 Peng Li1Wenqi Huang1Lingyu Liang1Zhen Dai1Shang Cao1*Huanming Zhang1Xiangyu Zhao1Jiaxuan Hou1Wenhao Ma2
Peng Li1Wenqi Huang1Lingyu Liang1Zhen Dai1Shang Cao1*Huanming Zhang1Xiangyu Zhao1Jiaxuan Hou1Wenhao Ma2 Liang Che2
Liang Che2- 1Southern Power Grid Digital Grid Research Institute, Guangzhou, China
- 2College of Electrical and Information Engineering, Hunan University, Changsha, China
Reinforcement learning (RL) is recently studied for realizing fast and adaptive power system dispatch under the increasing penetration of renewable energy. RL has the limitation of relying on samples for agent training, and the application in power systems often faces the difficulty of insufficient scenario samples. So, scenario generation is of great importance for the application of RL. However, most of the existing scenario generation methods cannot handle time-series correlation, especially the correlation over long time scales, when generating the scenario. To address this issue, this paper proposes an RL-based dispatch method which can generate power system operational scenarios with time-series correlation for the agent’s training. First, a time-generative adversarial network (GAN)-based scenario generation model is constructed, which generates system operational scenarios with long- and short-time scale time-series correlations. Next, the “N-1” security is ensured by simulating “N-1” branch contingencies in the agent’s training. Finally, the model is trained in parallel in an actual power system environment, and its effectiveness is verified by comparisons against benchmark methods.
1 Introduction
In 2022, the global installed capacity of renewable energy has increased by nearly 295GW, and renewables accounted for 40% of global installed power capacity (IRENA, 2023). Renewable energy generation has uncertainty and volatility, and the high penetration of multiple renewable energies exacerbates the uncertainty, strong coupling, and non-linearity of the power system. Although traditional model-based optimization methods (Ji et al., 2018; Huang et al., 2021; López-Garza et al., 2022) with certainty have strong interpretability, they are difficult to handle the dispatch problems of renewable energy generation with uncertainty (Han et al., 2023).
Artificial intelligence can reduce the dependence on physical modeling and efficiently process multi-dimensional complex information (Wang and Ouyang, 2022; Chen et al., 2023a). Therefore, data-driven methods based on artificial intelligence have gradually demonstrated superior control advantages, especially the RL-based dispatch method in data-driven models has been researched recently due to its advantages of fast decision-making, balancing long-term and short-term benefits, and solving non-convex and non-linear problems (Tang et al., 2022). Han et al. (2023) proposed deep-RL based on soft actor-critic autonomous control, which is used to cope with large-scale renewable energy dispatch scenarios. Wei et al. (2022) proposed a dispatch method based on RL to optimize the utilization rate of renewable energy. Luo et al. (2023) combined the Kullback–Leibler (KL) divergent penalty factor with RL to maximize the absorption of renewable energy.
Although RL has been investigated in power system dispatch, it has the disadvantage of low sample utilization (Seo et al., 2019), which means that the agent needs a long time to randomly explore the environment and collect sufficient samples for learning the optimal policy. The power system may encounter extreme operational scenarios such as contingencies, mismatch between generation and load, and fast changes of load or renewables. These extreme scenarios typically have much lower occurrence possibility than normal scenarios and thus have the problem of insufficient samples. This will aggravate the low sample utilization issue and negatively impact the agent’s capability to learn the optimal dispatch policy when applying RL (He et al., 2023).
To address the aforementioned issue, scenario generation is one of the important means, which mainly includes statistics methods (Goh et al., 2022; Krishna and Abhyankar, 2023) and artificial intelligence methods (Bagheri et al., 2022; Goh et al., 2022; Krishna and Abhyankar, 2023). The uncertainty features of renewable energy can be explicitly modeled using statistical methods. It is difficult to model energy systems with significant differences, complexity, and high-dimensional non-linear features. Considering that generative adversarial network (GAN) has the advantages of flexibility, simple structure, and simulating the complex distribution of high-dimensional data, Bagheri et al. (2022) used GAN to generate photovoltaic generation and load scenarios, Qian et al. (2022) applied GAN to generate wind and solar scenarios, and Tang et al. (2023) proposed an improved GAN to generate scenarios for wind farms. To ensure the effectiveness and accuracy of scenario generation, the time-series correlation among the generated scenarios should be well-considered. Fraccaro et al. (2016) proposed a time variational auto-encoder (Time-VAE)-based method, using an encoder to extract time-series data features for generating hidden variables, and a decoder to decode the hidden variables into time-series data, thus achieving time-series scenario generation. However, these existing methods only ensure the time-series correlation between adjacent time instants but cannot handle the time-series correlation for relatively long-time scales. The root cause is that they lack the mechanisms of time-series correlation evaluation and generator network auxiliary updates. This will negatively impact the performance of the RL-based dispatch model. Moreover, all the existing scenario generation methods ignore the “N-1” security, which is critical in power system dispatch.
To address the aforementioned issues, this paper proposes an RL-based dispatch method that integrates an improved operational scenario generation considering long time scale time-series correlation and “N-1” security. The contributions are as follows.
1) Existing scenario generation methods ignore the scenarios’ time-series correlation over relatively long-time scales. To address this issue, a Time-GAN-based scenario generation method is proposed using the mechanism of time-series correlation evaluation and GAN-based generator auxiliary update. The proposed method can generate operational scenarios with time-series correlation over long and short time scales.
2) To overcome the limitation of traditional data-driven methods that have not addressed the “N-1” security, the proposed method ensures the “N-1” security by simulating “N-1” branch contingencies during the agent’s training when generating the scenarios.
The rest of this paper is organized as follows: Section 2 introduces the framework of data-driven dispatch with scenario generation. Sections 3 and 4 propose the Time-GAN-based scenario generation model and the RL-based dispatch model, respectively. Section 5 introduces the training and execution processes. Section 6 provides the simulation. Finally, Section 7 concludes the paper.
2 Framework of data-driven dispatch with scenario generation
To enhance the policy accuracy of data-driven dispatch models under extreme operational scenarios, a framework of data-driven dispatch with scenario generation is introduced, as shown in Figure 1. The scenario generation model based on Time-GAN (Yoon et al., 2019) serves as the data support for the construction of the power system dispatch model based on the proximal policy optimization (PPO) algorithm (Yang et al., 2020) and the dispatch model as algorithmic support for online execution.
(a) A scenario generation model based on Time-GAN. First, the real scenario data on the grid are normalized and preprocessed. Then, Time-GAN is trained and evaluated using the preprocessed data. Finally, the scenario generation model that has completed the training is obtained. To mine typical extreme scenarios and improve the generation effect of uncertain scenarios, it is necessary to scenario clustering before scenario generation. The combination of the scenario generation model with RL is focused, and numerous scholars have proposed different methods for scenario clustering. A Gaussian mixture model (Jang et al., 2021) is used for scenario clustering and will not focus on this topic in this paper.
(b) A power system dispatch model based on the PPO algorithm. The construction of the model mainly includes two parts: the construction of a dispatch model based on PPO and parallel offline training. The construction of the model is to transform the actual operating rules of the power system into a simulation environment of RL. It mainly includes state space, action space, and reward function design. Parallel offline training uses parallel methods to accelerate the training process of the model.
(c) Online execution. For system dispatch tasks, power system operation status data are input into the trained RL dispatch model to achieve real-time dispatch.
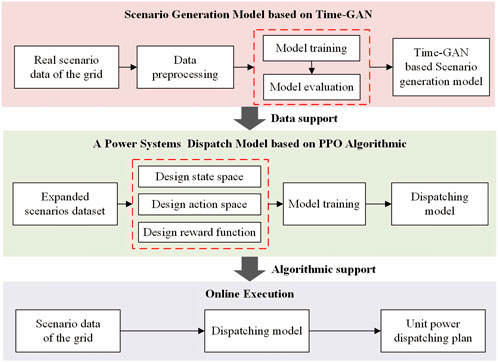
FIGURE 1. Framework of data-driven dispatch with scenario generation.
3 Time-GAN-based scenario generation
Based on the framework of data-driven dispatch with scenario generation in Section 1, a Time-GAN-based scenario generation model is constructed in this section. A scenario generation model based on Time-GAN is constructed to solve the problem of insufficient samples in data-driven models. It provides data support for the data driven distribution model in Section 3.
3.1 Scenario generation
The scenario generation process based on Time-GAN is shown in Figure 2, which is mainly divided into the following four steps.
(a) Preprocessing real scenarios. To obtain the distribution features of the data, the real scenarios obtained are subjected to data cleaning and normalization.
(b) Training Time-GAN for scenario generation. The Time-GAN parameters are set, including the sampling time step, the maximum training step, the hyperparameter, and batch size, and training the Time-GAN model.
(c) Generating renewable energy generation and load scenarios. The trained scenario generation network and test data are utilized for scenario generation.
(d) Evaluating the quality of scenario generation. The distribution features and spatiotemporal correlation of the generated scenarios are evaluated.
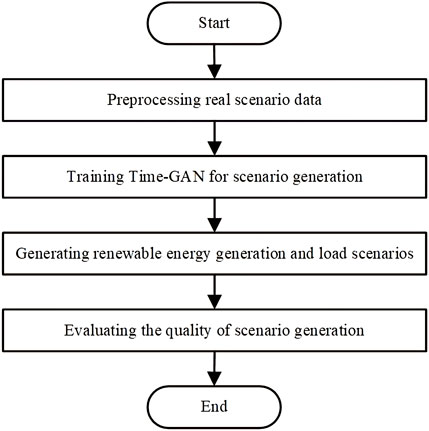
FIGURE 2. Flow of scenario generation based on Time-GAN.
3.2 Scenario generation based on Time-GAN
For Time-GAN, while preserving the structure of the generator and discriminator of GAN, AEN was added for joint training to achieve adversarial and supervised training, enabling the model to learn time-series data that conform to the feature distribution of the real data, as shown in Figure 3.
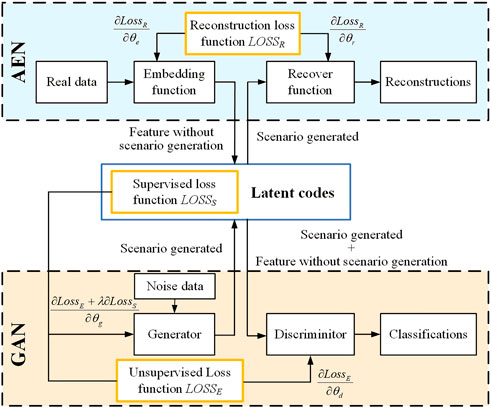
FIGURE 3. Time-GAN model structure.
First,
Second, the real scenarios obtained will be used as the training set, and it will be normalized as follows:
where
Third, the real data on renewable energy or load containing both static and dynamic features are reconstructed in the autoencoder. The embedding function and recover function are given as follows:
where (2. a) maps
Meanwhile, the discriminator is used to determine whether the generated data are similar to the real data. The generator and discriminator are given as follows:
where
where
Finally, defining the supervised loss function
3.3 Scenario generation quality assessment
To verify the effectiveness of the scenario generation model based on Time-GAN, this paper uses t-SNE (Wang et al., 2022) to evaluate the data distribution features, the autocorrelation coefficient method (Chen et al., 2018) to evaluate time-series correlation, and the Pearson method (Burgund et al., 2023) to evaluate spatial correlation.
(a) Data distribution feature evaluation based on t-SNE. t-SNE can display clear boundaries in low-dimensional space while preserving the original information on the data, making the visualization results more intuitive. Therefore, t-SNE is used to evaluate the effectiveness of the scenario generation model based on Time-GAN in this paper. The algorithm steps are listed as follows:
1) In a high-dimensional space, assume
where
2) In a low-dimensional space, the low-dimensional representation of
3) The cost function
where
(b) Time-series correlation evaluation based on the autocorrelation coefficient method. The autocorrelation coefficient represents the correlation between moments, which can provide a very intuitive understanding of the relationship between time-series variables. Therefore, the autocorrelation coefficient method is used to analyze the time-series correlation of scenarios. The autocorrelation coefficient of scenarios is given as follows:
where
(c) Spatial correlation evaluation based on the Pearson coefficient method. The advantage of using the Pearson coefficient method to evaluate the correlation of spatial sequences is that it can quickly measure the degree of correlation between two spatial sequences, to better understand the relationship between scenarios. The spatial correlation of scenarios is analyzed using the Pearson method; the Pearson coefficient of scenarios is expressed as follows:
where
4 Data-driven dispatch model considering “N-1” security
The high proportion of renewable energy penetration significantly enhances the uncertainty of the power system, and multiple energy sources bring strong coupling and non-linearity. It results in difficultly for traditional methods to model and achieve rapid optimization solutions. RL can enhance decision-making and reduce dependence on physical modeling. Therefore, based on scenario generation in the previous section, a data-driven dispatch model was constructed, which is implemented by the RL algorithm.
4.1 Model formulation
4.1.1 Objective
The objective function includes minimizing the total operating cost of the units and maximizing the consumption of renewable energy.
1) Operating cost objective is given as follows:
where
2) Renewable energy consumption objective is given as follows:
where
4.1.2 Constraints
1) The alternating current power flow constraint is given as follows:
where
2) The unit generating capacity constraint is given as follows:
where
3) The renewable energy generating capacity constraint is given as follows:
4) The unit operating ramping constraint is given as follows:
where
5) The swing-bus unit generating capacity constraint is given as follows:
After the power flow calculation, the output power of the swing-bus unit is less than 110% of the up limit or greater than 90% of the down limit.
where
6) “N-1” security constraint is given as follows:
In this paper, the operational risk of the power system “N-1” is considered. The voltage of adjacent nodes with line disconnection can neither be greater than the up limit of the voltage of that node nor can it be less than the lower limit of the voltage of that node.
where
4.2 Solution based on the RL algorithm
The aforementioned dispatch problem would be transformed into a RL power system dispatch model based on the data-driven approach, specifically including the design of state space, action space, and reward function.
4.2.1 State space
The information that can be obtained by the agent in actual environments will be considered due to the limitations of physical communication systems and data privacy. The influence of the large-scale state space on model convergence speed is also considered. The agent obtains the state space
where
4.2.2 Action space
In the dispatch model based on RL, the output of the agent at time
4.2.3 Reward function
Reward function used to describe environmental evaluation agent action
1) Reward function for line power exceeding limit is expressed as follows:
where
2) Reward function for renewable energy consumption is expressed as follows:
3) Reward function for swing-bus units exceeding limit is expressed as follows:
where
4) The unit operating cost reward function is expressed as follows:
5) Reward function for line node voltage exceeding limit is expressed as follows:
where
The reward functions
In summary, the domain values of
where
5 Offline training and online execution
Based on the scenario generation model in Section 2 and the dispatch model in Section 3, the process of offline training and online execution of the dispatch model is discussed in this section and shown in Figure 4.

FIGURE 4. Offline training and online execution process.
5.1 Offline training process
Compared to other RL methods, the PPO algorithm adopts important sampling technology to effectively utilize historical data, avoiding the problem of large variance and being able to handle the problem of continuous action space. So the PPO algorithm is chosen to study the power system dispatch problem.
First, the policy network and value network make actions
For value network updates,
where
Unlike the parameter update of the value network, the performance of the policy network is improved according to the advantage function
where
5.2 Online execution process
As shown in Figure 4, in the online execution process, the dispatch policy of the power system only relies on the trained policy network and does not require the participation of the value network. When the dispatch task arrives, the dispatch action
6 Simulation
The environment is constructed based on a real power system in a province in south China, which includes 748 nodes, 845 branches, and 187 units (55 renewable energy generation, 131 thermal units, and 1 swing-bus unit). The dispatch interval is 15 min. The sampling time step in Time-GAN is 96, the maximum training step is 35,000, the hyperparameter
6.1 Scenario generation example analysis
The aforementioned grid structure historical scenario is used to build a scenario generation model based on Time-GAN, and the scenario generation effect of the model is verified. The real scenario contains 2000 scenario section data, and the ratio of training and testing scenarios is 4:1.
(a) Analysis of the distribution of scenario generation. To test the performance of the algorithm, the scenarios generated by Time-GAN and Time-VAE were compared and analyzed. The feature distribution between the generated scenarios and the real scenarios was visualized using t-NSE, as shown in Figure 5. It can be seen that the feature distribution of Time-VAE-generated scenarios is significantly different from that of the real scenarios, and a large number of scenarios that deviate from the distribution features of the real scenarios were generated. It indicates that its effectiveness in generating scenarios is not high. The feature distribution of scenarios generated by Time-GAN is relatively close to that of real scenarios, fitting the feature distribution of the real scenarios. It indicates that Time-GAN is more effective in generating scenarios than Time-VAE.
(b) Analysis of scenario time-series correlation features based on the autocorrelation coefficient. To study the correlation between generated scenarios and real scenarios in terms of time-series correlation features, autocorrelation coefficients are introduced. The autocorrelation coefficients of scenarios are shown in Figure 6. Within the lag range of 0–20 h, the autocorrelation coefficients of the generated renewable energy and the real scenarios are consistent. This indicates that the generated scenarios can accurately simulate and preserve the correlation features of time series in real scenarios. The long-time scale time-series correlation features of the generated scenarios meet the requirements of the time-series correlation features of the real scenarios.
(c) Analysis of the scenario spatial correlation based on the Pearson coefficient method. To study the correlation between generated scenarios and real scenarios in terms of spatial features, the Pearson coefficient method is introduced. The Pearson coefficient results of renewable energy and load are shown in Tables 1–4. It can be seen that the spatial correlation between the renewable energy and load scenarios generated by this method and real scenarios is relatively close. The overall generated scenarios comply with the correlation rule of real scenarios. This shows that the renewable energy and load scenario generation method in this paper can learn the complex coupling between renewable energy and loads, and has a good generalization effect.
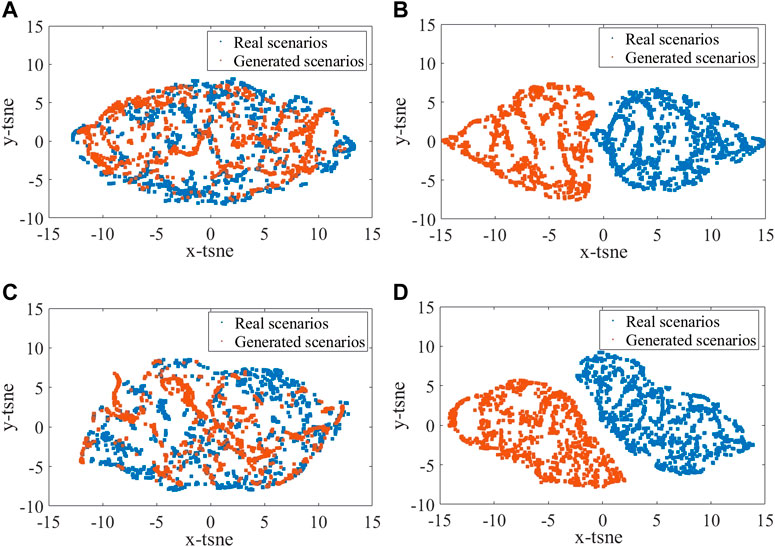
FIGURE 5. t-SNE visualization of Time-GAN-based renewable energy scenarios (A). Time-VAE-based renewable energy scenarios (B). Time-GAN-based load scenarios (C). Time-VAE-based load scenarios (D).
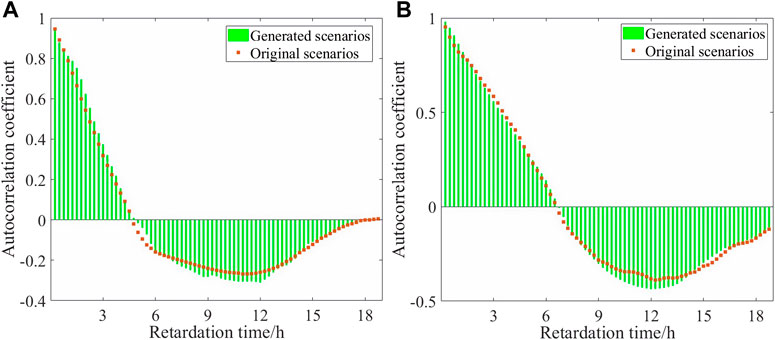
FIGURE 6. Autocorrelation coefficients of renewable energy scenarios (A) and load scenarios (B).
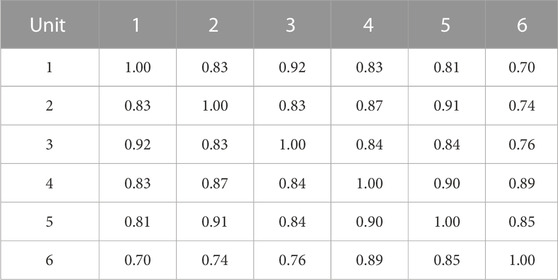
TABLE 1. Correlation of real renewable energy scenarios.
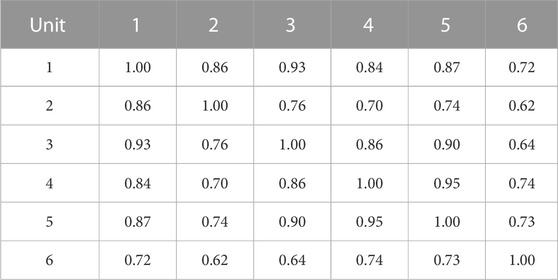
TABLE 2. Correlation of renewable energy scenarios generated.
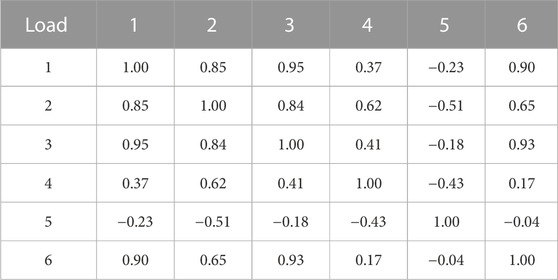
TABLE 3. Correlation of real load scenarios.
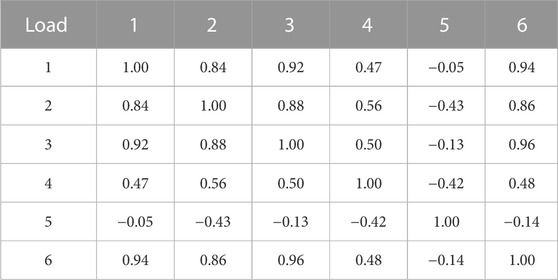
TABLE 4. Correlation of load scenarios generated.
6.2 Analysis of power system dispatch results
A data-driven power system dispatch model is constructed based on the aforementioned scenario generation. First, the original 2000 section scenarios are expanded to 10,000 section scenarios through the scenario generation model. Second, the dispatch model is training. Finally, the trained dispatch model was tested using actual real sample scenarios to verify its effectiveness.
6.2.1 Analysis of RL convergence
This paper not only compares the training effects of the dispatch model before and after scenario generation but also compares the PPO algorithm with other RL methods. The reward convergence of model training is shown in Figure 7. “O-PPO” represents the convergence curve of the PPO algorithm training based on real scenarios, and “G-PPO, G-A3C, G-A2C, G-DDPG, and G-APPO” represents the convergence curve of training based on scenario generation. From Figure 7, the following can be observed:
(a) Comparing the convergence curves of O-PPO and G-PPO, it can be seen that scenario generation can improve the training effect of the dispatch model based on the PPO algorithm. From the perspective of the average reward value, the overall training effect of G-PPO has improved by 607.49% compared to O-PPO. This means that by using scenarios generated by the scenario generation model for training, the data-driven dispatch model can be better optimized and its performance improved. A key advantage of using scenario generation models for training is that it can generate a large amount of rich and diverse scenario data, which expands the diversity of the training dataset. Due to the possible differences between the generated scenario data and the real scenario, the model can learn a wider range of situations and coping methods, thus possessing stronger generalization ability. This demonstrates the importance of scenario generation in improving the performance of the data-driven dispatch model.
(b) Comparing the convergence curves of G-PPO with other RL algorithms (G-A3C, G-A2C, G-DDPG, and G-APPO), it can be seen that the average reward convergence effect of the PPO algorithm is better. The dispatch model based on the PPO algorithm is more suitable for optimizing dispatch execution in this scenario.
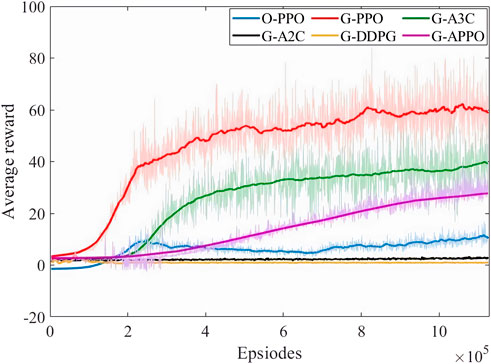
FIGURE 7. Curve of reward function during the training process.
6.2.2 Analysis of dispatch results
(a) Analysis of output power of units. A certain section is selected as the testing scenario, and the method proposed is used for real-time dispatch. The dispatch results are shown in Figure 8. In the time sections numbered 1–28, when output power of renewable energy is low, the method proposed achieves load demand by increasing the output of thermal power units in this paper. This method prioritizes using renewable energy to meet the load and reduce output power of thermal power units. In the time sections of 44–96, when output power of renewable energy is high, this method prioritizes using renewable energy to meet the load demand and reduce output power of thermal power units. In the time sections of 29–43, when the load demand and the renewable energy output power are low, this method makes a reasonable dispatch plan for output power of thermal power units to meet the load demand. At the same time, output power of the swing-bus unit is always maintained between 300 and 800 MW (the generating capacity up limit of the swing-bus unit is 878.9 MW), meeting the real-time safety regulation margin of the swing-bus unit.
(b) Analysis of the consumption of renewable energy. The consumption of renewable energy has always been a key issue in the operation and planning of the power system. The method proposed in this paper aims to achieve the actual output power of renewable energy as close as possible to its maximum power through reasonable dispatch of the system. The maximum power, actual output power, and consumption rate of renewable energy power are shown in Figure 9. In this paper, 100% renewable energy consumption cannot be guaranteed using the method proposed, but the overall renewable energy consumption rate reaches 94.06%. Based on Figure 8, it can be seen that a high level of renewable energy consumption can also be ensured during the large-scale development of renewable energy. This is of great significance for promoting the development of renewable energy and improving the sustainability of the power system.
(c) Analysis of node voltage exceeding the limit for “N-1”. At the same time, the aforementioned dispatch plan was verified using alternating current power flow through “N-1” safety verification, and the node voltage at different times under any fault was obtained, as shown in Figure 10. By comparing voltage values with the set safety range, it can be determined whether the system is experiencing abnormal or overload situations. From Figure 9, it is observed that the node voltage remains within a safe range, indicating that the dispatch scheme ensures the stability and safety of the power system under the “N-1” fault state. The power system dispatch plan based on RL can ensure the stability of node voltage in the event of a fault, which is crucial for the operation of the power system and thus ensures the reliable power supply of the power system.
(d) Comparative analysis with traditional methods. To further verify the rationality and effectiveness of the method proposed in this paper, the convex optimization problem (OPT) (Tejada-Arang et al., 2017) is used for comparative analysis, and the Gurobi solver was used for the solution. The comparison results of cross-section scenarios A and B are shown in Table 5. Due to the large scale of the optimization problem in this paper, although the training speed of the method in this paper is slow, the online solution time is reduced by more than 99% compared to traditional OPT methods. At the same time, neither the method proposed in this paper nor traditional OPT methods can fully guarantee 100% renewable energy consumption throughout the entire time period. However, compared to the OPT method, this method can also provide a higher level of the renewable energy consumption rate. In summary, the method proposed in this paper not only has fast dispatch decision-making speed but also can achieve high renewable energy consumption.
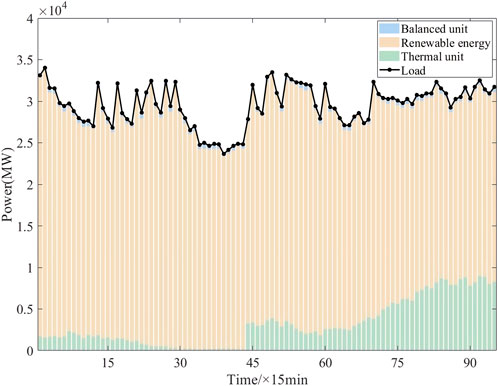
FIGURE 8. Dispatch results of units by the PPO algorithm.
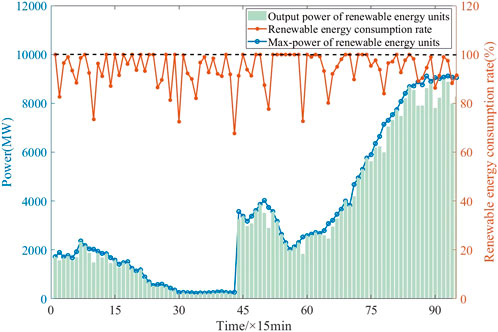
FIGURE 9. Output power and consumption rate of renewable energy.
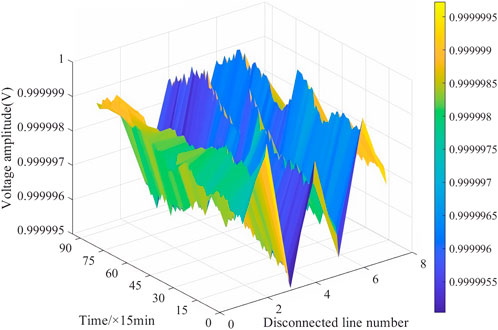
FIGURE 10. Node voltage under “N-1” faults.

TABLE 5. Comparison of dispatch results under different methods.
7 Conclusion
To ensure the effectiveness of the data-driven dispatch under insufficient scenario samples, a data-driven dispatch method with time-series correlated scenario generation is proposed. The results verify that the performance can be effectively improved by scenario generation. The proposed dispatch model can bring significant economic benefits and renewable energy consumption. It can also ensure the security under “N-1″ contingencies. Compared with traditional optimization-based methods, the proposed method reduces the online solution time by more than 99%.
Future research can focus on the action of safety and interpretability issues when applying RL in power systems.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author contributions
PL: writing–review and editing, data curation, and investigation. WH: writing–review and editing, data curation, resources, and supervision. LL, ZD, and JH: writing–review and editing, investigation, and supervision. SC: writing–review and editing, formal analysis, and supervision. HZ: writing–review and editing, investigation, resources, and supervision. XZ: writing–review and editing and supervision. WM: conceptualization, methodology, software, and writing–original draft. LC: writing–review and editing, conceptualization, formal analysis, and supervision.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work is supported by the Science and Technology Project of China Southern Power Grid Digital Grid under grant number (670000KK52220002).
Conflict of interest
PL, WH, LL, ZD, SC, HZ, XZ, JH was employed by the Southern Power Grid Digital Grid Research Institute.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors declare that this study received funding from the Science and Technology Project of China Southern Power Grid Digital Grid Research Institute [670000KK52220002]. The funder had the following involvement in the study: Study sponsor.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bagheri, F., Dagdougui, H., and Gendreau, M. (2022). Stochastic optimization and scenario generation for peak load shaving in Smart District microgrid, sizing and operation. Energy Build. 275, 112426. doi:10.1016/j.enbuild.2022.112426
Burgund, D., Nikolovski, S., Galić, D., and Maravić, N. (2023). Pearson correlation in determination of quality of current transformers. Sensors 23 (5), 2704. doi:10.3390/s23052704
Chen, H., Zhuang, J., Zhou, G., Wang, Y., Sun, Z., and Levron, Y. (2023b). Emergency load shedding strategy for high renewable energy penetrated power systems based on deep reinforcement learning. Energy Rep. 9, 434–443. doi:10.1016/j.egyr.2023.03.027
Chen, Q., Lin, N., Bu, S., Wang, H., and Zhang, B. (2023a). Interpretable time-adaptive transient stability assessment based on dual-stage attention mechanism. IEEE Trans. Power Syst. 38 (3), 2776–2790. doi:10.1109/tpwrs.2022.3184981
Chen, Y., Wang, Y., Kirschen, D., and Zhang, B. (2018). Model-free renewable scenario generation using generative adversarial networks. IEEE Trans. Power Syst. 33 (3), 3265–3275. doi:10.1109/tpwrs.2018.2794541
Fraccaro, M., Sønderby, S. K., Paquet, U., et al. (2016). Sequential neural models with stochastic layers. Adv. neural Inf. Process. Syst., 2207–2215.
Goh, H., Peng, G., Zhang, D., Dai, W., Kurniawan, T. A., Goh, K. C., et al. (2022). A new wind speed scenario generation method based on principal component and R-Vine copula theories. Energies 15 (7), 2698. doi:10.3390/en15072698
Han, X., Mu, C., Yan, J., and Niu, Z. (2023). An autonomous control technology based on deep reinforcement learning for optimal active power dispatch. Int. J. Electr. Power & Energy Syst. 145, 108686. doi:10.1016/j.ijepes.2022.108686
He, Y., Zang, C., Zeng, P., Dong, Q., Liu, D., and Liu, Y. (2023). Convolutional shrinkage neural networks based model-agnostic meta-learning for few-shot learning. Neural Process. Lett. 55 (1), 505–518. doi:10.1007/s11063-022-10894-7
Huang, B., and Wang, J. (2020). Deep-reinforcement-learning-based capacity scheduling for PV-battery storage system. IEEE Trans. Smart Grid 12 (3), 2272–2283. doi:10.1109/tsg.2020.3047890
Huang, Y., Li, P., Zhang, X., Mu, B., Mao, X., and Li, Z. (2021). A power dispatch optimization method to enhance the resilience of renewable energy penetrated power networks. Front. Phys. 9, 743670. doi:10.3389/fphy.2021.743670
Irena, (2023). The cost of financing for renewable power. https://www.irena.org/Publications/2023/May/The-cost-of-financing-for-renewable-power.
Jang, M., Jeong, H. C., Kim, T., and Joo, S. K. (2021). Load profile-based residential customer segmentation for analyzing customer preferred time-of-use (TOU) tariffs. Energies 14 (19), 6130. doi:10.3390/en14196130
Ji, X., Li, Y., Yu, Y., and Fan, S. (2018). Optimal dispatching and game analysis of power grid considering demand response and pumped storage. Syst. Sci. Control Eng. 6 (3), 270–277. doi:10.1080/21642583.2018.1553074
Krishna, A. B., and Abhyankar, A. R. (2023). Time-coupled day-ahead wind power scenario generation, A combined regular vine copula and variance reduction method. Energy 265, 126173. doi:10.1016/j.energy.2022.126173
López-Garza, E., Domínguez-Cruz, R. F., Martell-Chávez, F., and Salgado-Tránsito, I. (2022). Fuzzy logic and linear programming-based power grid-enhanced economical dispatch for sustainable and stable grid operation in eastern Mexico. Energies 15 (11), 4069. doi:10.3390/en15114069
Luo, J., Zhang, W., Wang, H., Wei, W., and He, J. (2023). Research on data-driven optimal scheduling of power system. Energies 16 (6), 2926. doi:10.3390/en16062926
Qian, T., Shi, F., Wang, K., Yang, S., Geng, J., Li, Y., et al. (2022). N-1 static security assessment method for power grids with high penetration rate of renewable energy generation. Electr. Power Syst. Res. 211, 108200. doi:10.1016/j.epsr.2022.108200
Seo, M., Vecchietti, L. F., Lee, S., and Har, D. (2019). Rewards prediction-based credit assignment for reinforcement learning with sparse binary rewards. IEEE Access 7, 118776–118791. doi:10.1109/access.2019.2936863
Tang, H., Lv, K., Bak-Jensen, B., Pillai, J. R., and Wang, Z. (2022). Deep neural network-based hierarchical learning method for dispatch control of multi-regional power grid. Neural Comput. Appl. 34, 5063–5079. doi:10.1007/s00521-021-06008-4
Tang, J., Liu, J., Wu, J., Jin, G., Kang, H., Zhang, Z., et al. (2023). RAC-GAN-based scenario generation for newly built wind farm. Energies 16 (5), 2447. doi:10.3390/en16052447
Tejada-Arango, D. A., Sánchez-Martın, P., and Ramos, A. (2017). Security constrained unit commitment using line outage distribution factors. IEEE Trans. power Syst. 33 (1), 329–337. doi:10.1109/tpwrs.2017.2686701
Wang, H., and Ouyang, Y. (2022). Adaptive data recovery model for PMU data based on SDAE in transient stability assessment. IEEE Trans. Instrum. Meas. 71, 1–11. doi:10.1109/tim.2022.3212551
Wang, L., Tian, T., Xu, H., and Tong, H. (2022). Short-term power load forecasting model based on t-SNE dimension reduction visualization analysis, VMD and LSSVM improved with chaotic sparrow search algorithm optimization. J. Electr. Eng. Technol. 17 (5), 2675–2691. doi:10.1007/s42835-022-01101-7
Wei, T., Chu, X., Yang, D., and Ma, H. (2022). Power balance control of RES integrated power system by deep reinforcement learning with optimized utilization rate of renewable energy. Energy Rep. 8, 544–553. doi:10.1016/j.egyr.2022.02.221
Yang, J., Zhang, J., and Wang, H. (2020). Urban traffic control in software defined internet of things via a multi-agent deep reinforcement learning approach. IEEE Trans. Intelligent Transp. Syst. 22 (6), 3742–3754. doi:10.1109/tits.2020.3023788
Keywords: power system dispatch, scenario generation, reinforcement learning, time series, generative adversarial network
Citation: Li P, Huang W, Liang L, Dai Z, Cao S, Zhang H, Zhao X, Hou J, Ma W and Che L (2023) Power system data-driven dispatch using improved scenario generation considering time-series correlations. Front. Energy Res. 11:1267713. doi: 10.3389/fenrg.2023.1267713
Received: 27 July 2023; Accepted: 24 October 2023;
Published: 14 November 2023.
Edited by:
Shengyuan Liu, State Grid Zhejiang Electric Power Co., Ltd., ChinaReviewed by:
Kaiping Qu, China University of Mining and Technology, ChinaHuaiyuan Wang, Fuzhou University, China
Copyright © 2023 Li, Huang, Liang, Dai, Cao, Zhang, Zhao, Hou, Ma and Che. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Shang Cao, Y2Fvc2hhbmdAY3NnLmNu