 Jiawen Li
Jiawen Li Yaping Li2
Yaping Li2- 1College of Electric Power, South China University of Technology, Guangzhou, China
- 2China Electric Power Research Institute (Nanjing), Nanjing, China
In order to improve the proton exchange membrane fuel cell (PEMFC) working efficiency, we propose a deep-reinforcement-learning based PID controller for realizing optimal PEMFC stack temperature. For this purpose, we propose the Improved Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm, a tuner of the PID controller, which can adjust the coefficients of the controller in real time. This algorithm accelerates the learning speed of an agent by continuously changing the soft update parameters during the training process, thereby improving the training efficiency of the agent, and further reducing training costs and obtaining a robust strategy. The effectiveness of the control algorithm is verified through a simulation in which it is compared against a group of existing algorithms.
Introduction
The proton exchange membrane fuel cell (PEMFC) (Cheng and Yu, 2019a), as a high-efficiency energy conversion device, has a high hydrogen energy utilization rate, and is expected to become a widely used electric power source in the future (Cheng et al., 2018).
The PEMFC converts chemical energy into electrical energy. During this process, the remaining energy is dissipated as heat due to the limited conversion efficiency of the fuel cell (Cheng et al., 2020). In order to maintain the necessary temperature required for sustaining the reaction inside the fuel cell, two heat dissipation inputs are usually used: cooling water, and air. These inputs differ in terms of the increase in power generation with increasing heat load. If the heat is not dissipated timeously, the heat will accumulate in the stack and the temperature will become excessive, which in turn will have an adverse effect on the working performance of the stack, even endangering operational safety (Cheng and Yu, 2019b).
Low-power stacks require air-injecting cooling equipment such as cooling fans, while high-power stacks require cooling water circulation systems with larger specific heat capacity (Ai et al., 2013).
However, the inclusion of auxiliary equipment in the thermal management system complicates the water-cooled fuel cell arrangement.
Control methods for fuel cell stack temperature control systems proposed by domestic and foreign scholars in recent years include proportional integral (PI) and state feedback control (Ahn et al., 2020; Liso et al., 2014; Zhiyu et al., 2014; Cheng et al., 2015a), Model Predictive Control (MPC) (Pohjoranta et al., 2015; Chatrattanawet et al., 2017), Fuzzy control (Wang et al., 2016; Hu et al., 2010; Cheng et al., 2015a; Ou et al., 2017), and Neural Network Control (NNC) (Li et al., 2006; Li and Li, 2006). However, the inherent nonlinearity of the PEMFC system and the uncertainty of model parameters greatly limit the effectiveness of these control methods (Li and Yu, 2021b). Since these algorithms cannot adapt easily to the nonlinearity of the PEMFC environment, and in many cases possess an overly complex architecture, the scope for their application in practice is greatly restricted (Li et al., 2015; Sun et al., 2020; Li and Yu, 2021a). For these reasons, the PEMFC requires a model-free algorithm that can perform parameter tracking independent of the PEMFC, which is guided by simple control principles (Li et al., 2021; Yang et al., 2021a; Yang et al., 2021b; Yang et al., 2021c). The Deep Deterministic Policy Gradient (DDPG) algorithm in deep reinforcement learning (Lillicrap et al., 2015) is a model-free method (Yang et al., 2018; Yang et al., 2019a; Yang et al., 2019b; Yang et al., 2021). Due to its strong adaptive ability, the DDPG algorithm can adapt to the uncertainty inherent in nonlinear control systems, and it is applied in various control fields (Zhang et al., 2019; Zhao et al., 2020; Zhang et al., 2021). However, due to its low robustness, DDPG is rarely used in the PEMFC control field.
In recognition of the low robustness of the DDPG algorithm, in this paper we propose an enhancement of the DDPG algorithm which can be used for PEMFC stack temperature control. We can improve the DDPG algorithm by combining it with the PID algorithm-based deep-reinforcement-learning based PID controller in order to realize more accurate stack temperature control in the PEMFC environment. For this purpose, an improved Twin Delayed Deep Deterministic Policy Gradient algorithm operates as a tuner of the PID controller, thereby adjusting the coefficients of the controller in real time. The algorithm accelerates the learning speed of an agent by continuously changing the soft update parameters during the training process, thereby improving the training efficiency of the agent, and further reducing training costs and thus obtaining a robust strategy.
The innovations detailed in this paper are as follows:
1) A deep-reinforcement-learning based PID controller for realizing optimal stack temperature control in the PEMFC is proposed.
2) The Improved Twin Delayed Deep Deterministic Policy Gradient (ITD3) algorithm is proposed as a tuner of the PID controller as it can adjust the coefficients of the controller in real time.
PEMFC Heat Management System
Heat Management System
To maintain the operation of the fuel cell stack in a safe, stable and efficient state, it is necessary to sustain a suitable temperature range. This is the core principle of the PEMFC heat management system. We propose a heat management system model for a water-cooled PEMFC, the design parameters of which reflect the law on the conservation of energy.
The principle of the heat management system in the water-cooled PEMFC stack is to adjust the internal temperature of the fuel cell by controlling the temperature and flow rate of the cooling water entering and leaving the stack, thus determining the heat taken away by the cooling water. It comprises a cooling water circulating pump, radiator fan, controller and sensor. The cooling water pump drives the cooling water into circulating in the stack at a certain flow rate. When it passes through the stack, the cooling water absorbs and removes heat, and so its temperature will increase. Then, when the cooling water from the stack flows through the radiator, the radiator fan rotates in order to create a convection flow between the air and the cooling water, so that excess heat can be eliminated, and the inlet temperature of the cooling water is restored to an acceptable level. In the method proposed in this paper, the cooling water flow rate is treated as the control quantity, the stack temperature is controlled by adjusting the cooling water flow rate, and the radiator is set to run at a fixed speed to meet the heat dissipation requirements.
PEMFC Stack Temperature
According to the law of the conservation of energy, when the hydrogen in the PEMFC reacts with oxygen, all the chemical energy released is converted into electric energy and heat. Then, according to the heat balance equation
Chemical Energy
According to Figure 1, The chemical energy converted by hydrogen per unit time is:
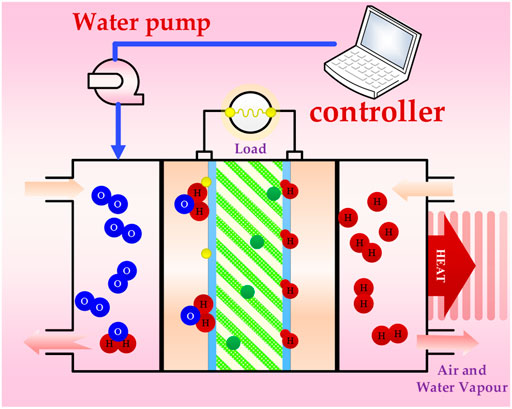
FIGURE 1. PEMFC control framework.
Electric Power
The output electric power of the PEMFC stack is:
Gas Cooling
The stack gas cooling system is designed in accordance with the laws of conservation of energy and matter. The gas and water are consumed and generated in the stack. Based on the energy difference between the intake and the exhaust, the heat caused by the exhaust can be calculated as follows:
Circulating Cooling Water for Heat Dissipation
Circulating cooling water is the main method for dissipating heat in the PEMFC stack. The circulating water pump provides pressure, which drives the cooling water through the stack at a certain flow rate, thus removing excess heat, so that the stack can operate at a safe and efficient temperature. The heat dissipation is calculated as follows:
The cooling water absorbs heat when it flows through the stack, and so the outlet temperature is much higher than the inlet temperature. In order to ensure that the inlet temperature remains at 339.15K, a cooling fan supplies air flow sufficient for transferring heat from the cooling water to the air. The relationship is as follows:
Heat Radiator
Any material of a sufficient temperature will radiate heat in the form of electromagnetic radiation, and the same is true for the PEMFC stack. The heat radiated by it is related to the temperature of the stack:
Intelligent Control of Stack Temperature Based on ITD3 Algorithm
DDPG
The Deep Deterministic Policy Gradient (DDPG) is an improved algorithm based on Deep Q-learning (DQN), which effectively solves the problem of multi-dimensional continuous action output. In addition, similar to other model-free reinforcement learning algorithms, the DDPG algorithm is capable of black-box learning. It only needs to pay attention to the state, action, and reward value at runtime, rather than rely on a detailed mathematical model of the system.
The loss function of the current value network is calculated as follows:
Wherein,
The loss function of the real value network is calculated as follows:
Among them, by using the gradient descent method to find the minimum value of the loss function
The target value network and target strategy network are updated in the following ways:
Τ is the soft update coefficient, and thus the update speed of the neural network can be controlled by adjusting τ. In order to avoid excessive updating of the neural network, τ usually ranges between 0.01 and 0.1. The update frequency of the target value network and the target strategy network is specified by the parameter f. Therefore, every time step t reaches an integer multiple of f, the target network is updated once.
ITD3
Clipped Double Q-Learning
According to Figure 2, In ITD3, the Clipped Double Q-learning method is used to calculate the target value:
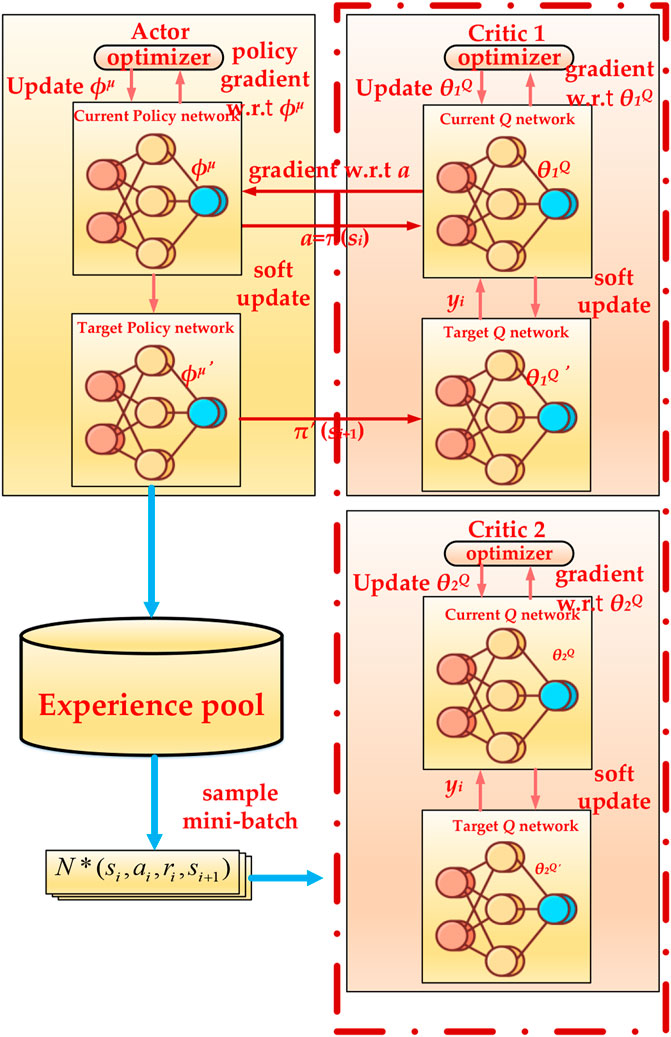
FIGURE 2. ITD3 algorithm.
Policy Delay Update
After every d times of the critic network update, the actor network is updated once to ensure that the actor network can be updated with a low Q error, so as to improve the update efficiency of the actor network.
Smooth Regularization of Target Strategy
The ITD3 algorithm introduces a regularization method for reducing the variance of the target value, and smoothes the Q value estimation by bootstrapping the estimated value of the similar state action pair:
Smooth regularization is achieved by adding a random noise to the target strategy and averaging on the mini-batch:
Changeable Soft Update Coefficient
The DDPG algorithm uses a soft update method to update the target deep neural network parameters; however, this method undermines the training efficiency of the DDPG algorithm and increases the training cost. In order to overcome this problem, the soft update coefficient increases with the increase in episodes, as detailed below:
Case Studies
The effectiveness of the proposed method is demonstrated in a simulation in which the proposed algorithm is compared against the following: Apex-DDPG, TD3 controller [6], DDPG controller [2], PSO tuned PID controller (PSO-PID) [8], PID controller and NNC controller [3].
In the experiment, the operating time in the working condition is 120s.
It is demonstrated in Figure 3 that when the load current changes step by step, the ITD3 controller can more effectively realize the stack temperature control and effectively control the output characteristics of the PEMFC, compared with the other algorithms. The overshoot of the output voltage is small, with quick response. The ITD3 controller has better adaptive ability and robustness, which makes it possible to obtain a faster response speed for restoring the temperature at the midpoint prior to the early stage of the disturbance, and thus obtain better stability at the later stage of the disturbance, which leads to less overshoot of the stack temperature, and no static error when the system is stable. In addition, because the proposed method can learn a large number of samples under different load conditions during offline training, it has extremely high adaptive ability and robustness, so it is able to automatically arrive at the best decision in the current state according to the collected PEMFC state. Therefore, the proposed method can smoothly control the stack temperature and obtain better control performance under variable load disturbances. By comparison, the TD3 algorithm, DDPG algorithm and NNC algorithm are less robust due to their low exploration ability and excessive reliance on samples. The other conventional algorithms in the simulation lack the capacity for adapting to the time-varying characteristics and nonlinearity of the PEMFC environment.
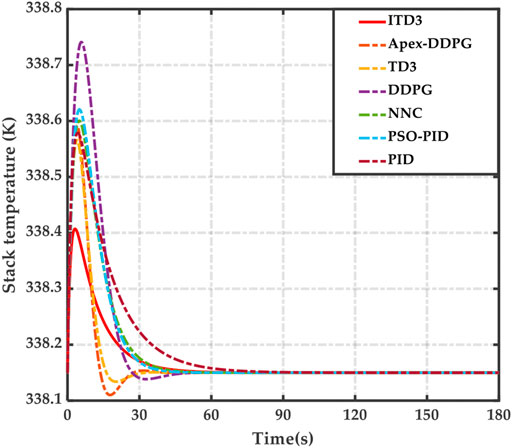
FIGURE 3. Stack temperature.
The ITD3 algorithm has better static and dynamic performance and is able to control the output voltage more effectively than the existing algorithms involved in the simulation.
Conclusion
In this paper, we have proposed a deep reinforcement learning-based PID controller for optimal stack temperature of the PEMFC. To this end, we have devised and tested what we term the ITD3 algorithm. This serves as the tuner of the PID controller by adjusting the coefficients of the controller in real time. The algorithm introduces Clipped Double Q-learning, strategy delay update, smooth and smooth regularization of target strategy, and changeable soft update coefficients in the training process, in order to speed up agent learning, thereby improving agent training efficiency, reducing training costs, and obtaining a robust strategy.
The simulation results indicate that the proposed control algorithm can achieve effective control of the temperature of the PEMFC stack. In addition, it has been compared with other RL control methods, including adaptive FOPID algorithm, adaptive PID algorithm and PID algorithm with optimized parameters, and the neural network control algorithm. In summary, the results demonstrate that the proposed control method achieves better control performance and robustness.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
JL: Conceptualization, Methodology, Software. YL: Data curation, Writing-Original draft preparation. TY: Supervision.
Funding
This work was jointly supported by the National Natural Science Foundation of China (U2066212).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Ahn, J.-W., and Choe, S.-Y. (2008). Coolant Controls of a PEM Fuel Cell System. J. Power Sourc. 179, 252–264. doi:10.1016/j.jpowsour.2007.12.066
Ai, G., Chen, W., Liu, Z., Qi, L., and Zhang, J. (2013). “Tempreture Model and Predictive Control for Fuel Cells in Switcher Locomotive,” in Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27-29 July 2016 (IEEE).
Chatrattanawet, N., Hakhen, T., Kheawhom, S., and Arpornwichanop, A. (2017). Control Structure Design and Robust Model Predictive Control for Controlling a Proton Exchange Membrane Fuel Cell. J. Clean. Prod. 148, 934–947. doi:10.1016/j.jclepro.2017.02.033
Cheng, L., Liu, G., Huang, H., Wang, X., Chen, Y., Zhang, J., et al. (2020). Equilibrium Analysis of General N-Population Multi-Strategy Games for Generation-Side Long-Term Bidding: An Evolutionary Game Perspective. J. Clean. Prod. 276, 124123. doi:10.1016/j.jclepro.2020.124123
Cheng, L., and Yu, T. (2019). A New Generation of AI: A Review and Perspective on Machine Learning Technologies Applied to Smart Energy and Electric Power Systems. Int. J. Energ. Res. 43, 1928–1973. doi:10.1002/er.4333
Cheng, L., and Yu, T. (2019). Smart Dispatching for Energy Internet with Complex Cyber‐physical‐social Systems: A Parallel Dispatch Perspective. Int. J. Energ. Res. 43, 3080–3133. doi:10.1002/er.4384
Cheng, L., Yu, T., Zhang, X., and Yang, B. (2019). Parallel Cyber-Physical-Social Systems Based Smart Energy Robotic Dispatcher and Knowledge Automation: Concepts, Architectures, and Challenges. IEEE Intell. Syst. 34, 54–64. doi:10.1109/MIS.2018.2882360
Cheng, S., Fang, C., Xu, L., Li, J., and Ouyang, M. (2015). Model-based Temperature Regulation of a PEM Fuel Cell System on a City Bus. Int. J. Hydrogen Energ. 40, 13566–13575. doi:10.1016/j.ijhydene.2015.08.042
Hu, P., Cao, G.-Y., Zhu, X.-J., and Hu, M. (2010). Coolant Circuit Modeling and Temperature Fuzzy Control of Proton Exchange Membrane Fuel Cells. Int. J. Hydrogen Energ. 35, 9110–9123. doi:10.1016/j.ijhydene.2010.06.046
Li, D., Li, C., Gao, Z., and Jin, Q. (2015). On Active Disturbance Rejection in Temperature Regulation of the Proton Exchange Membrane Fuel Cells. J. Power Sourc. 283, 452–463. doi:10.1016/j.jpowsour.2015.02.106
Li, G., and Li, Y. (2016). “Temperature Control of PEMFC Stack Based on BP Neural Network,” in Proceedings of the 2016 4th International Conference on Machinery, Materials and Computing Technology, March-2016 (Atlantis: Atlantis Press), 1372–1376. doi:10.2991/icmmct-16.2016.270
Li, J., Li, Y., and Yu, T. (2021a). Distributed Deep Reinforcement Learning-Based Multi-Objective Integrated Heat Management Method for Water-Cooling Proton Exchange Membrane Fuel Cell. Case Stud. Therm. Eng. 27, 101284. doi:10.1016/j.csite.2021.101284
Li, J., and Yu, T. (2021a). A New Adaptive Controller Based on Distributed Deep Reinforcement Learning for PEMFC Air Supply System. Energ. Rep. 7, 1267–1279. doi:10.1016/j.egyr.2021.02.043
Li, J., and Yu, T. (2021b). Distributed Deep Reinforcement Learning for Optimal Voltage Control of PEMFC. IET Renew. Power Generation 15, 2778–2798. doi:10.1049/rpg2.12202
Li, J., Yu, T., Zhang, X., Li, F., Lin, D., and Zhu, H. (2021b). Efficient Experience Replay Based Deep Deterministic Policy Gradient for AGC Dispatch in Integrated Energy System. Appl. Energ. 285, 116386. doi:10.1016/j.apenergy.2020.116386
Li, Y., Wang, H., and Dai, Z. (2006). “Using Artificial Neural Network to Control the Temperature of Fuel Cell,” in Proceedings of the 2006 International Conference on Communications, Circuits and Systems, 25-28 june-2006 (IEEE), 2159–2162. doi:10.1109/icccas.2006.284926
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., et al. (2015). Continuous Control with Deep Reinforcement Learning. arXiv preprint arXiv:1509.02971. doi:10.1016/S1098-3015(10)67722-4
Liso, V., Nielsen, M. P., Kær, S. K., and Mortensen, H. H. (2014). Thermal Modeling and Temperature Control of a PEM Fuel Cell System for Forklift Applications. Int. J. Hydrogen Energ. 39, 8410–8420. doi:10.1016/j.ijhydene.2014.03.175
Ou, K., Yuan, W.-W., Choi, M., Yang, S., and Kim, Y.-B. (2017). Performance Increase for an Open-Cathode PEM Fuel Cell with Humidity and Temperature Control. Int. J. Hydrogen Energ. 42, 29852–29862. doi:10.1016/j.ijhydene.2017.10.087
Pohjoranta, A., Halinen, M., Pennanen, J., and Kiviaho, J. (2015). Model Predictive Control of the Solid Oxide Fuel Cell Stack Temperature with Models Based on Experimental Data. J. Power Sourc. 277, 239–250. doi:10.1016/j.jpowsour.2014.11.126
Sun, L., Li, G., Hua, Q. S., and Jin, Y. (2020). A Hybrid Paradigm Combining Model-Based and Data-Driven Methods for Fuel Cell Stack Cooling Control. Renew. Energ. 147, 1642–1652. doi:10.1016/j.renene.2019.09.048
Wang, Y.-X., Qin, F.-F., Ou, K., and Kim, Y.-B. (2016). Temperature Control for a Polymer Electrolyte Membrane Fuel Cell by Using Fuzzy Rule. IEEE Trans. Energ. Convers. 31, 667–675. doi:10.1109/TEC.2015.2511155
Yang, B., Li, D., Zeng, C., Chen, Y., Guo, Z., Wang, J., et al. (2021). Parameter Extraction of PEMFC via Bayesian Regularization Neural Network Based Meta-Heuristic Algorithms. Energy 228, 120592. doi:10.1016/j.energy.2021.120592
Yang, B., Swe, T., Chen, Y., Zeng, C., Shu, H., Li, X., et al. (2021). Energy Cooperation between Myanmar and China under One Belt One Road: Current State, Challenges and Perspectives. Energy 215, 119130. doi:10.1016/j.energy.2020.119130
Yang, B., Wang, J., Zhang, X., Yu, T., Yao, W., Shu, H., et al. (2020). Comprehensive Overview of Meta-Heuristic Algorithm Applications on PV Cell Parameter Identification. Energ. Convers. Manag. 208, 112595. doi:10.1016/j.enconman.2020.112595
Yang, B., Yu, T., Shu, H., Dong, J., and Jiang, L. (2018). Robust Sliding-Mode Control of Wind Energy Conversion Systems for Optimal Power Extraction via Nonlinear Perturbation Observers. Appl. Energ. 210, 711–723. doi:10.1016/j.apenergy.2017.08.027
Yang, B., Yu, T., Zhang, X., Li, H., Shu, H., Sang, Y., et al. (2019). Dynamic Leader Based Collective Intelligence for Maximum Power point Tracking of PV Systems Affected by Partial Shading Condition. Energ. Convers. Manag. 179, 286–303. doi:10.1016/j.enconman.2018.10.074
Yang, B., Zeng, C., Wang, L., Guo, Y., Chen, G., Guo, Z., et al. (2021). Parameter Identification of Proton Exchange Membrane Fuel Cell via Levenberg-Marquardt Backpropagation Algorithm. Int. J. Hydrogen Energ. 46, 22998–23012. doi:10.1016/j.ijhydene.2021.04.130
Yang, B., Zhong, L., Zhang, X., Shu, H., Yu, T., Li, H., et al. (2019). Novel Bio-Inspired Memetic Salp Swarm Algorithm and Application to MPPT for PV Systems Considering Partial Shading Condition. J. Clean. Prod. 215, 1203–1222. doi:10.1016/j.jclepro.2019.01.150
Zhang, X., Li, S., He, T., Yang, B., Yu, T., Li, H., et al. (2019). Memetic Reinforcement Learning Based Maximum Power point Tracking Design for PV Systems under Partial Shading Condition. Energy 174, 1079–1090. doi:10.1016/j.energy.2019.03.053
Zhang, X., Tan, T., Zhou, B., Yu, T., Yang, B., and Huang, X. (2021). Adaptive Distributed Auction-Based Algorithm for Optimal Mileage Based AGC Dispatch with High Participation of Renewable Energy. Int. J. Electr. Power Energ. Syst. 124, 106371. doi:10.1016/j.ijepes.2020.106371
Zhao, D., Li, F., Ma, R., Zhao, G., and Huangfu, Y. (2020). An Unknown Input Nonlinear Observer Based Fractional Order PID Control of Fuel Cell Air Supply System. IEEE Trans. Ind. Applicat. 56, 5523–5532. doi:10.1109/TIA.2020.2999037
Keywords: proton exchange membrane fuel cell, twin delayed deep deterministic policy gradient algorithm, stack temperature, PID controller, robustness
Citation: Li J, Li Y and Yu T (2021) Temperature Control of Proton Exchange Membrane Fuel Cell Based on Machine Learning. Front. Energy Res. 9:763099. doi: 10.3389/fenrg.2021.763099
Received: 23 August 2021; Accepted: 13 September 2021;
Published: 28 September 2021.
Edited by:
Yaxing Ren, University of Warwick, United KingdomReviewed by:
Du Gang, North China Electric Power University, ChinaYunzheng Zhao, The University of Hong Kong, Hong Kong, SAR China
Chenhao Ren, The University of Hong Kong, Hong Kong, SAR China
Copyright © 2021 Li, Li and Yu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tao Yu, dGFveXUxQHNjdXQuZWR1LmNu, ZXB0YW95dTFAMTYzLmNvbQ==