 Zhenbing Zhao
Zhenbing Zhao Xuechun Lv1,4
Xuechun Lv1,4 Siyu Miao
Siyu Miao
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Energy Res. , 03 November 2023
Sec. Smart Grids
Volume 11 - 2023 | https://doi.org/10.3389/fenrg.2023.1287024
This article is part of the Research Topic Application of Image Processing and Knowledge Reasoning in the Construction of New Power System View all 23 articles
Introduction: The aim of this paper is to address the problem of the limited number of defect images for both metal tools and insulators, as well as the small range of defect features.
Methods: A defect detection method for key area-guided transmission line components based on knowledge distillation is proposed. First, the PGW (Prediction-Guided Weighting) module is introduced to improve the foreground target distillation region, and the distillation range is precisely concentrated in the position of the first k feature pixels with the highest quality score in the form of a mask. The feature knowledge of defects of hardware and insulators is used as the focus for the teacher network to guide the student network. Then, the GcBlock module is used to capture the relationship between the target defects of the hardware and the transmission lines in the background, and the overall relationship information of the image is used to promote the students’ network to learn the teacher’s network perception ability of the relationship information. Finally, the classification task mask and regression task mask generated by the PGW module, combined with the overall image relationship loss, form a distillation loss function for network training to improve the accuracy of students’ network detection accuracy.
Results and Discussion: The effectiveness of the proposed method is verified by using self-build metal fittings and insulator defect data sets. The experimental results show that the student network mAP_50 (Mean Average Precision at 50) in the Faster R-CNN model with the knowledge distillation algorithm added in this paper increases by 8.44%, and the RetinaNet model increases by 2.6%. The Cascade R-CNN model improved by 5.28%.
The transmission line is one of the most important infrastructures of China’s energy Internet, and ensuring the reliability of the transmission line is one of the important contents of the construction of the energy Internet. Transmission line components are an important part of mechanical connection, fixing, protection and insulation. However, they are susceptible to abnormalities and defects such as defects, corrosion and soiling due to the influence of the complex natural environment and harsh climatic conditions (Nguyen et al., 2018). Therefore, regular inspection and maintenance of transmission line fittings, insulators and other important components can effectively reduce a series of safety accidents caused by transmission line faults.
Inspection is a way to guarantee the continuous and stable power supply of the power grid, the purpose of which is to carry out online condition detection and fault diagnosis of components such as shockproof hammers and insulators on the lines (Zhao and Cui, 2018). The current transmission line inspection methods include manual inspection, robot inspection (Toth and Gilpin-Jackson, 2010), helicopter (Pham et al., 2020), unmanned aerial vehicle inspection (Li et al., 2021), and remote sensing satellite inspection (Yang et al., 2021). “Drone inspection is the main focus, supplemented by manual labor” has developed into the main operation and maintenance mode of China’s power system (Yang et al., 2020). The construction of intelligent and manual synergistic inspection system is an important initiative to promote the safe operation of the power grid (Du et al., 2022).
The development of deep learning technology provides an effective means for transmission line inspection and can more effectively complete the task of defect detection of transmission components in aerial images. At present, a lot of research work has been done. Literature (Zhai et al., 2023) proposes a transmission line multi-fitting detection method based on implicit spatial knowledge fusion, aiming at the tiny-size and dense occlusion problem in the transmission line multi-fitting detection task. First, in order to mine the implicit spatial knowledge between transmission line fittings to assist the model in detection, the spatial box setting module and the spatial context extraction module are proposed to set the spatial box and extract the spatial context information. Then, the spatial context memory module is designed to filter and remember the spatial context information to assist the location of the multi-fitting detection model. Finally, the post-processing part of the model is improved to further alleviate the low detection accuracy problem caused by dense occlusion fittings. The experimental results show that the proposed model has a promotion effect on the detection of various kinds of fitting. Literature (Li et al., 2023) proposes a metal fittings equipment detection algorithm based on improved YOLOV7. This method adds a CA attention mechanism to the network structure of YOLOV7 to enhance the feature extraction of hardware devices in the network model. At the same time, it reduces the interference of complex backgrounds on the network model to extract features of hardware devices, allowing the network model to extract features in detail, thereby improving the network model’s detection generalization for hardware devices. In order to alleviate the problem of misdetection and recheck caused by the lack of context information in various existing hardware and defect detection methods, literature (Zhao et al., 2023) proposes a method of transmission line hardware and defect detection based on context-structure reasoning. First, the image is input into the target detection model; Then, the output result of the detection model is sent to the structural reasoning module, and the output result is sent to the bidirectional gated cycle unit and self-attention for processing. The structural knowledge of transmission line fittings and their defects is used to improve the confidence degree of the correct positive sample and reduce the confidence degree of the wrong positive sample. Finally, the final output result is obtained through the regressor. To achieve the purpose of improving the average accuracy. Literature (Sun et al., 2023) proposes a two-stage insulator defect detection framework composed of attention-based insulator detection network and defect detection network. Among them, the attention-based insulator detection network is responsible for the location of the insulator, and the defect detection model determines whether the insulator is damaged. The two-stage design of first positioning and then detection avoids the interference of complex background and can realize the high-precision detection of defects. Literature (Li et al., 2023) proposes a multi-scale feature fusion insulator defect detection network for solving the problem of insulator defective regions with little pixel information and varying shapes and sizes. The network used a residual attention network to obtain insulator defect features with different resolutions, and designed a multi-scale feature fusion network based on inverse convolution and multi-branch detection, which gradually fused the deep feature maps with the shallow feature maps. In this way, more abundant image semantic information can be generated for target classification and location regression. In addition, the literature also used Focal loss and Gaussian non-great suppression methods to further enhance the detection effect.
Although these methods improve the accuracy of detection, they inevitably increase the complexity of the model, consume a lot of computing resources and time, and are difficult to deploy on resource-limited equipment. The knowledge distillation algorithm provides a solution to this problem. Literature (Gu et al., 2023) proposes a deep neural network model compression algorithm for knowledge distillation of multi-teacher models, which takes advantage of the integration of multi-teacher models and takes the predictive cross-entropy of each teacher model as the quantitative criterion for screening to select the teacher model with better performance to guide students, and allows the student model to extract information from the feature layer of the teacher model. And give better performing teacher models a greater say in instruction. Literature (Wang et al., 2022) proposes an attention mechanism based on the feature map quality evaluation algorithm (IQE). The knowledge distillation method based on the IQE attention mechanism uses the IQE method to identify important knowledge in the pre-trained SAR target recognition deep neural network. Then in the process of knowledge distillation, the lightweight network is forced to focus on the learning of important knowledge. Through this mechanism, the method proposed in this paper can efficiently transfer the knowledge of the pre-trained SAR target recognition network to the lightweight network, which makes it possible to deploy the SAR target recognition algorithm on the edge computing platform. Literature (Zhao et al., 2022) propose a target detection model distillation (TDMD) framework using feature transition and label registration for remote sensing imagery. A lightweight attention network is designed by ranking the importance of the convolutional feature layers in the teacher network. Multiscale feature transition based on a feature pyramid is utilized to constrain the feature maps of the student network. A label registration procedure is proposed to improve the TDMD model’s learning ability of the output distribution of the teacher network.
At present, some researches have applied the knowledge distillation method to the field of electric power. Literature (Yang et al., 2022) proposes a compression and integration application method based on knowledge distillation. In this method, the Detr model is used to identify the initial target, and the Deformable Detr algorithm is used to compress the Detr model, so that the compression ratio reaches 87.5% and the target detection accuracy is maintained at a high level, and the effective integrated application of the target detection model in the substation inspection robot body is realized. Literature (Zhao et al., 2021) proposes a bolt defect image classification method based on dynamically supervised knowledge distillation, aiming to solve the problem of high computational resource consumption of large models. The method utilizes adaptive weighting and attention transfer techniques to improve the ability of the small model to learn and represent bolt defects, which in turn enhances its classification performance. In addition, literature (Zhang et al., 2022) improved the YOLOv4 model and introduced the PCSA (Positional Contextual Attention Shift) attention module for the problem of anti-vibration hammer small target detection. This method combines pruning and knowledge distillation techniques to tailor and compress the network parameters, and constructs a lightweight anti-vibration hammer detection network model, PCSA-YOLOs, to improve the detection accuracy of small targets in complex backgrounds.
With the intelligent development of power system inspection technology, it is urgent to deploy models on UAV and helicopter aerial photography and online monitoring equipment. Knowledge distillation can help improve the performance of the model with a small number of parameters, but making the student network simulate the teacher’s network feature extraction ability without difference cannot achieve the best effect. The focus of this paper is to enable students to learn the effective feature processing ability of teachers’ networks. In this paper, the PGW module is first introduced to refine the feature knowledge of foreground object distillation, and the first k most important pixels are extracted to form a feature mask to improve the distillation performance of student network for detecting hardware defects. Then, the GcBlock module is used to capture the relationship between the target defects of the hardware and the transmission lines in the background, and the overall relationship information of the image is used to promote the students’ network to learn the teacher’s network perception ability of the relationship information. The combination captures information about the relationship between transmission line components and components, and between components and backgrounds, helping to improve target detection accuracy.
The application of knowledge distillation algorithms to image target detection has focused on models using feature pyramid networks. Past approaches usually directly used the output of the classification and regression tasks of the teacher network as the target of the student network. With the development, knowledge distillation can guide the training of the student network in a more targeted way to improve the detection accuracy. As shown in the literature (Guo et al., 2021), unlike the general classification task, the classification and regression tasks in the detection network can be negatively affected if the same objective function is used for both tasks. This is because the two tasks have different preferences for features: classification requires regions with rich semantic information, whereas regression prefers to focus on the edge portion of feature information. Features that produce better classification scores are not accurate enough in predicting bounding boxes (Song et al., 2020). Therefore, the same sensory field does not guarantee optimal performance for both classification and regression tasks. As shown by the images of defects of gold tools and insulators, important feature knowledge exists for defects of the same kinds of gold tools and insulators, and the datasets of defects of gold tools and insulators are much smaller, which should be fully utilized to guide the students’ network by taking advantage of the ability of the teacher’s network to deal with the feature knowledge of the defects.
Therefore the features are scored to determine whether they are good for classification or regression tasks, in order to reduce the adverse effect of complex background on the detection of defective targets of gildings and insulators, with the help of ground-turth box first decouple each layer of features of FPN (Feature Pyramid Network) whether it belongs to the foreground target region or the background region as shown in Eq. 1:
Let
Amplifying the most meaningful feature distillation signals generated by the teacher network and using them to guide the student network is the purpose of knowledge distillation. For this purpose, we look at the quality of a teacher’s bounding box predictions taking both classification and localization into consideration. Formally, the quality score of a box
where
Use of mass fraction
The features of fitting and insulator defects are very different from those of their intact targets; the features are more consistent between parts of the same species, but the features of each component defect are variable and complex (Zhao et al., 2021), and when labeling the dataset, the size of the labeled box is as close to the target as possible, and the defects are damages that are produced on the component targets, which have a more reduced range of effective features compared to the intact targets. Therefore, we would like to use the knowledge of features of defects in gold tools and insulators as a focus for the instructor network to guide the student network. Therefore, the PGW (Prediction-Guided Weighting) (Yang et al., 2022) module is introduced to improve the prospect distillation region. And the PGW module is precisely concentrated in the first k feature pixels with the highest mass fraction in the prospect region. The effect of each position is then smoothed according to the two-dimensional Gaussian distribution fitted for each ground-truth box by the maximum likelihood estimation method. Finally, only the k position is extracted in the foreground target region, and the weight of the position is assigned by the Gaussian function, the schematic is shown in Figure 1.

FIGURE 1. Schematic diagram of the processing principle for the foreground target area.
We smooth the effects of each position according to the 2D Gaussian distribution fitted by the maximum likelihood estimate (MLE) for each ground-truth box. Finally, foreground distillation is performed only for those k positions, whose weights are assigned by Gaussian. For detection targets with ground-truth
Each feature pixel
where
The high-level network of the feature extraction network can output better semantic features, but due to the size of the feature map is too small, the geometric information is not sufficient, which is not conducive to the detection of the target; the shallow network contains more geometric information, but the semantic features of the image are not much, which is not conducive to the classification of the image. Therefore, when the network is trained, the student network is made to learn the ability of the teacher network to extract and process features at each layer of the FPN. By distilling the classification and regression tasks separately, the student network integrally learns the generalization ability of the teacher network for these two tasks, which leads to an increase in its detection accuracy.
Formally, at each feature level in FPN, this paper utilizes the PGW module to generate two distinct foreground distillation masks,
In order to distill background information, the GcBlock (Cao et al., 2019) module is utilized to capture the relationship between defects in the hardware target and the transmission lines present in the background. This module leverages the overall relationship information in the image (Park et al., 2019). It encourages the student network to learn the teacher network’s ability to perceive relationship information (Hu et al., 2018). The representation of the overall image relationship loss is given by Eq. 13.
In the equation,
In this context,
The structural diagram of the distillation method in this paper is shown in Figure 2. It consists of two parts: foreground object region distillation and background relationship distillation. For foreground object region distillation, the PGW module is used to calculate the masks for both the classification and regression tasks, which together form the loss function used for training the foreground object region. The background relationship distillation area adopts the GcBlock module to capture relationships in the image. The overall distillation loss function in this paper is represented as Eq. 15.

FIGURE 2. Overall distillation structure.
This article uses 5 types of fittings and insulators, along with their defects, as the research dataset. Each type of defect has a corresponding normal target feature for comparison, including normal vibration damper, vibration damper cross, vibration damper corrosion, normal single insulator, and insulator drop. There are a total of 2,497 images, with 1997 images in the training set, 250 images in the test set, and 249 images in the evaluation set, with a ratio of 8:1:1. The dataset contains a total of 4,628 objects to be detected.
The model described in this article is trained and tested using the NVIDIA GeForce GTX 1080Ti professional accelerator card. The operating system used is Ubuntu 16.04.6 LTS, with training accelerated using CUDA 10.1. The computer language used is Python 3.7.11, and the network development framework is PyTorch. All programs are executed based on the MMDetection 2.16 toolbox. This article uses the commonly used evaluation metric in object detection models, mean Average Precision (mAP), to assess the performance of the model. The mAP is calculated by computing the Average Precision (AP) for each class of objects and then taking the mean of all class APs. The resulting mAP is used as the final evaluation metric for the object detection model.
In the experiments, the teacher network, student network, and the network with the distillation algorithm all use a learning rate of 0.0001. The backbone network for the teacher network is ResNet101, while for the student network, it is ResNet50. The training is conducted for 24 epochs (training rounds), and the batch size used is 50.
The experimental process in this article mainly consists of two steps.
1) Train the object detection models separately using the teacher network (with a larger number of parameters) and the student network (with a smaller number of parameters) on the fittings defect dataset. Calculate and record their respective accuracy.
2) Train the student network, which has a smaller number of parameters, using the knowledge distillation algorithm with the fittings defect dataset. After training, calculate and record its accuracy.
To validate the effectiveness of the proposed knowledge distillation algorithm, a comparative experiment is conducted using the evaluation metrics mentioned earlier. The experimental results are presented in Table 1. Three image detection models, namely, Faster R-CNN, RetinaNet, and Cascade R-CNN, are used in the experiments. Each model is separately trained as a teacher model, a student model, and a model with the knowledge distillation algorithm introduced in this article. The detailed process is to put the same data set into the same model with the backbone model of Resnet101 and Resnet50. The backbone network is identified as the teacher network by Resnet101 and the backbone network is identified as the student network by Resnet50. The results of two different backbone network training were analyzed. After adding the distillation algorithm in this paper, the student network is trained again, and the difference between the student network with distillation algorithm added and the student network without distillation algorithm added is compared. The control parameters adopted in these processes are consistent, the learning rate is 0.0001, and the epoch of the training rounds is 24. The batch size is 50.
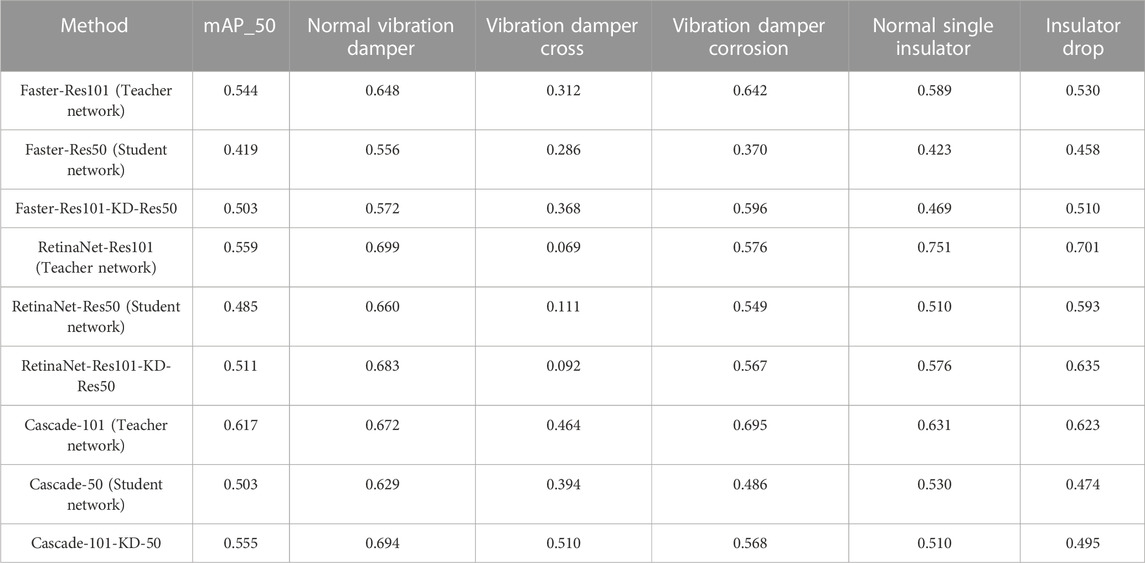
TABLE 1. AP results for different models and after applying the knowledge distillation algorithm.
To verify the general applicability of the proposed method, both single-stage and two-stage models are used in the experiments. From the data in Table 1, it can be observed that the detection performance of the student network improves significantly after the knowledge distillation algorithm is applied. This distillation algorithm, as presented in this article, utilizes a decoupling approach between foreground and background information regions. By focusing on the foreground object regions and reducing the interference caused by complex backgrounds, the algorithm enhances the localization ability of the model. By setting the k value to 45 in the foreground object regions, the data indicates that, in most cases, adding the knowledge distillation algorithm proposed in this article improves the detection accuracy of the student network for both normal component targets and defects. Particularly, the improvement in detecting fittings and insulator defects is greater than the improvement in detecting normal targets. In the case of the RetinaNet model, where the teacher network’s accuracy is lower than the student network’s accuracy in detecting vibration damper corrosion, adding the distillation algorithm does not improve the performance of the student network. This could be because the teacher network’s performance is inferior to the student network’s performance, which hinders its ability to guide the student network in improving accuracy. In the case of Faster R-CNN, the highest improvement is achieved in detecting vibration damper corrosion, reaching up to 22.6%. For RetinaNet, the highest improvement is seen in detecting normal insulators, with a maximum improvement of 6.6%. Cascade R-CNN shows the highest improvement in detecting vibration damper corrosion, reaching 8.2%.
The table shown in Table 2 compares the Grad-CAM distillation algorithm (decoupling common feature scores) with the distillation algorithm proposed in this article, using Faster R-CNN and RetinaNet as representatives of two-stage and single-stage detection models, respectively. The Grad-CAM distillation algorithm improves the detection performance of most targets, but for fittings defects, its improvement is slightly inferior to the distillation algorithm proposed in this article. In the case of the Faster R-CNN model, the detection accuracy for normal vibration damper targets and normal single insulator targets is slightly lower in this article’s method compared to the Grad-CAM method. However, for vibration damper cross defects, our method outperforms the Grad-CAM method by 6.5 percentage points, and for vibration damper corrosion and insulator String defects, it outperforms the Grad-CAM method by 13.3% and 4.8%, respectively. The analysis shows that the feature used for defect target detection is more concentrated in the critical pixel regions. Using ground-truth boxes as the range of foreground object regions introduces more noise for defects. This article’s method selects the top-k highest-scored pixels to form a mask, which includes essential features for defect detection while avoiding introducing noise from other parts of the foreground object regions. Figure 3 shows visualized detection images for different student networks, teacher networks, and networks after applying the distillation method.
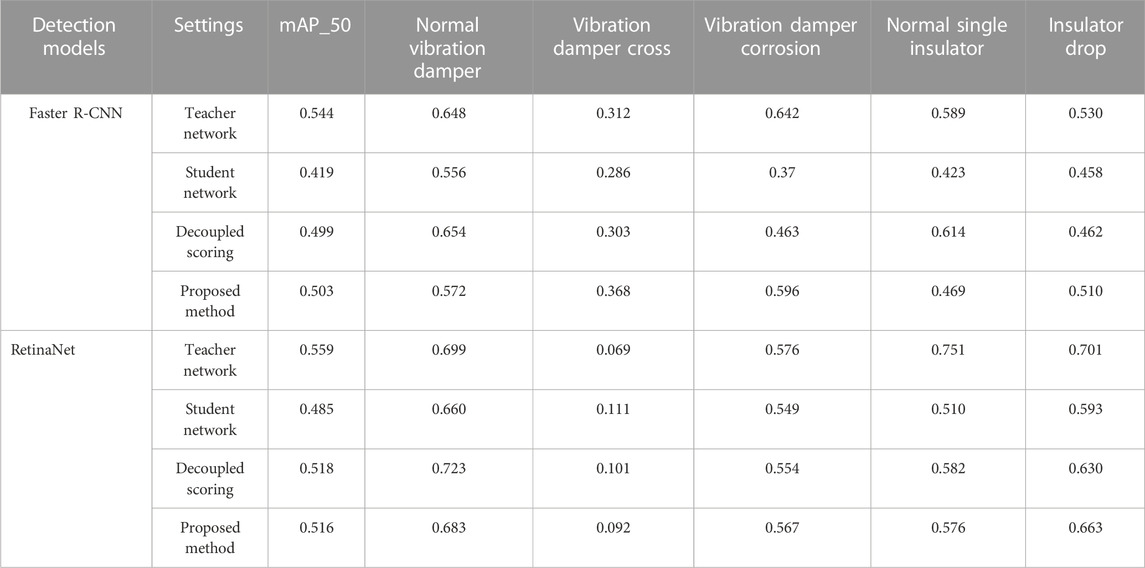
TABLE 2. Comparison of two foreground knowledge distillation methods.

FIGURE 3. Comparison of different network experiment results (A) Teacher network (B) Student network (C) Distilled student.
To investigate the impact of different k values on improving the accuracy of the student network, ablation experiments were conducted based on the Faster-RCNN model, using ResNet-100 as the teacher network and ResNet-50 as the student network. The mAP_50 values of the student network were observed for different k values, and the results are shown in Table 3. From the results, it can be observed that the student network achieves the optimal mAP_50 value when k is set to 45. It is speculated that if k is too small, it may not capture crucial defect features, while setting k to a large value introduces too much noise from foreground object regions, leading to negative effects.

TABLE 3. Ablation Experiments with Different k Values.
Due to the limited dataset of hardware defects, hardware defects occur as damage to the hardware target. Compared to the hardware target, the effective feature range of hardware defects is smaller. In order to improve the detection accuracy of hardware defects in power transmission lines by the student network, this paper improves the foreground target region distillation. It guides the student network with more refined feature knowledge generated by the teacher network. Considering the influence of the two tasks, classification, and regression, in the foreground target region, pixels are scored, and the top k important pixels’ generated masks containing feature knowledge are used to guide the student network. Experimental results show that the proposed method applied to three different single-stage and two-stage detection models, Faster-RCNN, RetinaNet, and Cascade R-CNN, has improved the detection accuracy of hardware and its defects. In Faster R-CNN, after adding the knowledge distillation algorithm in this paper, mAP_50 has improved by 8.44% for the student network. RetinaNet improved by 2.6%, and Cascade R-CNN improved by 5.28%. This lays a solid foundation for lightweighting the hardware and its defects detection models in power transmission lines.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
ZZ: Conceptualization, Funding acquisition, Investigation, Project administration, Supervision, Writing–review and editing. XL: Conceptualization, Investigation, Methodology, Software, Validation, Visualization, Writing–original draft, Writing–review and editing. YX: Writing–original draft, Writing–review and editing. SM: Formal Analysis, Supervision, Writing–review and editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was supported by the National Natural Science Foundation of China (61871182 and U21A20486), the Natural Science Foundation of Hebei Province (F2020502009, F2021502008, and F20211502013), and the Fundamental Research Funds for the Central Universities (2023JC006).
Heartfelt thanks to everyone who contributed to this paper.
Author XL was employed by China Nuclear Power Engineering Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Cao, Y., Xu, J., Lin, S., Wei, F., and Hu, H. (October 2019). “Gcnet: non-local networks meet squeeze-excitation networks and beyond,” in Proceedings of the IEEE/CVF international conference on computer vision workshops. Montreal, BC, Canada 0-0
Du, Q., Dong, W., Su, W., and Wang, Q. (September 2022). “UAV inspection technology and application of Transmission Line,” in Proceedings of the 2022 IEEE 5th International Conference on Information Systems and Computer Aided Education (ICISCAE), 594–597. Dalian, China. doi:10.1109/iciscae55891.2022.9927674.8
Du, Z., Zhang, R., Chang, M., Zhang, X., Liu, S., Chen, T., et al. (2021). Distilling object detectors with feature richness. Adv. Neural Inf. Process. Syst. 34, 5213–5224. doi:10.48550/arXiv.2111.00674
Gu, M., Ming, R., Qiu, C., and Wang, X. (2023). A multi-teacher knowledge distillation model compression algorithm for deep neural network. Appl. Electron. Tech. 49 (08), 7–12. doi:10.16157/j.issn.0258-7998.233812
Guo, J., Han, K., Wang, Y., Wu, H., Chen, X., Xu, C., et al. (June 2021). “Distilling object detectors via decoupled features,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA 2154–2164.
Hu, H., Gu, J., Zhang, Z., Dai, J., and Wei, Y. (June 2018). “Relation networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA 3588–3597.
Li, B., Qu, L., Zhu, X., Guo, Z., Tian, Y., Yu, F., et al. (2023). TMT proteomics analysis reveals the mechanism of bleomycin-induced pulmonary fibrosis and effects of Ginseng honeysuckle superfine powdered tea. Trans. China Electrotech. Soc. 38 (01), 60–70. doi:10.1186/s13020-023-00769-x
Li, J., Wang, Q., Hong, S., Fan, L., Chen, X., and Ai, C. (June 2023). “Improved YOLOV7 algorithm for transmission line metal fittings equipment detection: algorithm improvement for integrating attention mechanism,” in Proceedings of the 2023 4th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT), Nanjing, China 496–500.
Li, X., Li, Z., Wang, H., and Li, W. (2021). Unmanned aerial vehicle for transmission line inspection: status, standardization, and perspectives. Front. Energy Res. 9. 713634 doi:10.3389/fenrg.2021.713634
Nguyen, V., Jenssen, R., and Roverso, D. (2018). Automatic autonomous vision-based power line inspection: a review of current status and the potential role of deep learning. Int. J. Electr. Power & Energy Syst. 99, 107–120. doi:10.1016/j.ijepes.2017.12.016
Park, W., Kim, D., Lu, Y., and Cho, M. (June 2019). “Relational knowledge distillation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, New Orleans, LA, USA. 3967–3976.
Pham, H. C., Ta, Q.-B., Kim, J.-T., Ho, D.-D., Tran, X.-L., and Huynh, T.-C. (2020). Bolt-loosening monitoring framework using an image-based deep learning and graphical model. Sensors 20 (12), 3382. doi:10.3390/s20123382
Song, G., Liu, Y., and Wang, X. (June 2020). “Revisiting the sibling head in object detector,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, New Orleans, LA, USA 11563–11572.
Sun, S., Li, W., Song, C., Cong, X., and Ding, L. (August 2023). “Attention-based insulator defect detection,” in Proceedings of the 2023 IEEE International Conference on Mechatronics and Automation (ICMA), 414–419. Harbin, Heilongjiang, China. doi:10.1109/ICMA57826.2023.10215660
Toth, J., and Gilpin-Jackson, A. (October 2010). “Smart view for a smart grid— unmanned Aerial Vehicles for transmission lines,” in Proceedings of the 2010 1st International Conference on Applied Robotics for the Power Industry (CARPI 2010), 1–6. Montreal, QC, Canada. doi:10.1109/carpi.2010.5624465
Wang, J., Jiang, T., Cui, Z., Cao, Z., Cao, C., and Li, S. (2022). Seed germination traits and dormancy classification of 27 species from a degraded karst mountain in central Yunnan-Guizhou Plateau: seed mass and moisture content correlate with germination capacity. IGARSS 2022-2022 IEEE Int. Geoscience Remote Sens. Symposium 24, 1043–1056. doi:10.1111/plb.13451
Yang, C., Ochal, M., Storkey, A., and Crowley, E. J. (October 2022). “Prediction-guided distillation for dense object detection,” in Proceedings of the European Conference on Computer Vision, Cham: Springer Nature Switzerland. 123–138.
Yang, L., Fan, J., Liu, Y., Li, E., Peng, J., and Liang, Z. (2020). A review on state-of-the-art power line inspection techniques. IEEE Trans. Instrum. Meas. 69 (12), 9350–9365. doi:10.1109/tim.2020.3031194
Yang, Y. (2022). Model compression and integration applications of substation objects detection based on knowledge distillation. Inf. Comput. 34 (13), 50–57.
Yang, Z., Fei, X., Ma, X., Ou, W., Zhao, B., Liu, B., et al. (December 2021). “Design method of core index of remote sensing satellite for power transmission and transformation equipment patrol system, signal and information processing, networking and computers,” in Proceedings of the 7th International Conference on Signal and Information Processing, Networking and Computers (ICSINC), Singapore. 271–279.
Zhai, Y., Guo, C., Wang, Q., Zhao, K., Bai, Y., and Zhang, Y. (2023). Multi-fittings detection method for transmission lines based on implicit spatial knowledge fusion. J. Graph. 9, 1–10.
Zhang, K., Yue, Q., Huang, W., Huang, C., Ren, Y., and Hou, J. (2022). Clinical study of factors associated with pregnancy outcomes in pregnant women with systemic lupus erythematosus in the southern China. Adv. Technol. Electr. Eng. Energy 41 (11), 59–66. doi:10.46497/ArchRheumatol.2022.8870
Zhao, B., Wang, Q., Wu, Y., Cao, Q., and Ran, Q. (2022). Target detection model distillation using feature transition and label registration for remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 15, 5416–5426. doi:10.1109/jstars.2022.3188252
Zhao, Z., and Cui, Y. (2018). Research progress of visual detection methods for transmission line key components based on deep learning. Electr. Power Sci. Eng. 34 (03), 1–6. doi:10.3969/j.ISSN.1672-0792.2018.03.001
Zhao, Z., Jiang, Z., Li, Y., Qi, Y., Zhai, Y., Zhao, W., et al. (2021). Overview of visual defect detection of transmission line components. J. Image Graph. 26 (11), 2545–2560. doi:10.11834/jig.200689
Zhao, Z., Jin, C., Qi, Y., Zhang, K., and Kong, Y. (2021). Image classification of transmission line bolt defects based on dynamic supervision knowledge distillation. High. Volt. Eng. 47 (02), 406–414. doi:10.13336/j.1003-6520.hve.20200834
Keywords: knowledge distillation, key region guidance, component defects, teacher model, student model
Citation: Zhao Z, Lv X, Xi Y and Miao S (2023) Defect detection method for key area guided transmission line components based on knowledge distillation. Front. Energy Res. 11:1287024. doi: 10.3389/fenrg.2023.1287024
Received: 01 September 2023; Accepted: 23 October 2023;
Published: 03 November 2023.
Edited by:
Fuqi Ma, Xi’an University of Technology, ChinaReviewed by:
Kaixun He, Shandong University of Science and Technology, ChinaCopyright © 2023 Zhao, Lv, Xi and Miao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Siyu Miao, c2l5dW1pYW9faGJ1QDE2My5jb20=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.