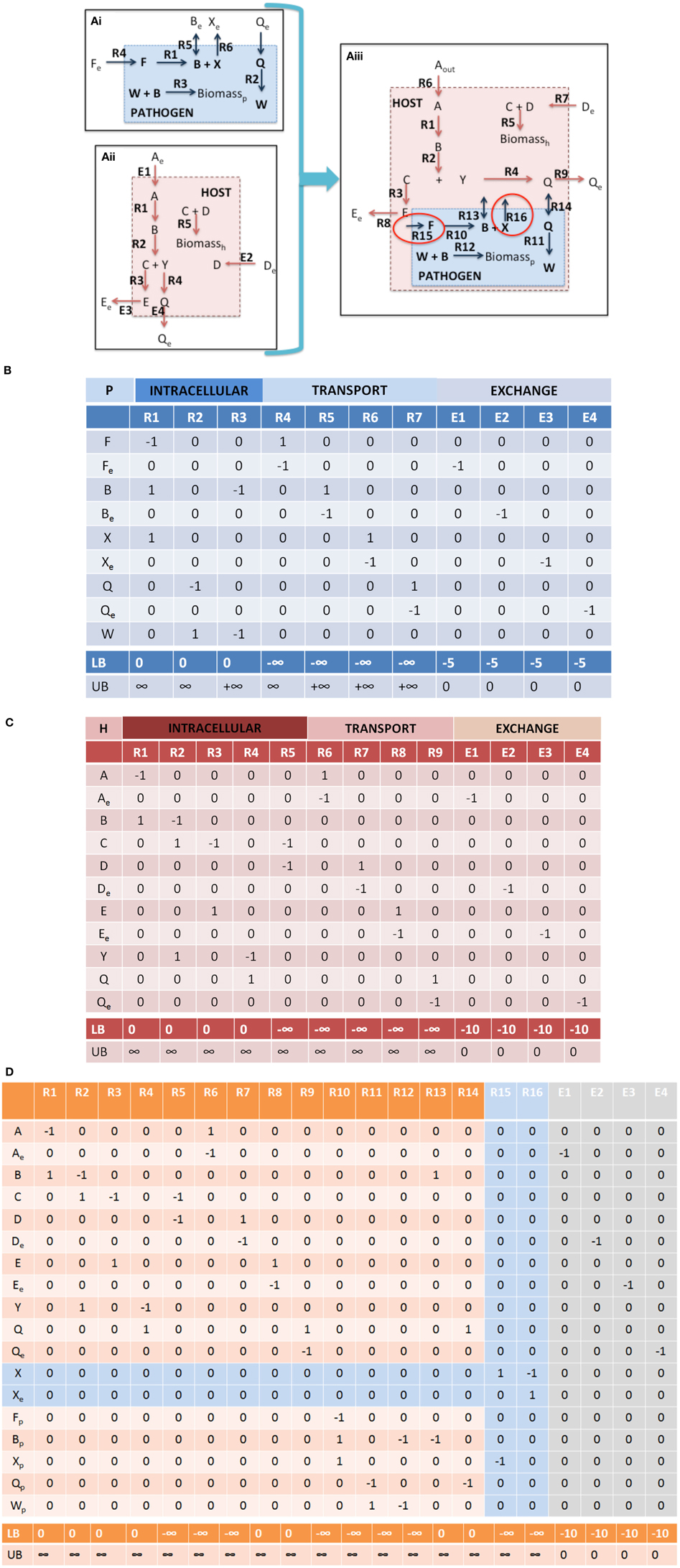
Figure 4. Integration of toy a host cell model with an intracellular pathogen model. (A) depicts a cartoon schematic of a pathogen model, host model, and integrated host-pathogen model with the corresponding stoichiometric matrices for each of the models (B corresponds to Ai, C corresponds to Aii, and D depicts the stoichiometric matrix for the hp network in Aiii). Note that when the pathogen “infects” the host the transporters for metabolites B and Q enable usurpation of host resources and will consequently limit the biomass construction capabilities of the host (potentially the pathogen as well, depending on the size of the demand). In the provided example, metabolites F and X are not within the intracellular environment of the host, thus R10, R15, and R16 will not be able to carry a flux. In spite of this however, since there is a transporter for metabolite B, the pathogen biomass can still be produced even though R10 will not be able to carry a flux. It is also possible that metabolite F and/or X actually are available in the host, but that the particular metabolites were outside the scope of the reconstruction at that time. In this case, the host model can be updated to include the relevant reactions that would make the metabolites available within the intracellular environment. The multiple points within the protocol that would allow for evaluation of the appropriateness of including additional reactions during the iterative revisions, particularly Steps 3.iii, 3.iv, and 4.i. Intracellular organelles are not described in this toy example, however if the pathogen infects the host and resides within a particular organelle within the host cell, the procedure would be the same. Note that the exchange reactions are not explicitly illustrated within the figures, but the columns are present in the stoichiometric matrices.
Although stoichiometric matrix integration of two models is trivial from a technical standpoint, the functional integration of a simulation-capable host and pathogen network reconstruction is a non-trivial process. The panels in Figure 4 provide a concrete illustration of the integration of two toy models.
2.i S matrix merge. The stoichiometric matrices are joined through a compartment specific, row wise-merge (Figure 4). Generally compartment specific reactions (i.e., the compartment in which nutrients are directly exchanged between the host and pathogen) will not be shared between the host and pathogen model, however it is important to confirm this when constructing the new stoichiometric matrix.
Note that Equation 3 is defined by an inequality, whereas Equation (4) is an approximation. The degree of integration and subsequent complexity of the interactions between the models is dependent on the number of metabolites that overlap between the two organisms. If the organisms do not share any metabolites (mhp = mh + mp), then integration of the two models will not result in any novel predictions. On the other hand, the number of reactions in the combined network may be equal to, less than, or greater than the sum of the two individual models. In toy model integration depicted in Figure 4, mp = 9, mh = 11, and mhp = 18, satisfying the Equation (3) inequality. For the toy model, Equation (4) is an equality, since the number of reactions in the combined model is equal to the sum of the individual models.
2.ii New constraints. Integration of two models includes the introduction of additional constraints that will make the simulation environment context specific and more representative of the actual biological environment.
• Nutrient availability and demand. These constraints are the most simple to implement and should provide strong coupling between the host and pathogen. In addition to biomass (growth and non-growth associated constraints), additional condition dependent constraints can be incorporated, for example demands on micronutrients, sequestration of metabolites, etc. (Rodriguez et al., 2002; Pan et al., 2010; Weiss and Schaible, 2015). For example in the toy model (Figure 4), further curation may be needed in order to identify the appropriate bounds for the intracellular pathogen uptake conditions as well as any potential new demands on available host nutrients (not depicted in this example).
• Coupling constraints. The host and pathogen networks will interact by virtue of the compartment specific shared metabolites. However, physiologically, the infection of a host by the pathogen frequently results in additional interdependencies between the two species, such as competition for a shared resource. Coupling constraints are the mathematical relationships formalizing the explicitly link between the host and pathogen models together as a constraint. This relationship may take the form as an interaction between two molecules, concordant activity between two enzymes, or some other biological process. For example,
in which αk is a physiologic constant or data dependent variable (e.g., protein production rates, mRNA expression, etc.). Non-unity coefficients can be added to the reactions, if there is known to be a fixed, stoichiometric balance between the two (or more) reactions. Depending on the type of relationship represented, this relationship can be expressed as a continuous flux based problem, or a discontinuous/discrete problem; the latter would require formulation as a Mixed Integer Linear Programming (MILP) problem (Burgard et al., 2001; Phalakornkule et al., 2001; Pharkya et al., 2004; Kumar and Maranas, 2009). In the case of hp models, MILP constraints may be used to express conditionally active reaction constraints. For example in the toy model depicted in Figure 4, if pathogen growth (i.e., biomass production, Figure 4Aiii, R12) were to only occur if the host cell would take up a particular metabolite (e.g., metabolite D, Figure 4Aiii, R7).
• State changes. To date methodologies for representing changes in infectious states during an infectious cycle or a pathogens life cycle have been represented as discrete, independent simulations. Depending on the type of data that is available, context specific models can be constructed for each different state or alternatively, conditional, state dependent constraints MILP constraints can be defined.
2.iii New objectives. Flux balance analysis is an optimization problem and while there are formulations of the constraint-based modeling problem that do not require the definition of a metabolic objective to be optimized (Lewis et al., 2012), the incorporation of an objective function to be maximized or minimized is often of great utility, since it enables more specific predictions to be made by reducing the size of the steady state solution space (right null space). The definition and identification of objective functions is an area of great importance in these models (particularly mammalian cell models) that is a very rich area for exploration and in need of further development in the current literature (Khannapho et al., 2008; Schuetz et al., 2012; Shoval et al., 2012; Szekely et al., 2013). The flexibility in designing cellular objectives to tailor hp specific responses is critical for achieving success with this approach. The biomass objective function has been discussed in great detail and is generally considered in terms of two general components: a growth associated component (accounting for biomass constituent components) and a non-growth associated component (Feist and Palsson, 2010). The biomass reaction can be treated as a constraint on the system or as a prediction to be made by the model as a means to validate a network reconstruction (Price et al., 2004). Since the growth of the solution space can increase dramatically when two models are merged, defining lower bound constraints on growth associated and non-growth associated biomass functions for the host or pathogen is a practical necessity in order to calculate meaningful results. Organism specific objectives may be developed from the new constraints that are defined or identified experimentally.
The specification of appropriate objective functions requires detailed understanding of pathogen physiology and host pathogen interactions. These can be separated into two general categories, single objective and multi-objective problems (Figure 5). Examples of potential objective functions include but are not restricted to, the (pathogen) biomass pseudo-reaction, iron acquisition (Ratledge and Dover, 2000; Nairz et al., 2015), lactate dehydrogenase levels as a indicator level of cytotoxicity (Korzeniewski and Callewaert, 1983; Decker and Lohmann-Matthes, 1988), enterotoxin production, pathogen specific metabolite production (Glickman et al., 2000; Takayama et al., 2005), reactive oxygen species minimization (Brynildsen et al., 2013), and other critical minerals and metabolites.
Multi-objective functions are more complex, but may reflect a more accurate representation of the biology (Gianchandani et al., 2008; Schuetz et al., 2012; Zakrzewski et al., 2012). The practical challenge is knowledge of the adequate data to specify these objectives.
• Weighted objectives. New objective functions can be constructed from the linear combination of reactions representing cellular demands and requirements. By combining different reactions together to generate “compound” or weighted objectives, more complex behavior can be captured. The obvious weakness of this approach is that the stoichiometric coefficients are fixed for the different components, thus this approach is only applicable in situations in which fluxes (or metabolite production/consumption) occur in fixed ratios with one another (as in biomass).
• Bi-level optimizations across host-pathogen boundaries. Bi-level optimization algorithms designed for bioengineering and evolutionary objectives (Burgard et al., 2003; Zomorrodi and Maranas, 2012) can be extended and applied to understand the dynamics across host and pathogen during an interaction. Depending on the experimental conditions, this may include optimization of pathogen biomass within the host. For example there may be competing objective functions, as in the case of maximization of pathogen biomass and host biomass concurrently or in diametric opposition, i.e., maximization of pathogen biomass with minimization of host substrate availability (either through minimization of pathogen transport uptake or host transport uptake).
• Multi-level optimization. Although, computationally intensive, multi-objective optimization (Zakrzewski et al., 2012; Zomorrodi et al., 2014) can enable a more accurate representation and in turn more accurate mathematical simulation of the host-pathogen interaction.
• Step wise algorithmic multi-objectives i.e., sequential optimizations that apply additional constraints at each iteration. Iterative optimizations are approach for including multilayered omic or physiological constraints allow to be added in order to asses hp behavior in varying environments or host niche's (D'Huys et al., 2012). Such approaches also support the integration of heterogeneous data types. A limitation of this approach is that the optimization is order dependent, and thus may be a more valuable tool for assessing the effects of different constraints as opposed to a more physiological objective.
2.iv Dimensionality assessment. Dimensionality assessment of the network includes determining the size of the network, including the number of metabolites and reactions, as well as the size of the “functional” space of the network, such as the right and left null spaces. These components can be directly calculated from m, n, and the rank of the new stoichiometric matrix Shp. These quantities can be used to calculate the size of the right and left null spaces (Nr = n–R and Nl = m–R). These simple calculations allow assessment of the dimensionality of the new model (in terms of number of components and reactions, as well as the steady state solution space), which will assist in debugging and interpretation of calculated results and simulations (notably Steps 3 and 4). Table 1 summarizes these results for the toy models described in Figure 4. Knowledge of the right null space in particular is useful when debugging potential problems and interpreting simulation results. Integration of the two models results in an increase in the steady state solution space (i.e., at least 1 new independent metabolic pathway) as a result of the integration from the host and pathogen. The left null space contains the conserved chemical moieties within a network (Famili and Palsson, 2003; Sauro and Ingalls, 2004). The size and contents of the left null space can be used to understand how metabolites may pool together based on network structure and often provides functional insights (Famili and Palsson, 2003; Thomas et al., 2014).
Additional graph theoretic measures can be calculated (Girvan and Newman, 2002; Estrada and Rodríguez-Velázquez, 2005; Fatumo et al., 2011), although their utility in assessment of functional characteristics and trouble-shooting in the context of hp model construction is currently limited.
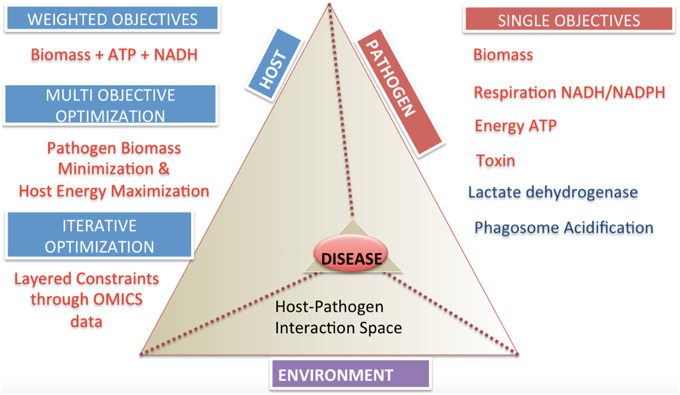
Figure 5. Categories and classifications of objective functions in host-pathogen models. The host-pathogen interaction pyramid is shown that integrates host, pathogen and environment to result in the diseased state phenotype. The diseased state can be queried with the correct formulation of objective functions as discussed for the three components delineated here. The two sides of the triangle represent the host and the pathogen and the connecting side represents the environment or niche. The sides converge on the vertex of the prism reflecting the lethal disease state. The space outside the host pathogen interaction prism lists objectives and their classification. Single objectives help define pathogen or host state, while multi-objectives or weighted objective functions allow definition of complex phenotypes.
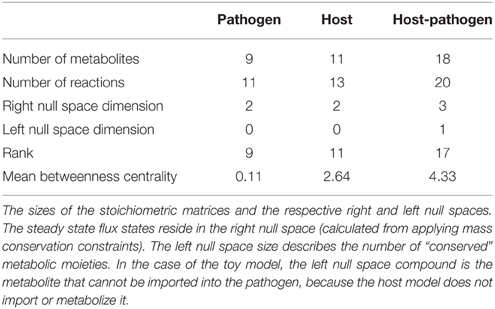
Table 1. Descriptive summary of the toy models.
On the surface, integration of two models is a trivial step given the general simplicity of the basic formulation of constraint-based models. The initial technical challenge is to identify the overlapping set of metabolites and corresponding abbreviation mappings between the host and pathogen metabolites.
Although there are laudable efforts to use standardized nomenclature (Radrich et al., 2010; Dräger and Palsson, 2014), a persistent challenge in the field is the use of different abbreviations and nomenclature, which has often required dedicated efforts to reconcile multiple versions of network reconstructions (Herrgård et al., 2008; Thiele and Palsson, 2010). Fortunately, however, for host pathogen models, every metabolite within the two models does not need to be compared, but rather just the boundary metabolites, which are generally a fraction of the total number of metabolites in a model. This is relatively straightforward through the comparison of abbreviations, if the reconstruction has been appropriately annotated [e.g., molecular formula, SMILES (Weininger, 1988), ChEBI (Degtyarenko et al., 2008), etc.]. Once the shared metabolite complement is identified, the stoichiometric matrices can be merged (Figure 4). However, “blind” integration without proper quality control/quality assurance and test conditions in place, the results will be difficult and quickly overwhelming to interpret.
The first three sub-steps for Step 3 are similar to Step 1. Depending on the type and complexity of new constraints that are applied to the integrated host-pathogen model, there are situations that may introduce behavior that violates mass conservation, thus it is necessary to confirm that no “free metabolites” are produced. For situations in which the pathogen is an intracellular organism, the test needs to be applied to the host-pathogen model, as well as the isolated pathogen, within the host.
3.i Check mass balances. See Step 2. Model Integration, 2.i and Figure 3, 2.i.
3.ii Identify boundary points. Identification of the right null space boundary points through FVA of the host-pathogen draft model will permit a detailed, yet global view of the capabilities of the combined host-pathogen and enable comparisons to the individual organisms (Step 1.ii). This comparison may identify reactions or constraints that may require revisions to be made. For example, upper bounds constraints may need to be increased if the combined model enables the pathogen to exceed the upper limit of some reactions in comparison to the isolated organism. In the case of the toy model illustrated in Figure 4 (integrated host pathogen model), if host's intracellular environment is much richer than the “open” environment for the pathogen and in the infected state, R4 >> R12 (Figure 4Aiii), then the upper bound of R12 may need be increased in order to permit a larger potential rate of biomass accumulation.
3.iii The functionality test suite. The functionality test suite of the combined host-pathogen model will also enable a basis for comparison with 1.iii and assist subsequent analyses (Step 4). Note that the FTS for the individual host and pathogen models may not be identical to the hp set of test reactions, since the metabolic network capabilities of the host and pathogen will not be identical in the infected versus uninfected states.
3.iv Interdependence test This test requires identifying objective functions that are expected to influence or be influenced by the coupling between the host and pathogen. The biomass function is a very good candidate for such tests, as it is connected to many different pathways within each respective organism, and subsequently more likely to be directly connected to the host (or pathogen). The biomass pseudo-reaction, however, is not the only possible objective to test and other cellular/metabolic functions may be of utility, such as ATP production, oxidative phosphorylation, or constraints on secretion/uptake of particular metabolites (Schuetz et al., 2007, 2012; Khannapho et al., 2008; García Saánchez and Torres Sáez, 2014).
The interdependence test involves two steps,
a. Calculate the optimal host biomass production in the host-pathogen model, then fix the lower bound of the host biomass reaction to a specified value (1-ε1) and then optimize for the biomass of the pathogen:
b. Calculate the optimal pathogen biomass production in the host-pathogen model, then fix the lower bound of the pathogen biomass reaction to a specified value (1-ε2) and then optimize for the biomass of the host:
Comparison of α1 to α2 as well as β1 to β2 provides an indication of the degree of coupling between the two models. If α1 ≈ α2 and β1 ≈ β2, then there is no significant coupling between the two models. Conversely, if these values are significantly different from one another then there is evidence of interaction between the models on a metabolic level. It is more common to have uni-directional coupling between the models, often in favor of the pathogen, i.e., β1 ≈ β2 and α1 > α2 due to usurpation of host resources by the pathogen. The ε coefficients are empiric, simulation based parameter whose value will vary depending on the specific organism, the biomass composition, and the media growth conditions. The “ideal” ε will be large enough to force the consumption of metabolites and resources required to produce biomass, but small enough not to introduce a significant bias in the flux state. When the coefficient ε is equal to 0, then the interdependence test is equivalent to a stepwise optimization comparison. Generally the coefficient ε is small, typically 0.01–0.1, when the biomass function is used. A phase portrait analysis (Edwards et al., 2002) may be useful in assessing and determining an appropriate ε value. Since ε is a specified value, the degree of coupling between the host and pathogen can be titrated to a certain degree. Note that since the growth rates of the host and pathogen may be very different from one another, then ε1 and ε2 may be different from one another.
Since the corners of the right null space generally become increasingly acute as the size of the model increases, when the biomass is fixed at the optimum level there is a dramatic decrease in the available alternative solutions. However when this constraint is relaxed even by a small amount, the number of alternative solution points dramatically expands; thus in order to assess robust coupling between the host and pathogen, generally a non-zero ε should be chosen.
For example in the toy model depicted in Figure 4, the pathogen biomass function is dependent on substrates provided by the host. If the uptake of metabolite A (Figure 4Aiii, R6) is unbounded (or not known to have any constraint), then the intra-cellular reproduction of the pathogen is not significantly constrained and independent of the host. However, if the host's uptake of metabolite A is limited, then the pathogen's growth rate will be limited. A common source of error and potential difficulty during the integration of a host and pathogen model is for the pathogen biomass production rate lower bound to be set above the availability of the particular metabolite (i.e., either the host uptake constraints or the host to pathogen transport reactions), which results in a non-functional model. In these cases, the data used for defining the constraints must be re-evaluated and either the constraints would need to be revised or there additional reactions would need to be added to provide alternative routes for availability of the requisite metabolite(s).
The type of simulation of interest is principally dependent on (1) the type of data available, (2) the biological organism of interest, and (3) the data available to validate or test the simulations. Due to the broad scope and scale of the realm of possible simulations, it is not practical to specify a list of calculations that can be applied for every condition. The purpose of this step is to assist in bridging the construction of the model to a meaningful use of the model in the subsequent analysis steps. A common characteristic of the simulation stage however involves evaluation steps and the question of how to reconcile inconsistent results between the model simulations and experimental observations. Suffice it to say that the use of integrated omic data is one of the most successful aspects of constraint-based modeling and there are a number of growing methods being developed for incorporating genomic sequence, transcriptomic, proteomic, and metabolomic data; interested readers are referred to available review articles outlining some of these methods (Blazier and Papin, 2012; Lewis et al., 2012; Wang et al., 2012; Machado and Herrgård, 2014; Robaina Estévez and Nikoloski, 2014). For the purpose of organization and simplifying the debugging process, the simulation tests can be classified into two general areas,
4.i Physiological constraints. Simulations validating (or invalidating) predictions of the model using available physiologic data sets.
4.ii Omic constraints. Simulations validating (or invalidating) predictions of the hp model through omic data sets.
“Failure” of specific steps in the protocol (Figure 3) requires an iterative adjustment to be made through revision of the original models, the integration step, or in some cases further literature curation and updating of model content or constraints.
1.i Check mass balances (individual models). Failure: Return to Step 1 (or before). If either the host or the pathogen model result in violation of mass conservation constraints, then the respective model needs to be critically evaluated and debugged, so that the offending reaction(s) is/are identified and removed or adjusted appropriately. The appropriate definition and representation of system boundaries is a simple, yet critical step. Consequences of undefined or inappropriately defined system boundaries will lead to an ill-formulated model that will likely result in mass balance errors. The cartoon illustration in Figure 2 highlights the appropriate definition of system boundaries when before and after integration of a host with a pathogen reconstruction. The most direct and common consequence of poorly defined boundaries is an ill-formulated description of the optimization problem with subsequent errors in mass balance, resulting in irrelevant and even non-sensical results.
Failure: Return to Step 2.i. “Failure” of this step constitutes violation of Equation (3). When merging two (or more reconstructions) there must be a mapping between metabolites that are shared by each of the two models. At minimum there must be at least 1 metabolite that is shared between each model, although in practice there are generally at least 30–40 metabolites that are shared. Once compartment specific identification of shared metabolites has been performed, then the two sets of models can be merged through merging the stoichiometric matrices “row-wise.” If mh + mp = mhp, then there has likely been an error in integration [either through formulation of the problem (Step 1) or implementation of the matrix merge (Step 2.i)]. As noted above, in general, nhp ≈ nh + np, with the approximation being dependent on whether additional constraints or new objective reactions are added in the integrated network.
Failure: Return to 2.i. If the integrated host-pathogen model results in violation of mass conservation, but the individual models did not, then there was an error in the model integration (Steps 2.i-2.iii). Evaluation of the boundary exchanges of the pathogen should be the first area of critical evaluation.
Failure: Return to 1.iii. Depending on the type of error and the type of functional test, this may be “real” or it may reflect incomplete knowledge (such as an incompletely defined biomass function). Failures in the FTS should be analyzed to determine the source of the limited constraint (the FVA calculations 3.ii can be helpful in tracking this within the network). Once the cause of the failure is identified, it needs to be determined if this is the result of erroneous reaction constraints or a real prediction (i.e., a reaction that is active in the “uninfected” state but is inactive in the infected state). Referral to the primary literature is frequently needed to resolve these issues.
Failure: Return to Step 1 and 2.ii. The lack of interdependence may require revision of the model(s) (through additional curation and scope expansion) and/or re-assessment of the new constraints and objective functions that were added. For example, in the toy model depicted in Figure 4Aiii, further evaluation of the literature may suggest that R15 and/or R16 are active in the pathogen during infections, which would require further evaluation as to how metabolites F and/or X, respectively are made available to the pathogen inside the host cell.
Inconsistencies between model predictions and observed experimental results or invalidating predictions should first be assessed in terms of the model and how the specific prediction was made, i.e., identification of the specific pathways leading to the calculated results. If there is no evidence to suggest a model related or numerical error, then there will need to be further perusal of the literature. For example in Figure 4Aiii, if there is biochemical or physiologic evidence in the literature suggesting that biochemical transformation carried out by R10 should be active (and able to carry a flux) in the infected state, then there needs to be further evaluation of the literature to determine how metabolite F is taken into the cell, or if there exists an alternative pathway for production of metabolite F within the pathogen (or host). This example also highlights the need for multiple iterative steps that often necessitate re-evaluation of the primary literature. In this case, the pathogen is still able to grow within the host, so there were no errors in Steps 3.i, 3.ii, 3.iii, or 3.iv (assuming that R10 was not contained in the FTS). This example is also illustrative of the need for the multiple checkpoints in the protocol (Figure 3) and the necessity of re-evaluating results and possibly revising the model(s) at each step of the integration process.
The systematic procedure described above enables construction of host-pathogen constraint-based models that is applicable to organisms ranging from obligate parasites to multi-cellular pathogens, including viruses, bacteria, and fungi. The methods described above are most directly relevant and applicable to bacterial and fungal organisms. Viruses and parasitic organisms each demonstrate characteristics that may require further considerations, particularly with respect to conditional (e.g., transcription) dependent constraints. Some parasites are multi-cellular organisms that are capable of residing in multiple tissues within a host, thus the challenge by some of these organisms will require the integration of multiple, multi-cellular models. This process will be more involved, but will include the same systematic process. One should recognize the importance of “buffering” compartments and should include them, as they may play an important role in balancing protons, water, phosphate, etc.
Achievement of the steps outlined in Figure 3 will result in a functional host-pathogen model that should represent a more biologically accurate, quantitative, simulatable description of the interaction between a host and pathogen (Figure 5), in turn enabling a more objective, quantitative assessment of the interactions between these cells. Interrogation of these hp models would allow probing pathogen adaptation and carbon source utilization in vivo and host manipulation by pathogen. Such models should then be used to answer questions regarding causality during the infection process, condition dependent (or context specific) differences, and ultimately advance diagnosis and treatment related challenges by providing an environment to evaluate and generate hypothesis as well as interpret and analyze data.
The ability to measure and represent data on a genome-scale and the development of constraints based modeling strategies can help explore the complex host-pathogen interaction space (Figure 5). While the methods have reached a degree of maturity that enable the application to a wide range of conditions, there still remain many areas that deserve further exploration, including more elegant representation of changes in the environment (e.g., pH changes between different compartments and the associated charge changes that may occur with certain species) as well as more fluid descriptions in the transitions between different growth stages (e.g., rather than static representations for each stage, developing the analog of kinetic models, in which the change from one state to another can be simulated).
The process of host infection is complex and future developments will build upon studies that have, for example, investigated immune responsive signaling pathways such as the Toll-like receptor (Li et al., 2009) as well as the dynamics of pathogen metabolism (Penkler et al., 2015). With continual developments in approaches to expand the scope of reconstructions (Thiele et al., 2009; Lerman et al., 2012) and the development of new methods and approaches for generating genome scale network reconstructions (Overbeek et al., 2005; Henry et al., 2010; Monk et al., 2013), it is anticipated that there will be a dramatic rise in the development of hp models. Ultimately the objective of integrative constraint-based methods is to develop new strategies for treatment of pathogenic infections through novel target identification and new combination therapies for treatment (Trawick and Schilling, 2006; Jamshidi and Palsson, 2007; Karlsson et al., 2011; Chavali et al., 2012).
Constraint-based modeling allows meeting the challenge of complex omic data integration across time and space at multiple levels of hierarchy in the reductionist causal chain to shrink and explore the solution space of host-pathogen interaction. On a genome-scale, multi-cellular level, constraint-based hp modeling has great potential for the prediction of resultant physiologically perturbed cellular states. Implementation across these hierarchical levels of resolution (individual metabolites to mulit-cellular inter-species interactions) at several levels of abstraction will hopefully lead to further elucidation of the metabolic underpinnings of the acute and chronic process of infection, emergent mechanisms of pathogenesis, and therapeutic strategies to counteract such changes.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
h, a host model; p, a pathogen model; hp, a host-pathogen model; BM,h, host biomass pseudo-reaction; BM,p, pathogen biomass pseudo-reaction; S, the stoichiometric matrix for a metabolic network; v, flux vector in a metabolic network; x, metabolite vector in a metabolic network; m, the number of unique, compartment specific metabolites in a stoichiometric matrix, i.e., |x|; n, the number of unique, compartment specific reaction fluxes in a metabolic network, i.e., |v|; R, rank of the stoichiometric matrix; Nr, size of the right null space; Nl, size of the right null space; α, biomass optimum of host model; β, biomass optimum of pathogen model; ϵ, simulation constant for setting lower bound minimum of biomass production.
Ahn, S. Y., Jamshidi, N., Mo, M. L., Wu, W., Eraly, S. A., Dnyanmote, A., et al. (2011). Linkage of organic anion transporter-1 to metabolic pathways through integrated “omics”-driven network and functional analysis. J. Biol. Chem. 286, 31522–31531. doi: 10.1074/jbc.M111.272534
Barrett, C. L., Price, N. D., and Palsson, B. O. (2006). Network-level analysis of metabolic regulation in the human red blood cell using random sampling and singular value decomposition. BMC Bioinformatics 7:132. doi: 10.1186/1471-2105-7-132
Bazzani, S., Hoppe, A., and Holzhütter, H. G. (2012). Network-based assessment of the selectivity of metabolic drug targets in Plasmodium falciparum with respect to human liver metabolism. BMC Syst. Biol. 6:118. doi: 10.1186/1752-0509-6-118
Beg, Q. K., Vazquez, A., Ernst, J., de Menezes, M. A., Bar-Joseph, Z., Barabási, A. L., et al. (2007). Intracellular crowding defines the mode and sequence of substrate uptake by Escherichia coli and constrains its metabolic activity. Proc. Natl. Acad. Sci. U.S.A. 104, 12663–12668. doi: 10.1073/pnas.0609845104
Beste, D. J., Nöh, K., Niedenführ, S., Mendum, T. A., Hawkins, N. D., Ward, J. L., et al. (2013). 13C-flux spectral analysis of host-pathogen metabolism reveals a mixed diet for intracellular Mycobacterium tuberculosis. Chem. Biol. 20, 1012–1021. doi: 10.1016/j.chembiol.2013.06.012
Blazier, A. S., and Papin, J. A. (2012). Integration of expression data in genome-scale metabolic network reconstructions. Front. Physiol. 3:299. doi: 10.3389/fphys.2012.00299
Bordbar, A., Feist, A. M., Usaite-Black, R., Woodcock, J., Palsson, B. O., and Famili, I. (2011). A multi-tissue type genome-scale metabolic network for analysis of whole-body systems physiology. BMC Syst. Biol. 5:180. doi: 10.1186/1752-0509-5-180
Bordbar, A., Lewis, N. E., Schellenberger, J., Palsson, B. Ø., and Jamshidi, N. (2010). Insight into human alveolar macrophage and M. tuberculosis interactions via metabolic reconstructions. Mol. Syst. Biol. 6:422. doi: 10.1038/msb.2010.68
Bordel, S., Agren, R., and Nielsen, J. (2010). Sampling the solution space in genome-scale metabolic networks reveals transcriptional regulation in key enzymes. PLoS Comput. Biol. 6:e1000859. doi: 10.1371/journal.pcbi.1000859
Brynildsen, M. P., Winkler, J. A., Spina, C. S., MacDonald, I. C., and Collins, J. J. (2013). Potentiating antibacterial activity by predictably enhancing endogenous microbial ROS production. Nat. Biotechnol. 31, 160–165. doi: 10.1038/nbt.2458
Burgard, A. P., Pharkya, P., and Maranas, C. D. (2003). Optknock: a bilevel programming framework for identifying gene knockout strategies for microbial strain optimization. Biotechnol. Bioeng. 84, 647–657. doi: 10.1002/bit.10803
Burgard, A. P., Vaidyaraman, S., and Maranas, C. D. (2001). Minimal reaction sets for Escherichia coli metabolism under different growth requirements and uptake environments. Biotechnol. Prog. 17, 791–797. doi: 10.1021/bp0100880
Cakir, T., Patil, K. R., Onsan, Z., Ulgen, K. O., Kirdar, B., and Nielsen, J. (2006). Integration of metabolome data with metabolic networks reveals reporter reactions. Mol. Syst. Biol. 2, 50. doi: 10.1038/msb4100085
Chang, H. H., Cohen, T., Grad, Y. H., Hanage, W. P., O'Brien, T. F., and Lipsitch, M. (2015). Origin and proliferation of multiple-drug resistance in bacterial pathogens. Microbiol. Mol. Biol. Rev. 79, 101–116. doi: 10.1128/MMBR.00039-14
Chang, R. L., Ghamsari, L., Manichaikul, A., Hom, E. F., Balaji, S., Fu, W., et al. (2011). Metabolic network reconstruction of Chlamydomonas offers insight into light-driven algal metabolism. Mol. Syst. Biol. 7, 518. doi: 10.1038/msb.2011.52
Chavali, A. K., D'Auria, K. M., Hewlett, E. L., Pearson, R. D., and Papin, J. A. (2012). A metabolic network approach for the identification and prioritization of antimicrobial drug targets. Trends Microbiol. 20, 113–123. doi: 10.1016/j.tim.2011.12.004
Chavali, A. K., Whittemore, J. D., Eddy, J. A., Williams, K. T., and Papin, J. A. (2008). Systems analysis of metabolism in the pathogenic trypanosomatid Leishmania major. Mol. Syst. Biol. 4, 177. doi: 10.1038/msb.2008.15
Deatherage Kaiser, B. L., Li, J., Sanford, J. A., Kim, Y. M., Kronewitter, S. R., Jones, M. B., et al. (2013). A multi-omic view of host-pathogen-commensal interplay in -mediated intestinal infection. PLoS ONE 8:e67155. doi: 10.1371/journal.pone.0067155
Decker, T., and Lohmann-Matthes, M. L. (1988). A quick and simple method for the quantitation of lactate dehydrogenase release in measurements of cellular cytotoxicity and tumor necrosis factor (TNF) activity. J. Immunol. Methods 115, 61–69. doi: 10.1016/0022-1759(88)90310-9
Degtyarenko, K., de Matos, P., Ennis, M., Hastings, J., Zbinden, M., McNaught, A., et al. (2008). ChEBI: a database and ontology for chemical entities of biological interest. Nucleic Acids Res. 36, D344–D350. doi: 10.1093/nar/gkm791
D'Huys, P. J., Lule, I., Vercammen, D., Anné, J., Van Impe, J. F., and Bernaerts, K. (2012). Genome-scale metabolic flux analysis of Streptomyces lividans growing on a complex medium. J. Biotechnol. 161, 1–13. doi: 10.1016/j.jbiotec.2012.04.010
Dräger, A., and Palsson, B. Ø. (2014). Improving collaboration by standardization efforts in systems biology. Front. Bioeng. Biotechnol. 2:61. doi: 10.3389/fbioe.2014.00061
Duarte, N. C., Becker, S. A., Jamshidi, N., Thiele, I., Mo, M. L., Vo, T. D., et al. (2007). Global reconstruction of the human metabolic network based on genomic and bibliomic data. Proc. Natl. Acad. Sci. U.S.A. 104, 1777–1782. doi: 10.1073/pnas.0610772104
Durmuş, S., Çakir, T., Özgür, A., and Guthke, R. (2015). A review on computational systems biology of pathogen-host interactions. Front. Microbiol. 6:235. doi: 10.3389/fmicb.2015.00235
Ebrahim, A., Lerman, J. A., Palsson, B. O., and Hyduke, D. R. (2013). COBRApy: COnstraints-Based Reconstruction and Analysis for Python. BMC Syst. Biol. 7:74. doi: 10.1186/1752-0509-7-74
Edwards, J. S., Ramakrishna, R., and Palsson, B. Ø. (2002). Characterizing the metabolic phenotype: a phenotype phase plane analysis. Biotechnol. Bioeng. 77, 27–36. doi: 10.1002/bit.10047
Ellis, T., Wang, X., and Collins, J. J. (2009). Diversity-based, model-guided construction of synthetic gene networks with predicted functions. Nat. Biotechnol. 27, 465–471. doi: 10.1038/nbt.1536
Estrada, E., and Rodríguez-Velázquez, J. A. (2005). Subgraph centrality in complex networks. Phys. Rev. E Stat. Nonlin. Soft Matter Phys. 71:056103. doi: 10.1103/PhysRevE.71.056103
Famili, I., and Palsson, B. O. (2003). The convex basis of the left null space of the stoichiometric matrix leads to the definition of metabolically meaningful pools. Biophys. J. 85, 16–26. doi: 10.1016/S0006-3495(03)74450-6
Fatumo, S., Plaimas, K., Adebiyi, E., and Konig, R. (2011). Comparing metabolic network models based on genomic and automatically inferred enzyme information from Plasmodium and its human host to define drug targets in silico. Infect. Genet. Evol. 11, 708–715. doi: 10.1016/j.meegid.2011.04.013
Feist, A. M., Herrgård, M. J., Thiele, I., Reed, J. L., and Palsson, B. Ø. (2009). Reconstruction of biochemical networks in microorganisms. Nat. Rev. Microbiol. 7, 129–143. doi: 10.1038/nrmicro1949
Feist, A. M., and Palsson, B. O. (2010). The biomass objective function. Curr. Opin. Microbiol. 13, 344–349. doi: 10.1016/j.mib.2010.03.003
Fell, D. A., and Small, J. R. (1986). Fat synthesis in adipose tissue. An examination of stoichiometric constraints. Biochem. J. 238, 781–786. doi: 10.1042/bj2380781
Frezza, C., Zheng, L., Folger, O., Rajagopalan, K. N., MacKenzie, E. D., Jerby, L., et al. (2011). Haem oxygenase is synthetically lethal with the tumour suppressor fumarate hydratase. Nature 477, 225–228. doi: 10.1038/nature10363
García Saánchez, C. E., and Torres Sáez, R. G. (2014). Comparison and analysis of objective functions in flux balance analysis. Biotechnol. Prog. 30, 985–991. doi: 10.1002/btpr.1949
Gawronski, J. D., Wong, S. M., Giannoukos, G., Ward, D. V., and Akerley, B. J. (2009). Tracking insertion mutants within libraries by deep sequencing and a genome-wide screen for Haemophilus genes required in the lung. Proc. Natl. Acad. Sci. U.S.A. 106, 16422–16427. doi: 10.1073/pnas.0906627106
Gianchandani, E. P., Oberhardt, M. A., Burgard, A. P., Maranas, C. D., and Papin, J. A. (2008). Predicting biological system objectives de novo from internal state measurements. BMC Bioinformatics 9:43. doi: 10.1186/1471-2105-9-43
Girvan, M., and Newman, M. E. (2002). Community structure in social and biological networks. Proc. Natl. Acad. Sci. U.S.A. 99, 7821–7826. doi: 10.1073/pnas.122653799
Glickman, M. S., Cox, J. S., and Jacobs, W. R. Jr. (2000). A novel mycolic acid cyclopropane synthetase is required for cording, persistence, and virulence of Mycobacterium tuberculosis. Mol. Cell 5, 717–727. doi: 10.1016/S1097-2765(00)80250-6
Han, J., Antunes, L. C., Finlay, B. B., and Borchers, C. H. (2010). Metabolomics: towards understanding host-microbe interactions. Future Microbiol. 5, 153–161. doi: 10.2217/fmb.09.132
Harcombe, W. R., Riehl, W. J., Dukovski, I., Granger, B. R., Betts, A., Lang, A. H., et al. (2014). Metabolic resource allocation in individual microbes determines ecosystem interactions and spatial dynamics. Cell Rep. 7, 1104–1115. doi: 10.1016/j.celrep.2014.03.070
Henningham, A., Döhrmann, S., Nizet, V., and Cole, J. N. (2015). Mechanisms of group A Streptococcus resistance to reactive oxygen species. FEMS Microbiol. Rev. 39, 488–508. doi: 10.1093/femsre/fuu009
Henry, C. S., DeJongh, M., Best, A. A., Frybarger, P. M., Linsay, B., and Stevens, R. L. (2010). High-throughput generation, optimization and analysis of genome-scale metabolic models. Nat. Biotechnol. 28, 977–982. doi: 10.1038/nbt.1672
Herrgård, M. J., Swainston, N., Dobson, P., Dunn, W. B., Arga, K. Y., Arvas, M., et al. (2008). A consensus yeast metabolic network reconstruction obtained from a community approach to systems biology. Nat. Biotechnol. 26, 1155–1160. doi: 10.1038/nbt1492
Huthmacher, C., Hoppe, A., Bulik, S., and Holzhutter, H. G. (2010). Antimalarial drug targets in Plasmodium falciparum predicted by stage-specific metabolic network analysis. BMC Syst. Biol. 4:120. doi: 10.1186/1752-0509-4-120
Jamshidi, N., and Palsson, B. Ø. (2007). Investigating the metabolic capabilities of Mycobacterium tuberculosis H37Rv using the in silico strain iNJ661 and proposing alternative drug targets. BMC Syst. Biol. 1:26. doi: 10.1186/1752-0509-1-26
Kafsack, B. F., and Llinás, M. (2010). Eating at the table of another: metabolomics of host-parasite interactions. Cell Host Microbe 7, 90–99. doi: 10.1016/j.chom.2010.01.008
Karlsson, F. H., Nookaew, I., Petranovic, D., and Nielsen, J. (2011). Prospects for systems biology and modeling of the gut microbiome. Trends Biotechnol. 29, 251–258. doi: 10.1016/j.tibtech.2011.01.009
Khannapho, C., Zhao, H., Bonde, B. K., Kierzek, A. M., Avignone-Rossa, C. A., and Bushell, M. E. (2008). Selection of objective function in genome scale flux balance analysis for process feed development in antibiotic production. Metab. Eng. 10, 227–233. doi: 10.1016/j.ymben.2008.06.003
Kim, K., and Weiss, L. M. (2008). Toxoplasma: the next 100years. Microbes Infect. 10, 978–984. doi: 10.1016/j.micinf.2008.07.015
Kim, Y. M., Schmidt, B. J., Kidwai, A. S., Jones, M. B., Deatherage Kaiser, B. L., Brewer, H. M., et al. (2013). Salmonella modulates metabolism during growth under conditions that induce expression of virulence genes. Mol. Biosyst. 9, 1522–1534. doi: 10.1039/c3mb25598k
Korzeniewski, C., and Callewaert, D. M. (1983). An enzyme-release assay for natural cytotoxicity. J. Immunol. Methods 64, 313–320. doi: 10.1016/0022-1759(83)90438-6
Kumar, V. S., and Maranas, C. D. (2009). GrowMatch: an automated method for reconciling in silico/in vivo growth predictions. PLoS Comput. Biol. 5:e1000308. doi: 10.1371/journal.pcbi.1000308
Kümmel, A., Panke, S., and Heinemann, M. (2006a). Putative regulatory sites unraveled by network-embedded thermodynamic analysis of metabolome data. Mol. Syst. Biol. 2, 0034. doi: 10.1038/msb4100074
Kümmel, A., Panke, S., and Heinemann, M. (2006b). Systematic assignment of thermodynamic constraints in metabolic network models. BMC Bioinformatics 7:512. doi: 10.1186/1471-2105-7-512
Le Chevalier, F., Cascioferro, A., Majlessi, L., Herrmann, J. L., and Brosch, R. (2014). Mycobacterium tuberculosis evolutionary pathogenesis and its putative impact on drug development. Future Microbiol. 9, 969–985. doi: 10.2217/fmb.14.70
Lerman, J. A., Hyduke, D. R., Latif, H., Portnoy, V. A., Lewis, N. E., Orth, J. D., et al. (2012). In silico method for modelling metabolism and gene product expression at genome scale. Nat. Commun. 3, 929. doi: 10.1038/ncomms1928
Lewis, N. E., Nagarajan, H., and Palsson, B. O. (2012). Constraining the metabolic genotype-phenotype relationship using a phylogeny of in silico methods. Nat. Rev. Microbiol. 10, 291–305. doi: 10.1038/nrmicro2737
Lewis, N. E., Schramm, G., Bordbar, A., Schellenberger, J., Andersen, M. P., Cheng, J. K., et al. (2010). Large-scale in silico modeling of metabolic interactions between cell types in the human brain. Nat. Biotechnol. 28, 1279–1285. doi: 10.1038/nbt.1711
Li, F., Thiele, I., Jamshidi, N., and Palsson, B. Ø. (2009). Identification of potential pathway mediation targets in Toll-like receptor signaling. PLoS Comput. Biol. 5:e1000292. doi: 10.1371/annotation/5cc0d918-83b8-44e4-9778-b96a249d4099
Liao, Y. C., Tsai, M. H., Chen, F. C., and Hsiung, C. A. (2012). GEMSiRV: a software platform for GEnome-scale metabolic model simulation, reconstruction and visualization. Bioinformatics 28, 1752–1758. doi: 10.1093/bioinformatics/bts267
Machado, D., and Herrgård, M. (2014). Systematic evaluation of methods for integration of transcriptomic data into constraint-based models of metabolism. PLoS Comput. Biol. 10, e1003580. doi: 10.1371/journal.pcbi.1003580
Mahadevan, R., and Schilling, C. H. (2003). The effects of alternate optimal solutions in constraint-based genome-scale metabolic models. Metab. Eng. 5, 264–276. doi: 10.1016/j.ymben.2003.09.002
McAdam, P. R., Richardson, E. J., and Fitzgerald, J. R. (2014). High-throughput sequencing for the study of bacterial pathogen biology. Curr. Opin. Microbiol. 19, 106–113. doi: 10.1016/j.mib.2014.06.002
Mcconville, M. (2014). Open questions: microbes, metabolism and host-pathogen interactions. BMC Biol. 12:18. doi: 10.1186/1741-7007-12-18
Metris, A., George, S., and Baranyi, J. (2012). Modelling osmotic stress by Flux Balance Analysis at the genomic scale. Int. J. Food Microbiol. 152, 123–128. doi: 10.1016/j.ijfoodmicro.2011.06.016
Mintz-Oron, S., Meir, S., Malitsky, S., Ruppin, E., Aharoni, A., and Shlomi, T. (2012). Reconstruction of Arabidopsis metabolic network models accounting for subcellular compartmentalization and tissue-specificity. Proc. Natl. Acad. Sci. U.S.A. 109, 339–344. doi: 10.1073/pnas.1100358109
Mo, M. L., Jamshidi, N., and Palsson, B. Ø. (2007). A genome-scale, constraint-based approach to systems biology of human metabolism. Mol. Biosyst. 3, 598–603. doi: 10.1039/b705597h
Monk, J. M., Charusanti, P., Aziz, R. K., Lerman, J. A., Premyodhin, N., Orth, J. D., et al. (2013). Genome-scale metabolic reconstructions of multiple Escherichia coli strains highlight strain-specific adaptations to nutritional environments. Proc. Natl. Acad. Sci. U.S.A. 110, 20338–20343. doi: 10.1073/pnas.1307797110
Nairz, M., Ferring-Appel, D., Casarrubea, D., Sonnweber, T., Viatte, L., Schroll, A., et al. (2015). Iron regulatory proteins mediate host resistance to salmonella infection. Cell Host Microbe 18, 254–261. doi: 10.1016/j.chom.2015.06.017
Orth, J. D., Thiele, I., and Palsson, B. Ø. (2010). What is flux balance analysis? Nat. Biotechnol. 28, 245–248. doi: 10.1038/nbt.1614
Osterlund, T., Nookaew, I., and Nielsen, J. (2012). Fifteen years of large scale metabolic modeling of yeast: developments and impacts. Biotechnol. Adv. 30, 979–988. doi: 10.1016/j.biotechadv.2011.07.021
Overbeek, R., Begley, T., Butler, R. M., Choudhuri, J. V., Chuang, H. Y., Cohoon, M., et al. (2005). The subsystems approach to genome annotation and its use in the project to annotate 1000 genomes. Nucleic Acids Res. 33, 5691–5702. doi: 10.1093/nar/gki866
Pacchiarotta, T., Deelder, A. M., and Mayboroda, O. A. (2012). Metabolomic investigations of human infections. Bioanalysis 4, 919–925. doi: 10.4155/bio.12.61
Palsson, B. (2015). Systems Biology: Constraint-based Reconstruction and Analysis. Cambridge: Cambridge University Press.
Pan, X., Tamilselvam, B., Hansen, E. J., and Daefler, S. (2010). Modulation of iron homeostasis in macrophages by bacterial intracellular pathogens. BMC Microbiol. 10:64. doi: 10.1186/1471-2180-10-64
Papoutsakis, E. T. (1984). Equations and calculations for fermentations of butyric acid bacteria. Biotechnol. Bioeng. 26, 174–187. doi: 10.1002/bit.260260210
Penkler, G., Du Toit, F., Adams, W., Rautenbach, M., Palm, D. C., Van Niekerk, D. D., et al. (2015). Construction and validation of a detailed kinetic model of glycolysis in Plasmodium falciparum. FEBS J. 282, 1481–1511. doi: 10.1111/febs.13237
Phalakornkule, C., Lee, S., Zhu, T., Koepsel, R., Ataai, M. M., Grossmann, I. E., et al. (2001). A MILP-based flux alternative generation and NMR experimental design strategy for metabolic engineering. Metab. Eng. 3, 124–137. doi: 10.1006/mben.2000.0165
Pharkya, P., Burgard, A. P., and Maranas, C. D. (2004). OptStrain: a computational framework for redesign of microbial production systems. Genome Res. 14, 2367–2376. doi: 10.1101/gr.2872004
Pornputtapong, N., Nookaew, I., and Nielsen, J. (2015). Human metabolic atlas: an online resource for human metabolism. Database (Oxford) 2015, bav068. doi: 10.1093/database/bav068
Price, N. D., Reed, J. L., and Palsson, B. Ø. (2004). Genome-scale models of microbial cells: evaluating the consequences of constraints. Nat. Rev. Microbiol. 2, 886–897. doi: 10.1038/nrmicro1023
Radrich, K., Tsuruoka, Y., Dobson, P., Gevorgyan, A., Swainston, N., Baart, G., et al. (2010). Integration of metabolic databases for the reconstruction of genome-scale metabolic networks. BMC Syst. Biol. 4:114. doi: 10.1186/1752-0509-4-114
Raghunathan, A., Reed, J., Shin, S., Palsson, B., and Daefler, S. (2009). Constraint-based analysis of metabolic capacity of Salmonella typhimurium during host-pathogen interaction. BMC Syst. Biol. 3:38. doi: 10.1186/1752-0509-3-38
Raghunathan, A., Shin, S., and Daefler, S. (2010). Systems approach to investigating host-pathogen interactions in infections with the biothreat agent Francisella. Constraints-based model of Francisella tularensis. BMC Syst Biol 4:118. doi: 10.1186/1752-0509-4-118
Ratledge, C., and Dover, L. G. (2000). Iron metabolism in pathogenic bacteria. Annu. Rev. Microbiol. 54, 881–941. doi: 10.1146/annurev.micro.54.1.881
Reed, J. L., and Palsson, B. Ø. (2003). Thirteen years of building constraint-based in silico models of Escherichia coli. J. Bacteriol. 185, 2692–2699. doi: 10.1128/JB.185.9.2692-2699.2003
Robaina Estévez, S., and Nikoloski, Z. (2014). Generalized framework for context-specific metabolic model extraction methods. Front. Plant Sci. 5:491. doi: 10.3389/fpls.2014.00491
Rodriguez, G. M., Voskuil, M. I., Gold, B., Schoolnik, G. K., and Smith, I. (2002). ideR, An essential gene in mycobacterium tuberculosis: role of IdeR in iron-dependent gene expression, iron metabolism, and oxidative stress response. Infect. Immun. 70, 3371–3381. doi: 10.1128/IAI.70.7.3371-3381.2002
Sadhukhan, P. P., and Raghunathan, A. (2014). Investigating host-pathogen behavior and their interaction using genome-scale metabolic network models. Methods Mol. Biol. 1184, 523–562. doi: 10.1007/978-1-4939-1115-8_29
Saha, R., Suthers, P. F., and Maranas, C. D. (2011). Zea mays iRS1563: a comprehensive genome-scale metabolic reconstruction of maize metabolism. PLoS ONE 6:e21784. doi: 10.1371/journal.pone.0021784
Sauro, H. M., and Ingalls, B. (2004). Conservation analysis in biochemical networks: computational issues for software writers. Biophys. Chem. 109, 1–15. doi: 10.1016/j.bpc.2003.08.009
Savinell, J. M., and Palsson, B. O. (1992). Optimal selection of metabolic fluxes for in vivo measurement. I. Development of mathematical methods. J. Theor. Biol. 155, 201–214. doi: 10.1016/S0022-5193(05)80595-8
Schellenberger, J., and Palsson, B. Ø. (2009). Use of randomized sampling for analysis of metabolic networks. J. Biol. Chem. 284, 5457–5461. doi: 10.1074/jbc.R800048200
Schellenberger, J., Que, R., Fleming, R. M., Thiele, I., Orth, J. D., Feist, A. M., et al. (2011). Quantitative prediction of cellular metabolism with constraint-based models: the COBRA Toolbox v2.0. Nat. Protoc. 6, 1290–1307. doi: 10.1038/nprot.2011.308
Schoen, C., Kischkies, L., Elias, J., and Ampattu, B. J. (2014). Metabolism and virulence in Neisseria meningitidis. Front. Cell. Infect. Microbiol. 4:114. doi: 10.3389/fcimb.2014.00114
Schuetz, R., Kuepfer, L., and Sauer, U. (2007). Systematic evaluation of objective functions for predicting intracellular fluxes in Escherichia coli. Mol. Syst. Biol. 3, 119. doi: 10.1038/msb4100162
Schuetz, R., Zamboni, N., Zampieri, M., Heinemann, M., and Sauer, U. (2012). Multidimensional optimality of microbial metabolism. Science 336, 601–604. doi: 10.1126/science.1216882
Seaver, S. M., Henry, C. S., and Hanson, A. D. (2012). Frontiers in metabolic reconstruction and modeling of plant genomes. J. Exp. Bot. 63, 2247–2258. doi: 10.1093/jxb/err371
Shoaie, S., and Nielsen, J. (2014). Elucidating the interactions between the human gut microbiota and its host through metabolic modeling. Front. Genet. 5:86. doi: 10.3389/fgene.2014.00086
Shoval, O., Sheftel, H., Shinar, G., Hart, Y., Ramote, O., Mayo, A., et al. (2012). Evolutionary trade-offs, Pareto optimality, and the geometry of phenotype space. Science 336, 1157–1160. doi: 10.1126/science.1217405
Stavrinides, J., McCann, H. C., and Guttman, D. S. (2008). Host-pathogen interplay and the evolution of bacterial effectors. Cell. Microbiol. 10, 285–292. doi: 10.1111/j.1462-5822.2007.01078.x
Stolyar, S., Van Dien, S., Hillesland, K. L., Pinel, N., Lie, T. J., Leigh, J. A., et al. (2007). Metabolic modeling of a mutualistic microbial community. Mol. Syst. Biol. 3, 92. doi: 10.1038/msb4100131
Szekely, P., Sheftel, H., Mayo, A., and Alon, U. (2013). Evolutionary tradeoffs between economy and effectiveness in biological homeostasis systems. PLoS Comput. Biol. 9:e1003163. doi: 10.1371/journal.pcbi.1003163
Takayama, K., Wang, C., and Besra, G. S. (2005). Pathway to synthesis and processing of mycolic acids in Mycobacterium tuberculosis. Clin. Microbiol. Rev. 18, 81–101. doi: 10.1128/CMR.18.1.81-101.2005
Thiele, I., Jamshidi, N., Fleming, R. M., and Palsson, B. Ø. (2009). Genome-scale reconstruction of Escherichia coli's transcriptional and translational machinery: a knowledge base, its mathematical formulation, and its functional characterization. PLoS Comput. Biol. 5:e1000312. doi: 10.1371/journal.pcbi.1000312
Thiele, I., and Palsson, B. Ø. (2010). Reconstruction annotation jamborees: a community approach to systems biology. Mol. Syst. Biol. 6, 361. doi: 10.1038/msb.2010.15
Thomas, A., Rahmanian, S., Bordbar, A., Palsson, B. Ø., and Jamshidi, N. (2014). Network reconstruction of platelet metabolism identifies metabolic signature for aspirin resistance. Sci. Rep. 4, 3925. doi: 10.1038/srep03925
Trawick, J. D., and Schilling, C. H. (2006). Use of constraint-based modeling for the prediction and validation of antimicrobial targets. Biochem. Pharmacol. 71, 1026–1035. doi: 10.1016/j.bcp.2005.10.049
Tymoshenko, S., Oppenheim, R. D., Agren, R., Nielsen, J., Soldati-Favre, D., and Hatzimanikatis, V. (2015). Metabolic needs and capabilities of toxoplasma gondii through combined computational and experimental analysis. PLoS Comput. Biol. 11:e1004261. doi: 10.1371/journal.pcbi.1004261
Väremo, L., Scheele, C., Broholm, C., Mardinoglu, A., Kampf, C., Asplund, A., et al. (2015). Proteome- and transcriptome-driven reconstruction of the human myocyte metabolic network and its use for identification of markers for diabetes. Cell Rep. 11, 921–933. doi: 10.1016/j.celrep.2015.04.010
Varma, A., Boesch, B. W., and Palsson, B. Ø. (1993). Stoichiometric interpretation of Escherichia coli glucose catabolism under various oxygenation rates. Appl. Environ. Microbiol. 59, 2465–2473.
Wang, Y., Eddy, J. A., and Price, N. D. (2012). Reconstruction of genome-scale metabolic models for 126 human tissues using mCADRE. BMC Syst. Biol. 6:153. doi: 10.1186/1752-0509-6-153
Weininger, D. (1988). SMILES, a chemical language and information system. 1. Introduction to methodology and encoding rules. J. Chem. Inform. Model. 28, 31–36. doi: 10.1021/ci00057a005
Weiss, G., and Schaible, U. E. (2015). Macrophage defense mechanisms against intracellular bacteria. Immunol. Rev. 264, 182–203. doi: 10.1111/imr.12266
Yao, J., and Rock, C. O. (2015). How bacterial pathogens eat host lipids: implications for the development of fatty acid synthesis therapeutics. J. Biol. Chem. 290, 5940–5946. doi: 10.1074/jbc.R114.636241
Zakrzewski, P., Medema, M. H., Gevorgyan, A., Kierzek, A. M., Breitling, R., and Takano, E. (2012). MultiMetEval: comparative and multi-objective analysis of genome-scale metabolic models. PLoS ONE 7:e51511. doi: 10.1371/journal.pone.0051511
Zomorrodi, A. R., Islam, M. M., and Maranas, C. D. (2014). d-OptCom: Dynamic multi-level and multi-objective metabolic modeling of microbial communities. ACS Synth. Biol. 3, 247–257. doi: 10.1021/sb4001307
Keywords: constraint-based model, host-pathogen, optimization methods, mathematical models, omics-technologies, tuberculosis, salmonella typhimurium, flux balance analysis
Citation: Jamshidi N and Raghunathan A (2015) Cell scale host-pathogen modeling: another branch in the evolution of constraint-based methods. Front. Microbiol. 6:1032. doi: 10.3389/fmicb.2015.01032
Received: 19 March 2015; Accepted: 11 September 2015;
Published: 06 October 2015.
Edited by:
Tunahan Cakir, Gebze Technical University, TurkeyReviewed by:
Pinar Pir, Babraham Institute, UKCopyright © 2015 Jamshidi and Raghunathan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Neema Jamshidi, Institute of Engineering in Medicine, University of California, San Diego, 9500 Gilman Dr., La Jolla, CA 92093-0412, USA;
Department of Radiological Sciences, University of California, Los Angeles, BOX 951721, Los Angeles, CA 90095-1721, USA,bmVlbWFAdWNzZC5lZHU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.