 Lin-Lin Xu1†
Lin-Lin Xu1† Di Zhang2,3,4†
Di Zhang2,3,4† Hao-Yi Weng2,3,4
Hao-Yi Weng2,3,4 Li-Zhong Wang2,3,4Ruo-Yan Chen2,3,4Gang Chen2,3,4
Li-Zhong Wang2,3,4Ruo-Yan Chen2,3,4Gang Chen2,3,4 Su-Fang Shi1Li-Jun Liu1
Su-Fang Shi1Li-Jun Liu1 Xu-Hui Zhong5
Xu-Hui Zhong5 Shen-Da Hong6Li-Xin Duan7
Shen-Da Hong6Li-Xin Duan7 Ji-Cheng Lv1
Ji-Cheng Lv1 Xu-Jie Zhou1*
Xu-Jie Zhou1* Hong Zhang1
Hong Zhang1- 1Renal Division, Peking University First Hospital, Kidney Genetics Center, Peking University Institute of Nephrology, Key Laboratory of Renal Disease, Ministry of Health of China, Key Laboratory of Chronic Kidney Disease Prevention and Treatment, Peking University, Ministry of Education, Beijing, China
- 2Hunan Provincial Key Lab on Bioinformatics, School of Computer Science and Engineering, Central South University, Changsha, China
- 3WeGene, Shenzhen Zaozhidao Technology, Shenzhen, China
- 4Shenzhen WeGene Clinical Laboratory, Shenzhen, China
- 5Department of Pediatrics, Peking University First Hospital, Beijing, China
- 6Institute of Medical Technology, Health Science Center of Peking University, Beijing, China
- 7The Sichuan Provincial Key Laboratory for Human Disease Gene Study, Research Unit for Blindness Prevention of Chinese Academy of Medical Sciences (2019RU026), Sichuan Academy of Medical Sciences and Sichuan Provincial People’s Hospital, University of Electronic Science and Technology of China, Chengdu, China
Background: Immunoglobulin A nephropathy (IgAN) is one of the leading causes of end-stage kidney disease (ESKD). Many studies have shown the significance of pathological manifestations in predicting the outcome of patients with IgAN, especially T-score of Oxford classification. Evaluating prognosis may be hampered in patients without renal biopsy.
Methods: A baseline dataset of 690 patients with IgAN and an independent follow-up dataset of 1,168 patients were used as training and testing sets to develop the pathology T-score prediction (Tpre) model based on the stacking algorithm, respectively. The 5-year ESKD prediction models using clinical variables (base model), clinical variables and real pathological T-score (base model plus Tbio), and clinical variables and Tpre (base model plus Tpre) were developed separately in 1,168 patients with regular follow-up to evaluate whether Tpre could assist in predicting ESKD. In addition, an external validation set consisting of 355 patients was used to evaluate the performance of the 5-year ESKD prediction model using Tpre.
Results: The features selected by AUCRF for the Tpre model included age, systolic arterial pressure, diastolic arterial pressure, proteinuria, eGFR, serum IgA, and uric acid. The AUC of the Tpre was 0.82 (95% CI: 0.80–0.85) in an independent testing set. For the 5-year ESKD prediction model, the AUC of the base model was 0.86 (95% CI: 0.75–0.97). When the Tbio was added to the base model, there was an increase in AUC [from 0.86 (95% CI: 0.75–0.97) to 0.92 (95% CI: 0.85–0.98); P = 0.03]. There was no difference in AUC between the base model plus Tpre and the base model plus Tbio [0.90 (95% CI: 0.82–0.99) vs. 0.92 (95% CI: 0.85–0.98), P = 0.52]. The AUC of the 5-year ESKD prediction model using Tpre was 0.93 (95% CI: 0.87–0.99) in the external validation set.
Conclusion: A pathology T-score prediction (Tpre) model using routine clinical characteristics was constructed, which could predict the pathological severity and assist clinicians to predict the prognosis of IgAN patients lacking kidney pathology scores.
1 Introduction
Immunoglobulin A (IgA) nephropathy (IgAN) is one of the most common forms of glomerulonephritis worldwide. The clinical manifestations are heterogeneous, ranging from asymptomatic proteinuria or microscopic hematuria to rapid deterioration in kidney function (1). It was reported that approximately 20%–30% of patients with IgAN would progress to kidney failure within 20 years (2). Therefore, early identification of high-risk patients with IgAN prone to ESKD is beneficial for early intervention in delaying disease progression. Great endeavors have been taken by many researchers to search for the risk factors for developing ESKD in patients with IgAN. Generally accepted risk factors affecting the progression of IgAN included decreased glomerular filtration rate (GFR), 24-h proteinuria >1 g/day, hypertension, and renal pathological manifestations (3–9). These risk factors have been used to build various scoring models for predicting the prognosis of IgAN based on traditional statistical methods (4, 10–14). However, these scoring models are constructed by the small sample sizes and different pathological scoring criteria, which may affect the accuracy and generalization of these scoring models. Moreover, the interactions between the characteristics and their effect on ESKD, the non-linear relationship among predictors, and the effects of therapeutic regimens make the interpretation of the data more complicated.
Machine learning, as a branch discipline of artificial intelligence, has obvious advantages in processing high-dimensional and sparse data. Machine learning algorithms can learn the relationship between input features and target outcomes as well as the relationship between features through a large amount of training data. Several studies have successfully constructed ESKD prediction models for patients with IgAN through machine learning algorithms (15–20). By comparing the performance of traditional statistical methods and different machine learning algorithms in predicting ESKD or halving of estimated glomerular filtration rate from baseline, Chen et al. showed that the XGBoost algorithm performed best (16). XGBoost, as a machine learning algorithm, assembles the weak prediction models to construct a prediction model (16, 21). Several studies have tried to construct event prediction models for a specific clinical outcome based on the XGBoost algorithm (22, 23). However, no matter whether it was a traditional prediction formula or a machine learning-based predictive model in IgAN, pathology scores showed consistently significant weighting among many parameters (15, 16, 19, 24). In 2009, the Oxford classification, an international consensus, was proposed to classify IgA nephropathy based on histopathological features to predict its prognosis and guide clinical treatment. The revised Oxford classification in 2017 divided IgAN into five categories, namely, “(1) mesangial hypercellularity (M); (2) endocapillary hypercellularity (E); (3) segmental glomerulosclerosis (S); (4) tubular atrophy/interstitial fibrosis (T); (5) cellular/fibrocellular crescents (C)” (25), which were shown to be the independent predictors in predicting renal outcome (24, 26). Since 2009, over 20 validation studies have tried to prove the predictive value of the MEST scores in some retrospective cohorts of patients with IgAN, which provided consistent evidence that the mesangial hypercellularity (M), segmental glomerulosclerosis (S), and tubular atrophy/interstitial fibrosis (T) each reliably provided prognostic value by univariate analysis (26), but T lesion was suggested to be the strongest predictor of renal survival. Hernan et al. summarized the results of these studies and found that M was of independent prognostic value in 5 out of 19, E in 4 out of 19, S in 7 out of 19, and T in 13 out of 19 (26). The C-score was adopted in the revised classification system in 2017, and three of the five prognostic studies on IgA nephropathy showed that C-score was associated with poor prognosis (26–28). In the constructed IgAN prognosis prediction models, it was observed that the T lesions showed greater weight in predicting prognosis compared with many other clinical and pathological parameters (14, 16). For example, in the prognosis prediction model constructed by Chen et al., there were three indexes that can be integrated to predict ESKD, namely, T, global sclerosis, and urine protein, among which the T-score ranked first in the weight of importance (16). However, the T-score is derived from the kidney biopsy, an invasive manipulation, sometimes refused by patients and cannot be repeated in clinical routine for detecting disease progression. Hence, it is of great significance to explore whether pathological T lesions can be predicted by the patient’s clinical variables at the same time.
The purposes of our study are 1) to construct a pathology T-score (Tpre) prediction model based on the patient’s clinical variables at the same time which may be able to predict whether there is a pathological T lesion and 2) to evaluate whether the predicted T can be used to assist in predicting ESKD.
2 Methods
2.1 Study participants
This study had two independent datasets. Dataset 1, a baseline dataset without follow-up data, comprised 690 patients with IgAN. These patients received the kidney biopsy in our center but returned to local for follow-up. Dataset 2, a follow-up dataset (PKU-IgAN cohort), included 1,808 patients with IgAN who were registered and with long-term follow-up in the Peking University First Hospital IgAN database from 1997 to 2020 (29). All patients with IgAN were diagnosed based on the histologic and immunofluorescence study of the renal biopsy, and those with <8 glomeruli per biopsy section were excluded (29). After excluding 243 patients without blood lipid data, 28 patients presented at younger than 16 years of age, and 14 patients presented acute kidney failure, 1,523 patients in dataset 2 were finally enrolled in this study, consisting of 1,168 patients with Oxford MEST-C scores and 355 patients lacking Oxford MEST-C scores.
Finally, a total of 690 patients in dataset 1 and 1,168 patients with Oxford MEST-C scores in dataset 2 were enrolled in our study as the modeling group, and 355 patients without Oxford MEST-C scores in dataset 2 were enrolled in this study as the external validation group (Figure 1).
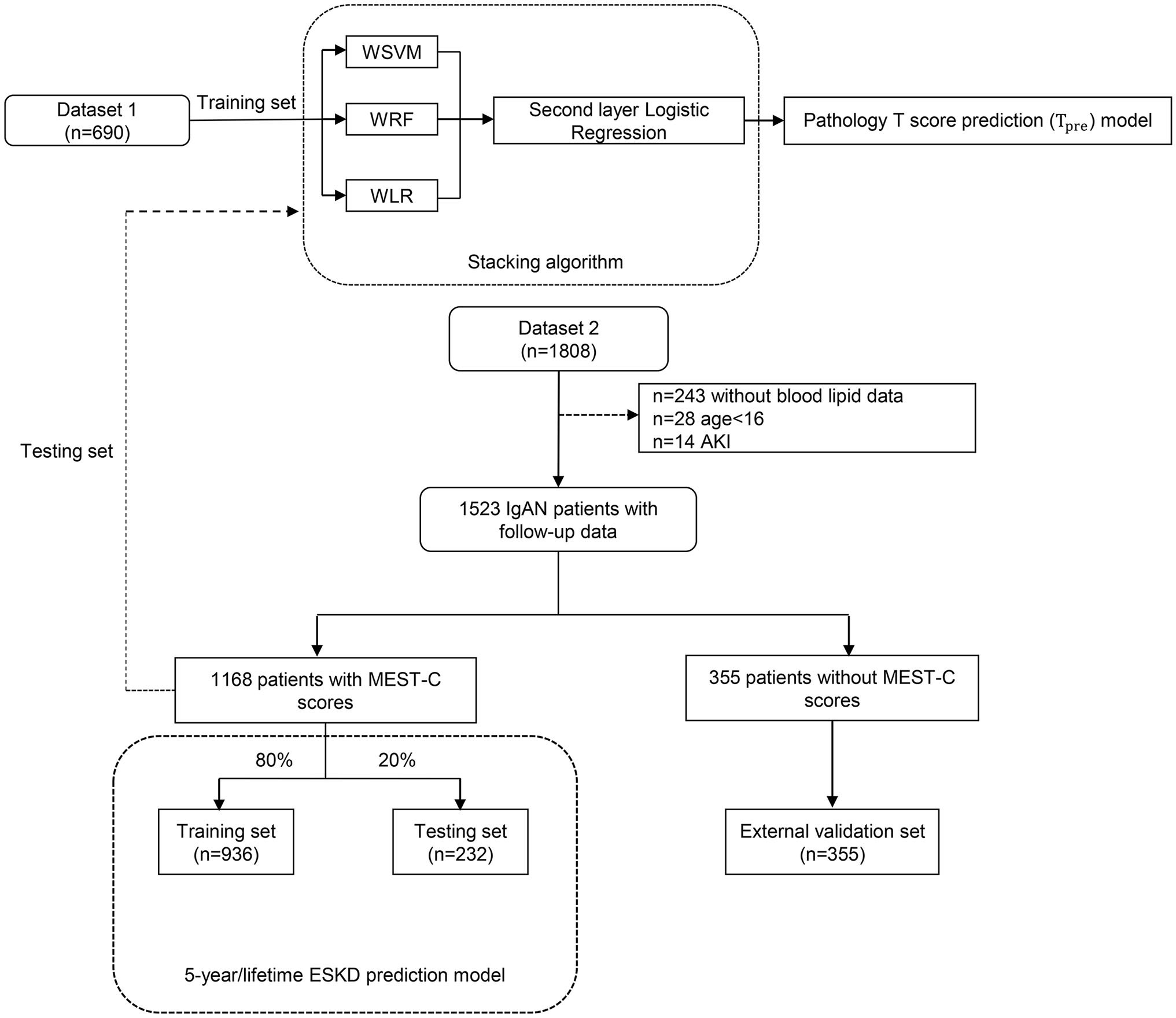
Figure 1 The flowchart of this study. WSVM, weighted support vector machine; WRF, weighted random forest; WLR, weighted logistic regression; AKI, acute kidney injury.
All clinical characteristics were collected at the time of the renal biopsy. The estimated glomerular filtration rate (eGFR) was calculated using the Chronic Kidney Disease Epidemiology Collaboration (CKD-EPI) formula (30). Renal biopsies were categorized according to established criteria for the Oxford MEST-C scoring system (24, 26, 31). Mean arterial pressure (MAP, mm Hg) was defined as diastolic pressure plus a third of the pulse pressure. The end-stage kidney disease (ESKD) was defined as eGFR <15 ml/min/1.73 m2, dialysis, or kidney transplantation. Our study was approved by the Ethics Committee of Peking University First Hospital (IRB number 2020Y197). Written informed consent was provided by all participants.
2.2 Pathology T-score prediction model
The pathology T-score prediction (Tpre) model, constructed by the stacking algorithm, was used to predict whether IgAN patients would have T lesions (yes or no). The stacking algorithm is an integrated machine learning algorithm that can summarize several models and predict new observations. It utilizes the prediction of a collection of models as input for training a second-level model. This second-level model aims to find the best combination of the prediction of first-level models. Stacking can shield the capabilities of a range of well-performing models so that a better output prediction model can be achieved (32). In our study, we combined three machine learning algorithms, namely, support vector machine (SVM), random forest (RF), and logistic regression as first-level models, and then logistic regression as the second-level model to output the final probability of the binary T-score (with or without tubular atrophy/interstitial fibrosis, Tpre).
The input variables used in this model were chosen by AUCRF (33), a method using the random forest to find the optimal set for prediction. Variables entered into the AUCRF included age, sex, body mass index, systolic arterial pressure, diastolic arterial pressure, mean arterial pressure, hypertension, eGFR, proteinuria, microhematuria, history of gross hematuria, serum IgA, serum uric acid, serum triglycerides, total cholesterol, high-density lipoprotein, and low-density lipoprotein.
2.3 Five-year ESKD prediction model
Several studies have demonstrated the value of tubular atrophy/interstitial fibrosis (T) in predicting ESKD in patients with IgAN (16, 19, 24, 34, 35). To evaluate whether the predicted T-score could help predict ESKD and how effective it was, we constructed a 5-year ESKD prediction model based on the XGBoost algorithm. To illustrate the significance of tubular atrophy/interstitial fibrosis in predicting ESKD, we first constructed a 5-year ESKD prediction model with only clinical variables as input variables (base model). Then, the 5-year ESKD prediction model using clinical variables and the real pathological T lesions score (Tbio, T0 was assigned 0, T1 and T2 were assigned 1) was also developed (base model plus Tbio) to evaluate the additive value of atrophy/interstitial fibrosis (T) in predicting ESKD. Finally, to evaluate whether the value of Tpre in predicting ESKD of patients with IgAN was consistent with real pathological T lesions (Tbio) when the base model plus Tbio was trained in the training set, the Tbio of the testing set was replaced by the corresponding Tpre predicted by the pathology T-score prediction model and then the testing set was used to evaluate the model performance (the base model plus Tpre). For the base model plus Tpre, the purpose of training the model using real pathological T-score (Tbio) was for the model to learn the true value of T for predicting ESKD.
XGBoost is a kind of ensemble of the decision tree, whose advantages include higher-order interactions and complex non-linear relationships between the model features and the outcome (21). It has been shown to achieve impressive performance in predicting renal failure risk and provide explanations for variables by ranking their importance (16, 34). We also applied other machine learning algorithms to our data set for evaluating whether the predicted T could be used in ESKD prediction models based on different algorithms, including RF, penalized regression, artificial neural network (ANN), and SVM.
Characteristics selected by the Cox proportional hazards model were collected at the time of the renal biopsy at enrollment [age, sex, systolic arterial pressure, diastolic arterial pressure, proteinuria, eGFR, serum IgA, serum uric acid, serum triglycerides, total cholesterol, low-density lipoprotein, and history of previous use of renin–angiotensin system (RAS) inhibitors and immunosuppressants as well as pathological T lesions], whereas the binary outcome (ESKD within 5 years after diagnostic kidney biopsy, yes or no) represented the output data. For these variables, we imputed missing values to the means for continuous characteristics and the mode for categorical characteristics. Because of missing information on serum triglycerides, total cholesterol, and low-density lipoprotein in some cases, 243 patients without blood lipid data were excluded to avoid inaccuracy due to missing value filling (Figure 1).
To confirm that the Tpre can be used in the ESKD prediction model at multiple levels, we also constructed a lifetime ESKD prediction model based on XGBoost. The process and approach were the same as building the 5-year ESKD prediction model. The primary outcome was time-to-event ESKD. The survival time for the kidney without ESKD event was calculated from the kidney biopsy to the last follow-up.
The XGBoost was allowed to generate boosting trees at most 110 times, and the maximum depth of each tree was constrained to 5. To avoid overfitting, we further set the L2 regularization term on weights as 1 and stop training if the performance did not improve by more than 15 rounds. At last, the optimal prediction model parameters and architectures were selected by the five-fold cross-validation.
The patients of dataset 2 without Oxford MEST-C scores combined with the corresponding Tpre were used as an additional external validation set to evaluate the performance of the ESKD prediction model using Tpre.
2.4 Statistical analysis
The sociodemographic and clinical variables were calculated and expressed as the mean ± standard deviation for variables with approximately symmetrical distributions and as median (interquartile range 25th–75th percentile) for variables with skewed distribution. All categorical variables are expressed as frequencies and percentages. Univariate analyses based on the Cox proportional hazards model (36) were conducted to evaluate the association between the baseline clinical characteristics and ESKD event. Clinical characteristics associated with ESKD event in univariate analysis (P < 0.05) or if they were clinically relevant were used as input features of the 5-year ESKD prediction model.
For predicting 5-year ESKD status (yes or no) and T-score (0 or 1), the performance of the models was assessed by calculating the accuracy, sensitivity, specificity, and area under the receiver operating characteristic (ROC) curve (AUC). For predicting lifetime ESKD risk, we quantify the performance of the model by concordance statistic (C-statistic), which is a general concept of the area under the curve (AUC) for time-to-event survival data (37). The C-statistic compares the rank of predicting probability and the rank of the survival time in the real world. The calibration ability of the models was assessed by the Hosmer–Lemeshow test and calibration scatter plot, in which P-value >0.05 indicated no very significant difference between the predicted probability predicted by the model and the true outcome frequencies during a certain time period. SPSS version 26.0 software and R 3.6.3 were used for the statistical analysis. All P-values were two-tailed, and P <0.05 was considered statistically significant.
3 Results
3.1 Characteristics of the study participants
The clinical characteristics of 690 patients with IgAN in dataset 1 are shown in Table 1. The mean age of these patients was 32.38 ± 11.32 years at the time of renal biopsy. The male-to-female ratio was 1.2:1. The mean arterial pressure was 94.44 ± 14.02 mm Hg. The median value of eGFR was 84.66 (range, 63.32–107.50) ml/min per 1.73 m2, and daily proteinuria was 1.38 (range, 0.66–2.89) g/day.
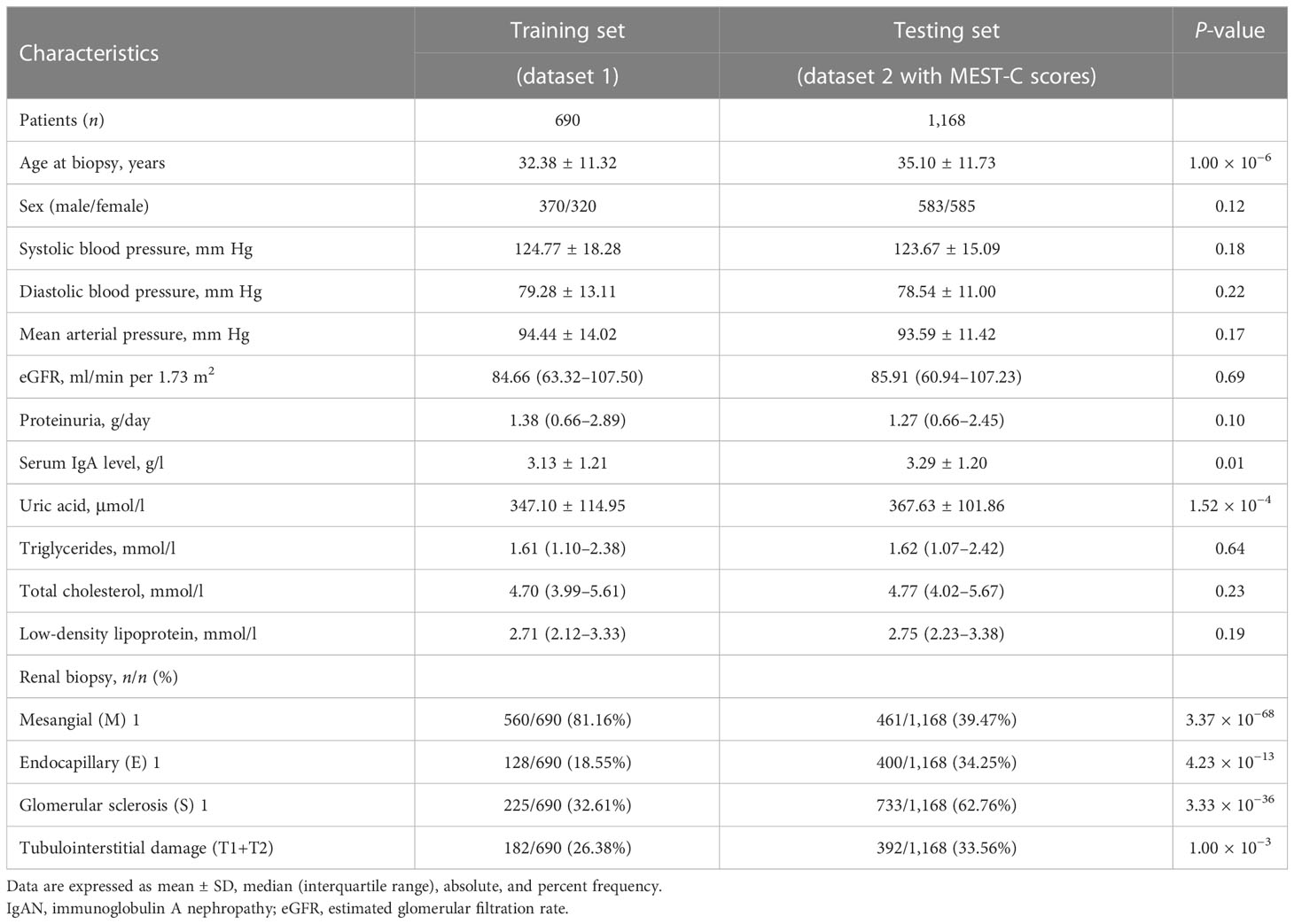
Table 1 Baseline characteristics of patients with IgAN enrolled in this study to construct the pathology T-score prediction model at the time of kidney biopsy.
For the 1,168 follow-up patients with Oxford MEST-C scores in dataset 2, the mean age was 35.10 ± 11.73 years at the time of renal biopsy. The male-to-female ratio was 1:1. The mean arterial pressure was 93.59 ± 11.42 mm Hg. The eGFR was 85.91 (range, 60.94–107.23) ml/min per 1.73 m2, and daily proteinuria was 1.27 (range, 0.66–2.45) g/day (Table 1). For the variables used to train the pathology T-score prediction (Tpre) model, there were no statistically significant differences in clinical parameters between dataset 1 and dataset 2 except for age (32.38 ± 11.32 vs. 35.10 ± 11.73, P = 1.00 × 10−6), serum IgA level (3.13 ± 1.21 vs. 3.29 ± 1.20, P = 0.01), and serum uric acid level (347.10 ± 114.95 vs. 367.63 ± 101.86, P = 1.52 × 10−4). Among these, 158 patients (13.53%) had reached the event of ESKD during the median 67.5-month follow-up. The unadjusted hazard ratios (HRs) between the different variables and ESKD are reported in Table 2. The risk of ESKD significantly increased for every 10.0 mm Hg increase in the MAP [HR: 1.34, 95% confidence interval (CI): 1.18–1.53, P = 1.10 × 10−5] and increased for every 1.0 g/day in the daily proteinuria (HR: 1.10, 95% CI: 1.05–1.15, P = 1.60 × 10−5). For each ml/min per 1.73 m2 decrease in eGFR, the risk of ESKD increased by 4% (HR: 0.96, 95% CI: 0.96–0.97, P = 1.24 × 10−27). For each mg/dl increase in uric acid, the risk of ESKD increased by 38% (HR: 1.38, 95% CI: 1.29–1.49, P = 1.47 × 10−19). Moreover, there was the strongest association between the risk of ESKD and the presence of tubulointerstitial lesions (HR: 3.34, 95% CI: 2.73–4.07, P = 1.72 × 10−32).
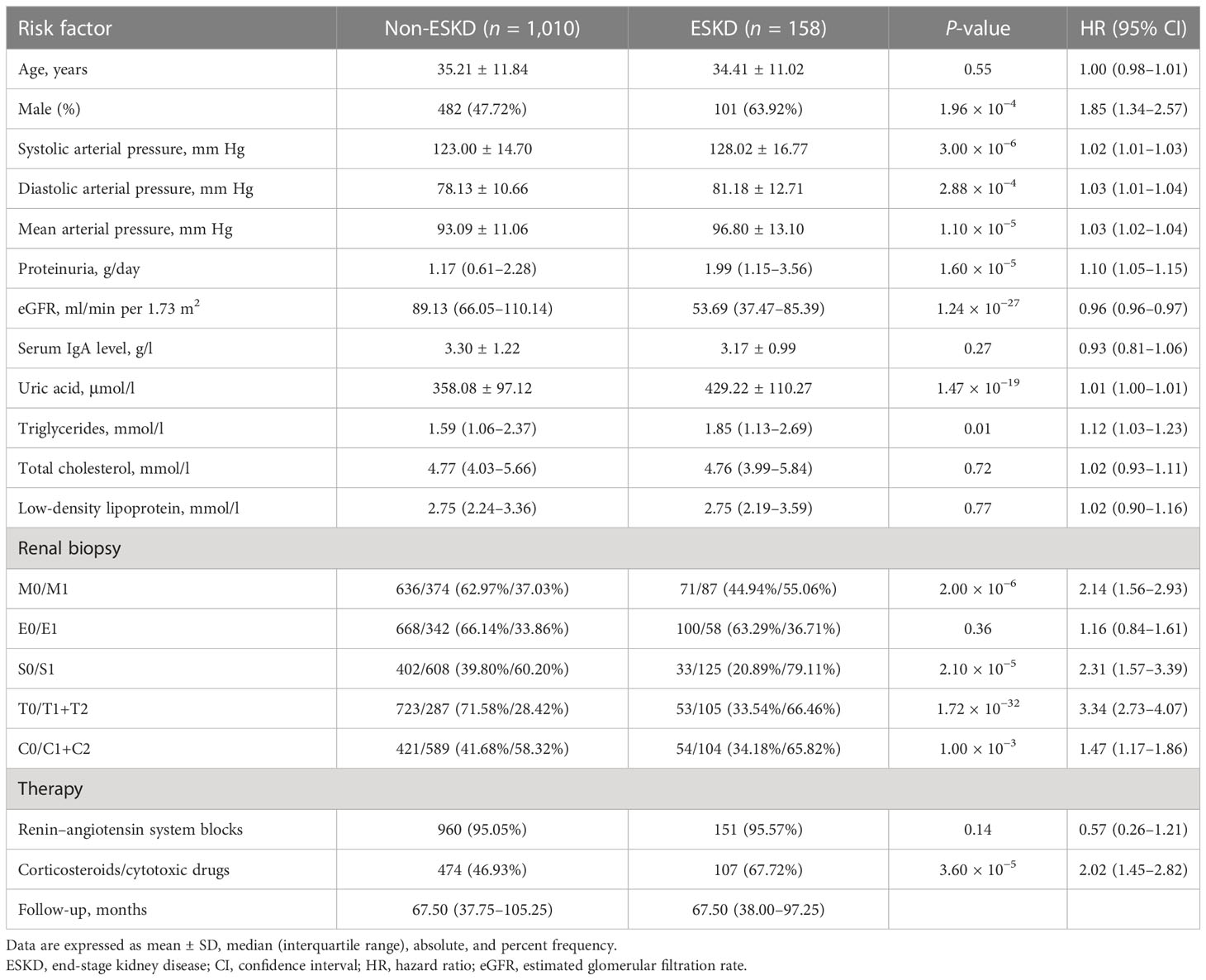
Table 2 Risk estimated by Cox proportional hazard model for ESKD in patients of dataset 2 with Oxford MEST-C scores.
3.2 Performance of the pathology T-score prediction model
Feature reductions were conducted using the AUCRF algorithm, which was used to select the optimal random forest model with the least number of predictive variables to predict the presence or absence of T lesions. Clinical variables with a probability of selection higher than 0.7 were selected in repeated cross-validation of the optimal random forest model (optimal AUC = 0.82). Finally, the features selected by AUCRF for the T prediction model included age, systolic arterial pressure, diastolic arterial pressure, proteinuria, eGFR, serum IgA, and uric acid (Figure 2). The 690 IgAN patients with Oxford MEST-C scores in dataset 1 as the training set were taken to develop a pathology T-score prediction model. The 1,168 IgAN patients with Oxford MEST-C scores in dataset 2 as the testing set were used only for reporting the performance of the model and were not used for development or fine-tuning.
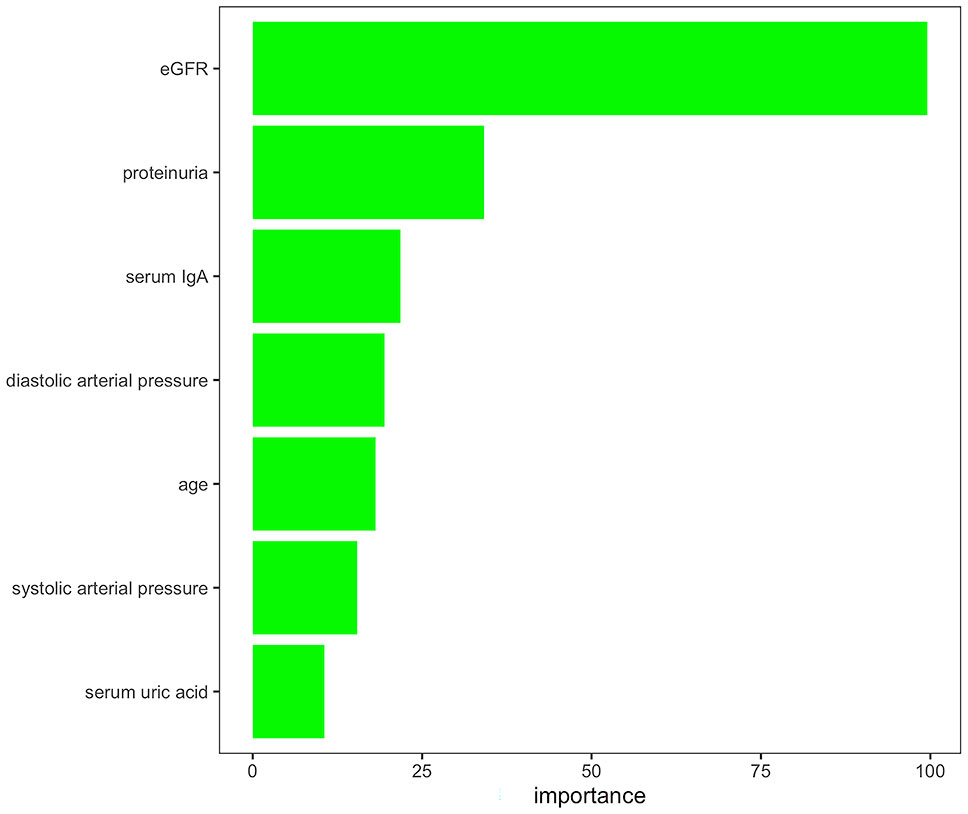
Figure 2 Variables selected by AUCRF for the pathology T-score prediction model. The importance scores of the clinical variables with a probability of selection higher than 0.7 in repeated cross-validation of the optimal random forest model to predict the presence or absence of T lesions.
If a predictive model has an AUC of higher than 0.75, it will be considered to have a good discriminating ability. The pathology T prediction model achieved a discrimination of 0.82 (95% CI: 0.80–0.85) [area under the receiver operating characteristic (ROC) curve (AUC)] in the testing set (Figure 3A). The ROC curve had 0.74 sensitivity and 0.77 specificity, which indicated that it had better clinical utility.
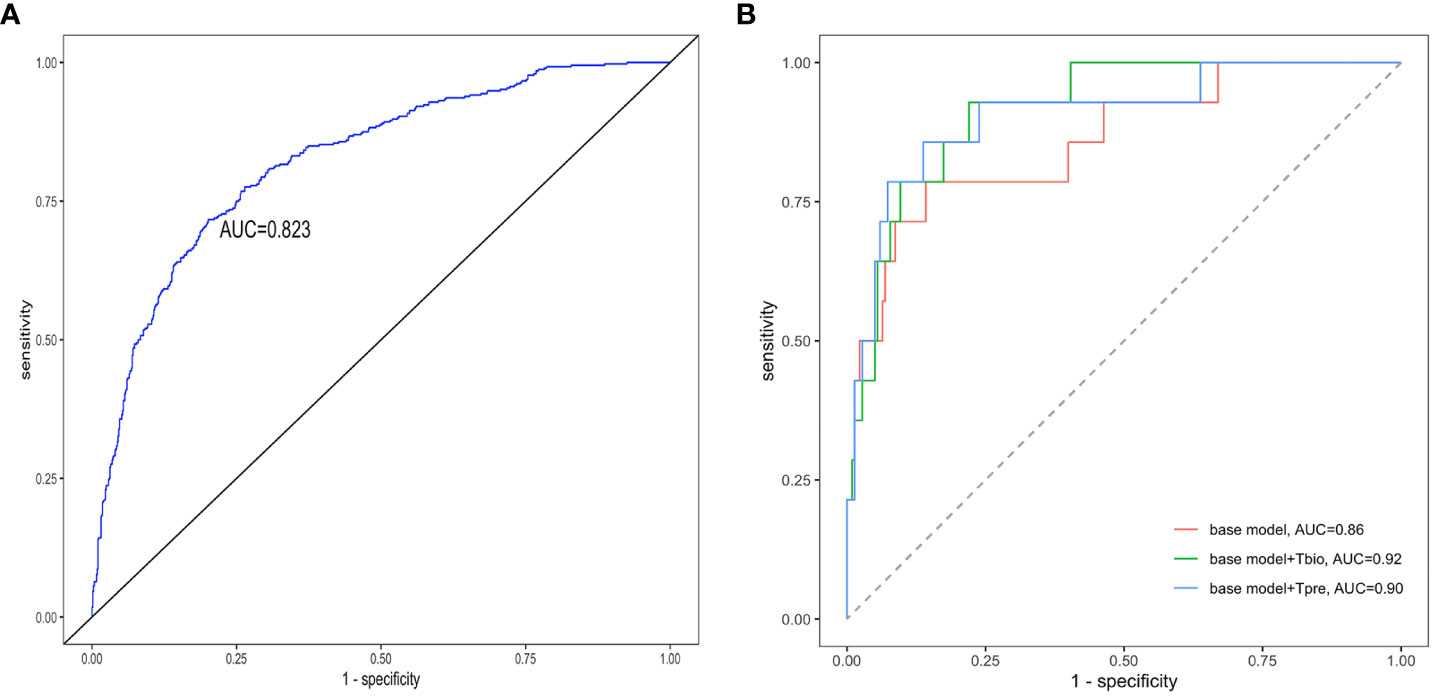
Figure 3 Receiver operating characteristic curves of the prediction models. The receiver operating characteristic curves for (A) the pathology T-score prediction (Tpre) model and (B) the 5-year ESKD prediction model. The base model was the 5-year ESKD prediction model based on the XGBoost algorithm with only clinical variables as input variables. The base model + Tbio was the 5-year ESKD prediction model based on XGBoost using clinical variables and the real pathological T lesions score (Tbio, T0 was assigned 0, and T1 and T2 were assigned 1). The base model + Tpre was when the base model plus Tbio was trained using clinical variables and Tbio, and the Tbio of the testing set was replaced by the corresponding Tpre predicted by the pathology T-score prediction model. The clinical variables used for the 5-year ESKD prediction model included age, sex, systolic arterial pressure, diastolic arterial pressure, proteinuria, eGFR, serum IgA, uric acid, triglycerides, total cholesterol, low-density lipoprotein, and history of previous use of renin–angiotensin system (RAS) inhibitors and immunosuppressants. AUC, area under the curve.
3.3 Performance of the 5-year ESKD prediction model
The unadjusted Cox regression analysis suggested that sex, systolic arterial pressure, diastolic arterial pressure, proteinuria, eGFR, uric acid, triglycerides, and tubular atrophy/interstitial fibrosis (T) were risk factors for developing ESKD (Table 2). A study supported elevated serum IgA as a causal factor in IgA nephropathy through Mendelian randomization (38). Some studies have suggested the association between the poor prognosis of renal disease and dyslipidemia. Higher triglycerides and cholesterol levels have been proven to be independent risk factors for the progression of kidney disease (39). Hence, clinical variables (age, sex, systolic arterial pressure, diastolic arterial pressure, proteinuria, eGFR, serum IgA, uric acid, triglycerides, total cholesterol, low-density lipoprotein, history of previous use of RAS inhibitors and immunosuppressants) and the pathology T lesions (Tbio, T0 was assigned 0, T1 and T2 were assigned 1) were used as the input variables of the 5-year ESKD prediction model.
To make the predictive model achieve a good performance, the 1,168 follow-up IgAN patients with Oxford MEST-C scores in dataset 2 were randomly divided into training and testing sets at a ratio of 8:2. The training set included 936 patients and the testing set included 232 patients. The training set was used to perform five-fold cross-validation to select the optimal prediction model. The testing set was used to assess the performance.
The performance value of the 5-year ESKD prediction model using only the above clinical variables as input variables (base model) was 0.86 (95% CI: 0.75–0.97) in the test set (Figure 3B). To test whether the Tbio could improve the predictive performance of the 5-year ESKD prediction model, we added Tbio to the base model. An increase in AUC [from 0.86 (95% CI: 0.75–0.97) to 0.92 (95% CI: 0.85–0.98); P = 0.03] showed a better discriminating ability, which indicated that the T was important for judging the prognosis of patients with IgAN (Figure 3B). To test whether Tpre had a similar effect on judging the prognosis of IgAN patients, after training the 5-year ESKD prediction model with the training set, we replaced the Tbio in the testing set with the corresponding Tpre to see the discrimination effect. The AUC was 0.90 (95% CI: 0.82–0.99) in the testing set (Figure 3B). The performance of the base model plus Tpre did not differ from that of the base model plus Tbio [AUC for the base model plus Tpre 0.90 (95% CI: 0.82–0.99) vs. AUC for the base model plus Tbio 0.92 (95% CI: 0.85–0.98), P = 0.52, Table 3], which showed that the value of the Tpre in predicting the ESKD of patients was comparable to that of Tbio. The calibration of the three prediction models is shown in Figures 4A–C. The P-values for the Hosmer–Lemeshow test of the base model, the base model plus Tbio, and the base model plus Tpre were 0.42, 0.79, and 0.92, respectively, which indicated that these models had a good calibration. These results suggested the importance of T in predicting ESKD, and Tpre can be used to assist clinicians in assessing the prognosis of patients without pathology reports.
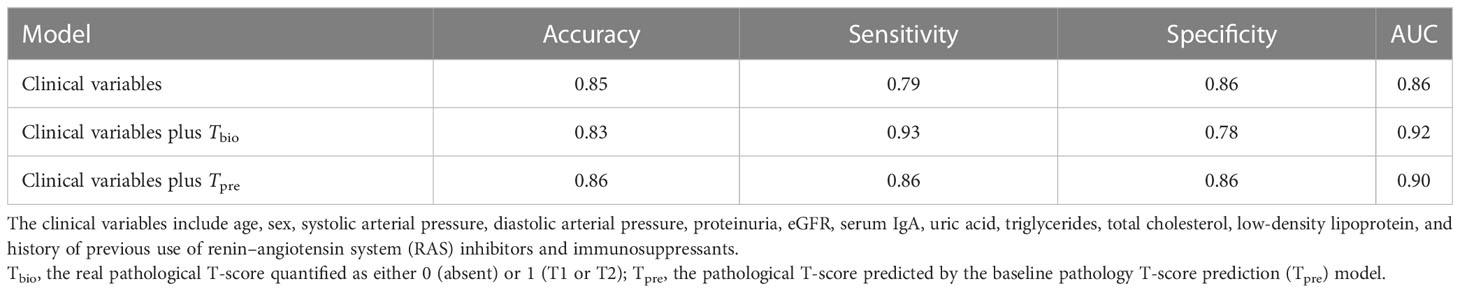
Table 3 Performance comparison for the prediction on 5-year ESKD status with different predictors in the testing subset.
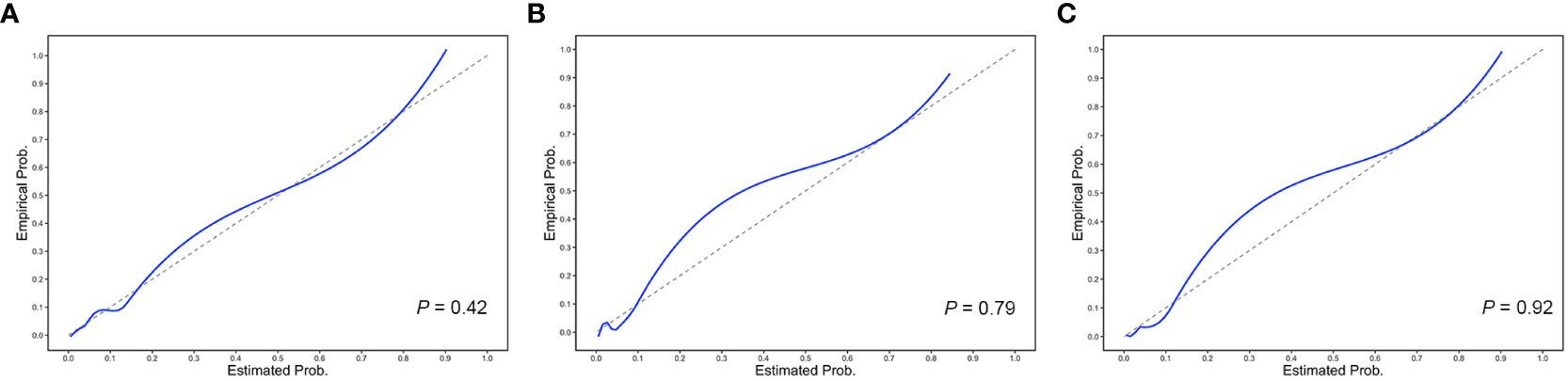
Figure 4 Calibration plots of the 5-year ESKD prediction models. The calibration plots for (A) the base model, (B) the base model plus Tbio, and (C) the base model plus Tpre. The P-values for the Hosmer–Lemeshow test of the base model, the base model plus Tbio, and the base model plus Tpre were 0.42, 0.79, and 0.92, respectively, which indicated that these models had a good calibration.
Table 4 shows the performance of the 5-year ESKD prediction model based on different machine learning algorithms in the testing set using Tpre. All models have good prediction performance, which indicated that Tpre could be used in ESKD predictive models built on different algorithms.
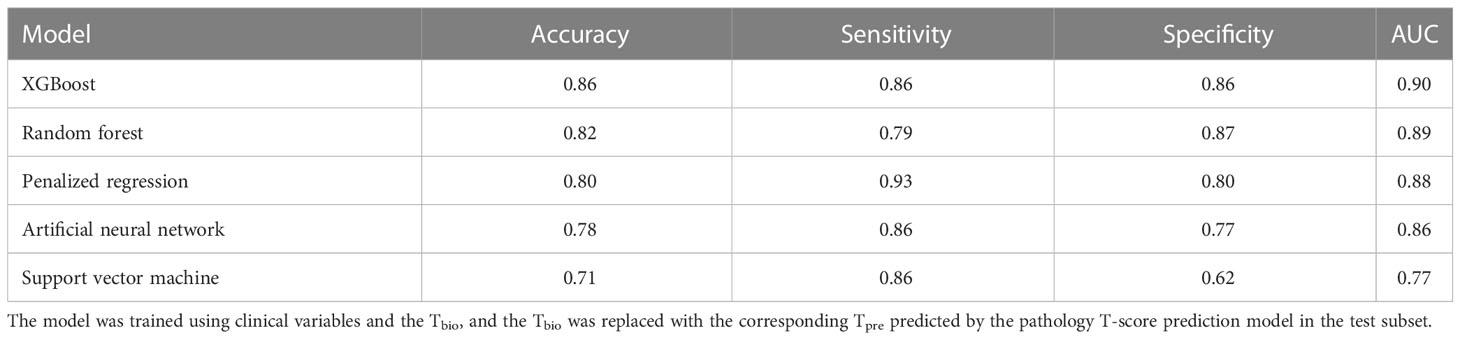
Table 4 Performance of the 5-year ESKD prediction model using Tpre based on different machine learning algorithms in the testing set.
For the lifetime ESKD prediction model based on XGBoost using only clinical variables (base model), the C-statistic was 0.82 (95% CI: 0.80–0.84) in the testing set. The discriminating ability of the base model plus Tpre was also comparable to the base model plus Tbio [C-statistic: 0.85 (95% CI: 0.83–0.86) vs. 0.85 (95% CI: 0.83–0.86), P = 0.11] in the testing set.
3.4 External validation of the ESKD prediction model using Tpre
The 355 patients without MEST-C scores in dataset 2 were included as the external validation population for evaluating the performance of the 5-year ESKD prediction model. Because patients did not have MEST-C scores, the Tpre predicted by the pathology T-score prediction model was used in the 5-year ESKD prediction model. The AUC of the 5-year ESKD prediction model using Tpre based on XGBoost was 0.93 (95% CI: 0.87–0.99). We listed the AUC of the applied other machine learning algorithms in Table 5.
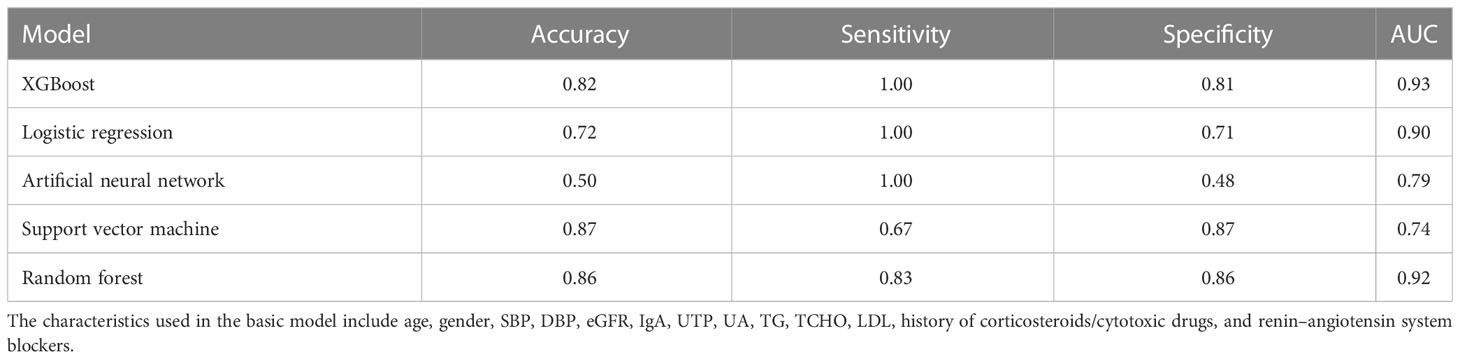
Table 5 Performance of the 5-year ESKD prediction model using Tpre based on different machine learning algorithms in the external validation set.
In the lifetime ESKD prediction model using Tpre, the C-statistic was 0.92 (95% CI: 0.90–0.94). We have shown here that both models have a good performance in the external validation set, indicating the reliability of Tpre for assisting in evaluating the prognosis of IgAN.
4 Discussion
We developed a pathology T-score prediction (Tpre) model that can predict whether the patient with IgAN may have tubulointerstitial lesions at this time based on clinical variables when the patient did not undergo a renal biopsy or did not want to repeat the renal biopsy for progression assessment. We further constructed the 5-year/lifetime ESKD prediction model based on the XGBoost algorithm to confirm the importance of T in predicting ESKD, and Tpre can replace the real pathological T lesions for assisting clinicians in evaluating the prognosis of IgAN patients without pathology reports. In addition, the ESKD prediction model built based on different machine learning algorithms had good discriminating ability by using clinical variables and Tpre, which indicated the reliability and universality of Tpre for assisting in evaluating the prognosis of IgAN.
For developing the pathology T-score (Tpre) prediction model, we first used the AUCRF algorithm to select the clinical variables that may be associated with the tubulointerstitial lesions. Feature selection before training the predictive model can prevent dimensional disaster, reduce training time, prevent overfitting, enhance model generalization ability, and enhance the understanding of features and feature values, which also determines the upper limit of the effect of a machine learning task. The AUCRF is based on the RF algorithm, which is used for feature reduction based on optimizing the area under the ROC curve (AUC) of the random forest (33). It was found that age, systolic arterial pressure, diastolic arterial pressure, proteinuria, eGFR, serum IgA, and uric acid may be the clinical characteristics associated with tubular atrophy/interstitial fibrosis. Mechanism studies are needed to explore the inherent causality of these correlations and predictive capability. There have been reports indicating the association between reduced initial eGFR, higher initial MAP, proteinuria, and tubular atrophy/interstitial fibrosis (31). Next, we used the stacking algorithm to construct the pathology T-score prediction (Tpre) model based on the clinical characteristics selected by the AUCRF. A single learner has over- or underfitting problems, and to obtain a learner with excellent generalization performance, we can train multiple individual learners to form a strong learner through a certain combination strategy. This method of integrating multiple individual learners is called ensemble learning. Stacking is one of the methods of ensemble learning. The advantage of integration is that different models can learn different features of the data, and the results after fusion tend to perform better (40). As our results showed, when we used an independent dataset as the testing set, the AUC of the pathological T-score prediction (Tpre) model reached 0.82, which indicates the good discriminating ability of this Tpre prediction model.
A host of studies have indicated that pathological T lesions play an important role in predicting prognosis (14, 35, 41). At the same time, most current ESKD prediction models based on different methods or algorithms all include pathology T-score (14, 16, 19). Nevertheless, a renal puncture is invasive, which may cause a series of complications and has a host of contraindications, such as severe hypertension, coagulation disorders, solitary kidney, and so on (42). Furthermore, the number of patients at high risk of renal puncture may increase in the near future because of the aging of the population and the increased use of anticoagulant medication (43). For the patients who lack the report of kidney biopsy or do not want to undergo repeat renal puncture for disease progression assessment and evaluation of the effect of drug therapy, the clinician could not assess the prognosis of these patients with IgAN by using the established ESKD prediction model. The pathology T-score prediction (Tpre) model we developed may solve this problem. We also constructed a 5-year/lifetime ESKD prediction model based on XGBoost to assess whether the value of Tpre in predicting ESKD of patients with IgAN was consistent with real pathological T-score. The performance of the base model plus Tpre was similar to the base model plus Tbio, which showed that the Tpre can replace the real pathological T-score for prognostic prediction.
As far as we know, this study is the first to construct a pathology T-score prediction model in IgA nephropathy. At the same time, it is also the first study to use a machine learning algorithm to identify clinical variables that may influence the development of tubular atrophy/interstitial fibrosis, which may be useful for assessing the prognosis and targeted medication guidance. However, there is a limitation in our study. The model has been developed and tested in a single-center cohort of patients with IgAN; therefore, multicenter prospective cohort and ethnic-based cohort studies are necessary, which will further confirm the reliability of the pathology T-score prediction model, expand the scope of application of the model, and provide possibilities for clinical application.
In conclusion, our pathology T-score prediction (Tpre) model is a reliable tool for predicting the presence or absence of pathological T lesions. At the same time, it can also be used to assist clinicians in predicting the prognosis of patients with IgAN. A prospective multicenter cohort study is necessary to explore the potential value and robustness of this T prediction tool in the management of IgA nephropathy.
Data availability statement
The data presented in the study are deposited in the GitHub repository (https://github.com/zhangd17-web/IGAN_MI).
Author contributions
Research idea and study design: HZ, X-JZ, LW, DZ, and LX. Data acquisition: LX, SS, X-JZ, and HZ. Data analysis/interpretation: LX, DZ, LW, HW, and X-JZ. Statistical analysis: LX and DZ. Supervision or mentorship: X-JZ, HZ, HW, LW, RC, GC, LL, SS, XZ, SH, LD, and JL. Each author contributed important intellectual content during manuscript drafting or revision and agrees to be personally accountable for the individual’s own contributions and to ensure that questions pertaining to the accuracy or integrity of any portion of the work, even one in which the author was not directly involved, are appropriately investigated and resolved, with documentation in the literature if appropriate.
Funding
This work was supported by the National Science Foundation of China (82022010, 82131430172, 81970613, 82070733), Beijing Natural Science Foundation (Z190023), Academy of Medical Sciences—Newton Advanced Fellowship (NAFR13\1033), King’s College London—Peking University Health Science Center Joint Institute for Medical Research (BMU2021KCL004), Fok Ying Tung Education Foundation (171030), Chinese Academy of Medical Sciences (CAMS) Innovation Fund for Medical Sciences (2019-I2M-5-046, 2020-JKCS-009), and National High Level Hospital Clinical Research Funding (Interdisciplinary Clinical Research Project of Peking University First Hospital, 2022CR41, 2022CR40). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Acknowledgments
We thank all the patients and researchers who participated in the study.
Conflict of interest
Authors DZ, HW, LW, RC and GC were employed by company WeGene.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The reviewer JZ declared a shared parent affiliation with the authors LX, SS, LL, X-HZ, JL, X-JZ, and HZ to the handling editor at the time of review.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Lai KN, Tang SC, Schena FP, Novak J, Tomino Y, Fogo AB, et al. IgA nephropathy. Nat Rev Dis Primers (2016) 2:16001. doi: 10.1038/nrdp.2016.1
2. Magistroni R, D'Agati VD, Appel GB, Kiryluk K. New developments in the genetics, pathogenesis, and therapy of IgA nephropathy. Kidney Int (2015) 88(5):974–89. doi: 10.1038/ki.2015.252
3. Le W, Liang S, Hu Y, Deng K, Bao H, Zeng C, et al. Long-term renal survival and related risk factors in patients with IgA nephropathy: results from a cohort of 1155 cases in a Chinese adult population. Nephrol Dial Transplant (2012) 27(4):1479–85. doi: 10.1093/ndt/gfr527
4. Goto M, Wakai K, Kawamura T, Ando M, Endoh M, Tomino Y. A scoring system to predict renal outcome in IgA nephropathy: a nationwide 10-year prospective cohort study. Nephrol Dial Transplant (2009) 24(10):3068–74. doi: 10.1093/ndt/gfp273
5. Beukhof JR, Kardaun O, Schaafsma W, Poortema K, Donker AJ, Hoedemaeker PJ, et al. Toward individual prognosis of IgA nephropathy. Kidney Int (1986) 29(2):549–56. doi: 10.1038/ki.1986.33
6. Rekola S, Bergstrand A, Bucht H. Development of hypertension in IgA nephropathy as a marker of a poor prognosis. Am J Nephrol (1990) 10(4):290–5. doi: 10.1159/000168122
7. Radford MG Jr., Donadio JV Jr., Bergstralh EJ, Grande JP. Predicting renal outcome in IgA nephropathy. J Am Soc Nephrol JASN (1997) 8(2):199–207. doi: 10.1681/ASN.V82199
8. Chen D, Liu J, Duan S, Chen P, Tang L, Zhang L, et al. Clinicopathological features to predict progression of igA nephropathy with mild proteinuria. Kidney Blood Pressure Res (2018) 43(2):318–28. doi: 10.1159/000487901
9. Barbour SJ, Espino-Hernandez G, Reich HN, Coppo R, Roberts IS, Feehally J, et al. The MEST score provides earlier risk prediction in lgA nephropathy. Kidney Int (2016) 89(1):167–75. doi: 10.1038/ki.2015.322
10. Wakai K, Kawamura T, Endoh M, Kojima M, Tomino Y, Tamakoshi A, et al. A scoring system to predict renal outcome in IgA nephropathy: from a nationwide prospective study. Nephrol Dial Transplant (2006) 21(10):2800–8. doi: 10.1093/ndt/gfl342
11. Okonogi H, Utsunomiya Y, Miyazaki Y, Koike K, HIrano K, Tsuboi N, et al. A predictive clinical grading system for immunoglobulin A nephropathy by combining proteinuria and estimated glomerular filtration rate. Nephron Clin Pract (2011) 118(3):c292–300. doi: 10.1159/000322613
12. Xie J, Kiryluk K, Wang W, Wang Z, Guo S, Shen P, et al. Predicting progression of IgA nephropathy: new clinical progression risk score. PloS One (2012) 7(6):e38904. doi: 10.1371/journal.pone.0038904
13. Tanaka S, Ninomiya T, Katafuchi R, Masutani K, Tsuchimoto A, Noguchi H, et al. Development and validation of a prediction rule using the Oxford classification in IgA nephropathy. Clin J Am Soc Nephrol CJASN (2013) 8(12):2082–90. doi: 10.2215/CJN.03480413
14. Barbour SJ, Coppo R, Zhang H, Liu ZH, Suzuki Y, Matsuzaki K, et al. Evaluating a new international risk-prediction tool in igA nephropathy. JAMA Internal Med (2019) 179(7):942–52. doi: 10.1001/jamainternmed.2019.0600
15. Liu Y, Zhang Y, Liu D, Tan X, Tang X, Zhang F, et al. Prediction of ESRD in igA nephropathy patients from an asian cohort: A random forest model. Kidney Blood Pressure Res (2018) 43(6):1852–64. doi: 10.1159/000495818
16. Chen T, Li X, Li Y, Xia E, Qin Y, Liang S, et al. Prediction and risk stratification of kidney outcomes in igA nephropathy. Am J Kidney Dis (2019) 74(3):300–9. doi: 10.1053/j.ajkd.2019.02.016
17. Han X, Zheng X, Wang Y, Sun X, Xiao Y, Tang Y, et al. Random forest can accurately predict the development of end-stage renal disease in immunoglobulin a nephropathy patients. Ann Trans Med (2019) 7(11):234. doi: 10.21037/atm.2018.12.11
18. Konieczny A, Stojanowski J, Krajewska M, Kusztal M. Machine learning in prediction of igA nephropathy outcome: A comparative approach. J Pers Med (2021) 11(4):312. doi: 10.3390/jpm11040312
19. Schena FP, Anelli VW, Trotta J, Di Noia T, Manno C, Tripepi G, et al. Development and testing of an artificial intelligence tool for predicting end-stage kidney disease in patients with immunoglobulin A nephropathy. Kidney Int (2021) 99(5):1179–88. doi: 10.1016/j.kint.2020.07.046
20. Diciolla M, Binetti G, Di Noia T, Pesce F, Schena FP, Vågane AM, et al. Patient classification and outcome prediction in IgA nephropathy. Comput Biol Med (2015) 66:278–86. doi: 10.1016/j.compbiomed.2015.09.003
21. Chen T, Guestrin C. XGBoost: A Scalable Tree Boosting System. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, California, USA: Association for Computing Machinery (2016). p. 785–94.
22. Khera R, Haimovich J, Hurley NC, McNamara R, Spertus JA, Desai N, et al. Use of machine learning models to predict death after acute myocardial infarction. JAMA Cardiol (2021) 6(6):633–41. doi: 10.1001/jamacardio.2021.0122
23. Pfaff ER, Girvin AT, Bennett TD, Bhatia A, Brooks IM, Deer RR, et al. Identifying who has long COVID in the USA: a machine learning approach using N3C data. Lancet Digital Health (2022) 4(7):e532–e41. doi: 10.1016/S2589-7500(22)00048-6
24. Cattran DC, Coppo R, Cook HT, Feehally J, Roberts IS, Troyanov S, et al. The Oxford classification of IgA nephropathy: rationale, clinicopathological correlations, and classification. Kidney Int (2009) 76(5):534–45. doi: 10.1038/ki.2009.243
25. Rui Y, Yang Z, Zhai Z, Zhao C, Tang L. The predictive value of Oxford MEST-C classification to immunosuppressive therapy of IgA nephropathy. Int Urol Nephrol (2022) 54(4):959–67. doi: 10.1007/s11255-021-02974-9
26. Trimarchi H, Barratt J, Cattran DC, Cook HT, Coppo R, Haas M, et al. Oxford Classification of IgA nephropathy 2016: an update from the IgA Nephropathy Classification Working Group. Kidney Int (2017) 91(5):1014–21. doi: 10.1016/j.kint.2017.02.003
27. Schimpf JI, Klein T, Fitzner C, Eitner F, Porubsky S, Hilgers RD, et al. Renal outcomes of STOP-IgAN trial patients in relation to baseline histology (MEST-C scores). BMC Nephrol (2018) 19(1):328. doi: 10.1186/s12882-018-1128-6
28. Liu Y, Wei W, Yu C, Xing L, Wang M, Liu R, et al. Epidemiology and risk factors for progression in Chinese patients with IgA nephropathy. Medicina clinica (2021) 157(6):267–73. doi: 10.1016/j.medcli.2020.05.064
29. Zhang Y, Guo L, Wang Z, Wang J, Er L, Barbour SJ, et al. External validation of international risk-prediction models of igA nephropathy in an asian-caucasian cohort. Kidney Int Rep (2020) 5(10):1753–63. doi: 10.1016/j.ekir.2020.07.036
30. Levey AS, Stevens LA, Schmid CH, Zhang YL, Castro AF 3rd, Feldman HI, et al. A new equation to estimate glomerular filtration rate. Ann Internal Med (2009) 150(9):604–12. doi: 10.7326/0003-4819-150-9-200905050-00006
31. Roberts IS, Cook HT, Troyanov S, Alpers CE, Amore A, Barratt J, et al. The Oxford classification of IgA nephropathy: pathology definitions, correlations, and reproducibility. Kidney Int (2009) 76(5):546–56. doi: 10.1038/ki.2009.168
32. Wolpert DH. Stacked generalization. Neural Networks (1992) 5(2):241–59. doi: 10.1016/S0893-6080(05)80023-1
33. Calle ML, Urrea V, Boulesteix AL, Malats N. AUC-RF: a new strategy for genomic profiling with random forest. Hum heredity (2011) 72(2):121–32. doi: 10.1159/000330778
34. Li Y, Chen T, Chen T, Li X, Zeng C, Liu Z, et al. An interpretable machine learning survival model for predicting long-term kidney outcomes in igA nephropathy. AMIA Annu Symposium Proc AMIA Symposium (2020) 2020:737–46.
35. Lv J, Shi S, Xu D, Zhang H, Troyanov S, Cattran DC, et al. Evaluation of the Oxford Classification of IgA nephropathy: a systematic review and meta-analysis. Am J Kidney Dis (2013) 62(5):891–9. doi: 10.1053/j.ajkd.2013.04.021
36. Prentice RL, Zhao S. Regression models and multivariate life tables. J Am Stat Assoc (2021) 116(535):1330–45. doi: 10.1080/01621459.2020.1713792
37. Park SH, Hahm MH, Bae BK, Chong GO, Jeong SY, Na S, et al. Magnetic resonance imaging features of tumor and lymph node to predict clinical outcome in node-positive cervical cancer: a retrospective analysis. Radiat Oncol (London England) (2020) 15(1):86. doi: 10.1186/s13014-020-01502-w
38. Liu L, Khan A, Sanchez-Rodriguez E, Zanoni F, Li Y, Steers N, et al. Genetic regulation of serum IgA levels and susceptibility to common immune, infectious, kidney, and cardio-metabolic traits. Nat Commun (2022) 13(1):6859. doi: 10.1038/s41467-022-34456-6
39. Trevisan R, Dodesini AR, Lepore G. Lipids and renal disease. J Am Soc Nephrol JASN (2006) 17(4 Suppl 2):S145–7. doi: 10.1681/ASN.2005121320
40. Naimi AI, Balzer LB. Stacked generalization: an introduction to super learning. Eur J Epidemiol (2018) 33(5):459–64. doi: 10.1007/s10654-018-0390-z
41. Myllymäki JM, Honkanen TT, Syrjänen JT, Helin HJ, Rantala IS, Pasternack AI, et al. Severity of tubulointerstitial inflammation and prognosis in immunoglobulin A nephropathy. Kidney Int (2007) 71(4):343–8. doi: 10.1038/sj.ki.5002046
42. Hergesell O, Felten H, Andrassy K, Kühn K, Ritz E. Safety of ultrasound-guided percutaneous renal biopsy-retrospective analysis of 1090 consecutive cases. Nephrol Dial Transplant (1998) 13(4):975–7. doi: 10.1093/ndt/13.4.975
Keywords: IgA nephropathy, machine learning, Oxford classification system, prediction model, end-stage kidney disease
Citation: Xu L-L, Zhang D, Weng H-Y, Wang L-Z, Chen R-Y, Chen G, Shi S-F, Liu L-J, Zhong X-H, Hong S-D, Duan L-X, Lv J-C, Zhou X-J and Zhang H (2023) Machine learning in predicting T-score in the Oxford classification system of IgA nephropathy. Front. Immunol. 14:1224631. doi: 10.3389/fimmu.2023.1224631
Received: 18 May 2023; Accepted: 21 July 2023;
Published: 04 August 2023.
Edited by:
Huji Xu, Tsinghua University, ChinaReviewed by:
Youhua Xu, Macau University of Science and Technology, Macao SAR, ChinaJinxia Zhao, Peking University Third Hospital, China
Copyright © 2023 Xu, Zhang, Weng, Wang, Chen, Chen, Shi, Liu, Zhong, Hong, Duan, Lv, Zhou and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xu-Jie Zhou, emhvdXh1amllQGJqbXUuZWR1LmNu
†These authors have contributed equally to this work and share first authorship