 Zhong Chen1
Zhong Chen1 Ruisheng Wang
Ruisheng Wang- 1School of Electrical Engineering, Southeast University, Nanjing, China
- 2EHV Voltage Branch Company, State Grid Jiangsu Electric Power Co., Ltd., Nanjing, China
- 3Suzhou Power Supply Branch, State Grid Jiangsu Electric Power Co., Ltd., Suzhou, China
To improve the decision-making level of active distribution networks (ADNs), this paper proposes a novel framework for coordinated scheduling based on the long short-term memory network (LSTM) with deep reinforcement learning (DRL). Considering the interaction characteristics of ADNs with distributed energy resources (DERs), the scheduling objective is constructed to reduce the operation cost and optimize the voltage distribution. To tackle this problem, a LSTM module is employed to perform feature extraction on the ADN environment, which can realize the recognition and learning of massive temporal structure data. The concerned ADN real-time scheduling model is duly formulated as a finite Markov decision process (FMDP). Moreover, a modified deep deterministic policy gradient (DDPG) algorithm is proposed to solve the complex decision-making problem. Numerous experimental results within a modified IEEE 33-bus system demonstrate the validity and superiority of the proposed method.
1 Introduction
To reduce greenhouse gas emissions, numerous government policies have been established to encourage the development of renewable energy sources. Along with this trend, conventional distribution networks are being transformed into active distribution networks (ADNs) (Wei et al., 2021). Meanwhile, the intermittent and volatility output of high penetration distributed energy resources (DERs), such as photovoltaic generations (PVs), energy storage systems (ESSs), and wind farms, increases the uncertainty of ADNs (Usman et al., 2018; Ehsan and Yang, 2019). Especially, the increasingly severe issues of voltage violation and network loss have attracted widespread attention. Thus, it is necessary to coordinate the scheduling of DERs to promote the flexibility and interaction of ADNs.
Recently, various research efforts have been paid to study coordinated scheduling policies to optimize the decision-making and control of DERs. Studies (Zamzam et al., 2022; Prabawa and Choi, 2021) maintain voltage quality and optimize power losses by coordinating ESSs with charging stations (CSs). In (Zamzam et al., 2022), the scheduling of DERs in a fast time resolution is solved by the interior point method. It is verified that ESSs along with CSs are promising entities for reducing network voltages deviations and system losses. Similarly, Prabawa et al. propose a hierarchical volt/var control (VVC) framework to minimize the total active power losses and voltage deviations through the coordination of smart CSs, PVs, and ESSs at both global and local stages (Prabawa and Choi, 2021). However, limited by the model complexity and computational efficiency, the proposed VVC method may be incapable of handling a large distribution network with various DERs. Additionally, these scholars (Ma et al., 2021; Zhu et al., 2020) dissect the random fluctuation characteristics of PV plants via multi-scenario modeling, improving ADNs’ efficiencies and economics. To reduce the PV curtailment and network loss, a non-dominated sorting genetic algorithm II (NSGA-II)-based voltage regulation method is proposed in (Ma et al., 2021). Although the NSGA-II algorithm is easy to implement, it does not guarantee the global optimum in practical applications. The study reported in (Zhu et al., 2020) constructs a typical scenario set-based approach to address the stochastic economic dispatching, preestablishing charging and discharging schemes for controllable generation units, PV systems, wind farms, and ESSs. However, it suffers a heavy computational burden due to the need to consider many scenarios. Furthermore, studies (Li et al., 2020a; Luo et al., 2021) establish robust optimal operation strategies to deal with the randomness of DERs. In (Luo et al., 2021), the uncertainty of DERs is described based on beta distribution, and a robust optimization model is established to optimize the network loss, power purchase cost, and voltage distribution. Li et al. propose a distributed adaptive robust VVC method (Li et al., 2020a). It robustly mitigates the network loss while keeping voltage within regulation scope. However, the decisions made by the above methods only rely on the current status of ADNs, and the long-term information and objectives are ignored. These scholars (Zhang Z. et al., 2021; Chen et al., 2021; Sheng et al., 2021) consider the cooperative relationship between fast and slow response resources and mainly establish a multi-timescale scheduling architecture to improve the economics of ADNs. For example, studies (Chen et al., 2021; Sheng et al., 2021) propose a day-ahead economic scheduling model and establish a real-time scheduling method using model predictive control (MPC). The authors (Zhang Z. et al., 2021) formulate a double-layer MPC method to achieve minute-level control of mechanical voltage regulation devices and distributed generations (DGs). Furthermore, the MPC method combined with decentralized inter-area coordination is proposed by (Li et al., 2020b) to cope with the high volatility of DGs efficiently.
Although the aforementioned methodologies help us master the nature of coordinated scheduling decision-making for ADNs, the conventional physical model-based methods highly rely on specific optimization models, resulting in low computational efficiency and unstable solution performance. The time-varying DERs gradually infiltrate into ADNs, and it is challenging for the above methods to respond quickly to real-time dispatching demands.
Fortunately, in recent literature, deep reinforcement learning (DRL) has received growing interest in addressing the ADN scheduling issue. The nonlinear programming problem is formulated as a finite Markov decision process (FMDP) in (Cao et al., 2021a), and the proximal policy optimization is utilized to coordinate ESSs and wind farms. Bahrami et al. develop a deep neural network as the approximator of the state-action value function to benefit load aggregators and users (Bahrami et al., 2021). Further, reference (Zhang Y. et al., 2021) controls switchable capacitors, voltage regulators, and smart inverters via a deep Q-network (DQN) and designs a delicate reward function to maintain the voltage range. Besides, these researches (Gao et al., 2021; Cao et al., 2021b; Zhang J. et al., 2021) introduce the multi-agent DRL technology into ADN controlling and decision-making. Based on a multi-agent and multi-objective architecture, DRL is adopted in (Gao et al., 2021) to develop operation schedules for voltage regulators, on-load tap changers, and capacitors, improving the communication efficiency of multi-agent. Research (Cao et al., 2021b) proposes a multi-agent soft actor-critic approach to analyze the impact of PV fluctuation on voltage distribution. However, the state vector consists of node active power, reactive power, and PV output. For optimization problems with a large power system, the perception of the state variables usually leads to low training efficiency and poor optimization solutions. In reference (Zhang J. et al., 2021), DQN and deep deterministic policy gradient (DDPG) are utilized to control discrete and continuous variables, respectively. It rapidly responds to the state changes of distribution networks through the coordinated training of two agents. Other studies (Sun and Qiu, 2021a; Sun and Qiu, 2021b) focus on the collaborative optimization of conventional programming methods and DRL methods. Sun et al. (Sun and Qiu, 2021a) present a two-stage control method to alleviate fast voltage violations. The day-ahead scheduling model is established as a mixed-integer second-order cone programming (MISOCP), while the real-time scheduling problem is solved by a multi-agent DDPG scheme. A similar situation is discussed in (Sun and Qiu, 2021b), where the day-ahead scheduling of ADNs, considering the active and reactive power capacity of electric vehicles (EVs), is constructed as a MISCOCP. Moreover, the DDPG algorithm is adopted to formulate the reactive power control and V2G control schedules.
Given the state-of-the-art ADN scheduling solutions in this field, there are still two significant limitations. Firstly, the DRL algorithms represented by DQN and DDPG still suffer shortcomings in terms of low training efficiency, overlearning, and poor stability. Secondly, in terms of application, DQN-based methods fail to learn the mapping relationship between continuous state and action spaces. Although DDPG-based methods output continuous actions, they lack an understanding of temporal structural characteristics and are incapable of handling large state spaces. It results in a lower perception of the continuous state information of ADNs.
It can be found that methods for extracting high-dimensional temporal characteristics in real-time scheduling of ADNs are limited, and the DRL-based methods lack the assessment of the integration of multi-extension. To fill these research gaps, this paper presents a long short-term memory (LSTM) and modified DDPG (namely, MLDDPG)-based coordinated scheduling solution. The comprehensive optimization objective is constructed to minimize the operating cost and maintain the voltage range of ADNs. The temporal features of the ADN environment are extracted by a LSTM module. While the DDPG agent is leveraged to strategize real-time operation schemes for DERs. The main contributions of this paper are threefold.
1) To our best knowledge, the existing DRL-based approaches are challenging to handle the massive temporal structure data generated by ADNs. Conversely, relying on the high-dimensional understanding and mining ability, we employ a LSTM module to characterize the temporal data of ADNs. It helps the DRL agent extract and learn the changes of temporal characteristics from both the generation and demand sides and improves the modeling ability for node features.
2) Although the classic DDPG can rapidly respond to the scheduling requirements, it still suffers from overlearning, cold start, and poor stability issues. Thus, the learning rate decay strategy is proposed to balance the exploration and exploitation of DRL agents. Besides, the collaborative assistance policy combined with the modified prioritized experience replay mechanism is proposed to prevent the agent from falling into non-optimal strategies. The combination of extensions improves the convergence speed and application stability and enhances agents’ reliability in decision-making scenarios.
3) A modified LSTM-DDPG (MLDDPG) method is developed to tackle the ADN scheduling issue, which is formulated as a FMDP. In this way, the optimal ADN scheduling decisions can better satisfy the real-time response requirements of DERs. The simulation results demonstrate that our approach significantly improves the operation efficiency and economy of ADNs while optimizing voltage distributions.
The remainder of this paper is organized as follows. Problem Formulation Section sketches the modeling process of the ADN coordinated scheduling problem. Then our proposed solution approach is presented in Proposed Real-Time Scheduling Method Section. Case studies are reported in Case Studies Section. Finally, Conclusion Section concludes the paper.
2 Problem Formulation
Figure 1 exhibits the established ADN coordinated scheduling architecture based on LSTM and modified DDPG algorithm. The ADN control problem involving DERs is appropriately formulated as a FMDP. Specifically, a LSTM module is utilized to capture the temporal information characteristics of the ADN load and PV output, which, together with the real-time information of CSs and ESSs, constitute the environment state. A DRL-based agent is developed to formulate the ADN control strategy and evaluate the environmental feedback. Further, the agent is trained and optimized based on a modified DDPG module to accelerate the convergence and improve the application stability of the algorithm. Finally, the optimal mapping relationship from the environment state to the control strategy is output to realize the optimal economic operation of ADNs. The details about the modeling process are as follows.
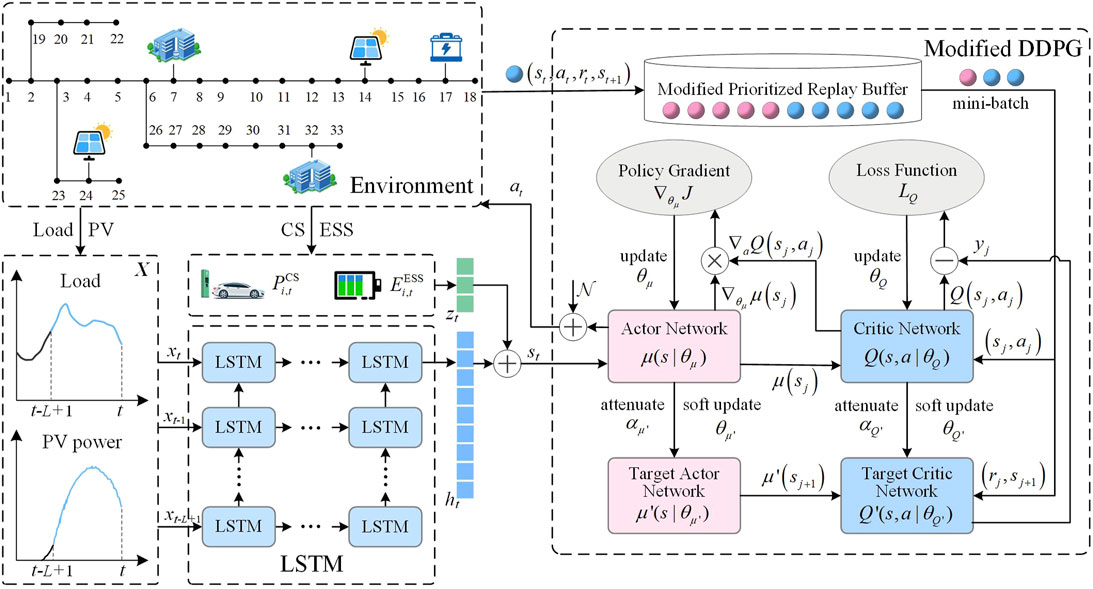
FIGURE 1. Overall scheme of the proposed ADN coordinated scheduling method.
2.1 Coordinated Scheduling Model
2.1.1 Objective Function
The sub-objectives consist of substation power purchase cost, ESS charging and discharging degradation cost, and CS response cost to realize the economic operation of ADNs. Mathematically, the comprehensive objective is expressed as:
where:
2.1.2 Constraints
2.1.2.1 Power Flow Constraints
where:
2.1.2.2 Safety Operation Constraints
where:
2.1.2.3 Operation Constraints of ESSs
where:
2.1.2.4 Operation Constraints of CSs
where:
2.2 Long Short-Term Memory for Information Perception
DERs with different operating characteristics bring high-dimensional and complex information to ADNs, while DRL agents are challenging to capture their high-dimensional feature changes. On the other hand, ADN load and PV output are less affected by control decisions and show high correlation characteristics on the time scale. As an improved version of recurrent neural network (RNN), LSTM effectively solves gradient disappearance and gradient explosion issues and shows remarkable performance in time series data prediction and feature extraction. Therefore, a LSTM module is employed to extract the temporal characteristics of loads and PVs and further improve the long-term performance of the scheduling model. The temporal structure information input X generated by ADNs can be expressed as:
where: L represents the time-step.
LSTM defines the input gate, forget gate, and output gate based on the RNN. The formulations of all nodes in a LSTM structure are given by Equations 23–27.
where:
The temporal characteristics of loads and PVs are captured relying on the feature extraction ability of the LSTM module. The LSTM output
2.3 Finite Markov Decision Process-Based Scheduling Model
After the temporal environment information is extracted, the agent completes the scheduling of the ADN by making a sequence of decisions on DERs. We construct the ADN scheduling problem as a FMDP. The details about the FMDP formulation are described as follows.
1) State: the agent captures the real-time environment information. In this study, the environment information is divided into two parts: temporal information and instant information. The temporal information of loads and PVs are extracted by the LSTM module. The instant information consists of the real-time states of ESSs and CSs. Thus, the environment state
where:
2) Action: the agent selects the action to be executed according to the ADN state. Slow devices are usually scheduled in an offline manner due to their limited allowable daily switching times (Liu and Wu, 2021). To sufficiently absorb the PV power, thus, the active and reactive output of ESSs and the response power of CSs are regarded as the action
3) Reward: the feedback value that the agent obtains from the environment after executing the control action. The substation power purchase cost
where:
4) State-action value function: the total expected rewards that the current policy
where:
The primary purpose of the ADNs scheduling problem is to find the optimal policy
3 Proposed Real-Time Scheduling Method
3.1 Classic Deep Deterministic Policy Gradient
DDPG adopts a classic actor-critic-based architecture and realizes agent learning and training through four deep neural networks. It adopts the actor network
The action of DERs can be expressed in the following equation.
where:
The critic network can be updated by minimizing the loss function
where:
The parameter of the actor network can be updated based on the policy gradient, which can be expressed as:
Then, the weights of target networks are soft-updated via Eq. 39.
where:
3.2 Proposed Modified Strategies
The classic DDPG algorithm is widely applied in continuous action decision processing. Nevertheless, it has the following two significant shortcomings in practical application.
1) DDPG updates the network parameters with a fixed learning rate
2) Based on the experience replay buffer, the prioritized experience replay buffer refines the learning efficiency of the agent (Hou et al., 2017). In the early training stage, however, the samples with the larger deviations are frequently selected for training, which may cause the overfitting issue. The repeated training of such samples makes the agent fall into the locally optimal solution, and the agent’s generalization ability is significantly reduced.
For the shortcomings of the classic DDPG algorithm, we propose three improved strategies as fellows: learning rate decay strategy, collaborative assistance policy, and modified prioritized experience replay to improve the basic agent. The details of the proposed modified model are as below.
3.2.1 Learning Rate Decay
An exponential decay model is introduced to change the learning rate
where:
3.2.2 Collaborative Assistance
Generally, agents can be equipped with a specific scheduling ability to deal with ADNs environment after a long training period. However, considering the importance of ADNs’ security indicators, agents are often difficult to be trusted in some critical decision-making scenarios. To this end, we propose the collaborative assistance mechanism to help the agent efficiently learn the coordinated control strategy. Specifically, we first generate
3.2.3 Modified Prioritized Experience Replay
The main idea of the modified prioritized experience replay is to reconstruct the replay buffer D and the mini-batch sampling method. Firstly, the replay buffer with a capacity
where:
3.3 Training Process of the Proposed Solution Method
Table 1 demonstrates the training process of our proposed solution approach for solving the ADN scheduling problem as described in Problem Formulation Section. In each episode, we first use LSTM to extract the temporal feature

TABLE 1. Training process of the proposed MLDDPG-based method.
4 Case Studies
4.1 Case Study Setup
In this study, the performance of the proposed approach is illustrated using a modified IEEE 33-bus distribution system. The system consists of two PV plants at buses 14 and 24, two CSs at buses 7 and 32, and an ESS at bus 17. The capacities of all PV plants are 400 kWp, and their power generation characteristics are described by real-world data. The installed capacity of the ESS is 600 kWh, and the charging and discharging capacity limit is 250 kVA. The charging efficiency
The electricity price for power loss is modeled by the time of use (TOU) price. The unit costs of the CS scheduling
4.2 Training Process
Let the simulation step length be 5 min, and the temporal data over the past 12 time steps are fed into the LSTM module. Table 2 details the parameters of the proposed method, and Figure 2 illustrates the obtained rewards under 1000 training episodes.

TABLE 2. Parameters of the proposed method.
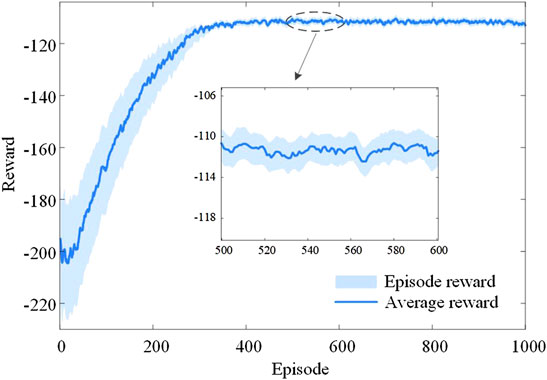
FIGURE 2. Training process of our proposed MLDDPG method.
As attested by Figure 2, the agent learns from the ADN environment by undergoing trials and errors, and the rewards oscillate obviously in the initial stage. Then, the solution process tends to converge steadily from the middle to the final late stage. Especially, the initial learning rate is 0.015, so the agent is encouraged to explore the environment with a high probability in the first 30 episodes. Therefore, the rewards fluctuate obviously, and the average reward in this stage is −201.36. From 30 to 300 episodes, the agent quickly learns successful samples via the collaborative assistance policy and accumulates a certain amount of successful experience. The average reward in this stage increases to −201.36. After that, the agent can learn the optimal mapping from 300 to 1000 episodes. Meanwhile, the learning rate decreases to 8.86 × 10−4 to steadily exploit the existing experience, and the average reward of the agent is stable at −111.76.
4.3 Practical Application Results
Figures 3, 4 separately exhibit the active power output and voltage amplitude distribution in the testing period. As attested by Figure 3, the well-trained agent can schedule the output of the ESS and CSs as well as cooperate with PVs to respond to the power demand of the ADN. Herein, the agent chooses to charge the ESS during 0:00-7:00 due to the low load level and TOU price. It plays a positive role in reducing the load peak-valley difference and network loss, and the average power loss is 58.06 kW in this period. At around 20:00, the operating pressure of the ADN is alleviated by reducing the charging load and adjusting the ESS discharging power. The final operating cost of the distribution network throughout the day is ¥31,936.62. Moreover, it can be seen from Figure 4 that the operating voltage of each node in the ADN is within the safe range. The minimum voltage is 0.966 3 p.u., which appears on bus 18 at 11:35.
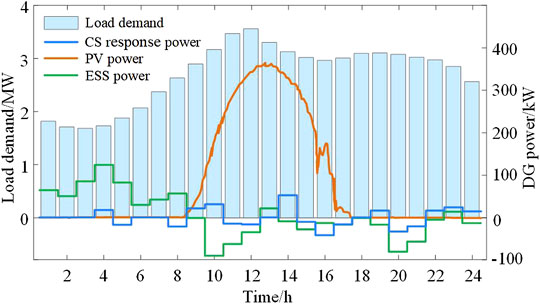
FIGURE 3. The active power output of each unit in the ADN.
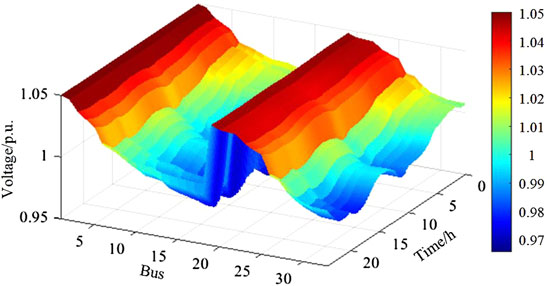
FIGURE 4. Voltage amplitude distribution of the ADN throughout the day.
4.4 Numerical Comparison of Different Methods
To comprehensively evaluate the implementation effect of our method, DRL algorithms, including DQN, DDPG, and LSTM-DDPG (LDDPG), are taken as benchmark solutions to compare the decision-making capabilities in coordinated scheduling. The parameter settings of DQN, DDPG, and LDDPG are listed in Supplementary Material. Figure 5 details the reward in each episode for different DRL algorithms, and Figure 6 exhibits the cumulative costs of their online testing over 100 days. As depicted, although the DQN algorithm converges rapidly, it has relatively weak convergence and stability in dealing with decision-making problems with high-dimensional state and action spaces. The average convergence reward of DQN is −126.79. Due to the capacity for coping with continuous action spaces, the performance of DDPG is better than that of DQN in terms of convergence performance and stability. Obviously, the LDDPG method initially shows the worst convergence performance, and the reward stabilizes at −117.78 after about 500 episodes. The proposed MLDDPG method improves the convergence performance using three modified mechanisms, and the rewards are stable at −111.59, which is increased by 9.72% compared with the classic DDPG algorithm. Moreover, MLDDPG also achieves excellent decision-making results in the online testing stage, reducing the operation cost by 18.89%.
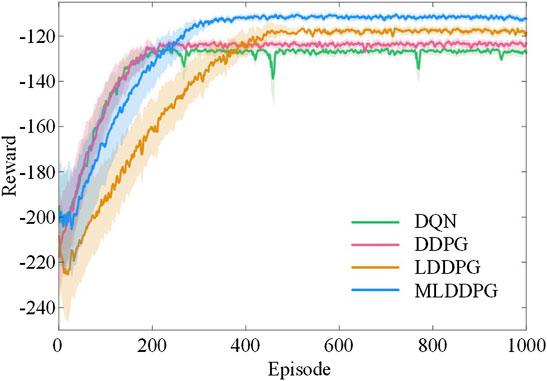
FIGURE 5. Training rewards of different algorithms (DQN, DDPG, LDDPG, and MLDDPG).
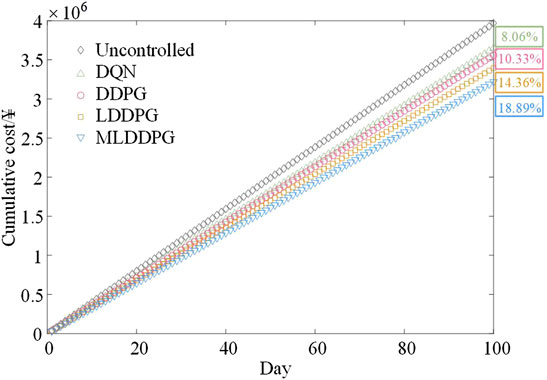
FIGURE 6. Cumulative total costs of different methods (Uncontrolled, DQN, DDPG, LDDPG, and MLDDPG).
Furthermore, we define the ADN voltage qualification rate

TABLE 3. Application results of different methods (Uncontrolled, DQN, DDPG, LDDPG, MLDDPG, MPC, and CPLEX).
4.5 Sensitivity Analysis
Furthermore, the influence of ESS and CS planning schemes and running states on the proposed model is analyzed. Figure 7 illustrates the influence of ESS capacity and CS capacity planning schemes on the ADN operation cost. As attested, the total cost of the ADN gradually decreases with the increase of ESS capacity. For every 100-kWh increase in the ESS capacity, the total operation cost of the ADN is reduced by ¥29.18. Meanwhile, for every 40-kW increase in the CS capacity, the total cost only decreases by ¥6.80. Notably, when the CS capacity is larger than 400 kW, there is little impact on the operating cost of the ADN, indicating that the CS capacity configuration far covers the EV charging demand.
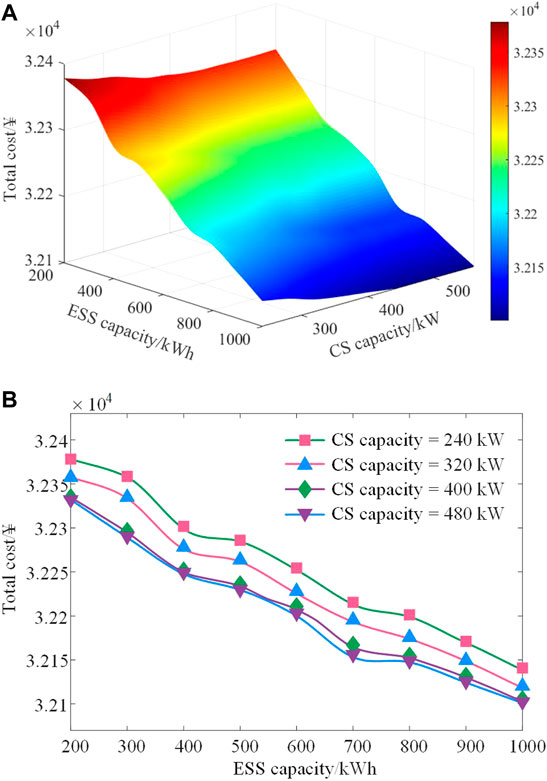
FIGURE 7. Influence of ESS and CS planning schemes on the operation cost of the ADN. (A) Total operation cost of the ADN under different ESS capacity and CS capacity; (B) Total operation cost under different ESS capacity when the CS capacity is 240, 320, 400, and 480 kW, respectively.
Assuming that the number of vehicles is 2 000 in this area, Figure 8 exhibits the impact of EV penetration rates and charger power operation status on the total cost of the ADN. With the EV penetration rate increasing, the total cost increases gradually. For every 1% increase in the EV penetration rate, the operation cost of the ADN increases by ¥31.20. The increase of the charger power improves the carrying capacity of CS but also increases the operation burden of the ADN. For every 1-kW increase in the charger power, the operation cost increases by ¥15.61. Note that the total cost remains stable when the EV penetration rate increases to a specific value. For example, when the charger power is 20 kW, the operation cost is stabilized at around ¥33,998.07 after the EVPR is increased to 20%, which means that the CS carrying capacity and dispatchable potential reach the upper limits.
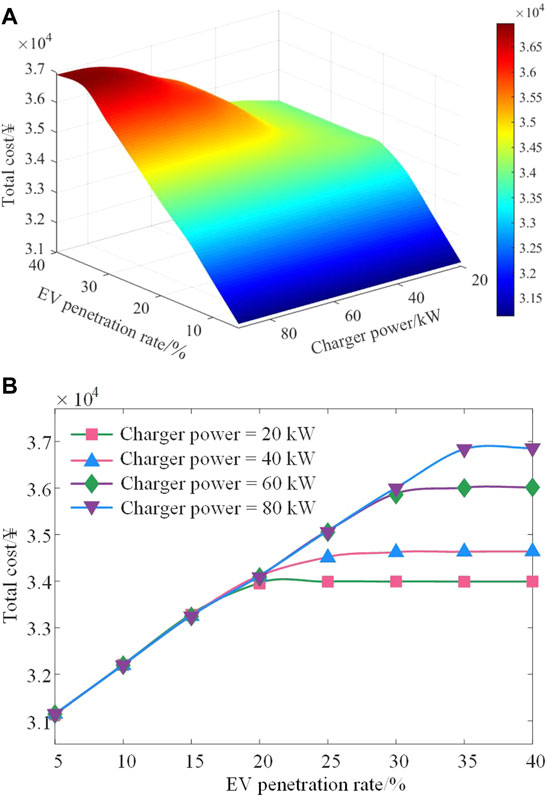
FIGURE 8. Influence of EV and CS running states on the operation cost of the ADN. (A) Total operation cost of the ADN under different EV penetration rates and charger power; (B) Total operation cost under different EV penetration rates when the charger power is 20, 40, 60, and 80 kW, respectively.
4.6 Scalability Performance
Finally, simulations are also performed on a modified IEEE 123-bus test system to evaluate the scalability of the proposed method. As shown in Figure 9, the test system is modified by integrating 6 PV units, 3 ESSs, and 3 CSs. The parameter setting of each unit is the same as that in Case Study Setup Section. Table 4 lists the numerical results in the modified IEEE 123-bus test system, and Figure 10 exhibits the voltage distribution at peak power consumption.
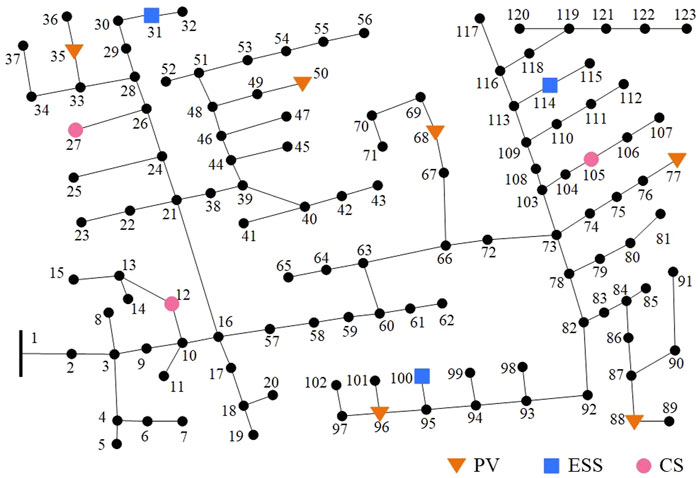
FIGURE 9. Topology of the modified IEEE 123-bus test system.

TABLE 4. Numerical results in the modified IEEE 123-bus test system.
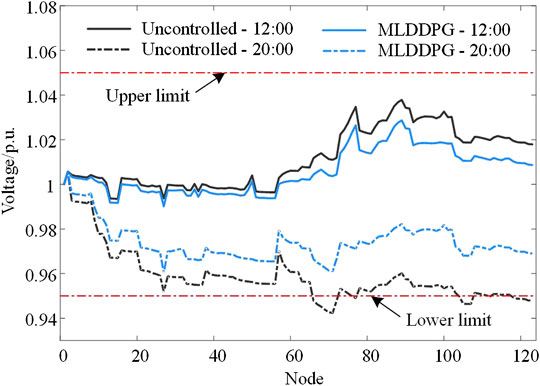
FIGURE 10. Voltage distribution of the test system at 12:00 and 20:00.
It can be observed that there are voltage violation issues when no control is applied, especially during peak power consumption. The uncontrolled method also suffers from high network loss and operating cost issues due to the lack of coordination. Limited by the dimension of environmental states, the DDPG algorithm makes slight improvements in dealing with voltage violation issues. By contrast, the proposed method captures the temporal trends and high-dimensional features of DERs to against uncertainties and provides a basic state for the coordination of each unit. The total operating cost of the MLDDPG method is ¥25,813.86, which is 25.39% lower than that of the uncontrolled mode. The results demonstrate that the proposed MLDDPG method effectively realizes improvements in economic performance and voltage violation mitigation. We conclude that the scalability performance of our method in a large system is validated.
5 Conclusion
Based on the LSTM and modified DDPG algorithm, this paper proposes a novel DRL method for coordinated scheduling of ADNs. Specifically, the LSTM is employed to capture the temporal information of DERs. Then, the extracted state features are fed into the modified DDPG to formulate the operation schedules for CSs and ESSs. Case studies are carried out within a modified IEEE 33-bus system embedded with PVs, ESSs, and CSs. The training and testing results show that the proposed MLDDPG method can not only maintain the safe voltage range but also reduce the economic cost of ADNs. The convergence performance and stability of the proposed method are also improved, which is 9.72% higher than that of the classic DDPG algorithm. Furthermore, the sensitivity analysis is performed, and the scalability of the proposed method is validated in a modified IEEE 123-bus test system. One future direction is to evaluate the sensitivity of DRL-based training parameters and further enhance the robustness of the proposed method. In addition, slow devices will be considered to coordinate with the proposed method and further improve the scalability of the scheduling model.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding author.
Author Contributions
ZC: Conceptualization and methodology. RW: Methodology, writing, and original draft preparation. KS: Review and editing. TZ: Formal analysis and visualization. PD: Investigation and review. QZ: Data curation.
Funding
This research was funded by the State Grid Technology Project under Grant 5108-202018026A-0-0-00.
Conflict of Interest
KS and QZ were employed by the company State Grid Jiangsu Electric Power Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
Thanks to the contributions of colleagues and institutions who assisted in this work.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fenrg.2022.913130/full#supplementary-material
References
Bahrami, S., Chen, Y. C., and Wong, V. W. S. (2021). Deep Reinforcement Learning for Demand Response in Distribution Networks. IEEE Trans. Smart Grid 12 (2), 1496–1506. doi:10.1109/TSG.2020.3037066
Cao, D., Hu, W., Xu, X., Wu, Q., Huang, Q., Chen, Z., et al. (2021a). Deep Reinforcement Learning Based Approach for Optimal Power Flow of Distribution Networks Embedded with Renewable Energy and Storage Devices. J. Mod. Power Syst. Clean Energy 9 (5), 1101–1110. doi:10.35833/MPCE.2020.000557
Cao, D., Zhao, J., Hu, W., Ding, F., Huang, Q., Chen, Z., et al. (2021b). Data-driven Multi-Agent Deep Reinforcement Learning for Distribution System Decentralized Voltage Control with High Penetration of PVs. IEEE Trans. Smart Grid 12 (5), 4137–4150. doi:10.1109/TSG.2021.3072251
Chen, S., Wang, C., and Zhang, Z. (2021). Multitime Scale Active and Reactive Power Coordinated Optimal Dispatch in Active Distribution Network Considering Multiple Correlation of Renewable Energy Sources. IEEE Trans. Ind. Appl. 57 (6), 5614–5625. doi:10.1109/TIA.2021.3100468
Cui, S., Wang, Y.-W., Shi, Y., and Xiao, J.-W. (2020). An Efficient Peer-To-Peer Energy-Sharing Framework for Numerous Community Prosumers. IEEE Trans. Ind. Inf. 16 (12), 7402–7412. doi:10.1109/TII.2019.2960802
Ehsan, A., and Yang, Q. (2019). State-of-the-art Techniques for Modelling of Uncertainties in Active Distribution Network Planning: A Review. Appl. Energy 239, 1509–1523. doi:10.1016/j.apenergy.2019.01.211
Fujimoto, S., van Hoof, H., and Meger, D. (2018). Addressing Function Approximation Error in Actor-Critic Methods. arXiv e-printsarXiv:1802.09477.
Gao, Y., Wang, W., and Yu, N. (2021). Consensus Multi-Agent Reinforcement Learning for Volt-VAR Control in Power Distribution Networks. IEEE Trans. Smart Grid 12 (4), 3594–3604. doi:10.1109/TSG.2021.3058996
Hou, Y., Liu, L., Wei, Q., Xu, X., and Chen, C. (2017). “A Novel DDPG Method with Prioritized Experience Replay,” in 2017 IEEE International Conference on Systems, Man, and Cybernetics (Banff, CanadaIEEE), 316–321. doi:10.1109/SMC.2017.8122622
Hu, J., Wu, J., Ai, X., and Liu, N. (2021). Coordinated Energy Management of Prosumers in a Distribution System Considering Network Congestion. IEEE Trans. Smart Grid 12 (1), 468–478. doi:10.1109/TSG.2020.3010260
Kong, W., Dong, Z. Y., Jia, Y., Hill, D. J., Xu, Y., and Zhang, Y. (2019). Short-term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 10 (1), 841–851. doi:10.1109/TSG.2017.2753802
Li, P., Ji, J., Ji, H., Jian, J., Ding, F., Wu, J., et al. (2020b). MPC-based Local Voltage Control Strategy of DGs in Active Distribution Networks. IEEE Trans. Sustain. Energy 11 (4), 2911–2921. doi:10.1109/TSTE.2020.2981486
Li, P., Zhang, C., Wu, Z., Xu, Y., Hu, M., and Dong, Z. (2020a). Distributed Adaptive Robust Voltage/VAR Control with Network Partition in Active Distribution Networks. IEEE Trans. Smart Grid 11 (3), 2245–2256. doi:10.1109/TSG.2019.2950120
Liu, H., and Wu, W. (2021). Two-stage Deep Reinforcement Learning for Inverter-Based Volt-VAR Control in Active Distribution Networks. IEEE Trans. Smart Grid 12 (3), 2037–2047. doi:10.1109/TSG.2020.3041620
Luo, Y., Nie, Q., Yang, D., and Zhou, B. (2021). Robust Optimal Operation of Active Distribution Network Based on Minimum Confidence Interval of Distributed Energy Beta Distribution. J. Mod. Power Syst. Clean Energy 9 (2), 423–430. doi:10.35833/MPCE.2020.000198
Ma, W., Wang, W., Chen, Z., Wu, X., Hu, R., Tang, F., et al. (2021). Voltage Regulation Methods for Active Distribution Networks Considering the Reactive Power Optimization of Substations. Appl. Energy 284, 116347. doi:10.1016/j.apenergy.2020.116347
Prabawa, P., and Choi, D.-H. (2021). Hierarchical Volt-VAR Optimization Framework Considering Voltage Control of Smart Electric Vehicle Charging Stations under Uncertainty. IEEE Access 9, 123398–123413. doi:10.1109/ACCESS.2021.3109621
Sheng, H., Wang, C., Li, B., Liang, J., Yang, M., and Dong, Y. (2021). Multi-timescale Active Distribution Network Scheduling Considering Demand Response and User Comprehensive Satisfaction. IEEE Trans. Ind. Appl. 57 (3), 1995–2005. doi:10.1109/TIA.2021.3057302
Sun, X., and Qiu, J. (2021b). A Customized Voltage Control Strategy for Electric Vehicles in Distribution Networks with Reinforcement Learning Method. IEEE Trans. Ind. Inf. 17 (10), 6852–6863. doi:10.1109/TII.2021.3050039
Sun, X., and Qiu, J. (2021a). Two-stage Volt/Var Control in Active Distribution Networks with Multi-Agent Deep Reinforcement Learning Method. IEEE Trans. Smart Grid 12 (4), 2903–2912. doi:10.1109/TSG.2021.3052998
Usman, M., Coppo, M., Bignucolo, F., and Turri, R. (2018). Losses Management Strategies in Active Distribution Networks: A Review. Electr. Power Syst. Res. 163, 116–132. doi:10.1016/j.epsr.2018.06.005
Wang, R., Chen, Z., Xing, Q., Zhang, Z., and Zhang, T. (2022). A Modified Rainbow-Based Deep Reinforcement Learning Method for Optimal Scheduling of Charging Station. Sustainability 14 (3), 1884. doi:10.3390/su14031884
Wei, B., Qiu, Z., and Deconinck, G. (2021). A Mean-Field Voltage Control Approach for Active Distribution Networks with Uncertainties. IEEE Trans. Smart Grid 12 (2), 1455–1466. doi:10.1109/TSG.2020.3033702
Zamzam, T., Shaban, K., Gaouda, A., and Massoud, A. (2022). Performance Assessment of Two-Timescale Multi-Objective Volt/VAR Optimization Scheme Considering EV Charging Stations, BESSs, and RESs in Active Distribution Networks. Electr. Power Syst. Res. 207, 107843. doi:10.1016/j.epsr.2022.107843
Zhang, J., Li, Y., Wu, Z., Rong, C., Wang, T., Zhang, Z., et al. (2021c). Deep-reinforcement-learning-based Two-Timescale Voltage Control for Distribution Systems. Energies 14 (12), 3540. doi:10.3390/en14123540
Zhang, Y., Wang, X., Wang, J., and Zhang, Y. (2021b). Deep Reinforcement Learning Based Volt-VAR Optimization in Smart Distribution Systems. IEEE Trans. Smart Grid 12 (1), 361–371. doi:10.1109/TSG.2020.3010130
Zhang, Z., Da Silva, F. F., Guo, Y., Bak, C. L., and Chen, Z. (2021a). Double-layer Stochastic Model Predictive Voltage Control in Active Distribution Networks with High Penetration of Renewables. Appl. Energy 302, 117530. doi:10.1016/j.apenergy.2021.117530
Keywords: active distribution network, deep reinforcement learning, long short-term memory, modified deep deterministic policy gradient, coordinated scheduling
Citation: Chen Z, Wang R, Sun K, Zhang T, Du P and Zhao Q (2022) A Modified Long Short-Term Memory-Deep Deterministic Policy Gradient-Based Scheduling Method for Active Distribution Networks. Front. Energy Res. 10:913130. doi: 10.3389/fenrg.2022.913130
Received: 05 April 2022; Accepted: 20 May 2022;
Published: 13 June 2022.
Edited by:
Peng Li, Tianjin University, ChinaReviewed by:
Guanyu Song, Tianjin University, ChinaShenxi Zhang, Shanghai Jiao Tong University, China
Copyright © 2022 Chen, Wang, Sun, Zhang, Du and Zhao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ruisheng Wang, MjIwMjAyOTc1QHNldS5lZHUuY24=