 Shiqian Wang1
Shiqian Wang1 Yang Liu
Yang Liu- 1Economic Research Institute, State Grid Henan Electric Power Company, Zhengzhou, China
- 2College of Electrical Engineering, Sichuan University, Chengdu, China
In modern power systems, analyzing the behaviors of the end users can help to improve the system’s security, stability, and economy. Load classification provides an efficient way to implement awareness of the user’s behaviors. However, due to the development of data collection, transmission, and storage technologies, the volumes of the load data keep increasing. Meanwhile, the structure and knowledge hidden in the data become ever more complicated. Therefore, the parallelized ensemble learning method has been widely employed in recent load classification research. Although the positive performance of ensemble learning has been proven, two critical issues remain: class imbalance and base classifier redundancy. These issues raise challenges of improving the classification accuracy and saving computational resources. Therefore, to solve the issues, this article presents an improved selective ensemble learning approach to enable load classification considering base classifier redundancy and class imbalance. First, a Gaussian SMOTE based on density clustering (GSDC) is introduced to handle the class imbalance, which aims to achieve higher classification accuracy. Second, the classifier pruning strategy and the optimization strategy of the ensemble learning are further introduced to handle the base classifier redundancy. The experimental results indicate that when combined with the popular classifiers, the presented approach shows effectiveness for serving the load classification tasks.
1 Introduction
Along with the evolution of the power system, brand new techniques and features have been introduced (e.g., renewable energies, energy storage, and various user demands), which all impact the operations of the system. These points significantly increase the difficulties of the resource dispatch of the power system and this may lead to security, stability, and economy issues. It has been proven that on the user side, guiding the load of the users according to their power consumption behaviors to participate in power system dispatch could be an effective way of relieving these difficulties (Muthirayan et al., 2000; Aderibole et al., 2019; Wei et al., 2022). Therefore, to accurately and efficiently identify the user’s behaviors based on the load dataset has become a significant challenge (Zhu et al., 2020; Zhu et al., 2021). A number of researchers have suggested that load classification shows enormous potential to implement the user behavior awareness task (Zhang et al., 2015; Zhu et al., 2020; Liu et al., 2021).
Tambunan et al. (2020) present an improved k-means clustering algorithm, which is able to classify the load dataset based on the concept of clustering. Although their algorithm improves the stability of the traditional k-means, flaws still exist (e.g., the difficulty of determining the number of the initial centroids). Zhou and Yang (2012) present a self-adaptive fuzzy c-means algorithm to implement the load clustering and the authors claim that local optimal issue could be partially solved. Shi et al. (2019) present a deep learning and multi-dimensional fuzzy c-means clustering based load classification approach. Their experimental results show that this approach can provide satisfactory performances of dimension reduction, feature extraction, algorithm stability, algorithm efficiency, and so on. Zhang et al. (2020) present a Gaussian mixture model and multi-dimensional scaling analysis that is based on the load classification approach. The authors also report that the computational efficiency can be improved, while the computational cost can be reduced. However, although these studies contribute to our understanding of load classification, their methodologies are mainly based on distance-based clustering algorithms that lack of the ability of revealing the correlated features in the high-dimensional load data. Additionally, the presented algorithms have a serial algorithm architecture, which has limited capacity for serving the current large-volume load data in terms of efficiency. Therefore, to further improve the classification accuracy and processing efficiency of large-volume load data, supervised machine learning algorithms and the distributed computing technologies are widely employed in load classification research (Liu et al., 2019; Li et al., 2020; Tang et al., 2020; Wang et al., 2021). Among the supervised learning algorithms, artificial neural networks show remarkable performance and almost dominate the recent classification studies. Liu et al. (2019) employ the back propagation neural network as an underlying algorithm to achieve better load classification accuracy. To highlight the time series characteristics of the load data, the long short-term memory neural network is adopted to implement the classification in these studies (Li et al., 2020; Tang et al., 2020; Wang et al., 2021). Zhang et al. (2022) employ bi-directional temporal convolutional network and data augmentation to achieve high-accurate load classification. These authors supply great load classification in terms of accuracy. However, the authors still report that low efficiency issue occurs when the algorithms are dealing with the large-volume load data due to the algorithm overhead. As a result, Liu et al. (2016), Liu et al. (2017), and Liu et al. (2020) finally introduce the distributed computing to improve the efficiency of the large-scale load data classification. The authors report that because of the difficulties in the algorithm decoupling, the ensemble learning technology is a necessary tool to implement algorithm parallelization. This idea has also been proven by a number of researches (Liu et al., 2019; Li et al., 2020; Liu et al., 2016; Liu et al., 2017; Liu et al., 2020). Ensemble learning is able to create a number of parallel base classifiers, which facilitates the parallelization of the classification algorithm. However, among the base classifiers, the redundancy issue is inevitable (Liu et al., 2021; Wang et al., 2022). This point further causes the base classifier homogenization issue, which deteriorates the performance of ensemble learning and the final classification in terms of computational resource consumption and accuracy.
Class imbalance is another critical issue that impacts supervised classification algorithms. Due to imbalanced class distribution, the majority class may overwhelm the minority class and this causes imbalanced insufficient training. Therefore, the final classification accuracy may be severely affected. However, because of various user power consumption behaviors, the class imbalance issue naturally exists in the load data (Liu et al., 2019; Zhang et al., 2022). Consequently, a number of researchers have presented solutions, among which oversampling is considered to be the most effective. Liu et al. (2019) adopt the SMOTE algorithm to balance the classes of the load data, and effectively synthesized samples belonging to the minority class. Li et al. (2020) improve the traditional SMOTE and presents the Borderline-SMOTE algorithm, and successfully highlighted the borderline of the classes. Liu et al. (2020) present an improved BS algorithm considering the ratio of the sample synthesis, which also shows effectiveness of balancing the class distribution. However, it should be noted that the basic concept of these studies is based on stochastic oversampling. Their most crucial drawback is that stochastic sampling may not accurately simulate the real sample distribution of the original load data. As a result, the side effect (for example) of the class overlapping may seriously impact the generalization of the classifier, which may finally deteriorate the classification accuracy.
Motivated by the previous studies, this article initially presents a GSDC approach to solve the class imbalance issue. GSDC first constructs a directly density-reachable graph using density clustering. The algorithm then uses the shortest weighted graph path between the sample and the cluster centroid to form the sampling path to synthesize the minority samples. Then, the oversampling with the Gaussian stochastic perturbation is employed to enhance the diversities of the synthesized samples. This article will then present a fuzzy increment of diversity (FID) based clustering pruning strategy (CPS) to solve the base classifier redundancy issue. In this strategy, the FID eigenvector of each base classifier is firsts constructed. The FID characteristic matrix of all the base classifiers is then constructed. The affinity propagation clustering algorithm is then applied on the matrix to achieve the clusters and the corresponding centroids of the base classifiers. Based on two presented indices, the pruning strategy is implemented on the clusters. This finally leads us to achieve an optimal number of the base classifiers. To further maintain the diversity and accuracy of the redundancy eliminated base classifiers, a surrogate empirical risk with regular term-based optimization selection integration (OSI) composed of the surrogate empirical risk function, Huber function, and K-fold cross validation method is presented. Ultimately, combined with the popular classifiers, the performance of the presented class balancing algorithm and the improved selective ensemble learning algorithm are evaluated and validated.
The rest of this article is organized as follows. Section 2 presents the class balancing algorithm. Section 3 presents the improved selective ensemble learning algorithm. Section 4 shows the experimental results and discussions. Finally, Section 5 concludes this study.
2 Class balancing using GSDC
The class imbalance issue naturally exists in the load dataset, which increases the difficulties of minority class identification in the classifier. Although the stochastic oversampling algorithms can handle this issue to some extent, the flaws, for example, of the class overlapping and inaccurate sample distribution may deteriorate the performance of the classifier. Therefore, this article presents the GSDC algorithm to solve the flaws and improve the performance of the traditional SMOTE algorithm. It should be noted that there is currently no numerical definition of the concept minority class. Therefore, according to Liu et al. (2019), a threshold of 20% is employed to identify if a class is a minority class. If the number of the samples in a class is less than 20% of those in a class with the largest number of samples, then class is identified as a minority class.
2.1 Basic definitions in GSDC
1)
2) Core: For a given sample
3) Directly density-reachable: For two given samples
4) Directly density-reachable graph: Let
2.2 Detailed steps of GSDC
Step 1, identify the minority sample and class. A given load dataset D is composed of samples belonged to a number of M classes
Step 2, clustering of the minority samples. Let
Step 3, direct density-reachable graph construction based on clusters. Based on the clustering results in Step 2, the directly density-reachable graph
Step 4, determine the number of synthesized samples for each
Step 5, search of the sampling path. In each sample synthetic operation, a real sample
Step 6, sample synthetic. A directly density-reachable edge
Then, randomly generate the interpolation coordinates
Afterward, to improve the diversities of the synthesized samples, a random disturbance vector
where
Keep synthesizing the samples until the number of the samples in the minority class reaches to 20% of those in a class with the largest number of samples, the algorithm terminates.
The entire process of GSDC in enabling class balance of the load dataset is shown in Figure 1.
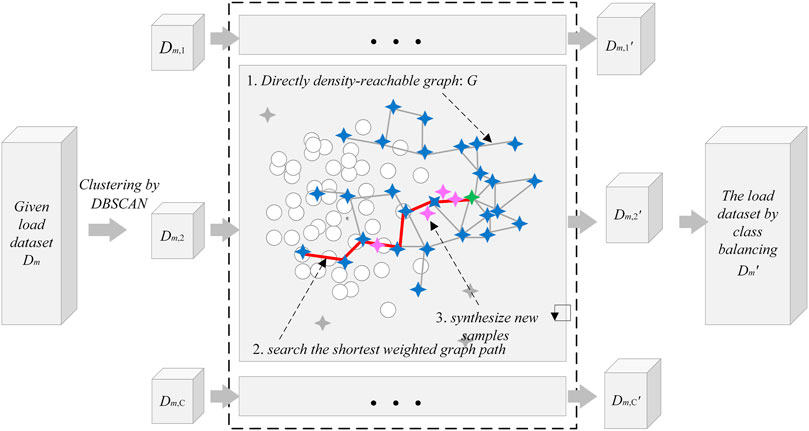
FIGURE 1. The entire process of GSDC in enabling class balance of the load dataset.
3 Improved selective ensemble learning
The essential method of the ensemble learning is based on one concept that a series of weak classifiers (base classifiers) are able to compose one strong classifier. The performance of the ensemble learning is depending on the diversity and the decision accuracy of the base classifier (Kuncheva and Whitaker, 2003; Yang et al., 2014). The diversity refers to the trend that the classifiers generate diverse misclassification of the samples, while the decision accuracy refers to the correct classification of the samples. It is obvious that along with the increasing scale of the base classifiers, the homogenization of the classifiers is inevitable. This point significantly deteriorates the diversity of the classifiers and finally causes the base classifier redundancy issue.
Therefore, to balance the diversity and accuracy of the classifiers, this article presents a fuzzy increment of diversity (FID) based clustering pruning strategy (CPS) and a surrogate empirical risk with regular term-based optimization selection integration (OSI) to implement the improved selective ensemble learning which finally serves the load classification and the identification of the load behaviors.
3.1 Clustering pruning strategy
The presented fuzzy increment of diversity (FID) based clustering pruning strategy (CPS) first constructs the FID eigenvectors and the FID characteristic matrix for the base classifiers. The affinity propagation (AP) clustering algorithm is then applied on the matrix (Gan and Ng, 2014). According to the Euclidean distance-based and cosine distance-based measurement indices, the optimal centroids of the base classifiers can be achieved from the clustered clusters. This finally leads to the pruning of the redundancy base classifiers.
3.1.1 Eigenvector of FID
Q-statistics are employed to construct the FID eigenvector (Kuncheva and Whitaker, 2003). Q-statistics are able to measure the decision diversity between two base classifiers. The Q-statistic
where
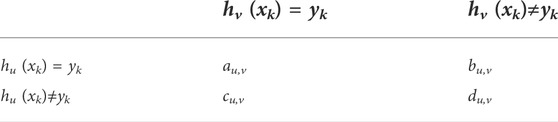
TABLE 1. Joint distribution for the two base classifiers.
In Table 1,
To delineate the impact of an individual base classifier on the sum of pair-wise diversity among all the base classifiers, the FID of the base classifier u in the mth class of the training dataset is defined using Eq.8:
where
3.1.2 Optimal number of centroids for base classifiers
The Euclidean distance and the cosine distance are frequently employed to measure the similarity between two data sequences. Based on the FID eigenvectors of all the base classifiers, the AP clustering algorithm is applied on the rows of
where
3.1.3 Steps of the presented CPS
Step 1: generate the base classifiers. In the load dataset
Step 2: Based on the generated base classifiers and the load dataset
Step 3: Cluster the base classifiers. The AP clustering algorithm is applied once on the row vectors of the characteristic matrix
Step 4: Cluster pruning of the base classifiers. Keep executing Step 3 and compute
3.2 Surrogate empirical risk with regular term-based optimization selection integration
To improve the generalization of the presented improved selective ensemble learning, this article further presents the OSI strategy. This strategy introduces the concept of ensemble margin to construct the minimum surrogate empirical risk with a regular term function to optimize the weights assigned to the base classifier in ensemble leaning.
3.2.1 Maximum ensemble margin strategy considering model complexity
Ensemble margin (Yang et al., 2014) is adopted to measure the correct classification tendency of the samples. Let
where
The presented OSI is able to improve the generalization of the classification model using the loss function. Furthermore, to control the complexity of the ensemble learning and reduce the overfitting caused by the optimization, this article also presents Eq. 14 considering the regular term in the weights of the base classifiers, which is an optimization problem:
where
3.2.2 Huber function based surrogate empirical risk function
The loss function
Finally, based on Eqs. 15 and 14 can be reformed into Eq. 16, which is ultimately employed to optimize the participating weights of the base classifiers:
3.2.3 K-fold cross validation method-based base classifier selection
K-fold cross validation method is adopted to achieve a number of K verifying datasets
where
where the value of the function
3.3 Steps of the presented improved selective ensemble learning approach in enabling load classification
Step 1: A dataset
Step 2: In
Step 3: Each base classifier in
Step 4: The presented CPS is then applied on
Step 5: In the presented OSI phase, K-fold cross validation method is adopted.
Step 6: Each base classifier in
Step 7: Repeat Step 6 for K times. According to Eq. 17, the K-time weights
Step 8: For each base classifier in
4 Experimental results
4.1 The datasets employed to evaluate the presented approach
This article mainly employs three load datasets including the synthetic binary dataset, Electrical Grid Stability Simulated Dataset (EGSSD) (Arzamasov, 2018), and Electricity Load Diagrams 20112014 Dataset (ELDD) (Trindade, 2015). The samples in the synthetic binary dataset are labeled. The samples in EGSSD are also already labeled (system stability and system instability). In contrast, the samples in ELDD are not labeled. Therefore, the labels of the samples in ELDD can be achieved using the approach presented by Liu et al. (2019). The details of three datasets are listed in Table 2.
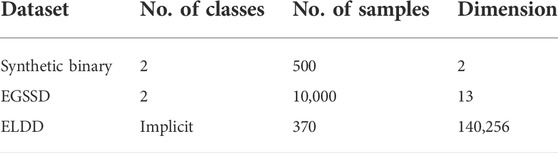
TABLE 2. Detailed information of the synthetic binary, EGSSD, and ELDD datasets.
The sampling interval for each sample in ELDD is 15 min. Therefore, in 1 day there are 96 sampling points in total. According to the sample dimension 140,256, each sample contains the load information for 1,461 days. In terms of analyzing the load data for 1 day, each sample in ELDD is converted into the daily load. As a result, the finally converted ELDD dataset contains
4.2 Indices employed to evaluate the classification performance
Besides the accuracy Acc, which represents the overall classification accuracy of the samples is employed to evaluate the performance of the binary classification, the recall Pre and the precisions including Ppr, Gmeans, and Fvalue are also employed (López et al., 2013). Pre represents the proportion of the correctly classified minority samples. Ppr represents the real proportion of the minority samples in the samples that are classified as the minority samples. Gmeans represents the geometric mean of the proportion of the correctly classified samples in all majority classes and the proportion of the correctly classified samples in all minority classes. Gmeans presents the tendency of the classifiers of classifying different classes. If the value of Gmeans is close to the value of Acc, then the performance of the presented class balancing approach can be regarded as better. Fvalue represents the harmonic mean of Pre and Ppr. A greater value of Fvalue indicates that the improvements of classifying the minority classes generate less impact on classifying the majority classes.
Although the confusion matrix is frequently employed in multi-class classification evaluations, it is difficult to quantitatively assess the performance of the classification model. Therefore, based on the confusion matrix, this article presents the index named as the class confusion equilibrium entropy. The equations composing the index are presented as follows. First, the confusion matrix of binary classification
where
A greater value of Sb represents more equilibrium of the class confusion for the classifier, which also indicates the better class balancing performance of the presented GSDC algorithm.
4.3 Evaluation of GSDC
To evaluate the performance of the presented GSDC algorithm, this section employs the synthetic binary dataset, EGSSD dataset, and ELDD dataset. As aforementioned, the EGSSD dataset contains two classes and the ELDD dataset contains multiple classes.
4.3.1 Experiments using the synthetic binary dataset
The classification experiment is carried out using the synthetic binary dataset. The ratio of the minority class (in blue) and the majority class (in red) is 1:10. Support vector machine (SVM) is employed as the classifier.
Figure 2B shows that, based on the class balance using the presented GSDC algorithm, the sample distribution can be positively enhanced. The samples of the minority class can be significantly highlighted. Compared to the classification result without being processed by GSDC, as shown in Figure 2A, the hyperplane of SVM in Figure 2B is improved. Additionally, the minority samples in the area overlapping with the majority samples are not obviously affected by GSDC. Therefore, the presented class balancing strategy only has a limited influence on the classification of the majority samples, which demonstrates that GSDC can effectively synthesize the minority samples according to the sample distribution characteristic.
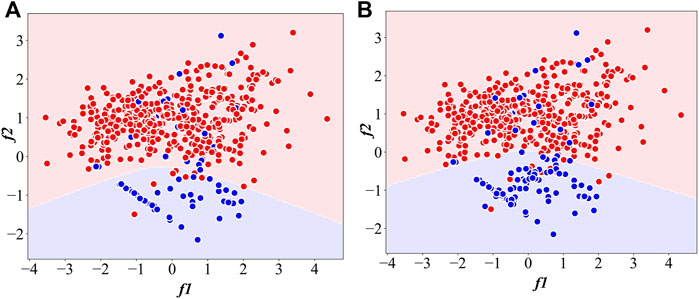
FIGURE 2. The classification (A) without processing by GSDC and (B) with processing by GSDC.
4.3.2 Experiments using the EGSSD dataset
First, the testing dataset is generated. In total, 2000 samples are randomly selected form the transient stability class and the transient instability class to form the testing dataset. Second, the training dataset is generated. A number of 4,000 transient stability samples and a number of 400 transient instability samples are also randomly selected to form the training dataset. The back propagation neural network (BPNN) classifier is employed in this section. In addition, the conventional SMOTE and BS class balancing algorithms are also implemented in terms of comparison. The classification results are listed in Table 3.
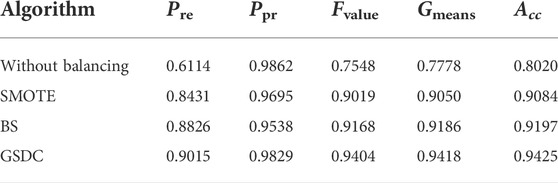
TABLE 3. Classification results based on the EGSSD dataset with different class balancing algorithms.
According to the results shown in Table 3, if the classification is carried out without class balancing, then due to the insufficient training of the minority class, the samples belonged to the minority class have higher chances to be misclassified. This results in higher
To evaluate the impact of the imbalance class proportion on the performance of GSDC, a series of the training datasets are generated. First, 4,000 samples belonged to the transient instability class are randomly selected. Then, based on the ratios of 20:1, 40:1, 80:1, and 160:1, the corresponding numbers of the samples belonged to the transient stability class are randomly selected. Therefore, four imbalanced training datasets can be achieved. The classification results are listed in Table 4.

TABLE 4. lassification accuracy based on different imbalance ratios.
It can be observed that along with the increasing imbalance ratio, the classification accuracies based on different class balancing algorithms gradually deteriorate. This means that in the extremely imbalanced dataset, the balancing algorithm can supply limited improvement in terms of the classification accuracy. However, GSDC still outperforms the other algorithms.
4.3.3 Experiments using the ELDD dataset
The samples in ELDD are not labeled, which causes difficulty in their classification. Therefore, according to Liu et al. (2019), the labeling operation is applied on the dataset, and therefore the labeled dataset can be achieved. In terms of facilitating the experiments, a labeled subset
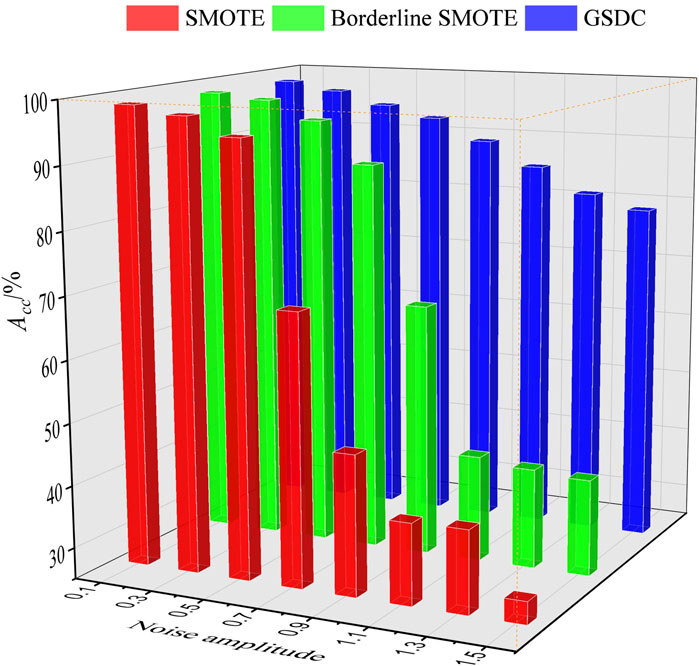
FIGURE 3. The classification accuracy based on different class balancing algorithms and different levels of noise.
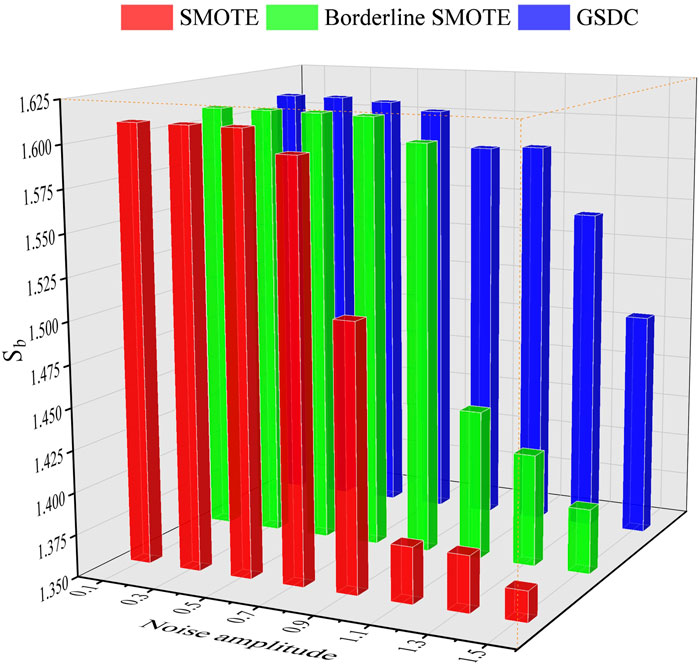
FIGURE 4. The values of Sb based on different class balancing algorithms and different levels of noise.
From Figures 3, 4, it can be observed that when the noise level is low, with the improvements of the class balancing algorithms, the accuracy of the classification results is quite similar. However, along with the increasing noise level, especially when the level reaches 0.9, the accuracy Acc and values of Sb of the classification based on SMOTE and BS sharply decreased. In contrast, the accuracy Acc and values of Sb of the classification based on the presented GSDC still maintain higher levels. This point significantly suggests that GSDC has great abilities in terms of robust and noise immunity.
4.4 Evaluation of the improved selective ensemble learning approach
4.4.1 The parameters employed in the evaluation
The base classifiers employed in the evaluation include BPNN, classification and regression tree (CART), and long short-term memory neural network (LSTM). The performance of the presented improved selective ensemble learning approach is based on the classification performance of these base classifiers. First, according to step 2 in Section 3.3, a total of 100 labeled training sub-datasets are generated based on
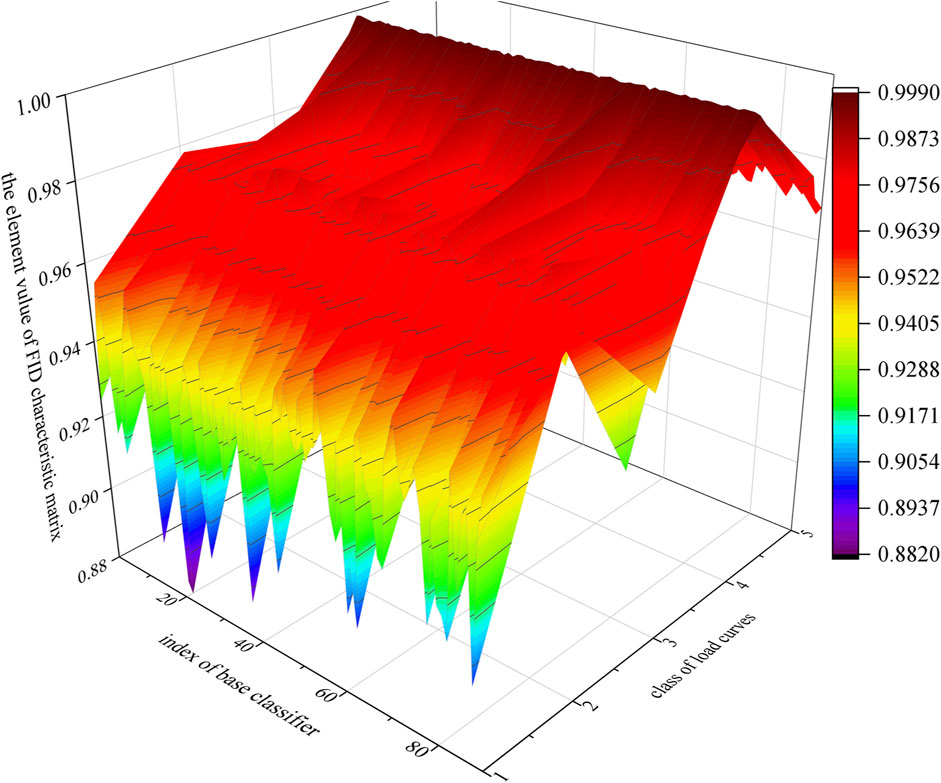
FIGURE 5. The FID characteristic matrix of 100 BPNN base classifiers.
According to step 4 in Section 3.3, the CPS strategy is then applied on the base classifiers. The redundancy removed set of base classifiers can be achieved.
Figures 6A,B indicate that when
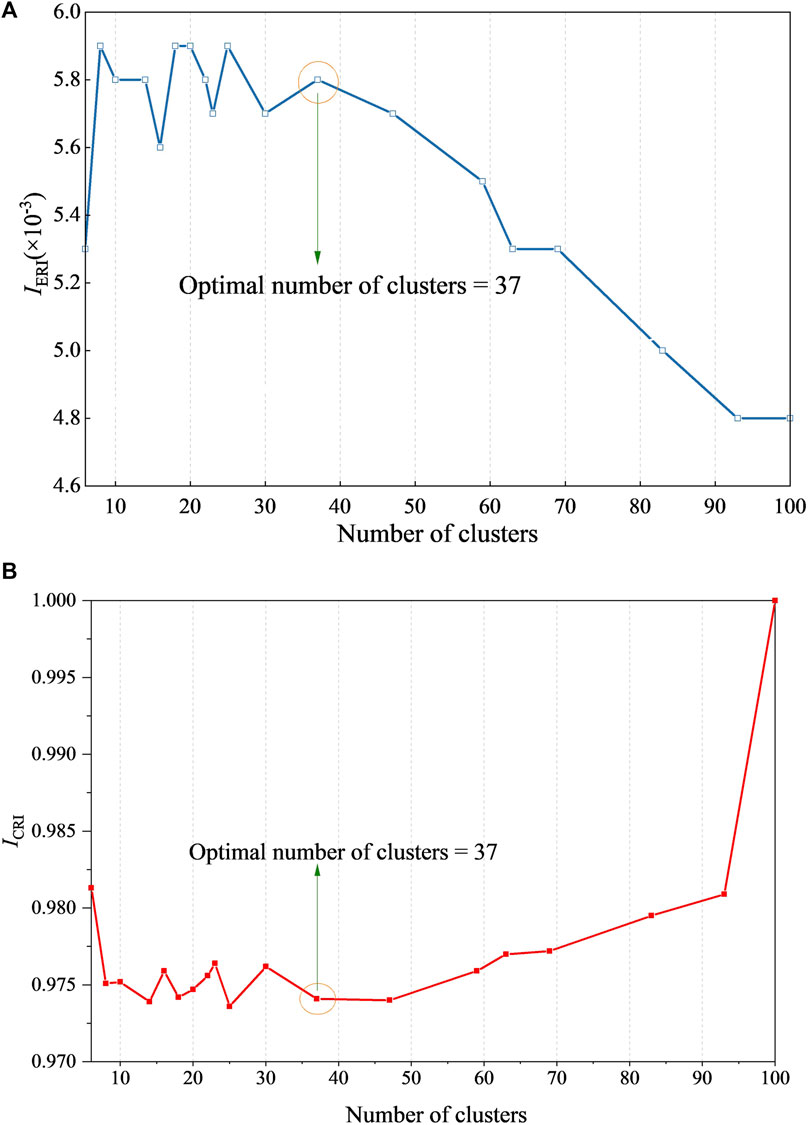
FIGURE 6. The value variations of (A) IERI and (B) ICRI.
4.4.2 Performance evaluation of load classification using ELDD
According to steps 5 to 7 in Section 3.3, A five-fold cross validation is employed in this section. Repeat step 5 for five times, in each of which the weights of base classifiers in
BPNN, CART, and LSTM algorithms are adopted as the base classifiers, on which the improved selective ensemble learning is applied. In terms of comparison, famous ensemble learning strategies, including bagging and adaboosting, are also implemented. Based on the presented approach, and other ensemble learning strategies, the classification results including Acc and Sb of classifying
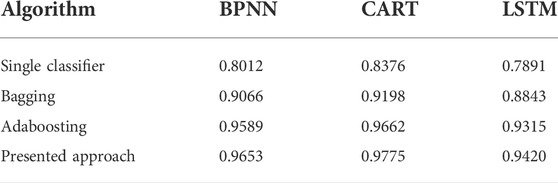
TABLE 5. omparisons of the accuracy of different ensemble learning strategies.
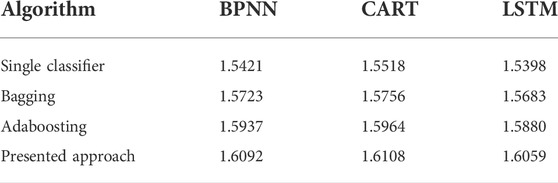
TABLE 6. omparisons of Sb of different ensemble learning strategies.
From Tables 5, 6, it can be observed that in terms of Acc and Sb, the presented approach outperforms the famous ensemble learning algorithms including bagging and adaboosting. In addition, the classification results suggest that the presented approach is able to serve different classifiers with significant performance improvement.
4.4.3 Stability evaluations of the improved selective ensemble learning
To demonstrate the stability of the presented improved selective ensemble learning based load classification, this section employs BPNN as the base classifier. GSDC is employed to balance the testing dataset
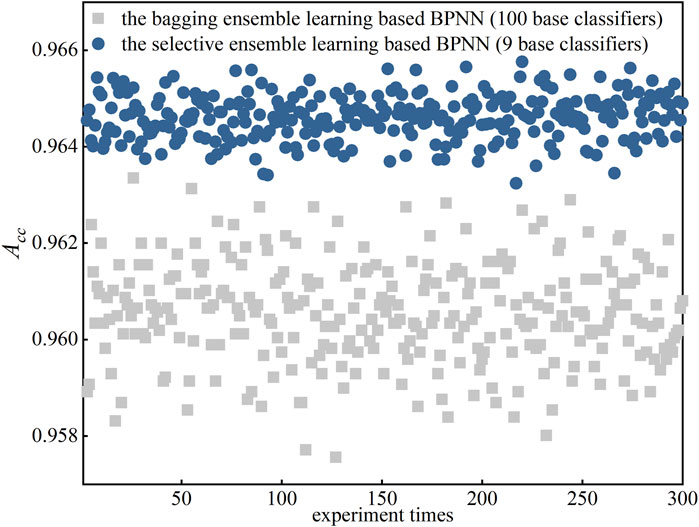
FIGURE 7. A comparison of the stability of two ensemble learning approaches.
Figure 7 first shows that in 300-time experiments, although more base classifiers involved in bagging, the improved selective ensemble learning based BPNN outperforms the bagging ensemble learning based BPNN in terms of classification accuracy. Second, the improved selective ensemble learning also performs a correspondingly stable performance. The accuracies of 300-time experiments are quite close. The results shown in Figure 7 prove that the presented selective ensemble learning can improve both the classification accuracy and the classification stability.
5 Conclusion
Class imbalance and low efficiency prevent load classification from being effectively carried out. Therefore, this article presents an improved selective ensemble learning approach to enable load classification considering base classifier redundancy and class imbalance. First, a Gaussian SMOTE based on density clustering is proposed. The minority samples can be effectively synthesized, mainly using sampling techniques, DBSCAN clustering algorithm, and Dijkstra algorithm. Therefore, the original dataset can be significantly balanced. Second, a fuzzy increment of diversity based clustering pruning strategy is further proposed. Based on FID characteristic matrix and AP clustering algorithm, the redundancy of the base classifiers can be discovered and removed. To improve the generalization of the classification model, the ensemble margin based empirical risk function, the Huber loss function, and the K-fold cross validation method-based optimization selection integration are proposed. According to the experimental results, the presented GSDC is able to effectively balance the classes, which finally leads to an improvement of the classification accuracy. The presented CPS and OSI strategies can also remove the redundancy of the base classifiers, which significantly improves the efficiency of the ensemble learning. All of the positive results indicate that the presented improved selective ensemble learning approach considering base classifier redundancy and class imbalance can be an effective tool to serve practical large-scale load classification tasks.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, and further inquiries can be directed to the corresponding author.
Author contributions
The authors contributed their original works respectively for this article. SW and YL presented the basic idea of the article. They also presented the employed algorithms of the article. DH, YH, and LW implemented the algorithms and further presented the experiments of evaluating and validating the performances of the algorithms. YW organized and structures the article and finally finished the writing works.
Funding
The authors would like to appreciate the support from the State Grid Henan Economic Research Institute with the project “Big Data based Residential Load Data Identification, Analysis, and Power Consumption Management Research” under Grant No. 5217L021000C.
Conflict of interest
SW, DH, YH, and YW are employed by State Grid Henan Electric Power Company.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Aderibole, A., Zeineldin, H. H., Hosani, M. A., and El-Saadany, E. F. (2019). Demand side management strategy for droop-based autonomous microgrids through voltage reduction. IEEE Trans. Energy Convers. 34 (2), 878–888. doi:10.1109/TEC.2018.2877750
Arzamasov, V. (2018). Data from: Electrical Grid stability simulated data dataset. Orange County, California: Machine Learning Repository. Available at: http://archive.ics.uci.edu/ml/machine-learning-databases/00471/.
Borah, P., and Gupta, D. (2020). Functional iterative approaches for solving support vector classification problems based on generalized Huber loss. Neural comput. Appl. 32 (13), 9245–9265. doi:10.1007/s00521-019-04436-x
Ester, M., Kriegel, H-P., Sander, J., and Xu, X. (1996). “A density-based algorithm for discovering clusters in large spatial databases with noise,” in The 2nd international conference on knowledge discovery and data mining (Portland, Oregon, USA: AAAI), 226–231.
Gan, G., and Ng, M. K. -P. (2014). Subspace clustering using affinity propagation. Pattern Recognit. DAGM. 48, 1455–1464. doi:10.1016/j.patcog.2014.11.003
Kuncheva, L. I., and Whitaker, C. J. (2003). Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach. Learn. 51 (2), 181–207. doi:10.1023/A:1022859003006
Li, X., Wang, P., Liu, Y., and Xu, L. (2020). Massive load pattern identification method considering class imbalance. Proc. CSEE 40 (01), 128–137+380. doi:10.13334/j.0258-8013.pcsee.190098
Liu, S., Reviriego, P., HernÁndez, J. A., and Lombardi, F. (2021). Voting margin: A scheme for error-tolerant k nearest neighbors classifiers for machine learning. IEEE Trans. Emerg. Top. Comput. 9 (4), 2089–2098. doi:10.1109/TETC.2019.2963268
Liu, W. (2021). “Cooling, heating and electric load forecasting for integrated energy systems based on CNN-LSTM,” in 2021 6th international conference on power and renewable energy (ICPRE) (Shanghai, China: IEEE). doi:10.1109/ICPRE52634.2021.9635244
Liu, Y., Gao, L., and Liu, L. (2020a). Parallel load type identification algorithm considering sample class imbalance. Power Syst. Technol. 44 (11), 4310–4317. doi:10.13335/j.1000-3673.pst.2020.0116
Liu, Y., Li, X., and Chen, X. (2020b). High-performance machine learning for large-scale data classification considering class imbalance. Scientific Programming. doi:10.1155/2020/1953461
Liu, Y., Liu, Y., Xu, L., and Wang, J. (2019). A high performance extraction method for massive user load typical characteristics considering data class imbalance. Proc. CSEE 39 (14), 4093–4104. doi:10.13334/j.0258-8013.pcsee.181495
Liu, Y., Ma, C., Xu, L., Shen, X., Li, M., and Li, P. (2017). MapReduce-based parallel GEP algorithm for efficient function mining in big data applications. Concurr. Comput. Pract. Exper. 30, e4379. doi:10.1002/cpe.4379
Liu, Y., Xu, L., and Li, M. (2016). The parallelization of back propagation neural network in MapReduce and spark. Int. J. Parallel Program. 45, 760–779. doi:10.1007/s10766-016-0401-1
López, V., Fernandez, A., Garcia, S., Palade, V., and Herrera, F. (2013). An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Inf. Sci. 250, 113–141. doi:10.1016/j.ins.2013.07.007
Muthirayan, D., Kalathil, D., Poolla, K., and Varaiya, P. (2000). Mechanism design for demand response programs. IEEE Trans. Smart Grid 11 (1), 61–73. doi:10.1109/TSG.2019.2917396
Shi, L., Zhou, R., and Zhang, W. (2019). Load classification method using deep learning and multi-dimensional fuzzy C-means clustering. Proc. CSU-EPSA 31 (7), 43–50. doi:10.19635/j.cnki.csu-epsa.000089
Tambunan, H. B., Barus, D. H., Hartono, J., Alam, A. S., Nugraha, D. A., and Usman, H. H. H. (2020). “Electrical peak load clustering analysis using K-means algorithm and silhouette coefficient,” in 2020 international conference on technology and policy in energy and electric power (ICT-PEP) (Bandung, Indonesia: IEEE). doi:10.1109/ICT-PEP50916.2020.9249773
Tang, Z., Liu, Y., and Xu, L. (2020). Imbalanced-load pattern extraction method based on frequency domain characteristics of load data and LSTM network. Electr. Power Constr. 41 (8), 17–24. doi:10.12204/j.issn.1000-7229.2020.08.003
Trindade, A. (2015). Data from: ElectricityLoadDiagrams20112014 dataset. Orange County, California: Machine Learning Repository. Available at: http://archive.ics.uci.edu/ml/machine-learning-databases/00321/.
Wang, L., Liu, Y., Li, W., Zhang, J., Xu, L., and Xing, Z. (2022). Two-stage power user classification method based on digital feature portraits of power consumption behavior. Electr. Power Constr. 43 (2), 70–80. doi:10.12204/j.issn.1000-7229.2022.02.009
Wang, Z., Li, H., Tang, Z., and Liu, Y. (2021). User-level ultra-short-term load forecasting model based on optimal feature selection and bahdanau attention mechanism. J. Circuits, Syst. Comput. 30. doi:10.1142/S0218126621502790
Wei, Z., Ma, X., and Guo, Y. (2022). Optimized operation of integrated energy system considering demand response under carbon trading mechanism. Electr. Power Constr. 43 (1), 1–9. doi:10.12204/j.issn.1000-7229.2022.01.001
Xu, M. H., Liu, Y. Q., Huang, Q. L., Zhang, Y., and Luan, G. (2007). An improved dijkstra's shortest path algorithm for sparse network. Appl. Math. Comput. 185 (1), 247–254. doi:10.1016/j.amc.2006.06.094
Yang, C., Yin, X. C., and Hao, H. W. (2014). Classifier ensemble with diversity: Effectiveness analysis and ensemble optimization. Acta Autom. Sin. 40 (4), 660–674. doi:10.3724/SP.J.1004.2014.00660
Zhang, J., Liu, Y., Li, W., Wang, L., and Xu, L. (2022). Power load curve identification method based on two-phase data enhancement and Bi-directional deep residual TCN. Electr. Power Constr. 43 (2), 89–97. doi:10.12204/j.issn.1000-7229.2022.02.011
Zhang, M., Li, L., and Yang, X. (2020). A load classification method based on Gaussian mixture model clustering and multi-dimensional scaling analysis. Power Syst. Technol. 44 (11), 4283–4296. doi:10.13335/j.1000-3673.pst.2019.1929
Zhang, P., Wu, X., Wang, X., and Bi, S. (2015). Short-term load forecasting based on big data technologies. CSEE Power Energy Syst. 1 (3), 59–67. doi:10.17775/CSEEJPES.2015.00036
Zhou, K., and Yang, S. (2012). An improved fuzzy C-Means algorithm for power load characteristics classification. Power Syst. Prot. Control 40 (22), 58–63. CNKI:SUN:JDQW.0.2012-22-013.
Zhu, Q., Zheng, H., and Tang, Z. (2021). Load scenario generation of integrated energy system using generative adversarial networks. Electr. Power Constr. 42 (12), 1–8. doi:10.12204/j.issn.1000-7229.2021.12.001
Keywords: load classification, ensemble learning, class imbalance, classifier redundancy, base classifier
Citation: Wang S, Han D, Hua Y, Wang Y, Wang L and Liu Y (2022) An improved selective ensemble learning approach in enabling load classification considering base classifier redundancy and class imbalance. Front. Energy Res. 10:987982. doi: 10.3389/fenrg.2022.987982
Received: 06 July 2022; Accepted: 25 July 2022;
Published: 19 September 2022.
Edited by:
Yikui Liu, Stevens Institute of Technology, United StatesReviewed by:
Anan Zhang, Southwest Petroleum University, ChinaChunyi Huang, Shanghai Jiao Tong University, China
Copyright © 2022 Wang, Han, Hua, Wang, Wang and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yang Liu, eWFuZy5saXVAc2N1LmVkdS5jbg==