 Andrei A. Kudinov
Andrei A. Kudinov Minna Koivula
Minna Koivula Gert P. Aamand2
Gert P. Aamand2 Ismo Strandén
Ismo Strandén Esa A. Mäntysaari
Esa A. Mäntysaari
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet. , 21 November 2022
Sec. Livestock Genomics
Volume 13 - 2022 | https://doi.org/10.3389/fgene.2022.1012205
This article is part of the Research Topic Insights in Livestock Genomics: 2022 View all 9 articles
Single-step genomic BLUP (ssGBLUP) model for routine genomic prediction of breeding values is developed intensively for many dairy cattle populations. Compatibility between the genomic (G) and the pedigree (A) relationship matrices remains an important challenge required in ssGBLUP. The compatibility relates to the amount of missing pedigree information. There are two prevailing approaches to account for the incomplete pedigree information: unknown parent groups (UPG) and metafounders (MF). unknown parent groups have been used routinely in pedigree-based evaluations to account for the differences in genetic level between groups of animals with missing parents. The MF approach is an extension of the UPG approach. The MF approach defines MF which are related pseudo-individuals. The MF approach needs a Γ matrix of the size number of MF to describe relationships between MF. The UPG and MF can be the same. However, the challenge in the MF approach is the estimation of Γ having many MF, typically needed in dairy cattle. In our study, we present an approach to fit the same amount of MF as UPG in ssGBLUP with Woodbury matrix identity (ssGTBLUP). We used 305-day milk, protein, and fat yield data from the DFS (Denmark, Finland, Sweden) Red Dairy cattle population. The pedigree had more than 6 million animals of which 207,475 were genotyped. We constructed the preliminary gamma matrix (Γpre) with 29 MF which was expanded to 148 MF by a covariance function (Γ148). The quality of the extrapolation of the Γpre matrix was studied by comparing average off-diagonal elements between breed groups. On average relationships among MF in
Genomic prediction in dairy cattle started in 2009 for US Holsteins, Jersey, and Brown Swiss (Wiggans et al., 2017). Since then, most dairy populations publish genomic estimated breeding values (GEBV) using a multi-step approach (Masuda et al., 2022). The term “multi” stands for a cascade of steps used to obtain GEBV: calculation of pseudo-observations for genotyped proven bulls and cows, estimation of SNP effects, prediction of direct genomic values, and blending of genomic values with pedigree index (Wiggans et al., 2011). In contrast, a single-step genomic BLUP (ssGBLUP) model accounts for pedigree, phenotypic, and genomic data simultaneously to obtain GEBVs for all animals (Legarra et al., 2009; Aguilar et al., 2010; Christensen and Lund, 2010). Despite the preselection bias in the multi-step GEBV (Patry and Ducrocq, 2011) and the benefits of the single-step model (Legarra et al., 2014), the latter is used only for a few dairy populations (Mäntysaari et al., 2020; Misztal et al., 2020; Masuda et al., 2022). High computational load, compatibility challenges for the genomic and the pedigree relationship matrices, and improper accounting of unknown parents impede the wide implementation of the single-step approach (Mäntysaari et al., 2020). In dairy cattle, these problems can be expected to be amplified due to the many generations in pedigrees, intensive selection, and the vast exchange of breeding material between populations.
The original ssGBLUP requires the inverse matrices of A22 and G in the inverted joint relationship matrix H−1 (Aguilar et al., 2010; Christensen and Lund, 2010) where A22 is the pedigree relationship matrix of the genotyped animals and G is the genomic relationship matrix. When the number of genotyped animals in the G matrix (n) exceeds the number of markers (m), direct inversion of the G matrix is not possible without regularization such as adding a small value to the diagonal or a residual polygenic matrix (Mäntysaari et al., 2017). When n >> m, the single-step method becomes computationally challenging. Several computational approaches have been proposed for the computation of G−1 to allow feasible application of ssGBLUP for large datasets (see review by Misztal et al., 2020). For instance, the method called ssGTBLUP (Mäntysaari et al., 2017) uses the relationship matrix of genotyped animals (A22) as the regularization matrix to avoid singularity, the Woodbury matrix identity for the G inverse, and a sparse presentation of the A22−1 to solve the computational challenges. In the data set with 178K genotyped animals to obtain GEBV, the ssGTBLUP model used 33% of the memory and 55% of the wall-clock time needed by the original ssGBLUP (Koivula et al., 2021a).
The difference in average off- and diagonal elements of A22 and G matrices is known as a single-step compatibility issue (Vitezica et al., 2011). To balance the matrices implies adjusting either the pedigree or the genomic relationship matrix to make the matrices more similar. The concept of the A adjustment was suggested by Christensen (2012) and further developed into the metafounder (MF) approach (Legarra et al., 2015). Metafounders are related inbreed pseudo-individuals that are used as unknown parents in the pedigree. Relationships between MF are described by a covariance matrix (Γ), which is used to build a relationship matrix AΓ. Estimation of Γ can be based on estimates of base allele frequencies (AF) for each MF (Garcia-Baccino et al., 2017). An important assumption of the MF approach is that the G matrix is constructed with all AF equal to 0.5 (Legarra et al., 2015). Applicability of MF has been shown in livestock (Koivula et al., 2021b, 2022), sheep (Granado-Tajada et al., 2020), and pig (Xiang et al., 2017) data sets. The MF approach was also reported as a perfect choice for multi-breed evaluations in case computation of accurate Γ is possible (Poulsen et al., 2022).
The number of MF in the reported studies on ssGBLUP in the large dairy cattle breeds has nearly always been less than the number of unknown parent groups (UPG). Allocation of few MF by breed or by breed by time help to achieve an accurate estimation of Γ due to the even distribution of MF across genotyped animals (Kudinov et al., 2020; Masuda et al., 2021). When MF are used in ssGBLUP, it would be natural to use the same number of MF as there are UPG in the pedigree-based animal model (PBLUP). However, accurate estimation of an unstructured Γ matrix of large size is difficult, especially if some of the UPG groups have no descendants among the genotyped animals or genotyped individuals are several generations away.
The aim of this study was to propose an approach to construct Γ with the same number of MF as routinely defined UPG. The proposed approach was applied to the Red Dairy Cattle 305-day data and pedigree used for the milk production evaluation in Nordic countries (Denmark, Finland, and Sweden). Both PBLUP and ssGTBLUP models were used. The predictions used either UPG or MF in equal numbers. Thus, the predictive performance of four models was investigated.
Data were 305-day milk, protein, and fat yield records from three lactations of Nordic Red Dairy Cattle (RDC), Finnish Holstein (HOL), and Finncattle (FIC) cows. Records were from January 1988 to June 2021. The total number of records by trait were: 9.45, 8.99, and 8.98 million for milk, protein, and fat, respectively (Table 1). Pedigree included 6.05 million cows and 118,363 bulls, of which 8,427 were RDC and 278 were FIC proven bulls. Genetic groups were defined as breed x country x five- or 10-year period for RDC, and as breed x five- or 10-year period for HOL, FIC, and other breeds. In total, there were 148 groups: 61 RDC, 45 HOL, 16 FIC, and 26 for breed group OTHER. The group OTHER included 23 breeds majorly beef cattle.
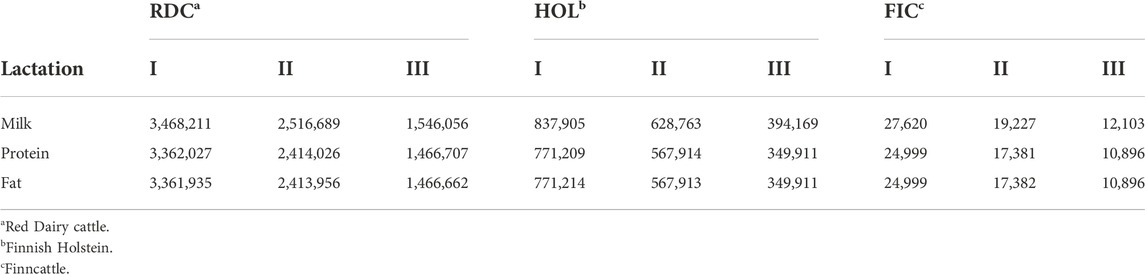
TABLE 1. Number of records by lactation, trait, and breed in 305-day Nordic (Denmark, Finland, Sweden) Red Dairy cattle production data.
Genomic data were used from 206,140 RDC animals (6,018 proven bulls and 85,142 cows with records) and 1,335 FIC animals (160 proven bulls and 845 cows with records). Before 2019 the bulls were genotyped with Illumina Bovine SNP50 array and most cows with Illumina Bovine LD array (Illumina, San Diego, CA, USA). Since 2019 both bulls and cows were genotyped with Eurogenomics EG MD array (https://www.eurogenomics.com/). Quality control and imputation of genotypes to 46,914 SNPs were performed by NAV (Nordic Genetic Evaluation, Denmark). Genomic markers were not filtered on minor allele frequency and no edits were done concerning across and within breeds polymorphism. HOL genotypes were not presented in the current study.
Four prediction models were investigated using a multi-trait multi-lactation model: single-step GTBLUP with UPG in H−1 (ssUPG), single-step GTBLUP with MF (ssMF), pedigree-based BLUP with UPG in A−1 (pUPG), and pedigree-based BLUP with MF (pMF). The traits were milk, protein, and fat yield in three lactations i.e. - nine traits total. The linear mixed effects model was:
where y is the vector of phenotypes, X is the design matrix relating fixed effects to the phenotypes, b is the vector of fixed effects, Z is the design matrix relating the breeding values to the phenotypes,
The mixed model equations (MME) of the original ssGBLUP model require the inverse of a joint relationship matrix H−1 (Aguilar et al., 2010; Christensen and Lund, 2010):
where, A22 is the part in A for the genotyped animals, and G is the genomic relationship matrix (VanRaden, 2008). Regularization matrix C = wA22 was added to the marker-based matrix G, where w is the residual polygenic proportion, i.e., the genomic relationship matrix was Gc_w = (1-w)G+ wA22 (Mäntysaari et al., 2017). We used w equal to 30% to keep the comparability to the studies by Koivula et al. (2021b, 2022). The Gc_w matrix was constructed with the assumption that AF of all markers was equal to 0.5. Thus, Gc_w = (1-w)Z101Z101´/k + wA22 where k = m/2 is the scaling factor, m is the number markers, and Z101 is the matrix of genotype counts with values of 0 for the heterozygote and values -1 and +1 for homozygotes. The inverse genomic relationship matrix can be expressed as (Mäntysaari et al., 2017)
The joint relationship matrix augmented by UPG (Quaas and Pollak, 1981; Misztal et al., 2013; Matilainen et al., 2018) was computed as shown in Koivula et al. (2021a):
where
and
The Q matrix has proportions of genes contributed from each UPG according to pedigree information. The subscripts 1 and 2 in Q pertain to genotyped and non-genotyped animals. Subscripts 1 and 2 in B pertain to genotyped animals and UPGs, respectively. The UPGs were modeled as random effect. Inbreeding coefficients were accounted in both pedigree-based relationship matrices.
In the MF approach (Christensen, 2012; Legarra et al., 2015), the H−1 matrix was replaced by:
where Gc_w=(1-w)G+ w
The pedigree-based models (pUPG and pMF) were similar to their corresponding single-step models, except that the genomic data was excluded from the prediction. In pUPG model UPGs were accounted in A−1 (
Let the number of MF be r such that the Γ matrix has size r. In the MF approach, the Γ matrix describes the variance-covariance structure of MF. It can be estimated by
a) Estimate allele frequencies for a set of base groups;
b) From estimated allele frequencies, calculate the preliminary Γ matrix (Γpre) for the base groups;
c) Solve the matrix K in the covariance function Γpre=
d) Compute the Γ for the large number of groups as
The model matrices
The technical detailed steps used to compute Γ for 148 groups (Γ148) were:
a) The pedigree was pruned to include only one ancestor generation of genotyped animals as in Kudinov et al. (2020). Truncation of the pedigree helped to achieve equal distribution of the genomic information over UPGs. Missing parents in the truncated pedigree were replaced by 26 groups formed by breed, country, and time interval (Table 2). All HOL ancestors were assigned to the same group regardless of country and time. Estimation of base population AF for each of the groups (PRDC) was performed using the GLS method (McPeek et al., 2004; Garcia-Baccino et al., 2017). The HOL group estimated from RDC genotypes was dropped from PRDC. The HOL AF (PHOL) were the same as used in Kudinov et al. (2020)—calculated using Holstein genotypes (M. Koivula, personal communication). The joint PRDC_HOL matrix of size 29 by 45,823 was created by merging compatible SNPs in PRDC and PHOL. Number of SNPs dropped from PRDC and PHOL where 1,091 and 519, respectively.
b) Three Γ matrices (ΓRDC_HOL, ΓRDC, and ΓHOL) were computed using PRDC_HOL, PRDC, and PHOL. A pre-Γ matrix (Γpre, Figure 1) was created by replacing the diagonal elements of ΓRDC_HOL by diagonal elements of ΓRDC and ΓHOL at corresponding places. The diagonal values in Γpre were larger than in ΓRDC_HOL.
c) Structure of Γpre was computed with covariance function
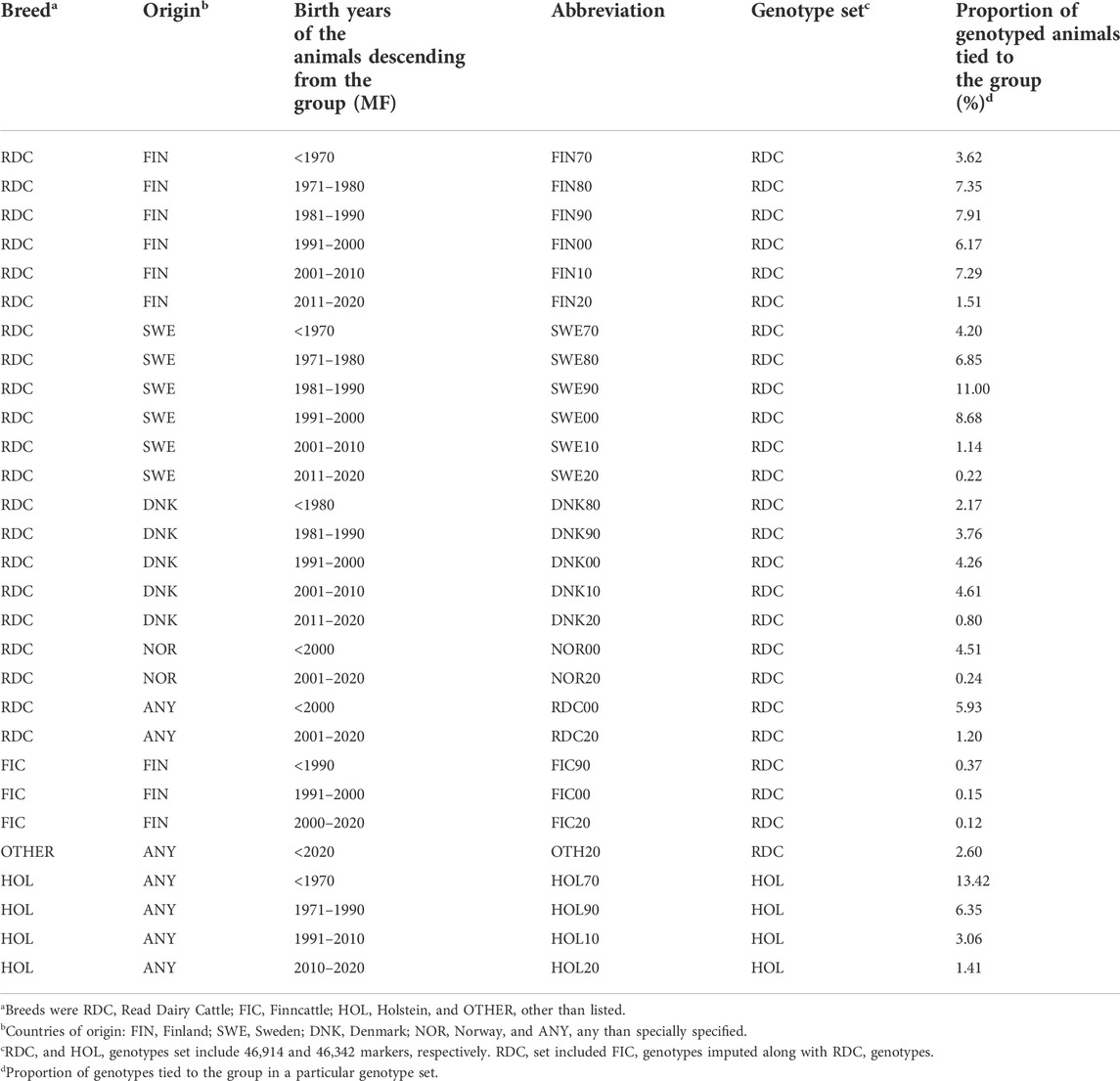
TABLE 2. Groups used to compute preliminary Γ matrix.
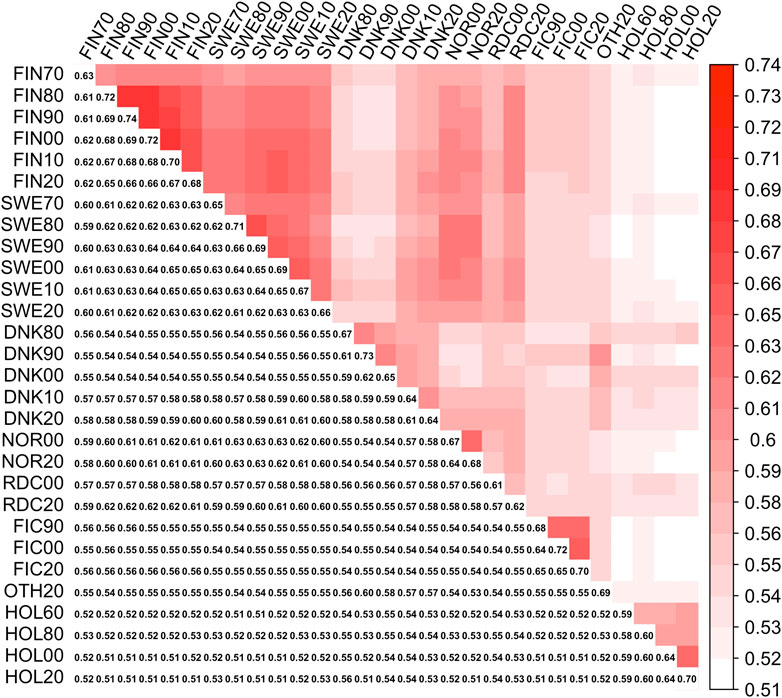
FIGURE 1. Symmetrical covariance matrix between 29 MFs (Γpre). Lower triangle present diagonal (MFs self-relationships) and off-diagonal (between MFs relationships) elements in Γpre
Matrix K was estimated as (Tijani et al., 1999):
leading to estimate
d) Finally, the Γ148 was estimated as
Validation of the prediction models was done using modified forward prediction (Mäntysaari et al., 2010). For the validation a reduced phenotypic data set was constructed by removing records from the last 4 years of data, i.e., June 2017 to June 2021. Daughter yield deviations (DYD) for bulls and yield deviations (YD) for cows were computed using the full data set using the same model which was applied to reduced data. Bias of evaluation was estimated by the linear regression coefficient (b1) from the weighted regression of DYD/YD on the corresponding [G]EBV predicted with the reduced data. The weight of DYD for bull i was EDCi/(EDCi + λb), where λb is (4—h2)/h2, h2 is heritability of the trait, and EDCi is the effective daughter contributions of bull i computed as in Taskinen et al. (2014). Weight for cow YDj was computed as ERCj/(ERCj + λc), where λc is (1-h2)/h2 and ERCj is the effective record contribution of cow j (Přibyl et al., 2013). Adjusted validation reliability was attained by dividing the coefficient of determination from the regression model (
Pedigree truncation and estimation of the inbreeding coefficients was done using RelaX2 v.1.95 software. The AF were estimated using Bpop v. 0.98 program (Strandén and Vuori, 2006; Strandén and Mäntysaari, 2020), T matrix and its diagonal needed in the ssGTBLUP model were computed using hgtinv v.0.83 program. The computation of [G]EBV predictions and the estimation of EDC/ERC used MiX99 software (Strandén and Lidauer, 1999). MiX99 software uses preconditioned conjugate gradient (PCG) iteration. The PCG method was assumed to be converged when convergency criteria <1e-6 was achieved. Convergency criteria was defined as a Euclidean norm of the difference between the right-hand side (RHS) of the MME and the one predicted by the current solutions relative to the norm of RHS. The matrices
Elements of Γpre ranged from 0.59 to 0.74 and from 0.51 to 0.69 for the diagonal and off-diagonal elements, respectively. The lowest and highest diagonal values (self-relationship, Legarra et al., 2015) were in groups HOL 1960 and RDC FIN 1990, respectively. In the Γ148 matrix, diagonal elements were in a range from 0.61 to 0.73 (Figure 2). The lowest and highest self-relationships were in HOL SWE 1970 and OTHER 1960 groups, respectively. The off-diagonal elements of Γ148 ranged from 0.48 to 0.69. The highest average relationships were observed between the FIN and SWE RDC groups, as expected. Relationships between HOL and RDC DNK were higher than with the other RDC groups due to the larger proportion of HOL sires in the RDC DNK pedigree. Similarly, the FIC groups were genetically closer to RDC FIN than to the other groups due to historical crossbreeding. Relationship coefficients between the RDC subgroups in our study ranged from 0.54 to 0.65 which was much higher than the range 0.09–0.18 presented between the biological types of Montana cattle breed (Kluska et al., 2021). Average relationships between RDC and HOL breed (0.52) was close to presented between HOL and Jersey breeds (0.48, Legarra et al., 2015).
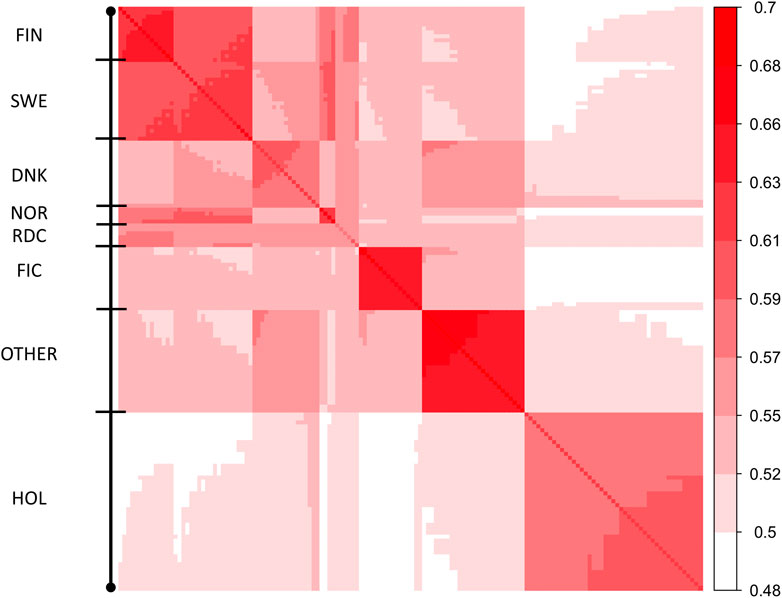
FIGURE 2. Heatmap of covariances between 148 MFs (Γ148). Diagonal of the heatmap plot are self-relationships of the MFs; off-diagonals are relationships between MFs.
Because Γ148 is an extrapolated matrix of Γpre we expect these to be alike. The difference between the two matrices was assessed using percentage deviation from the mean off-diagonal values in breed groups (Table 3). The average off-diagonal value of
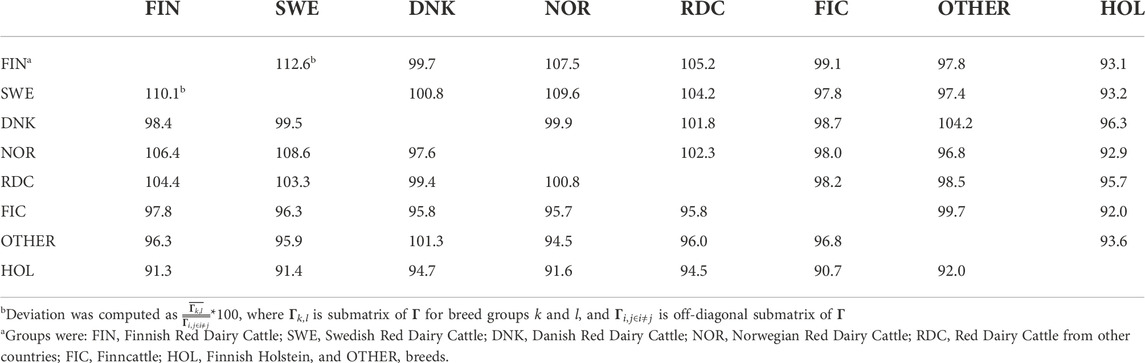
TABLE 3. Deviation from average relationships between breed groups in Γpre (lower triangle) and Γ148 (upper triangle).
Application of the Γ148 matrix to the pedigree-based relationship matrix lifted the average diagonal elements of A22 closer to G05 (Figure 3). The smallest diagonal and off-diagonal values of A22 increased by 0.25 (from one to 1.25) and by 0.50 (from 0 to 0.50), respectively, by using
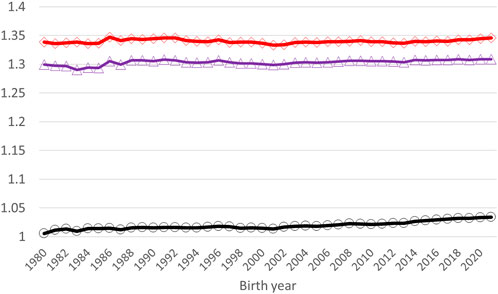
FIGURE 3. Average diagonal elements of A22 (black circles), AΓ (blue triangles), and G05 (red diamonds) by the birth year of a genotyped animal.
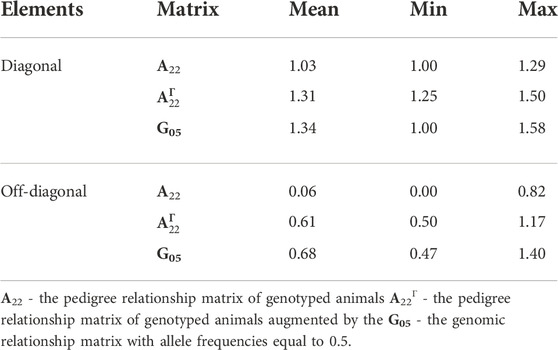
TABLE 4. Mean, minimum (Min), and maximum (Max) element values of A22,
In addition to Γpre, ΓRDC_HOL was tested as source for Γ148* and corresponding
Filtering of the SNPs by minor allele frequency (MAF) for the
The presented approach in our study allows to fit the same number of MF as UPG and define MF for base population groups not linked to the genotypes. However, approach requires several arbitrary steps that need to be customized for each population. For instance, definition of the groups will be different in Γpre. We defined the groups in Γpre by breed, country, and time. If any of defined groups had less than 0.1% of genotyped animals, we have had to combine it. In our study, the definition of the time variable in the base populations used to compute AF was the last year of the time interval, another way is to use mean, median or the first year. Because the year definition in each of the groups is used in the model matrix Φ and resulting covariance function, average diagonal of
The ssMF and ssUPG models converged in 1,388 and 2,802 iterations. The wall-clock time per iteration was similar for ssMF and ssUPG models. The mix99 runtime for ssMF model in Intel Xeon 2.8 Ghz machine with four cores was 11 h 19 min.
Table 5 presents bull validation results for the nine traits. For all traits, the highest prediction reliability was obtained by the ssMF model. The regression slopes (
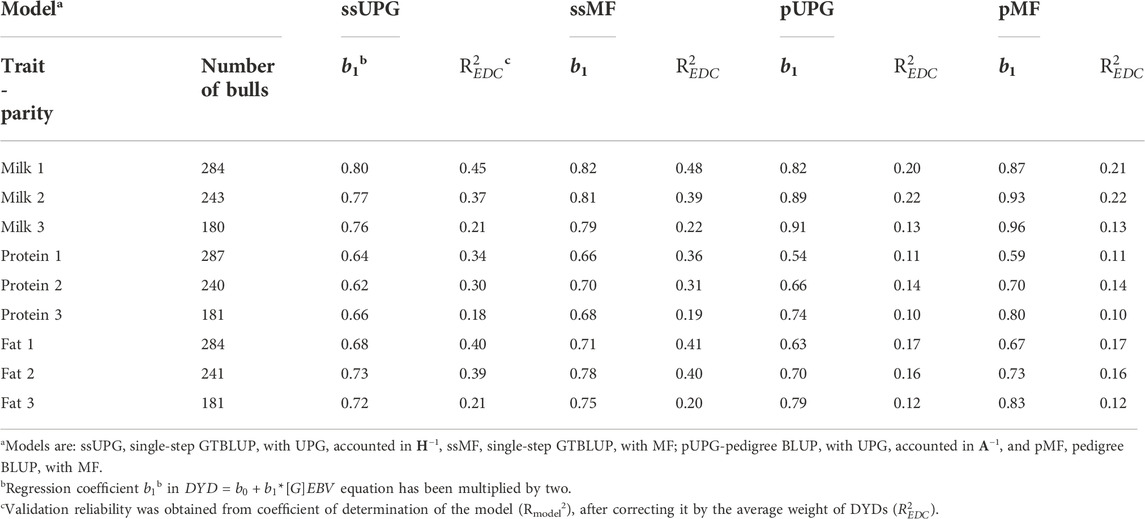
TABLE 5. [G]EBV validation test regression coefficients (b1) and weighted validation reliabilities (
TABLE 6. [G]EBV validation test regression coefficients (b1) and weighted validation reliabilities (
Genetic trends for combined milk, fat, and protein GEBVs are presented for the genotyped bulls with at least 50 daughters and all RDC cows in Figures 4, 5, respectively. Average GEBV were centered using the mean GEBV of RDC cows born in 2007. Both genomic and non-genomic models had similar shape in the UPG and MF instance. The average GEBV levels were higher than the average EBV levels. Similar difference has been observed in other single-step studies (Ma et al., 2015; Silva et al., 2019; Koivula et al., 2022). Overprediction in single-step with MF was reduced in our study similar to reported in Masuda et al. (2021) and Koivula et al. (2022).
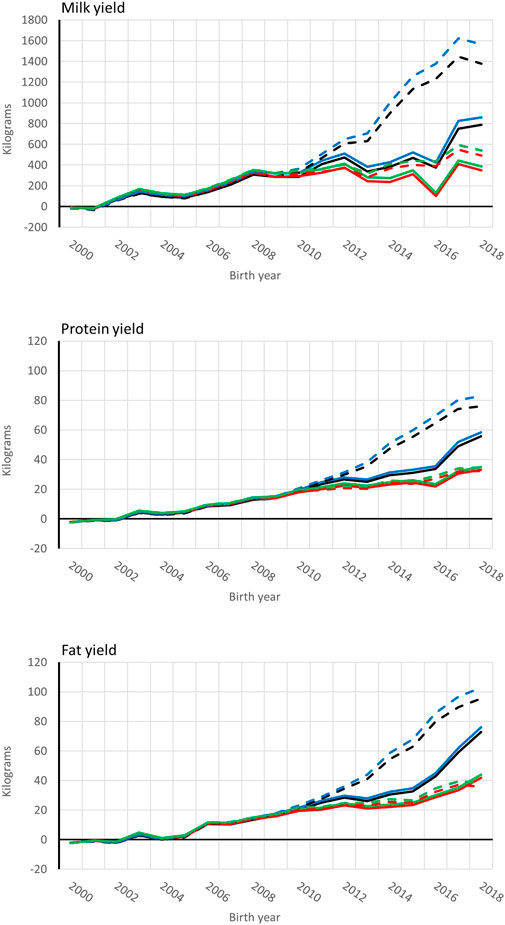
FIGURE 4. Average [genomic] breeding value of bulls by birth year in 305-d milk, protein, and fat yield (kg). Each bull had at least 50 daughters. Solid and dashed lines are from the model runs with full and reduced (minus four production year) data. Models are ssUPG—single-step GTBLUP with UPG accounted in H−1 (blue lines), ssMF—single-step GTBLUP with MF (black lines); pUPG-pedigree BLUP with UPG accounted in A−1 (green lines), and pMF—pedigree BLUP with MF (red lines).
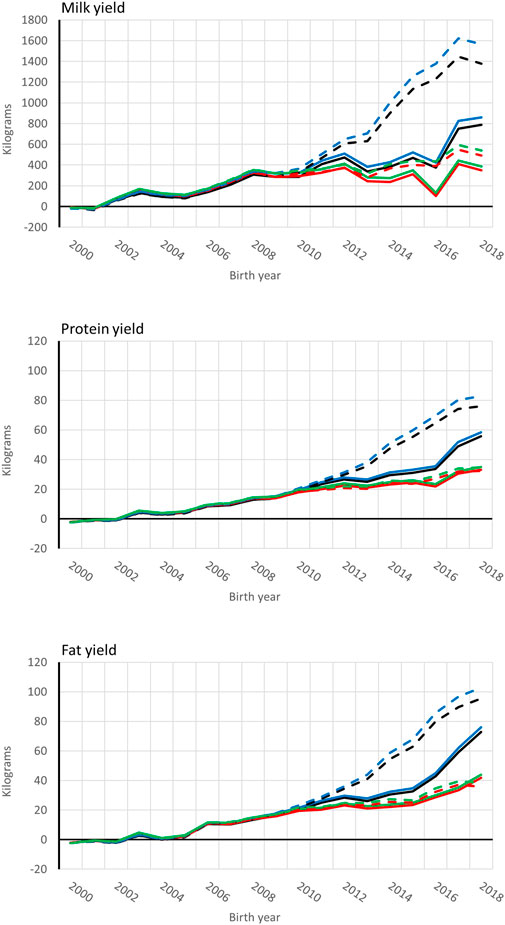
FIGURE 5. Average [genomic] breeding value of cows by birth year in 305-d milk, protein, and fat yield (kg). Solid and dashed lines are from the model runs with full and reduced (minus four production year) data. Models are ssUPG—single-step GTBLUP with UPG accounted in H−1 (blue lines), ssMF—single-step GTBLUP with MF (black lines); pUPG-pedigree BLUP with UPG accounted in A−1 (green lines), and pMF—pedigree BLUP with MF (red lines).
Reduction of heritability by additive variance scaling was suggested by Legarra et al. (2015) when MF are used for genomic prediction. Base populations in models with UPGs are assumed unrelated, which is contrary to MF. In order to solve that problem additive variance was suggested to be scaled by
We presented a method to utilize the same number of MF as UPG in single-step GBLUP. The Covariance functions allowed smooth extrapolation of the
The data analyzed in this study was obtained from Finncattle Foundation (Finland), Finnish Breeder Association (FABA, Finland), Swedish Cattle Farmers Association (Växa), Landbrug and Fødevarer F.m.b.A (L and F), Nordic Cattle Genetic Evaluation (NAV, Denmark), Viking Genetics (Denmark), and corresponding farmers. Requests to access these datasets should be directed to the Director of Nordic Cattle Genetic Evaluation, Gert P. Aamand, Z2FwQGxmLmRr.
AK executed the analysis and wrote the manuscript. EM did the study design. MK, GA, IS, and EM provided support during analysis execution, reviewed, and edited the manuscript. All authors contributed to the article and approved the submitted version.
Project “Genomic evaluations for Western Finncattle” financed by Luke (Finland) and Finncattle Foundation (Finland).
We acknowledge Finncattle Foundation (Finland), Finnish Breeder Association (Finland), Nordic Cattle Genetic Evaluation (Denmark), and Viking Genetics (Denmark). We kindly acknowledge two reviewers participated in production of the current manuscript.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Aguilar, I., Misztal, I., Johnson, D. L., Legarra, A., Tsuruta, S., and Lawlor, T. J. (2010). Hot topic: A unified approach to utilize phenotypic, full pedigree, and genomic information for genetic evaluation of Holstein final score. J. Dairy Sci. 93, 743–752. doi:10.3168/jds.2009-2730
Bradford, H. L., Masuda, Y., VanRaden, P. M., Legarra, A., and Misztal, I. (2019). Modeling missing pedigree in single-step genomic BLUP. J. Dairy Sci. 102, 2336–2346. doi:10.3168/jds.2018-15434
Christensen, O. F. (2012). Compatibility of pedigree-based and marker-based relationship matrices for single-step genetic evaluation. Genet. Sel. Evol. 44, 37. doi:10.1186/1297-9686-44-37
Christensen, O. F., and Lund, M. S. (2010). Genomic prediction when some animals are not genotyped. Genet. Sel. Evol. 42, 2. doi:10.1186/1297-9686-42-2
Garcia-Baccino, C. A., Legarra, A., Christensen, O. F., Misztal, I., Pocrnic, I., Vitezica, Z. G., et al. (2017). Metafounders are related to Fst fixation indices and reduce bias in single-step genomic evaluations. Genet. Sel. Evol. 49, 34. doi:10.1186/s12711-017-0309-2
Granado-Tajada, I., Legarra, A., and Ugarte, E. (2020). Exploring the inclusion of genomic information and metafounders in Latxa dairy sheep genetic evaluations. J. Dairy Sci. 103 (7), 6346–6353. doi:10.3168/jds.2019-18033
Kirkpatrick, M., Lofsvold, D., and Bulmer, M. (1990). Analysis of the inheritance, selection and evolution of growth trajectories. Genetics 124 (4), 979–993. doi:10.1093/genetics/124.4.979
Kluska, S., Masuda, Y., Ferraz, J. B. S., Tsuruta, S., Eler, J. P., Baldi, F., et al. (2021). Metafounders may reduce bias in composite cattle genomic predictions. Front. Genet. 12, 678587. doi:10.3389/fgene.2021.678587
Koivula, M., Strandén, I., Aamand, G. P., and Mäntysaari, E. A. (2022). Accounting for missing pedigree information with single-step random regression test-day models. Agriculture 12, 388. doi:10.3390/agriculture12030388
Koivula, M., Strandén, I., Aamand, G. P., and Mäntysaari, E. A. (2021b). Meta-model for genomic relationships of metafoundersapplied on large scale single-step random regression test-day model. Interbull Bull. 56, 76–81.
Koivula, M., Strandén, I., Aamand, G. P., and Mäntysaari, E. A. (2021a). Practical implementation of genetic groups in single-step genomic evaluations with Woodbury matrix identity-based genomic relationship inverse. J. Dairy Sci. 104 (9), 10049–10058. doi:10.3168/jds.2020-19821
Kudinov, A. A., Mäntysaari, E. A., Aamand, G. P., Uimari, P., and Strandén, I. (2020). Metafounder approach for single-step genomic evaluations of Red Dairy cattle. J. Dairy Sci. 103 (7), 6299–6310. doi:10.3168/jds.2019-17483
Legarra, A., Aguilar, I., and Misztal, I. (2009). A relationship matrix including full pedigree and genomic information. J. Dairy Sci. 92, 4656–4663. doi:10.3168/jds.2009-2061
Legarra, A., Christensen, O. F., Aguilar, I., and Misztal, I. (2014). Single Step, a general approach for genomic selection. Livestock Sci. 166, 54–65. doi:10.1016/j.livsci.2014.04.029
Legarra, A., Christensen, O. F., Vitezica, Z. G., Aguilar, I., and Misztal, I. (2015). Ancestral relationships using metafounders: Finite ancestral populations and across population relationships. Genetics 200, 455–468. doi:10.1534/genetics.115.177014
Lidauer, M. H., Pösö, J., Pedersan, J., Lassen, J., Madsen, P., Mäntysaari, E. A., et al. (2015). Across-country test-day model evaluations for Holstein, nordic red cattle, and Jersey. J. Dairy Sci. 98, 1296–1309. doi:10.3168/jds.2014-8307
Ma, P., Lund, M. S., Nielsen, U. S., Aamand, G. P., and Su, G. (2015). Single-step genomic model improved reliability and reduced the bias of genomic predictions in Danish Jersey. J. Dairy Sci. 98, 9026–9034. doi:10.3168/jds.2015-9703
Macedo, F. L., Christensen, O. F., Astruc, J. M., Aguilar, I., Masuda, Y., and Legarra, A. (2020). Bias and accuracy of dairy sheep evaluations using BLUP and SSGBLUP with metafounders and unknown parent groups. Genet. Sel. Evol. 52 (47), 47. doi:10.1186/s12711-020-00567-1
Mäntysaari, E. A., Koivula, M., and Strandén, I. (2020). Symposium review: Single-step genomic evaluations in dairy cattle. J. Dairy Sci. 103 (6), 5314–5326. doi:10.3168/jds.2019-17754
Mäntysaari, E. A., Evans, R., and Strandén, I. (2017). Efficient single-step genomic evaluation for a multibreed beef cattle population having many genotyped animals. J. Anim. Sci. 95, 4728–4737. doi:10.2527/jas2017.1912
Masuda, Y., Tsuruta, S., Bermann, M., Bradford, H. L., and Misztal, I. (2021). Comparison of models for missing pedigree in single-step genomic prediction. J. Anim. Sci. 99 (2), skab019. doi:10.1093/jas/skab019
Masuda, Y., VanRaden, P. M., Shogo, T., Lourenco, D. A. L., and Misztal, I. (2022). Invited review: Unknown-parent groups and metafounders in single-step genomic BLUP. J. Dairy Sci. 105 (2), 923–939. doi:10.3168/jds.2021-20293
Matilainen, K., Strandén, I., Aamand, G. P., and Mäntysaari, E. A. (2018). Single step genomic evaluation for female fertility in Nordic Red dairy cattle. J. Anim. Breed. Genet. 135, 337–348. doi:10.1111/jbg.12353
McPeek, M. S., Xiaodong, W., and Ober, C. (2004). Best linear unbiased allele-frequency estimation in complex pedigrees. Biometrics 60, 359–367. doi:10.1111/j.0006-341X.2004.00180.x
Misztal, I., Lourenco, D. A. L., and Legarra, A. L. (2020). Current status of genomic evaluation. J. Anim. Sci. 98, skaa101. doi:10.1093/jas/skaa101
Misztal, I., Vitezica, Z. G., Legarra, A., Aguilar, I., and Swan, A. A. (2013). Unknown-parent groups in single-step genomic evaluation. J. Anim. Breed. Genet. 130, 252–258. doi:10.1111/jbg.12025
Patry, C., and Ducrocq, V. (2011). Evidence of biases in genetic evaluations due to genomic preselection in dairy cattle. J. Dairy Sci. 94, 1011–1020. doi:10.3168/jds.2010-3804
Poulsen, B. G., Ostersen, T., Nielsen, B., and Christensen, O. F. (2022). Predictive performances of animal models using different multibreed relationship matrices in systems with rotational crossbreeding. Genet. Sel. Evol. 54 (1), 25–17. doi:10.1186/s12711-022-00714-w
Přibyl, J., Madsen, P., Bauer, J., Přibylová, J., Šimečková, M., Vostrý, L., et al. (2013). Contribution of domestic production records, Interbull estimated breeding values, and single nucleotide polymorphism genetic markers to the single-step genomic evaluation of milk production. J. Dairy Sci. 96 (3), 1865–1873. doi:10.3168/jds.2012-6157
Quaas, R. L., and Pollak, E. J. (1981). Modified equations for sire models with groups. J. Dairy Sci. 64, 1868–1872. doi:10.3168/jds.S0022-0302(81)82778-6
Silva, A. A., Silva, D. A., Silva, F. F., Costa, C. N., Lopes, P. S., Caetano, A. R., et al. (2019). Autoregressive single-step test-day model for genomic evaluations of Portuguese Holstein cattle. J. Dairy Sci. 102 (7), 6330–6339. doi:10.3168/jds.2018-15191
Strandén, I., and Lidauer, M. (1999). Solving large mixed linear models using preconditioned conjugate gradient iteration. J. Dairy Sci. 82, 2779–2787. doi:10.3168/jds.S0022-0302(99)75535-9
Strandén, I., and Mäntysaari, E. A. (2020). Bpop: An efficient program for estimating base population allele frequencies in single and multiple group structured populations. AFSci. 29 (3), 166–176. doi:10.23986/afsci.90955
Strandén, I., and Vuori, K. (2006). “RelaX2: Pedigree analysis program,” in Proceedings of the 8th World Congress on Genetics Applied to Livestock Production, 13-18 August 2006 (Belo Horizonte, MG, Brazil: Instituto Prociência), 27–30.
Taskinen, M., Mäntysaari, E. A., Aamand, G. P., and Strandén, I. (2014). “Comparison of breeding values from single-step and bivariate blending methods,” in Proceedings of the 10th World Congress on Genetics Applied to Livestock Production, August 2014 (Vancouver, BC, Canada: WCGALP), 17–22.
Tijani, A., Wiggans, G. R., Van Tassell, C. P., Philpot, J. C., and Gengler, N. (1999). Use of (co) variance functions to describe (co)variances for test day yield. J. Dairy Sci. 82 (1), 22610–22614. doi:10.3168/jds.S0022-0302(99)75228-8
VanRaden, P. M. (2008). Efficient methods to compute genomic predictions. J. Dairy Sci. 91, 4414–4423. doi:10.3168/jds.2007-0980
Vitezica, Z. G., Aguilar, I., Misztal, I., and Legarra, A. (2011). Bias in genomic predictions for populations under selection. Genet. Res. 93, 357–366. doi:10.1017/S001667231100022X
Wiggans, G. R., Cole, J. B., Hubbard, S. M., and Sonstegard, T. S. (2017). Genomic selection in dairy cattle: The USDA experience. Annu. Rev. Anim. Biosci. 5 (1), 309–327. doi:10.1146/annurev-animal-021815-111422
Wiggans, G. R., VanRaden, P. M., and Cooper, T. A. (2011). The genomic evaluation system in the United States: Past, present, future. J. Dairy Sci. 94 (6), 3202–3211. doi:10.3168/jds.2010-3866
Xiang, T., Christensen, O. F., and Legarra, A. (2017). Technical note: Genomic evaluation for crossbred performance in a single-step approach with metafounders. J. Anim. Sci 95, 1472–1480. doi:10.2527/jas.2016.1155
1 STY - birth year of the group standardized as
Keywords: genetic groups, genomic evaluation, red dairy cattle, finncattle, co-variance function
Citation: Kudinov AA, Koivula M, Aamand GP, Strandén I and Mäntysaari EA (2022) Single-step genomic BLUP with many metafounders. Front. Genet. 13:1012205. doi: 10.3389/fgene.2022.1012205
Received: 05 August 2022; Accepted: 31 October 2022;
Published: 21 November 2022.
Edited by:
Martino Cassandro, University of Padua, ItalyReviewed by:
Andres Legarra, INRAE Occitanie Toulouse, FranceCopyright © 2022 Kudinov, Koivula, Aamand, Strandén and Mäntysaari. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Andrei A. Kudinov, YW5kcmVpLmt1ZGlub3ZAbHVrZS5maQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.