 Ming Ma1,2
Ming Ma1,2 Cangbi Ding
Cangbi Ding
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Energy Res., 11 January 2023
Sec. Smart Grids
Volume 10 - 2022 | https://doi.org/10.3389/fenrg.2022.1097319
This article is part of the Research TopicDistributed Learning, Optimization, and Control Methods for Future Power GridsView all 10 articles
A large number of distributed generators (GDs) such as photovoltaic panels (PVs) and energy storage (ES) systems are connected to distribution networks (DNs), and these high permeability GDs can cause voltage over-limit problems. Utilizing new developments in deep reinforcement learning, this paper proposes a multi-timescale control method for maintaining optimal voltage of a DN based on a DQN-DDPG algorithm. Here, we first analyzed the output characteristics of the devices with voltage regulation function in the DN and then used the deep Q network (DQN) algorithm to optimize the voltage regulation over longer times and the deep deterministic policy gradient (DDPG) algorithm to optimize the voltage regulation mode over short time periods. Second, the design strategy of the DQN-DDPG algorithm as based on the Markov decision process transformation was presented for the stated objectives and constraints considering the state of ES charge for prolonging the energy storage capacity. Lastly, the proposed strategy was verified on a simulation platform, and the results obtained were compared to those from a particle swarm optimization algorithm, demonstrating the method’s effectiveness.
Because of fluctuations in the output and the intermittent nature of DGs, connecting them to light load DNs such as in mountainous areas will cause periodic overvoltage problems in the whole feeder (Impram et al., 2020; Dai et al., 2022). Similarly, the problem of periodic undervoltages will occur when DGs are connected to a heavy-duty DN in an area with major industry production. Traditional voltage control devices, such as on-load tap changers (OLTCs), distributed static synchronous compensators, and switch capacitors can mitigate the overvoltage problem to a certain extent (Kekatos et al., 2015; Zeraati et al., 2019). However, because of the mechanical losses and slow response times, traditional voltage regulation devices cannot prevent voltage problems quickly in real time. At the same time, the frequent regulation may greatly shorten the service life of equipment and affect the voltage quality of the whole DN.
For a DN connected to DGs with strong coupling between active and reactive power, it is obviously not possible for a regulation system to only consider reactive power (Hu et al., 2021; Wang et al., 2021). To ensure safe and stable operation of the DN, both active and reactive power should be taken into account in the control link. Le et al. (2020) adopted different operational modes for DGs, based on the exchange power between the DN and the external power grid. They considered the capacity utilization rate and power factors as consistent controlling variables to adjust the parameters of the control algorithm, so as to achieve cooperative optimization of voltage and power of the DN. Li et al. (2020) and Zhang et al. (2020) aimed at reducing deviations in reactive power distribution by decreasing the dependence on the transmission of voltage information and adopting an event-triggered consistency control method for distributed voltage control with multiple DG units. Based on active voltage sensitivity, Gerdroodbari et al. (2021) changed the parameters of the active voltage control method of PV inverters in the DN, which improved the regulation of each active PV power reduction (Feng et al., 2018).
In recent years, reinforcement learning, as a type of artificial intelligence technology, has been widely used in smart grids. It has the advantage of not relying on any analytical formula, and it uses a large number of existing data points to produce a mathematical model and generate approximate solutions for grid control. Shuang et al. (2021) used Deep Q network agents and actor-critic agents simultaneously to coordinately control different reactive devices and optimize reactive power online. This method has good robustness and does not depend on communication technology. In contrast to the method of Shuang et al. (2021), Zhang et al. (2021) adopted the DQN algorithm and DDPG algorithm. The DQN-DDPG algorithm was employed in this paper, but we also considered whether the DGs and the reactive voltage regulation equipment were connected as variables for optimizing the active and reactive power. Zhang et al. (2021) did not take into account the effects of active DPV power reduction on voltage regulation of the DN. Liu et al., (2021) and Zhou et al. (2021) proposed a scheduling scheme for an ES system on a DN based on deep reinforcement learning with high permeability DPV access to reduce voltage deviations.
The aforementioned researchers mainly focused on DN regulation using new types of voltage regulation equipment, while ignoring the effects of traditional, stable voltage controllers (SVCs) such as the online tap changer (OLTC) on regulation of the system. Since there have been a large number of traditional voltage regulation devices used in practical DN engineering, this work focused on both the traditional and the new voltage regulation equipment such as DPV and ES in an active DN based on the different response characteristics of each device. We took advantage of the DQN and DDPG algorithms, which can handle discrete variables and continuous variables, respectively, to efficiently and reliably deal with off-limit voltage problems in the DN. At the same time, it is necessary to consider the voltage control method of centralized coordination and distributed cooperation from the perspective of the multi-terminal cooperation of various types of voltage regulation devices.
This paper proposes a multi-timescale method based on the DQN-DDPG algorithms for optimal voltage control in a DN. The DQN algorithm and the DDPG algorithm were used to train the dynamic responses of the different voltage regulators in the framework of the proposed deep reinforcement learning algorithm. Converting the mathematical model of voltage control into a Markov decision process allowed us to decrease the difficulty involved in modeling the several different types of voltage regulation devices. This allowed us to achieve control over long timescales by using OLTC to adjust the average domain voltage of the whole DN; DGs and other devices were used to control local nodes cooperatively over short timescales. Lastly, an IEEE 33-node DN system was constructed on a MATLAB simulation platform and compared with a traditional PSO (particle swarm optimization) algorithm. The proposed control strategy resulted in a faster calculation speed and higher calculation accuracy.
In order to solve the time period and intermittent voltage overlimit problems caused by high permeability DPVs on the DN, we proposed a voltage control strategy with cooperation among multi-terminal DGs. In a DN with different types of voltage regulation equipment, OLTCs belong to the slower type of discrete regulation devices, while DPVs, ES, and SVCs are continuously active devices, adjusting time to second grade. Therefore, multi-timescale control of the active and reactive power outputs of DPVs, the outputs of ES and SVCs, and the output and network-end OLTC split-regulation were proposed to effectively regulate the voltage of large-scale DN bus nodes.
A centralized coordination controller (CCC) was configured for the OLTC in this paper and was divided into different control regions according to the location of the devices on the branch. Each region was configured with a distributed cooperative controller (DCC), which was regarded as a centralized cooperative agent (CCA) and a distributed cooperative agent (DCA), respectively. The CCC was used to adjust the OLTC splitter and the power and output distribution of the nodes in the region. The DCA and CCA communicated with each other and shared node information in the region. The connection diagram of the centralized coordination-distributed cooperative control method in a DN is shown in Figure 1.
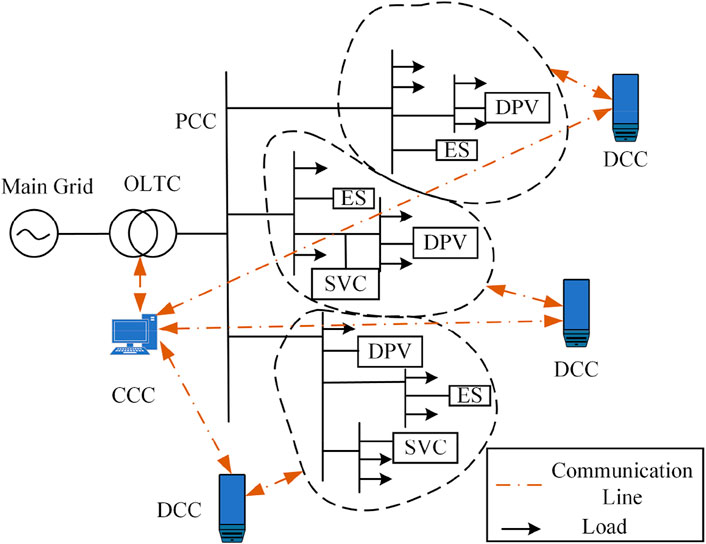
FIGURE 1. Connection diagram of the proposed control method.
The DCA collects the voltage information of each node in the regional DN and the power information of the incorporated voltage regulation equipment. The voltage unit value of each node can be calculated by Eq. 1:
where
The aforementioned adjustment method can only ensure that the average standard unit value of voltage reaches the safety threshold. If the voltage of some bus nodes still exceeds the safety threshold range after adjusting the OLTC splitter, the power coordination control strategy based on the DPV, SVC, and ES output characteristics is adopted. The generalized node-based partitioning method is used to divide the control region of the DN (Zhang et al., 2014). In the region where the bus nodes are located, deep reinforcement learning is used to train the optimal power regulation sequence by coordinating the active and reactive power outputs of DPVs, the reactive power output of SVCs, and the ES output (Amir et al., 2022). The CCC determines the optimal control strategy and then issues commands to the CCC communicating with the area to adjust the power output of the inverter of each voltage regulation device. After receiving the instructions for executing the adjustments, the inverters guarantee that the voltage of each node is kept within the safety threshold, reducing the problem of bus node voltage overlimit. In the process of voltage regulation, the DPVs follow the principle that reactive power control voltage is first regulated before active power control voltage is cut, so as to give full play to the absorption capability of the PVs. According to the response times of DPVs, ES, and SVCs over the short timescale (Liu et al., 2022), the specific regulation priority is: OLTC > PV reactive power, ES, and SVC > PV active power. If it is necessary to reduce the active power of the DPVs, the active power reduction of a PV shall not exceed half of the DPV output active power. The overall control process is shown in Figure 2.
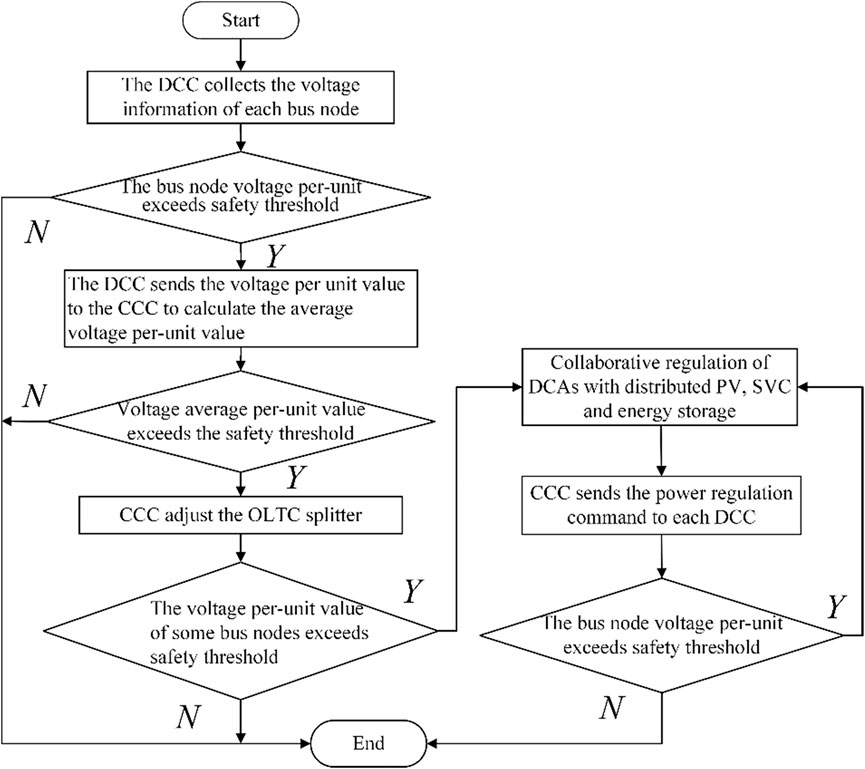
FIGURE 2. Overall framework of the cooperative voltage control strategy.
As used in this paper, the DPV inverter adopts PQ control, and its controller is divided into inner and outer rings. The outer ring tracks the DC side of the active power output
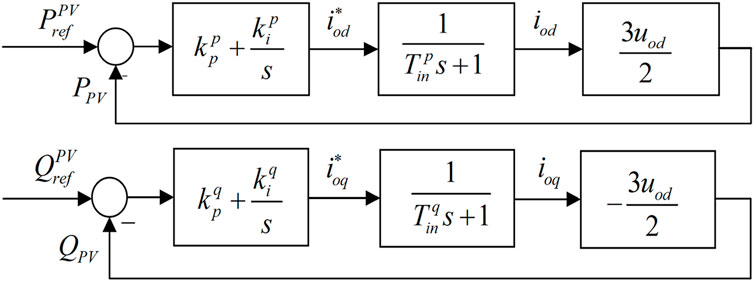
FIGURE 3. PQ control block diagram of the DPV inverter.
The active power output and the reactive power output of a model DPV inverter can be calculated as follows:
where
The OLTC regulates the voltage of the secondary side of the transformer by adjusting the location of the transformer connector, changing the ratio and the distribution of reactive power in the DN line (Wu et al., 2017). In this paper, the regulation of the on-load OLTC by the discrete variable ratio was used to control the voltage value of the secondary side of the transformer to keep it within the allowable range during operation. The adjusting process of the splitter is as follows:
where
The SVC used in this paper is a thyristor-controlled reactor model, and the control diagram is shown in Figure 4. The SVC is connected to the DN through an inverter, and the equivalent transfer function of the control loop of the inverter in reactive power control mode is given by the following formula (Chen et al., 2018):
where

FIGURE 4. Equivalent transfer function of the control loop in the SVC.
The ES system can be equivalent to a voltage source. Figure 5 shows the charging and discharging schematic diagram of the ES system (Yang et al., 2014; Gush et al., 2021), where
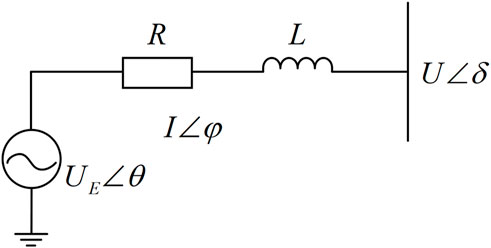
FIGURE 5. Charging and discharging schematic diagram of the ES battery.
ES uses SOC to represent the actual capacity of the battery at a certain time, and the ratio of the residual current
SOC changes during the charging and discharging process as follows:
Battery discharging:
Battery charging:
where
The DQN algorithm uses an experience playback mechanism, which stores the experience data
where
where
where
The DDPG algorithm was based on and developed from the DQN algorithm. It mainly uses an actor network to make up for the shortcoming that DQN cannot deal with continuous control problems. The DDPG is an algorithm based on the ‘actor-critic’ architecture to obtain the optimal control sequence. In the actor-critic architecture, the actor network takes the state vector as the input, and the action vector as the output. The critic network takes the state and the action vector as the input, and the estimated Q value is the output (Sutton and Barto, 2018; Qin et al., 2022). The output of the network obtains the maximum value of Q. At the same time, the actor target network and the critic target network are established to output the target Q value, and the optimization training is completed by minimizing the difference between the target Q values and the target Q value. The relationship between actor and critic networks is shown in Figure 6.
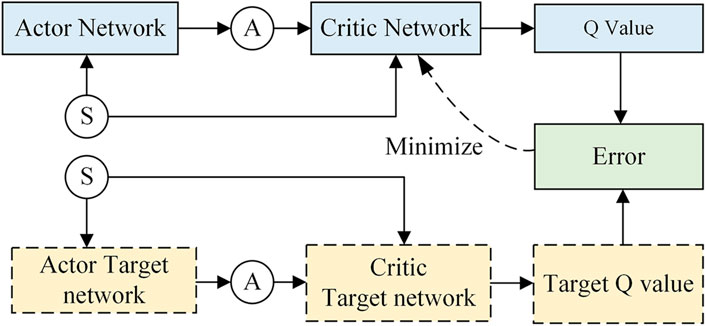
FIGURE 6. Diagram of the relationship between the actor and critic networks.
The actor network obtains the current state from the environment and outputs a definite action
The algorithm updates the parameters of the critic network by minimizing the loss function
Finally, by a
where
Combined with the multi-time scale voltage coordination control framework described in the second part, the voltage cooperative control architecture based on the DQN-DDPG algorithm can be divided into a top algorithm layer and a bottom control layer, as shown in Figure 7.
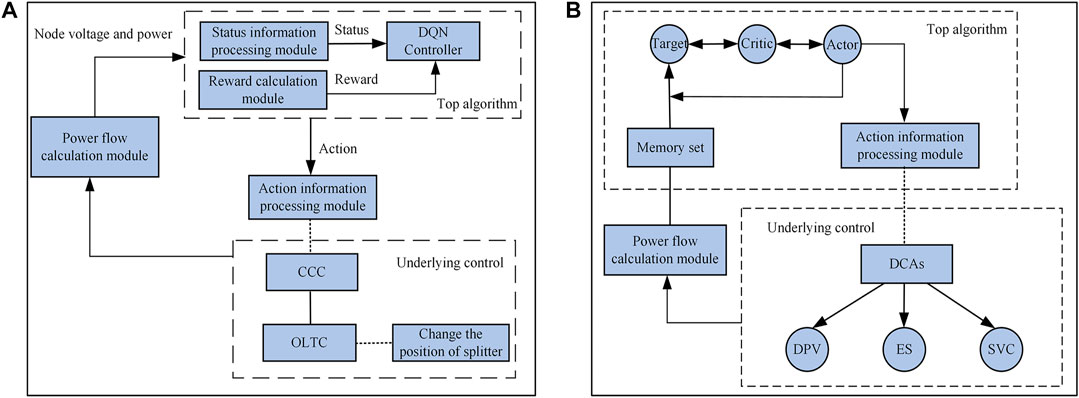
FIGURE 7. Voltage control architecture based on DQN-DDPG; (A) DQN algorithm; (B) DDPG algorithm.
In adjusting the OLTC splitter, the control objective is to minimize the average voltage exceedances of the bus nodes in the whole DN:
where
where
The constraints are as follows:
1) Power flow constraints
where
2) ES output constraints
where
3) SOC constraints of ES
where
4) SVC output constraints
where
5) Regulation constraints of the OLTC splitter
where
The objective of the voltage control strategy in this paper was to modulate the voltage of the bus nodes. The power input of each node needs to be monitored in real time, and the OLTC splitter needs to be adjusted accordingly. Therefore, the state space of the DQN algorithm was defined as the voltage of each bus node in the DN:
where
The voltage amplitude is changed by changing the tap position of the OLTC splitter, so the action space
The centralized cooperative controller calculates the average per-unit value of the voltage after receiving voltage information from the bus nodes in the whole DN. If the average per-unit value of voltage exceeds the safety threshold, that is, [.95,1.05]p.u., it is adjusted by the OLTC splitter. Therefore, the immediate reward function is as follows:
where
where
The DDPG algorithm is mainly used to prevent voltage control problems in the DN area where the voltage overlimit nodes are located. Therefore, the DDPG state space is different from that of DQN algorithm, and the power output of each node in this area needs to be collected in real time to follow up on the regulation of power output by the voltage regulation equipment. Therefore, the state space of the DDPG algorithm is defined as follows:
where
If the voltage at some nodes still exceeds the safety threshold after adjusting the OLTC splitter according to the DQN algorithm, then the active and reactive power outputs of the DPVs, the ES output, and the reactive power output of the SVCs in the control region where the node is located can be adjusted to control the voltage. The action space of the DDPG algorithm is defined as follows:
When only DPV reactive power regulation is used,
The DDPG algorithm controls the voltage of each node by adjusting the outputs of the DPVs, ES, and SVCs connected to each node. The control objective is to stabilize the voltage and keep it from exceeding the safety threshold; thus, the immediate reward function is set as the sum of the quadratic form of the higher limit voltage of each node, the active power and reactive power regulation of the DPV output, the active power regulation of the ES output, and the reactive power regulation of the SVC output:
where
1) The iterative process of OLTC tap adjustment based on DQN is as follows:
S1: Calculate the average standard per-unit value of voltage according to DN environment. If the average standard value of voltage exceeds the safety threshold, the DQN agent will be trained at the initial position of the OLTC splitter.
S2: The standard unit value of voltage at each bus node in the DN obtained by the CCC is taken as the set,
S3: Select the corresponding action
S4: Sampling the empirical data set randomly from the experience pool according to the sampled data set,
S5: After updating the state set, the per-unit value of the bus node changes, and it must be recalculated to determine if the average per-unit value of the voltage meets the conditions of the safety threshold [.95,1.05]p.u. If the conditions are met, the iteration will be terminated. The target Q value
S6: Use the gradient descent method to update the parameter
S7: Update the parameters,
S8: Continue to perform S3 until the set of states meets the termination iteration condition.
2) If the standard voltage value of some bus nodes is still beyond the safety threshold [.95,1.05] after adjusting the OLTC splitter by DQN algorithm, the output power of DPVs, ES, and SVCs should be optimized and adjusted by the DDPG algorithm. The specific control process is as follows:
S1: The per-unit value of the voltage and the power information from all bus nodes in the control region where the overlimit bus node is located are used as the initial state set,
S2: Select the actions,
S3:
S4: The critic network parameters are updated by minimizing the loss function,
S5: Update the critic target network parameters
S6: If the standard value of the bus node voltage in the control region lies within the safety threshold [.95, 1.05]p.u., the iteration ends. If the conditions are not met, perform Step 3.
To verify the effectiveness of the cooperative voltage optimization control method considering the load and storage of the source network proposed in this paper, the improved IEEE 33-node DN system was adopted to perform a simulation analysis on a MATLAB r2019a platform. The improved topology diagram of the DN is shown in Figure 8. The total load was 3715.0 kW + j2300.0kVar, and the rated voltage was 10 kV in the DN. The node loads and generator parameters in the DN system are shown in Table 1, and the DN branch parameters are shown in Table 2. The OLTC of the DN is located at node 1, its rated capacity is 100MVA, and the adjustment range is
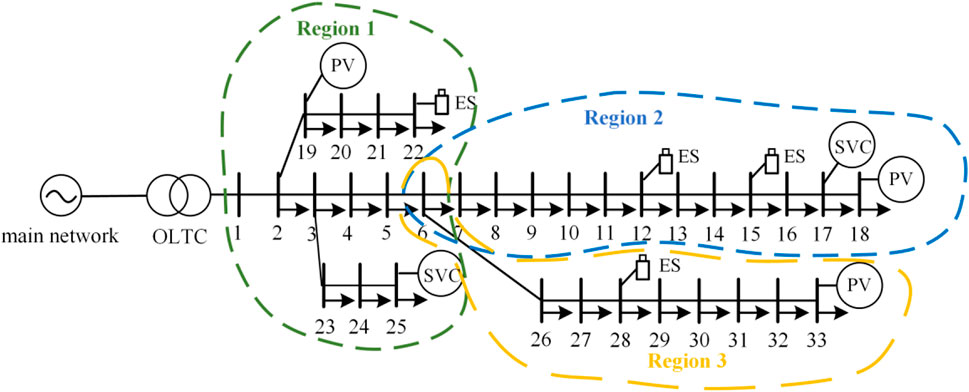
FIGURE 8. DN topology of the IEEE-33 node.
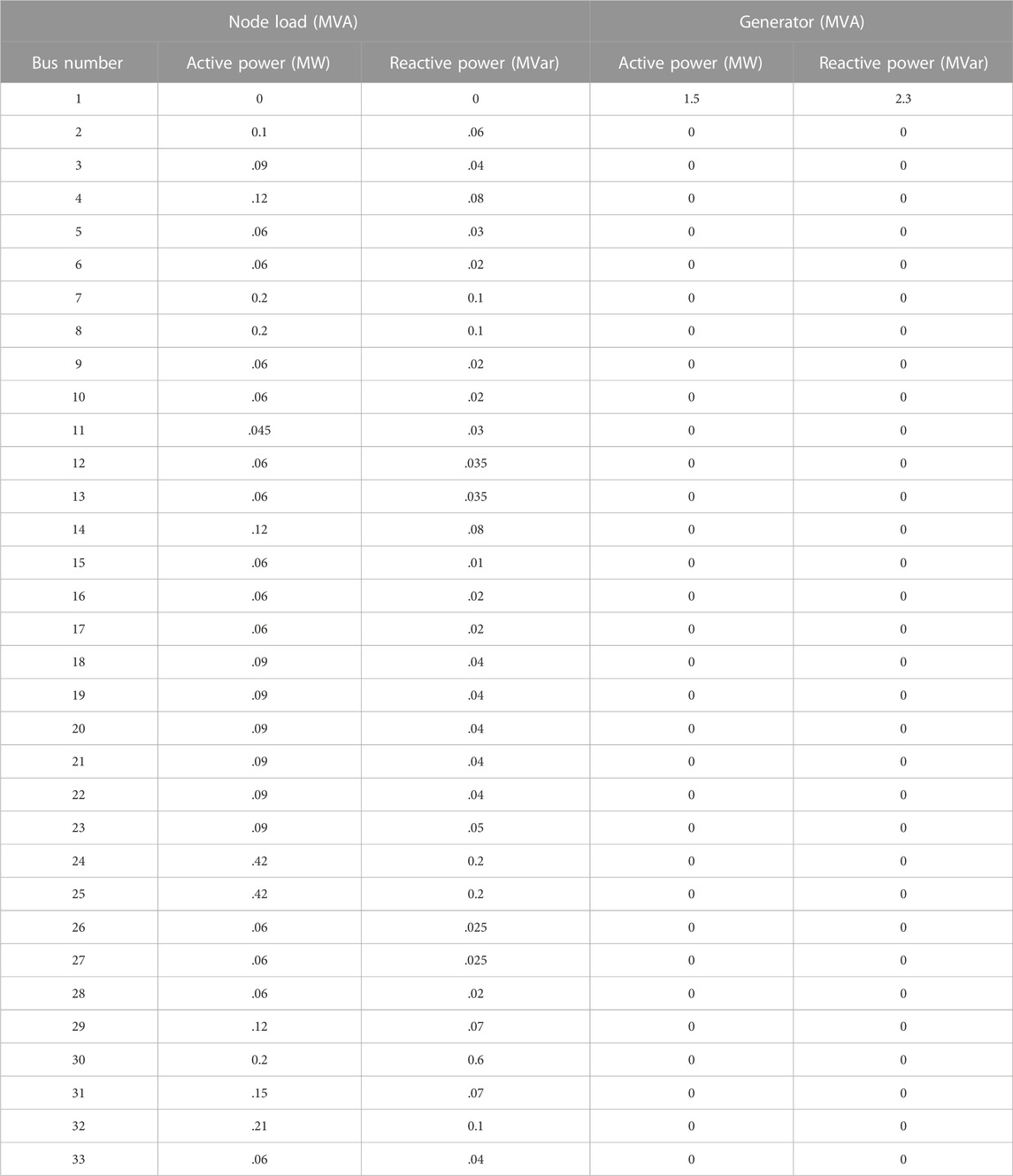
TABLE 1. Load and generator parameters of the standard IEEE 33-node DN system.
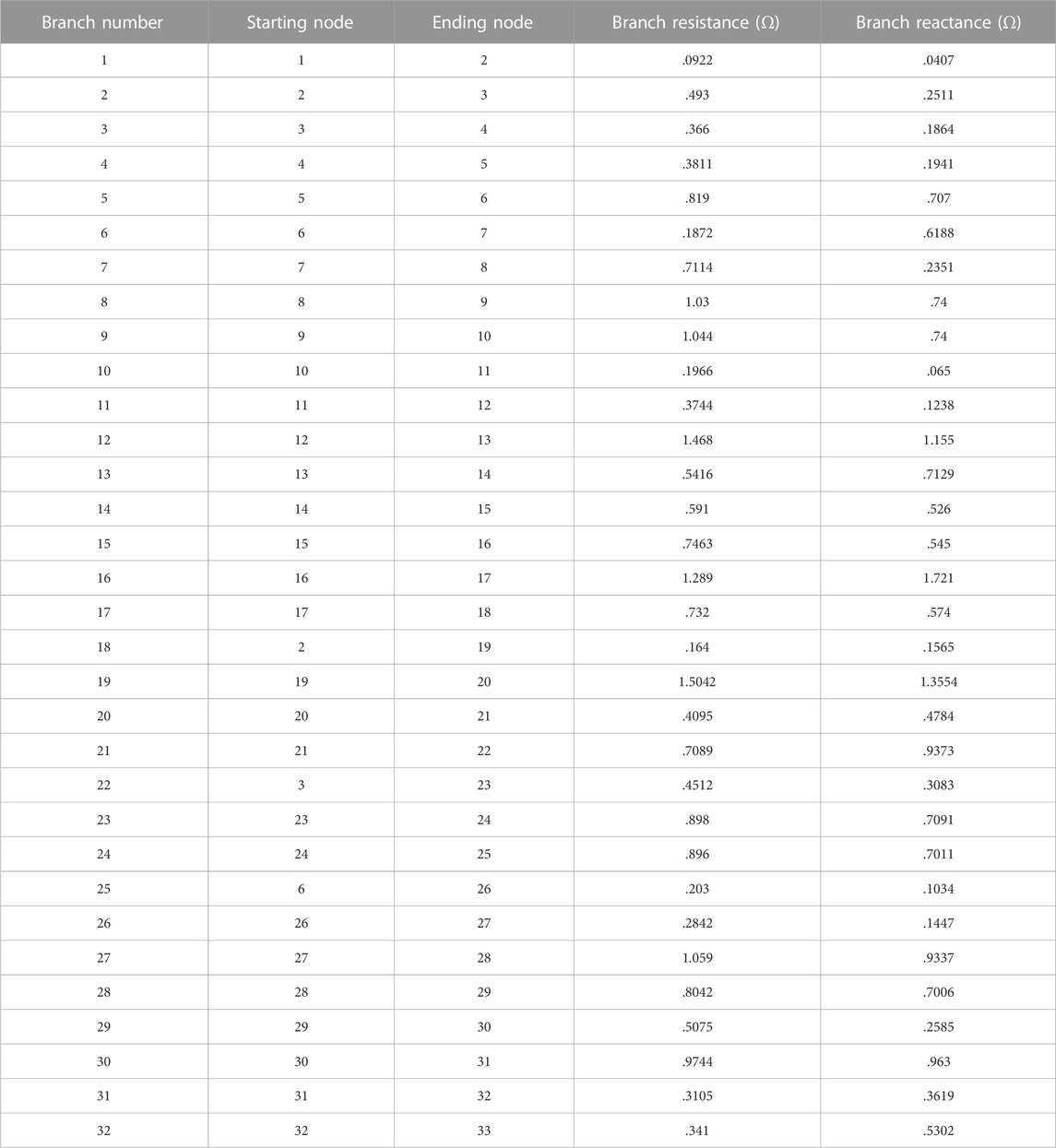
TABLE 2. Branch parameters of the standard IEEE 33-node DN system.
The power disturbance was introduced into the DN at a certain time, and the voltage amplitude of each node is shown in Figure 7.
Overvoltage events occurred at nodes 9–18, 32, and 33 (Figure 9). The DQN algorithm was first designed according to the regulation range of the OLTC:
• State Space. There are 33 bus nodes in the whole-domain DN, and the state space of the DQN algorithm can be obtained by using Eq. 24,
• Action Space. The regulation range of the OLTC is
• Reward Function. The purpose of the OLTC splitter is to keep the average per-unit value of the voltage in the DN within the safety threshold range. According to Eq. 26, the reward function of the DQN algorithm can be obtained as follows:
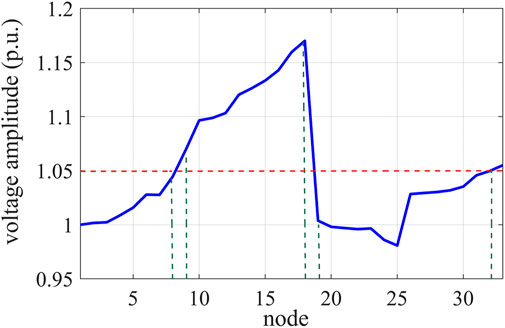
FIGURE 9. Voltage amplitude of each bus node without control.
The learning rate of the neural network was chosen as .001, the discount coefficient was .99, the capacity of the experience pool was 4,000, and the capacity of the mini-batch was 64. DQN agents were trained with a total of 500 episodes, and each episode was completed after 300 samples were trained. The results of training the agents according to the iterative process of algorithm 4.1 are shown in Figure 10. The episode reward is the cumulative reward value in an episode obtained by the agent during training, and the average reward is the average of the reward values in every four episodes. As can be seen from Figure 8, at the beginning of the training, the reward value was very low due to the limited learning experience. As the training continued, the agents kept exploring and learning, and the reward value kept increasing. After 250 episodes, the reward value of the DQN agent fluctuated within a small range, which indicated that the algorithm gradually converged and the agents’ training had developed an optimal strategy for controlling the voltage by adjusting the OLTC splitter.
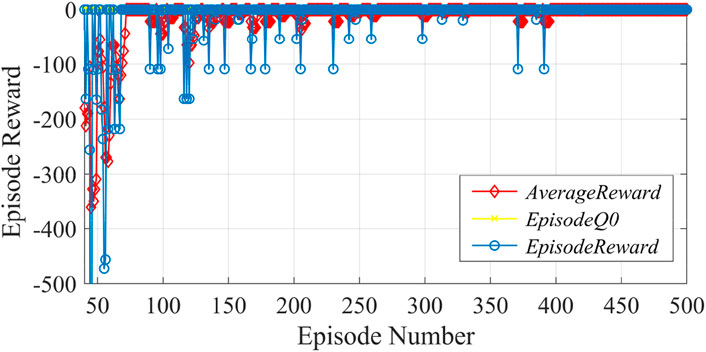
FIGURE 10. DQN agent training process.
During the test, the OLTC training data were used as the control. Figure 11 shows the effects of adjusting the OLTC splitter, at which point the OLTC splitter was set at
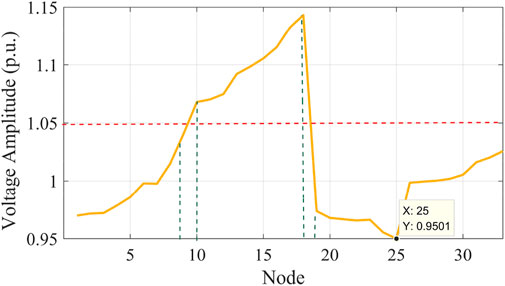
FIGURE 11. Voltage amplitude of each bus node after adjusting OLTC.
The DDPG algorithm was then applied according to the DPV, ES, and SVC in the region where the voltage overlimit node is located.
• State Space. Control region 2 contains 13 bus nodes. As can be seen from Figure 11, after adjusting the OLTC splitter, the standard voltage values at nodes 9, 32, and 33 were controlled within the safety threshold, but the voltages at nodes 10–18 were still beyond the upper limit of the safety threshold. According to Eq. 28, the state space of the DDPG algorithm can be obtained as follows:
• Action Space. Node 18 incorporates DPV, nodes 12 and 15 are ES, and node 17 is SVC. The DDPG action space can be obtained according to Eq. 29:
According to variations in the active power output of DPVs, the adjustable range of the DPV reactive power can be obtained as follows:
According to the SOC consistency protocol for ES, the SOC reference value is .5, the convergence error threshold is .02, and the charge–discharge efficiency is 80%.
• Reward Function. The DDPG algorithm controls node voltage by regulating the DPVs, ES, and SVCs connected in Region 2. The reward function can be expressed by Eq. 30:
where
The parameters of the DDPG algorithm for the neural network were set as follows. The learning rate of the actor network was .001, the learning rate of the critic network was .0001, the discount coefficient was .99, the update coefficient was .01, and the capacity of the experience pool was 4,000. The capacity of the mini-batch was selected as 64, and the noise variable was .3. The DDPG agent was trained with 1,000 episodes according to the iterative process of algorithm 4.2 and each episode involved training 300 samples (Figure 12). It can be seen at the beginning of the training that the reward value was very low due to the limited learning experience. As the training continued, the agent kept exploring and learning, and the reward value kept increasing. After 800 episodes, the reward value of the DDPG agent fluctuated very little within a small range, which indicated that the algorithm gradually converged; the agent’s exercise training had developed an optimal strategy for voltage control of DPV and ES in the regulation region.
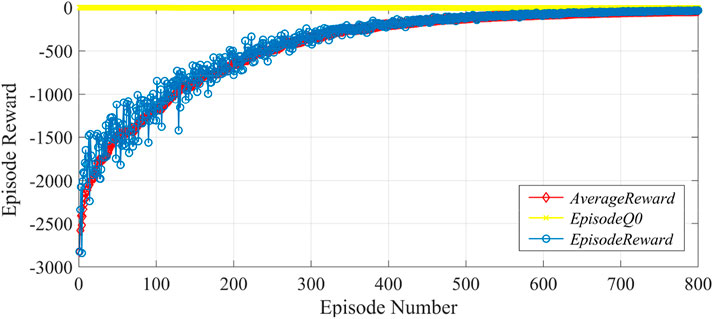
FIGURE 12. DDPG agent training process.
To make full use of the active DPV power consumption capacity, the DPV reactive power and ES were regulated. During the test, the power output training data on the voltage regulation equipment were used as control. Figure 13 shows the effect of controlling nodes 9–18 without reducing the active DPV power. It can be seen that the bus contact voltage in this control region at this time was not regulated within the safety threshold. Thus, DPV reactive power and ES cannot achieve the desired voltage control, so the active power must be further reduced. Figure 14 shows the voltage control effect of nodes 9–18 with active power reduction, and Figure 15 shows the level of power adjustment of each voltage regulation device in this control region.
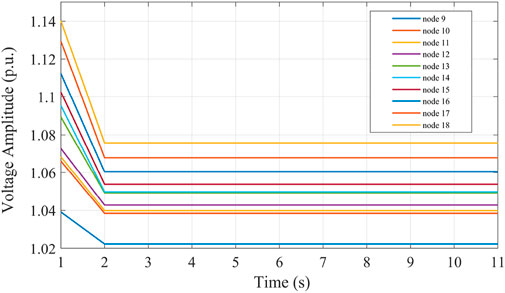
FIGURE 13. Voltage control effect in the case of no active power reduction.
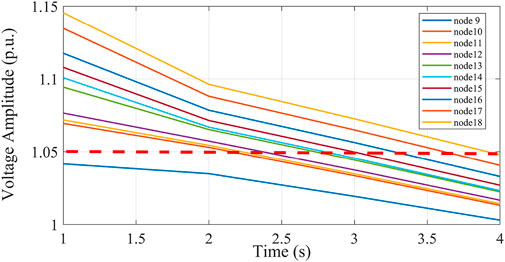
FIGURE 14. Voltage control effect when active power reduction is added.

FIGURE 15. Power adjustments of each voltage regulation device.
The DDPG algorithm was used for voltage control for 0.04 s. According to Figures 14, 15, the ES was discharged, and the output active power was about 250 KW. The SVC reactive power output was about 537.3 kVar, the DPV reactive power output was 372.8 kVar, and the active power reduction was less than 200 KW. The consumption capacity of the DPVs in the DN can be improved by reducing the active power reduction of the DPVs as much as possible. By adjusting the output power of the DPVs and the ES in the control region, the voltage of the bus node can be quickly and effectively maintained within the safety threshold.
To demonstrate the advantages of the rapid calculation speed of the DQN-DDPG algorithm, this paper compared it with the PSO algorithm. Figure 16 shows the effect of testing the voltage control model using the PSO algorithm with a consumption time of 19.52 s, and it is obvious that the DDPG algorithm was able to control voltage more quickly. This is because the PSO must obtain the optimal control strategy through continuous iteration, and the solution process was an iterative process of the objective function, while DDPG achieved the optimal strategy through the exploration and learning of the environment by the agents; the optimal strategy was the trained optimization sequence.
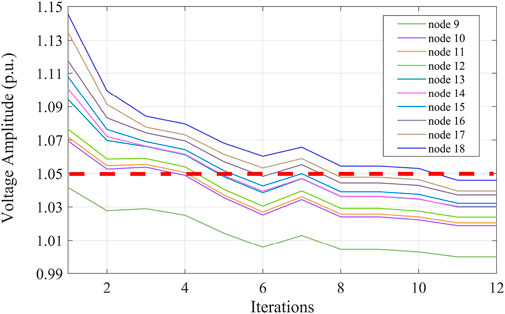
FIGURE 16. Voltage control effects of the PSO algorithm.
In order to give full play to the voltage regulating potential of the high permeability DGs in the DN, a deep reinforcement learning algorithm was used to test the voltage control model of the corresponding DN. The voltage control model was converted to a Markov decision process, and the whole series of steps of the algorithm to improve its design depth according to the objective function and constraint conditions were put forward. By combining the DQN and the DDPG algorithms with deep reinforcement learning, the discrete and continuous variables could be processed simultaneously, and the algorithms could control the DN in real time according to the current state of the power grid. The algorithms were independent of changes in the DN environment, and the optimal strategy was obtained through the exploration and learning of agents in the environment. This method effectively solved the problems of large model dimensions and high data volumes, to complete complex tasks, and achieve cooperative control of different voltage regulation devices.
However, this paper still has some imperfections. When the controller issues voltage regulation instructions to the inverter, there is an unavoidable communication delay, which can affect the real-time performance and effectiveness of the voltage regulation equipment. Also, this paper only considered a DN with OLTC, DPV, ES and SVC access, and did not conduct in-depth research on newer DNs with large-scale access to wind power and hydrogen energy or flexible loads such as electric vehicles.
The original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding author.
Conceptualization, MM and LW; methodology, CD and WD; software, MM; validation, SL; formal analysis, WD; investigation, CD and MM; resources, LW; data curation, WD; writing and preparation of the original draft, SL and LW; writing—reviewing and editing, LW and CD; visualization, WD; supervision, MM; funding acquisition, SL and WD. All authors have read and agreed to the published version of the manuscript.
MM, WD, and LW were employed by the Electric Power Research Institute of the Guangdong Power Grid Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Amir, M., Prajapati, A. K., and Refaat, S. S. (2022). Dynamic performance evaluation of grid-connected hybrid renewable energy-based power generation for stability and power quality enhancement in smart grid. Front. Energy Res. 10, 861282. doi:10.3389/fenrg.2022.861282
Atia, R., and Yamada, N. (2016). Sizing and analysis of renewable energy and battery systems in residential microgrids. IEEE Trans. Smart Grid. 7 (3), 1204–1213. doi:10.1109/TSG.2016.2519541
Chen, H., Prasai, A., and Divan, D. (2018). A modular isolated topology for instantaneous reactive power compensation. IEEE Trans. Power Electron. 33, 975–986. doi:10.1109/TPEL.2017.2688393
Dai, N., Ding, Y., Wang, J., and Zhang, D. (2022). Editorial: Advanced technologies for modeling, optimization and control of the future distribution grid. Front. Energy Res. 10, 885659. doi:10.3389/fenrg.2022.885659
Feng, J., Wang, H., Xu, J., Su, M., Gui, W., and Li, X. (2018). A three-phase grid-connected microinverter for AC photovoltaic module applications. IEEE Trans. Power Electron. 33, 7721–7732. doi:10.1109/TPEL.2017.2773648
Gerdroodbari, Y. Z., Razzaghi, R., and Shahnia, F. (2021). Decentralized control strategy to improve fairness in active power curtailment of PV inverters in low-voltage distribution networks. IEEE Trans. Sustain. Energy 12 (4), 2282–2292. doi:10.1109/TSTE.2021.3088873
Gush, T., Kim, C.-H., Admasie, S., Kim, J.-S., and Song, J.-S. (2021). Optimal smart inverter control for PV and BESS to improve PV hosting capacity of distribution networks using slime mould algorithm. IEEE Access 9, 52164–52176. doi:10.1109/ACCESS.2021.3070155
Hu, J., Yin, W., Ye, C., Bao, W., Wu, J., and Ding, Y. (2021). Assessment for voltage violations considering reactive power compensation provided by smart inverters in distribution network. Front. Energy Res. 9, 713510. doi:10.3389/fenrg.2021.713510
Impram, S., Varbak Nese, S., and Oral, B. (2020). Challenges of renewable energy penetration on power system flexibility: A survey. Energy Strategy Rev. 31, 100539. doi:10.1016/j.esr.2020.100539
Kekatos, V., Wang, G., Conejo, A. J., and Giannakis, G. B. (2015). Stochastic reactive power management in microgrids with renewables. IEEE Trans. Power Syst. 30, 3386–3395. doi:10.1109/TPWRS.2014.2369452
Labash, A., Aru, J., Matiisen, T., Tampuu, A., and Vicente, R. (2020). Perspective taking in deep reinforcement learning agents. Front. Comput. Neurosci. 14, 69. doi:10.3389/fncom.2020.00069
Le, J., Zhou, Q., Wang, C., and Li, X. (2020). Research on voltage and power optimal control strategy of distribution network based on distributed collaborative principle. Proc. CSEE. 40 (04), 1249. doi:10.13334/j.0258-8013.pcsee.182229
Li, Z., Yan, J., Yu, W., and Qiu, J. (2020). Event-triggered control for a class of nonlinear multiagent systems with directed graph. IEEE Trans. Syst. Man, Cybern. Syst. 51 (11), 6986–6993. doi:10.1109/TSMC.2019.2962827
Liu, S., Ding, C., Wang, Y., Zhang, Z., Chu, M., and Wang, M. (2021). “Deep reinforcement learning-based voltage control method for distribution network with high penetration of renewable energy,” in Proceedings of the in 2021 IEEE Sustainable Power and Energy Conference, Nanjing, China, December 2021, 287–291.
Liu, S., Zhang, L., Wu, Z., Zhao, J., and Li, L. (2022). Improved model predictive dynamic voltage cooperative control technology based on PMU. Front. Energy Res. 10, 904554. doi:10.3389/fenrg.2022.904554
Qin, P., Ye, J., Hu, Q., Song, P., and Kang, P. (2022). Deep reinforcement learning based power system optimal carbon emission flow. Front. Energy Res. 10, 1017128. doi:10.3389/fenrg.2022.1017128
Shuang, N., Chenggang, C., Ning, Y., Hui, C., Peifeng, X., and Zhengkun, L. (2021). Multi-time-scale online optimization for reactive power of distribution network based on deep reinforcement learning. Automation Electr. Power Syst. 45 (10), 77–85. doi:10.7500/AEPS20200830003
Vinnikov, D., Chub, A., Liivik, E., Kosenko, R., and Korkh, O. (2018). Solar optiverter—a novel hybrid approach to the photovoltaic module level power electronics. IEEE Trans. Industrial Electron. 66 (5), 38693869–38803880. doi:10.1109/TIE.2018.2850036
Wang, Y., He, H., Fu, Q., Xiao, X., and Chen, Y. (2021). Optimized placement of voltage sag monitors considering distributed generation dominated grids and customer demands. Front. Energy Res. 9, 717089. doi:10.3389/fenrg.2021.717089
Wu, W., Tian, Z., and Zhang, B. (2017). An exact linearization method for OLTC of transformer in branch flow model. IEEE Trans. Power Syst. 32, 2475–2476. doi:10.1109/TPWRS.2016.2603438
Yang, P., and Nehorai, A. (2014). Joint optimization of hybrid energy storage and generation capacity with renewable energy. IEEE Trans. Smart Grid. 5 (4), 1566–1574. doi:10.1109/TSG.2014.2313724
Zeraati, M., Golshan, M. E. H., and Guerrero, J. M. (2019). Voltage quality improvement in low voltage distribution networks using reactive power capability of single-phase PV inverters. IEEE Trans. Smart Grid. 10, 5057–5065. doi:10.1109/TSG.2018.2874381
Zhang, J., Li, Y., Wu, Z., Rong, C., Wang, T., Zhang, Z., et al. (2021). Deep-reinforcement-learning-based two-timescale voltage control for distribution systems. Energies 14 (12), 3540. doi:10.3390/en14123540
Zhang, X., Zhang, X., and Liu, X. (2014). Partition operation on distribution network based on theory of generalized node. Power Syst. Prot. Control 42 (7), 122–127.
Zhang, Z., Dou, C., Yue, D., Zhang, B., and Zhang, H. (2020). Event-triggered voltage distributed cooperative control with communication delay. Proc. CSEE 40 (17), 5426–5435. doi:10.13334/j.0258-8013.pcsee.200456
Zhou, W., Zhang, N., Cao, Z., Chen, Y., Wang, M., and Liu, Y. (2021). “Voltage regulation based on deep reinforcement learning algorithm in distribution network with energy storage system,” in Proceedings of the in 2021 4th International Conference on Energy Electrical and Power Engineering, Chongqing, China, April 2021, 892–896.
Zimmerman, R. D., Murillo-Sánchez, C. E., and Thomas, R. J. (2011). Matpower: Steady-state operations, planning, and analysis tools for power systems research and education. IEEE Trans. Power Syst. 26, 12–19. doi:10.1109/TPWRS.2010.2051168
Keywords: distributed photovoltaic, deep reinforcement learning, voltage control, multi-timescale, distribution network
Citation: Ma M, Du W, Wang L, Ding C and Liu S (2023) Research on the multi-timescale optimal voltage control method for distribution network based on a DQN-DDPG algorithm. Front. Energy Res. 10:1097319. doi: 10.3389/fenrg.2022.1097319
Received: 13 November 2022; Accepted: 22 December 2022;
Published: 11 January 2023.
Edited by:
Xiao-Kang Liu, Huazhong University of Science and Technology, ChinaReviewed by:
Qi-Fan Yuan, Huazhong University of Science and Technology, ChinaCopyright © 2023 Ma, Du, Wang, Ding and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Cangbi Ding, ZGNiMTk5NjA5MjZAMTYzLmNvbQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.