

 A. Zinovyev3 and V. Noel4
A. Zinovyev3 and V. Noel4
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Genet. , 19 July 2012
Sec. Computational Genomics
Volume 3 - 2012 | https://doi.org/10.3389/fgene.2012.00131
Biochemical networks are used in computational biology, to model mechanistic details of systems involved in cell signaling, metabolism, and regulation of gene expression. Parametric and structural uncertainty, as well as combinatorial explosion are strong obstacles against analyzing the dynamics of large models of this type. Multiscaleness, an important property of these networks, can be used to get past some of these obstacles. Networks with many well separated time scales, can be reduced to simpler models, in a way that depends only on the orders of magnitude and not on the exact values of the kinetic parameters. The main idea used for such robust simplifications of networks is the concept of dominance among model elements, allowing hierarchical organization of these elements according to their effects on the network dynamics. This concept finds a natural formulation in tropical geometry. We revisit, in the light of these new ideas, the main approaches to model reduction of reaction networks, such as quasi-steady state (QSS) and quasi-equilibrium approximations (QE), and provide practical recipes for model reduction of linear and non-linear networks. We also discuss the application of model reduction to the problem of parameter identification, via backward pruning machine learning techniques.
During the last decades, biologists have identified a wealth of molecular components and regulatory mechanisms underlying the control of cell functions. Cells integrate external signals through sophisticated signal transduction pathways, ultimately affecting the regulation of gene expression, including that of the signaling components. Metabolic functions are sustained and controlled by complex machineries involving genes, enzymes, and metabolites. The genetic regulations result from the coordinate effect of many, mutually interacting genes. These regulations involve many molecular actors, including proteins and regulatory RNAs, which form large, intricate networks.
Current dynamical models of cellular molecular processes are small size networks. These small scale models, that are subjective simplifications of reality, can not take into account the specificities of regulatory mechanisms. New methods are needed, allowing to reconcile small scale dynamical models and large scale, but static, network architectures. The main obstacle to increasing the size of dynamical networks is the incomplete information, on the parameters and on the mechanistic details of the interactions. In vivo values of the parameters depend on crowding and heterogeneity of the intracellular medium, and can be orders of magnitude different from what is measured in vitro. Furthermore, learning models from data suffer for non-identifiability and over-fitting problems. Thus, model reduction is an avoidable step in the study of large networks, allowing to extract the essential features of the model, that can then be identified from data. Model reduction in computational biology should have several features.
First of all, model reduction should cope with parametric incompleteness and/or uncertainty.
A certain class of reduction methods are parameter independent and automatically comply with this specificity. In biochemical networks, the number of possible chemical species grows combinatorially due to numerous possibilities of interactions between molecules with multiple interaction sites. The exact lumping methods (Borisov et al., 2005; Conzelmann et al., 2006) reduce the number of microstates and avoid combinatorial explosion in the description and analysis of large models of receptor and scaffold signaling. A similar technique (Feret et al., 2009) is used to rationally organize supramolecular complexes in rule-based modeling (Danos et al., 2007a) of biochemical networks. Other, parameter independent, coarse-graining techniques are graphical methods formalizing node deletion and merging operations in biochemical networks (Gay et al., 2010), pooling of metabolites in large scale metabolic networks (Papin et al., 2004; Jamshidi and Palsson, 2008), or extensive searches in the set of all possible lumps (Dokoumetzidis and Aarons, 2009). Finally, qualitative reduction methods were used to simplify large logical regulatory graphs, adequately suppressing nodes and defining sub-approximating dynamics (Naldi et al., 2009, 2011).
Secondly, biochemical processes governing network dynamics span over many timescales. For example, changing gene expression programs can take hours and even days while protein complex formation goes on the second scale and post-translational protein modifications take minutes to happen. Protein life half-times can vary from minutes to days. Model reduction can strongly benefit from the network multiscaleness. Asymptotic dynamics of networks with slow and fast processes, can be strongly simplified using various ideas such as inertial and invariant manifolds (IM) and averaging approximations.
The iterative methods of IM aim to find a slow low dimensional IM, containing the asymptotic dynamics (Gorban and Karlin, 1994, 2003; Roussel and Fraser, 1991). The Computational Singular Perturbation (CSP) (Lam and Goussis, 1994; Chiavazzo et al., 2007) aims to find even more, the slow IM and, in addition, the geometry of its fast foliation. IM can be calculated by various other methods (Gorban and Karlin, 2005; Gorban et al., 2004; Roussel and Fraser, 1991; Kazantzis and Good, 2002; Krauskopf et al., 2005).
Very popular are the methods for computation of “first approximations” to the slow IM. The classical quasi steady-state approximation (QSS) was proposed by Bodenstein (1913) and was elaborated into an important tool for analysis of chemical reaction mechanism and kinetics (Semenoff, 1939; Christiansen, 1953; Helfferich, 1989). The classical QSS is based on the relative smallness of concentrations of some of active reagents (radicals, concentration of enzyme and substrate-enzyme complexes, or amount of active centers on the catalyst surface) (Aris, 1965; Segel and Slemrod, 1989; Yablonskii et al., 1991). The quasi-equilibrium approximation (QE) has two basic formulations: the thermodynamic approach, based on conditional entropy maximum (or free energy conditional minimum), or the kinetic formulation, based on equilibration of fast reversible reactions. The very first use of the entropy maximum dates back to Gibbs (Gibbs, 2010). Corrections to QE approximation with applications to physical and chemical kinetics were developed by (Gorban et al., 2001; Gorban and Karlin, 2005). An important, still unsolved, problem of these two approximations is the detection of QSS species and QE reactions without application of all machinery of the IM or CSP methods. Indeed, not all reactions with large constants are at QE, and there are no simple rules to find QSS species if there is no such hints as a small amount of a conserved quantity (like the total concentration of enzyme). The method of Intrinsic Low Dimensional Manifolds (ILDM) (Maas and Pope, 1992; Bykov et al., 2006) provides an approximation of a low dimensional IM and works as a first step of CSP (Kaper and Kaper, 2002).
Another method allowing to simplify multiscale dynamics is averaging. This idea can be tracked back to Poincarée's perturbative treatment of the many body problem in celestial mechanics (Poincarè, 1899), further developed in classical mechanics by other authors (Arnold, 1978; Lochack and Meunier, 1988), and also known as adiabatic or Born-Oppenheimer approximation in quantum mechanics (Messiah, 1962). Rather generally, averaging can be applied when some fine scale variables of the system are rapidly oscillating. Then, the dynamics of slow, coarse scale variables, can be obtained by time averaging the system over a timescale much larger than the period of the fast oscillations. The way to perform averaging, depends on the structure of the system, namely on the definition of the coarse grained and fine variables (Bogoliubov and Mitropolski, 1961; Artstein and Vigodner, 1996; Givon et al., 2004; Acharya and Sawant, 2006; Sawant and Acharya, 2006; Acharya, 2010; Slemrod, 2011).
Some of these ideas have been implemented in computational biology tools. Systems biology markup language SBML (Hucka et al., 2003) can allocate a “fast” attribute to reaction elements. Fast reaction specification can be taken into account by computational biology softwares such as VirtualCell (Slepchenko et al., 2003) that implements a QE approximation algorithm (Slepchenko et al., 2000). Similarly, the simulation tool COPASI (Hoops et al., 2006) implements the ILDM method (Surovtsova et al., 2009).
Finally, multiscaleness does not uniquely apply to timescales, but equivalently to abundances of various species in these networks. mRNA copy numbers can change from some units to tens of thousands, and the dynamic concentration range of biological proteins can reach up to five orders of magnitude. Furthermore, the DNA molecule has only one or a few copies. Low copy numbers lead, directly or indirectly (a species can be stochastic even if present in large copy numbers), to stochastic gene expression. In computational biology, model reduction should thus cope not only with deterministic, but also with stochastic and hybrid models. The need to reduce large scale stochastic models is acute. Indeed, stochastic simulation algorithm (SSA, Gillespie, 1976, 1977) can be very expensive in computer time when applied to large unreduced models, precluding model analysis and identification. For this reason, extensive effort has been dedicated to adapting the main ideas used for model reduction of deterministic models, namely exact lumping, IM, QSS, QE, and averaging, to the case of stochastic models.
Reduction of stochastic rule-based models, based on a weakened version of the exact lumpability criterion, has been proposed by Feret et al. (2012) to define abstract species or stochastic-fragments that can be further used in simplified calculations. More generally, rule-based models alow to overcome combinatorial complexity in stochastic simulations (Danos et al., 2007b). The performance of rule-based stochastic simulators such as NFsim (Sneddon et al., 2011) scales independently of the reaction network size. Approximate reduction of the number of states of the Markov chains describing stochastic networks were proposed in Munsky and Khammash (2006).
Multiscaleness of stochastic networks is two-fold, it affects both species and reaction rates. This has been exploited in hybrid stochastic simulation schemes that are, for the most of them, based on a partition of the biochemical reactions in fast and slow reactions (Haseltine and Rawlings, 2002; Burrage et al., 2004; Alfonsi et al., 2005; Haseltine and Rawlings, 2005; Alfonsi et al., 2004; Salis and Kaznessis, 2005; Kaznessis, 2006; Harris and Clancy, 2006; Surovtsova et al., 2006; Salis et al., 2006; Griffith et al., 2006; Ball et al., 2006; Li et al., 2008; Gómez-Uribe et al., 2008; Pahle, 2009). Conversely, mixed partitions, using both reactions and species can exploit both types of multiscaleness and more appropriately unravel a rich variety of stochastic functioning regimes such as piece-wise deterministic, switched diffusions, diffusions with jumps, as well as averaged processes (Radulescu et al., 2007; Crudu et al., 2009, 2012) only partially covered by some situations discussed in Mastny et al. (2007).
Machine learning approaches to parameter identification (Golightly and Wilkinson, 2011) could profit from Fokker–Planck approximations, also known as diffusion approximations or Langevin approach, of the master equation describing dynamics of stochastic networks. Traditional approaches such as central limit theorem (Gillespie, 2000; Mélykúti et al., 2010), the Ω and the Kramers–Moyal expansions (Radulescu et al., 2007; Crudu et al., 2009) where used to derive diffusion approximations. Alternatively, (Erban et al., 2006) propose diffusion approximations for slow/fast stochastic networks, in which the drift and diffusion parameters were obtained numerically. More recently, these parameters were derived directly from the master equation of stochastic networks with species in small and large copy numbers (Radulescu et al., 2012). Furthermore, by the ergodic theorem, time averaging of multiscale stochastic models boils down to a QE assumption for the fast variables. This idea has been used in Crudu et al. (2009) to reduce stochastic networks. A few computational biology tools implement stochastic approximations (Salis et al., 2006).
With the exception of the parameter independent methods, all the model reduction methods described above need a full parametrization of the model. This is a stringent requirement, and can not be easily bypassed. Indeed, the reduction has a local validity. The elements defining a reduced model such as IM, QSS species, QE species, depend on the model parameters and also on the position in phase space and along trajectories. What one can expect is that model reduction is robust, i.e., a given reduced model provides an accurate approximation of the dynamics of the initial model for a wide range of parameters and variables values. One can show that this property is satisfied by biochemical networks with separated constants, because in this case the simplified networks depend on the order relations among model parameters and not on the precise values of these parameters (Gorban and Radulescu, 2008; Radulescu et al., 2008; Noel et al., 2011).
The purpose of this review is not the exhaustive description of all the reduction methods that we have delineated. We will revisit the fundamental concepts of model reduction in the light of a new framework, that should, in the long-term, lead to a new generation of reduction tools satisfying all the specific requirements of computational biology. Due to space limitations, we restrict ourselves to deterministic models.
To construct a dynamic reaction network we need the list of components, and the list of reactions (the reaction mechanism):
where j ∈ [1, r] is the reaction number.
Dynamics of non-linear networks in homogeneous isochoric systems (fixed volume) is described by a system of differential equations:
c ∈ ℝn is the concentration vector, νj = βj − αj is the global stoichiometric vector. The reaction rates R+/−j(c) are non-linear functions of the concentrations. For instance, the mass action law reads R+j(c) = k+j ∏i cαjii, R−j(c) = k−j ∏icβjii, in which case Pi(c) is a multivariate polynomial on the concentrations cj.
Monomolecular reaction networks are the simplest reaction networks. The structure of these networks is completely defined by a digraph, in which vertices correspond to chemical species Ai, edges correspond to reactions Ai → Aj with kinetic constants kji > 0.
The kinetic equation is
or in matrix form: .
The solutions of (3) can be expressed in terms of left and right eigenvectors of the kinetic matrix K:
where Krk = λkrk, and lk K = λklk.
Each eigenvalue λk is the inverse of a timescale of the network. A reduced network having solutions of the type (4), with eigenvectors rk, lk, and eigenvalues λk approximating the eigenvectors and the eigenvalues of the original network is called a multiscale approximation.
We say that the network constants are totally separated if for all (i, j) ≠ (i′, j′) one of the relations kji << kj′i′, or kji >> kj′i′ is satisfied.
It was shown in Gorban and Radulescu (2008); Radulescu et al. (2008); Gorban et al. (2010) that the multiscale approximations of arbitrary monomolecular reaction networks with totally separated constants are acyclic (have no cycles), and deterministic (have no nodes from which leave more than one edge) digraphs.
In order to reduce a network with total separation, one needs only qualitative information on the constants. More precisely, each edge of the reaction digraph can be labeled by a positive integer representing the rank of the reaction parameter in the ordered series of parameter values, the largest parameter (the quickest reaction) having the lowest label. These integer labels also indicate the timescales of the processes modeled by the network reactions.
The reduced network is not always a subgraph of the initial graph. It is obtained from this integer labeled digraph by graph re-writing operations, that can be generically described as pruning and pooling. Two types of pruning operations are of primary importance (see also Figure 1):
Rule a) If one has one node from which leave more than one edge,
then all the edges are pruned with the exception of the fastest one
(lowest integer label). This operation corresponds to keeping
the dominant term among the terms cikij consuming a species Ai,
and reduces the node outdegree to one. The same
principle can not be applied to reduce the indegree, because which
production term is dominant among kij cj, j ∈ [1, n],
depends not only on kij but also on the concentrations cj.
Rule b) Cycles with separated constants can be transformed into chains,
by elimination of the slowest step. This can be justified intuitively by
topology, because any two nodes of a cycle are connected
by two paths, one containing the slowest step and the other
one not containing the slowest step. The latter shortcuts the former.
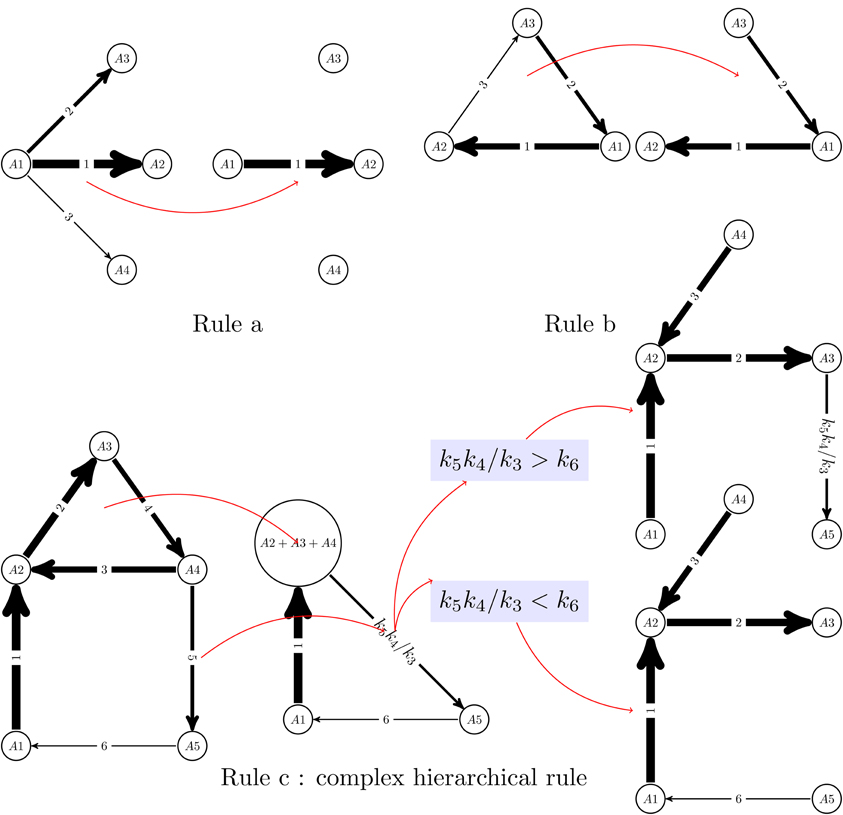
Figure 1. Reduction algorithm for linear networks. A monomolecular network with total separation can be represented as a digraph with integer labels (the quickest reaction has label 1). Two simple rules allow to eliminate competition between reactions (rule a) and transform cycles into chains (rule b). Rule b can not be applied to cycles with outgoing slow reactions, in which case more complex, hierarchical rules should be applied (rule c). In the rule c, first the cycle A2 → A3 → A4 → A2 is “glued” to a new node (pool A2+ A3+ A4) and the constant of the slow outgoing reaction renormalized to a monomial k5k4/k3. Rule b is applied to the resulting network, which is a cycle with no outgoing reactions. The comparison of the constants k5k4/k3 and k6 dictates where this cycle is cut. Finally, the glued cycle is restored, with its slowest step removed.
However, a combination of rules a) and b) is not allowed to prune slow reactions leaving a cycle and further transform the cycle into a chain by eliminating the limiting step. Indeed, the total mass of such cycles is slowly decaying because of outgoing reactions. Pruning the slow reactions that leave a cycle would keep the total cycle mass constant and produce the wrong long time approximation. In this case, pooling operations are needed:
Rule c) Glue each cycle in the pruned system into a new vertex and
transform the network of all initial reactions into a new one.
The concentration of this new component is the sum of the
concentration of the glued vertices. Reactions to the cycles
transform into reactions to the correspondent new vertices
(with the same constants). To transform the reactions from the
cycles, we have to calculate the normalized quasi-stationary
distributions inside each cycle (with unit sum of the concentrations
in each cycle). Let for the vertex Ai from a cycle this
concentration be coi. Then the reaction Ai → Aj with the
constant kji transforms into the reaction from the new (“cycle”)
vertex with the constant kji coi. The destination vertex of this
reaction is Aj if it does not belong to a cycle of the pruned system,
it is the correspondent glued cycle if it includes Aj and does not
include Ai and the reaction vanishes if both Ai and Aj belong to
the same cycle of the pruned system.
After pooling we have to prune (Rule a) and so on, until we get an acyclic pruned system. Then the way back follows: we have to restore cycles and cut them (Rule b).
In more detail, the graph re-writing operations, are described in the Appendix and illustrated in Figure 1. The dynamics of reduced acyclic deterministic digraphs follows from their topology and from the timescale labels. First of all, let us notice that the network has as many timescales as remaining edges in the reduced digraph. The computation of eigenvectors of acyclic deterministic digraphs is straightforward (Gorban and Radulescu, 2008; Radulescu et al., 2008; Gorban et al., 2010). For networks with total separation, these eigenvectors satisfy, in the first approximation, a 0−1 type property, the coordinates of lk, rk belong to the sets {0, 1}, and {0, 1, −1}, respectively. The 0−1 property of eigenvectors has a non-trivial consequence. On the timescale tk = (λk)−1, the reduced digraph behaves as an effective reaction (single step approximation). The effective reaction receives (from reactions acting on smaller timescales) the mass coming from the species with coordinate 1 in lk (pool) and transfers it (during a time tk) to the species with coordinate 1 in rk. The successive single step approximations of an acyclic deterministic digraph are illustrated in Figure 2.
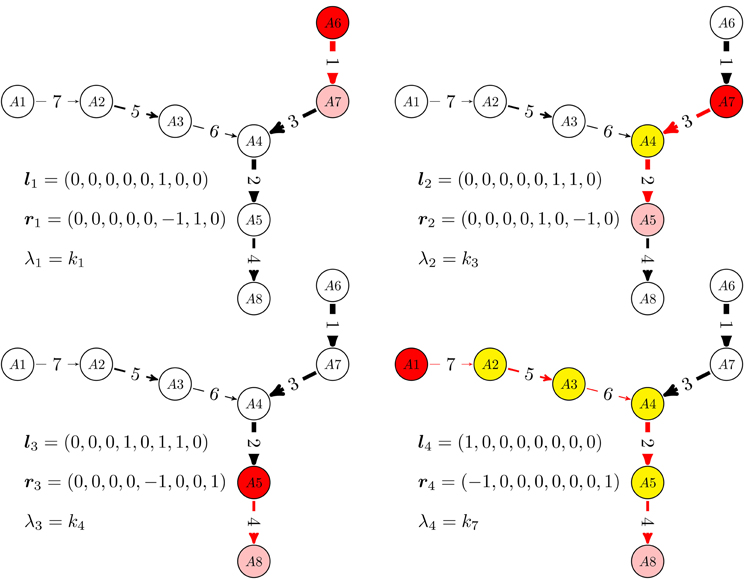
Figure 2. Relaxation modes of linear multiscale networks. For a given timescale, monomolecular networks with total separation behave as a single step: the concentrations of some species (white) are practically constant, some species (yellow) are rapid, low concentration, intermediates, one species (red) is gradually consumed and another (pink) is gradually produced. We have represented the sequence of one step approximations of a reduced, acyclic, deterministic digraph, from the quickest time-scale t1 = λ−11 to the slowest one t4 = λ−14. These one step approximations are activated when mass is introduced at t = 0 via the “boundary nodes” A1 and A6.
Monomolecular networks with separation represent instructive examples where reduction and qualitative dynamics result from the network topology and from the orders of magnitude of the kinetic constants. This type of models can be used in computational biology to reduce linear subnetworks or even binary reactions for which one reactant is present in much larger quantities than the other (pseudo-monomolecular approximation).
As argued by a few authors, total separation could be a generic property of biochemical networks (Furusawa and Kaneko, 2003). This property can be checked empirically by investigating the distribution of network timescales in logarithmic scale. Whenever one finds distributions with large support in logarithmic scale a log-uniform distribution is equivalent to the Zipf law, i.e., a power law distribution with exponent −1, well known in critical systems (Furusawa and Kaneko, 2003) total separation is valid and the above reduction method applies.
The previously presented algorithm is based on the idea of dominance, which occurs at many levels. For instance, when several reactions compete for the same pool, all can be pruned, excepting the dominant one [Rule a]. This simple idea is widely spread, and corresponds to max-plus algebra: the sum of positive, well separated terms, can be replaced by the maximum term. Max-plus algebra, that found many applications to dynamical systems (Cohen et al., 1999; van den Boom and De Schutter, 2006; Aubin, 2010), belong to the new mathematical field of tropical geometry (Pachter and Sturmfels, 2004). Tropical geometry offers convenient solutions to finding approximate roots of simultaneous polynomial equations, as well as to simplifying and hybridizing systems of polynomial or rational ordinary differential equations with separated monomials. Tropical geometry concepts can be used to rationalize many model reduction operations and find new ones.
The logarithmic transformation ui = log xi, 1 ≤ i ≤ n, well known for drawing graphs on logarithmic paper, plays a central role in tropical geometry (Viro, 2008).
Let us consider multivariate monomials M(x) = aαxα, where xα= xα11xα22 … xαnn. Monomials with positive coefficients aα>0, become linear functions, log M = log aα + < α, log(x) >, by this transformation.
There is a straightforward way to use the logarithmic transformation from tropical geometry in order to obtain approximations of dynamical networks of the type (2). Let us suppose that reaction rates are polynomial functions of the concentrations (this is satisfied by mass action law and obviously, also by monomolecular networks), such that ∑rj=1 νj(R+j(c) − R−j(c)) = ∑α ∈ Aaαcα, A ⊂ ℕn.
We call tropicalization of the smooth ODE system (2) the following piecewise-smooth system:
where log(c) = (log c1,…, log cn), si = sign(ai,αmax) and ai,αmax, αmax∈ Ai denotes the coefficient of a monomial for which the maximum occurring in (5) is attained.
The tropicalization associates to a polynomial ∑α ∈ A aαcα, the max-plus polynomial
In other words, a polynomial is replaced by a piecewise smooth function, equal to the largest, in absolute value, of its monomials. Thus, (5) is a piecewise smooth model (Naldi et al., 2011; Noel et al., 2011, 2012) because the dominating monomials in the max-plus polynomials can change from one domain to another of the concentration space. The singular set where at least two of the monomials are equal, and where the max-plus polynomial Pτ(c) is not smooth is called tropical manifold (Mikhalkin, 2007). On logarithmic paper, the tropical manifolds of various species define polyhedral domains inside which the dynamics is defined by monomial differential equations (Figure 3). Tropicalized systems remind of, but are not equivalent to, Savageau's S-systems (Savageau and Voit, 1987) that have been used for modeling metabolic networks. S-systems are smooth systems such that the production and consumption terms of each species are multivariate monomials. Tropicalized systems are S-systems locally, within the polyhedral domains defined by the tropical manifolds, and also along some parts of the tropical manifold (that carry sliding modes, see next section).
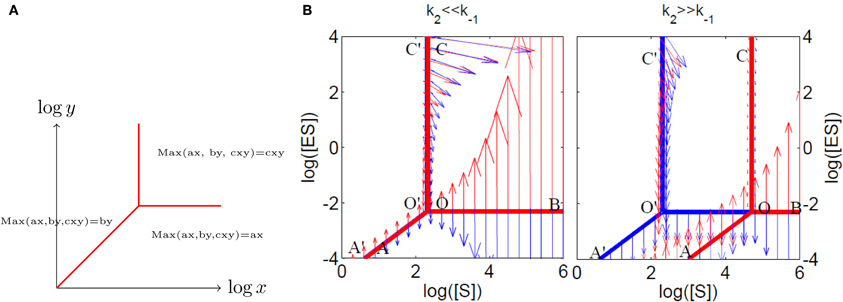
Figure 3. Tropical geometry and Michaelis–Menten mechanism. (A) The tropical manifold of the polynomial ax + by + cxy on “logarithmic paper” is a three lines tripod. (B) The tropical manifolds for the species ES (in red) and S (in blue) for the Michaelis–Menten mechanism. The tropicalized flow is also represented on both sides of the tropical manifolds (with arrows, red on one side, blue on the other side). Sliding modes correspond to blue and red arrows pointing in opposite directions.
The tropicalization unravels an important property of multiscale systems, that is to have different behavior on different timescales. We have seen that, on every timescale, monomolecular networks with total separation behave like a single reaction step. This is akin to considering only the dominant processes in the network and implies that the tropicalization is a good approximation for monomolecular networks with total separation.
The tropical geometry framework is particularly interesting for non-linear networks. In this case, it is less straightforward to define separation rigorously. Very roughly, one can say that a system (2) with polynomial rates is separated, if the monomials composing the rates are separated almost all the time on a trajectory, or, equivalently, almost everywhere in phase space (except on the tropical manifolds). Separation of non-linear models results either from separated kinetic constants, or from separated species concentrations, or both. In the next section, we discuss some examples when the tropicalization provides useful approximations of smooth non-linear networks.
Two simple methods are principally useful for model reduction of non-linear models with multiple timescales: the quasi-equilibrium (QE) and the quasi-steady state (QSS) approximations. As discussed in Gorban et al. (2010); Gorban and Shahzad (2011), these two approximations are physically and dynamically distinct. In order to understand these differences let us refer to the simple example of the Michaelis–Menten mechanism,
The QSS approximation, proposed for this system by Briggs and Haldane, considers that the total concentration of enzyme, Etot=[E]+[ES], is much lower than the total concentration of substrate, therefore, the complex ES is a low concentration, fast species. The complex concentration is slaved by the concentration of S, meaning that the value of [ES] almost instantly relaxes to a value depending on [S]. The simplified mechanism correspond to pooling the two reactions of the mechanism into a unique irreversible reaction , which means that . The QSS value of the complex concentration results from the equation k1 [S] (Etot − [ES]QSS) = (k−1 + k2) [ES]QSS. From this, it follows that R([S], Etot) = k2Etot[S]/(km + [S]), where km = (k−1 + k2)/k1.
The QE approximation considers that the first reaction of the mechanism is a fast, reversible reaction. The simplified mechanism corresponds to a pooling of species. Two pools, Stot = [S] + [ES], and Etot = [E] + [ES] are conserved by the fast reversible reaction, but only one, Etot is conserved by the two reactions of the mechanism. The pool Stot is slowly consumed by the second reaction and represents the slow variable of the system. The single step approximation reads , or equivalently . The QE value of the complex concentration is the unique positive solution of the quadratic equation k1 (Stot − [ES]QE) (Etot − [ES]QE) = k−1 [ES]QE. From this it follows that
. When the concentration of enzyme is small, Etot << Stot, we obtain the original equation of Michaelis and Menten, .
One of the main difficulties to applying QE or QSS reduction to computational biology models is that QE reactions and QSS species should be specified a priori. For some models, biological information can be used to rank reactions according to their rates. For instance, one knows that metabolic processes and post-transcriptional modifications are more rapid than gene expression. However, this information is rather vague. In detailed gene expression models, some processes can be rapid, while others are much slower. Furthermore, the relative order of these processes can be inverted from one functioning regime to another, for instance the binding and unbinding rates of a repressor to DNA, can be slow or fast depending on various conditions. Even if some numerical approaches such as iterative IM, CSP, and ILDM propose criteria for detecting fast and slow processes, at present there is no general direct method to identify QE reactions and QSS species.
Here we present two methods, based, the first one on singular perturbations, and the second on tropical geometry ideas, allowing to detect QE reactions and QSS species.
The first method uses simulation of the trajectories, therefore, it can only be applied to a fully parametrized model. However, in systems with separation, the sets of QE reactions and QSS species are robust, i.e., remain the same for broad ranges of the parameters. One can use imprecise parameters (resulting for instance from crude estimates or fitting) to compute these sets. The method starts by detecting slaved species. Given the trajectories c(t) of all species, the imposed trajectory of the i-th species is a real, positive solution c*i(t) of the polynomial equation
where Pi is the i-th component of the rhs of (2). We say that a species i is slaved if the distance between the trajectory ci(t) and some imposed trajectory c*i(t) is small for some time interval i, supt ∈ I | log(ci(t)) − log(c*i(t))| < δ, for some δ>0 sufficiently small. The remaining species, that are not slaved, are called slow species.
Slaved species are rapid and are constrained by the slow species. The minimum number of variables that we expect for a reduced model is equal to the number of slow species. The slow species can be obtained by direct comparison of the imposed and actual trajectories. This method is illustrated for a model of NFκB canonical pathway in Figure 4.
Figure 4. Tropical geometry and cell cycle modeling. We considered the five variables cell cycle model defined by the differential equations y′1 = k9y2 − k8y1 + k6y3, y′2 = k8y1 − k9y2 − k3y2y5, y′3 = k′4 y4 + k4y4y23/C2 − k6y3, y′4 = − k′4 y4 − k4y4y23/C2 + k3y2y5, y′5 = k1 − k3y2y5, proposed in Tyson (1991). (A) Comparison of trajectories and imposed trajectories show that variables y1, y2, y5 are always slaved, meaning that the trajectories are close to the 2 dimensional hyperplane defined by the QE condition k8y1 = k9y2, the QSS condition k1 = k3y2y5 and the conservation law y1 + y2 + y3 + y4 = C. The variables y3, y4 are slaved and the corresponding species are quasi-stationary on intervals. This means that the dimensionality of the dynamics is further reduced to 1, on intervals. (B) Tropicalization on logarithmic paper, in the plane of the variables y3, y4. The tropical manifold consists of two tripods, represented in blue and red, which divide the logarithmic paper into six polygonal sectors. Monomial vector fields defining the tropicalized dynamics change from one polygonal domain to another. The tropicalized (approximated) and the smooth (not reduced) limit cycle dynamics stay within bounded distance one from another. This distance is relatively small on intervals where the variables y3 or y4 are quasi-stationary, which correspond to sliding modes of the tropicalization.
There are two types of slaved species. Low concentration, slaved species satisfy QSS conditions. Large concentration, slaved species are consumed and produced by fast QE reactions and satisfy QE conditions. Because the reduction schemes are different in the two situations, it is useful to have a method to separate the two cases. Using the values of concentrations can work when concentrations are well separated, but may fail for a continuum of values. A better method is to identify which are the dominant terms in the Equation (7). Using again the example of Michaelis–Menten mechanism, the complex ES will be detected as slaved in both QSS and QE conditions. Equation (7) reads k1 [S] [E] = (k−1 + k2) [ES]. For QE condition, the term k2 will be dominated by k−1. We call pruned version of Equation (7) the equation obtained after removing all the dominated monomials, in this case the equation k1 [S] [E] − k−1 [ES] = 0. When the pruned version is a combination of reversible reaction rates set to zero, then the slaved species satisfy QE conditions. Again, the comparison of monomials is possible for a fully parametrized model, however we expect this comparison to be robust for models with separation.
The second method to identify QE and QSS conditions, follows from the calculation of the tropicalization (5). This can be done formally and do not require simulation of trajectories and numerical knowledge of the parameters. Indeed, is was shown in Noel et al. that there is a relation between sliding modes of the tropicalized system (5) and the QSS or QE conditions. The system (5) belongs to the class of ordinary differential equations with discontinuous vector fields (Filippov, 1988). In such systems, the dynamics can follow discontinuity hypersurfaces where the vector field is not defined. This type of motion is called sliding mode. When the discontinuity hypersurfaces are smooth and n − 1 dimensional (n is the dimension of the vector field) then the conditions for sliding modes read:
where f+, f− are the vector fields on the two sides of Σ and n+ = −n− are the interior normals.
In Noel et al. (2012) we have shown the following. If the smooth dynamics obeys QE or QSS conditions and if the pruned polynomial defining the fast dynamics is a 2-nomial, then the QE or QSS equations define a hyperplane of the tropical manifold of , namely S = {< log(c),α1−α2> = log (|a1|/|a2|)}. The stability of the QE or QSS manifold implies the existence of a sliding mode of the tropicalization (5) along this hyperplane. This result suggests that checking the sliding mode condition (8) on the tropical manifold, provides a method of detecting QE reactions and QSS species.
To illustrate this method, let us use again the Michaelis–Menten example. In this case, two conservation laws allow elimination of two variables E and P and the dynamics can be described by two ODEs:
The tropical manifolds of the two species S and ES are tripods with parallel arms like in Figure 3. Indeed, the slopes of the arms of tropical manifold are only given by the powers of different variables of the monomials, and these are the same for the two species. Investigation of the flow field close to the tripod arms identifies sliding modes on an unbounded subset AOB of the tropical manifold of the species ES. This subset is a global attractor of the tropicalized dynamics and represents a tropicalized version of the IM of the smooth system. If the initial data is not in this set, the tropicalized trajectory converges quickly to it and continues on it as a sliding mode. When k2 >> k−1, ES satisfies QSS conditions leading to the Michaelis–Menten equation. The arm AO of the tropical manifold of the species ES carry a sliding mode, has the equation k1Etot[S] = (k−1 + k2)[ES] >> k1 [S] [ES], and corresponds to the linear regime of the Michaelis–Menten equation. Similarly, the arm OB of the tropical manifold of ES has the equation k1Etot[S] = k1 [S] [ES] >> (k−1 + k2)[ES] and corresponds to the saturated regime of the Michaelis–Menten equation. When k2 << k−1, the tropical manifolds of the two species S and ES practically coincide. Both species are rapid and satisfy QE conditions, namely k1Etot[S] = k−1[ES] >> k1 [S] [ES] on the arm AO, and k1Etot[S] = k1 [S] [ES] >> k−1[ES] on the arm OB.
The tropicalization can thus be used to obtain global reductions of models. Even when global reductions are not possible (sliding modes leave the tropical manifold or simply do not exist), the tropicalization can be used to hybridize smooth models, i.e., transform them into piecewise simpler models (modes) that change from one time interval to another. These changes occur when the piecewise smooth trajectory of the system meets a hyperplane of the tropical manifold and continues as a sliding mode along this hyperplane or leaves immediately the hyperplane. Hybridization is a particularly interesting approach to modeling cell cycle. Indeed, progression of the cell cycle is a succession of several different regimes (phases). This strategy is illustrated in Figure 4 for a simple cell cycle model.
We have seen in section 3 that model reduction of monomolecular networks with total separation is based on graph rewriting operations.
Similarly, QSS and QE approximations can be used to produce simpler networks from large non-linear networks. The classical implementation of these approximations leads to differential-algebraic equations. It is, however, possible to reformulate the simplified model as a new, simpler, reaction network. We showed in the previous section how to do this for the Michaelis–Menten mechanism under different conditions. In general, one has to solve the algebraic equations corresponding to QE or QSS conditions, eliminate (prune) QSS species and QE reactions, pool reactions (for QSS approximation) or species (for QE approximation), and finally calculate the kinetic laws of the new reactions.
By reaction pooling we understand here replacing a set of reactions by a single reaction whose stoichiometry vector ν is the sum of the stoichiometry vectors νi of the reactions in the pool, ν = ∑i γi νi. If the reactions are reversible then the coefficients γi can be arbitrary integers, otherwise they must be positive integers. Reaction pools conserve certain species that where previously consumed or produced by individual reactions in the pools. These species were called intermediates in Radulescu et al. (2008). The species that are either produced or consumed by the pools were called terminal in Radulescu et al. (2008). For example, an irreversible chain of reactions A1 → A2 → A3 can be pooled onto a single reaction A1 → A3, which in terms of stoichiometry vectors reads . In this example A1, A3 are terminal species and A2 is an intermediate species. Reaction pooling is used with QSS conditions, in which case the intermediates are the QSS species.
By species pooling we understand replacing a set of species concentrations {ci} by a linear combination with positive coefficients of species concentrations, ∑ibici. Species pooling is used with QE conditions.
In general, the reaction and species pools result from linear algebra. Indeed, let us consider the matrix Sf that defines the stoichiometry of the rapid subsystem. For the QSS approximation, the matrix Sf has a number of lines equal to the number of QSS species. The columns of this matrix are the stoichiometries of the reactions in the model, restricted to the QSS species. We exclude zero valued columns, i.e., reactions that do not act on QSS species. For the QE approximation, the number of columns of the matrix Sf is equal to the number of QE reactions, and the lines of Sf are the stoichiometries of QE reactions. We exclude zero valued lines corresponding to species that are not affected by QE reactions.
In QE conditions, species pools are defined by vectors in the left kernel of Sf,
The vectors b, that are conservation laws of the fast subsystem, define linear combinations of species concentrations that are the new slow variables of the system. Of course, one could eliminate from these combinations, the conservation laws of the full reaction network, that will be constant (see Appendix).
In QSS conditions, reaction pools (also called routes) are defined by vectors in the right kernel of Sf,
According to the definition (11), a reaction pool does not consume or produce QSS species (these are intermediates). One can impose, like in Radulescu et al. (2008), a minimality condition for choosing the reaction pools. A reaction pool is minimal if there is no other reaction pool with less non-zero stoichiometry coefficients. This is equivalent to choosing reaction pools as elementary modes (Von Kamp and Schuster, 2006) of the fast subsystem.
After pooling, QE and QSS algebraic conditions must be solved and the rates of the new reactions calculated. The new rates should be chosen such that the remaining species and pools of species satisfy the simplified ODEs. The choice of the rates is not always unique (some uniqueness conditions are discussed in Radulescu et al. (2008), see also the Appendix). In order to compute the new rates, one has to solve QE and QSS equations. For network with polynomial or rational rates, this implies solving large systems of polynomial equations. The complexity of this task is double exponential on the size of the system (Noel et al., 2011), therefore, one needs approximate solutions. Approximate solutions of polynomial equations can be formally derived when the monomials of these equations are well separated. Some simple recipes were given in Radulescu et al. (2008) and could be improved by the methods of tropical geometry.
These ideas were used in Radulescu et al. (2008) to reduce several models of NF-κB signaling (Figures 5,6).
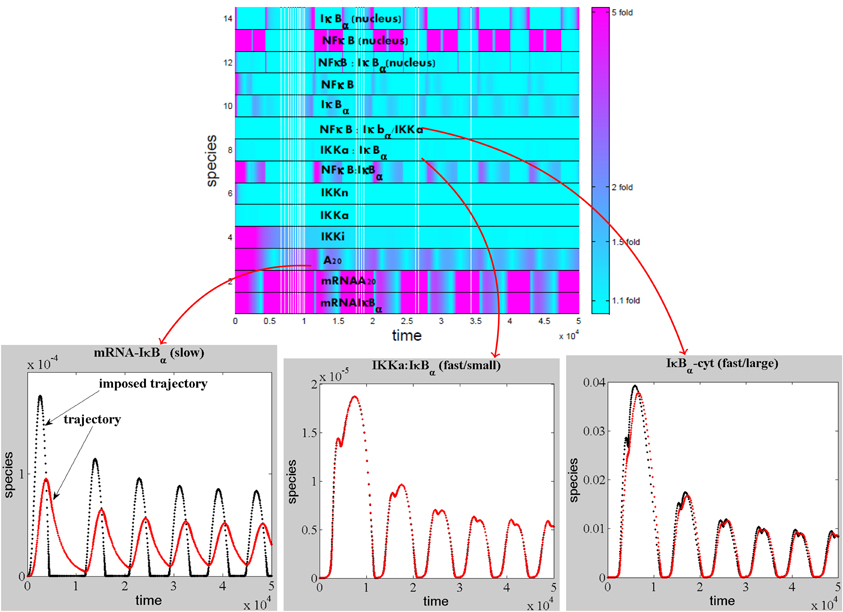
Figure 5. Detection of the slaved species for a NF-κB pathway model. The modulus of the log-ratio, |log(ci(t)/c*i(t))|, between actual and imposed trajectories has been calculated as a function of time for each species of the model of NFκB canonical pathway (proposed in Lipniacki et al., 2004), model ℳ(14, 25, 28) from Radulescu et al. (2008). If the modulus is close to zero (ratio close to one fold from above, or from below) the species is slaved, otherwise the species is slow. Among the slaved species, some have low concentrations and satisfy quasi-steady-state conditions, whereas other have large concentrations and are involved in quasi-equilibrium reactions.
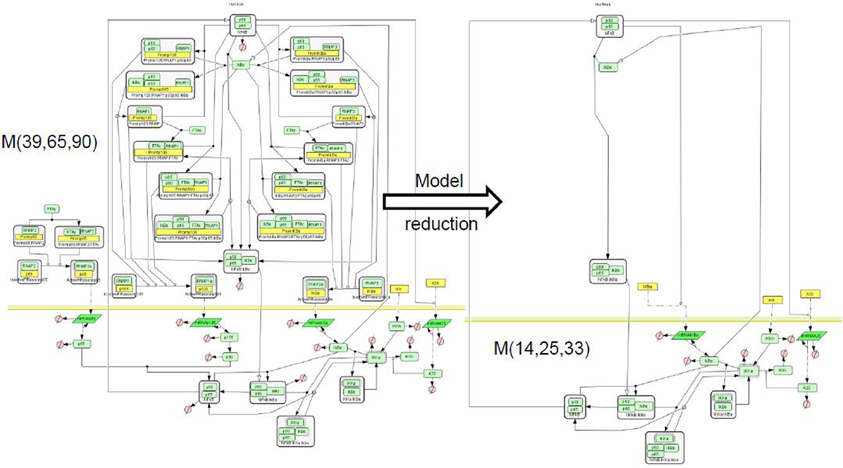
Figure 6. Reduction of a NF-κB pathway model. We considered the model of NF-κB signaling [BIOMD0000000227 in Biomodels database (Le Novère et al., 2006)], proposing separate production of the subunits p50, p65, the full combinatorics of their interactions as well as with the inhibitor IκB, the positive self-regulation of p50, and in addition an A20 molecule whose production is enhanced upon NF-κB stimulation, and which negatively regulates the activity of the stimulus responding kinase IKK (Radulescu et al., 2008). This model, denoted ℳ(39, 65, 90) contains 39 species, 65 reactions, and 90 parameters. We have reduced it to various levels of complexity. Among the reduced model we obtained one, ℳ(14, 25, 33) that has the same stoichiometry (but different rate functions) as a model published elsewhere by another author (Lipniacki et al., 2004) and denoted ℳ(14, 25, 28) (BIOMD0000000226 in Biomodels database). Incidently, this is also the simplest model in the hierarchy related to ℳ(39, 65, 90). Comparison (not shown) of the rate functions and of the trajectories of the models ℳ(14, 25, 33) and ℳ(14, 25, 28) provided insight into the consequences of various mechanistic modeling choices. The model graphical representation is based on the SBGN standard (Le Novère et al., 2009).
The NF-κB activation pathway is complex at many levels. NF-κB is sequestered in the cytoplasm by inactivating proteins named IκB. There are five known members of the NF-κB family in mammals, Rel (c-rel), RelA (p65), RelB, NF-κB1 (p50 and its precursor p105) and NF-κB2 (p52 and its precursor p100). This generates a large combinatorial complexity of dimers, affinities, and transcriptional capabilities. IκB family comprises seven members in mammals (IκBα, IκBβ, IκBε, IκBγ, Bcl-3). All these inhibitors display different affinities for NF-κB dimers, multiplying the combinatorial complexity. The activation of NF-κB upon signaling, occurs by phosphorylation by a kinase complex, then ubiquitination, and finally degradation of IκB molecules. The activation signal is transmitted by several possible pathways most of them activating the kinase IKK that modifies IκB. In the canonical pathway, one important determinant of IKK dynamics is the protein A20 that inhibits IKK activation. A20 expression is controlled by NF-κB. In order to cope with this complexity a model containing 39 species, 65 reactions, and 90 parameters was proposed in Radulescu et al. (2008). Of course, not all reactions and parameters of this complex model are important. In order to determine, in a rational and systematic way, which of the model features are critical, we have used model reduction.
Graph rewriting was performed in a modular way, by applying the pruning and pooling rules to tightly connected submodels of the NF-κB network. The computation of the reaction pools was performed using Matlab and METATOOL (Von Kamp and Schuster, 2006). Using submodel decomposition reduces the complexity of computing elementary modes and of solving large systems of algebraic equations needed for recalculating the reaction rates.
To give an example of modular reduction, let us consider the set of reactions involving six cytoplasmic located intermediates (IKK|active, IKK|inactive, IKK, IKK|active:IkBa, IKK|active:IkBa:p50:p65, p50:p65@csl) and four terminal species (A20, IkBa@csl, IkBa:p50:p65@csl, p50:p65@ncl). As can be seen from Figure 5, the six intermediate species are slaved. The reactions of this submodel form the cytoplasmic part of the signaling mechanism, including 11 kinase transformation reactions, a complex release reaction, a complex formation reaction, and the NF-κB translocation reaction. The elementary modes of the submodel [computed using METATOOL (Von Kamp and Schuster, 2006)] are used to define the reactions pools. For this submodel, we find two elementary modes, that can be described as the modulated inhibitor degradation (IkBa@csl → ∅), and a reaction summarizing the NF-κB release and translocation (IkBa:p50:p65@csl → p50:p65@ncl), respectively. In order to compute the reaction rates of the two elementary modes as functions of the concentrations of the terminal species, we find approximate solutions of the QSS equations for the intermediate species and equate, for the variation rates of each terminal species, the contributions of elementary modes to the total known variation rate in the unreduced model (see Appendix). The two rates are k21p1 [IkBa@csl] [IkBa:p50:p65@csl]/((k21p2 + [IkBa@csl])(k21p3+ [A20])) for the modulated inhibitor degradation, and k15p1 [IkBa:p50:p65@csl]/((k15p2 + [IkBa@csl])(k15p3+ [A20])) for the release and translocation reaction.
Computational biology models contain mechanistic details that can not all be identified from available experimental data. Determining the parameters of such complex models could lead to overfitting, describing noise, rather than features of data, or can be simply meaningless, when model behavior is not sensitive to the parameters. Furthermore, many model identification methods (Golightly and Wilkinson, 2011) suffer from the “curse of dimensionality” as it becomes increasingly difficult to cover the parameter space when the number of parameters increases. A rather efficient strategy to bypass these problems is to use model reduction. This method is known in machine learning as backward pruning or post-pruning (Witten and Frank, 2005). It consists in finding a complex model that fits data well and then prune it back to a simpler one that also fits the data well. Far from being redundant, backward pruning can be successfully used in computational biology. Rather often, one starts with a complex model coping with mechanistic details of the network regulation. Then, over-fitting and problems of identifiability of the parameters are avoided by model reduction. By model reduction, the mechanistic model is mapped onto a simpler, phenomenological model. For instance, gene transcription and translation can be represented as one step and one constant in a phenomenological model, but can consist of several steps such as initiation, transcription of mRNA leading region, ribosome binding, translation, folding, maturation, etc., in a complex model. Not all of these steps are important for the network functioning and not all parameters are identifiable from the observed quantities. Following reduction, the inessential steps are pruned and several sensitive parameters are compacted into a few effective parameters that are identifiable.
As discussed in Radulescu et al. (2006, 2008); Radulescu and Gorban (2009); Ferguson et al. (2012), model reduction unravels the important features and the sensitive parameters of the model.
Using model reduction for determining critical features of the model has many advantages relative to numerical sensitivity studies (Rabitz et al., 1983; Ihekwaba, 2004; Gunawan et al., 2005). This approach is less time consuming, brings more insight, and is based on qualitative comparison of the order of the parameters and therefore does not need exhaustive scans of parameter values. In the applications described in Radulescu et al. (2006, 2008); Radulescu and Gorban (2009); Ferguson et al. (2012), the sensitive parameters of the pruned model are combinations (most often monomials) of the parameters of the complex models. As only the sensitive combinations can be fitted from data, it is important to have estimates of some individual parameters, allowing to determine the remaining ones.
This methodology has been first proposed in Radulescu et al. (2008). The model reduction of the NF-κB model in Radulescu et al. (2008) leads to new, effective parameters that are monomials of the parameters of the complex model. The correspondence between the initial parameters and the effective parameters is shown in Figure 7. Although not fully exploited in the theoretical study (Radulescu et al., 2008), this mapping can be used for model parameter identification. Effective parameters have increased observability and could be obtained from experimental data. The values of the effective parameters can be used to constrain the parameters of the full model. Some of the parameters of the full model, that are not sensitive or contribute to effective parameters together with other parameters remain arbitrary and could be fixed to generic values.
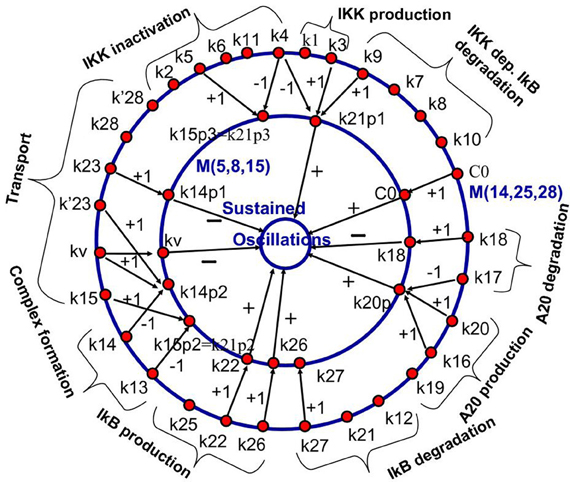
Figure 7. Backward pruning strategy. The model ℳ(14, 25, 28) from Radulescu et al. (2008) (first proposed in Lipniacki et al. (2004), see also BIOMD0000000226 in Biomodels database) was used to generate a hierarchy of simpler models, the simplest one being ℳ(5, 8, 15). We show the mapping between the parameters of the models ℳ(14, 25, 28) and ℳ(5, 8, 15). Parameters of the first model are gathered into monomials that are parameters of the reduced model. The integers on the arrows connecting parameters represent the corresponding powers of the parameters in the monomial. The innermost circle represents a dynamical property of the model that is influenced positively, negatively, or negligibly by the effective parameters (parameters of the reduced model). From Radulescu et al. (2008).
The mathematical techniques described in this paper define strategies for the study of large dynamical network models in computational biology. Large networks are needed in order to understand context dependence, specialization, and individuality of the cell behavior. Extensive pathway database accumulation supports somehow the idea that biological cell is a puzzle of networks and pathways, and that once these are put together in a tightly bound, coherent map, the cell physiology should be unraveled by a computer simulation. Actually, confronting biochemical networks with real life is not an easy challenge. Model reduction techniques are needed to bring us one step closer to this objective, as these methods can reveal critical features of complex organizations.
We have proposed that the ideas of limitation and dominance are fundamental for understanding computational biology dynamical models. The essential, critical features of systems with many separated time scales, can be resumed by a dominant, reduced, subsystem. This dominant subsystem depends on the order relations between model parameters or combinations of model parameters. We have shown how to calculate such a dominant subsystem for linear and non-linear networks. Geometrical interpretation of these concepts in terms of tropicalization provides a powerful framework, allowing to identify IM, QSS species, and QE reactions. We have also discussed how model reduction can be applied to backward pruning parameter learning strategies.
Future efforts are needed to extend these mathematical ideas and model reduction algorithms and implement them into computational biology tools.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acharya, A. (2010). Coarse-graining autonomous ode systems by inducing a separation of scales: practical strategies and mathematical questions. Math. Mech. Solids 15, 342–352.
Acharya, A., and Sawant, A. (2006). On a computational approach for the approximate dynamics of averaged variables in nonlinear ode systems: toward the derivation of constitutive laws of the rate type. J. Mech. Phys. Solids 54, 2183–2213.
Alfonsi, A., Cancès, E., Turinici, G., Di Ventura, B., and Huisinga, W. (2004). Exact simulation of hybrid stochastic and deterministic models for biochemical systems. Research Report RR-5435, INRIA.
Alfonsi, A., Cances, E., Turinici, G., Di Ventura, B., and Huisinga, W. (2005). “Adaptive simulation of hybrid stochastic and deterministic models for biochemical systems,” in CEMRACS 2004 – Mathematics and Applications to Biology and Medicine: ESAIM Proceedings, Vol. 14 (Marseille, France), 1–13.
Aris, R. (1965). Introduction to the Analysis of Chemical Reactors. Englewood Cliffs, NJ: Prentice-Hall.
Artstein, Z., and Vigodner, A. (1996). Singularly perturbed ordinary differential equations with dynamic limits. Proc. R. Soc. Edinburgh Sect. A 126, 541–569.
Aubin, J. (2010). Macroscopic traffic models: shifting from densities to “celerities”. Appl. Math. Comput. 217, 963–971.
Ball, K., Kurtz, T. G., Popovic, L., and Rempala, G. (2006). Asymptotic analysis of multiscale approximations to reaction networks. Ann. Appl. Probab. 16, 1925–1961.
Bodenstein, M. (1913). Eine theorie der photochemischen reaktionsgeschwindigkeiten. Z. Phys. Chem. 85, 329–397.
Bogoliubov, N. N., and Mitropolski, Y. A. (1961). Asymptotic Methods in the Theory of Nonlinear Oscillations. New York, NY: Gordon and Breach.
Borisov, N. M., Markevich, N. I., Hoek, J. B., and Kholodenko, B. N. (2005). Signaling through receptors and scaffolds: independent interactions reduce combinatorial complexity. Biophys. J. 89, 951–966.
Burrage, K., Tian, T., and Burrage, P. (2004). A multi-scaled approach for simulating chemical reaction systems. Prog. Biophys. Mol. Biol. 85, 217–234.
Bykov, V., Goldfarb, I., Gol'dshtein, V., and Maas, U. (2006). On a modified version of ILDM approach: asymptotic analysis based on integral manifolds. IMA J. Appl. Math. 71, 359–382.
Chiavazzo, E., Gorban, A. N., and Karlin, I. V. (2007). Comparisons of invariant manifolds for model reduction in chemical kinetics. Commun. Comput. Phys. 2, 964–992.
Christiansen, J. (1953). The elucidation of reaction mechanisms by the method of intermediates in quasi-stationary concentrations. Adv. Catal. 5, 311–353.
Cohen, G., Gaubert, S., and Quadrat, J. (1999). Max-plus algebra and system theory: where we are and where to go now. Ann. Rev. Contr. 23, 207–219.
Conzelmann, H., Saez-Rodriguez, J., Sauter, T., Kholodenko, B. N., and Gilles, E. D. (2006). A domain-oriented approach to the reduction of combinatorial complexity in signal transduction networks. BMC Bioinformatics 7, 34.
Crudu, A., Debussche, A., Muller, A., and Radulescu, O. (2012). Convergence of stochastic gene networks to hybrid piecewise deterministic processes. Ann. Appl. Probab. (Future paper).
Crudu, A., Debussche, A., and Radulescu, O. (2009). Hybrid stochastic simplifications for multiscale gene networks. BMC Syst. Biol. 3, 89.
Danos, V., Feret, J., Fontana, W., Harmer, R., and Krivine, J. (2007a). “Rule-based modelling of cellular signalling,” in Proceedings of the Eighteenth International Conference on Concurrency Theory, CONCUR' 2007, Lisbon, Portugal, Vol. 4703, eds L. Caires and V. T. Vasconcelos (Berlin: Springer, Lecture Notes in Computer Science), 17–41.
Danos, V., Feret, J., Fontana, W., and Krivine, J. (2007b). “Scalable simulation of cellular signaling networks,” in Proceedings of the Fifth Asian Symposium on Programming Languages and Systems, APLAS'07, Vol. 4807}, ed Z. Shao (Berlin: Springer, Lecture Notes in Computer Science), 139–157.
Dokoumetzidis, A., and Aarons, L. (2009). Proper lumping in systems biology models. Syst. Biol. IET 3, 40–51.
Erban, R., Kevrekidis, I., Adalsteinsson, D., and Elston, T. (2006). Gene regulatory networks: a coarse-grained, equation-free approach to multiscale computation. J. Chem. Phys. 124, 084106.
Feret, J., Danos, V., Krivine, J., Harmer, R., and Fontana, W. (2009). Internal coarse-graining of molecular systems. Proc. Natl. Acad. Sci. U.S.A. 106, 6453.
Feret, J., Henzinger, T., Koeppl, H., and Petrov, T. (2012). Lumpability abstractions of rule-based systems. Theor. Comput. Sci. 431, 137–164.
Ferguson, M., Le Coq, D., Jules, M., Aymerich, S., Radulescu, O., Declerck, N., and Royer, C. (2012). Reconciling molecular regulatory mechanisms with noise patterns of bacterial metabolic promoters in induced and repressed states. Proc. Natl. Acad. Sci. U.S.A. 109, 155–160.
Filippov, A. F. (1988). Differential Equations with Discontinuous Righthand Sides. Dordrecht: Kluwer.
Gay, S., Soliman, S., and Fages, F. (2010). A graphical method for reducing and relating models in systems biology. Bioinformatics 26, i575–i581.
Gibbs, J. (2010). Elementary Principles in Statistical Mechanics: Developed with Especial Reference to the Rational Foundation of Thermodynamics. Cambridge: Cambridge University Press.
Gillespie, D. (1977). Concerning the validity of the stochastic approach to chemical kinetics. J. Stat. Phys. 16, 311–318.
Gillespie, D. T. (1976). A general method for numerically simulating the stochastic time evolution of coupled chemical reactions. J. Comput. Phys. 22, 403.
Givon, D., Kupferman, R., and Stuart, A. (2004). Extracting macroscopic dynamics: model problems and algorithms. Nonlinearity 17, R55–R127.
Golightly, A., and Wilkinson, D. (2011). Bayesian parameter inference for stochastic biochemical network models using particle mcmc. Interface Focus 1, 807–820.
Gómez-Uribe, C., Verghese, G., and Tzafriri, A. (2008). Enhanced identification and exploitation of time scales for model reduction in stochastic chemical kinetics. J. Chem. Phys. 129, 244112.
Gorban, A. N., and Karlin, I. V. (1994). Method of invariant manifolds and regularization of acoustic spectra. Transp. Theory Stat. Phys. 23, 559–632.
Gorban, A. N., and Karlin, I. V. (2003). Method of invariant manifold for chemical kinetics. Chem. Eng. Sci. 58, 4751–4768.
Gorban, A. N., and Karlin, I. V. (2005). “Invariant manifolds for physical and chemical kinetics,” in Lecturer Notes Physics, Vol. 660 (New York, Berlin, Heidelberg: Springer).
Gorban, A. N., Karlin, I. V., Ilg, P., and Öttinger, H. C. (2001). Corrections and enhancements of quasi-equilibrium states. J. Non-Newton. Fluid Mech. 96, 203–219.
Gorban, A. N., Karlin, I. V., and Zinovyev, A. Y. (2004). Invariant grids for reaction kinetics. Phys. A 333, 106–154.
Gorban, A. N., and Radulescu, O. (2008). “Dynamic and static limitation in multiscale reaction networks, revisited,” in Advances in Chemical Engineering: Mathematics and Chemical Engineering and Kinetics, Vol. 34, eds G. Marin, D. West, and G. Yablonsky (Amsterdam: Elsevier), 103–173.
Gorban, A. N., Radulescu, O., and Zinovyev, A. (2010). Asymptotology of chemical reaction networks. Chem. Eng. Sci. 65, 2310–2324.
Gorban, A. N., and Shahzad, M. (2011). The Michaelis-Menten-Stueckelberg theorem. Entropy 13, 966–1019.
Griffith, M., Courtney, T., Peccoud, J., and Sanders, W. (2006). Dynamic partitioning for hybrid simulation of the bistable HIV-1 transactivation network. Bioinformatics 22, 2782.
Gunawan, R., Cao, Y., Petzold, L., and Doyle, F. III. (2005). Sensitivity analysis of discrete stochastic systems. Biophys. J. 88, 2530–2540.
Harris, L., and Clancy, P. (2006). A partitioned leaping approach for multiscale modeling of chemical reaction dynamics. J. Chem. Phys. 125, 144107.
Haseltine, E., and Rawlings, J. (2005). On the origins of approximations for stochastic chemical kinetics. J. Chem. Phys. 123, 164115.
Haseltine, E. L., and Rawlings, J. B. (2002). Approximate simulation of coupled fast and slow reactions for stochastic chemical kinetics. J. Chem. Phys. 117, 6959–6969.
Helfferich, F. (1989). Systematic approach to elucidation of multistep reaction networks. J. Phys. Chem. 93, 6676–6681.
Hoops, S., Sahle, S., Gauges, R., Lee, C., Pahle, J., Simus, N., Singhal, M., Xu, L., Mendes, P., and Kummer, U. (2006). Copasi, a complex pathway simulator. Bioinformatics 22, 3067–3074.
Hucka, M., Finney, A., Sauro, H. M., Bolouri, H., Doyle, J. C., Kitano, H., Arkin, A. P., Bornstein, B. J., Bray, D., Cornish-Bowden, A., Cuellar, A. A., Dronov, S., Gilles, E. D., Ginkel, M., Gor, V., Goryanin, I. I., Hedley, W. J., Hodgman, T. C., Hofmeyr, J.-H., Hunter, P. J., Juty, N. S., Kasberger, J. L., Kremling, A., Kummer, U., Le Novère, N., Loew, L. M., Lucio, D., Mendes, P., Minch, E., Mjolsness, E. D., Nakayama, Y., Nelson, M. R., Nielsen, P. F., Sakurada, T., Schaff, J. C., Shapiro, B. E., Shimizu, T. S., Spence, H. D., Stelling, J., Takahashi, K., Tomita, M., Wagner, J., and Wang, J. (2003). The systems biology markup language (sbml): a medium for representation and exchange of biochemical network models. Bioinformatics 19, 524–531.
Ihekwaba, A. E. C. (2004). Sensitivity analysis of parameters controlling oscillatory signalling in the NF-κB pathway: the roles of IKK and IκBα. Syst. Biol. 1, 93–102.
Jamshidi, N., and Palsson, B. (2008). Formulating genome-scale kinetic models in the post-genome era. Mol. Syst. Biol. 4, 171.
Kaper, H. G., and Kaper, T. J. (2002). Asymptotic analysis of two reduction methods for systems of chemical reactions. Phys. D 165, 66–93.
Kazantzis, N., and Good, T. (2002). Invariant manifolds and the calculation of the long-term asymptotic response of nonlinear processes using singular PDEs. Comput. Chem. Eng. 26, 999–1012.
Krauskopf, B., Osinga, H., Doedel, E. J., Henderson, M. E., Guckenheimer, J., Vladimirsky, A., Dellnitz, M., and Junge, O. (2005). A survey of method's for computing (un)stable manifold of vector ields. Int. J. Bifurcat. Chaos 15, 763–791.
Lam, S. H., and Goussis, D. A. (1994). The CSP method for simplifying kinetics. Int. J. Chem. Kinet. 26, 461–486.
Le Novère, N., Bornstein, B., Broicher, A., Courtot, M., Donizelli, M., Dharuri, H., Li, L., Sauro, H., Schilstra, M., Shapiro, B., Snoep, J. L., and Hucka, M. (2006). BioModels Database: a free, centralized database of curated, published, quantitative kinetic models of biochemical and cellular systems. Nucleic Acids Res. 34, D689–D691.
Le Novère, N., Hucka, M., Mi, H., Moodie, S., Schreiber, F., Sorokin, A., Demir, E., Wegner, K., Aladjem, M. I., Wimalaratne, S. M., Bergman, F. T., Gauges, R., Ghazal, P., Kawaji, H., Li, L., Matsuoka, Y., Villéger, A., Boyd, S. E., Calzone, L., Courtot, M., Dogrusoz, U., Freeman, T. C., Funahashi, A., Ghosh, S., Jouraku, A., Kim, S., Kolpakov, F., Luna, A., Sahle, S., Schmidt, E., Watterson, S., Wu, G., Goryanin, I., Kell, D. B., Sander, C., Sauro, H., Snoep, J. L., Kohn, K., and Kitano, H. (2009). The systems biology graphical notation. Nat. Biotechnol. 27, 735–741.
Li, H., Cao, Y., Petzold, L., and Gillespie, D. (2008). Algorithms and software for stochastic simulation of biochemical reacting systems. Biotechnol. Prog. 24, 56–61.
Lipniacki, T., Paszek, P., Brasier, A. R., Luxon, B., and Kimmel, M. (2004). Mathematical model of NF-kB regulatory module. J. Theor. Biol. 228, 195–215.
Lochack, P., and Meunier, C. (1988). Multiphase Averaging for Classical Systems. New York, NY: Springer.
Maas, U., and Pope, S. B. (1992). Simplifying chemical kinetics: intrinsic low-dimensional manifolds in composition space. Combust. Flame 88, 239–264.
Mastny, E., Haseltine, E., and Rawlings, J. (2007). Two classes of quasi-steady-state model reductions for stochastic kinetics. J. Chem. Phys. 127, 094106.
Mélykúti, B., Burrage, K., and Zygalakis, K. (2010). Fast stochastic simulation of biochemical reaction systems by alternative formulations of the chemical langevin equation. J. Chem. Phys. 132, 164109.
Munsky, B., and Khammash, M. (2006). The finite state projection algorithm for the solution of the chemical master equation. J. Chem. Phys. 124, 044104.
Naldi, A., Remy, E., Thieffry, D., and Chaouiya, C. (2009). “A reduction of logical regulatory graphs preserving essential dynamical properties,” in Computational Methods in Systems Biology (Berlin, Heildelberg: Springer), 266–280.
Naldi, A., Remy, E., Thieffry, D., and Chaouiya, C. (2011). Dynamically consistent reduction of logical regulatory graphs. Theor. Comput. Sci. 412, 2207–2218.
Noel, V., Grigoriev, D., Vakulenko, S., and Radulescu, O. (2012). “Tropical geometries and dynamics of biochemical networks. Application to hybrid cell cycle models,” in Electronic Notes in Theoretical Computer Science, Vol. 284 (Amsterdam: Elsevier), 1–138.
Noel, V., Vakulenko, S., and Radulescu, O. (2011). “Algorithm for identification of piecewise smooth hybrid systems; application to eukaryotic cell cycle regulation,” in Lecture Notes in Computer Science, Vol. 6833 (Berlin, Heidelberg: Springer), 225–236.
Pachter, L., and Sturmfels, B. (2004). Tropical geometry of statistical models. Proc. Natl. Acad. Sci. U.S.A. 101, 16132.
Pahle, J. (2009). Biochemical simulations: stochastic, approximate stochastic and hybrid approaches. Brief. Bioinform. 10, 53–64.
Papin, J., Reed, J., and Palsson, B. (2004). Hierarchical thinking in network biology: the unbiased modularization of biochemical networks. Trends Biochem. Sci. 29, 641–647.
Rabitz, H., Kramer, M., and Dacol, D. (1983). Sensitivity analysis in chemical kinetics. Annu. Rev. Phys. Chem. 34, 419–461.
Radulescu, O., Gorban, A., Zinovyev, A., and Lilienbaum, A. (2008). Robust simplifications of multiscale biochemical networks. BMC Syst. Biol. 2, 86.
Radulescu, O., and Gorban, A. N. (2009). “Limitation and averaging for deterministic and stochastic biochemical reaction networks,” in International Workshop Model Reduction in Reacting Flow, (Notre Dame, IN: University of Notre Dame).
Radulescu, O., Gorban, A. N., Vakulenko, S., and Zinovyev, A. (2006). “Hierarchies and modules in complex biological systems,” in Proceedings of ECCS'06, (Oxford, UK: Said Business School, University of Oxford).
Radulescu, O., Muller, A., and Crudu, A. (2007). Theoremes limites pour des processus de markov a sauts. synthese des resultats et applications en biologie moleculaire. Tech. Sci. Inf. 26, 443–469.
Radulescu, O., Innocentini, G. C. P., and Hornos, J. E. M. (2012). Relating network rigidity, time scale hierarchies, and expression noise in gene networks. Phys. Rev. E 85, 041919.
Roussel, M., and Fraser, S. (1991). On the geometry of transient relaxation. J. Chem. Phys. 94, 7106–7113.
Salis, H., and Kaznessis, Y. (2005). Accurate hybrid stochastic simulation of a system of coupled chemical or biochemical reactions. J. Chem. Phys. 122, 054103.
Salis, H., Sotiropoulos, V., and Kaznessis, Y. (2006). Multiscale Hy3S: hybrid stochastic simulation for supercomputers. BMC Bioinformatics 7, 93.
Savageau, M., and Voit, E. (1987). Recasting nonlinear differential equations as s-systems: a canonical nonlinear form. Math. Biosci. 87, 83–115.
Sawant, A., and Acharya, A. (2006). Model reduction via parametrized locally invariant manifolds: some examples. Comput. Methods Appl. Mech. Eng. 195, 6287–6311.
Segel, L., and Slemrod, M. (1989). The quasi-steady-state assumption: a case study in perturbation. SIAM Rev. 31, 446–477.
Slemrod, M. (2011). “Coping with complexity,” in Lecture Notes in Computational Science and Engineering, Vol. 75, eds A. N. Gorban and D. Roose (Berlin, Heidelberg: Springer).
Slepchenko, B., Schaff, J., and Choi, Y. (2000). Numerical approach to fast reactions in reaction-diffusion systems: application to buffered calcium waves in bistable models. J. Comput. Phys. 162, 186–218.
Slepchenko, B., Schaff, J., Macara, I., and Loew, L. (2003). Quantitative cell biology with the virtual cell. Trends Cell Biol. 13, 570–576.
Sneddon, M. W., Faeder, J. R., and Emonet, T. (2011). Efficient modeling, simulation and coarse-graining of biological complexity with NFsim. Nat. Methods 8, 177–183.
Soliman, S., and Heiner, M. (2010). A unique transformation from ordinary differential equations to reaction networks. PLoS ONE 5:e14284. doi: 10.1371/journal.pone.0014284
Surovtsova, I., Sahle, S., Pahle, J., and Kummer, U. (2006). “Approaches to complexity reduction in a systems biology research environment (SYCAMORE),” in Proceedings of the 37th Conference on Winter Simulation, Winter Simulation Conference, (Orlando, FL), 1683–1689.
Surovtsova, I., Simus, N., Lorenz, T., König, A., Sahle, S., and Kummer, U. (2009). Accessible methods for the dynamic time-scale decomposition of biochemical systems. Bioinformatics 25, 2816.
Tyson, J. (1991). Modeling the cell division cycle: cdc2 and cyclin interactions. Proc. Natl. Acad. Sci. U.S.A. 88, 7328.
van den Boom, T., and De Schutter, B. (2006). Modelling and control of discrete event systems using switching max-plus-linear systems. Control Eng. Pract. 14, 1199–1211.
Von Kamp, A., and Schuster, S. (2006). Metatool 5.0, fast and flexible elementary modes analysis. Bioinformatics 22, 1930–1931.
Witten, I., and Frank, E. (2005). Data Mining: Practical Machine Learning Tools and Techniques. San Francisco, CA: Morgan Kaufmann Publishers.
Yablonskii, G. S., Bykov, V. I., Gorban, A. N., and Elokhin, V. I. (1991). Kinetic Models of Catalytic Reactions. Amsterdam: Elsevier.
This algorithm consists of three procedures.
For each Ai branching node (substrate of several reactions) let us define κi as the maximal kinetic constant for reactions Ai → Aj: κi = maxj {kji}. For correspondent j we use the notation ϕ(i): ϕ(i) = arg maxj {kji}.
An auxiliary reaction network is the set of reactions obtained by keeping only Ai → Aϕ(i) with kinetic constants κi and discarding the other, slower reactions. Auxiliary networks have no branching, but they can have cycles and confluences. The correspondent kinetic equation is
If the auxiliary network contains no cycles, the algorithm stops here.
In general, the auxiliary network has several cycles C1, C2, … with lengths τ1, τ2,…>1.
These cycles will be “glued” into points and all nodes in the cycle Ci, will be replaced by a single vertex Ai. Also, some of the reactions that were pruned in the first part of the algorithm are restored with renormalized rate constants. Indeed, reaction exiting a cycle are needed to render the correct dynamics: without them, the total mass accumulates in the cycle, with them the mass can also slowly leave the cycle. Reactions A → B exiting from cycles (A ∈ Ci, B ∉ Ci) are changed into Ai → B with the rate constant renormalization: let the cycle Ci be the following sequence of reactions A1 → A2 → … Aτi → A1, and the reaction rate constant for Aj → Aj+1 is kj (kτi for Aτi → A1). The quasi-stationary normalized distribution in the cycle is:
The reaction Aj → B (A ∈ Ci, B ∉ Ci) with the rate constant k is changed into Ai → B with the rate constant coj k.
Let the cycle Ci have the limiting steps that is much slower than other reactions. For the limiting reaction of the cycle Ci we use notation klim i. In this case, coj = klim i/kj. If A = Aj and k is the rate constant for A → B, then the new reaction Ai → B has the rate constant kklim i/kj. This rate is obtained using quasi-stationary distribution for the cycle.
The new auxiliary network is computed for the network with glued cycles. Then we prune it, extract cycles, glue them, iterate until a acyclic network is obtained , where m is the number of iterations.
The previous procedure gives us the sequence of networks , … , with the set of vertices , … , and reaction rate constants defined for each in the processes of pruning and gluing.
The dynamics of species inside glued cycles is lost after their gluing. A full multi-scale approximation (including relaxation inside cycles) can be obtained by restoration of cycles. This is done starting from the acyclic auxiliary network back to through the hierarchy of cycles. Each cycle is restored according to the following procedure:
After all, we restore all the glued cycles, and construct an acyclic reaction network on the set . This acyclic network approximates relaxation of the initial network. We call this system the dominant system.
Note that the reduction algorithm does not need precise values of the constants. It is enough to have an initial ordering of the constants. Then, the auxiliary network is obtained only from this ordering. However, after a first iteration, and if the initial network contains cycles, some of the exit constant are renormalized and the new rate constants become monomials of the old ones. In order to prune again, we need to compare these monomials. Monomials of well separated constants are generically well separated (Gorban and Radulescu, 2008). However, a freedom remains on ordering these new monomials, leading to several possible reduced acyclic digraphs, given an initial digraph with ordering of the constants (Figure 1 of the main text).
This algorithm consists of the following procedures.
There are two methods of identification, trajectory-based, and tropicalization-based. Presently we are using the trajectory based method.
Detect slaved species. After generating trajectories c(t) for t ∈ I, for each species compute the distances δi = supt ∈ I |log(ci(t)) − log(c*i(t))|. Use k-means clustering to separate species into two groups, slaved (small values of δ) and slow (large values of δ) species.
Prune. For each Pi (polynomial rate) corresponding to slaved species, compute the pruned version by eliminating all monomials that are dominated by other monomials of Pi.
Identify QE reactions and QSS species. Identify, in the structure of the forward and reverse rates of QE reactions. This step can be performed by recipes presented in Soliman and Heiner (2010). The slaved species not involved in QE reactions are QSS.
Define subsets and matrices. Given the set of QSS (intermediate) species I, one defines the set of reactions acting on them. The terminal species T, are the other species, different from i, on which act the reactions from . Define two stoichiometric matrices Sf and ST. Sf defines the fast subsystem and has a number of lines equal to the number of QSS species, and a number of columns equal to the number of reactions . ST contains the stoichiometries of the terminal species for the same reactions . Species I will be pruned, and reactions will be pooled.
Compute elementary modes (EMs). Compute elementary modes of non-zero terminal stoichiometry as minimal solutions of Sf γ = 0, ST γ ≠ 0, the minimality being defined with respect to the number of non-zero coefficients. ST γ ≠ 0 on the output of elementary modes packages such as METATOOL. If the terminal stoichiometries of the EMs are dependent, restrict to a subset of independent terminal stoichiometries.
Solve QSS equations. Find approximate formal solutions for systems of QSS algebraic equations. This step is not yet automatic. It will be automatized in subsequent work by using tropical geometry methods.
Find rates of EMs. To each elementary mode γi, associate a kinetic law giving the rate of the EM as a function of the terminal species concentrations R*i(cT). Let R(cT) be the vector of rates of reactions in . The dependence of these rates on cT is direct, or indirect, via cI that can be now expressed as function of cT. Then, the EM rates R*i(cT) must satisfy ST R(cT) = ∑ R*i(cT) ST γi. This equation has an unique solution if the vectors ST γi are independent (this justifies the independence condition for the terminal stoichiometries of EMs).
Define subsets and matrices. Given the set of QE reactions Q, one defines the set S of species that are affected by them. The species S are also affected by other reactions that we call terminal, QT. Define two stoichiometric matrices Sf and ST. Sf defines the fast subsystem and has a number of lines equal to the cardinal of E, and a number of columns equal to the cardinal of Q. ST contains the stoichiometries of the reactions QT for the same species S (it has the same number of lines as Sf). Reactions Q will be pruned and species E will be pooled.
Compute species pools. Species pools are computed as minimal solutions of bSf = 0, bST ≠ 0 (the second condition stands for looking for conservation laws of the fast subsystem that are not conserved by the entire network; the minimality condition means that we compute elementary modes of the transpose matrix Sf).
Solve QE equations. Same methods as for QSS conditions. Solve the QSS equations together with the conservation of pools and express the concentrations of the species E as functions of the pools c*i = < bi, c >.
Find new rates. Re-express (by substitution) the rate of each reaction from QT in terms of pools c*i.
Keywords: computational biology, dynamical networks, model reduction, quasi-equilibrium approximation, quasi-steady state approximation
Citation: Radulescu O, Gorban AN, Zinovyev A and Noel V (2012) Reduction of dynamical biochemical reactions networks in computational biology. Front. Gene. 3:131. doi: 10.3389/fgene.2012.00131
Received: 15 January 2012; Paper pending published: 27 March 2012;
Accepted: 26 June 2012; Published online: 19 July 2012.
Edited by:
Raya Khanin, Memorial Sloan-Kettering Cancer Center, USACopyright © 2012 Radulescu, Gorban, Zinovyev and Noel. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits use, distribution and reproduction in other forums, provided the original authors and source are credited and subject to any copyright notices concerning any third-party graphics etc.
*Correspondence: O. Radulescu, DIMNP UMR CNRS 5235, University of Montpellier 2, Montpellier, France. e-mail:b3ZpZGl1LnJhZHVsZXNjdUB1bml2LW1vbnRwMi5mcg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.