 Renato Erohildes Ferreira1
Renato Erohildes Ferreira1 Fernando Antonio Basile Colugnati
Fernando Antonio Basile Colugnati- 1Post-Graduation Program in Health, School of Medicine, Federal University of Juiz de Fora, Juiz de Fora, Brazil
- 2NIEPEN, Department of Clinics, School of Medicine, Federal University of Juiz de Fora, Juiz de Fora, Brazil
- 3NIEPEN, Department of Internship, School of Medicine, Federal University of Juiz de Fora, Juiz de Fora, Brazil
Introduction: Chronic kidney disease (CDK) progression studies increasingly use surrogate endpoints based on the estimated glomerular filtration rate. The clinical characteristics of these endpoints bring new challenges in comparing groups of patients, as traditional Cox models may lead to biased estimates mainly because they do not assume a hazard function.
Objective: This study proposes the use of parametric survival analysis models with the three most commonly used endpoints in nephrology based on a case study. Estimated glomerular filtration rate (eGFR) decay > 5 mL/year, eGFR decline > 30%, and change in CKD stage were evaluated.
Method: The case study is a 5-year retrospective cohort study that enrolled 778 patients in the predialysis stage. Exponential, Weibull, Gompertz, lognormal, and logistic models were compared, and proportional hazard and accelerated failure time (AFT) models were evaluated.
Results: The endpoints had quite different hazard functions, demonstrating the importance of choosing appropriate models for each. AFT models were more suitable for the clinical interpretation of the effects of covariates on these endpoints.
Conclusion: Surrogate endpoints have different hazard distributions over time, which is already recognized by nephrologists. More flexible analysis techniques that capture these relevant clinical characteristics in decision-making should be encouraged and disseminated in nephrology research.
1. Introduction
Chronic kidney disease (CKD) is progressive, and its evolution is associated with a complex network of multifactorial interactions among etiology, comorbidities, and behavioral aspects. Treatments aim to preserve renal function, postponing as much as possible the needs of any renal replacement therapy (RRT) (1–3).
Although adequate management and treatment of the underlying clinical conditions effectively delay CKD progression, adverse outcomes remain high, and conflicting results are observed (4, 5). Nevertheless, there is a consensus among nephrologists that early predictions of CKD progression are essential for optimizing clinical management and reducing the burden of associated diseases (5).
Because it is a highly heterogeneous disease with hazards competing for the need for RRT and/or death, it is difficult to distinguish the onset of critical renal function decline from periodic variations in glomerular filtration rate (GFR) measurements (5, 6). Recent studies suggest that 12 months is a critical window of control to reverse the deterioration of CKD associated with diabetes mellitus (DM) after diagnosis of the previous stage (5, 6). However, for CKD of other causes, the ideal time to define rapid decline (3, 6, 24, and 48 months) is controversial (5, 6). Several surrogate endpoints have been proposed as reference endpoints for rapid disease progression: annual decay > 5 mL/min/1.73 m2 of estimated GFR (eGFR) (3), 30% loss of eGFR relative to the baseline in up to 24 or 48 months (7–9), or change in CKD stage (3, 5).
The use of surrogate endpoints to evaluate CKD progression in randomized clinical trials has been justified by the possibility of reducing sample sizes and follow-up time. A surrogate endpoint is also expected to predict a treatment’s clinical benefit, damage, or lack thereof, especially at shorter time intervals, which adds important complexity to the data analysis, as seen below (10–14).
Recent studies on the evolution of CKD suggest that the eGFR slope can be a viable surrogate endpoint for clinical trials with large samples (14). However, for observational studies, a predetermined loss of eGFR may be considered an event that occurs as a function of time based on periodic clinical evaluations. In real-life data, these evaluations are scheduled according to the severity of the disease and comorbidities, resulting in varying measurement times among patients.
Therefore, survival analysis (SA) techniques can be applied to evaluate factors that influence the time to occurrence of these endpoints, similar to the analysis of traditional endpoints, such as the need for RRT or death (15). Another issue to consider is that the incidence of these surrogate endpoints is not constant throughout treatment. Alternative and more flexible forms of SA beyond the Cox proportional hazards models should be considered. Parametric models of SA provide such alternatives and flexibility and deserve greater attention in studies of these issues (16, 17).
This article aims to introduce the use of parametric regressions in SA for observational studies of the progression of predialysis CKD. We provide step-by-step instructions for this technique and a critical reference for its application in the field of nephrology. To achieve this goal, we analyze the behaviors of surrogate endpoints that are commonly used to evaluate rapid CKD progression in a case study.
1.1. Gentle introduction to survival analysis
SA techniques model the time until the occurrence of a given event.
Consider the random variable, defined as the time until the occurrence of an endpoint of interest. follows the probability distribution which describes the probability of an individual reaching the endpoint by time t, i.e., . Thus, the survival function is defined as the probability of an individual surviving for more than a certain time or for at least one time equal to and is expressed as (18). The choice of an adequate probability distribution is a key point in the parametric modeling of SA, as will be seen below (18–20).
The hazard function,, is defined as the instantaneous hazard of an individual suffering the endpoint, where f(t) is the function distance derived from F(t). This function can be represented graphically in the form of curves, which are very useful in interpreting the occurrence of the endpoint. These curves are essential for understanding the patterns of the functional form of hazard for different conditions, such as types of treatment or explanatory covariates. In general, the curves should reflect previous clinical knowledge about the progression of the disease/treatment (18, 20).
From a descriptive point of view, nonparametric techniques for SA such as life tables, the Kaplan–Meier (21) and Nelson–Aalen (22, 23) estimators are the most commonly applied. These techniques, available in most statistical packages, have great graphical appeal and allow testing of differences between survival curves, albeit for only one categorical variable (16, 17). The main limitation of this approach is the impossibility of performing multivariate analysis.
The popular proportional hazards model introduced by Cox (24) is a semiparametric model, which has the advantage of not making assumptions about the probability distribution F(t) and consequently the underlying hazards function. The name proportional hazards (PH) comes from the assumption that the hazard ratio (HR) between categories of a variable is constant over time. This assumption is often violated, especially when the follow-up time is long, which reduces the accuracy of assumptions (15–17, 25, 26).
In the parametric approach, the hazard function is defined based on a probability distribution assumed according to the empirical experience of the occurrence of events over time in the population under study. Therefore, parametric approaches are more informative and flexible than nonparametric and semiparametric approaches (26, 27), despite the additional difficulty of choosing the most appropriate probability distribution.
Advantageously, the parametric models can assume two types of parameterization: (1) proportional hazards (PH), the same assumption used in the Cox models, which should be used when the interest is in the average hazard, or (2) accelerated failure time (AFT), if the researcher is interested in the time of occurrence, i.e., if the endpoint will occur earlier or later in a given follow-up period (26, 27). This reparameterization allows a more intuitive clinical interpretation because the parameter measures the effect of the covariate over time until the endpoint, i.e., if there is an acceleration or a delay of the endpoint (26).
The flexibility of parametric models may be more appropriate for evaluating CKD surrogate endpoints and allowing a better understanding of critical levels of renal function decline. However, few methodological studies have comparatively evaluated the adequacy of SA statistical techniques in clinical studies (19).
2. Methods
This methodological study proposes a critical evaluation of parametric regression techniques in survival analysis (SA) by applying them to a historical cohort with real data from patients with predialysis CKD. We present interpretations of the main concepts of SA and compare the adequacy and performance of the parametric models for proportional hazards (PH) and accelerated failure time (AFT) using the distributions most commonly found in statistical software: exponential, Weibull, Gompertz, lognormal, and loglogistic. We provide a step-by-step model for parametric survival analysis, and interested parties may request the programs used for the analyses by contacting the corresponding author.
2.1. The case study sample
The data used for the proposed modeling are from a retrospective cohort extracted from an electronic records database. The sample used in the study consisted of patients seen at the Hiperdia Center of Juiz de Fora [Secondary Health Care Program created in 2010 by the Health Secretariat of the Government of Minas Gerais for the treatment of hypertension (AH), DM, and CKD from August 2010 to December 2014] (28, 29). The study was approved by the Human Research Ethics Committee of UFJF (CAAE no. 0173.0.180.420-11).
This dataset serves as a case study to demonstrate the step-by-step process of modeling with real-world data. However, our analysis does not intend to advance clinical knowledge. The selection of variables included in the model, as presented, follows commonly used covariates in studies related to the progression of chronic kidney disease (CKD). The data used in this study were not specifically collected for this article but were obtained through ethical and administrative agreements. The inclusion criteria for admission of patients with AH to the Hiperdia Center were as follows: diagnosis of lack of response to concomitant use of three or more antihypertensive drugs prescribed in pharmacologically effective doses, target organ damage or suspicion of secondary arterial hypertension; and for patients diagnosed with DM, type 1 DM or type 2 DM with metabolic control according to the therapeutic goal (28, 29).
The historical cohort was defined as patients aged ≥ 18 years with AH and/or DM who had records of at least two consultations in the predialysis multidisciplinary CKD outpatient clinic (3).
The data were collected by consulting electronic medical records. Demographic information was collected at admission, and the other variables were collected during periodic follow-up visits (28, 29).
2.2. Demographic and clinical variables
eGFR was calculated from serum creatinine using the CKD-EPI equation (3). For the purposes of the methodological application, we used the following variables for multivariate adjustment of the models: sex, age (≤ or > 69 years, given the median was 69.5 years), eGFR at the first visit, diagnosis of DM and diagnosis of AH with high hazard for cardiovascular disease (CVD). The risk of CVD was estimated using the Framingham score [≥ 14 points (risk of cardiovascular outcome > 20% in 10 years)] (28, 29).
2.3. Endpoints
As surrogate endpoints, we used the Kidney Disease: Improving Global Outcomes (KDIGO) proposals as indicators of CKD progression:
• Annual GFR decay > 5 mL/min/1.73 m2, calculated as the difference between two measurements multiplied by the proportion of the number of months separating the measurements in the year (months/12) (3);
• Decrease in eGFR of 30% compared with baseline in up to 24 or 48 months (7–9); or
• Change in the CKD stage (3–5).
In our analysis, we only considered the initial occurrence of each endpoint, and as a result, our dataset includes the time of the first measurement when the endpoint is achieved, or the last observation, which serves as a form of censorship.
2.4. Survival analysis modeling
In addition to the descriptive analyses, survival models were fit to exponential, Gompertz, Weibull, lognormal and loglogistic distributions in both parameterizations (PH and AFT).
The method for adjusting the models is presented step-by-step to show in a didactic manner important steps that ensure adequate modeling. The syntaxes used to generate the models and graphs presented in this document will be made available in Supplementary material.
In a practical manner, we can summarize the parametric SA in the five main steps presented below. All analyses were performed using STATA 15 software (Data Analysis and Statistical Software, College Station, Texas, United States).
Step 01—define the endpoint and statement of the survival study:
We used the surrogate endpoints to predict CKD progression, as already mentioned. For the SA study statement, we used the time variable in “months” relative to the number of months of patient follow-up from their first consultation (baseline or month zero) until the occurrence of the event or end of the follow-up defined for the study (censorship). The event variable was a decrease > 5 mL/year in eGFR compared with the baseline during the analysis period, i.e., eGFR > 5%, generating a dichotomous variable called “failure” (failure = 1). The same procedure was used for the other two endpoints: 30% drop in eGFR (failure = 1) or change in stage (failure = 1). The time variable should be related to these events. The censorship variable was coded (censorship = 0).
Step 02—general survival function by the Kaplan–Meier (KM) method and general hazard function by the smoothed hazard estimate method:
Graphically estimate the survival function using the KM method. Patients were censored for death, beginning of RRT or end of follow-up (censorship = 0). The nonparametric approach to estimate the hazard function is flexible, modeless and data-driven. No form assumptions are imposed, except that the hazard function is a smooth function, for which we used the smoothed hazard estimate graph for the one already enabled in STATA.
Step 03—estimate the curves for the functions and the parametric models:
The forms of the survival function and hazard function were calculated according to the models available in STATA: exponential, Weibull, loglogistic, lognormal and Gompertz, always adjusting for the CKD-EPI value at baseline. The models can be compared using an estimated fit measure and visual inspection by graphs. At this point, the nephrologist’s view is important because the curves should represent the expected clinical evolution for the endpoint.
Step 04—generate multivariate models for the preselected covariates as being explanatory for the eGFR decay:
The eGFR at baseline and the comorbidities DM and AH were fit as explanatory variables only for illustrative purposes of comparison between the models. The first type of model was for PH, and the expressed parameter was HR. Values >1 indicate an increased hazard of eGFR decay, an increased hazard of a 30% decrease in eGFR, or an increased hazard of changing stages. The second type of model was for AFT, which had a reverse interpretation in which values <1 indicate that the three endpoints may occur earlier.
Step 05—compare the fits of the models by the graphical method:
Several methods of graphical adjustment have been proposed, such as those suggested by Allison (30), which analyze the adequacy of the generalized gamma model based on the diagnostic graphs, that is, through the analysis of residuals. Several types of residuals have been proposed for survival models, and the most frequently reported alternative is the use of generalized Cox-Snell residuals.
3. Results
The sample consisted of 778 individuals, most of whom were female (51.6%). The mean age was 68.7 ± 11.8 years and ranged from 20 to 97 years. The mean eGFR was 35.8 ± 12.6 mL/min, with a similar distribution in stages 3A (26.3%), 3B (39.7%) and 4 (27.5%) and less than 10% in stage 5. The follow-up period was 60 months. The prevalence of DM was 29.0% (n = 226), and patients with AH were diagnosed with a high risk of CVD (29.8%, n = 232; Table 1).
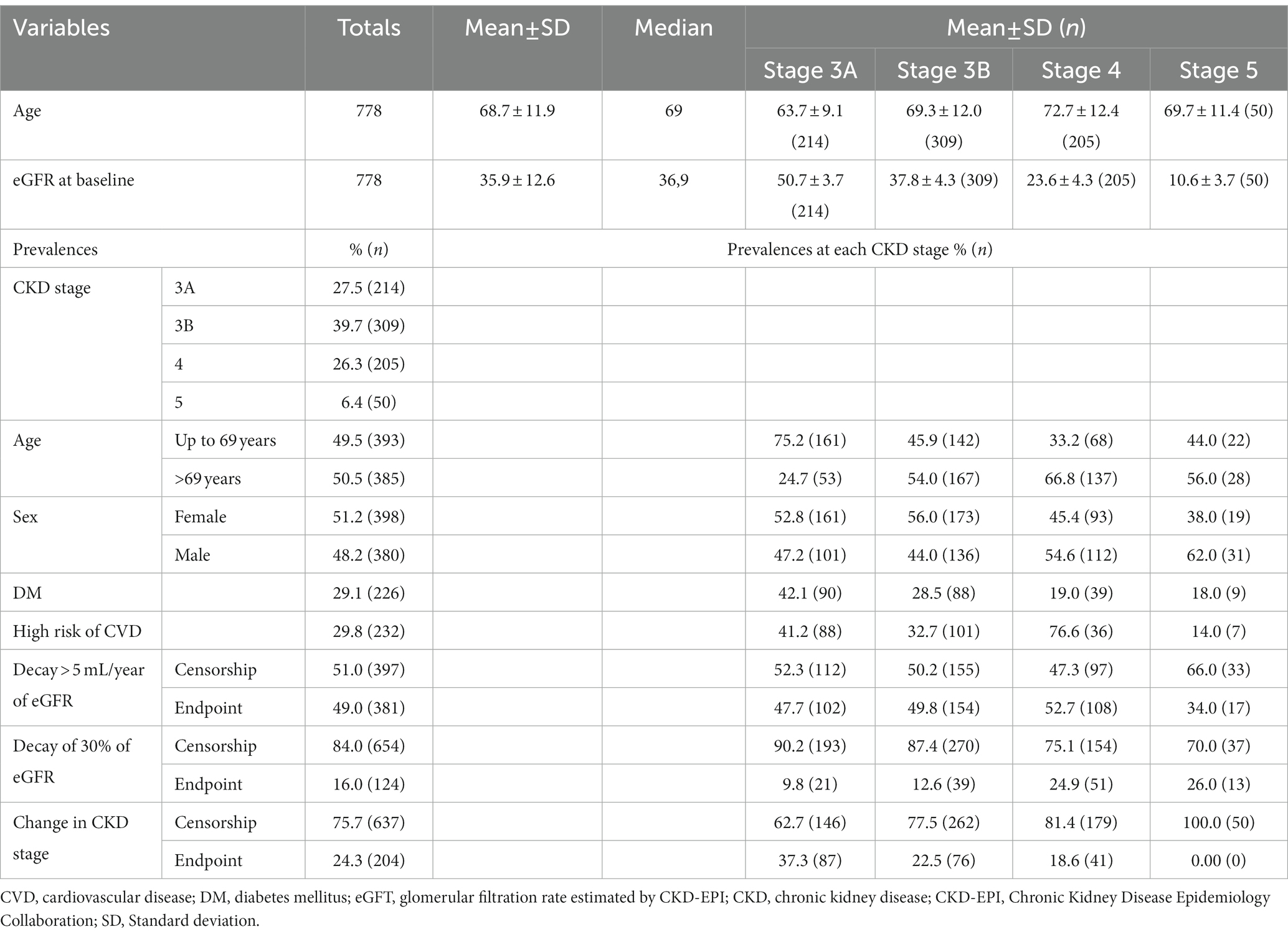
Table 1. Demographic and clinical characteristics of the sample at baseline and in relation to the three surrogate endpoints.
Regarding progression to CKD, the prevalence of endpoints was as follows: (I) eGFR decay > 5 mL/year: 381 failures (49.0%), (II) eGFR decay >30%: 124 failures (16.0%) and (III) change in CKD stage: 204 failures (24.3%).
In terms of the time until the occurrence of each event, for eGFR decay > 5 mL/year, approximately 60.9% of the failures occurred within 6 months and 26.5% within 12 months. For eGFR decay >30%, most failures (56.4%) occurred after 12 months. For patients with a change in CKD stage, the vast majority of stage changes occurred within 12 months (67.8%; Table 2).
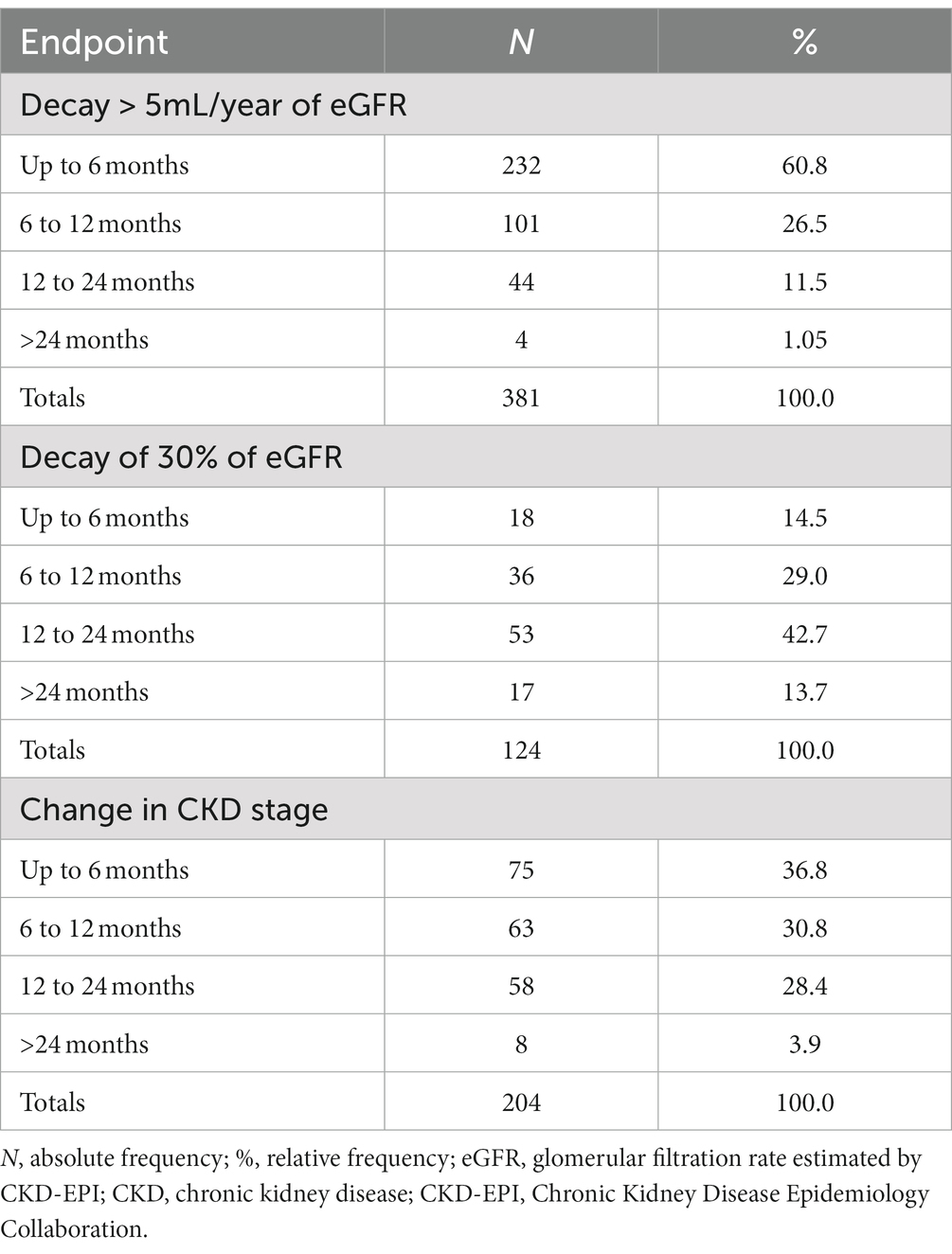
Table 2. Occurrence of the surrogate endpoints for CKD progression over follow-up time intervals.
This can be understood as a first approach to the hazard function h(t). Decay > 30% has a nonmonotonic characteristic, with peak occurrence between 12 and 24 months, while the other endpoints decay monotonically over time (Table 2). The endpoint of the study was defined as described in “Step 1.” Figures 1, 2 correspond to the curves of Steps 1 and 2 (syntax on Supplementary material). The survival estimates of the parametric models are contrasted with those calculated using the nonparametric Kaplan–Meier and smoothed hazard estimate methods.
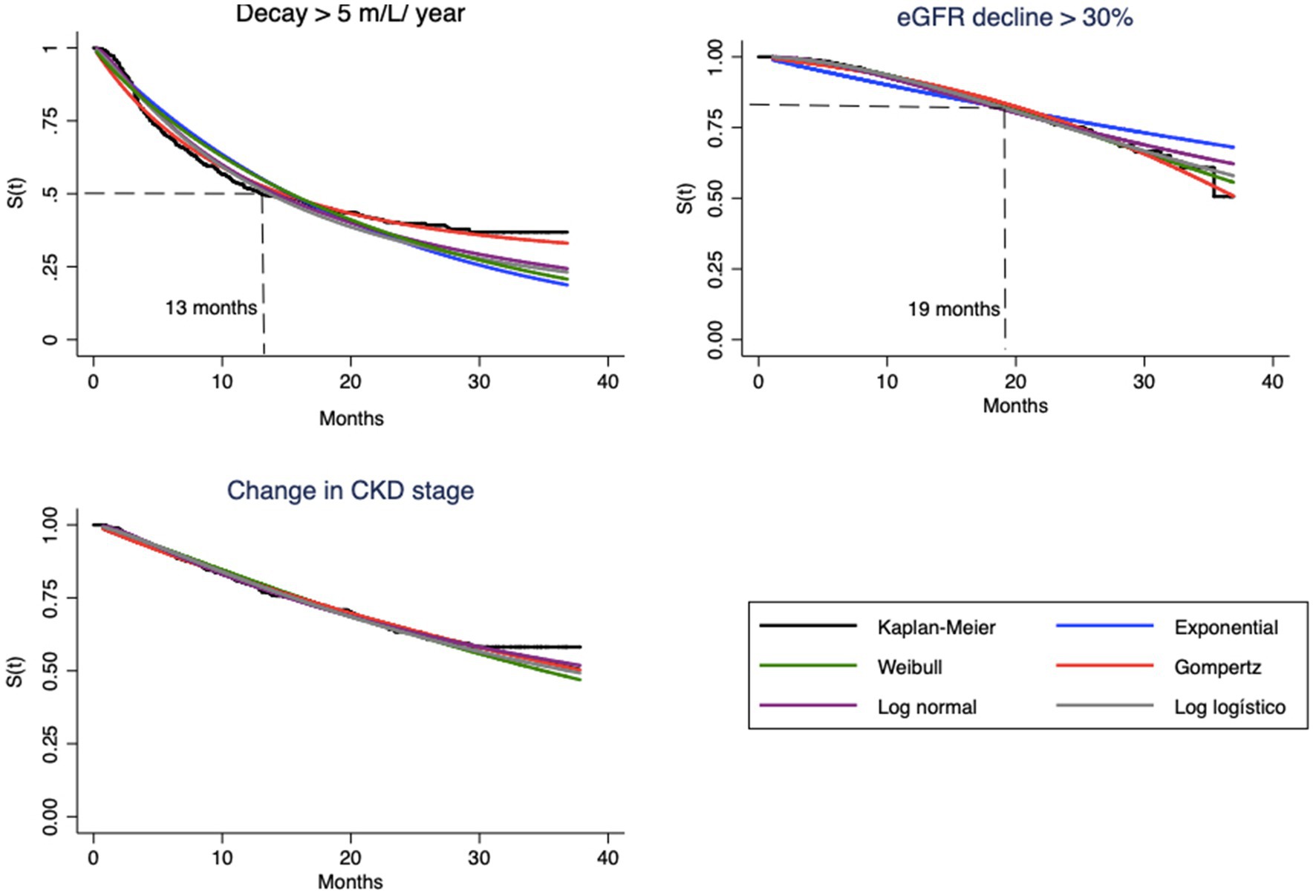
Figure 1. Survival curves estimated by Kaplan–Meier method and parametric model based, for each endpoint.
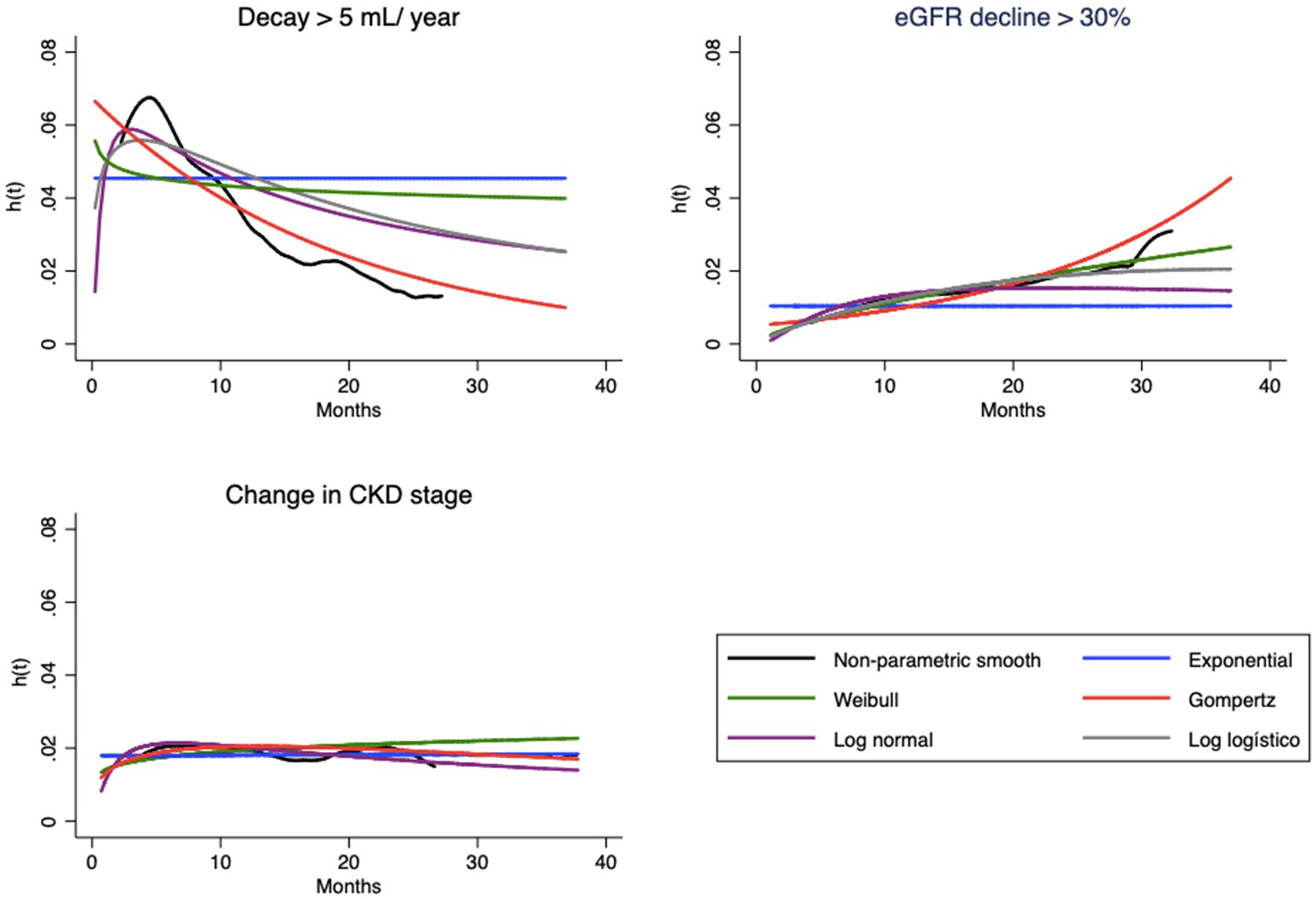
Figure 2. Hazard functions [h(t)] estimated by empirical smooth method and parametric model based, for each endpoint.
Visual evaluation of the graphs for eGFR decay > 5 mL/year shows that the best superposition of the survival curves with the Kaplan–Meier curve indicates almost perfect fits of the Gompertz model (Figure 1) and the hazard function curve (Figure 2). Regarding eGFR decay > 30%, the best fits for the S(t) function were the Gompertz, Weibull and loglogistic distributions (Figure 1). In the case of change in stage, the behavior of the curve was adequately captured by nearly all models, which can be explained by the practically linear trend of the survival function, which facilitated the independent adjustment of the model type (a line is always captured by any model). This behavior only changes after month 30, when no more events occur (Figure 1).
The hazard function h(t), as previously mentioned, should represent the evolution of hazard from a clinical point of view. Note that the shapes of the curves vary according to the type of endpoint (Figure 2). In the case of eGFR loss of 5 mL/year, the tendency is for the instantaneous hazard to decrease as a function of time; i.e., events tend to occur with greater probability at the beginning of treatment. The opposite relationship is observed for eGFR decrease > 30%, with an increase in hazard over time. In both cases, the curves of the Gompertz model are again similar to the empirical curve; the loglogistic curve fits well for the annual drop, and the Weibull curve fits well for the 30% loss. For change in stage, this hazard is apparently constant, which allows the use of any model, including the simplest, such as the exponential model.
Three covariates were used for multivariate fit with the PH and AFT models: eGFR (expressed by CKD-EPI at baseline), diagnosis of DM and AH with high hazard of CVD. Table 3 shows the results for the three endpoints in the different types of models. In grayscale, the best models for each endpoint stand out according to the visual inspection of survival curves and hazard functions, in addition to the analysis of generalized Cox-Snell residuals.
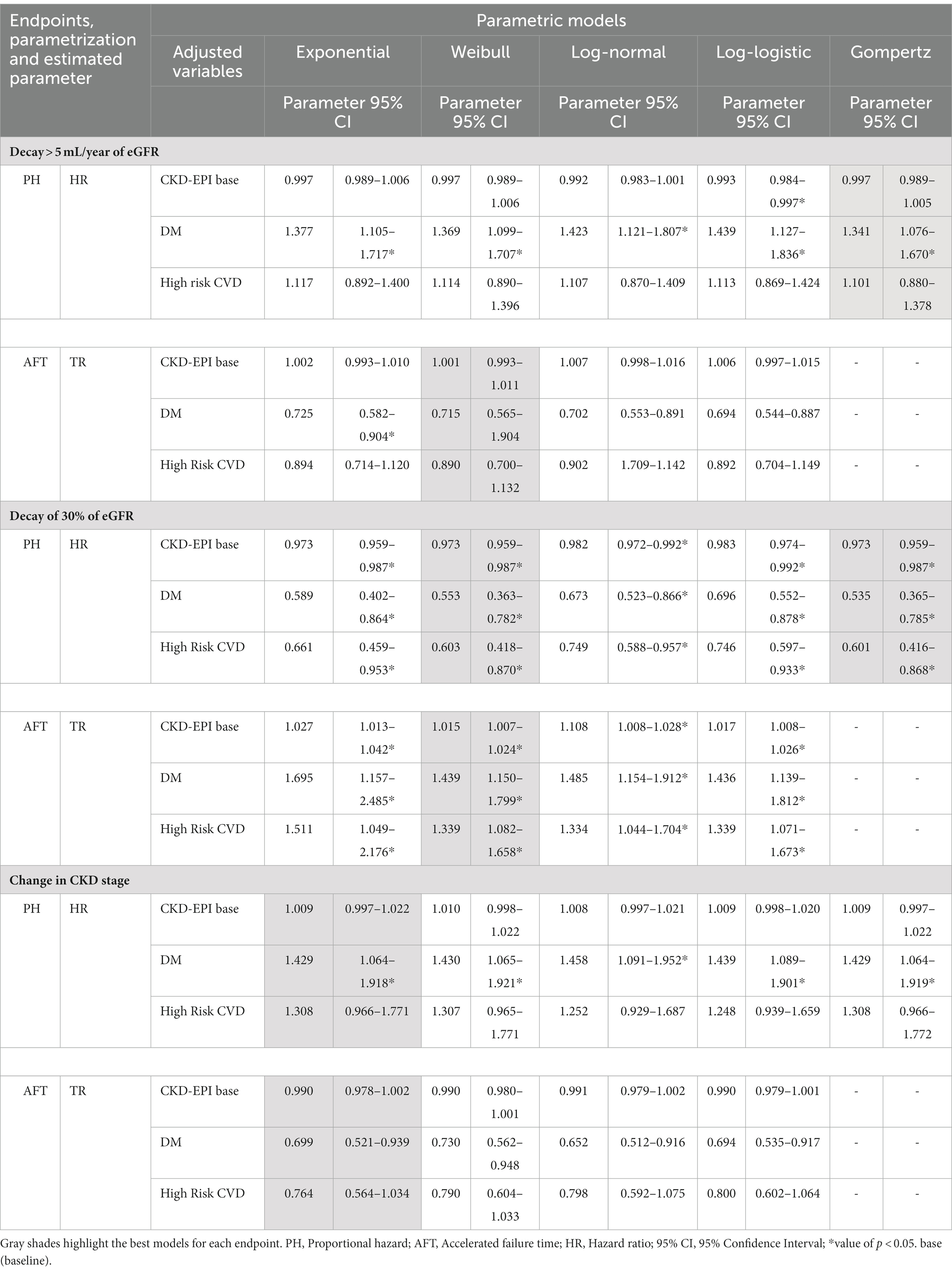
Table 3. Multivariate parametric survival models for each surrogate endpoint.
Note that in some situations, the estimated parameters are different. Taking the estimates for the DM, for the first endpoint, the HR ranges from 1.34 to 1.44 (for the Gompertz and loglogistic models, respectively), while TR varies much less, between 0.69 and 0.74. The parameters of the second endpoint are in the opposite direction. For example, diabetic patients have a 55% mean risk of eGFR loss >30% according to the Weibull model and a 44% longer time for this occurrence. For the other endpoints, the effects are increased hazard and decreased time. This fact can be explained by the data in Table 1; there is a greater share of diabetic patients in the early stages of CKD, and the occurrence of diabetes increases with CKD severity. The opposite pattern is observed for the other endpoints.
The AFT parameterization for the Gompertz model, which showed a good fit for all endpoints, presents mathematical challenges that are only circumventable through intensive computational methods and cannot be implemented in most statistical software, including STATA; consequently, it was not performed.
Thus, Table 4 presents a summary of the interpretations of HR and TR. For this purpose, we use as an example the Weibull model, which presented the second-best fit for the three endpoints based on the visual inspection of the curves of the S(t) and h(t) functions and the interpretation of the DM effect in the occurrence of endpoints.
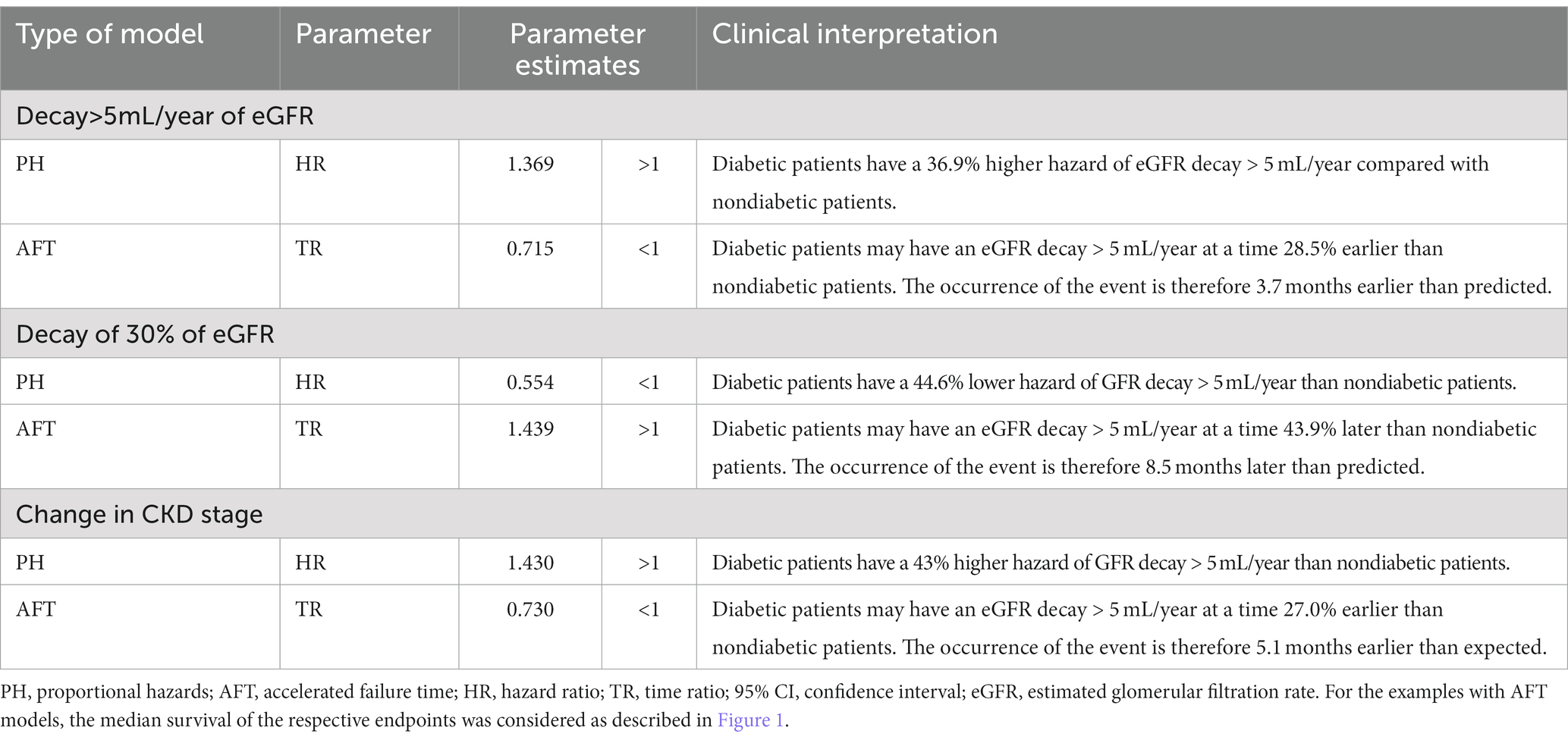
Table 4. Clinical interpretation of the parameters of the Weibull model for the effect of diabetes mellitus in the PH and AFT models for the surrogate endpoints of CKD progression.
After performing the multivariate adjustments, we must verify the quality of the fit of each parametric model before selecting a model, which is Step 5.
Most of the techniques proposed for this purpose are graphical and residual analyses. For each model and endpoint, we calculated the values of the Cox-Snell residuals to measure the adequacy of the adjustments. Figure 3 shows the models chosen as the best fit. A good fit of the models is observed, given that the residuals overlap on the reference line of the quartiles of the respective distributions. The residuals move slightly away from the line only near the end of the follow-up time, without compromising the adjustment.
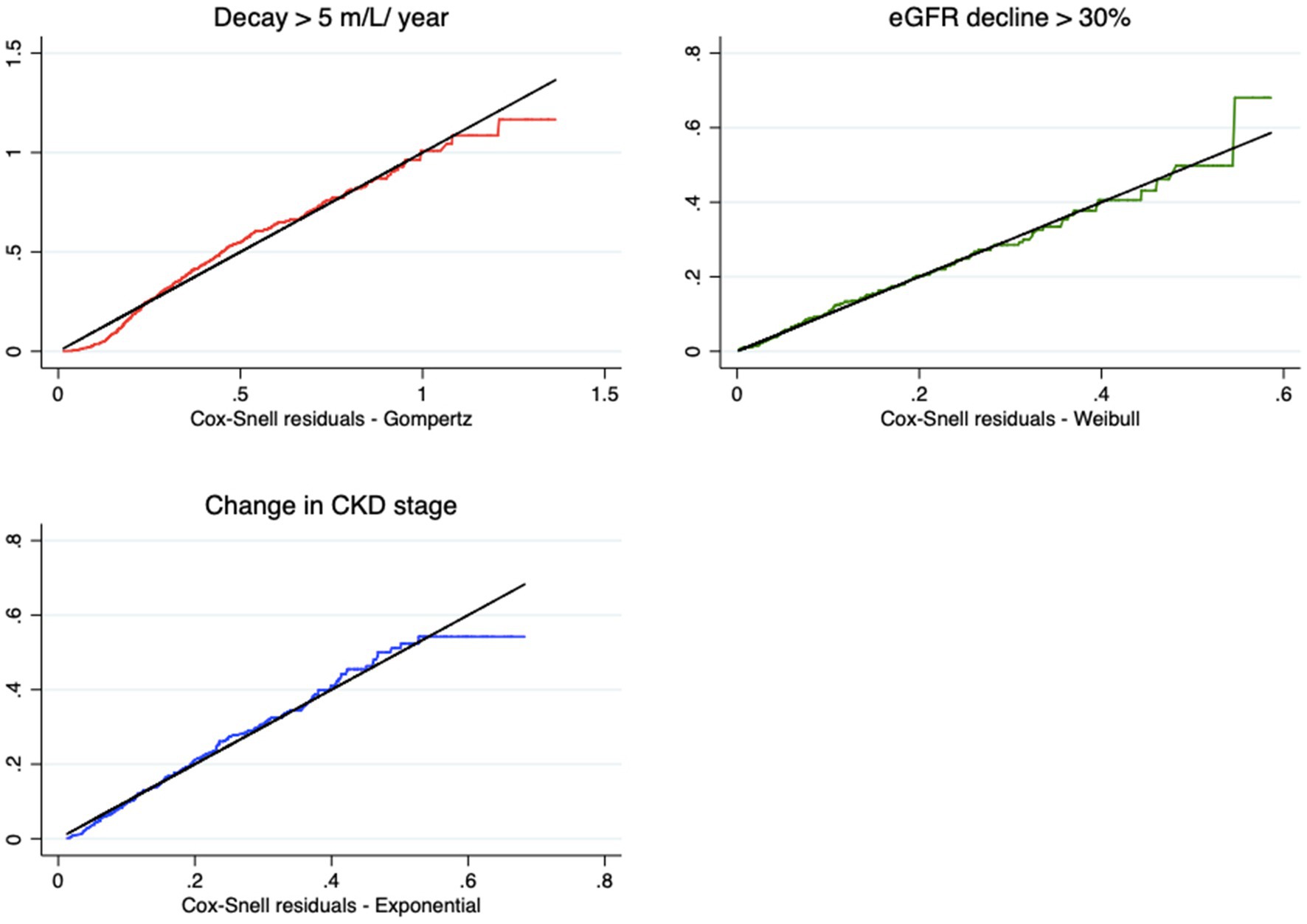
Figure 3. Cox-Snell residuals for the best models for each endpoint.
4. Discussion
We present the methodology and apply parametric survival models for surrogate endpoints of CKD progression, using a real-world dataset from a historical cohort of patients with CKD undergoing predialysis treatment as a practical example. Despite the increasing use of SA in clinical research in recent decades, interpretations are mostly limited to HRs estimated by Cox semiparametric models. These models, despite answering many research questions, fall short in some situations and may limit the scope of important clinical interpretations of parametric models, as in the case of surrogate endpoints (15).
The use of surrogate endpoints, also termed intermediate endpoints, is increasing and is even defining the design of randomized clinical trials. Consequently, these endpoints will soon cease to be surrogates and will become primary endpoints, which demands a better exploration of this knowledge gap among clinical researchers as a reference for their analyses and interpretations (12–16).
The preference for semiparametric models may reflect the difficulties that researchers in the field often face when dealing with parametric modeling. In parametric models, probability distributions must be assumed and then compared, which requires further technical decisions to be made in a subject that is not typically well-understood by clinical researchers. This complexity may lead to a bias toward simpler semiparametric models, which may have limitations in terms of clinical interpretation, but require less technical expertise (15).
Although the Cox PH model is very flexible, it is not immune to the typical assumptions of statistical modeling. Its fundamental assumption is that the factors under study should have a constant effect on the hazard over time. This assumption is violated for most biological phenomena (31). The assumption of proportionality is violated in almost two-thirds of studies (31). Further, only 36% of studies mentioned the assumption of proportionality, and only 20% mathematically tested this assumption (32).
Patients with CKD undergoing predialysis treatment are routinely compared using absolute or relative measures of treatment effect for primary endpoints such as death and RRT. A limitation of this approach is that its clinical significance depends heavily on the baseline or progression of the patient over time (33). These measures can be very useful when the goal is only to estimate the effect of a covariate at baseline on the final endpoint, that is, whether it increases or decreases the hazard of the patient suffering the endpoint of interest regardless of when it occurs (33, 34). In the case of surrogate endpoints, a complete understanding of how the hazards vary over time may be fundamental for helping the clinician decide the ideal time of interventions to postpone this endpoint. Therefore, understanding whether the endpoint occurs in a shorter or longer time, conditioned on the levels of explanatory or predictive variables, is a key clinical issue for predicting prognosis (35, 36). Therefore, complementary results that allow an understanding of the evolution of treatment as a function of follow-up time, such as the interpretation of survival curves and hazard function, are informative tools to evaluate this evolution (33, 37, 38).
For this reason, we focused in this study on the interpretation of hazard curves. The hazards may vary over time, and the follow-up times of each individual are usually very different; thus, a more flexible functional form tends to be more reliable than the actual average clinical trajectory of the sample under analysis. It is also possible to use estimates of the survival and hazard curves to construct predictions of expected behaviors (6).
The sample used in the study is similar to the nondialysis CKD populations described by other authors (10–14), particularly the average age, which was close to 70 years. In one-third of CKD patients, the etiology is DM. For patients in the early (3) and intermediate (4, 5) stages, in which the benefit of treatment is potentially greater (5), this representativeness reinforces the hazard estimates.
The differences in modeling on the three types of surrogate endpoints in this study highlights the importance of considering these issues. The hazard curves were markedly distinct. The change of stage endpoint the hazard was constant. As a result, we recommend the use of basic models such as exponential model or even the standard Cox models. For the endpoints defined based on threshold amounts of renal function decay, the hazards exhibit inverse relationship over time. While annual decay > 5 mL monotonically decreases over time, with greater hazards at the beginning of treatment, decay in eGFR greater than 30% showed an increased hazard in later periods. The use of Cox models in this case would fail to capture this information, which has great clinical value, and would probably lead to a biased or incorrect interpretation of the relative hazards (15–17, 25, 26).
We also emphasize that the parametric form of the model can be based entirely on the clinical experience of the researchers. For example, when comparing the predictions of the percentage of patients who remain event-free after a certain follow-up period, the plausibility of the choice of a parametric distribution can be assessed a priori by reference to previous relevant studies. If such studies are not available, it will be necessary to rely on the opinions of clinical experts. The opinions of an expert clinician and/or experienced analyst can provide valuable information on the plausibility of certain models and their extrapolations compared with known disease patterns (39).
It is very likely that the results will coincide, at least in the general form of trend and monotonicity, with the empirical estimate of the hazard function, even if only approximately. Hence, the option for a parametric model of SA, followed by the fit analysis of the model chosen by graphical means or information criteria such as the Akaike information criterion (AIC), can bring estimates of effects closer to the clinical reality (39).
Therefore, this study intends to encourage the use of parametric models and serve as a reference for this approach mainly in nephrology. This is perhaps the greatest potential contribution of this study, as it used real data from clinical practice at a CKD treatment center.
However, limitations should be considered. We do not consider any causal model and/or the process of selection of final explanatory/predictor variables for a clinical research statistical model. These issues warrant full discussion in separate articles, and good references are Greenland and Gelman (40, 41). No further modeling aspects were included, such as the inclusion of terms of frailty (individual random effects) or cure fraction (42). The inclusion of these terms in the models may yield completely different results than the present analyses but would require a deeper understanding of these concepts, which is beyond the intended introductory scope of this article. There was also no consideration of establishing an explanatory model for the endpoints studied. The variables, which are well known for their effects among nephrologists, were used as illustrative examples, and one should avoid generalizing these results to clinical practice or even other studies investigating comorbidities such as DM and coronary diseases in patients with CKD.
5. Conclusion
Our study aimed to explore the possible applications of parametric survival models in a cohort of CKD patients in the predialysis stage. Although medical research has focused on semiparametric models in recent decades, Violations of the proportionality assumption can lead to biased or inaccurate measurements that may not align with clinical practice. Given the complex nature of CKD and the nuances of clinical practice, the input of a nephrologist is crucial for determining the plausibility of a final model results, and its interpretation. Given the flexibility of the parametric models, by comparing parametric models with relevant studies and expert opinions, we can gain insights into disease patterns and identify potential avenues for future research.
Data availability statement
The data analyzed in this study is subject to the following licenses/restrictions: the owner did not authorized the publication of the original dataset, even without any identification variable. Requests to access these datasets should be directed to ZmVybmFuZG8uY29sdWduYXRpQG1lZGljaW5hLnVmamYuYnI=.
Ethics statement
The studies involving human participants were reviewed and approved by Comitê de Ética em Pesquisa Humana—UFJF. The patients/participants provided their written informed consent to participate in this study.
Author contributions
RF: project development, statistical analysis, manuscript writing, and manuscript review. HS-P: writing of the manuscript and critical review of the manuscript. FC: project coordination, statistical analysis, manuscript writing, and manuscript review. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES), financial code 001.
Acknowledgments
We would like to thank Renata Romanholi Pinhati, Wander Barros do Carmo, and Luis Gustavo Modelli De Andrade for their valuable contribution and suggestions.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmed.2023.1029165/full#supplementary-material
References
1. Kalantar-Zadeh, K, Jafar, TH, Nitsch, D, Neuen, BL, and Perkovic, V. Chronic kidney disease. Lancet. (2021) 398:786–802. doi: 10.1016/S0140-6736(21)00519-5
2. Webster, AC, Nagler, EV, Morton, RL, and Masson, P. Chronic kidney disease. Lancet. (2017) 389:1238–52. doi: 10.1016/S0140-6736(16)32064-5
3. Stevens, PE, and Levin, A. Kidney Disease: Improving Global Outcomes Chronic Kidney Disease Guideline Development Work Group Members. Evaluation and management of chronic kidney disease: synopsis of the kidney disease: improving global outcomes 2012 clinical practice guideline. Ann Intern Med. (2013) 158:825–30. doi: 10.7326/0003-4819-158-11-201306040-00007
4. Shlipak, MG, Sri Tummalapalli, SL, Boulware, EL, et al. The case for early identification and intervention of chronic kidney disease: conclusions from a kidney disease: improving global outcomes (KDIGO) Controversies conference. Kidney Int. (2021) 99:34–47. doi: 10.1016/j.kint.2020.10.012
5. Yang, L, Chu, TK, Lian, J, Lo, CW, Zhao, S, He, D, et al. Individualised risk prediction model for new-onset, progression and regression of chronic kidney disease in a retrospective cohort of patients with type 2 diabetes under primary care in Hong Kong. BMJ Open. (2020) 10:e035308. doi: 10.1136/bmjopen-2019-035308
6. Nojima, J, Meguro, S, Ohkawa, N, Furukoshi, M, Kawai, T, and Itoh, H. One-year eGFR decline rate is a good predictor of prognosis of renal failure in patients with type 2 diabetes. Proc Jpn Acad Ser B Phys Biol Sci. (2017) 93:746–54. doi: 10.2183/pjab.93.046
7. Ku, E, Xie, D, Shlipak, M, Hyre-Anderson, A, Chen, J, and Go, AS. Change in measured GFR versus eGFR and CKD outcomes. J Am Soc Nephrol. (2015) 27:2196–204. doi: 10.1681/ASN.2015040341
8. Levey, AS, and Stevens, LA. Estimating GFR using the CKD epidemiology collaboration (CKD-EPI) creatinine equation: more accurate GFR estimates, lower CKD prevalence estimates, and better risk predictions. Am J Kidney Dis. (2010) 55:622–7. doi: 10.1053/j.ajkd.2010.02.337
9. Inker, LA, Lambers Heerspink, HJ, Mondal, H, Schmid, CH, Tighiouart, H, Noubary, F, et al. GFR decline as an alternative end point to kidney failure in clinical trials: a Meta-analysis of treatment effects from 37 randomized trials. Am J Kidney Dis. (2014) 64:848–59. doi: 10.1053/j.ajkd.2014.08.017
10. Schievink, B, Mol, PG, and Lambers Heerspink, HJ. Surrogate endpoints in clinical trials of chronic kidney disease progression: moving from single to multiple risk marker response scores. Curr Opin Nephrol Hypertens. (2015) 24:492–7. doi: 10.1097/MNH.0000000000000159
11. Levey, AS, Inker, LA, Matsushita, K, Greene, T, Willis, K, Lewis, E, et al. GFR decline as an end point for clinical trials in CKD: a scientific workshop sponsored by the National Kidney Foundation and the US Food and Drug Administration. Am J Kidney Dis. (2014) 64:821–35. doi: 10.1053/j.ajkd.2014.07.030
12. Greene, T, Teng, CC, Inker, LA, Redd, A, Ying, J, Woodward, M, et al. Utility and validity of estimated GFR-based surrogate time-to-event end points in CKD: a simulation study. Am J Kidney Dis. (2014) 64:867–79. doi: 10.1053/j.ajkd.2014.08.019
13. Lambers Heerspink, HJ, Tighiouart, H, Sang, Y, Ballew, S, Mondal, H, Matsushita, K, et al. GFR decline and subsequent risk of established kidney outcomes: a meta-analysis of 37 randomized controlled trials. Am J Kidney Dis. (2014) 64:860–6. doi: 10.1053/j.ajkd.2014.08.018
14. Inker, LA, and Chaudhari, J. GFR slope as a surrogate endpoint for CKD progression in clinical trials. Curr Opin Nephrol Hypertens. (2020) 29:581–90. doi: 10.1097/MNH.0000000000000647
15. Emura, T, Matsui, S, and Rondeau, V. Survival Analysis with correlated endpoints joint frailty-copula models In: Kunitomo, N, and Takemura, A. editors. Springer briefs in statistics: JSS research series in statistics. Springer (2019)
16. Kleinbaum, DG, and Klein, M. Survival analysis: A self learning text. 3rd ed. New York, NY: Global Journal of Health Science (2012).
17. Lee, LT, and Wang, JW. Statistical methods for survival data Analysis. 3rd ed New Jersey, USA: John Wiley Sons. Wiley Series in Probability and Statistics (2003).
18. Carvalho, MS, Andreozzi, L, Codeco, CT, Campos, DP, Barbosa, MTS, and Shimakura, SE. Análise de sobrevivência: teoria e aplicações em saúde. 2nd ed Rio de Janeiro, Brazil: FIOCRUZ (2011).
19. Jenkins, SP. Survival Analysis. Colchester: Institute for Social and Economic Research, University of Essex (2004).
20. Efron, B. The efficiency of Cox's likelihood function for censored data. J Am Stat Assoc. (1977) 72:557–65. doi: 10.1080/01621459.1977.10480613
21. Kaplan, EL, and Meier, P. Nonparametric estimation from incomplete observations. J Am Stat Assoc. (1958) 53:457–81. doi: 10.1080/01621459.1958.10501452
22. Nelson, W. Hazard plotting for incomplete failure data. J Qual Technol. (1969) 1:27–52. doi: 10.1080/00224065.1969.11980344
23. Nelson, W. Theory and applications of hazard plotting for censored failure data. Technometrics. (1792) 14:945–65.
25. George, B, Seals, S, and Aban, I. Survival analysis and regression models survival analysis and regression models. J Nucl Cardiol. (2014) 21:686–94. doi: 10.1007/s12350-014-9908-2
26. Garson, GD. Parametric survival Analysis—event history Analysis. North Carolina: Statistical Associates Publishing, North Carolina State University (2012).
27. Bower, H, Crowther, MJ, Rutherford, MJ, Andersson, TML, Clements, M, Liu, XR, et al. Capturing simple and complex time-dependent effects using flexible parametric survival models: a simulation study. Commun Stat. (2019) 50:3777–93. doi: 10.1080/03610918.2019.1634201
28. Pinhati, R, Ferreira, R, Carminatti, M, Colugnati, F, de Paula, R, and Sanders-Pinheiro, H. Adherence to antihypertensive medication after referral to secondary healthcare: a prospective cohort study. Int J Clin Pract. (2021) 75:e13801. doi: 10.1111/ijcp.13801
29. Huaira, RMNH, Paula, RB, Bastos, MG, Colugnati, FAB, and Fernandes, NMDS. Validated registry of pre-dialysis chronic kidney disease: description of a large cohort. Braz J Nephrol. (2018) 40:112–21. doi: 10.1590/2175-8239-jbn-3841
30. Allison, PD. Survival Analysis Using the SAS System: A Practical Guide. Cary: SAS Institute, Inc. (1995).
31. Xue, X, Xie, X, Gunter, M, Rohan, TE, Wassertheil-Smoller, S, Ho, GYF, et al. Testing the proportional hazards assumption in case-cohort analysis. BMC Med Res Methodol. (2013) 13:88. doi: 10.1186/1471-2288-13-88
32. Kuitunen, I, Ponkilainen, VT, Uimonen, MM, Eskelinen, A, and Reito, A. Testing the proportional hazards assumption in cox regression and dealing with possible non-proportionality in total joint arthroplasty research: methodological perspectives and review. BMC Musculoskelet Disord. (2021) 22:489. doi: 10.1186/s12891-021-04379-2
33. Altman, DG, and De Stavola, BL. Practical problems in fitting a proportional hazards model to data with Udated measurements of the covariates. Stat Machine. (1994) 13:301–41.
34. Zhang, Z, Ambrogi, F, Bokov, AF, Gu, H, De Beurs, E, and Eskaf, K. Estimate risk difference and number needed to treat in survival analysis. Ann Transl Med. (2018) 6:120. doi: 10.21037/atm.2018.01.36
35. Abrahamowicz, M, Mackenzie, T, and Esdaile, JM. Time-dependent hazard ratio: modeling and hypothesis testing with application in lupus nephritis. J Am Stat Assoc. (1996) 91:1432–9. doi: 10.1080/01621459.1996.10476711
36. Clark, TG, Bradburn, MJ, Love, SB, and Altman, DG. Survival analysis part IV: further concepts and methods in survival analysis. Br J Cancer. (2003) 89:781–6. doi: 10.1038/sj.bjc.6601117
37. Fischer, LD, and Lin, DY. Time-dependent covariates in the cox proportional-hazards regression model. Annu Rev Public Health. (1999) 20:145–57. doi: 10.1146/annurev.publhealth.20.1.145
38. Coory, M, Lamb, KE, and Sorich, M. Risk-difference curves can be used to communicate time-dependent effects of adjuvant therapies for early stage cancer. J Clin Epidemiol. (2014) 67:966–72. doi: 10.1016/j.jclinepi.2014.03.006
39. Gallacher, D, Kimani, P, and Stallard, N. Extrapolating parametric survival models in health technology assessment: a simulation study. Med Decis Mak. (2021) 41:37–50. doi: 10.1177/0272989X20973201
40. Greenland, S, Division of Epidemiology. Modeling and variable selection in epidemiologic analysis. Am J Public Health. (1989) 79:340–9. doi: 10.2105/AJPH.79.3.340
41. Gelman, A, Carlin, JB, Stern, HS, Dunson, DB, Vehtari, A, and Rubin, DB. Bayesian data analysis. Florida, USA: Chapman and Hall/CRC (2013).
Keywords: survival analysis, chronic kidney disease, parametric regression models, surrogate endpoint, kidney disease progression
Citation: Erohildes Ferreira R, Sanders-Pinheiro H and Basile Colugnati FA (2023) A proposal to analyze the progression of non-dialytic chronic kidney disease by surrogate endpoints: introducing parametric survival models. Front. Med. 10:1029165. doi: 10.3389/fmed.2023.1029165
Edited by:
Ana Cusumano, Norberto Quirno Medical Education and Clinical Research Center (CEMIC), ArgentinaReviewed by:
Precil Neves, University of São Paulo, BrazilJulia Kerschbaum, Innsbruck Medical University, Austria
Copyright © 2023 Erohildes Ferreira, Sanders-Pinheiro and Basile Colugnati. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fernando Antonio Basile Colugnati, ZmVybmFuZG8uY29sdWduYXRpQG1lZGljaW5hLnVmamYuYnI=