
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet. , 11 August 2022
Sec. Genetics of Common and Rare Diseases
Volume 13 - 2022 | https://doi.org/10.3389/fgene.2022.891055
 Mohd Murshad Ahmed1
Mohd Murshad Ahmed1 Zoya Shafat1Safia Tazyeen1Rafat Ali1,2Majed N. Almashjary3Rajaa Al-Raddadi4Steve Harakeh5
Zoya Shafat1Safia Tazyeen1Rafat Ali1,2Majed N. Almashjary3Rajaa Al-Raddadi4Steve Harakeh5 Aftab Alam1Shafiul Haque6
Aftab Alam1Shafiul Haque6 Romana Ishrat1*
Romana Ishrat1*Chronic kidney disease (CKD) is defined as a persistent abnormality in the structure and function of kidneys and leads to high morbidity and mortality in individuals across the world. Globally, approximately 8%–16% of the population is affected by CKD. Proper screening, staging, diagnosis, and the appropriate management of CKD by primary care clinicians are essential in preventing the adverse outcomes associated with CKD worldwide. In light of this, the identification of biomarkers for the appropriate management of CKD is urgently required. Growing evidence has suggested the role of mRNAs and microRNAs in CKD, however, the gene expression profile of CKD is presently uncertain. The present study aimed to identify diagnostic biomarkers and therapeutic targets for patients with CKD. The human microarray profile datasets, consisting of normal samples and treated samples were analyzed thoroughly to unveil the differentially expressed genes (DEGs). After selection, the interrelationship among DEGs was carried out to identify the overlapping DEGs, which were visualized using the Cytoscape program. Furthermore, the PPI network was constructed from the String database using the selected DEGs. Then, from the PPI network, significant modules and sub-networks were extracted by applying the different centralities methods (closeness, betweenness, stress, etc.) using MCODE, Cytohubba, and Centiserver. After sub-network analysis we identified six overlapped hub genes (RPS5, RPL37A, RPLP0, CXCL8, HLA-A, and ANXA1). Additionally, the enrichment analysis was undertaken on hub genes to determine their significant functions. Furthermore, these six genes were used to find their associated miRNAs and targeted drugs. Finally, two genes CXCL8 and HLA-A were common for Ribavirin drug (the gene-drug interaction), after docking studies HLA-A was selected for further investigation. To conclude our findings, we can say that the identified hub genes and their related miRNAs can serve as potential diagnostic biomarkers and therapeutic targets for CKD treatment strategies.
Chronic kidney disease (CKD) is considered among the major types of nephrosis across the globe, with a successive increase in its associated patients in recent years (Epstein et al., 1988; Carpenter and McHugh, 2017). CKD is a highly heterogeneous disease, wherein kidney structure and function are damaged (Webster et al., 2017; Tonelli et al., 2006; De Nicola and Zoccali, 2016; Guo et al., 2019; Wilson et al., 2021). Over recent years, although clinical and experimental studies have provided knowledge on the CKD causes (Lovisa et al., 2016; Hewitson et al., 2017; Lajdová et al., 2016; Johnson and Nangaku, 2016), the underlying mechanisms leading to the progression and development of CKD remain poorly understood. After CKD has been diagnosed, the specific CKD stage is determined. CKD is categorized into a five distinct stages on the basis of the glomerular filtration rate (GFR), i.e., G1 (GFR ≥ 90 ml/min/1.73 m2), G2 (GFR 60–89 ml/min/1.73 m2), G3a (45–59 ml/min/1.73 m2), G3b (30–44 ml/min/1.73 m2), G4 (15–29 ml/min/1.73 m2), and G5 (Kidney International Supplements, 2013). The early CKD stages (Epstein et al., 1988; Carpenter and McHugh, 2017), show few symptoms, and the disease is not detected till it reaches later stages (Rajapurkar et al., 2012). The rate of morbidity and mortality increases with the succession of CKD stages. Particularly adults suffering from CKD have an increased risk of hospitalization due to infections (Dalrymple et al., 2012). The mechanisms linking immune function and kidney function in earlier stages remain poorly understood. CKD entails the slow but regular loss of kidney function and leads to late-stage renal diseases. Transcriptomics is considered a promising strategy for the selection and detection of biomarkers as well as for monitoring the activity of diseases (Szabo and Devlin, 2019). Microarray technologies facilitate the explication of mRNA profiles related to human disease thereby providing a comprehensive and balanced approach for analyzing the processes of disease systematically (Hu et al., 2016). Recent gene expression studies have been successfully carried out on various diseases, such as cancer (Yang et al., 2018; Liu et al., 2015; Zhai et al., 2017), angiocardiopathy (Yan, 2018; Guo et al., 2018), asthma (Modena et al., 2017; Liu et al., 2019), etc. to identify early diagnostic biomarkers. In this context, an in-depth study of the CKD-associated mechanisms is required in order to understand its underlying pathophysiology, which is crucial to identify predictors as well as the therapeutic targets of the disease. Recently, a study has been conducted on CKD gene expression profiles which have identified some of the differentially expressed genes (DEGs) implicated in the development and progression of this disease (Nandakumar et al., 2017). However, we performed an integrated analysis on some of the other unexplored gene expression profiles of CKD. Thus, our identified DEGs show discrepancies with the previous study results due to heterogeneity in CKD cases and control subjects.
The molecular components in human cells are not functionally independent, i.e., interdependent, which means that a particular disease or syndrome is due to the consequence of perturbations of complex intracellular and intercellular interactions. With the enlargement and progression of the network biology field, many potential key genes related to diseases along with their improved drug targets have been identified (Barabási et al., 2011). Thus, this emerging field of network medicine methodically explores drug targets, biomarkers, or key genes of the network through the identification of modules and pathways, therefore, serving as a platform for improved diagnosis, prognosis, and the treatment of complex diseases (Silverman et al., 2020; Conte et al., 2020; Fiscon et al., 2018; Paci et al., 2021).
The present study reports the bioinformatics analysis of the Gene Expression Omnibus (GEO) database available at NCBI (National Center for Biotechnology Information). At first, we applied the meta-approach to CKD patients and healthy controls and retrieved data, to identify the signature DEGs. A total of five gene expression profiling datasets based on CKD (GSE15072, GSE23609, GSE43484, GSE62792, and GSE66494) were selected for the present analysis to screen the DEGs. The overlapped DEGs among all datasets were proceeded to perform the functional enrichment analysis to explore the molecular mechanisms associated with CKD. Then, we carried out the protein-protein interaction (PPI) network analysis to reveal the potential hub genes for CKD. From the PPI network, the modules of interest and hub genes in each module were identified and displayed using Cytoscape. Furthermore, molecular docking of CXCL8 and HLA-A genes was employed with a common drug Ribavirin. Our findings established a reliable biomarker for further research, which may provide a further understanding of the potential molecular mechanisms associated with CKD.
The workflow of the integrative network-based method used for the present analysis is illustrated in Figure 1. The gene expression datasets (GSE15072, GSE23609, GSE43484, GSE62792, and GSE66494), consisting of normal (healthy control) and treated (diseased patient) samples, were downloaded from the NCBI GEO database (https://www.ncbi.nlm.nih.gov/geo/). The criteria for selection of data in the NCBI website search bar were made using keywords, such as “CKD,” “chronic kidney disease,” and human (Organism). Subsequently, the data obtained from these five datasets were used for the present analysis. The details of the retrieved GSE series are mentioned in Table 1.
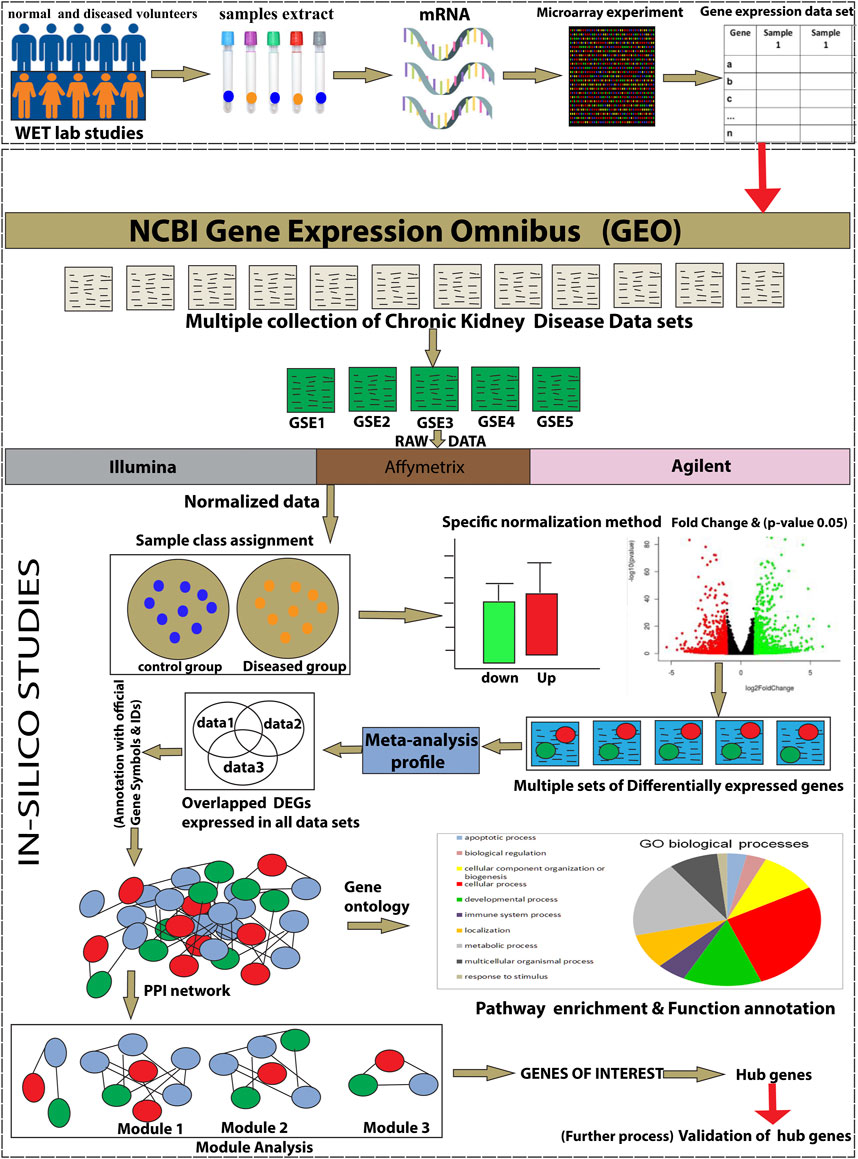
FIGURE 1. The schematic representation of the present study workflow through an integrative network-based approach.
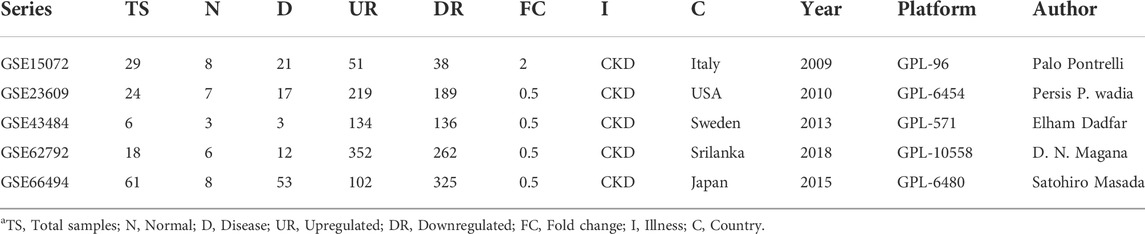
TABLE 1. The details of the present analysis GSE series.
The retrieved CKD-associated GSE series (the originally obtained data of gene expression datasets) were further processed for normalization through the GEO2R (http://www.ncbi.nlm.nih.gov/geo/geo2r/) tool. It is an interactive web-based tool that allows a user to identify the genes which are differentially expressed across samples. The DEGs were selected by applying default settings, i.e., a p‐value < 0.05 after being adjusted by a false discovery rate and |log2FC| > 0.5–2, where FC represents fold change. The linear model analysis of the microarray data package (LIMMA) in R was used to identify DEGs (by defaults in GEO2R) (Ritchie et al., 2015).
The obtained genes (upregulated and downregulated) from the meta-analysis were utilized for the construction of the PPI network. In the process of analysis of DEGs, the Benjamini-Hochberg correction method was used to correct the significant P-values obtained by the original hypothesis test.
For further evaluation of the functional interactions among obtained DEGs, the PPI network was constructed from these DEGs using an online database STRING (Search Tool for the Retrieval of Interacting Genes) Version 11.3, of known and predicted protein-protein interactions. These interactions include physical and functional associations, and the data are mainly derived from computational predictions, high-throughput experiments, automated text mining, and co-expression networks. In order to build a native PPI network of the DEGs, the Gene ID/Probe ID genes were mapped to their respective officially gene symbol/gene name, and their associated p-value and FC values were retrieved. Subsequently, Cytoscape 3.8.3 was used to visualize and construct the PPI network. In the PPI network, each node represented the gene and edges represented the connection between nodes.
The following properties in the constructed PPI network were analyzed to find out important behaviors of the network:
In a network study, the degree (k) of node (n) constitutes the total number of connections or links with other nodes (Gursoy et al., 2008).
In a network, a node’s betweenness centrality reflects the importance of the flow of information from one node to another based on the shortest path.
In a network, closeness centrality reflects how quickly the information is passing from one node to another (Przulj et al., 2004).
In a network, stress is represented as the addition of all nearest paths of all node pairs (Shimbel, 1953).
To date, various centrality measures have been anticipated in the topology-based network to address the difficulty in locating hub nodes. To discover the most influential nodes or hubs in a complex network constitutes a major problem for researchers. The location of an important node or edge in the network analysis is a major challenge and plays a crucial role. For the identification of significant modules (based on centrality measurement), three different software were employed to identify the significant modules in the PPIN network. CytoHubba (version 0.1) (Cytoscape plugin cytoHubba, a user-friendly interface that ranks nodes in a network based on its features) (Chin et al., 2014), Cytoscape plugin, Molecular Complex Detection (MCODE Version 1.31), and CentiServer (a comprehensive resource, web-based application, and the R Package for the centrality analysis) (Jalili et al., 2015).
Gene ontology is categorized into three indistinguishable terms, i.e., the molecular function (MF), biological process (BP), and cellular component (CC). These terms collectively give researchers a better idea about the functional annotation of genes. In order to reveal the functional difference among DEGs, the extracted DEGs were submitted to three different enrichment analysis tools, i.e., Enrichr (a comprehensive web server that performs the gene set enrichment analysis) (Kuleshov et al., 2016); g:Profiler, a web server that carries out the functional enrichment analysis of the genes; g:Profiler—a web server for functional enrichment analysis and conversions of gene lists (ut.ee); ToppGene (a web portal which rank or prioritize candidate genes on the basis of the similar function of the training gene list).
After the identification of hub genes, the miRNet 2.0 platform was used to find out the hub gene-associated miRNAs. MiRNet 2.0 is a web-based platform that helps in elucidating the miRNA using the integrative existing knowledge via network-based visual analytics (Fan et al., 2016).
The obtained hub genes were mapped onto the Drug-Gene Interaction database (DGIdb http://www.dgidb.org) (Freshour et al., 2021). The mapping was undertaken to identify better potential therapeutic drugs for CKD-associated genes. The drug-gene interaction complex was visualized using Cytoscape (Version 3.8.2) software. ADGI (Drug-Gene Interaction) is defined as a relationship that exists between a therapeutic and genetic variant and has the possibility to cause an effect on a patient’s treatment in response to a drug. The 3D modeled structures of the obtained hub genes, i.e., CXCL8 (PDB ID: 3IL8) and HLA-A (PDB ID: 1AKJ) were obtained from the RCSB PDB database (https://www.rcsb.org/), and the drug structures were taken from the PubChem database. Using ChemBio3D Ultra software, the 2D structures were transformed into 3D structures. Furthermore, the drug 3D structures were exported as pdbqt files for the docking analysis.
GEPIA (the Gene Expression Profiling Interactive Analysis) (http://gepia.cancer-pku.cn/detail.php) (Tang et al., 2017), a web server, is used to analyze the expression profiles of tumors (such as KIRC, KIRK, etc.) and normal samples included in TCGA (The Cancer Genome Atlas) (http://portal.gdc.cancer.gov/) and GTEx (the Genotype-Tissue Expression) (http://gtexportal.org/home/) databases. The default parameters were taken and the cutoff value was 50%. The sample was selected as the dataset and the hazard ratio (HR) was calculated based on the Cox proportional-hazards model. The 95% CI was not calculated in the present study. For HR, p < 0.05 was considered to indicate a statistically significant difference. Additionally, the validation was carried out for the hub genes using box plot analysis and subsequently their pathological stage was determined.
The microarray expression datasets GSE15072, GSE23609, GSE43484, GSE62792, and GSE66494 were downloaded from the GEO database. The DEGs between controls and the diseased samples were analyzed using the GEO2R tool. Considering the datasets altogether, our analysis revealed a total of 1793 specific DEGs which included 851 upregulated genes and 942 downregulated genes. For each of the datasets, the total number of upregulated and downregulated genes were also analyzed using the adjusted p values (p < 0.05) and |log2FC| > 0.5–2., and was further compared using an online tool (http://bioinformatics.psb.ugent.be/webtools/Venn/) or Venny 2.0.2. The total number of upregulated and downregulated genes in each dataset is as follows: GSE15072 (50 upregulated and 38 downregulated genes); GSE23609 (219 upregulated and 189 downregulated genes); GSE43484 (133 upregulated and 135 downregulated); GSE62792 (351 upregulated and 262 downregulated); GSE66494 (102 upregulated and 324 downregulated). The overlapped genes that were found to be the most common in at least two GSE series were referred to as final DEGs. The identified overlapped upregulated and downregulated genes in at least two CKD series are mentioned in Table 2.
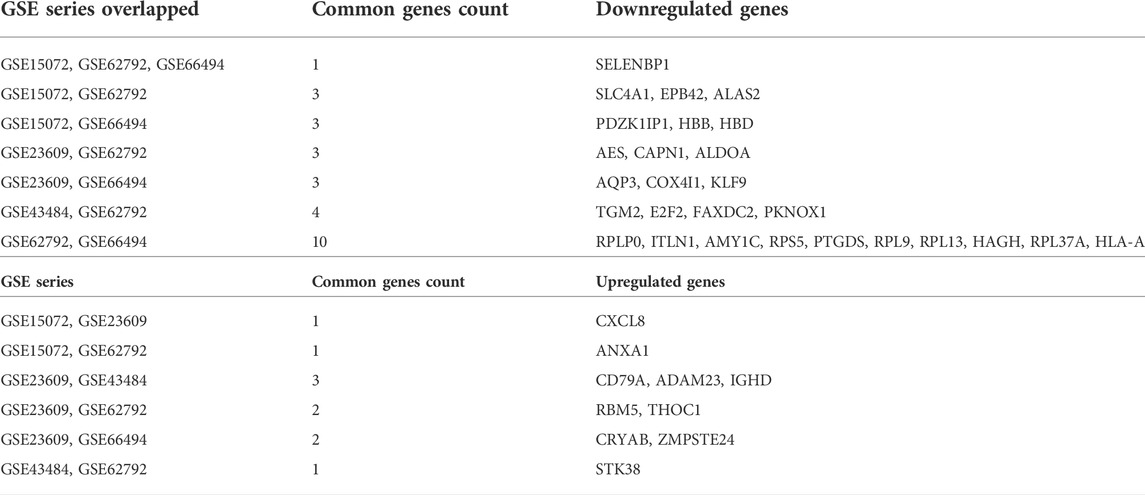
TABLE 2. The identified overlapped DEGs associated with CKD.
A total of 10 upregulated genes and 27 downregulated genes were proceeded for further investigation as shown in Figure 2.
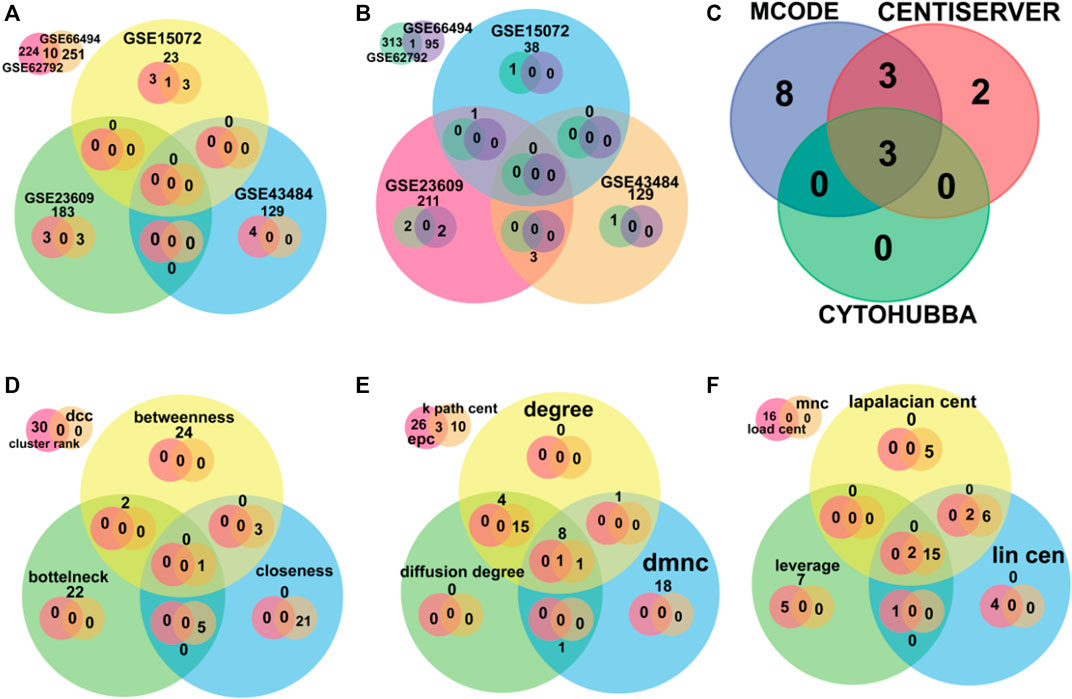
FIGURE 2. The Venn diagram depicts the overlapped data. (A,B) were used for finding overlapped DEGs upregulated and downregulated genes, respectively. (C) was used for finding the overlapped hub genes using software MCODE, Centiserver, and Cytohubba. (D–F) depict different centralities methods for overlapped genes.
The gene and its associated products constitute a biological system that forms the basis of a complex network wherein cells interact randomly. During the progression of development of a particular disease, the investigation at the level of gene expression is carried out using the biological information approach. The interrelationship among DEGs was undertaken to identify the overlapping DEGs. A total of 37 genes (including upregulated and downregulated) were submitted to the STRING database, which identified a PPI network that possessed 395 nodes and 17,923 edges. As a variety of pathways and genes are involved in the occurrence and development of a disease, enhanced understanding using network-based approaches is essential for researchers to shed light on disease-related mechanisms. Some crucial genes and signaling pathways perform important biological processes, therefore, they are utilized as therapeutic targets for various diseases. Tracing was applied to the PPI network for the genes of interest finding, which marks that 20 DEGs (out of 37 selected DEGs) represented as each node of the disease-specific gene-interaction network. The interactions of the genes (every single node) formed edges of the network. Then, each significant gene was extracted with its initial neighbors as shown in Figure 3.
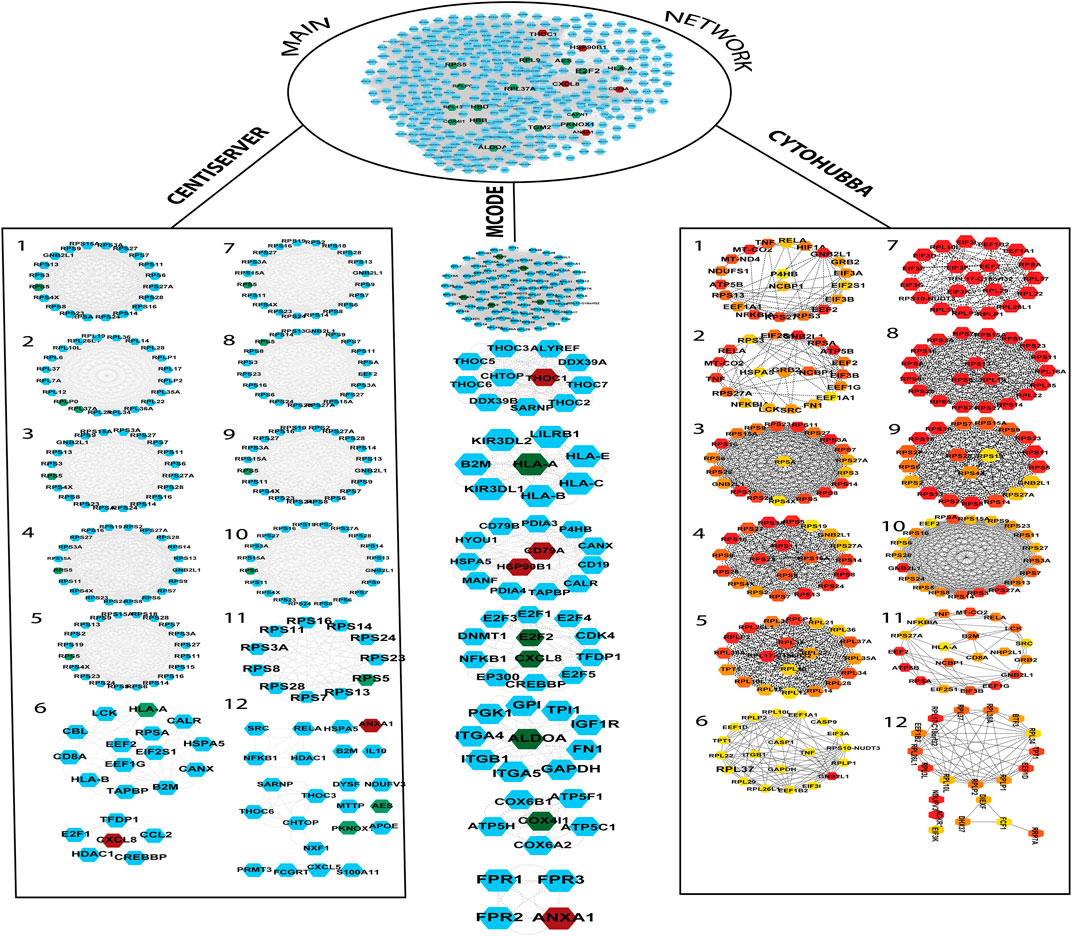
FIGURE 3. The PPI network was built by the String database. The network contains a total of 322 nodes and 17,239 edges. The PPI network was further divided into subnetworks by MCODE, Centiserver, and Cytohubba. The green color nodes depict downregulated genes, whereas the nodes in red color depict upregulated genes. CytoHubba color coding scheme is based on ranking, wherein the top to bottom gene ranks decline from red to light color.
It is important to find the most valuable nodes in the complex network. To do this, most researchers find the nodes that are based on centralities methods. In our study, we used 12 different centrality methods in Cytohubba, 12 methods (out of 27) in Centiserver, and one method by MCODE. In our previous research, the most influential nodes in the CVD and CKD network were identified using IVI packages in R. Three genes were traced out 12 modules from the Cytohubba, whereas six genes were traced in MCODE, and nine genes were traced from the Centiserver (Supplementary Table S1). It was observed that three hub genes (RPL37A, HLA-A, and RPS5) were found to be overlapping among three tools/databases (Cytohubba, MCODE, and Centiserver), whereas six genes (RPL37A, HLA-A, RPS5, CXCL8, RPLP0, and ANXA1) were overlapping among two methods/tools/databases (Centiserver and MCODE). The paradigms were exploited for the selection of the top 30 informative genes.
It is really important to find, whether a gene is involved in a process and the function of the gene with the location. For these three categories (process, function, and localization), the gene ontology analysis was performed by three different databases (Toppgene, gProfiler, and Enrichr). Various terms were found by these databases, so for the obtained huge data in form of GO terms, we considered only overlapped terms in three categories (MF, BP, and CC). Therefore, out of hundreds of terms, only 12 terms were found to be overlapping, of which two were from the molecular function, six were from the biological process, and four from the cellular process.
The hub genes that showed significant enrichment are listed in Table 3. The pathway analysis of the hub genes was extracted using the Enrichr database as shown in Table 4. Table 3 lists the significantly enriched pathways of hub genes associated with CDK. The significant pathways of hub genes were mainly enriched with Coronavirus disease, cellular senescence, Kaposi sarcoma-associated herpesvirus infection, human cytomegalovirus infection, allograft rejection, cancer, graft-versus-host disease, diabetes mellitus (Type 1), and malaria.
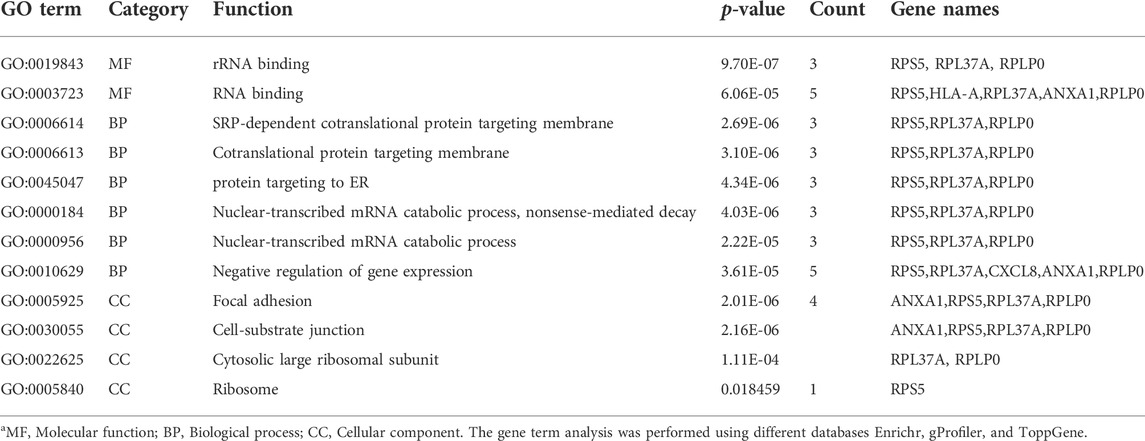
TABLE 3. The gene term enrichment analysis of hub genes associated with CKD.
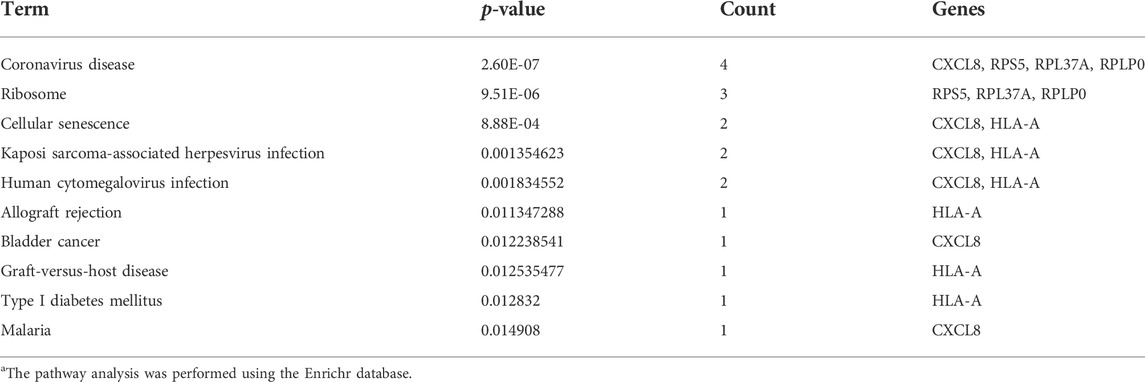
TABLE 4. The pathway analysis of hub genes in CKD.
The survival analysis of the selected genes (ANXA1, CXCL8, HLA-A, RPL37A, RPLP0, and RPS5) was undertaken. Survival curves are used to show the survival ability with time and survival rate (Figure 4). The relation between hub genes expression and pathological stage in CKD patients was estimated through GEPIA (Figure 5). Further, we utilized GEPIA tool to validate the expression of hub genes using box plot analysis (Figure 6).
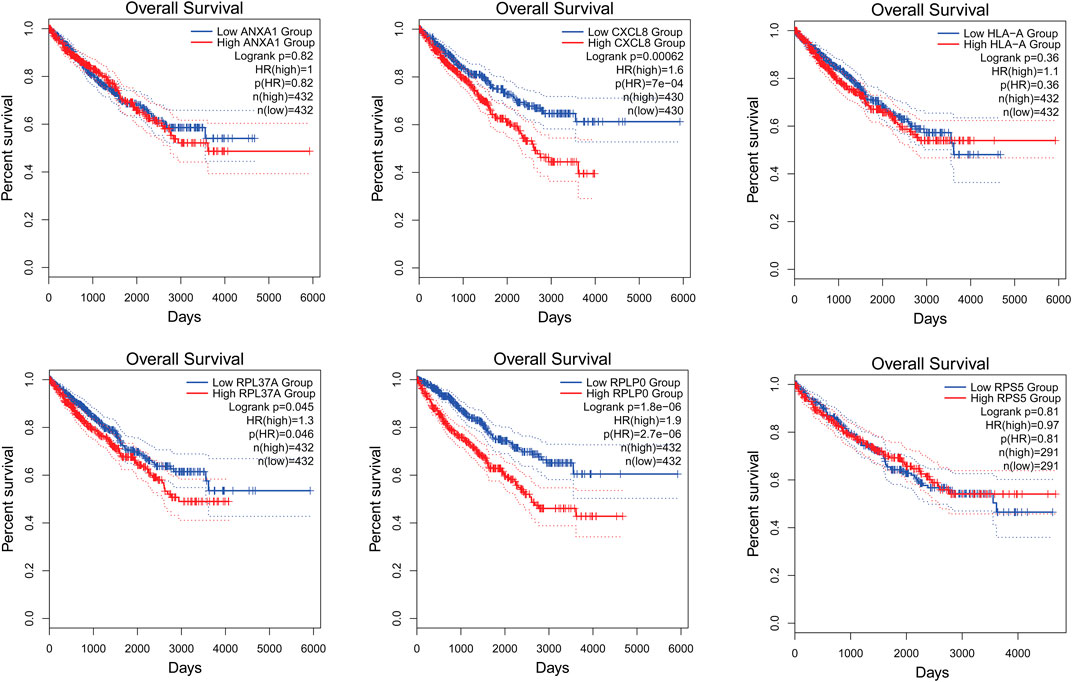
FIGURE 4. Survival curves of ANXA1, CXCL8, HLA-A, RPL37A, RPLP0, and RPS5 in patients with CKD. Survival curves were used to show the survival ability with time and survival rate.
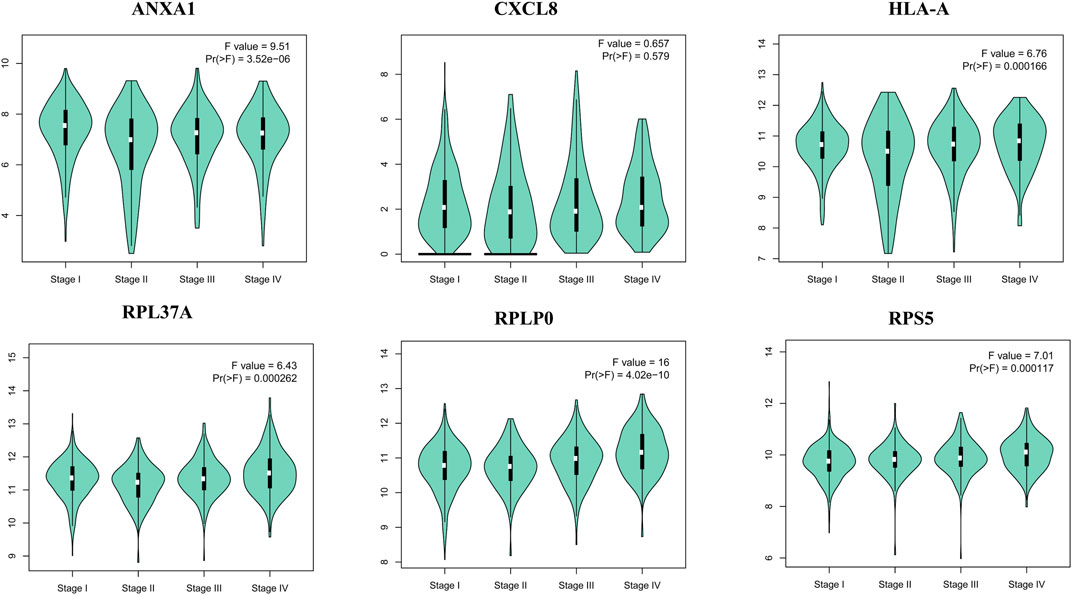
FIGURE 5. Violin plots of selected hub genes ANXA1, CXCL8, HLA-A, RPL37A, RPLP0, and RPS5 in kidney cancer.
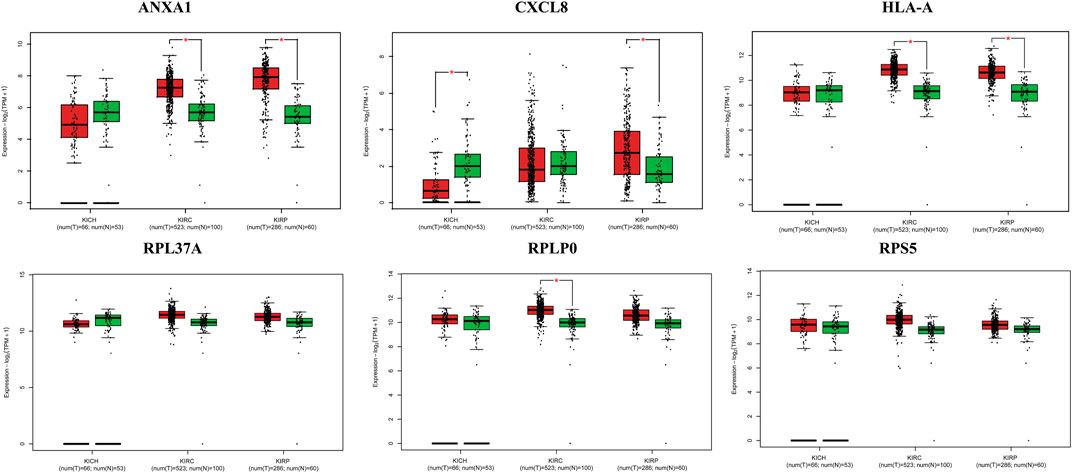
FIGURE 6. Box plots of selected hub genes ANXA1, CXCL8, HLA-A, RPL37A, RPLP0, and RPS5 in kidney cancer (KIRC, KIRP, and KICH).
The resultant six hub genes (on the basis of centrality approaches) were utilized subsequently to find their target miRNAs see Table 5. For CXCL8 and HLA-A, one miRNA was common hsa-miR-124-3p. They identified six hub genes that were submitted to the DGIdb database and formed a network (the mRNA-Drugs interaction network) with 67 nodes and 61 edges that connected other interacting genes. The network was further analyzed to identify important hub genes with their drug targets. Finally, Ribavirin was identified as the common target for two hub genes (CXCL8 and HLA-A) (Figure 7).
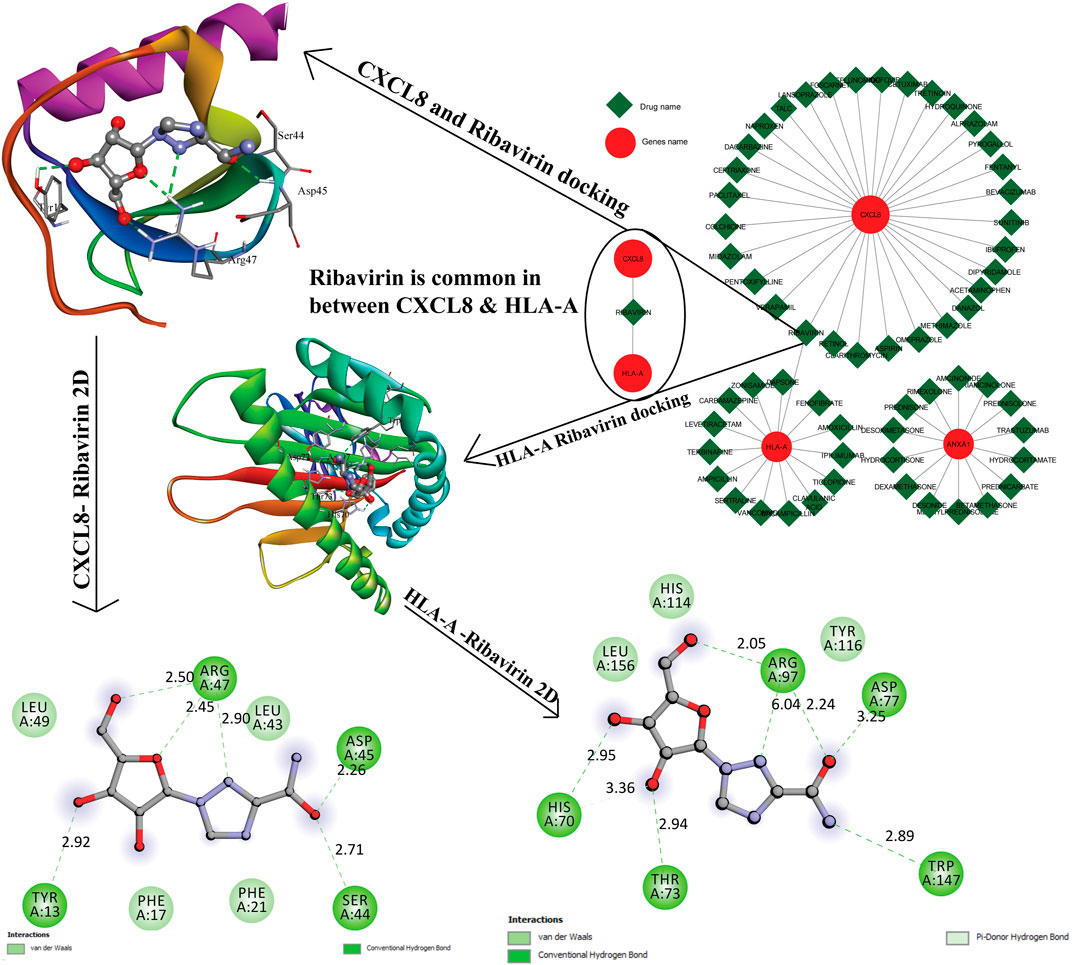
FIGURE 7. The gene-to-drug interaction network was shown in the figure, the red color nodes are key genes, and the green color nodes their targets drugs. Out of six genes, three genes were making interaction with their target drugs. Ribavirin was a common drug for two genes. This figure shows the 3D interaction and the 2D interaction with ribavirin and CXCL8, HLA-A genes.
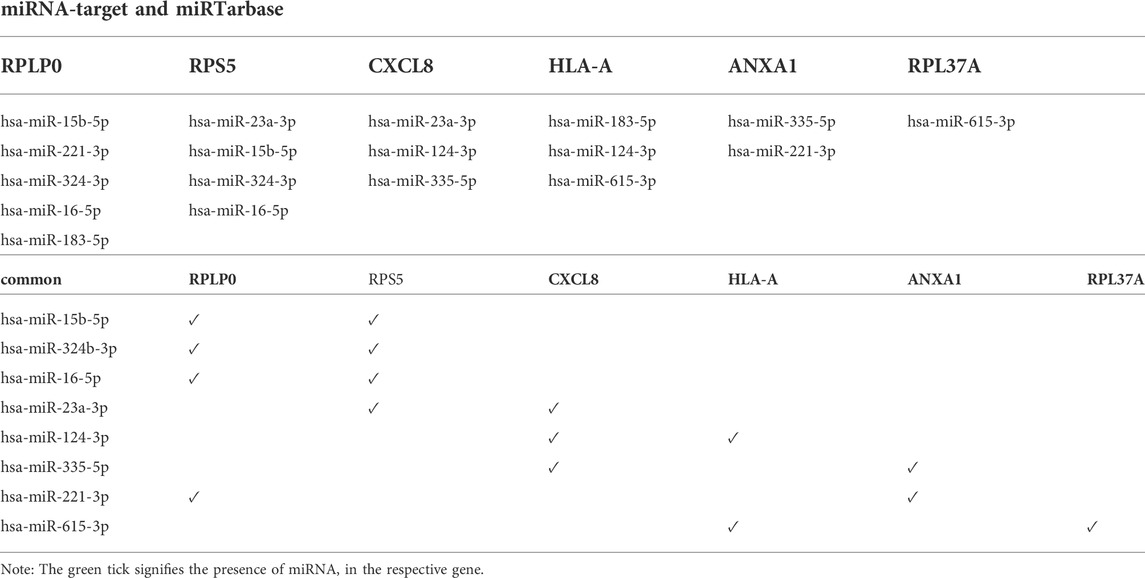
TABLE 5. The table shows the list of miRNAs associated with six selected hub genes.
CKD affects 8%–16% of the people across the globe. It is one of the major causes leading to death among individuals worldwide. Early diagnosis and staging, with appropriate management by primary care clinicians are important in reducing the burden of CKD worldwide. In past few years, although clinical and experimental studies have provided knowledge on the CKD causes (Lovisa et al., 2016; Hewitson et al., 2017; Johnson and Nangaku, 2016), the underlying molecular mechanisms that lead to the cause and progression of CKD remain to be explored completely. Studies have documented the complex and significant role played by miRNAs in a variety of human diseases including CKD (Liu et al., 2004; Volinia et al., 2006; Hui et al., 2011). MiRNA belongs to a class of small, noncoding, highly stable RNAs that regulate the mRNA and protein expression. Reports have suggested that miRNAs are associated with the regulation of various biological processes, such as proliferation, cellular differentiation, and metabolism (Carrington and Ambros, 2003; Suárez and Sessa, 2009; Hatley et al., 2010). The progression of CKD has been linked to miRNAs (Ahmed et al., 2022). In light of this, the primary objective of our study was to predict candidate miRNAs and hub genes that are associated with the pathogenesis of CKD. We utilized a global approach for the construction of a network based on centrality that predicted clusters of candidate genes involved in CKD.
In this study, five microarray gene expression series (GSE15072, GSE23609, GSE43484, GSE62792, and GSE66494) were retrieved from the Omnibus GEO database to study the relationship between the CKD gene expression and clinical traits. Specifically, from these five gene chips, a total of 1793 DEGs were screened including upregulated and downregulated genes. Our analysis revealed a total of 1,793 specific DEGs which included 851 upregulated and 942 downregulated genes [GSE15072 (50 upregulated and 38 downregulated genes), GSE23609 (219 upregulated and 189 downregulated genes), GSE43484 (133 upregulated and 135 downregulated), GSE62792 (351 upregulated and 262 downregulated), and GSE66494 (102 upregulated and 324 downregulated) in CKD datasets. Then next, we determined the overlapping genes among GEO datasets between the upregulated versus upregulated and downregulated versus downregulated genes. The gene term enrichment analysis revealed that the hub genes were mainly involved in RNA binding, co-translational protein targeting, and mRNA catabolic process activities. After putting it all together, a miRNA–mRNA interaction network was constructed. After the construction of the PPI network, we detected the significant modules/hub nodes in the network. The concept of centrality and its associated algorithms have been widely used in the identification of essential nodes in a distinct network. It is considered a promising approach or principal index in biological networks. Using the centrality approach, six hub genes (RPS5, RPL37A, RPLP0, CXCL8, HLA-A, and ANXA1) were selected from the PPI network and were further investigated.
It is interesting to mention that of these identified hub genes, the three hub genes RPS5 (encodes ribosomal protein S5), RPL37A (encodes ribosomal protein 37A), and RPLP0 (encodes ribosomal protein lateral stalk subunit P0), till date, have not been reported to show correlation to CKD. Annexin A1 (ANXA1), is an anti-inflammatory protein that is encoded by the ANXA1 gene. A study has shown the association of ANXA1 with progression and metastasis of cancer, suggesting its role in regulating tumor cell proliferation (Gastardelo et al., 2014). ANXA1 (as an endogenous mediator) has been demonstrated recently to play an important role in alleviating kidney injury in patients with diabetic nephropathy by resolving inflammation (Wu et al., 2021). It has been suggested that intracellular ANXA1 bond inhibits the activation of transcription factor NF-κB p65 by binding to its subunit, thereby, modulating the inflammatory state. Additionally, ANXA1 was found to be abundantly expressed in renal fibrosis (Neymeyer et al., 2015). CXCL8 encodes a protein IL-8 (interleukin-8), which belongs to the CXC chemokine family and is a major mediator of the inflammatory response. IL-8 is also known to promote tumor migration, invasion, angiogenesis, and metastasis (CXCL8 C-X-C motif chemokine ligand 8 [Homo sapiens (human)]—Gene—NCBI (nih.gov). The encoded protein is commonly referred to as. Several studies have documented the role of cytokines in chronic kidney disease (CKD) (Vianna et al., 2013). Nagy et al. (2016) also confirmed the expression of CXCL8 in ESRD/ACRD (end-stage renal disease or acquired cystic renal disease kidney) through an immunohistological analysis. Previous investigation has shown the involvement of human leukocyte antigens (HLA) in chronic kidney disease (CKD) patients (Yamakawa et al., 2014). It was revealed that HLAs could act as markers that might be involved in the development of CKD (Yamakawa et al., 2014). Furthermore, a study has demonstrated the genetic association of HLA with a variety of kidney diseases (Robson et al., 2018). Several studies have reported that besides CXCL8 (Noah et al., 2002), other chemokines including CCL2 (Noah and Becker, 2000), CCL3, and CCL5 (Smyth et al., 2002), are found to be upregulated during RSV infection in the nasal fluids. In line with this, Noah and Becker (2000) reported that the level of these chemokines is found to be elevated during the period of illness (viral shedding). A recent investigation has demonstrated that RPL37A and RPLP0 are among the best reference genes (Asiabi et al., 2020). Ovaries from healthy individuals all well as from patients having OEA (ovarian endometrioid adenocarcinoma), OMA (ovarian mucinous adenocarcinoma), OSPC (ovarian serous papillary carcinoma), and PCOS (polycystic ovary syndrome) were identified with some suitable housekeeping genes including RPL37A and RPLP0. Reference genes or housekeeping genes (HKGs) are very important in normalizing mRNA levels between different samples. Since the use of inappropriate reference gene can lead to undependable results, the selection of suitable one is vital for gene expression studies. Therefore, it can be hypothesized that these hub genes may be potential diagnostic biomarkers and therapeutic targets for patients with CKD.
Subsequently, these resultant hub genes were utilized to find their target miRNAs. Moreover, hsa-miR-124-3p was found to be a common miRNA target for both CXCL8 and HLA-A. MicroRNA-124a-3p is related to tumor progression in certain malignant tumors. Esophageal cancer includes a major subtype, i.e., ESCC (esophageal squamous cell carcinoma). The downregulated expression of miR-124-3p has been reported in ESCC tissues, which was found to be correlated with the inhibition of DNA methyltransferase 1 (Zeng et al., 2019). The previous finding has demonstrated hsa-miR-124-3p as a potential target for the diagnosis and prognosis of hepatocellular carcinoma (Long et al., 2018). Thus, the current study suggested that hsa-miR-124-3p plays a crucial role in CKD development by targeting CXCL8 and HLA-A. The investigation of the regulation among hsa-miR-124-3p and CXCL8, HLA-A may shed light on the knowledge of underlying molecular mechanisms of CKD.
Furthermore, the gene-drug interaction was also investigated in order to identify the hub genes and their associated drugs in the CKD network. It was observed that only three (out of the six hub genes) hub genes interacted with drugs and ribavirin was found to be commonly associated with both HLA-A and CXCL8 genes. Unfortunately, ribavirin is not widely used to treat CKD. It has been suggested that treatment with ribavirin prevented RSV-induced CXCL8 production in epithelial cells of humans (Fiedler et al., 1996). It has been revealed in patients (suffering from chronic HCV infection), that the HLA allele is associated with Peg-IFN plus ribavirin therapy (Farag et al., 2013). Altogether, it can be interpreted that our findings from the presented study can contribute to an improved understanding of the mechanisms underlying CKD and the identified hub genes and miRNAs in our study can serve as targets for CKD treatment approaches.
The present meta-analysis on CKD mRNA expression datasets might provide clues about the potential biomarkers in CKD. The six hub genes ANXA1, CXCL8, HLA-A, RPL37A, RPL3P0, and RPS5 were significantly expressed in these modules. Furthermore studies are underway to address the specific mechanisms of these hub genes in CKD. A detailed understanding of the roles served by these hub genes may provide insights into CKD, and lead to diagnostic and therapeutic opportunities for patients with CKD. Future external validation studies are required to reproduce our findings and determine whether these identified mRNAs or hub genes may influence the CKD progression.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
MA, ST, and RI conceptualized the work, MA, RI, ST, RA, and ZS did data curation, MA, RA, AA, and ZS preparation of the Figures. MA, ZS, and RI wrote the manuscript.
This research work was funded by the Institutional Fund projects under grant no. IFPDP-97-22. Therefore, the authors gratefully acknowledge technical and financial support from the Ministry of Education and King Abdulaziz University, Deanship of Scientific Research, Jeddah, Saudi Arabia.
We would like to thank Jamia Millia Islamia for providing infrastructure, journal access, and internet facilities. MA, ST, and RA, would like to thank the Indian Council of Medical Research (ICMR) for awarding the Senior Research Fellowship (grant numbers: ISRM 11/(04)/2019 to MA, ISRM 11/(07)/2019 to ST, BMI/11(35)/2020 to RA, AA would like to thank Department of Health Research (DHR) for awarding Young Scientist Fellowship (grant number: R.12014/06/2019-HR). ZS would like to acknowledge Maulana Azad National Fellowship (MANF) for providing fellowship. MA, RR, and StH would like to thank the Ministry of Education and King Abdulaziz University, Jeddah, Saudi Arabia 21589.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ahmed, M. M., Tazyeen, S., Haque, S., Sulimani, A., Ali, R., Sajad, M., et al. (2022). Network-based approach and IVI methodologies, a combined data investigation identified probable key genes in cardiovascular disease and chronic kidney disease. Front. Cardiovasc. Med. 8, 755321. doi:10.3389/fcvm.2021.755321
Asiabi, P., Ambroise, J., Giachini, C., Coccia, M. E., Bearzatto, B., Chiti, M. C., et al. (2020). Assessing and validating housekeeping genes in normal, cancerous, and polycystic human ovaries. J. Assist. Reprod. Genet. 37, 2545–2553. doi:10.1007/s10815-020-01901-8
Barabási, A-L., Gulbahce, N., and Loscalzo, J. (2011). Network medicine: A network-based approach to human disease. Nat. Rev. Genet. 12, 56–68. doi:10.1038/nrg2918
Carpenter, A. R., and McHugh, K. M. (2017). Role of renal urothelium in the development and progression of kidney disease. Pediatr. Nephrol. 32, 557–564. doi:10.1007/s00467-016-3385-6
Carrington, J. C., and Ambros, V. (2003). Role of MicroRNAs in plant and animal development. Science 301, 336–338. doi:10.1126/science.1085242
Chin, C-H., Chen, S-H., Wu, H-H., Ho, C-W., Ko, M-T., Lin, C-Y., et al. (2014). cytoHubba: Identifying hub objects and sub-networks from complex interactome. BMC Syst. Biol. 8, S11. doi:10.1186/1752-0509-8-S4-S11
Conte, F., Fiscon, G., Licursi, V., Bizzarri, D., D'Antò, T., Farina, L., et al. (2020). A paradigm shift in medicine: A comprehensive review of network-based approaches. Biochimica Biophysica Acta (BBA) - Gene Regul. Mech. 1863, 194416. doi:10.1016/j.bbagrm.2019.194416
Dalrymple, L. S., Katz, R., Kestenbaum, B., de Boer, I. H., Fried, L., Sarnak, M. J., et al. (2012). The risk of infection-related hospitalization with decreased kidney function. Am. J. Kidney Dis. 59, 356–363. doi:10.1053/j.ajkd.2011.07.012
De Nicola, L., and Zoccali, C. (2016). Chronic kidney disease prevalence in the general population: Heterogeneity and concerns: Table 1. Nephrol. Dial. Transpl. 31, 331–335. doi:10.1093/ndt/gfv427
Epstein, F. H., Klahr, S., Schreiner, G., and Ichikawa, I. (1988). The progression of renal disease. N. Engl. J. Med. 318, 1657–1666. doi:10.1056/NEJM198806233182505
Fan, Y., Siklenka, K., Arora, S. K., Ribeiro, P., Kimmins, S., Xia, J., et al. (2016). miRNet - Dissecting miRNA-target interactions and functional associations through network-based visual analysis. Nucleic Acids Res. 44, W135–W141. doi:10.1093/nar/gkw288
Farag, R. E., Arafa, M. M., El-Etreby, S., Saudy, N. S., Eldeek, B. S., El-Alfy, H. A., et al. (2013). Human leukocyte antigen class I alleles can predict response to pegylated interferon/ribavirin therapy in chronic hepatitis C Egyptian patients. Arch. Iran. Med. 16, 68–73.
Fiedler, M. A., Wernke-Dollries, K., and Stark, J. M. (1996). Inhibition of viral replication reverses respiratory syncytial virus-induced NF-kappaB activation and interleukin-8 gene expression in A549 cells. J. Virol. 70, 9079–9082. doi:10.1128/jvi.70.12.9079-9082.1996
Fiscon, G., Conte, F., Licursi, V., Nasi, S., and Paci, P. (2018). Computational identification of specific genes for glioblastoma stem-like cells identity. Sci. Rep. 8, 7769. doi:10.1038/s41598-018-26081-5
Freshour, S. L., Kiwala, S., Cotto, K. C., Coffman, A. C., McMichael, J. F., Song, J. J., et al. (2021). Integration of the drug-gene interaction database (DGIdb 4.0) with open crowdsource efforts. Nucleic Acids Res. 49, D1144–D1151. doi:10.1093/nar/gkaa1084
Gastardelo, T. S., Cunha, B. R., Raposo, L. S., Maniglia, J. V., Cury, P. M., Lisoni, F. C. R., et al. (2014). Inflammation and cancer: Role of annexin A1 and FPR2/ALX in proliferation and metastasis in human laryngeal squamous cell carcinoma. PLoS ONE 9, e111317. doi:10.1371/journal.pone.0111317
Guo, N., Zhang, N., Yan, L., Lian, Z., Wang, J., Lv, F., et al. (2018). Weighted gene co‑expression network analysis in identification of key genes and networks for ischemic‑reperfusion remodeling myocardium. Mol. Med. Rep. 18, 1955–1962. doi:10.3892/mmr.2018.9161
Guo, Y., Ma, J., Xiao, L., Fang, J., Li, G., Zhang, L., et al. (2019). Identification of key pathways and genes in different types of chronic kidney disease based on WGCNA. Mol. Med. Rep. 20, 2245–2257. doi:10.3892/mmr.2019.10443
Gursoy, A., Keskin, O., and Nussinov, R. (2008). Topological properties of protein interaction networks from a structural perspective. Biochem. Soc. Trans. 36, 1398–1403. doi:10.1042/BST0361398
Hatley, M. E., Patrick, D. M., Garcia, M. R., Richardson, J. A., Bassel-Duby, R., van Rooij, E., et al. (2010). Modulation of K-Ras-Dependent lung tumorigenesis by MicroRNA-21. Cancer Cell 18, 282–293. doi:10.1016/j.ccr.2010.08.013
Hewitson, T. D., Holt, S. G., and Smith, E. R. (2017). Progression of tubulointerstitial fibrosis and the chronic kidney disease phenotype - role of risk factors and epigenetics. Front. Pharmacol. 8, 520. doi:10.3389/fphar.2017.00520
Hu, J. X., Thomas, C. E., and Brunak, S. (2016). Network biology concepts in complex disease comorbidities. Nat. Rev. Genet. 17, 615–629. doi:10.1038/nrg.2016.87
Hui, A., How, C., Ito, E., and Liu, F-F. (2011). Micro-RNAs as diagnostic or prognostic markers in human epithelial malignancies. BMC Cancer 11, 500. doi:10.1186/1471-2407-11-500
Jalili, M., Salehzadeh-Yazdi, A., Asgari, Y., Arab, S. S., Yaghmaie, M., Ghavamzadeh, A., et al. (2015). CentiServer: A comprehensive Resource, web-based application and R package for centrality analysis. PLoS ONE 10, e0143111. doi:10.1371/journal.pone.0143111
Johnson, R. J., and Nangaku, M. (2016). Endothelial dysfunction: The secret agent driving kidney disease. J. Am. Soc. Nephrol. 27, 3–5. doi:10.1681/ASN.2015050502
Kidney International Supplements Chapter 1: Definition and classification of CKD. Kidney Int. Suppl. (2011) (2013) 3:19–62. doi:10.1038/kisup.2012.64
Kuleshov, M. V., Jones, M. R., Rouillard, A. D., Fernandez, N. F., Duan, Q., Wang, Z., et al. (2016). Enrichr: A comprehensive gene set enrichment analysis web server 2016 update. Nucleic Acids Res. 44, W90–W97. doi:10.1093/nar/gkw377
Lajdová, I., Okša, A., and Spustová, V. (2016). Vitamin D3 supplementation and cellular calcium homeostasis in patients with chronic kidney disease. Vnitr. Lek. 62 (Suppl. 6), 40–45.
Liu, C-G., Calin, G. A., Meloon, B., Gamliel, N., Sevignani, C., Ferracin, M., et al. (2004). An oligonucleotide microchip for genome-wide microRNA profiling in human and mouse tissues. Proc. Natl. Acad. Sci. U.S.A. 101, 9740–9744. doi:10.1073/pnas.0403293101
Liu, R., Cheng, Y., Yu, J., Lv, Q-L., and Zhou, H-H. (2015). Identification and validation of gene module associated with lung cancer through coexpression network analysis. Gene 563, 56–62. doi:10.1016/j.gene.2015.03.008
Liu, Z., Li, M., Fang, X., Shen, L., Yao, W., Fang, Z., et al. (2019). Identification of surrogate prognostic biomarkers for allergic asthma in nasal epithelial brushing samples by WGCNA. J Cell. Biochem. 120, 5137–5150. doi:10.1002/jcb.27790
Long, H-D., Ma, Y-S., Yang, H-Q., Xue, S-B., Liu, J-B., Yu, F., et al. (2018). Reduced hsa-miR-124-3p levels are associated with the poor survival of patients with hepatocellular carcinoma. Mol. Biol. Rep. 45, 2615–2623. doi:10.1007/s11033-018-4431-1
Lovisa, S., Zeisberg, M., and Kalluri, R. (2016). Partial epithelial-to-mesenchymal transition and other new mechanisms of kidney fibrosis. Trends Endocrinol. Metabolism 27, 681–695. doi:10.1016/j.tem.2016.06.004
Modena, B. D., Bleecker, E. R., Busse, W. W., Erzurum, S. C., Gaston, B. M., Jarjour, N. N., et al. (2017). Gene expression correlated with severe asthma characteristics reveals heterogeneous mechanisms of severe disease. Am. J. Respir. Crit. Care Med. 195, 1449–1463. doi:10.1164/rccm.201607-1407OC
Nagy, A., Walter, E., Zubakov, D., and Kovacs, G. (2016). High risk of development of renal cell tumor in end-stage kidney disease: The role of microenvironment. Tumor Biol. 37, 9511–9519. doi:10.1007/s13277-016-4855-y
Nandakumar, P., Tin, A., Grove, M. L., Ma, J., Boerwinkle, E., Coresh, J., et al. (2017). MicroRNAs in the miR-17 and miR-15 families are downregulated in chronic kidney disease with hypertension. PLoS ONE 12, e0176734. doi:10.1371/journal.pone.0176734
Neymeyer, H., Labes, R., Reverte, V., Saez, F., Stroh, T., Dathe, C., et al. (2015). Activation of annexin A1 signalling in renal fibroblasts exerts antifibrotic effects. Acta Physiol. 215, 144–158. doi:10.1111/apha.12586
Noah, T. L., and Becker, S. (2000). Chemokines in nasal secretions of normal adults experimentally infected with respiratory syncytial virus. Clin. Immunol. 97, 43–49. doi:10.1006/clim.2000.4914
Noah, T. L., Ivins, S. S., Murphy, P., Kazachkova, I., Moats-Staats, B., Henderson, F. W., et al. (2002). Chemokines and inflammation in the nasal passages of infants with respiratory syncytial virus bronchiolitis. Clin. Immunol. 104, 86–95. doi:10.1006/clim.2002.5248
Paci, P., Fiscon, G., Conte, F., Wang, R-S., Farina, L., Loscalzo, J., et al. (2021). Gene co-expression in the interactome: Moving from correlation toward causation via an integrated approach to disease module discovery. NPJ Syst. Biol. Appl. 7, 3. doi:10.1038/s41540-020-00168-0
Przulj, N., Wigle, D. A., and Jurisica, I. (2004). Functional topology in a network of protein interactions. Bioinformatics 20, 340–348. doi:10.1093/bioinformatics/btg415
Rajapurkar, M. M., John, G. T., Kirpalani, A. L., Abraham, G., Agarwal, S. K., Almeida, A. F., et al. (2012). What do we know about chronic kidney disease in India: First report of the Indian CKD registry. BMC Nephrol. 13, 10. doi:10.1186/1471-2369-13-10
Ritchie, M. E., Phipson, B., Wu, D., Hu, Y., Law, C. W., Shi, W., et al. (2015). Limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 43, e47. doi:10.1093/nar/gkv007
Robson, K. J., Ooi, J. D., Holdsworth, S. R., Rossjohn, J., and Kitching, A. R. (2018). HLA and kidney disease: From associations to mechanisms. Nat. Rev. Nephrol. 14, 636–655. doi:10.1038/s41581-018-0057-8
Shimbel, A. (1953). Structural parameters of communication networks. Bull. Math. Biophysics 15, 501–507. doi:10.1007/BF02476438
Silverman, E. K., Schmidt, H. H. H. W., Anastasiadou, E., Altucci, L., Angelini, M., Badimon, L., et al. (2020). Molecular networks in network medicine: Development and applications. WIREs Mech. Dis. 12, e1489. doi:10.1002/wsbm.1489
Smyth, R. L., Mobbs, K. J., O'Hea, U., Ashby, D., and Hart, C. A. (2002). Respiratory syncytial virus bronchiolitis: Disease severity, interleukin-8, and virus genotype. Pediatr. Pulmonol. 33, 339–346. doi:10.1002/ppul.10080
Suárez, Y., and Sessa, W. C. (2009). MicroRNAs as novel regulators of angiogenesis. Circulation Res. 104, 442–454. doi:10.1161/CIRCRESAHA.108.191270
Szabo, D. T., and Devlin, A. A. (2019). “Transcriptomic biomarkers in safety and risk assessment of chemicals,” in Biomarkers in toxicology (Elsevier), 1125–1134. doi:10.1016/B978-0-12-814655-2.00063-3
Tang, Z., Li, C., Kang, B., Gao, G., Li, C., Zhang, Z., et al. (2017). Gepia: A web server for cancer and normal gene expression profiling and interactive analyses. Nucleic Acids Res. 45, W98–W102. –W102. doi:10.1093/nar/gkx247
Tonelli, M., Wiebe, N., Culleton, B., House, A., Rabbat, C., Fok, M., et al. (2006). Chronic kidney disease and mortality risk: A systematic review. J. Am. Soc. Nephrol. 17, 2034–2047. doi:10.1681/ASN.2005101085
Vianna, H. R., Soares, C. M. B. M., Silveira, K. D., Elmiro, G. S., Mendes, P. M., de Sousa Tavares, M., et al. (2013). Cytokines in chronic kidney disease: Potential link of MCP-1 and dyslipidemia in glomerular diseases. Pediatr. Nephrol. 28, 463–469. doi:10.1007/s00467-012-2363-x
Volinia, S., Calin, G. A., Liu, C-G., Ambs, S., Cimmino, A., Petrocca, F., et al. (2006). A microRNA expression signature of human solid tumors defines cancer gene targets. Proc. Natl. Acad. Sci. U.S.A. 103, 2257–2261. doi:10.1073/pnas.0510565103
Webster, A. C., Nagler, E. V., Morton, R. L., and Masson, P. (2017). Chronic kidney disease. Lancet 389, 1238–1252. doi:10.1016/S0140-6736(16)32064-5
Wilson, S., Mone, P., Jankauskas, S. S., Gambardella, J., and Santulli, G. (2021). Chronic kidney disease: Definition, updated epidemiology, staging, and mechanisms of increased cardiovascular risk. J Clin. Hypertens. 23, 831–834. doi:10.1111/jch.14186
Wu, L., Liu, C., Chang, D-Y., Zhan, R., Sun, J., Cui, S-H., et al. (2021). Annexin A1 alleviates kidney injury by promoting the resolution of inflammation in diabetic nephropathy. Kidney Int. 100, 107–121. doi:10.1016/j.kint.2021.02.025
Yamakawa, R. H., Saito, P. K., da Silva Junior, W. V., de Mattos, L. C., and Borelli, S. D. (2014). Polymorphism of leukocyte and erythrocyte antigens in chronic kidney disease patients in southern Brazil. PLoS ONE 9, e84456. doi:10.1371/journal.pone.0084456
Yan, S. (2018). Integrative analysis of promising molecular biomarkers and pathways for coronary artery disease using WGCNA and MetaDE methods. Mol. Med. Rep. 18, 2789–2797. doi:10.3892/mmr.2018.9277
Yang, M., Wan, Q., Hu, X., Yin, H., Hao, D., Wu, C., et al. (2018). Coexpression modules constructed by weighted gene co‑expression network analysis indicate ubiquitin‑mediated proteolysis as a potential biomarker of uveal melanoma. Exp. Ther. Med. 17, 237–243. doi:10.3892/etm.2018.6945
Zeng, B., Zhang, X., Zhao, J., Wei, Z., Zhu, H., Fu, M., et al. (2019). The role of DNMT1/hsa-miR-124-3p/BCAT1 pathway in regulating growth and invasion of esophageal squamous cell carcinoma. BMC Cancer 19, 609. doi:10.1186/s12885-019-5815-x
Keywords: chronic kidney disease (CKD), DEGs, gene ontology, KEGG, network analysis, molecular docking
Citation: Ahmed MM, Shafat Z, Tazyeen S, Ali R, Almashjary MN, Al-Raddadi R, Harakeh S, Alam A, Haque S and Ishrat R (2022) Identification of pathogenic genes associated with CKD: An integrated bioinformatics approach. Front. Genet. 13:891055. doi: 10.3389/fgene.2022.891055
Received: 16 March 2022; Accepted: 28 June 2022;
Published: 11 August 2022.
Edited by:
Ahmed Rebai, Centre of Biotechnology of Sfax, TunisiaReviewed by:
Panagiotis Moulos, Alexander Fleming Biomedical Sciences Research Center, GreeceCopyright © 2022 Ahmed, Shafat, Tazyeen, Ali, Almashjary, Al-Raddadi, Harakeh, Alam, Haque and Ishrat. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Romana Ishrat, cmlzaHJhdEBqbWkuYWMuaW4=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.