
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Genet., 11 December 2023
Sec. Livestock Genomics
Volume 14 - 2023 | https://doi.org/10.3389/fgene.2023.1298114
This article is part of the Research TopicFrom Agricultural Genome to Phenome: Genome-Wide Association, Prediction and Selection, Volume IIView all 6 articles
 Xiao-Lin Wu1,2*
Xiao-Lin Wu1,2* George R. Wiggans1
George R. Wiggans1 H. Duan Norman1
H. Duan Norman1 Malia J. Caputo1
Malia J. Caputo1 Asha M. Miles3
Asha M. Miles3 Curtis P. Van Tassell3
Curtis P. Van Tassell3 Ransom L. Baldwin VI3Steven Sievert4Jay Mattison4Javier Burchard1João Dürr1
Ransom L. Baldwin VI3Steven Sievert4Jay Mattison4Javier Burchard1João Dürr1Various methods have been proposed to estimate daily yield from partial yields, primarily to deal with unequal milking intervals. This paper offers an exhaustive review of daily milk yields, the foundation of lactation records. Seminal advancements in the late 20th century concentrated on two main adjustment metrics: additive additive correction factors (ACF) and multiplicative correction factors (MCF). An ACF model provides additive adjustments to two times AM or PM milk yield, which then becomes the estimated daily yields, whereas an MCF is a ratio of daily yield to the yield from a single milking. Recent studies highlight the potential of alternative approaches, such as exponential regression and other nonlinear models. Biologically, milk secretion rates are not linear throughout the entire milking interval, influenced by the internal mammary gland pressure. Consequently, nonlinear models are appealing for estimating daily milk yields as well. MCFs and ACFs are typically determined for discrete milking interval classes. Nonetheless, large discrete intervals can introduce systematic biases. A universal solution for deriving continuous correction factors has been proposed, ensuring reduced bias and enhanced daily milk yield estimation accuracy. When leveraging test-day milk yields for genetic evaluations in dairy cattle, two predominant statistical models are employed: lactation and test-day yield models. A lactation model capitalizes on the high heritability of total lactation yields, aligning closely with dairy producers’ needs because the total amount of milk production in a lactation directly determines farm revenue. However, a lactation yield model without harnessing all test-day records may ignore vital data about the shapes of lactation curves needed for informed breeding decisions. In contrast, a test-day model emphasizes individual test-day data, accommodating various intervals and recording plans and allowing the estimation of environmental effects on specific test days. In the United States, the patenting of test-day models in 1993 used to restrict the use of test-day models to regional and unofficial evaluations by the patent holders. Estimated test-day milk yields have been used as if they were accurate depictions of actual milk yields, neglecting possible estimation errors. Its potential consequences on subsequent genetic evaluations have not been sufficiently addressed. Moving forward, there are still numerous questions and challenges in this domain.
Accurate lactation records play an indispensable role in the genetic advancement and comprehensive management of dairy cattle, with test-day yields constituting the core of these records. In countries such as the United States, most cows participating in milk recording programs have their milk sampled and milk weights documented monthly (Voelker, 1981). The term “test-day milk yield” thus defines the milk quantity produced by a dairy cow on the specific day when her yield is assessed. Test-day milk yields are used subsequently to predict lactation milk yields (VanRaden, 1997; Cole et al., 2009). Analyzing milk samples provides further information about components, including fat, protein, and somatic cell count. For effective herd management, periodic test-day records serve as a significant source of information about the productivity of individual cows and the overall herd (Everett et al., 1994). Such information is also routinely utilized to assess the cow’s health and milk quality and, in some instances, help determine milk pricing. For genetic evaluations, test-day records are used to calculate estimated breeding values (EBVs) for traits related to milk production (e.g., Jamrozik et al., 1997a; VanRaden et al., 2014). The latter information is instrumental in making breeding decisions to improve the herd’s genetic potential for these traits for future generations (Powell and Norman, 2006).
The frequency of test-day recordings can vary depending on the herd management strategies employed. While a cow is milked multiple times on a test day, not all these milkings are weighed. This practice, emerging in the United States in the 1960s, reflected the shift from the standard supervised twice-daily, monthly testing scheme towards cost-efficient milking plans to minimize costs associated with DHIA supervisor visits (Putnam and Gilmore, 1968). Plans such as the AM-PM method alternate sampling during morning or evening milkings across lactation. Initially, each test-day milk yield was taken to be twice a single yield, assuming that morning and evening milking sessions are equally spaced, each spanning precisely 12 h. Or, the biases will cancel out if the unevenness is complementary between AM and PM milkings. However, the practical situations are different. The AM and PM milking intervals may differ, and the rates of milk secretion can fluctuate between daytime and nighttime. AM milking intervals are typically more extended than PM milking intervals, and AM milk yields usually surpass PM milk yields (Putnam and Gilmore, 1970). While the differences are present, they do not necessarily cancel out. Wu et al. (2022) showed a broader range for morning milking intervals (from 5.6 to 23.67 h) compared to evening milking intervals (from 5.0 to 18.4 h), based on a US Holstein dairy cattle dataset comprising 7,544 milking records from 5,201 Holstein cows across 23 herds. The average morning and evening milking intervals were 12.3 and 11.6 h, respectively. Coinciding with the extended morning milking interval, the mean morning milk yield (16.4 kg) exceeded the mean evening milk yield (15.3 kg). Further, a generalized additive model applied to the same dataset indicated that an average US Holstein cow had a higher probability (63.0%) of producing more milk in the morning milking compared to the evening milking, primarily due to more extended AM milking intervals, whereas the reverse probability favoring a larger evening milk yield was only 35.8% (Wu et al., 2023b).
A plethora of methodologies has been proposed to address biases in daily yield computations, primarily arising from unequal milking intervals (Figure 1). Central to these advancements, from the 1980s to the 1990s, were the additive correction factors (ACFs) and multiplicative correction factors (MCFs). For instance, with AM-PM milking, an ACF model supplies additional adjustment quantities over twice the AM (or PM) yields to estimate the daily totals. In contrast, an MCF is defined as a ratio of daily yield to the yield from a single milking, hence also referred to as a ratio factor. Both ACFs and MCFs are computed for discrete milking interval classes. MCFs have been proposed in multiple forms (e.g., Shook et al., 1980; DeLorenzo and Wiggans, 1986), and their exact statistical interpretations differ (Wu X-L. et al., 2023). Wu et al. (2023a) argued that the MCF models encounter a particular challenge, termed ‘the ratio problem’, due to the use of a ratio variable (i.e., proportional daily yield) as the dependent variable in the data density (Wiggans, 1986) or the smoothing functions (Shook et al., 1980; DeLorenzo and Wiggans, 1986). The potential ramifications of this issue could lead to biases in two main areas: the bias from omitted variables and the bias from measurement errors (Lien et al., 2017). In response to ‘the ratio problem’, Wu et al. (2022), Wu et al. (2023b) further proposed an alternative solution in the form of an exponential regression model, which demonstrated improved accuracy for estimating test-day milk yields. Wu et al. (2003b) also evaluated non-linear modeling strategies that relax the linearity assumption of the Wiggans (1986) model in a US Holstein milking dataset. Their results demonstrated that some non-linear models, such as cubic splines, LOESS (locally estimated scatterplot smoothing), and generalized additive models (GAM), were promising as they enhanced the accuracy of estimated daily milk yields. Particularly, GAM provides a flexible tool to capture non-linear relationships in the data by utilizing different non-linear functions for different predictor variables. GAM, when optimally constructed, had the smallest errors and highest accuracies for estimating daily milk yields among all the non-linear models evaluated (Wu et al., 2023b).
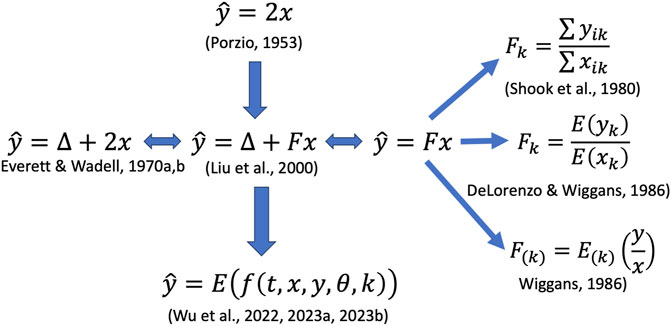
FIGURE 1. Illustration of various methods proposed for estimating daily milk yields. Notations:
The past 2 decades have witnessed a surge in genomic selection studies focusing mainly on genotypes and statistical paradigms. Although lactation records are equally significant, they have been overlooked. The current systems for lactation records and adjustments are somewhat outdated. Recent endeavors for a large-scale dairy data collection, backed jointly by the US Council on Dairy Cattle Breeding, the USDA Animal Genomics and Improvement Laboratory, and the National Dairy Herd Information Association, are converging toward updating the parameters for the current lactation recording systems, assessing existing methods, and exploring new methodologies for producing more reliable lactation records. This paper offers an exhaustive review of daily milk yields, the foundation of lactation records. We aim to provide readers with a multifaceted and in-depth understanding of test-day milk yields, emphasizing daily yield correction factors for estimating daily milk yields and their implications for genetic evaluations. While test-day yields bear immense significance for dairy management, this review does not delve into its expansive scope. Nonetheless, we aspire that this technical overview enlightens a broad spectrum of stakeholders in the dairy sector, encompassing dairy farmers, geneticists, animal scientists, and developers of dairy technology.
The “AM-PM milking” was the standard practice in dairy farming, whereby cows were milked twice daily: once in the morning (AM) and once in the evening (PM). Originating from the era when manual milking was ubiquitous, this regimen facilitated convenience by allowing cows to be milked in the mornings and evenings (Porzio, 1953; Putnam and Gilmore, 1968). The protocol for each milking session is similar: cows are brought in from the pasture or housing, and their udders and teats are cleaned. Then, the milking process commences, either mechanically or manually. After milking, cows are fed and returned to their resting areas. The AM-PM milking plan not only promotes the cow’s comfort by avoiding overfilling its udder, thus lowering the chance of cow distress and some possible health problems, but also fosters the milking consistency that a cow responds positively to. Additionally, it allows the farmers to monitor the cows for any health and behavior anomalies regularly.
Technological advancements, notably automatic (robotic) milking systems, have ushered in an era where thrice daily milking (3X) or even more frequent sessions are becoming common. Such systems permit more frequent and voluntary milking, potentially elevating milk yield and augmenting animal welfare (Barnes et al., 1990; Erdman and Varner, 1995; Smith et al., 2002; Hart et al., 2013). From a biological standpoint, more frequent milking entails more frequent udder emptying, potentially stimulating heightened milk production. However, these more frequent milkings are not without challenges because they demand more labor, potentially increase cow stress if mismanaged, and necessitate additional diet modifications to cater to increased nutritional needs for augmented milk production. Studies have indicated that while milk yield might rise, milk fat and protein contents could otherwise decline (Barnes et al., 1990; Erdman and Varner, 1995; Smith et al., 2002; Hart et al., 2013). A 2014 USDA report revealed that roughly 88% of dairy operations still predominantly milked cows twice daily, a trend especially prevalent in very small (<30 heads), small (30–99 heads), and medium operations (100–499 heads), with 84.4%–97.9% milking most cows twice daily. In contrast, around 57% of large operations opted for a three-times daily milking schedule (https://www.aphis.usda.gov/animal_health/nahms/dairy/ downloads/dairy14/Dairy14_dr_PartI_1.pdf).
In the 1960s, cost-saving milking strategies emerged wherein not all milkings on a test day were weighed. For instance, in the AM-PM plan, AM and PM milkings were alternately measured on test days throughout lactation. Initially, the daily milk yield was determined as double the amount of a single sampled milking, mathematically represented as (Figure 1):
where
An original ACF model is essentially a factorial (or analysis of variance) model that evaluates the difference between AM and PM yield as the response variable. The factorial variables or predictors include milking interval classes, lactation months, and more as appropriate (Everett R. W. and Wadell L. H., 1970; Everett R. W. and Wadell L. H., 1970). Wu et al. (2022), Wu X-L. et al. (2023) have shown that an ACF model can be interpreted as a linear regression of test-day milk yield on the partial yield, milking interval, and other covariates or factors as the predictor variables where applicable. Consider milking interval time (t) as the only predictor variable for simplicity. Let x be a PM yield and y be the daily total. Then, (y-x) quantifies the AM yield. The ACF model can then be expressed as follows:
where
where
Multiplicative correction factors are ratios of daily yield to yield from single milkings, denoted as
Liu et al. (2000) reviewed various linear (and quadratic regression) models where the dependent variable was test-day milk yields. For instance, the linear model is mathematically represented as (Figure 1):
where
Here, we illustrate the methods using AM-PM milking as an example. Yet, these same principles can be applied to three times or even more frequent milkings. We also presume that unequal milking interval represents the only source of variation for daily milk yields to simplify the discussion at this stage. Nevertheless, incorporating more affecting variables or factors, such as DIM, into the model is feasible and straightforward.
The exponential regression model proposed by Wu et al. (2022), Wu X-L. et al. (2023) can be interpreted as a linear function of the logarithm of daily milk yield (
Applying exponentiation on both sides of the above equation gives:
Recognizing
where
Wu et al. (2022) demonstrated that all these models gave similar daily yield estimates for milking intervals between 10 and 14 h. However, discrepancies in the estimated daily milk yields become pronounced outside this range. Specifically, ACF and MCF models were markedly superior to the baseline 2X model, producing drastically more minor errors and greater accuracies. The MCF models slightly surpassed the ACF models. Compared to the currently used methods, the exponential model stood out for its accuracy. For instance, relative to the Wiggans (1986) model, the exponential regression model boosted the precision of estimated daily milk yields by approximately 0.9% for Holstein cows and 1.5% for Jersey cows.
The Wiggans (1986) model, a de facto method for estimating daily milk yields in the United States, hinges on the assumption of linearity between proportional daily yields and milking interval time. Designed initially to determine MCFs for cows milked three times a day, the assumption stands due to the short milking intervals involved. However, Wu et al. (2023b) have recently demonstrated that this linearity assumption does not apply to cows milked twice daily, as longer, irregular milking intervals are involved. Historical data indicated that daily milk yield (including fat and solids-not-fat) did not have a linear relationship with milking intervals exceeding 12 h (e.g., Ragsdale et al., 1924; Bailey et al., 1955; Elliott and Brumby, 1955; Schmidt, 1960). Hence, early studies tended to postulate exponential milk curves up to 36 h (e.g., Brody, 1945). Klopcic et al. (2013) suggested a modified Michaelis-Menten function as a better fit for the trajectory of daily milk yields in relation to a milking interval over the same duration. Mathematically, the modified Michaelis-Menten function is an altered exponential function, where the base is one plus the yield for an interval of 720 min (i.e., 12 h), and the exponent is a non-linear function of milking interval time. Neal and Thornley (1983) showed that milk and component productions exhibited an exponential increase in relation to the interval between the current and the previous milkings, which later leveled off to an asymptote, potentially due to cell degradation and milk present in the udder.
Biologically, the milk secretion rate vitally influences the required frequency for milking cows and the acceptable intervals between milkings. The milk secretion rate depends on the pressure accumulating within the mammary gland. When milk builds up and accumulates in the mammary gland for a long enough time period, sufficient pressure is generated to inhibit secretion, leading to milk reabsorption by the blood (Schmidt, 1971). A marked increase in pressure occurs 1 hour after milking. Residual milk or complementary milk then moves from the alveoli into the teat and gland cisterns, causing a gradual increase in pressure due to the milk flow from the alveoli to the teat and gland cisterns. The rate of milk secretion remains linear for approximately 10–12 h after the last milking, then decreases slightly afterward. This decrease continues until it ceases around 35 h after the previous milking (Tucker et al., 1961; Schmidt, 1971). Therefore, while the linearity assumption is valid for approximately 12 h post-milking, it is not sustainable beyond.
Wu et al. (2023b) evaluated various non-linear modeling strategies in the Holstein dairy cattle. First, polynomial regression is a common non-linear model. Shook et al. (1980) used quadratic regression as a smoothing function to fit empirically computed MCFs in practical scenarios. Second, rather than fitting a single polynomial over the entire range of milking intervals, it is feasible to fit multiple polynomials over different segments of milking interval time. These segments are delineated by time points, known as “knots”, leading to piecewise polynomial regression. Positioning k knots throughout the milking interval range results in fitting k+1 distinct cubic polynomials. Introducing more knots defines a more flexible piecewise polynomial regression. With local smoothing, it is often necessary to enforce constraints for smoothness to ensure that the fitted curves are continuous and smooth at each knot. Mathematically, this implies that the first and second derivatives of the piecewise polynomial must be continuous at each knot, thus producing the third type of curve known as cubic splines. Splines can exhibit high variance at the extremes of the predictor range, primarily when milking interval times are very short or long. Hence, an additional constraint can be applied to mitigate this issue, compelling the function to be linear at the boundary. This method is known as natural splines. Likewise, step functions fit piecewise constant regression coefficients within different milk interval bins. We note that the model proposed by DeLorenzo and Wiggans (1986), denoted by (D-W), shares some commonalities with step functions, except that the D-W model does not define an intercept. Additionally, in the D-W model, the response variable is a test-day milk yield rather than a proportional test-day milk yield, and the predictor variable is a single milk yield (AM or PM yield) rather than the milking interval time. Lastly, Local regression, smoothing splines, and generalized additive models are three examples of promising models that can potentially improve the accuracy of estimated test-day milk yields (Wu et al., 2023b). Local regression, such as LOESS, allows for fitting flexible non-linear functions by computing a fit at a target point using only the nearby (“local”) observations (Cleveland, 1979). Local regression is also known as moving regression, a generalization of the moving average and polynomial regression (Harrell, 2015). Smoothing splines are functions that balance a measure of goodness of fit with a derivative-based measurement of smoothness (Craven and Wahba, 1979). In contrast, a spline tends to interpolate all the observed data points, which can lead to overfitting. Hence, a smoothing spline function can maintain the smoothness of the curve while minimizing the residual sum of squares. A GAM predicts the relationship between a response variable and one or more predictor variables while allowing for non-linear relationships. GAMs were initially developed by Hastie and Tibshirani (1990) to combine the properties of generalized linear models with additive models.
Mathematically, most non-linear models can generally be expressed using basis functions. For instance, consider m polynomials. The concept here is to have available a set of basis functions or transformations that can be applied to the variable of a milking interval
where
Here,
Here,
where
Finally, a cubic spline with k knots can be represented using a basis function. One possible form is a truncated power basis defined per knot, as follows:
where c is the knot. To fit a cubic spline with K knots to the data, we perform a least squares regression with an intercept and
Mathematically, GAMs do not represent a different form of non-linear functions, but they provide a generalized model framework that additively accommodates non-linear functions or predictors. Consider milking interval (
In the above,
Non-linear model performance often rests on the appropriate selection of hyperparameter values. Figure 2 shows the effects of two distinct hyperparameters with GAM. In this example, we assigned LOESS to fit the milking interval with the span value varying from 0.1 to 1.0 and employed smoothing splines for DIM, modulating its degrees of freedom between 3 and 30. The smoothing splines are, in essence, natural cubic splines with knots set at every distinct predictor variable value—the milking interval time. The degrees of freedom in these splines influence the penalized likelihood’s shrinkage and the splines’ overall smoothness. For LOESS, the span parameter determines the data percentage used in the local regression, with a smaller value featuring a localized regression and a larger value catering to a more global regression. The results showed that the mean absolute errors (MAE) were smaller with a small span value than a large value when fitting LOESS on milking interval time. With smoothing splines fitted on DIM, MAE was smaller with large degrees of freedom than with small degrees of freedom. Therefore, the most optimal values of these two parameters are span = 0.1 for LOESS and 30 degrees of freedom for the smoothing splines in this example.
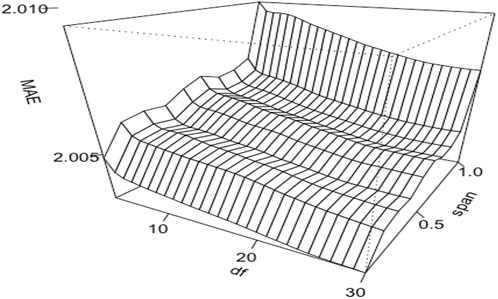
FIGURE 2. Three-dimensional relationships contour plots of mean absolute errors (MAE) of estimated daily milk yields obtained from a generalized additive model that fitted proportional test-day milk yields (
Wu et al. (2023b) compared the performance of the aforementioned non-linear models for estimating daily milk yields. Overall, these non-linear models, except step functions, demonstrated smaller errors and greater accuracies for estimated test-day milk yields to varying extents compared to the traditional linear models. Among the non-linear models, GAMs yielded the least bias and the greatest accuracy. This accentuates the potential of further harnessing GAMs to estimate test-day milk yields. Other non-linear models which are also promising include LOWESS and smoothing splines.
Additive correction factors are calculated for discrete milking interval classes, with the additive correction amount quantified by
where
Wu et al. (2022), Wu X-L. et al. (2023) show that the sum of ACFs within each milking interval class was constant. For traditional AM-PM ACF models, where the regression coefficient for the partial yield is
For linear regression, where
Using a simulation dataset, Wu X-L. et al. (2023) showed that the sum of ACFs within each milking interval class was 0 for conventional ACF models (
Multiplicative correction factors are also calculated for discrete milking intervals. For the DeLorenzo and Wiggans (1986) model, the regression coefficient is obtained for each milking interval class, denoted by
The above form of MCFs aligns with that empirically derived by Shook et al. (1980). Both share the same interpretation of an MCF as the ratio of the expected value of daily milk yields over the expected value of a single (AM or PM) milk yield. Shook et al. (1980) evaluated MCFs empirically as the ratio of bulk daily milk yield to bulk AM or PM milk yield. In the above, we observe that
For the Wiggans (1986) model, MCFs are obtained by locally taking the expected value on both sides of the model equation, assuming that
The above MCF corresponds to the expected value of the ratio of a test-day yield to a partial yield, not the same as that derived from DeLorenzo and Wiggans (1986). Still, both forms coincide with each other approximately because taking the first-order Taylor series approximation to the term on
The relationship between morning and evening MCFs, confined to the same dataset, is the following (Wu X-L. et al., 2023):
Multiplicative correction factors for non-linear models, such as the exponential regression model, can also be constructed, e.g., by following the second interpretation of DeLorenzo and Wiggans (1986). Please refer to Wu et al. (2023a) for a detailed description.
The practice of deriving daily yield correction factors on discrete milking interval classes has been in place for decades, but it was recently under scrutiny (Wu et al., 2023b). On the one hand, calculating correction factors on discrete milking interval bins presumes that these factors remain consistent within each bin, imposing a theoretically debatable contention. On the other hand, determining the optimal size for these discrete bins is practically challenging. A bin size that is too small might not provide enough data to calculate yield correction factors for every bin accurately. Conversely, a large bin size can inevitably compromise the accuracy of the estimated daily milk yields.
Instead, continuous daily yield correction factors can be derived (Wu et al., 2023b). For example, assuming there is sufficient data for every milking interval time range, continuous MCFs can be derived based on the Wiggans (1986) model as follows:
By noting
Here,
In practice, however, there may not always be sufficient data for every milking interval time unit. A more favorable approach, in line with the concept of locally weighted regression, involves calculating the MCF for each milking interval time
where
Figure 3A shows MCFs calculated with both approaches using a simulation dataset (Wu X-L. et al., 2023). Continuous MCFs were generated every 0.1-h time using LOESS and the Wiggans (1986) model (GW1). The Wiggans (1986) model was also used to generate discrete MCFs for 30-min milking interval bins (GW2). Overall, the MCFs obtained from GW1 were more akin to the MCFs obtained from LOESS with larger span parameter values (0.9) because LOESS with large span parameter values featured global regression. Nevertheless, both models did not give identical MCFs, suggesting that they still performed differently. The weights assigned to each dataset with LOESS are different: the closer a data point was to the mid-point of the neighborhood, the larger weight it got. In contrast, GW1 assigned the same weights to all data points. Therefore, LOESS can achieve the best local fitting while retaining excellent global smoothing.

FIGURE 3. Multiplicative milk yield correction factors (MCFs) obtained using two different strategies (A) Discrete versus continues MCFs for the morning (AM) and evening (PM) milkings, derived from the Wiggans (1986) model (GW) and locally weighted regression (LOESS; span = 0.1, 0.5, and 0.9, and degree = 1) (B) Discrepancies between smoothed average test-day milk yields and average estimated test-day milk yields obtained based on MCFs obtained using the Wiggans (1986) model. GW1 = MCFs computed for every 0.01-h time unit based on the Wiggans (1986) linear regression model; GW2 = MCFs computed for 30-min bins based on the Wiggans (1986) model; LOESS_
To show the presence of systematic biases in daily milk yields estimated from discrete MCFs, we calculated average estimated daily milk yields thus obtained with the Wiggans (1986) model and, meanwhile, fitted smoothing splines on the actual test-day milk yields and calculated average estimated test-day milk yields. The absolute deviation between the smoothed average of actual daily milking yields and the average of estimated daily milk yields was minimal at the mid-point of each milking interval class or bin; it then increased as the milking interval time moved away toward the boundaries (Figure 3B). Similar results were also obtained using the real dataset in the US Holstein dairy cattle (Wu et al., 2022). These recurrent patterns suggest that systematic biases were minimal at the central location of each milking interval bin and maximum on the boundaries between milking interval bins. Wu et al. (2022), Wu et al. (2023a), Wu et al. (2023b) have analytically shown why large milking interval classes or bins can lead to systematic errors. All these results, when combined, forcefully suggest that the periodical biases arising from deriving correction factors on large discrete milking interval classes were not just theoretical. Still, it is playing out in the real world, too.
Utilizations of test-day milk yields in genetic evaluations fall into two broad categories. In countries such as Canada, Finland, Germany, Italy, the Netherlands, and Switzerland, genetic evaluations are performed directly based on test-day yield records. This approach is referred to as the test-day yield model or, simply, the test-day model. In contrast, the United States employs a distinct strategy wherein genetic evaluations are derived from projected 305-day lactation yields, calculated from a subset of test-day yields throughout the lactation period. The latter method is referred to as the lactation yield model. Notably, test-day data have been collected in the United States since 1905 for management and have contributed to national genetic evaluations since 1936. However, the patenting of the test-day model in the United States in 1993 confined its application primarily to regional and unofficial evaluations under the exclusive purview of the patent holders (Powell and Norman, 2006).
A lactation yield model capitalizes on the high heritability of total lactation yield, providing an assessment directly pertinent to dairy producers. The total amount of milk produced over a lactation is a direct determinant of farm revenue. However, an intrinsic drawback of a lactation model is that it does not utilize all available test-day records, though lactation curves can be inferred by additional steps based on test-day milk yields. Knowing individual lactation curves can be useful in making informed breeding decisions.
Projection of lactation milk yields Accurately projecting total lactation milk yields is crucial to genetic evaluations under the lactation milk yield model. The Centering Data Method (CDM; McKellip and Seath, 1941) and the Test Interval Method (TIM; Sargent et al., 1968) were two well-known empirical methods used to estimate lactation milk yields in the 20th century. CDM calculated lactation yields based on yields from two consecutive milkings per month. The sampling day was centered as nearly as possible in the test month period but not necessarily aligned with the calendar month. Nevertheless, CDM overestimated actual yields until peak lactation and the yield following the last test day, typically underestimating yields for other test periods. Consequently, TIM supplanted CDM in the US in 1969 (McDaniel, 1969). TIM interprets the span between two test days as a distinct test period, with production credits bifurcated based on the data from each test day. Production credits for the first half of the test period are computed based on the first test-day information. Production credits for the second half of the test period were based on the second test-day information. For the first and last test intervals, yield credits were calculated similarly to CDM. Hence, TIM produced more accurate estimates when milk weights and component samples were obtained monthly, permitting greater flexibility than CDM (Norman et al., 1999). Shook et al. (1980) further proposed adjusting the credits for the first and second test intervals for the nonlinear shape of the lactation curve and the last test for a continuation of the expected decline, aiming to minimize the biases from overestimating credits for the first and last test intervals and underestimating credits for the second test interval.
Beginning in February 1999, the Best Prediction (BP) methodology was employed to estimate unobserved daily yields based on known daily yields (VanRaden, 1997; Cole and VanRaden, 2006). A fundamental assumption underlying BP is the prior knowledge of means and (co)variances, coupled with the premise that deviations of observed and unobserved milk yields from their respective population means follow a multivariate normal distribution. Consequently, the 305-day milk yield is calculated by the sum of the population mean and the product of covariance between observed and unobserved test-day yields, the inverse variance of observed test-day yields, and the deviations of observed test-day yields. The population means are often derived from the population average of lactation curves, for instance, the Wood lactation curve (Wood, 1967). Studies have shown that BP yielded more accurate 305days yields than TIM (e.g., Norman et al., 1999). Aggregating all the measured and estimated daily yields up to 305 days in milk gives the lactation yield. An added advantage of this aggregation method is its capacity to facilitate inference on individual lactation curves. Alternatively, lactation milk yields can be calculated directly without aggregating daily yields. BP was initially implemented limited to 305-day lactations. However, longer lactations can be accommodated by estimating covariances for days in milk greater than 365 days (Cole et al., 2007; Cole et al., 2009). Lactation milk yields can be estimated via a single-trait prediction exclusively from test-day milk yields or through multi-trait analysis encompassing other component traits, such as fat and protein. Multiple-trait predictions exhibit heightened accuracy, especially when some component samples are lacking (Schaeffer and Jamrozik, 1996).
Standardization of lactation records In the United States, lactation records have been standardized to a mature equivalent yield since the beginning of the 20th century (Freeman, 1971). Adjustments to age metrics other than mature age have also been considered (e.g., McDaniel, 1973). A mature-equivalent lactation yield delineates the hypothetical amount of milk a cow would have produced if she were mature (roughly 4–5 years old) under a twice-daily milking regime for 305 days. Milk records extending beyond 305 days are truncated, whereas those falling short are projected to 305-day yields (VanRaden, 1997). The key to adjusting milking frequencies is quantifying the relative increase of daily yields when switching from non-standard milking to standard, twice-daily milking. Notably, such gains can vary with age, season, and region. Wiggans and Powell (1980) estimated the relative increase in milk yield from 3X milking compared to 2X milking daily, which was 20% for 2-year-old cows, 17% for 3-year-old cows, and 15% for 4-year-old cows. Furthermore, a recent proposal by VanRaden et al. (2023) advocates a negative exponential function to derive correction factors tailored for adjusting milking frequencies. It is evident that current correction factors for adjusting milking frequencies are outdated and necessitate updating. Powell and Norman (2006) also argued against adjusting milking frequencies independent of multiplicative independent of milk yield standardization for other factors, positing that discerning yield variations solely based on milking frequency is challenging.
Additionally, lactation standardization considers factors such as age of the cow (or age-parity), and month of the year at calving (or season-region) (Norman et al., 1995; Miles et al., 2023). The mature-equivalent factors currently used in the national evaluation were derived almost 30 years ago (Schutz and Norman, 1994). The USDA updated age factors routinely in 1935, 1942, 1953, and 1974. Norman et al. (1995) reported changes in maturity patterns across time. Adjustments catering to 5-year periods were integrated into the national animal model from 1995 onwards. Multiplicative factors standardize the mean and standard deviation proportionally, and separate pre-adjustment factors standardize the genetic variances of records across time and herds before their incorporation into the animal model (Wiggans and VanRaden, 1989). A further pre-adjustment was added in 2007 to standardize variance across parities. Notably, the base adjustment varies with countries. For instance, while the United States, Australia, Canada, and Italy adjust records to mature age, some other countries opt for adjusting records to a first-lactation age ranging from 24 to 30 months. Israel adjusts to 36 months or the age of average production. Recommendations from Interbull lean towards adjusting to the average age. While the rationale for mature age adjustments may be entrenched in tradition, adjustment to average age may be more realistic because it puts records on the scale of an average cow in the herds, and, on average, adjusted and actual yields would be similar for a herd (Powell and Norman, 2006). Nevertheless, as Miller (1973) analytically highlighted, for any set of age means from which adjustment factors are constructed, the base to which records are adjusted exerts minimal influence on ranking animals.
US dairy genetic evaluations In the United States, the genetic merits of animals are assessed on mature equivalent 305-day lactation yields, utilizing a multiple-trait, animal model (Wiggans et al., 1988; Wiggans and VanRaden, 1989; VanRaden et al., 1995). Incoming data undergo rigorous checks for plausible values and alignment with pre-existing records (Norman et al., 1994; Miles et al., 2023). Multiplicative adjustments are conducted for calving age and month within each breed, times milked per day (adjusted to twice daily milking), previous days open, and heterogeneous variance. The base for mean and variance adjustments is set at 36-month-old and second-parity cows. Unequal variances across time, herds, and breeds are adjusted to the base variance calculated from standardized records of first lactation cows that calved in 2007.
The current CDCB genetic evaluations are scheduled tri-annually (April, August, December), encompassing lactation records from animals that calved post-1960, with the pedigree data from birth years as far back as 1950. The animal model, operational since 1989, is represented as:
In this model equation,
A test-day model is an animal model directly evaluating test-day observations. These models accommodate diverse data structures, from varied intervals to distinct recording plans. For instance, while some herds may only record milk yields, others may also include records of fat and protein contents. Test-day models offer a nuanced way to account for factors with varying effects on each test day (Druet et al., 2003). Moreover, specialized curves for distinct factors can be deduced by nesting the DIM class into the source of variation (Stanton et al., 1992). Historically, two-step test-day models emerged in regions such as Australia (Beard, 1983; Jones and Goddard, 1990), New Zealand (Johnson, 1996), and the Northeastern United States (Kachman and Everett, 1989; Everett et al., 1994; Wiggans and Gengler, 1999). This methodology first corrects test-day records for factors such as age-season, previous open days, milking regularity, lactation stage, milking age, and gestation days. Post-adjustments, breeding values for lactation traits are then ascertained via an animal model. On the other hand, one-step models perform both processes concurrently. The latter approaches fall into two categories. The first category includes test-day models with fixed regression of yield on DIM, assuming that test-day records within a lactation are repeated records (Meyer et al., 1987; Ptak and Shaeffer, 1993), hence referred to as repeatability test-day (REP-TD) models. The second category includes random regression test-day (RR-TD) models that define the animal’s genetic effect by random regression coefficients, also allowing for covariances among them.
Repeatability test-day models. Meyer et al. (1987) originally proposed one-step REP-TD models in Australia in the form of a sire model. Ptak and Schaeffer (1993) advocated using a repeatability animal model for genetic evaluations of dairy sires and cows, making it popular. A general scalar representation of a REP-TDM is the following:
where y is a test-day yield, HTD is a fixed herd test-day effect, a is a random genetic effect of an animal, p denotes the permanent environmental effect associated with each lactation, and e is the residual term. The lactation curve is accounted for by several coefficients of a fixed regression of yield on DIM or functions of DIM,
Random regression test-day models. A REP-TD model is ideal if genetic correlations among test-day yields are very high or near unity. But, in reality, they are not. To better fit the latter scenario, Schaeffer and Dekkers (1994) proposed using random regressions for evaluating animals’ genetic effects, permitting a covariance structure among the regression coefficients. Their model underwent further refinements, culminating in Canada’s adoption of a multiple-trait (milk, fat, protein, and somatic cell score), random regression test-day animal model in February 1999 (Jamrozik et al., 1997b; Schaeffer et al., 2000). Typically, the model includes fixed regressions accounting for similarities of lactation curves within specified groups of animals (e.g., regions and age classes), and random regressions are added to account for the individual variation of animal genetic effects and permanent environmental effects (Jamrozik et al., 1997a; Jamrozik and Schaeffer, 1997). A similar model was proposed by Kettunen et al. (1998), which included a random herd test month of production effect with different submodels for the genetic and permanent environmental components. Gengler et al. (1999) proposed an RR-TD model with an alternate strategy for solving the system of equations. The general concept of random regressions was previously described by Henderson (1982) and Laird and Ware (1982).
The general scalar representation of the RR-TD model adopted in Canada (Jamrozik et al., 1997c; Schaeffer et al., 2000) is the following:
where y is a test-day record, HTD is the fixed herd test-day effect, b is a vector of fixed regressions within region, age, and season, a is a vector of random regression genetic coefficients specific for each animal, p is a vector of random regression coefficients for permanent environmental effects for each cow, and e is the residual term for each observation. The submodel for the shape of the lactation curve is identical for fixed and random regressions. For instance, when Wilmink’s function is used (Wilmink, 1987), the function is defined by
Estimated breeding values and persistency proofs. The REP-TD model operates on the premise that genetic variation remains constant throughout lactation. As a result, while EBVs can be computed for any stage of lactation, their interrelationships result in a basic linear function when calculated for distinct periods. On the other hand, RR-TD models permit changes in an individual’s genetic merit at any given day during lactation. Hence, an RR-TD model calculated the breeding value for an animal as integrals from the individual curve, enabling EBVs to be presented as curves of genetic merit (White et al., 1999). The inherent advantage of genetic merit curves lies in their capacity to visually portray genetic merit level while simultaneously depicting lactation persistency of lactation (Swalve, 2000). This feature aids breeders in selecting bulls most suitable for their production systems, especially when contemplating the optimal lactation length, even if it falls short of the standard 305-day lactation duration.
Persistency proofs can be deducted from the daily genetic merit curves derived from RR-TD models (Jamrozik et al., 1997b; Jamrozik et al., 1998). Persistency, an economically pivotal trait, influences feed expenses, health, and fertility traits (Dekkers et al., 1998). Of these aspects, the repercussions of persistency on health, specifically metabolic stress causing health problems in cows, may outweigh its effect on feeding costs. Assessing feed expenses involves determining how supplementing concentrates to persistent cows can be partially offset by roughage, thus reducing overall costs (Swalve and Gengler, 1998).
Random-regression test-day models allow for estimating the genetic variance and ‘genetic yields’ for each individual day of lactation, thus paving the way for establishing precise persistency benchmarks. Such adaptability allows diverse persistency criteria to be determined from genetic assessments with RR-TD models. For instance, Jamrozik et al. (1998) proposed using the average slope of an animal’s lactation curve between days 60 and 280 as a measure of persistency. Their findings pointed to heritability levels in the range of 0.20–0.30 for milk, fat, and protein yields over the first three lactation cycles, alongside an almost negligible genetic interrelation between persistency and yield. However, a challenge surfaced from their analysis: the genetic correlations of persistency across lactations remained consistently low, roughly around 0.35. The underpinnings for this tenuous interplay between lactations remain speculative. Indirect selection predicated on such feeble correlations would prove inefficacious. Further complexities emerge, such as the challenge of achieving consensus on a singular persistency definition, like the slope of the lactation trajectory between days 60 and 280, which opposes the aspiration of providing EBV for diverse production systems.
During the 1980s, exporting North American semen to multiple countries led to numerous globally located daughters of highly ranked bulls. This widespread distribution fueled the interest in evaluating bull merits internationally. In 1994, the International Bull Evaluation Service (Interbull), rooted in Sweden, was founded by four Nordic countries and incorporated two breeds.
Interbull harmonized national genetic evaluations from various countries to present assessments of a comprehensive set of bulls based on each participating country’s metrics. In August 1995, Interbull adopted the multiple-trait, cross-country evaluation system (MACE) proposed by L. R. Schaeffer (1994), which encompasses genetic correlations between countries that are less than unity. This model fundamentally functions as a single-trait sire (lactation) model, integrated with a vector of phantom parent genetic group effects, and is designed to facilitate the comparison of dairy sires across multiple nations.
In the above,
Subsequent model advancements encompass a multiple-trait, sire (lactation) model devoid of the phantom genetic group effect, as proposed by Weigel et al. (2001), and a multiple-trait, test-day (animal) model, as introduced by Jamrozik et al. (2002). In the former model, the fixed effects additionally include herd-year-season of calving, age at calving, milking frequency, and heterosis (breed composition) classes. In the latter model, the fixed effects integrate herd-test day effects and a combination factor compromising of breed composition, age at calving, season of calving, and DIM effect; the random effects include random regression coefficients for the permanent environmental effect, random regression coefficients for animal genetic effect, and regression coefficients for genetic group effects, in addition to the residuals.
Estimated test-day milk yields have been used as if they were accurate depictions of actual test-day milk yields, neglecting the fact of possible estimation errors. The potential consequences arising from the disturbances linked to these estimates on subsequent genetic evaluations have not been sufficiently addressed. Liu et al. (2000) assessed six linear and non-linear regressions compared to the 2X method for estimating daily yields in AM-PM milking schedules. They reported a reduction in the variances of estimated yields compared to actual daily yields from different lactation stages, underscoring the need to expand the variance of estimated yields to a comparable scale with actual yields in genetic evaluation. Adjustments enabling comparable variances between actual and projected lactation yields were previously proposed by VanRaden et al. (1991). Essentially, linear (and quadratic) regression models are ACF models (Wu et al., 2022; Wu et al., 2023 X-L.). Hence, they did not preserve the actual variance structures as did MCF models (Miller, 1973). Even when estimated daily yields from single milkings were expanded to a comparable scale to actual daily yields, they could be assigned to more significant error variances than actual daily yields. Hence, variance-rescaling approaches could lower heritability and repeatability for expanded daily yields. Consequently, for estimating a cow’s breeding value, her own records received less weight when she was in AM-PM milking schemes than in a standard A4 testing program (Liu et al., 2000).
In this section, we analytically show the influence of errors associated with estimated test-day milk yields from two perspectives: estimating lactation milk yields using best prediction and genetic evaluation per se. In the former scenario, let
where
where
Denote projected lactation yields by
Here,
Replacing
where
When using the estimated test-day milk yields with measurement errors to estimate the actual lactation yields, the resulting linear regression coefficients also do not correspond to their “true” values. For instance, let
Therefore, disregarding the errors linked to projected lactation milk yields from estimated test-day yields, instead of actual yields, does not imply their nonexistence. On the contrary, these errors give rise to biases known as regression dilution or regression attenuation (Frost and Thompson, 2000).
When measurement errors associated with test-day yields are significant, how do they affect the estimation of heritability, an important genetic parameter for genetic evaluations? Here, we give an analytical illustration based on a simplified animal model, where the overall mean (
Here, for example,
The mixed-effect model equation (MME), in matrix form, is the following:
Following Henderson (1986), the estimated animal effects and residuals are the following:
Here,
In (37),
The estimated variances for the random genetic effects and residuals are the following (Henderson, 1986):
where
Then, the heritability for this test-day milk yield is estimated as follows:
When daily milk yield is not measured directly but estimated from partial yields, the estimated daily yields may not precisely correspond to the actual test-day milk yields. Let
Then, the animal model becomes:
In the above, we used * to distinguish between variables in the model (44) from those in the model (34). Then, we show that the overall mean, when obtained as the arithmetic average of corrected test-day milk yields, remains the same as in (39):
The above holds because
Assume that deviates happen randomly such that
Letting
Following a similar strategy and letting
Consequently, the heritability estimate obtained from estimated test-day milk yields also deviates from the heritability of actual daily milk yields. The following adjustments are needed to retain the same heritability as (42).
Otherwise, if large in magnitude, the estimation errors associated with test-day milk yields would have significant implications, potentially influencing heritability estimates and the estimated breeding values. A thorough understanding of this situation hinges on further studies.
We provided a comprehensive review of test-day milk yields, focusing on two primary daily yield correction methods and their applications, drawing insights from seminal studies over the past century. Test-day records offer meticulous insights into a cow’s productive life, elucidating the intricate interplay of genetic and environmental determinants shaping the quantity and quality of milk production. Such information is pivotal in formulating advanced mathematical models, thereby refining milk yield projections. The incorporation of test-day milk yields in dairy cattle genetic evaluations is instrumental in establishing a basis for heritability assessment and breeding value determination. This, in turn, steers breeding strategies aimed at elevating future milk yields and overall herd efficacy. Moreover, these yield records furnish invaluable perspectives for informed dairy management decisions, from fine-tuning feed efficiency and fortifying animal wellbeing to strategic culling decisions. This paper deliberates on the ramifications of modulating test-day milk yields, highlighting possible challenges and their potential effects on ensuing genetic evaluations.
The consistent acquisition and nuanced analysis of test-day data remain central to the progressive, sustainable, and profitable evolution of the dairy industry. In an ongoing endeavor, extensive, high-resolution milking data are being gathered for subsequent research. This initiative receives joint support from the US Council on Dairy Cattle Breeding, the USDA Agricultural Genomics and Improvement Laboratory, and the National Dairy Herd Information Association. Access to this new dataset will enable a thorough re-evaluation of existing systems and the development of novel tools, ensuring they reflect the most current and relevant realities. It will also facilitate the updating of pertinent parameters. Follow-up projects will include the reassessment of corrections applied to lactation yields and the refinement of adjustments for mature equivalent yields. These are crucial aspects for the future planning and enhancement of genetic evaluations and dairy production systems in the United States. As scientific and technological capabilities advance, we anticipate a heightened utilization of milk yield records, promoting more efficient genetic selection and herd management practices, thereby driving the dairy sector towards a profoundly knowledge-based and data-informed future.
X-LW: Conceptualization, Data curation, Formal Analysis, Investigation, Methodology, Resources, Software, Validation, Visualization, Writing–original draft, Writing–review and editing. GW: Investigation, Methodology, Validation, Writing–review and editing. HN: Investigation, Methodology, Validation, Writing–review and editing. MC: Methodology, Validation, Writing–review and editing. AM: Investigation, Methodology, Validation, Writing–review and editing. CV: Investigation, Methodology, Writing–review and editing. RB: Investigation, Methodology, Validation, Writing–review and editing. SS: Validation, Writing–review and editing. JM: Validation, Writing–review and editing. JB: Funding acquisition, Investigation, Project administration, Resources, Validation, Writing–review and editing. JD: Funding acquisition, Project administration, Resources, Validation, Writing–review and editing.
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Bailey, G. L., Clough, P. A., and Dodd, F. H. (1955). 568. The rate of secretion of milk and fat. J. Dairy Res. 22, 22–36. doi:10.1017/s0022029900007512
Barnes, M. A., Pearson, R. E., and Lukes-Wilson, A. J. (1990). Effects of milking frequency and selection for milk yield on productive efficiency of Holstein cows. J. Dairy Sci. 73, 1603–1611. doi:10.3168/jds.s0022-0302(90)78831-5
Beard, K. (1983). “Prediction of total lactation yield in dairy cows,” (Victoria, Australia: University of Melbourne). M.S. thesis.
Chesher, A. (1991). The effect of measurement error. Biometrika 78 (3), 451–462. doi:10.1093/biomet/78.3.451
Cleveland, W. S. (1979). Robust locally weighted regression and smoothing scatterplots. J. Am. Stat. Assoc. 74 (368), 829–836. doi:10.1080/01621459.1979.10481038
Cole, J. B., Null, D. J., and VanRaden, P. M. (2009). Best prediction of yields for long lactations. J. Dairy Sci. 92, 1796–1810. doi:10.3168/jds.2007-0976
Cole, J. B., and VanRaden, P. M. (2006). Genetic evaluation and best prediction of lactation persistency. J. Dairy Sci. 89, 2722–2728. doi:10.3168/jds.S0022-0302(06)72348-7
Cole, J. B., VanRaden, P. M., and Dematawewa, C. M. B. (2007). Estimation of yields for long lactation using best prediction. J. Dairy Sci. 90 (Suppl. 1), 421.
Craven, P., and Wahba, G. (1979). Smoothing noisy data with spline functions. Numer. Math. 31 (4), 377–403. doi:10.1007/bf01404567
Dekkers, J. C. M., Ten Haag, J. H., and Weersink, A. (1998). Economic aspects of persistency of lactation in dairy cattle. Livest. Prod. Sci. 53, 237–252. doi:10.1016/s0301-6226(97)00124-3
DeLorenzo, M. A., and Wiggans, G. R. (1986). Factors for estimating daily yield of milk, fat, and protein from a single milking for herds milked twice a day. J. Dairy Sci. 69, 2386–2394. doi:10.3168/jds.s0022-0302(86)80678-6
Druet, T., Jaffrezic, F., Boichard, D., and Ducrocq, V. (2003). Modeling lactation curves and estimation of genetic parameters for first lactation test-day records of French Holstein cows. J. Dairy Sci. 86, 2480–2490. doi:10.3168/jds.S0022-0302(03)73842-9
Elliott, G. M., and Brumby, P. J. (1955). Rate of milk secretion with increasing interval between milking. Nature 176, 350–351. doi:10.1038/176350a0
Erdman, R. A., and Varner, M. (1995). Fixed yield responses to increased milking frequency. J. Dairy Sci. 78 (5), 1199–1203. doi:10.3168/jds.S0022-0302(95)76738-8
Everett, R. W., Schmitz, F., and Wadell, L. H. (1994). A test-day model for monitoring management and genetics in dairy cattle. J. Dairy Sci. 77 (Suppl. 1), 267.
Everett, R. W., and Wadell, L. H. (1970a). Relationship between milking intervals and individual milk weights. J. Dairy Sci. 53, 548–553. doi:10.3168/jds.s0022-0302(70)86251-8
Everett, R. W., and Wadell, L. H. (1970b). Sources of variation affecting the difference between morning and evening daily milk production. J. Dairy Sci. 53, 1424–1429. doi:10.3168/jds.s0022-0302(70)86410-4
Frost, C., and Thompson, S. (2000). Correcting for regression dilution bias: comparison of methods for a single predictor variable. J. R. Stat. Soc. Ser. A 163, 173–189. doi:10.1111/1467-985x.00164
Gengler, N., Tijani, A., and Wiggans, G. R. (1999). “Iterative solution of random regression models by sequential estimation of regressions and effects on regressions,” in Proc. Computational cattle breeding ’99. Tuusula, Finland. Interbull bull. No. 20 (Uppsala, Sweden: International Bull Evaluation Service).
Griliches, Z., and Ringstad, V. (1970). Error-in-the-Variables bias in nonlinear contexts. Econometrica 38 (2), 368–370. doi:10.2307/1913020
Harrell, F. E. (2015). Regression modeling strategies: with applications to linear models, logistic and ordinal regression, and survival analysis. Berlin, Germany: Springer.
Hart, K. D., McBride, B. W., Duffield, T. F., and DeVries, T. J. (2013). Effect of milking frequency on the behavior and productivity of lactating dairy cows. J. Dairy Sci. 96, 6973–6985. doi:10.3168/jds.2013-6764
Hastie, T. J., and Tibshirani, R. J. (1990). Generalized additive models. Boca Raton, Florida: Chapman and Hall/CRC.
Henderson, C. R. (1986). Estimation of variances in animal model and reduced animal model for single traits and single records. J. Dairy Sci. 69, 1394–1402. doi:10.3168/jds.s0022-0302(86)80546-x
Henderson, C. R. (1982). Analysis of covariance in the mixed model: higher-level, nonhomogeneous, and random regressions. Biometrics 38, 623–640. doi:10.2307/2530044
Jamrozik, J., Jansen, G., Schaeffer, L. R., and Liu, Z. (1998). Analysis of persistency of lactation calculated from a random regression test day model. Proc. Interbull Mtg. Rotorua, Int. Bull. Eval. Serv. Upps. Swed. Interbull Bull. No. 17, 64–69.
Jamrozik, J., Kistemaker, G. J., Dekkers, J. C. M., and Schaeffer, L. R. (1997a). Comparison of possible covariates for use in a random regression model for analysis of test day yields. J. Dairy Sci. 80, 2250–2556.
Jamrozik, J., and Schaeffer, L. R. (1997). Estimates of genetic parameters for a test day model with random regressions for yield traits of first lactation Holsteins. J. Dairy Sci. 80, 762–770. doi:10.3168/jds.S0022-0302(97)75996-4
Jamrozik, J., Schaeffer, L. R., and Dekkers, J. C. (1997b). Genetic evaluation of dairy cattle using test day yields and random regression model. J. Dairy Sci. 80 (6), 1217–1226. doi:10.3168/jds.S0022-0302(97)76050-8
Jamrozik, J., Schaeffer, L. R., Liu, Z., and Jansen, G. (1997c). Multiple trait random regression test day model for production traits. Interbull Mtg. Vienna, International Bull Evaluation Service, Uppsala, Sweden. Interbull Bull. No. 16, 43–47.
Jamrozik, J., Schaeffer, L. R., and Weigel, K. A. (2002). Genetic evaluation of bulls and cows with single- and multiple-country test-day models. J. Dairy Sci. 85, 1617–1622. doi:10.3168/jds.S0022-0302(02)74232-X
Johnson, D. L. (1996). Estimation of lactation yield from repeated measure of test day yields. Proc. N.Z. Soc. Anim. Prod. 56, 16–18.
Jones, L. P., and Goddard, M. E. (1990). Five years’ experience with the animal model for dairy evaluations in Australia. Proc. 4th World Congr. Genet. Appl. Livest. Prod. Edinb. Scotl. XIII, 382–385.
Kachman, S. D., and Everett, R. W. (1989). Test day data model with individual herd correction factors. J. Dairy Sci. 72 (Suppl. 1), 60.
Kettunen, A., Mantysaari, E. A., Stranden, I., Poso, J., and Lidauer, M. (1998). Estimation of genetic parameters for first lactation milk production using random regression models. Proc. 6th World Congr. Genet. Appl. Livest. Prod. Armidale, N. S. W. Aust. 23, 307–310.
Klopcic, M., Koops, W. J., and Kuipers, A. (2013). Technical note: a mathematical function to predict daily milk yield of dairy cows in relation to the interval between milkings. J. Dairy Sci. 96, 6084–6090. doi:10.3168/jds.2012-6391
Laird, N. M., and Ware, J. H. (1982). Random-effects models for longitudinal data. Biometrics 38, 963–974. doi:10.2307/2529876
Lien, D., Hu, Y., and Liu, L. (2017). A note on using ratio variables in regression analysis. Econ. Lett. 150, 114–117. doi:10.1016/j.econlet.2016.11.019
Liu, Z., Reents, R., Reinhardt, F., and Kuwan, K. (2000). Approaches to estimating daily yield from single milk testing schemes and use of a.m.-p.m. records in test-day model genetic evaluation in dairy cattle. J. Dairy Sci. 83, 2672–2682. doi:10.3168/jds.S0022-0302(00)75161-7
McDaniel, B. T. (1969). Accuracy of sampling procedures for estimating lactation yields: a review. J. Dairy Sci. 52, 1742–1761. doi:10.3168/jds.s0022-0302(69)86837-2
McDaniel, B. T. (1973). Merits and problems of adjusting to other than mature age. J. Dairy Sci. 56, 959–967. doi:10.3168/jds.s0022-0302(73)85286-5
McKellip, I., and Seath, D. A. (1941). A comparison of the different methods of calculating yearly milk and butterfat records. J. Dairy Sci. 24 (3), 181–192. doi:10.3168/jds.s0022-0302(41)95403-6
Meyer, K., Graser, H.-U., and Smith, S. P. (1987). Estimation of adjustment factors and variance components for test-day production in Australian Black and White populations. Summary report to ADHIS on analysis of production records conducted by AGBU during 1985–1987. Armidale, Australia: Compiled by H.-U. Graser. AGBU, UNE.
Miles, A., VanRaden, P., Hutchison, J., Fok, G., and Schutz, M. (2023). Standardizing lactation yields from national data with age-parity-season-region corrections for fair comparisons across individual cows and environments. ADSA Oral Present. 2716.
Miller, P. (1973). A recent study of age adjustment. J. Dairy Sci. 56, 952–958. doi:10.3168/jds.s0022-0302(73)85285-3
Neal, H. D.St. C., and Thornley, J. H. M. (1983). The lactation curve in cattle: a mathematical model of the mammary gland. J. Agric. Sci. 101, 389–400. doi:10.1017/s0021859600037710
Norman, H. D., Meinert, T. R., Schutz, M. M., and Wright, J. R. (1995). Age and seasonal effects on Holstein yield for four regions of the United States over time. J. Dairy Sci. 78, 1855–1861. doi:10.3168/jds.s0022-0302(95)76810-2
Norman, H. D., VanRaden, P. M., Wright, J. R., and Clay, J. S. (1999). Comparison of test interval and best prediction methods for estimation of lactation yield from monthly, a.m.-p.m., and trimonthly testing. J. Dairy Sci. 82, 438–444. doi:10.3168/jds.S0022-0302(99)75250-1
Norman, H. D., Waite, L. G., Wiggans, G. R., and Walton, L. M. (1994). Improving accuracy of the United States genetics database with a new editing system for dairy records. J. Dairy Sci. 77, 3198–3208. doi:10.3168/jds.s0022-0302(94)77263-5
Powell, R. L., and Norman, H. D. (2006). Major advances in genetic evaluation techniques. J. Dairy Sci. 89, 1337–1348. doi:10.3168/jds.S0022-0302(06)72201-9
Ptak, E., and Schaeffer, L. R. (1993). Use of test day yields for genetic evaluation of dairy sires and cows. Livest. Prod. Sci. 34, 23–34. doi:10.1016/0301-6226(93)90033-e
Putnam, D. N., and Gilmore, H. C. (1968). The evaluation of an alternate AM-PM monthly testing plan and its application for use in the DHIA program. J. Dairy Sci. 51, 985.
Putnam, D. N., and Gilmore, H. C. (1970). Factors to adjust milk production to a 24-hourbasiswhen milking intervals are unequal. J. Dairy Sci. 53, 685.
Ragsdale, A. C., Turner, C. W., and Brody, S. (1924). The rate of milk secretion as affected by an accumulation of milk in the mammary gland. J. Dairy Sci. 7, 249–254. doi:10.3168/jds.s0022-0302(24)94019-7
Reents, R., Dekkers, J. C. M., and Schaeffer, L. R. (1995a). Genetic evaluation for somatic cell score with a test day model for multiple lactations. J. Dairy Sci. 78, 2858–2870. doi:10.3168/jds.S0022-0302(95)76916-8
Reents, R., Jamrozik, J., Schaeffer, L. R., and Dekkers, J. C. M. (1995b). Estimation of genetic parameters for test day records of somatic cell score. J. Dairy Sci. 78, 2847–2857. doi:10.3168/jds.S0022-0302(95)76915-6
Sargent, F. D., Lytton, V. H., and Wall, O. G. (1968). Test interval method of calculating dairy herd improvement association records. J. Dairy Sci. 51, 170–179. doi:10.3168/jds.s0022-0302(68)86943-7
Schaeffer, L. R. (1994). Multiple-country comparison of dairy sires. J. Dairy Sci. 77, 2671–2678. doi:10.3168/jds.S0022-0302(94)77209-X
Schaeffer, L. R., and Dekkers, J. C. M. (1994). “Random regressions in animal models for test-day production in dairy cattle,” in Proc. 5th World Congr. Genet. Appl. Livest. Prod., Guelph, Ontario, Canada, August 7-12, 1994, 443–446.
Schaeffer, L. R., and Jamrozik, J. (1996). Multiple-trait prediction of lactation yields for dairy cows. J. Dairy Sci. 79, 2044–2055. doi:10.3168/jds.S0022-0302(96)76578-5
Schaeffer, L. R., Jamrozik, J., Kistemaker, G. J., and Van Doormaal, B. J. (2000). Experience with a test-day model. J. Dairy Sci. 83, 1135–1144. doi:10.3168/jds.s0022-0302(00)74979-4
Schmidt, G. H. (1960). Effect of milking intervals on the rate of milk and fat secretion. J. Dairy Sci. 43, 213–219. doi:10.3168/jds.s0022-0302(60)90143-0
Schutz, M. M., and Norman, H. D. (1994). Adjustment of Jersey milk, fat, and protein records across time for calving age and season. J. Dairy Sci. 72 (Suppl. l), 267.
Shook, G., Jensen, E. L., and Dickinson, F. N. (1980). Factors for estimating sample-day yield in am-pm sampling plans. DHI Lett. 56, 25–30.
Smith, J. W., Ely, L. O., Graves, W. M., and Gilson, W. D. (2002). Effect of milking frequency on DHI performance measures. J. Dairy Sci. 85, 3526–3533. doi:10.3168/jds.S0022-0302(02)74442-1
Stanton, T. L., Jones, L. R., Everett, R. W., and Kachman, S. D. (1992). Estimating milk, fat, and protein lactation curves with a test day model. J. Dairy Sci. 75, 1691–1700. doi:10.3168/jds.S0022-0302(92)77926-0
Swalve, H. H. (2000). Theoretical basis and computational methods for different test-day genetic evaluation methods. J. Dairy Sci. 83, 1115–1124. doi:10.3168/jds.S0022-0302(00)74977-0
Swalve, H. H., and Gengler, N. (1998). “Genetics of lactation persistency,” in Proc. Int. Symp. Metabolic stress in dairy cows (Scotland: British Society of Animal Science), 75–82.
Tucker, H. A., Reece, R. P., and Mather, R. E. (1961). Udder capacity estimates as affected by rate of milk secretion and intramammary pressure. J. Dairy Sci. 44, 1725–1732. doi:10.3168/jds.s0022-0302(61)89947-5
VanRaden, P. M. (1997). Lactation yields and accuracies computed from test day yields and (co)variances by best production. J. Dairy Sci. 80, 3015–3022. doi:10.3168/jds.s0022-0302(97)76268-4
VanRaden, P. M., Miles, A. M., Wu, X.-L., and Noordhoff, D. R. (2023). Combined effects of milking intervals and frequencies. Ottawa, Canada: ADSA: Oral presentation 2717.
VanRaden, P. M., Tooker, M. E., Wright, J. R., Sun, C., and Hutchison, J. L. (2014). Comparison of single-trait to multi-trait national evaluations for yield, health, and fertility. J. Dairy Sci. 97 (12), 7952–7962. doi:10.3168/jds.2014-8489
VanRaden, P. M., and Wiggans, G. R. (1991). Derivation, calculation, and use of national animal model information. J. Dairy Sci. 74, 2737–2746. doi:10.3168/jds.S0022-0302(91)78453-1
VanRaden, P. M., Wiggans, G. R., Powell, R. L., and Norman, H. D. (1995). Changes in USDA-DHIA genetic evaluations (January 1995). AIPL Res. Rpt. 1995; CH3.
VanRaden, P. M., Wiggans, G. W., and Ernst, C. A. (1991). Expansion of projected lactation yield to stabilize genetic variance. J. Dairy Sci. 74, 4344–4349. doi:10.3168/jds.S0022-0302(91)78630-X
Weigel, K. A., Rekaya, R., Zwald, N. R., and Fikse, W. F. (2001). International genetic evaluation of dairy sires using a multiple-trait model with individual animal performance records. J. Dairy Sci. 84, 2789–2795. doi:10.3168/jds.S0022-0302(01)74734-0
White, I. M. S., Thompson, R., and Brotherstone, S. (1999). Genetic and environmental smoothing of lactation curves with cubic splines. J. Dairy Sci. 82, 632–638. doi:10.3168/jds.S0022-0302(99)75277-X
Wiggans, G. R. (1986). Estimating daily yields of cows milked three times a day. J. Dairy Sci. 69, 2935–2940. doi:10.3168/jds.S0022-0302(86)80749-4
Wiggans, G. R., and Gengler, N. (1999). Strategies for combining test day evaluations into an index for lactation performance. J. Dairy Sci. 82 (Suppl. 1), 102.
Wiggans, G. R., Misztal, I., and Van Vleck, L. D. (1988). Implementation of an animal model for genetic evaluation of dairy cattle in the United States. J. Dairy Sci. 71 (Suppl. 2), 54–69. doi:10.1016/s0022-0302(88)79979-8
Wiggans, G. R., and Powell, R. L. (1980). Projection Factors for milk and fat lactation records. USDA Dairy Herd Impr. Ltr. 56 (1), 1–15.
Wiggans, G. R., and VanRaden, P. M. (1989). “USDA-DHIA animal model genetic evaluations,” in National cooperative dairy herd improvement program handbook, fact sheet H-2. Extension Service (Washington, DC: U.S. Department of Agriculture).
Wilmink, J. B. M. (1987). “Studies on test-day and lactation milk, fat and protein yield of dairy cows,” (Wageningen, Netherlands: Landbouwuni- versiteit). Ph.D. thesis.
Wood, P. D. P. (1967). Algebraic model of the lactation curve in cattle. Nature 216, 164–165. doi:10.1038/216164a0
Wu, X.-L., Miles, A. M., Van Tassell, C. P., Wiggans, G. R., Norman, H. D., Baldwin VI, R. L., et al. (2023c). Does modeling causal relationships improve the accuracy of predicting lactation milk yields? JDS Comm. 4 (5), 358–362. doi:10.3168/jdsc.2022-0343
Wu, X.-L., Wiggans, G., Norman, H. D., Miles, A., Van Tassell, C. P., Baldwin VI, R. L., et al. (2023a). Daily milk yield correction factors: what are they? JDS Comm. 4, 40–45doi:10.3168/jdsc.2022-0230
Wu, X.-L., Wiggans, G. R., Norman, H. D., Enzenauer, H. A., Miles, A. M., Van Tassell, C. P., et al. (2023b) Estimating test-day milk yields by modeling proportional daily yields: going beyond linearity J. Dairy Sci. Online ahead of print. doi:10.3168/jds.2023-23479
Keywords: dairy cattle, genetic evaluation, lactation curve, non-linear models, test-day yields
Citation: Wu X-L, Wiggans GR, Norman HD, Caputo MJ, Miles AM, Van Tassell CP, Baldwin RL VI, Sievert S, Mattison J, Burchard J and Dürr J (2023) Updating test-day milk yield factors for use in genetic evaluations and dairy production systems: a comprehensive review. Front. Genet. 14:1298114. doi: 10.3389/fgene.2023.1298114
Received: 21 September 2023; Accepted: 27 November 2023;
Published: 11 December 2023.
Edited by:
Li Ma, University of Maryland, United StatesReviewed by:
Bradley Heins, University of Minnesota Twin Cities, United StatesCopyright © 2023 Wu, Wiggans, Norman, Caputo, Miles, Van Tassell, Baldwin, Sievert, Mattison, Burchard and Dürr. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiao-Lin Wu, bmljay53dUB1c2NkY2IuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.