
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Med., 29 July 2022
Sec. Family Medicine and Primary Care
Volume 9 - 2022 | https://doi.org/10.3389/fmed.2022.950327
This article is part of the Research TopicArtificial Intelligence and Big Data for Value-Based CareView all 14 articles
 Hyeonhoon Lee1
Hyeonhoon Lee1 Yujin Choi2
Yujin Choi2 Byunwoo Son3Jinwoong Lim1,4Seunghoon Lee5Jung Won Kang5Kun Hyung Kim6Eun Jung Kim7
Byunwoo Son3Jinwoong Lim1,4Seunghoon Lee5Jung Won Kang5Kun Hyung Kim6Eun Jung Kim7 Changsop Yang2*†Jae-Dong Lee5*†
Changsop Yang2*†Jae-Dong Lee5*†Pattern identification (PI) is a diagnostic method used in Traditional East Asian medicine (TEAM) to select appropriate and personalized acupuncture points and herbal medicines for individual patients. Developing a reproducible PI model using clinical information is important as it would reflect the actual clinical setting and improve the effectiveness of TEAM treatment. In this paper, we suggest a novel deep learning-based PI model with feature extraction using a deep autoencoder and k-means clustering through a cross-sectional study of sleep disturbance patient data. The data were obtained from an anonymous electronic survey in the Republic of Korea Army (ROKA) members from August 16, 2021, to September 20, 2021. The survey instrument consisted of six sections: demographics, medical history, military duty, sleep-related assessments (Pittsburgh sleep quality index (PSQI), Berlin questionnaire, and sleeping environment), diet/nutrition-related assessments [dietary habit survey questionnaire and nutrition quotient (NQ)], and gastrointestinal-related assessments [gastrointestinal symptom rating scale (GSRS) and Bristol stool scale]. Principal component analysis (PCA) and a deep autoencoder were used to extract features, which were then clustered using the k-means clustering method. The Calinski-Harabasz index, silhouette coefficient, and within-cluster sum of squares were used for internal cluster validation and the final PSQI, Berlin questionnaire, GSRS, and NQ scores were used for external cluster validation. One-way analysis of variance followed by the Tukey test and chi-squared test were used for between-cluster comparisons. Among 4,869 survey responders, 2,579 patients with sleep disturbances were obtained after filtering using a PSQI score of >5. When comparing clustering performance using raw data and extracted features by PCA and the deep autoencoder, the best feature extraction method for clustering was the deep autoencoder (16 nodes for the first and third hidden layers, and two nodes for the second hidden layer). Our model could cluster three different PI types because the optimal number of clusters was determined to be three via the elbow method. After external cluster validation, three PI types were differentiated by changes in sleep quality, dietary habits, and concomitant gastrointestinal symptoms. This model may be applied to the development of artificial intelligence-based clinical decision support systems through electronic medical records and clinical trial protocols for evaluating the effectiveness of TEAM treatment.
Pattern identification (PI), a diagnostic method in Traditional East Asian medicine (TEAM), is a meaningful step for TEAM doctors when making treatment decisions such as selection of an appropriate acupuncture point and herbal medicine. It uses clinical information based on traditional diagnostic criteria, which include observation, listening, questioning, and pulse detection (1). Particularly, the use of PI in selecting an optimal combination with a few acupuncture points has been an important research subject to reveal those used in actual clinical practice (2, 3). Most clinical trials on the effectiveness of acupuncture treatment used a fixed-point approach, which is different from the clinical practice that uses a more individualized approach (4). Although some study designs such as conventional randomized clinical trials (RCTs) with a personalized acupuncture protocol or a pragmatic clinical trial have been suggested to overcome the gap between acupuncture research and clinical practice, the results of an individualized approach vs. a fixed-point approach are still controversial (5–9). Nonetheless, several recent experimental studies have supported the significance of acupuncture point selection (10–13). Therefore some studies with data-mining methods were conducted using RCT data, medical records, virtual diagnosis data, and classical medical texts to systematically prove the relationship between symptoms, diseases, PI, and acupuncture point selections (3, 14–16).
Artificial intelligence (AI) techniques have also emerged in the research of TEAM. Previous studies used artificial neural network models to differentiate patterns for acupuncture point selections (17, 18), and clustering algorithms to discover the combination rules of herbal medicine (19). Also, the recent deep learning models such as bidirectional encoder representations from transformers generated some new herbal medicine prescriptions from a few medical records (20, 21). However, to the best of our knowledge, there are few AI studies that assist PI from large amounts of clinical information, though most clinical guidelines recommend a PI process by a TEAM doctor prior to providing acupuncture or herbal medicine treatment (22, 23).
With the appropriate PI, a wide variety of conditions can be addressed by TEAM treatment. Sleep disturbances were one of the major target conditions for TEAM treatment in several previous studies (19, 24–28). The Korean Medicine Clinical Practice Guidelines for insomnia disorder, which was officially developed by research funded by the government, suggest that TEAM doctors may consider six types of PI before TEAM treatment (29). Furthermore, a recent systematic review for insomnia showed that acupuncture treatment using PI significantly improved the total effectiveness rate compared to conventional medication (30). However, the effect of TEAM treatment using PI is not reproducible since PI types and processes may be inconsistent among TEAM doctors in clinical settings. Therefore, the development of a model that can consistently produce the same PI for certain patient details required.
In this paper, we suggested a novel data-driven PI method for TEAM treatment using emerging bioinformatics techniques in combination with feature extraction using a deep autoencoder, one of the self-supervised deep learning models, and clustering using k-means clustering, an unsupervised machine learning model. To develop a new model using various types of clinical information as input data and provide reproducible PI as an output for TEAM treatment decisions in patients with sleep disturbances, we used cross-sectional study data which examined the association between sleep and diet/digestion in Republic of Korea Army (ROKA) active duty service members.
A multi-site cross-sectional study was conducted using an anonymous electronic survey. The study was posted in five units of the ROKA through printed recruitment posters and electronic bulletin boards from August 16, 2021, to September 20, 2021. The participants were recruited during the same period. The original aim of this study was to examine the association between sleep and diet/digestion in ROKA active duty service members. The results will be published in another paper.
Among active duty service members in five units of the ROKA who met the inclusion criteria, the participants who provided informed consent were enrolled in the study. The inclusion criteria were (1) age 19 years or over; (2) active duty service members (private, private first class, corporal, and sergeants) who completed the basic military training course, and (3) those who voluntarily agreed to participate in the study. There were no exclusion criteria.
Assuming that the total number of all active duty service members in the ROKA is approximately 300,000, the sample size was calculated using the following equation. The margin of error was 3% and the confidence level was 95%, and the sample size result was 1,064 (the target number of completed surveys).
Previous studies using surveys showed that various factors such as the survey method, survey content, and participant compensation were associated with the response rate of the study subjects. In particular, the online survey method is known to have about a 10% lower response rate compared to other media, but the actual response rate was different in each study (31). In this study, referring to the response rate (3.4%) reported in a previous study that conducted a health-related survey in adult males, the response rate was set to 3%, and the target number of questionnaires was determined to be 35,467 (31).
The survey instruments were refined to reveal the military environment by healthcare professionals (seven TEAM doctors including five military doctors). This involved the refinement of the questionnaire by changing the phrasing and modifying questions to clarify the premise of each item within the questionnaire. The final questionnaire was designed and distributed through the web-based application Survey Monkey.
The survey consisted of six sections: (1) demographics (birth, recruitment date, height, weight, military identification number, rank, military unit, education, smoking status, alcohol consumption habits, caffeine consumption, exercise, and physical grade); (2) medical history (present/past history of sleep disorders, present/past history of gastrointestinal disorders, present/past history of general diseases including hypertension, diabetes, hyperlipidemia, and cardiac disease, stress status, and drug history); (3) military duty (branch, position, night shift with or without tomorrow duty-off, and its effect on sleep and/or fatigue); (4) sleep-related assessments (Pittsburgh sleep quality index (PSQI), Berlin questionnaire, and sleeping environment); (5) diet/nutrition-related assessments [dietary habit survey questionnaire and nutrition (32) quotient (NQ)]; and (6) gastrointestinal-related assessments [gastrointestinal symptom rating scale (GSRS) and Bristol stool scale (BSS)].
The PSQI, a self-assessment questionnaire to evaluate sleep quality within the past month, contains 19 items consisting of seven component scores, including sleep quality, sleep latency, sleep duration, daytime dysfunction, sleep efficiency, sleep disturbances, and sleeping medication use (33). A final score of >5 out of 21 indicates significant sleep disturbance.
The Berlin questionnaire has 11 questions grouped into three categories (34). The first category comprises five questions concerning snoring, witnessed apnea, and the frequency of such events. The second category comprises four questions addressing daytime sleepiness, with a sub-question on drowsy driving. The third category comprises two questions concerning a history of high blood pressure (> 140/90 mmHg) and a body mass index (BMI) of >30 kg/m2. Categories 1 and 2 were considered positive if there were two positive responses in each category, while category 3 was considered positive with a self-report of high blood pressure and/or a BMI of > 30 kg/m2. The study patients were scored as being at high risk of having obstructive sleep apnea (OSA) if the scores were positive for two or more of the three categories.
The dietary habit survey questionnaire consists of 25 items to evaluate the dietary habits of Korean adults (35). It includes the number of meals per day, mealtime regularity, the amount consumed, time taken for a meal, the frequency of missed meals, the frequency of having breakfast, the reason for missing breakfast, the frequency of dinners with family, the frequency of overeating, meal at which overeating occurred (breakfast, lunch, dinner or not), the frequency of eating out, the frequency of eating snacks, the time of eating snacks, the types of snacks, the time of late-night meals, whether certain foods were not eaten, the reasons for not eating certain foods, and the frequency of food intake (grains, meat, fish, eggs and legumes, fruits, vegetables, milk and dairy products, fatty foods, instant foods, and fast foods).
The NQ comprehensively evaluates the nutritional status and meal quality of individuals or groups of Korean adults through a checklist consisting of 21 items (36). It provides the global NQ score (NQ global), and scores for four factors: nutritional balance (NQ balance), food diversity (NQ diversity), moderation in the amount of food eaten (NQ moderation), and dietary behavior (NQ behavior). It is considered “good” if the score is 58 or higher, and “monitoring is necessary” if it is below 58.
The GSRS evaluates gastrointestinal symptoms via an inquiry table consisting of 15 items for the evaluation of general gastrointestinal symptoms (37). Each GSRS item is rated on a 7-point Likert scale ranging from “no discomfort” to “very severe discomfort.”
The BSS examines the stool status in the past 24 h (32). The score is based on a one to seven scale where one corresponds to a hard stool and seven corresponds to watery diarrhea.
Data preprocessing to improve data quality and impute missing values was performed in three steps. In the first step, from all survey responders, the participants who provided multiple responses were eliminated to ensure survey reliability. Second, the participants who did not meet the inclusion criteria were removed. The participants who completed the survey remained. Last, a few samples with outliers, which might be caused by miswriting in open question items such as height, weight, smoking amount, and smoking duration were also eliminated after exploratory data analysis (EDA).
Each PSQI, Berlin questionnaire, NQ, and GSRS score was calculated and the remaining questionnaire responses were used for input data. In clinical practice, TEAM doctors' questions to patients are closer to each item of the questionnaire, and conversely, calculating each questionnaire's scores one by one is closer to the purpose of the clinical study. The calculated scores were used for external cluster evaluation.
Since this study was conducted to examine patients with sleep disturbances, the participants with PSQI scores of over five were collected as a total data set. Then, the data set was randomly split into a training set (80%) and test set (20%) for evaluating the machine learning models.
The autoencoder is a simple unsupervised learning model. It learns hidden features through encoding and decoding unlabeled data. Consider a d-dimensional data set X = {x1, x2, …, xd}, where d is the number of variables presented at the input layer. The autoencoder attempts to reconstruct X at the output layer, which is the same as the identity function f(x) = x (38). Then, the hidden layer is forced to learn a compressed representation of the data X from the input layer, which is reconstructed at the output layer as . The optimized model can be evaluated by the root mean squared error (RMSE) between X and .
In this study, we built a symmetric deep autoencoder model composed of d-dimensional input and output layers, and three hidden layers: J nodes for the second hidden layer (bottleneck), and 8 × J nodes for the first and third hidden layers. Also, a grid search using 1 ≤ J ≤ 10 was conducted to find the optimal number of nodes in the hidden layers. When compiling the model, RMSE and Adam were applied as the loss function and training optimizer, respectively. For the training process with 10-fold cross-validation, the batch size and the number of epochs were set to 64 and 100, respectively. Finally, representative nodes in the second hidden layer were used to extract features for the clustering process. We also conducted principal component analysis (PCA), one of the conventional feature extraction methods, before k-means clustering.
K-means clustering is an unsupervised machine learning algorithm (39). This algorithm is less computationally intensive for processing our large study data than hierarchical clustering. Also, the number of clusters (k) can be predefined by this algorithm to reveal our prior medical knowledge since the number of PI types is generally ≤ 10 in TEAM. Consider a d-dimensional data set X = {x1, x2, …, xn}, where d is the number of variables, this algorithm aims to partition the n observations into k (≤ n) sets S = {S1, S2, …, Sk} to minimize the within-cluster sum of squares (WCSS). Formally, the objective is to find:
In this study, k-means clustering was performed on the data set using raw data and PCA-extracted and deep autoencoder-extracted features. The performance of the clusters was compared between each input type. We set the candidate number of clusters from k = 1 to k = 10, and 300 iterations for each k using the expectation-maximization style algorithm.
Cluster evaluation was conducted in two parts, internal cluster evaluation and external cluster evaluation. The Calinski-Harabasz index and silhouette coefficient were initially assessed for internal cluster evaluation (40). The optimal number of clusters was determined by the elbow method after plotting the WCSS with k values. All the above processes were conducted using the training set only. After determining the whole PI model including the feature extraction and clustering methods, the test set was inferred by the trained PI model. The PSQI, Berlin questionnaire, GSRS, and NQ scores, which were not used in feature extraction, were compared by external cluster evaluation.
Summaries of the continuous variables are presented as means and standard deviations, and the categorical variables are presented as frequencies and percentages. For continuous variables, one-way analysis of variance (ANOVA) was used for comparing means among three clusters, followed by the Tukey-Kramer test for post-hoc multiple comparisons between two clusters with unequal sample sizes. For categorical variables, the chi-squared test was also performed. Statistical significance was set at p < 0.05.
Python 3.8.0 (Python Software Foundation, Wilmington, DE, USA) was used for data preprocessing, model development and validation, visualization, and statistical analysis. The Python libraries Pandas and Numpy were adopted for data preprocessing; Scikit-learn was used for data preprocessing, PCA, and k-means clustering; Keras with Tensorflow backend for building and evaluating the deep autoencoder model; Statsmodels for statistical analysis of comparisons between clusters, and Seaborn with Matplotlib for data visualization. Google Colab, a cloud service for machine learning research, was used in this study. It provides various libraries and frameworks for deep learning and a robust graphics processing unit.
Of a total of 4,869 survey responders, 35 multiple responders, and 139 responders who did not meet the inclusion criteria were excluded. A total of 4,408 responders completed the survey. After removing a few outliers for height (below 110 cm or above 200 cm), weight (below 40 kg or above 160 kg), smoking amount (above five packs per day), and smoking duration (above 20 years) through EDA, 4,389 responses remained. The data set of 2,579 patients with sleep disturbances was obtained after filtering by PSQI scores of >5, which were randomly split into a training set (n = 2,063; 80%) and a test set (n = 516; 20%). The flow chart of the data set construction process is shown in Figure 1.
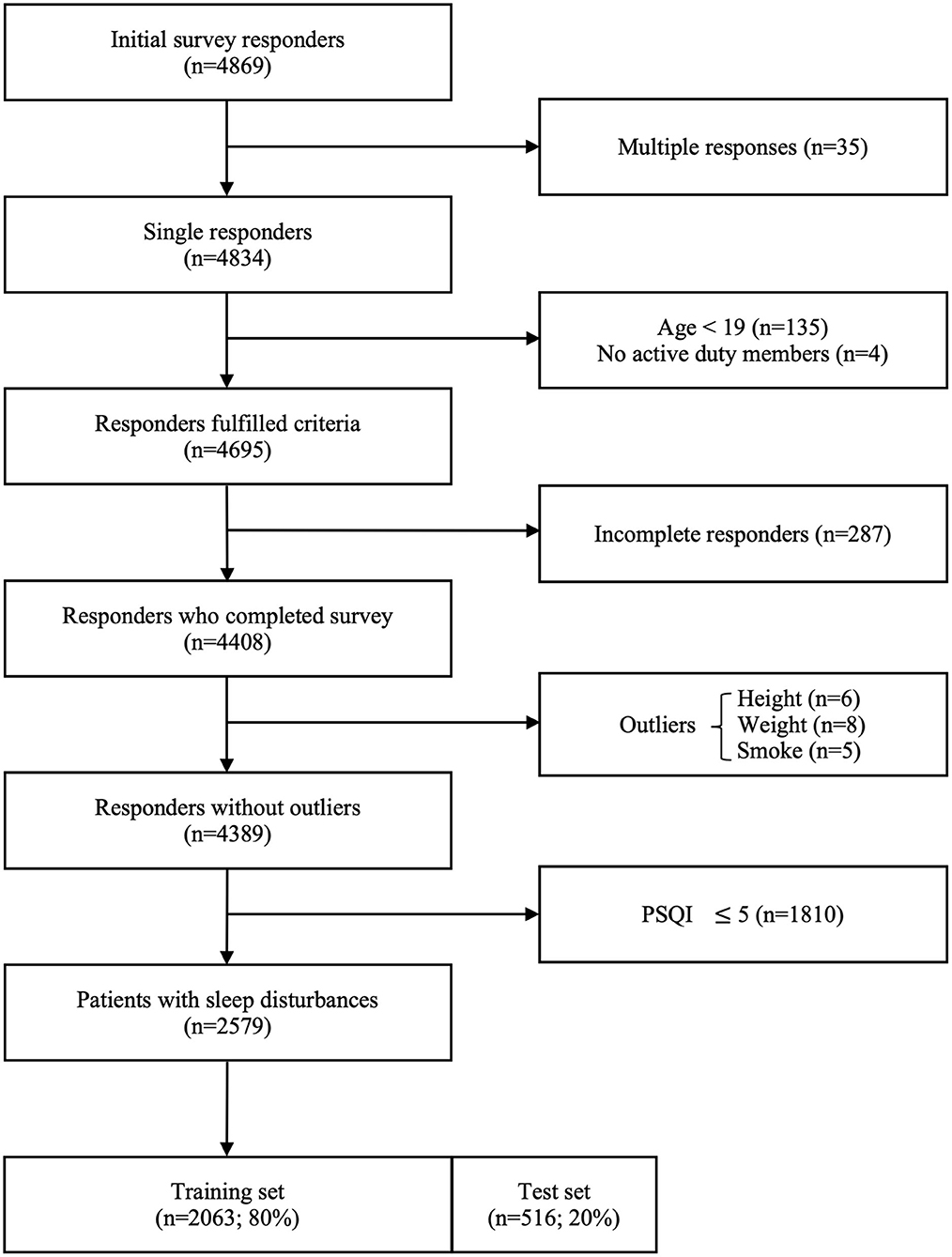
Figure 1. Flow chart illustrating the construction of the data set for the study.
For comparison with the main feature extraction method, the deep autoencoder, PCA was first conducted using the training set. It showed that variance dropped off when the number of components was four, and the first four components explained the majority of the variance in the training set (Figure 2). Therefore, feature extraction using PCA was conducted with four components.
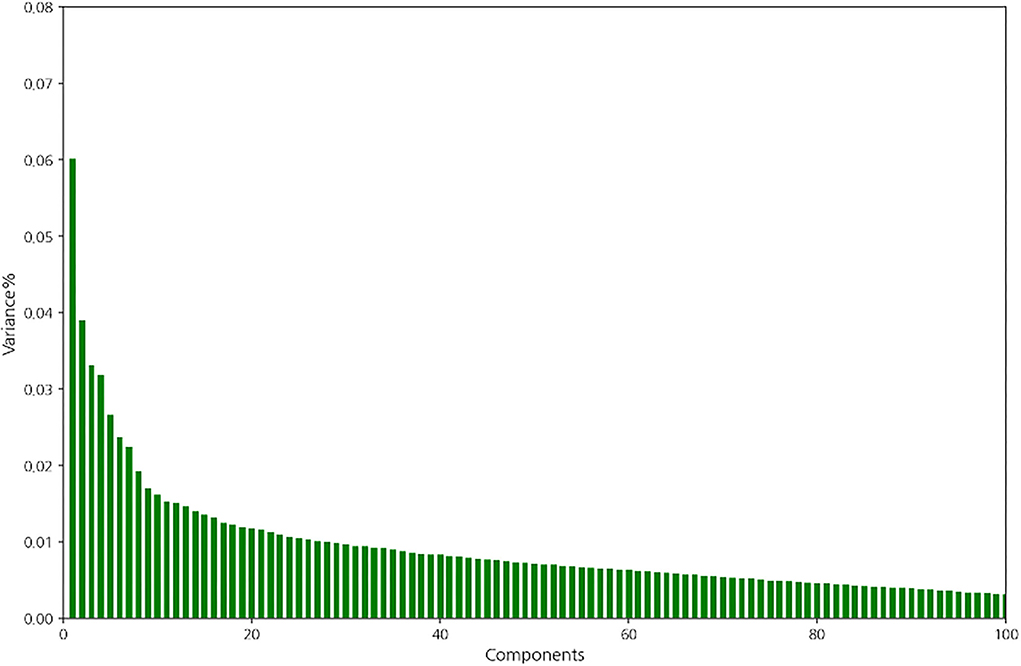
Figure 2. Variance of the components in the training set.
Ten-fold cross-validation was conducted while training the deep autoencoder. The mean RMSE of the training set and validation set after 100 epochs (Table 1), and the change in RMSE of the validation set during training (Figure 3) are presented in each deep autoencoder architecture (the number of nodes in the second hidden layer).

Table 1. The mean RMSE for each model.
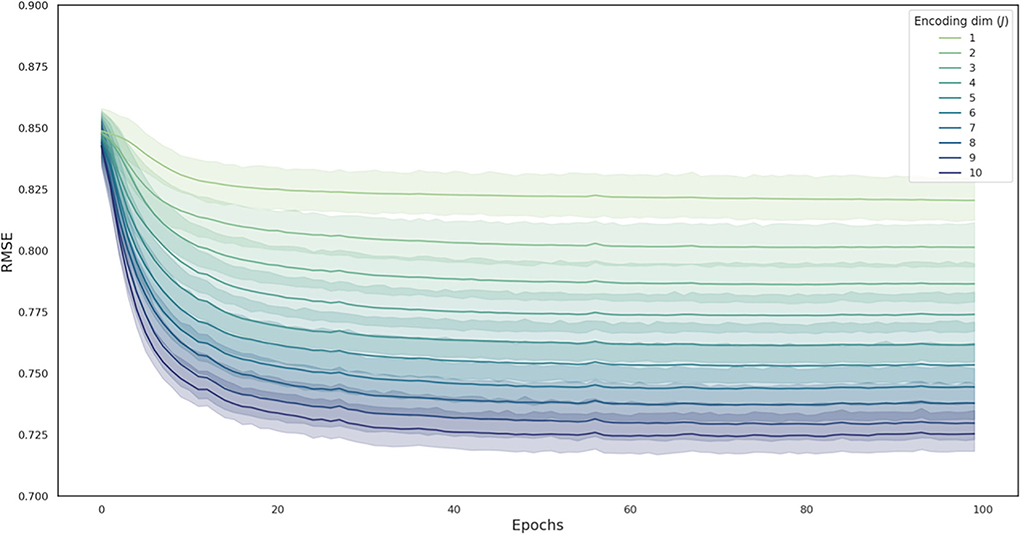
Figure 3. The change in RMSE during the model training process in each deep autoencoder architecture. Curves are averaged over 10 folds, with the shaded area representing the 95% confidence interval across folds. RMSE, root mean squared error.
The Calinski-Harabasz index and silhouette coefficient after k-means clustering (2 ≤ k ≤ 10) are presented in Figure 4; Supplementary Table 1. The performance of clustering after feature extraction with the deep autoencoder was much better than that with raw data or PCA. Comparing the results of clustering after all feature extraction methods including PCA and the deep autoencoder in this study, the deep autoencoder (J = 2)—which presented the highest values of both the Calinski-Harabasz index and the silhouette coefficient in the small numbers of clusters (k ≤ 4)–might be the best feature extraction method for k-means clustering. The final deep autoencoder model architecture is shown in Figure 5. Also, considering both the Calinski-Harabasz index and the silhouette coefficient, k = 2 or 3 might be candidate clustering numbers. Finally, the optimal number (k = 3) of clusters was determined by the elbow method, a heuristic approach for determining the appropriate point for the local optimum (41, 42), as shown in Figure 6.
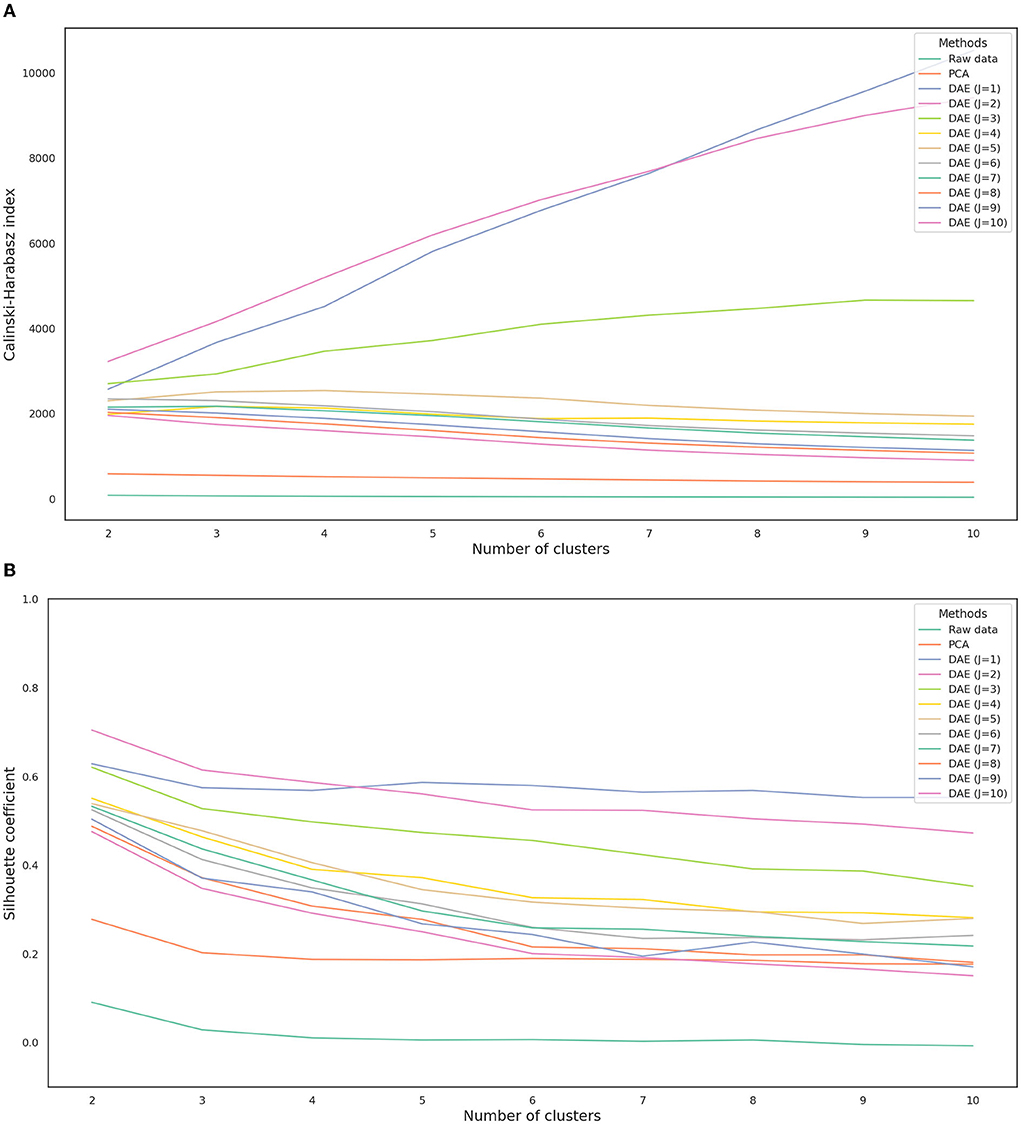
Figure 4. Calinski-Harabasz index (A) and silhouette coefficient (B) depending on each feature extraction method. J is the number of nodes in the second hidden layer. DAE, deep autoencoder; PCA, principal component analysis.
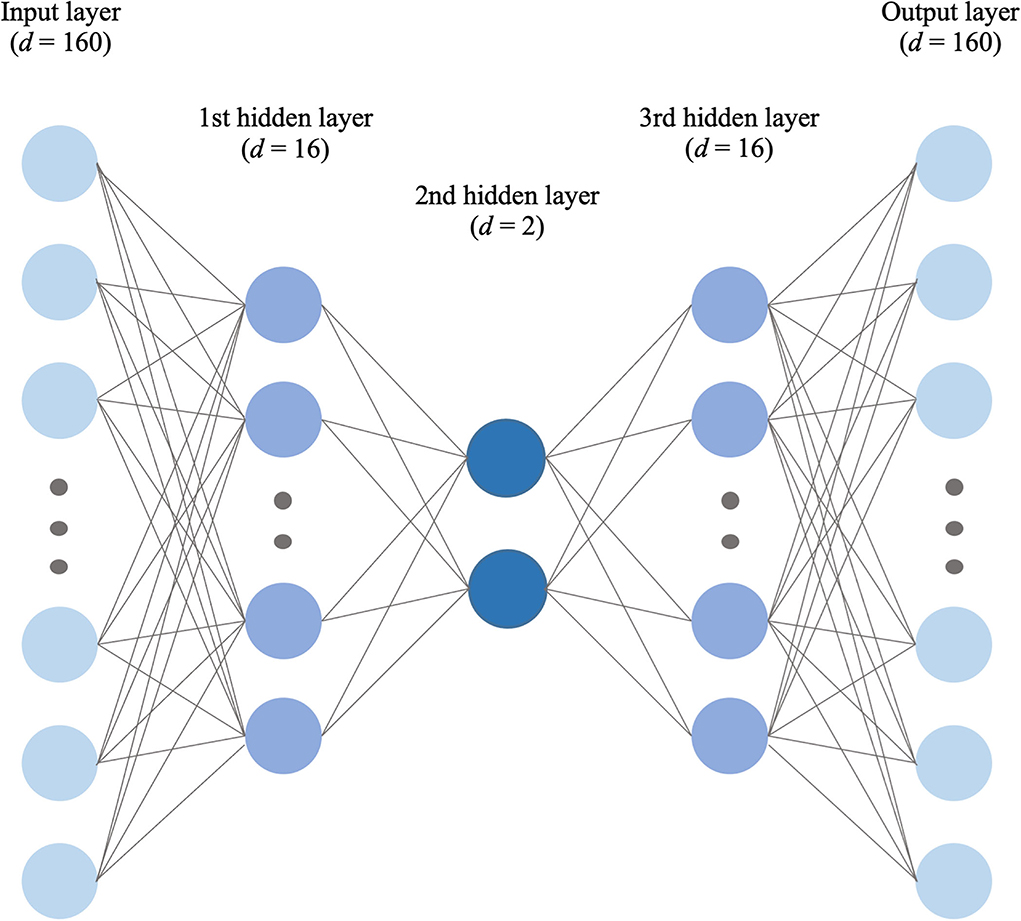
Figure 5. The final selected deep autoencoder model architecture for feature extraction.
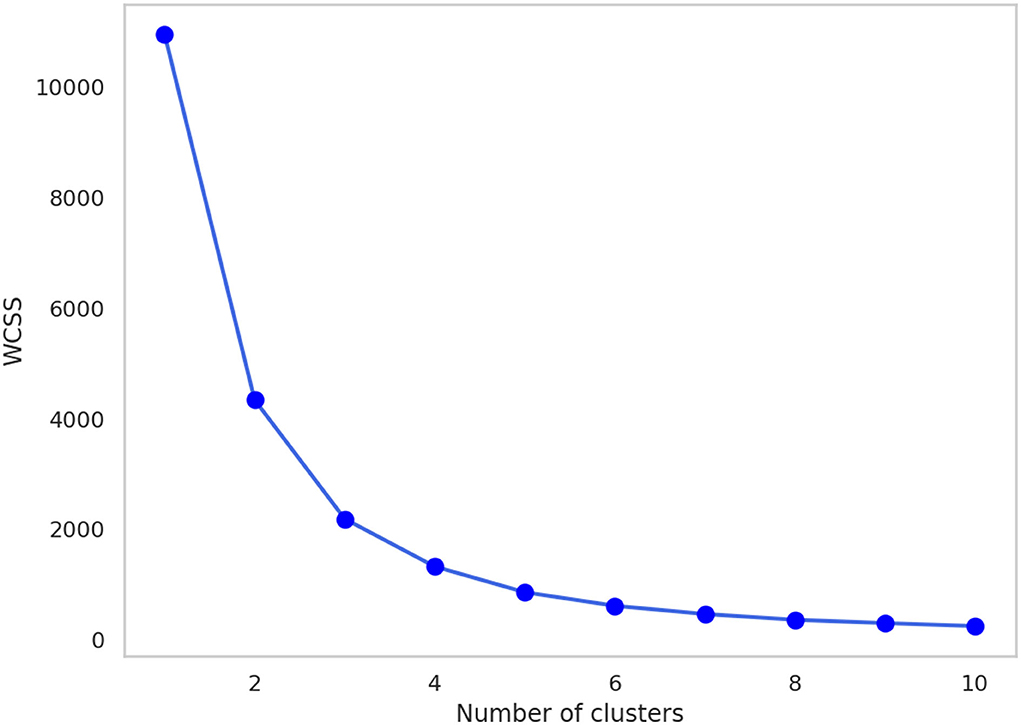
Figure 6. The change in WCSS with the number of clusters after feature extraction by the deep autoencoder (J = 2). WCSS, within-cluster sum of squares.
The patient characteristics in each cluster of the training set and test set are presented in Tables 2, 3 respectively. Among the clusters, the PSQI (p < 0.001), GSRS (p < 0.001), NQ balance (p = 0.008), NQ moderation (p < 0.001), NQ behavior (p < 0.001), and Berlin scores (p < 0.001) were significantly different in the training set, and PSQI (p < 0.001), GSRS (p < 0.001), NQ global (p < 0.001), NQ moderation (p < 0.001), and Berlin scores (p < 0.001) were significantly different in the test set (Table 4).
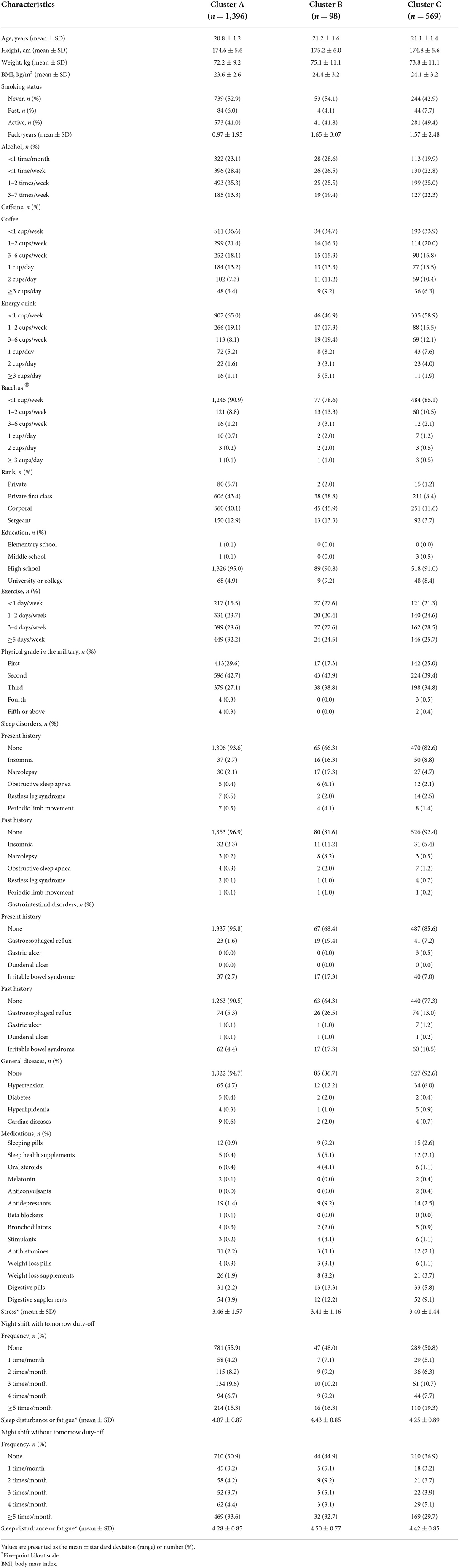
Table 2. Patient characteristics in each training set cluster.
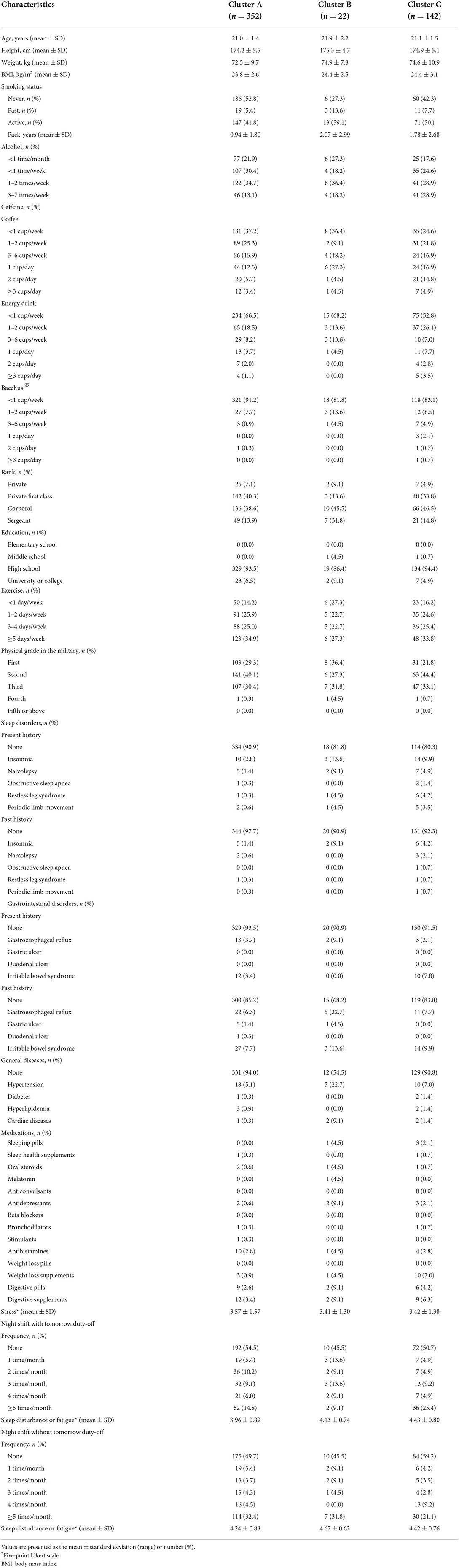
Table 3. Patient characteristics in each test set cluster.
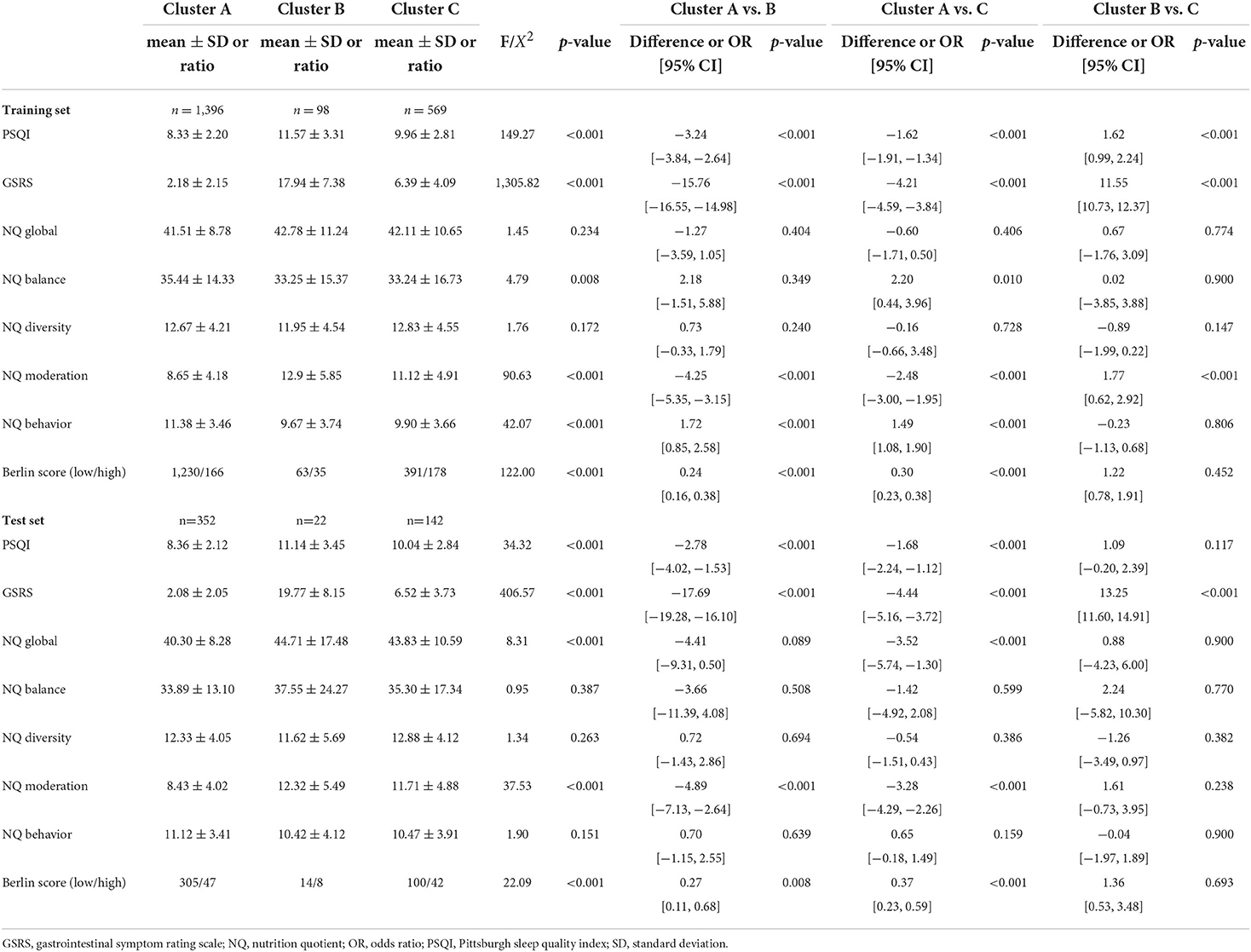
Table 4. Results of external cluster validation in the training set and test set.
Through post-hoc analysis (Table 4), the mean PSQI score of cluster A was significantly lower than that of cluster B (−3.24, 95% confidence interval (CI) −3.84, −2.64], p < 0.001) and cluster C (−1.62, 95% CI [−1.91, −1.34], p < 0.001) in the training set. The mean PSQI score of cluster B was significantly higher than that of cluster C (1.62, 95% CI [0.99, 2.24], p < 0.001) in the training set. The mean PSQI score of cluster A was significantly lower than that of cluster B (−2.78, 95% CI [−4.02, −1.53], p < 0.001) and cluster C (−1.68, 95% CI [−2.24, −1.12], p < 0.001) in the test set. The mean PSQI score of cluster B was also higher but not significantly different than that of cluster C (1.09, 95% CI [−0.20, 2.39], p = 0.117) in the test set.
The mean GSRS score of cluster A was significantly lower than that of cluster B (−15.76, 95% CI [−16.55, −14.98], p < 0.001) and cluster C (−4.21, 95% CI [−4.59, −3.84], p < 0.001) in the training set. The mean GSRS score of cluster B was significantly higher than that of cluster C (11.55, 95% CI [10.73, 12.37], p < 0.001) in the training set. The mean GSRS score of cluster A was significantly lower than that of cluster B (−17.69, 95% CI [−19.28, −16.10], p < 0.001) and cluster C (−4.44, 95% CI [−5.16, −3.72], p < 0.001) in the test set. The mean GSRS score of cluster B was significantly higher than that of cluster C (13.25, 95% CI [11.60, 14.91], p < 0.001) in the test set.
The mean NQ global score of cluster A was lower but not statistically different from that of cluster B (−1.27, 95% CI [−3.59, 1.05], p = 0.404) and cluster C (−0.60, 95% CI [−1.71, 0.50], p = 0.406) in the training set. The mean NQ global score of cluster B was higher but not significantly different than that of cluster C (0.67, 95% CI [−1.76, 3.09], p = 0.774) in the training set. The mean NQ global score of cluster A was lower but not statistically different than that of cluster B (−4.41, 95% CI [−9.31, 0.50], p = 0.089) and significantly lower than that of cluster C (−3.52, 95% CI [−5.74, −1.30], p < 0.001) in the test set. The mean NQ global score of cluster B was higher but not significantly different than that of cluster C (0.88, 95% CI [−4.23, 6.00], p = 0.900) in the test set.
The mean NQ balance score of cluster A was higher but not statistically different than that of cluster B (2.18, 95% CI [−1.51, 5.88], p = 0.349) and significantly higher than that of cluster C (2.20, 95% CI [0.44, 3.96], p = 0.010) in the training set. The mean NQ balance score of cluster B was higher but not significantly different than that of cluster C (0.02, 95% CI [−3.85, 3.88], p = 0.900) in the training set. The mean NQ balance score of cluster A was lower but not statistically different than that of cluster B (−3.66, 95% CI [−11.39, 4.08], p = 0.508) and cluster C (−1.42, 95% CI [−4.92, 2.08], p = 0.599) in the test set. The mean NQ balance score of cluster B was higher but not significantly different than that of cluster C (2.24, 95% CI [−5.82, 10.30], p = 0.770) in the test set.
The mean NQ diversity score of cluster A was higher but not statistically different than that of cluster B (0.73, 95% CI [−0.33, 1.79], p = 0.240) and lower but not statistically different than that of cluster C (−0.16, 95% CI [−0.66, 3.48], p = 0.728) in the training set. The mean NQ diversity score of cluster B was lower but not significantly different than that of cluster C (−0.89, 95% CI [−1.99, 0.22], p = 0.147) in the training set. The mean NQ diversity score of cluster A was higher but not statistically different than that of cluster B (0.72, 95% CI [−1.43, 2.86], p = 0.694) and lower but not statistically different than that of cluster C (−0.54, 95% CI [−1.51, 0.43], p = 0.386) in the test set. The mean NQ diversity score of cluster B was lower but not significantly different than that of cluster C (−1.26, 95% CI [−3.49, 0.97], p = 0.382) in the test set.
The mean NQ moderation score of cluster A was significantly lower than that of cluster B (−4.25, 95% CI [−5.35, −3.15], p < 0.001) and cluster C (−2.48, 95% CI [−3.00, −1.95], p < 0.001) in the training set. The mean NQ moderation score of cluster B was significantly higher than that of cluster C (1.77, 95% CI [0.62, 2.92], p < 0.001) in the training set. The mean NQ moderation score of cluster A was significantly lower than that of cluster B (−4.89, 95% CI [−7.13, −2.64], p < 0.001) and cluster C (−3.28, 95% CI [−4.29, −2.26], p < 0.001) in the test set. The mean NQ moderation score of cluster B was also higher but not significantly different than that of cluster C (1.61, 95% CI [−0.73, 3.95], p = 0.238) in the test set.
The mean NQ behavior score of cluster A was significantly higher than that of cluster B (1.72, 95% CI [0.85, 2.58], p < 0.001) and cluster C (1.49, 95% CI [1.08, 1.90], p < 0.001) in the training set. The mean NQ behavior score of cluster B was lower but not significantly different than that of cluster C (−0.23, 95% CI [−1.13, 0.68], p = 0.806) in the training set. The mean NQ behavior score of cluster A was higher but not significantly different than that of cluster B (0.70, 95% CI [−1.15, 2.55], p = 0.639) and cluster C (0.65, 95% CI [−0.18, 1.49], p = 0.159) in the training set. The mean NQ behavior score of cluster B was lower but not significantly different than that of cluster C (−0.04, 95% CI [−1.97, 1.89], p = 0.900) in the test set.
The Berlin score showed that cluster A had a significantly lower risk of OSA than that of cluster B (odds ratio (OR) = 0.24, 95% CI [0.16, 0.38], X2 = 42.61, p < 0.001) and cluster C (OR = 0.30, 95% CI [0.23, 0.38], X2 = 103.92, p < 0.001) in the training set. The Berlin score showed that cluster B had a higher risk than that of cluster C (OR = 1.22, 95% CI [0.78, 1.91], X2 = 0.57, p = 0.452) in the training set. The Berlin score showed that cluster A had a significantly lower risk of OSA than that of cluster B (OR = 0.27, 95% CI [0.11, 0.68], X2 = 7.00, p = 0.008) and cluster C (OR = 0.37, 95% CI [0.23, 0.59], X2 = 16.95, p < 0.001) in the test set. The Berlin score showed that cluster B had a higher risk than that of cluster C (OR = 1.36, 95% CI [0.53, 3.48], X2 = 0.16, p = 0.693) in the test set.
Three–dimensional clustering visualizations were presented with the major components that were statistically different by multi-comparison and post-hoc analysis in both the training and test sets, and statistically different by multi-comparison only in both the training and test sets; NQ moderation between cluster B and C was not statistically different by post-hoc analysis in the test set (Figure 7).
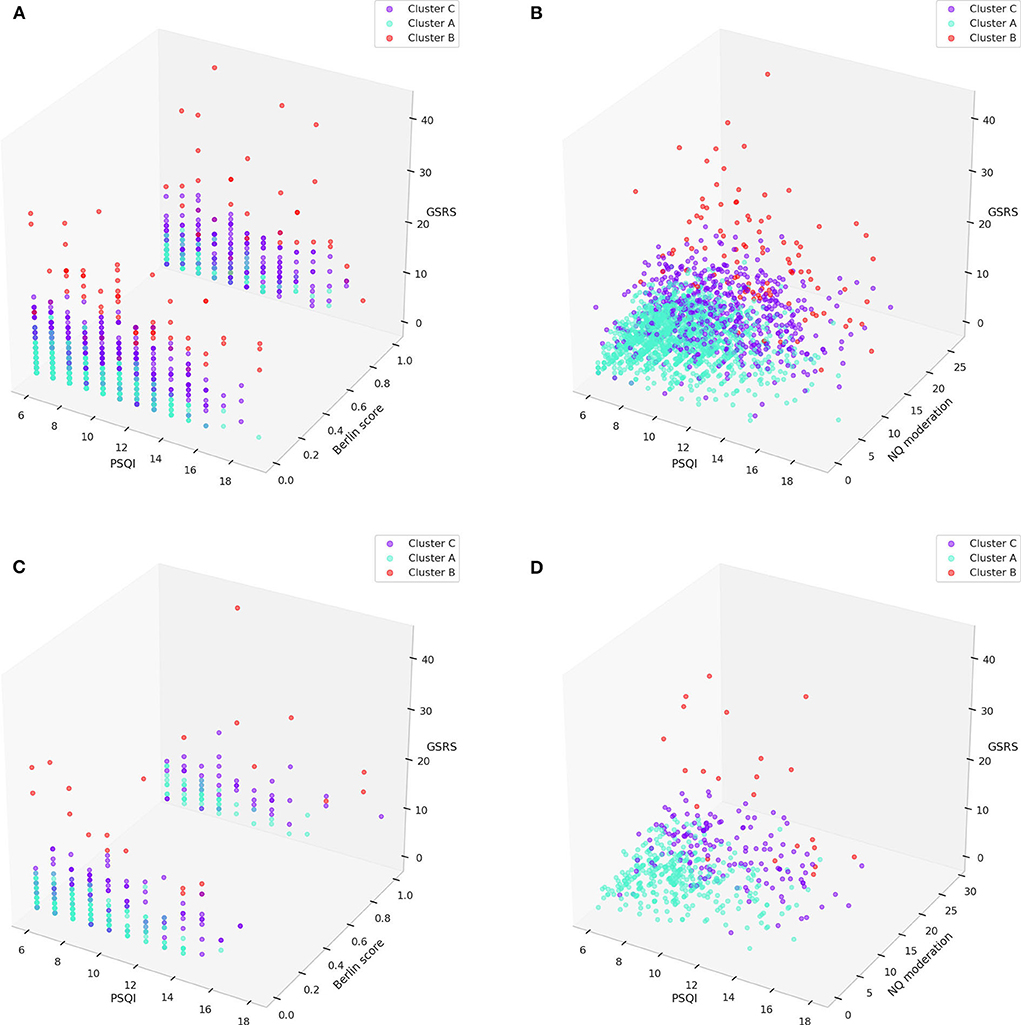
Figure 7. 3D visualization of clusters with major components (PSQI, Berlin, GSRS scores, and NQ moderation) in the training set (A,B) and test set (C,D). GSRS, gastrointestinal symptom rating scale; NQ, nutrition quotient; PSQI, Pittsburgh sleep quality index.
This study demonstrated that the deep autoencoder method was a better feature extraction method for the clustering of sleep disturbances than PCA. This result is comparable to that of other studies in that the autoencoder effectively reduces the high-dimensionality of the various types of data since it can learn non-linear feature representations (43–45). Specifically, based on internal cluster validation and the elbow method, the best architecture of the deep autoencoder for extracting features for clustering our study samples with sleep disturbances was 16 nodes for the first and third hidden layers, and two nodes for the second hidden layer, while the optimal number of clusters was considered to be three. After external cluster validation, three PI types were differentiated by changes in sleep quality, dietary habits, and concomitant gastrointestinal symptoms.
PI has been used in TEAM for the personalized care of various conditions including sleep disorders. As the accurate diagnosis and precise evaluation of individual patients are the key for personalized care in conventional medicine, PI, as well as diagnosis according to the International Classification of Diseases, Tenth Revision (ICD-10), is an important principle in personalized TEAM treatments such as acupuncture point selections and combinations of herbal medicines. Although several previous studies have tried to standardize PI and suggested new methods for PI in different types of data, it is considered a “black box” in which the external validity or usability in clinical TEAM practice cannot be ensured (14, 15, 46–48). Therefore, in another aspect of PI standardization, we proposed a new paradigm, the clinical data-driven PI model, applying advanced machine learning techniques. The PI model is flexible in the data characteristics that can be used and is reproducible for certain data to enhance the effectiveness of TEAM treatment in clinical practice (Figure 8).
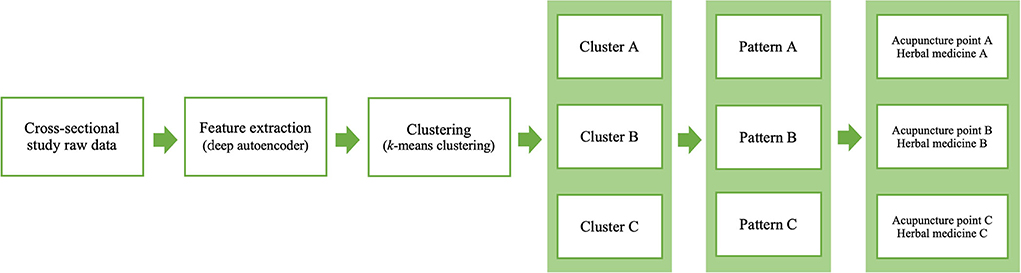
Figure 8. Flow diagram of the proposed PI model for acupuncture point and herbal medicine selection.
There were three main aspects to this study, data type, feature extraction, and clustering. First, whole raw data from a cross-sectional study were used. The cross-sectional study data were generally composed of fundamental clinical information such as age, sex, and medical history, and symptoms, and/or a disease-related questionnaire. Particularly, our used cross-sectional study included several questionnaires with different domains including sleep, diet, nutrition, and gastrointestinal status. Since TEAM doctors usually ask not only about sleep conditions but also about other conditions to select the appropriate acupuncture points and/or herbal medicines for treating insomnia patients (28, 30), this type of data was suitable for reflecting clinical settings. Furthermore, this data type may assure external cluster validation. Clustering validation, which measures the goodness of clustering results, can be categorized into two methods: internal cluster validation and external cluster validation (49). The internal cluster validation is conducted without the need to obtain any additional information, such as evaluating the average between- and within-cluster sums of squares (Calinski-Harabasz index), or the difference of the between- and within-cluster distances (silhouette coefficient). On the other hand, the external cluster validation is conducted with other external information, such as a true class of cluster or previous knowledge about data. In this study, instead of obtaining the true labels of each cluster, which require large amounts of cost and time for TEAM doctors, we used the final scores of PSQI, NQ, GSRS, and the Berlin score, which were not used in the input features of clustering, but which could be calculated using specific non-linear functions respectively to externally compare the clustering results.
Second, feature extraction was conducted by a deep autoencoder model. Two methods have been used before the clustering process, feature selection (selecting a small subset of actual features from the data) and feature extraction (constructing a small set of artificial features from the data). Most clinical studies conducted feature selection through statistical methods such as the t-test or chi-squared test between two groups or it was determined by clinical experience or medical knowledge. However, in a large series of data, so-called high-dimensional data, it was difficult to find the best feature selection strategy for efficiently reducing the dimension of the data (50). Therefore, some algorithms such as PCA and the autoencoder have been suggested for feature extraction (51), very similar to a TEAM doctor's PI process made by observing patients with not just a few pieces of clinical information but comprehensively, using a lot of clinical information. This characteristic of TEAM doctors' decision-making might also be related to the reason why deep autoencoder model extraction was much more efficient than that of other methods in our study. As decision-making in TEAM is complex and the interactions between clinical information and PI are non-linear, autoencoder architecture learning non-linear mapping allows for the transformation of high-dimensional data into more clustering-friendly representations, whereas PCA is fundamentally limited to linear embedding, and it is possible to lose essential features (38). Another strength of using the deep autoencoder for feature extraction is that it can extract features from non-quantizable questionnaire responses (e.g., dietary habit survey questionnaire), which does not use a formula to generate a single score, and efficiently prevents the curse of dimensionality without suffering from high computational complexity in large-scale data (38).
Third, k-means clustering, an unsupervised machine learning algorithm serving as a powerful computational method to analyze high-dimensional data in the form of sequences or expressions, was used in this study (38). It does not need data labeling, which is costly and time-consuming in biomedical research using supervised learning. In addition, even if data labeling is performed by several TEAM doctors, the labeling results are highly likely to be inconsistent because the types of PI are inconsistent among TEAM doctors and each TEAM society and different depending upon the disease. Therefore, a data-driven approach to PI for TEAM research, which is flexible for changes in data and reproducible for certain data, might be more reasonable than a standardization approach using a few TEAM research experts.
Each cluster of sleep disturbance patients could be differentiated, as shown in Figure 7. The patients in cluster A had relatively mild sleep disturbances, severe immoderation in the amount of food consumed, and good gastrointestinal status compared to the other clusters. The patients in cluster B had relatively severe sleep disturbances, mild immoderation in the amount of food consumed, and severe gastrointestinal problems compared to the other clusters. The patients in cluster C had relatively moderate sleep disturbances, moderate immoderation in the amount of food consumed, and mild-to-moderate gastrointestinal problems compared to the other clusters. Although the statistical analysis of the Berlin score indicated that cluster A had a much lower risk than the other two clusters, it could not be observed in the 3-dimensional visualizations.
The clustering results can be interpreted in two aspects, the changes in sleep quality and the concomitant symptoms. As sleep quality deteriorates, the appetite associated with food moderation decreases, and the condition of the gastrointestinal system worsens. Based on a recent systematic review and meta-analysis of acupuncture using PI and TEAM clinical guidelines for insomnia patients, cluster A may be matched to the “stomach disharmony pattern” type using ST36, CV12, and ST25; cluster C may be matched to the “pattern of lingering phlegm” type using ST40 and CV12; and cluster B may be matched to the “pattern of dual deficiency of heart and spleen” type using CV12, ST36, and ST40 (29, 30). This clustering model can automatically and consistently provide the same PI for a certain patient, which ensures reliability for both TEAM doctors and patients. However, it should be noted that this clustering model is flexible to the number of patient data, changes in patient features, or changes in the target disease, so-called “transfer learning” and “fine-tuning” in machine learning techniques (52), which might provide a different output for the number or types of patterns identified. Therefore, the novel PI model in the present study can be advanced, modified, or expanded for other studies.
The applications of this study include AI-based clinical decision support systems (CDSSs) through electronic medical records (EMRs) and clinical trial protocols for evaluating the effectiveness of TEAM treatment. If a TEAM doctor in clinical practice obtains clinical data from insomnia patients and documents them in the EMR, the PI model in AI-based CDSSs suggests the candidate PI with the associated probability and recommends a fundamental combination of acupuncture points and herbal medicines. In addition, most pragmatic trial protocols with individualized TEAM treatment depend completely upon (one person or more) the TEAM doctor's PI for each patient. The reliability and validity of PI itself, which might affect the effect size of individualized TEAM treatments, are limited. However, the PI model in this study could suggest a consistent PI technique for patients with similar features, although the model's effect on the results of individualized TEAM treatment should be validated in a prospective clinical trial.
Some limitations of this study follow. First, this cross-sectional study data might not be fully sufficient to mimic the interaction between doctors and patients in clinical practices. Some data obtained from free medical notes or an AI speaker in clinical settings might be helpful to overcome this limitation. Second, since this data was obtained from a single sample of sleep disturbances in the ROKA, another study sample is required for external validation of our proposed model. Third, this study sequentially used a feature extraction model and a clustering model separately. Emerging machine learning research such as a deep clustering network, which optimizes the feature extraction model and the clustering model simultaneously, might perform better than the techniques used in our study. This will be considered in future studies. Fourth, the PI data used for each patient made by TEAM doctors were limited in this study. However, the correlation between our model's output and actual PI by TEAM doctors in this study should be observed to externally and more robustly validate our clustering results. Fifth, although all features of data were included to reflect a clinical setting wherein TEAM doctors might consider all information of patients as much as possible to find the appropriate PI, the feature selection algorithms, such as univariate statistical test, Lasso regularization, or Boruta algorithm can be applied in future studies to improve upon our results. Finally, the specific combinations of acupuncture points and herbal medicines after PI process were not represented in this study. Although this study revealed the basic concepts of the novel data-driven PI model, more research such as a systematic review of published clinical articles, including case series, or a survey of TEAM doctors is required to recommend the appropriate acupuncture points and/or herbal medicines after the determination of PI.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Code for this paper is provided at https://github.com/HyeonhoonLee/DeepPI.
The studies involving human participants were reviewed and approved by Institutional Review Board of the Armed Forces Medical Command (AFMC-202107-HR-054-02). The patients/participants provided their written informed consent to participate in this study.
HL and YC designed the research study. CY and J-DL supervised the study. HL, YC, BS, and SL collected and analyzed the survey data. HL drafted the manuscript. SL, JK, KK, and EK provided critical comments for improvement of the manuscript. All authors contributed to the article and approved the submitted version.
This research was supported by grants from Korea Institute of Oriental Medicine (KSN2022210).
This paper was modified and developed from the Ph.D. thesis of HL.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmed.2022.950327/full#supplementary-material
1. Zhao C, Li GZ, Wang C, Niu J. Advances in patient classification for traditional chinese medicine: a machine learning perspective. Evid Based Complement Alternat Med. (2015) 2015:376716. doi: 10.1155/2015/376716
2. Choi EM, Jiang F, Longhurst JC. Point specificity in acupuncture. Chin Med. (2012) 7:4. doi: 10.1186/1749-8546-7-4
3. Lee YS Ryu Y, Yoon DE, Kim CH, Hong G, Hwang YC, et al. Commonality and specificity of acupuncture point selections. Evid Based Complement Alternat Med. (2020) 2020:2948292. doi: 10.1155/2020/2948292
4. Liu W, Cohen L. Overcoming barriers for clinical research of acupuncture. Med Acupunct. (2020) 32:348–51. doi: 10.1089/acu.2020.1480
5. Pach D, Yang-Strobel X, Ludtke R, Roll S, Icke K, Brinkhaus B, et al. Standardized vs. individualized acupuncture for chronic low back pain: a randomized controlled trial. Evid Based Complement Alternat Med. (2013) 2013:125937. doi: 10.1155/2013/125937
6. Ko SJ, Kuo B, Kim SK, Lee H, Kim J, Han G, et al. Individualized acupuncture for symptom relief in functional dyspepsia: a randomized controlled trial. J Altern Complement Med. (2016) 22:997–1006. doi: 10.1089/acm.2016.0208
7. Nielsen A, Ocker L, Majd I, Draisin JA, Taromina K, Maggenti MT, et al. Acupuncture intervention protocol: consensus process for a pragmatic randomized controlled trial of acupuncture for management of chronic low back pain in older adults: an nih heal initiative funded project. Glob Adv Health Med. (2021) 10:21649561211007091. doi: 10.1177/21649561211007091
8. Brinkhaus B, Roll S, Jena S, Icke K, Adam D, Binting S, et al. Acupuncture in patients with allergic asthma: a randomized pragmatic trial. J Altern Complement Med. (2017) 23:268–77. doi: 10.1089/acm.2016.0357
9. Chung VC, Wong CH, Wu IX, Ching JY, Cheung WK, Yip BH, et al. Electroacupuncture plus on-demand gastrocaine for refractory functional dyspepsia: pragmatic randomized trial. J Gastroenterol Hepatol. (2019) 34:2077–85. doi: 10.1111/jgh.14737
10. Liu S, Wang Z, Su Y, Qi L, Yang W, Fu M, et al. A Neuroanatomical basis for electroacupuncture to drive the vagal-adrenal axis. Nature. (2021) 598:641–5. doi: 10.1038/s41586-021-04001-4
11. Lee DY, Jiu YR, Hsieh CL. Electroacupuncture at Zusanli and at Neiguan characterized point specificity in the brain by metabolomic analysis. Sci Rep. (2020) 10:10717. doi: 10.1038/s41598-020-67766-0
12. Liu S, Wang ZF, Su YS, Ray RS, Jing XH, Wang YQ, et al. Somatotopic organization and intensity dependence in driving distinct Npy-expressing sympathetic pathways by electroacupuncture. Neuron. (2020) 108:436-50 e7. doi: 10.1016/j.neuron.2020.07.015
13. Ma Q. Somato-Autonomic reflexes of acupuncture. Med Acupunct. (2020) 32:362–6. doi: 10.1089/acu.2020.1488
14. Kim CH, Yoon DE, Lee YS, Jung WM, Kim JH, Chae Y. Revealing associations between diagnosis patterns and acupoint prescriptions using medical data extracted from case reports. J Clin Med. (2019) 8:1663. doi: 10.3390/jcm8101663
15. Hwang YC, Lee IS Ryu Y, Lee YS, Chae Y. Identification of acupoint indication from reverse inference: data mining of randomized controlled clinical trials. J Clin Med. (2020) 9:3027. doi: 10.3390/jcm9093027
16. Hwang YC, Lee IS, Ryu Y, Lee MS, Chae Y. Exploring traditional acupuncture point selection patterns for pain control: data mining of randomised controlled clinical trials. Acupunct Med. (2020):964528420926173. doi: 10.1177/0964528420926173
17. Jung WM, Park IS, Lee YS, Kim CE, Lee H, Hahm DH, et al. Characterization of hidden rules linking symptoms and selection of acupoint using an artificial neural network model. Front Med. (2019) 13:112–20. doi: 10.1007/s11684-017-0582-z
18. Huang WT, Hung HH, Kao YW, Ou SC, Lin YC, Cheng WZ, et al. Application of neural network and cluster analyses to differentiate tcm patterns in patients with breast cancer. Front Pharmacol. (2020) 11:670. doi: 10.3389/fphar.2020.00670
19. Lee SH, Lim SM. Acupuncture for insomnia after stroke: a systematic review and meta-analysis. BMC Complement Altern Med. (2016) 16:228. doi: 10.1186/s12906-016-1220-z
20. Han N, Qiao S, Yuan G, Huang P, Liu D, Yue K, et al. Novel Chinese herbal medicine clustering algorithm via artificial bee colony optimization. Artif Intell Med. (2019) 101:101760. doi: 10.1016/j.artmed.2019.101760
21. Liu Z, Luo C, Fu D, Gui J, Zheng Z, Qi L, et al. A novel transfer learning model for traditional herbal medicine prescription generation from unstructured resources and knowledge. Artif Intell Med. (2022) 124:102232. doi: 10.1016/j.artmed.2021.102232
22. Ang L, Lee HW, Choi JY, Zhang J, Soo Lee M. Herbal medicine and pattern identification for treating COVID-19: a rapid review of guidelines. Integr Med Res. (2020) 9:100407. doi: 10.1016/j.imr.2020.100407
23. Xu Q, Guo Q, Wang CX, Zhang S, Wen CB, Sun T, et al. Network differentiation: a computational method of pathogenesis diagnosis in traditional chinese medicine based on systems science. Artif Intell Med. (2021) 118:102134. doi: 10.1016/j.artmed.2021.102134
24. Yin X, Gou M, Xu J, Dong B, Yin P, Masquelin F, et al. Efficacy and safety of acupuncture treatment on primary insomnia: a randomized controlled trial. Sleep Med. (2017) 37:193–200. doi: 10.1016/j.sleep.2017.02.012
25. Pei W, Peng R, Gu Y, Zhou X, Ruan J. Research trends of acupuncture therapy on insomnia in two decades (from 1999 to 2018):a bibliometric analysis. BMC Complement Altern Med. (2019) 19:225. doi: 10.1186/s12906-019-2606-5
26. Abanes JJ, Ridner SH, Dietrich MS, Hiers C, Rhoten B. Acupuncture for Sleep Disturbances in Post-Deployment Military Service Members: A Randomized Controlled Trial. Clin Nurs Res. (2022) 31:239–50. doi: 10.1177/10547738211030602
27. Choi Y, Kim Y, Kwon O, Chung SY, Cho SH. Effect of herbal medicine (Huanglian-Jie-Du Granule) for somatic symptoms and insomnia in patients with Hwa-Byung: a randomized controlled trial. Integr Med Res. (2021) 10:100453. doi: 10.1016/j.imr.2020.100453
28. Leach MJ, Page AT. Herbal medicine for insomnia: a systematic review and meta-analysis. Sleep Med Rev. (2015) 24:1–12. doi: 10.1016/j.smrv.2014.12.003
29. Lim JH, Jeong JH, Kim SH, Kim KO, Lee SY, Lee SH, et al. The pilot survey of the perception on the practice pattern, diagnosis, and treatment on Korean medicine insomnia: focusing on the difference between korean medical neuropsychiatry specialists and Korean medical general practitioners. Evid Based Complement Alternat Med. (2018) 2018:9152705. doi: 10.1155/2018/9152705
30. Kim SH, Jeong JH, Lim JH, Kim BK. Acupuncture using pattern-identification for the treatment of insomnia disorder: a systematic review and meta-analysis of randomized controlled trials. Integr Med Res. (2019) 8:216–26. doi: 10.1016/j.imr.2019.08.002
31. Fan W, Yan Z. Factors affecting response rates of the web survey: a systematic review. Comput Human Behav. (2010) 26:132–9. doi: 10.1016/j.chb.2009.10.015
32. Lewis SJ, Heaton KW. Stool form scale as a useful guide to intestinal transit time. Scand J Gastroenterol. (1997) 32:920–4. doi: 10.3109/00365529709011203
33. Backhaus J, Junghanns K, Broocks A, Riemann D, Hohagen F. Test-retest reliability and validity of the Pittsburgh sleep quality index in primary insomnia. J Psychosom Res. (2002) 53:737–40. doi: 10.1016/S0022-3999(02)00330-6
34. Netzer NC, Stoohs RA, Netzer CM, Clark K, Strohl KP. Using the Berlin questionnaire to identify patients at risk for the sleep apnea syndrome. Ann Intern Med. (1999) 131:485–91. doi: 10.7326/0003-4819-131-7-199910050-00002
35. Jo JS, Kim KN. Development of a questionnaire for dietary habit survey of Korean adults. Korean J Community Nutr. (2014) 19:258–73. doi: 10.5720/kjcn.2014.19.3.258
36. Lee J-S, Kim H-Y, Hwang J-Y, Kwon S, Chung HR, Kwak T-K, et al. Development of nutrition quotient for korean adults: item selection and validation of factor structure. J Nutr Health. (2018) 51:340–56. doi: 10.4163/jnh.2018.51.4.340
37. Kwon S, Jung H-K, Hong JH, Park HS. Diagnostic validity of the Korean Gastrointestinal Symptom Rating Scale (KGSRS) in the assessment of gastro-esophageal reflux disease. Ewha Med J. (2008) 31:73–80. doi: 10.12771/emj.2008.31.2.73
38. Karim MR, Beyan O, Zappa A, Costa IG, Rebholz-Schuhmann D, Cochez M, et al. Deep learning-based clustering approaches for bioinformatics. Brief Bioinform. (2021) 22:393–415. doi: 10.1093/bib/bbz170
39. Ahmed M, Seraj R, Islam SMS. The K-means algorithm: a comprehensive survey and performance evaluation. Electronics. (2020) 9:1295. doi: 10.3390/electronics9081295
40. Wang X, Xu Y. An Improved Index For Clustering Validation Based on Silhouette Index and Calinski-Harabasz Index. IOP Conference Series: Materials Science and Engineering. (2019) 569:052024. doi: 10.1088/1757-899X/569/5/052024
41. Sammouda R, El-Zaart A. An optimized approach for prostate image segmentation using K-means clustering algorithm with elbow method. Comput Intell Neurosci. (2021) 2021:4553832. doi: 10.1155/2021/4553832
42. Lee M, Lee S, Park J, Seo S. Clustering and characterization of the lactation curves of dairy cows using K-medoids clustering algorithm. Animals.(2020) 10:1348. doi: 10.3390/ani10081348
43. Portnova-Fahreeva AA, Rizzoglio F, Nisky I, Casadio M, Mussa-Ivaldi FA, Rombokas E. Linear and non-linear dimensionality-reduction techniques on full hand kinematics. Front Bioeng Biotechnol. (2020) 8:429. doi: 10.3389/fbioe.2020.00429
44. Tran B, Tran D, Nguyen H, Ro S, Nguyen T. Sccan: single-cell clustering using autoencoder and network fusion. Sci Rep. (2022) 12:10267. doi: 10.1038/s41598-022-14218-6
45. Nasser M, Salim N, Saeed F, Basurra S, Rabiu I, Hamza H, et al. Feature reduction for molecular similarity searching based on autoencoder deep learning. Biomolecules. (2022) 12:508. doi: 10.3390/biom12040508
46. Lee JA, Park TY, Lee J, Moon TW, Choi J, Kang BK, et al. Developing indicators of pattern identification in patients with stroke using traditional Korean medicine. BMC Res Notes. (2012) 5:136. doi: 10.1186/1756-0500-5-136
47. Jang E, Lee EJ, Yun Y, Park YC, Jung IC. Suggestion of Standard Process in Developing Questionnaire of Pattern Identification. J Physiol Pathol Korean Med. (2016) 30:190–200. doi: 10.15188/kjopp.2016.06.30.3.190
48. Wang J, Guo Y, Li GL. Current status of standardization of traditional Chinese medicine in China. Evid Based Complement Alternat Med. (2016) 2016:9123103. doi: 10.1155/2016/9123103
49. Liu Y, Li Z, Xiong H, Gao X, Wu J, Wu S. Understanding and enhancement of internal clustering validation measures. IEEE Trans Cybern. (2013) 43:982–94. doi: 10.1109/TSMCB.2012.2220543
50. Tadist K, Najah S, Nikolov NS, Mrabti F, Zahi A. Feature selection methods and genomic big data: a systematic review. J Big Data. (2019) 6:79. doi: 10.1186/s40537-019-0241-0
51. Bakrania MR, Rae IJ, Walsh AP, Verscharen D, Smith AW. Using dimensionality reduction and clustering techniques to classify space plasma regimes. Front Astron Space Sci. (2020) 7:80. doi: 10.3389/fspas.2020.593516
Keywords: deep autoencoder, deep learning, pattern identification, clustering, sleep
Citation: Lee H, Choi Y, Son B, Lim J, Lee S, Kang JW, Kim KH, Kim EJ, Yang C and Lee J-D (2022) Deep autoencoder-powered pattern identification of sleep disturbance using multi-site cross-sectional survey data. Front. Med. 9:950327. doi: 10.3389/fmed.2022.950327
Received: 22 May 2022; Accepted: 11 July 2022;
Published: 29 July 2022.
Edited by:
Md. Mohaimenul Islam, Aesop Technology, TaiwanReviewed by:
Diego Pedro Pinto-Roa, National University of Asunción, ParaguayCopyright © 2022 Lee, Choi, Son, Lim, Lee, Kang, Kim, Kim, Yang and Lee. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Changsop Yang, eWFuZ3VuamFAa2lvbS5yZS5rcg==; Jae-Dong Lee, bGpka2h1QGdtYWlsLmNvbQ==
†These authors have contributed equally to this work and share last authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.