
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
BRIEF RESEARCH REPORT article
Front. Genet. , 06 July 2021
Sec. RNA
Volume 12 - 2021 | https://doi.org/10.3389/fgene.2021.699141
 Ewan P. Plant*
Ewan P. Plant* Zhiping Ye
Zhiping YeA new codon-pair bias present in the genomes of different types of influenza virus is described. Codons with fewer network interactions are more frequency paired together than other codon-pairs in influenza A, B, and C genomes. A shared feature among three different influenza types suggests an evolutionary bias. Codon-pair preference can affect both speed of protein translation and RNA structure. This newly identified bias may provide insight into drivers of virus evolution.
The limited size of viral genomes places constraints on the evolution that can occur without accruing deleterious mutations (Holmes, 2003). Open reading frames (ORFs) are the major component of viral genomes. Our understanding of the composition of viral ORFs informs our understanding of the virus itself. A message RNA (mRNA) is transcribed from the viral genome and the host cell ribosomes then translate mRNAs into proteins. The proteins that form the virus particles, the enzymes that replicate the viral genomes, and the proteins that counter the host cell response to the intruder are all projected by the triplet codons that lie between the initiation AUG and the termination codon of the ORFs. Different genomic sequences can encode the same proteins, yet preferences exist for codons.
Redundancy in the genetic code means that different codons can fulfill the same function. However, there are biases in synonymous codon use that appear to be related to the GC content of the genome and the availability of host cell tRNAs to decode the message (Chevance et al., 2014; Kustin and Stern, 2021). Recent work by Grosjean and Westhof (2016) has mapped the network interactions linked to codon usage (Figure 1). The GC rich codons encode the earliest prebiotic amino acids while the more diverse amino acids associated with metabolic and modifying enzymes use the AU rich codons. While the codon grouping is based primarily on the GC or AU content at the first two codon positions, the grouping isn’t based on GC content alone. For example, the GGU (Gly) codon with “strong” network interactions has the same nucleotide content as the GUG (Val) and UGG (Trp) codons with “intermediate” network interactions (Figure 1). This interpretation of the genetic code has not previously been used to contribute to our understanding of influenza genomes.
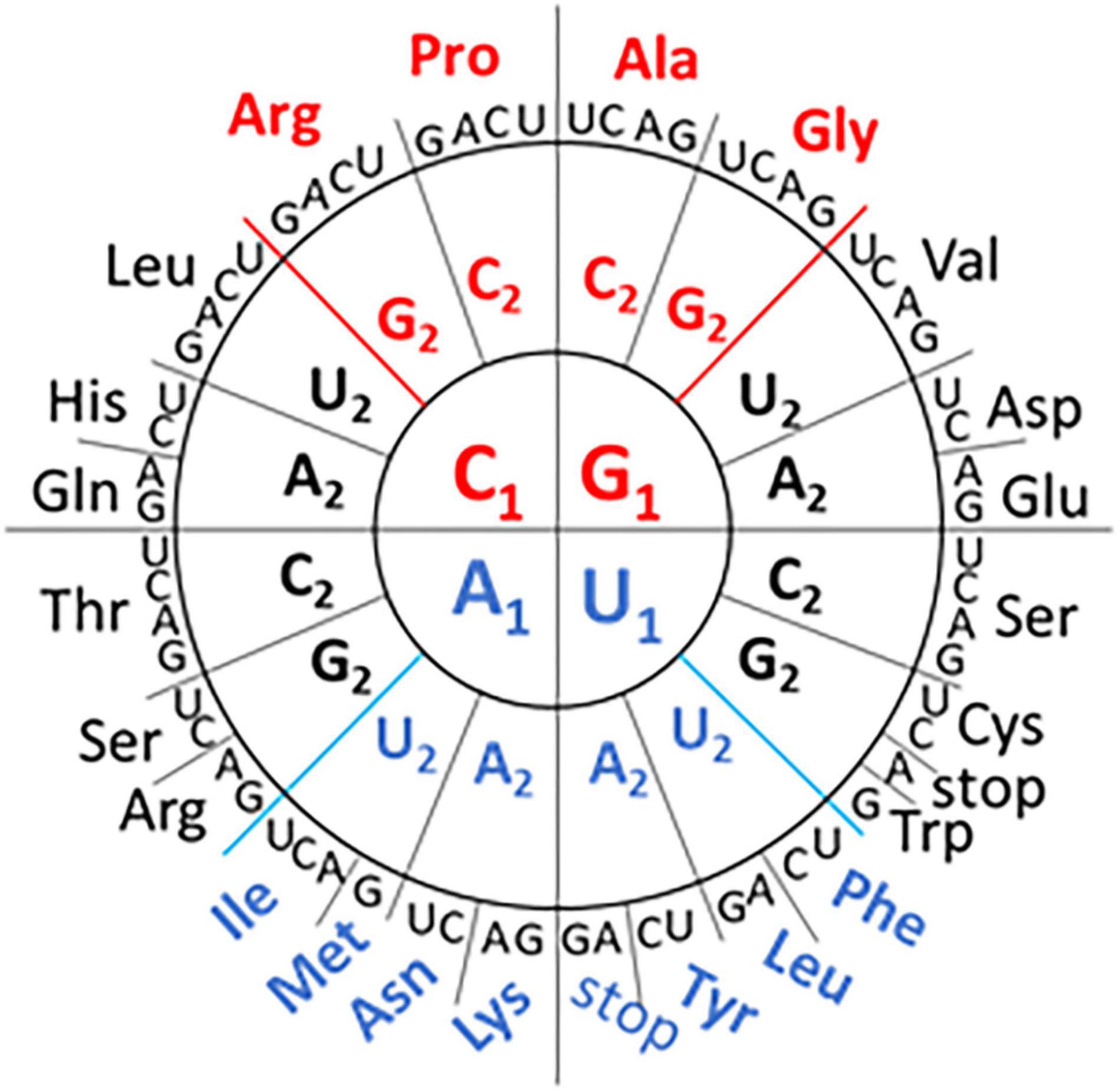
Figure 1. Codon Wheel adapted from Grosjean and Westhof (2016). The first nucleotide (N1) of the codon is displayed in the inner circle, the second nucleotide (N2) in the middle circle, and the third nucleotide (N3) in the outer circle with the encoded amino acid three letter code. GC-rich codons (in the first two positions) with “strong” network interactions are shown in red font and the AU-rich codons with “weak” network interactions are shown in blue font. The remaining codons are classified as having “intermediate” network interactions.
Influenza viruses are segmented negative-strand RNA viruses that replicate in the host cell nucleus [reviewed in Dou et al. (2018)]. There are no DNA intermediates. A virus-encoded RNA-dependent RNA polymerase (RdRP) is associated with the end of each viral RNA (Murti et al., 1988). The influenza replicative machinery may recruit different co-factors to accomplish the production of different products (cRNA, gRNA, and mRNA) (Moncorge et al., 2010; Krischuns et al., 2021). The process of genomic replication is error prone (Cheung et al., 2014; Pauly et al., 2017). The low fidelity of RdRPs results in a high mutational burden in RNA viral genomes (Fitzsimmons et al., 2018). The composition of this population must be conserved enough to propagate the species but also diverse enough to include variants that can survive a range of selective pressures.
A virus must survive a range of selective pressures during its lifecycle: environmental conditions prior to encountering a new host, host immune responses, and competition for resources. Some selective pressures, such as those involving antigenic interactions, occur at the protein level (Wong et al., 2010). Others, such as the stability of genomic folding, are influenced by nucleic acid sequence (Atkinson et al., 2014; Phakaratsakul et al., 2018). Because viral genomes are mostly comprised of ORFs the robustness of the genome will depend on codon usage and the prevalence of codon-pairs plays a role in this. Deoptimizing codon or codon-pair usage has been used as a strategy to create attenuated viral vaccine strains (Le Nouen et al., 2019). Here we use various analyses of influenza genomes to reveal a trend in nucleotide content over time and a bias in codon-pair preference among influenza genomes. An awareness of this bias may help our understanding of virus evolution and inform the creation of codon deoptimized viral genomes.
Influenza sequence data was obtained from different sources. Sequence source information for individual virus genomes is provided in Table 1. The relative synonymous codon usage (RSCU) and nucleotide composition was calculated for each genome using CAIcal (Puigbo et al., 2008). Results were exported to Microsoft Excel files to generate graphs.
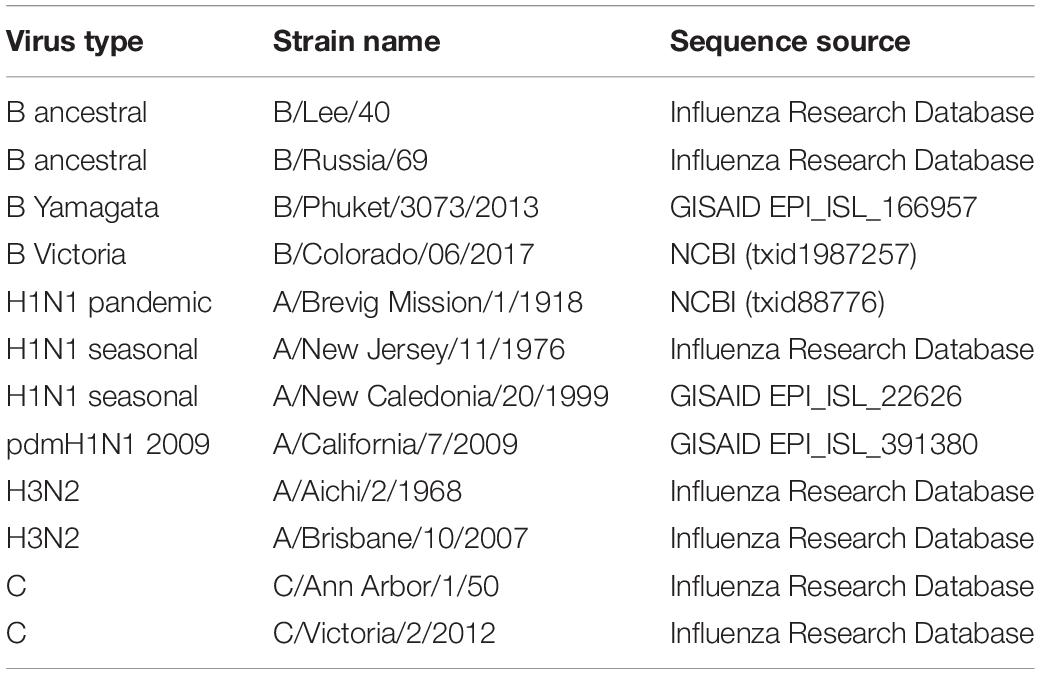
Table 1. Influenza strain name and source location for sequences used for nucleotide and dinucleotide composition and RSCU analyses.
Codon usage tables (including codon-pair frequencies) were obtained from the High-performance Integrated Virtual Environment tables (Athey et al., 2017) for influenza A virus (NCBI:txid11320), influenza B virus (NCBI:txid11520), influenza C virus (NCBI:txid11552), three mammalian genomes (Homo sapiens, Sus scrofa, and Gyotis) and one avian genome (Gallus gallus). The codon-pairs present in each of the genomes were tabulated and the frequency calculated. Codon-pairs that were more frequent (greater than three standard deviations above the mean) or absent from the influenza genomes were identified. Each codon was characterized by type (“weak,” “strong,” or “intermediate”) based on network interactions shown in Figure 1 and the 4,096 possible codon- pairs were grouped as follows: weak:weak, 196 pairs; weak:intermediate, 868 pairs; intermediate:intermediate, 961 pairs; weak:strong, 448 pairs; strong:intermediate, 992 pairs; and strong:strong, 256 pairs. The 340 codon-pairs that included a termination codon were excluded from the analysis. The frequency of absent and overrepresented codon-pairs within the group was calculated.
Genome composition changes over time and evolutionary trends have been reported for different influenza viruses (Wong et al., 2010; Smith et al., 2018; Gu et al., 2019). We expand on our previous comparison of the nucleotide variant composition of two influenza B viruses (Plant et al., 2020a,b) and include influenza A and C viruses. The dinucleotide composition of three reference influenza genomes are compared with that of three mammalian genomes and one avian genome (Supplementary Figure 1). The dinucleotide composition of the three influenza genomes more closely resembled each other than the mammalian and avian genomes. The trend for higher AU content has previously been described for influenza and other RNA virus genomes (Kustin and Stern, 2021). Because the influenza genomes contain similar nucleotide composition and are subjected to similar evolutionary pressures, we next looked for genomic changes over time.
Here we compare the changes in influenza A, B, and C genomes (Table 1) isolated at different times over the last century. Influenza A H1N1 viruses have been isolated from humans infected from 1918 on (Taubenberger et al., 1997). Some influenza A lineages have arisen from zoonoses and circulated for several decades before being displaced by new lineages (Saunders-Hastings and Krewski, 2016). Influenza B viruses have been isolated from humans since the 1940s. In the 1970s the influenza B viruses split into two antigenically distinct lineages which have continued to co-circulate (Rota et al., 1990). Around the same time the influenza B lineage split occurred the influenza A H3N2 viruses emerged in the human population and have circulated since (Both et al., 1983). Influenza C viruses cause less disease than influenza A and B viruses, but sequence information is available from strains from the 1950s onward (Buonagurio et al., 1986). Representative influenza A, B, and C genomes isolated at different times over the last century were selected for further analysis (Table 1).
The nucleotide composition at the first, second, and third codon position of temporally distinct influenza B viruses was calculated (Figure 2B). A decrease in the percentage of C1 and U3 usage and increases in U1 and C3 usage are observed. Similar trends are seen when the same analysis performed for influenza A/H3N2 viruses and the seasonal A/H1N1 viruses A/New Jersey/11/1976 and A/New Caledonia/20/1999 (Figure 2A). The trend is not observed for the pandemic viruses A/Brevig Mission/1/1918 and A/California/7/2009 are included with the seasonal viruses but is apparent when the pandemic viruses are analyzed separately (Supplementary Figure 2). These viruses differ from the subsequent and preceding H1 viruses, respectively, because they are both zoonotic viruses with genomes adapted to the prior host species. The trend at the first codon position is also observed in the influenza C viruses (Supplementary Figure 2). The pressures driving adaptation to a new host species may differ from those that drive change in viruses (like influenza B and C) that have a sustained presence in one host species (Bhatt et al., 2013).
Figure 2. Codon nucleotide composition for influenza A (A) and influenza B (B) viruses. The frequency of each of the four nucleotides at each of the three codon positions is shown.
The similar trends in influenza A, B, and C genome composition prompted further comparison of the influenza genomes as a group. We looked to see if the trends in pyrimidine usage at the third codon position were reflected in changes to the relative synonymous codon usage (RSCU). A pyrimidine transition in the third codon position does not change the amino acid sequence (Figure 1). However, we did not observe any consistent trends in RSCU between influenza types (Supplementary Figure 3). This suggests that selective pressures that led to altered pyrimidine content at the third position are not constrained by host tRNA abundance. A similar conclusion was reached by other researchers in the analysis of bias in a wider selection of RNA viruses (Kustin and Stern, 2021). We next looked at codon-pair content in the three influenza genomes.
A comparison of codon-pair frequency among influenza A, B, and C genomes reveals a pattern in the codon-pairs that are more frequent or absent. The codon-pairs were grouped according to the strength of the network interaction (Figure 1). The majority of over-represented pairs present in all three influenza genomes are those with both codons having weak network interactions (Figure 3A). Conversely, the majority of codon-pairs missing in all three influenza types (excluding codon-pairs with termination codons) are those with strong network interactions for both codons. Thirteen percent (26 of the 196 possible) weak:weak codon-pairs are present in the influenza genomes at a frequency greater than three standard deviations above the mean (Figure 3A). Twenty-six percent (67 of the 256 possible) strong:strong codon-pairs are absent from the influenza genomes. These results indicate that codon-pairs with weak network interactions are preferable in influenza genomes.
Figure 3. Frequency of influenza codon-pairs grouped by type. Codon-pairs from influenza A, B, and C genomes were grouped by network interaction strength [weak (W), intermediate (I), strong (S); see Figure 1]. The frequency of the codon-pairs that were absent or over-represented (>3 standard deviations above the mean frequency of all codon-pairs) was calculated for each group (A). The expected frequency of the codon-pairs was calculated from the codon usage for influenza A, B, and C viruses (B).
The evolutionary robustness of a genome enables a virus to persist and avoid extinction. There are different characteristics of robust genomes and analogies may be made between different organisms (Mestek Boukhibar and Barkoulas, 2016). Here we describe a codon-pair bias common among three types of influenza virus and postulate that it facilitates virus survival. The dinucleotide content is similar among the three viral genomes (Supplementary Figure 1). For the viruses that have persisted in humans for longer periods of time (not recent zoonoses) there is also a trend in mononucleotide content in the third codon position (Figure 2). However, the trend for pyrimidine choice at this position does not translate into an obvious trend in the relative synonymous codon usage among the three influenza virus types. This suggests that the N3-N1 dinucleotide that borders the codon-pair has a role in influenza genome evolution as described by others (Gu et al., 2019). While investigating this trend we uncovered a bias in codon-pairs related to the strength of network interactions.
The better adapted a virus is to its host environment the better it will be able to compete with other viruses. Humans are the common host species for influenza A, B, and C viruses and other respiratory viruses. Competition among these viruses for the same resources will result in selection of viruses that replicate more efficiently. These selective pressures could affect both RNA transcription and protein production. At a molecular level we suggest that genomes dominated by codons with weak network interactions may have an advantage and that selection for these types of genomes may be observed in different viruses competing in the same host environment. It has been proposed that A-rich RNA genomes promote less secondary structure which would provide fewer targets for the eukaryotic immune system (Kustin and Stern, 2021). The same A-rich genome would also lead to fewer interactions between the mRNA and tRNA (Grosjean and Westhof, 2016). One study suggests that codon bias in influenza genomes may be associated with tRNA content during infection (Smith et al., 2018). But analysis of RSCU indicated that the speed of translation was not a likely cause of mutational bias in viral genomes (Kustin and Stern, 2021). These observations align with codon-pair bias we describe in this study.
A balance between replication speed and polymerase fidelity is required to maintain a viable genome (Fitzsimmons et al., 2018). The speed of transcription is dependent on the template and available substrates (Coggins et al., 2020). RNA structure has been implicated in reducing transcription speed (Zamft et al., 2012). It has been suggested that, because other nucleotides have more pairing options, A-rich viral genomes have less structure (Kustin and Stern, 2021). Additionally, it has been proposed that the pairing of codons fine tunes mRNA structure (Moura et al., 2007). The implication from these studies is that efficient replication of an RNA virus is better served by a genome with minimal structural requirements and our work links that to codon-pair preferences.
There are multiple pressures that affect virus genome composition and it is difficult to tease them apart. Influenza strains that have jumped from one host species to another are reported to evolve faster than strains that have circulated in the same host species during the same timeframe (Bhatt et al., 2013). In this work we have focused on the strains that have circulated in humans for extended periods of time and the results suggest that competition is affecting the rate of evolution. The H1N1 viruses re-entered the human population in 1976 and temporal changes in CG dinucleotides content reported since 1977 were not observed in the first half of the twentieth century (Gu et al., 2019). Because H1N1 viruses previously circulated in humans without change in CG content we suggest that the change in dinucleotide content reported by Gu et al., was due to a new selective pressure, such as competition from H3N2 strains. We hypothesize that the mononucleotide change and codon-pair preference described in herein derive from different selective pressures as the trend and bias was also observed in H3N2, influenza B and influenza C viruses during different time frames.
There is evidence demonstrating that some trends in virus nucleotide content are related to host cell responses. Low CG dinucleotide content has been reported in a wide range of viral genomes (Kunec and Osterrieder, 2016). Increasing the CG dinucleotide content in HIV genomes makes them more susceptible to RNA degradation by the ZAP enzyme (Takata et al., 2017). Suppression of genomic CpG content, including at the C3-G1 dinucleotide that borders codon-pairs, disproportionately reduces the number of codons with “strong” network interactions. However, when we calculate the expected frequency of codon-pairs, grouped by network interaction strength (Figure 3B), we still observe a bias in the frequency of over-represented weak:weak pairings and an absence of strong:strong codon-pairs (Figure 3A).
There are limitations to this study. Viral genomes are tightly packed with information including overlapping ORFs, replication and packaging signals (Li et al., 2021). These place constraints on different parts of the genome and, because of this, any analysis of the genome as a whole must be considered in this context. In our analyses we use only the coding regions of the genomes. The 5′ and 3′ non-coding portions of each segment of the genome are highly conserved where the RdRP interacts with these regions (Murti et al., 1988; Krischuns et al., 2021). Some regions of the segment contain packaging signals or are more densely associated with nucleoprotein (Li et al., 2021) and we did not analyze these separately. Future studies examining the relationship between codon-pair bias and specific coding regions will require the comparison of larger numbers of viruses. The changes in mononucleotide composition reported here are from just two temporally distinct strains (for influenza B, C, and influenza A/H1N1, and A/H3N2 strains). A more expansive analysis of strains spanning the timeframe for each influenza type is needed to improve the robustness of this analysis. Our analysis was limited to influenza virus genomes. More work is needed to determine if a bias related to network interactions is present in positive-strand RNA viruses, DNA viruses, or genomes of cellular organisms.
Here we have described a bias in codon-pairs in three types of influenza. A codon-pair bias identified by Kunec and Osterrieder (Kunec and Osterrieder, 2016) negatively correlated with GC content in RNA viruses but not DNA viruses. Codon grouping using network interactions has a relationship with GC content at the first two nucleotide positions but also groups codons with the same GC content separately (Figure 1). This feature might be useful in furthering our understanding of how different genomes evolve.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
EP analyzed the data and drafted the manuscript. ZY provided supervision. Both authors contributed to the article and approved the submitted version.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
This article is dedicated to the memory of Prof. Russell T. M. Poulter whose joy of genetics was infectious.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2021.699141/full#supplementary-material
Athey, J., Alexaki, A., Osipova, E., Rostovtsev, A., Santana-Quintero, L. V., Katneni, U., et al. (2017). A new and updated resource for codon usage tables. Bmc Bioinformatics 18:391. doi: 10.1186/s12859-017-1793-7
Atkinson, N. J., Witteveldt, J., Evans, D. J., and Simmonds, P. (2014). The influence of CpG and UpA dinucleotide frequencies on RNA virus replication and characterization of the innate cellular pathways underlying virus attenuation and enhanced replication. Nucleic Acids Res. 42, 4527–4545. doi: 10.1093/nar/gku075
Bhatt, S., Lam, T. T., Lycett, S. J., Leigh Brown, A. J., Bowden, T. A., Holmes, E. C., et al. (2013). The evolutionary dynamics of influenza A virus adaptation to mammalian hosts. Philos. Trans. R. Soc. Lond. B Biol. Sci. 368:20120382. doi: 10.1098/rstb.2012.0382
Both, G. W., Sleigh, M. J., Cox, N. J., and Kendal, A. P. (1983). Antigenic drift in influenza virus H3 hemagglutinin from 1968 to 1980: multiple evolutionary pathways and sequential amino acid changes at key antigenic sites. J. Virol. 48, 52–60. doi: 10.1128/jvi.48.1.52-60.1983
Buonagurio, D. A., Nakada, S., Fitch, W. M., and Palese, P. (1986). Epidemiology of influenza C virus in man: multiple evolutionary lineages and low rate of change. Virology 153, 12–21. doi: 10.1016/0042-6822(86)90003-6
Cheung, P. P., Watson, S. J., Choy, K. T., Fun Sia, S., Wong, D. D., Poon, L. L., et al. (2014). Generation and characterization of influenza A viruses with altered polymerase fidelity. Nat. Commun. 5:4794. doi: 10.1038/ncomms5794
Chevance, F. F., Le Guyon, S., and Hughes, K. T. (2014). The effects of codon context on in vivo translation speed. PLoS Genet. 10:e1004392. doi: 10.1371/journal.pgen.1004392
Coggins, S. A., Mahboubi, B., Schinazi, R. F., and Kim, B. (2020). Mechanistic cross-talk between DNA/RNA polymerase enzyme kinetics and nucleotide substrate availability in cells: implications for polymerase inhibitor discovery. J. Biol. Chem. 295, 13432–13443. doi: 10.1074/jbc.REV120.013746
Dou, D., Revol, R., Ostbye, H., Wang, H., and Daniels, R. (2018). Influenza A Virus Cell Entry, Replication, Virion Assembly and Movement. Front. Immunol. 9:1581. doi: 10.3389/fimmu.2018.01581
Fitzsimmons, W. J., Woods, R. J., McCrone, J. T., Woodman, A., Arnold, J. J., Yennawar, M., et al. (2018). A speed-fidelity trade-off determines the mutation rate and virulence of an RNA virus. PLoS Biol. 16:e2006459. doi: 10.1371/journal.pbio.2006459
Grosjean, H., and Westhof, E. (2016). An integrated, structure- and energy-based view of the genetic code. Nucleic Acids Res. 44, 8020–8040. doi: 10.1093/nar/gkw608
Gu, H., Fan, R. L. Y., Wang, D., and Poon, L. L. M. (2019). Dinucleotide evolutionary dynamics in influenza A virus. Virus Evol. 5:vez038. doi: 10.1093/ve/vez038
Holmes, E. C. (2003). Error thresholds and the constraints to RNA virus evolution. Trends Microbiol. 11, 543–546. doi: 10.1016/j.tim.2003.10.006
Krischuns, T., Lukarska, M., Naffakh, N., and Cusack, S. (2021). Influenza Virus RNA-Dependent RNA Polymerase and the Host Transcriptional Apparatus. Annu. Rev. Biochem. doi: 10.1146/annurev-biochem-072820-100645 [Epub ahead of print].
Kunec, D., and Osterrieder, N. (2016). Codon Pair Bias Is a Direct Consequence of Dinucleotide Bias. Cell Rep. 14, 55–67. doi: 10.1016/j.celrep.2015.12.011
Kustin, T., and Stern, A. (2021). Biased Mutation and Selection in RNA Viruses. Mol. Biol. Evol. 38, 575–588. doi: 10.1093/molbev/msaa247
Le Nouen, C., Collins, P. L., and Buchholz, U. J. (2019). Attenuation of Human Respiratory Viruses by Synonymous Genome Recoding. Front. Immunol. 10:1250. doi: 10.3389/fimmu.2019.01250
Li, X., Gu, M., Zheng, Q., Gao, R., and Liu, X. (2021). Packaging signal of influenza A virus. Virol. J. 18:36. doi: 10.1186/s12985-021-01504-4
Mestek Boukhibar, L., and Barkoulas, M. (2016). The developmental genetics of biological robustness. Ann. Bot. 117, 699–707. doi: 10.1093/aob/mcv128
Moncorge, O., Mura, M., and Barclay, W. S. (2010). Evidence for avian and human host cell factors that affect the activity of influenza virus polymerase. J. Virol. 84, 9978–9986. doi: 10.1128/JVI.01134-10
Moura, G., Pinheiro, M., Arrais, J., Gomes, A. C., Carreto, L., Freitas, A., et al. (2007). Large scale comparative codon-pair context analysis unveils general rules that fine-tune evolution of mRNA primary structure. PLoS One 2:e847. doi: 10.1371/journal.pone.0000847
Murti, K. G., Webster, R. G., and Jones, I. M. (1988). Localization of RNA polymerases on influenza viral ribonucleoproteins by immunogold labeling. Virology 164, 562–566. doi: 10.1016/0042-6822(88)90574-0
Pauly, M. D., Procario, M. C., and Lauring, A. S. (2017). A novel twelve class fluctuation test reveals higher than expected mutation rates for influenza A viruses. Elife 6:e26437. doi: 10.7554/eLife.26437.020
Phakaratsakul, S., Sirihongthong, T., Boonarkart, C., Suptawiwat, O., and Auewarakul, P. (2018). Genome polarity of RNA viruses reflects the different evolutionary pressures shaping codon usage. Arch. Virol. 163, 2883–2888. doi: 10.1007/s00705-018-3930-7
Plant, E. P., Manukyan, H., Laassri, M., and Ye, Z. (2020a). Insights from the comparison of genomic variants from two influenza B viruses grown in the presence of human antibodies in cell culture. PLoS One 15:e0239015. doi: 10.1371/journal.pone.0239015
Plant, E. P., Manukyan, H., Sanchez, J. L., Laassri, M., and Ye, Z. (2020b). Immune Pressure on Polymorphous Influenza B Populations Results in Diverse Hemagglutinin Escape Mutants and Lineage Switching. Vaccines 8:125. doi: 10.3390/vaccines8010125
Puigbo, P., Bravo, I. G., and Garcia-Vallve, S. (2008). CAIcal: a combined set of tools to assess codon usage adaptation. Biol. Direct 3:38. doi: 10.1186/1745-6150-3-38
Rota, P. A., Wallis, T. R., Harmon, M. W., Rota, J. S., Kendal, A. P., and Nerome, K. (1990). Cocirculation of two distinct evolutionary lineages of influenza type B virus since 1983. Virology 175, 59–68. doi: 10.1016/0042-6822(90)90186-U
Saunders-Hastings, P. R., and Krewski, D. (2016). Reviewing the History of Pandemic Influenza: understanding Patterns of Emergence and Transmission. Pathogens 5:66. doi: 10.3390/pathogens5040066
Smith, B. L., Chen, G., Wilke, C. O., and Krug, R. M. (2018). Avian Influenza Virus PB1 Gene in H3N2 Viruses Evolved in Humans To Reduce Interferon Inhibition by Skewing Codon Usage toward Interferon-Altered tRNA Pools. mBio 9, e01222–18. doi: 10.1128/mBio.01222-18
Takata, M. A., Goncalves-Carneiro, D., Zang, T. M., Soll, S. J., York, A., Blanco-Melo, D., et al. (2017). CG dinucleotide suppression enables antiviral defence targeting non-self RNA. Nature 550, 124–127. doi: 10.1038/nature24039
Taubenberger, J. K., Reid, A. H., Krafft, A. E., Bijwaard, K. E., and Fanning, T. G. (1997). Initial genetic characterization of the 1918 “Spanish” influenza virus. Science 275, 1793–1796. doi: 10.1126/science.275.5307.1793
Wong, E. H., Smith, D. K., Rabadan, R., Peiris, M., and Poon, L. L. (2010). Codon usage bias and the evolution of influenza A viruses. Codon Usage Biases of Influenza Virus. BMC Evol. Biol. 10:253. doi: 10.1186/1471-2148-10-253
Keywords: influenza, codon deoptimization, attenuation, selective pressure, codon-pair, evolutionary bias
Citation: Plant EP and Ye Z (2021) A Codon-Pair Bias Associated With Network Interactions in Influenza A, B, and C Genomes. Front. Genet. 12:699141. doi: 10.3389/fgene.2021.699141
Received: 22 April 2021; Accepted: 16 June 2021;
Published: 06 July 2021.
Edited by:
Dominique Belin, Université de Genève, SwitzerlandReviewed by:
Dominique Garcin, University of Geneva, SwitzerlandCopyright © 2021 Plant and Ye. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ewan P. Plant, ZXdhbi5wbGFudEBmZGEuaGhzLmdvdg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.