
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Med. , 13 January 2023
Sec. Ophthalmology
Volume 9 - 2022 | https://doi.org/10.3389/fmed.2022.1040562
This article is part of the Research Topic Big Data and Artificial Intelligence in Ophthalmology - Clinical Application and Future Exploration View all 10 articles
 Syed Muhammad Ali Imran1†
Syed Muhammad Ali Imran1† Muhammad Waqas Saleem2
Muhammad Waqas Saleem2 Muhammad Talha Hameed2Abida Hussain1
Muhammad Talha Hameed2Abida Hussain1 Rizwan Ali Naqvi3*†Seung Won Lee4*
Rizwan Ali Naqvi3*†Seung Won Lee4*Introduction: Ophthalmic diseases are approaching an alarming count across the globe. Typically, ophthalmologists depend on manual methods for the analysis of different ophthalmic diseases such as glaucoma, Sickle cell retinopathy (SCR), diabetic retinopathy, and hypertensive retinopathy. All these manual assessments are not reliable, time-consuming, tedious, and prone to error. Therefore, automatic methods are desirable to replace conventional approaches. The accuracy of this segmentation of these vessels using automated approaches directly depends on the quality of fundus images. Retinal vessels are assumed as a potential biomarker for the diagnosis of many ophthalmic diseases. Mostly newly developed ophthalmic diseases contain minor changes in vasculature which is a critical job for the early detection and analysis of disease.
Method: Several artificial intelligence-based methods suggested intelligent solutions for automated retinal vessel detection. However, existing methods exhibited significant limitations in segmentation performance, complexity, and computational efficiency. Specifically, most of the existing methods failed in detecting small vessels owing to vanishing gradient problems. To overcome the stated problems, an intelligence-based automated shallow network with high performance and low cost is designed named Feature Preserving Mesh Network (FPM-Net) for the accurate segmentation of retinal vessels. FPM-Net employs a feature-preserving block that preserves the spatial features and helps in maintaining a better segmentation performance. Similarly, FPM-Net architecture uses a series of feature concatenation that also boosts the overall segmentation performance. Finally, preserved features, low-level input image information, and up-sampled spatial features are aggregated at the final concatenation stage for improved pixel prediction accuracy. The technique is reliable since it performs better on the DRIVE database, CHASE-DB1 database, and STARE dataset.
Results and discussion: Experimental outcomes confirm that FPM-Net outperforms state-of-the-art techniques with superior computational efficiency. In addition, presented results are achieved without using any preprocessing or postprocessing scheme. Our proposed method FPM-Net gives improvement results which can be observed with DRIVE datasets, it gives Se, Sp, and Acc as 0.8285, 0.98270, 0.92920, for CHASE-DB1 dataset 0.8219, 0.9840, 0.9728 and STARE datasets it produces 0.8618, 0.9819 and 0.9727 respectively. Which is a remarkable difference and enhancement as compared to the conventional methods using only 2.45 million trainable parameters.
Ophthalmic diseases are increasing at an alarming rate. Early and automated diagnosis can help in preventing chronic ophthalmic disorders. Ophthalmic diseases include glaucoma, macular degeneration, Sickle cell retinopathy (SCR), and hypertensive and diabetic retinopathy. All of these are common but serious ophthalmic diseases and can lead to vision loss if not diagnosed at an early stage. An ophthalmological image assessment is commonly used for retinal disease analysis which shows retinal vessel changes that can lead to vision loss problems (1). Another vision loss syndrome that is affected by retinal ischemia is Sickle cell retinopathy (SCR). Reduced vessel density and altered vasculature shape are symptoms of sickle cell retinopathy (SCR) illness. Important biomarkers for early SCR identification include retinal vessels (1). A high blood sugar level causes the retinal illness known as diabetic retinopathy, which causes retinal vessels to enlarge or leak (2). A retinal condition called hypertensive retinopathy causes restricted retinal vessels as a result of elevated blood pressure which can be especially noticeable in the micro-vasculature (3). The location of the retinal vascular blockage can be determined using retinal vascular changes, which are often seen in bigger arteries. These retinal vascular illnesses are strongly related to the retinal morphologies of arteries and some other vessel diseases (1). Aimed at the early finding of chronic ophthalmic disorders by using different fundus images are retinal vessels which are a vital biomarker.
Precise retinal image analysis is necessary for early ophthalmic diagnosis. The complicated nature of the retinal blood vessels makes them essential biomarkers for diagnosing and analyzing many retinal disorders. However, it can be difficult to detect little changes in retinal vessels. Retinal vascular morphology includes location, thickness, tortuosity, formation, and removal, and is linked to several ocular illnesses (4). Ophthalmologists assess and record changes in the retinal vasculature manually. This procedure is time-consuming and labor-intensive. Additionally, the diagnosis of the aforementioned disorders can be made using the size of the retinal vessels, which is a distinct change that is difficult to find and evaluate using manual image analysis (4) by medical practitioners. Automatic illness inquiry is becoming more prevalent as deep learning technology progresses to help doctors make quicker and more accurate diagnoses (1). As the analysis of medical images is a crucial component of computer-aided disease diagnosis. Due to their dependability and adaptability, artificially intelligence-based approaches are more well-known in syndrome investigation than traditional image processing techniques. Deep learning-based algorithms help medical specialists to analyze various diseases using computer vision approaches (1–8).
Computer vision has an immense potential to evaluate these retinal disorders through image analysis for premature diagnosis. Ophthalmologists and other medical professionals are dealing with a variety of diagnostic challenges with the use of deep learning techniques like medical image segmentation. Semantic segmentation using deep learning is a cutting-edge technology for medical image segmentation that helps to avoid the manual processing of images for disease or symptom diagnosis (7). Most of the work done already for the retinal vessels segmentation is based on general image processing schemes; in which several image augmentation patterns were used to enhance the image contrast and detection process, which is usually based on some specific threshold. In such a case, a specific threshold cannot perform better with changes in the image acquisition system. Therefore, to incorporate the portability of the method, learning-based-segmentation algorithms are famous.
The process of semantic segmentation entails giving class labeling to each pixel of the image. Semantic segmentation may be thought of as the process of identifying an image class and isolating it from the other image classes by overlaying a segmentation mask on top of it. Features extraction features and representations are frequently necessary for semantic segmentation to obtain an optimal correlation of the image, effectively reducing the noise. The suggested study explains the deep-learning-based semantic segmentation technique called Feature Preserving Mesh Network (FPM-Net) for the detection of precise retinal vasculature in fundus images. Here, we use multiple convolution layers with a combination of depth-wise separable convolutions to lessen the overall trainable parameters. Due to the spatial information being lost as a result of the pooling of layers, we employed feature-preserving blocks to maintain feature map sizes that were large enough to handle the lost spatial information. The dense connection prevents the vanishing gradient issue that plagues traditional networks' feature latency (9), leading to improved training. This feature-preserving block results in enhanced sensitivity of the suggested FPM Network without using costly preprocessing techniques. Finally, preserved features, low-level input image information, and up-sampled spatial features are aggregated at the final concatenation stage for improved prediction accuracy.
The suggested FPM-Net method was applied to the fundus images in three different publically available databases (5), The technique is reliable since it performs better even after being trained on the DRIVE database (2), STARE database (10), and CHASE-DB1 (10), making it appropriate for images captured under various situations without retraining. After experiments, the outcomes of segmentation concluded a meliorated performance with accuracy (Acc), sensitivity (Se), specificity (SP), and area under the curve (AUC) for retinal vasculature segmentation. The suggested method FPM-Net has a much better performance than conventional methods.
The structure of this paper is as follows. Some conventional and automated methods relevant to this work will be presented in Section 2. The embedding strategy and method are given in Section 3. Results can be found in Section 4 and discussions in Section 5. In Section 6, a conclusion is provided.
An increasing rate of growth is being observed in ophthalmic illnesses. Chronic ocular problems can be avoided with early and automated diagnosis. Retinal vascular alterations, which are frequently observed in larger arteries, can be used to pinpoint the exact location of the retinal vascular occlusion. The retinal morphology of arteries and a few other vessel diseases are closely related to these retinal vascular diseases (1). Retinal vessels, an important biomarker, are used to detect chronic retinal problems early by employing various fundus image observations. However, it could be challenging to spot slight variations in retinal vessels. The location, thickness, tortuosity, creation, and removal of retinal vessels all affect their morphology and are associated with several retinal diseases (4). Ophthalmologists manually evaluate and document changes to the retinal vasculature. This process takes a lot of time and effort. Additionally, the size of the retinal vessels, which is a unique alteration that is challenging to discover and analyze using manual image analysis (4), can be used to diagnose the aforementioned illnesses.
The evaluation of these retinal illnesses by image processing for early diagnosis has enormous potential for computer vision. Ophthalmologists and other medical practitioners are using deep learning methods like medical image segmentation to address a range of diagnostic issues. Deep learning-based semantic segmentation is an absolute technique for medical image segmentation that eliminates the need for manual image processing for the identification of illness or symptom (7).
Automated approaches are important for lowering the diagnostic workload of medical specialists, and the detection of retinal vasculature can be helpful for the premature investigation of a variety of eye-related diseases. There are two basic methods for segmenting retinal vessels: feature-based deep learning techniques and traditional image processing approaches. Various studies have been conducted using traditional techniques and common image-processing algorithms. Here we describe recent advances in image analysis and deep functionality learning techniques. Traditional image processing techniques have been studied recently, and deep learning-based techniques have grown with great constancy and performance (1). Researchers have previously developed a variety of machine-learning methods to separate the blood vessels from imaging the retinal fundus. When handling testing conditions such as recognized low-contrast micro-vessels, vessels with focal reflexes, and vessels within the sight of diseases, a significant number of visible retinal vessel division techniques are prone to more unfavorable results (2).
Numerous image-enhancement techniques are frequently used before thresholding in traditional image processing-based vessel segmentation approaches. In addition to using contrast-limited adaptive histogram equalization (CLAHE) to rise the divergence of fundus images, Alhussein et al. developed a segmentation method centered on Wiener and morphological filtering (3). The primary vascular region was located using the detector-based vessel identification approach developed by Zhou et al., and after the noise was removed, a Markov model was used to locate retinal vasculatures (11). In a similar vein, Ahamed et al. reported segmenting the autonomic vasculature multiscale line detection-based approach. To increase contrast, they added CLAHE toward the green channel and for the final segmentation, they combined morphological thresholding and hysteresis (4). For the segmentation of retinal vessels, Shah et al. employed a multiscale line-detection technique. The images aimed at vessel segmentation were made better on the green channel using Gabor wavelet superposition and multiscale line detection (4). Using top hat with homomorphic filtering, Soto et al. presented a three-stage method. Following the initial stage of visual smoothing for image enhancement, two phases were employed to separately segment both thin and thick vessels. The segmentation findings were improved in the final stage with the application of morphological post-processing (5). Li et al. introduced an unsupervised technique in which integrated-tube marked point processes were applied to extract the vascular network from the images and to preprocess the images, image-enhancing techniques were applied. Utilizing the discovered tube width expansion, the final segmentation was carried out (7). Aswini et al. introduced an un-supervised technique consisting of hysteresis thresholding with two folds to identify retinal vessels. In their approach, morphological smoothness and background reduction were used to improve the fundus images before thresholding (8). Another approach based on image processing segmented the vasculature using the curvelet transform and line operation after pre-processing using anisotropic diffusion filtering, adaptive histogram equalization, and color space translation (11). Sundaram et al. suggested a hybrid strategy based on bottom-hat transform and multiscale image augmentation, where the segmentation work was carried out using morphological procedures (10). To reduce the aggravating noise that prevents vessel segmentation, using a probabilistic patch-based denoiser was recommended by Khawaja et al. (2) that combines a customized Frangi filter with a denoiser. After the CLAHE procedure, images are enhanced using an aggregated block-matching 3-D speckled filter, Naveed et al. suggested an unsupervised technique. Multiscale line detectors along with Frangi detectors were used in their model to segment data (12).
All the above-discussed methods are traditional image processing and some deep-feature-based learning techniques are used to investigate retinal vasculature segmentation. Learning-based approaches are increasingly well-known because, through feature-based learning, they may imitate the expertise of medical professionals. Furthermore, techniques for image augmentation make it possible to complete the task with lesser training samples. For supervised vessel segmentation, Oliveira et al. suggested an entirely convolutional deep-learning technique. They employed a multiscale convolutional network in a patch-based scenario, which was investigated by some kind of stationary wavelet transform (13).
Fraz et al. integrated the vessel centerlines identification method with the morphological bit plane slicing technique. They coupled bit plane slicing with vessel centerline on the enhanced gray-level images of retinal blood vessels (14). In addition to performing a mathematical morphological procedure on the image, Ghoshal et al. suggested an enhanced vascular extraction method from retinal images. They made negative grayscale images from the original and the image that had been removed from the vessels, then they excised to balance the image and then improved to produce thin vessels by turning the produced image into a binary image. To produce the vessel-extracted image, they finally combined the thin vessel image and binary image. They claimed that their performance results were satisfactory (15). The answers from the two-dimensional Gabor wavelet transform at various scales of each pixel were utilized as features by Soares et al. after they used this transform with supervised learning. They rapidly categorized a complicated model using a Bayesian classifier (16). To determine the properties necessary for segmenting retinal blood vessels, Ricci and Perfetti suggested a technique based on line operators. Because their model uses a line detector to analyze the green channel of retinal images, it is quicker and requires fewer features than prior approaches (17). A multi-layered forward-oriented artificial neural network was trained using the suggested artificial neural network approach by Marin et al. using a seven-dimensional feature vector. They employed the sigmoid activation function in each neuron of the three-layer network. They claimed that additional datasets are also successfully used by the trained network (18). A technique using a CNN architecture was created by Melinscak et al. to determine if each pixel is a vessel or a backdrop (19). According to Wang et al. proposal for a new retinal vascular segmentation approach that uses patch-based learning and Dense U-net, the approach seems attractive in terms of standard performance criteria (20). For segmenting retinal vessels, Guo et al. developed a CNN-based two-class classifier comprising two convolution layers and pooling layers, one dropout layer, and one loss layer. They concluded that the suggested approach had good accuracy and was quick to teach (21). Concerning the information loss brought on by image scaling during preprocessing, Leopold et al. proposed PixelBNN, an effective deep learning system for automatically segmenting fundus morphologies, and reported that it had a reduced test time and reasonably high performance (9). Technology advancements have produced images with a higher pixel density, sharp features, and a lot of data. As a result, good image quality can satisfy the requirements for actual application in image analysis and image comprehension (22). CNN is effective in classifying images and detecting objects, although the results vary depending on the network design, activation function chosen, and input picture quality. Poor quality input images have a detrimental impact on a CNN's performance, according to research (23), even if it is not immediately apparent. IterNet, a novel model based on UNet that can uncover hidden vessel information from the segmented vessel image rather than the raw input image, was proposed by Li et al. IterNet is made up of several mini-UNet iterations that can be up to four times deeper than a typical UNet (24). A new approach for segmenting blood vessels in retinal images was put out by Tchinda et al. The artificial neural networks and conventional edge detection filters are the foundation of this approach. The features vector is first extracted using edge detection filters. An artificial neural network is trained using the obtained characteristics to determine whether or not each pixel is a part of a blood artery (25).
According to the properties of the retinal vessels in fundus images, a residual convolution neural network-based retinal vessel segmentation technique is presented. The encoder-decoder network structure is built by joining the low-level and high-level feature graphs, and atrous convolution is added to the pyramid pooling. The improved residual attention module and deep supervision module are used. The results of the trials performed using the fundus image data set from DRIVE and STARE demonstrate that this algorithm can successfully segment all retinal vessels and identify related vessel stems and terminals. This approach can identify more capillaries and is viable and successful for segmenting retinal vessels in fundus images (11). One of the most serious infectious diseases in the world, tuberculosis causes 25% of all preventable deaths in underdeveloped nations. This cross-sectional descriptive research set out to assess the effects of ocular TB on visual acuity both before and after 2 months of vigorous anti-tubercular treatment. Three individuals with pleural TB, seven with disseminated tuberculosis, and 133 with pulmonary tuberculosis comprised the sample. Every patient got a standard eye examination, which included measuring visual acuity and performing necessary indirect ophthalmoscopes, biomicroscopy, applanation tonometry, and fluorescence angiography. None of the patients exhibited tuberculosis-related vision impairment. The incidence of ocular involvement was determined to be 4.2% (6/143). Five of the six individuals with ocular involvement and one of the suspected ocular lesions satisfied the diagnostic criteria for probable ocular lesions. Two individuals showed bilateral findings of different ocular lesions: one had sclera uveitis and the other had choroidal nodules. The remaining four patients all had unilateral lesions, including unilateral choroidal nodules in the right eye, unilateral choroidal nodules in the left eye, and unilateral peripheral retinal artery blockage in the right eye (two cases). After 2 months of rigorous therapy, patients made favorable improvements with no discernible visual loss (26).
As explained in section 2, retinal vessels are assumed as an important potential biomarker for the diagnosis of many ophthalmic diseases. A very growing number of ophthalmic illnesses are found in a large number of people around the globe. Preventing persistent ocular problems can be aided by early and automated diagnosis. Precise retinal image analysis is necessary for early ophthalmic diagnosis. Numerous AI-based techniques provide intelligent solutions for automatic retinal vessel recognition. However, segmentation performance, complexities, and computing efficiency were significantly constrained by previous approaches. Due to the vanishing gradient issue, and conventional architectural design, the majority of the currently used approaches specifically failed to achieve a higher true positive rate. Figure 1 provides an outline of the suggested technique. The suggested technique simply uses fundus images as input deprived of applying the requirement of any pre-processing scheme. FPM-Net is applied to the input image for pixel-wise classification. The suggested network categorizes each pixel into two major categories: “vessel” (for vessel pixel) and “background” (for pixels other than vessels). Because of this, it provides a binary segmentation mask with values of “1” on vessels as well as “0” on the other classes. FPM-Net incorporates a feature-preserving block for enhanced performance and fast convergence.
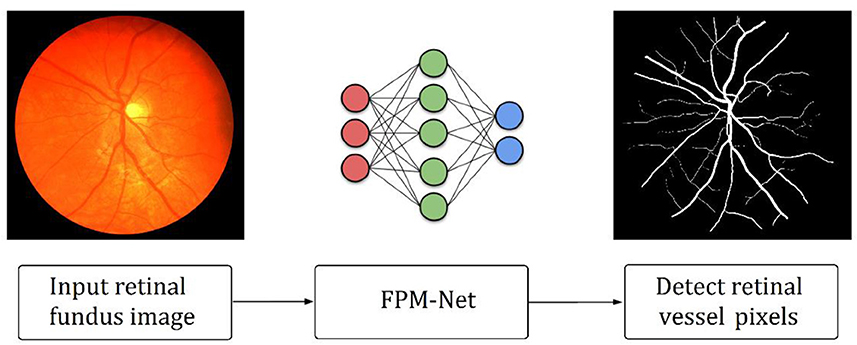
Figure 1. Outline of the suggested FPM-Net approach.
A suggested network for segmenting vessels that was created especially to improve the sensitivity (a better true positive rate) of retinal vascular detection is called a Feature Preserving Mesh Network (FPM-Net). The suggested FPM-Net is shown in Figure 2. Observe (Figure 2) that FPM-Net is a dense network composed of multiple convolution operations, and a shallow feature up-sampling block (FUB) followed by mesh-connected dense feature down-sampling block (FDB), and this overall architecture differs from conventional semantic segmentation networks like Seg-Net, U-Net, and DeepLabV3 in terms of encoder-decoder architecture where the decoder is same as an encoder.
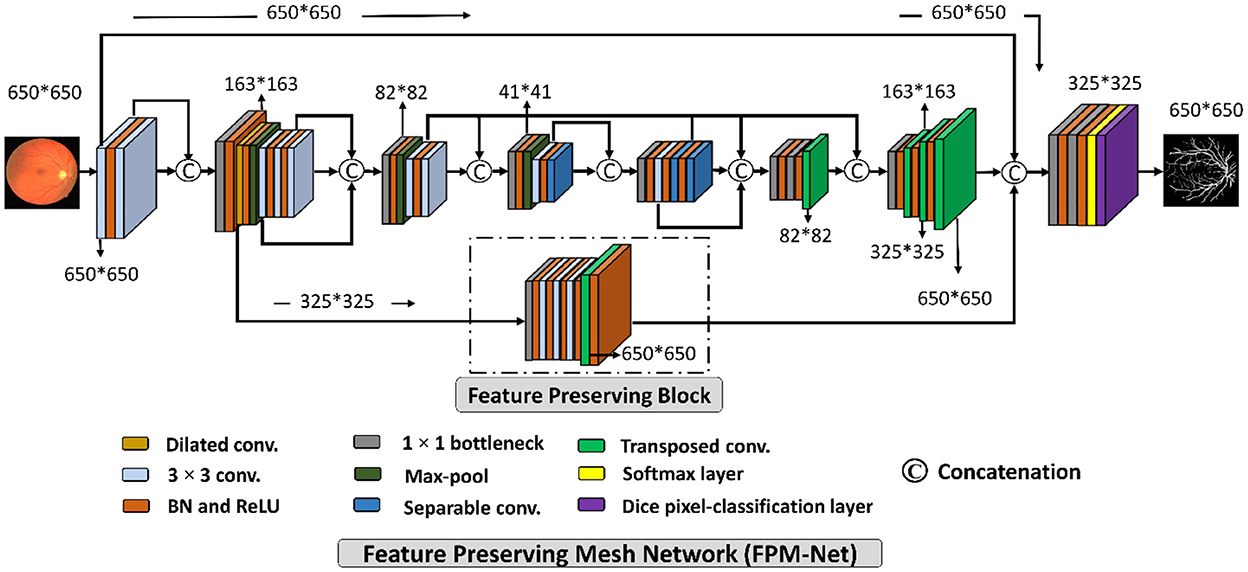
Figure 2. The suggested Feature Preserving Mesh Network (FPM-Net) architecture for retinal vessels segmentation.
To address above mentioned issues with conventional networks, FPM-Net is following four design principles. First, multiple uses of convolution layers in deep networks (e.g., VGG16) cause spatial loss if they are used without a feature reuse policy and the overall performance deteriorates (27). Following Dense-Net (22), to cover the spatial loss, dense connections are used between the convolution layers available in the network which guarantees the immediate feature transfer without latency. Secondly, the convolution layers with a larger number of channels contribute to increasing the number of learnable parameters substantially. To reduce the network cost, we use depth-wise separable convolution on the deep side of the network. Third, the spatial information that is available in the initial layers is very important as it contains the low-level features to represent the edges. The FPM-Net is utilizing a dense mesh that is connecting all the convolutional layers and transfers this valuable low-level information from FDB to FUB directly. This ensures the immediate edge information transfer without latency which results in better segmentation performance and quicker convergence of the network. Fourth, the multiple pooling operation causes severe spatial information loss that inevitably leads to a deterioration in performance (28). Traditional convolutional neural networks employ excessive pooling operations for reducing the feature map size which is equally important to control memory usage. To cover the issues created by multiple pooling layers (minor information loss due to small feature map size), FPM-Net is using the feature preserving block (FPB) which keeps the feature map size larger to represent approximately all the valued features that can signify the vessel pixels. FPB is composed of a few low-cost convolution layers, and it is responsible to transfer a large feature map to the FUB. This FPM-Net provides better segmentation accuracy and is computationally efficient because it does not require a huge number of parameters for its training. This structure is completely diverse from traditional structures like Segmentation Networks (SegNet) (29) and U-Shaped Network (U-Net) (30), which employ a decoder similar to an encoder to produce an architecture that is excessively deep and has a lot of trainable parameters with many channels. Figure 2 explains the connectivity pattern of FPM-Net.
Figure 3 represents a schematic diagram for FPM-Net interconnection and the solid feature concatenation standards. The input convolution block uses the fundus images as input, runs them through many convolutional layers in FDB to extract significant features Fed for the investigation of the retinal vasculatures, and then sends the enhanced dense features Fed to the UB-A of FUB. K (Fed) is created by concatenating the enhanced dense features T(Fed) and intermediate feature information Fif that were acquired by the DFB-B and DFB-D, respectively. The K(Fed) feature, represented by Equation (1), is produced via depth-wise concatenation using both T(Fed) and Fif, where © represented depth-wise concatenation in green color. The Fb feature is being added to the feature-preserving block from the DFB-A. Since there haven't been any significant pooling operations, the feature Fp originating from the feature-preserving block (FPB) contains rich feature information that corresponds to the majority of the vessels in the images transfer to the final concatenation represented in red color.
Here, M is a densely concatenated feature made through the K'(Fed), a feature after the up-sampling block, Fp preserved features, upcoming from the feature preserving block, and edge information fei, upcoming from the input convolution block. Where © denotes depth-wise concatenation. After final concatenation represented in red color concluded the output result having Equation (2).
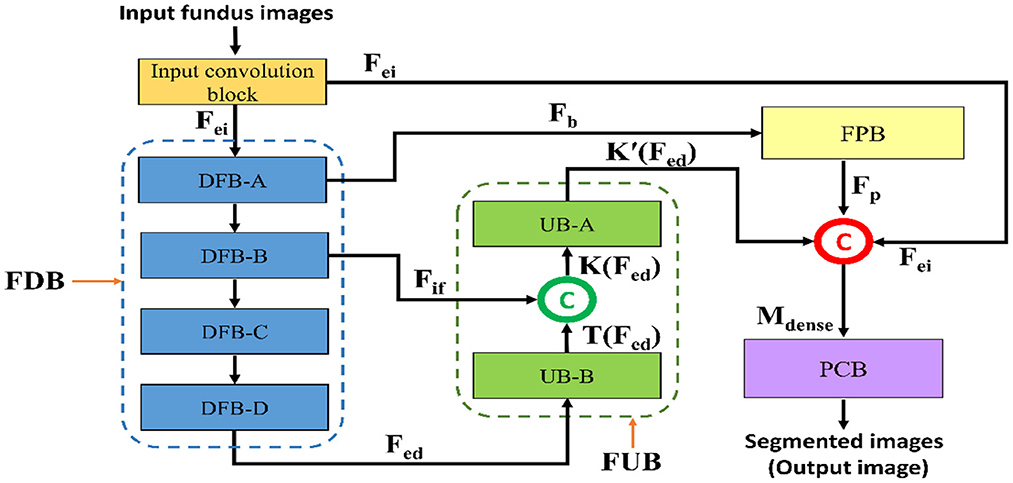
Figure 3. The schematic diagram for FPM-Net connectivity, FDB, FUB, FPB, and PCB represents the feature down-sampling block, feature up-sampling block, feature preserving block, and pixel classification block, respectively.
As shown in Figure 2, the suggested FPM-Net uses a feature-preserving block (FPB) to preserve valuable spatial information and disseminates it for the final concatenation. FPB takes the input from the dilated convolution, performs its function, and provides the feature results for the concatenation to the later layer. Because in the initial layer there is potential spatial information and features that can signify most of the vasculatures which will be helpful in the final prediction. The main problem that occurs while segmenting the image, the small objects were lost called the vanishing gradient but in FPB this vanishing gradient issue is solved. It simply uses three convolution layers and one transposed convolution to increase feature map size the feature map is resized to its original size using transposed convolution. As discussed above, the edge information from the initial layer, preserved features from FPB, and enhanced dense features are concatenated in the final stage which will boost the segmentation performance and improve the overall accuracy. After the final concatenation, softmax and pixel classification layers are utilized. The schematic structure of the feature-preserving block is mentioned in Figure 4.
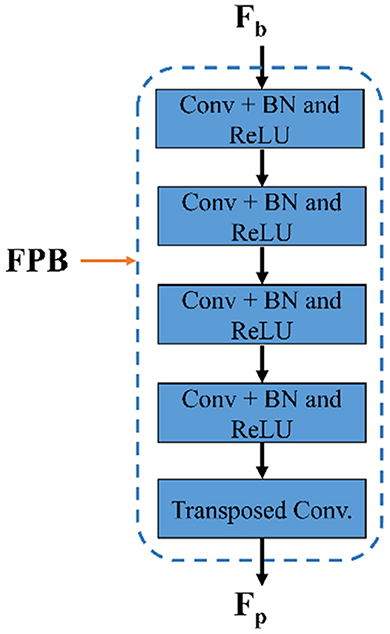
Figure 4. The structure of feature preserving block.
The final concatenation has shown in red before the pixel classification block is given the rich features, K, from the up-sampling block. The PCB encompasses a 1 × 1 bottleneck (used to reduce the number of channels for pixel classification block), softmax, and dice pixel classification layer. The image pixels are categorized using a dice pixel classification layer that uses dice loss to solve the class imbalance and give improved segmentation. In this instance, “vessel” and “background” are two segmentation classes with values of “1” and “0,” respectively. The pixel classification block is made up of a convolution whose filters are matched to the number of classes. The image pixels are identified using a pixel classification layer that uses dice loss to solve the class imbalance (31) and give improved segmentation. The dice loss (LDL) is represented mathematically as,
Where j refers to all of the image's observable pixels, i is the pixel under consideration, Q refers to the predicted labels, and R refers to the actual ground truth labels. RT − i is the actual ground truth label, and Qp − i is the expected possibility that pixel i belongs to a certain class.
Intend to find results, vessels analysis was done on the DRIVE (2), CHASE-DB1 (10), and STARE (10) datasets for the suggested technique and additional studies for overall evaluation. These datasets are publicly accessible, and pixel-wise expert annotations on the photographs allow researchers to assess the algorithms. The following describes these datasets.
In the DRIVE dataset, 40 red, green, and blue fundus images in total are included in the collection. The dataset comes with carefully separated ground truths for analysis. The images have a 565 x 584-pixel resolution and a 45° field of view (FOV). For improved training, the 20 training images are enhanced. Examples of expertly annotated images on or after the DRIVE dataset are displayed in Figure 5A. In the CHASE-DB1 dataset with 28 images using a fundus camera (Nidek NM-200D) with a typical FOV of 30°. Complying with the validation requirement, with a total of 28 images, 20 images (with augmentation) were used in our studies for training purposes and the remaining eight for testing purposes. Examples of image pairings with professional annotations are shown in Figure 5B. The STARE dataset is a collection of 20 retinal images taken by a TopCon TRV-50 with a FOV of 35°. For assessment reasons, professional image annotations are given per image. We used cross-validation using the leave-one-out method in our studies, in which training is done on 19 images and just one left for testing. Similarly to this, each image in the 20 studies was chosen specifically for testing. Twenty experiments on average were used to get the data. Examples of image pairings with professional annotations from the STARE dataset are shown in Figure 5C. The training and testing image descriptions for each dataset are displayed in Table 1.

Figure 5. (A) DRIVE Dataset visualizations of the suggested FPM-Net: (i) Input original image, (ii) Expert annotation (Ground truth), and (iii) Predicted mask by FPM-Net. (B) CHASE-DB1 Dataset visualizations of the suggested FPM-Net (i) Input original image, (ii) Expert annotation (Ground truth), and (iii) Predicted mask by FPM-Net. (C) STARE Dataset visualizations of the suggested FPM-Net (i) Input original image, (ii) Expert annotation (Ground truth), and (iii) Predicted mask by FPM-Net.
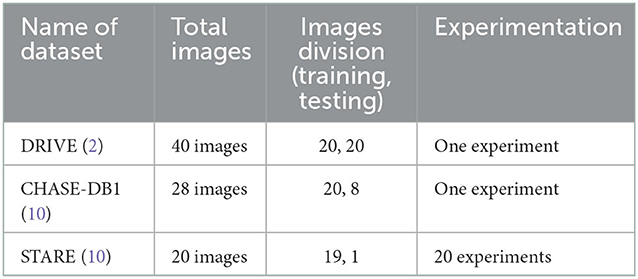
Table 1. Details of the testing and specifications of all three used datasets in our method.
The suggested FPM-Net was developed using Microsoft Windows 10, MathWorks MATLAB R2022a, with a laptop having specifications. An Intel Core i7-11800H processor and RAM of 16 GB. The tests were performed using an NVIDIA GeForce RTX 3070 8GB GDDR6 graphics processing unit. Without using any method for weight initialization, migration, sharing, or fine-tuning from previous networks, the suggested models were trained from scratch. Tables 3A–C lists the important training hyperparameters.
Deep learning's segmentation effectiveness is closely correlated with the capacity of training data with labels; effective training requirements, and a substantial amount of training data with labels. To boost the quantity of data, we used image flipping and translation. The modified augmentation method involved flipping 20 original images in both vertical direction and horizontal directions to produce a total of 60 images. Then, the total images produced after the flipping procedure are 3,000, from the DRIVE dataset were produced by repeatedly translating these 60 images into (x, y) values and then continuing to flip them. A training set is prepared using a random image generation procedure, where the points (x, y) satisfy the conditions. The CHASE-DB and STARE databases were similarly enhanced to provide 1,500 and 1,300 images, respectively.
Considering the training details FPM-Net utilized an epsilon of 0.000001, and the initial learning rate of 0.00005 was applied. Global L2 normalization is utilized for training due to the benefits of quicker convergence and robustness over rising variation. To train the FPM-Net, a mini-batch size of 16 images is used because it is a dense network and requires less GPU memory due to bottleneck layers. In 25 epochs, both networks converge (5,000 iterations).
The rich edge information is found in the starting layers by the network detection. By minimizing the vanishing gradient problem, the network's convergence is aided by the import of this data through skip connections (44). To investigate the efficacy of preserved features and dense connectivity for the suggested FPM-Net, an ablation study was conducted. In the ablation study, the training was done on FPM-Net architecture with and without FPB. Table 2 shows that, while maintaining the almost same number of parameters, FPB with preserved feature outperformed FPM-Net with dense connectivity in terms of true positive rate (SE), with a greater true positive rate. Table 2 clearly shows that feature concatenation caused a significant performance difference.
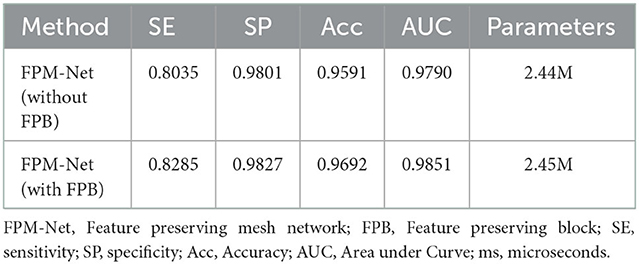
Table 2. Performance measures with ablation study.
For the suggested network output, FPM-Net offers a mask that displays all of the background and vessel pixels as “0” and “1,” respectively. Sensitivity (SE), Specificity (SP), Accuracy (Acc), and area under curve AUC, to measure the performance of segmentation which are frequently utilized to assess how well-retinal images are segmented, were computed using the output mask of the suggested network and expert annotations (16). SE is denoted as a true positive rate, which illustrates how well the network can find vessel pixels. The SP as a true negative rate demonstrates the capacity to identify non-vessel pixels. The whole percentage of accurate predictions made thru the approach is represented by Acc. Equations (4)–(6) give the respective expressions for SE, SP, and Acc. A pixel with the prefix TP is identified in the expert's annotation as a vessel pixel and is projected to be one. FN denotes a pixel that the expert annotation classifies as a vessel pixel even if it is expected to be a background pixel. A pixel with the prefix TN is identified in the expert's annotation as a vessel pixel and is expected to be one. FP denotes a pixel that the expert annotation classifies as a background pixel but which is expected to be a vessel pixel.
To evaluate and compare the suggested FPM network with the conventional techniques, vessel analysis was done on the publicly accessible DRIVE CHASE-DB1, and STARE datasets. For the vessel category and the background category, the network generates a mask with both the corresponding grayscale values of “1” and “0,” respectively. The visual outcomes of the suggested strategy for the three datasets stated above are shown in Figure 5. The suggested FPM-Net network's segmented image with the mask overlapped is shown in the figures along with the original images that were used as input into the network, experts provided the expert annotated image to evaluate research methods, the predicted mask at the network's production, and the predicted mask itself. The Numerical Comparison of Suggested FPM-Net utilizing the most recent technique is described in Tables 3A–C. By using our proposed method FPM-Net, there is significant improvement can be observed with DRIVE datasets, it gives Se, Sp, and Acc as 0.8285, 0.98270, 0.92920, for CHASE-DB1 dataset 0.8219, 0.9840, 0.9728 and STARE datasets it produces 0.8618, 0.9819 and 0.9727 respectively. Which is a remarkable difference and enhancement as compared to old and conventional methods.
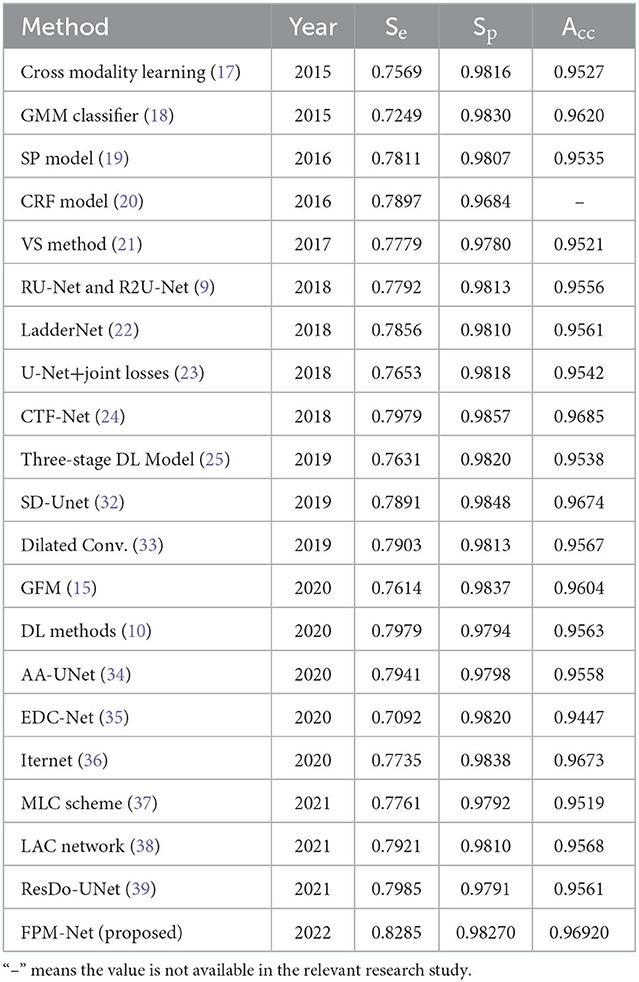
Table 3A. The comparison of the DRIVE data set's segmentation results using various segmentation techniques.
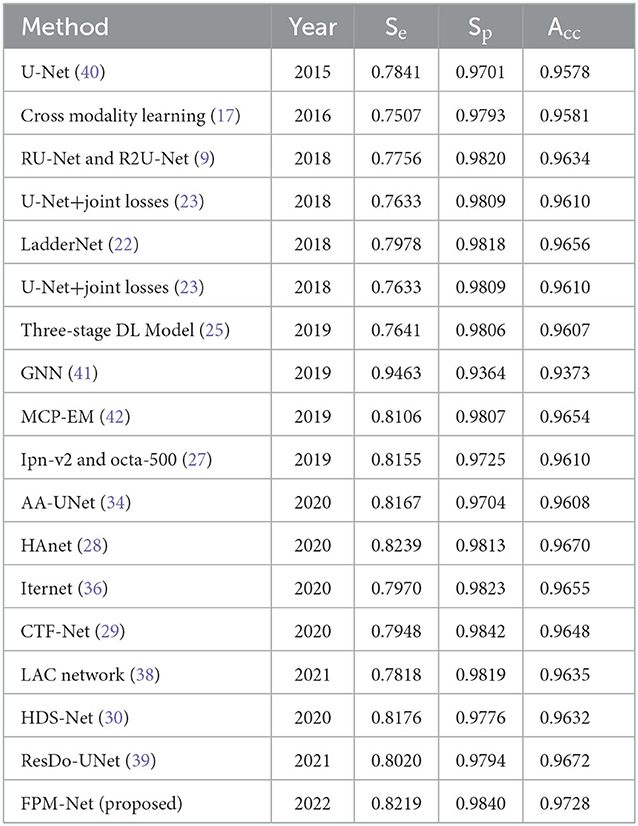
Table 3B. The comparison of the CHASE-DB1 data set's segmentation results using various segmentation techniques.
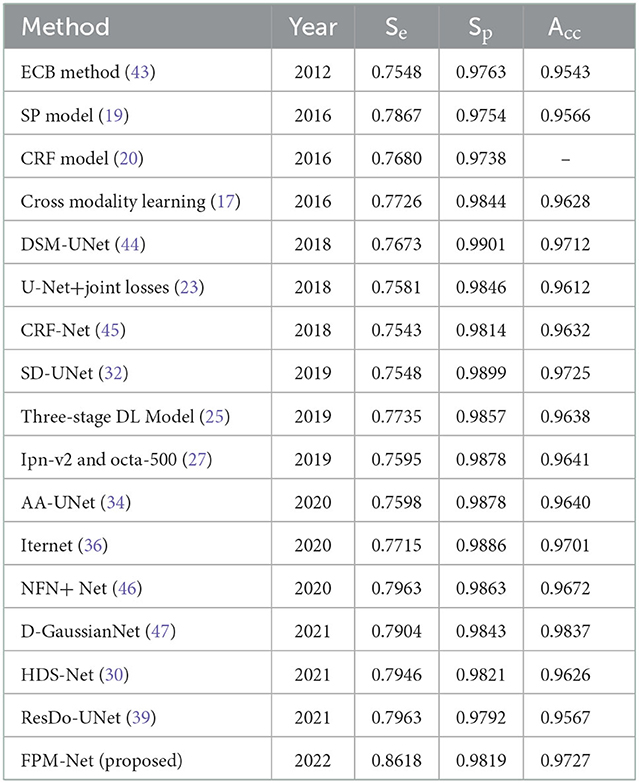
Table 3C. The comparison of the STARE data set's segmentation results using various segmentation techniques.
In this instance, the suggested method's graphical outcomes for the identification of retinal vessels on the datasets of fundus image e.g., DRIVE, CHASE-DB1, and STARE are shown. (i) input original image, (ii) expert annotation (Ground truth), and (iii) FPM-Net mask are shown in Figures 5A–C.
Precise retinal image analysis is necessary for early ophthalmic diagnosis. The complicated nature of the retinal blood vessels makes them essential biomarkers for diagnosing and analyzing many retinal disorders. However, it can be difficult to detect little changes in retinal vessels. Ophthalmologists assess and record changes in the retinal vasculature manually. To evaluate these retinal disorders through image investigation for premature diagnosis, computer vision has immense potential. Ophthalmologists and other medical professionals are dealing with a variety of diagnostic challenges with the use of deep learning techniques like medical image segmentation. Semantic segmentation using deep learning is a cutting-edge technology for medical image segmentation that helps to avoid the manual processing of images for disease or symptom diagnosis. With the advancement of supervised learning, autonomous sickness analysis is becoming more prevalent to help doctors make a quicker and more precise diagnosis. This semantic segmentation technique using deep learning will help ophthalmologists in this regard. The suggested study suggests the deep-learning-based semantic segmentation technique called FPM-Net for the detection of precise retinal vasculature in fundus images. Here, we use multiple convolution layers with a combination of depth-wise separable convolutions to lessen the overall trainable parameters. Due to the spatial information being lost as a result of the pooling of layers, we employed feature-preserving blocks to maintain feature map sizes that were large enough to handle the lost spatial information. The dense connection prevents the vanishing gradient issue that plagues traditional networks' feature latency (9), leading to improved training. This feature preserves block outcomes in improved sensitivity of the suggested FPM-Net deprived of using costly preprocessing techniques. Finally, preserved features, low-level input image information, and up-sampled spatial features are aggregated at the final concatenation stage for improved prediction accuracy. In previous studies, researchers used different networks such as AA-UNet (34), Iternet (36), NFN+ Net (46), D-GaussianNet (47), HDS-Net (30), and ResDo-Net (39) for the identification of Sensitivity (SE), Specificity (SP), Accuracy (Acc), and area under curve AUC, to measure the performance of segmentation which are frequently utilized to assess how well retinal images are segmented. But in this paper, our proposed FPM-Net produced more accurate results for SE, SP, Acc, and AUC than the rest of the research done by others. In this paper, a solid architecture is shown that enables precise semantic segmentation of the retinal blood vessels. The central ideas are discussed below.
• An efficient semantic segmentation network may give precise vessel detection deprived of the need for costly preprocessing.
• The network can learn adequate features for enhanced segmentation and quicker convergence because it delivers enhanced spatial information from the initial layers.
• Creating a shallow architecture can save many trainable parameters and it is not necessary to make feature up-sampling and feature down-sampling blocks identical. To reduce the network cost, we use depth-wise separable convolution on the deeper side of the network.
• While considering vessel segmentation, a shallower architecture with fewer layers and a smaller quantity of trainable parameters performs superior to robust architecture.
• The size of the ultimate feature map is essential. In contrast to existing architectures that significantly down-sample the image, FPM-Net avoids pooling layers and maintains enough feature map size which contains valuable features and offers better performance.
• Those techniques which are based on deep learning could help ophthalmologists do analysis more quickly and offer numerous approaches for analyzing diseases.
The original images used as input into the network, the expert-annotated image provided by experts to assess research methodologies, the predicted mask at the network's production, and the predicted mask itself are all displayed in the figures along with the suggested FPM-Net network's segmented image with the mask overlapped. Tables 3A–C describes the Numerical Comparison of the Suggested FPM-Net using the most recent method. By using our proposed method FPM-Net, there is significant improvement can be observed with DRIVE datasets, it gives Se, Sp, and Acc as 0.8285, 0.98270, 0.92920, for CHASE-DB1 dataset 0.8219, 0.9840, 0.9728 and STARE datasets it produces 0.8618, 0.9819 and 0.9727 respectively. Which is a remarkable difference and enhancement in results as compared to old and conventional methods.
Even though the suggested FPM-Net recognizes retinal vessels with better segmentation performance, the suggested technique still has certain limitations. A learning-based segmentation technique, the suggested FPM-Net largely depends on the input training data. Medical data for disease analysis are extremely challenging to organize in large quantities. The amount of training data must thus be artificially increased by data augmentation. Additionally, the learning-based approaches produce output masks depending on the knowledge they have acquired, and the network's ultimate prediction may contain pixels that are both false positive and false negative.
We want to minimize the network's overall cost in the future by efficiently reducing the number of convolutions. The proposed technique is based on deep learning, as well as its efficiency solely depends on excellent training with sufficient training data. Additionally, the accuracy of the labeling generated by an ophthalmologist directly affects the precision of learning-based techniques. This will make it feasible to evaluate how well-upcoming deep-learning techniques screen for these particular disorders. We also want to develop a little system for mobile applications that run instantly. The medical sector will subsequently utilize these networks for more semantic segmentation purposes.
The goal of this study was to develop a network for segmenting shallow vessels that might effectively be used to support computer-aided diagnostics in the identification and diagnosis of retinal disease. The proposed method utilized the FPM-Net shallow network, which provides a successful remedy for retinal vasculature for computer-aided diagnostics. The recommended FPM network uses less memory, has more trainable parameters, and fewer layers, and can be trained with larger mini-batch sizes. A separate network with the name of FPM-Net is used to maintain a reduced final feature map during its convolutional phase. FPM-Net contains an improved portion of FPB that incorporates an external path that saves and delivers essential spatial information to increase the accuracy and robustness of the technique. As a result, when compared to other traditional approaches for detecting retinal vessels, our suggested vessel segmentation networks are more reliable and perform better without preprocessing, and they may be utilized to help medical professionals to diagnose and analyze diseases.
Publicly available datasets were analyzed in this study. This data can be found at: Khawaja et al. (2) and Sundaram et al. (10).
SI: methodology and writing—original draft. MS, MH, and AH: validations. RN and SL: supervision and writing—review and editing. All authors have read and agreed to the published version of the manuscript.
This work was supported by a National Research Foundation (NRF) grant funded by the Ministry of Science and ICT (MSIT) and South Korea through the Development Research Program (NRF2022R1G1A1010226 and NRF2021R1I1A2059735).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Owais M, Arsalan M, Choi J, Mahmood T, Park KR. Artificial intelligence based classification of multiple gastrointestinal diseases using endoscopy videos for clinical diagnosis. J Clin Med. (2019) 8:986. doi: 10.3390/jcm8070986
2. Khawaja A, Khan TM, Naveed K, Naqvi SS, Rehman NU, Junaid Nawaz S. An improved retinal vessel segmentation framework using frangi filter coupled with the pobabilistic patch based denoiser. IEEE Access. (2019). 7:164344–61.
3. Alhussein M, Aurangzeb K, Haider SI. An unsupervised retinal vessel segmentation using Hessian and intensity based approach. IEEE Access. (2020) 8:165056–70. doi: 10.1109/ACCESS.2020.3022943
4. Ahamed ATU, Jothish A, Johnson G, Krishna SBV. Automated system for retinal vessel segmentation. In: 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT). IEEE (2018).
5. Ramos-Soto O, Rodr-Esparza E, Balderas-Mata SE, Oliva D, Hassanien AE, Meleppat RK, et al. An efficient retinal blood vessel segmentation in eye fundus images by using optimized top-hat and homomorphic filtering. Comput Methods Programs Biomed. (2021) 201:105949. doi: 10.1016/j.cmpb.2021.105949
6. Shah SAA, Shahzad A, Khan MA, Li C-K, Tang TB. Unsupervised method for retinal vessel segmentation based on gabor wavelet and multiscale line detector. IEEE Access. (2019) 7:167221–8.
7. Li T, Comer M, Zerubia J. An unsupervised retinal vessel extraction and segmentation method based on a tube marked point process model. In: ICASSP 2020-2020 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE (2020).
8. Aswini S, Suresh A, Priya S, Krishna BVS. Retinal vessel segmentation using morphological top hat approach on diabetic retinopathy images. In: 2018 Fourth International Conference on Advances in Electrical, Electronics, Information, Communication and Bio-Informatics (AEEICB). IEEE (2018).
9. Leopold HA, Orchard J, Zelek JS, Lakshminarayanan V. PixelBNN: Augmenting the PixelCNN with batch normalization and the presentation of a fast architecture for retinal vessel segmentation. J Imaging. (2019) 5:26. doi: 10.3390/jimaging5020026
10. Sundaram R, Ravichandran KS, Jayaraman P. Extraction of blood vessels in fundus images of retina through hybrid segmentation approach. Mathematics (2019) 7:169. doi: 10.3390/math7020169
11. Zhou C, Zhang X, Chen H. A new robust method for blood vessel segmentation in retinal fundus images based on weighted line detector and hidden Markov model. Comput Methods Programs Biomed. (2020) 187:105231. doi: 10.1016/j.cmpb.2019.105231
12. Naveed K, Abdullah F, Madni HA, Khan MAU, Khan TM, Naqvi SS. Towards automated eye diagnosis: An improved retinal vessel segmentation framework using ensemble block matching 3D filter. Diagnostics (Basel). (2021) 11:114. doi: 10.3390/diagnostics11010114
13. Oliveira A, Pereira S, Silva CA. Retinal vessel segmentation based on fully convolutional neural networks. Exp Syst Appl. (2018) 112:229–42. doi: 10.1016/j.eswa.2018.06.034
14. Fraz MM, Barman SA, Remagnino P, Hoppe A, Basit A, Uyyononvara B, et al. An approach to localize the retinal blood vessels using bit planes and centerline detection. Comput Method Pgm Biomed. (2012) 108:600–16. doi: 10.1016/j.cmpb.2011.08.009
15. Ghoshal R, Saha A, Das S. An improved vessel extraction scheme from retinal fundus images. Multimedia Tools Appl. (2019) 78:25221–39. doi: 10.1007/s11042-019-7719-9
16. Soares JVB, Leandro JJG, Ceser RM, Jelinek HF, Cree MJ. Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification. IEEE Trans Med Imag. (2006) 25:1214–22.
17. Ricci, E, Perfetti R. Retinal blood vessel segmentation using line operators and support vector classification. IEEE Trans Med Imag. (2007) 26:1357–65.
18. Marin D, Aquino A, Gegundez-Arias ME, Bravo JM.A new supervised method for blood vessel segmentation in retinal images by using gray-level and moment invariants-based features. IEEE Trans Med Imag. (2010) 30:146–58.
19. Melinscak M, Prentasic P, Loncaric S. Retinal Vessel Segmentation using Deep Neural Networks. VISAPP (2015).
20. Wang C, Zhao Z, Ren Q, Xu Y, Yu Y.Dense U-net based on patch-based learning for retinal vessel segmentation. Entropy. (2019) 21:168. doi: 10.3390/e21020168
21. Guo C, Szemenyei M, Pei Y, Yi Y, Zhou W. SD-UNet: A structured dropout U-Net for retinal vessel segmentation. In: 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE). IEEE (2019).
22. Zhuang J. LadderNet: Multi-path networks based on U-Net for medical image segmentation. arXiv [Preprint]. (2018). arXiv: 1810.07810. doi: 10.48550/arXiv.1810.07810
23. Yan Z, Yang X, Cheng K-T. Joint segment-level and pixel-wise losses for deep learning based retinal vessel segmentation. IEEE Trans Biomed Eng. (2018) 65:1912-23. doi: 10.1109/TBME.2018.2828137
24. Li L, Verma M, Nakashima Y, Nagahara H, Kawaski R. Iternet: Retinal image segmentation utilizing structural redundancy in vessel networks. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. IEEE (2020).
25. Tchinda BS, Tchioptop S, Noubom M, Louis-Dorr V, Wolf D. Retinal blood vessels segmentation using classical edge detection filters and the neural network. Inform Medicine Unlocked. (2021) 23:100521. doi: 10.1016/j.imu.2021.100521
26. de Oliveira SBV, Passos F, Hadad DJ, Zbyszynski L, de Almeida JPS, Castellani LGS, et al. The impact of ocular tuberculosis on vision after two months of intensive therapy. Braz J Infect Dis. (2018) 22:159–65. doi: 10.1016/j.bjid.2018.03.005
27. Li M, Zhang Y, Ji Z, Xie K, Yuan S, Liu Q, et al. Ipn-v2 and octa-500: Methodology and dataset for retinal image segmentation. arXiv [Preprint]. (2020). arXiv: 2012.07261. doi: 10.48550/arXiv.2012.07261
28. Wang D, Haytham A, Pottenburgh J, Saeedi O, Tao Y. Hard attention net for automatic retinal vessel segmentation. IEEE J Biomed Health Inform. (2020) 24:3384–96. doi: 10.1109/JBHI.2020.3002985
29. Wang K, Zhang X, Huang S, Wang Q, Chen F. Ctf-net: Retinal vessel segmentation via deep coarse-to-fine supervision network. In: 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI). Iowa City, IA: IEEE (2020). p. 1237–41.
30. Yang L, Wang H, Zeng Q, Liu Y, Bian G, A. hybrid deep segmentation network for fundus vessels via deep-learning framework. Neurocomputing. (2021) 448:168–78. doi: 10.1016/j.neucom.2021.03.085
31. Sudre CH, Li W, Vercauteren T, Ourselin S, Jorge Cardoso M. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In: Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. Quebec City, QC: Springer (2017). p. 240–8.
32. Guo C, Szemenyei M, Pei Y, Yi Y, Zhou W. SD-UNet: A structured dropout UNet for retinal vessel segmentation. In: 2019 IEEE 19th International Conference on Bioinformatics and Bioengineering (BIBE). Athens: IEEE (2019). p. 439–44.
33. Lopes AP, Ribeiro A, Silva CA. Dilated convolutions in retinal blood vessels segmentation. In: 2019 IEEE 6th Portuguese Meeting on Bioengineering (ENBENG). Lisbon: IEEE (2019). p. 1–4.
34. Lv Y, Ma H, Li J, Liu S. Attention guided U-Net with atrous convolution for accurate retinal vessels segmentation. IEEE Access. (2020) 8:32826–39. doi: 10.1109/ACCESS.2020.2974027
35. Sule O, Viriri S. Enhanced convolutional neural networks for segmentation of retinal blood vessel image. In: 2020 Conference on Information Communications Technology and Society (ICTAS). Durban: IEEE (2020). p. 1–6.
36. Li L, Verma M, Nakashima Y, Nagahara H, Kawasaki R. Internet: Retinal image segmentation utilizing structural redundancy in vessel networks. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE (2020). p. 3656–65.
37. Zou B, Dai Y, He Q, Zhu C, Liu G, Su Y, et al. Multi-label classification scheme based on local regression for retinal vessel segmentation. IEEE/ACMTrans Comput Biol Bioinform. (2020) 18:2586–97. doi: 10.1109/TCBB.2020.2980233
38. Li X, Jiang Y, Li M, Yin S. Lightweight attention convolutional neural network for retinal vessel image segmentation. IEEE Trans Indust Inform. (2020) 17:1958–67. doi: 10.1109/TII.2020.2993842
39. Liu Y, Shen J, Yang L, Bian G, Yu H. ResDO-UNet: A deep residual network for accurate retinal vessel segmentation fromfundus images. Biomed Signal Process Control. (2023) 79:104087. doi: 10.1016/j.bspc.2022.104087
40. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich: Springer (2015). p. 234–241.
41. Shin SY, Lee S, Yun ID, Lee KM. Deep vessel segmentation by learning graphical connectivity. Med Image Anal. (2019) 58:101556. doi: 10.1016/j.media.2019.101556
42. Tang P, Liang Q, Yan X, Zhang D, Coppola G, Sun W. Multiproportion channel ensemble model for retinal vessel segmentation. Comput Biol Med. (2019) 111:103352. doi: 10.1016/j.compbiomed.2019.103352
43. Fraz MM, Remagnino P, Hoppe A, Uyyanonvara B, Rudnicka AR, Owen CG, et al. An ensemble classification-based approach applied to retinal blood vessel segmentation. IEEE Trans Biomed Eng. (2012) 59:2538–48. doi: 10.1109/TBME.2012.2205687
44. Zhang Y, Chung A. Deep supervision with additional labels for retinal vessel segmentation task. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Hong Kong: Springer (2018). p. 83–91.
45. Hu K, Zhang Z, Niu X, Zhang Y, Cao C, Xiao F, et al. Retinal vessel segmentation of color fundus images using multiscale convolutional neural network with an improved cross-entropy loss function. Neurocomputing. (2018) 309:179–91. doi: 10.1016/j.neucom.2018.05.011
46. Wu Y, Xia Y, Song Y, Zhang Y, Cai W. NFN+: a novel network followed network for retinal vessel segmentation. Neural Netw. (2020) 126:153–62. doi: 10.1016/j.neunet.2020.02.018
Keywords: ophthalmic diseases, retinal vasculature, retinal image segmentation, semantic segmentation, computer–aided diagnosis
Citation: Imran SMA, Saleem MW, Hameed MT, Hussain A, Naqvi RA and Lee SW (2023) Feature preserving mesh network for semantic segmentation of retinal vasculature to support ophthalmic disease analysis. Front. Med. 9:1040562. doi: 10.3389/fmed.2022.1040562
Received: 09 September 2022; Accepted: 20 December 2022;
Published: 13 January 2023.
Edited by:
Steven Fernandes, Creighton University, United StatesReviewed by:
Usman Ali, Sungkyunkwan University, Republic of KoreaCopyright © 2023 Imran, Saleem, Hameed, Hussain, Naqvi and Lee. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rizwan Ali Naqvi,  cml6d2FuYWxpQHNlam9uZy5hYy5rcg==; Seung Won Lee, c3dsZWVtZEBnLnNra3UuZWR1
cml6d2FuYWxpQHNlam9uZy5hYy5rcg==; Seung Won Lee, c3dsZWVtZEBnLnNra3UuZWR1
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.