 Jie Gong1,2
Jie Gong1,2 Min Liu
Min Liu Fan Deng
Fan Deng
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Earth Sci. , 06 July 2023
Sec. Hydrosphere
Volume 11 - 2023 | https://doi.org/10.3389/feart.2023.1226451
This article is part of the Research Topic Risk Assessment and Management of Water Conservancy Projects View all 16 articles
Identifying snow phenomena in images from automatic weather station (AWS) is crucial for live weather monitoring. In this paper, we propose a convolutional neural network (CNN) based model for snow identification using images from AWS cameras. The model combines the attention mechanism of the DANet model with the classical residual network ResNet-34 to better extract the features of snow cover in camera images. To improve the generalizability of the model, we also use images from public datasets in addition to images taken by cameras from unmanned weather stations. Our results show that the proposed model achieved a POD of 91.65%, a FAR of 7.34% and a TS score of 85.45%, demonstrating its effectiveness in snow identification. This study has the potential to facilitate more efficient and effective weather monitoring in a variety of locations.
The formation of snow is a complex process influenced by various meteorological factors at the ground level (Yang et al., 2019). Snow is a major winter disaster that can result in extensive accumulation, which can damage crops and disrupt transportation (Andrey et al., 2003). However, the occurrence and intensity of snow vary greatly at a local level, making it difficult to predict using traditional statistical methods (Strle and Ogrin, 2022). Therefore, accurate identification of snow weather from images is crucial for understanding these variations and improving real-time weather monitoring.
Satellite observations from space provide a major data source for identifying different types of weather, including rain, clouds, and snow. Many image processing and recognition algorithms have been developed based on different satellite and ground radar remote sensing data to identify snow surface cover or weather phenomena such as snow or rain. For multispectral satellite images, the Normalized Difference Snow Index (NDSI) is often used to identify snow because it is sensitive to snow signals in the image (Song et al., 2011). Satellite-borne passive microwave radiometers have been used to retrieve snow depth on Arctic sea ice using lower frequencies and artificial neural networks (Rostosky et al., 2018) (Zaerpour et al., 2020). Although satellite images are useful for weather monitoring at regional, continental, and global scales, they have relatively coarse spatial resolutions and are not suitable for real-time weather identification (Liang et al., 2008; Jiang et al., 2014; Getirana et al., 2020).
Compared to satellite sensors, AWS provide a different method for weather identification in local areas. AWS have become essential infrastructure for urban meteorological forecasting, disaster prevention, and mitigation in many countries (Lu et al., 2020). They are usually equipped with video and meteorological equipment, making them more suitable for monitoring real-time weather at a local scale (Munandar et al., 2017). While meteorological equipment captures meteorological parameters such as temperature and humidity, video captures sequence images of the surroundings, enabling the identification of different types of weather (Kumari et al., 2020).
Traditional manual identification methods suffer from low efficiency and are not conducive to conducting large-scale data analysis. Consequently, automatically identifying snow weather from video images is valuable but challenging for real-time weather identification. Many image classification methods, such as supervised support vector machines, have been used to identify local weather phenomena (Roser and Moosmann, 2008). The NDSI is widely used for ice and snow identification, and some studies have also developed a similar RGBNDSI index for snow identification in RGB images (Hinkler et al., 2002). However, these methods often require a specially designed camera system and careful arrangement of the camera position and shooting angle to observe specific targets. There is also the use of blue channel thresholding for snow and non-snow recognition in RGB images, which is based on the digital number value of blue channel component histogram (Salvatori et al., 2011). This method is sensitive to lighting conditions, surface roughness, and the distance from the camera (Härer et al., 2013).
The identification of snow in video images obtained by meteorologists is a challenging task due to issues such as deformation, illumination, and blur. In recent years, deep learning methods, particularly convolutional neural networks (CNNs), have emerged as effective alternatives to traditional machine learning algorithms for extracting semantic information from images (Ibrahim et al., 2019). One example of a CNN-based method is the Faster R-CNN approach, which uses a region generation network to directly determine the region for image identification (Ren et al., 2017). The Inception V3 model of Google Inception has also been applied to CNNs for snow cover identification from video images taken by weather stations (Huang et al., 2019). Despite their effectiveness, there is still room for improvement in CNN models. In recent years, attention mechanisms have gained significant attention in the deep learning community. These modules allow CNNs to focus on relevant regions or features, leading to improved performance (Li et al., 2020). The limitation of insufficient training data poses a challenge in CNN applications, as models may struggle to generalize well (Alzubaidi et al., 2021).
However, there are still challenges to be addressed in this field. For instance, current methods do not fully exploit local snow cover information, and the incorporation of attention modules into different features may be necessary as CNNs continue to evolve. Additionally, the construction of CNNs for snow identification should consider the use of various open-source images containing different weather phenomena, as the limited images captured by each AWS camera at a fixed angle, height, and view may not be representative of the full range of snow and other weather phenomena.
This paper presents a novel CNN-based approach for snow identification in AWS images. The proposed method has two main advantages compared to previous models. Firstly, it utilizes an attention convolutional neural network model, specifically a double attention network (DANet), to enhance the accuracy of snow identification. By incorporating both channel attention and spatial attention, the DANet can focus on the target area of snow in the global image and suppress irrelevant information. Secondly, the proposed method is based on open-source weather images, rather than video images from a single camera, as in previous studies. The performance of the DANet was evaluated using a dataset of more than 20,000 images and compared to traditional CNN models. The results demonstrate the effectiveness of the proposed approach in accurately identifying snow in unattended AWS images.
The study area is located in Wuhan, China, which is situated in the middle reaches of the Yangtze River. Wuhan has a subtropical monsoon climate with four distinct seasons, and experiences frequent occurrences of snow and rime in the winter months. The research utilized video images of snow captured by a weather station located in the Dongxihu district of Wuhan (30°60′ N, 114°05′ E). The station’s camera, which has a fixed shooting angle and a shooting distance of approximately 50 m, was used to provide the images for snow identification.
The video images used for snow identification in this study were obtained from the camera of an automatic meteorological observation station at the Wuhan weather station. The snow images were collected between Beijing local time 11:00 and 15:30, and from 18:00 to 21:00 on 29 December 2020, when there was snow in Wuhan. The non-snow images were from 14 December 2020, and were also taken from the same camera at the Wuhan weather station. Images of the ground covered in snow or experiencing ongoing snowfall are manually labeled as snow images. A total of 1,000 images with or without snow labels were extracted from the video data by automatically selecting every 10th frame, forming the test dataset for this study. The images have a resolution of 2,048 × 1,536 pixels and were resized to 600 × 400 pixels for computation efficiency.
The location and climatic conditions of Wuhan Station are particularly distinctive, with a scarcity of significant snowfall events, making it challenging to acquire a comprehensive dataset of snow-related images. Consequently, this study aims to address this limitation by selecting publicly available weather datasets as the training data and leveraging real-time observational data for testing and precision evaluation purposes. Among them, the positive samples consist of 10,000 images depicting snowy weather conditions, while the negative samples encompass 2,000 images each of clear, rainy, foggy, cloudy, and thunderstorm weather phenomena.
The flowchart of the proposed snow identification network based on the attention convolutional neural network is shown in Figure 1. It can be divided into a data preparation module and a snow identification module. In the data preparation module, the open-source weather image set is used to construct the training and validation sets for neural network training. The total sample is split into a training set and a validation set in a 4:1 ratio. The images are normalized and standardized to improve numerical stability during backpropagation and accelerate the convergence of the neural network. In the snow identification module, the residual network model (ResNet-34) is used for image convolution and deep semantic feature extraction to obtain the convolutional snow feature map. ResNet-34 consists of 34 layers, with the majority being 3 × 3 convolutional layers. It incorporates residual learning and skip connections to address the degradation problem in deep networks. Then, the attention module, including position and channel attention, is used to focus on the snow feature for snow identification. The position attention module performs position-weighted summation on the convolutional layer, while the channel attention module performs channel-dependent correlation on the same convolutional layer. Both pixel feature maps obtained from these processes are superimposed pixel-wise, focusing simultaneously on the most salient position and channel characteristics in the image. Finally, the fully connected layer is used for snow identification. An image with a probability greater than 0.5 is identified as a snow image, while an image with a probability less than 0.5 is identified as a non-snow image. The details of the various modules are described in the following sections.
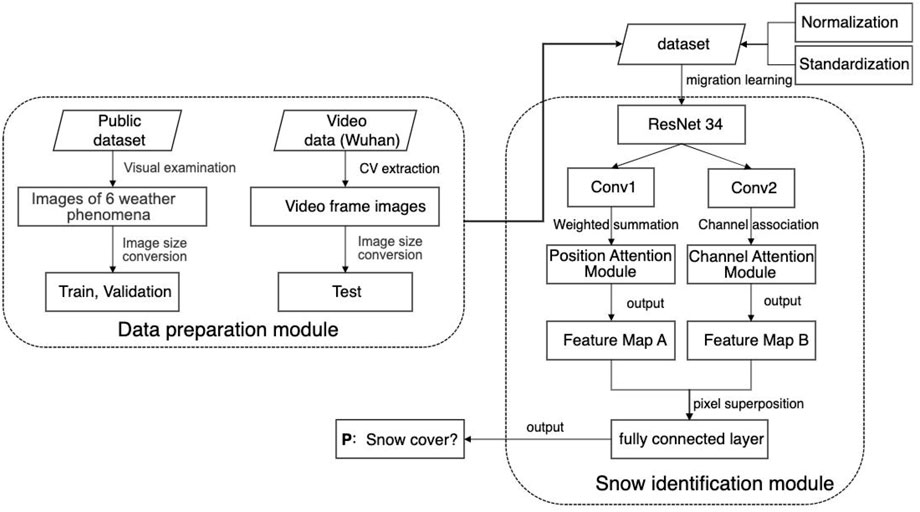
FIGURE 1. Snow identification network based on attention convolutional neural network.
The residual network (ResNet) is a convolutional neural network that addresses the problem of gradient explosion and network recession in the Visual Geometry Group (VGG) algorithm by adding residual units to the deep neural network. ResNets have been shown to improve identification accuracy and are well-suited for practical scenarios (Glorot et al., 2011; He et al., 2016). ResNets are a popular choice for feature extraction and classification, and can be divided into various structures based on their convolutional depth, including ResNet-18, ResNet-34, ResNet-50, ResNet-101, and ResNet-152. In this paper, the ResNet-34 structure is adopted, which consists of a 7 × 7 × 64 convolutional layer, 16 blocks of residual modules each composed of two convolutional layers, and a fully connected layer. The network structure of ResNet-34 is shown in Figure 2.
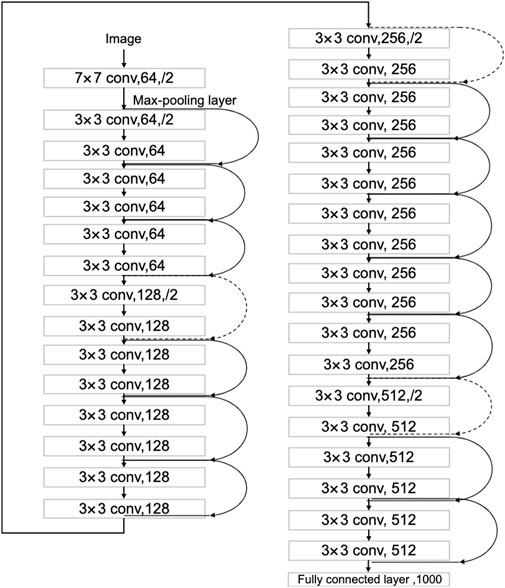
FIGURE 2. ResNet-34 network structure.
The DANet model, introduced in CVPR 2019 (Xue et al., 2019), uses deep semantic information about snow extracted by ResNet-34 to adaptively integrate local and global features. This is achieved through the use of two modules: a position attention module and a channel attention module. The position attention module allows the network to selectively focus on the features of individual positions by using weighted summation. The channel attention module emphasizes the interrelated channel graph by combining relevant features from all channel graphs. The feature graphs produced by these two modules are combined to enhance the representation of snow cover features.
To address the issue of lacking sensitivity in detecting local features of snow due to CNN convolution and pooling, a position attention module is used to extract more context information about these local features. This allows the network to more efficiently focus on and better detect both large- and small-scale features of snow. The position attention module is illustrated in Figure 3. It takes in a local feature map (A) with dimensions of C × H × W. The module then generates two feature maps (B and C) through a convolution layer, which have dimensions of C × H × W. The dimensions of B and C are changed to C × N, where N is the number of pixels (N = H × W). B is transposed and multiplied with C, and the softmax function is used to calculate the spatial attention map (S) (Eq. 1) with dimensions of N × N (Liu et al., 2016). The map helps the network focus on specific parts of the feature map, which has dimensions of C × H × W.
where
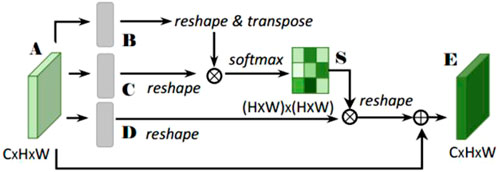
FIGURE 3. Position attention module.
The feature map D is created in a similar way to feature maps B and C, through a convolution and a change in dimensions. It has dimensions of C × H × W. Then, D and S are multiplied and transformed through transposition and a change in dimensions. The resulting map is multiplied by a scale parameter (α) and added to the original feature map A, resulting in the final output feature map E (Eq. 2) with dimensions of C × H × W.
where the scale parameter (α) is initially set to 0 and gradually learns to assign more weight to certain features. In Eq. 2, all the points on the E feature map are the weighted sum of features from all positions and the original features, allowing the network to obtain a large amount of global information and selectively focus on local features according to the spatial attention map. This helps to better express similar features, leading to increased compactness and semantic consistency within the class.
Each high-dimensional feature channel mapping can be thought of as a specific response to a particular class, and there should be a relationship between the information between classes. To better understand this interdependence and emphasize interdependent feature mappings, a channel attention module is used to explicitly model the relationship between channels in order to improve the representation of original features. This module is shown in Figure 4.

FIGURE 4. Channel attention module.
Unlike the position attention module, the channel attention module directly calculates feature map X with dimensions of C × C from feature map A with dimensions of C × H × W. To do this, the dimensions of A are transformed and multiplied with a matrix of A, and the resulting map is passed through the softmax function (Eq. 3) to generate the final feature map X.
where
In addition, matrix multiplication is used to transform feature map X and multiply it with the transpose of feature map A. The resulting map has dimensions of C × H × W, similar to the scale parameter α. A new scale parameter (β) is introduced for this multiplication, and the result is added to the pixels of feature map A to produce the final feature map E (Eq. 4) with dimensions of C × H × W.
In Eq. 4, the final feature of each channel is the weighted sum of all channel features and original features, using a scale parameter (β) that starts at zero and gradually learns to assign more weight. This helps to strengthen the relationship between different channel feature maps and improve the representation of distinctive features of snow by emphasizing the rich semantic dependence between channels.
To fully incorporate information about spatial context, local details, and class information, this paper combines the features from the location and channel attention modules. The output of these two modules is mapped to the same feature map through a convolution layer and then combined by adding their respective pixels. Finally, the snow is identified through a fully connected layer, namely:
where
The hyperparameters for the DANet model, including the number and size of layers, convolution kernel size and step length, pooling window size and step length, regularization weight, learning rate, node loss rate, and batch size, are listed in Table 1. The network is constructed using Linear, ReLU, Normalization, and Dropout layers. The Adam optimization algorithm and a learning rate attenuation technique are used to speed up the convergence of the model. The learning rate is continuously adjusted during training to reduce and stabilize the loss value. Specifically, the model is trained in 80 batches, with a learning rate of 10–2 for the first 20 batches, 10–3 for batches 21–40, 10–4 for batches 41–60, and 10–5 for batches 61–80.
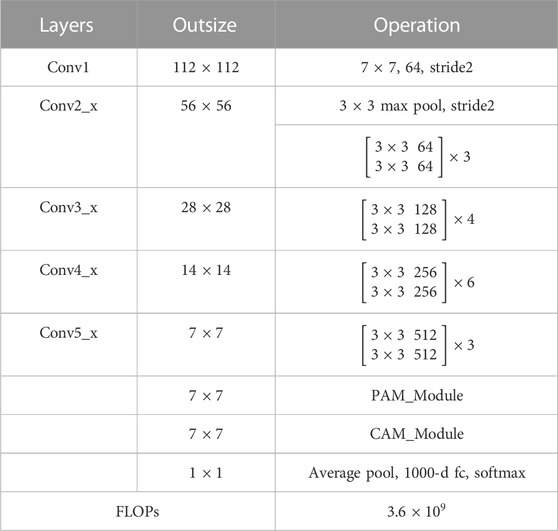
TABLE 1. DANet model parameter change table.
This paper used a total of 8,000 snow images and 8,000 non-snow images to train the proposed DANet model, and 2,000 snow images and 2,000 non-snow images were used for validation. 2,000 images from the AWS were used for model testing (Table 2). The performance of the model was evaluated using the Probability of Detection (POD) (Eq. 6), False Alarm Rate (FAR) (Eq. 7), and Threat Score (TS) (Eq. 8).
where TP (true positive) is the number of forecasts and observations that are both true, FN (false negative) is the number of false forecasts and true observations, and FP(false positive) is the number of true forecasts and false observations.
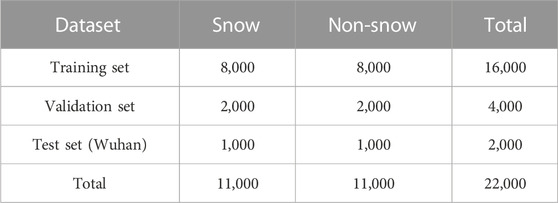
TABLE 2. Distribution of snow and non-snow images in datasets.
This paper evaluated the trained DANet model using a validation image set and a separate test image set. Images were classified as snow if they had a probability of higher than 50% and classified as non-snow if they had a probability of less than 50%. The addition of the attention module led to significant improvements in the overall TS and POD of the model, as indicated by the results (Table 3). However, it is worth noting that FAR also increased with the inclusion of the attention module. The FAR increased because the model occasionally recognized fuzzy features similar to snow as actual snow, leading to false positive judgments (Figure 5).
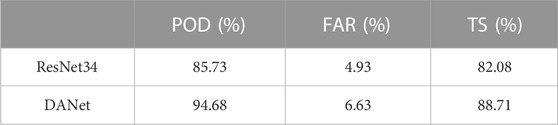
TABLE 3. Comparison of verification accuracy between ResNet and DANet models.

FIGURE 5. Missing judgment images and false alarm images at Wuhan station at night.
The accuracy metrics for the proposed DANet model are shown in Table 4. According to the test data, POD is 91.65%, FAR is 7.34%, the TS score is 85.45%. These high accuracy scores demonstrate the efficiency of the proposed model in snow identification. The majority of the missing alarm errors occurred at night, with 75.6% of the 84 mission alarm images being captured during the night. Similarly, 69.1% of the 73 false alarm images were also captured at night. This is likely due to the strong contrast between night and daytime, as well as the camera shake in windy conditions causing some images to be unclear.
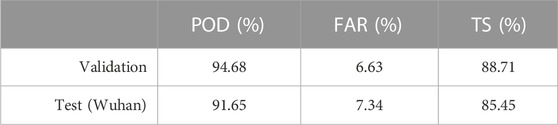
TABLE 4. Accuracy evaluation of the DANet model.
According to the test results at the Wuhan station, the TS score was higher than 85%. The trained model was able to effectively extract the features of snow and positively impact snow identification. However, the winter weather in Wuhan can be unstable, so it is recommended to increase the observation time in the modelling process to ensure continuous snow weather phenomena and improve accuracy. In cases where sufficient data is available, it is recommended to use a “one station one model” approach, which involves creating a separate model for each station. This can help to better capture the unique characteristics of the snow at each station.
In order to improve real-time weather monitoring, it is important to develop methods for accurately identifying snow in local areas. AWS equipped with video offers one potential approach to this problem. In this paper, we address the problem of recognizing weather phenomena from images at meteorological stations, and propose improvements through the use of open-source weather images and double attention mechanisms.
The result shows that using an attention convolutional neural network (CNN) with channel and position attention modules can improve the accuracy of snow identification. When compared to a traditional CNN model, the attention module CNN resulted in a 6.63% increase in the TS score and a 8.95% increase in the POD. The attention module is able to focus on specific areas and extract relevant details while ignoring unnecessary information, leading to better classification performance. Additionally, our proposed method simplifies the process of training the CNN by using an open-source weather image set rather than relying on a large amount of video camera images, which can be difficult to obtain and time-consuming. This proposed DANet model has demonstrated the ability to handle images from various AWS cameras with different viewing angles and heights, making it a potentially suitable tool for identifying weather phenomena globally. The proposed improvements in this study have not only advanced the field of meteorological image and video analysis, but also have practical value for widespread use and implementation at meteorological stations.
Further research could explore the application of this model to other types of weather phenomena and in different environments, as well as investigate ways to optimize and refine the model for improved performance.
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
JG: conceptualization and writing-original draft. FD: conceptualization, writing-review and editing and funding acquisition. YW: data curation. ML: data curation. All authors contributed to the article and approved the submitted version.
The project is supported by the Open Fund of Key Laboratory of Urban Land Resources Monitoring and Simulation, Ministry of Natural Resources.
We thank Li Xiaodong for help in reviewing and editing the English language and grammar.
Authors JG, YW, and FD were employed by Wuhan Huaxin Lianchuang Technology Engineering Co., Ltd.
The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Alzubaidi, L., Zhang, J., Humaidi, A. J., Al-Dujaili, A., Duan, Y., Al-Shamma, O., et al. (2021). Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. big Data 8, 53–74. doi:10.1186/s40537-021-00444-8
Andrey, J., Mills, B., Leahy, M., and Suggett, J. (2003). Weather as a chronic hazard for road transportation in Canadian cities. Nat. hazards 28 (2), 319–343. doi:10.1023/a:1022934225431
Getirana, A., Kirschbaum, D., Mandarino, F., Ottoni, M., Khan, S., and Arsenault, K. (2020). Potential of GPM IMERG precipitation estimates to monitor natural disaster triggers in urban areas: The case of rio de Janeiro, Brazil. Remote Sens. 12 (24), 4095. doi:10.3390/rs12244095
Glorot, X., Bordes, A., and Bengio, Y. “Deep sparse rectifier neural networks,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics, Fort Lauderdale, FL, USA, April 2011, 315–323.JMLR Workshop Conf. Proc.
Härer, S., Bernhardt, M., Corripio, J. G., and Schulz, K. (2013). Practise–photo rectification and classification software (v. 1.0). Geosci. Model Dev. 6 (3), 837–848. doi:10.5194/gmd-6-837-2013
He, K., Zhang, X., and Ren, S., “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, June 2016, 770–778.
Hinkler, J., Pedersen, S. B., Rasch, M., and Hansen, B. U. (2002). Automatic snow cover monitoring at high temporal and spatial resolution, using images taken by a standard digital camera. Int. J. Remote Sens. 23 (21), 4669–4682. doi:10.1080/01431160110113881
Huang, X. Y., Zhang, Y., and Ye, C. Z. (2019). Research on artificial intelligence observation and identification of snow cover weather phenomenon on surface. Meteor Mon. 45 (9), 1189–1198. doi:10.7519/j.issn.1000-0526.2019.09.001
Ibrahim, M. R., Haworth, J., and Cheng, T. (2019). WeatherNet: Recognising weather and visual conditions from street-level images using deep residual learning. ISPRS Int. J. Geo-Information 8 (12), 549. doi:10.3390/ijgi8120549
Jiang, L. M., Wang, P., Zhang, L. X., Yang, H., and Yang, J. (2014). Improvement of snow depth retrieval for FY3B-MWRI in China. Sci. China Earth Sci. 57 (6), 1278–1292. doi:10.1007/s11430-013-4798-8
Kumari, N., Gosavi, S., and Nagre, S. S. “Real-time cloud based weather monitoring system,” in Proceedings of the 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, March 2020, 25–29.
Li, W., Liu, K., Zhang, L., and Cheng, F. (2020). Object detection based on an adaptive attention mechanism. Sci. Rep. 10 (1), 11307. doi:10.1038/s41598-020-67529-x
Liang, T. G., Huang, X. D., Wu, C. X., Liu, X., Li, W., Guo, Z., et al. (2008). An application of modis data to snow cover monitoring in a pastoral area: A case study in northern xinjiang, China. Remote Sens. Environ. 112 (4), 1514–1526. doi:10.1016/j.rse.2007.06.001
Liu, W., Wen, Y., Yu, Z., et al. “Large-margin softmax loss for convolutional neural networks,” in Proceedings of the International Conference on Machine Learning. PMLR, New York NY USA, June 2016, 507–516.
Lu, Z., Peng, B., Zhao, C., and Liu, Z. (2020). Research on unattended implementation of surface meteorological observation and its guarantee method. Meteorological Hydrological Mar. Instrum. 37 (02), 14–18. doi:10.3969/j.issn.1006-009X.2020.02.004
Munandar, A., Fakhrurroja, H., and Rizqyawan, M. I.“Design of real-time weather monitoring system based on mobile application using automatic weather station,” in Proceedings of the 2017 2nd International Conference on Automation, Cognitive Science, Optics, Micro Electro-Mechanical System, and Information Technology (ICACOMIT), Jakarta, Indonesia, October 2017, 44–47.
Ren, S., He, K., Girshick, R., and Sun, J. (2017). Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Analysis Mach. Intell. 39 (06), 1137–1149. doi:10.1109/tpami.2016.2577031
Roser, M., and Moosmann, F. “Classification of weather situations on single color images,” in Proceedings of the 2008 IEEE intelligent vehicles symposium, Eindhoven, Netherlands, June 2008, 798–803.
Rostosky, P., Spreen, G., Farrell, S. L., Frost, T., Heygster, G., and Melsheimer, C. (2018). Snow depth retrieval on Arctic sea ice from passive microwave radiometers—improvements and extensions to multiyear ice using lower frequencies. J. Geophys. Res. Oceans 123 (10), 7120–7138. doi:10.1029/2018jc014028
Salvatori, R., Plini, P., Giusto, M., Valt, M., Salzano, R., Montagnoli, M., et al. (2011). Snow cover monitoring with images from digital camera systems. Ital. J. Remote Sens. 43 (6), 137–145. doi:10.5721/itjrs201143211
Song, Z., Chen, X., Liu, H., Tian, L., and Wu, W. (2011). Snow cover extraction based on the HJ-1A/1B satellite data. Resour. Environ. Yangtze Basin 20 (5), 553–558.
Strle, D., and Ogrin, M. (2022). Five different types of lowered snow line in alpine valleys. J. Mt. Sci. 19, 73–84. doi:10.1007/s11629-020-6237-6
Xue, H., Liu, C., and Wan, F.“Danet: Divergent activation for weakly supervised object localization,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), October 2019, 6589–6598.
Yang, C., Liu, C., Sun, T., Zhang, A., Ouyang, D., Deng, S., et al. (2019). High breakdown voltage and low dynamic ON-resistance AlGaN/GaN HEMT with fluorine ion implantation in SiNx passivation layer. Meteorol. Mon. 45 (2), 191–202. doi:10.1186/s11671-019-3025-8
Keywords: snow identification, automatic weather station (AWS), attention mechanism, DANet model, weather monitoring
Citation: Gong J, Wang Y, Liu M and Deng F (2023) Snow identification from unattended automatic weather stations images using DANet. Front. Earth Sci. 11:1226451. doi: 10.3389/feart.2023.1226451
Received: 21 May 2023; Accepted: 26 June 2023;
Published: 06 July 2023.
Edited by:
Wei Ge, Zhengzhou University, ChinaReviewed by:
Huiliang Wang, Zhengzhou University, ChinaCopyright © 2023 Gong, Wang, Liu and Deng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fan Deng, ZGVuZ2ZhbkB5YW5ndHpldS5lZHUuY24=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.