 Fatima Rauf1
Fatima Rauf1 Muhammad Attique Khan1*Ali Kashif Bashir2Kiran Jabeen1Ameer Hamza1
Muhammad Attique Khan1*Ali Kashif Bashir2Kiran Jabeen1Ameer Hamza1 Ahmed Ibrahim Alzahrani3Nasser Alalwan3
Ahmed Ibrahim Alzahrani3Nasser Alalwan3 Anum Masood4,5*
Anum Masood4,5*- 1Department of Computer Science, HITEC University, Taxila, Pakistan
- 2Department of Computing and Mathematics, Manchester Metropolitan University, Manchester, United Kingdom
- 3Computer Science Department, Community College, King Saud University, Riyadh, Saudi Arabia
- 4Department of Circulation and Medical Imaging, Norwegian University of Science and Technology, Trondheim, Norway
- 5Institute of Neurosciences and Medicine (INM), Forschungszentrum Jülich, Jülich, Germany
Despite a worldwide decline in maternal mortality over the past two decades, a significant gap persists between low- and high-income countries, with 94% of maternal mortality concentrated in low and middle-income nations. Ultrasound serves as a prevalent diagnostic tool in prenatal care for monitoring fetal growth and development. Nevertheless, acquiring standard fetal ultrasound planes with accurate anatomical structures proves challenging and time-intensive, even for skilled sonographers. Therefore, for determining common maternal fetuses from ultrasound images, an automated computer-aided diagnostic (CAD) system is required. A new residual bottleneck mechanism-based deep learning architecture has been proposed that includes 82 layers deep. The proposed architecture has added three residual blocks, each including two highway paths and one skip connection. In addition, a convolutional layer has been added of size 3 × 3 before each residual block. In the training process, several hyper parameters have been initialized using Bayesian optimization (BO) rather than manual initialization. Deep features are extracted from the average pooling layer and performed the classification. In the classification process, an increase occurred in the computational time; therefore, we proposed an improved search-based moth flame optimization algorithm for optimal feature selection. The data is then classified using neural network classifiers based on the selected features. The experimental phase involved the analysis of ultrasound images, specifically focusing on fetal brain and common maternal fetal images. The proposed method achieved 78.5% and 79.4% accuracy for brain fetal planes and common maternal fetal planes. Comparison with several pre-trained neural nets and state-of-the-art (SOTA) optimization algorithms shows improved accuracy.
1 Introduction
The brain is the key organ of our body, and as such, it influences every aspect of the body. Brain disorders bring on multiple diseases (1). In this way, a mother’s healthy lifestyle affects her child’s brain development. The trajectory of the organism across the lifespan and succeeding lifelong functions are determined by fetal and newborn brain development (2). The story of the human fetal brain is an intricate journey marked by substantial alterations in size, configuration, and advancement, following a distinctive spatiotemporal pattern (3). Irregular fetal brain development can have significant short-term and long-term impacts on the newborn (4). Therefore, precise quantitative evaluation of fetal brain growth is crucial for the early detection of developmental disorders (5). Furthermore, early detection of these abnormalities might enhance the accuracy of the diagnosis and follow-up preparation (6).
A standard medical tool for non-invasively assessing and monitoring the state of the developing brain in utero is magnetic resonance imaging (MRI) (7). Ultrasound also serves as a standard method for tracking the progress of a developing human fetus, offering valuable insights into its growth and general well-being (8). Throughout the different stages of gestation, ultrasound examinations are conducted to verify pregnancy, assess its position, condition, dimensions, growth rate, alignment, and gestational age, detect possible congenital disabilities and complications, and gather various other details crucial for ensuring the fetus’s healthy development and delivery (9). Fetal brain abnormalities can often be found with ultrasound. Doctor’s lack of familiarity with complicated brain anatomy and pathology, obsolete technology, an improper fetal head position, an early or late gestational age, and maternal obesity all reduce the detection rate. To become experts, doctors must have years of experience (10).
The researchers have employed computer-aided diagnosis techniques, including advanced tools based on deep learning, to automate the measurement of fetal body parts (11). Due to their excellent prediction accuracy and human-level performance across several medical imaging applications, deep learning models have gained prominence (12). Deep learning consists of layers of nonlinear information processing within a hierarchical structure designed for extracting features, analyzing patterns, and classifying data (13). In the realm of fetal ultrasound image analysis, deep learning, notably convolutional neural networks (CNNs), has become increasingly pivotal over the past few decades (14). Its application has significantly enhanced decision support for medical professionals by providing advanced capabilities in the interpretation of fetal ultrasound images. As a result, a substantial body of literature is dedicated to this field (15).
Shinde et al. (16) combined the information of deep learning features with the traditional machine learning methods for classifying fetal brain abnormalities using MRI scans. The Random Forest (RF) classifier is employed for machine learning, whereas a pre-trained architecture has been employed for deep learning. The experimental findings from the DNN + RF model were compared with those from the DNN + SVM and plain DNN frameworks. It demonstrates that the presented method performed well for the DNN + RF framework with an accuracy of 94 and 87% for training and validation, respectively. Kumar et al. (17) presented a cloud environment to discover and categorize fetal brain disorders automatically. The system’s main goal was to perfect the art of fetal brain abnormality detection while eliminating or drastically cutting down on time, expense, and accuracy. The YOLO v4 architecture was used to identify the fetal brain with its orientation. The presented method obtained an accuracy of 97.27%.
Qu et al. (18) introduced a distinctive CNN architecture to autonomously discern six fetal brain standard planes (FBSPs) from non-standard planes. The supplementary differential feature maps within this framework were formulated by extracting differential operators from the feature maps in the original CNN. A significant benefit of differential convolution maps was their ability to analyze the directional pattern of pixels and their surroundings utilizing additional calculations. The differential CNN performed well and obtained an improved accuracy of 92.93%. Płotka et al. (19) developed an end-to-end multi-task neural network named Fetal Net. The presented method analyzes spatiotemporal fetal ultrasound scan videos by means of integrated modules and an attention mechanism. Its objective is to measure, classify, and determine several fetal body parts at the same time once. In order to achieve effective localization of scan planes, researchers used an attention mechanism combined with a stacked module. Ye et al. (20) introduced a deep neural network for classifying five fetal head ultrasound planes, including trans ventricular plane (TV), trans thalamic plane (TT), transcerebellar plane (TC), coronal view of eyes (Eyes), coronal view of the nose. This model also identified non-standard fetal head ultrasound images effectively. Ruowei et al. (21) designed two primary methods based on deep convolutional neural networks to recognize fetal brains automatically. One method used a deep convolutional neural network (CNN), while the other employed CNN-based domain transfer learning.
Shankar et al. (22) suggested deep learning (DL) method for computing three key fetal brain biometric measurements from 2D ultrasound images of the transcerebellar plane (TC) through automated caliper placement. Di et al. (23) presented a regression convolutional neural network (CNN) architecture for fetal brain classification from Ultrasound images. Singh et al. (24) used a pre-trained ResNet-50 architecture to classify fetal ultrasound images of crown-to-rump length (CRL). The model employed a skip connection strategy to develop a deeper network with task-specific hyper parameters. The presented architecture performed well on the selected dataset.
The studies discussed above are focused on CNN architectures to compute the improved recognition accuracy of maternal-fetal (25). In this work, our core aim is to explore the strength of deep learning architectures for classifying common maternal fetuses, including brain classes. The ultrasound images dataset has been utilized in this work for the validation process, with a selection of sample images depicted in Figure 1. In this figure, it is noted that there are similar characteristics of the maternal brain fetal planes with a high chance of false negative rate. Similarly, the common maternal anatomical planes are similar and difficult to recognize with simple machine learning or deep learning models. There are challenges in classifying maternal-fetal complexities using traditional methods, which include shape, texture, and point features, because of their intricate and similar textures. Therefore, the deep learning architecture based on the bottleneck mechanism can work more effectively to classify the maternal-fetal tasks. We introduced an innovative deep learning architecture that leverages residual bottleneck blocks and minimizes pooling layers, capitalizing on the benefits of the deep bottleneck mechanism. The primary contributions of our work are outlined as follows:
- Proposed a new CNN architecture based on the residual-bottleneck mechanism that includes three residual blocks (two paths and one bypass). One skip connection and traditional layers path include three convolutional layers of 1 × 1, 3 × 3, and 1 × 1 filter sizes.
- Bayesian optimization is performed to initialize the hyper parameters of the designed residual bottleneck CNN architecture: the learning rate, epochs, momentum, batch size, and L2-regularization factor.
- The average pooling layer is used to extract deep features, and an improved moth flame optimization algorithm is presented with an updated search space for the best feature selection. Several neural network classifiers are used to classify the selected features.
- A detailed ablation study has been performed to compare the performance of the proposed architecture with several other combinations of feature selection algorithms and neural nets. Also, a comparison has been conducted with few recent published methods.
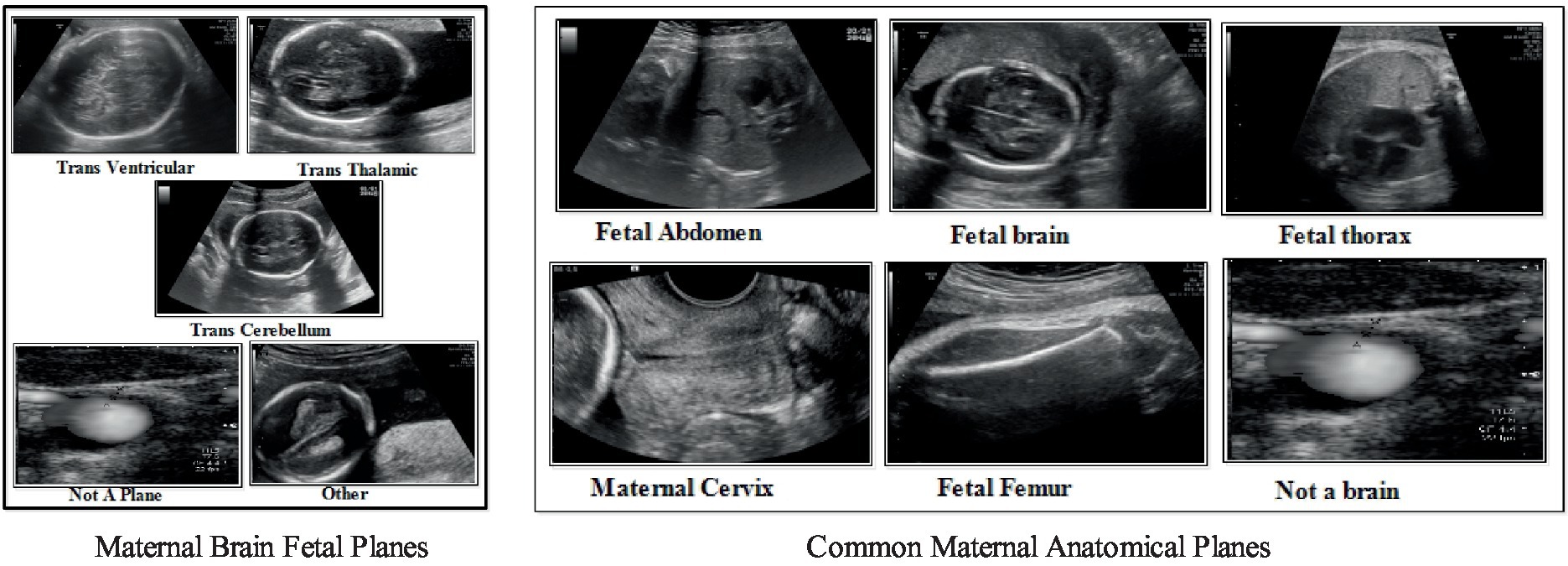
Figure 1. A few sample images of common maternal fetal and fetal brain ultrasound images.
The article’s remaining sections are arranged as follows: proposed methodology is presented under section 2. Results and detailed ablation study discussed in Section 3. Section 4 concludes the manuscript that followed the references.
2 Proposed methodology
The proposed maternal brain fetal planes and common maternal fetal classification architecture have been presented in this section. The proposed framework consists of two phases: first, classify the fetal brain using ultrasound images, and second, fetal general characteristics using ultrasound images. Figure 2 illustrates the proposed framework. In the proposed framework, a new model has been proposed based on three residual blocks that include a bottleneck mechanism. The proposed model consists of 3 residual blocks that include several layers in a bottleneck fashion. In the training phase, hyper parameters have been initialized using Bayesian optimization. The self-attention layer has been selected and activation is performed for deep feature extraction. The deep features extracted are fine-tuned through an enhanced moth flame optimization algorithm that incorporates a position update mechanism. Neural network classifiers are finally used in the last stage to perform the final classification.
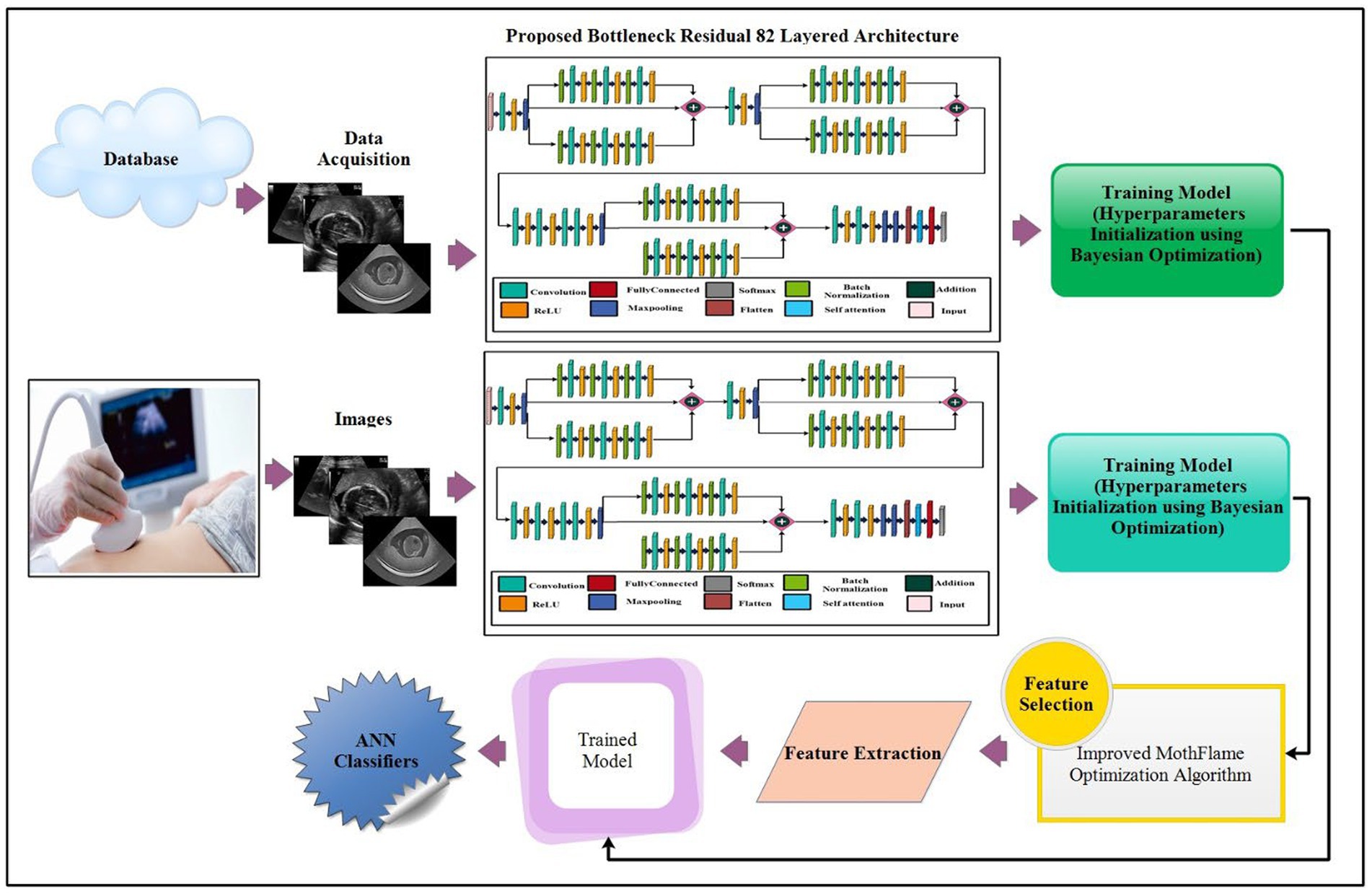
Figure 2. Proposed architecture of brain fetal planes and common maternal fetal planes classification using bottleneck residual CNN.
2.1 Datasets
This study uses a publicly available dataset downloaded from the cloud and stored in a local cloud (Google Drive). The dataset contains two types: Fetal Brain and common maternal fetal classes. The details of the datasets are given below.
2.1.1 Fetal brain classes
In the fetal brain, five classes have been included: trans cerebellum (TC), trans thalamic (TT), trans ventricular (TV), not a brain, and others. A few examples of images are shown in Figure 1. Each class has a different number of images, as presented in Table 1. The table illustrates that the highest count of images in a single class is 9,308 (not a brain), while the lowest count is 143.
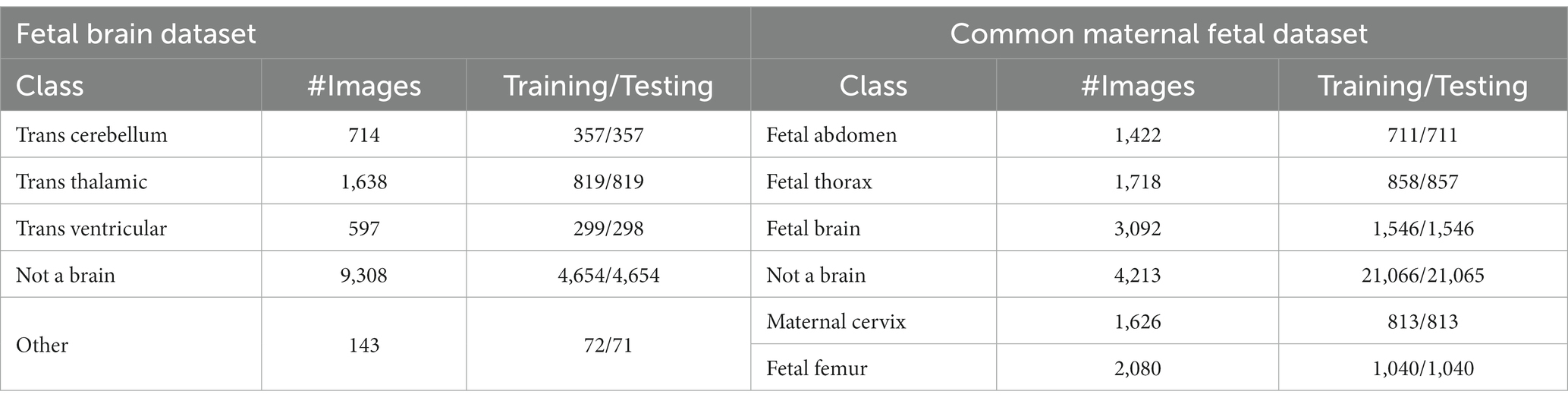
Table 1. A summary of Fetal Brain and common maternal fetal images of the selected dataset.
2.1.2 Common maternal fetal
In the common maternal fetal dataset, six classes have been included: fetal abdomen, fetal brain, fetal femur, fetal thorax, maternal cervix, and not a brain. A few examples of images are shown in Figure 1. A summary of the number of images has been added under Table 1. This table shows that the number of images is in the range of 1,422–4,213. Therefore, it seems there is a class imbalance issue for both types. However, we did not perform augmentation and tried to resolve this issue by proposing a new deep model with complex structures that can easily classify the maternal-fetal classes.
2.2 Proposed 82 layered bottleneck architecture
The parallel residual blocks have been consist of two paths with different convolutional operations, and the filter sizes may vary across paths. These blocks are instrumental in capturing and processing information at different levels of abstraction in parallel, contributing to the overall depth and expressiveness of the model. A new architecture has been proposed in this work based on the concepts of residual blocks, bottleneck mechanisms, and hyper parameters optimization. The proposed architecture is shown in Figure 3. This figure shows the initial input layer of dimension 224 × 224 with a depth of 3. The model consist of total 26 convolutional layers. The subsequent layer is the first convolutional layer, which has a depth of 32 and employs a 3 × 3 convolutional filter size and stride of 2. Following each convolutional layer, a Rectified Linear Unit (ReLU) layer is added that is succeeded by a max-pooling layer featuring a 3 × 3 filter size and a stride of 1.
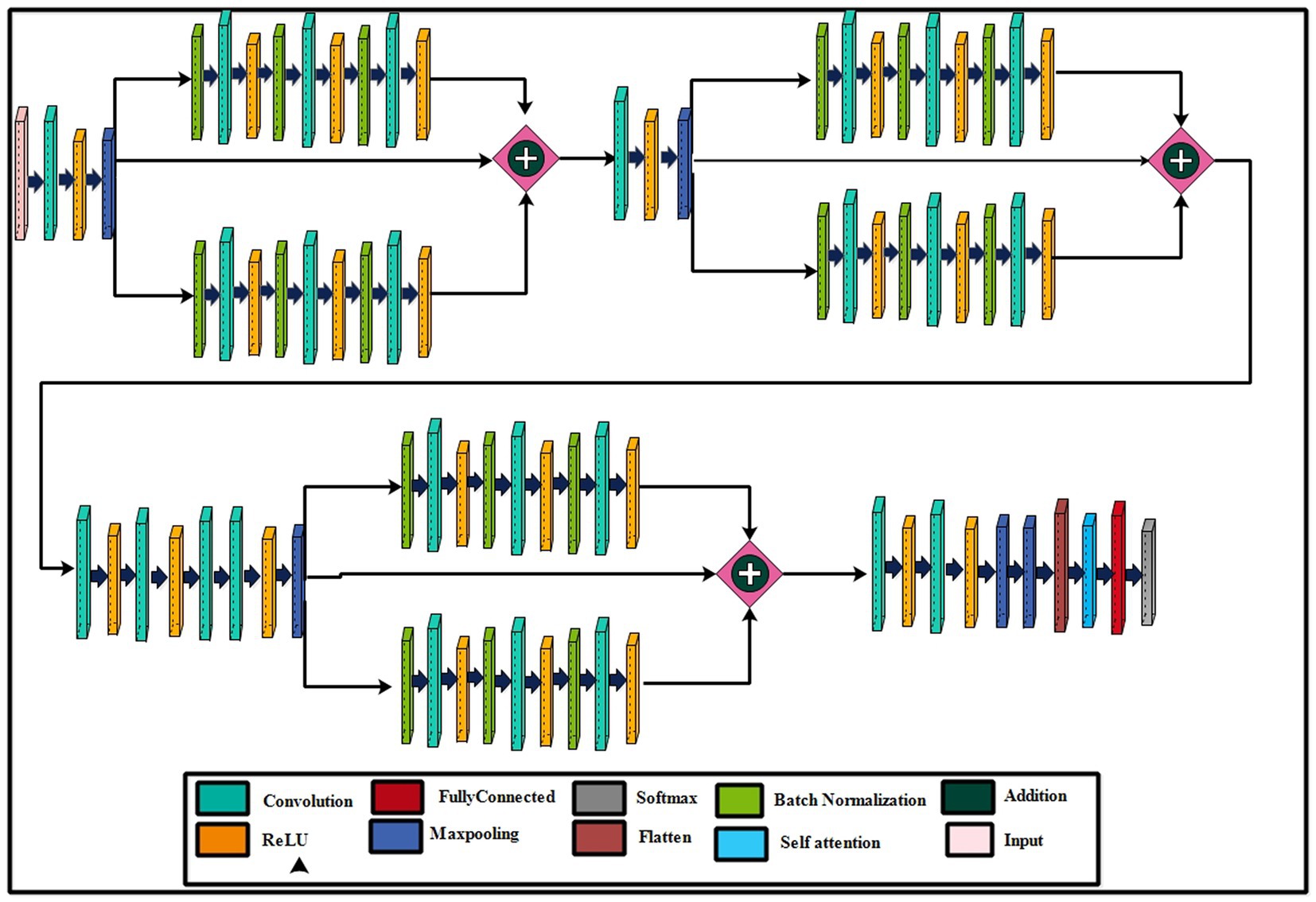
Figure 3. A visual architecture of the proposed 82-layered residual bottleneck CNN architecture.
2.2.1 First parallel bottleneck residual block
This network’s first bottleneck residual block is in parallel and shares a consistent layer pattern, totaling nine layers each. Each path of this block consists of batch normalization, convolutional, and ReLU layers. In the first block, a batch normalization layer with 32 channels is followed by a convolutional layer with a depth 128, a 1 × 1 filter size, and a stride of 1, concluding with a ReLU activation layer. The second block involves batch normalization with 128 channels, a convolutional layer with a depth of 512, a 3 × 3 filter size, and a stride of 1, followed by a ReLU layer. The third block encompasses batch normalization with 512 channels, a convolutional layer with a depth of 32, a 1 × 1 filter size, and a stride of 1, ending with a ReLU activation layer. A first addition layer connects these residual blocks to other layers.
2.2.2 Intermediate layers 1
Following this, several additional layers are inserted within the network before the next parallel residual block has been added. A convolutional layer with a depth size 128 has been added, whereas the filter size is 3 × 3 and a stride of 2. After that, a ReLU activation layer was added, followed by the second max-pooling layer with a 3 × 3 filter size and a stride of 1.
2.2.3 Second parallel bottleneck residual block
The second bottleneck residual block consists of two paths and one skip connection. Each path contains a total of nine layers, with each set consisting of batch normalization, convolutional, and ReLU layers. This block’s depth and filter sizes are similar to block 1. The main reason for the similar filter sizes of this block is to get deeper information on the processed images. After this, an additional layer has been added that connects the weights of both paths and skips the connection.
2.2.4 Intermediate layers 2
Two sets of convolutional + ReLu layers have been added following these blocks. The first convolutional layer has a depth size of 128, while the second has a depth size of 256. The filter size of both convolutional layers has a 1 × 1 filter and maintains a stride of 2. Subsequently, two consecutive convolutional layers with depths of 64 and 512 have been added, having a 1 × 1 filter size and stride 2. After that, a max-pooling layer of filter size 3 × 3 and stride of 1 for downsampling has been added.
2.2.5 Last bottleneck residual block
The last residual bottleneck block consists of similar layers like residual blocks 1 and 2. This block’s depth sizes are 256, 512, and 1,024. The filter size of the first convolutional is 1 × 1, the second layer is 3 × 3, and the last layer is 1 × 1, respectively. In addition, batch normalization and max pooling layer have been added in this block to speed up the training process and downsampling. Hence, nine layers have been added to each path, and finally, the additional layer with a skip connection.
2.2.6 Final layers
At the end of the model, a third addition layer connects these blocks with the remaining layers. Two convolutional layers are added, each followed by ReLU activation layers. The first convolutional layer has a depth of 1,024, whereas the second layer has a depth of 2048. The filter size of both layers is 3 × 3, and the stride value is 2. A max pool layer of filter size 3 × 3 and stride two has been added. Ultimately, a global average pooling layer is incorporated, succeeded by a fully connected layer, a Softmax layer, and a classification output layer. In addition, a tabular summary of the proposed architecture has been shown in Figure 4. The weights, filter sizes, stride, and total learnable have been added to this figure.
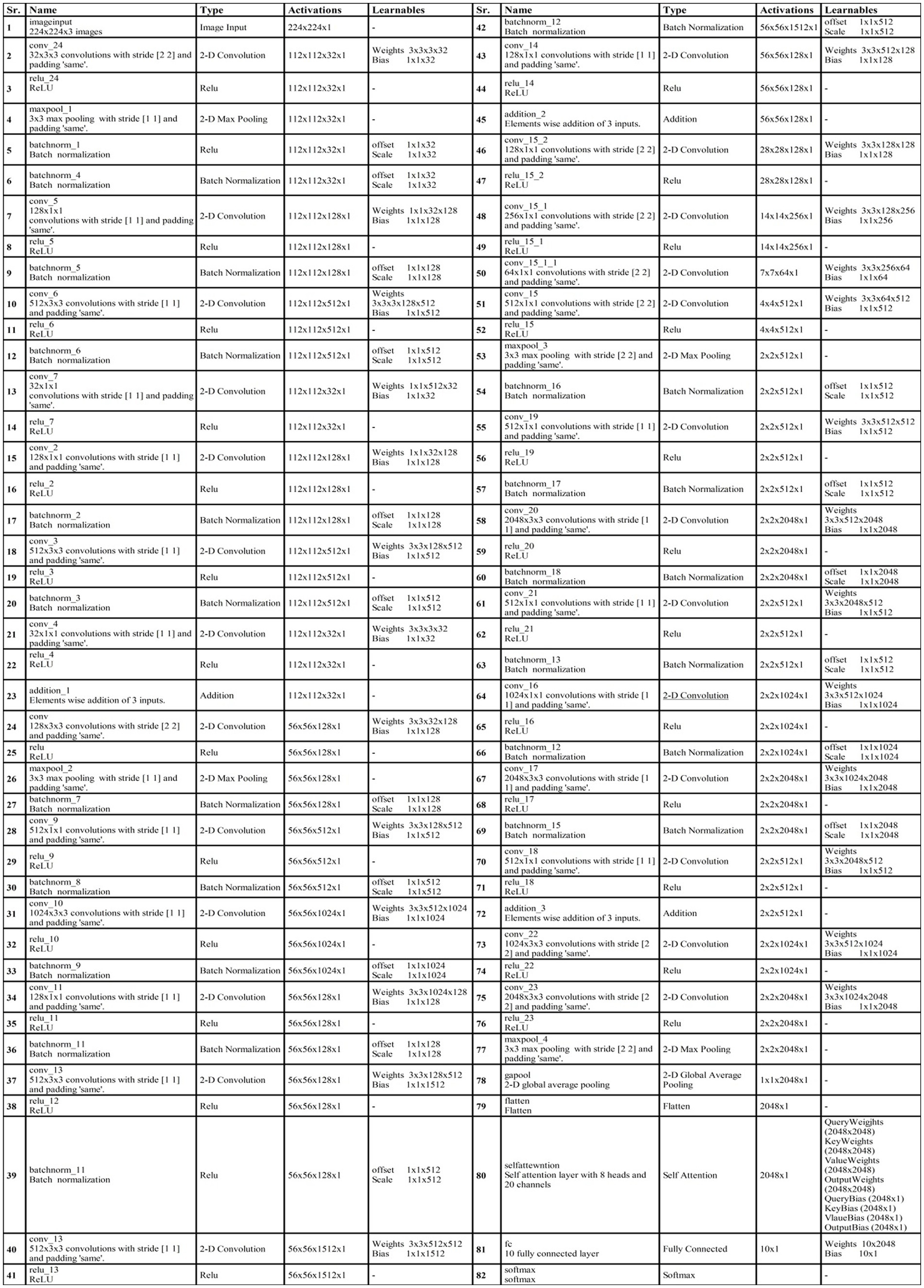
Figure 4. Detailed layered architecture of proposed bottleneck residual CNN architecture.
2.3 Proposed architecture training and features extraction
In the training procedure of the proposed architecture, several hyper parameters (HP) have been required to initialize. 78.5 M parameters have been trained for the proposed model. However, the manual selection of HP is always based on the expert person. Therefore, we tried to automate this system and implemented Bayesian optimization for the HP initialization. The following HP has been used in this work, optimized using BO: maximum epochs, initial learning rate, the mini-batch size, momentum, and L2-regularization factor.
2.3.1 Bayesian optimization
An optimization problem known as “hyper parameter tuning” has an unidentified or “black-box” goal function. Using conventional optimization techniques like the Newton method or gradient descent is impossible. When handling this optimization problem, Bayesian optimization is a very successful optimization strategy (26). Using Bayesian formulas, it combines previous knowledge about unknown functions with sampled knowledge to compute posterior information. Finally, using this posterior knowledge, we may determine where the function gets its ideal value. The following are the main steps in the optimization process (27):
• The results of function are updated using the posterior distribution taken by the Gaussian process.
• Selecting the ideal point using an acquisition function for the function The expected improvement is used as an acquisition function in this work.
• Recognizing the suggested sampling locations that were acquired by the acquisition function.
• Obtaining outcomes in the validation set using an objective function.
• Adding the most optimized sample points to the previously chosen data.
• Refreshing the model of the statistical Gaussian distribution.
This is repeated up to a predetermined number of times to fine-tune the validation set and produce optimized parameters that improve categorization. An illustration of the process is shown in Figure 5. This figure shows that the data has been selected at the initial stage and then defines the HP that needs to be optimized. After that, define the acquisition function that further executes the number of trials and choose the best HP to train the proposed architecture. The BO returned the selected HP as listed in Table 2.
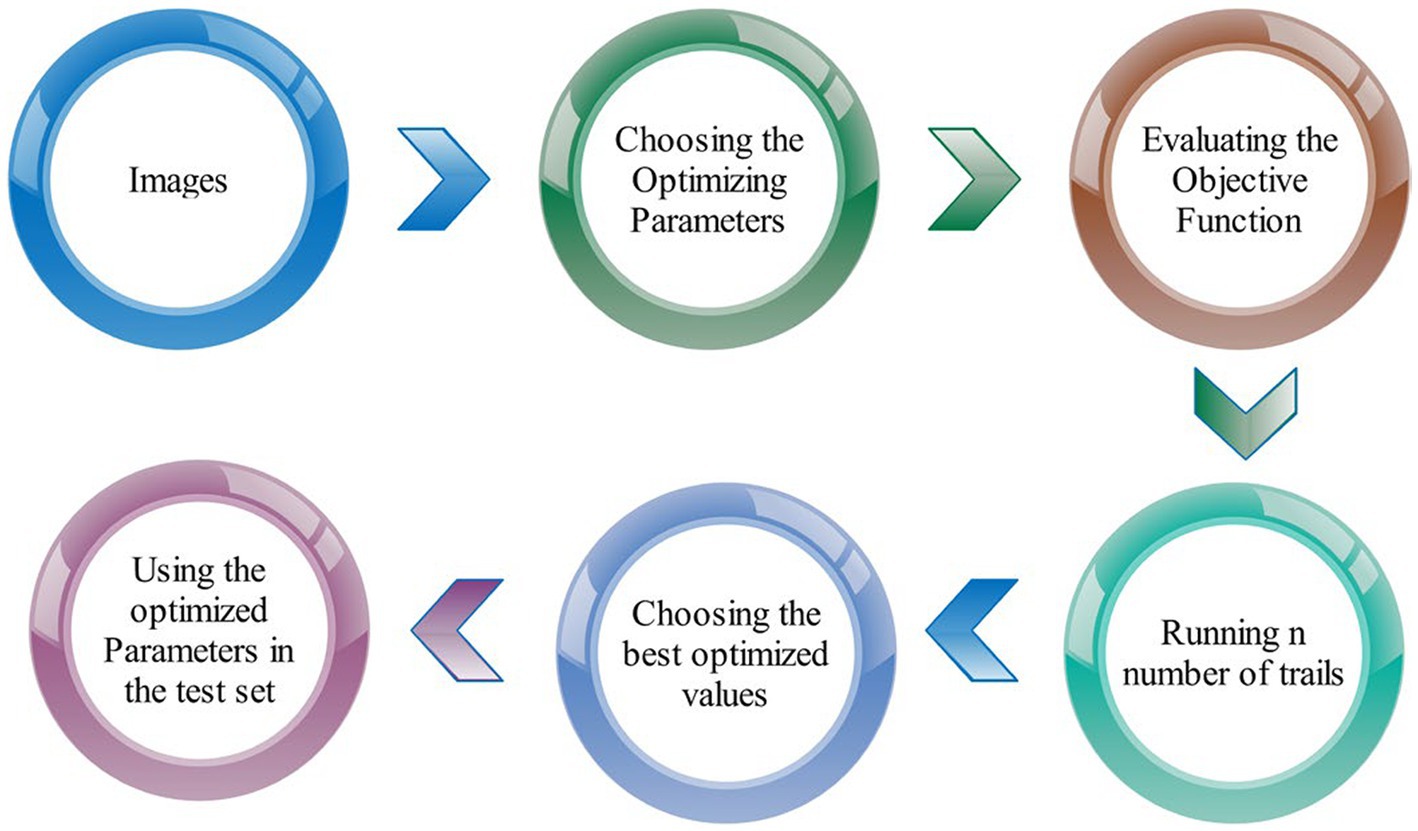
Figure 5. A visual framework of Bayesian optimization (BO) for HP selection.
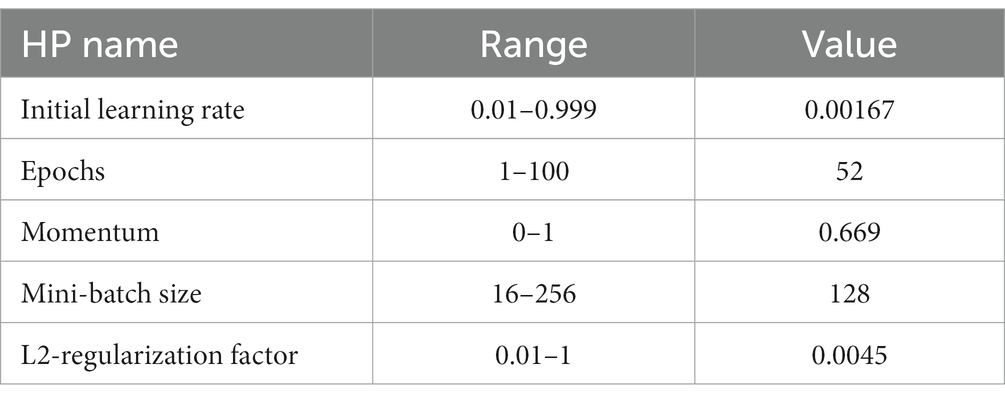
Table 2. Optimized hyper parameters for network training using BO.
The utilized acquisition function is the expected improvement (EI). EI calculates the anticipated level of enhancement achievable when exploring the vicinity around the current optimal value. If the function value’s apparent improvement is less than what was predicted after the process, indicating that a local optimum may exist, the algorithm will look into other areas of the domain to determine the ideal value. The quantification of improvement (L) hinges on evaluating the disparity between the function value at the sampled point and the prevailing optimal value. If the function value at the sampled point is below the current optimum value, the improvement is set to 0.
The goal is to optimize the expected improvement (EI) by maximizing it with regard to the current optimal value (f) through the implementation of the expected improvement (EI) optimization approach.
When the distribution of follows a normal distribution with the mean , and the standard deviation, consequently, the distribution of the random variable is also a normal distribution, with the mean and standard deviation both being equal to . The probability density function of is
The E(I) function is utilized to compute the expected degree of improvement attainable by exploring the vicinity around the current optimal value. If the observed increase in the function value during algorithm execution falls short of the expected value, it indicates that the current optimal value point might represent a local optimum. In such cases, the algorithm will continue to search for the optimal value point in alternative domain locations. The formulation of expected improvement is outlined as follows:
where
The anticipated improvement (I) is expressed by Eq. (4), encapsulating the definition of the expected improvement (EI) function. The stopping criterion for Bayesian optimization (BO) was set at 30 iterations. Following the completion of 30 iterations, the model with the minimum error among all iterations was chosen for the feature extraction process.
2.3.2 Features extraction
Deep features are extracted from the self-attention activation of the trained deep learning architecture. In this layer, a feature vector of size N × 2048 is obtained. However, examination reveals that the features that were collected contain redundant data that can be optimized by utilizing a moth-flame optimization technique inspired by nature, specifically modified search-based moth-flame optimization.
2.4 Algorithm for modified search-based moth-flame optimization
This work selects the moth-flame optimization algorithm due to the improved performance of a few existing methods such as GSA, PSO, BA, FA, FPA, and a few more [(see 28)]. The key advantage of MFO over other algorithms is its ability to solve difficult issues with confined and unknown search spaces (29). More than 160,000 various kinds of moths have been identified in nature; their life cycles are similar to those of butterflies (29). The most remarkable aspect of moth life is their unique night navigational system. They have developed the ability to use moonlight to fly at night.
Moreover, moths employ transverse orientation as a navigation strategy. By consistently adjusting their angle relative to the moon, moths efficiently navigate and cover substantial distances in a straight line. This approach ensures straight-line flight since the moon remains far from the moth. Interestingly, humans can adopt a similar navigation method. For instance, when the moon is situated in the southern sky, a person heading east can maintain a straight path by keeping the moon on their left side. While moths utilize a spiraling motion around lights, diverging from the straight-line flight, this behavior is a result of the transverse orientation’s effectiveness with distant light sources like moonlight. In contrast, moths attempt to maintain a consistent angle with the light source in artificial human-generated light, leading them to travel in spiraling patterns around such lights.
There are three basic steps in the MFO algorithm. We have updated each phase with mathematical formulation. In the first phase, the initial population is defined as follows:
where represents the number of dimensions in the solution space, and is the number of moths. These initial populations have been sorted into a descending order as follows:
where denotes the sorted population of moth and dimension. Please note the initial matrix should be as defined in Eq. (6). The main purpose of this update is to maintain the best populations in the descending order for selection in the next step with minimum computational time. Additionally, an array is memorized that contains the following fitness values for each moth, where :
Flames make up the remaining components of the MFO algorithm. The flames in -dimensional space are displayed in the matrix below, along with a vector representing their fitness function:
MFO uses three different functions to converge towards the global optimum in optimization problems. These functions have the following definitions:
where denotes the moths’ initial, haphazard positions, Moth movement in the search area is denoted by the letters , and search completion is denoted by . This function, denoted by M, produces the fitness value and random populations of moths.
The moth’s travel to search space is denoted by and defined as follows:
The function represents the stop criteria, and it is defined as follows:
This process is processed through a fitness function defined in Eq. (15).
The exploitation phase focuses on improving the MFO algorithm’s utilization (updating the moth’s positions in different places throughout the search area may reduce the likelihood of exploitation of the most promising solutions). Based on the fitness value, it can define whether the best position moth is selected. The updated position is defined as follows:
where denotes the distance among selected flames, and is a fitness function. The final selection is usually performed by employing a threshold value of 0.5, but in this work, we consider the mean value of the selected features in each iteration and the cost function is defined as:
In the above equation, and denotes the coefficients and the values of , presented the cost function and presented the accuracy obtained from the fitness function. The selected optimized features are finally classified using neural network classifiers for the final classification.
Where denotes the distance among selected flames, and is a fitness function. The final selection is usually performed by employing a threshold value of 0.5, but in this work, we consider the mean value of the selected features in each iteration. The resulting feature vector for the fetal dataset is of size N × 2048, and for the Brain dataset, it is N × 996.
The selected optimized features are finally classified using neural network classifiers for the final classification.
3 Results and analysis
The experimental process of this work has been discussed in this section using tabular information, visual graphs, and confusion matrices. In addition, a comparison is also conducted to show the effectiveness of the proposed method.
3.1 Experimental setup
A publicly available dataset has been utilized, as discussed in section 2.1. The selected datasets were in RGB nature and the whole datasets were partitioned into 50:50 ratio. The 50% is used for training process and remaining 50% data is utilized for testing phase. The entire experimental process has been conducted utilizing a 10-fold cross-validation approach. The entire experimental process has been conducted utilizing a 10-fold cross-validation approach. The proposed CNN architecture has been trained with optimized HP using the common maternal fetal and fetal brain plane datasets, as presented in Table 2. During the validation phase, several neural networks were employed, and the best classifier was chosen based on the calculated performance measures such as accuracy, processing time, sensitivity rate, precision rate, the number of observations, Kappa, MCC, FNR, and F1-score. The simulations of this work have been conducted utilizing MATLAB 2023a on a workstation with 256 GB of RAM and 12GB graphics card RTX 3000.
3.2 Performance measures and experiments
The evaluation of the classification model for fetal brain and general fetal characteristics was based on a set of performance evaluation measures, as presented in Table 3. True positive (TP) denotes the rate of accurately predicted positive instances, while true negative (TN) represents the accuracy of the predicted negative class. False positive (FP) signifies an incorrect prediction of the positive rate, and false negative (FN) indicates an erroneous prediction of the negative rate.
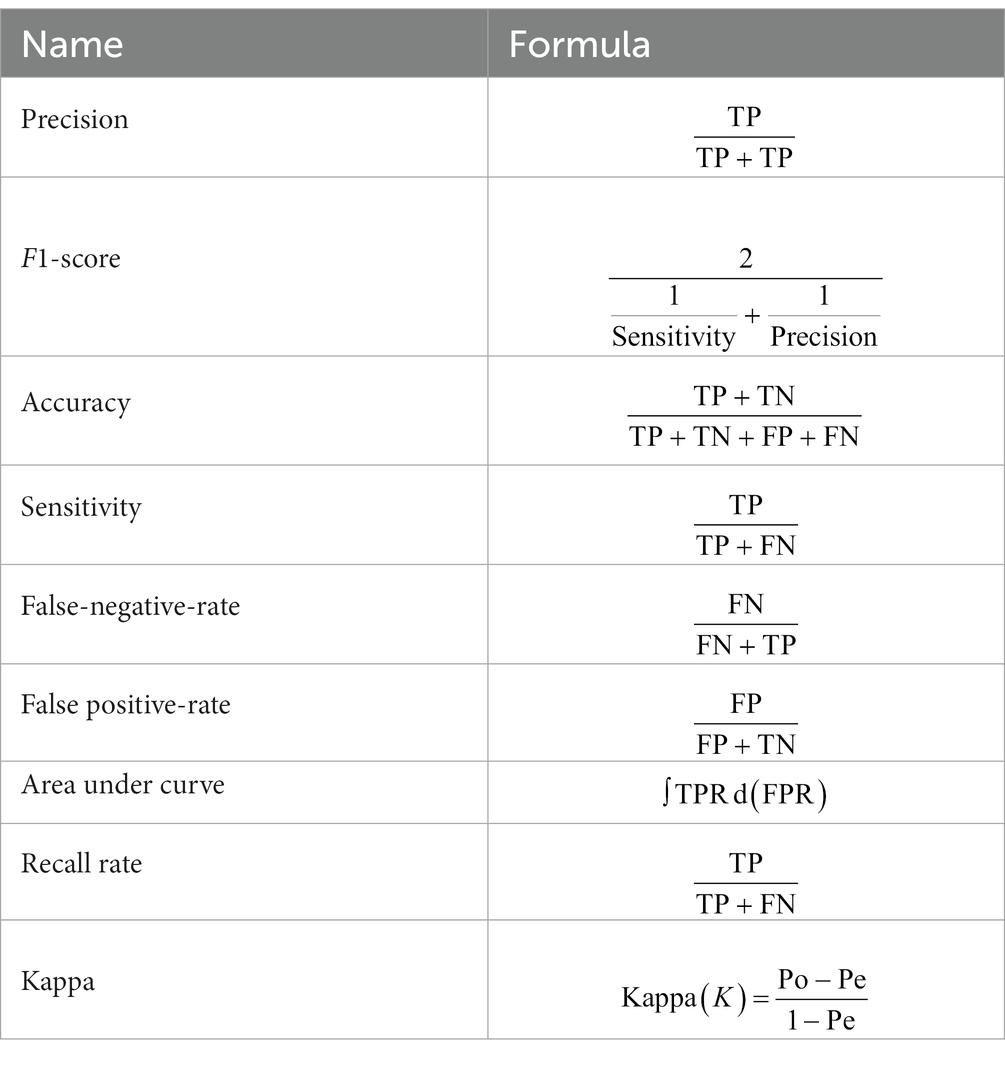
Table 3. Performance measures for the evaluation of the proposed framework.
3.3 Fetal brain dataset
Table 4 demonstrates the classification results of the proposed CNN architecture without feature optimization. The fetal brain dataset has been employed for the classification results. The maximum reported accuracy in this table is 79.7% for the WN2 classifier. For this classifier, the recall rate of 39.42%, the precision rate of 40.26%, F1 scores of 39.69%, and AUC values of 0.80. Moreover, the classifier’s confusion matrix is shown in Figure 6, which can be used to verify the calculated performance measures according to Table 3’s specifications. The rest of the classifiers also obtained 76.9% to 78.6% accuracy. Every classifier’s computational time is also recorded; the WN2 classifier has the lowest recorded computational time of 155.46 s.

Table 4. Classification results of proposed CNN architecture using ultrasound images (fetal brain).
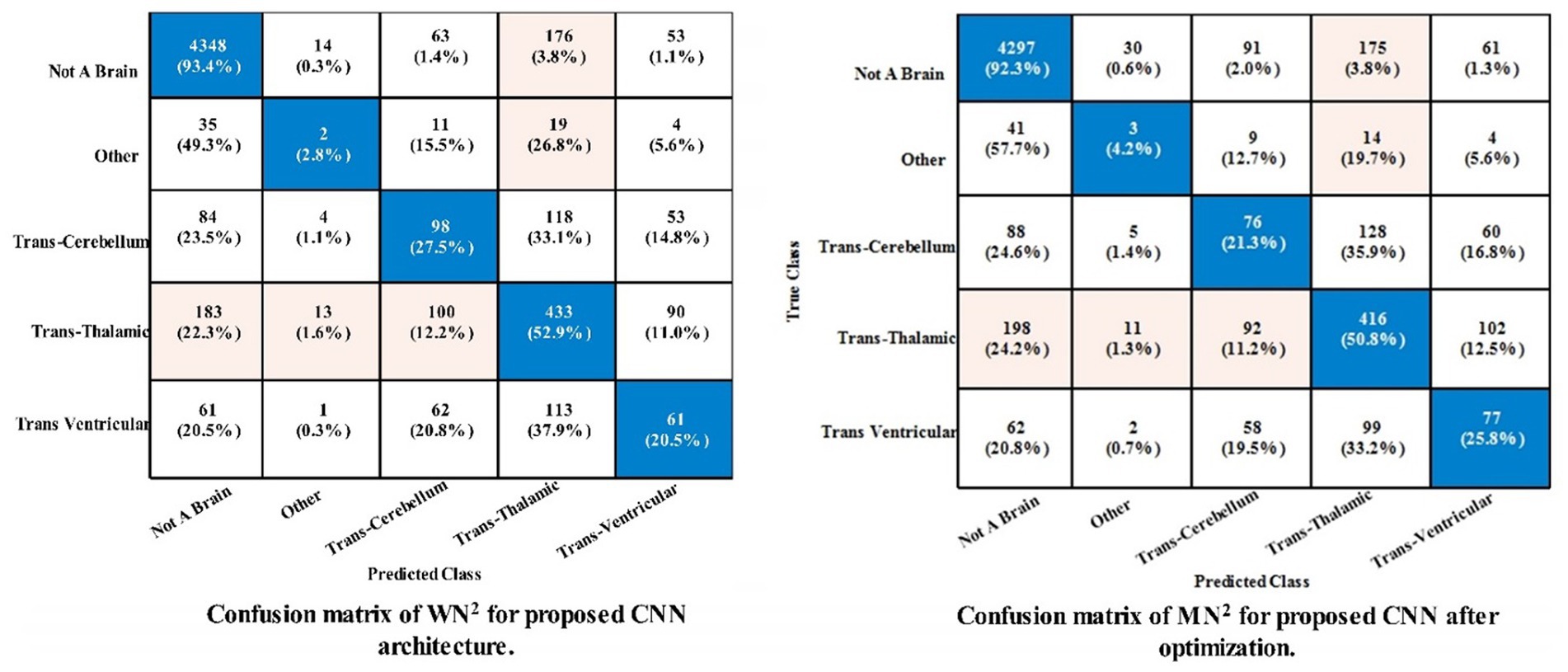
Figure 6. Confusion matrix of the proposed framework using fetal brain dataset.
The classification outcomes of the proposed framework using an improved optimization technique are displayed in Table 5. The best features are selected and obtained the highest accuracy value of 78.5% for MN2 classifier. Other parameters are also computed for this classifier, such as a recall rate of 38.88%, precision rate of 39.24%, F1 scores of 0.3903%, and AUC values of 0.70%. Moreover, Figure 6 depicts the MN2 confusion matrix. Through this figure, the computed measures of this classifier can be confirmed. Table 5 also lists the computational time for each classifier. There is an apparent reduction in time after the application of the optimization algorithm as compared to Table 4. The minimum noted time after this step is 115.14 s for WN2 classifier.
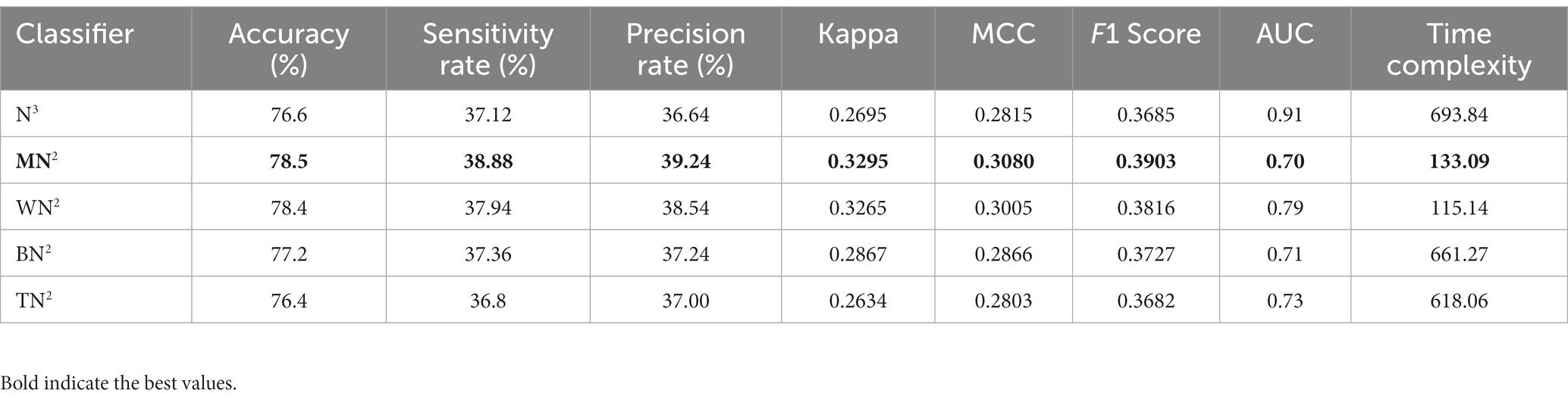
Table 5. Classification results of proposed architecture after employing improved optimization using brain fetal ultrasound images.
3.4 Common maternal fetal dataset results
Table 6 demonstrates the classification of proposed CNN architecture results for common maternal fetal dataset. The proposed architecture obtained a maximum accuracy of 79.8% for MN2. The recall rate of this classifier is 80.15%, a precision rate of 79.08%, F1 score of 0.795, and AUC value of 0.91, respectively. To further confirm the accuracy of each class’s prediction rate and computed performance metrics, refer to Figure 7, which shows the confusion matrix of this classifier. The computational time of each classifier is also noted, and the minimum time is 215.87 s for the WN2 classifier, whereas the highest reported time is 1476.1 (sec). The comparison is also performed with a few other classification methods, as given in this table, and the computed accuracy range is between 77.3% and 79.8%.
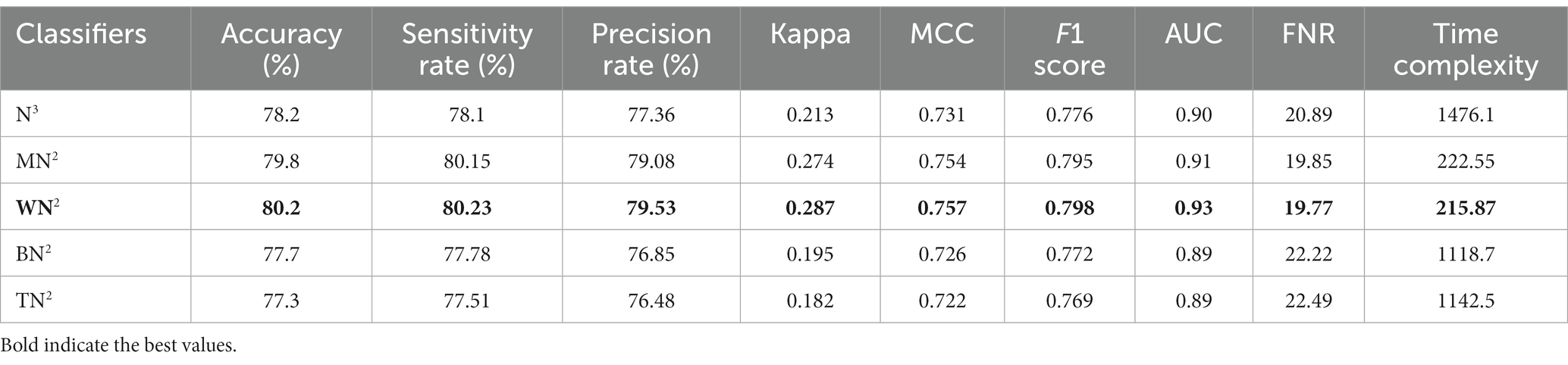
Table 6. Classification results of proposed bottleneck CNN architecture using common maternal fetal ultrasound planes.
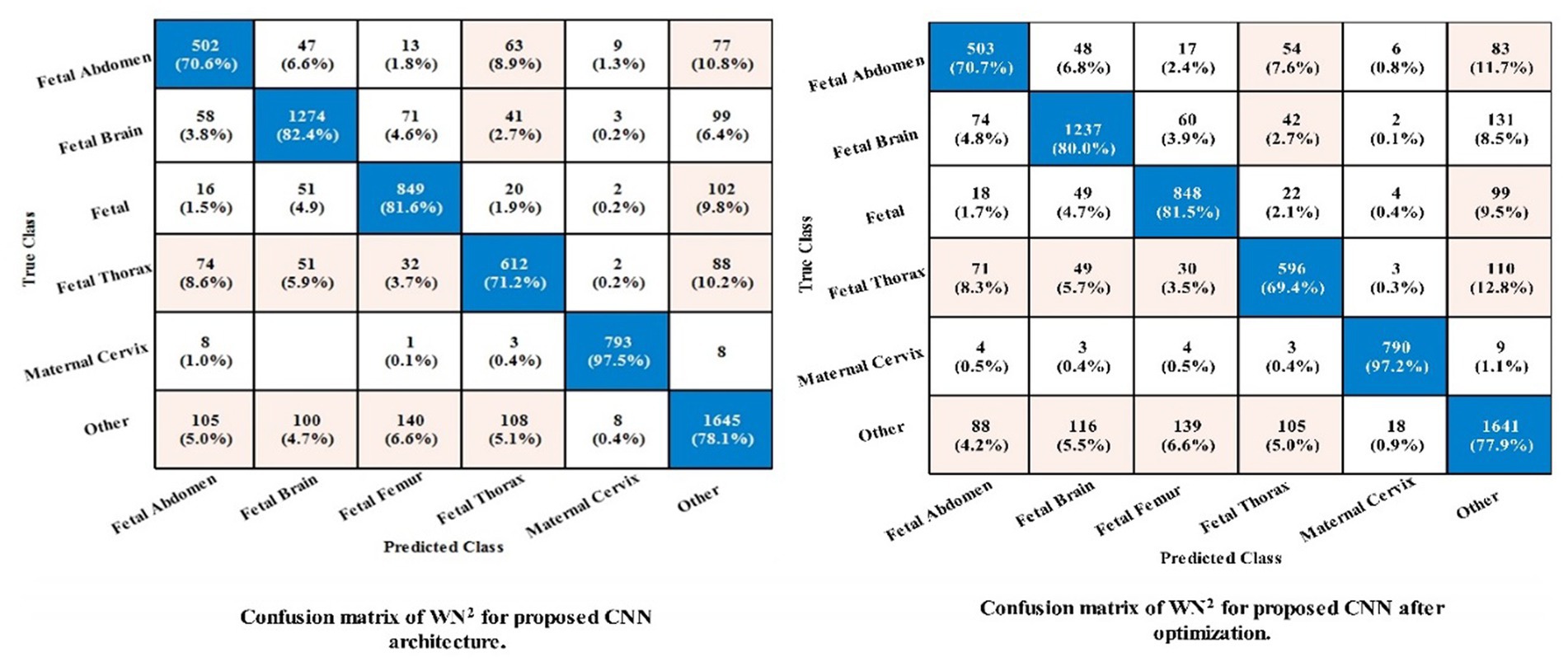
Figure 7. Confusion matrix of the proposed framework using common maternal fetal dataset.
The noted accuracy is better, but the computational time is inefficient; therefore, we employed the optimization algorithm, and Table 7 provides a full breakdown of the outcomes. In this table, the best obtained accuracy of 79.4% for WN2, which is minor decreased than the original architecture accuracy but time is 81.438 (sec). The accuracy of this classifier can be confirmed by a Figure 7 (confusion matrix). In this figure, each class correct prediction rate is given diagonally. The previous time of WN2 was 215.87 (sec); hence, the time of the proposed architecture after employing the optimization algorithm is reduced which is a strength of this work.
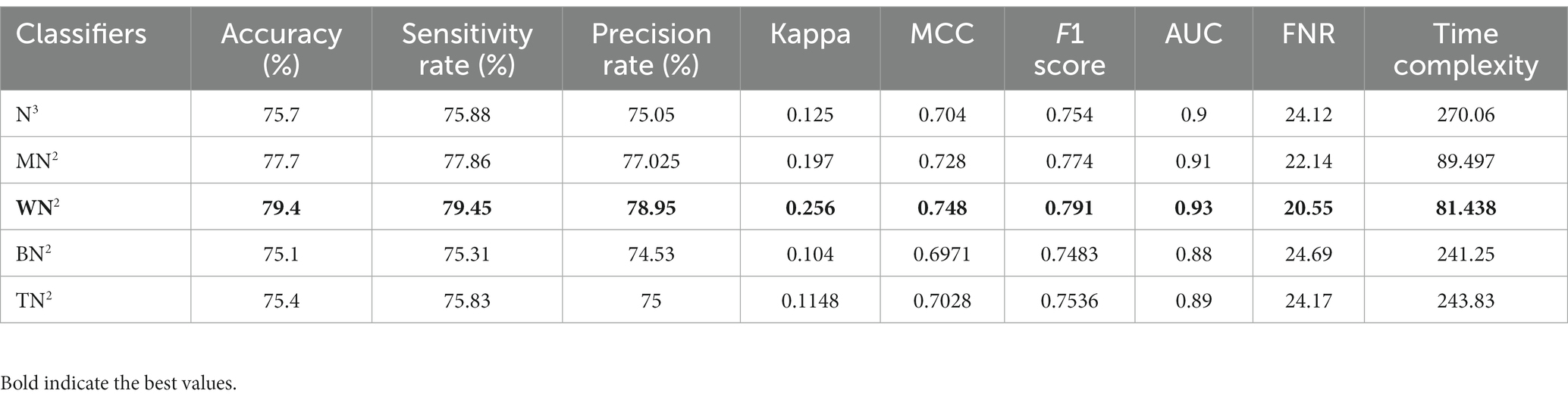
Table 7. Classification results of proposed architecture after employing improved optimization using common maternal fetal ultrasound images.
3.5 Comparison with SOTA
This section presents a detailed comparison between the proposed framework and several state-of-the-art (SOTA) approaches is given in this section. The comparison is carried out in two stages. In the first step, several pre-trained neural networks were chosen and trained on the same datasets (fetal brain and common maternal-fetal). Figure 8 compares several pre-trained neural nets with the proposed CNN architecture for the brain fetal dataset. The proposed architecture accuracy is improved, and almost a 2% difference is noted in accuracy. After the proposed architecture, the ResNet models show improved accuracy. Figure 9 compares several pre-trained neural nets using the common maternal fetal dataset with the proposed architecture. This figure shows that the maximum obtained accuracy by other neural nets is 77.3% by ResNet101, whereas the proposed architecture shows an improved accuracy of 80.2%.
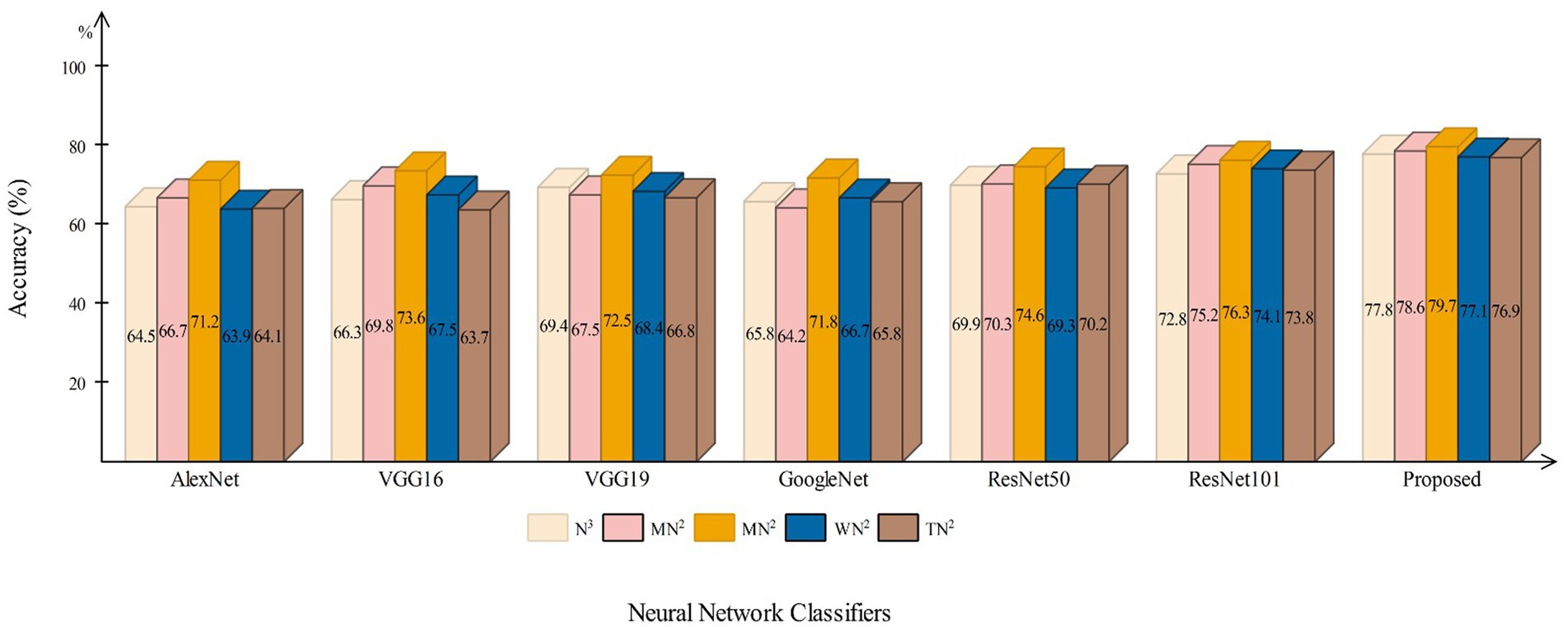
Figure 8. A comparison among several pre-trained neural nets with proposed architecture using brain fetal ultrasound images.
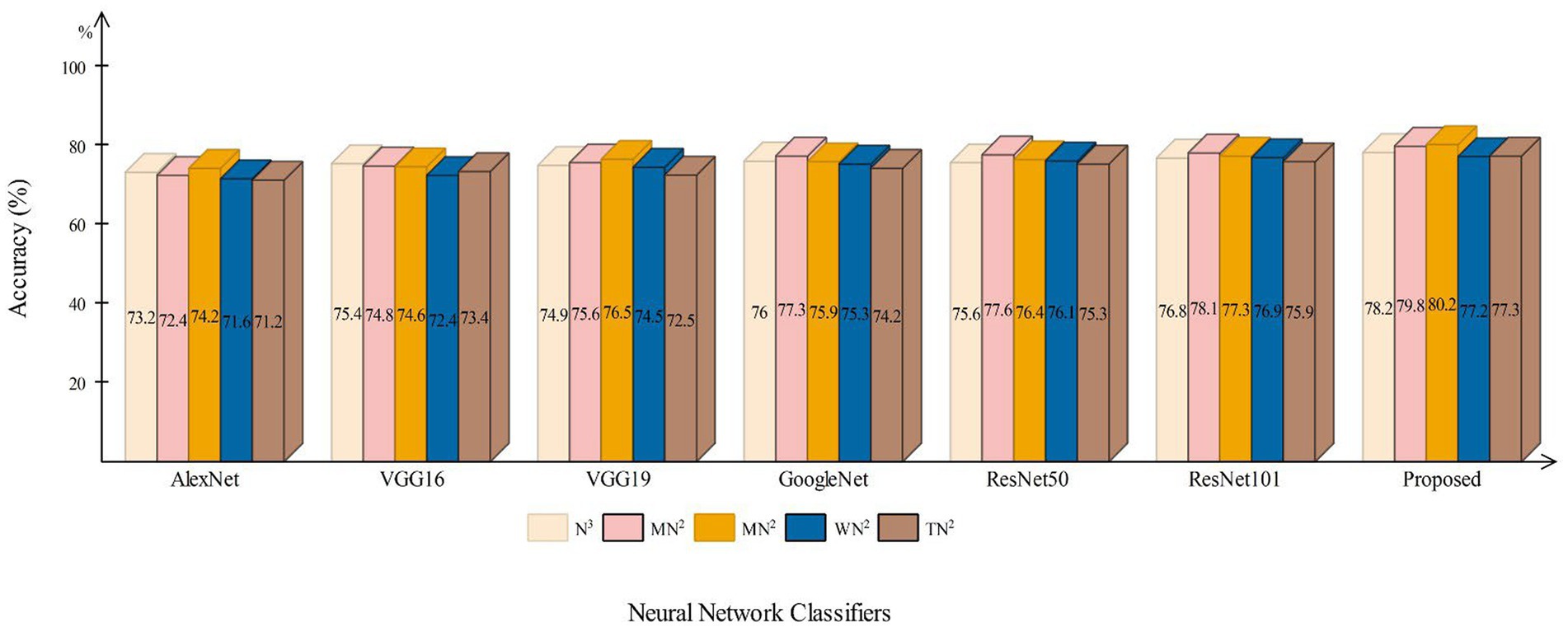
Figure 9. A comparison among several pre-trained neural nets with proposed architecture using common maternal fetal ultrasound images.
A comparison among improved MFO is also conducted with original MFO and a few other nature-inspired optimization algorithms. As described in Table 8, the proposed architecture obtained the highest accuracy of 78.5% and 79.4% using the IMFO algorithm for brain fetal planes and common maternal fetal planes, respectively. The proposed architecture obtained 73.8% and 74.6% accuracy for GA-based feature selection. For PSO-based feature selection, an accuracy of 74.9% and 75.1% were obtained, respectively. The paired proposed architecture with the Whale optimization algorithm (WOA) has achieved 73.3% and 75.6% accuracy, respectively. The paired firefly algorithm improved the accuracy value by 77.8%. The second highest accuracy for both datasets is 76.9% and 78.1% by the original moth flame optimization algorithm. Hence, this table shows that the proposed architecture performed well with IMFO. In addition, a computational time of each pair has been noted and it is observed that the IMFO algorithm time is minimum than all other combinations.
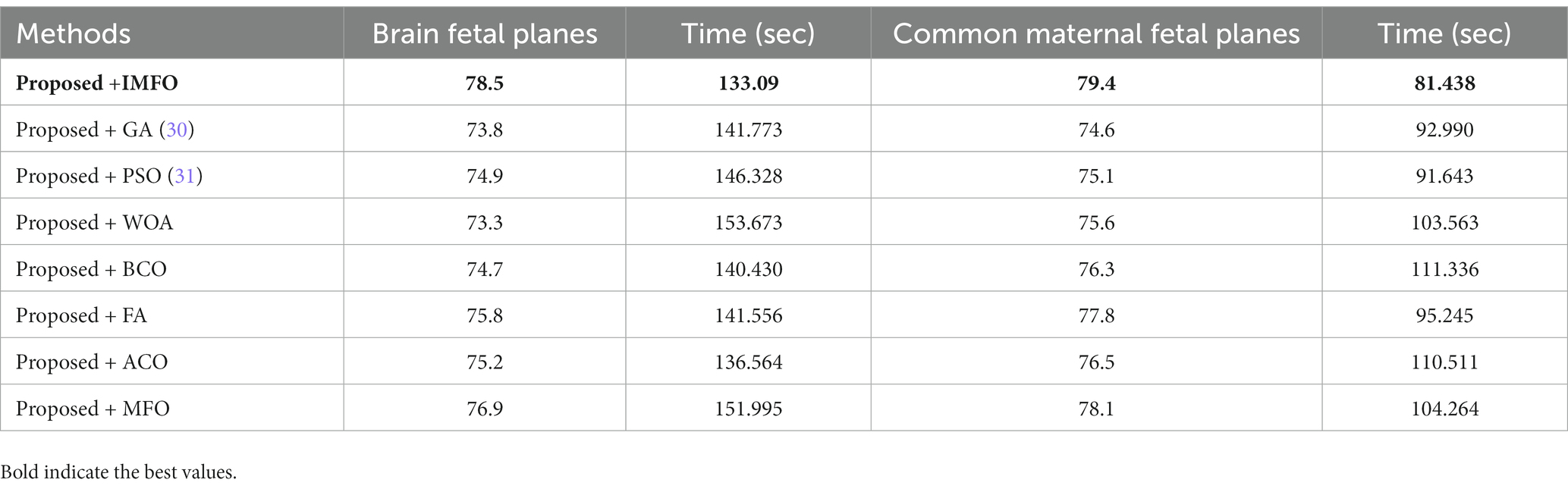
Table 8. Comparison of the proposed architecture with several other state-of-the-art optimization algorithms.
4 Conclusion
An automated deep learning architecture has been proposed in this work to classify brain and common maternal fetal plane classification. A new deep learning architecture has been designed based on bottleneck residual blocks. The proposed architecture consists of 82 layers with three blocks, including 2 highway paths and one skip connection. The hyper parameters have been chosen through Bayesian optimization (BO) rather than manual initialization. The proposed architecture obtained an accuracy of 78.5% and 79.4% for brain and common maternal fetal images. However, a high computational time is noted during the classification process; therefore, We implemented an enhanced optimization algorithm for feature selection, resulting in a substantial (100%) reduction in computational time. After employing the optimization algorithm, a minor change occurred in the accuracy and precision value. In addition, we compared the proposed optimization algorithm accuracy with several SOTA techniques, and the IMFO algorithm showed a better performance.
There are few dark sides of this work: (i) imbalanced dataset is a problem for the training of a deep learning model; (ii) irrelevant information extraction from the deep layer. In future, a problem of imbalance dataset has been resolved and proposed Self-attention mechanism architecture with an inverted bottleneck block to reduce computational time and irrelevant information extraction.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Author contributions
FR: Conceptualization, Methodology, Software, Writing – original draft. MK: Methodology, Software, Supervision, Writing – original draft, Writing – review & editing. AB: Data curation, Formal analysis, Investigation, Software, Writing – review & editing. KJ: Investigation, Methodology, Software, Writing – original draft, Writing – review & editing. AH: Conceptualization, Data curation, Resources, Software, Validation, Writing – original draft. AA: Formal analysis, Methodology, Project administration, Resources, Visualization, Writing – review & editing. NA: Conceptualization, Investigation, Methodology, Project administration, Validation, Visualization, Writing – review & editing. AM: Funding acquisition, Methodology, Visualization, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work is funded by the Researchers Supporting Project number (RSP2023R157), King Saud University, Riyadh, Saudi Arabia.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Krishna, TB, and Kokil, P. Automated classification of common maternal fetal ultrasound planes using multi-layer perceptron with deep feature integration. Biomed Signal Process Control. (2023) 86:105283. doi: 10.1016/j.bspc.2023.105283
2. Priya, M, and Nandhini, M. Detection of fetal brain abnormalities using data augmentation and convolutional neural network in internet of things. Meas: Sens. (2023) 28:100808. doi: 10.1016/j.measen.2023.100808
3. Komatsu, M, Sakai, A, Dozen, A, Shozu, K, Yasutomi, S, Machino, H, et al. Towards clinical application of artificial intelligence in ultrasound imaging. Biomedicines. (2021) 9:720. doi: 10.3390/biomedicines9070720
4. Chen, H, Bai, P, Yang, S, Jia, M, Tian, H, Zou, J, et al. Short-term and long-term outcomes of fetal ventriculomegaly beyond gestational 37 weeks: a retrospective cohort study. J Clin Med. (2023) 12:1065. doi: 10.3390/jcm12031065
5. Avisdris, N, Yehuda, B, Ben-Zvi, O, Link-Sourani, D, Ben-Sira, L, Miller, E, et al. Automatic linear measurements of the fetal brain on MRI with deep neural networks. Int J Comput Assist Radiol Surg. (2021) 16:1481–92. doi: 10.1007/s11548-021-02436-8
6. Attallah, O, Gadelkarim, H, and Sharkas, MA. Detecting and classifying fetal brain abnormalities using machine learning techniques. 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA). (2018). IEEE
7. Attallah, O, Sharkas, MA, and Gadelkarim, H. Deep learning techniques for automatic detection of embryonic neurodevelopmental disorders. Diagnostics. (2020) 10:27. doi: 10.3390/diagnostics10010027
8. Snider, EJ, Hernandez-Torres, SI, and Boice, EN. An image classification deep-learning algorithm for shrapnel detection from ultrasound images. Sci Rep. (2022) 12:8427. doi: 10.1038/s41598-022-12367-2
9. Prabakaran, BS, Hamelmann, P, Ostrowski, E, and Shafique, M. FPUS23: an ultrasound fetus phantom dataset with deep neural network evaluations for fetus orientations, fetal planes, and anatomical features. IEEE Access. (2023) 11:58308–17. doi: 10.1109/ACCESS.2023.3284315
10. Xie, B, Lei, T, Wang, N, Cai, H, Xian, J, He, M, et al. Computer-aided diagnosis for fetal brain ultrasound images using deep convolutional neural networks. Int J Comput Assist Radiol Surg. (2020) 15:1303–12. doi: 10.1007/s11548-020-02182-3
11. Fiorentino, MC, Villani, FP, di Cosmo, M, Frontoni, E, and Moccia, S. A review on deep-learning algorithms for fetal ultrasound-image analysis. Med Image Anal. (2023) 83:102629. doi: 10.1016/j.media.2022.102629
12. Płotka, S, Klasa, A, Lisowska, A, Seliga-Siwecka, J, Lipa, M, Trzciński, T, et al. Deep learning fetal ultrasound video model match human observers in biometric measurements. Phys Med Biol. (2022) 67:045013. doi: 10.1088/1361-6560/ac4d85
13. Abdou, MA. Literature review: efficient deep neural networks techniques for medical image analysis. Neural Comput Appl. (2022) 34:5791–812. doi: 10.1007/s00521-022-06960-9
14. Huang, Q, Tian, H, Jia, L, Li, Z, and Zhou, Z. A review of deep learning segmentation methods for carotid artery ultrasound images. Neurocomputing. (2023) 545:126298. doi: 10.1016/j.neucom.2023.126298
15. Sarker, MMK, Singh, VK, Alsharid, M, Hernandez-Cruz, N, Papageorghiou, AT, and Noble, JA. COMFormer: classification of maternal-fetal and brain anatomy using a residual cross-covariance attention guided transformer in ultrasound. IEEE Trans Ultrason Ferroelectr Freq Control. (2023) 70:1417–27. doi: 10.1109/TUFFC.2023.3311879
16. Shinde, K, and Thakare, A. Deep hybrid learning method for classification of fetal brain abnormalities. 2021 International Conference on Artificial Intelligence and Machine Vision (AIMV). (2021). IEEE
17. Kumar, NS, and Goel, AK. Detection, localization and classification of fetal brain abnormalities using YOLO v4 architecture. Int J Perform Eng. (2022) 18:720. doi: 10.23940/ijpe.22.10.p5.720-729
18. Qu, R, Xu, G, Ding, C, Jia, W, and Sun, M. Standard plane identification in fetal brain ultrasound scans using a differential convolutional neural network. IEEE Access. (2020) 8:83821–30. doi: 10.1109/ACCESS.2020.2991845
19. Płotka, S, Włodarczyk, T, Klasa, A, Lipa, M, Sitek, A, and Trzciński, T FetalNet: multi-task deep learning framework for fetal ultrasound biometric measurements Neural information Processing: 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, December 8–12, 2021. (2021). Springer
20. Ye, J, Liu, R, Zou, B, Zhang, H, Zhan, N, Han, C, et al. A deep convolutional neural network based hybrid framework for fetal head standard plane identification. Authorea. (2020). doi: 10.22541/au.158879105.54189382
21. Qu, R, Xu, G, Ding, C, Jia, W, and Sun, M. Deep learning-based methodology for recognition of fetal brain standard scan planes in 2D ultrasound images. IEEE Access. (2019) 8:44443–51. doi: 10.1109/ACCESS.2019.2950387
22. Shankar, H., Narayan, Adithya, Jain, Shefali, Singh, Divya, Vyas, Pooja, Hegde, Nivedita, et al. Leveraging clinically relevant biometric constraints to supervise a deep learning model for the accurate caliper placement to obtain sonographic measurements of the fetal brain. 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI). (2022). IEEE
23. Di Vece, C, Dromey, B, Vasconcelos, F, David, AL, Peebles, D, and Stoyanov, D. Deep learning-based plane pose regression in obstetric ultrasound. Int J Comput Assist Radiol Surg. (2022) 17:833–9. doi: 10.1007/s11548-022-02609-z
24. Singh, R, Mahmud, M, and Yovera, L. Classification of first trimester ultrasound images using deep convolutional neural network. Applied Intelligence and Informatics: First International Conference, AII 2021. Nottingham, UK, July 30–31, 2021. (2021). Springer
25. Ghabri, H, Alqahtani, MS, Ben Othman, S, al-Rasheed, A, Abbas, M, Almubarak, HA, et al. Transfer learning for accurate fetal organ classification from ultrasound images: a potential tool for maternal healthcare providers. Sci Rep. (2023) 13:17904. doi: 10.1038/s41598-023-44689-0
26. Wu, J, Chen, X-Y, Zhang, H, Xiong, L-D, Lei, H, and Deng, S-H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J Electr Sci Technol. (2019) 17:26–40. doi: 10.11989/JEST.1674-862X.80904120
27. Victoria, AH, and Maragatham, G. Automatic tuning of hyperparameters using Bayesian optimization. Evol Syst. (2021) 12:217–23. doi: 10.1007/s12530-020-09345-2
28. Mirjalili, S. Moth-flame optimization algorithm: a novel nature-inspired heuristic paradigm. Knowl-Based Syst. (2015) 89:228–49. doi: 10.1016/j.knosys.2015.07.006
29. Shehab, M, Abualigah, L, al Hamad, H, Alabool, H, Alshinwan, M, and Khasawneh, AM. Moth-flame optimization algorithm: variants and applications. Neural Comput Appl. (2020) 32:9859–84. doi: 10.1007/s00521-019-04570-6
30. Kundu, R, and Chattopadhyay, S. Deep features selection through genetic algorithm for cervical pre-cancerous cell classification. Multimed Tools Appl. (2023) 82:13431–52. doi: 10.1007/s11042-022-13736-9
Keywords: maternal fetal, biomedical imaging, deep learning, residual architecture, bottleneck layers, optimization
Citation: Rauf F, Khan MA, Bashir AK, Jabeen K, Hamza A, Alzahrani AI, Alalwan N and Masood A (2023) Automated deep bottleneck residual 82-layered architecture with Bayesian optimization for the classification of brain and common maternal fetal ultrasound planes. Front. Med. 10:1330218. doi: 10.3389/fmed.2023.1330218
Edited by:
Vinayakumar Ravi, Prince Mohammad bin Fahd University, Saudi ArabiaReviewed by:
Mamoona Humayun, Jouf University, Saudi ArabiaMuhammad Aslam, Aberystwyth University, United Kingdom
Inam Ullah, Gachon University, Republic of Korea
Copyright © 2023 Rauf, Khan, Bashir, Jabeen, Hamza, Alzahrani, Alalwan and Masood. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Muhammad Attique Khan, YXR0aXF1ZS5raGFuQGllZWUub3Jn; Anum Masood, YW51bS5tYXNvb2RudG51Lm5v