 Yanshuo Chu
Yanshuo Chu Chenxi Nie
Chenxi Nie Yadong Wang*
Yadong Wang*
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet. , 27 February 2020
Sec. Statistical Genetics and Methodology
Volume 10 - 2019 | https://doi.org/10.3389/fgene.2019.01374
This article is part of the Research Topic System Biology Methods and Tools for Integrating Omics Data View all 23 articles
State-of-the-art next-generation sequencing (NGS)-based subclonal reconstruction methods perform poorly on somatic copy number alternations (SCNAs), due to not only it needs to simultaneously estimate the subclonal population frequency and the absolute copy number for each SCNA, but also there exist complex bias and noise in the tumor and its paired normal sequencing data. Both existing NGS-based SCNA detection methods and SCNA’s subclonal population frequency inferring tools use the read count on radio (RCR) of tumor to its paired normal as the key feature of tumor sequencing data; however, the sequencing error and bias have great impact on RCR, which leads to a large number of redundant SCNA segments that make the subsequent process of SCNA’s subclonal population frequency inferring and subclonal reconstruction time-consuming and inaccurate. We perform a mathematical analysis of the solution number of SCNA’s subclonal frequency, and we propose a computational algorithm to reduce the impact of false breakpoints based on it. We construct a new probability model that incorporates the RCR bias correction algorithm, and by stringing it with the false breakpoint filtering algorithm, we construct a whole SCNA’s subclonal population reconstruction pipeline. The experimental result shows that our pipeline outperforms the existing subclonal reconstruction programs both on simulated data and TCGA data. Source code is publicly available as a Python package at https://github.com/dustincys/msphy-SCNAClonal.
Tumor heterogeneity introduces challenges in cancer tissue diagnosis and subsequent treatment (Nowell, 1976). Tumor heterogeneity cannot be inferred by the properties of biomolecular through the ontology or pathway analysis (Cheng et al., 2017; Cheng et al., 2018c), but could be inferred by measuring the quantity of biomoleculars (Cheng et al., 2018b; Cheng et al., 2018d; Cheng et al., 2019). To decipher cell composition in bulk cells, somatic copy number alternations (SCNAs), most commonly found in tumor cells (Beroukhim et al., 2010), are utilized as the representative to determine tumor subclonal populations in a tumor–normal tissue paired manner (Oesper et al., 2013; Li and Xie, 2015). The benefit of using SCNA to conduct subclonal reconstruction is that the WGS data doesn’t have to be deeply sequenced (Li and Xie, 2015), because SCNA affects large, multi-kilobase-sized or megabase-sized regions of the genome, which allows the average copy number of these regions to be accurately estimated with whole genome sequencing (WGS) (Deshwar et al., 2015).
SCNA’s subclonal reconstruction algorithms attempt to infer the population structure of heterozygous tumors based on the subclonal population frequency of SCNA (Deshwar et al., 2015). However, the cellular prevalence and the absolute copy number are intertwined and next-generation sequencing (NGS)-based subclonal reconstruction needs to simultaneously estimate population frequency and the absolute copy number for each SCNA. The solution space of subclonal frequency of SCNA remains poorly understood, and there might exist multiple solutions for subclonal frequency for some SCNAs (Oesper et al., 2013), which makes the infinite site assumptions (ISAs) (Kimura, 1969; Hudson, 1983; Jiao et al., 2014) invalid. ISA is the commonly accepted and powerful assumption, which posits that each mutation occurs only once in the evolutionary history of the tumor.
To infer the SCNA’s subclonal population frequency based on NGS data, the location of SCNAs in the genome needs to be obtained first. The SCNA breakpoints are detected through multiple bin-merging processes, during which rcr of tumor to its paired normal is used as a key feature (Xi et al., 2010). However, the sequencing error and bias have great impact on RCR, which leads to false positive breakpoints and incorrect subclonal reconstruction (Please refer to Figures S2 and S3, Tables S2 and S3 in the Supplementary). The higher sensitivity the SCNA detection tools show, the more prone to the sequencing error the tools would be. For example, BIC-seq (Xi et al., 2010) first splits whole genome into small bins, then uses the Bayesian Information Criterion as the bin merging and stopping criterion to detect SCNA breakpoints. When sensitivity parameter λ of BIC-seq is very high, the true positive rate and the false discovery rate will decrease simultaneously (Xi et al., 2010), which means the SCNA regions will be separated into small fragments by the false positive breakpoints (Xi et al., 2010). The choice of parameter λ is equivalent to setting type I error; in other words, when performing the loop of combining windows, two neighboring windows that should be combined are left separated apart. Since the reconstruction algorithm of subclone depends on the proportion of subclone populations of somatic mutation to define mutation set and its subpopulation (Deshwar et al., 2015) (Please refer to Figure S4 for the definition of subpopulation and subclonal population), in order to more precisely estimate the subclonal population ratio of every SCNA fragment, we need to choose a smaller λ to ensure the high true positive rate of breakpoints, so as to more accurately estimate the subclonal population frequency. However, the false positive breakpoints split the SCNA regions into many small SCNA fragments, which violates ISA and results in many redundant input data and causes the subclone reconstruction process to be extremely slow and time consuming.
Existing (NGS) based subclonal reconstruction methods, such as ThetA (Oesper et al., 2013) and Mixclone (Li and Xie, 2015), use expectation maximation (EM) or maximum likelihood method (MLM) to infer the subclonal frequency and the absolute copy number of every input data. To reduce the searching space, MixClone assumes that the number of subclonal population is less than 3, and this number (1 or 2) needs to be predefined. During the maximization step of the EM process, MixClone assumes the subclonal frequencies of all the subclonal population only equal to several combinations of discrete values to further reduce the searching space. Thus, MixClone’s accuracy is compromised for speed of computation. On the other side, Theta (Oesper et al., 2013) does not make any compromise on searching space. Thus, Theta is extremely time consuming while search optimal subclonal frequency in (0,1) for every input data, which makes it unable to perform subclonal reconstruction for more than three subclonal populations.
With the ever increasing data of biotechnology comes the chance of developing computational toolkit (Cheng et al., 2016; Cheng et al., 2018a; Cheng et al., 2019) to find out the pathogeny of diseases; in this article, we provide a pipeline for reconstructing SCNA’s subclonal population-based NGS data. We first perform a mathematical analysis of the solution number of SCNA’s subclonal frequency, propose and prove the theorem of solution number of SCNA’s subclonal frequency, and present a method to filter out false SCNA breakpoints based on it. Then we propose a probability model that incorporates rcr bias correction algorithm we previously developed, and we construct an SCNA’s subclonal population reconstruction pipeline by stringing it with the false breakpoint filtering algorithm. We model the read depth of tumor sample as a Poisson distribution with the expected tumor read count proportional to the absolute copy number and subclonal frequency. We use the tree-structured stick breaking Dirichlet process (Prescott Adams et al., 2010) to generate the tree structure of tumor’s evolutionary history, and use the Markov Chain Monte Carlo (MCMC) to obtain the result of subclonal reconstruction. The experimental result shows that our pipeline outperforms the existing subclonal reconstruction programs both on simulated data and TCGA data.
The RCR and the b-allele frequency (BAF) of the heterozygous single nucleotide polymorphism (SNP) locus in the SCNA segment are commonly used as input for the sequencing data-based SCNA’s copy number and subclonal frequency inferring tools (Wang et al., 2007; Oesper et al., 2013; Li and Xie, 2015). Since the number of reads mapped in certain genome region is proportional to the copy number of this region, the RCR is set to be proportional to by existing tools (Oesper et al., 2013; Li and Xie, 2015), where denotes its average copy number of the jth SCNA segment. Let ϕj denote the subclonal population cellular prevalence of the jth SCNA segment; denote its absolute copy number; represent the BAF of the kth heterozygous SNP locus in the jth SCNA segment; represent the average BAF of the kth heterozygous SNP locus in the jth SCNA segment. Then we have the following equation set
where Kj is the total number of heterozygous SNP loci in the jth SCNA segment. Since the B allele locates either in paternal or maternal haploid, both and could possibly be the BAF value in the same SCNA fragment and both and could possibly be the average BAF value in the same SCNA fragment. To reduce the complexity, we use to denote the smaller one of and ; to denote the smaller one of and . Here we give a theorem to help answer the solution space of equation set 1 and we prove it in the Supporting Information.
THEOREM 1. Given and and let , we have the following conclusions:
1. If < 2, there is only one solution ϕj in Equation set 1.
2. If > 2 and there is only one solution of ϕj in Equation set 1.
3. If > 2 and , there are infinite solutions of ϕj in Equation set 1.
4. If > 2 and , there are multiple solutions of ϕj in Equation set 1 on the curves of the family of function , under the restriction of maximum absolute copy number Cmax. Suppose segment sj′ and sj″ are the two solutions for given and , then . The multiple solution area would be ∈ (2, min(Cj′, Cj″)) and .
As shown in Figure 1, given the observation value and and maximum copy number Cmax = 15, only 7/43 of the curves of the family of function present multiple ϕj solutions (Please refer to Table S1 for the detail information of multi-solution range).
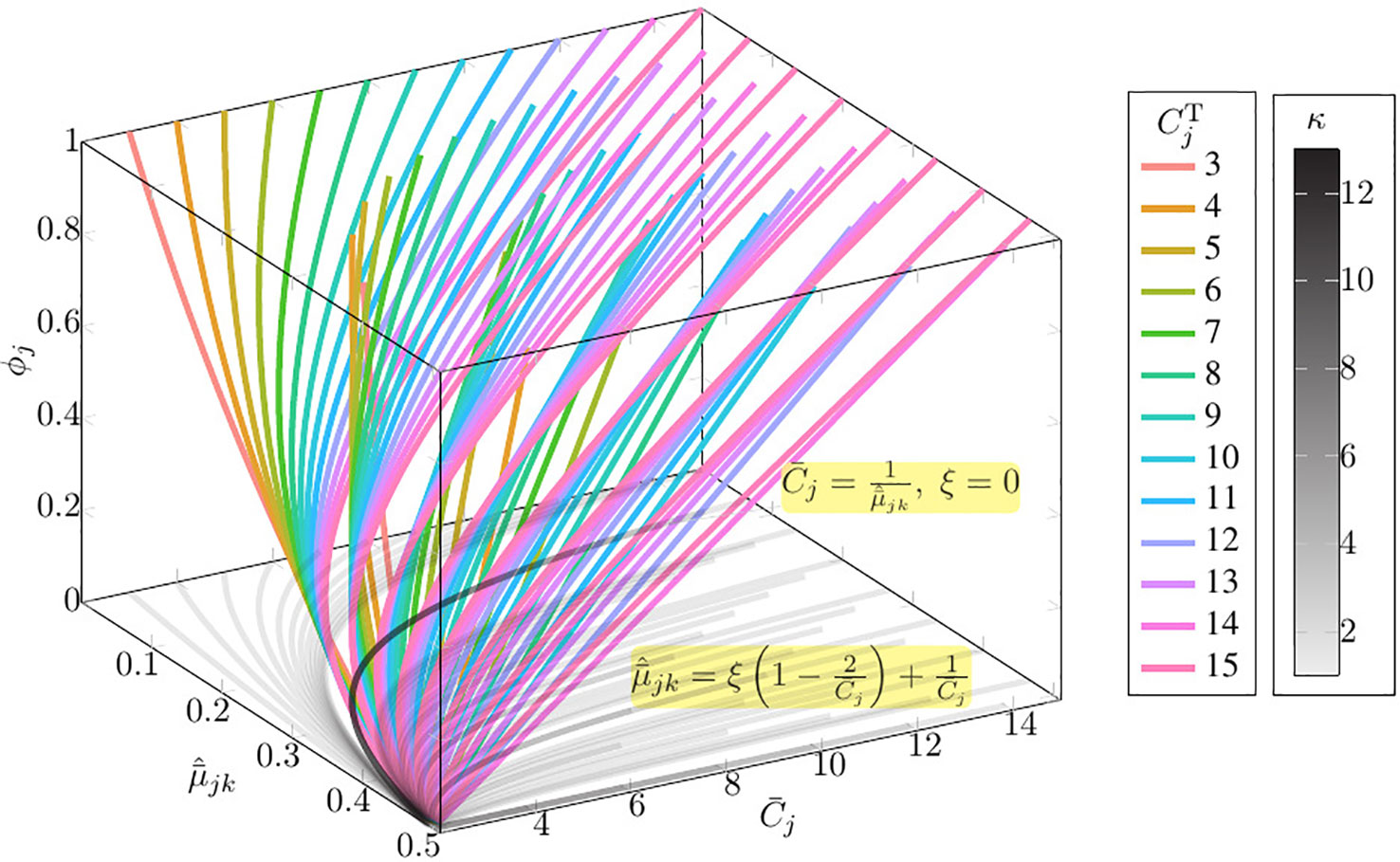
Figure 1 The solution space of Equation set 1 given the observation value and and maximum copy number Cmax = 15. In this figure, κ denotes the number of solutions; , where is the absolute copy number of SCNA in the jth segment sj, is the normalized BAF of tumor reads mapped at the kth heterozygous SNP loci in the jth segments sj; denotes the normalized average tumor reads mapped at the kth heterozygous SNP loci in the jth segments sj; denotes the average copy number of segment sj; ϕj denotes the subclonal frequency of segment sj.
We assume that there are no two adjacent SCNAs that present the same and and meanwhile the different ϕj and according to Theorem 1. We use the same method described in Li and Xie (2015) to model the read count ratio of tumor and its paired normal. Based on the Lander–Waterman model (Lander and Waterman, 1988), the probability of sampling a read from a given segment depends on three main factors: 1) its copy number, 2) its total genomic length, and 3) its mappability, which depends on factors such as repetitive sequence and GC content (Li and Xie, 2015). For each segment j, we associate a coefficient j) to account for the effect of its mappability and genomic length. Thus, the expected tumor read counts mapped to segment j, which is denoted as λj, are proportional to . For example, for segment x and segment y, we have
Because the mappability coefficients matter only in a relative sense, we take , as these segments should have the same sequence properties between the normal and tumor samples. Thus, Equation 2 is transformed into
However, our previous study (Chu et al., 2017a) has shown the RCR of tumor to its paired normal presents a log-linear GC content bias, and has described a bias correction software “Pre-SCNAClonal” (Chu et al., 2017a) to correct this bias specifically. Let denote the corrected read count ratio of tumor sample and its paired normal, and let Φ() denote the bias correction process. Then we have and
Then we use the following steps to filter out false positive SCNA breakpoints.
1. First, BIC-Seq with a small λ is used to detect SCNA breakpoints. Then the whole genome is separated into SCNA fragments by these breakpoints. We use to denote this SCNA fragment set.
2. Next, Pre-SCNAClonal (Chu et al., 2017a) is used to correct the bias of RCR.
3. Next, the hierarchical clustering algorithm is used to cluster based on of every segment with the maximum amount of cluster predefined as Cmax * τ, where τ is the number of subclonal populations. Suppose in this step, there are N clusters obtained by the hierarchical clustering algorithm. We denote the nth cluster as where n = 1, 2,…, N. For convenience, we call this step the aggregation step.
4. Next, the MeanShift algorithm is used to perform an unsupervised cluster search on , where is obtained by step 3. Assume there are Mn BAF clusters detected in , and we use to represent the cluster index. Then for every sj ∈ we define the BAF cluster of sj to be the BAF cluster of with the largest number. Then each is split into subclusters based on the BAF cluster of each sj. For convenience, we call this step the decomposition step.
5. For each , n = 1,2,…,N, m = 1,2,..,Mn, we merge two adjacent SCNA fragments, which are on the same chromosome and the distance between them is less than a predefined threshold ρ.
The space complexity of the algorithm of filtering out false positive SCNA breakpoints is o(J2). The computational complexity of “MeanShift” and “hierarchical clustering” are and o(J3), where In is the number of iterations for . Thus. the time complexity of the algorithm of filtering out false positive SCNA breakpoints is . The detail validation of this algorithm are described in Section 4 in the Supplementary (Please refer to Figures S5–S8 for the results).
The task of normal segments detection is to find out all the segments that , since the copy number in sj in normal sample equals 2, normally. A cancer genome differs from the reference genome by gains and losses of segments, or intervals, of the reference genome (Oesper et al., 2013).
However, due to two different sequencing processes and the coverage may not exactly be the same for tumor and its paired normal, does not always equal to 1 for the normal segments (Li and Xie, 2015). In this paper, we use the same normal segments detection method described in our previous work (Chu et al., 2017a), which utilizes BAF information to detect normal segments.
Equation set 1 implies following conclusion
We detect the normal segments from according to Equation 5 by the following two steps. First, we filter out all the segments with for . In the remaining segments, the possible could be any one in {0, 2, 4,…}, since all the possible genotypes of allele at the kth site for could be any one in {∅, PM, PPMM,…}. Next, we obtain all the normal segments from these segments by selecting the segments with the read depth at the kth heterozygous SNP site equal to the coverage of the aligned WGS data of the tumor sample.
Figure 2 shows the probabilistic graphical model of SCNA’s subclonal population frequency. In this figure, S denotes the set of all the SCNA segments; ℕ denotes the set of segments that contain no SCNA. We use the same method described in Li’s study (Li and Xie, 2015) to set the probability of BAF to obey binomial distribution
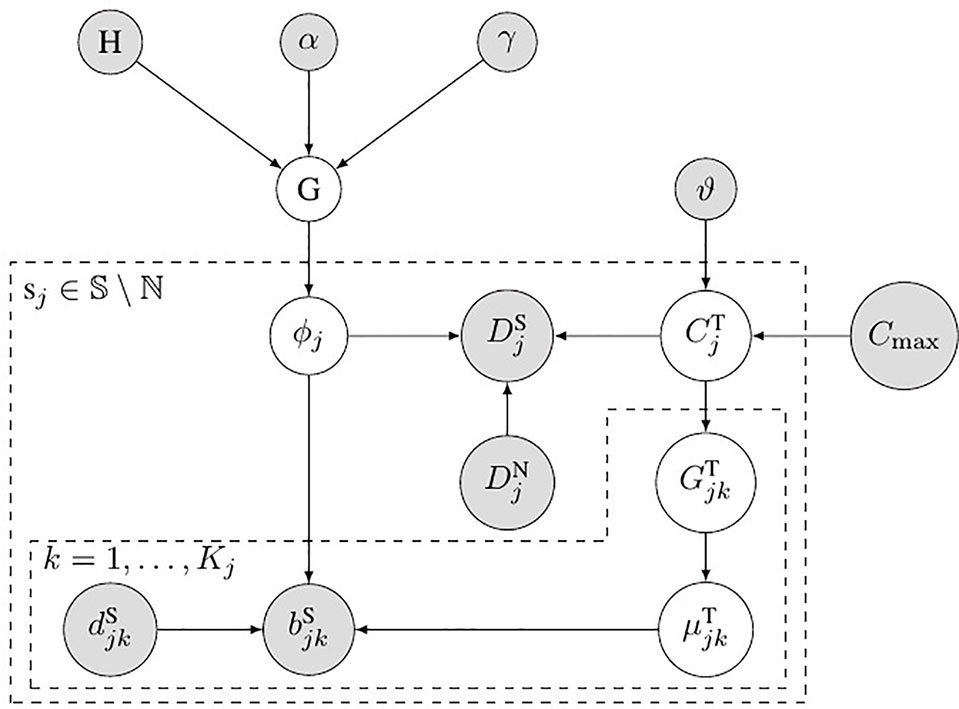
Figure 2 Bayesian network model for subclonal population frequency. In this figure, G denotes the tree-structured Dirichlet process; H denotes the base distribution; α and γ are the scaling parameters of G; ϕj denotes the subclonal frequency of SCNA in segment sj; denotes the number of tumor reads mapped in segment sj, while denotes the number of normal reads mapped in segment sj; denotes the absolute copy number of SCNA in segment sj; ϑ denotes the geometric mean of the read count ratio of all the baseline segments ℕ; Cmax is the maximum absolute copy number pre-defined; denotes the tumor genotype of the kth heterozygous SNP loci in the jth segments sj; denotes the tumor BAF of the kth heterozygous SNP loci in the jth segments sj; and denote the number of B-allele and the total allele at the kth heterozygous SNP loci in the jth segments sj.
where denotes the number of tumor reads that contain B allele at the kth heterogeneous SNP locus and denotes the total number of tumor reads mapped at this locus. In this figure, denote the allele’s genotype at the kth heterogeneous snp locus in segment sj.
According to Equation 4, we have the expected tumor read counts mapped to segment j
where Φ−1() denotes the reverse process of bias correction. Let |ℕ| denote the number of baseline segments (Li and Xie, 2015) (in which the absolute copy number ). We use the average of read count’s log ratio of all the baseline segments to calculate the expectation of tumor read count, and model the tumor read count as a Poisson distribution
It could be deduced from the first equation in Equation set 1 that . Therefore, we may conclude that , since must equal 2 if si contains no SCNA. We set obeys the categorical distribution
where function ς (ϑ) denotes ‘s range; ς (ϑ) = {0, 1, 2} if ; ς (ϑ) = {2, 3,…, Cmax} if .
The subclonal population frequency of certain mutation equals the sum of all its subpopulation frequencies (for details, refer to Figure S1 in the Supplementary), and all the subpopulation frequencies in the tumor sample sums to 1. Therefore, all the subpopulation frequencies in the tumor sample obey the Dirichlet distribution, and this Dirichlet distribution obeys the tree-structured Dirichlet process (DP) (Prescott Adams et al., 2010). Suppose there are P subpopulations in a tumor sample; let x1,…, xp denote all the subpopulation frequencies
where α1,…, αp are the concentration parameters. In this paper, we set α1 = … = αp = 1, then Equation 10 is transformed into a uniform distribution of (p −1)-dimension simplex. Therefore, the prior probability of subclonal frequency ϕj equals the probability of the tree structure. In Figure 2, G denotes the tree-structured DP; H denotes the base distribution; α and γ are the scaling parameters of G.
We use MCMC to obtain the prior distribution of ϕj since the probability of tree-structured DP cannot be explicitly expressed. We use the slice sampling method described in Prescott’s study (Prescott Adams et al., 2010) to generate tree structure. The complete posterior probability of the subclonal population frequencies of all the SCNA segments
where denotes the tree structure, and N denotes a node in . We select the tree structure with maximum posterior probability
where and denote tree structure and subclonal population frequencies of the ith sampling process. The absolute copy number of the ith sampling process is
where are absolute copy numbers with the maximum posterior probability if the i'-th sampling process is the solution of Equation 12.
As shown in Figure 3, the pipeline consists of five models. The tumor and its paired normal sequence alignment sequencing data in BAM format are used as input of the pipeline. The SCNA segments are detected by BIC-seq (Xi et al., 2010), then the bias of read count ratio is corrected by the correction model (Chu et al., 2017a) we previously proposed. We filter out the false positive breakpoints by the algorithm we proposed in this paper, then we use the probability model of subclonal population frequency proposed in this paper to infer the subclonal frequency of each SCNA segment. Finally, we use the tree structure learning algorithm (Prescott Adams et al., 2010) to reconstruct the SCNA’s subclonal population.
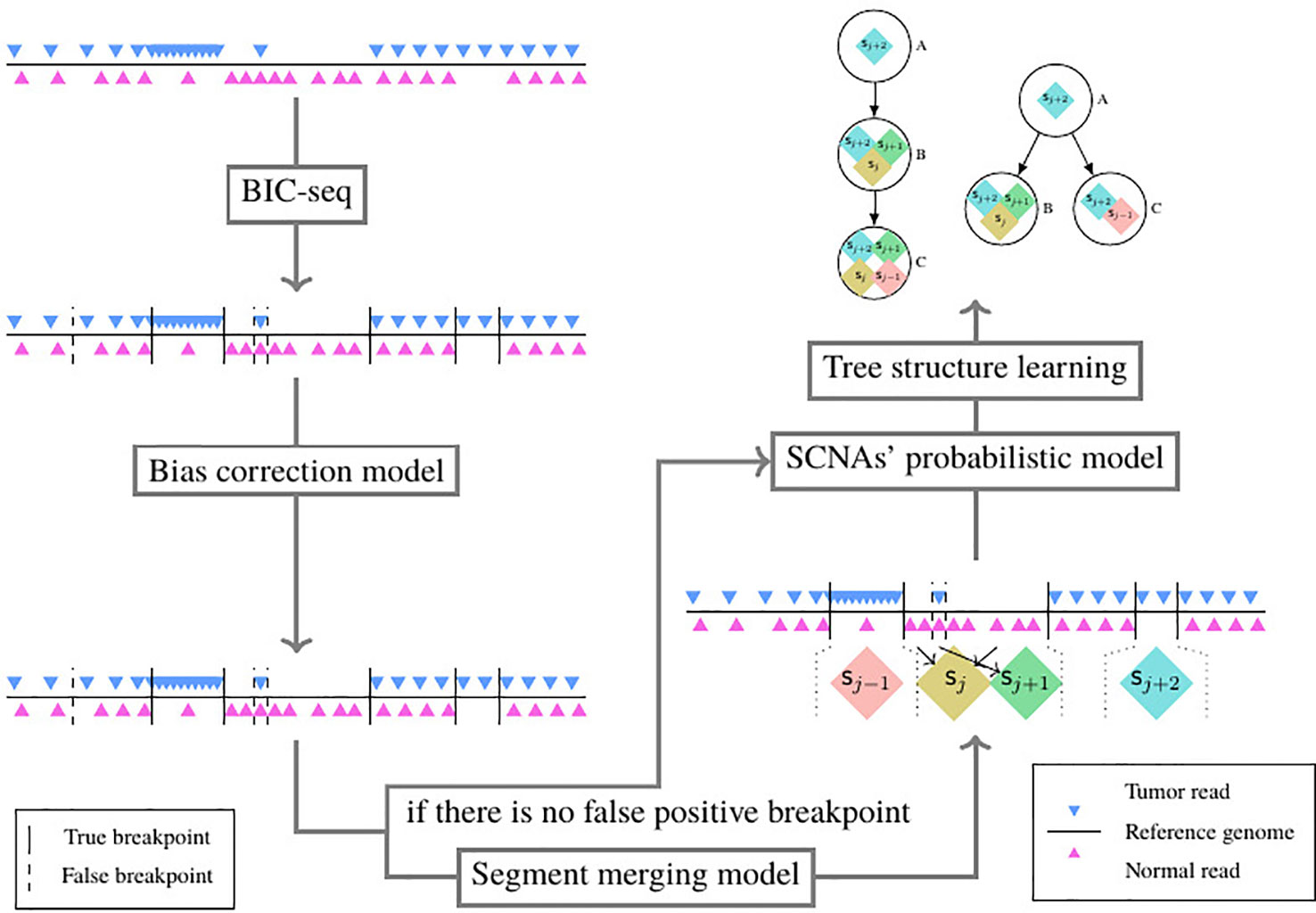
Figure 3 The structure of the whole NGS data-based SCNAs’ subclonal reconstruction pipeline.
In this section, we evaluate the performance of probabilistic model on both simulated and real datasets and compare its performance with existing tools. Existing tools such as Mixclone (Li and Xie, 2015) and TheatA (Oesper et al., 2013) could not calculate the subclonal frequencies of more than three subclonal populations. Therefore, we use the simulated data, which contain more than three subclonal populations and TCGA benchmark data together to evaluate our model.
We use Pysubsim-tree (Chu et al., 2017b) to simulate a tumor’s NGS read alignment data from Chromosome 21 with the evolution history configuration shown in Figure 4 and the acquired SCNA’s configuration listed in Table 1. In Figure 4, each circle represents a subpopulation; the squares with character a, b, c, d, e, and f represent five SCNAs; the number on the right side of the circle is the frequency of the subpopulation.
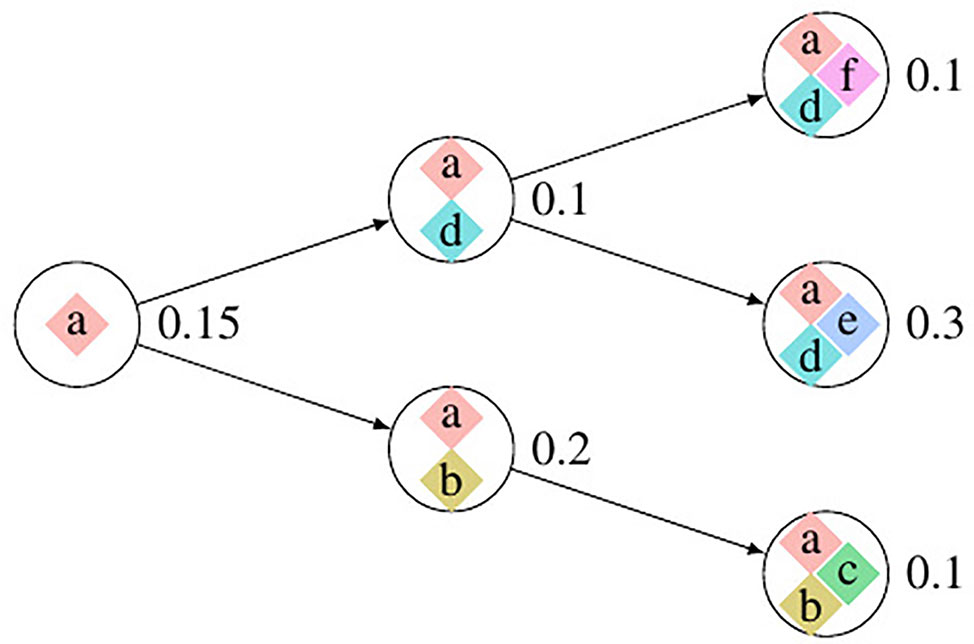
Figure 4 The evolution process of subclonal population in the simulation data. In this figure, each circle denotes a subpopulation; the number on the left is its frequency; each square inside the circle denotes an SCNA; each arrow points an offspring subpopulation.

Table 1 The SCNA’s configuration for each subpopulation of the simulation data.
We set the first 50 cycles of the MCMC sampling process as burn-in and use the result of the following 300 cycles to calculate the probability of the evolutionary relationship between subpopulations. We set α = 1.0, γ = 1.0, H to be the uniform distribution. Figures 5A, B are the dot-plots of the distribution of the output of subclonal population frequency model. Figure 5C shows the partial order plot (Jiao et al., 2014) of the evolutionary relationship obtained by the model proposed in this paper. The arrows in this figure denote the direct evolutionary relationship of the two subpopulations. The width of the arrow denotes the probability of this evolutionary relationship present in the 300 cycles of the MCMC process. Suppose denotes all the trees obtained in all the cycles of the MCMC process, denotes the evolutionary relationship from subpopulation a to b. Then the probability of this evolutionary relationship is
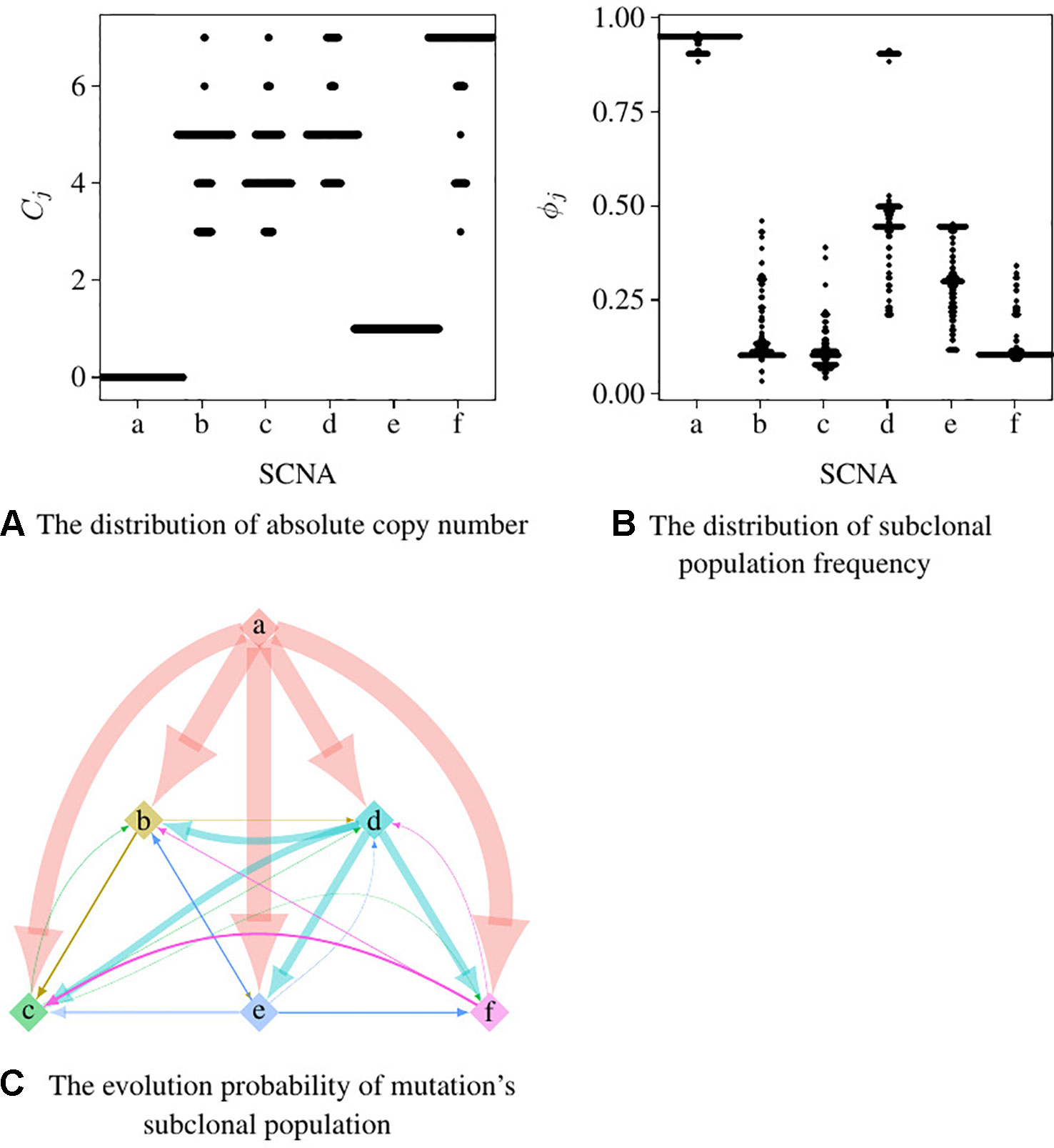
Figure 5 The result of subclonal reconstruction based on simulation data. (A, B) Dot-plots of the distribution of absolute copy number and subclonal frequency inferred by the 300 cycles of MCMC process. (C) The partial plot of the subclonal frequency.
According to Theorem 1, a and e have only one solution of ϕj while the others are not. The distribution of absolute copy numbers shown in Figure 5A is consistent with Theorem 1. The distribution of e’s subclonal frequency is quite scattered in Figure 5B because the small subclonal frequency and the absolute copy number of e (closed to normal) cause the coverage to decrease by 5%, which is almost the same as the noise. The subclonal frequencies of other SCNAs are highly distributed at the positions of subclonal frequencies listed in Table 1. Each SCNA’s absolute copy number and subclonal frequency with the maximum posterior probability are listed in Table 2. The subclonal frequencies of b and c are not correct because they have multiple solutions of subclonal frequencies according to Theorem 1, while the others are correct. The distribution of absolute copy number and subclonal frequency in Figure 5 and the result listed in Table 2 show that our SCNA probability model could correctly calculate the subclonal frequency of SCNA.
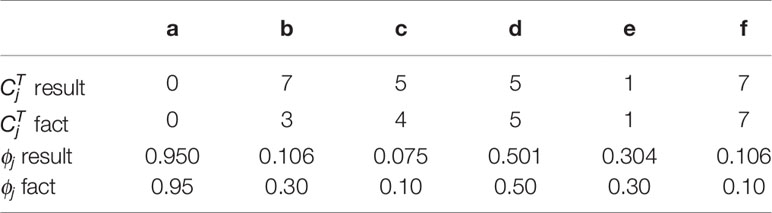
Table 2 The results of subclonal population frequency inferring based on simulation data.
We use the ngs data “HCC1954-spiked1-n25t35s40” and “HCC1954-spiked1-n25t55s20” (denoted as “n25t35s40” and “n25t55s20” for convenience) of Cancer Genome Atlas (TCGA) Benchmark 4 dataset, which is publicly available at the National Cancer Institute GDC Data Portal (https://gdc.cancer.gov/resources-tcga-users/tcga-mutation-calling-benchmark-4-files) to further validate the subclonal frequency model proposed in this paper. HCC1954 is an immortal cell line derived from an invasive ductal carcinoma of the breast diagnosed in a 61-year-old woman (Bignell et al., 2007). “G15512.HCC1954.1” is the NGS data of this cell line, which contains one subclonal population with purity 0.99; however, this data has no ground truth of absolute copy number of the SCNA regions. “HCC1954-spiked1-n25t35s40” is generated by merging 35% of “G15512.HCC1954.1” with 25% of its paired normal NGS data and 40% of “G15512.HCC1954.1” with some SCNAs randomly spiked in it. Therefore, there are two subclonal populations in the tumor sample “HCC1954-spiked1-n25t35s40,” and their subclonal frequencies are 75% and 40%, respectively. The ISA is invalid since each subclonal population contains multiple SCNAs; thus, we set the prior probability of tree structure to obey uniform distribution, and thus Equation 11 could be rewritten as follows:
Figure 6 shows the subclonal frequencies obtained by the model proposed in this paper. In this figure, “P” denotes the parent subclonal population (subclonal frequency 75%) and “C” denotes the child subclonal population (subclonal frequency 40%). As shown in Figure 6, the subclonal frequencies of these two population obtained by the model proposed in this paper are 72% and 42% for sample “n25t35s40” and 77% and 25% for sample “n25t55s20,” which are the most closed to the fact in comparison with MixClone and ThetA.
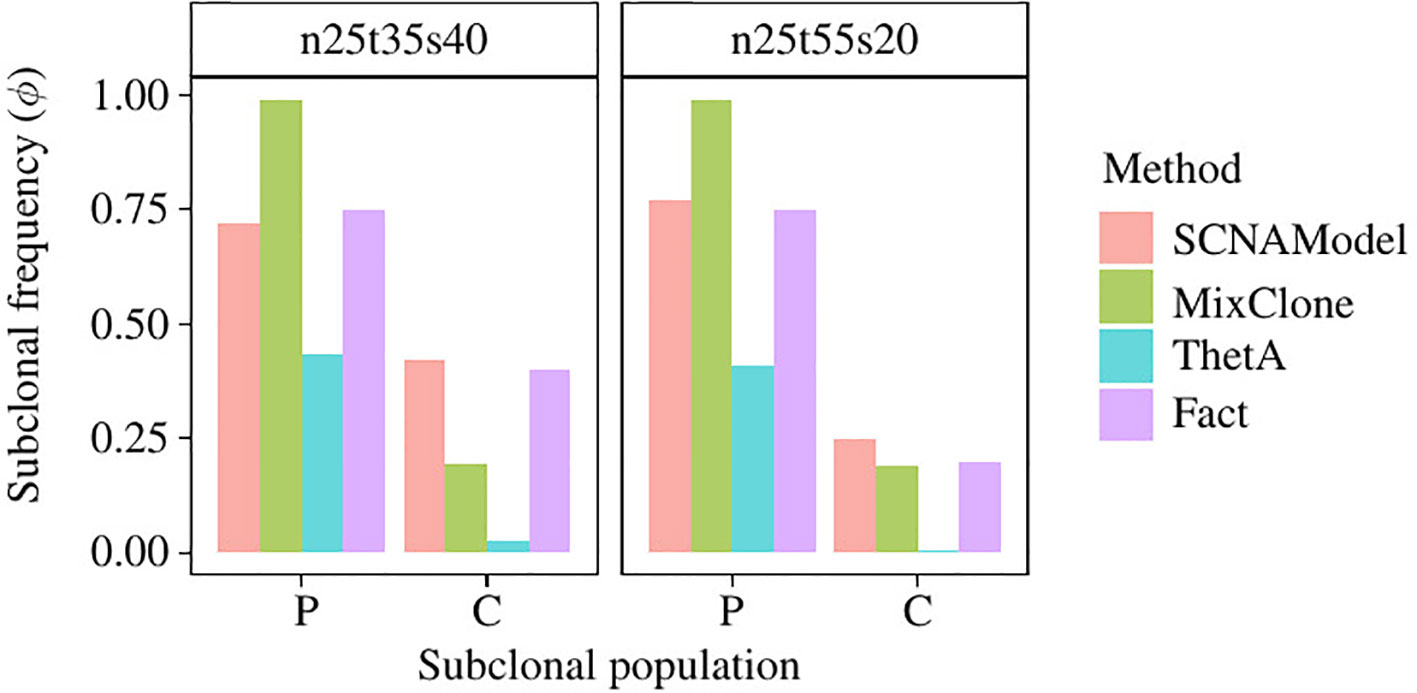
Figure 6 The subclonal proportion of SCNAs in HCC1954 data. In this figure, SCNAModel is the subclonal frequency inferring model proposed in this paper.
Generally, SCNAs with larger subclonal population frequency could relatively be more precisely located. However, due to the twice sequencing procedures of tumor and its paired normal, the read information of the genomic regions with the same copy number in tumor sample is not exactly the same as its paired normal’s. Moreover, the lower read coverage of NGS makes the noise/error more likely to be mistaken for an SCNA. As shown in Figure 7, the number of SCNA breakpoints obtained by SCNA detection tool is proportional to the subclonal population frequency. If there exists a large proportion of false negative breakpoints, it will cause the read count in the segments incapable to reveal the copy number property, then it will affect all the read count-based SCNA analysis tools. On the other hand, if there exists a large proportion of false positive breakpoints, the segment clustering step of filtering out the false positive breakpoints could reduce the data size and make the read count information more robust to noise by merging the SCNA segments with the same absolute copy number and subclonal population frequency. As shown in Theorem 1, the SCNA segments with the same RCR and average B-allele frequency are indistinguishable to the NGS-based SCNA analysis tools. Merging two non-adjacent SCNA segments with the same NGS properties could not affect the result of the NGS-based SCNA analysis tools.
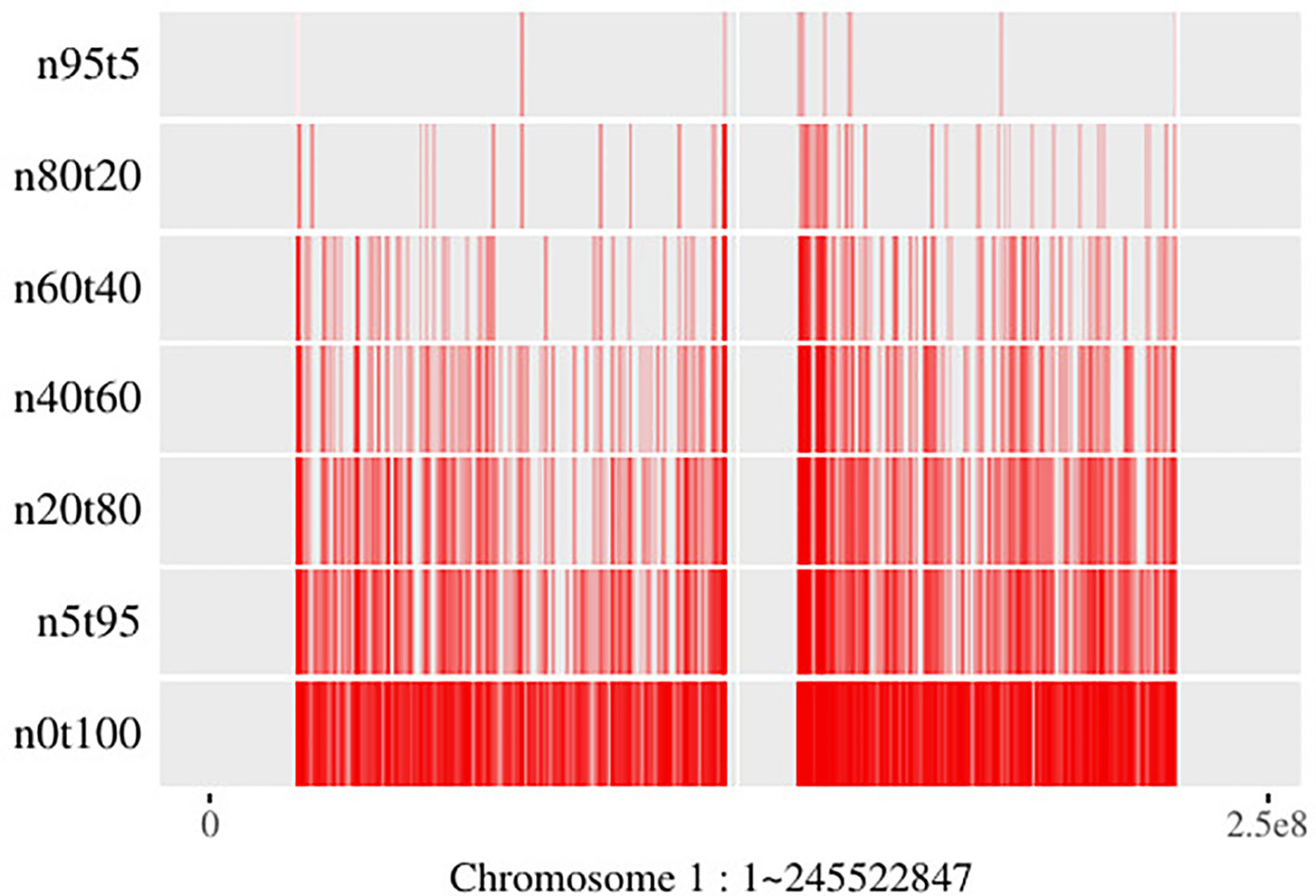
Figure 7 Breakpoints distribution on chromosome 1 of mixed “HCC1954” samples. Here the “n5t95” to “n95t5” respectively denote the tumor sample from “HCC1954.mix1.n5t95” to “HCC1954.mix1.n95t5.” “n0t100” denotes the tumor sample; “HCC1954” contains no normal contamination. Each of these samples contains one tumor subclone. All the breakpoints are obtained by BIC-seq (Xi et al., 2010).
Tree-Structured Stick Breaking (TSSB) process (Prescott Adams et al., 2010) could learn the tree structure of the hierarchical data. A tree structure space could be generated by intertwining two DP; then as described in Prescott’s paper (Prescott Adams et al., 2010), one can imagine throwing a dart (data) on the tree space and considering which node the dart hits. If we know subclonal number L in advance, then we could generate the tree structure in two steps. Step 1: generate a tree using all the data; Step 2: sort nodes by the sum of the size of the genome region hit, then find out the top L nodes and throw the rest of the darts (data not in the L nodes) into these L nodes randomly. Figure 7 shows that subclonal frequency affects the number of breakpoints; thus, there might present false positive or false negative breakpoints in the result of the SCNA detection tool. The false positive breakpoints could be filtered out by the algorithm in this paper. Even if there exist false breakpoints, the redundant data that contains the same SCNA might hit the same node in the tree space generated by the TSSB process. Thus, the redundant data affects the time and space consumption, but could not affect the result of subclonal reconstruction theoretically.
In this paper, we first perform a mathematical analysis of the solution space of SCNA’s subclonal frequency. Then based on the mathematical analysis, we propose an algorithm to filter out the false breakpoints and we construct a new probability model to reconstruct SCNA’s subclonal population, which incorporates the algorithms of RCR bias correction we previously proposed. We use the tree-structured stick breaking DP (Prescott Adams et al., 2010) to generate the tree structure space of tumor’s evolutionary history. In the probability model, the BAF of the heterozygous SNP locus in the SCNA segment is modeled as a binomial distribution and the read depth of tumor sampling data is modeled as a Poisson distribution with respect to the potential bias in RCR. We generate the distribution of subclonal frequency from the distribution of subpopulation frequency, which is drawn from the tree structure space. By stringing the model with the false breakpoint filtering algorithm, we construct a whole SCNA’s subclonal population reconstruction pipeline, which is capable of inferring SCNA’s absolute copy number and its subclonal population frequency and its evolutionary process while there are a lot of false positive SCNA breakpoints and the RCR presents bias. The results show that the model proposed in this paper could more accurately estimate the absolute copy number of SCNA segments and their subclonal population frequencies in comparison with existing methods both on simulated data and TCGA data.
Publicly available datasets were analyzed in this study. This data can be found here: https://gdc.cancer.gov/resources-tcga-users/tcga-mutation-calling-benchmark-4-files.
YC: Coming up with the theories and all the mathematical equations in this paper and implemented the initial version of P-SCNAClonal, the initial version of this paper. CN: Debugging of the initial version of P-SCNAClonal, experiments and result collecting, completed this paper with the result section. YW: Providing the basic idea and funding support.
This work was supported by funding from the National Key R&D Program of China (No: 2016YFC1202302 and 2017YFSF090117) and the National Nature Science Foundation of China (Grant No. 61822108 and 61571152).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2019.01374/full#supplementary-material
Beroukhim, R., Mermel, C. H., Porter, D., Wei, G., Raychaudhuri, S., Donovan, J., et al. (2010). The landscape of somatic copy-number alteration across human cancers. Nature 463, 899–905. doi: 10.1038/nature08822
Bignell, G. R., Santarius, T., Pole, J. C., Butler, A. P., Perry, J., Pleasance, E., et al. (2007). Architectures of somatic genomic rearrangement in human cancer amplicons at sequence-level resolution. Genome Res. 17, 000–000. doi: 10.1101/gr.6522707
Cheng, L., Sun, J., Xu, W., Dong, L., Hu, Y., Zhou, M. (2016). Oahg: an integrated resource for annotating human genes with multi-level ontologies. Sci. Rep. 6, 34820. doi: 10.1038/srep34820
Cheng, L., Yang, H., Zhao, H., Pei, X., Shi, H., Sun, J., et al. (2017). Metsigdis: a manually curated resource for the metabolic signatures of diseases. Briefings In Bioinf. 20, 203–209. doi: 10.1093/bib/bbx103
Cheng, L., Hu, Y., Sun, J., Zhou, M., Jiang, Q. (2018a). Dincrna: a comprehensive web-based bioinformatics toolkit for exploring disease associations and ncrna function. Bioinformatics 34, 1953–1956. doi: 10.1093/bioinformatics/bty002
Cheng, L., Jiang, H., Wang, S., Zhang, J. (2018b). Exposing the causal effect of c-reactive protein on the risk of type 2 diabetes mellitus: a mendelian randomisation study. Front. In Genet. 9, 657. doi: 10.3389/fgene.2018.00657
Cheng, L., Jiang, Y., Ju, H., Sun, J., Peng, J., Zhou, M., et al. (2018c). Infacront: calculating cross-ontology term similarities using information flow by a random walk. BMC Genomics 19, 919. doi: 10.1186/s12864-017-4338-6
Cheng, L., Wang, P., Tian, R., Wang, S., Guo, Q., Luo, M., et al. (2018d). Lncrna2target v2. 0: a comprehensive database for target genes of lncrnas in human and mouse. Nucleic Acids Res. 47, D140–D144. doi: 10.1093/nar/gky1051
Cheng, L., Qi, C., Zhuang, H., Fu, T., Zhang, X. (2019). gutmdisorder: a comprehensive database for dysbiosis of the gut microbiota in disorders and interventions. Nucleic Acids Res. D554–560. doi: 10.1093/nar/gkz843
Chu, Y., Teng, M., Wang, Z., Wang, Y., Wang, Y. (2017a).Pre-scnaclonal: Efficient gc bias correction for scna based tumor subclonal populations inferring, in: Bioinformatics and Biomedicine (BIBM), 2017 IEEE International Conference on (IEEE). pp. 262–265. doi: 10.1109/BIBM.2017.8217660
Chu, Y., Wang, L., Wang, R., Teng, M., Wang, Y. (2017b).Pysubsim-tree: A package for simulating tumor genomes according to tumor evolution history, in: Bioinformatics and Biomedicine (BIBM), 2017 IEEE International Conference on (IEEE). 48 (D1), 2195–2197. doi: 10.1109/BIBM.2017.8217998
Deshwar, A. G., Vembu, S., Yung, C. K., Jang, G. H., Stein, L., Morris, Q. (2015). Phylowgs: reconstructing subclonal composition and evolution from whole-genome sequencing of tumors. Genome Biol. 16, 1. doi: 10.1186/s13059-015-0602-8
Hudson, R. R. (1983). Properties of a neutral allele model with intragenic recombination. Theor. Popul Biol. 23, 183–201. doi: 10.1016/0040-5809(83)90013-8
Jiao, W., Vembu, S., Deshwar, A. G., Stein, L., Morris, Q. (2014). Inferring clonal evolution of tumors from single nucleotide somatic mutations. BMC Bioinf. 15, 35. doi: 10.1186/1471-2105-15-35
Kimura, M. (1969). The number of heterozygous nucleotide sites maintained in a finite population due to steady flux of mutations. Genetics 61, 893.
Lander, E. S., Waterman, M. S. (1988). Genomic mapping by fingerprinting random clones: a mathematical analysis. Genomics 2, 231–239. doi: 10.1016/0888-7543(88)90007-9
Li, Y., Xie, X. (2015). Mixclone: a mixture model for inferring tumor subclonal populations. BMC Genomics 16, S1. doi: 10.1186/1471-2164-16-S2-S1
Nowell, P. C. (1976). The clonal evolution of tumor cell populations. Science 194, 23–28. doi: 10.1126/science.959840
Oesper, L., Mahmoody, A., Raphael, B. J. (2013). Theta: inferring intra-tumor heterogeneity from high-throughput dna sequencing data. Genome Biol. 14, 1. doi: 10.1186/gb-2013-14-7-r80
Prescott Adams, R., Ghahramani, Z., Jordan, M. I. (2010). Tree-structured stick breaking processes for hierarchical data. arXiv preprint arXiv. 1006.1062, 1–16.
Wang, K., Li, M., Hadley, D., Liu, R., Glessner, J., Grant, S. F., et al. (2007). Penncnv: an integrated hidden markov model designed for high-resolution copy number variation detection in whole-genome snp genotyping data. Genome Res. 17, 1665–1674. doi: 10.1101/gr.6861907
Keywords: somatic copy number alternation, subclonal reconstruction, subclonal frequency, absolute copy number, bias correction
Citation: Chu Y, Nie C and Wang Y (2020) A Pipeline for Reconstructing Somatic Copy Number Alternation’s Subclonal Population-Based Next-Generation Sequencing Data. Front. Genet. 10:1374. doi: 10.3389/fgene.2019.01374
Received: 16 August 2019; Accepted: 16 December 2019;
Published: 27 February 2020.
Edited by:
Lei Deng, Central South University, ChinaCopyright © 2020 Chu, Nie and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yadong Wang, eWR3YW5nQGhpdC5lZHUuY24=">ydwang@hit.edu.cn
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.