 Nandhini Abirami R.
Nandhini Abirami R. Durai Raj Vincent P. M.
Durai Raj Vincent P. M.- School of Information Technology and Engineering, Vellore Institute of Technology, Vellore, India
Image enhancement is considered to be one of the complex tasks in image processing. When the images are captured under dim light, the quality of the images degrades due to low visibility degenerating the vision-based algorithms’ performance that is built for very good quality images with better visibility. After the emergence of a deep neural network number of methods has been put forward to improve images captured under low light. But, the results shown by existing low-light enhancement methods are not satisfactory because of the lack of effective network structures. A low-light image enhancement technique (LIMET) with a fine-tuned conditional generative adversarial network is presented in this paper. The proposed approach employs two discriminators to acquire a semantic meaning that imposes the obtained results to be realistic and natural. Finally, the proposed approach is evaluated with benchmark datasets. The experimental results highlight that the presented approach attains state-of-the-performance when compared to existing methods. The models’ performance is assessed using Visual Information Fidelitysse, which assesses the generated image’s quality over the degraded input. VIF obtained for different datasets using the proposed approach are 0.709123 for LIME dataset, 0.849982 for DICM dataset, 0.619342 for MEF dataset.
Introduction
Cameras are crucial in capturing real-world happenings in several accomplishments like remote sensing, autonomous driving solutions, and surveillance systems. Computer vision algorithms used for these applications require the images to be high visibility to achieve commendable performance (Lore et al., 2017). However, the quality of the images captured is greatly affected by the amount of light received by the camera’s sensor. Also, the low-light images are prone to have additional noise (Wang et al., 2020). Hence, high-quality images cannot be obtained under low-light conditions that affect the performance of computer vision applications like object detection, recognition, segmentation and classification (Ai and Kwon, 2020). Thus, developing a low-light image enhancement technique is essential to perform subsequent high-level computer vision tasks with ease and high accuracy. Recently, deep learning-based approaches gained popularity in many computer vision applications (Abiram et al., 2021; Abirami et al., 2021) as they achieved good results. The performance of conditional generative adversarial networks in computer vision-based applications (NandhiniAbirami et al., 2021) inspired us to explore the performance in low-light image enhancement. The experimental performance on the synthetic and real-world low-light image datasets demonstrates the robustness of the method.
Figure 1 showcases several examples of the image enhancement by the proposed method. It can be seen wall paintings fourth and fifth image, shadow and reflection on the floor in the third image are accurately captured and generated by the model. The proposed model brought out to light the intricate details that have almost been buried in the dark. As shown in Figure 1, our method works best visually, and the results are very similar to ground truth. To bring the buried information to light, image enhancement is necessary (Lv et al., 2021). Intensifying the image directly is the simplest and the inherent approach to bringing the low-light regions into the light. But, amplifying the low light regions paves the way to other problems like enhancing the naturally bright regions to get saturated and lose intricate details (Ke et al., 2020; Xie et al., 2020).

FIGURE 1. Left Column: Natural low-light images. Middle Row: Ground truth images. Right Column: The results enhanced by our method.
Several other existing methods for low-light image enhancements are performed using image dehazing (Li et al., 2015) Retinex theory (Park et al., 2017; XiaojieGuo et al., 2016; Park et al., 2018; Shi et al., 2019; Zhang et al., 2018) and histogram equalization algorithm (Singh et al., 2015; Xu et al., 2013; Celik, 2014; Arya and Pattanaik, 2013). The histogram equalization technique avoids saturation and it is also one of the widely used techniques for its effectiveness and simplicity. However, the histogram equalization technique enhances the low-light image utilizing the histogram details of the entire low-light image as its transformation function, resulting in excessive enhancement of the regions with a low level of contrast. In other words, the technique focuses on enhancing the contrast rather than performing actual illumination, causing under or over-enhanced regions in the image. The approach presented in (Wang et al., 2013) enhances contrast and retains the illumination in the image but fails to retain the image’s visual quality.
According to retinex theory, the amount of light reaching the sensor is composed of illumination and scene reflection represented by,
Where, E is the image irradiance, which is the illumination reaching the camera sensor, R is the reflection map and T is the illumination map while ∘ representing elementwise multiplication. Some methods obtained enhanced results by removing the illumination part (Wang et al., 2014), while some methods retained a part of the illumination to maintain the natural effects of the images (Wang et al., 2013). However, these methods introduce distortions to the enhanced images leading to reduced visual quality by ignoring the camera response characteristics. Methods based on image dehazing retain pixel values to maintain natural distribution. As observed in (Dong et al., 2011) proposed an approach to perform image dehazing on the input low visibility image. After this, image inversion is performed on the unnatural images to obtain the illuminated image. Although the above methods produced good results, those images did not reflect the true illumination and contrast of the scene. Some of the methods do not take into account the effect of noise in the resulting images. Also, some methods will get different results for different illuminations. Therefore, we propose a conditional generative adversarial network-based model to enhance and denoise the degraded low-light image in this work (Mirza and Osindero, 2014). This work
1) Rigorously analyses the efficiency of GAN in image-based tasks.
2) Presents a low-light image enhancement technique (LIMET) with a fine-tuned conditional generative adversarial network preserving the naturalness of the image.
3) Presents an approach that employs two discriminators to acquire a semantic meaning that imposes the obtained results to be realistic and natural.
Related Works
Generally, the image enhancement technique improves the visual quality of the low-quality low-light images. It supports further high-level computer vision tasks to extract valuable information from the captured images (Jung et al., 2017). The low-light image enhancement technique unveils the poorly exposed regions of the image. Many kinds of research have been proposed to improve the visibility of images regardless of the lighting conditions.
Based on the retinex theory, several models were proposed for low-light image enhancement (Fu et al., 2018). Diverse methods were proposed to separate the illumination component from the given image. SSR(Si et al., 2017), MSR, and MSR with color restoration (Ma et al., 2017) techniques have been popularly employed as image enhancement techniques. Guo et al. (XiaojieGuo et al., 2016) calculated the illumination of all the pixels by choosing the greatest value among RGB channels. The work non-uniformly enhanced the illumination instead of eliminating the color shift posed by light sources. Though these methods successfully extract the illumination invariant features in the estimated reflectance, the over-highlighted edges and color inconsistency often make the enhanced images visually unnatural and significantly degrades the viewing experience. To overcome these issues, methods have been proposed to apply the dehazing algorithm. Dong et al. (Lv et al., 2021) proposed a dehazing based image enhancement algorithm. The method shows the illumination element of the image the inverted low-light version of the image. The enhanced image is acquired by inverting the unrealistic estimated image once again (Dong et al., 2011). Fu et al. (2016a) proposed a fusion-based method where an illumination estimation algorithm to decompose the image into illumination and reflectance components. Then, contrast-enhanced and illumination-improved versions are derived from the illumination component by utilizing adaptive histogram equalization and sigmoid function. Although the fusion-based method provided promising results, it struggles to produce textual details across multiple scales.
The main focus of the histogram equalization algorithms is enhancing image contrast and balancing the histogram of the whole image as much as possible. It is frequently used as a prerequisite for object recognition and detection (Sellahewa and Jassim, 2010). However, the details hidden in the dark region are not enhanced properly as this method considers each image pixel individually, disregarding their neighborhood. This makes the image inconsistent with the real scene. Celik et al. (Celik and Tjahjadi, 2011) tried to overcome these issues by proposing variational methods that use various regularization terms on the histogram. The authors enhanced the contrast using the variational methods that mapped the elements between the histogram of the actual and the smoothened image. However, several dehazing methods can provide only reasonable results. Deep learning based Unsupervised GAN proposed by Yifan et al. (Jiang et al., 2021) that trains the model without image pairs captured under low-light and normal light. The authors used the information obtained from the input instead of using the ground truth image. Ning et al. (Rao et al., 2021) proposed a component GAN model to recover normal images from poor light images. The proposed network is composed of two components namely decomposition part and enhancement part. The decomposition part divides the low light images into illumination and reflectance component. The enhancement part generates good quality images.
Several techniques have been put forward for low-light image enhancement, but it still suffers from the over or under-enhanced images due to poor image visibility. Recently studies have been proposed to preserve the illumination structure by minimizing the color effects. Still, these methods suffer from loss of textural details resulting in smoothed out surfaces of objects. In contrast, the proposed model has a clear physical explanation preserving textural details of the objects in the image. Technical aspects of the LIMET model will be discussed below. Table 1 shows the advantages and disadvantages of low-light image enhancement techniques.
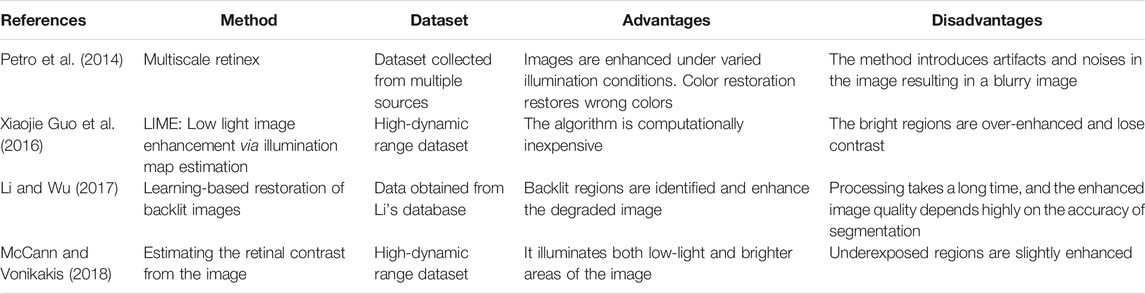
TABLE 1. Advantages and disadvantages of existing low-light image enhancement techniques.
Materials and Methods
The proposed approach, network structure, loss function, and implementation details are discussed in this section. Figure 2 presents the architecture of the proposed low-light image enhancement model. The model is proposed with a dual discriminator sharing a similar architecture but with varying sizes. The weights of the inputs passed to the two discriminators are the actual and 1/2 of the actual weight. This ensures that the discriminator guides the generator to generate realistic images and enhance the visual appeal of the input. This is because the existing discriminator does not guide generators to generate realistic or very close to realistic images. The discriminator model uses convolution-instance normalization-leaky ReLU blocks of layers. The convolutional layers have filters ranging from 64 to 512. Here, instance normalization is used instead of batch normalization to remove artifacts. The network architecture uses the Sigmoid activation function to determine the probability. The sigmoid activation function is most frequently used in classification problems. These dual discriminators are used to assist the generator in generating realistic images. The network is trained using an ADAM optimizer having a learning rate set to 0.0002,
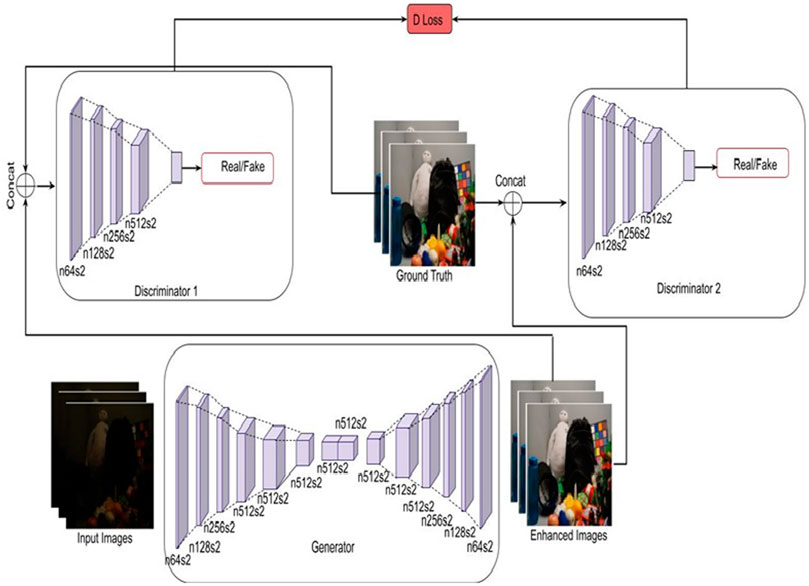
FIGURE 2. Proposed methodology.
The proposed methodology overcomes the disadvantages of classical image enhancement techniques, namely 1) retinex based methods that generate graying out and unnatural images, 2) unsharp masking algorithm that fails to achieve a good tradeoff between details and naturalness, 3) histogram equalization that fails to generate realistic images, 4) adaptive histogram equalization that does not produce effective results.
The generator not only reduces the loss from the discriminator but also generates the fake distribution close to the real distribution by using loss
Each discriminator block contains a convolution layer, instance normalization layer, and LeakyReLU represented by Eq. 5. The dual discriminator loss is calculated by taking in the actual and the fake images as the inputs. The discriminator loss is a summation of actual loss and generated loss. The real loss is a sigmoid cross-entropy loss of real images. The generated loss is a binary cross-entropy loss of fake images. Instance normalization is used to remove artifacts. A sigmoid activation function represented by Eq. 6 is used as a discriminator acts as a binary classifier classifying the real and fake images. A Sigmoid activation function converts any value to a 0–1 probability for two-class classifications. Figure 3 shows the flowchart for the proposed approach.
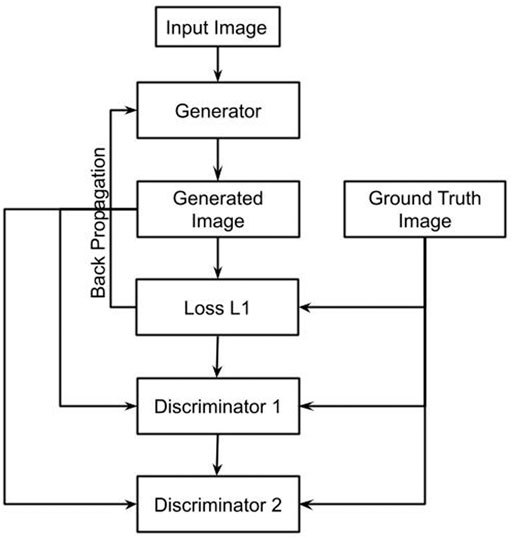
FIGURE 3. Flowchart of the proposed model.
Algorithm 1.
Experimental Results
The proposed model is trained using the LOL dataset (Wei et al., 2018), having 500 low-light image pairs. The image pairs in the LOL dataset are synthesized on real scenes. The ground truth images of the LOL dataset are normal light images. Figure 4 shows the degraded and the ground truth samples from the training data under different illumination conditions. In the training phase, a batch of paired low-light images is fed into the generator to learn the features of the image.

FIGURE 4. Samples of training data pairs showing low light image samples (left) and normal light image samples (right).
The results generated from LIMET for low-light image enhancement are compared with several exisiting state-of-the-art methods. The performance of the model is compared with Dehazing based fast efficient algorithm (Dong) (Dong et al., 2011), Naturalness preserved enhancement algorithm (NPE) (Wang et al., 2013), Low-light image enhancement via illumination map estimation (LIME) (Abiram et al., 2021), A fusion-based enhancing method (MF) (Fu et al., 2016a), Simultaneous Reflection and Illumination Estimation (SRIE) (Fu et al., 2016b), MultiscaleRetinex (Petro et al., 2014), GLobal illumination Aware and Detail-preserving Network (GLADNet) (Wang et al., 2018). The performance evaluations of these methods are performed using publicly available datasets, namely LIME (Abiram et al., 2021) dataset with ten low-light images, DICM(Lee et al., 2012) dataset 69 images captured by digital cameras, MEF (Ma et al., 2015) with 17 high-quality multi-exposure images that include natural scenaries and architectural pictures.
It can be visualized from Figure 5 that the proposed approach generates high-quality results compared to the existing studies. The evaluation of the proposed approach with previous studies in terms of VIF is presented below. The experimental results reveal that the proposed model is more robust, effective and provides enhanced results on degraded images with less noise.

FIGURE 5. Enhancement comparison of the proposed approach with existing approaches.
The performance of LIMET is compared with existing state-of-art-methods using Visual Information Fidelity. VIF is a measure of distortion of visual information used to evaluate the quality of the improved images. Fidelity is the similarity between the signals from the reference and distorted images. VIF is originally designed for degraded images, here as the images are enhanced, the original image is considered the degraded image. Hence, VIF is applied in reverse where the enhanced image, C is referred as the ground truth image and the original image as the degraded image, F. VIF is given by,
Here,
From Table 2 it is visible that LIMET performs superior compared to the existing best models. The results depict that the existing methods do not adequately enhance image quality when compared to the proposed approach. The proposed approach achieved better outputs with improved visual quality and low distortion. The proposed approach generates robust results and performs better than the existing methods in terms of VIF.
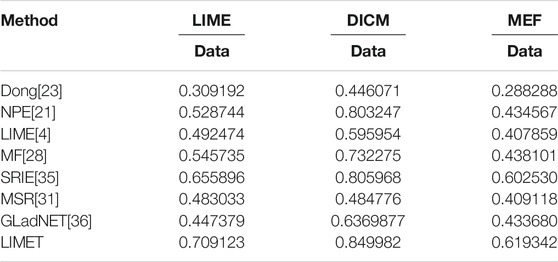
TABLE 2. Summarizes the VIF results in the images compared to the state-of-the-art models.
Conclusion
This work has presented a robust approach to improve the visual quality and offer vision-based applications with dependable inputs. The model is robust and the results obtained from LIMET can be fed to several computer vision-based applications like feature matching, edge detection, object recognition, with enhanced inputs improving their performances. Experimental results reveal that the proposed approach LIMET achieves visually enhanced and natural results that surpass the existing image enhancement methods. The proposed approach has a clear physical explanation preserving textural details of the objects in the image in comparison with other existing approaches. However, the proposed approach does not handle images with severe noise effects and in the future studies can be proposed to handle images with more noise. Future studies can utilize enhanced images for several applications, namely object detection, segmentation and classification.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://drive.google.com/file/d/157bjO1_cFuSd0HWDUuAmcHRJDVyWpOxB/view.
Author Contributions
NA performed data collection, performed the analysis and wrote the manuscript. DV performed the review and supervision.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Abbreviations
CGAN, conditional generative adversarial network; GLadNET, low-light enhancement network with global awareness; HE, histogram equalization; LIME, low-light image enhancement; LIMET, low-light image enhancement technique; LOL, low-light dataset; MSR, multiscaleretinex; NPE, naturalness preserved enhancement; ReLU, rectified linear unit; SSR, single scale retinex; SRIE, Simultaneous Reflection and Illumination Estimation; VIF, visual information fidelity.
References
Abiram, R. N., Vincent, P. D. R., and Vincent, P. M. D. R. (2021). Identity Preserving Multi-Pose Facial Expression Recognition Using fine Tuned VGG on the Latent Space Vector of Generative Adversarial Network. Mbe 18 (4), 3699–3717. doi:10.3934/mbe.2021186
Abirami, N., Vincent, D. R., and Kadry, S. (2021). P2P-COVID-GAN. Int. J. Data Warehousing Mining (Ijdwm) 17 (4), 101–118. doi:10.4018/ijdwm.2021100105
Ai, S., and Kwon, J. (2020). Extreme Low-Light Image Enhancement for Surveillance Cameras Using Attention U-Net. Sensors 20 (2), 495. doi:10.3390/s20020495
Arya, K. V., and Pattanaik, M. (2013). Histogram Statistics Based Variance Controlled Adaptive Threshold in Anisotropic Diffusion for Low Contrast Image Enhancement. Signal. Process. 93 (6), 1684–1693. doi:10.1016/j.sigpro.2012.09.009
Celik, T. (2014). Spatial Entropy-Based Global and Local Image Contrast Enhancement. IEEE Trans. Image Process. 23 (12), 5298–5308. doi:10.1109/tip.2014.2364537
Celik, T., and Tjahjadi, T. (2011). Contextual and Variational Contrast Enhancement. IEEE Trans. Image Process. 20 (12), 3431–3441. doi:10.1109/tip.2011.2157513
Dong, X., Wang, G., Pang, Y., Li, W., Wen, J., Meng, W., et al. (2011). “Fast Efficient Algorithm for Enhancement of Low Lighting Video,” in Multimedia and Expo (ICME), 2011 IEEE International Conference on (IEEE), 1–6. doi:10.1109/ICME.2011.6012107
Fu, Q., Jung, C., and Xu, K. (2018). Retinex-based Perceptual Contrast Enhancement in Images Using Luminance Adaptation. IEEE Access 6, 61277–61286. doi:10.1109/access.2018.2870638
Fu, X., Zeng, D., Huang, Y., Liao, Y., Ding, X., and Paisley, J. (2016). A Fusion-Based Enhancing Method for Weakly Illuminated Images. Signal. Process. 129, 82–96. doi:10.1016/j.sigpro.2016.05.031
Fu, X., Zeng, D., Huang, Y., Zhang, X.-P., and Ding, X. (2016). “A Weighted Variational Model for Simultaneous Reflectance and Illumination Estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (IEEE), 2782–2790. doi:10.1109/cvpr.2016.304
Jiang, Y., Gong, X., Liu, D., Cheng, Y., Fang, C., Shen, X., et al. (2021). Enlightengan: Deep Light Enhancement without Paired Supervision. IEEE Trans. Image Process. 30, 2340–2349. doi:10.1109/tip.2021.3051462
Jung, C., Yang, Q., Sun, T., Fu, Q., and Song, H. (2017). Low Light Image Enhancement with Dual-Tree Complex Wavelet Transform. J. Vis. Commun. Image Representation 42, 28–36. doi:10.1016/j.jvcir.2016.11.001
Ke, X., Lin, W., Chen, G., Chen, Q., Qi, X., and Ma, J. (2020). “EDLLIE-net: Enhanced Deep Convolutional Networks for Low-Light Image Enhancement,” in 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC) (IEEE), 59–68.
Lee, C., Lee, C., and Kim, C.-S. (2012). “Contrast Enhancement Based on Layered Difference Representation,” in 2012 19th IEEE International Conference on Image Processing (IEEE), 965–968.
Li, L., Wang, R., Wang, W., and Gao, W. (2015). “A Low-Light Image Enhancement Method for Both Denoising and Contrast Enlarging,” in 2015 IEEE International Conference on Image Processing (ICIP) (IEEE), 3730–3734. doi:10.1109/icip.2015.7351501
Li, Z., and Wu, X. (2017). Learning-based Restoration of Backlit Images. IEEE Trans. Image Process. 27 (2), 976–986. doi:10.1109/TIP.2017.2771142
Lore, K. G., Akintayo, A., and Sarkar, S. (2017). LLNet: A Deep Autoencoder Approach to Natural Low-Light Image Enhancement. Pattern Recognition 61, 650–662. doi:10.1016/j.patcog.2016.06.008
Lv, F., Li, Y., and Lu, F. (2021). Attention Guided Low-Light Image Enhancement with a Large Scale Low-Light Simulation Dataset. Int. J. Comput. Vis. 129 (7), 2175–2193. doi:10.1007/s11263-021-01466-8
Ma, J., Fan, X., Ni, J., Zhu, X., and Xiong, C. (2017). Multi-scale Retinex with Color Restoration Image Enhancement Based on Gaussian Filtering and Guided Filtering. Int. J. Mod. Phys. B 31 (16–19), 1744077. doi:10.1142/s0217979217440775
Ma, K., Zeng, K., and Wang, Z. (2015). Perceptual Quality Assessment for Multi-Exposure Image Fusion. IEEE Trans. Image Process. 24 (11), 3345–3356. doi:10.1109/tip.2015.2442920
McCann, J. J., and Vonikakis, V. (2018). Calculating Retinal Contrast from Scene Content: a Program. Front. Psychol. 8, 2079. doi:10.3389/fpsyg.2017.02079
Mirza, M., and Osindero, S. (2014). Conditional Generative Adversarial Nets. ArXiv. Available at: https://arxiv.org/abs/1411.1784.
Nandhini Abirami, R., Durai Raj Vincent, P. M., Srinivasan, K., Tariq, U., and Chang, C.-Y. (2021). Deep CNN and Deep GAN in Computational Visual Perception-Driven Image Analysis. Complexity 2021, 5541134. doi:10.1155/2021/5541134
Park, S., Yu, S., Kim, M., Park, K., and Paik, J. (2018). Dual Autoencoder Network for Retinex-Based Low-Light Image Enhancement. IEEE Access 6, 22084–22093. doi:10.1109/access.2018.2812809
Park, S., Yu, S., Moon, B., Ko, S., and Paik, J. (2017). Low-light Image Enhancement Using Variational Optimization-Based Retinex Model. IEEE Trans. Consumer Electron. 63 (2), 178–184. doi:10.1109/tce.2017.014847
Petro, A. B., Sbert, C., and Morel, J.-M. (2014). Multiscale Retinex. Image Process. Line 4, 71–88. doi:10.5201/ipol.2014.107
Rao, N., Lu, T., Zhou, Q., Zhang, Y., and Wang, Z. (2021). “Seeing in the Dark by Component-GAN,” in IEEE Signal Process. Lett. (IEEE). doi:10.1109/lsp.2021.3079848
Sellahewa, H., and Jassim, S. A. (2010). Image-quality-based Adaptive Face Recognition. IEEE Trans. Instrum. Meas. 59 (4), 805–813. doi:10.1109/tim.2009.2037989
Shi, Y., Wu, X., and Zhu, M. (2019). Low-light Image Enhancement Algorithm Based on Retinex and Generative Adversarial Network. arXiv. Available at: https://arxiv.org/abs/1906.06027.
Si, L., Wang, Z., Xu, R., Tan, C., Liu, X., and Xu, J. (2017). Image Enhancement for Surveillance Video of Coal Mining Face Based on Single-Scale Retinex Algorithm Combined with Bilateral Filtering. Symmetry 9 (6), 93. doi:10.3390/sym9060093
Singh, K., Kapoor, R., and Sinha, S. K. (2015). Enhancement of Low Exposure Images via Recursive Histogram Equalization Algorithms. Optik 126 (20), 2619–2625. doi:10.1016/j.ijleo.2015.06.060
Wang, L., Xiao, L., Liu, H., and Wei, Z. (2014). Variational Bayesian Method for Retinex. IEEE Trans. Image Process. 23 (8), 3381–3396. doi:10.1109/tip.2014.2324813
Wang, S., Zheng, J., Hu, H.-M., and Li, B. (2013). Naturalness Preserved Enhancement Algorithm for Non-uniform Illumination Images. IEEE Trans. Image Process. 22 (9), 3538–3548. doi:10.1109/tip.2013.2261309
Wang, W., Wei, C., Yang, W., and Liu, J. (2018). “GLADNet: Low-Light Enhancement Network with Global Awareness,” in 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018) (IEEE), 751–755. doi:10.1109/fg.2018.00118
Wang, W., Wu, X., Yuan, X., and Gao, Z. (2020). An experiment-based Review of Low-Light Image Enhancement Methods. IEEE Access 8, 87884–87917. doi:10.1109/access.2020.2992749
Wei, C., Wang, W., Yang, W., and Liu, J. (2018). Deep Retinex Decomposition for Low-Light Enhancement. arXiv. Available at: https://arxiv.org/abs/1808.04560.
Xiaojie Guo, X., Yu Li, Y., and Haibin Ling, H. (2016). LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 26 (2), 982–993. doi:10.1109/TIP.2016.2639450
Xie, J., Bian, H., Wu, Y., Zhao, Y., Shan, L., and Hao, S. (2020). Semantically-guided Low-Light Image Enhancement. Pattern Recognition Lett. 138, 308–314. doi:10.1016/j.patrec.2020.07.041
Xu, H., Zhai, G., Wu, X., and Yang, X. (2013). Generalized Equalization Model for Image Enhancement. IEEE Trans. Multimedia 16 (1), 68–82. doi:10.1109/TMM.2013.2283453
Keywords: computer vision, deep learning, facial expression recognition, convolutional neural network, human-robot interaction, generative adversarial network
Citation: Abirami R. N and Vincent P. M. DR (2021) Low-Light Image Enhancement Based on Generative Adversarial Network. Front. Genet. 12:799777. doi: 10.3389/fgene.2021.799777
Received: 22 October 2021; Accepted: 08 November 2021;
Published: 29 November 2021.
Edited by:
Leyi Wei, Shandong University, ChinaReviewed by:
Balachandran Manavalan, Ajou University School of Medicine, South KoreaHao Lin, University of Electronic Science and Technology of China, China
Copyright © 2021 Abirami R. and Vincent P. M.. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Durai Raj Vincent P. M., cG12aW5jZW50QHZpdC5hYy5pbg==