
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Energy Res. , 08 October 2021
Sec. Nuclear Energy
Volume 9 - 2021 | https://doi.org/10.3389/fenrg.2021.755638
This article is part of the Research Topic Artificial Intelligence Applications in Nuclear Energy View all 13 articles
 Wazif Sallehhudin1
Wazif Sallehhudin1 Aya Diab1,2*
Aya Diab1,2*In this paper the use of machine learning (ML) is explored as an efficient tool for uncertainty quantification. A machine learning algorithm is developed to predict the peak cladding temperature (PCT) under the conditions of a large break loss of coolant accident given the various underlying uncertainties. The best estimate approach is used to simulate the thermal-hydraulic system of APR1400 large break loss of coolant accident (LBLOCA) scenario using the multidimensional reactor safety analysis code (MARS-KS) lumped parameter system code developed by Korea Atomic Energy Research Institute (KAERI). To generate the database necessary to train the ML model, a set of uncertainty parameters derived from the phenomena identification and ranking table (PIRT) is propagated through the thermal hydraulic model using the Dakota-MARS uncertainty quantification framework. The developed ML model uses the database created by the uncertainty quantification framework along with Keras library and Talos optimization to construct the artificial neural network (ANN). After learning and validation, the ML model can predict the peak cladding temperature (PCT) reasonably well with a mean squared error (MSE) of ∼0.002 and R2 of ∼0.9 with 9 to 11 key uncertain parameters. As a bounding accident scenario analysis of the LBLOCA case paves the way to using machine learning as a decision making tool for design extension conditions as well as severe accidents.
Deterministic safety analysis has traditionally been utilized to demonstrate the robustness of nuclear power plants, usually adopting a conservative approach. However, the conservative approach relies on a number of assumptions that do not necessarily reflect the real plant performance (Queral et al., 2015). On the other hand, the best estimate (BE) approach provides a more realistic system response based on detailed thermal-hydraulic mechanistic models provided it is accompanied with uncertainty quantification (UQ). The integration of BE and UQ is known as best estimate plus uncertainty (BEPU) and is built upon a statistical foundation to provide a more realistic estimation of the safety margin and hence ensure that the safety limit is met.
Utilities were given an ample opportunity to apply the best estimate plus uncertainty (BEPU) methodology following the United States Regulatory Commission (USNRC) amendment of 10CFR50.46 Appendix-K in 1988. Accordingly, the USNRC assisted in the steady transition from the conservative to BEPU methodology by introducing the USNRC Regulatory Guide 1.157, “Best Estimate Calculations of Emergency Core Cooling System Performance” and the demonstration of code scaling, applicability and uncertainty (CSAU) methodology in 1989 aiming to quantify the uncertainty parameters (USNRC, 1989). In addition to the CSAU methodology, various international collaboration projects had been undertaken to propose and validate other uncertainty quantification methodologies such as the uncertainty method study, UMS, (OECD, 1998), the BEMUSE project (OECD, 2007a) and the SM2A study within the SMAP framework (OECD, 2007b).
The BEPU methodology has been used to predict key safety parameters such as the peak cladding temperature (PCT), departure from nucleate boiling ratio (DNBR), etc. for critical accident scenarios. In BEPU analysis, a BE code is used to simulate the plant response given the variations in a multitude of uncertain parameters (UPs) that can be propagated within the thermal-hydraulic system code. The process of uncertainty propagation is however lengthy and hence BEPU analysis has so far been limited to the analysis of bounding design basis accident (DBA) scenarios, e.g. large break loss of coolant accident (LBLOCA) (Chang et al., 2020) and only recently to the analysis of a station blackout (SBO) (Musoiu et al., 2019) and to the main steam line break (MSLB) (Petruzzi et al., 2016).
This concern can be addressed by using data-driven approaches that provide a prediction based only on the database previously obtained from experimental, or simulation results. A data-driven model tries to learn the salient characteristics embedded within the system by developing a mathematical relationship between the system parameters rather than solving the physics-based models to describe the system performance. This process is known as machine learning (ML).
ML is one of the branches of artificial intelligence (AI). Currently, there are many machine learning tools that can be used for prediction or classification such as artificial neural network (ANN), support vector machine (SVM), Naïve-Bayes algorithm, random forest, decision tree, logistic regression (LR), K- nearest neighbors (KNN), etc. Any of these tools may be used to develop a machine learning algorithm. Each algorithm is based on its unique strategy in making predictions. Generally speaking, ML algorithms learn from the datasets and try to decipher the salient characteristics within the data that reflect the relationship between the inputs and outputs. Based on the datasets, a mathematical relationship can be generated between the input vector variables and the scalar output variables. The learning process helps improve the relationship by constantly changing the learning parameters to tune the model until the objective function is optimized. The objective functions for each machine learning algorithm is different and needed to be specified accordingly.
Recently, the International Atomic Energy Agency (IAEA) has urged the nuclear community to integrate ML in the industry within the framework of emerging technologies, given its superior capability in handling big-data (IAEA, 2020). In fact, the potential of using ML technology has been explored to estimate some key figures of merit such as the power pin peaking factor (Bae et al., 2008), the wall temperature at critical heat flux (Park et al., 2020), the flow pattern identification (Lin, 2020), to detect anomalies and warn of equipment failure (Ahsan and Hassan, 2013; Chen and Jahanshahi, 2018; Devereux et al., 2019); to determine core configuration and core loading pattern optimization (Siegelmann et al., 1997; Faria and Pereira, 2003; Erdogan and Gekinli, 2003; Zamer et al., 2014; Nissan, 2019), to identify initiating events and categorize accidents (Santosh et al., 2003; Na et al., 2004; Lee and Lee, 2006; Ma and Jiang, 2011; Pinheiro et al., 2020; Farber and Cole, 2020) and to determine of key performance metrics and safety parameters (Ridlluan et al., 2009; Montes et al., 2009; Farshad Faghihi and Seyed, 2011; Patra et al., 2012; Young, 2019; Park et al., 2020; Alketbi and Diab, 2021), and in radiation protection for isotope identification and classification (Keller and Kouzes, 1994; Abdel-Aal and Al-Haddad, 1997; Chen, 2009; Kamuda and Sullivan, 2019), etc. However, it is worth noting that the application of ML in nuclear safety is still limited despite its potential to enhance performance, safety, as well as economics of plant operation (Chai et al., 2003) which warrants further research (Gomez Fernandez et al., 2017). For a more comprehensive review of the status and development efforts utilizing data-driven approaches in nuclear industry, the reader may consult (Gomez Fernandez et al., 2017; Gomez Fernandez et al., 2020).
In this study, an artificial neural network (ANN) is developed to predict the PCT under LBLOCA conditions as a bounding accident scenario. The goal is to develop a fast and cost-effective tool for uncertainty quantification of PCT under LBLOCA conditions using ML. This is achieved by using a database to train the ML algorithm, and once trained and tested, the meta-model can be used as a predictive tool. The database required to train and test the model is generated via the thermal hydraulic system code MARS-KS (KAERI, 2004) within an uncertainty quantification framework using Dakota (Adams et al., 2020). Once proven, the ML technology may be used to help the nuclear designers and/or operators to expedite the decision making process particularly in those situations that involve complex interconnected phenomena during design optimization or in the event of a nuclear accident.
ANN is a machine learning model inspired by the biological network of the nerve cells that make up the brain. Fundamentally, the ANN behaves in a way similar to the nerve cells. However, each biological structure is replaced with layers of neurons with a pre-defined architecture that communicates data between the input signals and output signals via weights, biases, and activation functions to find the best weight matrix that best describes the relationship between the inputs and outputs. The ANN structure can be split into three different classes; artificial neural network (ANN), convolutional neural network (CNN) and recurrent neural network (RNN). This research focuses only on ANN.
The ANN generally refers to the modelling of the data through a stack of computational layers. The ANN utilizes the back propagation based on the stochastic gradient descent (SGD) technique that approximates the loss function optimal points which guarantees convergence and terminate at the optimal solution (Dawani, 2020). Currently, the improvised gradient descent techniques such as the adaptive moment estimate (Adam) is being widely used for many ANN applications. The SGD teaches the ANN how to tweak the connection weights and biases in order to converge to the closest mathematical representation of the data at hand. A number of activation functions, such as the hyperbolic tangent function and the rectifier linear unit function (ReLU), may be used to provide signal transformations for each input layer and hence provide better representation of the underlying non-linearity of complex systems.
The ANN is based on a multi-layer perceptron model and can be used for both regression and classification problems. The training process of an ANN is a two-step process. The first is a forward propagation step and involves evaluating the error or loss function. In the second step, the resulting error is propagated backwards through the network to adjust the weights and biases. This process is repeated until no further improvement in the error between the predicted outputs and desired values is achieved. The complexity of the network is determined by the number of hidden layers, the number of nodes in each layer, the type of activation function. The output is predicted by summing the functions within the hidden layers to produce a net input function.
The goal of the training process is to tune the model hyper-parameters for better prediction. Those hyper-parameters include: the number of neurons, number of hidden layers, network structure, activation function, type of optimizer, loss function, etc. Common hyper-parameters associated with the regression problems are described in Table 1.

TABLE 1. Common hyper-parameters for ANN.
During the optimization process, provisions should be made to ensure a global minimum is achieved rather than a local minimum or saddle point, for which small neural networks are prone. A balance between generalization and fitness to the training data should be achieved to ensure that over-fitting or retaining redundant features in the neural network is avoided.
To achieve the goal of this paper, three main objectives can be identified which are, 1) the thermal hydraulic model development, 2) the uncertainty quantification and database creation and 3) machine learning model development. Each will be delineated in the next subsections.
This section focuses on the details of the thermal hydraulic model development. In this investigation, the best estimate system code, MARS-KS version 1.4, is used to simulate the nuclear power plant response under LBLOCA conditions. MARS-KS is a multi-dimensional two-phase thermal hydraulic system code developed by KAERI (2009). The model representation in MARS-KS, including nodalization, boundary and initial conditions as well as the main assumptions will be presented next.
First, the details of the APR1400 reactor are described using the system nodalization shown in Figure 1 to represent the key systems and components which includes a reactor pressure vessel, a pressurizer, two loops with four cold legs and two hot legs. The nodalization also includes detailed description of the two steam generators (SG), the main steam lines and associated valves (MSSV, MSIV, ADV, etc). The turbine however, is modeled as a boundary condition. The safety injection system (SIS) is modeled to represent the emergency core cooling system (ECCS) of the APR1400. The SIS modelling is necessary to understand the reactor dynamic behavior in dealing with the LBLOCA scenario and to ensure the safety parameters stay within the safety limits during the different phases of the accident.
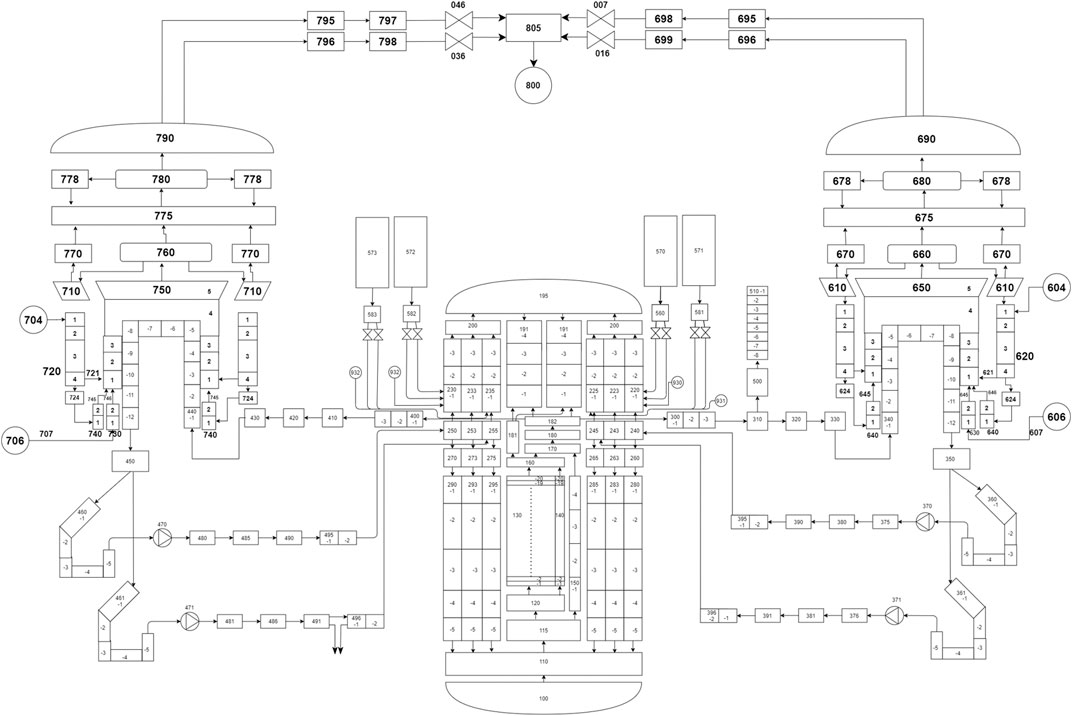
FIGURE 1. APR1400 nodalization for the LBLOCA thermal-hydraulic model.
The containment building is modelled as a boundary condition and the containment spray system (CSS) are excluded from the nodalization process as it is not required in the analysis of the reactor response under the LBLOCA scenario. The core is divided into a hot channel and an average channel. The hot channel represents the hottest fuel assembly; while the average channel represents the remaining 241 fuel assemblies in the APR1400 nuclear power plant core configuration.
The core channels are modeled in MARS using a pipe hydrodynamic component with a vertical orientation using 20 axial nodes. A solid structural element is attached to the hydrodynamic component to represent the fuel assembly with 20 axial nodes and nine radial nodes. For the downcomer, an annulus hydrodynamic component is used. The annulus is divided circumferentially into six channels at different angle (0°, 60°, 120°, 180°, 240°, 300°, 360°), each having five axial nodes with a vertical orientation.
The same nodalization scheme is used for the upper annulus region, which hosts the entry location of the emergency coolant from the SIS that should be directed to the core. The general pathway of emergency coolant should start from the upper annulus to the downcomer, to the lower plenum, to the bottom of the core and finally to the core itself.
The inlet and the outlet of the core are nodalized using branch components. The core inlet hosts the lower support structure (LSS) and in-core instrumentation while, the core outlet hosts the fuel alignment plate (FAP), the upper guide structure, the core shroud and the fuel barrel assembly. The crossflow is permitted between the downcomer regions, the upper annulus, the downcomer upstream, between the average channel and the hot channel and between the loop elevation reference regions. The cross flow allows the inventory to move sideways between the hydrodynamic components to represent the secondary cross flow. At the middle part of the reactor pressure vessel (RPV), a bypass is used to connect the bottom region of the core towards the fuel alignment plate without passing through the core site. The bypass allows liquid to move vertically from the lower plenum to the fuel alignment plate (FAP). To simulate the safety injection system (SIS), both the safety injection tanks (SITs) and the safety injection pumps (SIPs) are modelled in the nodalization. There are four units of SITs that are modelled using the accumulator hydrodynamic component. The SIT are connected to the upper annulus and is controlled using a combination of logical and variable trips. A set point that refers to the low pressurizer set point pressure is used to navigate the turning on of the SITs. The SIT valve is divided into two part for each train to represent the low-flow and high-flow conditions of the actual APR1400 fluidic device. The fluidic device act as a flow regulator in the actual APR1400 plant to optimize the usage of the emergency inventory during the loss of coolant scenario. Meanwhile, the SIPs are comprised of 4 units however, only two units of SIP are available in accordance to the conservative assumption adopted by the APR1400 Design Control Document (DCD) for LBLOCA evaluation. The SIPs will be available only for the break side and the opposite direction across from the break, i.e. located at 60° and 240°, respectively. The SIPs are modeled using a time dependent volume and a time dependent junction instead of pump hydrodynamic components. This configuration allows the user to impose flow boundary conditions and control the velocity of the coolant. Each SIP and SIT is connected to the upper annulus model at different circumferential angles based on APR1400 description.
Consistent with APR1400 DCD the decay heat model is based on the ANS-1973 model and a reactivity table is also provided in the code to account for the negative reactivity insertion due to control rod insertion. However, based on the APR1400 DCD, the negative reactivity contribution from the control rod is discredited for conservatism when conducting the LBLOCA analysis. This will allow the SIS capability in managing the accident and maintaining the core integrity to be fully tested during the LBLOCA accident. Regarding the reactor internals, the heat structure components are used and attached to the related hydrodynamic volumes to reflect the heat transfer boundary conditions and architecture of the APR1400 design. Meanwhile to describe LBLOCA scenario, a double ended guillotine break is placed on the cold leg after the pump discharge. This is achieved by incorporating two trip valves to divert the coolant from the vessel to the time dependent volume attached to each of the trip valves when the accident is initiated.
Following the DCD recommendation, a double ended guillotine break (DEGB) equivalent to double the area of the pipe with the largest cross section of the RCS, i.e. the cold leg piping is used in this work. The standard internal diameter of the connecting pipes between the pump discharge and the reactor pressure vessel inlet nozzle is 762 mm (30 inches) which corresponds to the break area of 0.456 m2. The thermal hydraulic model development is based on several assumptions similar to those reported in the DCD document: 1) LBLOCA occurs at loop B1 near the pump discharge site. 2) Break type is double ended guillotine break (DEGB). 3) Loss of offsite power (LOOP) for the RCPs. 4) No negative reactivity insertion from the control rods. 5) Single emergency diesel generator (EDG) is not functioning causing two out of four safety injection pumps (SIPs) to be non-operable. 6) All safety injection tanks (SIT) are in operation.
The statistical tool, Dakota (Adams et al., 2020), is used in this work to propagate the uncertainty parameters into the thermal hydraulic model. Dakota is an open source statistical software tool developed by Sandia National Laboratory. It can be used for optimization, sensitivity analysis and uncertainty quantification. The uncertainty propagation process is achieved by developing the uncertainty quantification framework by loosely coupling the best estimate system code, MARS-KS, and the statistical tool, Dakota, via a python script to manage the data exchange process. Several important files such as, the Dakota input file, the python interface script, the MARS steady state file and the MARS transient file are necessary for the uncertainty quantification framework to run smoothly and propagate the uncertainty parameters.
As indicated in the introduction, the current work explores the possibility of using ML to predict the PCT under the conditions of a LBLOCA, being an important bounding accident scenario. LBLOCA was used in nuclear safety as a design basis for the emergency core cooling system, ECCS, to provide assurance that the ECCS would not violate any of the safety limits and hence preserve the fuel integrity during a loss of coolant accident (LOCA). For LBLOCA, the key performance measure of the ECCS, as defined by the 10CFR50.46 Appendix-K guideline is that the PCT does not exceed the safety limit of 1477 K (2,200℉) to ensure the integrity of the fuel under the accident conditions (Martin and O’Dell).
Now for the ML algorithm to be developed and trained, it is necessary to use a database of the most important system parameters (features) that impact the safety parameter of interest, in this case the PCT. Generally speaking, the model can use a database originating from the plant historic data, which is not possible under DBA conditions. Alternatively, it can be generated using simulation results produced by system codes. In this work, the database is created, using the latter approach.
A BEPU analysis is undertaken to generate a database of the system response under LBLOCA. In general, uncertainty quantification can be achieved using either the input uncertainty propagation approach or the output uncertainty propagation approach (Martin and O’Dell, 2008). The former approach will be followed in this work.
To conduct the BEPU analysis, the uncertainty quantification process requires the identification of the uncertain parameters that can impact the PCT. Those uncertainty parameters can be derived from the phenomena identification and ranking table (PIRT). The PIRT describes the key phenomena and processes relevant to the plant’s thermal-hydraulic response for a specific accident condition. Most of the PIRT developed throughout the years centered on the LBLOCA cases due to its importance to nuclear safety as a bounding DBA scenario. Several PIRTs have been developed for LBLOCA scenario such as: Westinghouse PIRT (USNRC, 1988), AP600 PIRT (LA-UR-95-2718, 1995), KREM PIRT (KHNP, 2014), KNGR PIRT (KINS, 2001), APR1400 PIRT (KEPCO, 2014). For the current project, the investigation will focus on the APR1400 PIRT which is based on the KNGR PIRT, which in turn is derived from the Westinghouse PIRT.
Based on the work of (Lee et al., 2014; Kang, 2016), eight key phenomena were considered in this study. The key phenomena underlying the LBLOCA scenario are gap conductance, energy stored in the fuel, decay heat, rewetting process, reflooding heat transfer, critical flow, pump performance and core reflooding as shown in Table 2. A total of 19 uncertainty parameters have been derived from these key phenomena. These key uncertain parameters and the statistical information associated with each (range and distribution) are listed in Table 2.
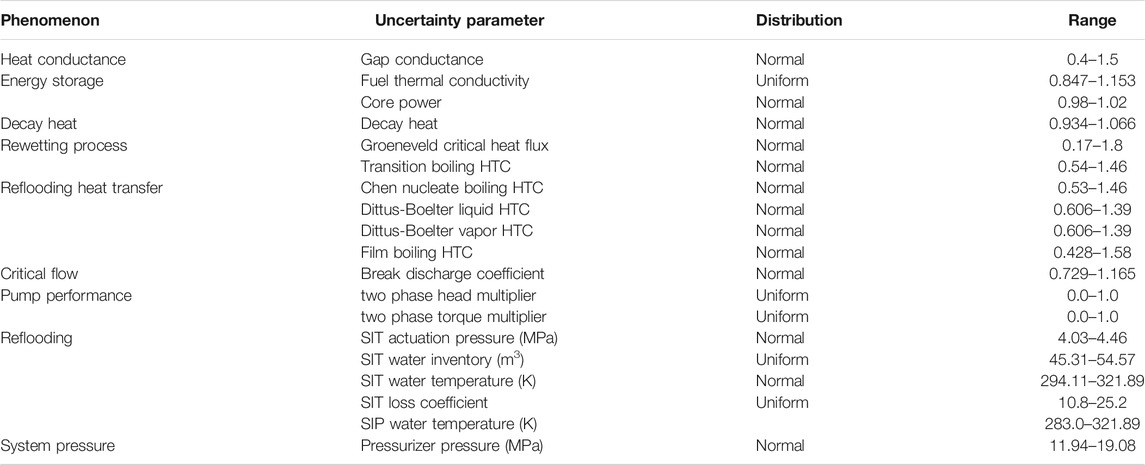
TABLE 2. Key uncertain phenomena and associated uncertain parameters.
Before propagating the uncertainty parameters into the best estimate thermal-hydraulic system model, it is essential for the uncertainty parameters to undergo a normalization process. The normalization is done with respect to the statistical information available for each uncertain parameter derived from the PIRT. First, the mean value is calculated using the following expression:
Next, the upper and lower limit can be scaled using this mean value as follows:
And finally for the standard deviation can be calculated as follows:
where
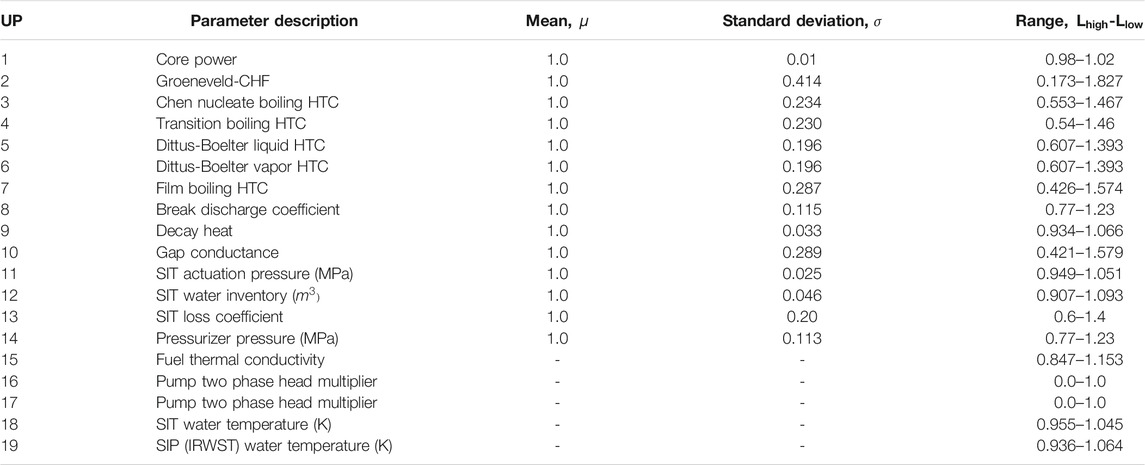
TABLE 3. Normalized uncertain parameters.
With the key uncertain parameters identified and scaled appropriately, they are randomly propagated into the thermal hydraulic system code, MARS-KS using DAKOTA. The goal is to generate a large enough sample that can be representative of the realistic system performance in accordance with the USNRC requirement specified in 10CFR50.46 Appendix-K, i.e. the safety criteria should be satisfied with a probability of 95% and a confidence level of 95%. The 95/95 rule has been recognized by the USNRC to have sufficient conservatism for LBLOCA analyses. Usually a large number of samples are required which can be achieved using the Monte-Carlo random sampling technique. To determine the minimum number of samples required for Monte Carlo method to achieve the safety criteria according to the 95/95 rule, it is essential to ensure convergence when the average output stabilizes over the number of samples.
In this investigation, six ANN model development steps are applied. The six steps are 1) input selection, 2) data splitting, 3) architecture selection, 4) structure selection, 5) model optimization and 6) model validation.
The input data for the ANN model will be a selected set of the uncertain parameters identified earlier and derived using the PIRT for LBLOCA. The feature selection process is important for ANN model development since too many variables will slow down the optimization process and may prevent the model from finding a good solution (Geron, 2019); whereas a few features may not be sufficient for the model to properly learn the system characteristics embedded in the data. A correlation matrix based on Spearman’s method is therefore used to identify the key features from the 19 uncertain parameters that impact the PCT the most.
Next, the random sampling technique is applied to split the database into three main categories: one for training (3,022 samples), validating and testing the model (202 and 332 samples, respectively). In order to improve the ANN performance metrics during training, the input and output parameters should have the same scale. Before the propagation of uncertainty, all input parameters have been scaled; hence only the output parameter (peak cladding temperature, PCT) needs to be normalized using the min-max scaling function:
where
Architecture selection refers to the choice of ANN hyper-parameters. Since there are a lot of hyper-parameters that can be tuned, choosing the suitable set is a delicate task given the large number of degrees of freedom that the user can manipulate during the ML tuning process. The tuning process of the ML model is therefore more an art than a science and depends on the problem at hand as well as the characteristics of the data. Hence, finding a set of optimal hyper-parameters that provide the best model performance without compromising either its predictive accuracy or generalization capability can be computationally challenging. This is particularly true for hyper-parameters as opposed to other model parameters since the former are not learnt by the model during the training process but must be set manually. Various techniques can be employed to search for the most appropriate hyper-parameters: grid search, random search and Bayesian optimization. In this work, the random search method is used to expedite the convergence. Table 4 shows all the hyper-parameters that are tuned in this study.

TABLE 4. List of considered hyper-parameters.
ANN tuning is an important step to enhance the model predictability by converging on the most optimum combination of hyper-parameters. In this study, an automatized optimization tool, the Talos (Autonomio Talos, 2019) software, is used. Talos is an open sources software written in Python language. It is compatible with Keras (Chollet, 2015) application programming interface (API) that is suited for the development of artificial neural network (ANN) models. Currently, Talos does not support any other machine learning model other than the ANN architecture and it only supports Keras backend machine learning algorithms.
Initially, the user needs to define the Keras for the ANN algorithm development. Then the user needs to define the search space boundary in the format of key-value pair python dictionary. Afterwards, the scan function is used to run the Talos experiment. The arguments of the scan function include the type of search method (grid or probabilistic), model’s name, number of epochs, batch size and search constraints. Talos will generate a list of possible hyper-parameters combinations along with their corresponding values that can be analyzed using the built in command such as report and predict functions. The size of the results list depends on the number of parameters defined in the search space boundary dictionary. The analysis process can be done by analyzing the whole or the specific model combinations.
If the user is satisfied with the value of the performance metric generated from the results list, then the deploy function is used to save and call the model from the defined python dictionary path and hence the Talos experiment is complete.
As mentioned earlier, the random quantum search method is used to optimize the model. To further reduce the computing time to find the optimized model, both early stopping and window reduction strategies are used. Early stopping prevents the Talos tool from evaluating models that shows unproductive permutation when its metrics are no longer improving; whereas, the window reduction strategy allows the Talos tool to compare the upcoming model with the previously evaluated model based on the specific metrics. Once any of the two criteria is satisfied first, the computation will stop and the results list is generated. Table 5 shows all the parameters used to reduce computation time.

TABLE 5. Variables for reducing computation time.
It should be noted that the Talos ability to find the optimized architecture based on hyper-parameters combinations relies heavily on the defined search space boundary. As such, if the final results do not provide reasonable performance metrics, it is essential to redefine the search space dictionary by adding new hyper-parameters or retuning their corresponding values in order to improve the model accuracy. Even though the Talos is an automated optimization tool, it is still based on a trial and error process that required extensive knowledge in regards to the behavior of each hyper-parameter towards the ANN model. However, the Talos can expedite the optimization process.
It is worth noting that neither under-fitting nor overfitting is desirable in machine learning. To prevent under-fitting, a large database has been generated to train the model, as many input parameters are used to develop the model and the training time was increased until the cost function is minimized to an acceptable value. To mitigate over-fitting, number of techniques can be used for example: cross validation, regularization, dropout, and early stopping. An overfitting model tends to have good learning metrics during training but performs poorly during the validation process. To avoid this, the data is split into “training”, “testing” and “validation” data subsets. The model uses the “training” subset during learning and used the unseen subsets for validation and prediction, respectively. Validation metrics were therefore generated using a subset of the database unseen during the training process to ensure that the ANN model is not overfitting the data. In addition to cross-validation, regularization and early stopping were also used to make sure the model does not memorize the data. Further a dropout layer was placed between the input and the hidden layer, whereby the drop rate is determined solely based on random search algorithm.
The regression type ANN was evaluated using the mean squared error (MSE) that represents the squared difference between the predicted and actual value as shown in Eq. 6:
where
This section is dedicated to the obtained results. The first subsection focuses on the results of the thermal hydraulic model. This is followed by the results of the uncertainty quantification and post-processing of the generated database. Finally, the results of the ML model are presented.
The thermal hydraulic system response is validated against values reported in the APR1400 DCD (KHNP, 2014) for both steady state and transient simulations. The comparison between the MARS and the APR1400 steady state response are shown in Table 6.
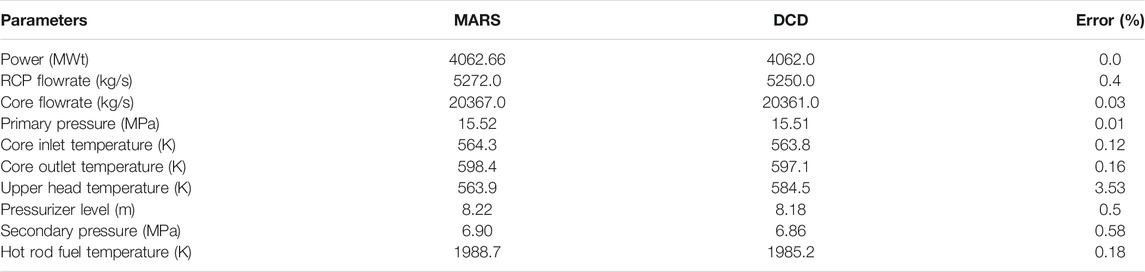
TABLE 6. Validation of steady state analysis.
Based on Table 6, the steady state simulation agrees reasonably well with the plant reference data and the calculated variables are considered to be within the acceptable error limit of less than 5% when compared to the corresponding values reported in the DCD for APR1400. For the transient simulation, key events for the LBLOCA scenario are listed and compared in Table 7.
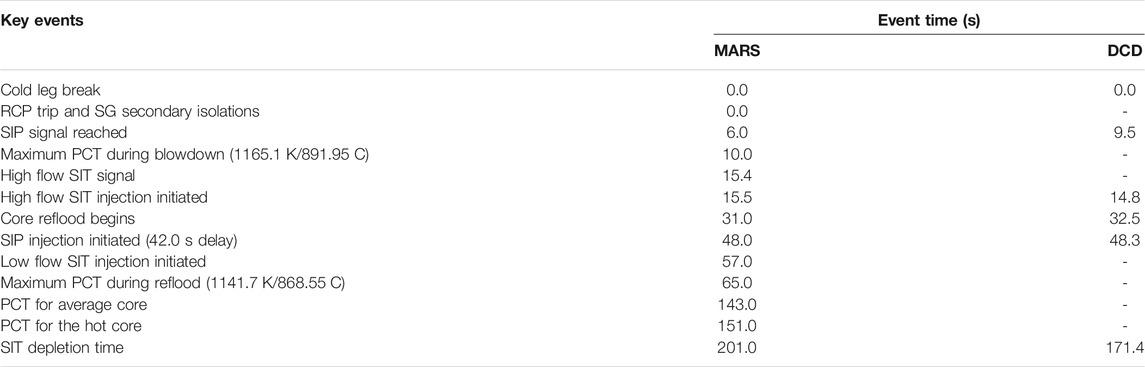
TABLE 7. Validation of the timing of key LBLOCA events.
The progression of the LBLOCA is characterized by three different phases; that is, the blowdown, refill, and reflood. At time t = 0 where blowdown phase is taking place, the RCP discharge piping starts to break with double ended guillotine break (DEGB) condition. Instantaneously, the loss of offsite power occurred causing all RCPs to coast down. For this scenario the loss of a single emergency diesel generator (EDG) unit is assumed. This leads to the loss of a single safety system train and hence the loss of two SIPs.
During the blowdown phase, the core uncovers and as a result the heat transfer coefficient drops significantly which causes the fuel cladding temperature to increase reaching a maximum of 1165.1 K (891.95°C) at ∼10 s which is still below the acceptance criterion of 1447.6 K (1204.44°C) as illustrated in Figure 2. Later on, as the decay heat drops the cladding temperature starts to decrease. Further reduction in the cladding temperature is observed due to the large condensation that occurs at the upper guide structure (UGS) and reactor vessel upper head. The condensate passes through the reactor core in reverse direction (from top to bottom) into the lower plenum and headed towards the downcomer region.
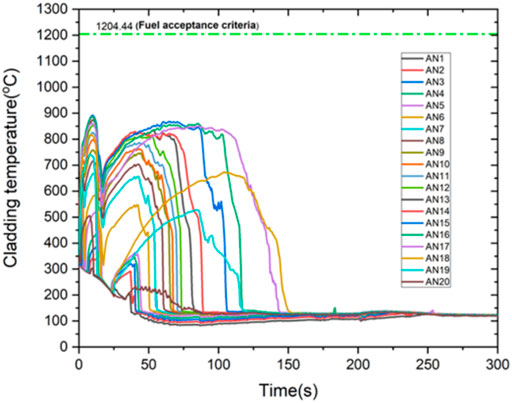
FIGURE 2. Cladding axial temperature for the hot core.
The cool down effect continues until the coolant inventory from the upper head of the reactor vessel is depleted. Once the top quenching is over, the fuel-cladding starts to reheat again approximately ∼17 s after the break due to the accumulation of decay heat. After this time, there is no longer any cooling mechanism for the core except the one initiated by the safety injection system (SIS) during the reflooding phase.
The refill period starts when the emergency coolant reaches the lower plenum of the vessel and stabilizes till is completely filled and ends when the water level in the lower plenum vessel reaches the core inlet. The SIT high-flow injection starts when the core pressure reaches the set point pressure, approximately 4.2 MPa (∼43 kg/cm2) at ∼ 17 s after the pipe break.
The emergency coolant will flow from the downcomer, towards the lower plenum and up into the core. However, even though the SIP is initiated earlier compared to the SIT because of the higher set point pressure approximately, 12.5 MPa (128 kg/cm2), the SIP starts to inject the emergency coolant at 48.0 s with a 42.0 s delay time. As such after the blowdown phase, the core is cooled initially by the UGS inventory before being assisted by the injection from the SIT followed by the SIP. This delay accounts for the time required for signal actuation time as well as the time needed to start the SIP.
The reflood phase is further subdivided into two phases: the early reflood and late reflood phases. During early reflood phase, sufficient injection from the SIS helps the downcomer to be filled up relatively quickly. However, due to the limited space available in the downcomer combined with the excess amount of emergency coolant, some of the inventory is bypassed through the pipe break regions causing inventory loss. Nonetheless, the amount of coolant available is still sufficient to maintain the core integrity.
The downcomer is nearly filled at around 50 s after the break. At this time, the water level in the downcomer region starts to stabilize as the fluidic device shifts from the high-flow injection to the low-flow injection. The low flow injection stabilizes the downcomer level as the water rises up into the core. The quench front moves vertically upwards to quench the whole core during this times. The maximum flow rate is reached approximately 30 s after the blowdown phase; while the low-flow injection will continue until 200 s. The SIP assist the low flow injection to cover and quench the core. This phase ends when the entire core is quenched from the bottom up gradually and the fuel rod temperature is slightly above the coolant saturation temperature.
During the early refill phase, the steam binding phenomenon may occur which may slow down the process. However, this effect diminishes once the vapor from the upper section of the core no longer received the de-entrainment liquid from the bottom part of the vessel at the surface of the quench front. Afterwards, the steam binding effect starts to disappear after some time which allows the reflooding phase to resume and the reactor core to be filled with water again.
The late reflood phase is marked by the SIT depletion as the SIT low-flow injection comes to an end. During this time, the task of replenishing and providing the emergency inventory for core cooling and core coverage process is achieved solely by the SIPs. The downcomer water level is maintained at a relatively constant value. Both the hot core and average core are finally quenched around 150 s without violating the fuel acceptance criterion of 1477.0 K.
Using the uncertainty quantification framework, the databases for the machine learning model was generated. The Monte Carlo random sampling technique is used to generate 5,000 runs in order to acquire a large data base for the machine learning model. The simulation is conducted using a single PC platform with 3 GHz Intel® Xeon® Gold CPU processor, with 64.0 GB random access memory (RAM), 24 parallel processors and a Windows 10 platform. The time taken to complete the simulation is approximately 3 days.
It is worth noting that, out of the 5,000 samples, only 3,556 samples were successful and used to train the machine learning model. To ensure the number of datasets is enough to represent the 95% probability and 95% confidence criteria, the mean value for the PCT is averaged over the number of samples. As seen in Figure 3, the Monte Carlo simulation stabilizes after approximately 2000 runs, hence, a sample size of the 3556 is adequate for to meet the criteria. Figure 3 shows the spread of PCT which follows a normal distribution with a mean value of 1169 K. The majority of the data are well below the PCT safety criterion of 1477 K. However, there are two data points that lie very close to the safety limit with values of 1462.3 K and 1451.8 K.
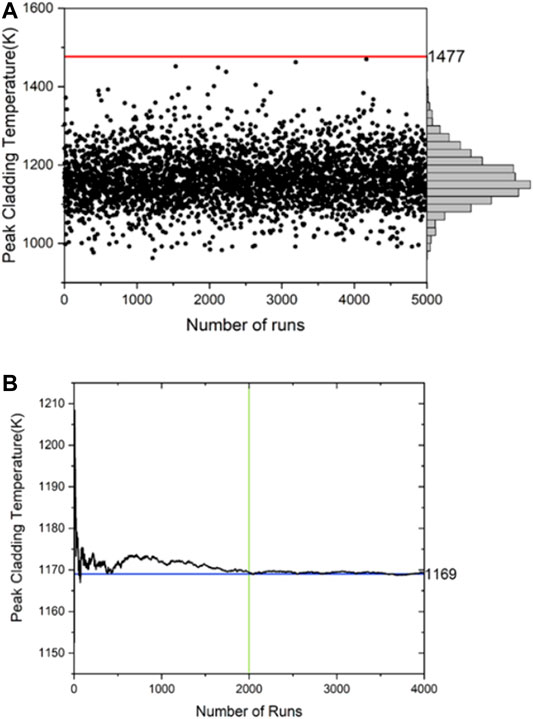
FIGURE 3. PCT convergence (A) and scatter plot (B) vs. number of runs.
As discussed earlier, 19 uncertain parameters are propagated into the thermal hydraulic model using the Dakota uncertainty framework in order to generate the PCT response under LBLOCA scenario. The independent variables are the uncertain parameters (UPs); while the dependent variable is the peak cladding temperature (PCT). However, each UP has different degree of influence towards the PCT. Hence, a sensitivity study is conducted to assess the correlation between the uncertain parameters and the PCT. Spearman’s rank correlation, which is a non—parametric measure of the statistical dependency between the variables, is used for the sensitivity analysis. Using the Spearman’s correlation coefficients, the strength and the direction of the relationship between the independent and the dependent variables can be evaluated using the following expression:
where
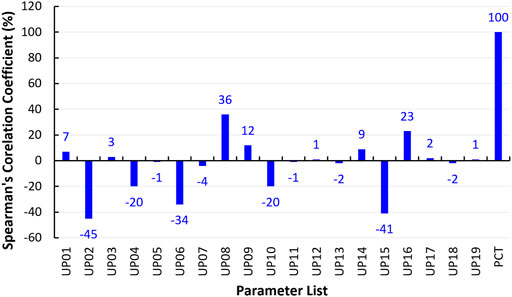
FIGURE 4. Spearman’s correlation matrix.
From the sensitivity analysis, a threshold value needs to be defined in order to choose the most significant parameters to reduce the number of inputs for the machine learning model. By selecting a threshold of ±20%, any correlation coefficient higher than the threshold value is deemed to be strongly correlated with the PCT either proportionally or inversely. However, selecting the threshold value is subjective as such it should be tested to find the best value possible.
The ANN algorithm has been successfully developed and trained using the database created via the uncertainty quantification framework. After tuning, the model was deployed using the Talos optimization tool. 20 models that differ in architectures and hyper-parameters are generated. Among those 20 models, the best model is selected based on the lowest validation metric, i.e. MSE. The final ANN structure recommended by the Talos optimization tool is composed of an input layer, three hidden layers and an output layer Table 8 shows the hyper-parameters for the selected ANN model achieving the best performance.
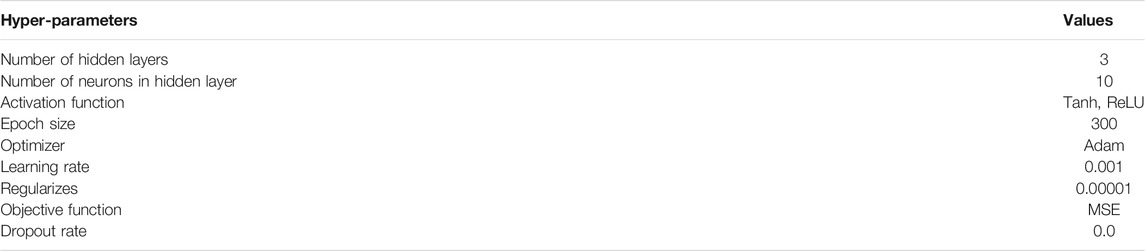
TABLE 8. Selected ANN model hyper-parameters.
The model is trained using the training subset of the available PCT database. Next, the validation dataset is used to measure the model ability to learn the salient characteristic of the data. Once the meta-model has been trained, its performance is tested using an unseen subset of data to make the predictions. Figure 5 shows a comparison between the model predictions of the PCT and the known values produced using the uncertainty quantification framework for all 19 key uncertain parameters. The ML meta-model predicts the PCT with reasonable accuracy (MSE = 0.0039); however, it tends to underestimate the high temperatures which is problematic from a safety point of view. This may be due to the fact that unnecessary data from other uncertainty parameters may confuse the ML algorithm and hence impact the model accuracy.
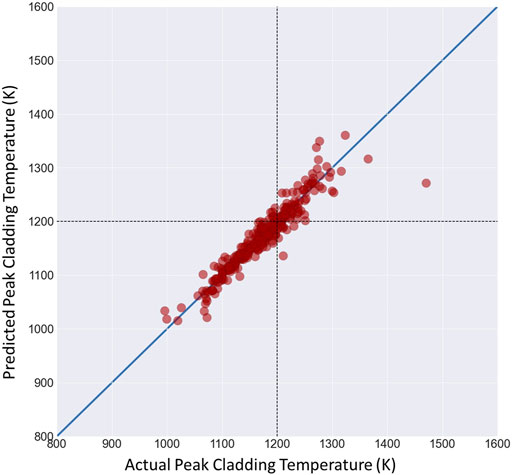
FIGURE 5. Scatter plot for PCT using 19 uncertain parameters.
However, the obtained MSE depends on the chosen input parameters. To assess the model sensitivity to the number of input parameters, the model is tested with multiple sets of inputs (5, 7, 9, 11, 17, and 19 UPs) that correspond to different threshold values for the Spearman’s correlation coefficient (i.e. level of importance to PCT). Table 9, summarizes the performance metrics of the model with different number of uncertain parameters used as inputs to the meta-model. After dimension reduction, the various cases investigated are compared to each other using a number of performance metrics: the determination coefficient (R2), the mean square error (MSE), the mean arithmetic error (MAE) and the mean logarithmic squared error (MLSE).

TABLE 9. ML model accuracy corresponding to number of input parameters.
Judging by both R2 and MSE, the model with 9 to 11 parameters achieves reasonable performance. Considering the results presented in Table 9, the lowest possible MSE is approximately 0.00185 which is obtained using 11 inputs with an R2 value of ∼0.89. When, the machine learning model is tested with nine inputs, approximately similar results are obtained with a loss function, MSE, of ∼0.00186 at an R2 value of ∼0.93. Outside this range (9 to 11 inputs) the ML model performance deteriorates. Given, the aleatory nature of the ANN model optimization which is based on random optimization, the optimum number of input parameters is expected to be within the range 9 to 11 variables with slight variation in performance metrics results (MSE ∼0.002, R2 ∼ 0.9). It is worth noting that from a safety perspective, it is better to tune the model for high temperatures.
Figure 6 shows the prediction results in comparison to the actual known PCT values with different number of input parameters. Clearly, the lower number of input parameters does not capture fully the relationship between inputs and outputs embedded in the database. On the other hand, the higher number of input parameters may include unnecessary details that may confuse the model. One would suspect an optimum number of input parameters may exist for better prediction capability as evidenced by the results shown in Table 9.
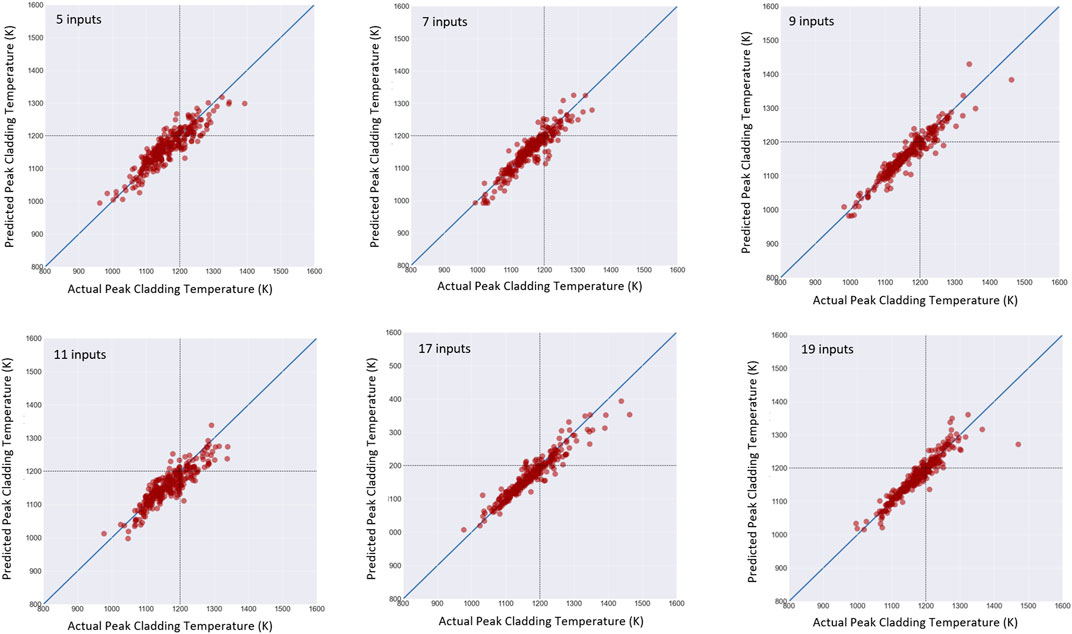
FIGURE 6. Scatter plot for PCT using different number of uncertain parameters as inputs.
The aim of this work is to develop a machine learning (ML) algorithm that is capable of accurately predicting the key safety parameter, PCT, under LBLOCA scenario. The algorithm was trained using a database created using the best estimate code MARS-KS V1.4, with uncertainty quantification using the statistical tool, Dakota to propagate the uncertainty parameters through the thermal hydraulic model. A Monte Carlo sampling method was used to generate 3,556 successful samples to train the ML model using 19 key uncertain parameters. The Monte Carlo simulation converged after 2,000 samples yielding the required average PCT in consistency with the USNRC requirement of 95% probability and 95% confidence interval.
An ANN model was developed, trained and optimized using the provided database. The ANN model was successfully tuned using the Talos optimization tool to predict the PCT with high accuracy. The optimum model is chosen based on the desirable objective function and the validations metric, MSE. A model with 9 to 11 inputs best represents the data and can be used to predict PCT accurately with a MSE of ∼0.002 with R2 value of ∼0.9.
This study successfully shows that ANN can be used as a surrogate to the thermal hydraulics MARS-KS model to predict the PCT value for the LBLOCA scenario using only the key uncertain input parameters with reasonable accuracy. For future work, the framework developed for this project can be used for uncertainty quantification of other key safety parameters such as Departure from Nucleate Boiling Ratio (DNBR) under LBLOCA or other critical scenarios. This is a preliminary step towards developing an expert support system that can be used to guide the operator actions under the stressful accident conditions. As a bounding accident scenario, the analysis of the LBLOCA case paves the way to using machine learning as a decision making tool for design extension conditions as well as severe accidents.
The datasets presented in this article may be available based on personal communication with the corresponding author. Requests to access the datasets should be directed to YXlhLmRpYWJAa2luZ3MuYWMua3I=.
CRediT authorship contribution statement: WS: Methodology, Software, Writing—original draft. AD: Conceptualization, Supervision, Analysis, Writing—review and editing.
This research was supported by the 2020 research fund of KEPCO International Nuclear Graduate School (KINGS), Republic of Korea. (Corresponding author: AD).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Abdel-Aal, R. E., and Al-Haddad, M. N. (1997). Determination of Radioisotopes in Gamma-ray Spectroscopy Using Abductive Machine Learning. Nucl. Instr. Methods Phys. Res. Section A: Acc. Spectrometers, Detectors Associated Equipment. 391 (2), 275–288. doi:10.1016/s0168-9002(97)00391-4
Adams, B. M., Bohnhoff, W. J., Dalbey, K. R., Ebeida, M. S., Eddy, J. P., Eldred, M. S., et al. (2020). Dakota, A Multilevel Parallel Object-Oriented Framework for Design Optimization, Parameter Estimation, Uncertainty Quantification, and Sensitivity Analysis: Version 6.12 User’s Manual. Albuquerque, New Mexico, USA: Sandia Technical Report; Sandia National Laboratories.
Ahsan, S. N., and Hassan, S. A. (2013). “Machine Learning Based Fault Prediction System for the Primary Heat Transport System of CANDU Type Pressurized Heavy Water Reactor,” in 2013 International Conference on Open Source Systems and Technologies Lahore. doi:10.1109/icosst.2013.6720608
Alketbi, S., and Diab, A. (2021). Using Artificial Intelligence to Identify the Success Window of FLEX Strategy Under an Extended Station Blackout. Nucl. Eng. Des. 382 (2021), 111368. doi:10.1016/j.nucengdes.2021.111368
Autonomio Talos [Computer software] (2019). Retrieved from http://github.com/autonomio/talos.
Bae, I. H., Na, M. G., Lee, Y. J., and Park, G. C. (2008). Calculation of the Power Peaking Factor in a Nuclear Reactor Using Support Vector Regression Models. Ann. Nucl. Energ. 35, 2200–2205. doi:10.1016/j.anucene.2008.09.004
Chai, J., Sisk, D. R., Bond, I. J., Jarrel, D. B., HatelyMeador, D. D. R. J., and Koehler Watkins Kim, T. M. K. S. W. (2003). On-line Intelligent Self-Diagnostic Monitoring System for Next Gernaeration Nuclear Power Plants. Southwest Washington, D.C., USA: United States Department of Energy.
Chang, Y., Wang, M., Zhang, J., Tian, W., Qiu, S., and Su, G. H. (2020). Best Estimate Plus Uncertainty Analysis of the China Advanced Large-Scale PWR during LBLOCA Scenarios. Int. J. Adv. Nucl. Reactor Des. Technology. 2, 34–42. doi:10.1016/j.jandt.2020.07.002
Chen, F.-C., and Jahanshahi, M. R. (2018). NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Trans. Ind. Electron. 65 (5), 4392–4400. doi:10.1109/tie.2017.2764844
Chen, L., and Wei, Y.-X. (2009). Nuclide Identification Algorithm Based on K-L Transform and Neural Networks. Nucl. Instr. Methods Phys. Res. Section A: Acc. Spectrometers, Detectors Associated Equipment. 598 (2), 450–453. doi:10.1016/j.nima.2008.09.035
Chollet, F. (2015). Keras. GitHub. Retrieved from https://github.com/fchollet/keras.
Devereux, M., Murray, P., and West, G. (2020). A New Approach for Crack Detection and Sizing in Nuclear Reactor Cores. Nucl. Eng. Des. 359. doi:10.1016/j.nucengdes.2019.110464
Erdogan, A., and Gekinli, M. (2003). A PWR Reload Optimization Code (XCORE) Using Artificial Neural Networks and Genetic Algorithms. Ann. Nucl. Energ. 30 (1), 35–53. doi:10.1016/S0306-4549(02)00041-5
Farber, J. A., and Cole, D. G. (2020). Detecting Loss-Of-Coolant Accidents Without Accident-Specific Data. Prog. Nucl. Energ. 128, 103469. doi:10.1016/j.pnucene.2020.103469
Faria, E. F., and Pereira, C. (2003). Nuclear Fuel Loading Pattern Optimisation Using a Neural Network. Ann. Nucl. Energ. 30 (5), 603–613. doi:10.1016/s0306-4549(02)00092-0
Farshad Faghihi, K. H., and Seyed, M. (2011). A Literature Survey of Neutronics and Thermal-Hydraulics Codes for Investigating Reactor Core Parameters: Artificial Neural Networks as the VVER-1000 Core Predictor, Chapter 6. Nuclear Power Systems Simulations and Operations. Shanghai, China: InTech, 103–122.
Geron (2019). Hands on Machine Learning with Scikit Learn, Keras & Tensorflow. Seebastopol: O'Reilly Publisher.
Gomez Fernandez, M., Tokuhiro, A., Welter, K., and Wu, Q. (2017). Nuclear Energy System's Behavior and Decision Making Using Machine Learning. Nucl. Eng. Des. 324, 27–34. doi:10.1016/j.nucengdes.2017.08.020
Gomez-Fernandez, M., Higley, K., Tokuhiro, A., Welter, K., Wong, W.-K., and Yang, H. (2020). Status of Research and Development of Learning-Based Approaches in Nuclear Science and Engineering: A Review. Nucl. Eng. Des. 359, 110479. doi:10.1016/j.nucengdes.2019.110479
IAEA (2020). Emerging Technologies Workshop Insight and Actionable Ideas for Key Safeguards Challenge. Vienna: International Atomic Energy Agency.
KAERI (2004). MARS Code Manual Volume 1 : Code Structure, System Models and Solution Methods. Daejeon: Korea Atomic Energy Research Institute.
KAERI (2009). “MARS Code Manual,” KAERI/TR2812/2004 Korea. Daejon: Atomic Energy Research Institute.
Kamuda, M., and Sullivan, C. J. (2019). An Automated Isotope Identification and Quantification Algorithm for Isotope Mixtures in Low-Resolution Gamma-ray Spectra. Radiat. Phys. Chem. 155, 281–286. doi:10.1016/j.radphyschem.2018.06.017
Kang, D. G. (2016). Analysis of LBLOCA Using Best Estimate Plus Uncertainties for Three-Loop Nuclear Power Plant Power Uprate. Ann. Nucl. Energ. 90, 318–330. doi:10.1016/j.anucene.2015.12.017
Keller, P. E., and Kouzes, R. T. (1994). Gamma Spectral Analysis via Neural Networks. Proc. 1994 IEEE Nucl. Sci. Symp. 1 1, 341–345. doi:10.1109/NSSMIC.1994.474365
KEPCO (2014). Design Control Document Chapter 15: Transient and Accident Analysis. Daejeon: Korea Electric Power Corporation.
KHNP (2014). Design Control Document Chapter 15 Transient and Accident AnalysesKorea Hydro and Nuclear Power.
Park, H. M., Lee, J. H., and Kim, K. D. (2020). Wall Temperature Prediction at Critical Heat Flux Using a Machine Learning Model. Ann. Nucl. Energ. 141, 2020. doi:10.1016/j.anucene.2020.107334
Lee, C.-J., and Lee, K. J. (2006). Application of Bayesian Network to the Probabilistic Risk Assessment of Nuclear Waste Disposal. Reliability Eng. Syst. Saf. 91, 515–532. doi:10.1016/j.ress.2005.03.011
Lee, S. W., Chung, B. D., Bang, Y.-S., and Bae, S. W. (2014). Analysis of Uncertainty Quantification Method by Comparing Monte-Carlo Method and Wilks' Formula. Nucl. Eng. Technology. 46 (4), 481–488. doi:10.5516/net.02.2013.047
Lin, Z., Liu, X., Lao, L., and Liu, H. (2020). Prediction of Two-Phase Flow Patterns in Upward Inclined Pipes via Deep Learning. Energy 210, 118541. doi:10.1016/j.energy.2020.118541
Ma, J., and Jiang, J. (2011). Applications of Fault Detection and Diagnosis Methods in Nuclear Power Plants: A Review. Prog. Nucl. Energ. 53 (3), 255–266. doi:10.1016/j.pnucene.2010.12.001
Martin, R. P., and O'Dell, L. (2008). Development Considerations of AREVA NP Inc.'s Realistic LBLOCA Analysis Methodology. Sci. Technology Nucl. Installations. 13. doi:10.1155/2008/239718
Montes, J. L., François, J. L., Ortiz, J. J., Martín-del-Campo, C., and Perusquía, R. (2009). Local Power Peaking Factor Estimation in Nuclear Fuel by Artificial Neural Networks. Ann. Nucl. Energ. 36 (1), 121–130. doi:10.1016/j.anucene.2008.09.011
Musoiu, R., Mihaela, R., Prisecaru, L., and Allison, C. (2019). “BEPU Approach in the CANDU 6 Severe Accident Analysis,” 2019 International Conference on ENERGY and ENVIRONMENT (CIEM), 73–77. doi:10.1109/ciem46456.2019.8937571
Na, M., Ho Shin, S., Mi Lee, S., Jung, D. W., Pyung Kim, S., Jeong, J., et al. (2004). Prediction of Major Transient Scenarios for Severe Accidents of Nuclear Power Plants. Nucl. Sci. IEEE Trans. 51 (5), 313–321. doi:10.1109/tns.2004.825090
Nissan, E. (2019). An Overview of AI Methods for In-Core Fuel Management: Tools for the Automatic Design of Nuclear Reactor Core Configurations for Fuel Reload, Arranging and Partly Spent Fuel. Designs 3 (3), 37. doi:10.3390/designs3030037
OECD (1998). Report on the Uncertainty Method Study. Paris, France: Organisation for Economic Co-operation and Development.
OECD (2007a). BEMUSE Phase III Report Uncertainty and Sensitivity Analysis of the LOFT L2-5 Test. Paris, France: Organisation for Economic Co-operation and Development.
OECD (2007b). Task Group on Safety Margin Action Plan (SMAP) Safety Margin Action Plan - Final Report. Paris, France: Organisation for Economic Co-operation and Development.
Petruzzi, M., Cherubini, M., D'Auria, F., Lanfredini, M., and Mazzantini, O. (2016). The BEPU Evaluation Model with RELAP5-3D for the Licensing of the Atucha-II NPP. Nucl. Technology. 193, 51. doi:10.13182/nt14-145
Pinheiro, V., Santos, M., Desterro, F., Schirru, R., Márcio, C., and Pereira, N. A. (2020). “Nuclear Power Plant Accident Identification System With “Don’t Know” Response Capability: Novel Deep Learning-Based Approaches”. Ann. Nucl. Energ. 137, 107111. doi:10.1016/j.anucene.2019.107111
Queral, C., Montero-Mayorga, J., Gonzalez-Cadelo, J., and Jimenez, G. (2015). AP1000 Large-Break LOCA BEPU Analysis With TRACE Code. Ann. Nucl. Energ. 85, 576–589. doi:10.1016/j.anucene.2015.06.011
Rani Patra, S., Jehadeesan, R., Rajeswari, S., Banerjee, I., A. V Satya Murty, S., Padmakumar, G., et al. (2012). Neural Network Modeling for Evaluating Sodium Temperature of Intermediate Heat Exchanger of Fast Breeder Reactor. Ac. 2, 16–22. doi:10.5923/j.ac.20120202.03
Ridlluan, A., Manic, M., and Tokuuhiro, A. (2009). EBaLM-HTP- A Neural Network Thermohydraulic Prediction Model of Advanced Nuclear System Components. Nucl. Eng. Des. 239 (2), 308–319. doi:10.1016/j.nucengdes.2008.10.027
Santosh, G., Babar, A. K., Kushwaha, H. S., and Venkat Raj, V. (2003). Symptom Based Diagnostic System for Nuclear Power Plant Operations Using Artificial Neural Networks. Reliability Eng. Syst. Saf. 82 (1), 33–40. doi:10.1016/s0951-8320(03)00120-0
Siegelmann, H. T., Nissan, E., Nissan, E., and Galperin, A. (1997). A Novel Neural/symbolic Hybrid Approach to Heuristically Optimized Fuel Allocation and Automated Revision of Heuristics in Nuclear Engineering. Adv. Eng. Softw. 28 (9), 581–592. doi:10.1016/s0965-9978(97)00040-9
USNRC (1988). Development of a Phenomena Identification and Ranking Table for Thermal Hydraulic Phenomena during PWR LBLOCA. Washington, DC, USA: United State Nuclear Regulatory Comission.
USNRC (1989). USNRC Regulatory Guide 1.157 Best Estimate Calculation of Emergency Core Cooling System Performance. Washington, DC, USA: U.S Office of Nuclear Regulatory Research.
Young, D. K., Ye, J. A., Chang-Hwoi, K., and Man, G. N. (2019). Nuclear Reactor Vessel Water Level Prediction During Severe Accidents Using Deep Neural Networks. Nucl. Eng. Technology. 51 (3), 723–730. doi:10.1016/j.net.2018.12.019
Keywords: nuclear safety, large break LOCA, artificial neural network, machine learning, uncertainty quantification, peak cladding temperature
Citation: Sallehhudin W and Diab A (2021) Using Machine Learning to Predict the Fuel Peak Cladding Temperature for a Large Break Loss of Coolant Accident. Front. Energy Res. 9:755638. doi: 10.3389/fenrg.2021.755638
Received: 09 August 2021; Accepted: 21 September 2021;
Published: 08 October 2021.
Edited by:
Xingang Zhao, Oak Ridge National Laboratory (DOE), United StatesReviewed by:
Yue Jin, Massachusetts Institute of Technology, United StatesCopyright © 2021 Sallehhudin and Diab. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Aya Diab, YXlhLmRpYWJAa2luZ3MuYWMua3I=, YXlhLmRpYWJAZW5nLmFzdS5lZHUuZWc=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.