 Hyung Woo Kim1†
Hyung Woo Kim1† Seok-Jae Heo2†
Seok-Jae Heo2† Minseok Kim2Jakyung Lee2Keun Hyung Park1
Minseok Kim2Jakyung Lee2Keun Hyung Park1 Gongmyung Lee1
Gongmyung Lee1 Song In Baeg3Young Eun Kwon3Hye Min Choi3Dong-Jin Oh3Chung-Mo Nam2,4*
Song In Baeg3Young Eun Kwon3Hye Min Choi3Dong-Jin Oh3Chung-Mo Nam2,4* Beom Seok Kim1*
Beom Seok Kim1*- 1Department of Internal Medicine, Yonsei University College of Medicine, Seoul, South Korea
- 2Department of Biostatistics and Computing, Yonsei University Graduate School, Seoul, South Korea
- 3Department of Internal Medicine, Myongji Hospital, Hanyang University College of Medicine, Goyang, South Korea
- 4Division of Biostatistics, Department of Biomedical Systems Informatics, Yonsei University College of Medicine, Seoul, South Korea
Objective: Previously developed Intradialytic hypotension (IDH) prediction models utilize clinical variables with potential privacy protection issues. We developed an IDH prediction model using minimal variables, without the risk of privacy infringement.
Methods: Unidentifiable data from 63,640 hemodialysis sessions (26,746 of 79 patients for internal validation, 36,894 of 255 patients for external validation) from two Korean hospital hemodialysis databases were finally analyzed, using three IDH definitions: (1) systolic blood pressure (SBP) nadir <90 mmHg (Nadir90); (2) SBP decrease ≥20 mmHg from baseline (Fall20); and (3) SBP decrease ≥20 mmHg and/or mean arterial pressure decrease ≥10 mmHg (Fall20/MAP10). The developed models use 30 min information to predict an IDH event in the following 10 min window. Area under the receiver operating characteristic curves (AUROCs) and precision-recall curves were used to compare machine learning and deep learning models by logistic regression, XGBoost, and convolutional neural networks.
Results: Among 344,714 segments, 9,154 (2.7%), 134,988 (39.2%), and 149,674 (43.4%) IDH events occurred according to three different IDH definitions (Nadir90, Fall20, and Fall20/MAP10, respectively). Compared with models including logistic regression, random forest, and XGBoost, the deep learning model achieved the best performance in predicting IDH (AUROCs: Nadir90, 0.905; Fall20, 0.864; Fall20/MAP10, 0.863) only using measurements from hemodialysis machine during dialysis session.
Conclusions: The deep learning model performed well only using monitoring measurement of hemodialysis machine in predicting IDH without any personal information that could risk privacy infringement.
Introduction
Intradialytic hypotension (IDH) is one of the most frequent complications in patients requiring maintenance hemodialysis. IDH is associated with an increased risk of cardiovascular and all-cause mortality (1–4). The definition of IDH varies among studies, while the prevalence of IDH ranges up to 40% (5). Although the risk factors involved in IDH are well known, including diabetes, cardiovascular disease, autonomic dysfunction, nutrition status, old age, anemia, and high interdialytic weight gain, most of these risk factors are difficult to correct immediately at the hemodialysis center. Therefore, treatments, such as temporarily stopping hemodialysis or reducing the rate of ultrafiltration, are preferentially performed when IDH occurs. In order to detect IDH early, it may be helpful to measure blood pressure (BP) more frequently, however, it is impossible to measure BP continuously due to the nature of the non-invasive BP measurement method. Thus, other non-invasive methods that can predict IDH in advance are needed.
However, it is difficult to predict IDH with a classical statistical model, because there many different factors play a role in IDH. Recently, some studies have reported prediction of IDH in hemodialysis patients by using machine learning or deep learning, approaches that can process multi-dimensional data (6–8). However, these models require various types of clinical information, some of which pose a risk of a breach of privacy. Additionally, because each prediction model developed in these studies used different variables, the models could not be applied in all hemodialysis units for universal use. On the other hand, various measurements, including blood flow rate, ultrafiltration rate, dialysate flow rates, arterial line pressure, venous line pressure, transmembrane pressure, temperature, bicarbonate level, and sodium level, can be generated during hemodialysis sessions. These values can be measured by any hemodialysis machine, from different manufacturers, can be used as variables in all hemodialysis units, and do not pose a high risk of privacy infringement.
Therefore, in this two-center validation study, we aimed to develop a real-time IDH prediction model using only data generated from the hemodialysis machine, excluding any personal information, to validate the performance of the developed models.
Materials and Methods
Study Population
Hemodialysis data were extracted from the databases of two hospitals in Korea (Severance Hospital and Myongji Hospital), which store information about each hemodialysis session. In total, 29,324 sessions of 135 patients aged over 19 years, which were automatically recorded in the Therapy Data Management System from May 2015 to May 2021, in Severance Hospital, and 37,380 sessions of 255 patients aged over 19 years, which were automatically recorded in the same system from June 2019 to August 2021, in Myongji Hospital, were screened. Among these 66,704 sessions, we excluded the following sessions: (1) sessions without consecutive BP measurements; (2) sessions without ultrafiltration; (3) sessions lasting less than 40 min; (4) no baseline BP measurement obtained within first 10 min; (5) sessions with missing variables; (6) sessions considered as containing other input errors (Figure 1).
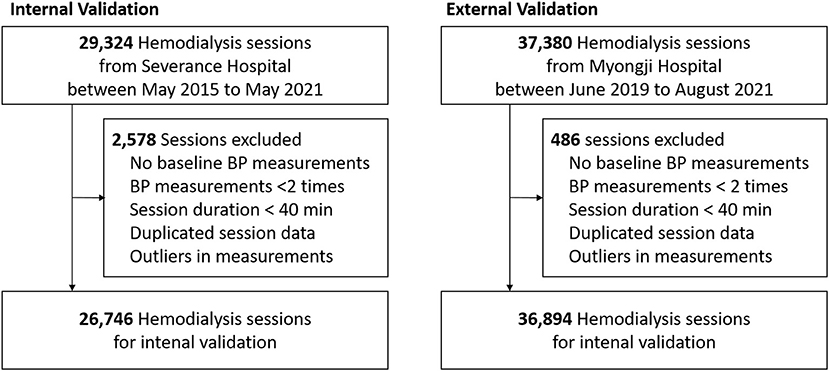
Figure 1. Flowchart of this study. BP, blood pressure.
Finally, 63,640 sessions involving 387 patients were included in this study. The study was performed following the Declaration of Helsinki principles. The institutional review boards of Severance Hospital (IRB No. 4-2021-0951) and Myongji Hospital (2021-08-022) approved this study and waived the need for obtaining informed patient consent, as only de-identified, previously collected data were accessed.
Hemodialysis Sessions
Each hemodialysis session was automatically saved to the database. Along with the initial hemodialysis settings, measured values, including arterial line pressure (AP), venous line pressure (VP), blood flow rate, dialysate flow rate, ultrafiltration rate, total ultrafiltration volume, temperature, and dialysate sodium level were collected from the hemodialysis machine every minute. Vital signs, including systolic blood pressure (SBP), diastolic blood pressure (DBP), mean arterial pressure (MAP), and pulse rate, were recorded every 1 h by default, and all additional measurements were also recorded at any time-point during hemodialysis session. Blood pressure was additionally measured when patient complained of any symptoms associated abnormal blood pressure.
Outcomes and Additional Variables
IDH was defined as a nadir SBP < 90 mmHg (Nadir90) or as a decrease in SBP ≥ 20 mmHg compared to the initial baseline BP (Fall20) within 10 min. In addition, it was also defined as a decrease in systolic BP ≥ 20 mmHg and/or a decrease in MAP of ≥ 10 mmHg (Fall20/MAP10) within 10 min. Age and sex were the only demographics collected from sessions. No other clinical information that could infringe privacy was collected.
Data Processing
In this study, to predict IDH within 10 min, a series of hemodialysis-related measurements obtained during the previous 30 min were collected in real time. Therefore, each segment was defined as 30 min from 40 min to 10 min before any time point at which SBP was measured (Figure 2). A segment had 30 time-points because variables from hemodialysis machines were measured every minute. We used 10 min of data from the start of hemodialysis as baseline data to adjust the volatility of AP and VP for each session and calculated the mean values of the AP and VP from baseline data for each session. Then, the calculated mean values were subtracted from the original AP and VP values.
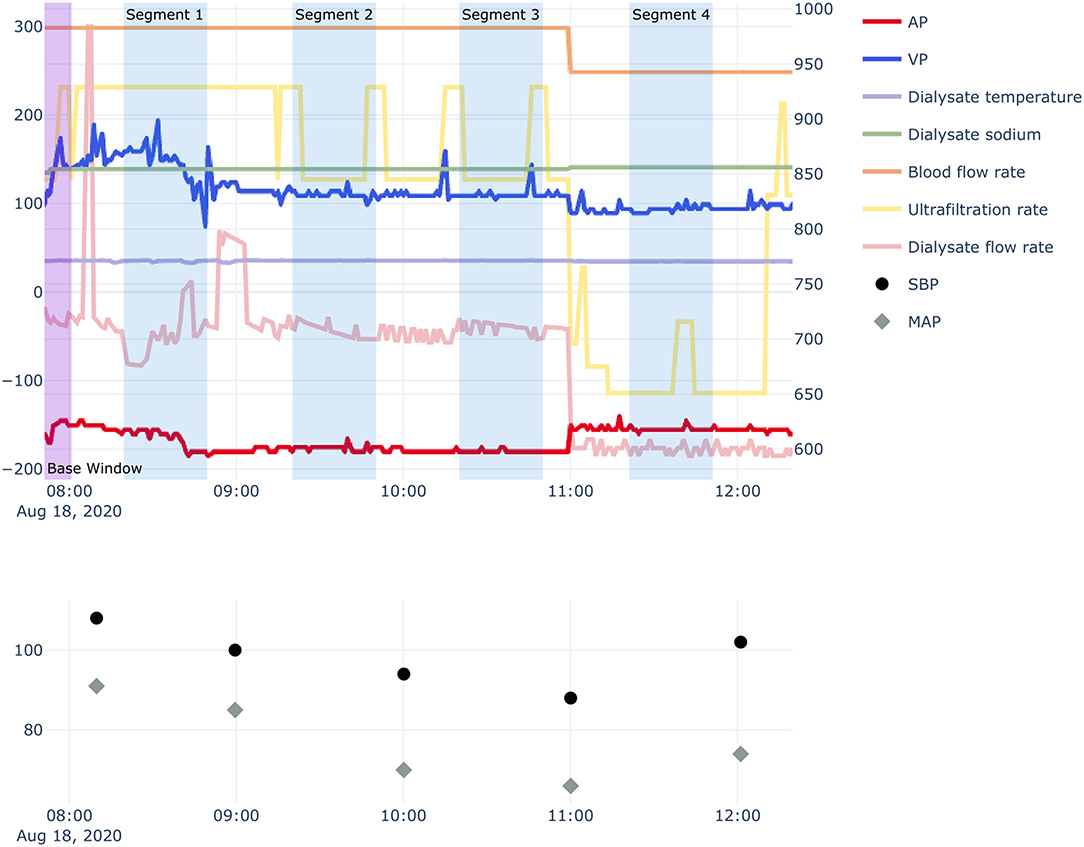
Figure 2. Example of hemodialysis session and segmentation recognition. AP, arterial pressure; VP, venous pressure; SBP, systolic blood pressure; MAP, mean arterial pressure. Segments contain hemodialysis-related measurement data obtained for 30 min, 10 min before each time-point of SBP measurement. Bottom panel: 10 min of data from the start of hemodialysis were used to adjust the volatility of the AP and VP for each session.
In addition, we created variables to obtain better performance for predicting IDH. To consider the possibility that the passage of time may influence the occurrence of IDH events, we used two additional variables related to the passage of time in each hemodialysis session: (1) the time elapsed from the initiation of the hemodialysis session to the beginning of each segment; (2) the time elapsed from the previous SBP measurement to the beginning of each segment. For analyses using logistic regression, random forest (9), and Extreme Gradient Boosting (XGBoost) methods (10), we extracted the mean and standard deviation (SD) of time-varying variables for each segment.
Model Development and Validation
We developed a deep learning model to predict IDH using a convolutional neural network (CNN). CNNs have generally been used to analyze image data, such as classification, segmentation, and object detection (11–14). They can also be used to detect abnormal events in time-series data (15–18). We processed 10 time-invariant variables as a one-dimension (1-D) array with a fixed value. Then, the time-varying and time-invariant variables were concatenated as a 1-D array with 30 time-points and channels corresponding to the number of variables. Then, we can extract new features that considers the relationship between various variables, including the relationship between time-invariant and time-variant variables through 1-D convolutional layer.
Our deep learning model used several features extracted through the CNN, which consisted of four blocks and one 1-D adaptive average pooling layer in a row. The block was composed of one 1-D convolutional layer, one batch normalization, one Scaled Exponential Linear Unit (SELU) activation function, and one 1-D average pooling layer in order. Then, the concatenated 1D layer was connected to an output layer via two fully connected layers, with 128 nodes, three SELU activation functions, and one dropout layer, with a 0.3 dropout rate. Since three IDH events could occur at the same time, we set output layer to return three predicted probabilities of IDH through the sigmoid activation function. Therefore, our deep learning model estimates probabilities for three different IDH events simultaneously. The detailed architecture of our deep learning model is illustrated in Figure 3.
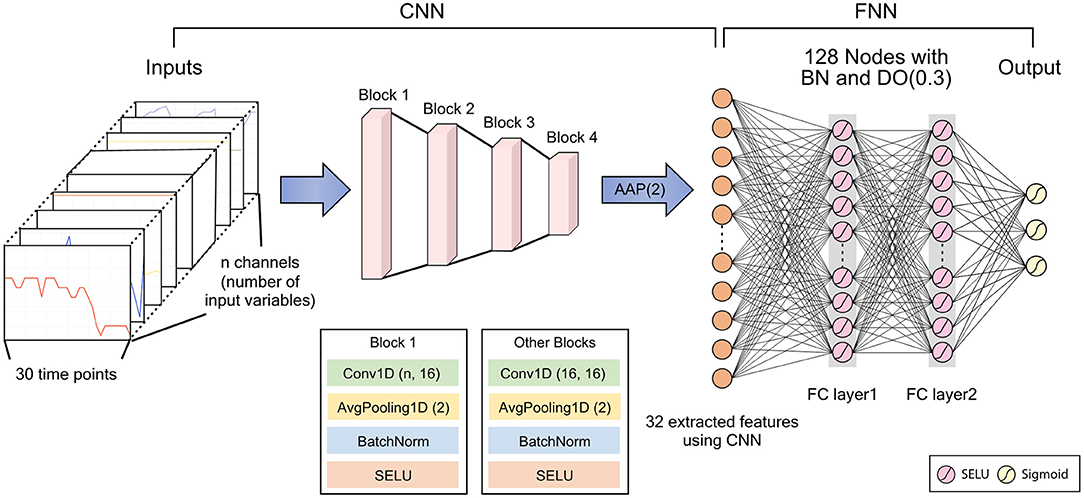
Figure 3. Architecture of the deep learning model. CNN, convolutional neural network; FNN, feedforward neural network; BN, batch normalization; DO, dropout; AAP, adaptive average pooling; SELU, scaled exponential linear unit; FC, fully connected. DO (dropout rate), Conv1D (kernel size, number of filters), AvgPooling1D (kernel size).
To train the deep learning model, we used the Adam optimizer (19), binary cross entropy loss, and a batch size of 64. We also used the one-cycle scheduler to reduce training time (20). In the random forest model, nodes were expanded until all leaves are pure or until all leaves contain less than the minimum number of samples required to split, and the Gini index was used to measurement of the quality of a split. The maximum tree depth in XGBoost model was set to 6, and the number of boosting rounds was set to 100. Detailed hyperparameter settings for the random forest and XGBoost model are summarized Supplementary Table S1. We trained the machine learning and deep learning models using the data from the Severance Hospital hemodialysis database only (internal validation) and used the data from the Myongji Hospital hemodialysis database for external validation. The internal validation was performed through the 5-fold cross-validation.
Model Interpretation
We used the SHapley Additive exPlanation (SHAP) analysis to assess variable importance and the effect of variables on IDH for our deep learning model (21). The SHAP value is based on the Shapley value, which is a solution concept in cooperative game theory. The SHAP value can be interpreted as how much a certain value of a variable affects the predicted value. Unlike standard variable importance, SHAP values are calculated for the subject-specific contributions of each variable. Therefore, it is possible to determine the effects of variables that may differ from subject to subject, as well as overall impact of variable. In this study, we accessed the effect of variables on IDH prediction over time as well as the overall variable importance.
Statistical Analyses
We used descriptive statistics to describe covariates. Categorical variables are expressed as number of patients with percentage, while continuous variables are presented as mean with SD. Standard deviation was previously defined in the Data processing section. For performance evaluation, we use the AUROC and the area under the precision-recall curve (AUPRC) as performance measurements. We calculated these performance measures through 5-fold cross-validation. We performed a sensitivity analysis to determine which variables had the most impact on IDH prediction. We divided variables into several groups: monitored pressure (AP, VP), setting measures (blood flow rate, dialysate flow rate, ultrafiltration rate, total ultrafiltration volume, temperature, and sodium), vital signs (SBP, DBP, MAP, and pulse rate), and time information. We trained models by excluding each group and evaluated these trained models. In addition, we also included demographic variables, such as age and sex, in building the models, to assess whether other clinical variables affected the performance of IDH prediction. Furthermore, since the ultrafiltration rate may have a different effect on the IDH events depending on the pre-dialysis weight, we conducted additional analysis using normalized ultrafiltration rate and average ultrafiltration rate by pre-dialysis weight.
All analyses were performed using R software (version 4.1.2; www.r-project.org; R Foundation for Statistical Computing, Vienna) and Python software (version 3.8; www.python.org; Python Software Foundation, Wilmington) with the PyTorch library. A computer with Xeon processor (24 core, Intel, Santa Clara, CA, USA) and Quadro RTX 6000 (Nvidia, Santa Clara, CA, USA) was used for all analyses.
Results
Characteristics of Hemodialysis Sessions
Of all hemodialysis sessions stored in the databases of two Korean hospitals (Severance Hospital and Myongji Hospital), 63,640 hemodialysis sessions were included (26,746 for internal validation, 36,894 for external validation) in our study. The baseline characteristics of the hemodialysis sessions are shown in Table 1. The mean dialysis time was 3.97 ± 0.18 h and 3.87 ± 0.30 h in Severance Hospital and Myongji Hospital, respectively. Total ultrafiltration was more likely lower in hemodialysis sessions performed at Severance Hospital than those performed at Myongji Hospital (2,287.36 ± 825.48 mL vs. 2,427.10 ± 880.45 mL). Pre-dialysis SBP was similar between the two hospitals (137.53 ± 21.84 mmHg vs. 137.89 ± 17.77 mmHg). Among 101,655 segments in the internal validation set, 3,755 (3.7%), 35,144 (34.6%), and 39,656 (39.0%) IDH events occurred according to three different IDH definitions (Nadir90, Fall20, and Fall20/MAP10, respectively). Similarly, 5,399 (2.2%), 99,844 (41.1%), and 110,018 (45.3%) IDH events occurred in the external validation set based on the Nadir90, Fall20, and Fall20/MAP10, respectively) (Table 2). The baseline characteristics of the patients are shown in Supplementary Table S2. In addition, we summarized the descriptive statistics of the variables according to the occurrence of IDH events (Supplementary Tables S3–S5).
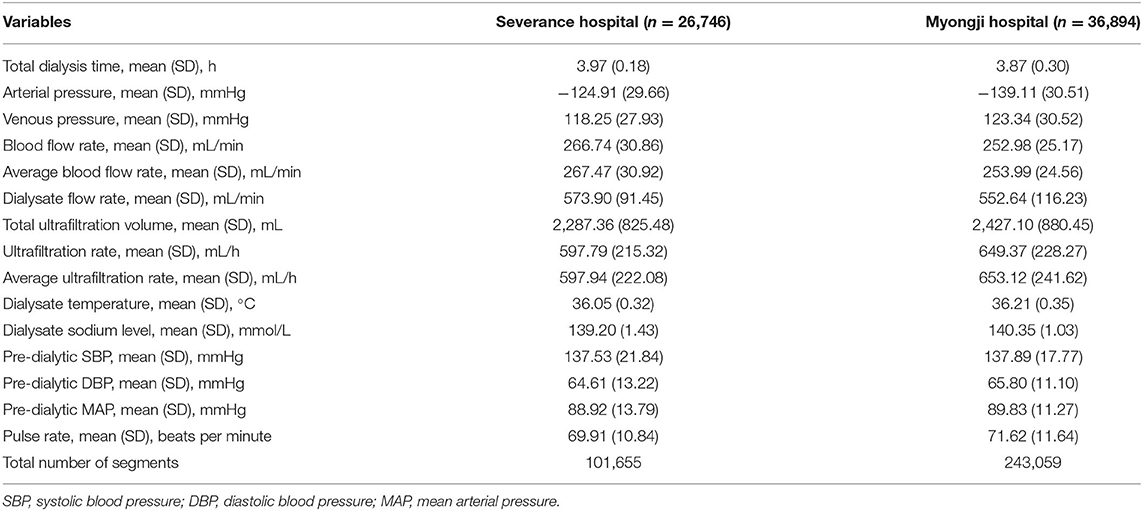
Table 1. Characteristics of the study population.
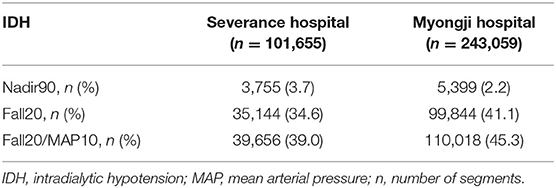
Table 2. Number of events among segments according to the definitions of intradialytic hypotension.
Model Performance
The model performance for internal and external validation is summarized in Table 3. First, we evaluated model performance for the dataset from Severance Hospital, using 5-fold cross-validation. In internal validation, our proposed deep learning model performed better than other models in terms of the AUROCs (Nadir90: 0.905, Fall20: 0.864, Fall20/MAP10: 0.863) and the AUPRC (Nadir90: 0.287, Fall20: 0.794, Fall20/MAP10: 0.812) in most cases. The logistic regression model showed the highest AUROC for Fall20 (0.868) and AUPRC for Nadir90 (0.298) for internal validation. Second, we conducted external validation using the Myongji Hospital dataset. In this validation, our proposed deep learning model showed the best performance by AUROC (Nadir90: 0.853, Fall20: 0.872, Fall20/MAP10: 0.853) and by AUPRC (Nadir90: 0.118, Fall20: 0.831, Fall20/MAP10: 0.841).
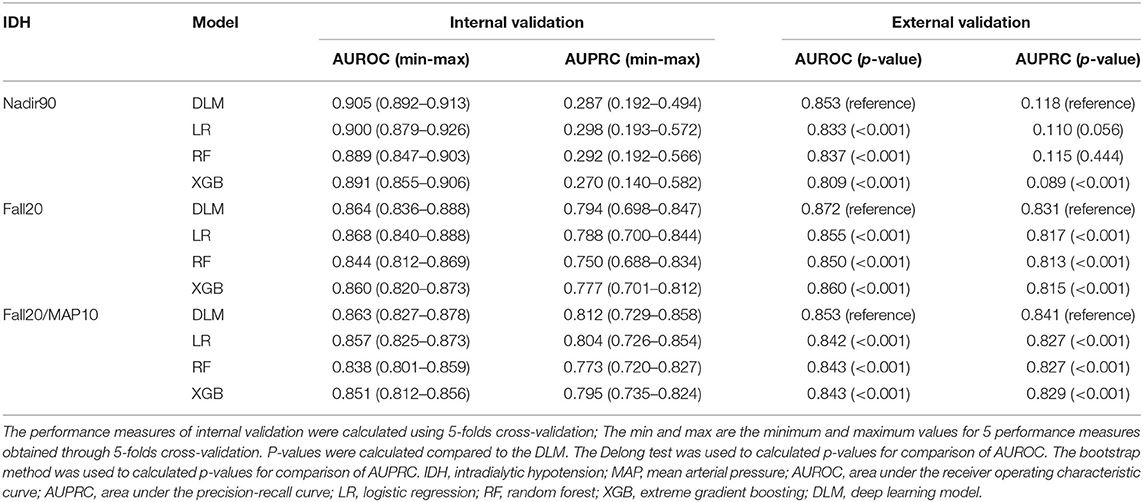
Table 3. Model performance for predicting intradialytic hypotension.
Variable Importance
We calculated overall variable importance using SHAP values for each definition of IDH to investigate which covariate most affected IDH (Supplementary Figures S1–S3). For all definitions of IDH, most vital signs were in the top ranks for variable importance. The blood flow rate, dialysate sodium, and AP were identified as the next most important variables, after SBP and MAP, for the Fall20 and Fall20/MAP10 IDH definitions. Also, the SHAP values can be used to determine whether variables decrease or increase the risks of IDH after 10 min in real time. The case-specific SHAP values over time were illustrated in Supplementary Figures S4–S6. The positive SHAP value was related to the decreased risk of IDH after 10 min, and vice versa if negative.
Sensitivity Analyses
Sensitivity analyses were performed to determine which variables had more impact on IDH prediction for our deep learning model, using the external validation dataset (Table 4). The model including vital sign variables (SBP, DBP, MAP, and pulse rate) was defined as a reference model. For the Nadir90 definition, setting measure variables (blood flow rate, dialysate flow rate, ultrafiltration rate, total ultrafiltration volume, dialysate temperature, and dialysate sodium level) improved model performance more than other variable groups (AUROC: 0.819 to 0.839, AUPRC: 0.106 to 0.112). The variables of monitored pressure (AP, VP) increased model performance the most for the Fall20 (AUROC: 0.858 to 0.862, AUPRC: 0.823 to 0.829) and Fall20/MAP10 (AUROC: 0.848 to 0.853, AUPRC: 0.835 to 0.841) IDH definitions. Sensitivity analyses for the internal validation dataset showed similar results to those for the external validation dataset (Supplementary Table S6). In addition, demographic variables, including age and sex, did not have a significant influence on IDH prediction (Supplementary Table S7). There was no significant difference in the results according to the normalized method for ultrafiltration rate (Table 3 and Supplementary Table S8).

Table 4. Sensitivity analysis of deep learning model for external validation dataset.
Discussion
In this retrospective two-center study, we built a concise model to predict IDH 10 min ahead, using only data generated continuously during hemodialysis, without any risk of a breach of personal information. Because there was no significant difference in model performance improvement even in models with information on age and sex, our study suggests that the use of personal clinical data could be minimized when building a deep learning model, without significant loss of accuracy. In addition, no additional effort is needed to collect clinical data, other than the data extracted from the hemodialysis machine, for predicting IDH by this model. The variables used in this model are available from dialysis machines from any manufacturer. Furthermore, our model can predict IDH events as defined by three different definitions simultaneously and will be beneficial for individualized IDH prediction. Therefore, our model is cost-effective for predicting IDH in terms of privacy protection, individualized medicine, and generalizability.
IDH is associated with an increased risk of cardiovascular and all-cause mortality in end-stage kidney disease patients (1–4, 22). IDH is typically defined as a decrease in SBP ≥ 20 mmHg (23, 24) or a nadir in SBP < 90 mmHg (4). In a recent meta-analysis, the prevalence of IDH in hemodialysis sessions was about 10% (5). Known causes of IDH include excessive ultrafiltration, decreased cardiac output, and failure to increase vascular resistance. Several methods have been suggested to prevent or treat IDH, such as decreasing the ultrafiltration rate, avoiding marked interdialytic weight gain, increasing weekly treatment time, increasing the sodium concentration of the dialysate, lowering dialysate temperature, avoiding food intake during hemodialysis, using high-flux convection, and using midodrine (25). Patients with end-stage kidney disease have many risk factors for IDH that are difficult to correct. Therefore, it is more effective to prevent IDH early than to cope with IDH after IDH occurred. Moreover, particularly in patients with congestive heart failure, there is a risk a vicious cycle if interdialytic weight gain is not removed properly due to IDH. Consequently, early prediction or detection is important. However, as described earlier, it is difficult to predict IDH with the traditional statistical method, because the development of IDH is related to numerous factors, patients are diverse, and complex variables must be considered.
Recently, many studies developed models for predicting hypotension events during hemodialysis using machine learning or deep learning (6–8, 26). Prediction models developed in those studies require different types of clinical information to predict IDH. Depending on the hemodialysis center, these clinical data could be impossible to collect, or could be difficult to use due to privacy issues. Since there are no established guidelines about how the data collected are used and shared with others, protection of privacy is an important issue in the development and use of machine learning or deep learning algorithms (27). In this respect, our model differs from other prediction models, because it does not use any personal information other than the monitoring data obtained from the hemodialysis machine. In addition, our model has the advantage that it needs a minimal number of variables, without accessing electronic medical records, and there is no additional cost for data merging from different platforms, allowing it to be applied in hemodialysis centers of various sizes. Furthermore, our model was designed to predict IDH after 10 min, so that medical staff in the hemodialysis center can effectively conduct acute management, including use of the Trendelenburg position, isotonic fluid administration, and reducing ultrafiltration rate, in advance. Although deep learning models need more computing power than other models including linear regression, XGBoost, and random forest, researchers might expect to monitor in real-time how variables affect IDH in deep learning models through SHAP value. It would be necessary to conduct further studies in order to investigate that our models could reduce the risk of IDH in real world. Moreover, real-time data at 1-min intervals were used to detect IDH events in this study. In some studies, time-varying variables were used to improve the efficacy of the prediction model, but real-time data continuously generated from the dialysis machine were not used, as in our study (8). Similarly, a previous study showed the feasibility of using data continuously measured by the hemodialysis machine to predict outcomes (28).
There were some limitations to our study. First, this study was a small retrospective study, using a hemodialysis database. Although it was a multicenter study, the number of participants was relatively small. Second, our model may not be suitable for predicting IDH in inpatients, since our study was conducted based on outpatient clinic data. In this reason, the number of blood pressure measurements is inevitably limited because unnecessary measurements of blood pressure could make the patients feel uncomfortable during hemodialysis. More frequent blood pressure measurements would be needed to build a more accurate model especially for inpatients. However, most of the patients with chronic hemodialysis undergo hemodialysis at outpatient clinics and preventing adverse events in these patients is more cost-effective. Third, due to the nature of the database platform used in this study, our model was based on data generated at 1-min intervals, rather than in real-time. In addition, a hardware interface that collects data from a hemodialysis machine is needed to implement our model. However, our model does not use any sensitive personal information, it may not be difficult to develop a platform for data collection and utilization. Fourth, the real-time monitoring data collected from hemodialysis machine in this study was anonymized and could not be merged with electronic medical record. Only limited clinical information including gender, and age can be merged. Although our models showed relatively good performance, the comparison with the models including clinical information was not possible in this study in this reason. Fifth, IDH event defined as decrease in blood pressure associated with symptoms and/or interventions were not considered due to the limitation of database. Further well-designed studies would be needed to consider symptoms associated with hypotension event. Finally, some of our models had low AUPRC as compared with other models. The frequency of Nadir90 events were reported as 9.7–11.3% among hemodialysis sessions in another large hemodialysis cohort (22). In contrast, only 2.2–3.7% of Nadir90 events were observed in our study. The relatively low AUPRC value for a certain outcome is thought to be due to the low incidence of these events. Despite the low AUPRC in one outcome, it might be helpful for clinicians to apply an individualized treatment, because our model allows prediction of IDH by various definitions simultaneously.
In conclusion, our study showed that IDH is sufficiently and accurately predictable using a deep learning model, without including any sensitive personal information. In addition, the variables used in our model can be obtained at any hemodialysis center globally, making it more generalizable than existing models. We expect that our model can be prospectively validated and used in various situations for the safety of hemodialysis patients.
Data Availability Statement
The datasets presented in this article are not readily available because the data underlying this article cannot be shared to other academics due to the privacy of individuals that participated in the study. Requests to access the datasets should be directed to HWK, ZHJod2ludEB5dWhzLmFj.
Ethics Statement
The studies involving human participants were reviewed and approved by the Institutional Review Boards of Severance Hospital and Myongji Hospital. The Ethics Committee waived the requirement of written informed consent for participation.
Author Contributions
HWK and BSK contributed to the research concept and the study design. HWK, BSK, SIB, YEK, HMC, and D-JO were involved in data acquisition and cleansing. HWK, S-JH, MK, JL, KHP, and GL contributed to the statistical analyses and model building. HWK and S-JH wrote the manuscript. BSK and C-MN were responsible for data analysis and interpretation and supervision or mentorship. All authors read and approved the final version of the manuscript.
Funding
This study was supported by a Severance Hospital Research fund for Clinical excellence (SHRC) (C-2020-0011).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmed.2022.878858/full#supplementary-material
References
1. Shoji T, Tsubakihara Y, Fujii M, Imai E. Hemodialysis-associated hypotension as an independent risk factor for two-year mortality in hemodialysis patients. Kidney Int. (2004) 66:1212–20. doi: 10.1111/j.1523-1755.2004.00812.x
2. Stefansson BV, Brunelli SM, Cabrera C, Rosenbaum D, Anum E, Ramakrishnan K, et al. Intradialytic hypotension and risk of cardiovascular disease. Clin J Am Soc Nephrol. (2014) 9:2124–32. doi: 10.2215/CJN.02680314
3. Yu J, Liu Z, Shen B, Teng J, Zou J, Ding X. Intradialytic hypotension as an independent risk factor for long-term mortality in maintaining hemodialysis patients: a 5-year follow-up cohort study. Blood Purif. (2018) 45:320–6. doi: 10.1159/000486231
4. Chou JA, Streja E, Nguyen DV, Rhee CM, Obi Y, Inrig JK, et al. Intradialytic hypotension, blood pressure changes and mortality risk in incident hemodialysis patients. Nephrol Dial Transplant. (2018) 33:149–59. doi: 10.1093/ndt/gfx037
5. Kuipers J, Verboom LM, Ipema KJR, Paans W, Krijnen WP, Gaillard C, et al. The prevalence of intradialytic hypotension in patients on conventional hemodialysis: a systematic review with meta-analysis. Am J Nephrol. (2019) 49:497–506. doi: 10.1159/000500877
6. Lin CJ, Chen CY, Wu PC, Pan CF, Shih HM, Huang MY, et al. Intelligent system to predict intradialytic hypotension in chronic hemodialysis. J Formos Med Assoc. (2018) 117:888–93. doi: 10.1016/j.jfma.2018.05.023
7. Gomez-Pulido JA, Gomez-Pulido JM, Rodriguez-Puyol D, Polo-Luque ML, Vargas-Lombardo M. Predicting the appearance of hypotension during hemodialysis sessions using machine learning classifiers. Int J Environ Res Public Health. (2021) 18:2364. doi: 10.3390/ijerph18052364
8. Lee H, Yun D, Yoo J, Yoo K, Kim YC, Kim DK, et al. Deep learning model for real-time prediction of intradialytic hypotension. Clin J Am Soc Nephrol. (2021) 16:396–406. doi: 10.2215/CJN.09280620
10. Chen T, Guestrin C. Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. (2016). doi: 10.1145/2939672.2939785
11. Kayalibay B, Jensen G, Smagt Pvd. CNN-based segmentation of medical imaging data. arXiv preprint arXiv:1701.03056 (2017). doi: 10.48550/arXiv.1701.03056
12. Dunnmon JA Yi D, Langlotz CP, Re C, Rubin DL, Lungren MP. Assessment of convolutional neural networks for automated classification of chest radiographs. Radiology. (2019) 290:537–44. doi: 10.1148/radiol.2018181422
13. Li Z, Dong M, Wen S, Hu X, Zhou P, Zeng Z. CLU-CNNs: object detection for medical images. Neurocomputing. (2019) 350:53–9. doi: 10.1016/j.neucom.2019.04.028
14. Suman G, Panda A, Korfiatis P, Goenka AH. Convolutional neural network for the detection of pancreatic cancer on CT scans. Lancet Digital Health. (2020) 2:e453. doi: 10.1016/S2589-7500(20)30190-4
15. Yildirim Ö, Baloglu UB, Acharya UR. A deep convolutional neural network model for automated identification of abnormal EEG signals. Neural Comput Appl. (2018) 32:15857–68. doi: 10.1007/s00521-018-3889-z
16. Baloglu UB, Talo M, Yildirim O, Tan RS, Acharya UR. Classification of myocardial infarction with multi-lead ECG signals and deep CNN. Pattern Recognit Lett. (2019) 122:23–30. doi: 10.1016/j.patrec.2019.02.016
17. Kwon J-m, Cho Y, Jeon K-H, Cho S, Kim K-H, Baek SD, et al. A deep learning algorithm to detect anaemia with ECGs: a retrospective, multicentre study. Lancet Digital Health. (2020) 2:e358–e67. doi: 10.1016/S2589-7500(20)30108-4
18. Kiranyaz S, Avci O, Abdeljaber O, Ince T, Gabbouj M, Inman DJ. 1D convolutional neural networks and applications: a survey. Mech Syst Signal Process. (2021) 151:107398. doi: 10.1016/j.ymssp.2020.107398
19. Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014). doi: 10.48550/arXiv.1412.6980
20. Smith LN, Topin N. Super-convergence: Very fast training of neural networks using large learning rates. In: Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications. International Society for Optics and Photonics (2019). doi: 10.1117/12.2520589
21. Lundberg SM, Lee S-I. A unified approach to interpreting model predictions. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. (2017).
22. Flythe JE, Xue H, Lynch KE, Curhan GC, Brunelli SM. Association of mortality risk with various definitions of intradialytic hypotension. J Am Soc Nephrol. (2015) 26:724–34. doi: 10.1681/ASN.2014020222
23. Workgroup KD. K/DOQI clinical practice guidelines for cardiovascular disease in dialysis patients. Am J Kidney Dis. (2005) 45:16–153. doi: 10.1053/j.ajkd.2005.01.019
24. Kooman J, Basci A, Pizzarelli F, Canaud B, Haage P, Fouque D, et al. EBPG guideline on haemodynamic instability. Nephrol Dial Transplant. (2007) 22:ii22–44. doi: 10.1093/ndt/gfm019
25. Kanbay M, Ertuglu LA, Afsar B, Ozdogan E, Siriopol D, Covic A, et al. An update review of intradialytic hypotension: concept, risk factors, clinical implications and management. Clin Kidney J. (2020) 13:981–93. doi: 10.1093/ckj/sfaa078
26. Thakur SS, Abdul SS, Chiu HS, Roy RB, Huang PY, Malwade S, et al. Artificial-intelligence-based prediction of clinical events among hemodialysis patients using non-contact sensor data. Sensors. (2018) 18:2833. doi: 10.3390/s18092833
27. Prabhu SP. Ethical challenges of machine learning and deep learning algorithms. Lancet Oncol. (2019) 20:621–2. doi: 10.1016/S1470-2045(19)30230-X
Keywords: deep learning, intradialytic hypotension, machine learning, privacy protection, hemodialysis
Citation: Kim HW, Heo S-J, Kim M, Lee J, Park KH, Lee G, Baeg SI, Kwon YE, Choi HM, Oh D-J, Nam C-M and Kim BS (2022) Deep Learning Model for Predicting Intradialytic Hypotension Without Privacy Infringement: A Retrospective Two-Center Study. Front. Med. 9:878858. doi: 10.3389/fmed.2022.878858
Received: 18 February 2022; Accepted: 20 June 2022;
Published: 07 July 2022.
Edited by:
Claudia Lerma, Instituto Nacional de Cardiologia Ignacio Chavez, MexicoReviewed by:
Marisol Martinez Alanis, Universidad Anahuac Mexico, MexicoJesus Arellano, Hospital General “Dr. Miguel Silva”, Mexico
Erik Bojorges, Universidad Iberoamericana Ciudad de México, Mexico
Copyright © 2022 Kim, Heo, Kim, Lee, Park, Lee, Baeg, Kwon, Choi, Oh, Nam and Kim. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Beom Seok Kim, ZG9jYnNrQHl1aHMuYWM=; Chung-Mo Nam, Y21uYW1AeXVocy5hYw==
†These authors have contributed equally to this work