
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Med., 04 October 2023
Sec. Intensive Care Medicine and Anesthesiology
Volume 10 - 2023 | https://doi.org/10.3389/fmed.2023.1089087
This article is part of the Research TopicClinical Application of Artificial Intelligence in Emergency and Critical Care Medicine, Volume IVView all 17 articles
 Diana J. Valencia Morales1†
Diana J. Valencia Morales1† Vikas Bansal2†Smith F. Heavner3Janna C. Castro4Mayank Sharma1
Vikas Bansal2†Smith F. Heavner3Janna C. Castro4Mayank Sharma1 Aysun Tekin1Marija Bogojevic1Simon Zec1
Aysun Tekin1Marija Bogojevic1Simon Zec1 Nikhil Sharma2Rodrigo Cartin-Ceba5
Nikhil Sharma2Rodrigo Cartin-Ceba5 Rahul S. Nanchal6
Rahul S. Nanchal6 Devang K. Sanghavi7Abigail T. La Nou8
Devang K. Sanghavi7Abigail T. La Nou8 Syed A. Khan9
Syed A. Khan9 Katherine A. Belden10Jen-Ting Chen11Roman R. Melamed12Imran A. Sayed13Ronald A. Reilkoff14
Katherine A. Belden10Jen-Ting Chen11Roman R. Melamed12Imran A. Sayed13Ronald A. Reilkoff14 Vitaly Herasevich1
Vitaly Herasevich1 Juan Pablo Domecq Garces2Allan J. Walkey15Karen Boman16
Juan Pablo Domecq Garces2Allan J. Walkey15Karen Boman16 Vishakha K. Kumar16
Vishakha K. Kumar16 Rahul Kashyap1* on behalf of Society of Critical Care Medicine’s Discovery, the Critical Care Research Network
Rahul Kashyap1* on behalf of Society of Critical Care Medicine’s Discovery, the Critical Care Research NetworkBackground: The gold standard for gathering data from electronic health records (EHR) has been manual data extraction; however, this requires vast resources and personnel. Automation of this process reduces resource burdens and expands research opportunities.
Objective: This study aimed to determine the feasibility and reliability of automated data extraction in a large registry of adult COVID-19 patients.
Materials and methods: This observational study included data from sites participating in the SCCM Discovery VIRUS COVID-19 registry. Important demographic, comorbidity, and outcome variables were chosen for manual and automated extraction for the feasibility dataset. We quantified the degree of agreement with Cohen’s kappa statistics for categorical variables. The sensitivity and specificity were also assessed. Correlations for continuous variables were assessed with Pearson’s correlation coefficient and Bland–Altman plots. The strength of agreement was defined as almost perfect (0.81–1.00), substantial (0.61–0.80), and moderate (0.41–0.60) based on kappa statistics. Pearson correlations were classified as trivial (0.00–0.30), low (0.30–0.50), moderate (0.50–0.70), high (0.70–0.90), and extremely high (0.90–1.00).
Measurements and main results: The cohort included 652 patients from 11 sites. The agreement between manual and automated extraction for categorical variables was almost perfect in 13 (72.2%) variables (Race, Ethnicity, Sex, Coronary Artery Disease, Hypertension, Congestive Heart Failure, Asthma, Diabetes Mellitus, ICU admission rate, IMV rate, HFNC rate, ICU and Hospital Discharge Status), and substantial in five (27.8%) (COPD, CKD, Dyslipidemia/Hyperlipidemia, NIMV, and ECMO rate). The correlations were extremely high in three (42.9%) variables (age, weight, and hospital LOS) and high in four (57.1%) of the continuous variables (Height, Days to ICU admission, ICU LOS, and IMV days). The average sensitivity and specificity for the categorical data were 90.7 and 96.9%.
Conclusion and relevance: Our study confirms the feasibility and validity of an automated process to gather data from the EHR.
The pandemic of the coronavirus disease 2019 (COVID-19) has created a need to develop research resources rapidly (1). In response to the global demand for robust multicenter clinical data regarding patient care and outcomes, the Society of Critical Care Medicine (SCCM) Discovery Viral Infection and Respiratory Illness Universal Study (VIRUS) COVID-19 registry was created early in the pandemic (2–4).
Due to the surging nature of pandemic waves, and the subsequent workload and staffing burdens, clinical researchers have encountered difficulty in engaging in rapid, reliable manual data extraction from the electronic health record (EHR) (5). Manual chart review is the gold standard method for gathering data for retrospective research studies (6, 7). This process, however, is time consuming and necessitates personnel resources not widely available at all institutions (8, 9). Prior to the pandemic, automated data extraction from the EHR utilizing direct database queries was shown to be faster and less error-pone than manual data extraction (8, 10). Nonetheless, data quality challenges related to high complexity or fragmentation of data across many EHR systems make automated extraction vulnerable (11–14). Both manual and automatic extraction rely on the EHR, which is an artifact with its own biases, mistakes, and subjectivity (15–20).
Although previous research has looked at these notions, the best methods for obtaining data from EHR systems for research still need to be discovered. In response, we sought to assess the feasibility, reliability, and validity of an automated data extraction process using data for the VIRUS COVID-19 registry.
The SCCM Discovery VIRUS COVID-19 registry (Clinical Trials registration number: NCT04323787) is a multicenter, international database with over 80,000 patients from 306 health sites across 28 countries (21). VIRUS COVID-19 registry is an ongoing prospective observational study that aims at real-time data gathering and analytics with a feedback loop to disseminate treatment and outcome knowledge to improve COVID-19 patient care (3). The Mayo Clinic Institutional Review Board authorized the SCCM Discovery VIRUS COVID-19 registry as exempt on March 23, 2020 (IRB number: 20–002610). No informed consent was deemed necessary for the study subjects. The procedures were followed in accordance with the Helsinki Declaration of 2013 (22). Among the participating sites, 30 individual centers are collaborating to rapidly develop tools and resources to optimize EHR data collection. These efforts are led by the VIRUS Practical EHR Export Pathways group (VIRUS-PEEP).
The VIRUS COVID-19 registry has over 500 variables which represents the pandemic registry common data standards for critically ill patients adapted from the World Health Organization- International Severe Acute Respiratory and Emerging Infection Consortium (WHO-ISARIC) COVID-19 CRF v1.3 24 February 2020 (23). The VIRUS-PEEP validation cohort was developed in an iterative, consensus process by a group of VIRUS: COVID-19 registry primary investigators to explore the feasibility of an automation process at each site. The Validation cohort variable was internally validated with seven core VIRUS COVID-19 investigators and subsequently validated from VIRUS-PEEP leads site’s principal investigators. Because of the timeline, the cohort could not be externally validated. A purposeful representative sample of the 25 most clinically relevant variables from each category (Baseline demographic and clinical characteristics of patient and ICU and Hospital-related outcomes) were selected and prioritized for this study (4). We focused on demographic data (age, sex, race, ethnicity, height, weight), comorbidities (coronary artery disease (CAD), hypertension (HTN), congestive heart failure (CHF), chronic obstructive pulmonary disease (COPD), asthma, chronic kidney disease (CKD), diabetes mellitus (DM), dyslipidemia/hyperlipidemia), and clinical outcomes (intensive care unit (ICU) admission, days to ICU admission, ICU length of stay (LOS), type to oxygenation requirement, extracorporeal membrane oxygenation (ECMO), ICU discharge status, hospital LOS, and in-hospital mortality).
To avoid data extraction errors, we utilized precise variable definitions [VIRUS COVID-19 registry code book, cases report form (CRF), and Standard Operating Procedure (SOP)], which were already implemented in the registry and during the pilot phase of the automation implementation. Additionally, all manual and automation data extraction personnel were educated regarding the definitions and procedures needed to collect and report the data.
De-identified data were collected through Research Electronic Data Capture software (REDCap, version 8.11.11, Vanderbilt University, Nashville, Tennessee) at Mayo Clinic, Rochester, MN, United States (24). The REDCap electronic data capture system is a secure, web-based application for research data capture that includes an intuitive interface for validated data entry; audit trails for tracking data manipulation and export procedures; automated export procedures for seamless data downloads to standard statistical packages; and provide a secure platform for importing data from external sources.
The VIRUS PEEP group has implemented a comprehensive process for data extraction, which involves training manual data extractors. These data extractors are trained to identify, abstract, and collect patient data according to the project’s SOP. During a patient’s hospitalization, extractors follow them until discharge, ensuring that all relevant information is collected. The CRF used in this process includes two main sections: demographics and outcomes, composed of categorical and continuous variables. Extractors answer a mix of binary (“yes” or “no”) and checkbox (“check all that apply”) questions in the nominal variable portions of the CRF. They are instructed to avoid free text and use the prespecified units for continuous variables. In any disagreement, a trainer is always available for guidance and correction. It’s important to note that the manual extractors are unaware of the automated data extraction results.
A package of sequential query language (SQL) scripts for the “Epic Clarity” database was developed at one institution and shared through the SCCM’s Secure File Transfer Platform (SFTP) with participating sites. A second site offered peer coaching on the development and utility of end-user Epic™ reporting functions and how to adapt and modify the SQL scripts according to their EHR environment and security firewall. Other tools included R-Studio™ scripts, Microsoft Excel™ macros, STATA 16, and REDCap calculators for data quality checks at participating sites before data upload to VIRUS Registry REDCap. These tools were designed to aid in data extraction, data cleaning, and adherence to data quality rules as provided in VIRUS COVID-19 Registry SOPs. Institutions participated in weekly conference calls to discuss challenges and share successes in implementing automated data abstraction; additionally, lessons learned from adapting the SQL scripts and other data quality tools to their EHR environments were shared between individual sites and members of the VIRUS PEEP group.
We summarized continuous variables of manual and automation process data using mean ± SD and calculated mean difference and SE by matched pair analysis. Pearson correlation coefficient (PCCs) and 95% confidence intervals (CI) were generated for continuous data as a measure of inter-class dependability (25). Pearson correlations were classified as trivial (0.00–0.30), low (0.30–0.50), moderate (0.50–0.70), high (0.70–0.90), and extremely high (0.90–1.00) (26). Bland–Altman mean-difference plots for continuous variables were also provided to aid in the understanding of agreement (27).
Percent agreements were determined for the data collected using each of the two extraction techniques in a categorical variable:
The total number of agreeing outcomes divided by the total number of results is the summary agreement for each variable. For categorical variables we used Cohen’s kappa coefficient (28). We used the scale created by Landis et al. to establish the degree of agreement (29). This scale is divided by almost perfect (ϰ =0.81–1.00), substantial (ϰ = 0.61–0.80), moderate (ϰ = 0.41–0.60), fair (ϰ = 0.21–0.40), slight (ϰ = 0.00–0.20), and poor (ϰ < 0.00). Additionally, the sensitivity and specificity were calculated by comparing the results of the automated data extractions method to the results of manual data extraction method (gold standard). The 95% confidence intervals were calculated using an exact test for proportions. We used JMP statistical software version 16.2 for all data analysis.
Our cohort consisted of data from 652 patients from 11 sites (Figure 1). A total of 25 variables were collected for each patient for manual and automated methods. Of these 25 variables, 16 (64.0%) were nominal, 7 (28.0%) were continuous, and 2 (8.0%) were categorical variables.
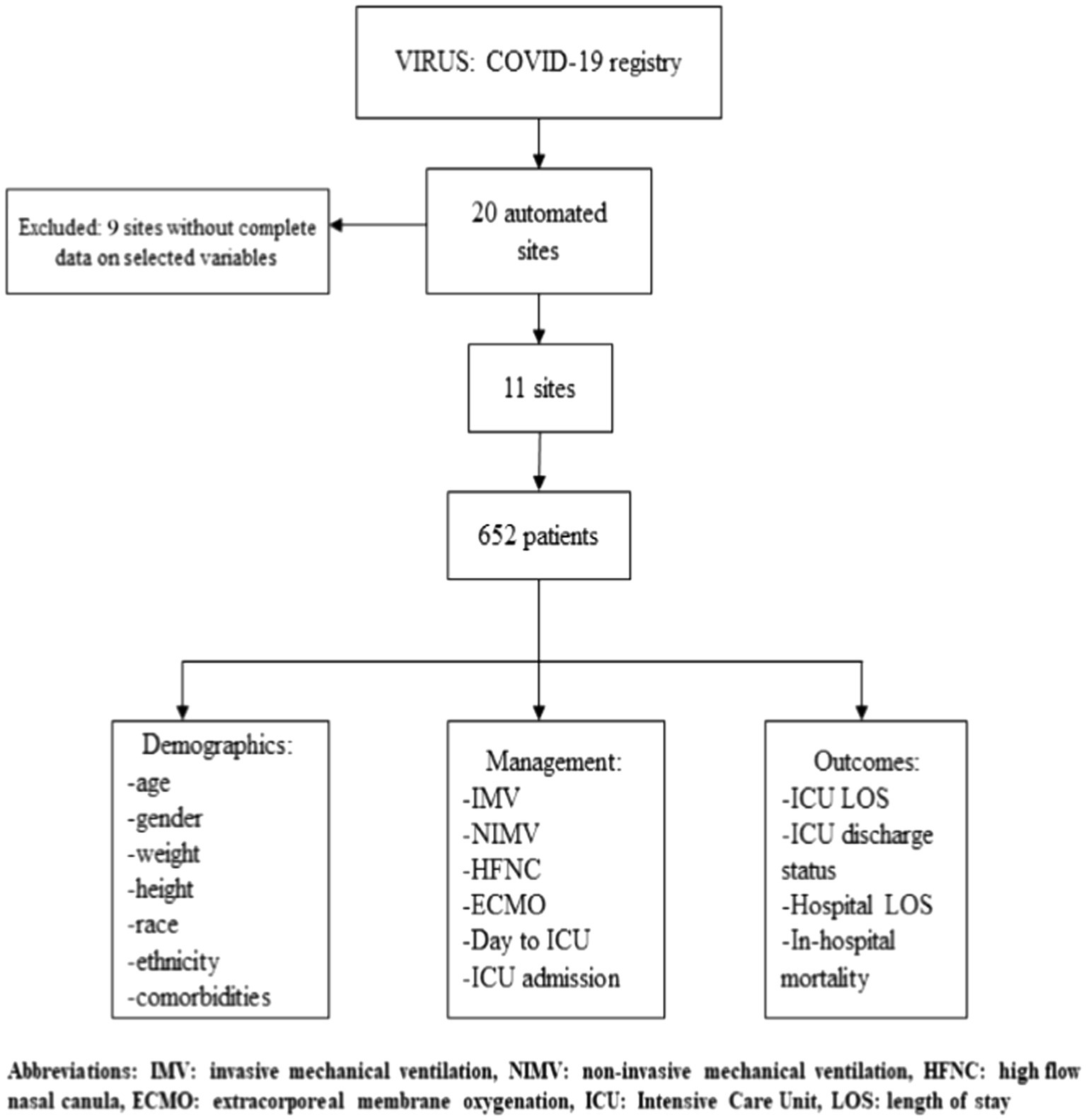
Figure 1. Study flowchart.
Table 1 summarizes the continuous variables. The automated results for three variables (age, weight and hospital LOS) agreed “extremely high” (>90%) to the manual extraction results. The agreement was “high” (70–90%) for height, days to ICU admission, ICU LOS, and IMV days. Figure 2 presents the Bland–Altman plots for seven continuous variables.
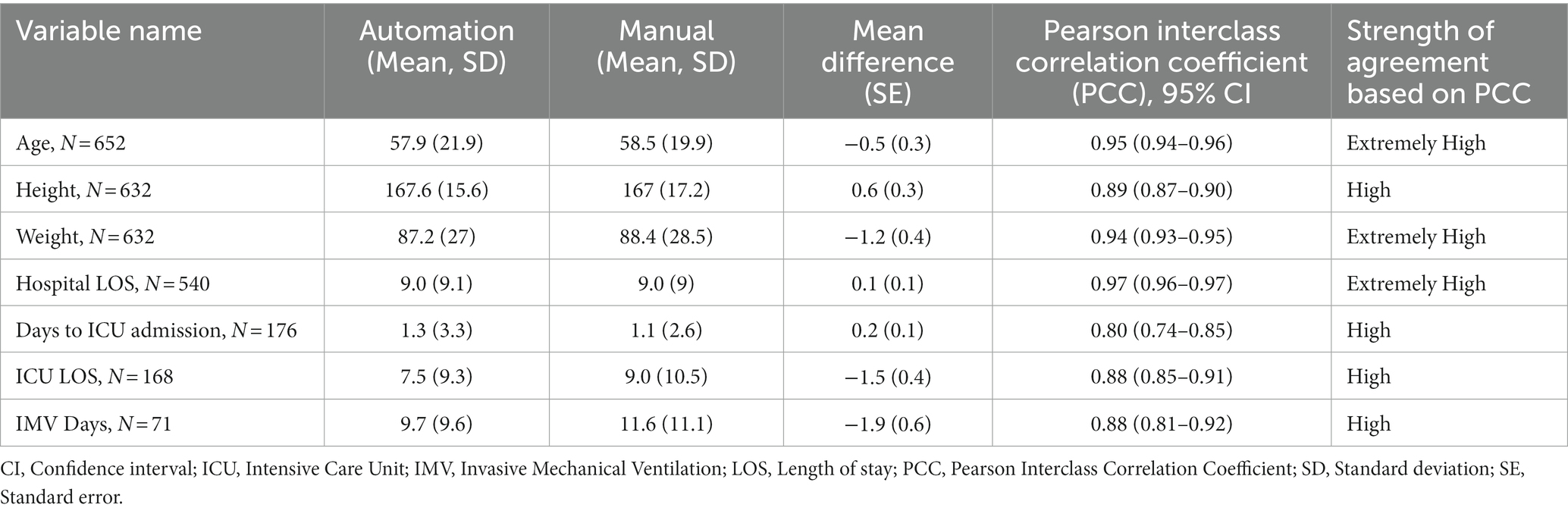
Table 1. Comparison of patients in automated versus manual reviews and measures of agreement for individual responses for continuous variables.
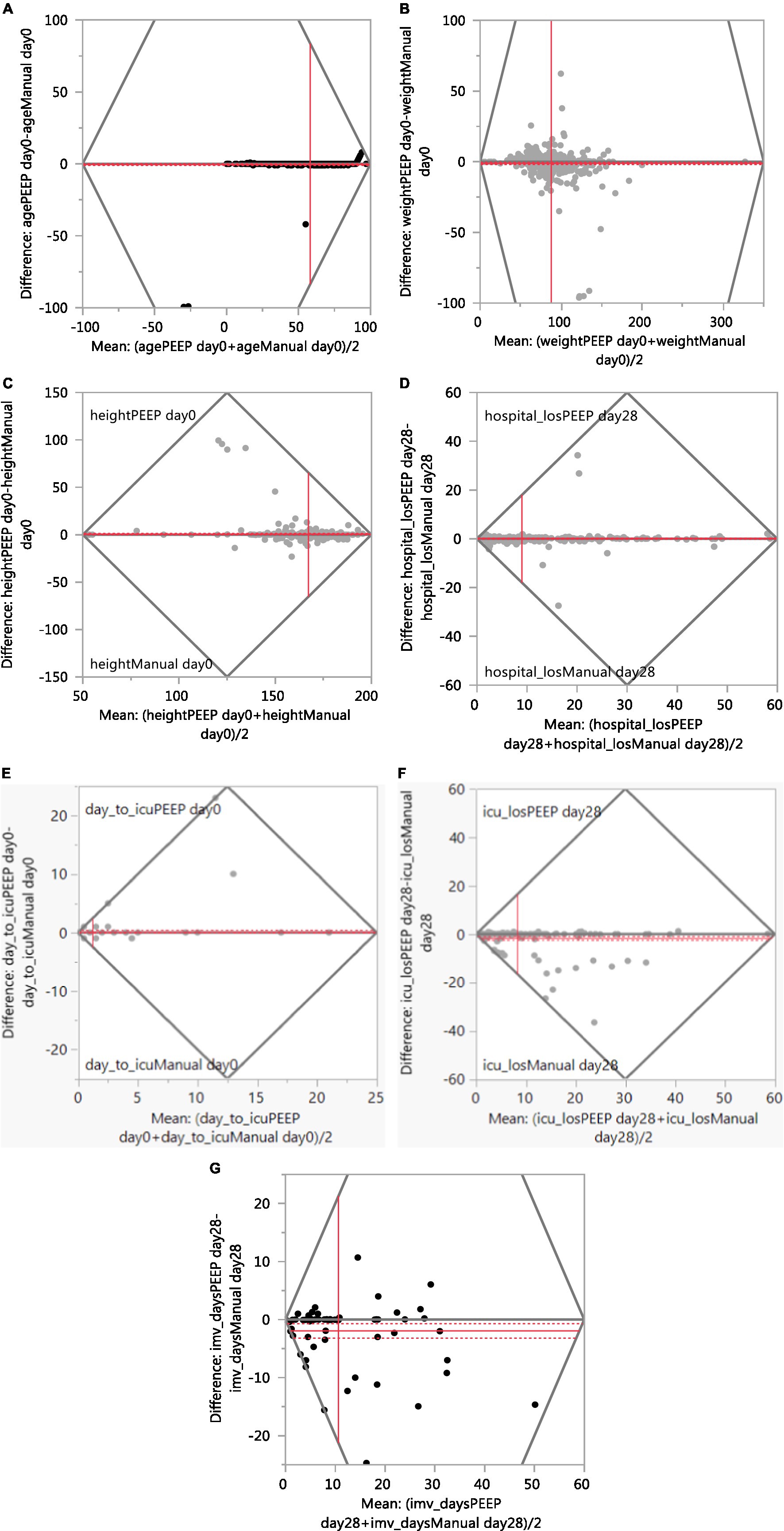
Figure 2. Agreement between manual and PEEP (Bland–Altman plot). (A) Age. (B) Weight. (C) Height. (D) Hospital Length of Stay. (E) Days to ICU admission. (F) ICU Length of Stay. (G) IMV Days.
Tables 2, 3 describe the ordinal and nominal variables. The agreement between manual and automated extraction was almost perfect in 13 (72.2%) of the studied variables, and substantial in five (27.8%). The comorbidity “dyslipidemia/hyperlipidemia” had the lowest degree of agreement (moderate 0.61); however, overall percent agreement was high (86.9%). The only variable that showed a Kappa Coefficient equal to 1 was “ICU-discharge status.” The average Kappa Coefficient was 0.81 for the eight comorbidities collected and was 0.86 for outcomes variables, considered almost perfect. The automated electronic search strategy achieved an average sensitivity of 90.7% and a specificity of 96.9%. The sensitivity and specificity of each data-extraction method for all variables are presented in Table 3.
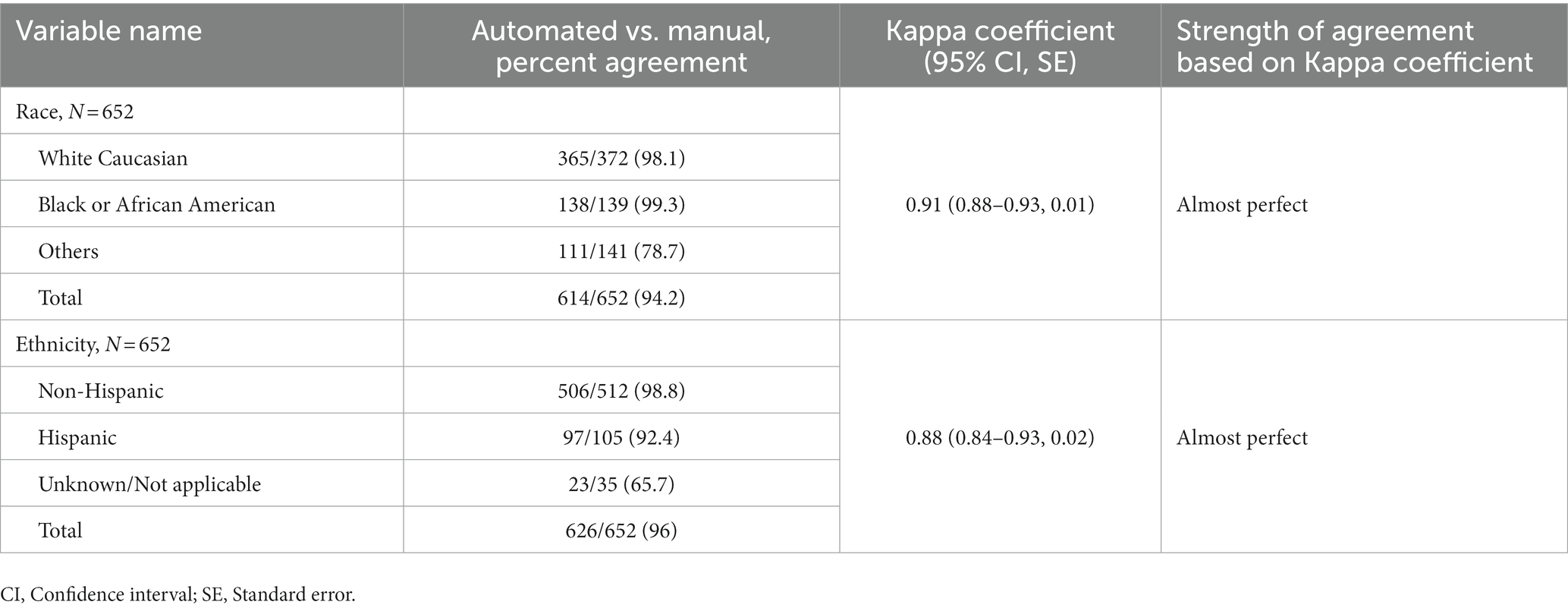
Table 2. Comparison of patients in automated versus manual reviews and measures of agreement for individual responses for categorical (ordinal) variables.
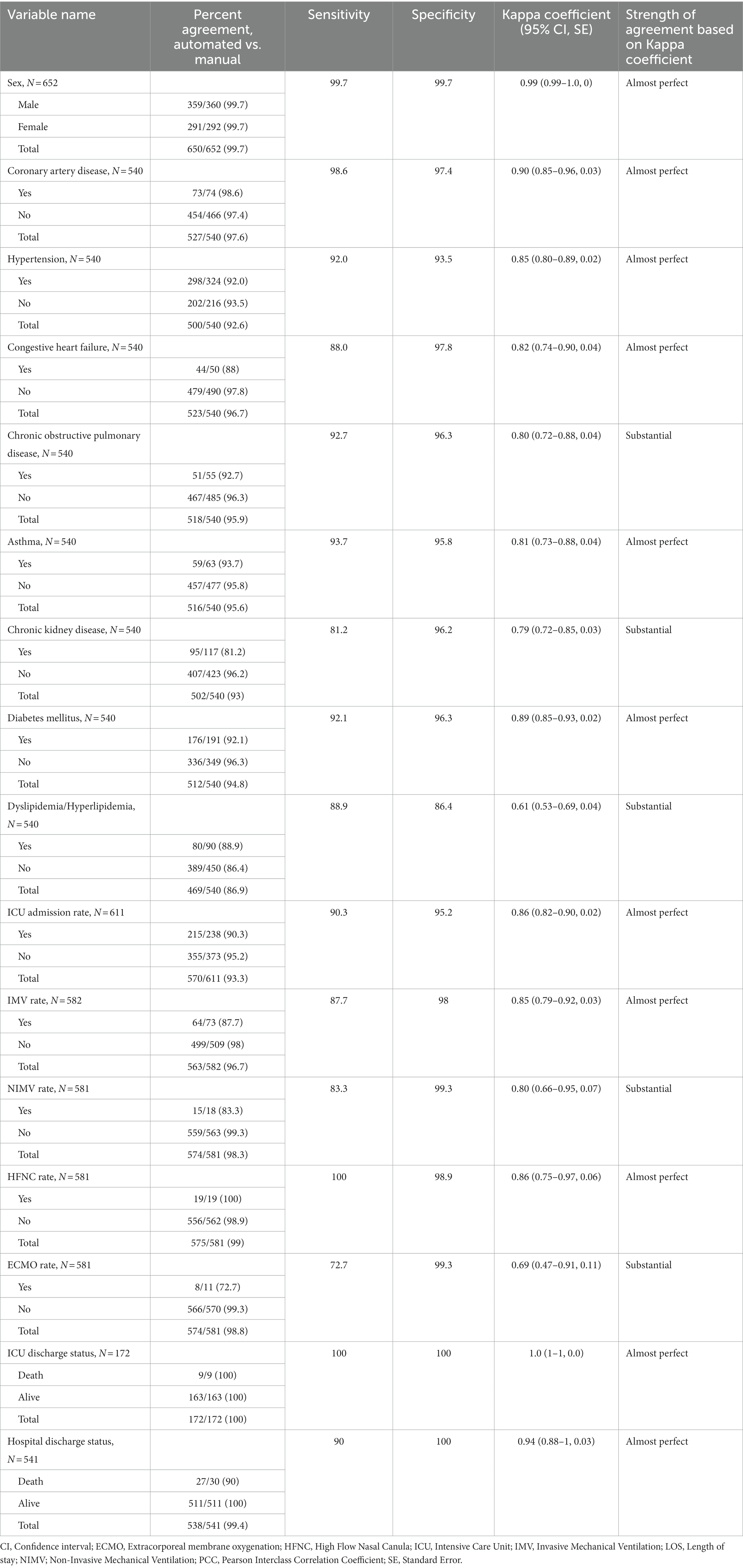
Table 3. Comparison of patients in automated versus manual reviews and measures of agreement for individual responses for categorical (nominal) variables.
The automated search strategy for EHR data extraction was highly feasible and reliable. Our investigation observed substantial and almost perfect agreement between automated and manual data extraction. There was almost perfect agreement in two-thirds of the categorical variables, and all continuous variables showed Extremely High or High agreement.
The results of our validation study are similar to other studies that validated and evaluated automated data (30–33). Singh et al. (31) developed several algorithm queries to identify every component of the Charlson Comorbidity Index and found median sensitivity and specificity of 98–100% and 98–100%, respectively. In the validation cohort, the sensitivity of the automated digital algorithm ranged from 91 to 100%, and the specificity ranged from 98 to 100% compared to ICD-9 codes. These results are comparable to our study as the comorbidities analyzed presented a sensitivity and specificity of 90.2 and 96.8%, respectively. Our results are superior to the results of Schaerfer et al. (34), who found a sensitivity of 72% and a specificity of 95% for comorbidities (CHF, cerebral vascular disease, CKD, cancer, DM, human immunodeficiency virus, HTN) in patients with COVID-19 pneumonia using ICD-10 base-data comparing to manual data collection. We also successfully compared seven continuous variables with three extremely high agreement and four high agreement in comparison to Brazeal et al. (35), who compared two variables (age and BMI) for manual versus automation in a study population comprised of patients with histologically confirmed advanced adenomatous colorectal polyp.
Manual data extractors can overcome diverse interface issues, read and analyze free text, and provide clinical judgment when retrieving and interpreting data; however, manual data extraction is limited to human resources and is prone to human error (7, 32, 36). In addition to requiring considerable amount of time, manual data extraction also necessitates qualified personnel (30, 33). During the COVID-19 pandemic, where real-time data is paramount, automated data has proven validity and efficacy, and may divert personnel to patient care and other vital tasks. Nonetheless, automated data is not flawless. A significant limitation is finding a unique algorithm that can be applied to every center. Variables collected as free text fields are another challenge for such validations. The automated VIRUS COVID-19 sites had reported over a large majority of variables collected using this method. Currently, more than 60,000 patients and their data variables in the registry had been collected through efforts of the VIRUS-PEEP group, which has allowed for updates and complete data in the shortest possible time.
The environment for data collection is often a shared environment within an institution, and there are limitations on how much data may be extracted and processed in one job and how much post-abstraction processing is necessary. Microsoft SQL and TSQL solutions process substantial amounts of data from many different tables and can take a long time to run on large populations. There are clinical documentation differences between the various sites requiring additional coding when applying the data requirements and rules. Establishing logic for data elements within a given EHR can be time consuming up front, requiring close collaboration between clinician and analytics teams. Data may be stored differently between multiple medical centers in one institution, requiring processing to comply with data requirements for standardization. While sites can share coding experience in data abstraction between similar data storage structure, variable coding schemes pose challenges for direct translation between sites. Lastly, one information technology employee often works on such projects with competing priorities.
To our knowledge this is first multicenter study to evaluate the feasibility of automation process during COVID-19 pandemic. This automation process should be applicable to any EHR vendor (EHR type agnostic), and these purposeful sampled representative data points would be relevant to any other clinical study/trial, which is a major strength of this study. Nonparticipation of 19 sites out of 30 sites in the VIRUS-PEEP group, which leads to a possibility of selection bias, is a major limitation. The time constraints in the ongoing pandemic at participating sites were the reason behind this non-participation in the validation process. However, extracting data across 11 different centers is one of the strengths of this study; it could also highlight the variations in staff, procedures, and patients at these institutions. Although the SQL queries could be applicable in most sites, some sites required a new SQL tailored to their data architecture. One key limitation for our group was that all sites found a portion of data extraction that could not be automated, including variables which are described in narrative, such as, patient symptoms, estimated duration of onset of symptoms, and imaging interpretations. Another limitation is a notable discrepancy between manual and EMR extraction for important outcomes like ICU LOS and IMV days. The automation process relies on procedure order date (intubation/extubation) and ADT (hospital/ICU admission discharge transfer) order date and time and discontinuation date in EHR; however the manual extractor look for first-time documented ICU or IMV in her, which probably could account for such notable discrepancy in outcomes like ICU LOS and IMV days. Transferring a patient to a location that was not a usual ICU due to COVID-19 surge may be another possible explanation for the observed lower sensitivity of ICU admission rate. Variation in creation of make-shift ICUs at different institution may have caused this discrepancy in automation of ICU admissions documentation. It partially explains the lower sensitivity and high specificity of ICU admission, IMV, NIMV, and ECMO rates by automation process. Another noticeable issue was that the manual data extraction was done in real time and automation was done when the patient was discharged and mainly relied on billing codes and manually verified data available in EHR.
Future research on this topic could involve a thorough comparison of all patient records extracted using two methods: manual extraction and automated SQL queries. The data comparison could be done by aligning data points across a wide range of variables for each data extraction method and then statistically analyzing their consistency and discrepancies. This detailed comparison would verify the reliability of automated data extraction and provide insights into areas that could be improved for greater accuracy.
This study confirms the feasibility, reliability, and validity of an automated process to gather data from the EHR. The use of automated data is comparable to the gold standard. The utilization of automated data extraction provides additional solutions when a rapid and large volume of patient data needs to be extracted.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
The studies involving humans were approved by Mayo Clinic Institutional Review Board. The studies were conducted in accordance with the local legislation and institutional requirements. The ethics committee/institutional review board waived the requirement of written informed consent for participation from the participants or the participants’ legal guardians/next of kin because The Mayo Clinic Institutional Review Board authorized the SCCM Discovery VIRUS COVID-19 registry as exempt on March 23, 2020 (IRB number: 20–002610). No informed consent was deemed necessary for the study subjects. The procedures were followed in accordance with the Helsinki Declaration of 2013.
DV and VB contributed equally in the defining the study outline and manuscript writing. VB, SH, JC, MS, AT, MB, SZ, NS, RC-C, RN, DS, AN, SK, KAB, J-TC, RM, IS, RR, and KB did the data review and collection. DV, VB, and SH did the statistical analysis. VH, JD, AW, VK, and RK did the study design and critical review. DV, VB, SH, and RK were guarantor of the manuscript and took responsibility for the integrity of the work as a whole, from inception to published article. All authors contributed to the article and approved the submitted version.
The VIRUS: COVID-19 Registry was supported, in part, by the Gordon and Betty Moore Foundation, and Janssen Research & Development, LLC. They have no role in data gathering, analysis, interpretation, and writing.
Data from this study was submitted and presented as an abstract format for the Chest 2023 Conferences at Hawaiʻi Convention Center, Honolulu, Hawaiʻi.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
CAD, Coronary artery disease; CHF, Congestive heart failure; CI, Confidence interval; CKD, Chronic kidney disease; COPD, Chronic obstructive pulmonary disease; CRF, Case report forms; DM, Diabetes mellitus; ECMO, Extracorporeal membrane oxygenation; EHR, Electronic health records; HFNC, High flow nasal canula; HTN, Hypertension; ICU, Intensive care unit; IMV, Invasive mechanical ventilation; IRB, Institutional review boards; LOS, Length of stay; NIMV, Non-invasive mechanical ventilation; PCC, Pearson interclass correlation coefficient; REDCap, Research electronic data capture software; SCCM, Society of critical care medicine; SD, Standard deviations; SE, Standard error; SFTP, Secure file transfer platform; SOP, Standard operating procedure; SQL, Sequential query language; VIRUS, Viral Infection and Respiratory Illness Universal Study; VIRUS-PEEP, VIRUS Practical EHR Export Pathways group; WHO, World Health Organization; WHO-ISARIC, World Health Organization- International Severe Acute Respiratory And Emerging Infection Consortium.
1. Wang, C, Horby, PW, Hayden, FG, and Gao, GF. A novel coronavirus outbreak of global health concern. Lancet. (2020) 395:470–3. doi: 10.1016/S0140-6736(20)30185-9
2. Domecq, JP, Lal, A, Sheldrick, CR, Kumar, VK, Boman, K, Bolesta, S, et al. Outcomes of patients with coronavirus disease 2019 receiving organ support therapies: the international viral infection and respiratory illness universal study registry. Crit Care Med. (2021) 49:437–48. doi: 10.1097/CCM.0000000000004879
3. Walkey, AJ, Kumar, VK, Harhay, MO, Bolesta, S, Bansal, V, Gajic, O, et al. The viral infection and respiratory illness universal study (VIRUS): an international registry of coronavirus 2019-related critical illness. Crit Care Explor. (2020) 2:e0113. doi: 10.1097/CCE.0000000000000113
4. Walkey, AJ, Sheldrick, RC, Kashyap, R, Kumar, VK, Boman, K, Bolesta, S, et al. Guiding principles for the conduct of observational critical care research for coronavirus disease 2019 pandemics and beyond: the Society of Critical Care Medicine discovery viral infection and respiratory illness universal study registry. Crit Care Med. (2020) 48:e1038–44. doi: 10.1097/CCM.0000000000004572
5. Grimm, AG Hospitals Reported That the COVID-19 Pandemic Has Significantly Strained Health Care Delivery Results of a National Pulse Survey. USA: U.S. Department of Health and Human Services Office of Inspector General. (2021). Available at: https://oig.hhs.gov/oei/reports/OEI-09-21-00140.pdf
6. Vassar, M, and Holzmann, M. The retrospective chart review: important methodological considerations. J Educ Eval Health Prof. (2013) 10:12. doi: 10.3352/jeehp.2013.10.12
7. Yin, AL, Guo, WL, Sholle, ET, Rajan, M, Alshak, MN, Choi, JJ, et al. Comparing automated vs. manual data collection for COVID-specific medications from electronic health records. Int J Med Inform. (2022) 157:104622. doi: 10.1016/j.ijmedinf.2021.104622
8. Byrne, MD, Jordan, TR, and Welle, T. Comparison of manual versus automated data collection method for an evidence-based nursing practice study. Appl Clin Inform. (2013) 4:61–74. doi: 10.4338/ACI-2012-09-RA-0037
9. Lan, H, Thongprayoon, C, Ahmed, A, Herasevich, V, Sampathkumar, P, Gajic, O, et al. Automating quality metrics in the era of electronic medical records: digital signatures for ventilator bundle compliance. Biomed Res Int. (2015) 2015:396508:1–6. doi: 10.1155/2015/396508
10. Brundin-Mather, R, Soo, A, Zuege, DJ, Niven, DJ, Fiest, K, Doig, CJ, et al. Secondary EMR data for quality improvement and research: a comparison of manual and electronic data collection from an integrated critical care electronic medical record system. J Crit Care. (2018) 47:295–301. doi: 10.1016/j.jcrc.2018.07.021
11. Hersh, WR, Cimino, J, Payne, PR, Embi, P, Logan, J, Weiner, M, et al. Recommendations for the use of operational electronic health record data in comparative effectiveness research. EGEMS. (2013) 1:1018. doi: 10.13063/2327-9214.1018
12. Hersh, WR, Weiner, MG, Embi, PJ, Logan, JR, Payne, PR, Bernstam, EV, et al. Caveats for the use of operational electronic health record data in comparative effectiveness research. Med Care. (2013) 51:S30–7. doi: 10.1097/MLR.0b013e31829b1dbd
13. Kahn, MG, Callahan, TJ, Barnard, J, Bauck, AE, Brown, J, Davidson, BN, et al. A harmonized data quality assessment terminology and framework for the secondary use of electronic health record data. EGEMS. (2016) 4:1244. doi: 10.13063/2327-9214.1244
14. Wei, WQ, Leibson, CL, Ransom, JE, Kho, AN, Caraballo, PJ, Chai, HS, et al. Impact of data fragmentation across healthcare centers on the accuracy of a high-throughput clinical phenotyping algorithm for specifying subjects with type 2 diabetes mellitus. J Am Med Inform Assoc. (2012) 19:219–24. doi: 10.1136/amiajnl-2011-000597
15. Botsis, T, Hartvigsen, G, Chen, F, and Weng, C. Secondary use of EHR: data quality issues and informatics opportunities. Summit Transl Bioinform. (2010) 2010:1–5.
16. Hripcsak, G, and Albers, DJ. Next-generation phenotyping of electronic health records. J Am Med Inform Assoc. (2013) 20:117–21. doi: 10.1136/amiajnl-2012-001145
17. Prokosch, HU, and Ganslandt, T. Perspectives for medical informatics. Reusing the electronic medical record for clinical research. Methods Inf Med. (2009) 48:38–44. doi: 10.3414/ME9132
18. Weiskopf, NG, Hripcsak, G, Swaminathan, S, and Weng, C. Defining and measuring completeness of electronic health records for secondary use. J Biomed Inform. (2013) 46:830–6. doi: 10.1016/j.jbi.2013.06.010
19. Weiskopf, NG, Cohen, AM, Hannan, J, Jarmon, T, and Dorr, DA. Towards augmenting structured EHR data: a comparison of manual chart review and patient self-report. AMIA Annu Symp Proc. (2019) 2019:903–12.
20. Kern, LM, Malhotra, S, Barrón, Y, Quaresimo, J, Dhopeshwarkar, R, Pichardo, M, et al. Accuracy of electronically reported “meaningful use” clinical quality measures: a cross-sectional study. Ann Intern Med. (2013) 158:77–83. doi: 10.7326/0003-4819-158-2-201301150-00001
21. The Society of Critical Care Medicine, Lyntek Medical Technologies Inc. VIRUS COVID-19 registry dashboard: a COVID-19 registry of current ICU and hospital care patterns USA2020. (2021). Available at: https://sccmcovid19.org/.
22. General Assembly of the World Medical Association. World medical association declaration of Helsinki: ethical principles for medical research involving human subjects. J Am Coll Dent. (2014) 81:14–8.
23. World Health Organization-International Severe Acute Respiratory and Emerging Infection Consortium (WHO-ISARIC). Clinical data collection – the COVID-19 case report forms (CRFs) (2020). Available at: https://media.tghn.org/medialibrary/2020/03/ISARIC_COVID-19_CRF_V1.3_24Feb2020.pdf
24. Harris, PA, Taylor, R, Thielke, R, Payne, J, Gonzalez, N, and Conde, JG. Research electronic data capture (REDCap)--a metadata-driven methodology and workflow process for providing translational research informatics support. J Biomed Inform. (2009) 42:377–81. doi: 10.1016/j.jbi.2008.08.010
25. Wang, J. Pearson correlation coefficient In: W Dubitzky, O Wolkenhauer, K-H Cho, and H Yokota, editors. Encyclopedia of systems biology. New York, NY: Springer (2013). 1671.
26. Mukaka, MM. Statistics corner: a guide to appropriate use of correlation coefficient in medical research. Malawi Med J. (2012) 24:69–71.
27. Altman, DG, and Bland, JM. Measurement in Medicine - the analysis of method comparison studies. J Roy Stat Soc D-Sta. (1983) 32:307–17. doi: 10.2307/2987937
28. Sun, S. Meta-analysis of Cohen’s kappa. Health Serv Outc Res Methodol. (2011) 11:145–63. doi: 10.1007/s10742-011-0077-3
29. Landis, JR, and Koch, GG. The measurement of observer agreement for categorical data. Biometrics. (1977) 33:159–74. doi: 10.2307/2529310
30. Alsara, A, Warner, DO, Li, G, Herasevich, V, Gajic, O, and Kor, DJ. Derivation and validation of automated electronic search strategies to identify pertinent risk factors for postoperative acute lung injury. Mayo Clin Proc. (2011) 86:382–8. doi: 10.4065/mcp.2010.0802
31. Singh, B, Singh, A, Ahmed, A, Wilson, GA, Pickering, BW, Herasevich, V, et al. Derivation and validation of automated electronic search strategies to extract Charlson comorbidities from electronic medical records. Mayo Clin Proc. (2012) 87:817–24. doi: 10.1016/j.mayocp.2012.04.015
32. Rishi, MA, Kashyap, R, Wilson, G, and Hocker, S. Retrospective derivation and validation of a search algorithm to identify extubation failure in the intensive care unit. BMC Anesthesiol. (2014) 14:41. doi: 10.1186/1471-2253-14-41
33. Smischney, NJ, Velagapudi, VM, Onigkeit, JA, Pickering, BW, Herasevich, V, and Kashyap, R. Retrospective derivation and validation of a search algorithm to identify emergent endotracheal intubations in the intensive care unit. Appl Clin Inform. (2013) 4:419–27. doi: 10.4338/ACI-2013-05-RA-0033
34. Schaefer, JW, Riley, JM, Li, M, Cheney-Peters, DR, Venkataraman, CM, Li, CJ, et al. Comparing reliability of ICD-10-based COVID-19 comorbidity data to manual chart review, a retrospective cross-sectional study. J Med Virol. (2022) 94:1550–7. doi: 10.1002/jmv.27492
35. Brazeal, JG, Alekseyenko, AV, Li, H, Fugal, M, Kirchoff, K, Marsh, C, et al. Assessing quality and agreement of structured data in automatic versus manual abstraction of the electronic health record for a clinical epidemiology study. Res Methods Med Health Sci. (2021) 2:168–78. doi: 10.1177/26320843211061287
Keywords: validation, data automation, electronic health records, COVID-19, VIRUS COVID-19 registry
Citation: Valencia Morales DJ, Bansal V, Heavner SF, Castro JC, Sharma M, Tekin A, Bogojevic M, Zec S, Sharma N, Cartin-Ceba R, Nanchal RS, Sanghavi DK, La Nou AT, Khan SA, Belden KA, Chen J-T, Melamed RR, Sayed IA, Reilkoff RA, Herasevich V, Domecq Garces JP, Walkey AJ, Boman K, Kumar VK and Kashyap R (2023) Validation of automated data abstraction for SCCM discovery VIRUS COVID-19 registry: practical EHR export pathways (VIRUS-PEEP). Front. Med. 10:1089087. doi: 10.3389/fmed.2023.1089087
Edited by:
Gulzar H. Shah, Georgia Southern University, United StatesReviewed by:
Kristie Cason Waterfield, Georgia Southern University, United StatesCopyright © 2023 Valencia Morales, Bansal, Heavner, Castro, Sharma, Tekin, Bogojevic, Zec, Sharma, Cartin-Ceba, Nanchal, Sanghavi, La Nou, Khan, Belden, Chen, Melamed, Sayed, Reilkoff, Herasevich, Domecq Garces, Walkey, Boman, Kumar and Kashyap. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rahul Kashyap, a2FzaHlhcG1kQGdtYWlsLmNvbQ==
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.