{kind=link}

94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet., 08 March 2019
Sec. Systems Biology Archive
Volume 10 - 2019 | https://doi.org/10.3389/fgene.2019.00066
This article is part of the Research TopicComputational Probability and Mathematical Modeling - a Stochastic Approach in Applied SciencesView all 7 articles
 M. Corona-Ruiz1
M. Corona-Ruiz1 Francisco Hernandez-Cabrera1*
Francisco Hernandez-Cabrera1* José Roberto Cantú-González2
José Roberto Cantú-González2 O. González-Amezcua1
O. González-Amezcua1 Francisco Javier Almaguer1*
Francisco Javier Almaguer1*This paper presents an exploratory analysis of the mitochondrial DNA (mtDNA) of 32 species in the subphylum Vertebrata, divided in 7 taxonomic classes. Multiple stochastic parameters, such as the Hurst and detrended fluctuation analysis (DFA) exponents, Shannon entropy, and Chargaff ratio are computed for each DNA sequence. The biological interpretation of these parameters leads to defining a triplet of novel indices. These new functions incorporate the long-range correlations, the probability of occurrence of nucleic bases, and the ratio of pyrimidines-to-purines. Results suggest that relevant regions in mtDNA can be located using the proposed indices. Furthermore, early results from clustering algorithms indicate that the indices introduced might be useful in phylogenetic studies.
Previous mathematical studies on DNA sequences have seen a variety of approaches and frequently involve a numerical representation of the nucleotide chains. For instance, distance matrices have been constructed using different metrics (Randi et al., 2003; Liao and Wang, 2004; Zhang and Tan, 2007; Kandiah and Shepelyansky, 2013). These matrices, in combination with clustering methods, are used to evaluate phylogenetic relationships among species (Yu and Huang, 2013).
Other studies involve the representation of DNA sequences as random-walks, known as DNA-walks (Peng et al., 1994). The main objectives of these studies focus on the long-range correlations among nucleotides; i.e., “how the frequency of each nucleotide of a pairing nucleotide couple changes locally” (Namazi and Kiminezhadmalaie, 2015). These DNA-walk studies find differences in the long-range correlation between coding and non-coding DNA sequences (Peng et al., 1994).
Recently, DNA-walk analysis has been used in combination with the fractal dimension and Hurst exponent to identify mosaic structures in DNA that allow distinguishing between healthy and cancerous cells (Namazi and Kiminezhadmalaie, 2015).
Additionally, alternative statistical tools frequently used in DNA sequence analysis include Shannon entropy, which is a measure of the amount of “information" stored within a system (López-Ruiz et al., 1995). In a biological sense, Shannon entropy evaluates the probability of independent occurrences of each nucleic base in a DNA sequence. In recent studies, fluctuations in local Shannon entropy in DNA sequences have been analyzed to identify regions of repeating patterns of one or more nucleotides, known as tandem repeats (Thanos et al., 2018). The capability of Shannon entropy to highlight important segments in DNA sequences has led to the supported notion that entropy studies might be used for biological classifications of species (Melnik and Usatenko, 2014).
Similarly, the concept of complexity has played a central role in various DNA sequence analyses. For instance, López-Mancini-Calbet (LMC) complexity, employed in this paper, has led to the development of an effective gene-predicting technique (López-Ruiz et al., 1995; Monge and Crespo, 2015). In a recent study, the symbolic complexity of DNA sequences is used to identify segments resulting from random duplication, as well as changes in the speed of accumulation of point mutations (Salgado-Garcia and Ugalde, 2016).
Our objective is to examine the parameters previously mentioned to determine a small number of coefficients with biological relevance that may be used to determine rates of change in nucleotide bases, establish comparisons between regions, and better understand the relation among species in a phylogenetic sense.
This paper is structured as follows: section 2 introduces the concepts and methodology; section 3 presents the results obtained and the variables introduced; and section 4 is devoted to a discussion of the results, comments on the methodology in general, and final remarks. Tables and figures are incorporated in sections 2 and 3, respectively. The Supplementary Material includes a table with the identification codes for the data.
GenBank® is the National Institutes of Health's genetic sequence database made possible by the collaboration of several organizations. All datasets used within this work were obtained through GenBank because of its availability of access, encouragement of use, and the advantage that the information stays up-to-date.
A total of 32 complete mtDNA sequences of different species in the subphylum Vertebrata were selected. The lengths vary from 16, 207 to 18, 254 base pairs (bp). The choice of this type of DNA presents multiple advantages: it is relatively small in size (in contrast, human chromosomal DNA contains hundreds of millions bp); the sequences contain conserved regions, can be compared in blocks among different species, and contain a small percentage of non-coding regions; and the interpretation of the mutations in mtDNA as an estimator of evolutionary change (Barton and Jones, 1983). For these reasons, the exploratory nature of this study does not require additional information on the species themselves. Thus, the selection criteria focused on 32 different members from 7 groups intuitively related in taxonomic classes. The 32 NCBI codes from the data files have been attached in the Table S1.
A pre-processing of the data files consists of a realignment of the sequences to set the control region of the heavy chain (H-chain) in the direction of transcription as the new ending point. This realignment is done once. The displacement loop, or D-loop, is within the control region and the most varying region in mtDNA, with substantial differences observed even among individuals of the same species (Yamamoto, 2001). See Figure S1 (Supplementary Material). Additionally, the header information was removed, which contains the identification key and the name of the organism. The downloaded files (in .fasta format) were processed using the programming language R version 3.4.4 (2018-03-15). The packages used are stringr and fractal.
DNA consists of sequences of nitrogenous bases: adenine (A), guanine (G), thymine (T), and cytosine (C). The length and distribution of the bases fluctuate from species to species. Several mappings have been introduced based on properties intrinsic to DNA. Moreover, adenine and guanine have a two-ring structure and belong to the purine group, while cytosine and thymine have a one-ring structure and belong to the pyrimidine group. Furthermore, adenine bonds with thymine through a double hydrogen bond, which is called a weak bond, while guanine and cytosine bond through a triple hydrogen bond, which is called a strong bond. Figure 1 illustrates these descriptions. In summary, we have:
• Purine (R): {A, G} / Pyrimidine (Y): {C, T}
• Strong Hydrogen bond (S): {G, C} / Weak Hydrogen bond (W): {A, T}
• Keto (K): {G, T} / Amino (M): {A, C}
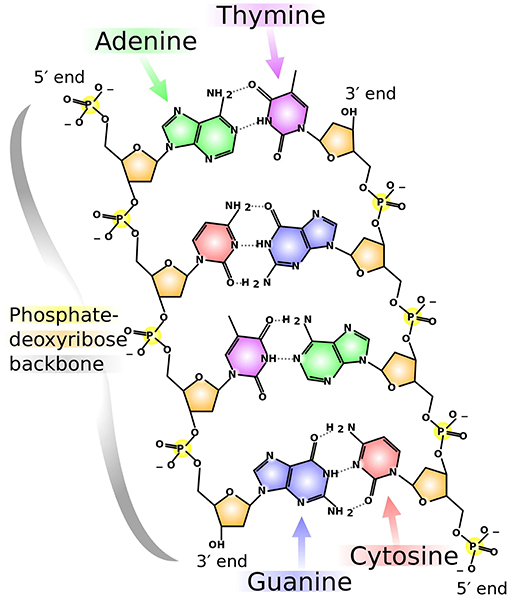
Figure 1. Chemical structure of DNA. Adenine, guanine, cytosine, and thymine are shown in colors green, blue, red, and purple, respectively. Notice the double-ring structure of the purines (A, G) and the single-ring structure of the pyrimidines (C, T). Similarly, the type of bond is readily observable: double- and triple-Hydrogen bonds for A, T and G, C, respectively. This illustration, by Madeleine Price Ball, has a Creative Commons Zero (CC0, i.e., “No Rights Reserved") license and has been published in previous articles (Wikimedia Commons Contributors, 2018).
Considering the properties described previously, it is possible to read a DNA sequence and assign either a +1 or −1 depending on whether the respective nucleotide is a purine or pyrimidine (RY rule). This can be interpreted as random steps xi of a one-dimensional walk. Then, the final position after n steps is given by
where x0 = 0 by definition.
Let S = {s1s2…sM} be a nucleotide sequence of length M, where sk ∈ {A, C, G, T} for k ∈ {1, 2, …, M}. Hence, a one-dimensional DNA-walk can be defined through the following rules:
• RY rule:
• SW rule:
• KM rule:
where sk is the k−th nucleotide and xk is the value of the k−th assigned step in a DNA sequence. The path of the DNA-walk after n steps is then defined as the partial sums , where n ∈ {1, 2, …, M} and x0 = 0.
In the context of DNA-walks, Equation (2) evaluates the tendency of changes between purines and pyrimidines. Transversions (substitutions of purines for pyrimidines, or vice versa) are less likely to happen and have been used to evaluate molecular evolution (Stoltzfus and Norris, 2016). Thus, using this rule within corresponding blocks of nucleotides in different species, it is possible to observe changes in the DNA-walk that could be interpreted as an evolutionary variation. Similarly, Equation (4) is associated with the rate of recombination between transversions and transitions (purine-purine or pyrimidine-pyrimidine substitutions).
Moreover, Equation (3) refers to the difference in abundance of the GC bond with respect to the AT bond. A higher GC content suggests a significantly higher temperature for DNA denaturing (melting temperature Tm). Previous studies have shown that GC content is associated to an age-related natural selection and environmental factors (Min and Hickey, 2008). Finally, it is assumed that each DNA-walk is an ergodic stochastic process. Specifically, the conceived notion adopted is that each DNA sequence may be used to represent the ensemble of DNA sequences of individuals within the same species.
In summary, the three assignment rules provide insight into the evolutionary aspects of the organisms considered.
Additional information of the long-range correlations of DNA-walks can be obtained via stochastic methods such as rescaled-range analysis and detrended fluctuation analysis. With these methods, it is possible to obtain the Hurst exponent, which represents a quantitative measure of the fractal nature of DNA sequences.
The Hurst exponent, here denoted by α, satisfies 0 < α < 1. In comparisons of mtDNA sequences, each Hurst exponent can be interpreted as a measure of the tendency of changes between nucleotides according to the rules mentioned in the previous section. The calculations used to obtain the Hurst exponent have been reported in previous studies (Peng et al., 1994; Buldyrev et al., 1995).
The Hurst exponent is directly related to the fractal dimension α′ by the relation:
The fractal dimension evaluates changes in detail of the pattern of a DNA-walk with respect to the scale used for measurement.
An alternative method to calculate the Hurst exponent of a DNA-walk is DFA. In contrast to the rescaled-range analysis, DFA analyzes the random fluctuations of the DNA-walk without trend in the data (Peng et al., 1994; Buldyrev et al., 1995). The DFA exponent is computed using the following algorithm:
• Given a numerical sequence X = {X1, X2, …, XM}, calculate the cumulative sum
• where k = 1, 2, …, M and is the mean value of X.
• Divide yk into M/L subintervals of length L. For each window, calculate the polynomial linear fit (the local trend) yk, L via least-squares minimization.
• Calculate the fluctuation, which is an average of the squares of the detrended sequence given by
• The slope β of the linear regression analysis in the scale logF(L)/logL is an estimator of the Hurst exponent.
This method tests for self-similarity at different window sizes L. No correlation (or short-range correlations) gives stochastic properties such as those of a random-walk, so β = 0.5; in contrast, long-range correlations give a value of β ≠ 0.5. Specifically, correlation yields β > 0.5, while anti-correlation gives β < 0.5.
This paper adopts a minimum block size of 4 nucleotides, while the maximum is , corresponding to half the length of the sequence in question. Should M be odd, B is rounded down.
In a remarkable discovery, Erwin Chargaff determined that there is a balance held in DNA by the nucleobases (Chargaff, 1950), known as Chargaff's Rule. These state: (1) that globally (i.e., considering both strands of DNA) adenine is equal to thymine in quantity, and (2) that guanine is equal to cytosine in quantity. This result was the basis for the Watson-Crick model, which determined that adenine binds with thymine and that guanine binds with cytosine (Watson and Crick, 1953).
On this basis, and in the context of this work, the Chargaff ratio is defined as the ratio of pyrimidines to purines:
where NC, NT, NA, NG represent the amount of cytosine, thymine, adenine, and guanine, respectively, within one strand of DNA. Note that this value is always positive. If 0 ≤ ξ < 1, there are more purines than pyrimidines (i.e., NC + NT < NA + NG); similarly, ξ > 1 reflects an excess of pyrimidines over purines. A Chargaff ratio with value 1 results from an equal number of either type of nucleotide bases.
In his seminal paper, Claude Shannon introduced the concept of information entropy. It measures the “amount" of information or uncertainty of a system (Shannon and Weaver, 1998). Let Ω = {ω1, ω2, …, ωN} be a set of events where each ωi has probability of occurrence pi ∈ [0, 1], for i = 1, 2, …, N. Thus, the Shannon entropy of the system is defined as
where K is a positive constant chosen appropriately according to the units desired for measurement (thus, for this work, K = 1). For the case when pi = 0, pi log2(pi) = 0 in the limit definition. Also, note that the logarithm is in base 2; this is because information in a computer is encoded in binary digits, or bits, which are the basic units of measurement of information.
For N = 2, events ω1 and ω2 have probability p and 1−p, respectively, see Figure S2 (Supplementary Material). Thus, it can be seen that a maximum is attained at . This result can be extended to the general case with N events. The proof requires Jensen's inequality for a concave function (in this case, the logarithmic function), and is given below. Using some algebra to rewrite Equation (9) with K = 1 yields
By the weighted arithmetic-mean and geometric-mean inequality, this implies that
where equality (the maximum) is satisfied when p1 = p2 = ⋯ = pN. That is, when
To evaluate Shannon entropy in the context of DNA sequence analysis, it seems rather reasonable to define the set of possible events as Ω = {A, G, C, T}. However, it is expected that the probability of occurrence of each nucleotide in a DNA sequence will likely be different for different species; thus, these associated probabilities will be calculated empirically for each DNA sequence in a straightforward fashion. That is, by counting the amount of each nucleotide within the sequence and taking the corresponding proportion by dividing by the total amount of nucleotides M. Thus, the probabilities will be given by
where NA, NC, NG, NT are the amount of adenine, cytosine, guanine, and thymine, respectively.
In the context of DNA sequence analysis, maximum entropy is attained whenever the nucleic bases within a DNA sequence are found with equiprobability. It may thus be interpreted that such a sequence is the result of a random combination of these events. Any departure from the maximum value of the Shannon entropy due to an underlying structure might contribute to determining any tendencies present in a sequence, see Figure S3 (Supplementary Material).
In a more general sense, the entropy fluctuations could be analyzed by means of the Local Shannon entropy. By studying the local fluctuations of entropy at a given scale, and across scales, an “entropic microscope" could highlight areas with a high degree of variation or, equally interesting, low degree of variation, as seen in previous studies (Melnik and Usatenko, 2014; Thanos et al., 2018).
Additional information of DNA sequences can be derived from the deviations from equiprobability of occurrence of each nucleotide. This measure is known as disequilibrium (López-Ruiz et al., 1995). The events in the set Ω have probability pi for i = 1, 2, 3, 4. The coefficient of disequilibrium, , is defined as:
This sum of squared distances can be seen as a type of variance. Note that in the case of equilibrium. Any deviation from this would result in . The maximum disequilibrium value, can be obtained using multivariate calculus.
The coefficient of disequilibrium may represent a measure of relatedness between a DNA sequence and one resulting from a random process if each (independent) event has a probability pi of occurrence. That is, larger deviations from an equiprobable space yield higher coefficients of disequilibrium. It can be observed that this behavior counters that of the Shannon entropy in an intuitive manner.
The coefficient of complexity is then given by the product of the Shannon entropy (9) and the coefficient of disequilibrium (12), as in (13). It can be seen from (12) that resembles the definition of variance; thus, the coefficient of complexity can be interpreted as a measure of dispersion within the information stored in a system (López-Ruiz et al., 1995).
The coefficient of complexity may thus be regarded as the Shannon entropy weighted by the coefficient of disequilibrium, which can be interpreted as the tendency of a random sequence.
The three DNA-walks for the 7 groups are depicted in Figures 2–4. Results for the Chargaff ratio ξ and Shannon entropy are shown in Table 1, while Tables 2, 3 contain the Hurst and DFA exponents for each type of random-walk and for each sequence.
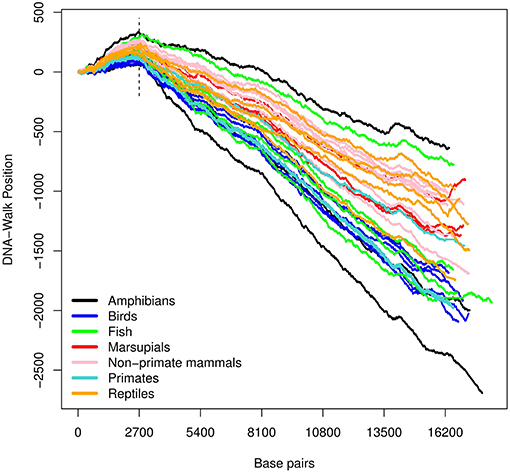
Figure 2. DNA-walk illustration for various species using the purine-pyrimidine rule. Observe the vicinity of nucleotide 2, 700 and the change in tendency from a purine-rich region (positive slope) to a predominance of pyrimidines for the remaining DNA-walk (negative slope).
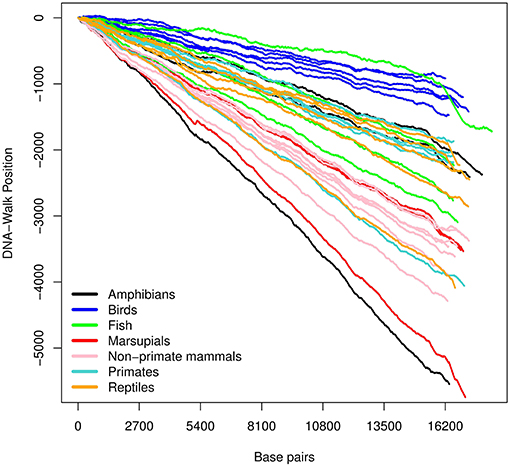
Figure 3. DNA-walk illustration for various species using the strong- and weak-bond rule. Observe the immediate (and consistent) tendency. This indicates that mtDNA is rich in adenine and thymine, whose type of bond is weaker than that of cytosine and guanine.
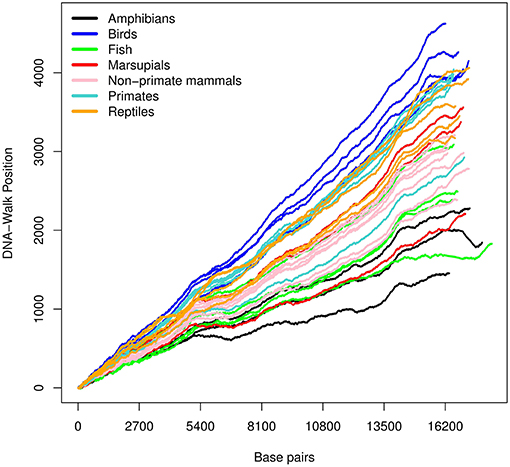
Figure 4. DNA-walk illustration for various species using the keto and amino rule. The figure shows a higher amount of adenine and cytosine.
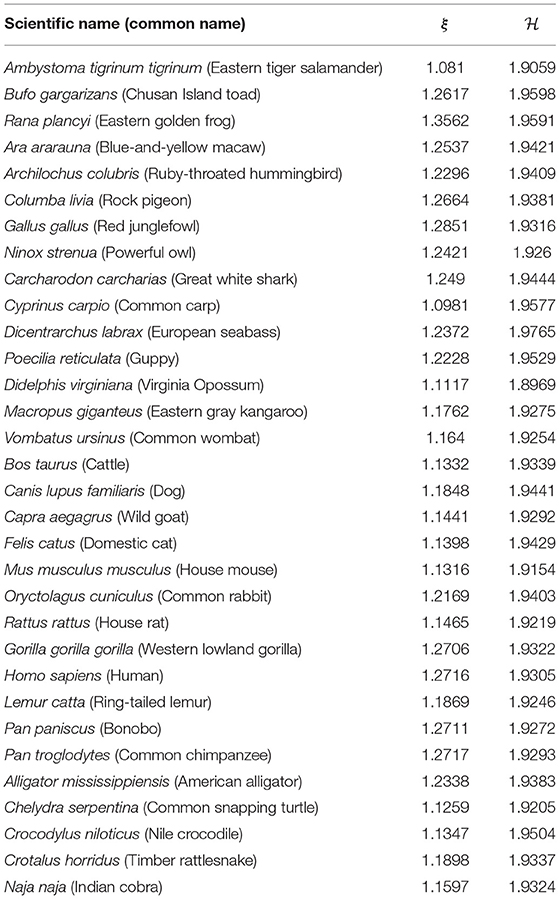
Table 1. Results of the Chargaff ratio and Shannon entropy for all groups.
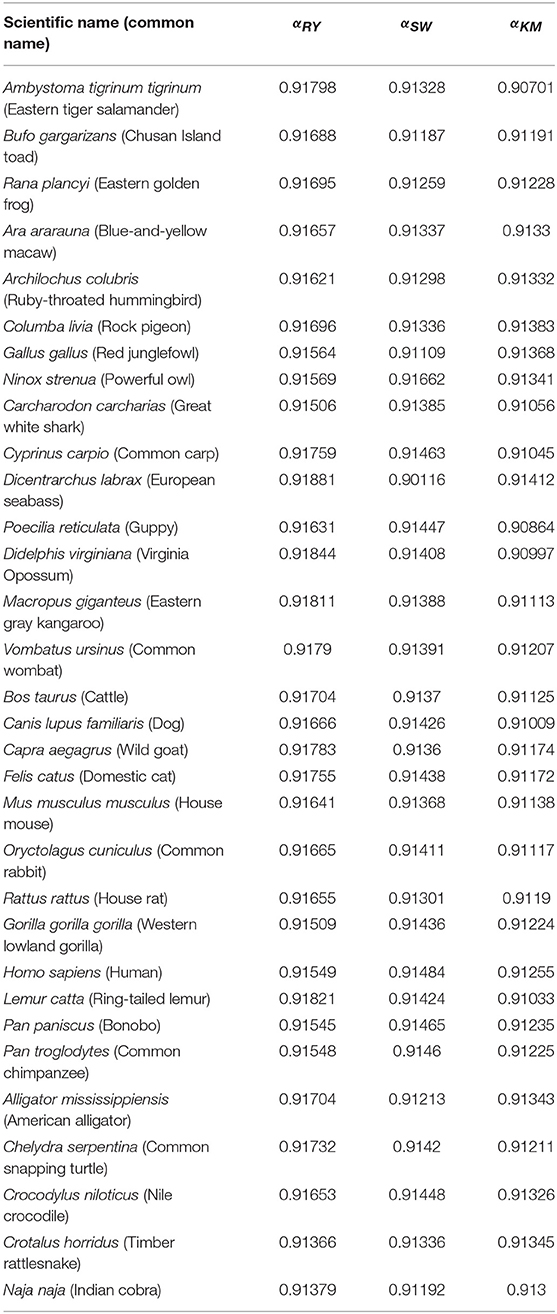
Table 2. Results of the Hurst exponent for all groups and each of the three random-walk rules.
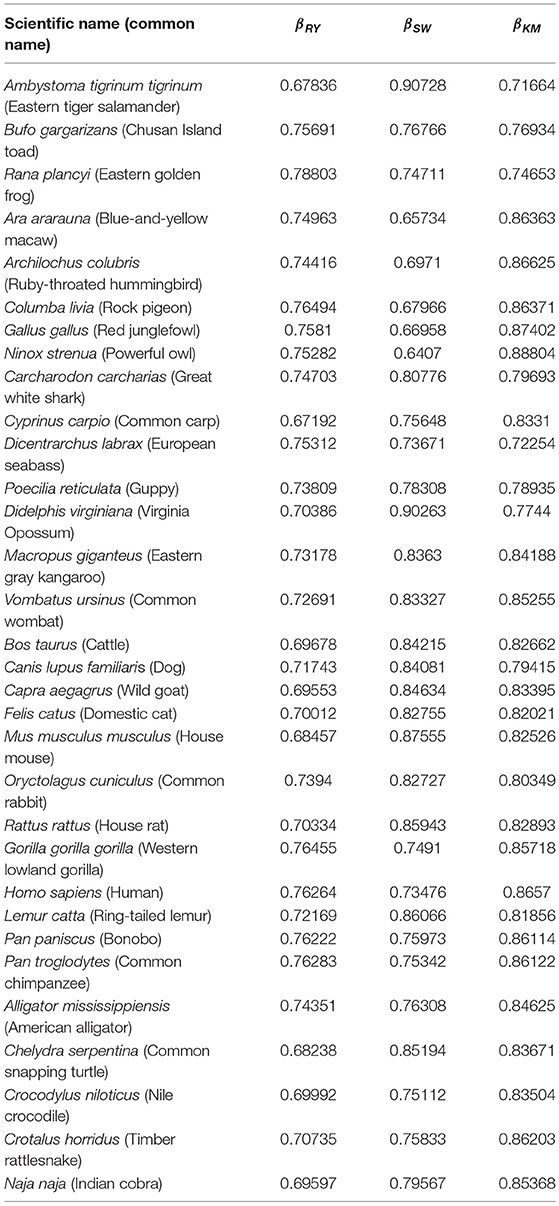
Table 3. Results of the DFA exponent for all groups and each of the three random-walk rules.
In Figure 2, there is an initial upward trend that is present irrespective of the species. The RY rule (Equation 2) implies that a (local) inclination toward the positive direction of the vertical axis corresponds to a (local) majority of purines (adenine or guanine). Similarly, the downward trend in Figure 3 reflects a consistent predominance of the weakly-pairing bases, adenine or thymine (considering rule SW). Thus, adenine dominates within the range 0− ~ 3, 000 bp.
The Hurst exponents for the rules RY, SW, and KM (Equations 2–4, respectively) fall in the range of 0.900−0.912 and imply a long-term positive autocorrelation. To put it into perspective, a Hurst exponent value of 0.9 indicates that, on average, the tendency of changes between nucleotides varies slightly as the sub-sequence size is changed. Moreover, the proximity of the Hurst exponent toward unity suggests that either purines or pyrimidines are predominant; it cannot distinguish, however, which one prevails. Similarly, the DFA exponents fall within 0.64−0.91 which implies the existence of strong long-range correlations in the sequences even after detrending. Interestingly, neither the Hurst nor DFA exponent values are near zero in any of the species considered. A possible explanation is that the tendency of changes between nucleotides does not vary randomly; i.e., mtDNA has an informational structure.
For all the DNA sequences, the Chargaff ratio is positive with ξ > 1, implying a larger amount of pyrimidines than purines. This implication is visually reflected in the overall downward tendency of the curves in Figure 2.
The disequilibrium coefficient takes values . From Equation (12), values near 0 imply that the probabilities for any of the four nucleic bases. In other words, the disequilibrium values obtained suggest that the four nucleotide bases appear with almost the same proportion within each of the 32 mtDNA sequences. This is further supported by the Shannon entropy values. In this case, Equation (10) and N = 4 yield a (theoretical) maximum entropy value . Hence, the empirical entropy values suggest near-equiprobability among the nucleic bases.
A graph of vs. the Shannon entropy suggests a linear relation. On this account, the disequilibrium coefficient is omitted for the remainder of the study. In addition, the complexity coefficient is omitted due to its direct proportionality to . See Figure S4 (Supplementary Material).
This work proposes three new evolutionary indices as functions of Shannon entropy, the Chargaff ratio, and the fractal dimensions derived from the Hurst and DFA exponents:
These indices reflect the long-range correlations found in DNA-walks and the information given by Shannon entropy and the Chargaff ratio.
The fractal dimensions α′ and β′ are derived from the Hurst and DFA exponents, respectively, using Equation (5). The natural logarithm can be seen as a transformation that maximizes the differences between the coefficients. Equations (14), (15), and (16) are defined from an evolutionary perspective, while Equation (16) provides information on the energy content of sequences.
In Equation (14), the logarithm of the fractal dimension derived from the Hurst exponent using the KM rule provides information regarding the transversions and transitions of the entire DNA sequence. On the other hand, the Chargaff ratio is used as a weighting factor for the fractal dimension derived using the RY rule. The logarithm of the product of these quantities provides an evolutionary measure related to the long-range correlations. The last term in the equation (the Shannon entropy) evaluates the probability of independent nucleotide changes for a given DNA sequence.
Equation (15) uses the fractal dimensions of the DFA exponents, which are computed using the detrended DNA-walks. Therefore, it is not accurate to include the Chargaff ratio or Shannon entropy as normalization parameters. Finally, Equation (16) represents a measure of the natural selection factors in relation to the environment. Results for v1, v2, v3 are shown in Table 4.
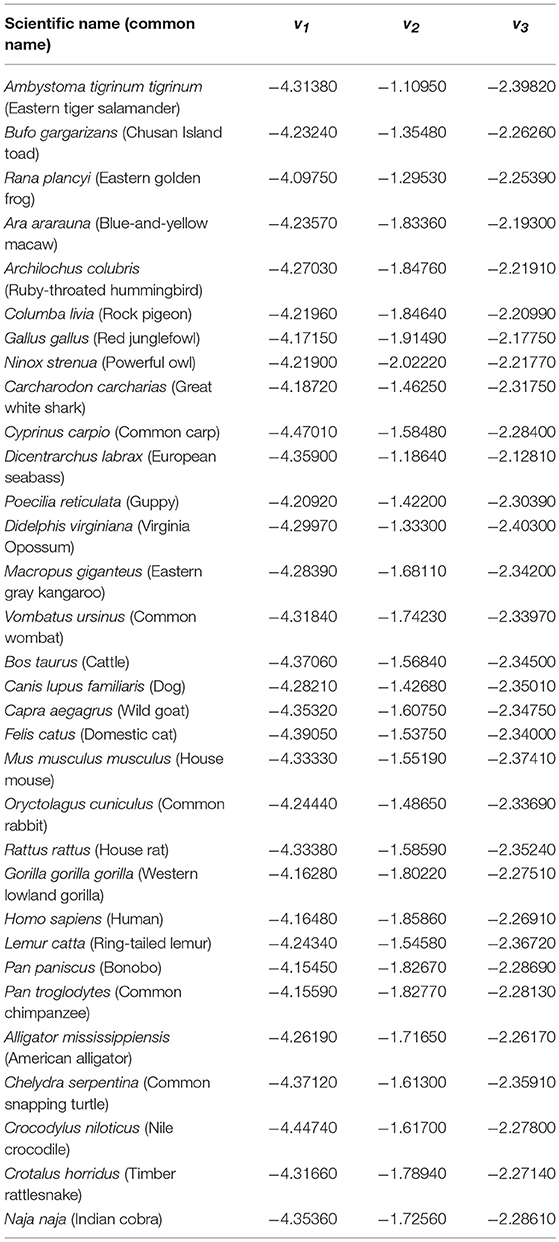
Table 4. New variables.
Clustering algorithms may benefit from the proposal. Preliminary results, shown in Figure 5, suggest a possible application in studies centering on the evolutionary relations among species. The proposed indices are used in the group-average agglomerative clustering algorithm with Euclidean metric and the sum of distances as the clustroid. Furthermore, an additional grouping was constructed using a traditional program, ClustalW, which is frequently applied to the study of phylogenetic trees, as seen in Figure 6.
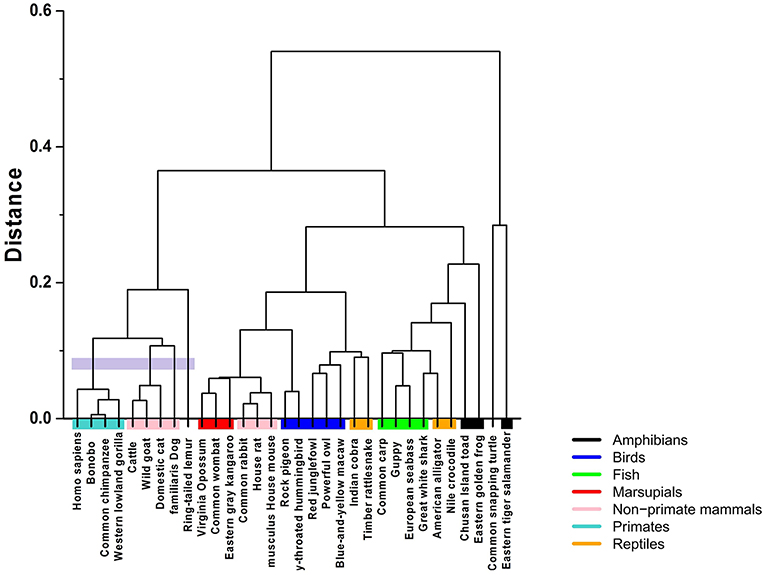
Figure 5. Hierarchical clustering of the 32 species using the Hurst exponent metric with and without tendency, weighted by the Chargaff ratio and Shannon entropy.
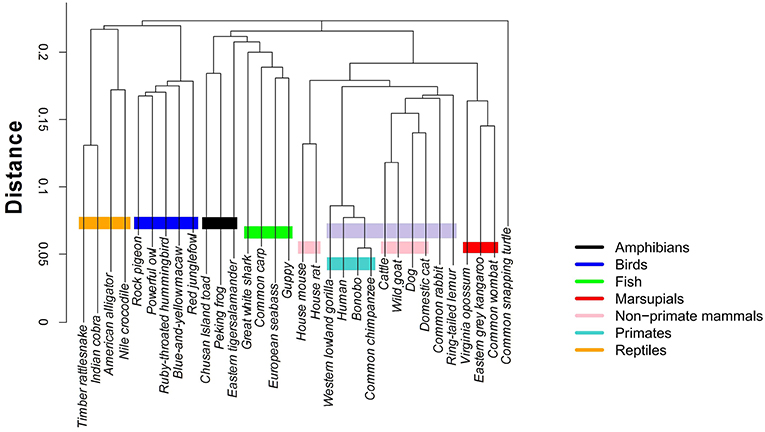
Figure 6. Hierarchical clustering of the 32 species using ClustalW https://www.ebi.ac.uk/Tools/msa/clustalo/.
The implementation of the algorithm using the R programming language is not computationally demanding, with running times of about 15–20 min. In comparison, ClustalW requires about 2 and a half hours for the construction of the phylogenetic tree of 32 mtDNA sequences.
The comparative analysis between the two methods shows consistency among the group of primates and other mammals sharing a common ancestry of similar lineage to the lemur. On the other hand, the marsupials and rodents (including the common rabbit) are more closely grouped with the stochastic algorithm and present a common ancestor, just as calculated by the traditional method. Other groups that share proximity with both methods are the reptiles and the birds, as well as the fish group and some amphibians.
The most pronounced differences are found in certain taxa. The proposed method relates the rabbit more closely to rodents, with characteristics similar to marsupials. Meanwhile, the traditional method positions the rabbit closer to primates. Another interesting point is that the proposed stochastic method shows that small reptiles and birds are more closely related, while the traditional method relates the birds closer to large reptiles.
As has been suggested by other studies, Shannon entropy and Hurst and DFA exponents provide insight into the properties of DNA sequences (Peng et al., 1994; Oiwa and Glazier, 2004; Melnik and Usatenko, 2014; Monge and Crespo, 2015; Namazi and Kiminezhadmalaie, 2015; Salgado-Garcia and Ugalde, 2016; Thanos et al., 2018). This exploratory analysis combines various measures utilized in the literature to establish a biologically meaningful measure of distinction among species.
Our proposal defines new indices as functions of Shannon entropy, the Chargaff ratio, and fractal dimensions using rescaled-range analysis and DFA. These indices can be employed to construct phylogenetic trees using clustering algorithms.
Long-range correlations attributed to DNA-walks can be identified during our study. These can represent data with persistence in its evolutionary memory; i.e., that mtDNA sequences contain highly conserved regions among similar species.
The comparison between the traditional and the proposed clustering method shows clear agreements; however, there are differences that must be analyzed under an evolutionary perspective. For example, we notice that the mtDNA sequences of the common rabbit and the common snapping turtle show different properties in both methods. According to the established phylogeny, the placement of the rabbit is closer to the rodents. Interestingly, results of the stochastic hierarchical clustering suggest a potential application for phylogenetic studies.
Evolutionary processes are associated to an adaptive selection of the species throughout millions of years. However, the fluctuations of the changes in nucleotide bases could be random in order to find new sequence combinations. The proposed method attempts to measure the stochastic fluctuations to yield indices that allow the observation of tendencies and correlations in the mutations that produce new species throughout evolutionary history.
MC-R provided data collection of the mtDNA sequences from the GenBank®, worked on numerical and graphical results, and drafted the article. FJ provided numerical analysis, methodology, and mathematical insight. FH-C rendered numerical analysis, as well as mathematical and biological interpretations. JC-G contributed with numerical analysis, revision, critical revision for important intellectual content, and co-final approval of the version to be published. OG-A provided textual and structural revision of the co-final version of this work.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Thanks are due to the Consejo Nacional de Ciencia y Tecnología (Conacyt) for providing a scholarship for one of the authors. Special recognition is given to the Universidad Autónoma de Nuevo León, the Facultad de Ciencias Físico-Matemáticas, and the Centro de Investigación en Ciencias Físico-Matemáticas for logistical support given during our research endeavors. Thanks are due to Programa para el Desarrollo Profesional Docente, para el Tipo Superior (PRODEP) for the support for the publication of the article.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2019.00066/full#supplementary-material
Barton, N., and Jones, J. (1983). Mitochondrial DNA: new clues about evolution. Nature 306, 317–318. doi: 10.1038/306317a0
Buldyrev, S. V., Goldberger, A. L., Havlin, S., Mantegna, R. N., Matsa, M. E., Peng, C.-K., et al. (1995). Long-range correlation properties of coding and noncoding dna sequences: genbank analysis. Phys. Rev. E 51, 5084–5091. doi: 10.1103/PhysRevE.51.5084
Chargaff, E. (1950). Chemical specificity of nucleic acids and mechanism of their enzymatic degradation. Experientia 6, 201–209. doi: 10.1007/BF02173653
Kandiah, V., and Shepelyansky, D. L. (2013). Google matrix analysis of DNA sequences. PLoS ONE 8:e61519. doi: 10.1371/journal.pone.0061519
Liao, B., and Wang, T.-M. (2004). 3-d graphical representation of DNA sequences and their numerical characterization. J. Mol. Struct. 681, 209–212. doi: 10.1016/j.theochem.2004.05.020
López-Ruiz, R., Mancini, H., and Calbet, X. (1995). A statistical measure of complexity. Phys. Lett. A 209, 321–326. doi: 10.1016/0375-9601(95)00867-5
Melnik, S., and Usatenko, O. (2014). Entropy and long-range correlations in DNA sequences. Comput. Biol. Chem. 53, 26–31. doi: 10.1016/j.compbiolchem.2014.08.006
Min, X. J., and Hickey, D. A. (2008). An evolutionary footprint of age-related natural selection in mitochondrial DNA. J. Mol. Evol. 67:412. doi: 10.1007/s00239-008-9163-8
Monge, R., and Crespo, J. (2015). Analysis of data complexity in human dna for gene-containing zone prediction. Entropy 17, 1673–1689. doi: 10.3390/e17041673
Namazi, H., and Kiminezhadmalaie, M. (2015). Diagnosis of lung cancer by fractal analysis of damaged dna. Comput. Math. Methods Med. 2015, 1–11. doi: 10.1155/2015/242695
Oiwa, N. N., and Glazier, J. A. (2004). Self-similar mitochondrial DNA. Cell Biochem. Biophys. 41, 41–62. doi: 10.1385/CBB:41:1:041
Peng, C.-K., Buldyrev, S. V., Havlin, S., Simons, M., Stanley, H. E., and Goldberger, A. L. (1994). Mosaic organization of DNA nucleotides. Phys. Rev. E 49, 1685–1689. doi: 10.1103/PhysRevE.49.1685
Randi, M., Vrako, M., Ler, N., and Plavi, D. (2003). Novel 2-d graphical representation of DNA sequences and their numerical characterization. Chem. Phys. Lett. 368, 1–6. doi: 10.1016/S0009-2614(02)01784-0
Salgado-Garcia, R., and Ugalde, E. (2016). Symbolic complexity for nucleotide sequences: a sign of the genome structure. J. Phys. A Math. Theor. 49:445601. doi: 10.1088/1751-8113/49/44/445601
Shannon, C. E., and Weaver, W. (1998). The Mathematical Theory of Communication. Urbana and Chicago, IL: University of Illinois Press.
Stoltzfus, A., and Norris, R. W. (2016). On the causes of evolutionary transition: transversion bias. Mol. Biol. Evol. 33, 595–602. doi: 10.1093/molbev/msv274
Thanos, D., Li, W., and Provata, A. (2018). Entropic fluctuations in dna sequences. Physica A 493, 444–457. doi: 10.1016/j.physa.2017.11.119
Watson, J. D., and Crick, F. H. (1953). Molecular structure of nucleic acids: a structure for deoxyribose nucleic acid. Nature 171, 737–738. doi: 10.1038/171737a0
Wikimedia Commons Contributors (2018). File:DNA Chemical Structure.svg—Wikimedia Commons, the Free Media Repository. Available online at: https://commons.wikimedia.org/w/index.php?title=File:DNA_chemical_structure.svg&oldid=328708739 (Accessed Feb 22, 2019).
Yamamoto, Y. (2001). “D-loop,” in Encyclopedia of Genetics, eds S. Brenner and J. H. Miller (New York, NY: Academic Press), 539–540.
Yu, H.-J., and Huang, D.-S. (2013). Graphical representation for dna sequences via joint diagonalization of matrix pencil. IEEE J. Biomed. Health Inform. 17, 503–511. doi: 10.1109/TITB.2012.2227146
Keywords: DNA, random-walk, Hurst exponent, detrended fluctuation analysis, Shannon entropy, coefficient of disequilibrium
Citation: Corona-Ruiz M, Hernandez-Cabrera F, Cantú-González JR, González-Amezcua O and Javier Almaguer F (2019) A Stochastic Phylogenetic Algorithm for Mitochondrial DNA Analysis. Front. Genet. 10:66. doi: 10.3389/fgene.2019.00066
Received: 01 April 2018; Accepted: 28 January 2019;
Published: 08 March 2019.
Edited by:
Olcay Akman, Illinois State University, United StatesReviewed by:
Kyle B. Gustafson, Naval Sea Systems Command (NAVSEA), United StatesCopyright © 2019 Corona-Ruiz, Hernandez-Cabrera, Cantú-González, González-Amezcua and Javier Almaguer. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Francisco Hernandez-Cabrera, ZnJhbmNpc2NvLmhlcm5hbmRlemNickB1YW5sLmVkdS5teA==
Francisco Javier Almaguer, ZnJhbmNpc2NvLmFsbWFndWVybXJ0QHVhbmwuZWR1Lm14
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.