

 Robert Stephenson2,3,4
Robert Stephenson2,3,4

95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Genet. , 20 August 2013
Sec. Applied Genetic Epidemiology
Volume 4 - 2013 | https://doi.org/10.3389/fgene.2013.00152
This article is part of the Research Topic Novel approaches to the analysis of family data in genetic epidemiology View all 11 articles
Background: Prostate cancer is a common and often deadly cancer. Decades of study have yet to identify genes that explain much familial prostate cancer. Traditional linkage analysis of pedigrees has yielded results that are rarely validated. We hypothesize that there are rare segregating variants responsible for high-risk prostate cancer pedigrees, but recognize that within-pedigree heterogeneity is responsible for significant noise that overwhelms signal. Here we introduce a method to identify homogeneous subsets of prostate cancer, based on cancer characteristics, which show the best evidence for an inherited contribution.
Methods: We have modified an existing method, the Genealogical Index of Familiality (GIF) used to show evidence for significant familial clustering. The modification allows a test for excess familial clustering of a subset of prostate cancer cases when compared to all prostate cancer cases.
Results: Consideration of the familial clustering of eight clinical subsets of prostate cancer cases compared to the expected familial clustering of all prostate cancer cases identified three subsets of prostate cancer cases with evidence for familial clustering significantly in excess of expected. These subsets include prostate cancer cases diagnosed before age 50 years, prostate cancer cases with body mass index (BMI) greater than or equal to 30, and prostate cancer cases for whom prostate cancer contributed to death.
Conclusions: This analysis identified several subsets of prostate cancer cases that cluster significantly more than expected when compared to all prostate cancer familial clustering. A focus on high-risk prostate cancer cases or pedigrees with these characteristics will reduce noise and could allow identification of the rare predisposition genes or variants responsible.
Prostate cancer is the most commonly diagnosed cancer in men and is the second leading cause of cancer deaths among men (ACS, 2013). While there is significant evidence of a genetic contribution (Cannon et al., 1982; Carter et al., 1993; Stanford and Ostrander, 2001; Langeberg et al., 2007), decades of investigation into the genetic causes of familial prostate cancer has yet to clearly identify genes or variants which explain much more than a small number of pedigrees with an excess of prostate cancer. Traditional linkage analysis of thousands of high-risk prostate cancer pedigrees has elucidated little in the identification of predisposition genes responsible for prostate cancer pedigrees. This may reflect the heterogeneous nature of prostate cancer, and this could confound identification of informative homogeneous pedigrees segregating rare predisposition variants.
We hypothesize that there exist rare prostate cancer predisposition variants that are responsible for our observation of high risk prostate cancer pedigrees including homogeneous prostate cancer cases (defined by clinical characteristics). We present a methodology to compare subsets of prostate cancer cases and identify those that show more familial clustering than expected for all prostate cancer cases.
Using a population-based resource in Utah that combines genealogy and cancer data, we identified 3 subsets of prostate cancer cases that cluster in pedigrees more than expected: prostate cancer which is diagnosed before age 50 years, lethal prostate cancer (leading to metastasis and death from prostate cancer), and prostate cancer in men with BMI ≥ 30. We propose that analysis of the high-risk prostate cancer cases or pedigrees with an excess of prostate cancer cases with these characteristics could lead to identification of the rare predisposition variants responsible.
The Utah Population Data Base (UPDB) integrates three key electronic datasets: a Genealogy of the Utah pioneers constructed in the 1970s and kept current (Skolnick, 1980), death certificates for Utah, and a statewide cancer registry. The original Utah genealogy had approximately 1.6 million individual records for 186,000 three-generation families. Since the genealogy was created in the 1970s, state vital records have been used to create genealogy triplets (mother, father, and child) to extend the genealogy to present day. The UPDB has become a person-oriented database with information on 7 million Utahns, some 2.5 million of whom have at least three generations of genealogy. The Utah Cancer Registry (UCR) was created in 1966 to collect data on all cancer diagnosed in Utah. It became a SEER (Surveillance, Epidemiology, and End-Results) Registry of the National Cancer Institute in 1973. The UCR individual records are linked to the Utah genealogy annually; approximately 2/3 of UCR cases link to a record in the UPDB. Cause of death from Utah state death certificates from 1904 to present have been coded to ICD Revisions 6–10, and record linked to the UPDB. Utah Drivers License records from 1970 have been linked to the UPDB and include height and weight measurements for calculation of body mass index (BMI). The combination of genealogy, death certificates, drivers license data, and cancer registry data facilitates the identification of all Utah prostate cancer cases and the genetic relationships between them.
To perform the genetic analyses presented here we restrict ourselves to those individuals in the UPDB with ancestral genealogy data. We identified all individuals in the UPDB who were born before 1972 (when the original Utah genealogy was constructed) and whose parents, four grandparents, and six (of eight total) great grandparents are present in the UPDB genealogy data. This identifies 1.2 million individuals with ancestral genealogy data who are used for all analyses.
We have extended a well-published analysis method, the Genealogical Index of Familiality (GIF), to enable comparison of the relatedness of a subset of prostate cancer cases to the relatedness of all prostate cancer cases. Those subsets with evidence for significantly more relatedness than all prostate cancer cases are hypothesized to represent homogeneous genetic subsets that will be most informative for gene identification studies.
For decades the GIF statistic has been used to quantify familial clustering of cancer and other phenotypes in the UPDB. This well-established statistical method has yielded strong evidence of heritability for several cancer phenotypes (Cannon et al., 1982; Cannon-Albright et al., 1994; Larson et al., 2006; Albright et al., 2012). The GIF was developed to test the hypothesis of excess relatedness of individuals with a common phenotype. Excess relatedness is measured by comparing the average relatedness between all pairs of cases of interest to the expected relatedness of matched controls from the Utah population. Since record linkage of any subset of UPDB records may indicate better or different quality data, for individuals with a death certificate, we select controls from all UPDB individuals who have a Utah death certificate. Since the UCR is statewide, we select controls for cancer cases from the entire UPDB resource.
The relatedness of a pair of individuals in a set is measured using the Malécot coefficient of kinship. The Malécot coefficient of kinship mathematically expresses Mendelian inheritance pattern probabilities that randomly selected homologous chromosomes are identical due to inheritance from a common ancestor. For example, the Malécot coefficient for siblings is 1/4, avunculars is 1/8, and first cousins 1/16. The GIF analysis tests excess relatedness by comparing all pairwise relationships within a set of cases to the expected relatedness measured in all pairwise relationships in 1000 sets of matched controls randomly selected from the UPDB. Controls were matched on characteristics that might be associated with record linking and disease rates, including five-year birth year cohort, sex, and birth state (Utah or not).
The overall GIF analysis tests for significant excess relatedness (over what is expected in the UPDB population) among a group of individuals. It can be performed on all prostate cancer cases, and on subsets of cases based on cancer characteristics. It cannot, however, determine which, if any, of these subsets exhibits the best evidence for a genetic predisposition, and which therefore might be the best set of high-risk pedigrees in which to search for genes.
Here we consider a modified GIF test and test the relatedness of multiple subsets of prostate cancer cases to identify those which exhibit excess relatedness above the observed relatedness among all Utah prostate cancer cases. This modified GIF test is referred to as the SubsetGif. Evidence for significant excess relatedness for a subset of prostate cancer cases above the expected for all prostate cancer cases could indicate the presence of a common genetic cause shared by the homogeneous subset. The identification and subsequent study of pedigrees including cases of such a homogeneous subset might facilitate the identification of rare predisposition genes.
It is possible to view the distribution of the contribution to the GIF statistic by the pairwise genetic distance of the different relationships observed in cases (and controls). The genetic distance represents the number of paths between a pair of individuals. Genetic distance 1 represents parent/offspring pairs, genetic distance 2 represents siblings or grandparent/grandchild, genetic distance 3 represents avunculars, and so forth.
In the UPDB resource, 18,291 prostate cancer cases were identified who also had ancestral genealogical records. The available prostate cancer subsets and their corresponding sample sizes are outlined in Table 1.

Table 1. Subsets of prostate cancer and sample size.
Previous studies have strongly supported evidence for a genetic contribution to predisposition to prostate cancer in the Utah population, as well as other populations (Cannon et al., 1982; Cannon-Albright et al., 1994, 2005). When all prostate cancer cases with genealogy data in the UPDB are analyzed there is evidence of excess relatedness (represented by both close and distant genetic relationships) over expected relatedness in matched Utah population controls. Table 2 shows the traditional GIF test for excess relatedness compared to matched Utah population controls for all prostate cancer cases, and for each subset. The mean relatedness for cases and controls is shown. All prostate cancer cases and subsets, except prostate cases who survived less than 10 months after diagnosis, show strong evidence for excess clustering compared to Utah population controls. These results suggest a genetic contribution to prostate cancer predisposition, and suggest that study of almost all subsets of prostate cancer could be fruitful, but the results do not allow identification of which, if any, of the subsets are significantly more related than expected when compared to all prostate cancer cases, and thus show the best evidence for a genetic contribution.
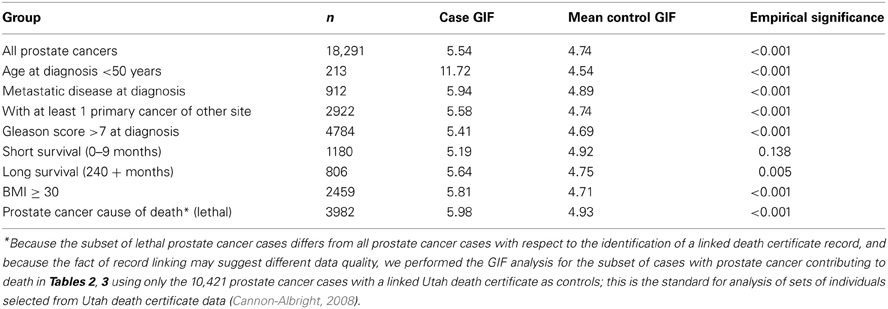
Table 2. GIF analysis of prostate cancer relatedness compared to expected relatedness in the UPDB population.
In order to consider the hypothesis that a subset of prostate cancer cases represents a more homogeneous subset of highly related cases, we propose use of the SubsetGif analysis. The average pairwise relatedness of each subset of cases is compared to the average pairwise relatedness of 1000 sets of matched “controls”; these controls are selected from the set of 18,291 Utah prostate cancer cases. The results for this SubsetGif test are shown in Table 3. The average pairwise relatedness of the cases does not change for any subset (as expected), but the mean control GIF statistic is higher than in Table 2 for each subset because the “controls” here are randomly selected prostate cancer cases, who are more closely related than random members of the Utah population.
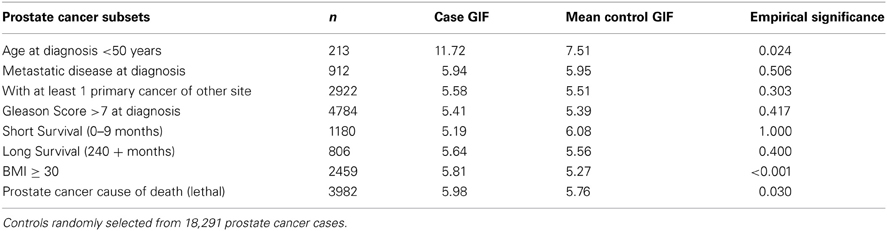
Table 3. Subset prostate cancer relatedness compared to expected prostate cancer case relatedness in the UPDB.
Table 3 results show that the average pairwise relatedness of three different subsets of prostate cancer cases is significantly higher than expected among prostate cancer cases, supporting the hypothesis that these subsets of cases cluster more than all prostate cancer cases and represent sets on which to focus for predisposition gene identification. The three subsets include prostate cancer cases diagnosed before age 50 years, prostate cancer cases with BMI ≥ 30, and prostate cancer cases whose cause of death is prostate cancer (lethal prostate cancer).
It is difficult to determine whether these three subsets represent independent groups of interest or whether there is overlap between the groups because not all cases have BMI and death certificate data. There were 222 prostate cancer cases with BMI ≥ 30 among the 3982 cases with prostate cancer as a cause of death (6% total and 17% of the 1300 lethal cases with BMI data), and 58 prostate cancer cases with BMI ≥ 30 of the 213 cases who were diagnosed before age 50 years (27%). Overall, 11,536 prostate cancer cases had BMI data, and 21.3% were BMI ≥ 30. There were 26 prostate cancer cases diagnosed before age 50 years (0.7%) among the 3982 lethal prostate cancer cases, and overall the 213 prostate cancer cases diagnosed before age 50 years represented 1% of all cases.
In order to determine the overall distribution of excess relatedness we can view the contribution to the GIF statistic by the pairwise genetic distance for cases and for controls. Figure 1 shows the GIF distribution for all 18,291 prostate cancer cases compared to the distribution for the 1000 sets of matched Utah population controls. The comparison shows that the relatedness for prostate cancer cases exceeds that expected in the Utah population, as observed in random matched Utah controls, for genetic distances up to 7 (e.g., second cousins once removed).
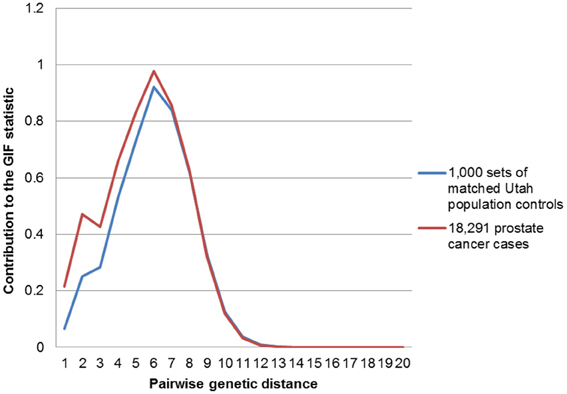
Figure 1. Contribution to the GIF statistic by pairwise genetic distance for cases and controls for all prostate cancers vs. population.
Figures 2–4 show the contribution to the GIF statistic for the three subsets of cases, with matched controls randomly selected from all Utah prostate cancer cases. Figure 2 shows this distribution for prostate cancer cases with BMI ≥ 30; as seen in Table 3 there is significant excess relatedness for prostate cases with BMI ≥ 30. This excess extends to a genetic distance of 5, equivalent to first cousins once removed, for example. Figure 3 shows this distribution for prostate cancer cases diagnosed before age 50 years, which is also observed to show significant excess relatedness. The excess relatedness is irregular, but is clearly observed for genetic distance = 2 (siblings primarily), and distance = 8 (third cousins, for example). Figure 4 shows the GIF distribution for lethal prostate cancer cases, also observed to show significant excess clustering when compared to all deceased prostate cancer cases. The excess extends to genetic distance = 4, equivalent to first cousins, for example.
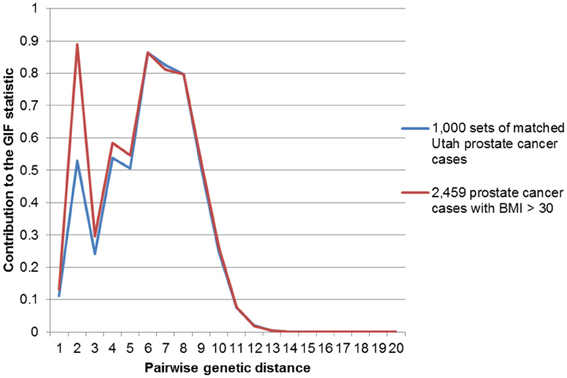
Figure 2. Contribution to the GIF statistic by pairwise genetic distance for cases and controls for prostate cancer cases with a BMI of 30 or greater.
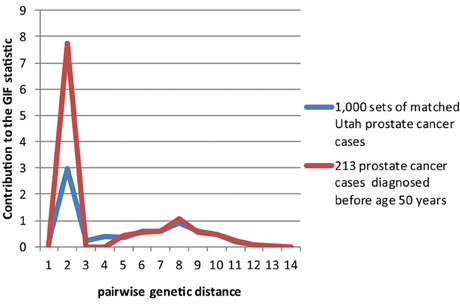
Figure 3. Contribution to the GIF statistic by pairwise genetic distance for cases and controls for prostate cancer cases diagnosed before age 50.
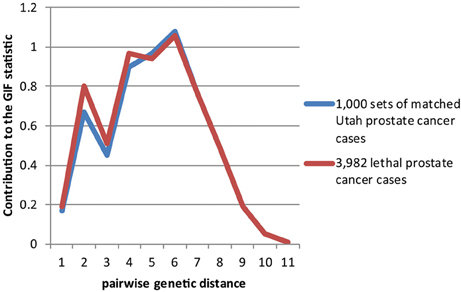
Figure 4. Contribution to the GIF statistic by pairwise genetic distance for cases and controls for prostate cancer cases that have prostate cancer as a cause of death.
Figures 5–7 show examples Utah high-risk prostate cancer pedigrees for each of the subset characteristics identified.
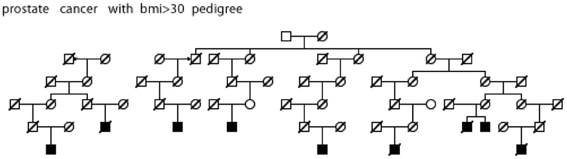
Figure 5. High risk Utah prostate cancer pedigree (56 prostate cancer cases observed among descendants of the pedigree founder, 36 expected, p = 0.001); cases with BMI ≥ 30 are shown.
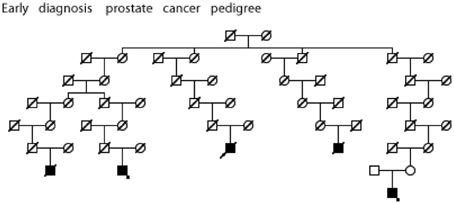
Figure 6. High risk Utah prostate cancer pedigree (173 prostate cancers observed among descendants of the pedigree founder, 131 expected, p = 0.0003); cases diagnosed before age 50 years are shown. The two cases with an asterisk were also observed to have BMI ≥ 30 (data not available for all cases).
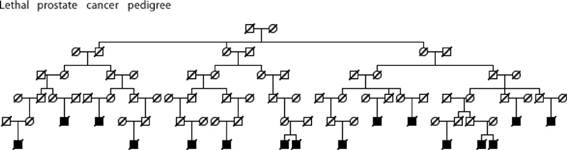
Figure 7. High risk Utah prostate cancer pedigree (76 prostate cancer cases observed among descendants of the pedigree founder, 51.5 expected, p = 0.0008); cases known to have died from prostate cancer are shown.
Analysis of a population-based Utah resource linking cancer characteristics data with genealogy data has previously shown evidence for a genetic contribution to prostate cancer predisposition (Cannon et al., 1982; Cannon-Albright et al., 1994, 2005; Albright et al., 2012; Teerlink et al., 2012). Here we have extended a well-published analysis method which tests for excess relatedness in a set of individuals to allow the identification of subsets of prostate cancer cases who show the strongest evidence for excess familial clustering. The subsets identified might be argued to represent the most informative sets of cases or pedigrees to be studied for rare predisposition gene identification.
Some of the subsets of prostate cancer cases that show significant evidence of clustering in excess of expected for prostate cancer were expected, some represent new subsets of interest for genetic studies. The subset of men diagnosed with prostate cancer before age 50 years is not surprising; there is much literature suggesting a strong genetic contribution to cancer of most sites that is diagnosed early (Goldgar et al., 1994; Brandt et al., 2008) and much analysis of this subset of prostate cancer cases and pedigrees has been performed (Gronberg et al., 1999; Xu et al., 2005). However, the other two groups of prostate cancer cases identified, high BMI (≥30) and lethal prostate cancer cases, have not been suggested previously as associated with a strong genetic contribution for prostate cancer. There was some overlap of prostate cancer cases between these sets; further investigation of specific high-risk pedigrees will determine whether they are independent.
Although epidemiologic studies have shown that systemic metabolic disorders including obesity might increase risk for prostate cancer, BMI in the context of high risk prostate cancer pedigrees does not appear to have been studied. Since there is evidence for familial clustering of high BMI or obesity (independent of cancer status), it is possible that these results are due, at least in part, to a shared predisposition to obesity. Nevertheless, these results suggest this is an informative set of pedigrees to be studied for prostate cancer risk.
The familiality of aggressive prostate cancer has been noted, and subsets of aggressive prostate cancer cases have been studied, without any gene identifications (Paiss et al., 2003; Lange et al., 2006; Schaid et al., 2006; Christensen et al., 2007). Little progress has been made in understanding why 30% of all patients with localized prostate cancer eventually develop recurrent, and subsequently fatal, prostate cancer. Rather than subset aggressive prostate cancers, we specifically targeted the pathogenesis of lethal prostate cancer. This subtle definition difference focuses on the subtype of prostate cancer which is associated with the worst prognosis i.e., which kills, but our definition ignores age at onset and pathology grading data for the individual, both of which are more commonly used to classify prostate cancer cases for aggressive status, but which can be poor markers for survival. This subset of lethal prostate cancer cases, among all others, is the most clinically significant and that which could yield the most translational opportunities were genes to be identified.
The Utah population has proven valuable to the study of many common cancers, and to the isolation of multiple cancer predisposition genes. The University of Utah group has been studying high-risk cancer pedigrees since 1972, and has built a resource of thousands of extended high-risk pedigrees that includes over 35,000 DNA samples. The study of extended pedigrees allowed our research group to isolate BRCA1 (Miki et al., 1994), to localize and isolate BRCA2 (Wooster et al., 1994; Tavtigian et al., 1996), to localize and isolate p16 (Cannon-Albright et al., 1992, 1994; Kamb et al., 1994), and to localize and isolate HPC2/ELAC2 (Tavtigian et al., 2001). These findings of excess relatedness in the UPDB for three subsets of prostate cancer cases represent multiple Utah high-risk prostate cancer pedigrees for each of the subsets. Analysis of these high risk pedigrees will lead to identification of the predisposition genes responsible, which might otherwise not be identifiable in studies of all high-risk prostate cancer pedigrees combined.
We have identified significant evidence for three characteristics of prostate cancer that independently coaggregate in both close and distant relatives. We have identified multiple high-risk prostate cancer pedigrees that independently include multiple prostate cancer cases with the characteristics of interest. Figures 5–7 show an example Utah high-risk prostate cancer pedigree for each of the three characteristics identified. We propose that linkage analysis or shared genomic segment (Thomas et al., 2008) analysis can identify chromosomal regions shared in the related cases and that sequence analysis of predisposition carriers in the targeted regions located will lead to identification of the responsible predisposition genes. Rather than studying all high-risk prostate cancer pedigrees, we instead will focus on those that exhibit multiple cases with those characteristics most likely to have a genetic contribution. These studies will examine fewer pedigrees than a typical prostate cancer pedigree study, but will focus on the homogeneous subsets most likely to represent rare segregating predisposition genes or variants.
These findings should be generalizable to the U.S.A. population. Utah was originally settled by ~10,000 Mormons of British, Scandinavian, and German origin. They, and the more than 50,000 migrants from the same areas who arrived in the next generations, have typical Northern European gene frequencies (McLellan et al., 1984) and low to normal levels of inbreeding compared to the U.S. (Jorde, 1989). These characteristics make this population appropriate for inferences in populations of Northern European descent. The predisposition genes identified in Utah are represented similarly in other studies in terms of frequency, penetrance, and interactions with risk factors and modifier genes. Utah cancer rates are lower than U.S. rates, most likely due to lower rates of smoking and alcohol use.
Recent advances in mapping the genome, combined with the unique resources of Utah, provide a rare opportunity for a successful search for predisposition genes or variants for prostate cancer and the definition of their role at a population level. Recent evidence has shown the advisability and efficiency of rare predisposition gene identification by study of extended pedigrees (Ewing et al., 2012; Roberts et al., 2012). Here we identify characteristics of prostate cancer that can be used to more specifically focus gene identification efforts on appropriate pedigrees. The eventual identification of predisposition genes for prostate cancer, accompanied by a greater understanding of how these genes contribute to morbidity and mortality, will lead to the development of diagnostic tests and more personalized treatments for prostate cancer.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Albright, F., Teerlink, C., Werner, T. L., and Cannon-Albright, L. A. (2012). Significant evidence for a heritable contribution to cancer predisposition: a review of cancer familiality by site. BMC Cancer 12:138. doi: 10.1186/1471-2407-12-138
American Cancer Society. (2013). Cancer Facts and Figures 2013. Atlanta, GA: American Cancer Society.
Brandt, A., Bermejo, J. L., Sundquist, J., and Hemminki, K. (2008). Age of onse in familial cancer. Ann. Oncol. 19, 2084–2088. doi: 10.1093/annonc/mdn527
Cannon, L., Bishop, D. T., Skolnick, M. H., Hunt, S., Lyon, J. L., and Smart, C. (1982). Genetic epidemiology of prostate cancer in the Utah Mormon genealogy. Cancer Surv. 1, 48–69.
Cannon-Albright, L. A. (2008). Utah family-based analysis: past, present and future. Hum. Hered. 65, 209–220. doi: 10.1159/000112368
Cannon-Albright, L. A., Goldgar, D. E., Meyer, L. J., Lewis, C. M., Anderson, D. E., Fountain, et al. (1992). Assignment of a locus for familial melanoma, MLM, to chromosome 9p13-p22. Science 258, 1148–1152. doi: 10.1126/science.1439824
Cannon-Albright, L. A., Goldgar, D. E., Neuhausen, S., Gruis, N. A., Anderson, D. E., Lewis, C. M., et al. (1994). Localization of the 9p melanoma susceptibility locus (MLM) to a 2-cM region between D9S736 and D9S171. Genomics 23, 265–268. doi: 10.1006/geno.1994.1491
Cannon-Albright, L. A., Schwab, A., Camp, N. J., Farnham, J. S., and Thomas, A. (2005). Population-based risk assessment for other cancers in relatives of hereditary prostate cancer (HPC) Cases. Prostate 64, 347–355. doi: 10.1002/pros.20248
Carter, B. S., Bova, G. S., Beaty, T. H., Steinberg, G. D., Childs, B., Isaacs, W. B., et al. (1993). Hereditary prostate cancer: epidemiologic and clinical features. J. Urol. 150, 797–802.
Christensen, G. G., Camp, N. J., Farnham, J. M., and Cannon-Albright, L. A. (2007). Genome-wide linkage analysis for aggressive prostate cancer in Utah high-risk pedigrees. Prostate 67, 605–613. doi: 10.1002/pros.20554
Ewing, C. M., Ray, A. M., Lange, E. M., Zuhlke, K. A., Robbins, C. M., Tembe, W. D., et al. (2012). Germline mutations in HOXB13 and prostate-cancer risk. N. Engl. J. Med. 366, 141–149. doi: 10.1056/NEJMoa1110000.
Goldgar, D. E., Easont, D. F., Cannon-Albright, L. A., and Skolnick, M. H. (1994). Systematic population-based assessment of cancer risk in first-degree relatives of cancer probands. J. Natl. Cancer Inst. 86, 1600–1608. doi: 10.1093/jnci/86.21.1600
Gronberg, H., Smith, J., Emanuelsson, M., Jonsson, B. A., Bergh, A., Carpten, J., et al. (1999). In Swedish families with hereditary prostate ccancer,linkage to the HPC1 locus on chromosome 1q24-25 is restricted to families with early-onset prostate cancer. Am. J. Hum. Genet. 65, 134–40. doi: 10.1086/302447
Jorde, L. B. (1989). Inbreeding in the Utah Mormons: an evaluation of estimates based on pedigrees, isonymy, and migration matrices. Ann. Hum. Genet. 53, 339–355.
Kamb, A., Shattuck-Eidens, D., Eeles, R., Liu, Q., Gris, N. A., Ding, W., et al. (1994). Analysis of the p16 gene (CDKN2) as a candidate for the chromosome 9p melanoma susceptibility locus. Nat. Genet. 8, 23–26. doi: 10.1038/ng0994-22
Lange, E. M., Ho, L. A., Beebe-Dimmer, J. L., Wang, Y., Gillanders, E. M., Trent, J. M., et al. (2006). Genome-wide linkage scan for prostate cancer susceptibility genes in men with aggressive disease: significant evidence for linkage at chromosome 15q12. Hum. Genet. 119, 400–407.
Langeberg, W. J., Isaacs, W. B., and Stanford, J. L. (2007). Genetic etiology of hereditary prostate cancer. Front. Biosci. 12, 4101–4110.
Larson, A. A., Leachman, S. A., Eliason, M. J., and Cannon-Albright, L. A. (2006). Population-based assessment of non-melanoma cancer risk in relatives of cutaneous melanoma probands. J. Invest. Dermatol. 127, 183–188. doi: 10.1038/sj.jid.5700507
McLellan, T., Jorde, L. B., and Skolnick, M. H. (1984) Genetic distances between the Utah Mormons and related populations. Am. J. Hum. Genet. 36, 836–857.
Miki, Y., Swensen, J., Shattuck-Eidens, D., Futreal, P. A., Harshman, K., Tavtigian, S., et al. (1994). A strong candidate for the breast and ovarian cancer susceptibility gene BRCA 1. Science 266, 66–71. doi: 10.1126/science.7545954
Paiss, T., Worner, S., Kurtz, F., Haeussler, J., Hautmann, R. E., Gschwend, J. E., et al. (2003). Linakge of aggressive prostate cancer to chromosome 7q31-33 in German prostate cancer families. Eur. J. Hum. Genet. 11, 17–22. doi: 10.1038/sj.ejhg.5200898
Roberts, N. J., Jiao, Y., Yu, J., Kopelovich, L., Petersen, G. M., Bondy, M. L., et al. (2012). ATM mutations in patients with hereditary pancreatic cancer. Cancer Discov. 2, 41–46. doi: 10.1158/2159-8290.CD-11-0194
Schaid, D. J., McDonnell, S. K., Zarfas, K. E., Cunningham, J. M., Hebbring, S., Thibodeau, S. N., et al. (2006). Pooled genome linkage scan of aggressive prostate cancer: results from the international consortium for prostate cancer genetics. Hum. Genet. 120, 471–485. doi: 10.1007/s00439-006-0219-9
Skolnick, M. H. (1980). “The Utah geneological data base: a resource for genetic epidemiology,” in Banbury Report 4: Cancer Incidence in Defined Populations, eds J. Cairns, J. H. Lyon, and M. H. Skolnick (Cold Spring Harbor, NY: Cold Spring Harbor Laboratory), 285–297.
Stanford, J. L., and Ostrander, E. A. (2001). Familial prostate cancer. Epidemiol. Rev. 23, 19–23, doi: 10.1093/oxfordjournals.epirev.a000789
Tavtigian, S. V., Simard, J., Rommens, J., Couch, F., Shattuck-Eidens, D., Neuhausen, S., et al. (1996). The complete BRCA2 gene and mutations in chromosome 13q-linked kindreds. Nat. Genet. 12, 333–337. doi: 10.1038/ng0396-333
Tavtigian, S. V., Simard, J., Teng, D. H., Abtin, V., Baumgard, M., Beck, A., et al. (2001). A candidate prostate cancer susceptibility gene at chromosome 17p. Nat. Genet. 27, 172–180. doi: 10.1038/84808
Teerlink, C. C., Albright, F. S., Lins, L., and Cannon-Albright, L. A. (2012). A comprehensive survey of cancer risks in extended families. Genet. Med. 14, 107–114. doi: 10.1038/gim.2011.2
Thomas, A., Camp, N. J., Farnham, J. M., Allen-Brady, K., and Cannon-Albright, L. A. (2008). Shared genomic segment analysis. mapping disease predisposition genes in extended pedigrees using SNP genotype assays. Ann. Hum. Genet 72(Pt 2), 279–287.
Wooster, R., Neuhausen, S., Mangion, J., Quirk, Y., Ford, D., Collins, N., et al. (1994). Localization of a breast cancer susceptibility gene (BRCA2) to chromosome 13q12-13. Science 265, 2088–2090. doi: 10.1126/science.8091231
Keywords: familiality, prostate cancer, lethal, UPDB
Citation: Nelson Q, Agarwal N, Stephenson R and Cannon-Albright LA (2013) A population-based analysis of clustering identifies a strong genetic contribution to lethal prostate cancer. Front. Genet. 4:152. doi: 10.3389/fgene.2013.00152
Received: 30 April 2013; Accepted: 22 July 2013;
Published online: 20 August 2013.
Edited by:
Robert C. Elston, Case Western Reserve University, USAReviewed by:
Lara E. Sucheston, Roswell Park Cancer Institute, USACopyright © 2013 Nelson, Agarwal, Stephenson and Cannon-Albright. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Lisa A. Cannon-Albright, Internal Medicine, University of Utah School of Medicine, 30 N 1900 E, Salt Lake City, UT 84132, USA e-mail:bGlzYS5hbGJyaWdodEB1dGFoLmVkdQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.