 Valentin Carlan
Valentin Carlan Thierry Vanelslander
Thierry Vanelslander- Department of Transport and Regional Economics, University of Antwerp, Antwerp, Belgium
The development and implementation of digital solutions are new in contemporary businesses in logistics. As a next step, the potential of advanced solutions that make use of an AI or ML algorithm and which leverage on data is highly promoted. Yet, the implementation on a large scale of these types of solutions is happening at a slow pace. Recent studies show that a considerable amount of data in the maritime supply chain (MarSC) is still transferred through traditional communication channels (e.g., via e-mails or attached xls, pdf, csv, xml, etc. documents). Human intervention is thus needed to fetch this information and type it over in internal ERP systems. This type of practice opens the scene for extra labor, misinterpretation, or faults. This research puts forward the port users’ perspective on the implementation of AI and ML-based applications for the automatic handling of data. To achieve this goal, a structured survey is launched. The survey results show that, while AI and ML technologies have a high potential to take over repetitive and fault-sensitive tasks, human operators are still needed to maintain customer relations or carry out other planning-related tasks. This initial inquiry shows that, although there are operational costs that are avoided by AI-based technologies, the logistics sector shows low willingness to pay or join development tracks for this type of solutions.
Introduction
New technologies and innovation are developed that can address the current challenges of the shipping industry and port operations. One container handled in international trade generates more than 60 documents (Ham and Kuipers, 2004), the majority of them are today still handled manually, being on paper, via mail or via platform xml exchanges. The manual handling leads to time loss and is risky, as it easily leads to errors, especially in an environment under constant pressure like port terminals, and it facilitates fraud. All of those features are to be avoided.
In this context, artificial intelligence (AI) is seen as a new technology that can overcome some of the existing challenges. More concretely, AI closes the list of six technologies that complement each other in the Industry 4.0 next to additive manufacturing, advanced robotics, drones, internet of things and blockchain. More specifically, AI makes use of IT systems and algorithms to imitate human intelligence to extract insights from data in order to perform descriptive, predictive or prescriptive analysis. This is further explained in this paper.
The potential that AI has in data collection and making this data available for other optimization algorithms is thus high. The present paper fills in the gap in the literature and provides new insight on the following topics. It shows which supply chain stakeholders types struggle with the issues caused by data entry, which potential solutions might exist to address the data entry issue and what is the availability to contribute to a solution that leverages today’s central communication tool about orders: the e-mails.
AI technology can be used in the first place for connecting to different sources of unstructured data, interpret it and feed this data further to prediction and optimization algorithms. This paper provides an overview of contemporary developments regarding AI and its potential to be further developed in port operations. Up to present date, there is no overview that also covers the use of AI applications from the information or financial flows. Adjacent to these outcomes, this paper takes pioneering steps to show the fundamentals to building new business models acceptable by logistics stakeholders to make use of AI services for data collection. Given the number of manual document transactions identified still in current-day logistics operations, it is clear that doing so should contribute to bringing significant financial savings for logistics, both through higher efficiency, fewer errors and reduced fraud potential.
The following section details the step-wise method used to achieve the goals of this research. As a follow-up, this paper shows in the next section the results of the survey regarding the type of logistics stakeholders that struggle with a data entry issue. The results of a desk research are then shown regarding the current status of techniques, including AI, used to address the data entry problem in port operations and the contemporary opportunities opened by artificial intelligence. Next, the paper shows results on the willingness of stakeholders to be involved in AI projects, namely orientated on data entry. Lastly, general conclusions, implications of research and future opportunities are discussed.
State of the Art Research in Artificial Intelligence
This section subsequently gives an overview of the scientific literature on AI in general and applied to logistics, which is the basis for defining the own research approach.
Contemporary Practices in Artificial Intelligence Learning
State of the art literature discusses AI concepts and makes a differentiation between AI dimensions is made either according to learning similarities with the human brain or according to the technology used to train. Table 1 provides a synopsis regarding the work that addresses each type of AI learning fundament.

TABLE 1. State of the art AI classification dimensions. Source: own compilation of literature review findings.
According to learning similarities to the human brain, literature makes a distinction between passive/reactive machines, limited-memory machines, theory of mind and self-aware AI. From the point of view of the technology used to train, academia makes a classification between rule-based expert systems, fuzzy expert systems artificial neural networks and evolutionary computation. The rule-based expert systems lay the focus on a solution within one specific domain, just as experts possess a lot of knowledge in their defined domain. The thought processes can then be represented using rules. These ideally follow extensive trained if-then forms. So, in a rule-based expert system, knowledge is represented using a set of rules. The fuzzy expert systems come from the idea that everything can occur in degrees, for example, velocity or mass. Thus, it is challenging to define separate classes. Yet, fuzzy logic is more likely to reflect the degree of membership in a particular class or the degree of truth rather than a unified classification. Artificial neural networks (ANN) are models built from the neurological structure of the brain. These models attribute weights to the connections between the neurons of the different layers. If there is an error in the output, the weights on the connections between the neurons are adjusted to counteract this error. ANN can be divided into supervised and unsupervised learning methods. The supervised methods include support vector machines, probabilistic neural networks, radial basis networks, k-nearest neighbors, while unsupervised neural networks include greedy layer-wise and cluster analysis (Abduljabbar et al., 2019). The last category is the evolutionary computation that are algorithms that are based on evolution according to Darwin, namely on survival of the fittest. The process of natural selection is mimicked by an evolutionary algorithm to be established. These technological advances represent the foundation of an application that helps and supports humans in daily solving operational and strategic challenges that involve the acquisition and interpretation of vast amounts of data. The following paragraph gives an overview of several studies that investigate the practical use of AI.
Review work taken up by academia shows the use of AI in different sectors as follows. Li et al. (2017) provide a review of applications that make use of AI in the manufacturing industry and show that intelligent products, intelligent connected products, and intelligent software are being massively produced. Their research concludes that AI application effects should be further studied with evaluation on the changes to competitiveness and the changes to social and economic benefits. Equally, the research of Dilek et al. (2015) shows that numerous bio-inspired computing methods of AI have been increasingly playing an important role in cybercrime detection and prevention, present the advances made so far in the field of applying AI techniques for combating cybercrimes. In parallel, a significant amount of studies has been carried out to check the potential of AI in the medical sector. With this regard, the review work of Stafford et al. (2020) regarding applications of artificial intelligence and machine learning in autoimmune diseases shows that the field may benefit from adopting a best practice of validation, cross-validation and independent testing of machine learning (ML) models. Many models achieved good predictive results in simple scenarios (e.g. classification of cases and controls). Progression to more complex predictive models may be achievable in the future through the integration of multiple data types. Relevant applications in logistics are reviewed by Abduljabbar et al. (2019) who conclude that the literature abounds with AI and ML high-level case studies. One of the few sources that has done research on the applicability of AI in logistics, is by Foster and Rhoden (2020). They find that stakeholders in the logistics and supply chain sector are creating awareness and slowly implementing AI and automation within their operations. These case studies are focused on determining the optimal network for the community, finding optimal schedule plans for public transport authorities, enhancing timing plans for traffic signals, and optimizing routes for individual drivers, by learning from previous decisions or events, and accounting for their impact.
AI technologies that used applications in logistics mostly consist of three main components, namely data collection, processing and learning (Woschank et al., 2020). Data collection is usually done by leveraging on sensors or connecting to structured data and make use of these components to gather data from real-world operations (Roh et al., 2021). The processing part is done with algorithms using software, it includes data cleaning components integrated into iterative loops and validation with (internal or external) databases (Birkel et al., 2020). Next, there are components that are responsible for learning. These components make the core of the AI solutions and rely on either validation from a human operator or carrying out the proposed solution to an optimization process. The learning component involves recognizing patterns and making correlations in structured or unstructured data. The studies carried out so far give general insights with regard to the potential brought by AI applications in port and logistics sectors, and there is little evidence regarding how specific applications can exactly function to bring potential new economic value to operations. In essence, contemporary models look at planning and transport flow optimization. Yet, the use of AI is broader than that and the transport industry. MarSC’s and ports can benefit from AI on other operational matters as well. There are various applications of this in logistics, for example, there are the optimal determination of routes for vehicles, predictive maintenance of assets in logistics or simply using algorithms to take over data interpretation and entry tasks. The following section presents the design of the research to investigate further insights regarding AI applications in the logistics and port sector that offer support for data entry tasks.
Research Design: Identifying State of the Art Artificial Intelligence Applications and Industry Practices for Data Entry
This research is triggered by the abundance of applications that claim the use of AI to solve problems in different sectors in general and the logistics and port sectors in particular. Equally, on the demand side, a second trigger to this research is the logistics stakeholders who request solutions for solving practical operational inefficiencies (and their derived effects), such as data entry. The method applied in this paper is an extensive desk research that includes both a literature review and the launch of a survey. While the literature review captures insights regarding the types of techniques applied to solve data interpretation and processing issues, the survey collects the state of preference for logistics stakeholders and port users regarding characteristics of AI solutions that can address the data interpretation and entry issues. Being carried out as the first step, the literature review provides the basis for building up the survey. During the review, literature of the period between 2004 and 2020 was consulted by selecting in Scopus, ScienceDirect and Web of Science databases for relevant publications featuring the following keywords: “logistics”, “supply chain” and “ports” in combination with “data interpretation challenges”, “data entry challenges” and “data processing challenges”. As follow-up, the survey was launched in the period of June–July 2020 and targeted logistics managers involved in various aspects of logistics operational activities of companies located in the vicinity of the port of Antwerp. The survey was made available online only, which was the only workable solution given the COVID-19 pandemic, but which was the preferred way of collecting data anyway in an effort to reduce the number of errors or misunderstandings. Given the large industry network of contacts that the research group has available, it was easy to find enough contact data. The survey was sent out to representatives of 450 companies.
The survey is structured in four main parts as follows: firstly, general questions inquire about the knowledge regarding AI solutions; secondly, a set of question retrieve statements regarding the current way of working regarding the data transfer, the third group of questions inquires about the economics of a potential AI-based solution and a final part concludes the survey by asking final details about the company represented. The survey model is added in the Annex.
A total of 46 attempts to fill in the survey were registered. From these attempts, 32 are complete and are kept for drawing the conclusions of this research. This selection was necessary, and it was done to keep only fill-in attempts that show consistency in answering all addressed questions. Hence, the survey benefits from answers from CEOs (6), CIOs (6), CFO (2), Division (BU) managers (7), Business analysts (4) and Project (innovation) managers (7). This sample is representative of the wider Antwerp port community, as it contains the main players that have sufficient size to be pioneering in innovation in general and AI in particular. The type of logistics stakeholders represented by these representatives is shown in Figure 1.
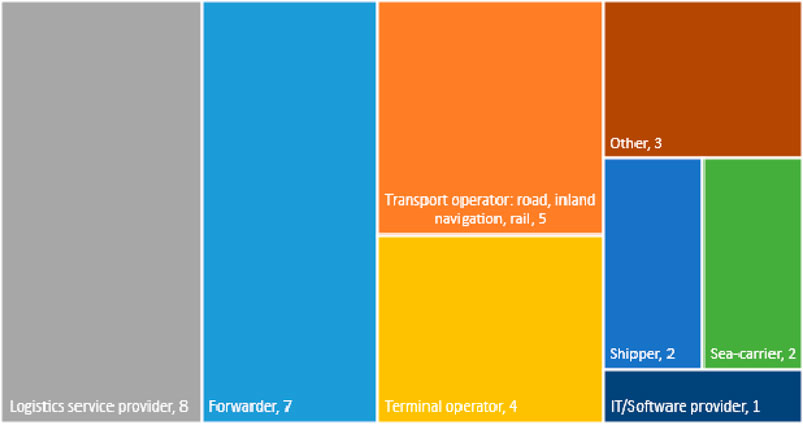
FIGURE 1. Share of logistics and port stakeholders participating in the survey.
As shown in the figure below, the survey benefits from answers from stakeholders that cover the supply chain, including answers from one IT/software provider. The information gathered through the survey enables an analysis regarding the fundamental aspects that need to be considered when one implements AI to facilitate data entry in logistics and for port users.
Types of Techniques Used in Data Entry
Existing solutions used for data processing and entry are either very generic (recognizing general information from documents, separate from the logistics problem domain), need manual configuration by document type (templating), or require long training (RPA). Moreover, the complexity of the data cannot be underestimated. Human operators do not only carry out actions to interpret personal data and e-mail addresses, or labeling and classifying documents, but conduct thorough extraction of the data. In addition, the function of the data (semantics) within the document is also decisive (an address can be sender, recipient, transporter, manufacturer, customs office, or even in extremis the software supplier who generated the document). Detailed information about time slots, dangerous goods (ADR), weights and dimensions are also very relevant to the logistics sector. New technologies and AI solutions are thought to take over these tasks.
Existing solutions are designed to solve similar issues in other sectors (outside logistics), or are more limited in their applicability, which makes their added value for the logistics market rather limited. The specificity of the data relevant to the logistics sector, as well as the importance of the right details and the lack of affinity with the problem domain, makes it difficult to use these existing solutions by the logistics stakeholders. The survey results show that within the logistics sector, contemporary solutions for data transfer without manual intervention are mainly based on the following technologies: Electronic Document Interchange (EDI), templating, robotic process automation (RPA) and trained AI. Each of these technologies is detailed in the below paragraphs:
EDI: Data integration service providers offer for their relatively big customers a software link that is made between the logistics service providers’ system and their customer’s systems. This link allows data to flow automatically between different systems. However, this requires a customized implementation for each different pair of systems. Up to present date there are no standard file formats for exchanging data within logistics processes, and such integration happens ad-hoc. Standardization is also difficult to realize because there are many different software systems in use.
Templating: Templating solutions involve the development of a model for each type of document layout that remembers at which position every type of information is to be found. The data extraction for new documents can then be done by first deriving the document type, then, according to the template, cutting out the right information at the right position and applying OCR techniques for text extraction. If the number of different types of electronic documents or e-mails is relatively high and does not change rapidly over time, this solution is feasible. Given the large number of contacts needed to help clients within the logistics and port industry, and the fact that these contacts also change frequently, it is unlikely that there is a stable document layout set on which templating makes sense. Therefore, there is the need for a solution that recognizes relevant information without prior knowledge regardless of the formatting of the input data.
RPA: This technique learns (by observing the actions of a human users) how to extract data from certain documents or systems. This type of solution deploys passive learning methods that train sets of rule-based algorithms of different complexity. However, this type of work requires extensive training, which often makes such a solution not cost-effective.
AI: solutions based on natural language programming (NLP) techniques interpret information in documents or communications as human operators do (i.e., not only recognizing an address, but also labeling the function of the address within the document) deploying self-aware AI, and this requires only limited training. This technique uses already developed back-end parts in different sectors and develops almost ready plug-and-play solutions. To start using AI in data entry, virtually no configuration or learning is required.
Table 2 provides the results of a comparative analysis regarding the performance of each type of technique discussed. The dimensions used in this comparison are the flexibility of the solution and the implementation speed.

TABLE 2. Comparative analysis of the performance of each technology. Source: own compilation of literature review findings.
As shown in Table 2, current technologies such as templating and RPA have slow implementation speed. These solutions take fields of information from the source documents and insert them into the target application. Yet, a relatively high amount of human labor is required when defining templates or training. The AI techniques, in addition to extracting relevant fields, also automatically carry out a syntactic and functional classification of the found elements (e.g., address with sender function), making these solutions highly flexible. Lastly, solutions based on AI carry out only an operational cost. As a result, the upfront investment is minimal (of course, for major customers, these applications can also use a CAPEX model when sufficient volume is predicted). The next section builds further on these results and presents the stated preferences of port users regarding the characteristics of AI solutions that can take over data entry tasks.
The Cost of Data Entry and Willingness to Pay
Logistics stakeholders and port users represent an atypical category of organizations that are mostly seen as laggards in implementing new technologies. The next sub-sections present valuable insights regarding the type of issues that arise in data entry, the type of costs generated to these organizations and the willingness to join in these developments.
Contemporary Practices in Data Entry
Initial inquiries with logistic service providers point out that much communication regarding operational aspects of transport and transport orders happens through one-to-one communication. This communication is done via e-mail, messages or by phone for example: placing out orders, asking the status of orders, quotations, sending updates (or extra information) on existing orders (transport files), updating orders with extra documents etc. This section provides an answer to the question regarding how severe this practice is in logistics and which type of stakeholders are confronted with it.
The transport and logistics market is very much segregated, with an abundant presence of small and medium players). In Europe, 780,000 logistics service providers are active (Transport Intelligence, 2021), of which around 10% are large enough and have a specific business operation where human communication is of high importance. At the current date, this type of communication practice cannot be replaced by automatic data processing. In Flanders (BE) alone there are over 10,035 road transport operators and only 7% have a fleet that counts more than 20 vehicles (FEBETRA, 2021). Moreover, companies offering customs-related services constitute a special market segment where segregated data needs to be bundled. Since the Brexit, the formalities to be fulfilled have increased significantly, and automatic processing of already available documents could significantly reduce the workload. The figure below presents results regarding the practice used to communicate data, namely the share of automatic transfer of data, use of standards formats or putting forward unstructured data.
As seen in Figure 2 there is a quasi-equal distribution between the type of approach used to communicate data. There is no overall practice of using one method independently. The following conclusions can be drawn. Sending unstructured data or having integrated data transfer connections is mostly applicable for less than 30% of the communication volumes. The use of standard formats or templates to transfer data is present for around 50% of information transfer needs. These results show that, for some of the stakeholders, sending unstructured data accounts for more than 60% of their data transfer flows. These results open up the question regarding the amount of labor set in manual processing of data. This question is answered by the results presented in Figure 3.
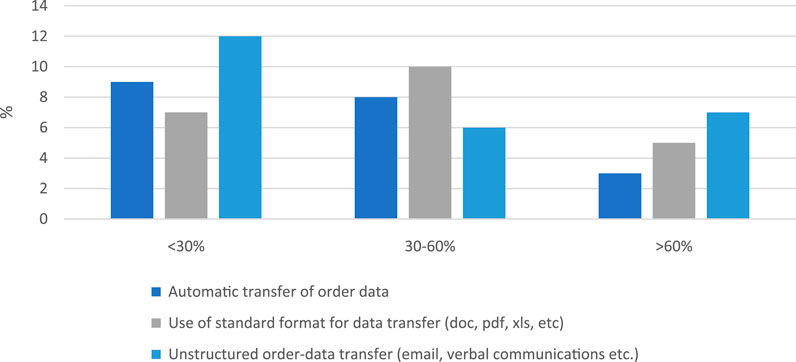
FIGURE 2. Answers regarding the percentage of orders that logistics companies receive: automatically, into a standard format (doc, pdf, XML etc.) or in unstructured e-mails.

FIGURE 3. Answers regarding the number of employees that have data-entry tasks in the organization.
The results regarding the number of employees that are involved in data communication and entry tasks are presented in Figure 3. As seen in this figure, most of the respondents indicate that 5 to 10 employees have tasks linked to manual data processing or entry activities. It is obvious that there are also organizations that have more than ten employees that take care of the same tasks.
Figure 4 puts forward results from the stated preference survey regarding the time spent on average for manual data entry tasks per employee. It is clear that most employees have data entry as a side task. This practice frequently happens amongst planners, dispatchers or financial administrations where data is received from multiple entities, for example: for dispatchers/planners from different clients, or for financial administrative employees that receive data from employees within the organization regarding their activity. It is worth mentioning that data entry activities currently do not refer only to reading data from different IT systems or communications, but it also consists of data entry from verbal communication, such as from calling. Hence, having a system that leverages on AI to (partially) carry out data entry tasks, the human operators will have more time to main customer relations or to carry out planning tasks for the remaining time increasing the quality of their services.
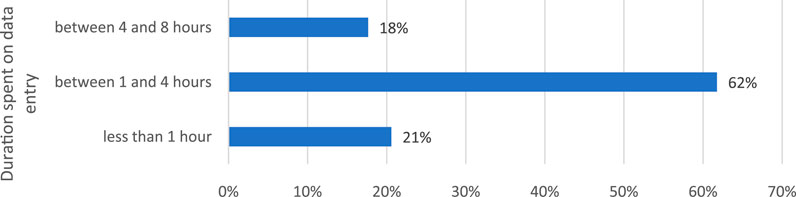
FIGURE 4. Answers regarding the daily duration that an operator spends on data entry reported to 8 h shift-length.
The main conclusions that can be taken from these observations are as follows. Data entry in logistics is present for these types of stakeholders who work with multiple parties from whom transport orders are received and for which there is no leverage to impose certain communication standards. These types of communication practices are mostly present at road transport operators, freight forwarders or customs agents who are in direct contact with their clients, sub-contractors or warehouses. The latter are less susceptible to change their current working practices. Moreover, the data entry tasks are mostly present at stakeholders that provide services on yearly-based contracts from tenders they apply to. In this type of service contracting, a high level of flexibility is needed, also considering that there is not certitude for a longer period of collaboration. Hence, the motivation to investments is low. Logistics stakeholders also use manual data processing and entry when they are dependent on data from systems that lack a technical solution to upgrade and make possible automatic data extraction, hence they face a lock-in effect. Moreover, human labor is still seen as the most flexible solution on the market and tested in a production environment. However, manual data entry processing generates high operational costs. The next section details the types of costs generated by manual data entry in logistics chains and port operations.
Costs Generated by Data Entry in Logistics Chains
AI technology enables human activities to be carried out by software with increased efficiency and at a low cost. More specifically, human operators have the opportunity of performing better by cutting errors, making operations faster, and finally, in the long term, enabling emissions cutting. As of now, uncertainty in complex problems leads to limitations at the decision-making stage. This section provides an overview of types of costs that are generated by manual entry of data in logistics. The cost of entering data is not only time-consuming, but also opens the scene for faultier operations. The cost of the latter occurs with lower frequency, yet they are greater in absolute value when it occurs. Any type of fault generates a chain reaction; therefore, port users give preference to anticipate certain errors and pay the cost for error prevention knowing that this cost is lower than the cost of remedying the error. Table 3 presents a list of costs that are typically generated by data entry at port users.

TABLE 3. Overview of cost types generated by manual data entry. Source: own compilation of literature review findings.
There are two main categories of costs. The first category refers to the direct cost generated by data entry, while the second refers to the indirect cost. The former refers to costs that are directly proportional to the cost of labor involved in reading, interpreting and/or processing data. The latter refers to costs generated by the extra movement of assets (containers, trucks, vessels, etc.) when data (regarding addresses, reference numbers, container codes, etc.) is typed in wrongly in information systems. The following section elaborates on the involvement of port users in AI solutions implementation.
Involvement in Artificial Intelligence Projects for Data Entry and Willingness to Pay
Port users struggle with identifying solutions to suppress costs generated by manual data entry. The inquiries done through the survey of this research show a common understanding and agreement on the following types of approaches. Port stakeholders can implement B2B integrated solutions and so anticipate potential lock-in effects. A more immediate solution is the recognition of incoming data and makes the first categorization for bulk processing. This type of solution works where a relative structure in data can be recognized and applied. This type of solution can be combined with advanced OCR applications for facile semi-automatic categorization. The use of data bots can follow this type of solution to recognize more complex bundles of data. Stakeholders believe in a community-supported solution in which everybody’s data can be used for training purposes or where the financial contribution can be split among a critical mass for an optimal cost-effective solution.
The willingness to participate in the development of new technologies or solutions that can be used by broad communities is mixed. The following figure shows this willingness by demonstrating the stated preference regarding the willingness to allocate resources and making a distinction between the number of participants who would allocate human resources, data or budget for AI solutions.
The following conclusions can be taken from the survey results. Most companies would not be open to being involved in the development of AI-based solutions. Among those who can be involved in AI development tracks, Figure 5 shows that most companies can free up data that would enable the training of an algorithm for data entry (26%). Few companies would allocate human resources to help with defining the specifications of a system (23%). Lastly, only a small fraction of 17% would be open to allocating budget to the early development of such a solution.
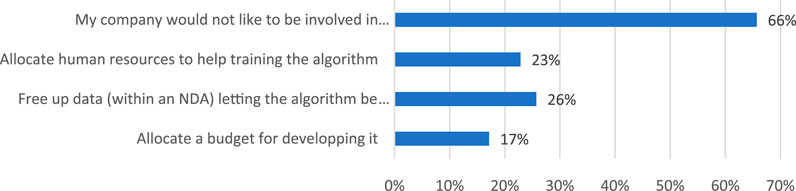
FIGURE 5. Stated preference regarding the type of resource allocation for AI solutions.
Despite the openness to collaborate for an AI-based solution that can support the data entry in logistics, the logistics stakeholders face several hard barriers to join common development projects. The first barrier that is mentioned is with regard to the opportunity to keep eventual competitive advantages and not join with competitors in developing common solutions. Moreover, a data entry solution should not be addressing the initial data-entry process only, but it should be kept flexible and have it integrated with other systems in use that rely on the same data, for example invoicing. The participation in this type of development makes a decision topic that needs to be deliberated by the higher management or shareholders of port users, anticipating that an AI solution would be possible to be adopted at the group level. Last, hard conditions are set with regard to the cost of this type of solution that should be lower than an FTE and that data is released with a non-disclosure agreement (NDA) or a guarantee for data protection. Data required for data entry training contains sensitive commercial information such as prices, clients’ addresses, or volumes. The following results show insight regarding the stated preference regarding the willingness to pay for a recurrent monthly fee for data entry.
As seen in Figure 6, the majority of respondents show a very low stated willingness to pay for an AI-based solution to take over the data interpretation and entry tasks (60%). One-fifth of the respondents show a monthly willingness to pay between 250–500 EUR. Lastly, an equal distribution of 7% of respondents shows a low stated willingness to pay situated between 500–1,000, 1,000–2,500 or more than 5000 EUR respectively. The next section closes this research and leverages the results presented above to present general conclusions.

FIGURE 6. Stated preference regarding the monthly willingness to pay for AI service to support data entry tasks.
Conclusion
Artificial intelligence (AI) is a much-discussed topic in recent years and it is making its appearance in many sectors, including the logistics and port sectors. Yet, limited research has investigated the needs of logistics stakeholders, the characteristics that these types of solutions should carry and the economics of introducing them in operations. In this regard, logistics operators face difficulties in integrating and processing data regarding orders that come in different electronic formats and structures from customers. The ICT infrastructure of contemporary logistics stakeholders has a high heterogeneity and the same data needs to be manually processed and input in multiple systems. This issue complicates the process of digitalization and stops the development and use of more advanced IT functionalities. The lack of coordination or standardization needs to stop and this issue can be solved now by AI.
Hence, this research sets pioneering steps regarding the types of AI technologies suitable to replace human labor for data entry tasks and shows results regarding the fundamentals of business models that can be further applied. The data collected and analyzed in this research shows the following key results in that respect. There is a relatively high willingness to free up data and so let AI algorithms be trained. Yet, logistics stakeholders are reserved and do not open up financial resources to invest in these solutions despite the fact that there is a high potential for cost-saving (from labor set in repetitive tasks and fault correction actions). Early estimations show even that the cost of human resources used for data entry is higher than the operational cost of AI-based solutions. The benefits are not immediately seen: there is a relatively high difference between the current cost for data entry and willingness to pay. Lastly, concrete implementation project developments should check, analyzing case-by-case, the cost-effectiveness of AI-based data-entry solutions. Furthermore, it appears that new solutions should be sufficiently flexible so that they can be integrated with existing IT systems and data platforms in use within the companies.
This research is relevant for the logistics stakeholders as well as for technology providers. The presented results and interpretation represent a basic foundation on which decisions with regard to the implementation of AI and ML-based solutions can be further made and supported. Moreover, academia and researchers are provided with an overview of the type of technologies that can be applied and a foundation of economics aspects that should be considered when further investigating the financial implications of state-of-the-art AI technologies.
This initial research into aspects of implementing AI technologies also opens the path to several opportunities for further investigation. Firstly, it would be valuable to examine more fully business models that can be applied for AI-based solutions in logistics and ports, including types of costs saved through the development of scenarios and comparing pricing strategies (e.g., considering the implementation of a subscription fee or a pay-per-use strategy). The business model may be crucial, as supply chain partners need to agree on the automated data transfer. This is needed both horizontally and vertically in the chain. Trust is crucial for data not to be shared further with non-desired and/or non-authorized parties, such as competitors or parties with whom it is to be negotiated. Such unwanted transfer of data may happen on purpose or by accident, through hacking for instance. From a user perspective, it might be of high interest to benefit from research results that investigate the return on investment for this type of solution and/or estimate the value of opportunities enabled by data standardization.
As a limitation, it is worth mentioning that this research did not explore the quantification of data-entry costs. In theory, this type of cost can be calculated as a function of time spent by employees in different repetitive manual data processing tasks or accounting for costs generated by human errors. Equally, the benefits enabled by AI-based application might be quantified as well, yet, identifying specific case studies did not make the object of this research and, since the opportunities enabled by AI remain uncertain in many cases (and may drag on for several years in some cases) their inclusion in cost-effectiveness analyses remains uncertain. Finally, this research focused very much on manual data entry. Hence, in parallel with this type of case study, other research can be developed to investigate the characteristics of AI-based solutions introduced to solve issues on routing, resource allocation or (financial) reporting.
Data Availability Statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Author Contributions
VC was responsible with coordinating the research, design the survey, collect data and interpret the data to describe the results. TV was responsible with supervising the research and manuscript coherency.
Funding
The authors would like to mention that this research was subsidized by the Interreg 2 Seas Programme 2014-2020 (CCI number: 2014TC16RFCB038), co-financed by the European Regional Development Fund through the SPEED (Smart Ports Entrepreneurial Ecosystem Development) project nr. 2S04-019.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank the survey respondents kindly. Their contribution made it possible to conclude this research.
References
Abduljabbar, R., Dia, H., Liyanage, S., and Bagloee, S. A. (2019). Applications of Artificial Intelligence in Transport: An Overview. Sustainability 11 (1), 189. doi:10.3390/su11010189
Badem, H., Basturk, A., Caliskan, A., and Yuksel, M. E. (2017). A New Efficient Training Strategy for Deep Neural Networks by Hybridization of Artificial Bee colony and Limited-Memory BFGS Optimization Algorithms. Neurocomputing 266, 506–526. doi:10.1016/j.neucom.2017.05.061
Birkel, H., Kopyto, M., and Lutz, C. (2020). “Challenges of Applying Predictive Analytics in Transport Logistics,” in SIGMIS-CPR'20 Proceedings of the 2020 on Computers and People Research Conference, Nuremberg, Germany, June 19–21, 2020 (New York, NY, USA: Association for Computing Machinery), 144–151. doi:10.1145/3378539.3393864
Bloch, T., and Sacks, R. (2018). Comparing Machine Learning and Rule-Based Inferencing for Semantic Enrichment of BIM Models. Automation in Construction 91, 256–272. doi:10.1016/j.autcon.2018.03.018
Chatila, R., Renaudo, E., Andries, M., Chavez-Garcia, O.-R., Luce-Vayrac, P., Gottstein, R., et al. (2018). Toward Self-Aware Robots. Front. Robotics AI 5, 88. doi:10.3389/frobt.2018.00088
Cohn, D., Atlas, L., and Ladner, R. (1994). Improving Generalization with Active Learning. Mach Learn. 15 (2), 201–221. doi:10.1007/bf00993277
Dey, S., and Ghose, D. (2020). “Artificial Neural Network: An Answer to Right Order Quantity”, in Proceedings of the Global AI Congress 2019 (Springer), 529–533. doi:10.1007/978-981-15-2188-1_41
Dilek, S., Cakır, H., and Aydın, M. (2015). Applications of Artificial Intelligence Techniques to Combating Cyber Crimes: A Review. Int. J. Artif. Intelligence Appl. 6 (1), 21–39. doi:10.5121/ijaia.2015.6102
FEBETRA (2021). Aantal Ondernemingen Beroepsvervoerders Over De Weg. Available at: https://febetra.be/wp-content/uploads/2021/03/1.-Aantal-ondernemingen.pdf (Accessed April 13, 2021).
Foster, M. N., and Rhoden, S. L. N. H. (2020). The Integration of Automation and Artificial Intelligence into the Logistics Sector. Worldwide Hospitality and Tourism Themes 12 (1), 56–68. doi:10.1108/WHATT-10-2019-0070
Golden, R. M. (2018). Adaptive Learning Algorithm Convergence in Passive and Reactive Environments. Neural Comput. 30 (10), 2805–2832. doi:10.1162/neco_a_01117
Ham, H. V., and Kuipers, B. (2004). “E-Commerce and the Container Shipping Industry,” in Transport Developments and Innovations in an Evolving WorldAdvances in Spatial Science. Editors M Beuthe, V Himanen, A Reggiani, and L Zamparini (Berlin, Heidelberg: Springer), 47–68. doi:10.1007/978-3-540-24827-9_4
Li, B.-H., Hou, B.-C., Yu, W.-T., Lu, X.-B., and Yang, C.-W. (2017). Applications of Artificial Intelligence in Intelligent Manufacturing: A Review. Front. Inf Technol Electron. Eng. 18 (1), 86–96. doi:10.1631/FITEE.1601885
Melin, P., Miramontes, I., and Prado-Arechiga, G. (2018). A Hybrid Model Based on Modular Neural Networks and Fuzzy Systems for Classification of Blood Pressure and Hypertension Risk Diagnosis. Expert Syst. Appl. 107, 146–164. doi:10.1016/j.eswa.2018.04.023
Nayyar, A., Garg, S., Gupta, D., and Khanna, A. (2018). “Evolutionary Computation: Theory and Algorithms,” in Advances in Swarm Intelligence for Optimizing Problems in Computer Science (New York, NY: Chapman and Hall/CRC), 1–26.
Parpinelli, R. S., Plichoski, G. F., Da Silva, R. S., and Narloch, P. H. (2019). A Review of Techniques for Online Control of Parameters in Swarm Intelligence and Evolutionary Computation Algorithms. Int. J. Bio-Inspired Comput. 13 (1), 1–20. doi:10.1504/ijbic.2019.10018955
Rabinowitz, N., Frank, P., Song, F., Zhang, C., Eslami, S. M. A., and Botvinick, M. (2018). “Machine Theory of Mind,” in International Conference on Machine Learning, Stockholm, Sweden, July 10–15, 2018 (PMLR), 4218–4227.
Rabkina, I., McFate, C., Forbus, K. D., and Hoyos, C. (2017). “Towards a Computational Analogical Theory of Mind,” in Proceedings of the 39th Annual Meeting of the Cognitive Science Society, London, United Kingdom, July 26–29, 2017. doi:10.24963/ijcai.2017/761
Roh, Y., Heo, G., and Whang, S. E. (2021). A Survey on Data Collection for Machine Learning: A Big Data - AI Integration Perspective. IEEE Trans. Knowl. Data Eng. 33 (4), 1328–1347. doi:10.1109/TKDE.2019.2946162
Stafford, I. S., Kellermann, M., Mossotto, E., Beattie, R. M., MacArthur, B. D., and Ennis, S. (2020). A Systematic Review of the Applications of Artificial Intelligence and Machine Learning in Autoimmune Diseases. Npj Digit. Med. 3 (1), 1–11. doi:10.1038/s41746-020-0229-3
Transport Intelligence (2021). Leading European Transport and Logistics Markets. Available at: https://theloadstar.com/wp-content/uploads/Leading-ETL-Markets-Report-Final.pdf (Accessed April 13, 2021).
Woschank, M., Rauch, E., and Zsifkovits, H. (2020). A Review of Further Directions for Artificial Intelligence, Machine Learning, and Deep Learning in Smart Logistics. Sustainability 12 (9), 3760. doi:10.3390/su12093760
Wu, C-J., Brooks, D., Chen, K., Chen, D., Choudhury, S., Dukhan, M., Kim, H., Isaac, E., Jia, Y., and Jia, B. (2019). “Machine Learning at Facebook: Understanding Inference at the Edge,” in 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), Washington, DC, February 16–20, 2019 (IEEE), 331–344.
Keywords: AI in logistics, willingness to pay, cost types, implementation requirements, data entry
Citation: Carlan V and Vanelslander T (2021) Economic Aspects of Introducing Artificial Intelligence Solutions in Logistics and Port Sectors: The Data Entry Case. Front. Future Transp. 2:710330. doi: 10.3389/ffutr.2021.710330
Received: 15 May 2021; Accepted: 07 July 2021;
Published: 23 July 2021.
Edited by:
Jeroen Pruyn, Delft University of Technology, NetherlandsReviewed by:
Marcella De Martino, Research Institute on Innovation and Development Services (IRISS), ItalyAntonio Comi, University of Rome Tor Vergata, Italy
Copyright © 2021 Carlan and Vanelslander. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Valentin Carlan, dmFsZW50aW4uY2FybGFuQHVhbnR3ZXJwZW4uYmU=