
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet. , 26 November 2019
Sec. Computational Genomics
Volume 10 - 2019 | https://doi.org/10.3389/fgene.2019.01214
 Xiaowei Niu1,2,3,4Jingjing Zhang5Lanlan Zhang1,2,3,4Yangfan Hou6Shuangshuang Pu7Aiai Chu8Ming Bai1,2,3,4
Xiaowei Niu1,2,3,4Jingjing Zhang5Lanlan Zhang1,2,3,4Yangfan Hou6Shuangshuang Pu7Aiai Chu8Ming Bai1,2,3,4 Zheng Zhang1,2,3,4*
Zheng Zhang1,2,3,4*Background: The development of heart failure (HF) remains a common complication following an acute myocardial infarction (AMI), and is associated with substantial adverse outcomes. However, the specific predictive biomarkers and candidate therapeutic targets for post-infarction HF have not been fully established. We sought to perform a weighted gene co-expression network analysis (WGCNA) to identify key modules, hub genes, and possible regulatory targets involved in the development of HF following AMI.
Methods: Genes exhibiting the most (top 50%) variation in expression levels across samples in a GSE59867 dataset were imported to the WGCNA. Gene Ontology and pathway enrichment analyses were performed on genes identified in the key module by Metascape. Gene regulatory networks were constructed using the microarray probe reannotation and bioinformatics database. Hub genes were screened out from the key module and validated using other datasets.
Results: A total of 10,265 most varied genes and six modules were identified between AMI patients who developed HF within 6 months of follow-up and those who did not. Specifically, the blue module was found to be the most significantly related to the development of post-infarction HF. Functional enrichment analysis revealed that the blue module was primarily associated with the inflammatory response, immune system, and apoptosis. Seven transcriptional factors, including SPI1, ZBTB7A, IRF8, PPARG, P65, KLF4, and Fos, were identified as potential regulators of the expression of genes identified in the blue module. Further, non-coding RNAs, including miR-142-3p and LINC00537, were identified as having close interactions with genes from the blue module. A total of six hub genes (BCL3, HCK, PPIF, S100A9, SERPINA1, and TBC1D9B) were identified and validated for their predictive value in identifying future HFs.
Conclusions: By using the WGCNA, we provide new insights into the underlying molecular mechanism and molecular markers correlated with HF development following an AMI, which may serve to improve risk stratification, therapeutic decisions, and prognosis prediction in AMI patients.
Acute myocardial infarction (AMI) is characterized by myocardial necrosis resulting from exposure to prolonged ischemia after occlusion of a coronary artery (Anderson and Morrow, 2017). With advances in interventional cardiology techniques, technologies, and pharmaceutical therapies, all-cause mortality has decreased during the acute phase of AMI over the past few decades (Anderson and Morrow, 2017). However, due to an increase in the number of patients surviving in hospitals after an AMI, and an increasingly aging global population, the incidence of heart failure (HF) is continuing to increase (Anderson and Morrow, 2017). The development of HF following an AMI has become a major public health concern because these patients exhibit the high rates of hospitalization and poor survival rates, comparable to that of cancer (Anderson and Morrow, 2017; Giustino et al., 2018).
The progression to HF after AMI is multifactorial and influenced by the extent of myocardial damage at the time of the index events as well as by the process of left ventricular remodeling (Maciejak et al., 2015; Giustino et al., 2018). A more comprehensive understanding of the mechanisms involved in development of HF following AMI will allow us to identify patients at risk and tailor individualized management regimens for each patient, ultimately reducing the socio-economic burden of HF. Several biomarkers are known to be associated with cardiac remodeling and the development of HF. For example, B-type natriuretic peptide and N-terminal pro-brain natriuretic peptide have been reported to exhibit strong prognostic values in patients with acute coronary syndromes in terms of the development of HF (Haeck et al., 2010). Inflammation biomarkers, leukocyte count, and neutrophil to lymphocyte ratio were independently predictive of HF and adverse events following an AMI (Seropian et al., 2016; Niu et al., 2018). However, robust early predictive methods for the development of HF following an AMI remain elusive.
Transcriptional profiling is an effective approach to provide biological insight and rapid, unbiased screening of nearly whole transcriptomes to reveal the most promising biomarkers for recognizing risk carriers. Moreover, some studies have identified the genes involved in AMI progression by using gene expression profiles (Qian et al., 2018). However, the previous studies were mostly concerned with differentially expressed genes (DEGs) and did not consider clusters of highly correlated genes, which may be responsible for specific clinical features of interests. Weighted gene co-expression network analysis (WGCNA) is a bioinformatics application for exploring the relationships between different gene sets (modules), or between gene sets and clinical features (Langfelder and Horvath, 2008). The WGCNA describes the correlation patterns between genes across microarray samples and provides straightforward biologically functional interpretations of gene network modules (Langfelder and Horvath, 2008). Currently, the WGCNA has been successfully used to construct gene co-expression networks in various diseases, most notably in different cancers, and identify centrally connected hub genes as promising biomarkers or therapeutic targets (Chen et al., 2016; Li et al., 2019b; Wang et al., 2019). Additionally, the use of WGCNA can provide novel insights into which functional regulators may be driving transcriptional signatures in the development of AMI, such as transcription factors (TFs) (Chen et al., 2016), microRNAs (miRNAs) (Li et al., 2019b), and long non-coding RNAs (lncRNAs) (Wang et al., 2019). To date, there are few studies identifying the biomarkers that are functionally implicated in ventricular remodeling and with the ability to predict HF development following an AMI using the WGCNA algorithm.
In the present study, the WGCNA was constructed based on data from the discovery dataset GSE59867 obtained from the Gene Expression Omnibus (GEO) database. Key gene modules associated with the development of HF after AMI were identified, and the biological functions and pathways of genes in the key modules were analyzed. Hub genes in the key module were detected using other datasets from the GEO database, namely the validation dataset GSE42955. The diagnostic performance of the identified hub genes for HF development after AMI was evaluated by receiver operating characteristic (ROC) curve analysis of dataset GSE1869. Information on gene expression patterns associated with AMI during a follow-up of 6 months was also revealed. Furthermore, since TFs, miRNAs, and lncRNAs play important regulatory roles in human diseases, detailed analyses of these regulators will allow us to better understand the molecular mechanisms underlying post-infarction HF. We constructed TF-gene regulation networks, miRNA-target regulatory networks, and lncRNA–mRNA co-expression patterns for the key module. Based on the bioinformatic analyses, our study is expected to provide novel insights into the pathogenesis and progression of AMI, and identify distinct biomarkers that correlate with HF development.
A workflow for this study was presented in Figure 1. The datasets of GSE59867, GSE1869, and GSE42955 were obtained from the GEO database (http://www.ncbi.nlm.nih.gov/geo/). In the GSE59867 dataset (Maciejak et al., 2015), details on the development of HF during the 6-month follow-up were recorded for 65 samples obtained from 17 patients with AMI. The transcriptional profiling of peripheral blood mononuclear cells (PBMCs) in these 17 patients, which were performed at admission, discharge (4–6 days), 1 month, and 6 months after AMI, were selected for further analysis. There were no significant differences observed in the baseline demographic and clinical characteristics between HF (n = 9) and non-HF (n = 8) patients. This data were sequenced using the GPL6244 platform [Affymetrix Human Gene 1.0 ST Array, transcript (gene) version]. The GSE1869 dataset included 10 patients with HF post-AMI and 6 non-HF patients, and was performed using the platform GPL96 (Affymetrix U133A microarray) (Kittleson et al., 2005). The GSE42955 dataset included 12 patients with HF post-AMI and 5 non-HF patients, and was performed using the platform GPL6244 (Molina-Navarro et al., 2013).
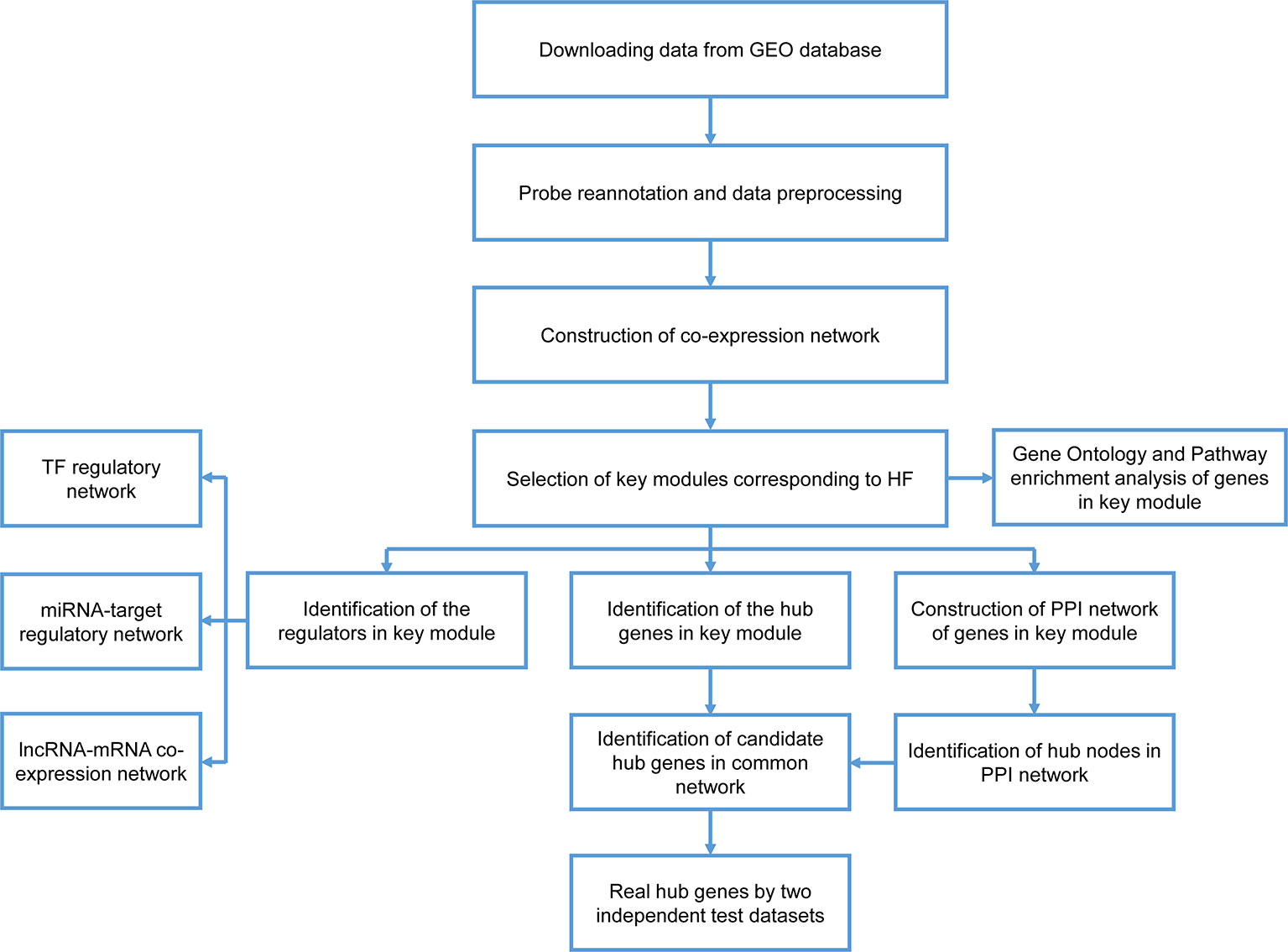
Figure 1 Flow chart of data preparation, processing, analysis, and validation.
The lncRNA expression data were obtained by reannotating the probes strategy according to previous studies (Zhang et al., 2012; Wang et al., 2017). Briefly, probe sets were mapped to RefSeq transcript IDs and/or Ensembl gene IDs based on the latest version of the NetAffx Annotation File (HuGene-1_0-st-v1 Probeset Annotations, CSV Format, Release 36). To make the screened lncRNAs be more reliable (Zhang et al., 2012; Wang et al., 2017), only probe sets that were labeled “NR” in the Refseq database and annotated with the non-coding RNA titles in the Ensembl database were retained, which resulted in 514 annotated lncRNA genes. If more than one probe corresponded to one gene, the expression value of that gene was computed by determining the median expression value of all its corresponding probes.
The data from the gene expression profiling analysis were preprocessed using Robust Multichip Average algorithm in the affy package within Bioconductor (http://www.bioconductor.org) in the R 3.3.1 software (R Foundation for Statistical Computing, Vienna, Austria). After correcting for background, and performing quantile normalization and log2-transformation, the data set containing 20,530 genes was further processed, and the 10,265 genes exhibiting the top 50% in high expression variance (minimize the loss of statistical information) were selected for the WGCNA (Li et al., 2017a).
The R package, WGCNA, was used to perform the weighted correlation network analysis (Langfelder and Horvath, 2008). Firstly, the gene co-expression similarity between genes m and n was defined as Smn = |cor(m, n)|. A power function was then applied to correlate adjacency of genes: amn = power (Smn, β) = |Smn|β. Scale independence and mean connectivity were then tested using a gradient method (the power value ranging from 1 to 20). When the degree of independence was determined to be above 0.80 (Langfelder and Horvath, 2008), an appropriate power value was screened out to obtain a scale-free network. Finally, the adjacency matrix was transformed into a topological overlap matrix, and modules were detected by hierarchical average linkage clustering analysis for the gene dendrogram. Additionally, we extracted the corresponding gene information for each module for further analysis.
After the modules were identified, the module eigengene (ME) was summarized by the first principal component of the module expression levels. Module–trait relationships were estimated using the correlation between MEs and clinical traits, which allowed efficient identification of the relevant modules. To evaluate the correlation strength, we calculated the module significance (MS), which is defined as the average absolute gene significance (GS) of all the genes involved in the module. The GS is measured as the log10 transformation of the P value (lgP) in the linear regression between gene expression and clinical information. In the WGCNA, modules with the highest MS score among all modules are usually defined as the key module and selected for further analysis (Langfelder and Horvath, 2008; Wright et al., 2015).
To understand the biological meaning of the key module, the gene information was loaded into Metascape (http://metascape.org) for Gene Ontology (GO) enrichment analysis (Zhou et al., 2019). Pathway enrichment analysis was carried out with the following ontology sources: Kyoto Encyclopedia of Genes and Genomes (KEGG) Pathway and Molecular Signatures Database (MSigDB) Hallmark Gene Sets (Zhou et al., 2019). Terms with a P value <0.05, a minimum count of 3, and an enrichment factor >1.5 were collected and grouped into clusters based on their membership similarities (Kappa scores >0.3) (Zhou et al., 2019). The most statistically significant term within a cluster was chosen to represent the cluster. If more than 20 terms for GO or pathway annotations were identified, the top 20 terms were chosen for visualization.
Enrichr (http://amp.pharm.mssm.edu/Enrichr/) is a comprehensive web-based tool that contains 180,184 annotated gene sets from 102 gene set libraries (Kuleshov et al., 2016). The gene information for the key module was imported into the Enrichr to obtain the interaction between transcription factors (TFs) and their target genes. To reduce the chance of identifying false-positives, we extracted TFs with consensus target genes existing in ChEA, ENCODE gene-set library, and position weight matrices from TRANSFAC and JASPAR. We then used the Cytoscape 3.4.0 software (Cytoscape Consortium, San Diego, CA, USA) to visualize the TF-target gene regulatory networks.
Two different miRNA target-predicting algorithms within the Enrichr tool, including TargetScan (Agarwal et al., 2015) and miRTarBase (Chou et al., 2018), were employed to screen potential miRNAs that regulate the genes in key modules. The TargetScan predicts biological targets of miRNAs by searching for the presence of mRNA sites that match the seed region of each miRNA (Agarwal et al., 2015). The miRTarBase is a curated database which has accumulated more than 50,000 miRNA–target interactions which are validated experimentally by reporter assay, western blot, microarray, and next-generation sequencing experiments (Chou et al., 2018). The common identified miRNAs were then used to construct miRNA–mRNA pairs. The regulatory association was displayed by the Cytoscape software.
Hub genes that are highly interconnected with nodes in a module have been shown to be functionally significant. Module membership (MM) represents how close a gene’s expression conforms to the characteristics of the module. The MM was calculated as correlation between individual gene expression values and ME. In this study, lncRNAs with highly intramodular connectivity (MM ≥ median) were retained to form connections of lncRNAs and mRNAs (Lunnon et al., 2012). The Pearson correlation coefficients (r) for the RNAs in the key module were calculated again to construct the lncRNA–mRNA co-expression network. Finally, the significant lncRNA–mRNA pairs (|r| ≥ median and P < 0.05) were visualized using the Cytoscape software.
Candidate hub genes were screened out using module connectivity, measured by MM ≥ median and clinical trait relationships, measured by GS ≥ median (Lunnon et al., 2012). To identify experimentally validated interactions in the key module, we uploaded all genes identified in the key module to the Search Tool for the Retrieval of Interacting Genes (STRING) database. Only protein–protein interactions (PPI) based on experiments with a combined score 0.4 were selected as significant. The subnetworks of PPI were then constructed with the plug-in MCODE in the Cytoscape (degree cut-off ≥2, node score cut-off ≥0.2, K-core ≥2, and max depth = 100). Genes identified in the MCODE subnetworks and exhibiting high MM and high GS in the co-expression network were chosen as the candidates for further analysis and validation.
The independent datasets GSE1869 and GSE42955 from the GEO database were extracted, and data were preprocessed by correcting for background and performing quantile normalization and log2-transformation. Another WGCNA using dataset GSE42955 were performed to validate the candidate hub genes. In the validation set GSE42955, a total of 11,653 genes exhibiting the top 50% in high expression variance were used for the WGCNA. The module with the maximal MS score among all modules was selected as the most relevant module in GSE42955. Genes with MM ≥ median and GS ≥ median in the relevant module were mapped to the candidate hub genes.
In GSE1869, the area under the curve (AUC) of the ROC was calculated to evaluate the diagnostic accuracy of the candidate hub genes mapped to genes in GSE42955. The AUC is the value of the Wilcoxon–Mann–Whitney statistic, and 95% confidence interval (CI) for AUC was computed using the standard normal distribution (Gengsheng and Hotilovac, 2008). Genes with the AUC ≥0.80 (P < 0.05) in ROC curve analysis represented clinically relevant genes and were defined as the real hub genes.
After preprocessing of the GSE59867 dataset, the microarray quality was evaluated by sample clustering according to the distance between different samples observed in Pearson’s correlation matrices. No outliers were detected in the clusters, and therefore 65 samples were used to construct a hierarchical clustering tree (dendrogram) (Supplementary Figure S1A). Next, a power of β = 12 was selected as the soft-threshold to ensure a scale-free network (Supplementary Figures S1B, C). As a result, 10,265 genes were grouped into a total of six modules using the average linkage hierarchical clustering algorithm.
As shown in Supplementary Figure S2, 2,933 genes to the blue module, 889 genes to the brown module, 170 genes to the green module, 4,753 genes to the turquoise module, and 332 genes to the yellow module. The genes that were not grouped into a module were included in the grey module, which was removed during the subsequent analysis.
The WGCNA was then used to correlate each module with all available clinical information (time points following AMI and HF progression) in the GSE59867 dataset by calculating the MS for each module–trait correlation (Figures 2A, B). After screening for strong correlations between all modules and HF progression, we found that the blue module had the highest MS value among all the selected modules. The ME in the blue module also exhibited a higher correlation with HF progression than other modules (R2 = 0.42 and P < 0.001). Additionally, we found that genes in the blue module were significantly affected on the first day of AMI (day of admission).
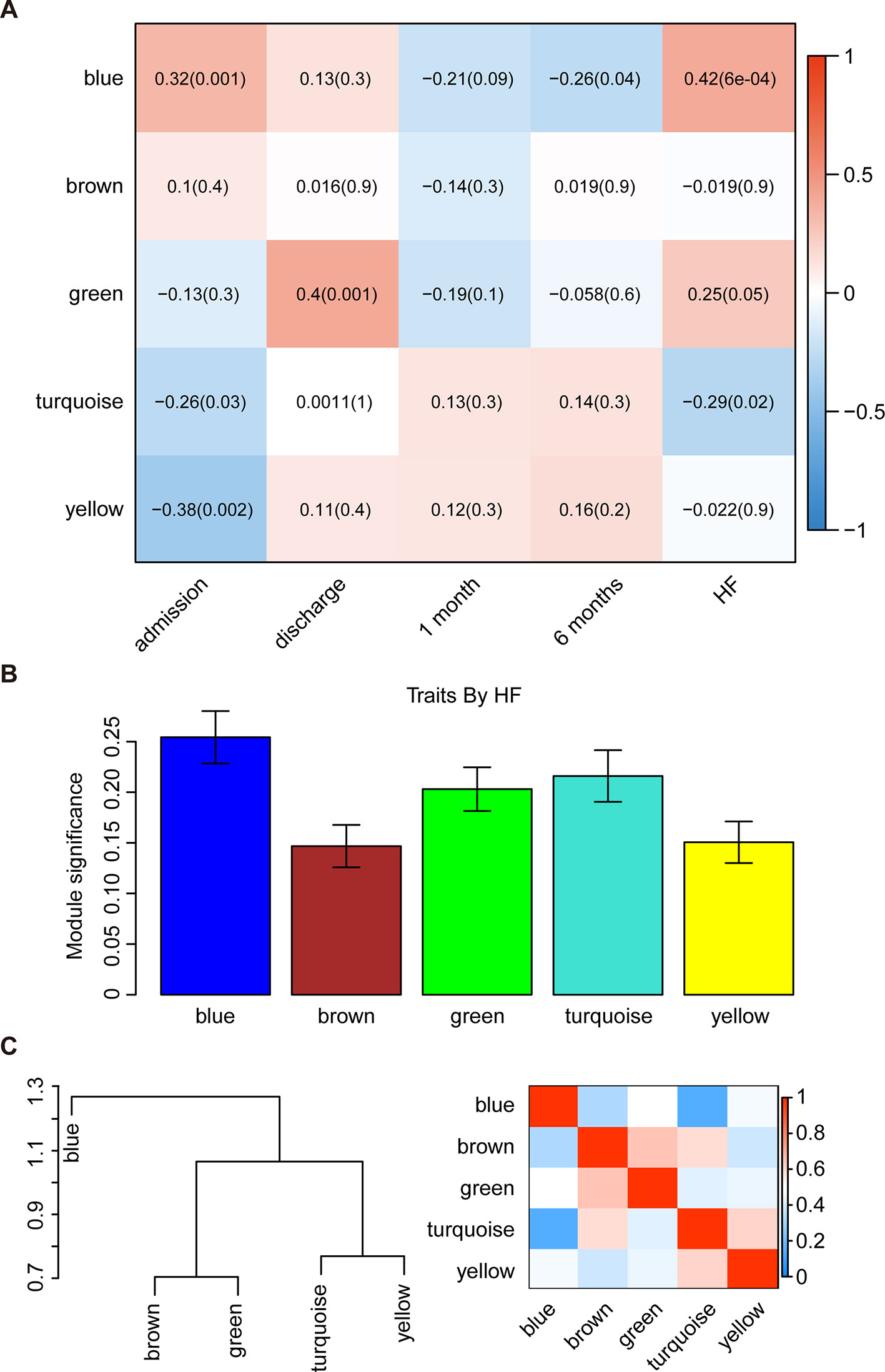
Figure 2 Identification of the key modules associated with the development of HF after AMI. (A) Heatmap depicting the correlation between module eigengenes and clinical traits of AMI. (B) Distribution of module significance and errors in the modules associated with the development of HF after AMI. (C) Hierarchical clustering dendrogram showing the module eigengenes and a heatmap of the adjacencies in the eigengene network (labeled according to by their module color names).
Interaction-based relationships for the five modules were illustrated in Figure 2C. The results revealed that the five modules were primarily divided into two clusters according to their ME correlation. Similar results were demonstrated using a heatmap, which showed the adjacencies in the eigengene network, suggesting a high level of independence among the modules. Therefore, the blue module was considered to be the key module, and was, therefore, chosen for further analysis.
To evaluate the affected functions for the genes clustered in the blue module, we performed GO and pathway analyses. We determined that these enriched pathways were closely connected with each other. The enriched results for the significant functions and pathways were presented in Figures 3A, B.
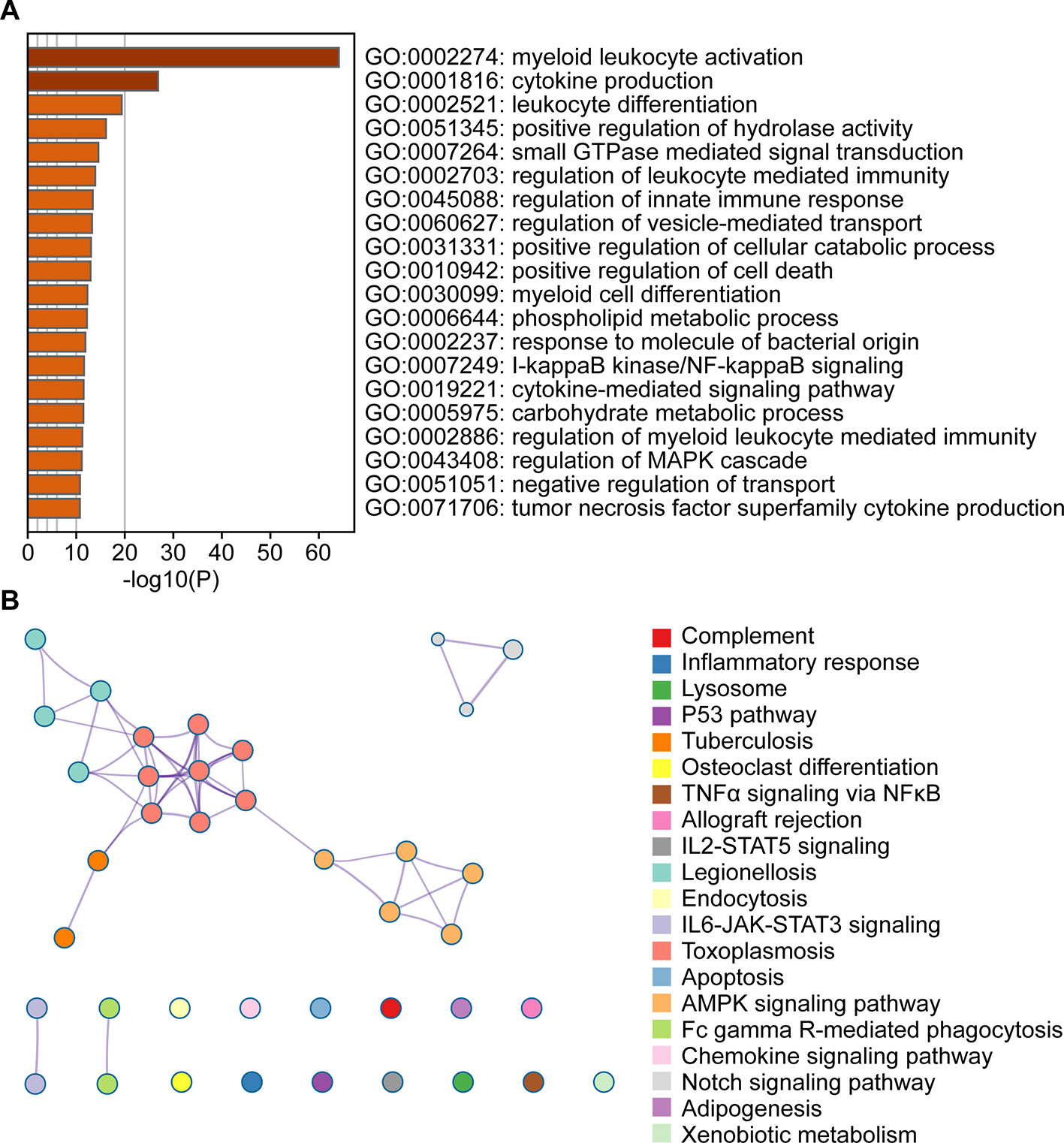
Figure 3 Functional enrichment analysis of the blue module genes. (A) Gene Ontology analysis of genes in the blue module. (B) KEGG pathway enrichment analysis of genes in the blue module.
To determine whether TFs may be responsible for the observed altered gene expression in the blue module, we inspected four data sources available in Enrichr, namely ENCODE, ChEA, TRANSFAC, and JASPAR. A total of 31 TFs were identified and seven among them were found to be present in the blue module, including Spi-1 proto-oncogene (SPI1) which had 20 target genes identified, zinc finger and BTB domain containing 7A (ZBTB7A) with 76 target genes, interferon regulatory factor 8 (IRF8) with 9 target genes, peroxisome proliferator activated receptor gamma (PPARG) with 27 target genes, P65 with 44 target genes, Kruppel like factor 4 (KLF4) with 29 target genes, and Fos proto-oncogene AP-1 transcription factor subunit (Fos) with 6 target genes. The TF-target gene regulatory network was displayed in Figure 4.
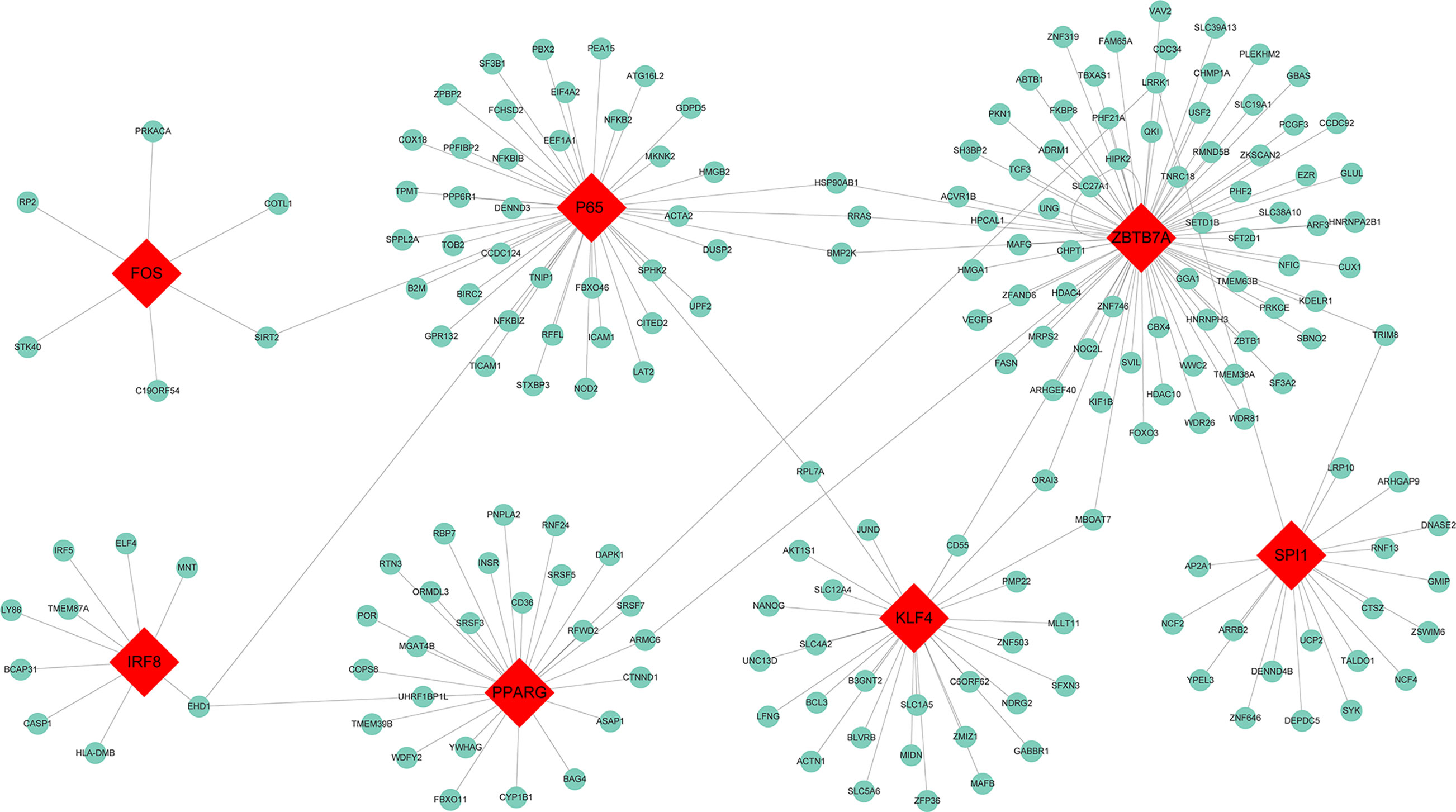
Figure 4 Transcription factor regulatory network for the genes in the blue module. Red diamonds represent the transcription factors, and green nodes represent the genes.
By using the TargetScan and miRTarBase databases, we were able to identify the 26 most common miRNAs responsible for regulating the target genes in the blue module (Figure 5). The greatest number of genes were regulated by miR-142-3p (degree = 47). Thus, these results indicated that miR-142-3p may serve a role in HF progression.
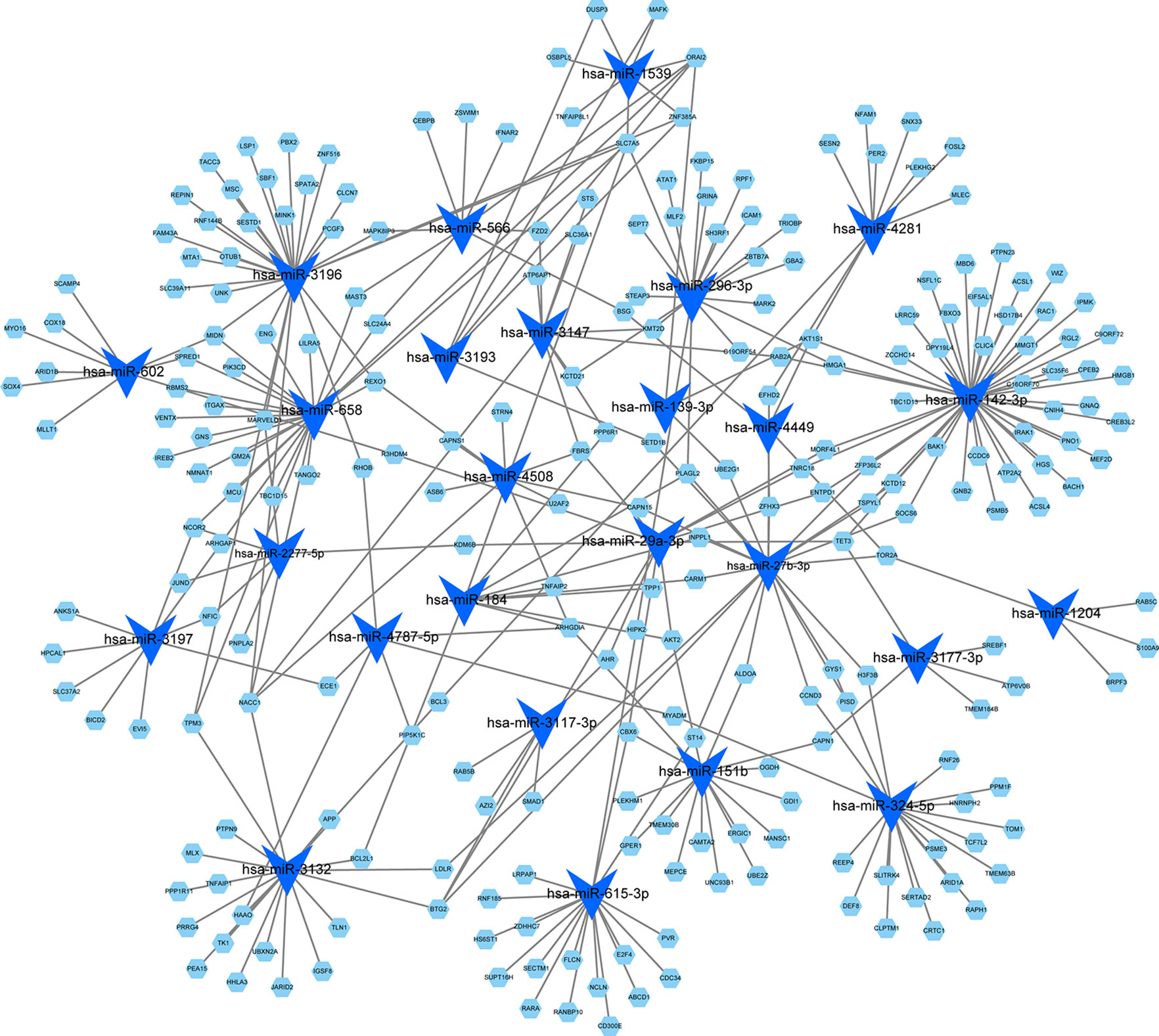
Figure 5 MicroRNA-target regulatory network for the blue module. Blue triangles represent the microRNAs, and green nodes represent the genes. The node size indicates the degree in the network.
The blue module contained 2,892 mRNAs and 41 lncRNAs. We extracted 13 lncRNAs with high MM (> 0.60) to calculate the |r| for each interaction pair, which included apoptosis associated transcript in bladder cancer (AATBC), ADAMTSL4 antisense RNA 1 (ADAMTSL4-AS1), EPB41L4A antisense RNA 1 (EPB41L4A-AS1), growth arrest specific 5 (GAS5), long intergenic non-protein coding RNA 00537 (LINC00537), long intergenic non-protein coding RNA 00852 (LINC00852), long intergenic non-protein coding RNA 00893 (LINC00893), long intergenic non-protein coding RNA 1000 (LINC01000), LOC254896, MIA-RAB4B readthrough (NMD candidate) (MIA-RAB4B), MIR4697 host gene (MIR4697HG), msh homeobox 2 pseudogene 1 (MSX2P1), and small nucleolar RNA host gene 12 (SNHG12). The gene pairs with |r| higher than 0.60 (P < 0.05) were retained to construct the lncRNA-mRNA co-expression network. As shown in Figure 6, the 13 lncRNAs were found to be functional associated with more than one gene. LINC00537 was found to be strongly connected (|r| range from 0.60 to 0.82) with the highest degree of connectivity (760) in the co-expression network.
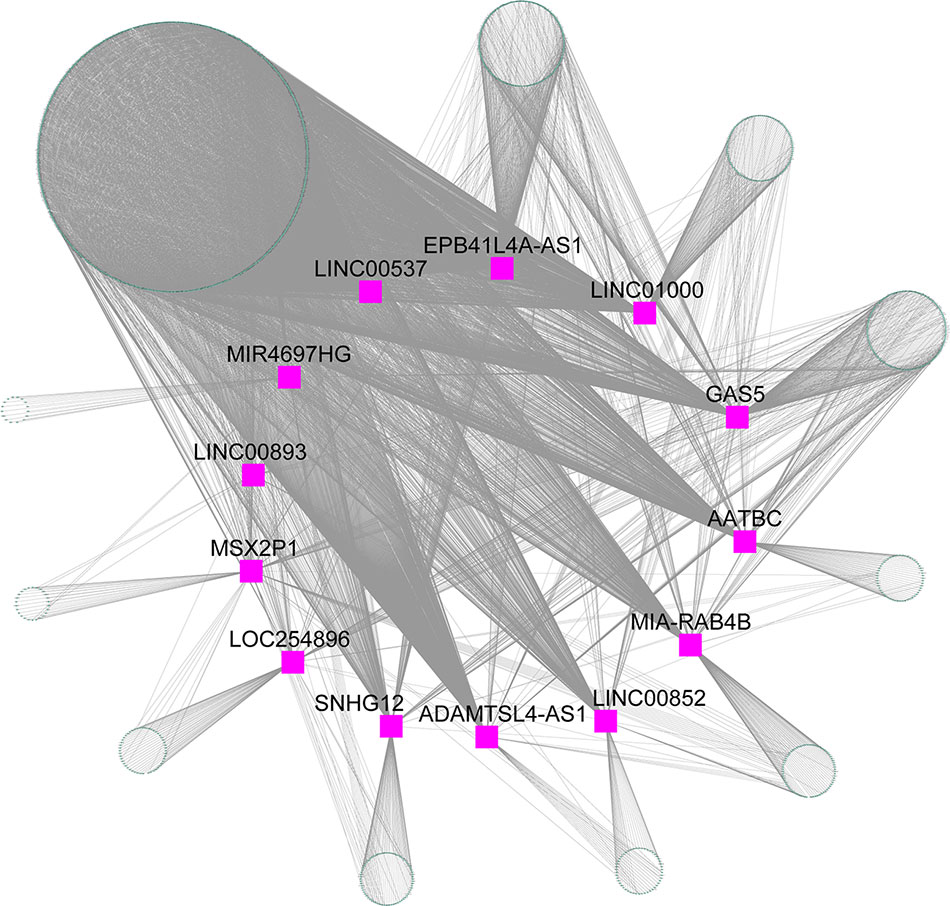
Figure 6 lncRNA-mRNA co-expression network for the blue module. Purple squares represent the lncRNA, and green nodes represent the genes.
To identify intramodular hub genes, we plotted the MM against the GS for traits that correlated with MEs. Under the condition of higher-than-median MM [≥0.60 (range 0.10–0.96)] and GS (≥ 0.24), 707 genes in the blue module were retained for further analysis (Figure 7A). The PPI network were constructed in the STRING database, which included a total of 2,520 nodes and 18,133 interaction pairs. Meanwhile, MCODE analysis was performed on the PPI network and an additional 899 genes, with high connective degrees, were filtered out (Figure 7B). A total of 211 candidate genes, identified both in the MCODE subnetworks and co-expression network, were included as potential intramodular hub genes (Figure 7B).
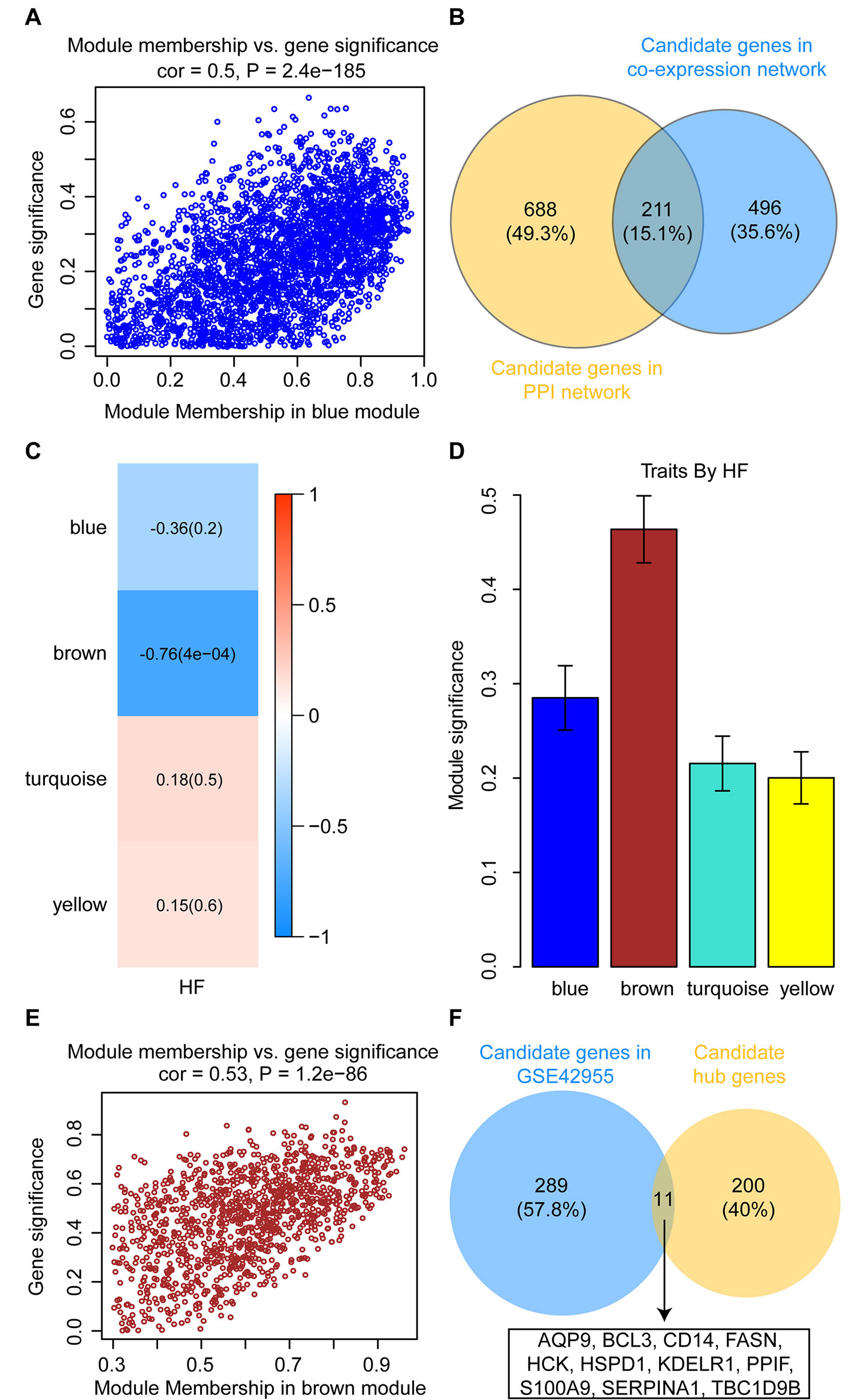
Figure 7 Identification and validation of candidate hub genes. (A) Scatterplot of gene significance versus module membership for the development of HF after AMI in the blue module. (B) Common genes between the co-expression network (GSE59867) and the MCODE sub-module of PPI network. (C) Heatmap depicting the correlation between module eigengenes and HF progression in the GSE42955 dataset. (D) Distribution of module significance and errors in the modules associated with the development of HF after AMI in the GSE42955 dataset. (E) Scatterplot of gene significance versus module membership for the development of HF after AMI in the brown module (GSE42955). (F) Common hub genes between the co-expression network (GSE42955) and the candidate hub genes.
In the GSE42955 dataset, 16 samples were used to construct a hierarchical clustering tree (dendrogram) (Supplementary Figure S3A). Next, a power of β = 14 was selected as the soft-threshold to ensure a scale-free network (Supplementary Figures S3B, C). The 11,653 genes were grouped into a total of five modules using the average linkage hierarchical clustering algorithm. As shown in Supplementary Figure S4, 2,355 genes to the blue module, 1,183 genes to the brown module, 5,817 genes to the turquoise module, and 1,165 genes to the yellow module. After screening for strong correlations between all modules and HF progression, we found that the brown module had the highest MS and ME values among all the selected modules (Figures 7C, D). Under the condition of higher-than-median MM [≥0.60 (range 0.30–0.96)] and GS (≥ 0.49), 300 genes in the brown module were retained for further analysis (Figure 7E). All candidate hub genes were mapped to the 300 genes in the GSE42955 datasets, and 11 genes of these candidate hub genes were validated (Figure 7F).
To further test the value of the candidate hub genes as prognostic biomarkers of HF, ROC curves were performed and the AUC (95% CIs) were calculated (Figure 8). The results indicated that six genes exhibited a high predictive accuracy for the development of HF after AMI, including B-cell leukemia/lymphoma 3 (BCL3), hematopoietic cell kinase (HCK), peptidylprolyl isomerase F (PPIF), S100 calcium binding protein A9 (S100A9), serpin family A member 1 (SERPINA1), and TBC1 domain family member 9B (TBC1D9B). Hence, these six genes were regarded as the real hub genes in the WGCNA.
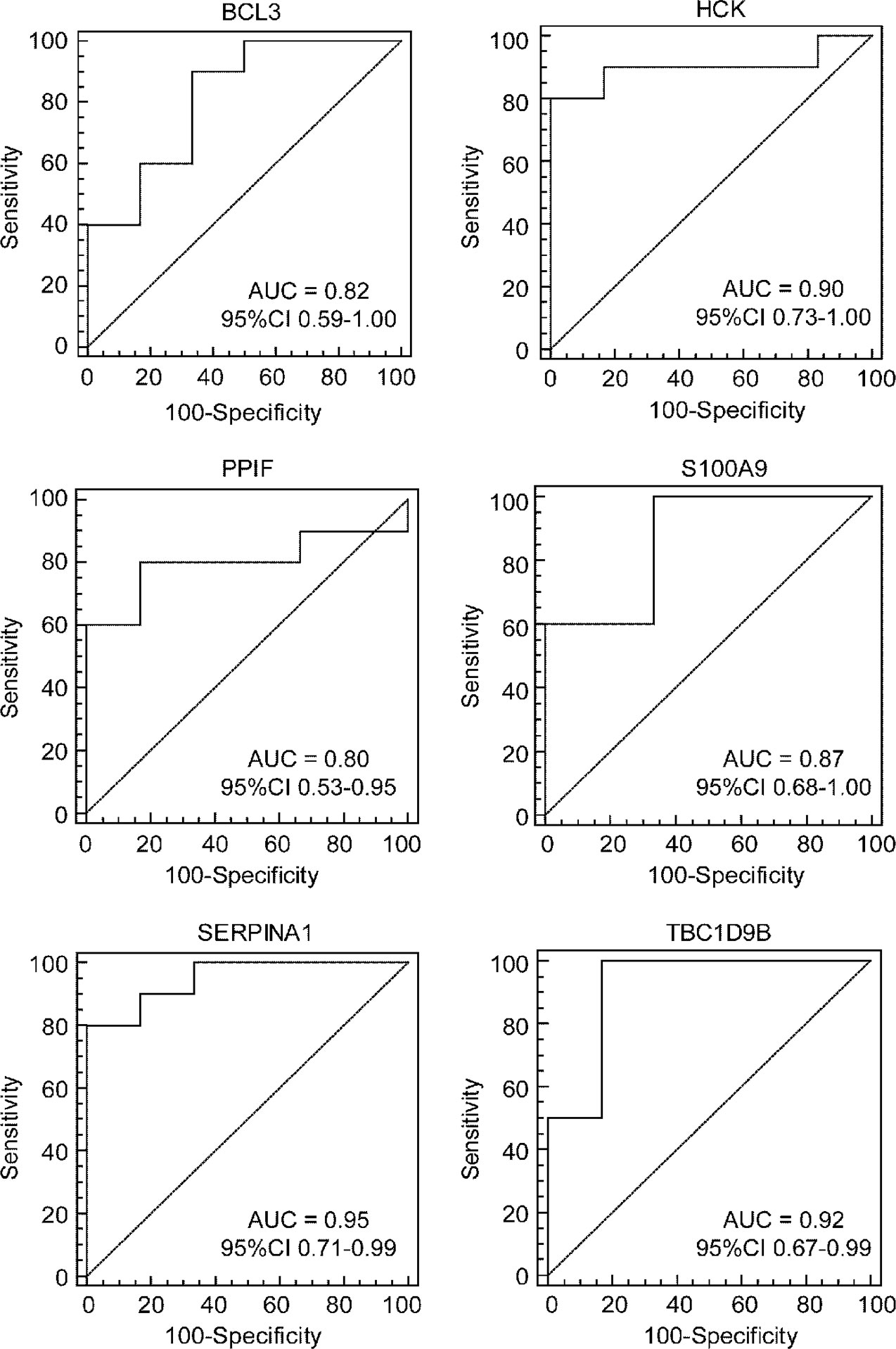
Figure 8 Identification of real hub genes. ROC curve analysis of the candidate hub genes in the GSE1869 dataset.
In the present study, we applied the WGCNA to identify biologically relevant transcripts significantly altered upon experiencing an AMI and throughout the subsequent clinical follow-up. We further identified the key modules and regulators of gene expression that were unique to patients who developed HF after AMI, and evaluated the usefulness of hub genes as prognostic biomarkers associated with post-infarction HF.
Compared with the previous studies, our investigation provides new insights into the pathogenesis of HF following AMI. Chen et al. analyzed DEGs between the AMI group and the healthy control group using the dataset GSE48060 (Chen et al., 2016). They revealed that TBX21 and PRF1 may be potential candidates for diagnostic biomarker in AMI. Similarly, Zhang et al. used the dataset GSE48060 to screen potential biomarkers for AMI development (Zhang et al., 2017b). Huan et al. analyzed coronary heart disease-related genes by constructing co-expression networks (Huan et al., 2013). In contrast, our study identified the key genes between AMI patients who developed HF within 6 months of follow-up and those who did not. Pang et al. constructed a comprehensive transcriptome profile using RNA-seq and miRNA-seq data of 16 patients with HF and 8 non-failing individuals (Pang et al., 2016). Their results provided deep insights into the critical roles of lncRNAs in the pathology of HF. However, the genes identified by Pang et al. came from patients with HF including ischemic and non-ischemic causes, which have been shown to be heterogeneous in terms of clinical presentation and prognosis (Zimmer et al., 2019). Our study identified the key genes in HF post-AMI, and determined the role the key genes as early prognostic biomarkers.
Transcriptional profiling has recently become a promising tool to investigate the specific molecular mechanisms underlying cardiovascular diseases, and to identify accurate biomarkers for disease progression (Vausort et al., 2014). Transcriptomic analysis of cardiac tissues would more accurately describe the etiology and pathophysiology of HF. However, biopsies may not always be a feasible option for patients with AMI. Peripheral blood cells are therefore an attractive alternative to cardiac biopsies. Numerous studies have demonstrated that PBMCs play important roles in the systemic and local inflammation associated with pathological remodeling after AMI (Epelman et al., 2015; Zimmer et al., 2019). Moreover, gene expression profiles of PBMCs and cardiomyocytes share common features in response to aldosterone treatment in hypertensive rats (Gerling et al., 2013), suggesting that transcriptional signatures of PBMCs may serve as early sentinels predictive of pathological remodeling. In addition to being non-invasive and convenient, the use of blood as a surrogate tissue has proven valuable in effectively revealing gene signatures for the development of diagnostic and prognostic biomarkers in coronary artery disease (Wingrove et al., 2008) and chronic HF (Cappuzzello et al., 2009).
AMI is the primary contributor of HF and loss of life among cardiovascular diseases (Anderson and Morrow, 2017). It is of clinical importance to identify factors associated with the molecular predisposition for developing HF to identify AMI patients requiring special care and treatment (Anderson and Morrow, 2017). In the WGCNA, we identified five unique gene modules based on gene expression profiling in PBMCs. The blue module was found to be most significantly related to the HF status in patients with AMI. The gene changes within the blue module were strongly induced on the first day of AMI, upon admission to the health care facility. These results suggested that the extent of myocardial damage during the acute phase is closely associated with the stable heart function progressing into HF (Epelman et al., 2015; Zimmer et al., 2019). The identified transcripts present during the first day of AMI can serve as a tool contributing to early diagnosis of the development of HF after AMI.
To comprehensively investigate the functions and pathways affected by genes in the blue module, a functional enrichment analysis was performed. We found that the genes in the blue module were significantly enriched in immunity and inflammation-related biological processes. These results were in accordance with previous reports which showed that the DEGs identified between HF and non-HF groups were highly associated with inflammatory-immune responses (Qian et al., 2018). Furthermore, our pathway analysis revealed that most annotated transcripts were associated with pathways related to inflammatory responses, the immune system, signal transduction, and apoptosis. Consistent with previous studies (Zhang et al., 2013), we also demonstrated that IL-6-JAK-STAT3 signaling played an important role in the pathogenesis of AMI. Multiple studies have suggested that high levels of pro-inflammatory cytokines like TNFα and IL-6 can contribute toward cardiac dysfunction and failure (Schumacher and Naga Prasad, 2018). The excessive apoptosis of myocardial cells has been demonstrated to induce the development of cardiac dysfunction after AMI (Zimmer et al., 2019). Therefore, these altered genes in the blue module are likely linked with the more severe initial injury to the myocardium which culminates in later stages of HF.
TFs are regulators of gene expression that are closely associated with the development and progression of post-infarction HF. In the current study, we assessed the effect of TFs on the expression of genes within the blue module, and identified seven TFs including SPI1, ZBTB7A, IRF8, PPARG, P65, KLF4, and Fos as significantly associated with these genes. Similarly, Qiao’s study also reported that SPI1, ZBTB7A, and IRF8 play crucial roles in the development of dilated cardiomyopathy and ischemic cardiomyopathy by regulating inflammation- and apoptosis-related genes (Qiao et al., 2017). The SPI1 gene encodes an ETS-domain TF that is involved in the differentiation or activation of macrophages and dendritic cells (Yashiro et al., 2019). Additionally, a recent study (Fischer et al., 2019) demonstrated that SPI1 shapes the neutrophil epigenome by positively, and negatively regulating distinct immune-associated gene sets, thereby protecting the host from undergoing uncontrolled activation of immune responses. Further, an RNA sequencing study examining cardiac hypertrophy demonstrated that SPI1 was significantly up-regulated in the pathogenesis of adverse myocardial remodeling (Song et al., 2012). ZBTB7A is a POZ-domain-containing protein that directly binds to many genomic regulatory sites and regulates transcription both by controlling chromatin structure and through recruiting TFs to genomic promoters and enhancers (Ramos Pittol et al., 2018). ZBTB7A has been reported to activate the transcription of nuclear factor kappa B (NF-κB)-induced genes by enhancing DNA accessibility in chromatin (Ramos Pittol et al., 2018). IRF8 is a TF from the interferon regulatory factor (IRF) family that is induced by interferon in a variety of cell types, such as macrophages and T cells (Jiang et al., 2014). IRF8 acts as a transcriptional activator or repressor through the formation of different DNA-binding heterocomplexes with multiple partners, including members of the IRF family (IRF1, IRF2, and IRF4) and non-IRF transcription factors (SPI1 and ZBTB17) (Jiang et al., 2014). Single-cell RNA sequencing analysis of the non-myocyte cellular landscape revealed that IRF8 is linked to chronic inflammation in the mouse heart (Skelly et al., 2018). Besides regulation of innate immune responses, IRF8 has been implicated as a tumor suppressor gene in certain cancers (Jiang et al., 2014). A study by Jiang et al. (2014) found that the expression level of IRF8 was down-regulated in the hearts of patients with dilated/hypertrophic cardiomyopathy. Moreover, the cardiac-specific overexpression of IRF8 in mice was found to be protective against aortic banding-induced cardiac hypertrophy. The authors provide mechanistic data to demonstrate that IRF8 interacts with nuclear factor of activated T cells 1 (NFATC1) to prevent nuclear translocation of the latter, and thus inhibits the hypertrophic response. PPARG is a member of the peroxisome proliferator-activated receptor subfamily of nuclear receptors (Mistry and Cresci, 2010). Once activated by a ligand, PPARG binds to its cognate DNA regulatory element as a heterodimer with retinoid X receptors and modulates conformation of the nuclear receptor complex resulting in the association of co-activators, release of co-repressors, and increased transcriptional activation of target genes (Mistry and Cresci, 2010). PPARG has been implicated in the pathology of numerous diseases including obesity, diabetes, atherosclerosis, and cancer (Mistry and Cresci, 2010). PPARG has also been shown to exert cardioprotective properties by suppressing inflammation, oxidative stress and apoptosis, and improving glucose and lipid metabolism (Mirza et al., 2019). Furthermore, when hypercholesterolemic rabbits were pretreated with the PPARG agonist rosiglitazone prior to ischemia/reperfusion or AMI, there was a significant decrease in the number of apoptotic cardiomyocytes and size of myocardial infarct observed (Liu et al., 2004). In a HF rat model, the PPARG agonist, pioglitazone, has also been shown to prevent myocardial fibrosis and HF development through the suppression of the Wnt-β-catenin signaling pathway (Kamimura et al., 2016). NF-κB is a homo- or heterodimeric complex formed by NFKB1/P105 or NFKB2/P52 bound to either REL, P65/RELA, or RELB (Sorriento and Iaccarino, 2019). The heterodimeric P65-NFKB1 complex is the most abundant form of NF-κB. Inappropriate activation of NF-κB initiates the inflammatory cascade and apoptosis-associated genes, which contributes to progressive cardiac dysfunction (Sorriento and Iaccarino, 2019). KLF4 can act both as activator and as repressor that binds the 5′-CACCC-3′ core sequence (Liao et al., 2010). KLF4-deficiency impairs mitochondrial homeostasis and leads to HF development (Liao et al., 2010). Fos can dimerize with proteins of the JUN family, thereby forming the TF complex AP-1. Activation of AP-1 has been shown to be a central component in TGFβ-mediated cardiac fibrosis (Gabriel-Costa, 2018). Collectively, our results revealed that the seven TFs formed a connected regulatory network with genes in the blue module, thus suggesting that the changes in these TF activities may have important roles in the occurrence and progression of post-infarction HF.
Although more than 90% of all mammalian genomes are positively transcribed, less than 2% are subsequently translated into proteins and a large proportion are transcribed as non-protein-coding RNAs (Djebali et al., 2012; Yang et al., 2014). Non-coding RNAs are known to regulate gene expression through diverse mechanisms, such as chromatin remodeling, post-transcriptional regulation, and translational control (Djebali et al., 2012). Among the non-coding RNAs, miRNAs and lncRNAs have been investigated in patients with AMI. A recent study by Li et al. integrated multiple microarray data sets including GSE48060, GSE66360, GSE97320, and GSE19339 to identify miRNAs in patients with AMI and in control subjects (Li et al., 2019b). Four miRNAs, namely, let-7d, let-7b, miR-124-3, and miR-9-1, were predicted to be involved in the pathogenesis of AMI. However, these four miRNAs were not detected in our study. This discrepancy may be attributed to different inclusion criteria for patient selection. Our study found that miR-142-3p regulated a large portion of the genes in the blue module that contributed to the development of HF after AMI. Up-regulating miR-142-3p has been reported to ameliorate myocardial ischemic injury (Su et al., 2019) and attenuate cardiac hypertrophy (Liu et al., 2018a). Recently, Vausort et al. quantified the expression levels of five lncRNAs in patients with AMI using quantitative polymerase chain reaction (Vausort et al., 2014). The results showed that the levels of specific lncRNAs including aHIF, ANRIL, KCNQ10T1, MALAT1, and MIAT in PBMCs were differentially expressed following AMI and may assist in the prediction of cardiac outcomes. However, the selection of these five lncRNAs was subjective. Therefore, an unbiased transcriptional profiling approach would be more informative in identifying many other lncRNAs regulated following AMI, and potentially in discriminating HF development. In our study, through transcriptomics-based screening, we found that the 13 identified lncRNAs exhibited close interactions with genes in the blue module. Studies have revealed that AATBC (Zhao et al., 2015), ADAMTSL4-AS1 (Annunziato et al., 2019), EPB41L4A-AS1 (Liao et al., 2019), MIA-RAB4B (Thean et al., 2017), MIR4697HG (Zhang et al., 2017a), GAS5 (Ni et al., 2019), SNHG12 (Tamang et al., 2019), MSX2P1 (Qiao et al., 2018), and LINC00852 (Liu et al., 2018b) are related to tumorigenesis and tumor progression in multiple cancers, such as bladder, breast, colorectal, and ovarian. Apart from the nine lncRNAs identified in biological experiments, LOC254896 (Singh et al., 2018), LINC01000 (Mitchell et al., 2017), LINC00893 (Li et al., 2019a), and LINC00537 (Li et al., 2017b) were also reported to be significantly differentially expressed between diseased and normal tissues in some transcriptional profiling analyses. Considering their reproducibility across platforms and cohorts, the three transcripts may not be technical artifacts, but rather surrogates of the underlying biology. To date, there are few studies on AMI showing the functional role of the miRNAs and lncRNAs identified in the present WGCNA. Functionally related genes often exhibit similar expression patterns under diverse conditions in DNA microarray experiments (Segal et al., 2003). Thus, analysis of gene co-expression relationships has been considered to be a useful method for exploring the functions of many genes for which information is currently unavailable (Wang et al., 2019). By constructing the miRNA-target regulatory network and lncRNA-mRNA co-expression network, the biological functions of the non-coding RNAs can be inferred from the GO and KEGG pathway enrichment analyses of the known genes in the module. Therefore, the functional annotation of the blue module detected by the WGCNA provided us with a first step toward uncovering functions of the miRNAs and lncRNAs in AMI on a global scale. Additional work will be required to delineate regulatory functions for these non-coding RNAs in the pathological remodeling after AMI.
Our study identified 211 transcripts significantly affected in HF patients, of which six of the most promising, namely, BCL3, HCK, PPIF, S100A9, SERPINA1, and TBC1D9B, were analyzed further. The IκB family member, BCL3, was initially identified as a proto-oncogene (Kreisel et al., 2011). Numerous studies have demonstrated that BCL3 not only inhibits the nuclear translocation of the NFκB p50 subunit in the cytoplasm, but also contributes to the regulation of NFκB target genes in the nucleus (Gordon et al., 2011). BCL3 expression has been shown to negatively regulate inflammatory responses through limiting emergency granulopoiesis (Kreisel et al., 2011). Increased expression of NFκB p50 promotes cardiac remodeling and deterioration of cardiac function following AMI (Frantz et al., 2006). Moreover, BCL3 was shown to synergize with PPARG coactivator 1α (PGC-1α) to activate estrogen-related receptor α (ERRα) (Yang et al., 2009). The deactivation of the PGC-1α/ERRα axis are implicated as important mechanisms in the transition from compensated cardiac hypertrophy to HF (Schilling and Kelly, 2011). HCK is a non-receptor tyrosine kinase and plays an important role in the regulation of innate immune responses, phagocytosis, cell survival and proliferation, and cell adhesion and migration (Kovács et al., 2014). HCK has also been described as the key regulator of phagocytosis in macrophages (Tao et al., 2015). When the phagocytosis of apoptotic cardiomyocytes is defective, a persistent proinflammatory state chronically exists in the setting of ischemic injury, thereby predisposing the patients to impaired cardiac function (Tao et al., 2015). PPIF locates in the inner mitochondrial membrane and is involved in regulation of the mitochondrial permeability transition pore (mPTP). The immunosuppressive agent cyclosporin A exhibited significant cardioprotective effects against ischemic injury through inhibiting mPTP formation via binding with PPIF (Zhang et al., 2019). S100A9 is a calcium- and zinc-binding protein and is constitutively expressed in neutrophils, dendritic cells, and monocytes. S100A9 deficiency leads to an exacerbated release of cytokines in dendritic cells following stimulation of toll-like receptors (Averill et al., 2011). Additionally, S100A9 has been shown to exert a protective role in preventing exaggerated tissue damage by scavenging oxidants (Gomes et al., 2013). SERPINA1 is the most abundant serine protease inhibitor in human blood and exerts anti-inflammatory and immune-modulatory effects. Genetic SERPINA1 deficiency was associated with increased cardiovascular risk (Curjuric et al., 2018). TBC1D9B, a GTPase-activating protein for Rab family protein, positively regulated autophagic flux by interacting with LC3B (Liao et al., 2018). Taken together, we found that BCL3, HCK, PPIF, S100A9, and SERPINA1 may have important roles in the development of HF through regulating local and systemic inflammation. Furthermore, the ROC analysis has indicated that the six identified hub genes are likely to be good biomarkers with high sensitivity and specificity for HF prognosis in patients with AMI. Further studies and experimental verification are needed to determine clinical usefulness of the six hub genes as a non-invasive test for prognosis of HF development.
This study is significant in that it identifies several key genes involved in HF development in post-AMI patients via comprehensive bioinformatics methods. To our knowledge, this was the first study to identify key lncRNAs associated with the development of post-infarction HF through the use of probe re-annotation and the WGCNA algorithm. These findings may serve to clarify the pathophysiology of cardiac remodeling and to identify blood biomarkers in patients at high risk for the development of HF following AMI. However, mRNA levels and protein expression of the identified genes, including 7 TFs, 26 miRNAs, 13 lncRNAs, and 6 hub genes were not confirmed via further experiments. Additionally, the probe re-annotation in microarrays is not capable of identifying all lncRNAs, and thus a deep RNA sequencing experiment that encompasses cardiac coding (mRNA) and non-coding (miRNA and lncRNA) transcriptomes will provide a more detailed understanding of the myocardial transcriptome landscape in HF after AMI.
Our study used the WGCNA to construct a gene co-expression network, and to identify and validate the key modules and hub genes associated with the development of HF after AMI. Six hub genes, including BCL3, HCK, PPIF, S100A9, SERPINA1, and TBC1D9B that differentiated on admission after myocardial infarction the HF patients from the non-HF ones, can serve as early prognostic biomarkers of post-AMI patients. Moreover, seven TFs (SPI1, ZBTB7A, IRF8, PPARG, P65, KLF4, and Fos), as well as miR-142-3p, and LINC00537 were predicted to regulate the key genes that contributed to the pathophysiological consequences of AMI. Although our investigation is of a preliminary nature, this study provides new insights into the pathogenesis of HF following AMI and may, therefore, have significant implications for potential therapeutic targets of AMI.
All datasets for this study are included in the article.
XN and ZZ conceived and designed the study. XN, JZ, LZ, YH, SP, AC, and MB performed the study. XN, LZ, YH, SP, and AC analyzed the data. XN and ZZ wrote the manuscript. JZ, LZ, YH, SP, AC, and MB critically revised intellectual content of the manuscript.
The authors acknowledge financial support from Research Project of Gansu Provincial Administration of Traditional Chinese Medicine (GZK-2018-48). Undergraduate Training Program for Innovation and Entrepreneurship of Lanzhou University (20190060188), and Excellent Plan for Student Scientific Research Innovation Cultivation Project (20190060188).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors sincerely thank Shaobo Sun and Yingdong Li from Traditional Chinese Medicine of Gansu Province for their support during the study.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2019.01214/full#supplementary-material
Supplementary Figure S1 | Clustering of samples and determination of soft-thresholding power in GSE59867. (A) Clustering dendrogram of 65 samples in the dataset GSE59867. Red, Yes; Green, No. (B) Analysis of the scale-free fit index for various soft-thresholding powers (β). (C) Analysis of the mean connectivity for various soft-thresholding powers.
Supplementary Figure S2 | Identification of distinct modules for co-expressed genes in AMI using WGCNA in GSE59867.
Supplementary Figure S3 | Clustering of samples and determination of soft-thresholding power in GSE42955. (A) Clustering dendrogram of 16 samples in the dataset GSE42955. Red, Yes; Green, No. (B) Analysis of the scale-free fit index for various soft-thresholding powers (β). (C) Analysis of the mean connectivity for various soft-thresholding powers.
Supplementary Figure S4 | Identification of distinct modules for co-expressed genes in AMI using WGCNA in GSE42955.
Agarwal, V., Bell, G. W., Nam, J. W., Bartel, D. P. (2015). Predicting effective microRNA target sites in mammalian mRNAs. Elife 4, e05005. doi: 10.7554/eLife.05005
Anderson, J. L., Morrow, D. A. (2017). Acute myocardial infarction. N. Engl. J. Med. 376 (21), 2053–2064. doi: 10.1056/NEJMra1606915
Annunziato, S., de Ruiter, J. R., Henneman, L., Brambillasca, C. S., Lutz, C., Vaillant, F. (2019). Comparative oncogenomics identifies combinations of driver genes and drug targets in BRCA1-mutated breast cancer. Nat. Commun. 10 (1), 397. doi: 10.1038/s41467-019-08301-2
Averill, M. M., Barnhart, S., Becker, L., Li, X., Heinecke, J. W., Leboeuf, R. C. (2011). S100A9 differentially modifies phenotypic states of neutrophils, macrophages, and dendritic cells: implications for atherosclerosis and adipose tissue inflammation. Circulation 123 (11), 1216–1226. doi: 10.1161/circulationaha.110.985523
Cappuzzello, C., Napolitano, M., Arcelli, D., Melillo, G., Melchionna, R., Di Vito, L. (2009). Gene expression profiles in peripheral blood mononuclear cells of chronic heart failure patients. Physiol. Genomics 38 (3), 233–240. doi: 10.1152/physiolgenomics.90364.2008
Chen, J., Yu, L., Zhang, S., Chen, X. (2016). Network analysis-based approach for exploring the potential diagnostic biomarkers of acute myocardial infarction. Front. Physiol. 7, 615. doi: 10.3389/fphys.2016.00615
Chou, C. H., Shrestha, S., Yang, C. D., Chang, N. W., Lin, Y. L., Liao, K. W. (2018). miRTarBase update 2018: a resource for experimentally validated microRNA-target interactions. Nucleic Acids Res. 46 (D1), D296–D302. doi: 10.1093/nar/gkx1067
Curjuric, I., Imboden, M., Bettschart, R., Caviezel, S., Dratva, J., Pons, M. (2018). Alpha-1 antitrypsin deficiency: from the lung to the heart?. Atherosclerosis 270, 166–172. doi: 10.1016/j.atherosclerosis.2018.01.042
Djebali, S., Davis, C. A., Merkel, A., Dobin, A., Lassmann, T., Mortazavi, A. (2012). Landscape of transcription in human cells. Nature 489 (7414), 101–108. doi: 10.1038/nature11233
Epelman, S., Liu, P. P., Mann, D. L. (2015). Role of innate and adaptive immune mechanisms in cardiac injury and repair. Nat. Rev. Immunol. 15 (2), 117–129. doi: 10.1038/nri3800
Fischer, J., Walter, C., Tönges, A., Aleth, H., Jordão, M. J. C., Leddin, M. (2019). Safeguard function of PU.1 shapes the inflammatory epigenome of neutrophils. Nat. Immunol. 20 (5), 546–558. doi: 10.1038/s41590-019-0343-z
Frantz, S., Hu, K., Bayer, B., Gerondakis, S., Strotmann, J., Adamek, A. (2006). Absence of NF-kappaB subunit p50 improves heart failure after myocardial infarction. FASEB J. 20 (11), 1918–1920. doi: 10.1096/fj.05-5133fje
Gabriel-Costa, D. (2018). The pathophysiology of myocardial infarction-induced heart failure. Pathophysiology 25 (4), 277–284. doi: 10.1016/j.pathophys.2018.04.003
Gengsheng, Q., Hotilovac, L. (2008). Comparison of non-parametric confidence intervals for the area under the ROC curve of a continuous-scale diagnostic test. Stat. Methods Med. Res. 17 (2), 207–221. doi: 10.1177/0962280207087173
Gerling, I. C., Ahokas, R. A., Kamalov, G., Zhao, W., Bhattacharya, S. K., Sun, Y. (2013). Gene expression profiles of peripheral blood mononuclear cells reveal transcriptional signatures as novel biomarkers of cardiac remodeling in rats with aldosteronism and hypertensive heart disease. JACC Heart Fail. 1 (6), 469–476. doi: 10.1016/s2213-1779(13)00374-0
Giustino, G., Redfors, B., Brener, S. J., Kirtane, A. J., Généreux, P., Maehara, A. (2018). Correlates and prognostic impact of new-onset heart failure after ST-segment elevation myocardial infarction treated with primary percutaneous coronary intervention: insights from the INFUSE-AMI trial. Eur. Heart J. Acute Cardiovasc. Care 7 (4), 339–347. doi: 10.1177/2048872617719649
Gomes, L. H., Raftery, M. J., Yan, W. X., Goyette, J. D., Thomas, P. S., Geczy, C. L. (2013). S100A8 and S100A9-oxidant scavengers in inflammation. Free Radic. Biol. Med. 58, 170–186. doi: 10.1016/j.freeradbiomed.2012.12.012
Gordon, J. W., Shaw, J. A., Kirshenbaum, L. A. (2011). Multiple facets of NF-κB in the heart: to be or not to NF-κB. Circ. Res. 108 (9), 1122–1132. doi: 10.1161/circresaha.110.226928
Haeck, J. D., Verouden, N. J., Kuijt, W. J., Koch, K. T., Van Straalen, J. P., Fischer, J. (2010). Comparison of usefulness of N-terminal pro-brain natriuretic peptide as an independent predictor of cardiac function among admission cardiac serum biomarkers in patients with anterior wall versus nonanterior wall ST-segment elevation myocardial infarction undergoing primary percutaneous coronary intervention. Am. J. Cardiol. 105 (8), 1065–1069. doi: 10.1016/j.amjcard.2009.12.003
Huan, T., Zhang, B., Wang, Z., Joehanes, R., Zhu, J., Johnson, A. D. (2013). A systems biology framework identifies molecular underpinnings of coronary heart disease. Arterioscler. Thromb. Vasc. Biol. 33 (6), 1427–1434. doi: 10.1161/atvbaha.112.300112
Jiang, D. S., Wei, X., Zhang, X. F., Liu, Y., Zhang, Y., Chen, K. (2014). IRF8 suppresses pathological cardiac remodelling by inhibiting calcineurin signalling. Nat. Commun. 5, 3303. doi: 10.1038/ncomms4303
Kamimura, D., Uchino, K., Ishigami, T., Hall, M. E., Umemura, S. (2016). Activation of peroxisome proliferator-activated receptor γ prevents development of heart failure with preserved ejection fraction; inhibition of Wnt-β-catenin signaling as a possible mechanism. J. Cardiovasc. Pharmacol. 68 (2), 155–161. doi: 10.1097/fjc.0000000000000397
Kittleson, M. M., Minhas, K. M., Irizarry, R. A., Ye, S. Q., Edness, G., Breton, E. (2005). Gene expression analysis of ischemic and nonischemic cardiomyopathy: shared and distinct genes in the development of heart failure. Physiol. Genomics 21 (3), 299–307. doi: 10.1152/physiolgenomics.00255.2004
Kovács, M., Németh, T., Jakus, Z., Sitaru, C., Simon, E., Futosi, K. (2014). The Src family kinases Hck, Fgr, and Lyn are critical for the generation of the in vivo inflammatory environment without a direct role in leukocyte recruitment. J. Exp. Med. 211 (10), 1993–2011. doi: 10.1084/jem.20132496
Kreisel, D., Sugimoto, S., Tietjens, J., Zhu, J., Yamamoto, S., Krupnick, A. S. (2011). Bcl3 prevents acute inflammatory lung injury in mice by restraining emergency granulopoiesis. J. Clin. Invest. 121 (1), 265–276. doi: 10.1172/jci42596
Kuleshov, M. V., Jones, M. R., Rouillard, A. D., Fernandez, N. F., Duan, Q., Wang, Z. (2016). Enrichr: a comprehensive gene set enrichment analysis web server 2016 update. Nucleic Acids Res. 44 (W1), W90–W97. doi: 10.1093/nar/gkw377
Langfelder, P., Horvath, S. (2008). WGCNA: an R package for weighted correlation network analysis. BMC Bioinf. 9, 559. doi: 10.1186/1471-2105-9-559
Li, S., Liu, X., Liu, T., Meng, X., Yin, X., Fang, C. (2017a). Identification of biomarkers correlated with the TNM staging and overall survival of patients with bladder cancer. Front. Physiol. 8, 947. doi: 10.3389/fphys.2017.00947
Li, S., Sun, X., Miao, S., Liu, J., Jiao, W. (2017b). Differential protein-coding gene and long noncoding RNA expression in smoking-related lung squamous cell carcinoma. Thorac. Cancer 8 (6), 672–681. doi: 10.1111/1759-7714.12510
Li, G., Shi, H., Wang, X., Wang, B., Qu, Q., Geng, H. (2019a). Identification of diagnostic long noncoding RNA biomarkers in patients with hepatocellular carcinoma. Mol. Med. Rep. 20 (2), 1121–1130. doi: 10.3892/mmr.2019.10307
Li, Y., He, X. N., Li, C., Gong, L., Liu, M. (2019b). Identification of candidate genes and microRNAs for acute myocardial infarction by weighted gene coexpression network analysis. BioMed. Res. Int. 2019, 5742608. doi: 10.1155/2019/5742608
Liao, X., Haldar, S. M., Lu, Y., Jeyaraj, D., Paruchuri, K., Nahori, M. (2010). Kruppel-like factor 4 regulates pressure-induced cardiac hypertrophy. J. Mol. Cell Cardiol. 49 (2), 334–338. doi: 10.1016/j.yjmcc.2010.04.008
Liao, Y., Li, M., Chen, X., Jiang, Y., Yin, X.-M. (2018). Interaction of TBC1D9B with mammalian ATG8 homologues regulates autophagic flux. Sci. Rep. 8 (1), 13496. doi: 10.1038/s41598-018-32003-2
Liao, M., Liao, W., Xu, N., Li, B., Liu, F., Zhang, S. (2019). LncRNA EPB41L4A-AS1 regulates glycolysis and glutaminolysis by mediating nucleolar translocation of HDAC2 . EBioMedicine 41, 200–213. doi: 10.1016/j.ebiom.2019.01.035
Liu, H. R., Tao, L., Gao, E., Lopez, B. L., Christopher, T. A., Willette, R. N. (2004). Anti-apoptotic effects of rosiglitazone in hypercholesterolemic rabbits subjected to myocardial ischemia and reperfusion. Cardiovasc. Res. 62 (1), 135–144. doi: 10.1016/j.cardiores.2003.12.027
Liu, B. L., Cheng, M., Hu, S., Wang, S., Wang, L., Tu, X. (2018a). Overexpression of miR-142-3p improves mitochondrial function in cardiac hypertrophy. BioMed. Pharmacother. 108, 1347–1356. doi: 10.1016/j.biopha.2018.09.146
Liu, P., Wang, H., Liang, Y., Hu, A., Xing, R., Jiang, L. (2018b). LINC00852 promotes lung adenocarcinoma spinal metastasis by targeting S100A9 . J. Cancer 9 (22), 4139–4149. doi: 10.7150/jca.26897
Lunnon, K., Ibrahim, Z., Proitsi, P., Lourdusamy, A., Newhouse, S., Sattlecker, M. (2012). Mitochondrial dysfunction and immune activation are detectable in early Alzheimer’s disease blood. J. Alzheimers Dis. 30 (3), 685–710. doi: 10.3233/jad-2012-111592
Maciejak, A., Kiliszek, M., Michalak, M., Tulacz, D., Opolski, G., Matlak, K. (2015). Gene expression profiling reveals potential prognostic biomarkers associated with the progression of heart failure. Genome Med. 7 (1), 26. doi: 10.1186/s13073-015-0149-z
Mirza, A. Z., Althagafi, I. I., Shamshad, H. (2019). Role of PPAR receptor in different diseases and their ligands: physiological importance and clinical implications. Eur. J. Med. Chem. 166, 502–513. doi: 10.1016/j.ejmech.2019.01.067
Mistry, N. F., Cresci, S. (2010). PPAR transcriptional activator complex polymorphisms and the promise of individualized therapy for heart failure. Heart Fail. Rev. 15 (3), 197–207. doi: 10.1007/s10741-008-9114-x
Mitchell, R. D., Wallace, A. D., Hodgson, E., Roe, R. M. (2017). Differential expression profile of lncRNAs from primary human hepatocytes following DEET and fipronil exposure. Int. J. Mol. Sci. 18 (10), E2104. doi: 10.3390/ijms18102104
Molina-Navarro, M. M., Roselló-Lletí, E., Ortega, A., Tarazón, E., Otero, M., Martínez-Dolz, L. (2013). Differential gene expression of cardiac ion channels in human dilated cardiomyopathy. PloS One 8 (12), e79792. doi: 10.1371/journal.pone.0079792
Ni, W., Yao, S., Zhou, Y., Liu, Y., Huang, P., Zhou, A. (2019). Long noncoding RNA GAS5 inhibits progression of colorectal cancer by interacting with and triggering YAP phosphorylation and degradation and is negatively regulated by the m(6)A reader YTHDF3 . Mol. Cancer 18 (1), 143. doi: 10.1186/s12943-019-1079-y
Niu, X., Liu, G., Huo, L., Zhang, J., Bai, M., Peng, Y. (2018). Risk stratification based on components of the complete blood count in patients with acute coronary syndrome: a classification and regression tree analysis. Sci. Rep. 8 (1), 2838. doi: 10.1038/s41598-018-21139-w
Pang, L., Hu, J., Zhang, G., Li, X., Zhang, X., Yu, F. (2016). Dysregulated long intergenic non-coding RNA modules contribute to heart failure. Oncotarget 7 (37), 59676–59690. doi: 10.18632/oncotarget.10834
Qian, C., Chang, D., Li, H., Wang, Y. (2018). Identification of potentially critical genes in the development of heart failure after ST-segment elevation myocardial infarction (STEMI). J. Cell. Biochem. 120, 7771–7777. doi: 10.1002/jcb.28051
Qiao, A., Zhao, Z., Zhang, H., Sun, Z., Cui, X. (2017). Gene expression profiling reveals genes and transcription factors associated with dilated and ischemic cardiomyopathies. Pathol. Res. Pract. 213 (5), 548–557. doi: 10.1016/j.prp.2016.12.017
Qiao, M., Li, R., Zhao, X., Yan, J., Sun, Q. (2018). Up-regulated lncRNA-MSX2P1 promotes the growth of IL-22-stimulated keratinocytes by inhibiting miR-6731-5p and activating S100A7 . Exp. Cell Res. 363 (2), 243–254. doi: 10.1016/j.yexcr.2018.01.014
Ramos Pittol, J. M., Oruba, A., Mittler, G., Saccani, S., van Essen, D. (2018). Zbtb7a is a transducer for the control of promoter accessibility by NF-kappa B and multiple other transcription factors. PloS Biol. 16 (5), e2004526. doi: 10.1371/journal.pbio.2004526
Schilling, J., Kelly, D. P. (2011). The PGC-1 cascade as a therapeutic target for heart failure. J. Mol. Cell. Cardiol. 51 (4), 578–583. doi: 10.1016/j.yjmcc.2010.09.021
Schumacher, S. M., Naga Prasad, S. V. (2018). Tumor necrosis factor-alpha in heart failure: an updated review. Curr. Cardiol. Rep. 20 (11), 117. doi: 10.1007/s11886-018-1067-7
Segal, E., Shapira, M., Regev, A., Pe’er , D., Botstein, D., Koller, D. (2003). Module networks: identifying regulatory modules and their condition-specific regulators from gene expression data. Nat. Genet. 34 (2), 166–176. doi: 10.1038/ng1165
Seropian, I. M., Sonnino, C., Van Tassell, B. W., Biasucci, L. M., Abbate, A. (2016). Inflammatory markers in ST-elevation acute myocardial infarction. Eur. Heart J. Acute Cardiovasc. Care 5 (4), 382–395. doi: 10.1177/2048872615568965
Singh, A., Shannon, C. P., Kim, Y. W., Yang, C. X., Balshaw, R., Cohen Freue, G. V. (2018). Novel blood-based transcriptional biomarker panels predict the late-phase asthmatic response. Am. J. Respir. Crit. Care Med. 197 (4), 450–462. doi: 10.1164/rccm.201701-0110OC
Skelly, D. A., Squiers, G. T., McLellan, M. A., Bolisetty, M. T., Robson, P., Rosenthal, N. A. (2018). Single-cell transcriptional profiling reveals cellular diversity and intercommunication in the mouse heart. Cell Rep. 22 (3), 600–610. doi: 10.1016/j.celrep.2017.12.072
Song, H. K., Hong, S. E., Kim, T., Kim, D. H. (2012). Deep RNA sequencing reveals novel cardiac transcriptomic signatures for physiological and pathological hypertrophy. PloS One 7 (4), e35552. doi: 10.1371/journal.pone.0035552
Sorriento, D., Iaccarino, G. (2019). Inflammation and cardiovascular diseases: the most recent findings. Int. J. Mol. Sci. 20 (16), 3879. doi: 10.3390/ijms20163879
Su, Q., Liu, Y., Lv, X. W., Ye, Z. L., Sun, Y. H., Kong, B. H. (2019). Inhibition of lncRNA TUG1 upregulates miR-142-3p to ameliorate myocardial injury during ischemia and reperfusion via targeting HMGB1- and Rac1-induced autophagy. J. Mol. Cell Cardiol. 133, 12–25. doi: 10.1016/j.yjmcc.2019.05.021
Tamang, S., Acharya, V., Roy, D., Sharma, R., Aryaa, A., Sharma, U. (2019). SNHG12: an lncRNA as a potential therapeutic target and biomarker for human cancer. Front. Oncol. 9, 901. doi: 10.3389/fonc.2019.00901
Tao, H., Yancey, P. G., Babaev, V. R., Blakemore, J. L., Zhang, Y., Ding, L. (2015). Macrophage SR-BI mediates efferocytosis via Src/PI3K/Rac1 signaling and reduces atherosclerotic lesion necrosis. J. Lipid Res. 56 (8), 1449–1460. doi: 10.1194/jlr.M056689
Thean, L. F., Wong, Y. H., Lo, M., Loi, C., Chew, M. H., Tang, C. L. (2017). Chromosome 19q13 disruption alters expressions of CYP2A7, MIA and MIA-RAB4B lncRNA and contributes to FAP-like phenotype in APC mutation-negative familial colorectal cancer patients. PloS One 12 (3), e0173772. doi: 10.1371/journal.pone.0173772
Vausort, M., Wagner, D. R., Devaux, Y. (2014). Long noncoding RNAs in patients with acute myocardial infarction. Circ. Res. 115 (7), 668–677. doi: 10.1161/circresaha.115.303836
Wang, S., Fan, W., Wan, B., Tu, M., Jin, F., Liu, F. (2017). Characterization of long noncoding RNA and messenger RNA signatures in melanoma tumorigenesis and metastasis. PloS One 12 (2), e0172498. doi: 10.1371/journal.pone.0172498
Wang, C. H., Shi, H. H., Chen, L. H., Li, X. L., Cao, G. L., Hu, X. F. (2019). Identification of key lncRNAs associated with atherosclerosis progression based on public datasets. Front. Genet. 10, 123. doi: 10.3389/fgene.2019.00123
Wingrove, J. A., Daniels, S. E., Sehnert, A. J., Tingley, W., Elashoff, M. R., Rosenberg, S. (2008). Correlation of peripheral-blood gene expression with the extent of coronary artery stenosis. Circ. Cardiovasc. Genet. 1 (1), 31–38. doi: 10.1161/circgenetics.108.782730
Wright, R. M., Aglyamova, G. V., Meyer, E., Matz, M. V. (2015). Gene expression associated with white syndromes in a reef building coral, Acropora hyacinthus. BMC Genomics 16 (1), 371. doi: 10.1186/s12864-015-1540-2
Yang, J., Williams, R. S., Kelly, D. P. (2009). Bcl3 interacts cooperatively with peroxisome proliferator-activated receptor gamma (PPARgamma) coactivator 1alpha to coactivate nuclear receptors estrogen-related receptor alpha and PPARalpha. Mol. Cell. Biol. 29 (15), 4091–4102. doi: 10.1128/mcb.01669-08
Yang, K. C., Yamada, K. A., Patel, A. Y., Topkara, V. K., George, I., Cheema, F. H. (2014). Deep RNA sequencing reveals dynamic regulation of myocardial noncoding RNAs in failing human heart and remodeling with mechanical circulatory support. Circulation 129 (9), 1009–1021. doi: 10.1161/circulationaha.113.003863
Yashiro, T., Nakano, S., Nomura, K., Uchida, Y., Kasakura, K., Nishiyama, C. (2019). A transcription factor PU.1 is critical for Ccl22 gene expression in dendritic cells and macrophages. Sci. Rep. 9 (1), 1161. doi: 10.1038/s41598-018-37894-9
Zhang, X., Sun, S., Pu, J. K., Tsang, A. C., Lee, D., Man, V. O. et al. (2012). Long non-coding RNA expression profiles predict clinical phenotypes in glioma. Neurobiol. Dis. 48 (1), 1–8. doi: 10.1016/j.nbd.2012.06.004
Zhang, S., Liu, X., Goldstein, S., Li, Y., Ge, J., He, B. et al. (2013). Role of the JAK/STAT signaling pathway in the pathogenesis of acute myocardial infarction in rats and its effect on NF-kappaB expression. Mol. Med. Rep. 7 (1), 93–98. doi: 10.3892/mmr.2012.1159
Zhang, L. Q., Yang, S. Q., Wang, Y., Fang, Q., Chen, X. J., Lu, H. S. et al. (2017a). Long noncoding RNA MIR4697HG promotes cell growth and metastasis in human ovarian cancer. Anal. Cell. Pathol. (Amst). 2017, 8267863. doi: 10.1155/2017/8267863
Zhang, S., Liu, W., Liu, X., Qi, J., Deng, C. (2017b). Biomarkers identification for acute myocardial infarction detection via weighted gene co-expression network analysis. Med. (Baltimore) 96 (47), e8375. doi: 10.1097/md.0000000000008375
Zhang, C. X., Cheng, Y., Liu, D. Z., Liu, M., Cui, H., Zhang, B. L. et al. (2019). Mitochondria-targeted cyclosporin A delivery system to treat myocardial ischemia reperfusion injury of rats. J. Nanobiotechnol. 17 (1), 18. doi: 10.1186/s12951-019-0451-9
Zhao, F., Lin, T., He, W., Han, J., Zhu, D., Hu, K. et al. (2015). Knockdown of a novel lincRNA AATBC suppresses proliferation and induces apoptosis in bladder cancer. Oncotarget 6 (2), 1064–1078. doi: 10.18632/oncotarget.2833
Zhou, Y., Zhou, B., Pache, L., Chang, M., Khodabakhshi, A. H., Tanaseichuk, O. (2019). Metascape provides a biologist-oriented resource for the analysis of systems-level datasets. Nat. Commun. 10 (1), 1523. doi: 10.1038/s41467-019-09234-6
Keywords: acute myocardial infarction, heart failure, weighted gene co-expression network, key module, transcriptional factor, non-coding RNA, hub gene
Citation: Niu X, Zhang J, Zhang L, Hou Y, Pu S, Chu A, Bai M and Zhang Z (2019) Weighted Gene Co-Expression Network Analysis Identifies Critical Genes in the Development of Heart Failure After Acute Myocardial Infarction. Front. Genet. 10:1214. doi: 10.3389/fgene.2019.01214
Received: 07 May 2019; Accepted: 04 November 2019;
Published: 26 November 2019.
Edited by:
Seungchan Kim, Prairie View A&M University, United StatesReviewed by:
Matteo Giulietti, Marche Polytechnic University, ItalyCopyright © 2019 Niu, Zhang, Zhang, Hou, Pu, Chu, Bai and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zheng Zhang, emhhbmdjY3VAeWVhaC5uZXQ=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.