 Lei Shao1
Lei Shao1 Xiaomei Zhang2
Xiaomei Zhang2 Teng Hu3
Teng Hu3 Yang Chen2
Yang Chen2 Chuan Zhang1
Chuan Zhang1 Li Dong1Saiguang Ling4Zhou Dong4Wen Da Zhou1Rui Heng Zhang1Lei Qin2*†
Li Dong1Saiguang Ling4Zhou Dong4Wen Da Zhou1Rui Heng Zhang1Lei Qin2*† Wen Bin Wei1*†
Wen Bin Wei1*†- 1Beijing Key Laboratory of Intraocular Tumor Diagnosis and Treatment, Beijing Ophthalmology & Visual Sciences Key Lab, Medical Artificial Intelligence Research and Verification Key Laboratory of the Ministry of Industry and Information Technology, Beijing Tongren Eye Center, Beijing Tongren Hospital, Capital Medical University, Beijing, China
- 2School of Statistics, University of International Business and Economics, Beijing, China
- 3School of Banking and Finance, University of International Business and Economics, Beijing, China
- 4EVision Technology (Beijing) Co. LTD., Beijing, China
Purpose: To predict the fundus tessellation (FT) severity with machine learning methods.
Methods: A population-based cross-sectional study with 3,468 individuals (mean age of 64.6 ± 9.8 years) based on Beijing Eye Study 2011. Participants underwent detailed ophthalmic examinations including fundus images. Five machine learning methods including ordinal logistic regression, ordinal probit regression, ordinal log-gamma regression, ordinal forest and neural network were used.
Main Outcome Measure: FT precision, recall, F1-score, weighted-average F1-score and AUC value.
Results: Observed from the in-sample fitting performance, the optimal model was ordinal forest, which had correct classification rate (precision) of 81.28%, while 34.75, 93.73, 70.03, and 24.82% in each classified group by FT severity. The AUC value was 0.7249. And the F1-score was 65.05%, weighted-average F1-score was 79.64% on the whole dataset. For out-of-sample prediction performance, the optimal model was ordinal logistic regression, which had precision of 77.12% on the validation dataset, while 19.57, 92.68, 64.74, and 6.76% in each classified group by FT severity. The AUC value was 0.7187. The classification accuracy of light FT group was the highest, while that of severe FT group was the lowest. And the F1-score was 54.46%, weighted-average F1-score was 74.19% on the whole dataset.
Conclusions: The ordinal forest and ordinal logistic regression model had the strong prediction in-sample and out-sample performance, respectively. The threshold ranges of the ordinal forest model for no FT and light, moderate, severe FT were [0, 0.3078], [0.3078, 0.3347], [0.3347, 0.4048], [0.4048, 1], respectively. Likewise, the threshold ranges of ordinal logistic regression model were ≤3.7389, [3.7389, 10.5053], [10.5053, 13.9323], > 13.9323. These results can be applied to guide clinical fundus disease screening and FT severity assessment.
Introduction
Although artificial intelligence has been widely applied to image identification (1), speech recognition (2), and natural language processing (3), its impact on medical care is only beginning. Machine learning has been applied to fundus images, optical coherence tomography, and visual field analysis in ophthalmology. It demonstrated excellent classification performance for diabetic retinopathy (4), macular edema (5), glaucoma (6), AMD (7), and retinopathy of prematurity (8). Artificial intelligence mixed with telemedicine has the potential to provide a long-term solution for screening and monitoring patients in primary eye care settings.
The sole straightforward approach to view the choroidal vascular structure under direct vision is fundus tessellation (FT), which is described as the sight of massive choroidal arteries at the posterior fundus pole outside of the peripapillary area (9, 10). Previous research has linked fundus tessellated density (FTD) to age and myopic refractive error, and it has been regarded as one of the most critical early signs of pathological myopia (11, 12). FT has also been linked to several ocular illnesses, including age-related macular degeneration (AMD) (13), choroidal neovascularization (11), central serous chorioretinopathy (14), etc.
Recently, with the development of artificial intelligence image processing technology, computer vision and region of interest (ROI) extraction can effectively identify subtle texture differences that cannot be recognized by human eyes (15). In the past, it has been studied to quantify FT using artificial intelligence methods (16). The purpose of this study is to obtain the threshold range of each grade of FTD by predicting the manual score of FT through machine learning. Fundus photos are commonly used to diagnose disease, but this study is unique in that it uses quantitative data FTD to predict descriptive analysis FT grades, resulting in a reference value range for each grade of FTD. The results can be used to better understand demographic characteristics and long-term follow-up.
Materials and Methods
Data Sources
The Beijing Eye Study is a long-term population-based study that began in 2011 (17). It was carried out in five communities in the Haidian district (a northern central Beijing metropolitan area) and three communities in the Daxing district (the village area in the south of Beijing). The study population was examined for the first time in 2011 and for the second time 5 years later in 2016. In the later examination, subjects having choroidal information underwent improved depth imaging spectral-domain optical coherence tomography. The database generated from this study was investigated in detail in the past several years and attracted much attention from the field of ophthalmology. According to the Declaration of Helsinki, the Medical Ethics Committee of the Beijing Tongren Hospital approved the study and all participants gave informed written consent. The ethics committee confirmed that all methods were performed following the relevant guidelines and regulations.
Participant Selection and Variables for Modeling
The criteria defined for inclusion in this study were aged more than 50 years. All the participants were interview edon standardized questions such as socio-economic characteristics, quality of life, depression, physical activity, known major systemic diseases and quality of vision. They also received a medical and detailed ophthalmological examination. Among a total population of 4,403 participants, 3,468 participants received the examinations, including 1,633 subjects in the rural area and 1,835 subjects in the urban area.
Generally, the same patient will be photographed at the same time with the optic disc and the macula as the center of the fundus, and the fundus map will be divided and graded. For a fundus image with a 45° field of view centered on the optic nerve head, the peripapillary area was divided into 4 quadrants (superior, nasal, inferior, and temporal). The sum of each quadrant's grade is the manual grading of FT, the ratio of the area of the leopard spots to the area of the fundus taken). According to the manual grading results, grading equals to 0 corresponds to no fundus tessellation (FT), grading between 1 and 4 corresponds to light FT, grading between 5 and 8 corresponds to moderate FT, and grading between 9 and 12 corresponds to severe FT. Gender, age, and FTD are employed as major factors in this work to predict FT classification using machine learning methods. Through an artificial intelligence image processing technology, we extracted the exposed choroid from the fundus, and then calculated the average exposed choroidal area per unit fundus area, which is called FTD (16).
Before statistical analysis, we removed the missing data, outliers of the selected variables, and duplicate data based on the ID and Eye indicators. Finally, 3,419 samples were included in our dataset.
Statistical Analysis
In this study, all statistical analyses were performed on R software version 4.1.2. Descriptive statistics and machine learning methods were employed for data analysis. The P < 0.05 was considered statistically significant.
Descriptive statistical analyses were conducted separately for a classified group by manual grading of FT (0, 1 ~ 4, 5 ~ 8, 9 ~ 12), means and standard deviation (SD) were reported for FTD and age, sample size was reported for gender. We used five machine learning methods including ordinal logistic regression, ordinal probit regression, ordinal log-gamma regression, ordinal forest and neural network to fit our dataset, and calculated the in-sample correct precision, recall, F1-score, and weighted-average F1-score on the whole dataset to assess the goodness of fit. In the process of model training, we introduced the square term of FTD to add the non-linear effect. To perform the out-of-sample validation, we randomly assigned 50% of the dataset as a training set and the remaining 50% of the dataset as the validation set, and reported the precision, recall, F1-score and weighted-average F1-score on the validation set. Then, the receiver operating characteristic (ROC) curve and the area under the curve (AUC) were employed to identify the accuracy of the five machine learning methods (18).
Machine Learning Methods
Ordinal Regression
The ordinal regression models are the extensions of binomial regression, and are also called ranking learning in machine learning. These models are used to predict the dependent variable with ordered multiple categories (19). Suppose the underlying process to be characterized is
where Y* is the exact but unobserved dependent variable; X is the vector of independent variables, ε is the error term, and β is the vector of regression coefficients that we wish to estimate. Further suppose that we cannot observe Y*, we instead can only observe the categories of response
where the parameters μi(i = 1, ⋯, K) are the externally imposed endpoints of the observable categories. Then the ordered regression techniques will use the observations Y, which are a form of censored data on Y* to fit the parameter vector β.
To estimate the coefficients in models, we need to choose a link function for defining cumulative probabilities, such as logit, probit, and log-gamma link function, and the corresponding models are ordinal logistic regression, ordinal probit regression, and ordinal log-gamma regression.
Ordinal Forest
The ordinal forest (OF) method allows ordinal regression with high-dimensional and low-dimensional data. After having constructed an OF prediction rule using a training dataset, it can be used to predict the values of the ordinal target variable for new observations (20). Moreover, using the (permutation-based) variable importance measure of OF, it is also possible to rank the covariates concerning their importance in the prediction of the values of the ordinal target variable. The concept and assumption of OF are similar to ordinal regression. The main idea of OF is to optimize score values μi(i = 1, ⋯, K) to be used in place of the class values 1, ⋯, K of the ordinal target variable in standard regression forests by maximizing the out-of-bag (OOB) prediction performance measured by a performance function.
Neural Networks
In this study, we used the neural network algorithm provided by the monmlp package. The monmlp package uses neural networks to predict ordinal response variables, it implements one and two hidden-layer multi-layer perceptron neural network (MLP) models. An optional monotone constraint, which guarantees monotonically increasing behavior of model outputs concerning specified covariates, can be added to the MLP. The resulting monotone MLP (MONMLP) regression model is based on Zhang and Zhang (21). Early stopping can be combined with bootstrap aggregation to control over-fitting. The model reduces to a standard MLP neural network if the monotone constraint is not invoked. In this paper, we have constructed a two-layer neural network, each layer contains eight neurons, the hidden layer transfer function is “tansig,” output layer transfer function is “linear,” and the optimx optimization method is “BFGS.”
Results
Table 1 showed that the study population consisted of 3,419 participants [1,445 male (42.26%) and 1,974 females (57.74%)], the mean age was 53.55 (SD = 9.51); the mean of FTD was 0.18 (SD = 0.09). The light FT group had the largest sample size [2,312 participants (67.62%)], the remaining three groups no FT, Moderate FT, and Severe FT containing 282 [8.25%], 684 [20.01%], and 141 [4.12%] participants, respectively. With the increase of FT severity, the FTD shows an upward trend, the mean FTD of no FT group was 0.07 (SD = 0.04), while the mean FTD of severe FT group reached 0.33 (SD = 0.06). The upward trend was also observed for age, the mean age of no FT group was 50.45 (SD = 8.30), while the mean age of severe FTgroup reached 65.04 (SD = 7.21). In the no FT group and light FT group, there were more females than males, but in the moderate FT group and severe FT group, there were more males than females.
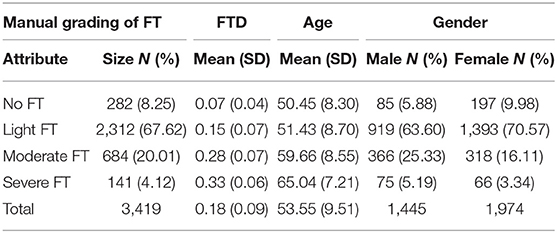
Table 1. Descriptive statistics of the original sample.
Table 2 summarized the model fitting results for each method. For Ordinal logistic regression, Ordinal probit regression and Ordinal log-gamma regression, the coefficients of age, gender, FTD, and FTD squared are all statistically significant. The threshold 1 ~ 4 in Table 2 represented the threshold of , which corresponds to the four types of FT. For example, in the ordinal logistic regression, if Y* < 3.7389, the corresponding result of fundus tessellation grading should be no FT group. The importance measures of each variable were reported for the ordinal forest algorithm, among which FTD was the most important variable.
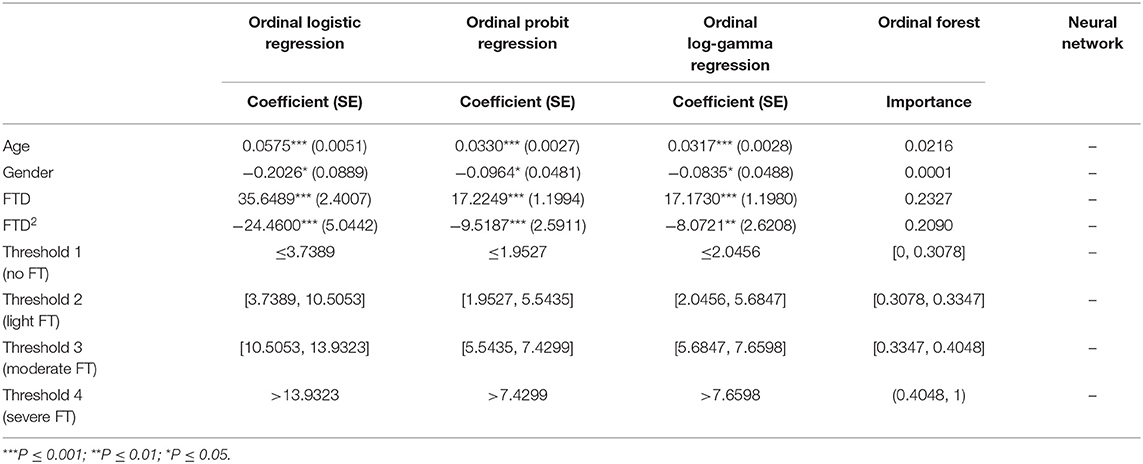
Table 2. The results of different algorithms.
Tables 3, 4 presented the in-sample and out-of-sample precision, recall, F1-score and weighted-average F1-score for each machine learning method. Accuracy was a metric for classification models that measures the number of predictions that are correct as a percentage of the total number of predictions that are made. It was a useful metric only when you have an equal distribution of classes on your classification. As can be seen from Table 1, the sample in this paper was unbalanced. Precision and Recall were two most common metrics that take into account class imbalance. They were also the foundation of the F1 score. The goal of the F1 score was to combine the precision and recall metrics into a single metric (7, 22). At the same time, the F1 score has been designed to work well on imbalanced data, which taken into account not only the number of prediction errors that your model makes, but that also look at the type of errors that are made. Then we weighted the F1-score of each class by the number of samples from that class to get the weighted-average F1-score.
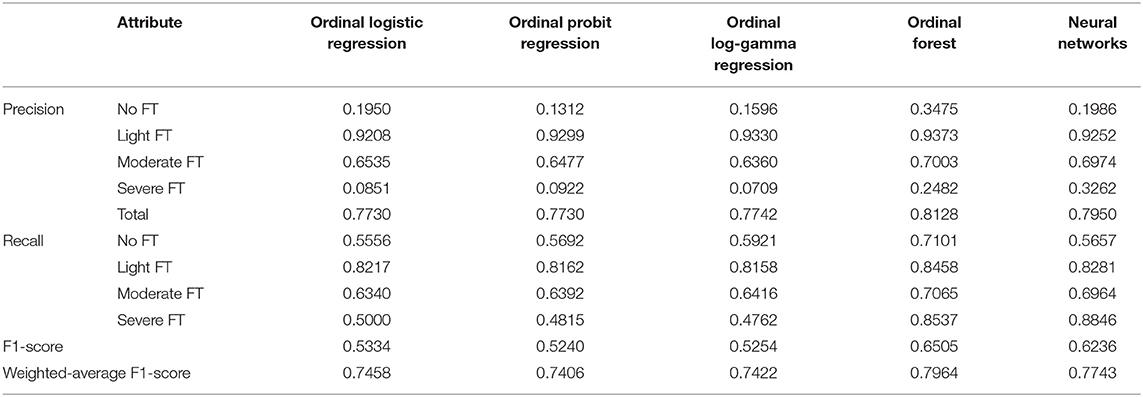
Table 3. In-sample correct classification rate for each machine learning method.
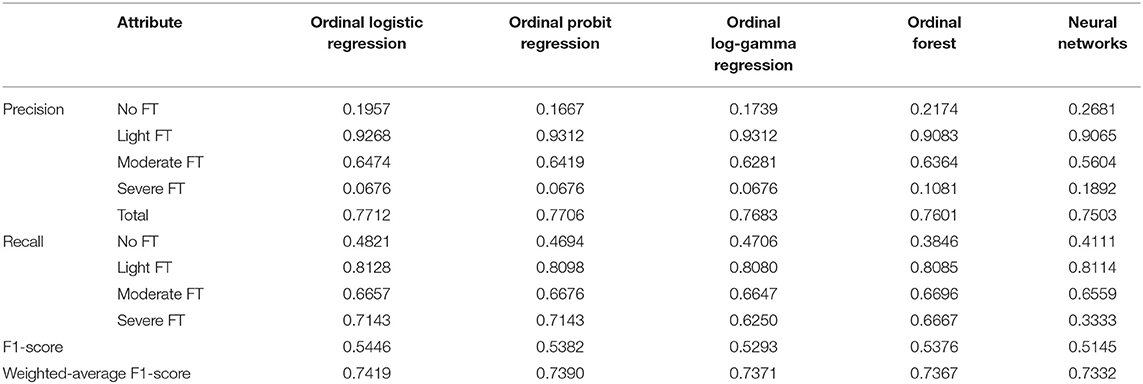
Table 4. Out-of-sample correct classification rate for each machine learning method.
Observed from the in-sample fitting performance, the optimal model was Ordinal forest, which had a weight-F1-score of 79.64%, F1-score of 65.05%, and precision of 81.28% on the whole dataset. The precision in each classified group by FT severity were 34.75, 93.73, 70.03, and 24.82%, while the recall were 71.01, 84.58, 70.65, and 85.37%. For out-of-sample prediction performance, the optimal model was Ordinal logistic regression, which had a weighted-average F1-scoreof 74.19%, a F1-score of 54.46% and a correct classification rate of 77.12% on the validation dataset. The precision in each classified group by FT severity were 19.57, 92.68, 64.74, and 6.76%, while the recall were 48.21, 81.28, 66.57, and 71.43%. It can also be seen that obvious differences existed in the correct classification rate of different FT groups, the light FT group had the highest correct classification rate, while the severe FT group was the lowest.
The ROC curve and AUC value of five machine learning methods were shown in Figure 1. Figure 1A showed in-sample performance and Figure 1B showed out-of-sample performance. From a single picture front, the light FTgroup and moderated FT group had better classification performance, in comparison, the classification performance of no FT group and severe FT group is poor. The values in the figure represented the weighted average area under the four curves (AUC), which was a generalized measure of multi-classification performance, weight was the reciprocal of the sample size of each class. The AUC value did not change drastically in the out-of-sample, which indicated that the performance of the five machine learning methods was relatively stable. Comparatively, observed from the in-sample fitting performance, the optimal model was Ordinal forest, the AUC value was 0.7249. For out-of-sample prediction performance, the optimal model was Ordinal logistic regression, which AUC value was 0.7187.
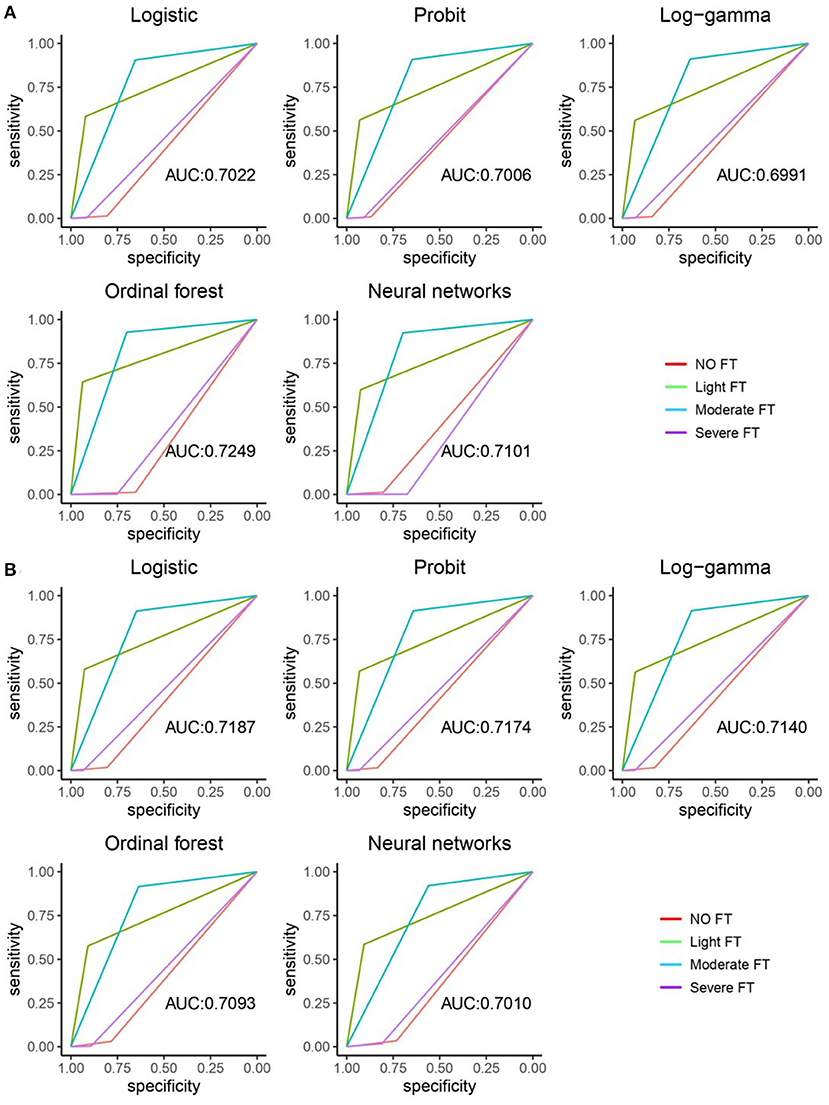
Figure 1. ROC curve and AUC value of five machine learning methods. (A) The in-sample ROC curves and AUC values of the five machine learning methods. (B) The out-sample ROC curves and AUC values of five machine learning methods.
Although the five methods showed relatively similar out-of-sample model performance metrics, we preferred the result of Ordinal logistic regression to give the following risk scheme to predict the severity of FT by age, gender and FTD from patients.
Discussion
As far as we are aware, this work is the first to forecast the FT classification using machine learning technology, and is also the first to give the FTD reference value range of FT classification. This study obtained the value of FTD through an artificial intelligence image processing technology, verified the accuracy of machine learning in predicting FT classification, provides 5 machine learning methods with high accuracy, and obtained the thresholds of 4 FT classification in each machine learning classification methods except the neural network method. Our findings suggest that observed from the in-sample fitting performance, the optimal model was ordinal forest. For out-of-sample prediction performance, the optimal model was ordinal logistic regression. The FTD reference value range generated in this study can be used for guiding clinical fundus disease screening and FT severity assessment.
Estimates of the severity of FT are crucial, but they can also be perplexing in the absence of a recognized objective marker of severity. We used five machine learning methods to fit our data set in this cohort study, including ordinal logistic regression, the ordinal probit regression, the ordinal log-gamma regression, ordinal forest and neural network, calculated the in-sample precision, recall, F1-score, weighted-average F1-score and AUC value to evaluate the goodness of fit, and reported the same model performance metrics of out-of-sample validation. Previous studies have reported that FT is related to age and gender (9). In our model, age, gender, and FTD were introduced as variables. At the same time, to improve the non-linear effect, we also introduced the square term of FTD. The coefficients of age, gender, FTD, and FTD squared were all statistically significant in Ordinal logistic regression, Ordinal probit regression, and Ordinal log-gamma regression. For the ordinal forest algorithm, the important measures of each variable were presented, with FTD being the most important variable and gender being the least important. From the observation of fitting performance within the sample, the optimal model was ordinal forest, and the correct classification rate on the whole data set was 81.28%, the F1 score was 65.05%, the weighted-average F1-score was 79.64%. For out-of-sample prediction performance, the best model was Ordinal logistic regression, and its correct classification rate on the validation dataset was 77.12%, the F1 score was 54.46%, the weighted-average F1-score was 74.19%. Overall, the classification accuracy of different FT groups differed significantly (Tables 3, 4). The light FT group had the best categorization precision, while the severe FT group has the lowest.
The low classification precision of severe FT could be a result of extensive or patchy chorioretinal atrophy (11, 23) in fundus pictures, which impairs FTD accuracy. Additionally, because this study is directed at those over the age of 50 when the degree of FT is severe, patients are more likely to be complicated with other eye diseases (24), which may introduce additional bias. Increasing the number of independent samples, repeating the model's training process and verifying the results may increase the model's accuracy. Furthermore, this large-scale cohort study based on the elderly population gathered detailed eye and whole-body data, including axis length, diopter, weight, and other characteristics that may be linked to FTD (16). Various research on FT risk variables might be added to this foundation. This cohort, for example, might aid in the development of a more accurate pathological myopia grading model.
In conclusion, we developed a valid approach to predict the severity classification of FT by using consistent clinician evaluation and machine learning, so as to obtain the threshold of each classification of FTD, which is expected to become the reference value of clinical FTD. FTD can be used to evaluate the severity of fundus lesions directly, and improve the treatment of chronic fundus diseases. We know that deep learning, such as convolutional neural network, can also predict FT classification through images, but so far, there is no research to compare its accuracy with machine learning methods. We think this may be the future research direction. Further, we should try modifying the data and repeating the training procedure with more samples to improve these outcomes. Additionally, while ordinal logistic regression is the most advanced technique commonly employed in biomedical data research, other technologies, such as deep learning, can be applied to enhance the quality of the produced results.
Potential limitations should be mentioned. First, in the Beijing Eye Study 2011, disparities between participants and non-participants may have resulted in a selection artifact with a reasonable response rate of 78.8%. Second, for the population-based study, we enrolled all eligible subjects from the study region. As a result, illnesses may have influenced FTD, particularly about choroidal thickening or thinning. Third, this study is not a random sample from the Chinese population. This may affect the applicability of the model trained on our data to other medical institutions.
Conclusions
We applied machine learning to collect FTD data from the Beijing Eye Study, evaluated the accuracy of FT classification, and obtained the threshold range of each grade of FTD. Our findings suggest that observed from the in-sample fitting performance, the optimal model was ordinal forest, which the threshold ranges of no FT, light, moderate, and severe FT were [0, 0.3078], [0.3078, 0.3347], [0.3347, 0.4048], [0.4048, 1]. For out-of-sample prediction performance, the optimal model was ordinal logistic regression, which had the threshold ranges of no FT, light, moderate, and severe FT were ≤ 3.7389, [3.7389, 10.5053], [10.5053, 13.9323], >13.9323, respectively. These results can be applied to guide clinical fundus disease screening and FT severity assessment.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Author Contributions
LS, WW, and LQ: design of the study. XZ, TH, and YC: development of the algorithm. LS, CZ, LD, WZ, and RZ: gathering the data. LS, XZ, TH, YC, SL, and ZD: performing the data analysis. LS and CZ: drafting the first version of the manuscript. All authors: revision and approval of the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This study was supported by National Natural Science Foundation of China (No. 82000916), the Priming Scientific Research Foundation for the junior researcher in Beijing Tongren Hospital, Capital Medical University (2016-YJJ-ZLL-009), Beijing Hospitals Authority Youth Programme, code: QML20180204, the Priming Scientific Research Foundation for the junior researcher in Beijing Tongren Hospital, Capital Medical University (No. 2018-YJJ-ZZL-045). Dongcheng District Outstanding Talent Nurturing Program (2020-dchrcpyzz-42), the Fundamental Research Funds for the Central Universities in UIBE (CXTD10-10), and University of International Business and Economics (UIBE) Huiyuan distinguished young scholars research fund (Grant 20JQ07).
Conflict of Interest
SL and ZD are employed by EVision Technology (Beijing) co. LTD., Beijing, China.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Shin HC, Roth HR, Gao M, Lu L, Xu Z, Nogues I, et al. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans Med Imaging. (2016) 35:1285–98. doi: 10.1109/TMI.2016.2528162
2. Wu J, Yilmaz E, Zhang M, Li H, Tan KC. Deep spiking neural networks for large vocabulary automatic speech recognition. Front Neurosci. (2020) 14:199. doi: 10.3389/fnins.2020.00199
3. Juhn Y, Liu H. Artificial intelligence approaches using natural language processing to advance EHR-based clinical research. J Allergy Clin Immunol. (2020) 145:463–9. doi: 10.1016/j.jaci.2019.12.897
4. Gargeya R, Leng T. Automated identification of diabetic retinopathy using deep learning. Ophthalmology. (2017) 124:962–9. doi: 10.1016/j.ophtha.2017.02.008
5. Roberts PK, Vogl WD, Gerendas BS, Glassman AR, Bogunovic H, Jampol LM, et al. Quantification of fluid resolution and visual acuity gain in patients with diabetic macular edema using deep learning: a post hoc analysis of a randomized clinical trial. JAMA Ophthalmol. (2020) 138:945–53. doi: 10.1001/jamaophthalmol.2020.2457
6. Hood DC, De Moraes CG. Efficacy of a deep learning system for detecting glaucomatous optic neuropathy based on color fundus photographs. Ophthalmology. (2018) 125:1207–8. doi: 10.1016/j.ophtha.2018.04.020
7. Burlina PM, Joshi N, Pekala M, Pacheco KD, Freund DE, Bressler NM. Automated grading of age-related macular degeneration from color fundus images using deep convolutional neural networks. JAMA Ophthalmol. (2017) 135:1170–6. doi: 10.1001/jamaophthalmol.2017.3782
8. Gensure RH, Chiang MF, Campbell JP. Artificial intelligence for retinopathy of prematurity. Curr Opin Ophthalmol. (2020) 31:312–7. doi: 10.1097/ICU.0000000000000680
9. Yan YN, Wang YX, Xu L, Xu J, Wei WB, Jonas JB. Fundus tessellation: prevalence and associated factors: the beijing eye study 2011. Ophthalmology. (2015) 122:1873–80. doi: 10.1016/j.ophtha.2015.05.031
10. Guo Y, Liu L, Zheng D, Duan J, Wang Y, Jonas JB, et al. Prevalence and associations of fundus tessellation among junior students from greater Beijing. Invest Ophthalmol Vis Sci. (2019) 60:4033–40. doi: 10.1167/iovs.19-27382
11. Ohno-Matsui K, Kawasaki R, Jonas JB, Cheung CM, Saw SM, Verhoeven VJ, et al. International photographic classification and grading system for myopic maculopathy. Am J Ophthalmol. (2015) 159:877–83.e7. doi: 10.1016/j.ajo.2015.01.022
12. Jagadeesh D, Philip K, Naduvilath TJ, Fedtke C, Jong M, Zou H, et al. Tessellated fundus appearance and its association with myopic refractive error. Clin Exp Optom. (2019) 102:378–84. doi: 10.1111/cxo.12822
13. Switzer DW Jr., Mendonça LS, Saito M, Zweifel SA, Spaide RF. Segregation of ophthalmoscopic characteristics according to choroidal thickness in patients with early age-related macular degeneration. Retina. (2012) 32:1265–71. doi: 10.1097/IAE.0b013e31824453ac
14. Warrow DJ, Hoang QV, Freund KB. Pachychoroid pigment epitheliopathy. Retina. (2013) 33:1659–72. doi: 10.1097/IAE.0b013e3182953df4
15. Song M, Yang Y, He J, Yang Z, Yu S, Xie Q, et al. Prognostication of chronic disorders of consciousness using brain functional networks and clinical characteristics. Elife. (2018) 7:e36173. doi: 10.7554/eLife.36173
16. Shao L, Zhang QL, Long TF, Dong L, Zhang C, Da Zhou W, et al. Quantitative assessment of fundus tessellated density and associated factors in fundus images using artificial intelligence. Transl Vis Sci Technol. (2021) 10:23. doi: 10.1167/tvst.10.9.23
17. Shao L, Xu L, You QS, Wang YX, Chen CX, Yang H, et al. Prevalence and associations of incomplete posterior vitreous detachment in adult Chinese: the Beijing eye study. PLoS ONE. (2013) 8:e58498. doi: 10.1371/journal.pone.0058498
18. Heagerty PJ, Lumley T, Pepe MS. Time-dependent ROC curves for censored survival data and a diagnostic marker. Biometrics. (2000) 56:337–44. doi: 10.1111/j.0006-341X.2000.00337.x
19. Alicioglu G, Sun B, Ho SS. Assessing accident risk using ordinal regression and multinomial logistic regression data generation. in 2020 International Joint Conference on Neural Networks, IJCNN 2020–Proceedings [9207105] (Proceedings of the International Joint Conference on Neural Networks). Glasgow: Institute of Electrical and Electronics Engineers Inc (2020). doi: 10.1109/IJCNN48605.2020.9207105
21. Zhang H, Zhang Z. Feedforward networks with monotone constraints. Int Joint Conf Neural Netw. (1999) 3:1820–3. doi: 10.1109/IJCNN.1999.832655
22. Huang-Fu CY, Liao CH, Wu JY. Comparing the performance of machine learning and deep learning algorithms classifying messages in Facebook learning group. in 2021 International Conference on Advanced Learning Technologies (ICALT). Tartu: IEEE (2021). p. 347–9. doi: 10.1109/ICALT52272.2021.00111
23. Tan NYQ, Tham YC, Ding Y, Yasuda M, Sabanayagam C, Saw SM, et al. Associations of peripapillary atrophy and fundus tessellation with diabetic retinopathy. Ophthalmol Retina. (2018) 2:574–81. doi: 10.1016/j.oret.2017.09.019
Keywords: fundus tessellation, fundus tessellated density, fundus tessellation severity, machine learning, the Beijing eye study
Citation: Shao L, Zhang XM, Hu T, Chen Y, Zhang C, Dong L, Ling SG, Dong Z, Zhou WD, Zhang RH, Qin L and Wei WB (2022) Prediction of the Fundus Tessellation Severity With Machine Learning Methods. Front. Med. 9:817114. doi: 10.3389/fmed.2022.817114
Received: 17 November 2021; Accepted: 28 January 2022;
Published: 10 March 2022.
Edited by:
Zhenzhen Liu, Sun Yat-sen University, ChinaReviewed by:
Shruti Jain, Jaypee University of Information Technology, IndiaWei Zhang, Sichuan University, China
Copyright © 2022 Shao, Zhang, Hu, Chen, Zhang, Dong, Ling, Dong, Zhou, Zhang, Qin and Wei. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wen Bin Wei, d2Vpd2VuYmludHJAMTYzLmNvbQ==; Lei Qin, cWlubGVpQHVpYmUuZWR1LmNu
†These authors have contributed equally to this work