 Ting Xu
Ting Xu Guo-An Qi
Guo-An Qi Jun Zhu
Jun Zhu Hai-Ming Xu
Hai-Ming Xu Guo-Bo Chen
Guo-Bo Chen
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet. , 05 March 2021
Sec. Statistical Genetics and Methodology
Volume 12 - 2021 | https://doi.org/10.3389/fgene.2021.612045
This article is part of the Research Topic Statistical Methods, Computing, and Resources for Genome-Wide Association Studies View all 13 articles
The estimation of heritability has been an important question in statistical genetics. Due to the clear mathematical properties, the modified Haseman–Elston regression has been found a bridge that connects and develops various parallel heritability estimation methods. With the increasing sample size, estimating heritability for biobank-scale data poses a challenge for statistical computation, in particular that the calculation of the genetic relationship matrix is a huge challenge in statistical computation. Using the Haseman–Elston framework, in this study we explicitly analyzed the mathematical structure of the key term tr(KTK), the trace of high-order term of the genetic relationship matrix, a component involved in the estimation procedure. In this study, we proposed two estimators, which can estimate tr(KTK) with greatly reduced sampling variance compared to the existing method under the same computational complexity. We applied this method to 81 traits in UK Biobank data and compared the chromosome-wise partition heritability with the whole-genome heritability, also as an approach for testing polygenicity.
Given the increasing sample size and sequencing capability, high-throughput genetic data is presented as the standard input that challenges statistical computation. For example, in the estimation of heritability for complex traits using all markers concurrently, both (i) constructing the genetic relationship matrix [GRM, denoted as K and the mathematical expression can be seen in section Materials and Methods, with its computational cost (MN2)] and (ii) the estimation of heritability using linear mixed model [(N3)] are computationally expensive (Yang et al., 2010). In order to alleviate computational burden, various solutions have been proposed. Modified Haseman–Elston regression (HE) can be used to estimate heritability with reduced computational cost in the estimation step [(N2)], but the construction of GRM is still needed (Chen, 2014). Using summary statistics, such as those estimated from the genome-wide association study (GWAS), rather than individual-level data, can provide a theoretical equivalence estimate of the heritability under the assumption that the source of summary statistics and the linkage disequilibrium (LD) reference are homogeneous (Bulik-Sullivan et al., 2015), if not always the case.
Even under the HE framework, given the availability of biobank-scale data, such as UK Biobank (UKB) data (Bycroft et al., 2018), the computational cost for GRM poses a challenge for heritability estimation mentioned procedure above. In order to reduce the computational cost of GRM, recently a randomized estimation of heritability has been introduced by Wu and Sankararaman (2018), called randomized Haseman–Elston regression (RHE), a promising method that can be used for both single-trait and bi-trait analyses (Sankararaman, 2019). This method is built on a hybrid framework which can be applied to biobank-scale data, and a key innovation involved is a quick evaluation for tr(KTK), the trace of the multiplication of GRM with its transpose. Direct computation of tr(KTK) can be time-consuming, at the time cost of (N2M), but in RHE the numerical evaluation of tr(KTK) can be realized via a randomization method expressed in quadric form. However, we found that the sampling variance of RHE in the original report is incorrect because of their wrong derivation (refer to Appendix A3 in Wu and Sankararaman's original report). In this study, we further investigate the statistical property of RHE, in particular the term about tr(KTK), and its relevant extensions.
This report was written for three purposes. First, we found that the provided randomization estimate for tr(KTK) is correct but with its sampling variance, which is proportional to tr(KTKKTK), not properly treated in Wu and Sankararaman's original report. We derived and numerically validated the sampling variance of tr(KTK). Second, recently a hybrid routine that can use either individual-level data and summary statistics has also been found (Zhou, 2017; Wu and Sankararaman, 2018), in which subsampling technique is used to evaluate tr(KTK); however, its sampling variance was not available. We provided a similar method as subsampling but with availability of its analytical sampling variance. Third, we partitioned the heritability based on the effective number of markers and applied them in the partitioning of heritability for some complex traits in UKB.
For a homogenous unrelated sample, its genotypic matrix can be written as X, a matrix of N rows—individuals, and M columns—coding the count of the reference allele for a biallelic locus. After standardization for each genotype , in which 2pl is the allele frequency and the square root of the variance, we can define GRM as . Given K, we can easily derive some characters of K. Denote Ko as the off-diagonal elements, and it is easy to see that , because the summation of the diagonal is N − 1. var (Ko) is the sampling variance of the all off-diagonal elements.
Of note, var (Ko) relates to the concept, so-called effective number of markers, denoted as Me thereafter. As noticed, Me is defined as the reciprocal of var (Ko). , in which 𝔼 (ρl1l2) is the expected Pearson's correlation between the and loci. Alternatively, . It is known that for a population, the averaged linkage disequilibrium across the genome is nearly a constant given the markers; in other words, Me is a constant genetic parameter. The definition of Me in this report allows researchers to calculate Me based on a reference population of the same origin to the population in question. Similarly, Me.c represents the averaged LD for any pair of markers on the cth chromosomes.
As the causal variants are hardly observed directly, their relationship with markers are surrogated by relationship between markers, as reflected in Me. As Me is a critical parameter in many genetic applications, a conceptional parameter is its involvement in genetic prediction (Dudbridge and Wray, 2013), or power calculation for the estimation of heritability (Visscher et al., 2014). In the estimation for variance components, as shown below, Me is a key parameter.
Haseman–Elston regression (HE) has been initially proposed for the linkage analysis (Haseman and Elston, 1972). With its original kernel relatedness between sib pairs via linkage replaced by linkage disequilibrium for unrelated samples, the modified HE can be used for the estimation of heritability (Chen, 2014). Due to its clear mathematical property, HE has been found a bridge to connect and develop various parallel methods for the estimation of heritability, such as LD score regression that estimates heritability and uses summary statistics from GWAS (Bulik-Sullivan et al., 2015; Zhou, 2017).
However, LD score regression is based on various assumptions that may or may not be met in practice. LD score regression uses SNPs in a sliding window instead of all genome-wide SNPs to calculate LD scores, which will lose efficiency if heterogeneity exists between the reference population and the population that generates the GWAS summary statistics. If we directly use individual-level data, the time cost will be unaffordable, such as for the restricted maximum likelihood estimation method (REML); in contrast, a method of moment (MoM) can provide equivalent estimation for the heritability for complex traits.
We assume that
in which y is the standardized phenotype for a trait of interest, is the standardized genotypic matrix of N individuals and M the biallelic markers, β is the additive effect associated with each marker, e is the residual, h2 is the SNP heritability, and is the residual variance. It is easy to know that .
Consequently, we extend the work by Wu and Sankararaman (2018); the moment estimator is to minimize
By taking the differentiation in terms of h2 and , we have
After algebra, we have the normal equations below:
The estimator for ĥ2 can be written as
However, different computational strategies deal with the computational expensive part for both the numerator and the denominator. In particular, for the numerator, yTKy can be decomposed as , and , equal to . Each element of is just the regression coefficient between the jth marker and y that can be computed via simple linear regression, or multivariate linear regression if covariates are included. It is easy to recognize that follows after scaling by the sample size N, and a possible non-central parameter related to the heritability of the trait. Alternatively, we derive the mathematical expectation , in which is the averaged LD score between a marker to a causal variants in LD.
The denominator involves the trace of KTK, a high-order function for GRM. Alternatively, according to the property of the trace of a matrix, it can be calculated that , a summation of the square of each element in K. From the first glance, it seems inevitable to compute K, the computational cost of which is , a substantial cost given a large sample size, such as for UKB of about 500,000 samples (Bycroft et al., 2018). In order to have a proper estimate for tr(KTK) but reduce computation cost, three methods are proposed for estimating tr(KTK).
We present three methods in estimating tr(KTK). Sampling method I has been proposed by Wu and Sankararaman, but we provide its correct sampling variance, which was incorrectly given in their original report (Wu and Sankararaman, 2018). Sampling method II derives the expectation of tr(KTK) and estimates it in a reference population with the similar genetic origin of the population of question. Sampling method III slightly modifies method II if the reference population is big and yields smaller sampling variance of tr(KTK) than that of method II.
Using randomized estimation, an unbiased estimator LB is employed to estimate tr(KTK) in RHE (Wu and Sankararaman, 2018). The rational for a randomized estimate is as below:
In each iteration, a vector z, of length N, is generated from the standard normal distribution. As long as z has been generated B time and B is large enough, it is guaranteed to approach tr(KTK). As can be calculated easily, the computational cost is . Then, LB can be plugged into a normal equation (Equation 2).
In Wu and Sankararaman's original report, the sampling variance of LB was given as , which was incorrect, and the correct one should have been
The derivation of the penultimate step uses the quadratic variance calculation formula. The sampling variance of LB is proportional to tr(KTKKTK), the computational cost of which is likely to be infeasible for biobank-scale data. However, its practical sampling variance can be estimated from B iterations above .
In an alternative route, we bypass the direct computation of tr(KTK). It is shown that for unrelated samples (see Supplementary Notes). N is the sample size, a known parameter; we only need to estimate Me. As noted above, Me can be estimated by subsampling a proportion of the study population (Figure 1) or by a reference population of the same origin with the population of study (Zhou, 2017). Thus, we can estimate Me using a small proportion of the sample, as long as we can estimate ; we can easily get the estimator of tr(KTK). We define a new LS estimator: . It is an unbiased estimate (see Supplementary Notes). Suppose the sample size of subsample is s, there are s2/2 off-diagonal elements and it takes (s2M/2) time to calculate . The sampling variance of LS is, using the Delta method, , in which the first derivative of LS and the sampling variance for . is not directly known but can be directly estimated in the third method proposed below.
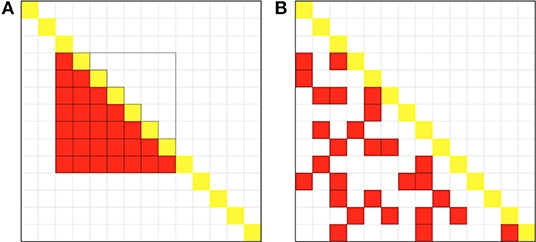
Figure 1. Schematic diagram of the sampling methods for the two estimators. The large square represents the entire genetic relationship matrix (GRM) with sample size N = 14, and each small an element in GRM, and the yellow the diagonal element of the matrix. (A) Schematic diagram of sampling methods for the LS estimator. The red squares in the lower triangular of GRM represent the pairs of samples for LS. This figure shows that when B = 2 (the parameter for the LB estimator given by Wu and Sankararaman, 2018), we set subsample size 7 for LS to guarantee the same computational cost. (B) Schematic diagram of sampling methods for the LT estimator. Equally total number (n = BN = 28) of GRM elements in the lower triangular in red represents the pair of the samples for LT. The elements are drawn as if they are randomly, as shot by a gun, to reduce correlation between individuals.
However, in method II is not analytical probably because each individual will be involved s times in the estimation of variance. With slightly modification, we developed a new estimator LT (lower triangle shotgun sampling estimator) to estimate tr(KTK) in RHE. The difference in sampling schemes between methods II and III can be visualized as Figure 1. Given the whole GRM, method II samples a square matrix of size s × s after rearrangement and calculates half elements, whereas method III randomly samples n = s2/2 elements in the whole GRM without replacement so as to reduce overlapping of samples (Figure 1). This sampling idea is similar to the shotgun method in the first-generation DNA sequencing technology, so we call the method III shotgun sampling estimator.
Given a random subset of n elements A ⊆ {1, 2, ⋯ , N(N − 1)/2}, we define
It can be proved that LT is an unbiased estimator of tr(KTK) with its sampling variance , which can be estimated by (see Supplementary Notes). Therefore, we can get the unbiased estimate of tr(KTK) and its sampling variance at the same time in one step. It does not need to calculate all the elements in Ko but the corresponding pairs of the individuals, and to calculate the mean of the product of all their genetic values. Therefore, each item in the summation can be computed in (M), and the total running time is (nM).
If we replace tr (KTK) with its subsampling estimators, we can get the synthesized estimator for heritability
where is the mean of for each SNP with or without the adjustment of covariates. Using the Delta method, we show in Supplementary Notes that the variance of ĥ2 can be formulated as
and each item in the above formula is estimable, then we can get the variance estimator of the variance component
Except for ĥ2, all other parts involved are independent to the phenotype, so given a specific sample of question, the estimator has a linear relationship with the square of the estimated heritability.
Yang et al. (2010) estimated the chromosome-wise partitioned heritability and found that the heritability of complex trait, such as human height is proportional to the length of the chromosome, that is, proportional to the number of causal variants. Some researchers gave more weight to large effects to explain heritability and to study polygenicity (O'Connor et al., 2019; Yang and Zhou, 2020). In this report, we instead calculated heritability based on and compared the chromosome-wise partition heritability with the whole-genome heritability
in which is the effective of markers for the cth chromosome and is the averaged squared correlation between a casual variant and a marker on the cth chromosome. Under the assumption of polygenicity, , and the ratio between . As both and are unknown, we use and as the surrogates for and .
By breaking the GRM of the whole genome K in Equation (1) into the GRMs for 22 autosomes, we can also estimate the chromosome heritability jointly in one model. This method has to inverse a 23 × 23 matrix. Under the assumption that the genotype of each chromosome contains the same N individuals, the inversed matrix is completely upon N and Me.c, so a computation cost linear to 23, without bothering the conventional matrix inversion procedure, a computation cost of 233, can be written down analytically. In particular, the cth diagonal element of the inverse matrix is , and the last column/row is . For more details, please see Supplementary Notes.
Given the definition of the weighted GRM
we can get an estimator of the weighted heritability as well as its variance estimator based on weighted GRM through a similar derivation
where is the estimation of Me for Kw, and is the square of the z-score for the lth SNP with or without the adjustment of covariates. The weighted chromosome-wise partition heritability can be expressed as
where is the estimation of weighted Me for the cth chromosome and Mc is the number of SNP of the cth chromosome.
The BOLT-LMM method (Loh et al., 2015) might be the most widely used method in the field of heritability estimation for large-scale data. Theoretically, the computational complexity of BOLT-LMM is , where P is the number of iterations for convergence. In the LT estimator, the subsample size n ≪ N1.5, so our calculation time is less than BOLT-LMM in theory. In terms of actual calculation, the LB estimator used less calculation time to get an accuracy similar to BOLT-LMM (Wu and Sankararaman, 2018); the variance of our estimators is about an order of magnitude smaller than LB under the same calculation time. Thus, our method is better than BOLT-LMM in calculation accuracy and time. In terms of memory, the memory complexity of BOLT-LMM is (NM/4), while the memory of our subsampling estimators is proportional to M and the subsample size s in the LS estimator, which generally does not exceed 10% of the total sample size.
Given the availability of the estimators and their sampling variances, it is able to evaluate the statistical power of the estimators and estimate the sample size for the given type I and type II error rates. Under the null hypothesis h2 = 0, the sampling variance for the additive variance component can be reduced to , which are equivalent to that of REML (Visscher et al., 2014). It is consequently known that the statistical power of the presented method will be equivalent to REML. In contrast, the original Haseman–Elston regression has doubled sampling variances where (Chen, 2014), because the original HE regression only uses the off/upper-diagonal of the matrix, as presented in the numerator above. The connection to LD score regression is obviously too; here, the whole Me can be seen as a genome LD score, rather than being partitioned into genomic bins.
In the simulation and in the real data, we compared the mean and variance of the three estimators LB, LS, and LT, and the results are as presented in Figure 2. We took n = BN and to make sure the three estimators are under the equal computational cost of (NMB) (see Figure 1 for an example). In the simulation, we set the genotype in two ways: (1) The minor allele frequency (MAF) of each SNP was randomly generated from a uniform distribution between 0.03 and 0.5, and two levels of LD (linkage disequilibrium, in terms of Lewontin's D′, the normalized LD parameter) strength were set as 0–0.2 (weak LD) and 0.6–0.8 (strong LD) with the SNP number M = 2,000, 5,000 and sample size N = 500, 1,000, and 2,000, respectively. (2) The real genotype data consisted of 12,980 adjacent markers on chromosome 22 of 2,000 randomly sampled unrelated white British individuals in UKB. B was set from 5 to 50 and repeated 100 times for each to assess the mean and variance of the three estimators.
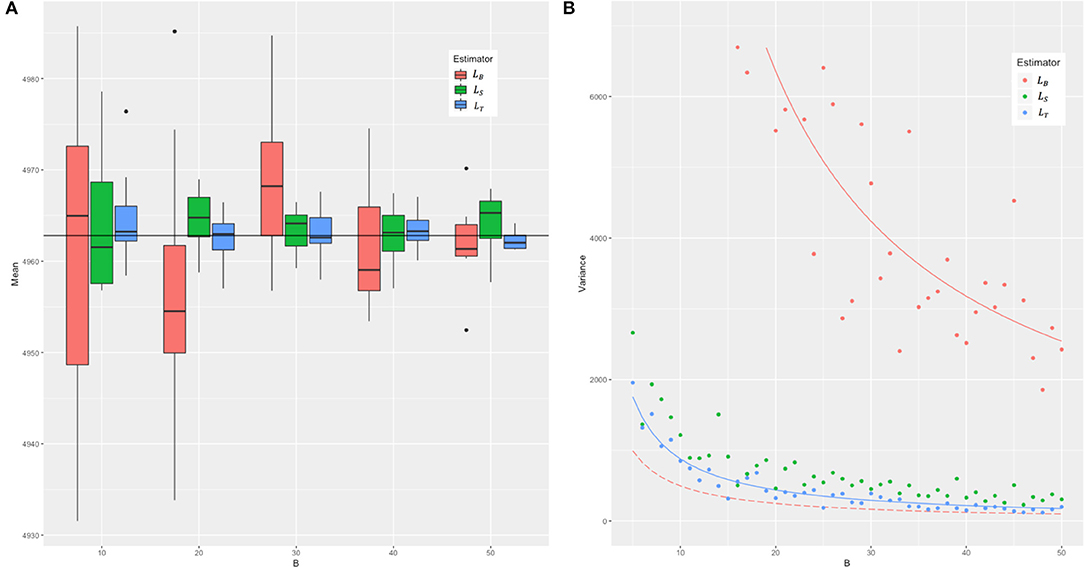
Figure 2. The means and the sampling variances of three estimators in simulation. The genotype data were constituted by 2,000 individuals and 2,000 markers with strong LD (from 0.6 to 0.8 in Lewontin's measure D′). B is the parameter related to the iteration for LB. For each B, the number of samples of the LS and LT estimators was adjusted to ensure that the three estimators have the same computational cost. (A) The boxplots of means and (B) the variance of 100 random experiments of three estimators for each B. In (A), we combined 10 cases with B = 5–14 into the first group, and so on, and the last five cases with B = 46–50 were combined into the fifth group. The red boxes represent the means of LB, green the means of LS, and blue the means of LT, respectively. The black horizontal line represents the real value of tr(KTK). In (B), the solid red line represents the true sampling variance of the LB estimator derived in this study, and in contrast the long-dash red line the sampling variance of the LB estimator incorrectly given by Wu and Sankararaman (2018). The solid blue line represents the theoretical sampling variance of LT. The solid green line is not given because we cannot get the theoretical sampling variance of LS yet.
Across different parameter settings (sample sizes, number of loci, MAF, and LD), it yielded a similar pattern for the evaluated results of tr(KTK). We chose M = N = 2,000 and strong LD for detailed presentation, and the rest were shown in Supplementary Figures 1, 2). Figure 2 shows that all the three estimators were unbiased. The variance of each of these estimators, as expected, was inversely proportional to B. The real sampling variance of LB was several times larger than the analytical incorrect result given in Wu and Sankararaman's study (refer to Appendix A3 in their original report) but was consistent with 2tr (KTKKTK)/B, just the corrected one as derived in this study (Equation 3). The sampling variance of LT was about an order of magnitude smaller than that of LB. The simulation results in the real data shown in Supplementary Figure 3 were consistent with Figure 2.
We compared the performance of the three estimators LB, LS, and LT in UKB. After quality control, 525,460 autosome SNPs with MAF > 0.01 for 278,788 unrelated British white individuals, whose pairwise genetic relationship coefficient <0.0125, were included for analysis. We set B = 5, 10, 20, 40, 60, 80, and 100, and calculated each of the three estimators 100 times to get the mean and the variance for each B. We compared the means of the three estimators with the expected value of , where was estimated from subsamples; given with 87,351, tr (KTK) was expected to be 1,168,573 for each of the three estimators.
The calculation was performed on an Intel(R) Xeon(R) Bronze 3104 CPU @ 1.70-GHz server cluster, and about 30 threads were allocated for each calculation. The actual calculation time of the three estimators were basically the same (see Supplementary Table 1) and conformed to the theoretical calculation complexity (NMB). The variances of the three estimators LB, LS, and LT for tr(KTK) are listed in Table 1. In particular, between the randomized estimator and the subsampling estimators, there was a huge difference between their variances. Under the real data, the sampling variance of LB was large, while the sampling variances of the other two estimators were smaller and the variance of LT was about half that of LS. The variances of each of the three estimators decreased with the increasing B, consistent with the simulation.

Table 1. The sampling variance of the three estimators.
Equation (2) presents how heritability is estimated using all 22 autosomes, and Equation (5) offers an alternative method by summation of chromosome-wise estimation for heritability. For ease of comparison, we only estimated heritability for 81 traits as demonstrated by Ge et al. (2017). We used the first two principal components as the covariates to control the possible population stratification; other covariates were adjusted upon the traits. The chromosome-wise partition heritability was calculated by the summation of the heritability estimated for Me.c for each chromosome (Table 2), and the whole-genome heritability was calculated from the GRM of the whole genome.
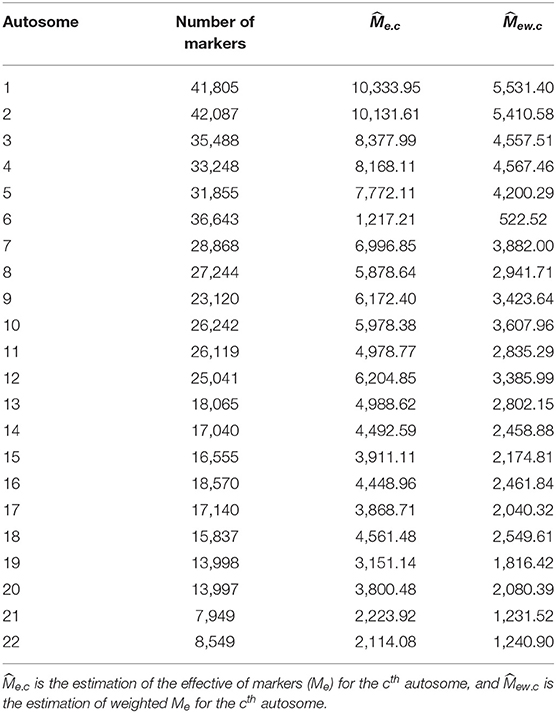
Table 2. and of each autosome.
The estimated heritability of some selected UKB traits is listed in Table 3 (see Supplementary Table 2 for all the 81 traits). The heritability of all traits was basically very similar to Ge et al.'s result and within the error range. Several physiological traits, such as height and weight had high heritability, while social traits that were more affected by social factors, such as the duration of certain activities, showed lower heritability. This result was consistent with the mainstream conclusion. The left part of Equation (4) for variance estimators of the whole-genome heritability () contributed a large part of the total variance (about 0.0017 in 0.002 for N = 270,000). Although the variances of the , , and were several times different, they influenced little on the variance of estimated heritability.

Table 3. Estimation of heritability for some traits in UK Biobank.
In the comparison of the two kinds of heritability for each trait, all the chromosome-wise partition heritability was higher than the whole-genome heritability except for the trait of the age diabetes diagnosed (the explanation of this exception is given below). For a certain polygenic trait, the heritability attributed to each chromosome was proportional to according to the heritability estimation formula (Equation 5). Since the LD score between chromosomes could be considered as 0, this causes the of the whole genome to be diluted by a large number of blank LD, so the overall was smaller than the average of each chromosome. In order to eliminate the influence of blank LD to see the contribution of effects of causal variants to heritability, Figure 3 shows the relationship of these two estimations of the heritability for the 81 traits. The slope of the solid gray line in the figure represents the ratio of the whole-genome to , a ratio of 0.729. This figure was to capture traits that do not meet the assumptions of polygenic assumption—or fitness of the model. If a trait were purely polygenic, the point representing this trait would be expected just along the solid gray line. However, the points were mostly distributed above the line, indicating that the effect size of causal variants was not evenly distributed on the chromosomes. In particular, the trait of the age diabetes was diagnosed, the Manhattan plot of which showed many statistically significant SNPs concentrated on the major histocompatibility complex (MHC) region on chromosome 6. They all belong to MHC, which is related to many human traits. Obviously, these loci breached the polygenic assumption underlying. After deleting these loci, we reestimated the two kinds of heritability, and all the traits were basically close to the solid gray line and were closer compared with Figure 3 (see Supplementary Figure 4). This shows that the model assumptions were basically valid, and the estimated value of heritability had a certain degree of reliability.
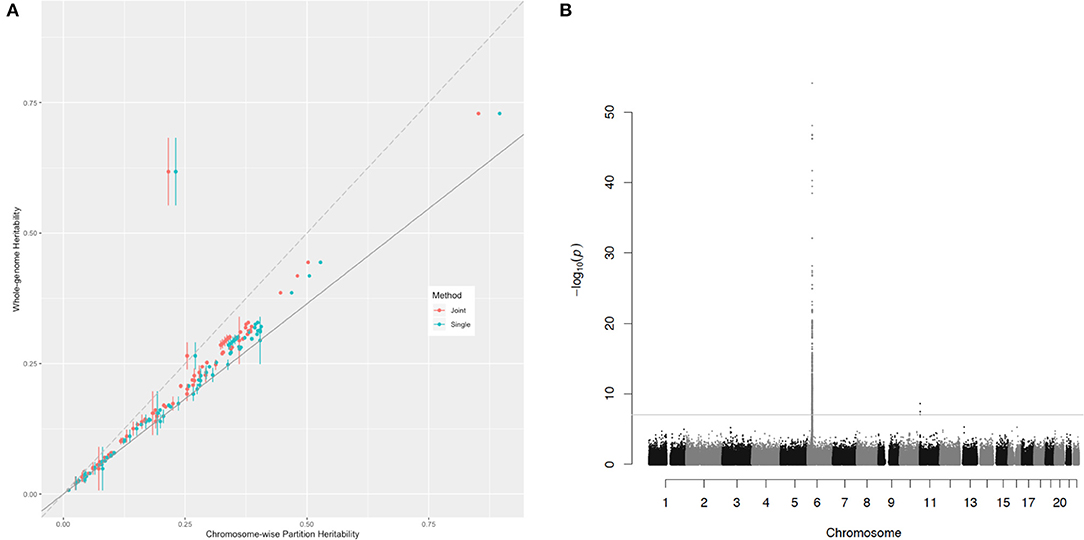
Figure 3. The relationship of the chromosome-wise partition heritability and the whole-genome heritability. (A) Each dot represents a trait in the UKB dataset listed in Supplementary Table 2. The horizontal axis represents their chromosome-wise partition heritability, and the vertical line at each point is their error bar; the vertical axis represents their whole-genome heritability. The red color represents the chromosome-wise partition heritability calculated jointly, and the green color represents the chromosome-wise partition heritability calculated singly. The long-dash line crosses the origin has a slope of 1. The slop of the solid line is 0.729, the ratio of . (B) The Manhattan plot for the trait age diabetes diagnosed, and the threshold is for genome-wise threshold for α= 0.05 after Bonferroni correction.
Alternatively, the chromosome-wise partitioning heritability could be estimated jointly by fitting 22 autosomes altogether. It was basically the same as those calculated singly but slightly lower than the latter. It was because when calculating the heritability of chromosomes jointly, we set N for the whole genome in Equation (5), but smaller N were taken in the equation for estimating the heritability of each chromosome singly, as fewer individuals met the quality control standards for a single chromosome. We mentioned in Method that the fast estimation of joint heritability should meet the precondition that N of each chromosome are equal. The heritability estimated by the two methods will be strictly equal if this precondition holds (see Supplementary Notes). For traits with large sample sizes, this precondition could be met well, and the heritability estimated by the two methods was almost the same.
We also estimated the weighted chromosome-wise partition heritability and the weighted whole-genome heritability for these traits (see Supplementary Figure 5). In general, the weighted estimation of heritability was similar to that without weight.
In this study, we corrected the erroneous variance of the LB estimator and proposed another two unbiased estimators of tr(KTK), which was the most time-consuming term in RHE (Wu and Sankararaman, 2018). Instead of plotting the running time and accuracy of different methods like most articles, we used a different experimental design to make a special comparison with the LB estimator. We borrowed the sampling size parameter B in LB and adjusted the sample size of our estimators so that the theoretical calculation time of the three estimators was the same under different sample size parameter B. Under the same time complexity, our results showed better stability with smaller variances. In other words, under the same accuracy requirements, our method could greatly reduce the computation cost.
We noted that Wu and Sankararaman further reduced the calculation time in matrix multiplication by introducing the mailman algorithm (Liberty and Zucker, 2009), which could also be used in our calculation by writing our estimators in the form of multiplication of genetic matrix and a random vector with multinoulli distribution. From these perspectives, our estimators were superior substitutions of the LB estimator in Haseman–Elston regression.
We also gave the sampling variance of the subsampling estimator, which could be calculated by one sampling without additional calculation. As a result, the variance estimator of the heritability could be easily derived. Although the variance of the LB estimator 2tr (KTKKTK)/B could also be derived by the subsampling method (beyond the scope of this study), its time complexity greatly exceeded the calculation of tr (KTK) as far as we know.
The variance of LS was always slightly larger than that of LT. This was because LT randomly extracted nearly uncorrelated elements in the lower triangular matrix Ko, while LS extracted all elements in a triangle of Ko (after reordering the individuals). Although their sampling variance was approximately equal to the population variance var(Ko), the sampling variance of LT was relatively smaller because it uses less related individuals.
One possible drawback of the LT estimator relies on a much larger reference population than that of LS. When the reference sample size is small, it is obvious that LT becomes LS. Therefore, the LT estimator can make full use of large sample size, such as that of UKB. Although the difference between the variances of these two estimators is small, and the difference in the final heritability estimation is even slight, we still provide a novel and simple subsampling idea, which can be used in many situations involving large samples.
In the early analysis of heritability, both GRM and Haseman–Elston regression were applied to related individuals under the context of linkage analysis using sibling data. Under linkage, relatedness is actually related to the concept of identity by descent (IBD). However, with the increasing amount of data, the significance and application range of GRM and HE have been expanded. The unrelated individuals we emphasize here are mainly to distinguish from the linkage analysis of pedigree data. There is no problem in the estimation of heritability with related individuals, as demonstrated below. The expression still holds true for related samples (see Supplementary Notes), which was confirmed in simulation (Supplementary Table 3). We have expanded the sample to all UKB British Whites, which included extra 131,850 individuals, totaling sample size N = 410,638, of various possible relatedness with the 278,788 unrelated samples and reestimated the heritability. The results are listed in Supplementary Table 4. In general, the heritability increased compared to the previous results of the unrelated set, but negligible. It shows that our estimators are basically applicable among a more realistic population even containing partially related individuals but leave some concerns in theoretical soundness.
Using modified Haseman–Elston regression to estimate heritability is becoming more and more popular in summary statistics. We further explored an important connection between Haseman–Elston regression and Me, the effective number of independent SNPs, which is also a critical concept in quantitative genetics. We found that Me plays a pivotal role in the estimation of variance components and heritability. As long as we get the estimation of Me, we can easily get the estimation of its corresponding variance components.
Although we used only individual-level data to estimate heritability in this report, the nature of Me allows researchers to estimate heritability based on a reference population of the same origin to the population in meta-analysis. However, the existence of family structure will make Me shrink (see Supplementary Table 3; the expansion of trace means the shrinkage of Me), and different family structures make it shrink differently, leading to inaccurate meta-analysis. Therefore, we do not recommend using our method in samples with various related individuals, but it raises a very interesting question for the estimation theory using mega-scale family trees (Kaplanis et al., 2018; Shor et al., 2019).
Due to the statistical property of Me, we can easily extend Me to the dominant model and use the same method to obtain both additive and dominant heritability, as long as their codes for the count of the reference allele are orthogonal, as discussed (Vitezica et al., 2017; Álvarez-Castro and Crujeiras, 2019). We can also extend Me to estimate a genetic correlation for a pair of traits, in which , where No is the overlap sample size between a pair of cohorts, which have N1 and N2 individuals, respectively.
URLs: The related source code, https://github.com/GuoanQi1996/LT-Estimator.
Publicly available datasets were analyzed in this study. This data can be found at: https://biobank.ctsu.ox.ac.uk/.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
TX developed the method and wrote the manuscript. G-AQ analyzed the data. JZ and H-MX revised the manuscript. G-BC designed the study and improved the manuscript. All authors read and approved the final manuscript.
This work was supported by the National Natural Science Foundation of China (31771392 to G-BC, 31671570 and 31871707 to H-MX) and Zhejiang Provisional People's Hospital Research Startup Fund (ZRY2018A004 to G-BC).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We thank the participants of UK Biobank for making this work possible (application 41376).
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2021.612045/full#supplementary-material
Álvarez-Castro, J. M., and Crujeiras, R. M. (2019). Orthogonal decomposition of the genetic variance for epistatic traits under linkage disequilibrium—applications to the analysis of Bateson-Dobzhansky-Müller incompatibilities and sign epistasis. Front. Genet. 10:54. doi: 10.3389/fgene.2019.00054
Bulik-Sullivan, B. K., Loh, P. R., Finucane, H. K., Ripke, S., Yang, J., Patterson, N., et al. (2015). LD Score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat. Genet. 47, 291–295. doi: 10.1038/ng.3211
Bycroft, C., Freeman, C., Petkova, D., Band, G., Elliott, L. T., Sharp, K., et al. (2018). The UK Biobank resource with deep phenotyping and genomic data. Nature 562, 203–209. doi: 10.1038/s41586-018-0579-z
Chen, G. B. (2014). Estimating heritability of complex traits from genome-wide association studies using IBS-based Haseman–Elston regression. Front. Genet. 5:107. doi: 10.3389/fgene.2014.00107
Dudbridge, F., and Wray, N. R. (2013). Power and predictive accuracy of polygenic risk scores. PLoS Genet. 9:e1003348. doi: 10.1371/annotation/b91ba224-10be-409d-93f4-7423d502cba0
Ge, T., Chen, C. Y., Neale, B. M., Sabuncu, M. R., and Smoller, J. W. (2017). Phenome-wide heritability analysis of the UK Biobank. PLoS Genet. 13:e1006711. doi: 10.1371/journal.pgen.1006711
Haseman, J. K., and Elston, R. C. (1972). The investigation of linkage between a quantitative trait and a marker locus. Behav. Genet. 2, 3–19. doi: 10.1007/BF01066731
Kaplanis, J., Gordon, A., Shor, T., Weissbrod, O., Geiger, D., Wahl, M., et al. (2018). Quantitative analysis of population-scale family trees with millions of relatives. Science 360, 171–175. doi: 10.1126/science.aam9309
Liberty, E., and Zucker, S. W. (2009). The mailman algorithm: a note on matrix–vector multiplication. Inform. Process. Lett. 109, 179–182. doi: 10.1016/j.ipl.2008.09.028
Loh, P. R., Tucker, G., Bulik-Sullivan, B. K., Vilhjálmsson, B. J., Finucane, H. K., Salem, R. M., et al. (2015). Efficient Bayesian mixed-model analysis increases association power in large cohorts. Nat. Genet. 47, 284–290. doi: 10.1038/ng.3190
O'Connor, L. J., Schoech, A. P., Hormozdiari, F., Gazal, S., Patterson, N., and Price, A. L. (2019). Extreme polygenicity of complex traits is explained by negative selection. Am. J. Hum. Genet. 105, 456–476. doi: 10.1016/j.ajhg.2019.07.003
Sankararaman, S. (2019). “Fast estimation of genetic correlation for Biobank-scale data,” in Research in Computational Molecular Biology. ed Cowen, L. J., (Washington, DC: Springer), 322.
Shor, T., Kalka, I., Dan, G., Erlich, Y., and Weissbrod, O. (2019). Estimating variance components in population scale family trees. PLoS Genet. 15:e1008124. doi: 10.1371/journal.pgen.1008124
Visscher, P. M., Hemani, G., Vinkhuyzen, A. A. E., Chen, G. B., Lee, S. H., Wray, N. R., et al. (2014). Statistical power to detect genetic (co)variance of complex traits using SNP data in unrelated samples. PLoS Genet. 10:e1004269. doi: 10.1371/journal.pgen.1004269
Vitezica, Z. G., Legarra, A., Toro, M. A., and Varona, L. (2017). Orthogonal estimates of variances for additive, dominance, and epistatic effects in populations. Genetics 206, 1297–1307. doi: 10.1534/genetics.116.199406
Wu, Y., and Sankararaman, S. (2018). A scalable estimator of SNP heritability for biobank-scale data. Bioinformatics 34, i187–i194. doi: 10.1093/bioinformatics/bty253
Yang, J., Benyamin, B., Mcevoy, B. P., Gordon, S., Henders, A. K., Nyholt, D. R., et al. (2010). Common SNPs explain a large proportion of the heritability for human height. Nat. Genet. 42, 565–569. doi: 10.1038/ng.608
Yang, S., and Zhou, X. (2020). Accurate and scalable construction of polygenic scores in large biobank data sets. Am. J. Hum. Genet. 106, 679–693. doi: 10.1016/j.ajhg.2020.03.013
Keywords: polygenicity, UK Biobank, subsampling estimator, effective number of markers, Haseman-Elston regression
Citation: Xu T, Qi G-A, Zhu J, Xu H-M and Chen G-B (2021) Subsampling Technique to Estimate Variance Component for UK-Biobank Traits. Front. Genet. 12:612045. doi: 10.3389/fgene.2021.612045
Received: 30 September 2020; Accepted: 18 January 2021;
Published: 05 March 2021.
Edited by:
Min Zhang, Purdue University, United StatesReviewed by:
Cen Wu, Kansas State University, United StatesCopyright © 2021 Xu, Qi, Zhu, Xu and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Guo-Bo Chen, Y2hlbmd1b2JvQGdtYWlsLmNvbQ==
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.