 Juan Cao
Juan Cao Zihao Xu1,2†
Zihao Xu1,2† Mengjia Xu
Mengjia Xu Yuhui Ma
Yuhui Ma Yitian Zhao
Yitian Zhao- 1School of Information Science and Engineering, Chongqing Jiaotong University, Chongqing, China
- 2Cixi Institute of Biomedical Engineering, Ningbo Institute of Materials Technology and Engineering, Chinese Academy of Sciences, Ningbo, China
- 3Affiliated Cixi Hospital, Wenzhou Medical University, Ningbo, China
Introduction: Optical Coherence Tomography Angiography (OCTA) is a new non-invasive imaging modality that gains increasing popularity for the observation of the microvasculatures in the retina and the conjunctiva, assisting clinical diagnosis and treatment planning. However, poor imaging quality, such as stripe artifacts and low contrast, is common in the acquired OCTA and in particular Anterior Segment OCTA (AS-OCTA) due to eye microtremor and poor illumination conditions. These issues lead to incomplete vasculature maps that in turn makes it hard to make accurate interpretation and subsequent diagnosis.
Methods: In this work, we propose a two-stage framework that comprises a de-striping stage and a re-enhancing stage, with aims to remove stripe noise and to enhance blood vessel structure from the background. We introduce a new de-striping objective function in a Stripe Removal Net (SR-Net) to suppress the stripe noise in the original image. The vasculatures in acquired AS-OCTA images usually exhibit poor contrast, so we use a Perceptual Structure Generative Adversarial Network (PS-GAN) to enhance the de-striped AS-OCTA image in the re-enhancing stage, which combined cyclic perceptual loss with structure loss to achieve further image quality improvement.
Results and discussion: To evaluate the effectiveness of the proposed method, we apply the proposed framework to two synthetic OCTA datasets and a real AS-OCTA dataset. Our results show that the proposed framework yields a promising enhancement performance, which enables both conventional and deep learning-based vessel segmentation methods to produce improved results after enhancement of both retina and AS-OCTA modalities.
1. Introduction
Medical images with clean presentation, adequate contrast and informative details are essential in medical image analysis for clinical applications: e.g., tissue segmentation, and disease diagnosis. However, stripe artifacts or poor contrast often occur during the medical image acquisition process (1). The accuracy of a computer-aided diagnosis system is highly dependent on the quality of pre-processing as errors can be propagated and accumulated due to poor imaging quality (2).
As a functional extension of optical coherence tomography (OCT), OCT Angiography (OCTA) is a new emerging non-invasive imaging modality that enables observation of microvasculatures up to capillary level (3, 4). Figure 1B demonstrates one high-quality retinal OCTA image sample. OCTA will reveal morphological changes of retinal vessels associated with a wide range of retinal diseases and has shown its potential clinical applications in facilitating monitoring and diagnosis of glaucoma (5), diabetic retinopathy (6), artery and vein occlusions (7), and age-related macular degeneration (AMD) (8), to name only the most widely occurring ones.
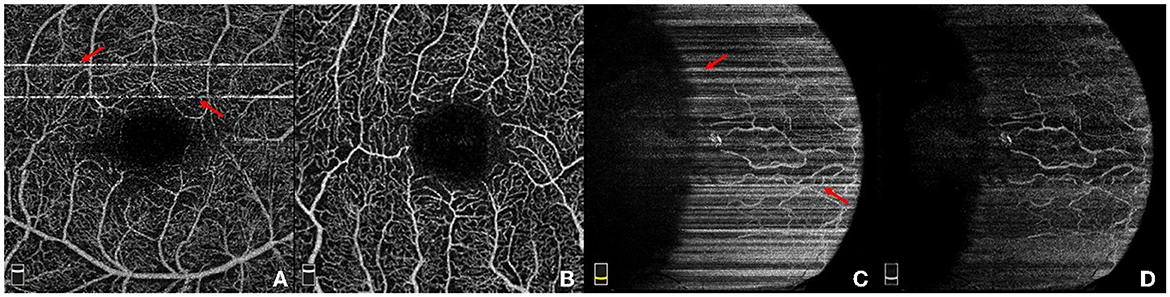
Figure 1. Illustration of four example OCTA images. (A) A retinal OCTA image with stripe noise; (B) Another retinal OCTA image without stripe noise; (C) A conjunctival AS-OCTA image with stripe noise; (D) The conjunctival AS-OCTA image in (C) with stripe noise removed.
Recently, OCTA has also been adopted to image the vessels in the anterior segment of the eye. Current commercial OCTA systems are not specifically designed for the anterior segment (9), the use of OCTA in assessments of the anterior segment has not been fully explored. The AS-OCTA technique has been used to quantify the vascular density and diameter in the cornea (10–13), conjunctiva (14), and iris (15), in order to seek better treatment options. Figures 1C, D illustrates one case of AS-OCTA imaging by scanning conjunctival region. Overall, OCTA technique opens up a new avenue to study the relation between ocular vessels and various eye and neurodegenerative diseases (4).
OCTA has the ability to produce three-dimensional (3D) images of the ocular vasculature at different depths, and the acquired 3D data is always mapped into two-dimensional (2D) en face image by using the maximum projection for the ease of visualization. However, acquisition of OCTA and AS-OCTA usually takes several seconds, e.g., 3–5 s by RTVue XR Avanti SD-OCT system (Optovue, Inc, Fremont, California, USA), and in consequence, OCTA images are inevitably susceptible to motion artifacts caused by involuntary eye movements. Adjacent OCT-scans present a variety of decorrelation and further degrades the image quality: motions like microsaccade leads to a momentary change in the location of the scan and produce visible horizontal or vertical white stripe artifacts in the en face images (16), as shown by red arrows in Figures 1A, C. These stripe artifacts lead to unpleasing visualization, inaccurate vessel quantification, and even hinder clinical decision making. Accelerating acquisition speed may mitigate motion artifacts, relatively low spatial sampling rate is often used in some devices, e.g., Topcon-DRI-OCT-1 machine (Topcon Corporation, Japan). Unfortunately, such accelerating process requires more complex design of the imaging systems (17), and may also lead to the presence of sample-based speckle and non-existent vessels. Other commercial OCTA imaging systems, e.g., RTVue XR Avanti SD-OCT system (Optovue, Inc, Fremont, California, USA), have the built-in motion detection and correction functions to suppress stripe artifacts. Nevertheless, there still exist slight stripe artifacts in the form of residual lines. Furthermore, these functions could increase scanning time or even cause imaging failures if patients are unable to hold their eyes still (18). In addition to stripe noise, low contrast or intensity inhomogeneity caused by poor illumination conditions usually leads to hardly visible or even discontinuous vasculatures. Figure 1D demonstrates the AS-OCTA image in Figure 1C after stripe noise removal, but the inherent poor contrast will still pose significant challenges to subsequent medical image analysis tasks, such as blood vessel segmentation (2) and disease/lesion detection (19).
As an alternative, it is crucial to design high-quality enhancement methods that are able to remove stripe artifacts and enhance image quality simultaneously, so as to enhance those details obscured in the originals. Nevertheless, it has been proved very difficult to design a single method that will work across a variety of different medical imaging modalities (20). For OCTA imaging modality, there exist two specific challenges in imaging quality improvement. On one hand, compared with other imaging modalities such as hyperspectral imagery, stripe artifacts in OCTA images always have more diversified characteristics with larger differences in intensity, length, thickness and position, and are easily confused with the vascular structures. Recently, there appears several deep learning based approaches for image de-striping, but few models combine with prior knowledge of stripe artifacts to further improve image de-striping performance. On the other hand, for poor contrast or intensity inhomogeneity in OCTA images, it is difficult to obtain such aligned low/high-quality image pairs for supervised learning. However, most existing unpaired learning frameworks have relatively insufficient constraints on local details, which is unfavorable to restore microvasculartures with poor contrast in OCTA images.
Thus in this paper, we propose a novel two-stage framework for OCTA (including both posterior and anterior segment) image enhancement. The proposed framework consists of the de-striping stage and the re-enhancing stage, with the aim to respectively remove stripe artifacts and improve the contrast in OCTA images. This paper makes the following main contributions:
• In the de-striping stage, we propose a U-shape network called Stripe Removal Net (SR-Net), which introduces a novel de-stripe loss containing low-rank prior of stripe artifacts and constraints on the vascular structure. To our best knowledge, this is the first time to introduce constraints on stripe artifacts in the objective function of a deep learning network.
• In the re-enhancing stage, we propose a novel generative adversarial network called Perceptual Structure GAN (PS-GAN), which integrates cyclic perceptual loss and structure loss into a bi-directional GAN like CycleGAN. By constraints on the vascular structure at different feature levels, both thick and thin vessels in low-contrast OCTA images can be further enhanced.
• The proposed method has undergone rigorous qualitative and quantitative evaluation using three datasets including OCTA and AS-OCTA imagery. For each medical image modality, we employ different image quality assessment schemes, and the experimental results demonstrate the superiority of the proposed framework.
The remainder of the paper is organized as follows. We review the related works to the proposed method in Section 2. The methodology of the proposed method is presented in Section 3. To validate the de-striping effectiveness and image quality improvement of the proposed method, we conduct extensive experiments in Sections 4, 5. We discuss the details of the proposed method and draw our conclusion in Section 6.
2. Related works
2.1. Stripe noise removal
Undesirable noise artifacts always exists in different medical imaging modalities, such as optical coherence tomography (OCT), computed tomography (CT), Ultrasound, magnetic resonance (MR) and positron emission tomography (PET). In the past decades, numerous methods have been proposed for medical image denoising. Conventional denoising approaches can be roughly divided into the following several categories: filtering-based methods (21) including NLM (22) and BM3D (23), transform-based methods such as wavelets (24), shearlets (25) and curvelets (26), and optimization-based algorithms including sparse representation (27, 28), low-rank decomposition (29, 30) and total variation (31, 32). Recently, there have appeared several methods based on convolutional neural networks. Ma et al. (33) designed an edge-sensitive conditional generative adversarial network for speckle noise reduction in OCT images. Chen et al. (34) proposed a Residual Encoder-Decoder CNN to remove noise from low-dose CT images. Jiang et al. (35) developed a Multi-channel DnCNN (MCDnCNN) with two training strategies to denoise MR images. Cui et al. (36) proposed an unsupervised deep learning approaches for PET image denoising.
As a kind of noise artifacts, stripe noise usually exists in some imaging modalities such as remote sensing image, microscopy and X-ray. Different from other noise artifacts such as speckle noise, stripe noise usually appears as several parallel lines randomly distributed through the whole image, which brings additional challenges for image interpretation.
In recent decades, several researches have investigated image de-striping. Conventional de-striping methods can be categorized into three types: filtering-based, optimization-based and deep learning-based. Filtering-based methods usually utilize Fourier transform (37, 38) or linear-phase (39) to remove the stripe or speckle artifacts and then reconstruct a noise-free image. They are relatively straightforward to implement and fast to process images, but they generally perform well only on periodic stripe noise and often cause the loss of details in the original images.
Recently, many optimization models have been proposed to remove stripe noise. Chang et al. (40) regarded the images and stripe noise as equally important information and used a low-rank-based single-image decomposition model to obtain high-quality images. He et al. (41) used TV-regularized low-rank matrix factorization to remove stripe noise in hyperspectral images. Chang et al. (42) used an Anisotropic Spectral-Spatial Total Variation (ASSTV) method to preserve edge information and details in stripe spectral images. Wu et al. (18) proposed a Cooperative Uniformity Destriping model (CUD) and a Cooperative Similarity Destriping model (CSD) to remove stripe noise from OCTA images by using the prior condition of low-rank and anisotropic TV, while the CSD model considers the association of stripes and blood vessels between different layers to remove stripe noise. However, these optimization models require complex numerical solutions to solve partial differential equations (PDEs) in an iterative manner, and thus are not applicable to real-time applications (43).
With the rapid development of deep learning, it has recently been applied for stripe artifact removal in different imaging modalities. Chang et al. (43) proposed a two-stage deep convolutional neural network (CNN) with the short-term and long-term connections, where the first stage acts as the noise subnet to guide the second stage to obtain the denoised image. He et al. (44) proposed a CNN model with residual learning modules to remove the synthetic stripe noise of infrared images, where the stripe noise images are generated from fixed pattern noise (FPN) module. Guan et al. (45) proposed a FPNR-CNN model that includes the coarse-fine convolution unit and the spatial and channel noise attention unit to remove stripe noise. However, most of existing deep learning methods for stripe removal tasks focus on exploring advanced CNN structures, such as residual learning modules, which might only perform well in specific types of medical images. In addition, few models formulated and incorporated the constraints on stripe artifact removal into their deep learning approaches. Motivated by the success of deep learning, in this work, we first propose a convolutional neural network called SR-Net for stripe noise removal in OCTA images. Different from other deep learning approaches for image destriping, the proposed SR-Net incorporates prior information of stripe distribution into its loss function for more effective learning of stripe characteristics. To our best knowledge, this is the first attempt to introduce constraints on stripe distribution in a convolutional neural network.
2.2. Image enhancement
Many image enhancement methods proposed in the field of computer vision have been applied to medical images, with the aim of improving image quality. Well-known examples of global enhancement methods, such as histogram equalization (HE) (46), and contrast-limited adaptive histogram equalization (CLAHE) algorithm (47), are widely-used methods in medical image enhancement. They aim to stretch the dynamic range of the input image, and adjust the intensities of pixels. However, these methods typically enhance images uniformly, irrespective of whether a given region is in the foreground or background. Guided image filtering (GIF) (48) and its accelerated version Fast Guided Filter (FGF) (49) are two promising methods proposed recently for single image enhancement. These methods have the limitation that they frequently over-smoothed regions close to flat, and in consequence struggle to preserve fine details. Several medical image enhancement models have been proposed based on the famous block matching & 3D collaborative filtering method (BM3D) (50) and its extension BM4D (51). These have been successfully adopted to improve the quality of CT, MRI, and OCT imagery (52). However, we noted that the enhanced images are often still blurred, these traditional methods usually fail to consider the global information of the image.
Recently, deep learning has provided new insights for medical image enhancement. LLNet (53) utilizes stacked sparse denoising auto-encoders trained on synthetic data to enhance and denoise low-light noisy images. MSR-Net (54) models conventional multi-scale Retinex (MSR) methods with a deep neural network. MBLLEN (55) extracts and fuses features at different levels in the network to solve the image enhancement problem. However, learning-based approaches are facing a critical challenge—it is difficult to collect a large number of medical image pairs (low- and high-quality) for training. Jiang et al. (56) proposed EnlightenGAN to enhance low-light images, which includes a global-local discriminator structure, a self-regularized perceptual loss fusion and attention mechanism. Ma et al. (20) proposed a structure and illumination constrained GAN (StillGAN), which enhances images from low-quality domain to high-quality domain through structure loss and illumination constraint. Zhao et al. (57) proposed a dynamic retinal image feature constraint in GAN for image enhancement to improve the quality of low-contrast retinal images. In this paper, we also developed a bi-directional GAN called PS-GAN as the re-enhancing stage, which incorporates cyclic perceptual loss and structure loss to constrain the enhancement model on the vascular structure at different feature levels.
3. Proposed method
In this section, we detail the proposed two-stage image enhancement framework which consists of a de-striping stage and a re-enhancing stage, and its overall architecture is shown in Figure 2.
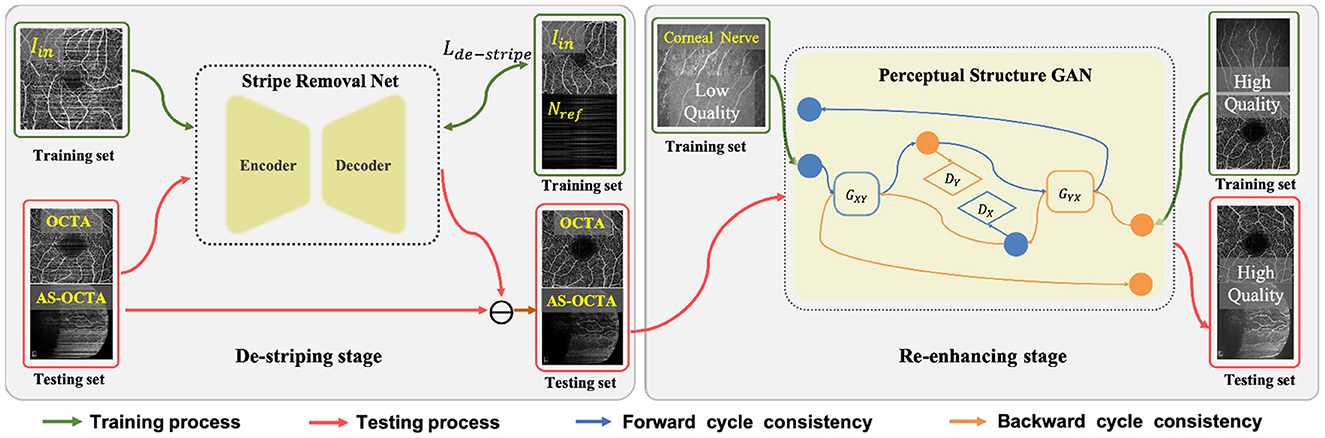
Figure 2. Overall framework of the proposed two-stage image enhancement method, which includes Stripe Removal Net and Perceptual Structural GAN for de-striping and image enhancement respectively.
3.1. De-striping stage: Stripe removal network
Since there exist obvious stripe noise in OCTA or AS-OCTA images, we developed a stripe removal network (SR-Net) to remove stripe noise, as illustrated in the de-striping stage of Figure 2. Our SR-Net adopts an encoder-decoder architecture with symmetric skip connections, following the general structure of U-Net (58), so that multi-scale features can be fused to produce better stripe-free results. The architecture of the proposed SR-Net is illustrated in Figure 3. In our work, we assume that a given OCTA or AS-OCTA image I can be decomposed into noise distribution map N and clean map C in the form of I = N + C. SR-Net outputs the noise map Nout by learning a mapping from the input image Iin to the reference stripe-noise image Nref. And we could acquire the Nref by clean images and stripe noise (18).
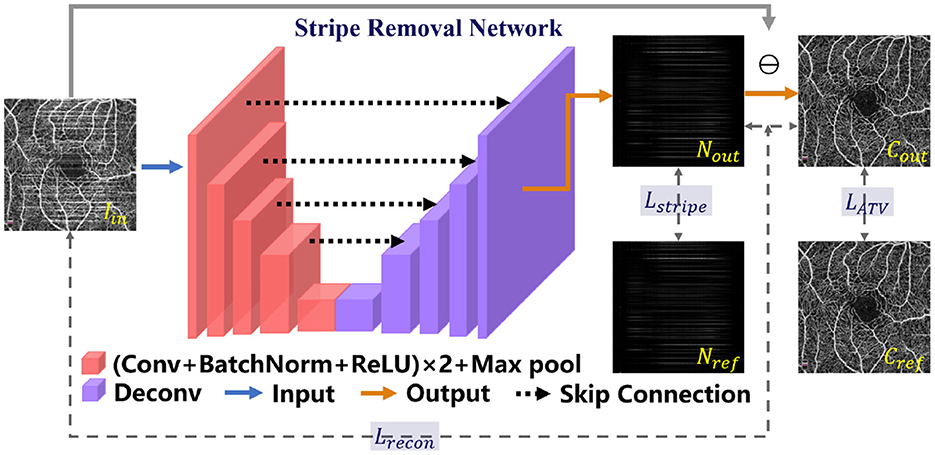
Figure 3. Illustration of the Stripe Removal Net (SR-Net) for the de-striping stage. The proposed objective function Ldestripe is a combination of Lrecon, Lstripe and LATV.
Then the output clean image Cout in the form of residual between Iin and Nout can be obtained: Cout = max{Iin − Nout, 0}. For more effective constraints to the de-striping framework, we construct a de-stripe loss function , which consists of three terms—reconstruction loss , stripe loss and anisotropic total variation (ATV) loss :
where α, β and γ are the positive weights to balance these terms respectively.
3.1.1. Reconstruction loss
In order to constrain the dependence of spatial distribution between the generated clean and noise distribution image, we introduce a reconstruction loss. Based on the assumption that the original image can be constructed by the output clean image and noise image, the reconstruction loss is defined as:
where ||·||F represents the Frobenius norm, and enables the output noise distribution and clean image, respectively to share the consistency in spatial distribution with the input image.
3.1.2. Stripe loss
Wu et al. (18) confirmed the existence of low-rank prior in stripe noise. According to the low-rank characteristic of stripe noise, the number of singular values of stripe-noise images should be approximated to zero after singular value decomposition. In order to keep the consistence between the generated stripe-noise map and the reference stripe-noise image of a synthesized image, we introduce a new stripe loss :
where Nref represents the reference stripe-noise image.Stripe(·) is the stripe degradation function aimed at reconstructing the primary stripe component via a soft-thresholding operation on singular values, which is denoted as: Stripe(N) = U · shrink(S) · VT, where N = U · S · VT is singular value decomposition on N. shrink(·) is the soft-thresholding operation aimed at selecting non-zero singular values on S:
where Sii represents the diagonal element of singular value matrix S, and λ is a small positive constant for selecting singular values.
3.1.3. ATV loss
Vessel structures are the most significant biomarkers in OCTA or AS-OCTA images for clinical diagnosis, which are prone to be corrupted during the de-striping process. To this end, ATV loss is introduced to maintain the completeness of vessel structures. ATV is able to measure the edge sharpness of an image (42) and has been widely applied in image restoration with edge preservation. The proposed ATV loss constrains the edge of two images and is defined as follows:
where Cref represents the reference clean image; ATV(·) is the function to extract gradient information defined as:
where ||·||1 represents the L1 norm; ▽ux and ▽uy represent the horizontal and vertical difference operations on the image C respectively.
Note that the proposed SR-Net was trained on our synthetic OCTA datasets, which contain the reference stripe-noise images Nref, the reference clean images Cref and corruption images synthesized from the both.
3.2. Re-enhancing stage: Perceptual structure GAN
Although the stripe noise can be effectively removed by the proposed SR-Net during the de-striping stage, it will not improve the low contrast issues between the vessels and background, which hinders clinicians from accurate identification and quantification of the vessels for informed diagnosis. To this end, we introduced a re-enhancing stage to improve the perceptual contrast of vessel structures adaptively.
In the re-enhancing stage, we proposed a novel bi-directional GAN called Perceptual Structure GAN (PS-GAN), which incorporates cyclic perceptual loss and structure loss into CycleGAN architecture (59). The architecture of the re-enhancing stage is shown in Figure 4. In this stage, low- and high-contrast images are treated as being in two different domains, and the mapping from low-contrast domain to high-contrast domain could be learned via PS-GAN. Our PS-GAN framework consists of two generators GXY, GYX and two discriminators DX, DY, where GXY (GYX) aims to translate an image from domain X (Y) to domain Y (X), and DX (DY) attempts to identify whether an image is the real one from domain X (Y) or the generated one from domain Y (X).
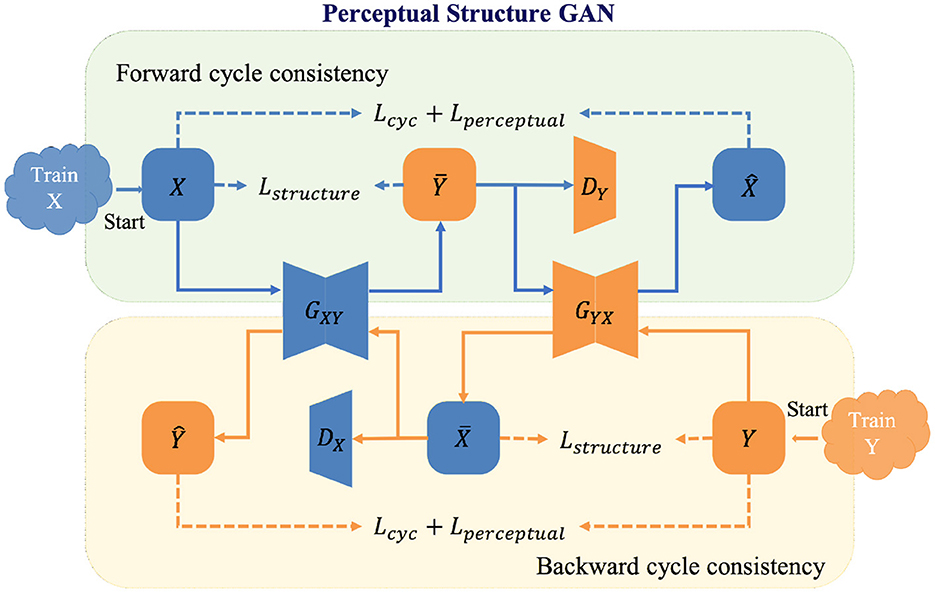
Figure 4. Illustration of the perceptual structure GAN (PS-GAN) for the re-enhancing stage.
The baseline objective function of the proposed PS-GAN includes adversarial loss, cycle-consistency loss and identity loss, following the configuration of CycleGAN. Although widely applied to unpaired image translation problems, the baseline objective function of such bi-directional GAN has several drawbacks. On one hand, cycle-consistency in the baseline objective function constrains generators at image level without capitalizing on features of different levels, which is prone to produce some unsatisfactory artifacts. On the other hand, adversarial and cycle-consistency constraints only enable generators to produce proper results in terms of global appearance, which might lead to loss of some vital structural details. To this end, cyclic perceptual loss and structure loss are integrated into our PS-GAN and they are introduced as follows.
3.2.1. Cyclic perceptual loss
CycleGAN will prevent two generators from contradicting each other by converting unpaired learning into paired learning via constructing a self-supervisory signal. However, image-level cycle-consistency of CycleGAN is not adequate to focus on both low- and high-level features, which will lead to unsatisfactory artifacts in the enhanced image. To overcome this shortcoming, extra feature-level cycle-consistency called cyclic perceptual loss is introduced in the objective function. Different from image-level cycle-consistency, cyclic perceptual loss calculates cycle-consistency loss based on low- and high-level features extracted from the VGG-19 (60). Cyclic perceptual loss is defined as:
where x ∈ X, y ∈ Y, and ϕl(·) represents the output of the l-th max pooling layer of the VGG-19 feature extractor pretrained on the ImageNet. In Equation (7), features extracted from the 2nd and 5th max pooling layer of the pretrained VGG-19 are treated as low- and high-level ones, respectively to calculate cyclic perceptual loss.
3.2.2. Structure loss
In order to preserve vessel structures of the enhanced images, we utilized the structure loss (20) to maintain the invariance of vessel structures. Inspired by the structure comparison function in structural similarity (SSIM) metrics, the structure loss measures the dissimilarity of structure between the original image and its enhancement in local windows and is defined as follows:
where M represents the number of local windows of the input image, xi and G(x)i represent the i-th local window of an image and its generated one respectively; σxi and σG(x)i represent the standard deviations of xi and G(x)i respectively; σxi,G(x)i represents the covariance of xi and G(x)i; c is a small positive constant.
Finally, the loss function of PS-GAN can be expressed as:
where represents the baseline objective function of PS-GAN; ξ, ρ1 and ρ2 are the weighted parameters of each term except for .
4. Experimental setup
4.1. Datasets
In this study, three datasets are used to validate the proposed image enhancement framework, including an OCTA dataset (PUTH), a public-accessible OCTA dataset (ROSE) (4), and our in-house AS-OCTA dataset. All the datasets used are collected under the approvals of relevant authorities and consented by the patients, following the Declaration of Helsinki.
PUTH is a private OCTA dataset that consists of clean and stripe noise corrupted image groups. The clean group contains 210 en face images from 210 eyes (including 47 with Alzheimer's disease (AD), 29 with neuromyelitis optica (NMO), 29 with white matter hyperintensities (WMH) and 105 healthy controls), which are high-contrast and noise-free images selected by our clinicians. All en face images were acquired at different imaging depths using RTVue XR Avanti SD-OCT system with AngioVue software (Optovue, USA) from the Peking University Third Hospital, Beijing, China. All these images cover a 3 × 3mm2 field of view centered at the fovea with 304 × 304 pixels. As the proposed SR-Net requires paired images for training, i.e., clean image and image with stripe noise, in this work stripe noise corrupted image groups were generated by adding stripe noise to those noise-free images in the clean group. In order to obtain the realistic stripe noise added to the noise-free images, we adopted CUD method described in Wu et al. (18) to remove real stripe artifacts from AS-OCTA images, and then extracted the stripe noise images by substracting the corresponding destriping results of CUD from the original stripe noise corrupted AS-OCTA images. Furthermore, we defines the number of stripe noise images added to one noise-free OCTA image as the stripe noise level of the synthetic stripe noise corrupted image. In this work, we synthesized stripe noise images with four stripe noise levels (i = 1, 2, 3, 4) to validate destriping capability of the proposed method for different noise levels. Figures 5A, C show a pair of clean and its synthetic corruption image at noise level i = 2, and Figure 5B illustrates the corresponding stripe noise. In our implementation, 180 pairs images were used for training and the rest for testing.
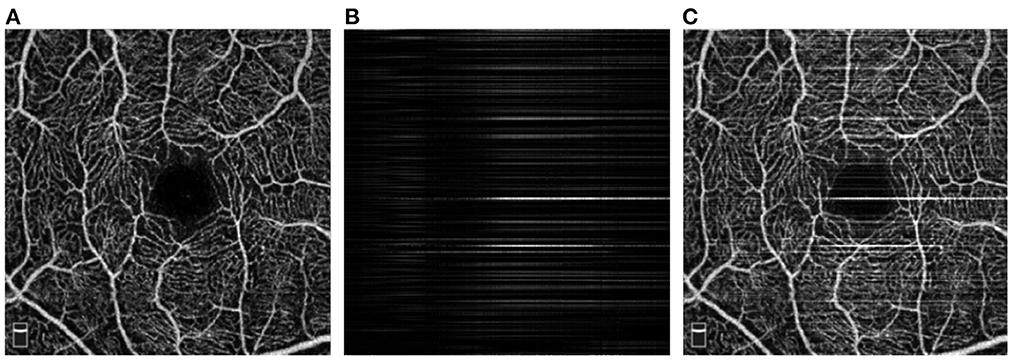
Figure 5. Illustration of paired OCTA images in PUTH dataset. (A) Clean image; (B) Stripe noise at noise level i = 2 generated by Wu et al. (18); (C) Stripe noise in (B) added on (A).
ROSE is a recently released OCTA dataset contains 229 images with manual vessel annotations provided, as shown in Figure 6. In this work, we selected the subset ROSE-1 for evaluation. ROSE-1 has 117 images, which were captured by RTVue XR Avanti SD-OCT system with AngioVue software (Optovue, USA), and image resolution is 304 × 304 pixels. We randomly selected 10 images from ROSE-1 and added stripe noise in the same way as above.

Figure 6. Original OCTA images and their vessel manual annotations in ROSE and AS-OCTA dataset.
AS-OCTA is an in-house dataset, which has 31 conjunctival OCTA images collected from the Peking University Third Hospital, Beijing, China. These images were acquired by RTVue XR Avanti SD-OCT system with AngioVue software (Optovue, USA), with a scan area of 6 × 6mm2. All the images in this dataset contain different levels of stripe noise, and the reference vessel were manually annotated by an image analysis expert using the open source software ImageJ at pixel-level (see Figure 6).
4.2. Evaluation metrics
To verify the effectiveness of our method for stripe noise removal and overall image quality enhancement, two validation strategies were employed. First, we utilized the widely-used image quality assessment metrics, peak signal-to-noise ratio (PSNR) and structural similarity (SSIM), to validate the proposed de-striping network. PSNR is defined as the ratio between power of maximum signal intensity and noise in an image and measures the image fidelity (the larger the better). SSIM measures the similarity of structural information between an image and its high-quality reference version (the larger the better). These two validation approaches were only applied on the datasets with corrupted (synthetic stripe noise added) image, i.e., PUTH and ROSE dataset.
Second, as both the ROSE and our AS-OCTA dataset have vessel annotations, we performed vessel segmentation on the enhanced images to confirm the relative benefits of the proposed framework and the other enhancement methods. Dice coefficient (Dice), Sensitivity (Sen), and G-mean score (G-mean) metrics were employed to evaluate the segmentation performance. These metrics are defined as follows:
where Spe = FP/(FP + TN) indicates the specificity; TP, TN, FP and FN represent the number of true positives, true negatives, false positives and false negatives, respectively.
4.3. Implementation details
The proposed framework was implemented using PyTorch library on the PC contained an NVIDIA GeForce GTX 3090 with 24 GB of memory.
4.3.1. SR-Net
We used the training set (n = 180) from the PUTH to train our SR-Net. The Adam optimizer with recommended parameters was used to optimize the model and batch size was set as 16. The initial learning rate was 2 × 10−4 and gradually decayed to zero after 300 epochs. The hyper-parameters used in the network were λ = 0.002, α = 0.5, β = 2 and γ = 1.
4.3.2. PS-GAN
Due to the lack of high-quality AS-OCTA images for training, and the high similarity of contrast and structural distribution between AS-OCTA image and corneal confocal microscopy, in this work, we combined the training set (n = 180) of the PUTH and a corneal confocal microscopy dataset (CCM) to form a new dataset to train our model. The public-accessible dataset CORN-2 (20) was used, and it contains unpaired 340 low-quality and 288 high-quality CCM images. In the experiment, domain X consists of low-contrast CCM, and all the images in PUTH and the high-quality images in CORN-2 were included in domain Y. All the images in both domains were resized to 400 × 400. The proposed PS-GAN was optimized using Adam and batch size was set to 1. The initial learning rate was 2 × 10−4 for the first 100 epochs and gradually decayed to zero after the next 100 epochs. The hyper-parameters used in the network were ξ = 0.5, ρ1 = ρ2 = 0.5.
5. Experimental results
We validated individual components of our two-stage OCTA image quality improvement framework: stripe noise removal and image enhancement stages.
5.1. Validation of SR-Net in stripe noise removal
5.1.1. Visual comparisons
As we mentioned in the dataset section, synthetic stripes were added to the images in the PUTH and ROSE datasets. In order to demonstrate the superiority of the de-striping stage, we compared our SR-Net with the state-of-the-art de-striping methods including CUD, CSD and CSD+ (18), as well as the baseline model (U-Net). Figures 7, 8, top present the stripe noise removal results produced by the different methods. As illustrated in Figure 7, top, SR-Net removes stripe noise more faithfully without losing vessel information comparing with other methods. CSD+ attempts to remove the effect of stripe artifacts from the given images, but it still contains noticeable stripe artifacts. Overall, the proposed SR-Net generate the best performance in eliminating stripe noise, i.e., with more visually informative results.

Figure 7. Illustrative stripe removal results using different methods on a synthetic OCTA image (i = 2) with stripe noise from the PUTH dataset.
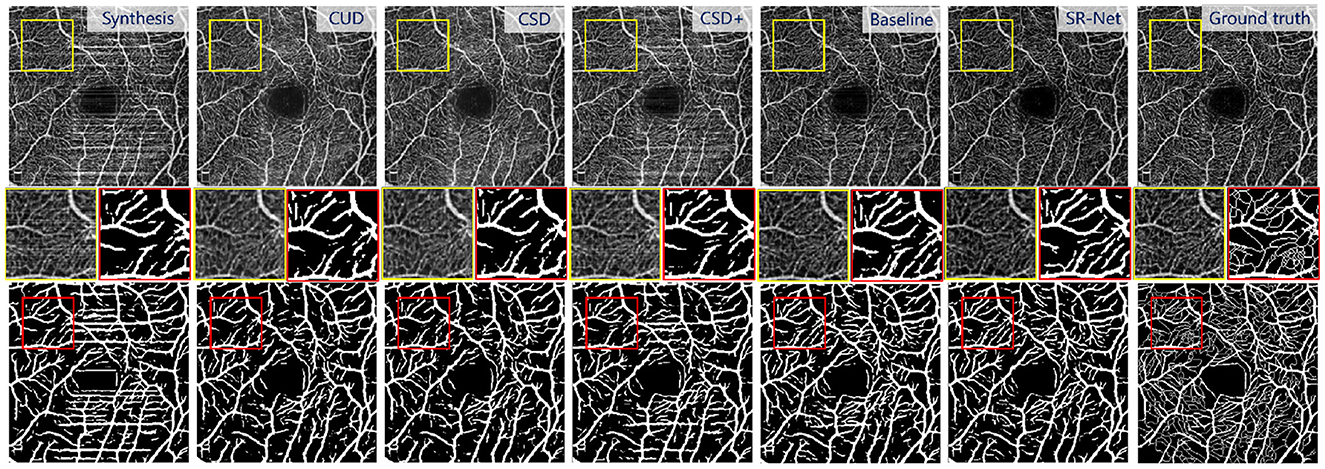
Figure 8. Illustrative results using different stripe removal methods on a synthetic OCTA image (i = 2) in ROSE dataset, and their vessel segmentation performances by OCTA-Net (4). Top: De-striped OCTA images by different methods. Bottom: vessel segmentation results. Middle: representative patches of de-striped and vessel segmentation results.
5.1.2. Evaluation by PSNR and SSIM
It is difficult to demonstrate conclusively the superiority of the enhancement method purely by the above visual inspection, in this section, a quantitative evaluation of de-striping is provided. The PSNR and SSIM values of different methods on both the PUTH and ROSE datasets are shown in the Table 1. As we can see, the higher stripe noise level (i = 1, 2, 3, 4, the larger i, the stronger corruption) usually lead to the lower PSNR and SSIM. It is evident that our SR-Net achieves the highest PSNR and SSIM under various levels of noise corruption. For those OCTA images with low-level stripe noise, all de-striping methods could achieve relatively high performance, and the proposed SR-Net achieves a slightly higher PSNR and SSIM scores than other approaches. For example, SR-Net achieves the improvements of only 8.98, 8.86, 9.16, 1.08, 1.08, and 0.21% when, respectively, compared with CUD, CSD, and CSD+ in terms of PSNR and SSIM on ROSE dataset at noise level i = 2. By contrast, the performance of CUD, CSD and CSD+ declines and the proposed SR-Net yields better performance with relatively more significant margins for those OCTA images with high-level stripe noise. For example, the proposed SR-Net achieves an increase of about 31.72, 31.71, 36.63, 7.01, 7.01, and 9.11% in terms of PSNR and SSIM when, respectively, compared with CUD, CSD, and CSD+ at noise level i = 4. Similarly, our method also yields better performance with large margins on the PUTH dataset when the images were corrupted by high-level noise. It indicates that the proposed SR-Net is robust to different stripe noise levels.
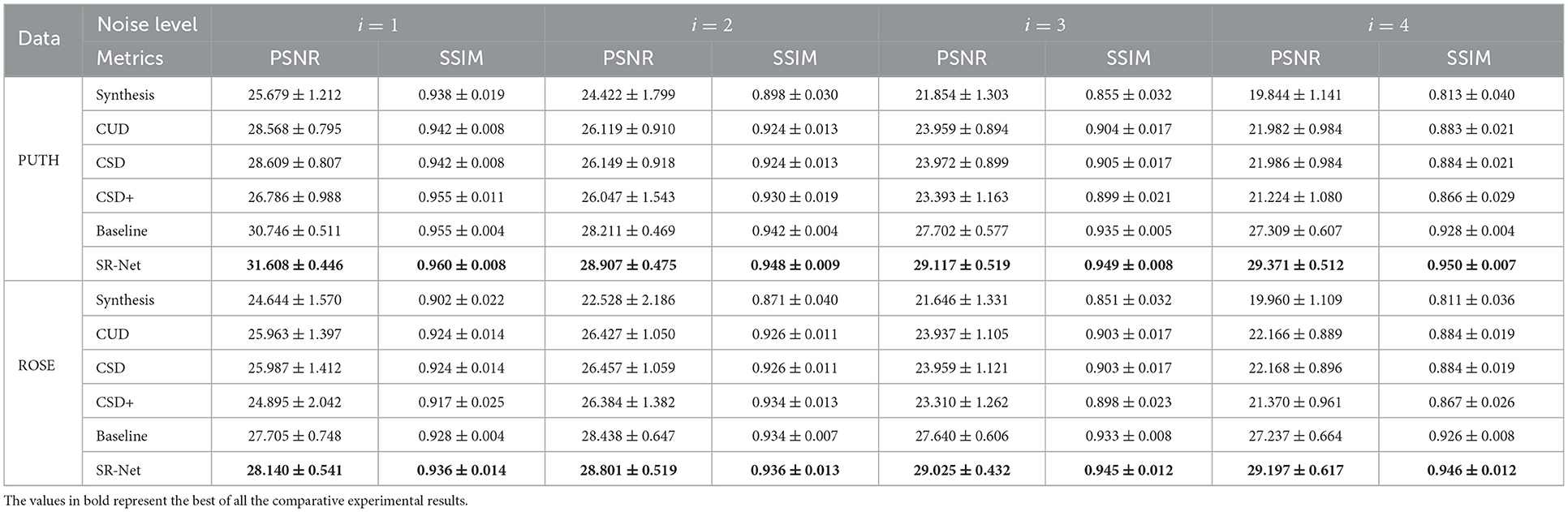
Table 1. De-striping performance in ROSE and PUTH dataset in terms of PSNR and SSIM.
5.1.3. Evaluation by vessel segmentation
We also perform vessel segmentation over de-striped images to confirm the relative benefits of the proposed method in comparison to the others. For vessel segmentation in OCTA images, we employed a recent proposed vessel segmentation network which is designed for OCTA images in the ROSE dataset: OCTA-Net (4). We utilized OCTA-Net to perform vessel segmentation on images with synthetic stripe noise and images after applying different de-striping methods.
The Figure 8, bottom shows the vessel segmentation results by different method on a noise corrupted image. The benefit of the proposed SR-Net method for segmentation may be observed from the representative region (red patches). It can be seen that more accurate and completed visible vessels have been identified by our SR-Net compared with original images with stripe noise and other destriping methods despite difficulties in small vessel detection. By contrast, a large portion of stripe noise has been identified as vessels by OCTA-Net in synthetic images and the de-striped images after applying other de-striping methods. This finding is also evidenced by segmentation results reported in Table 2. It is indeed that our SR-Net improves the segmentation performances when compared to the results of synthetic images: by an increase of about 7.79, 3.40, 7.80, and 8.42% in Dice and 2.71, 1.33, 2.96, and 3.59% in G-mean, respectively with various levels of stripe noise added in the original images. Moreover, when compared with CUD method, SR-Net achieves improvement of about 1.06, 0.79, 1.06, and 1.33% in Dice, 0.72, 0.72, 0.72, and 1.21% in G-mean, respectively, with various levels of stripe noise added. When compared with CSD method, SR-Net achieves improvement of about 1.06, 0.93, 1.06, and 1.33% in Dice, 0.60, 0.84, 0.72, and 1.09% in G-mean with the corruption of different noise levels. Similar to the results of PSNR and SSIM, vessel segmentation performance gain with larger margin has also been achieved by the proposed SR-Net when the images were corrupted by high-level noise.
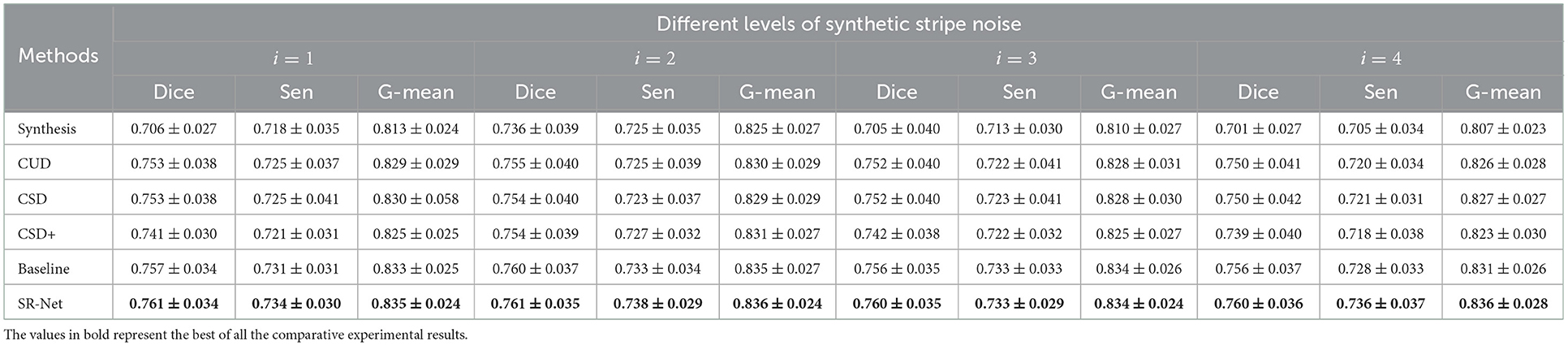
Table 2. Vessel Segmentation on de-striped images in ROSE dataset, in the presence of different levels of synthetic stripe noise.
For vessel segmentation in AS-OCTA dataset, we employed the Curvelet denoising based Optimally Oriented flux enhancement method (COOF) (61), which was proposed for segmentation of retinal microvasculature in OCTA images. It is worth noting that, on one hand, no pre-trained deep learning models may be utilized to performance the segmentation in AS-OCTA dataset, due to the lack of high-quality AS-OCTA images. On the other hand, it is our purpose to validate the proposed de-striping method would benefit both deep learning-based and conventional segmentation methods.
As shown in Figure 9, bottom and the representative patches (red box), it may be seen clearly that COOF is able to identify vessel structures more accurately in the images with less stripe noise falsely detected as vessels after our SR-Net is applied. We can observe that the competing methods have retained some stripe noise in Figure 9, top and the representative patches (yellow box), and the appearance of stripe and vessels are of great similarity, thus the COOF method falsely detects stripe noise as vessels. By contrast, most stripe noise similar to vessels has been well removed by the proposed SR-Net. Furthermore, Table 4 demonstrates the superiority of the proposed SR-Net in improving segmentation performances. It shows that our method yields the highest scores in terms of Dice, Sen, and G-mean. SR-Net achieves G-mean of 0.714, with an improvement of about 5.78%, 5.62%, and 3.03% over CUD, CSD, and CSD+.
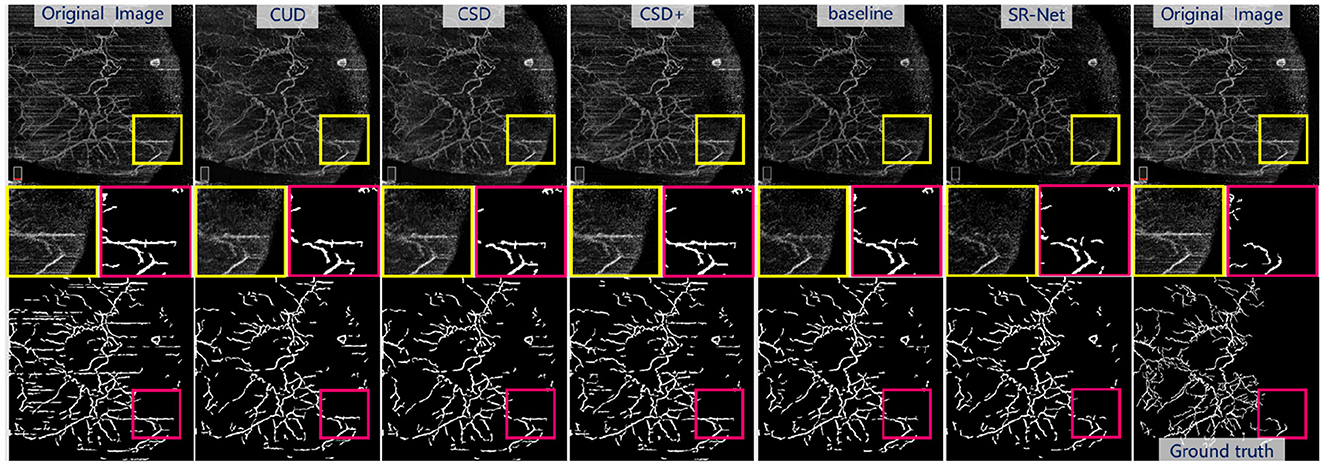
Figure 9. Illustrative stripe removal results using different methods on a real AS-OCTA image and their vessel segmentation performance by COOF (61). Top: De-striped AS-OCTA images by different methods. Bottom: Vessel segmentation results. Middle: Representative patches of de-striping and vessel segmentation results.
In summary, the proposed SR-Net is helpful in improving the accuracy of vessel segmentation, since more stripe noise has been removed, and it would enhance the visibility of the vascular structure for subsequent processing.
5.2. Validation of PS-GAN in image enhancement
5.2.1. Visual comparisons
In order to demonstrate the superiority of the re-enhancing stage, we compared our PS-GAN with several state-of-the-art image enhancement methods, including CycleGAN (59), EnlightenGAN (56), CycleDehaze (62), and StillGAN (20). All these competing methods are based on GAN, which aim to translate an image from low-quality to high-quality domain in this work.
The Figure 10, top presents the visual enhancement results via different methods. The results obtained by EnlightenGAN and CycleDehaze have image distortion and blurring affect because these methods are hard to guarantee the preservation of details in the images. CycleGAN and StillGAN produced relative better results than EnlightenGAN and CycleDehaze, however, they showed some side effects such as intensity inhomogeneity and vessel discontinuity. In contrast, the proposed method yielded more visually informative results, i.e., relatively visual pleasing contrast and clear visibility of vessel structures.
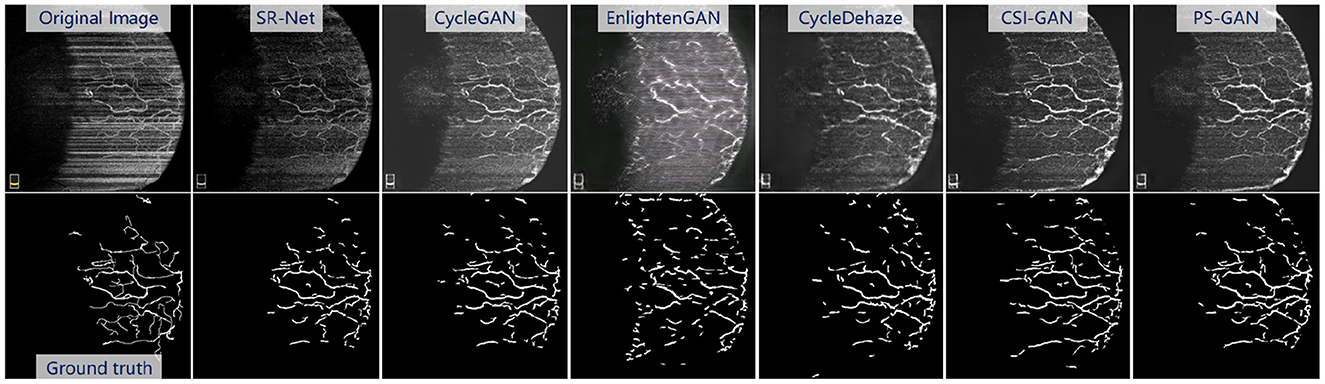
Figure 10. Results of the re-enhancing stage with PS-GAN on an AS-OCTA image. The (top) are the re-enhancing results after SR-Net and the (bottom) are the segmentation results by COOF (61).
5.2.2. Evaluation by PSNR and SSIM
We also calculated PSNR and SSIM for quantitative evaluation of re-enhancing stage over the PUTH and ROSE datasets. The quantitative results of different enhancement approaches are shown in Table 3. The proposed PS-GAN obtained the best performances in terms of both metrics - it shows large margin when compared with EnlightenGAN and CycleDehaze as they have changed the content of the given images.

Table 3. Comparison of re-Enhancing performance in terms of PSNR and SSIM on the synthetic datasets.
For example, PS-GAN achieves higher PSNR and SSIM scores in ROSE dataset when compared with EnlightenGAN, CycleDehaze and StillGAN if we added different levels of stripe noise, with 158.83, 54.16, 6.52, 100, 30.61, and 0.84% higher when compared with competing methods in terms of PSNR and SSIM when noise level i = 2. Similarly, our method also yields better performance with large margin in the PUTH dataset when the images were corrupted by different noise levels. These findings also demonstrate the robustness of PS-GAN to different stripe noise levels.
5.2.3. Evaluation by vessel segmentation
In order to confirm the impact of the re-enhancing stage on vessel segmentation, we further performed vessel segmentation and compared segmentation results from the enhanced images obtained by different methods on the AS-OCTA dataset.
For the vessel segmentation in the AS-OCTA dataset, we also employed COOF (61) as the vessel segmentation method. The Figure 10, bottom presents the segmentation results via COOF, it may be seen that COOF is able to identify vessel structures more accurately on the images after our PS-GAN is applied. Because of the hard presentation of details in the images, the segmentation results of EnlightenGAN and CycleDehaze are deviated from the ground truth. CycleGAN and StillGAN produced relative better segmentation results than EnlightenGAN and CycleDehaze, however, they showed some side effects such as intensity inhomogeneity and vessel discontinuity of vessel segmentation results. In contrast, the proposed PS-GAN yielded more visually informative results, COOF detects more vessel structures. Furthermore, Table 5 demonstrate the obvious advantage of the proposed PS-GAN in improving Dice, Sen and G-mean of vessel segmentation compared with other competing approaches. Moreover, our PS-GAN achieves G-mean of 0.812, with an improvement of about 12.62%, 13.57% and 8.12% over EnlightenGAN, CycleDehaze and StillGAN, respectively.
5.3. Ablation studies
5.3.1. SR-Net
In order to verify the effectiveness of our proposed method for the stripe noise removal, we regarded the U-Net which shares the same structure with SR-Net and adopts mean square error (MSE) loss function as the baseline model and confirmed the stripe removal effectiveness of the proposed loss function Ldestripe.
Visually For synthetic OCTA images in PUTH and ROSE datasets, comparative results of the baseline and our SR-Net are illustrated in Figure 7 and the top row of Figure 8, indicating that the baseline model still contains some noticeable stripe artifacts whilst our SR-Net can remove stripe artifacts satisfactorily. As illustrated in Figure 9, top in AS-OCTA, our SR-Net removes stripe artifacts more cleanly than the baseline, in addition, our method will not lose vessel information.
Vessel segmentation For synthesis OCTA with annotations in the ROSE dataset, the vessel segmentation results of baseline and SR-Net are shown in Figure 8, bottom, our method preserves vascular integrity better. This finding is also evidenced by the segmentation results reported in Table 2. When compared with the baseline, the proposed SR-Net achieves improvement of about 0.53, 0.13, 0.53, and 0.53% in Dice, 0.24, 0.12, 0.00, and 0.60% in G-mean with the corruption of different noise levels. For the AS-OCTA dataset, as illustrated in Figure 9, bottom, our SR-Net will remove stripe artifacts more cleanly without loss of any vessel information than the baseline. Furthermore, Table 4 demonstrates the superiority of the proposed SR-Net in improving segmentation performances. The proposed SR-Net achieves an improvement of about 5.88, 1.89, and 1.71% in Dice, Sen, G-mean over the baseline, respectively.
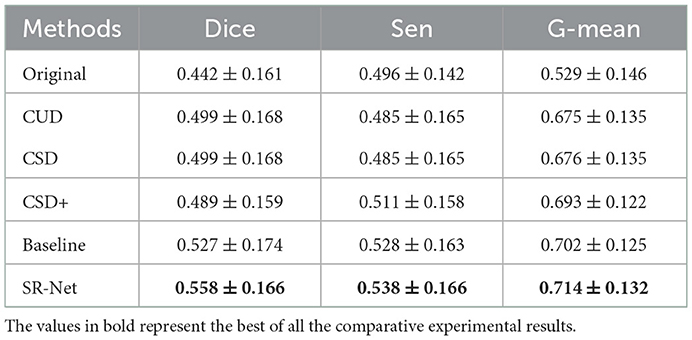
Table 4. Vessel segmentation performance on original images in AS-OCTA dataset and their de-striped versions via different methods.
5.3.2. PS-GAN
In order to verify the further quality improvement on AS-OCTA images in the re-enhancing stage, we regarded the results de-striped by our SR-Net as the input low-quality imagesof all re-enhancing approaches for unified comparison. CycleGAN was adopted as the baseline and cyclic perceptual loss Lp and structure loss Ls were added to baseline, respectively to confirm the effectiveness of the both.
Visually As shown in Figure 10, top, our method will improve the continuity of vessel compared with the baseline, and our method will not generate the non-existent vessels.
Vessel segmentation Illustrated in the Table 5, we also applied COOF (61) for the vessel segmentation to verify the effectiveness of enhancement results. Our method achieves the highest Dice, Sen and G-mean when compared with the baseline, Baseline+Lp and Baseline+Ls, indicating that the proposed PS-GAN is effective to restore more vascular information. Furthermore, as illustrated in Table 5, the proposed PS-GAN can improve the segmentation performances. The proposed PS-GAN achieves Dice of 0.599, with the improvement of about 0.50, 0.84, and 0.50% over the baseline, The baseline+Lp and baseline+Ls. Meanwhile, the proposed PS-GAN achieves G-mean of 0.812, with the improvement of about 1.75, 2.27, and 1.37% over the baseline, baseline+Lp and baseline+Ls.
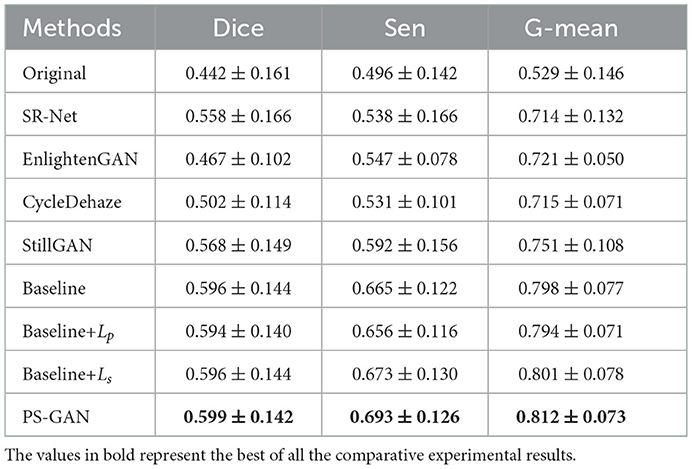
Table 5. Vessel segmentation performance on original images in AS-OCTA dataset, and their de-striping results of SR-Net and re-enhanced versions via different methods, and ablation study of our model.
In addition, we also validated the effectiveness of Lp and Ls on the synthetic OCTA datasets. As shown in Table 3, PSNR and SSIM were improved by adding Lp or Ls respectively. For example, the proposed SR-Net achieves the improvement in PSNR and SSIM scores in the ROSE dataset when compared with the baseline, baseline+Lp and baseline+Ls if we added different levels of stripe noise, i.e., 3.86, 1.34, 1.07, 1.06, 0.31, and 0.42% higher in terms of PSNR and SSIM for noise level i = 3. Similarly, our method also yields better performance in the PUTH dataset when the images were corrupted by different noise levels. Furthermore, the proposed PS-GAN achieves the best performance on image enhancement compared with the baseline, baseline+Lp and baseline+Ls.
6. Discussions and conclusions
In medical imaging, it often has two main degradation factors: imaging noise and poor contrast. The existing enhancement methods usually address contrast adjustment and noise reduction separately. In this paper, we have proposed a novel two stage framework that is effective across a variety of medical imaging modalities, in addressing noise, and poor contrast simultaneously. To this end, we introduced a stripe loss, perceptual loss, and structure loss to constrain the information of the stripe distribution, contrast and vessel structures respectively, in OCTA images.
In the de-striping stage, an encoder-decoder architecture with stripe noise constraints called SR-Net is proposed to remove stripe noise in AS-OCTA and synthesized OCTA images. In the re-enhancing stage, in order to obtain better quality images, a PS-GAN is developed to translate a de-stripped image from low-contrast domain to high-contrast domain via the cross-modality training strategy.
Our method has advantages of simple implementation, high efficiency and wide applicability, e.g., OCTA and AS-OCTA. The effectiveness of this enhancement framework was validated by conventional image quality assessment metrics and the application of vessel segmentation. Experimental results confirm that the proposed method can remove stripe artifacts and achieve higher quality than other state-of-the-art methods either in public or in-house datasets. In addition, the vessel segmentation performance showed that the proposed method yields a promising enhancement performance, that enables both conventional and deep learning-based segmentation methods to produce improved segmentation results across two OCT image modalities.
We believe that our work is of the interest of the computer vision community. Firstly, our task focuses on image enhancement and denoising, which would find applications in the other areas of object modeling, classification and recognition. Secondly, although we present our work based on medical image data, our algorithm is not medical-specific. The proposed loss functions are generalizable and can be used to enhance the performance of other networks such as U-Net and GAN. In the future, we will involve the research on explanation of the models and discuss what the proposed framework focuses on during the enhancement processing, such as regions with stripe noise or low contrast. In addition, we will consider combining stripe artifacts removal and image enhancement into an end-to-end process. Furthermore, This work can also be extended to other OCTA devices such as Zeiss and Heidelberg systems and we will further improve stability and robustness of the model on multi-center OCTA data. The potential application of the proposed framework is even not limited in the medical image domain, and can be applied in many other computer vision tasks, e.g., scratch detection for industrial quality assurance and enhancement of remote sensing images.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Ethics statement
The studies involving human participants were reviewed and approved by Ningbo Institute of Materials Technology and Engineering, Chinese Academy of Sciences. The patients/participants provided their written informed consent to participate in this study.
Author contributions
JC and ZX conceptualized the topic, researched and analyzed the background literature, wrote the manuscript, and including interpretations. MX, YM, and YZ provided substantial scholarly guidance on the conception of the topic, manuscript draft and interpretation, and revised the manuscript critically for intellectual content. All the authors approved the final version of the manuscript, ensured the accuracy and integrity of the work, and agreed to be accountable for all aspects of the work.
Funding
This work was supported in part by the Zhejiang Provincial Natural Science Foundation (LR22F020008 and LZ19F010001), in part by the Youth Innovation Promotion Association CAS (2021298), and in part by Ningbo 2025 S&T Mega projects (2019B10033, 2019B10061, and 2021Z054), in part by Health Science and Technology Project of Zhejiang Province (No. 2021PY073).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Cheng J, Tao D, Quan Y, Wong DWK, Cheung GCM, Akiba M, et al. Speckle reduction in 3D optical coherence tomography of retina by a-scan reconstruction. IEEE Trans Med Imaging. (2016) 35:2270–9. doi: 10.1109/TMI.2016.2556080
2. Zhao Y, Liu Y, Wu X, Harding SP, Zheng Y. Retinal vessel segmentation: an efficient graph cut approach with retinex and local phase. PLoS ONE. (2015) 10:e0122332. doi: 10.1371/journal.pone.0122332
3. Xie J, Liu Y, Zheng Y, Su P, Hu Y, Yang J, et al. Classification of retinal vessels into artery-vein in OCT angiography guided by fundus images. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Lima: Springer (2020). p. 117–27.
4. Ma Y, Hao H, Fu H, Zhang J, Yang J, Liu J, et al. ROSE: a retinal OCT-angiography vessel segmentation dataset and new model. IEEE Trans Med Imaging. (2020) 40:928–39. doi: 10.1109/TMI.2020.3042802
5. Jia Y, Wei E, Wang X, Zhang X, Morrison JC, Parikh M, et al. Optical coherence tomography angiography of optic disc perfusion in glaucoma. Ophthalmology. (2014) 121:1322–32. doi: 10.1016/j.ophtha.2014.01.021
6. Matsunaga DR, Jack JY, De Koo LO, Ameri H, Puliafito CA, Kashani AH. Optical coherence tomography angiography of diabetic retinopathy in human subjects. Ophthalmic Surg Lasers Imaging Retina. (2015) 46:796–805. doi: 10.3928/23258160-20150909-03
7. Alam M, Toslak D, Lim JI, Yao X. OCT feature analysis guided artery-vein differentiation in OCTA. Biomed Opt Express. (2019) 10:2055–66. doi: 10.1364/BOE.10.002055
8. Told R, Ginner L, Hecht A, Sacu S, Leitgeb R, Pollreisz A, et al. Comparative study between a spectral domain and a high-speed single-beam swept source OCTA system for identifying choroidal neovascularization in AMD. Sci Rep. (2016) 6:38132. doi: 10.1038/srep38132
9. Di Lee W, Devarajan K, Chua J, Schmetterer L, Mehta JS, Ang M. Optical coherence tomography angiography for the anterior segment. Eye Vis. (2019) 6:1–9. doi: 10.1186/s40662-019-0129-2
10. Cai Y, Barrio JLAD, Wilkins MR, Ang M. Serial optical coherence tomography angiography for corneal vascularization. Graefes Arch Clin Exp Ophthalmol. (2016) 255:1–5. doi: 10.1007/s00417-016-3505-9
11. Ang M, Cai Y, Shahipasand S, Sim DA, Wilkins MR. En face optical coherence tomography angiography for corneal neovascularisation. Br J Ophthalmol. (2016) 100:616–21. doi: 10.1136/bjophthalmol-2015-307338
12. Ang M, Sim DA, Keane PA, Sng CCA, Egan CA, Tufail A, et al. Optical coherence tomography angiography for anterior segment vasculature imaging. Ophthalmology. (2015) 122:1740–7. doi: 10.1016/j.ophtha.2015.05.017
13. Matthias B, Vito R, Bernhard S, Riccardo V, Samuel L, Bryan W, et al. Imaging of corneal neovascularization: optical coherence tomography angiography and fluorescence angiography. Invest Ophthalmol Vis. (2018) 59:1263–9. doi: 10.1167/iovs.17-22035
14. Akagi T, Uji A, Huang AS, Weinreb RN, Yamada T, Miyata M, et al. Conjunctival and intrascleral vasculatures assessed using anterior segment optical coherence tomography angiography in normal eyes. Am J Ophthalmol. (2018) 196:1–9. doi: 10.1016/j.ajo.2018.08.009
15. Skalet AH, Yan L, Lu CD, Jia Y, Huang D. Optical coherence tomography angiography characteristics of iris melanocytic tumors. Ophthalmology. (2017) 124:197–204. doi: 10.1016/j.ophtha.2016.10.003
16. Spaide RF, Fujimoto JG, Waheed NK. Image artifacts in optical coherence angiography. Retina. (2015) 35:2163. doi: 10.1097/IAE.0000000000000765
17. Zang P, Liu G, Zhang M, Dongye C, Wang J, Pechauer AD, et al. Automated motion correction using parallel-strip registration for wide-field en face OCT angiogram. Biomed Opt Express. (2016) 7:2823–36. doi: 10.1364/BOE.7.002823
18. Wu X, Gao D, Borroni D, Madhusudhan S, Jin Z, Zheng Y. Cooperative low-rank models for removing stripe noise from OCTA images. IEEE J Biomed Health Inform. (2020) 24:3480–90. doi: 10.1109/JBHI.2020.2997381
19. Zhao Y, Zheng Y, Zhao Y, Liu Y, Chen Z, Liu P, et al. Uniqueness-driven saliency analysis for automated lesion detection with applications to retinal diseases. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Granada: Springer (2018). p. 109–18.
20. Ma Y, Liu J, Liu Y, Fu H, Hu Y, Cheng J, et al. Structure and illumination constrained GAN for medical image enhancement. IEEE Trans Med Imaging. (2021) 40:3955–67. doi: 10.1109/TMI.2021.3101937
21. Ozcan A, Bilenca A, Desjardins AE, Bouma BE, Tearney GJ. Speckle reduction in optical coherence tomography images using digital filtering. JOSA A. (2007) 24:1901–10. doi: 10.1364/JOSAA.24.001901
22. Aum J, Kim Jh, Jeong J. Effective speckle noise suppression in optical coherence tomography images using nonlocal means denoising filter with double Gaussian anisotropic kernels. Appl Opt. (2015) 54:D43-D50. doi: 10.1364/AO.54.000D43
23. Chong B, Zhu YK. Speckle reduction in optical coherence tomography images of human finger skin by wavelet modified BM3D filter. Opt Commun. (2013) 291:461–9. doi: 10.1016/j.optcom.2012.10.053
24. Randhawa SK, Sunkaria RK, Puthooran E. Despeckling of ultrasound images using novel adaptive wavelet thresholding function. Multidimensional Syst Signal Process. (2019) 30:1545–61. doi: 10.1007/s11045-018-0616-y
25. Zhang J, Xiu X, Zhou J, Zhao K, Tian Z, Cheng Y. A novel despeckling method for medical ultrasound images based on the nonsubsampled shearlet and guided filter. Circ Syst Signal Process. (2020) 39:1449–70. doi: 10.1007/s00034-019-01201-2
26. Anandan P, Giridhar A, Lakshmi EI, Nishitha P. Medical image denoising using fast discrete curvelet transform. Int J. (2020) 8:3760–3765. doi: 10.30534/ijeter/2020/139872020
27. Adamidi E, Vlachos E, Dermitzakis A, Berberidis K, Pallikarakis N. A scheme for X-ray medical image denoising using sparse representations. In: 13th IEEE International Conference on BioInformatics and BioEngineering. Chania: IEEE (2013). p. 1–4.
28. Bai J, Song S, Fan T, Jiao L. Medical image denoising based on sparse dictionary learning and cluster ensemble. Soft Comput. (2018) 22:1467–73. doi: 10.1007/s00500-017-2853-7
29. Sagheer SVM, George SN. Denoising of low-dose CT images via low-rank tensor modeling and total variation regularization. Artif Intell Med. (2019) 94:1–17. doi: 10.1016/j.artmed.2018.12.006
30. Ji L, Guo Q, Zhang M. Medical image denoising based on biquadratic polynomial with minimum error constraints and low-rank approximation. IEEE Access. (2020) 8:84950–60. doi: 10.1109/ACCESS.2020.2990463
31. Varghees VN, Manikandan MS, Gini R. Adaptive MRI image denoising using total-variation and local noise estimation. In: IEEE-International Conference on Advances in Engineering, Science and Management (ICAESM-2012). Nagapattinam: IEEE (2012). p. 506–11.
32. Zhao W, Lu H. Medical image fusion and denoising with alternating sequential filter and adaptive fractional order total variation. IEEE Trans Instrument Meas. (2017) 26:2283–94. doi: 10.1109/TIM.2017.2700198
33. Ma Y, Chen X, Zhu W, Cheng X, Xiang D, Shi F. Speckle noise reduction in optical coherence tomography images based on edge-sensitive cGAN. Biomed Opt Express. (2018) 9:5129–46. doi: 10.1364/BOE.9.005129
34. Chen H, Zhang Y, Kalra MK, Lin F, Chen Y, Liao P, et al. Low-dose CT with a residual encoder-decoder convolutional neural network (RED-CNN). IEEE Trans Med Imaging. (2017) 36:2524–35. doi: 10.1109/TMI.2017.2715284
35. Jiang D, Dou W, Vosters L, Xu X, Sun Y, Tan T. Denoising of 3D magnetic resonance images with multi-channel residual learning of convolutional neural network. Jpn J Radiol. (2018) 36:566–74. doi: 10.1007/s11604-018-0758-8
36. Cui J, Gong K, Guo N, Wu C, Meng X, Kim K, et al. PET image denoising using unsupervised deep learning. Eur J Nuclear Med Mol Imaging. (2019) 46:2780–9. doi: 10.1007/s00259-019-04468-4
37. Chen SWW, Pellequer JL. DeStripe: frequency-based algorithm for removing stripe noises from AFM images. BMC Struct Biol. (2011) 11:7. doi: 10.1186/1472-6807-11-7
38. Liang X, Zang Y, Dong D, Zhang L, Fang M, Yang X, et al. Stripe artifact elimination based on nonsubsampled contourlet transform for light sheet fluorescence microscopy. J Biomed Opt. (2016) 21:106005. doi: 10.1117/1.JBO.21.10.106005
39. Georgiev M, Bregović R, Gotchev A. Fixed-pattern noise modeling and removal in time-of-flight sensing. IEEE Trans Instrument Meas. (2016) 65:808–20. doi: 10.1109/TIM.2015.2494622
40. Chang Y, Yan L, Wu T, Zhong S. Remote sensing image stripe noise removal: from image decomposition perspective. IEEE Trans Geoence Remote Sens. (2016) 54:7018–31. doi: 10.1109/TGRS.2016.2594080
41. He W, Zhang H, Zhang L, Shen H. Total-Variation-Regularized low-rank matrix factorization for hyperspectral image restoration. IEEE Trans Geoence Remote Sens. (2015) 54:178–88. doi: 10.1109/TGRS.2015.2452812
42. Yi, Chang, Luxin, Yan, Houzhang, Fang, et al. Anisotropic spectral-spatial total variation model for multispectral remote sensing image destriping. IEEE Trans Image Process. (2015) 24:1852–66. doi: 10.1109/TIP.2015.2404782
43. Chang Y, Yan L, Chen M, Fang H, Zhong S. Two-stage convolutional neural network for medical noise removal via image decomposition. IEEE Trans Instrument Meas. (2020) 69:2707–21. doi: 10.1109/TIM.2019.2925881
44. He Z, Cao Y, Dong Y, Yang J, Cao Y, Tisse CL. Single-image-based nonuniformity correction of uncooled long-wave infrared detectors:a deep-learning approach. Appl Opt. (2018) 57:D155–64. doi: 10.1364/AO.57.00D155
45. Guan J, Lai R, Xiong A, Liu Z, Gu L. Fixed pattern noise reduction for infrared images based on cascade residual attention CNN. Neurocomputing. (2020) 377:301–13. doi: 10.1016/j.neucom.2019.10.054
46. Reza AM. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J VLSI Signal Process Syst Signal Image Video Technol. (2004) 38:35–44. doi: 10.1023/B:VLSI.0000028532.53893.82
47. Abdullah-Al-Wadud M, Kabir MH, Dewan MAA, Chae O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans Consum Electron. (2007) 53:593–600. doi: 10.1109/TCE.2007.381734
48. He K, Sun J, Tang X. Guided image filtering. IEEE Trans Pattern Anal Mach Intell. (2012) 35:1397–409. doi: 10.1109/TPAMI.2012.213
49. He K, Sun J. Fast guided filter. arXiv preprint arXiv:150500996. (2015). doi: 10.48550/arXiv.1505.00996
50. Dabov K, Foi A, Katkovnik V, Egiazarian K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans Image Process. (2007) 16:2080–95. doi: 10.1109/TIP.2007.901238
51. Maggioni M, Katkovnik V, Egiazarian K, Foi A. Nonlocal transform-domain filter for volumetric data denoising and reconstruction. IEEE Trans Image Process. (2012) 22:119–33. doi: 10.1109/TIP.2012.2210725
52. Fang L, Cunefare D, Wang C, Guymer RH, Li S, Farsiu S. Automatic segmentation of nine retinal layer boundaries in OCT images of non-exudative AMD patients using deep learning and graph search. Biomed Opt Express. (2017) 8:2732–44. doi: 10.1364/BOE.8.002732
53. Lore KG, Akintayo A, Sarkar S. LLNet: a deep autoencoder approach to natural low-light image enhancement. Pattern Recogn. (2017) 61:650–62. doi: 10.1016/j.patcog.2016.06.008
54. Shen L, Yue Z, Feng F, Chen Q, Liu S, Ma J. Msr-net: Low-light image enhancement using deep convolutional network. arXiv preprint arXiv:171102488. (2017). doi: 10.48550/arXiv.1711.02488
55. Lv F, Lu F, Wu J, Lim C. MBLLEN: low-light image/video enhancement using CNNs. In: BMVC. Newcastle (2018). p. 220.
56. Jiang Y, Gong X, Liu D, Cheng Y, Fang C, Shen X, et al. Enlightengan: deep light enhancement without paired supervision. arXiv preprint arXiv:190606972. (2019). doi: 10.48550/arXiv.1906.06972
57. Zhao H, Yang B, Cao L, Li H. Data-driven enhancement of blurry retinal images via generative adversarial networks. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Shenzhen: Springer (2019). p. 75–83.
58. Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation. In: MICCAI. Munich (2015). p. 234–41.
59. Zhu JY, Park T, Isola P, Efros AA. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE (2017). p. 2223–32.
60. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv: Comput Vis Pattern Recogn. (2015). doi: 10.48550/arXiv.1409.1556
61. Zhang J, Qiao Y, Sarabi M, Khansari M, Gahm J, Kashani A, et al. 3D shape modeling and analysis of retinal microvascularture in OCT-angiography images. IEEE Trans Med Imaging. (2020) 39:1335–46. doi: 10.1109/TMI.2019.2948867
Keywords: OCTA, stripe removal, image enhancement, generative adversarial networks, two-stage framework
Citation: Cao J, Xu Z, Xu M, Ma Y and Zhao Y (2023) A two-stage framework for optical coherence tomography angiography image quality improvement. Front. Med. 10:1061357. doi: 10.3389/fmed.2023.1061357
Received: 02 November 2022; Accepted: 02 January 2023;
Published: 23 January 2023.
Edited by:
Qiang Chen, Nanjing University of Science and Technology, ChinaReviewed by:
Menglin Wu, Nanjing Tech University, ChinaHuiqi Li, Beijing Institute of Technology, China
Guang Yang, Imperial College London, United Kingdom
Copyright © 2023 Cao, Xu, Xu, Ma and Zhao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mengjia Xu,  eHVtZW5namlhJiN4MDAwNDA7bmltdGUuYWMuY24=; Yuhui Ma, bWF5dWh1aSYjeDAwMDQwO25pbXRlLmFjLmNu
eHVtZW5namlhJiN4MDAwNDA7bmltdGUuYWMuY24=; Yuhui Ma, bWF5dWh1aSYjeDAwMDQwO25pbXRlLmFjLmNu
†These authors have contributed equally to this work