 Muslima Nazir1
Muslima Nazir1 Reetika Mahajan1
Reetika Mahajan1 Sheikh Mansoor2
Sheikh Mansoor2 Sheezan Rasool1
Sheezan Rasool1 Rakeeb Ahmad Mir3
Rakeeb Ahmad Mir3 Ravinder Singh4
Ravinder Singh4 Vandana Thakral5
Vandana Thakral5 Virender Kumar5
Virender Kumar5 Parvaze A. Sofi6
Parvaze A. Sofi6 Hamed A. El-Serehy7Daniel Ingo Hefft8
Hamed A. El-Serehy7Daniel Ingo Hefft8 Sajad Majeed Zargar1*
Sajad Majeed Zargar1*- 1Proteomics Laboratory, Division of Plant Biotechnology, Sher-e-Kashmir University of Agricultural Sciences and Technology of Kashmir, Srinagar, India
- 2Division of Biochemistry, FBSc, Sher-e Kashmir University of Agricultural Sciences and Technology of Jammu, Jammu, India
- 3Department of Biotechnology, BGSB University, Rajouri, India
- 4School of Biotechnology, Sher-e-Kashmir University of Agricultural Sciences and Technology of Jammu, Jammu, India
- 5National Agr Food Biotechnology Institute (NABI), Mohali, India
- 6Division of Genetics and Plant Breeding, Sher-e-Kashmir University of Agricultural Sciences and Technology of Kashmir, Srinagar, India
- 7Department of Zoology, College of Science, King Saud University, Riyadh, Saudi Arabia
- 8University Centre Reaseheath, Reaseheath College, Nantwich, United Kingdom
Throughout the ages, the common bean has been consumed by humanity as an important food staple crop and source of nutrition on a global scale. Since its domestication, a wide spectrum of phenotypic and genotypic investigations have been carried out to unravel the potential of this crop and to understand the process of nutrient accumulation along with other desirable characteristics. The common bean is one of the essential legume crops due to its high protein and micronutrient content. The balance in micronutrients is critical for the growth and development of plants as well as humans. Iron (Fe), Zinc (Zn), Copper (Cu), Manganese (Mn), Magnesium (Mg), Calcium (Ca), and Molybdenum (Mo) are some of the important micronutrients present in legumes. Thus, we aimed to investigate the quantitative trait loci’s (QTLs)/single nucleotide polymorphisms (SNPs) to identify the candidate genes associated with micronutrients through genotyping by sequencing (GBS). In our investigation, through GBS we identified SNPs linked with traits and assessed seven micronutrients in 96 selected common bean genotypes for screening nutritionally rich genotypes. Among 96399 SNPs total identified through GBS, 113 SNPs showed significant phenotypic variance, ranging from 13.50 to 21.74%. SNPs associated with most of the seed micronutrients (Mg, Mn, Fe, Ca, Cu) were found on chr3 & chr11 (Mg, Mn, Mo, Ca, Zn). The findings from this study could be used for haplotype-based selection of nutritionally rich genotypes and for marker-assisted genetic enhancement of the common bean. Further, the identified SNPs for candidate genes/transporters associated with micronutrient content may pave the way for the enrichment of seeds by employing genomics-assisted breeding programs.
1 Introduction
Common bean (Phaseolus vulgaris L.), an important food legume, constitutes 50% of the grain legumes consumed as a human food source (Câmara et al., 2013; FAOSTAT, 2017). Common bean has huge genetic variation and based on domestication it is distinguished into two main gene pools, Andean and Mesoamerican. Cultivars in the mesoamerican gene pool have small to medium seed size and with “S” or “B” phaseolin patterns, while Andean cultivars have a large seed size with phaseolin patterns “T”/“C”/“H”/“A” (Bitocchi et al., 2012; Bellucci et al., 2014).
Being a great source of carbohydrates, dietary proteins, soluble and insoluble fibers, vitamins, and essential micronutrients such as minerals including Iron (Fe), Zinc (Zn), Copper (Cu), Manganese (Mn), Magnesium (Mg), Calcium (Ca) and Molybdenum (Mo), beans have often been considered a “poor man’s meat” (Fennema owen, 2000; Hayat et al., 2014; Yeken, 2018). These micronutrients play a pivotal role in the proper growth and development of plants and animals. The deficiency of any essential micronutrients hinders the proper functioning of biological processes leading to several metabolic and physiological implications. In many low- and lower-middle income countries, especially those in Asia, Africa, and Latin America, micronutrients Fe and Zn are the main components of hidden hunger (Darnton-Hill et al., 2006). Similarly, Fe and Zn deficiency cause severe yield loss in crops and metabolic disturbances in humans (Zargar et al., 2015). In addition, Cu is one of the important trace elements that play a vital role in maintaining metabolic activities. In humans, Cu deficiency leads to anemia, cardiac dysfunction, myeloneuropathy, and myelopathy, whereas in plants, its deficiency leads to lignification dysfunctioning (Geir, 2013; Lehmann and Rillig, 2015; Papamargaritis et al., 2015).
Food crops are the major source of essential minerals (Hardiman et al., 1984; Ali et al., 2014). Biofortification of nutrient-rich plants is important in addressing malnutrition-related issues. Thus, given today’s population explosion and food shortage issues, there is a need to introduce smart food crops into our diet. So far, research has been carried out using both conventional and modern breeding approaches to increase the nutrient content in cultivated plants. It is now important to identify genetic loci that regulate the uptake of essential minerals, as each genetic loci is an essential factor in the success of the biofortification breeding effort. Association mapping is one of the modern breeding approaches used to identify genetic loci that determine desired traits (Lewontin and Kojima, 1960). Association mapping has several advantages over the bi-parental QTL mapping approach (Yu and Buckler, 2006; Tian et al., 2011; Wen et al., 2014; Nadeem et al., 2021). For example, association mapping explores the allelic diversity that exists in the diverse germplasm, while QTL mapping can examine the allele variation present in only two parental lines. Undoubtedly, both approaches are indispensable and have their own advantages and disadvantages (Sonah et al., 2013). We believe an integrated approach involving both association mapping as well as biparental mapping can lead to a breakthrough in crop improvement.
Since the whole genome sequence of the common bean is available in the public domain, as such there is an excellent opportunity to perform Genome-wide association studies (GWAS) to identify QTLs followed by candidate genes that govern the uptake and accumulation of minerals (Schmutz et al., 2014). Genome-wide association study is one of the modern breeding approaches for mapping genes associated with different traits (Lu et al., 2015; Liu et al., 2016). The introduction of Next-generation sequencing (NGS) technologies has sped up the identification of SNPs and subsequent genotyping (Verma et al., 2015). Genotyping-by-sequencing (GBS) is a robust and cost-effective method wherein selective small genome fragments obtained by restriction digestion are sequenced by NGS platform to identify SNPs (Narum et al., 2013; Peterson et al., 2014; Schilling et al., 2014). In the last two decades, numerous studies have been performed using the GBS approach in diverse plant species, including wheat, canola, barley, and soybean, which are known to have a complex genome. In this regard, GWAS in common bean will allow us to estimate population structure and linkage disequilibrium (LD), connecting the variation in the genome with the phenotypic variations in the population. The LD-based analysis is organized based on population structure and genetic relatedness among populations. Several association studies with respect to micronutrient contents have been carried out in food crops like rice (Shao et al., 2011; Norton et al., 2014), pea (Diapari et al., 2015), chickpea (Diapari et al., 2014; Upadhyaya et al., 2016; Ozkuru et al., 2019), common bean (Nemli et al., 2016; Mahajan et al., 2017a; Erdogmus et al., 2020).
In the present study, we examined the germplasm of common beans of the Jammu and Kashmir region of northwestern Himalayas, India, for various micronutrients, followed by the identification of QTLs associated with the accumulation of nutrients. To identify genes/QTLs that regulate micronutrients in beans, GBS-based SNPs were discovered from natural populations of beans. Based on the preliminary studies, a set of 96 different bean genotypes was created, which were collected from other regions of the northwestern Himalayas (Zargar et al., 2014). In the present study, the ionome profile, which contains Ca, Cu, Mg, Mn, and Mo, of the bean core set was deciphered, and the QTLs contributing to their accumulation by GWAS have been identified. The investigation led us to inventory the micronutrients of the 96 different types of beans to determine candidate lines (nutrient-rich for different micronutrient levels in the seed) that can be used in breeding high-nutrient, high yielding bean varieties. In addition, the identification of QTLs can serve as critical genomic resources for improving the micronutrient profile in beans. These studies can improve the understanding of possible correlations for the accumulation of different elements. To understand the function of the respective candidate genes that regulate micronutrient uptake in beans, further studies need to be performed that may include knockout or overexpression of responsive candidate genes.
2 Experimental Procedures
2.1 Plant Material
A total of 96 common bean germplasm lines, mostly landraces and a few released varieties (SFB1, SR1, SR2, Arka Anoop, VLR-125) were used as plant material in the current study. Germplasm was collected from different geographical regions of Jammu and Kashmir (Supplementary Table S1) and maintained at the research fields at Division of Genetics and Plant Breeding, Faculty of Agriculture, Wadura, Sher-e-Kashmir University of Agricultural Sciences and Technology-Kashmir (SKUAST-K), Sopore. Most of the released varieties used in this study were developed through a single plant selection and have been used as checks.
2.2 Field Experiment and Micronutrient Profiling
Field experiments were conducted during 2016 and 2017 at the experimental field of the College of Agriculture, Wadura, SKUAST-Kashmir, India (34.34 North; 74.4 East; Altitude: 1,590.00 m). Clay loam textured soil with pH (7.2), organic carbon (.65%), electrical conductivity (.18 dS/m), CEC (16 meq/kg), and an available concentration of different elements in the soil i.e. P (4.91 mg kg−1), K (5.55 mg kg−1), Zn (.68 mg kg−1), Fe (5.1 mg kg−1), Cu (.29 mg kg−1), Mn (6.2 mg kg−1) was used for plantation of germplasm seeds in the experimental sites. The experiment was laid out according to augmented block design, which includes more than one released variety that is taken as replicated treatments, and these varieties are repeated in each block. Five released varieties (SFB1, SR1, SR2, Arka Anoop, VLR-125) were included in each block as checks. All the standard agronomical practices recommended were followed to raise healthy and disease-free crop plants. Harvesting was done at the time of 90% pod maturity. Further, the seed material of each genotype was powdered to analyze seven essential micronutrients i.e. Cu, Mn, Mg, Ca, Fe, Zn, and Mo. The elemental profiling of these genotypes was determined using a portable X-ray fluorescence spectrometer (pXFR). The pXRF instrument was calibrated as explained in Reidinger et al. (2012). In pXRF, a synthetic methylcellulose matrix was used to spike the known quantity of standard elements. Based on the methylcellulose pellet with know standards, an elemental composition standard curve was developed and subsequently used for sample evaluation. Similarly, samples were cross-verified with Energy Dispersive X-ray Fluorescence (ED-XRF).
2.3 Genotyping-by-Sequencing of Common Bean Genotypes
Genomic DNA was extracted from 15 day old leaves by using the CTAB method (Doyle and Doyle, 1990), and the quality, as well as quantity of DNA, was checked on both gel electrophoresis (.8% Agarose) and nano-drop (mySPEC, Wilmington, USA). The extracted genomic DNA was purified for the preparation of multiplex GBS libraries via Illumina HiSeq 2000 (SciGenom Pvt. Ltd., India). ApeK1 (from Aeropyrum pernix K1) restriction enzyme was employed for restriction digestion of genomic DNA. After quality filtering, de-multiplexed high-quality sequences were mapped to the reference common bean genome (Phtyozome v12.1 database), and SNPs were mined from the coding and non- coding regions of common bean genes and chromosomes. Subsequently, SNPs mined were structurally annotated on the diverse coding DNA sequence (CDS) and non-coding (upstream/downstream regulatory regions and introns) sequence components of genes and intergenic regions of the common bean genome.
2.4 Statistical Analysis
2.4.1 Micronutrient Profiling Analysis
All the observations were recorded in replicates of three, and values were then averaged. One-way ANOVA was applied to evaluate the variance of seven micronutrients among the genotype and Pearson’s pairwise correlation coefficient was calculated for all elements using the SPSS program (ver. 16).
2.4.2 Population Genetic Analysis
Population structure was estimated using a Bayesian Markov Chain Monte Carlo model (MCMC) implemented in STRUCTURE (Pritchard et al., 2000). Five runs were performed for each number of populations (K) set from 01 to 12. Burn-in time and MCMC replication number were both set to 100,000 for each run. The most likely K value was determined by the log probability of the data LnP(D) and delta K, based on the rate of change in LnP(D) between successive K values. These analyses were performed using Structure Harvester (Earl and vonHoldt, 2012). The neighbor-joining tree was built using Phylip and MEGA5 (Felsenstein, 1989; Tamura et al., 2011).
2.4.3 Genome-wide Association Analysis
All the analyses were performed using TASSEL3.0 and the Genomic Association and Prediction Integrated Tool (GAPIT) (Bradbury et al., 2007; Lipka et al., 2012). Mixed linear models (MLM) were used for the identification of SNPs associated with these traits. Van Raden method (K) was used to calculate the kinship matrix (Loiselle et al., 1995; Hyun et al., 2008). Covariate like P from principal component analysis and Q from STRUCTURE along with kinship matrix (K) were used for mixed linear models (MLM). The negative log(1/n) was used to establish a significance threshold (Wang et al., 2012; Yang et al., 2013).
2.4.4 LD Plots and Haplotype Blocks
The SNP matrix for all the samples was converted to HapMap format and TASSEL was used for the filtering out of SNP with major allele frequency (MAF) of less than .05. The LD plots for individual chromosomes were created in Tassel > Analysis > Diversity > Linkage Disequilibrium with LD Type as “Sliding Window” and LD Window size set to 50. The heterozygous sites were treated as missing and the R2 accumulated was calculated for 100 intervals with a size of .01. The R2 data obtained following LD analysis was used for plotting chromosome-wise LD information using MS Excel.
The PLINK v1.90b6.24 64-bit was used to determine the block size of SNP haplotypes. The individual chromosome Tassel files were saved to Plink format (.map and .ped) using the option available in Tassel. The haplotype blocks were calculated using—blocks no-pheno-req-- blocks-max-kb 100--make-founders command in Plink. The Haplotype Block analysis revealed the size of Haplo Blocks, including the number of SNPs on each block. The data was plotted using MS Excel.
2.5 Candidate Gene Identification
For candidate genes identification, the reference genome of P. vulgaris (V2.1) was used. The candidate genes were identified in .1 Mb both flanking regions of significant SNPs using the BioMart tool (Smedley et al., 2009), and the information related to gene function, Pfam ID, Panther ID, KOG ID, gene ontology ID, and their description were downloaded.
3 Results
3.1 Genetic Variation in Common Bean Seed Micronutrients
Micronutrient profiling of 96 genotypes was conducted to study the distribution and correlation among each other. Normal distribution was observed for Cu, Mn, Mg, Ca, Fe, Zn, and Mo (Figure 1; Supplementary Tables S2, S3). Seed micronutrient content showed continuous variation for Fe ranging from 67.351–133.02 mg kg−1 (with average (av) of 94.21 mg kg−1), 21.16–49.77 mg kg−1 (av 35.98 mg kg−1) for Zn, 1,293.21–2,657.46 mg kg−1 (av 1893.56 mg kg−1) for Ca, 2.02–28.02 mg kg−1 (av 13.11 mg kg−1) for Cu, 1,057.55 mg kg−1 208–2,492.26 mg kg−1 (av 1827.71 mg kg−1) for Mg, 22.34–93.36 mg kg−1 (av 58.26 mg kg−1) for Mn and 2.09–7.80 mg kg−1 (av 4.63 mg kg−1) for Mo (Table 1). Very low coefficients of variation (CVs) were observed for all these micronutrients.
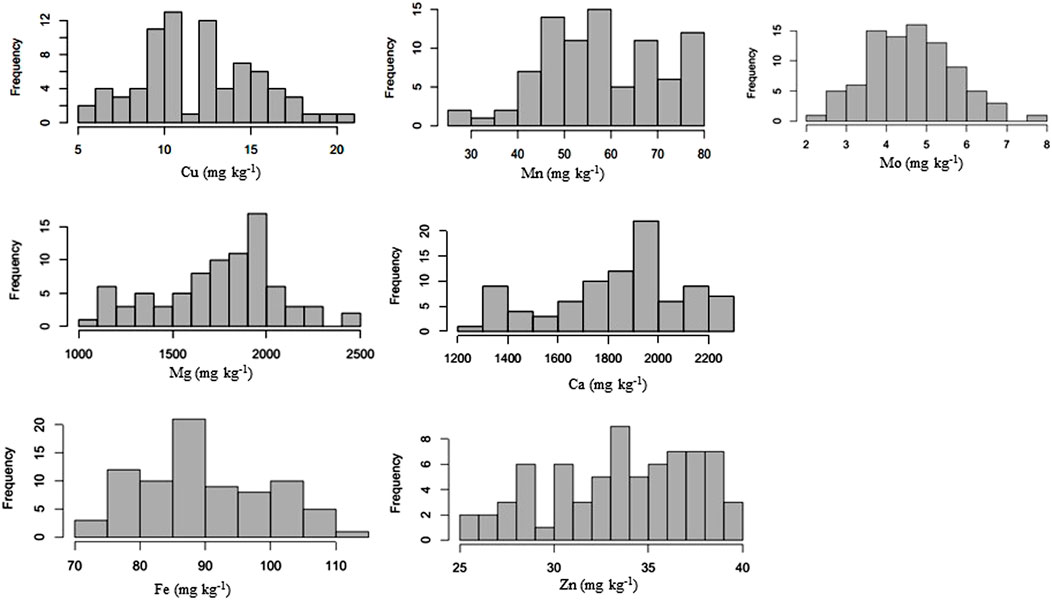
FIGURE 1. Frequency distribution of various micronutrients in common bean.
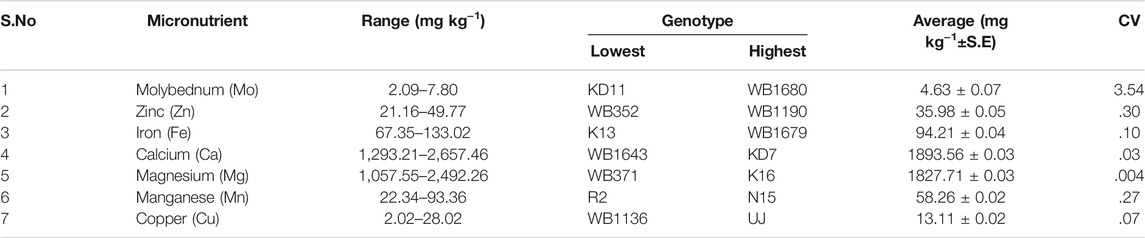
TABLE 1. Range, highest, lowest genotype and Coefficient of Variance (CV) of different micronutrient content of common bean seeds.
3.2 Correlation Analysis
Pearson’s correlation analysis showed a highly significant positive correlation between Fe and Zn (r = .61**), Ca and Mg (r = .37**), Cu and Fe (r = .28**), and Cu and Zn (r = .26*) (Table 2). All the other micronutrients showed a non-significant correlation with each other. Correlation studies between the micronutrient contents of the seeds in the present study showed that Mn is the only micronutrient that correlates negatively with all other micronutrients such as Fe, Zn, Cu, Ca, Mg, and Mo. However, the Zn content was found positively correlated with Fe and Cu and negatively correlated with Ca, Mo, and Mg. Mo was found to correlate positively with Ca, Mg, Cu and negatively with Fe, Zn, and Mn. The Fe content was found to be positively correlated with Ca, Mg, and Cu, while it was negatively correlated with Mo and Mn.
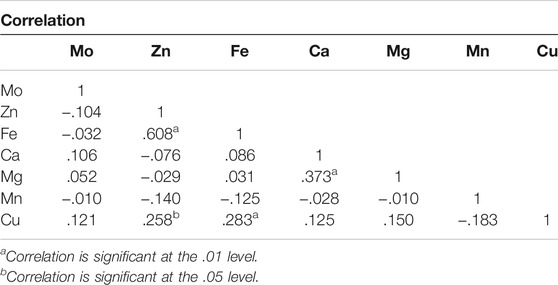
TABLE 2. Correlation among seed micronutrient content in common bean.
3.3 Characterization and Distribution of SNPs in the Common Bean
A total of 96,399 SNPs were found among a whole set of 96 diverse genotypes. The highest number of SNPs (10,978) were observed on chr. 3, whereas the lowest number of SNPs (6524) were observed on chr. 6 (Figure 2).
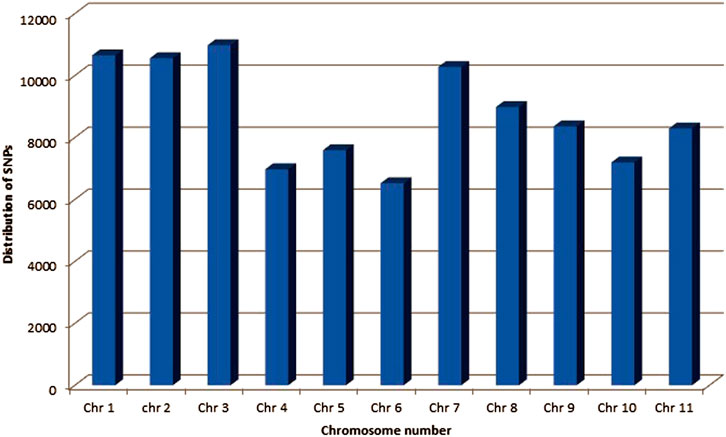
FIGURE 2. Frequency distribution of SNPs identified using GWAS on different chromosomes of common bean.
3.4 Genetic Diversity and Population Structure
In the present study, all paired genetic distances between the 96 bean lines were determined from SNP-based genotypic data. A neighboring tree based on these genetic distances showed that the genotypes were divided into five main and five subgroups (Figure 3A). The Dendrogram revealed that of the minor groups, one included only one genotype, WB6; another group included only two genotypes (N13, WB1137); while another two groups were found to have only three genotypes each (KD17, WB1664, KD5 in one group and WB877, KD11, WB864 in the second group) and yet another group comprised of four genotypes (WB1282, KD13, R9, WB1436). The released lines like SR2 and ARKAANOOP were grouped in one cluster with other local lines, whereas VLR-125 and SFB1 clustered in another group.
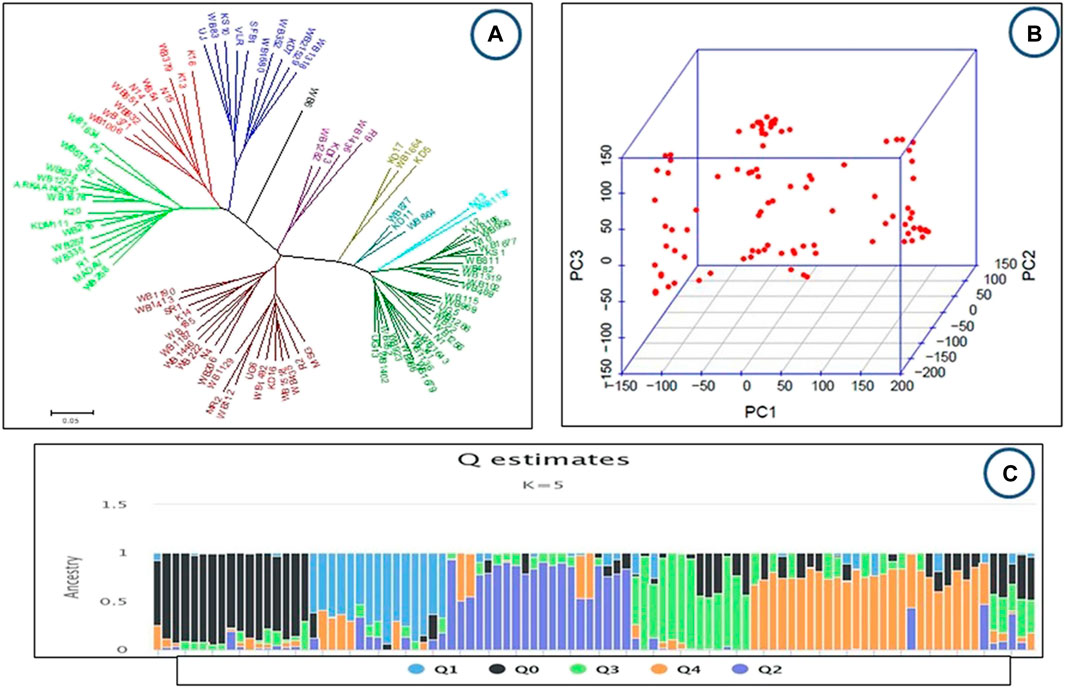
FIGURE 3. (A–C): Genetic diversity and population structure of the studied common bean accessions (A) Phylogenetic trees constructed using the neighbor-joining method by Phiylip and MEGA 5 (B) PCA Scatter plots of the first two principal components (PCA analyses), each dot represents one accession (C): Population structure K = 5, each accession is represented by a single vertical line and colors represent ancestries.
Principal component analysis (PCA) also showed diversity among the common bean genotypes (Figure 3B). The released bean lines and local lines have been pooled with no clear separation of local and released lines (Figure 3B). In addition, population structure analysis provides a robust analysis for understanding the genotypic origins of a particular crop. The population structure was scored for K values ranging from 1 to 12 across the panel using high-quality SNPs. The peak of delta K was found to be the highest at K = 5 and thus groups the 96 genotypes of the common bean into 5 populations (Figure 3C). Furthermore, this was in accordance with the neighbor-joining tree with little deviation (Figure 3A).
3.5 Genome-Wide Association Analysis
GWAS was performed for common bean seed micronutrient contents (Fe, Zn, Cu, Ca, Mn, Mg, and Mo). Out of 96,399 SNPs, 113 SNPs were found to be significantly associated with different seed micronutrient contents with 13.50–21.74% phenotypic variance (Figures 4A–G; Table 3). A total of 32 SNPs across all chromosomes except chr. 8 were found significantly associated with seed Mg content. The highest number of SNPs (7) associated with seed Mg content was found on chr.2, while only one associated SNP was found on chr.1 and chr.7. One SNP on chr.9 positioned at 31752041 (p-value = 1.61E-04) contributed 18.42% phenotypic variation. For seed Mo content, 29 SNPs were found significantly associated that are positioned on chr.4, chr.5, chr.6, chr.7, chr.10, and chr.11 with the highest number of SNPs (13) on chr.10 and the lowest (1) on chr.6 and chr.7. One SNP on chr.11 contributed to 21.42% phenotypic variation. About 15 SNPs were found associated with seed Ca content on each of chr.3, chr.4, chr.5, chr. 7, chr. 9, and chr. 11 and seed Cu content on chr.2, chr.3, chr.5, chr.6, and chr.8. For seed Ca content, SNP contributing to the highest phenotypic variation (17.10%) was found on chr. 3 whereas, SNP associated to seed Cu content located on chr.2 and chr.3 contributed 21.74% and 21.71% phenotypic variation. Around 13 SNPs were found associated with seed Mn content on chr.1, chr.3, chr.8, chr.10 and chr.11 whereas, only 5 SNPs were found associated with seed Zn content on chr.2, chr.10, and chr.11 and 4 SNPs were associated to seed Fe content on chr.1, chr.3, and chr.7.
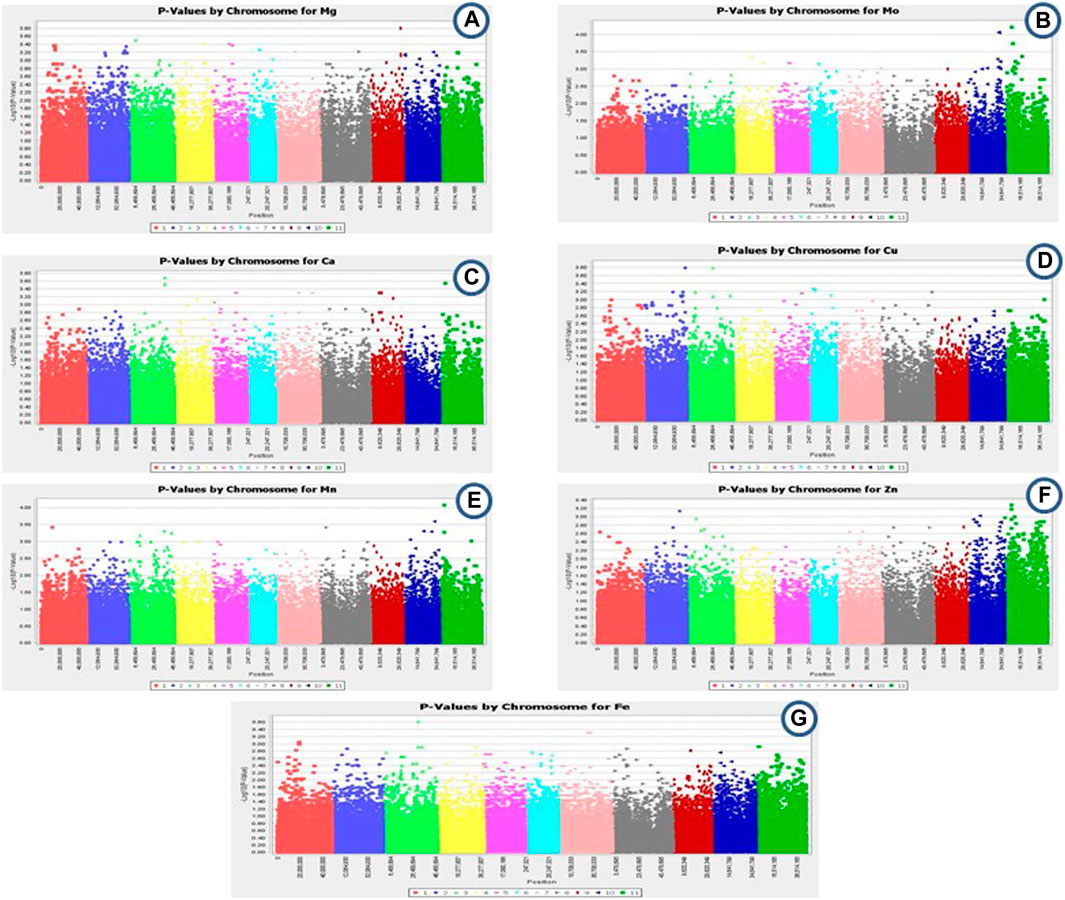
FIGURE 4. (A–G): Summary of Genome-wide association result: Manhattan plots depicting association of 113 SNP markers with seed. (A) Mg, (B) Mo, (C) Ca, (D) Cu, (E) Mn, (F) Zn, (G). Fe content in common bean.
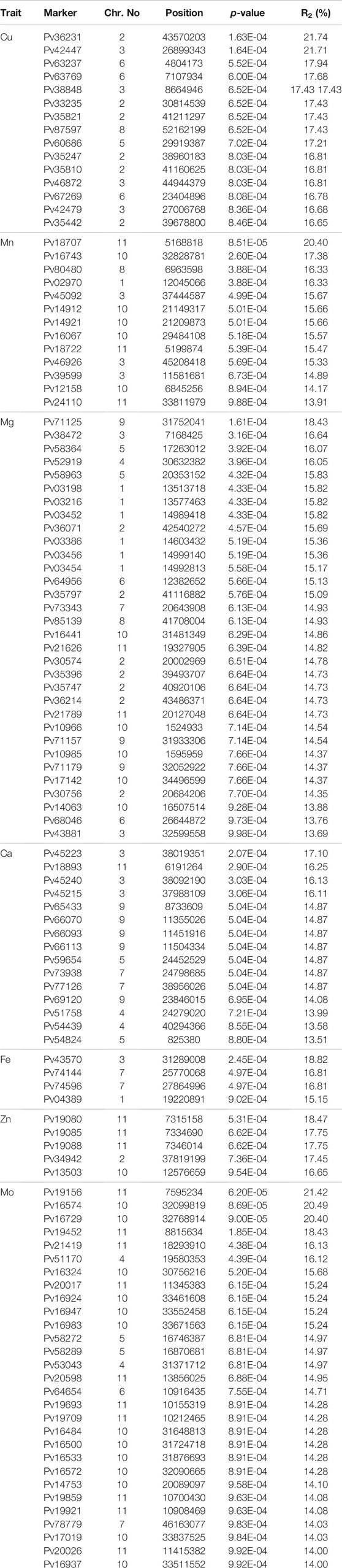
TABLE 3. Details of loci associated with accumulation of different elements.
3.6 LD Plot and Haplotype Blocks
Overall LD measured as R2 was correlated in all chromosomes (Figure 5; Supplementary Table S4). The maximum number of SNPs (125,580) correlated with other chromosomes were found on chr.10, whereas, a minimum number of SNPs (50,003) were found on chr.1 at R2 = .01. With the increase in R2 value, decreasing pattern in the number of associated SNPs across the 11 chromosomes was observed. At R2 = .93 the lowest number of SNPs correlation was found in all the chromosomes. The lowest (33) and highest (232) were found on chr. 6 and 1, respectively. Moreover, a total of 1879 SNPs on chr.1 were found to correlate with other chromosomes at R2 = .96, whereas 421 SNPs were found on chr.10. No SNPs were found associated across 11 chromosomes at R2 = .97–.99. Through haplotype analysis, a set of 7107 haploblocks representative of the 11 chromosomes, ranging from 1244 (chr. 1) to 503 (chr. 4) were identified. A total of 22,090 SNPs were distributed in these blocks, with an average of ∼3 SNPs per block. Chr. 1 (17) and chr. 4 and 10 (7 each) had the highest and lowest number of SNPs within their haploblocks, respectively (Figures 6A–K; Supplementary Table S5).
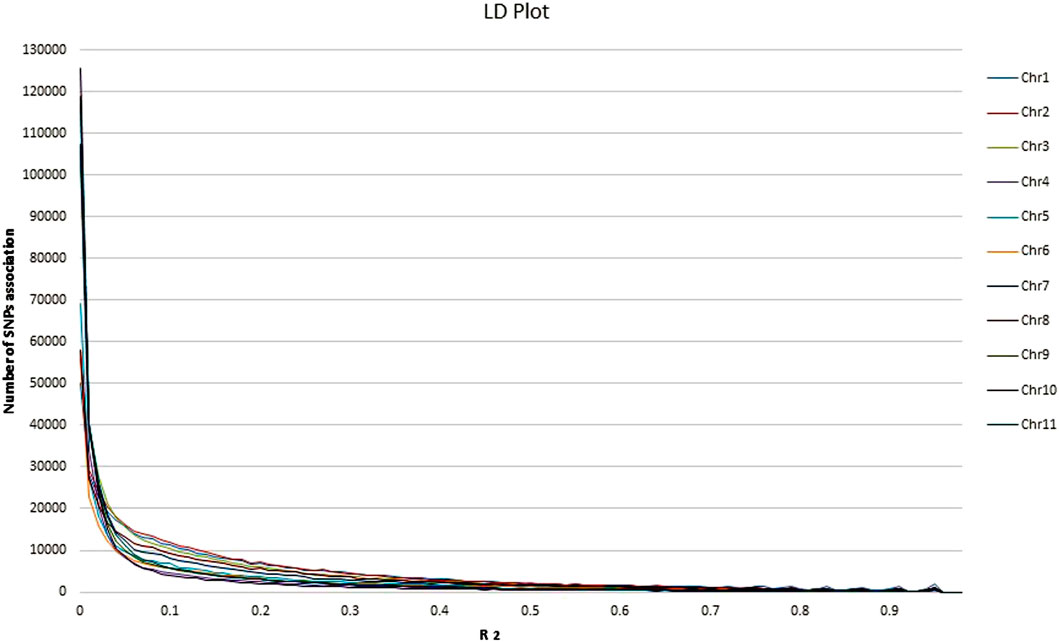
FIGURE 5. Analysis of linkage disequilibrium (LD) plot across the 11 common bean chromosomes.
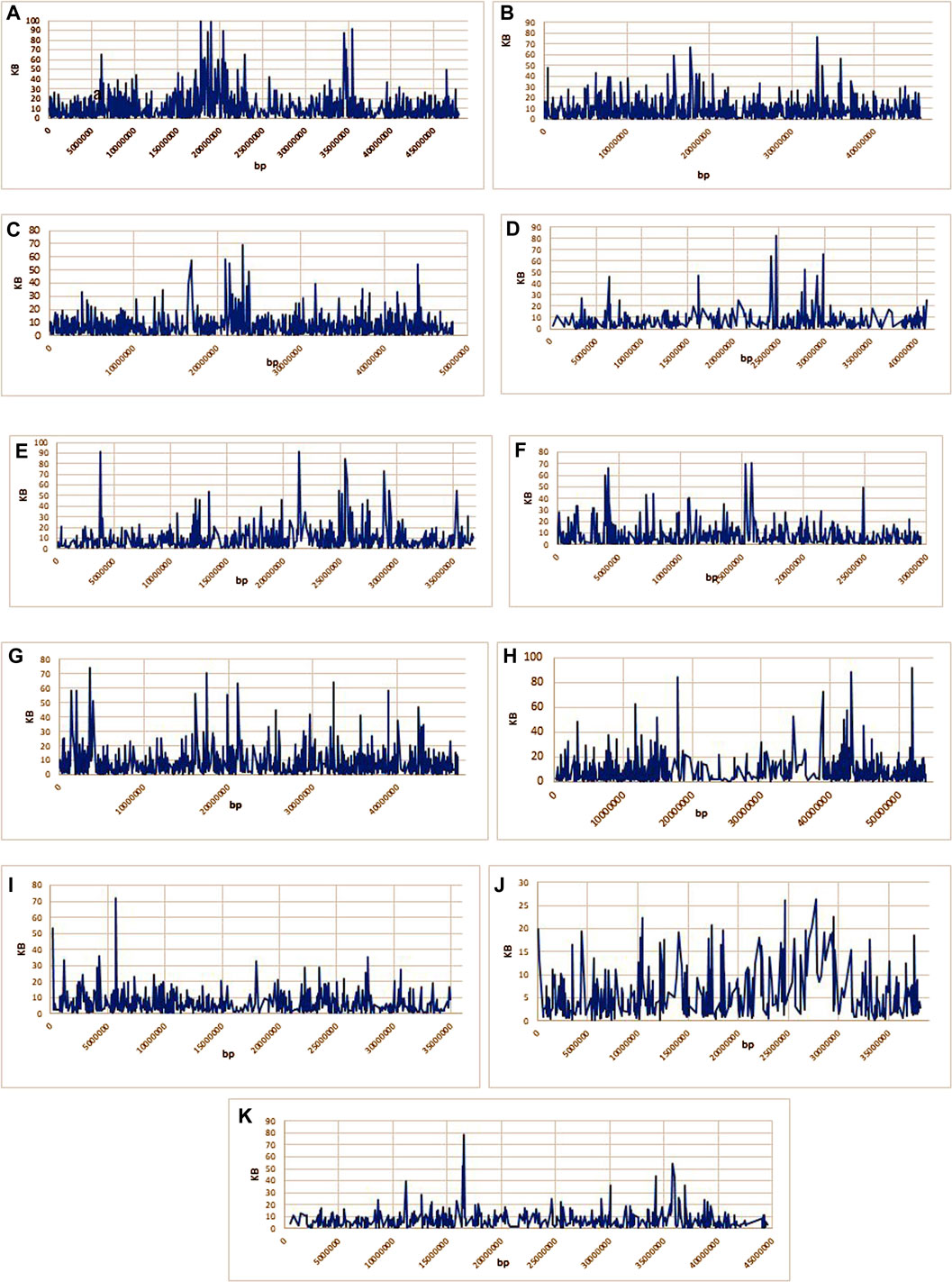
FIGURE 6. (A–K): Representing the haploblocks of 11 common bean chromosomes.
3.7 Candidate Gene Analysis
A total of 840 genes were identified in the .1 Mb flanking region of significant SNPs related to different traits; however, five SNPs were not co-localized with any gene in the .1 Mb flanking region (Supplementary Table S6). Out of these 840 genes, 16 transporter genes were identified (Table 4), some being metal transporters. We have also identified genes for 24 metal-binding proteins (Table 4) like zinc finger, calcium, and iron-binding proteins.
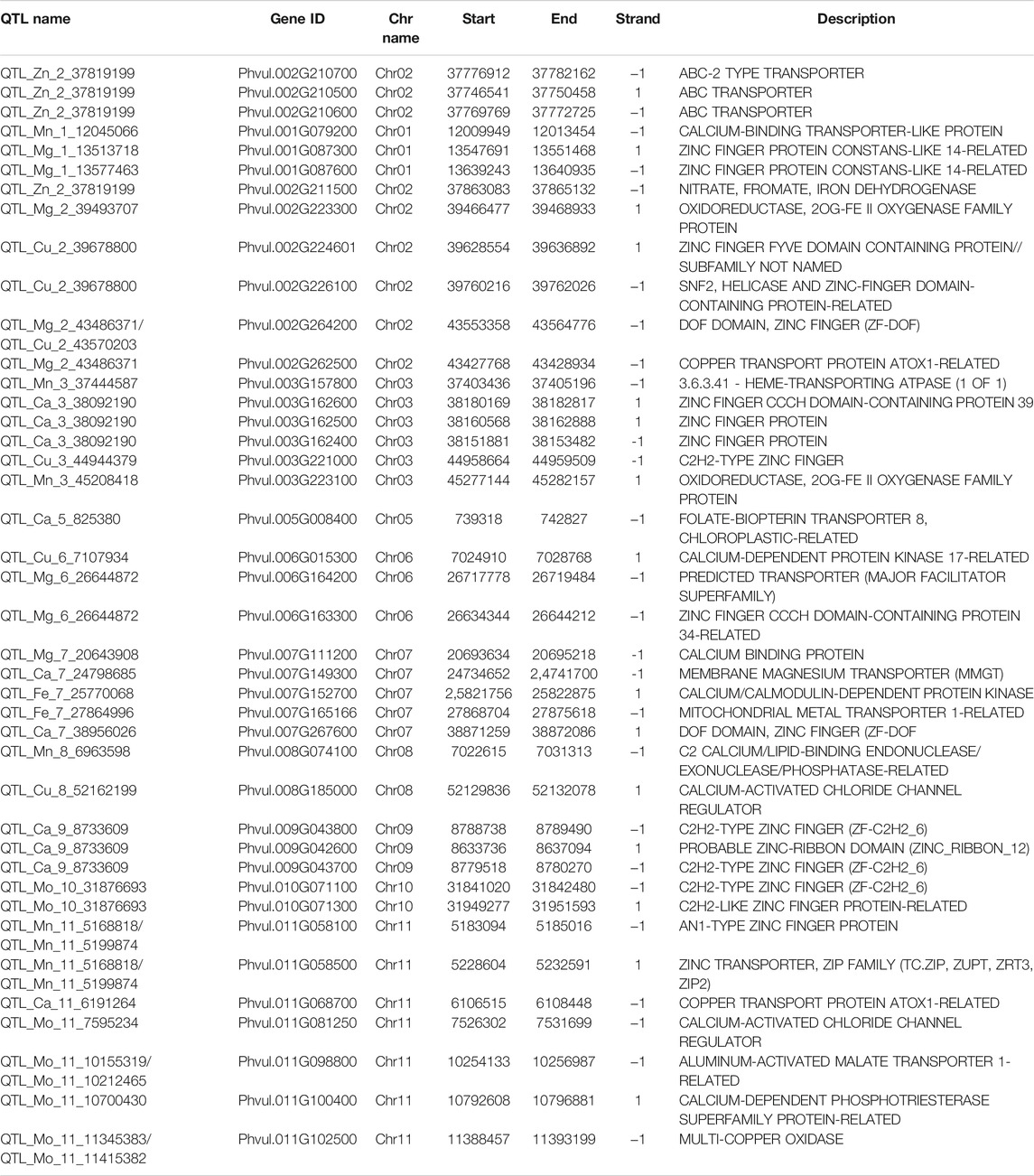
TABLE 4. Identified gene related to transporter/metal transporter and metal ion binding proteins.
4 Discussion
4.1 Micronutrients Variation and Correlation Among Micronutrients
Micronutrients play an indispensable role in the growth and development of eukaryotic organisms. A deficiency in these essential micro-and macronutrients leads to abnormal growth in living systems. Humans get most of their micronutrients from plant and animal sources. Therefore, the biofortification of important food crops is necessary nowadays. In the present study, an initiative was taken to investigate different micronutrient concentrations in the germplasm of common beans. The micronutrient content of the seeds has been varied widely in common bean seeds (Supplementary Table S2). Previous studies have shown that mineral variation has been observed in almost all major legumes, including the common bean. The different mineral content in beans has been studied in different parts of the world including India (O Abidemi et al., 2012; Martinez Meyer et al., 2013; Zaccardelli et al., 2013; Kumar and Chopra, 2014; Mahajan R et al., 2015; Erdogmus et al., 2020). Earlier reports also suggested that seed mineral content showed huge variation in common bean germplasm. Seed mineral concentrations such as Mg, Ca, Fe, Zn, and Cu of 60 common bean genotypes collected from the Western Himalayas varied from 1,220.5 to 2,737.5 ppm, 300–5,350 ppm, 80.5–180.6 ppm for Fe, 14.64–104.08 ppm, and .9–13.4 ppm, respectively (Jan et al., 2021). The average seed Ca concentration was recorded as 1.37 and 1.41 g kg−1, whereas, the average Fe seed content was recorded as 79.57 and 85.95 mg kg−1 from common bean seeds obtained through pedigree and single seed descent methods respectively (Ribeiro et al., 2014). Also, 88.14 mg kg−1of Fe, 49.24 mg kg−1of Zn, .25 g 100 g−1 of Mg, 11.30 mg kg−1of Cu, and 22.71 mg kg−1of Mn was found in common bean genotypes from Universidade Federal de Lavras (UFLA) (Silva et al., 2010) and 74.6 ppm Fe, 39.9 ppm Zn content in Ugandan common bean germplasm (Mukamuhirwa et al., 2012). The difference in micronutrient content in bean genotypes from different parts of the world may be due to the different number of samples taken for evaluation, environmental conditions such as climate and soil composition, and agricultural techniques. This diversity in the germplasm can help us identify potential candidate lines that can be used in the development of Multi-Parent Advanced Generation Intercross (MAGIC) or bi-parental mapping populations, the breeding of micronutrient-rich, high-yielding varieties of beans, can be used for investigating different levels of gene expression for different nutrients in common beans. The higher micronutrient bean lines could be used for biofortification programs.
Based on the Pearson’s correlation analysis our study reveals a significant positive correlation between Fe and Zn; Ca and Mg; Cu, Fe, and Zn. In previous studies, a similar correlation pattern between Zn and Fe and other minerals was observed in bean genotypes (Beebe et al., 2000; House et al., 2002; Gelin et al., 2007; Pfeiffer and McClafferty, 2007). Correlation studies have been conducted on other agronomical traits in the common bean (Nadeem et al., 2020). The negative correlation between the trait suggests that these traits are interdependent. In the present study, Mn was found negatively correlated with all other micronutrients, which means with the increase in Mn concentration there will be a decrease in the concentration of other micronutrients in common bean seeds. In addition, a positive correlation indicated that increasing the concentration of one micronutrient would positively affect the concentration of other micronutrients.
4.2 GWAS for Micronutrients
Genetic diversity is an important parameter for studying variability in any crop and identifying superior alleles controlling qualitative and quantitative traits through association mapping (Nachimuthu et al., 2015). Molecular markers such as SSRs and SNPs have an important role in studying genetic diversity in most crops (Nachimuthu et al., 2015; Zargar et al., 2016). Insights into the genomic diversity and population structure of common bean germplasm can expedite the genetic gains in common bean-breeding programs (Blair et al., 2012; Blair et al., 2013). The diversity based on the dissimilarity coefficient divided selected germplasm into five main groups and subgroups. The results of the clustering showed that the local germplasm of the common bean of Jammu & Kashmir (J&K) is very diverse and could be used as advanced lines for the genetic enhancement of the common bean. Further, intermixing of released and local lines collected from different regions of J&K indicated that the selected germplasm is diverse. Some of the previously conducted diversity studies on local landraces of the common beans collected from the J&K region have also divided the germplasm into different groups (Zargar et al., 2016; Mahajan et al., 2017a; Mahajan et al., 2017b). In order to have knowledge about the sub-populations in a particular crop structure analysis was performed.
Based on the sharp peak for the delta-K value and the results of the PCA, 96 common bean genotypes were classified into five major groups. A similar pattern of population structure K = 5 was also found in common bean germplasm from Jammu and Kashmir (Mahajan et al., 2017a; Mahajan et al., 2017b). However, earlier studies also classified the common bean germplasm into K = 2 (Gupta et al., 2020; Nkhata et al., 2020; Mir et al., 2021); K = 3 (Blair et al., 2012; Blair et al., 2013; Dennis et al., 2014; Nemli et al., 2014). The difference in cluster and structure analysis could be due to different algorithms used by the two approaches. The cluster analysis is based on evolutionary dissimilarity, while the population structure is based on a Bayesian algorithm. The deviations in the results can be attributed to the different germplasm, the different marker system, and the different geographical locations.
For the identification of genes associated with different traits in a large population, GWAS offers much higher mapping resolutions (Mamo et al., 2014; Norton et al., 2014). To the best of our knowledge, there are only a few association studies on different traits in common bean germplasm collected from the Himalayan region (Mahajan et al., 2017b; Choudhary et al., 2018; Gupta et al., 2020; Mir et al., 2021). However, in earlier studies, genic and genomic SSRs were used for GWAS. The present study is the first report on the association of SNPs related to seed micronutrient content in common bean germplasm from the Himalayan region. In the present study, it was found that SNPs associated with most of the seed micronutrients (Mg, Mn, Fe, Ca, Cu) were found on chr.3 and chr.11 (Mg, Mn, Mo, Ca, Zn) whereas, chr.8 have SNPs associated with Cu, Mg and Mn and chr.9 have SNPs associated with only Mg and Ca. Earlier studies revealed that QTLs linked with Fe content were found on chr. 2, 5, 6, 7, 9, and 10, whereas Zn content was found on chr.1, 2, 3, 5, 7, 8, and 10 (Blair et al., 2011; Mahajan et al., 2017a). In a recent study, a single QTL on chr. 9 and chr. 8 was found to be associated with seed Ca content and seed Mg content, respectively, whereas two QTLs on chr. 6 were associated with seed Zn content (Gunjača et al., 2021). In our study, we found that all of the 11 chromosomes have SNPs associated with more than one seed micronutrient content, which indicates the preciseness of using high throughput genotypic data in the present study.
4.3 LD Plot and Haploblock in Common Bean Germplasm
Knowledge about the LD properties in domesticated crops is important as it underlies all types of genetic mapping and may be used in the fine mapping of genes associated with complex traits in crop plants. It is said that in-depth LD in a crop is important for having more SNP-based associations to predict the average number of markers required for GWAS (Nordborg and Tavaré, 2002). Identification of QTLs inassociation mapping is based on Linkage Disequilibrium measurement. The population structure and genetic relatedness between the genotypes can lead to false-positive LD analysis. LD pattern in germplasm is affected by reducing genetic diversity by various factors like the type of selection, population admixture (Contreras-Soto et al., 2017). Our study is in accordance with the previous common bean LD estimation studies (Erdogmus et al., 2020; Gunjača et al., 2021). Hence, we can conclude that as the number of SNPs increases, there will be more R2 and the higher the likelihood of association of markers with traits of interest. This also indicated that a significant association would be possible with LD block having a higher number of SNPs compared to those windows having lower SNPs. The present study suggests that GBS is an advanced approach to analyzing genetic diversity and population structure in the common bean. The haplotype-based analysis showed that more haplocks were found in the centromeric region than in the telomeric region. In Chr.10 (26,295 kb) higher haplotypes per kb were found than in the rest of the chromosomes, which suggests that the LD decay in Chr.10 is stronger than in other chromosomes.
5 Candidate Genes
GWAS is often used for comparative genome analysis and helps explicitly in dissection as well as in understanding the complex quantitative feature analysis. The GWAS helps identify significant SNPs associated with a trait that is not the function of the region of interest, and sometimes these SNPs are present in non-coding or non-regulatory regions of chromosomes (Bararyenya et al., 2020). Thus, it is important to identify the candidate genes in the vicinity of the significant SNPs, and in our study, the significant SNP regions were examined for the identification of putative protein-coding genes using the P. vulgaris genome. The genes that are present in the .1 Mb flanking region of significant SNPs are given in Supplementary Table S6. Many previous studies also reported some markers linked with traits but no genes in the genomic region of markers (Bararyenya et al., 2020). The number of genes in SNPs revealed that chromosome 2, 6, 9, and 11 has more number of genes in 0.1 MB flanking region of SNPs has a high density of genes or the hot spot of QTLs.
6 Conclusion
Micronutrient deficiency is the leading cause of human health deterioration worldwide. An animal or plant-based diet alone cannot provide humans with excessive amounts of essential micronutrients. Biofortification of food crops is therefore important in order to provide humans with essential micronutrients. Modern breeding approaches such as QTL mapping and association mapping are important to identify QTLs that are related to micronutrient levels in plants. In the present study, a significant variation in the micronutrient content of the seeds in the germplasm of common beans was found. The present data on genetic loci, particularly the key SNPs associated with seven elements, will be helpful in identifying candidate genes, understanding molecular mechanisms, and developing molecular markers for breeding applications. We firmly believe that the results of the current studies will help accelerate bean biofortification efforts to overcome nutritional deficiencies.
Data Availability Statement
The data sets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/Supplementary Material.
Author Contributions
MN did experimental work and wrote the manuscript; RM helped in data analysis and editing the manuscript; SM helped in writing the manuscript; SR helped in experimental work; RAM helped with writing the manuscript and analysis; RS helped in data analysis; VT and VK: molecular data analysis; PS helped in fieldwork; HE-S and DH help in editing the manuscript; SZ developed the concept and guided all the laboratory work and edited the manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
MN and SZ acknowledge the financial support of SERB, New Delhi (Project File No: PDF/2016/000486) for the award of the National Postdoc Fellowship (NPDF) to MN under the mentorship of SZ. SZ also acknowledges Dr. Swarup Parida (NIPGR, New Delhi, India) for his support in genotyping; Dr. Humaira Sonah and Dr. Rupesh Deshmukh (NABI, Mohali, India) for their support in data analysis and editing the manuscript. SZ also acknowledges the Hon’ble Vice-Chancellor SKUAST-K (Prof. Nazir A. Ganai) for his support. The authors would like to extend their sincere appreciation to the Researchers Supporting Project Number (RSP-2021/19), King Saud University, Riyadh, Saudi Arabia.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2022.750814/full#supplementary-material
References
Ali, M., Choudhury, T. R., Hossain, B., and Ali, M. P. (2014). Determination of Traces of Molybdenum and lead in Foods by X-ray Fluorescence Spectrometry. SpringerPlus 3. doi:10.1186/2193-1801-3-341
Bararyenya, A., Olukolu, B. A., Tukamuhabwa, P., Grüneberg, W. J., Ekaya, W., Low, J., et al. (2020). Genome-wide Association Study Identified Candidate Genes Controlling Continuous Storage Root Formation and Bulking in Hexaploid Sweetpotato. BMC Plant Biol. 20, 3. doi:10.1186/s12870-019-2217-9
Beebe, S., Gonzalez, A. V., and Rengifo, J. (2000). Research on Trace Minerals in the Common Bean. Food Nutr. Bull. 21, 387–391. doi:10.1177/156482650002100408
Bellucci, E., Bitocchi, E., Rau, D., Rodriguez, M., Biagetti, E., Giardini, A., et al. (2014). Genomics of Origin, Domestica-Tion and Evolution of Phaseolus vulgaris. doi:10.1007/978-94-007-7572-53
Bitocchi, E., Nanni, L., Bellucci, E., Rossi, M., Giardini, A., Zeuli, P. S., et al. (2012). Mesoamerican Origin of the Common Bean (Phaseolus vulgaris L.) Is Revealed by Sequence Data. Proceedings of the National Academy of Sciences of the United States of America, 109. doi:10.1073/pnas.1108973109PMID:22393017
Bjorklund, G. (2013). The Role of Zinc and Copper in Autism Spectrum Disorders. Acta Neurobiol. Exp. Wars 73, 225–236.
Blair, M. W., Astudillo, C., Rengifo, J., Beebe, S. E., and Graham, R. (2011). QTL Analyses for Seed Iron and Zinc Concentrations in an Intra-genepool Population of Andean Common Beans (Phaseolus vulgaris L.). Theor. Appl. Genet. 122, 511–521. doi:10.1007/s00122-010-1465-8
Blair, M. W., Brondani, R. V. P., Díaz, L. M., and Del Peloso, M. J. (2013). Diversity and Population Structure of Common Bean from Brazil. Crop Sci. 53, 1983–1993. doi:10.2135/cropsci2012.09.0516
Blair, M. W., Soler, A., and Cortés, A. J. (2012). Diversification and Population Structure in Common Beans (Phaseolus vulgaris L.). PLoS ONE 7, e49488. doi:10.1371/journal.pone.0049488
Bradbury, P. J., Zhang, Z., Kroon, D. E., Casstevens, T. M., Ramdoss, Y., and Buckler, E. S. (2007). TASSEL: Software for Association Mapping of Complex Traits in Diverse Samples. Bioinformatics 23, 2633–2635. doi:10.1093/bioinformatics/btm308
Câmara, C., Urrea, C., and Schlegel, V. (2013). Pinto Beans (Phaseolus vulgaris l.) as a Functional Food: Implications on Human Health. Agriculture 3, 90–111. doi:10.3390/agriculture3010090
Choudhary, N., Bawa, V., Paliwal, R., Singh, B., Bhat, M. A., Mir, J. I., et al. (2018). Gene/QTL Discovery for Anthracnose in Common Bean (Phaseolus vulgaris L.) from North-western Himalayas. PLOS ONE 13, e0191700. doi:10.1371/journal.pone.0191700
Contreras-Soto, R. I., de Oliveira, M. B., Costenaro-da-Silva, D., Scapim, C. A., and Schuster, I. (2017). Population Structure, Genetic Relatedness and Linkage Disequilibrium Blocks in Cultivars of Tropical Soybean (Glycine max). Euphytica 213, 173. doi:10.1007/s10681-017-1966-5
Darnton-Hill, I., Bloem, M. W., and Chopra, M. (2006). Achieving the Millennium Development Goals through Mainstreaming Nutrition: Speaking with One Voice. Public Health Nutr. 9, 537–539. doi:10.1079/phn2006965
Dennis, O., Phinehas, T., James, K., Annet, N., Pamela, P., and Michael, U. (2014). The Genetic Diversity and Population Structure of Common Bean (Phaseolus vulgaris L) Germplasm in Uganda. Afr. J. Biotechnol. 13, 2935–2949. doi:10.5897/AJB2014.13916
Diapari, M., Sindhu, A., Bett, K., Deokar, A., Warkentin, T. D., Taran, B., et al. (2014). Genetic Diversity and Association Mapping of Iron and Zinc Concentrations in Chickpea (Cicer Arietinum L.). Genome 57. doi:10.1139/gen-2014-0108
Diapari, M., Sindhu, A., Warkentin, T. D., Bett, K., and Tar’an, B. (2015). Population Structure and Marker-Trait Association Studies of Iron, Zinc and Selenium Concentrations in Seed of Field Pea (Pisum Sativum L.). Mol. Breed. 35. doi:10.1007/s11032-015-0252-2
Earl, D. A., and vonHoldt, B. M. (2012). STRUCTURE HARVESTER: A Website and Program for Visualizing STRUCTURE Output and Implementing the Evanno Method. Conserv. Genet. Resour. 4. doi:10.1007/s12686-011-9548-7
Erdogmus, S., Ates, D., Nemli, S., Yagmur, B., Asciogul, T. K., Ozkuru, E., et al. (2020). Genome-wide Association Studies of Ca and Mn in the Seeds of the Common Bean (Phaseolus vulgaris L.). Genomics 112. doi:10.1016/j.ygeno.2020.03.030
Faostat, (2017). FAOSTAT. Available at: http://www.fao.org/faostat/en/#data/QC2017 (Accessed March 21, 2021).
Felsenstein, J. (1989). {PHYLIP} – Phylogeny Inference Package ({V}ersion 3.2). Cladistics 5. doi:10.1016/0168-9525(89)90204-7
Fennema owen, R. (2000). in Food Chemistry. Editor R. Fennema owen. 3rd ed. (NEW YORKNEW YORK: Marcel Dekker).
Gelin, J. R., Forster, S., Grafton, K. F., McClean, P. E., and Rojas-Cifuentes, G. A. (2007). Analysis of Seed Zinc and Other Minerals in a Recombinant Inbred Population of Navy Bean (Phaseolus vulgaris L.). Crop Sci. 47. doi:10.2135/cropsci2006.08.0510
Gunjača, J., Carović-Stanko, K., Lazarević, B., Vidak, M., Petek, M., Liber, Z., et al. (2021). Genome-Wide Association Studies of Mineral Content in Common Bean. Front. Plant Sci. 12, 636484. doi:10.3389/fpls.2021.636484
Gupta, N., Zargar, S. M., Singh, R., Nazir, M., Mahajan, R., and Salgotra, R. K. (2020). Marker Association Study of Yield Attributing Traits in Common Bean (Phaseolus vulgaris L.). Mol. Biol. Rep. 47, 6769–6783. doi:10.1007/s11033-020-05735-6
Hardiman, R. T., Banin, A., and Jacoby, B. (1984). The Effect of Soil Type and Degree of Metal Contamination upon Uptake of Cd, Pb and Cu in bush Beans (Phaseolus vulgaris L.). Plant Soil 81, 3–15. doi:10.1007/BF02206889
Hayat, I., Ahmad, A., Masud, T., Ahmed, A., and Bashir, S. (2014). Nutritional and Health Perspectives of Beans (Phaseolus vulgaris L.): An Overview. Crit. Rev. Food Sci. Nutr. 54, 580–592. doi:10.1080/10408398.2011.596639
House, W. A., Welch, R. M., Beebe, S., and Cheng, Z. (2002). Potential for Increasing the Amounts of Bioavailable Zinc in Dry Beans (Phaseolus vulgaris L) through Plant Breeding. J. Sci. Food Agric. 82. doi:10.1002/jsfa.1146
Hyun, M. K., Zaitlen, N. A., Wade, C. M., Kirby, A., Heckerman, D., Daly, M. J., et al. (2008). Efficient Control of Population Structure in Model Organism Association Mapping. Genetics 178. doi:10.1534/genetics.107.080101
Jan, S., Rather, I. A., Sofi, P. A., Wani, M. A., Sheikh, F. A., Bhat, M. A., et al. (2021). Characterization of Common Bean ( PHASEOLUS VULGARIS L.) Germplasm for Morphological and Seed Nutrient Traits from Western Himalayas. Legume Sci. 3. doi:10.1002/leg3.86
Kumar, V., and Chopra, A. K. (2014). Accumulation and Translocation of Metals in Soil and Different Parts of French Bean (Phaseolus Vulgaris L.) Amended with Sewage Sludge. Bull. Environ. Contam. Toxicol. 92. doi:10.1007/s00128-013-1142-0
Lehmann, A., and Rillig, M. C. (2015). Arbuscular Mycorrhizal Contribution to Copper, Manganese and Iron Nutrient Concentrations in Crops - A Meta-Analysis. Soil Biol. Biochem. 81. doi:10.1016/j.soilbio.2014.11.013
Lewontin, R. C., and Kojima, K. (1960). The Evolutionary Dynamics of Complex Polymorphisms. Evolution 14. doi:10.2307/2405995
Lipka, A. E., Tian, F., Wang, Q., Peiffer, J., Li, M., Bradbury, P. J., et al. (2012). GAPIT: Genome Association and Prediction Integrated Tool. Bioinformatics 28. doi:10.1093/bioinformatics/bts444
Liu, J., Wang, W., Mei, D., Wang, H., Fu, L., Liu, D., et al. (2016). Characterizing Variation of branch Angle and Genome-wide Association Mapping in Rapeseed (Brassica Napus L.). Front. Plant Sci. 7. doi:10.3389/fpls.2016.00021
Loiselle, B. A., Sork, V. L., Nason, J., and Graham, C. (1995). Spatial Genetic Structure of a Tropical Understory Shrub, Psychotria Officinalis (Rubiaceae). Am. J. Bot. 82. doi:10.2307/244586910.1002/j.1537-2197.1995.tb12679.x
Lu, Q., Zhang, M., Niu, X., Wang, S., Xu, Q., Feng, Y., et al. (2015). Genetic Variation and Association Mapping for 12 Agronomic Traits in Indica rice. BMC Genomics 16. doi:10.1186/s12864-015-2245-2
Mahajan, R., Zargar, S. M., Aezum, A. M., Farhat, S., Gani, M., Hussain, I. S. A., et al. (2015). Evaluation of Iron, Zinc, and Protein Contents of Common Bean (Phaseolus vulgaris L.) Genotypes: A Collection from Jammu & Kashmir, India. Legume Genomics Genet. doi:10.5376/lgg.2015.06.0002
Mahajan, R., Zargar, S. M., Salgotra, R. K., Singh, R., Wani, A. A., Nazir, M., et al. (2017a). Linkage Disequilibrium Based Association Mapping of Micronutrients in Common Bean (Phaseolus vulgaris L.): a Collection of Jammu & Kashmir, India. Biotech 3, 7. doi:10.1007/s13205-017-0928-x
Mahajan, R., Zargar, S. M., Singh, R., Salgotra, R. K., Farhat, S., and Sonah, H. (2017b). Population Structure Analysis and Selection of Core Set Among Common Bean Genotypes from Jammu and Kashmir, India. Appl. Biochem. Biotechnol. 182. doi:10.1007/s12010-016-2307-1
Mamo, B. E., Barber, B. L., and Steffenson, B. J. (2014). Genome-wide Association Mapping of Zinc and Iron Concentration in Barley Landraces from Ethiopia and Eritrea. J. Cereal Sci. 60. doi:10.1016/j.jcs.2014.08.007
Martinez Meyer, M. R., Rojas, A., Santanen, A., and Stoddard, F. L. (2013). Content of Zinc, Iron and Their Absorption Inhibitors in Nicaraguan Common Beans (Phaseolus vulgaris L.). Food Chem. 136. doi:10.1016/j.foodchem.2012.07.105
Mir, R. R., Choudhary, N., Bawa, V., Jan, S., Singh, B., Bhat, M. A., et al. (2021). Allelic Diversity, Structural Analysis, and Genome-wide Association Study (GWAS) for Yield and Related Traits Using Unexplored Common Bean (Phaseolus vulgaris L.) Germplasm from Western Himalayas. Front. Genet. 11, 609603. doi:10.3389/fgene.2020.609603
Mukamuhirwa, F., Tusiime, G., Mukankusi, C., Gibson, P., and Edema, R. (2012). Potential Sources of High Iron and Zinc Content in Ugandan Bean Germplasm. In: Third RUFORUM Biennial Meeting 24-28 September 2012, Entebbe, Uganda. 153–157.
Nachimuthu, V. V., Raveendran, M., Duraialaguraja, S., Sivakami, R., Pandian, B. A., Ponniah, G., et al. (2015). Analysis of Population Structure and Genetic Diversity in Rice Germplasm Using SSR Markers: An Initiative towards Association Mapping of Agronomic Traits in Oryza Sativa. Rice 8. doi:10.1186/s12284-015-0062-5
Nadeem, M. A., Karaköy, T., Yeken, M. Z., Habyarimana, E., Hatipoğlu, R., Çiftçi, V., et al. (2020). Phenotypic Characterization of 183 Turkish Common Bean Accessions for Agronomic, Trading, and Consumer-Preferred Plant Characteristics for Breeding Purposes. Agronomy 10, 272. doi:10.3390/agronomy10020272
Nadeem, M. A., Yeken, M. Z., Shahid, M. Q., Habyarimana, E., Yılmaz, H., Alsaleh, A., et al. (2021). Common Bean as a Potential Crop for Future Food Security: an Overview of Past, Current and Future Contributions in Genomics, Transcriptomics, Transgenics and Proteomics. Biotechnol. Biotechnol. Equip. 35, 758–786. doi:10.1080/13102818.2021.1920462
Narum, S. R., Buerkle, C. A., Davey, J. W., Miller, M. R., and Hohenlohe, P. A. (2013). Genotyping-by-sequencing in Ecological and Conservation Genomics. Mol. Ecol. 22. doi:10.1111/mec.12350
Nemli, S., Asciogul, T. K., Esiyok, D. D. A., and Tanyolac, M. B. (2016). Genome Wide Association Mapping (GWAS) of Nutrient Elements in Seed Using Genotyping by Sequencing (GWAS) in Common Bean (Phaseolus vulgaris L). in Proceeding of plant and animal genome conference XXIV.
Nemli, S., Asciogul, T. K., Kaya, H. B., Kahraman, A., Eşiyok, D., and Tanyolac, B. (2014). Association Mapping for Five Agronomic Traits in the Common Bean ( Phaseolus vulgaris L.): Association Mapping for Five Agronomic Traits. J. Sci. Food Agric. 94, 3141–3151. doi:10.1002/jsfa.6664
Nkhata, W., Shimelis, H., Melis, R., Chirwa, R., Mzengeza, T., Mathew, I., et al. (2020). Population Structure and Genetic Diversity Analyses of Common Bean Germplasm Collections of East and Southern Africa Using Morphological Traits and High-Density SNP Markers. PLOS ONE 15, e0243238. doi:10.1371/journal.pone.0243238
Nordborg, M., and Tavaré, S. (2002). Linkage Disequilibrium: what History Has to Tell Us. Trends Genet. 18, 890. doi:10.1016/S0168-9525(02)02557-X
Norton, G. J., Douglas, A., Lahner, B., Yakubova, E., Guerinot, M. L., Pinson, S. R. M., et al. (2014). Genome Wide Association Mapping of Grain Arsenic, Copper, Molybdenum and Zinc in rice (Oryza Sativa L.) Grown at Four International Field Sites. PLoS ONE 9. doi:10.1371/journal.pone.0089685
O Abidemi, O., Shittu, S., and Rebbeca, A. O. (2012). Evaluation of Heavy Metals in Three Common Nigerian Cowpea (Vigna Unguiculata) Paste End Product (“Moinmoin”) Using Different Packaging Materials-Indian Journals. Int. J. Environ. Sci., 833–840.
Ozkuru, E., Ates, D., Nemli, S., Erdogmus, S., Karaca, N., Yilmaz, H., et al. (2019). Association Mapping of Loci Linked to Copper, Phosphorus, and Potassium Concentrations in the Seeds of C. Arietinum and C. reticulatum. Genomics 111. doi:10.1016/j.ygeno.2018.12.010
Papamargaritis, D., Aasheim, E. T., Sampson, B., and le Roux, C. W. (2015). Copper, Selenium and Zinc Levels after Bariatric Surgery in Patients Recommended to Take Multivitamin- mineral Supplementation. J. Trace Elem. Med. Biol. 31, 167–172. doi:10.1016/j.jtemb.2014.09.005
Peterson, G. W., Dong, Y., Horbach, C., and Fu, Y. B. (2014). Genotyping-by-sequencing for Plant Genetic Diversity Analysis: A Lab Guide for SNP Genotyping. Diversity 6. doi:10.3390/d6040665
Pfeiffer, W. H., and McClafferty, B. (2007). “HarvestPlus: Breeding Crops for Better Nutrition,” in Crop Science. doi:10.2135/cropsci2007.09.0020IPBS
Pritchard, J. K., Stephens, M., and Donnelly, P. (2000). Inference of Population Structure Using Multilocus Genotype Data. Genetics 155, 945959.
Ribeiro, N. D., Jost, E., Maziero, S. M., Storck, L., and Rosa, D. P. (2014). Selection of Common Bean Lines with High Grain Yield and High Grain Calcium and Iron Concentrations. Rev. Ceres 61. doi:10.1590/S0034-737X2014000100010
Reidinger, S., Ramsey, M. H., and Hartley, S. E. (2012). Rapid and Accurate Analyses of Silicon and Phosphorus in Plants Using a Portable X-ray Fluorescence Spectrometer. New Phyt. 195, 699706. doi:10.1111/j.1469-8137.2012.04179.x
Schilling, M. P., Wolf, P. G., Duffy, A. M., Rai, H. S., Rowe, C. A., Richardson, B. A., et al. (2014). Genotyping-by-sequencing for Populus Population Genomics: An Assessment of Genome Sampling Patterns and Filtering Approaches. PLoS ONE 9. doi:10.1371/journal.pone.0095292
Schmutz, J., McClean, P. E., Mamidi, S., Wu, G. A., Cannon, S. B., Grimwood, J., et al. (2014). A Reference Genome for Common Bean and Genome-wide Analysis of Dual Domestications. Nat. Genet. 46. doi:10.1038/ng.3008
Shao, Y., Jin, L., Zhang, G., Lu, Y., Shen, Y., and Bao, J. (2011). Association Mapping of Grain Color, Phenolic Content, Flavonoid Content and Antioxidant Capacity in Dehulled rice. Theor. Appl. Genet. 122. doi:10.1007/s00122-010-1505-4
Silva, C. A., De Fátima Barbosa Abreu, Â., Antonio, M., Ramalho, P., Duarte Correa, A., Gontijo, L., et al. (2010). Genetic Variability for Protein and Minerals Content in Common Bean Lines. Phaseolus vulgaris, LEMBRAPA, Embrapa Scientific Information-Alice, Brazil.
Smedley, D., Haider, S., Ballester, B., Holland, R., London, D., Thorisson, G., and Kaspryzyk, A. (2009). BioMart–Biological Queries Made Easy. BMC Genomics 10, 22. doi:10.1186/1471-2164-10-22
Sonah, H., Bastien, M., Iquira, E., Tardivel, A., Légaré, G., Boyle, B., et al. (2013). An Improved Genotyping by Sequencing (GWAS) Approach Offering Increased Versatility and Efficiency of SNP Discovery and Genotyping. PLoS ONE 8. doi:10.1371/journal.pone.0054603
Tamura, K., Peterson, D., Peterson, N., Stecher, G., Nei, M., and Kumar, S. (2011). MEGA5: Molecular Evolutionary Genetics Analysis Using Maximum Likelihood, Evolutionary Distance, and Maximum Parsimony Methods. Mol. Biol. Evol. 28. doi:10.1093/molbev/msr121
Tian, F., Bradbury, P. J., Brown, P. J., Hung, H., Sun, Q., Flint-Garcia, S., et al. (2011). Genome-wide Association Study of Leaf Architecture in the maize Nested Association Mapping Population. Nat. Genet. 43. doi:10.1038/ng.746
Upadhyaya, H. D., Bajaj, D., Das, S., Kumar, V., Gowda, C. L. L., Sharma, S., et al. (2016). Genetic Dissection of Seed-Iron and Zinc Concentrations in Chickpea. Sci. Rep. 6. doi:10.1038/srep24050
Verma, S., Gupta, S., Bandhiwal, N., Kumar, T., Bharadwaj, C., and Bhatia, S. (2015). High- Density Linkage Map Construction and Mapping of Seed Trait QTLs in Chickpea (Cicer Arietinum L.) Using Genotyping-By-Sequencing (GWAS). Sci. Rep. 5. doi:10.1038/srep17512
Wang, M., Yan, J., Zhao, J., Song, W., Zhang, X., Xiao, Y., et al. (2012). Genome-wide Association Study (GWAS) of Resistance to Head Smut in maize. Plant Sci. 196. doi:10.1016/j.plantsci.2012.08.004
Wen, W., Li, D., Li, X., Gao, Y., Li, W., Li, H., et al. (2014). Metabolome-based Genome-wide Association Study of maize Kernel Leads to Novel Biochemical Insights. Nat. Commun. 5. doi:10.1038/ncomms4438
Yang, Z., Li, Z., and Bickel, D. R. (2013). Empirical Bayes Estimation of Posterior Probabilities of Enrichment: A Comparative Study of Five Estimators of the Local False Discovery Rate. BMC Bioinformatics 14. doi:10.1186/1471-2105-14-87
Yeken, M. Z. Assessment of Mineral Content Variations for Biofortification of the Bean Seed FasulyeTohumunun Biyofortifikasyonuic in Mineralİc erikVasyasyonlarının Değerlendirilmesi.2018;4: 261–269. doi:10.24180/ijaws.455311
Yu, J., and Buckler, E. S. (2006). Genetic Association Mapping and Genome Organization of maize. Curr. Opin. Biotechnol. 17. doi:10.1016/j.copbio.2006.02.003
Zaccardelli, M., Pentangelo, A., and Tripodi, P. (2013). Characterization of bean (Phaseolus vulgaris L.) ecotype “Fagiolo occhio nero di Oliveto Citra” using agronomic, biochemical and molecular approaches. Pak. J. Biol. Sci. 16. doi:10.3923/pjbs.2013.901.910
Zargar, S. M., Farhat, S., Mahajan, R., Bhakhri, A., and Sharma, A. (2016). Unraveling the Efficiency of RAPD and SSR Markers in Diversity Analysis and Population Structure Estimation in Common Bean. Saudi J. Biol. Sci. 23. doi:10.1016/j.sjbs.2014.11.011
Zargar, S. M., Mahajan, R., Farhat, S., Nazir, M., Mir, R. A., Nazir, M., et al. (2015). Understanding the Role of Iron and Zinc in Animals and Crop Plants from Genomics Perspective. Curr. Trends Biotechnol. Pharm. 9.
Keywords: common bean, single nucleotide polymorphism (SNP), genome wide association studies (GWAS), ionome, transporters, population structure
Citation: Nazir M, Mahajan R, Mansoor S, Rasool S, Mir RA, Singh R, Thakral V, Kumar V, Sofi PA, El-Serehy HA, Hefft DI and Zargar SM (2022) Identification of QTLs/ Candidate Genes for Seed Mineral Contents in Common Bean (Phaseolus vulgaris L.) Through Genotyping-by-Sequencing. Front. Genet. 13:750814. doi: 10.3389/fgene.2022.750814
Received: 31 July 2021; Accepted: 17 January 2022;
Published: 14 March 2022.
Edited by:
Aamir Raina, Aligarh Muslim University, IndiaReviewed by:
Parvaiz Ahmad, Government Degree College, Pulwama, IndiaVijay Gahlaut, Institute of Himalayan Bioresource Technology (CSIR), India
Copyright © 2022 Nazir, Mahajan, Mansoor, Rasool, Mir, Singh, Thakral, Kumar, Sofi, El-Serehy, Hefft and Zargar. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sajad Majeed Zargar, c216YXJnYXJAc2t1YXN0a2FzaG1pci5hYy5pbg==