 Huifen Liu1
Huifen Liu1 Peiyuan Lin
Peiyuan Lin- 1School of Transportation, Civil Engineering and Architecture, Foshan University, Foshan, Guangdong Province, China
- 2Southern Marine Science and Engineering Guangdong Laboratory (Zhuhai), Zhuhai, Guangdong Province, China
- 3School of Civil Engineering, Sun Yat-Sen University, Zhuhai, Guangdong Province, China
- 4Guangdong Wisdom Cloud Engineering Science and Technology Co Ltd, Foshan, China
The modulus of compression and coefficient of compressibility of soft soils are key parameters for assessing deformation of geotechnical infrastructure. However, the consolidation tests used to determine these two indices are time-consuming and the results are easily and heavily influenced by workmanship, testing apparatus, and other factors. Therefore, it is of great interest to develop a simple approach to accurately estimate these compressibility indices. This article presents the development of three machine learning (ML) models—at artificial neural network (ANN), a random forest model, and a support vector machine model—for mapping of the two compressibility indices for soft soils. A database containing 743 sets of measured physical and compression parameters of soft soils was adopted to train and validate the models. To quantify model uncertainty, the accuracies of the ML models were statistically evaluated using a bias factor defined as the ratio of the measured to the predicted compression indices. The results showed that all three ML models were accurate on average, with low dispersion in prediction accuracy. The ANN was found to be the best model, as it provides a simple analytical form and has no hidden dependency between the bias and predicted indices. Finally, the probability distribution functions of the bias factors were also determined using the fit-to-tail technique. The results of this study will be helpful in saving cost and time in geotechnical investigation of soft soils.
1 Introduction
The Guangdong–Hong Kong–Macao Greater Bay Area (GBA) in China is undergoing ongoing and extensive infrastructure construction. Due to the widely distributed marine sedimentary soft soils in the GBA, geotechnical infrastructure resting on soft soils is usually challenged by both excessive deformation and insufficient bearing capacity throughout the lifetime of service. To assess infrastructure deformation, a set of laboratory and in situ tests (Bo et al., 2018; Orense et al., 2018) must be routinely performed in order to determine both the physical and the mechanical properties of the soil for projects in soft soil areas. For example, consolidation tests (Zabielska and Katarzyna, 2018) are conducted to study the compressibility of soft soils and consolidation is typically quantified by two indices, namely, the modulus of compression and the coefficient of compressibility.
While consolidation tests are a routine type of geotechnical laboratory test, they have several drawbacks in cases of soft soil. First, the tests can be very time-consuming (Holtz et al., 2010) and costly, especially for multi-stage consolidations. Second, sample disturbance is usually unavoidable when transporting soft soils from sites to the laboratory. These disturbances can result in significant alterations of soil structures and, thus, the compressibility (Lunne et al., 2006). Finally, errors relating to testing apparatus are also uncontrollable.
Due to these drawbacks, the development of a simple, practical, and sufficiently accurate equation to rapidly assess soil compressibility indices is highly desirable. Koppula (1981) used the least squares technique to regress the physical parameters of soft clays against their compression indices. Empirical regressions are applicable to estimate the settlement of structures resting on cohesive soils. Amiri et al. (2018) used multiple linear regression to estimate unsaturated shear strength parameters using several indices of the physical properties of soil as function inputs. Liu et al. (2018) reported on the relationships between the mechanical properties of clays and temperature. Motaghedi and Eslami (2014), Mcgann et al. (2015), Cao and Wang (2013), Lim et al. (2020), and Schneider et al. (2008) empirically linked data from CPT on sleeve friction, cone tip resistance, and porewater pressure data to soil properties including cohesion, friction angle, soil classification, overconsolidation ratio, and shear wave velocity. Yoon et al. (2004) and Yan et al. (2009) proposed empirical correlations of compression index for marine clay based on regression analysis and Bayesian inference. Finally, Cao et al. (2019) determined soil stratigraphy using a Bayesian method based on CPT.
While the development of empirical equations using traditional regression approaches to predict the mechanical properties of soils has facilitated geotechnical analyses to a large extent, it remains challenging to establish accurate correlations, owing to the major uncertainty in and great complexity of soil properties (Ching and Phoon, 2014). Over the past decades, the applicability of machine learning (ML) approaches, such as artificial neural networks (ANNs), random forest (RF) methods, and support vector machines (SVMs), among others, has been well-proven in terms of their ability to efficiently and accurately map highly non-linear problems in a wide variety of areas of engineering (Arditi and Pulket, 2010; Chen et al., 2021), including geotechnical engineering. Successful examples of applications include analyses of slope stability (Kardani et al., 2021; Meng et al., 2021) and deformation (Zhang et al., 2019; Zhang et al., 2020a; Zhang W et al., 2021); pile designs (Makasis et al., 2018; Zhang et al., 2020e); prediction of the bearing capacity of strip footings (Acharyya, 2019; Sadegh et al., 2021); lateral wall deformation and basal heave stability for braced excavations (Goh et al., 1995; Zhang et al., 2020); soil constitutive relations (Najjar and Huang, 2007); liquefaction resistance of sands (Kim and Kim, 2006); lining response for tunnels (Zhang et al., 2020g); calibration of resistance factors for reliability-based load and resistance factor design (Hu and Lin, 2019); prediction of soil transparency (Wang et al., 2021); analysis of ground settlement induced by shield tunneling (Zhang et al., 2020c); reliability analysis by SVM (Pan and Dias, 2017); and mapping of groundwater potential using SVM, RF, and GA models (Naghibi et al., 2017), among others. In addition to solving geotechnical analysis problems, these ML approaches have also achieved success in mapping from the physical parameters of soil to the mechanical parameters. Moreover, Park, and Lee (2011), Pham et al. (2019a), Pham et al. (2019), and Zhang et al. (2020f) studied the compressibility feature of soils using ML techniques. Das et al. (2011), Kanungo et al. (2014), Kiran et al. (2016), Pham et al. (2018), and Zhang L et al. (2021) developed ML models to estimate the shear strength parameters of soils under various conditions. Çelik and Tan (2005) and Samui et al. (2008) determined preconsolidation pressure using an ANN and an SVM method, respectively. For details of additional applications, readers are also referred to the state-of-the-art reviews of ML applications in geotechnical and geoscience engineering areas conducted by Shahin Mohammad (2016), Moayedi et al. (2019), Zhang and Ching et al. (2021), Zhang et al. (2020f), and Hou et al. (2021).
Although the development of ML models of soil mechanical parameters remains a hot topic that continues to attract attention, few studies have reported employed bias statistics for quantification of model uncertainty. Most previous studies have used the mean absolute error (MAE), root mean square error (RMSE), and coefficient of determination (
The present study first introduces a large database consisting of 743 sets of measured physical property parameters and compressibility indices based on laboratory tests for soft soils sampled from a city in the GBA of China. The main physical property parameters are water content, density, and void ratio. The compressibility indices for the soils are the modulus of compression and the coefficient of compressibility. Next, a set of ML techniques (ANN, RF, and SVM) are adopted to develop useful models for efficient and accurate mappings from the three aforementioned common physical parameters to the two compressibility indices. Finally, the model uncertainties of the proposed ML models are evaluated, where model uncertainty is quantitatively defined by the statistics of the bias factor, defined as the ratio of the measured to predicted compression indices. The probability distributions of the model biases are also investigated. The performance of each of the machine learning models developed is discussed and the models are compared on performance. The results of this study demonstrate the feasibility of applying ML techniques to make prompt assessments of the compressibility of soft soils in the GBA area based on simple physical properties of the soil.
2 Methodology
The methodology used in this study consisted of two parts. The first was model development, in which several ML models (ANN, RF, and SVM) were developed. The second was model evaluation using the model bias method (Ching and Schweckendiek, 2021; Jin et al., 2018). In model development, the physical properties of the soils were used as inputs to the ML models and the mechanical properties were the targets. The main physical parameters were water content, void ratio, and density of soft soil. The mechanical parameters were compression indices obtained from compression (CP) tests. The database is introduced in Section 3.
Typically, the MSE is used as an indicator of the accuracy of machine learning models. However, the MSE is not sufficient to fully capture model uncertainty. Therefore, the present study adopted the model bias method described below for the characterization of the model uncertainty of the machine learning models. The bias is defined as the ratio of the measured to the predicted value. Technical details of the machine learning models and the model bias method are provided in this section.
2.1 Artificial neural network technique
The use of ANNs is widely accepted as a technique that is capable of efficiently handling almost any regression or classification problem given sufficient data. Structurally, an ANN consists of an input layer, several hidden layers, and an output layer (Figure 1A). The learning process of an ANN includes forward propagation of information and backpropagation to adjust the error (Rafiq et al., 2001). Figure 1B illustrates how a neuron transmits information in ANN forward propagation. Suppose there are m neurons in hidden layer k, denoted as
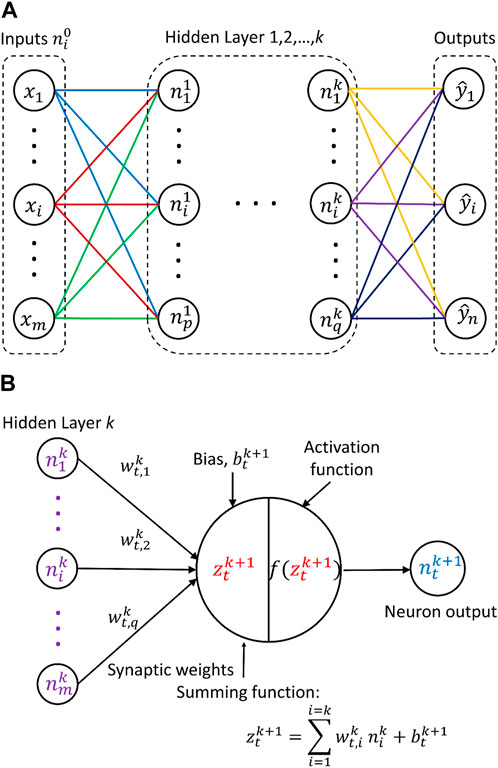
FIGURE 1. Construction of an ANN: (A) layered network; (B) artificial neuron.
The difference between the outputs (each predicted value
The input data are usually randomly divided into three subsets in the development of an ANN model: training, validation, and test sets. The same process is carried out for each set of the target (measured) data. The training set is used to determine the weights and biases of the neurons, and the validation set is utilized to prevent overfitting problems during the training process. Hence, the optimal weights and biases that minimize
2.2 Random forest technique
The random forest method is an ensemble learning method that provides solutions for classification and regression problems. The main idea is to grow a number of decision trees through bagging and random feature selection. Each decision tree has high variance and thus is often rather poor in generalization. As illustrated in Figure 2, the RF regression model is constructed by assembling several individual decision trees, and predictions are made by averaging. Note that the generalization ability of the classification model is improved by voting. The “forest” reduces the variance by averaging and greatly enhances prediction accuracy.
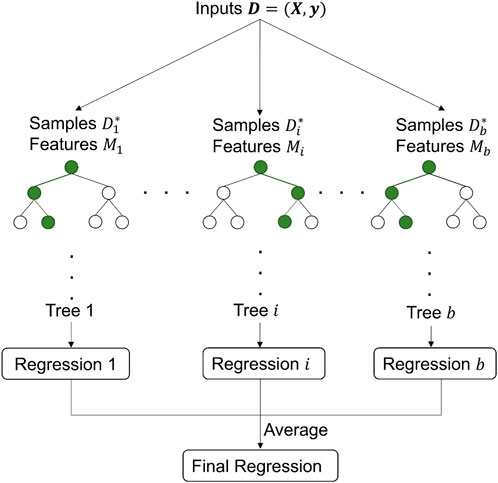
FIGURE 2. Diagram of a random forest regression model.
Suppose a training dataset
Step 1:. Select the number of trees
Step 2:. Bootstrap a subset of
Step 3:. Develop a tree
Step 4:. Bag these trees and take the average at any point
Step 5:. At each bootstrap, compute the OOB error for each response observation.The aggregate OOB error is obviously the average of each individual OOB error. The OOB error is a performance indicator that can be used to test the generalization ability of the RF model; hence, no cross-validation or additional testing set is required. The RF model can be optimized by adjusting the parameters
2.3 Support vector machines
The SVM method is a classifier in which the main idea is to establish a classification hyperplane as a decision surface. As shown in Figure 3, the optimal separating hyperplane is the classification hyperplane
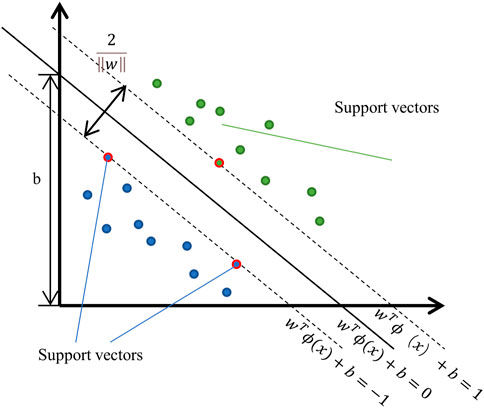
FIGURE 3. Diagram of a support vector machine model.
where
Equation (4) implicitly assumes that mapping precision
2.4 Characterization of model uncertainty
Bias statistics proposed in model bias methods, such as the bias mean, bias coefficient of variation (COV), and bias probability distribution, have been widely employed to characterize model uncertainty. In this study, the predicted values were the outputs of the machine learning models, while the measured values were available directly from the database. The bias mean represents the average accuracy of the model, while the bias COV represents the dispersion in prediction accuracy. The bias probability distribution is used as an input to reliability-based analyses of machine learning models. Lastly, the randomness of the bias also needs to be checked.
3 Database of soft soil properties
The database of compression indices of soil soft established by Lin et al. (2022) was used in the present study for the development of the machine learning models. For completeness, the database is briefly re-described here.
The database consists of 743 sets of physical properties and corresponding compression indices for soft soils. Soft soil samples were obtained from Shenzhen, a major megacity in China. The physical parameters of moisture content (
Figure 4 shows histograms and cumulative plots of the physical parameters from the CP tests. Essentially, the values of
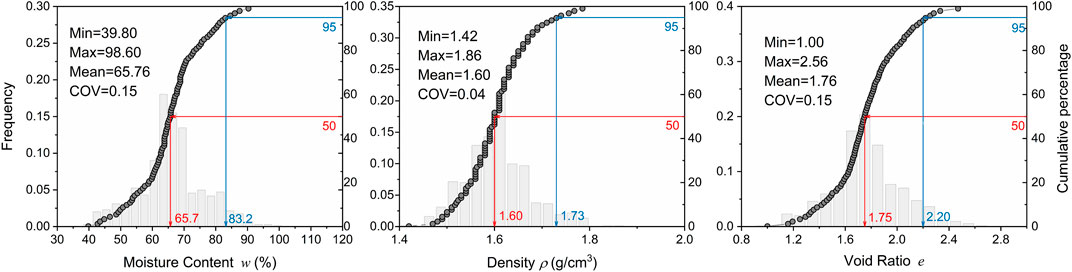
FIGURE 4. Histograms and cumulative distributions of the physical parameters (

TABLE 1. Summary of the minimum, mean, median, maximum, and COV values for the physical (
Figure 5 shows plots of the mechanical parameters (
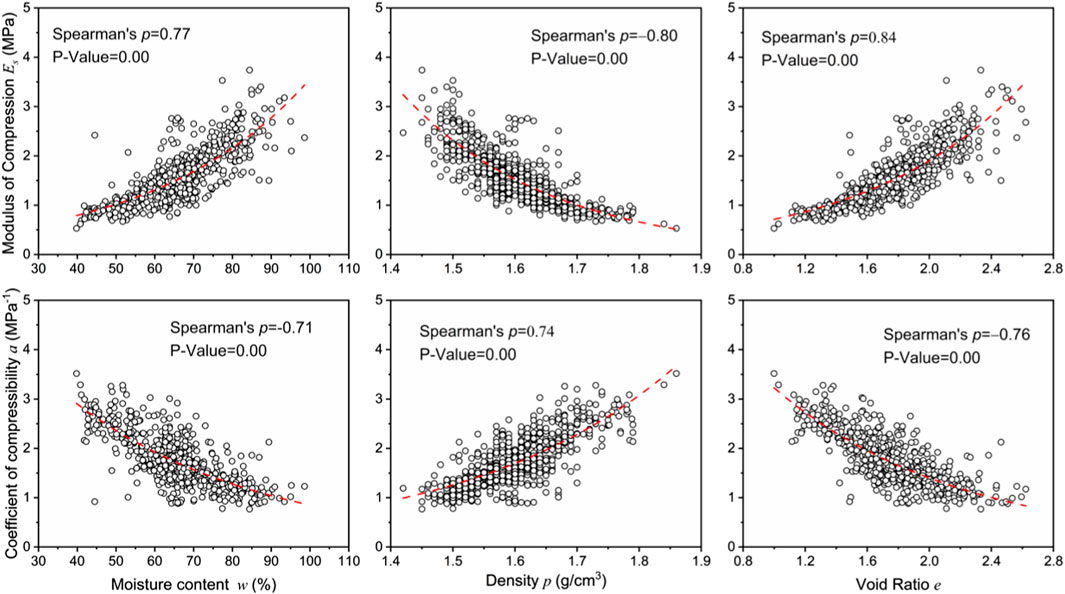
FIGURE 5. Plots of compression indices versus physical parameters in the CP test results.
It should be noted that various other factors, such as saturation, formation environment, stress history, liquid limit, plastic limit, and organic matter content, may also affect the compression indices of soft soils. Data on some of these are also available in the source database. For example, the degree of saturation was 100% for all soft soil samples. Moreover, all samples had similar formation environments and similar stress histories as they were taken from the same soil stratum. Hence, these two factors did not vary and were not explicitly considered here. Parameters such as liquid limit, plastic limit, and sampling depth were also excluded from the model input to keep the machine learning models simple, practical, and analytical.
4 Development and evaluation of ML models
This section first presents the details of the construction of machine learning models (i.e., the ANN, RF, and SVM models) for mapping to the compression indices of soft soils (i.e.,
4.1 Model construction
4.1.1 ANN model
The ANN configuration was determined using a trial-and-error approach, technical details of which are described by Lin et al. (2022). In this study, the use of one hidden layer containing three neurons was found to be adequate to yield satisfactorily accurate predictions while maintaining the simplicity of the network. It should be noted that, while the addition of more hidden layers and neurons can enhance the mapping ability of the ANN model, this did not produce a clear improvement in the present study and imposes a risk of overfitting due to an insufficiently large database (less than 103 data points). Figure 6 illustrates the proposed ANN model for compression indices.
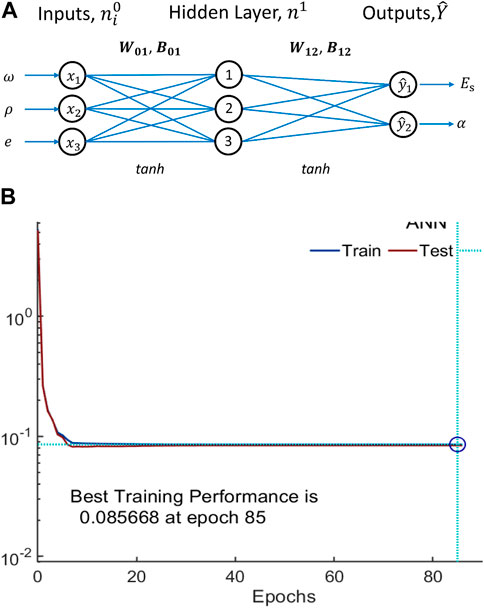
FIGURE 6. Plots of the training process for the ANN model: (A) illustration of the proposed ANN for mapping the compression indices of soft soils; (B) mean squared error (MSE) versus number of epochs during training of the ANN model.
As shown in Figure 6A, the tanh activation function was used in connections both from the input layer to the hidden layer and from the hidden layer to the output layer. The corresponding weight and bias matrices are
The ANN model was constructed, trained, and tested via the MATLAB™ platform using Bayesian regularization (BR) training algorithms. Since the built-in BR backpropagation algorithm in MATLAB™ simultaneously trains and verifies an ANN model, designation of an additional validation set was not necessary. Hence, the input matrix
As shown in Figure 6B, the MSE gradually reached a minimum value as the epoch increased. Here, an epoch is a complete training cycle in which all data are used once and the weights and biases are optimized to yield the minimum MSE. Training was stopped at epoch 85, at which point the best training performance (lowest MSE) was 0.085668. The optimal
This ANN is simple, having an explicitly analytical form consisting of simple physical parameters, and it offers convenience for engineers in that the model can readily be applied in practice. The technical details are described by Lin et al. (2022).
4.1.2 RF model
The RF model was also developed using the MATLAB™ platform. As discussed in Section 2.2, OOB error is used as an optimization indicator for RF models, and is determined by the numbers of trees (B) and leaves (
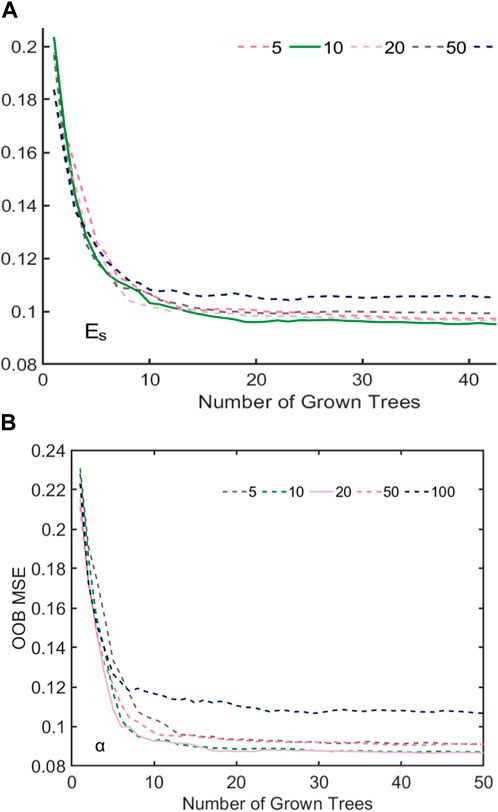
FIGURE 7. Influence of the number of trees and leaves on OOB MSE in the RF model: (A) for
4.1.3 SVM model
The key points in establishing an SVM regression model are to determine the kernel function and to optimize the model parameters. In this study, the main options considered for the kernel function were Gaussian, polynomial, sigmoid, and linear kernels. The corresponding MSEs for the SVM model using each of these kernels, based on the full dataset, were computed as 0.0840 for the Gaussian kernel, 0.1178 for the polynomial kernel, 0.0929 for the sigmoid kernel, and 0.0925 for the linear kernel. In addition, the corresponding coefficients of determination (
Optimization of model parameters for this type of model mainly involves the penalty
4.2 Model evaluation
The

TABLE 2. Summary of the mean, COV, and probability distributions of the model biases for the ANN, RF, and SVM models.
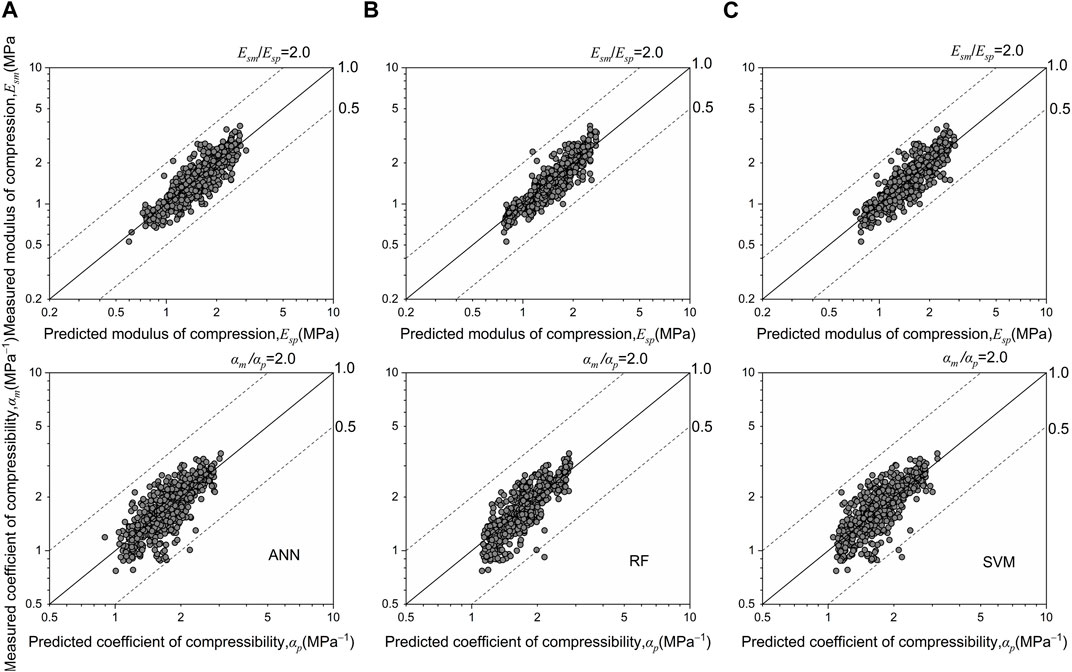
FIGURE 8. Measured compression indices versus values predicted by the trained ML models using all datasets: (A–C)
Figure 9 shows the plots of
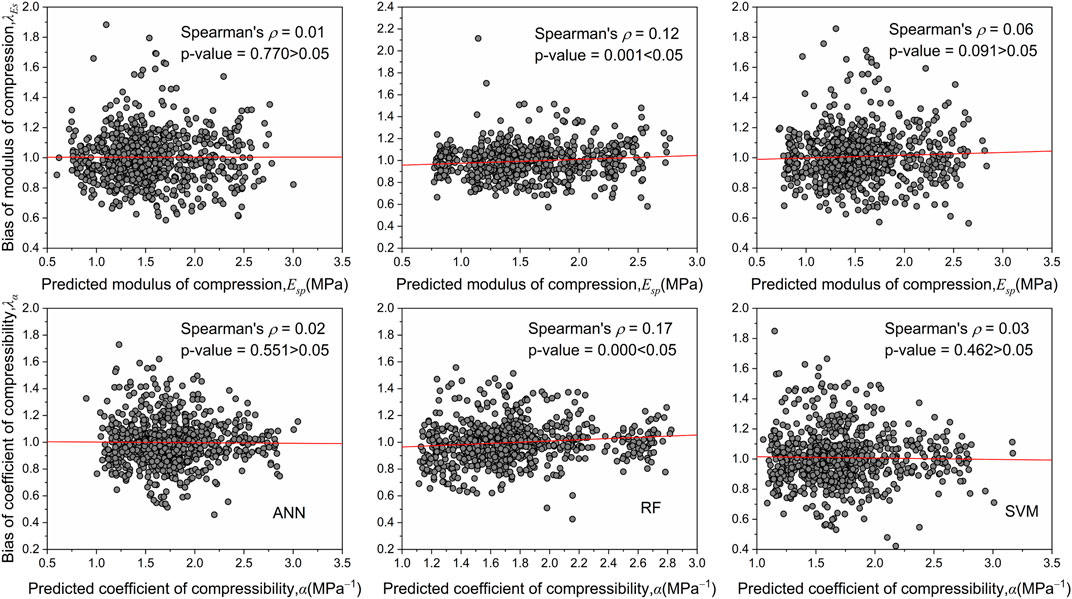
FIGURE 9. Plots of model biases versus predicted compression indices for the ANN, RF, and SVM models.
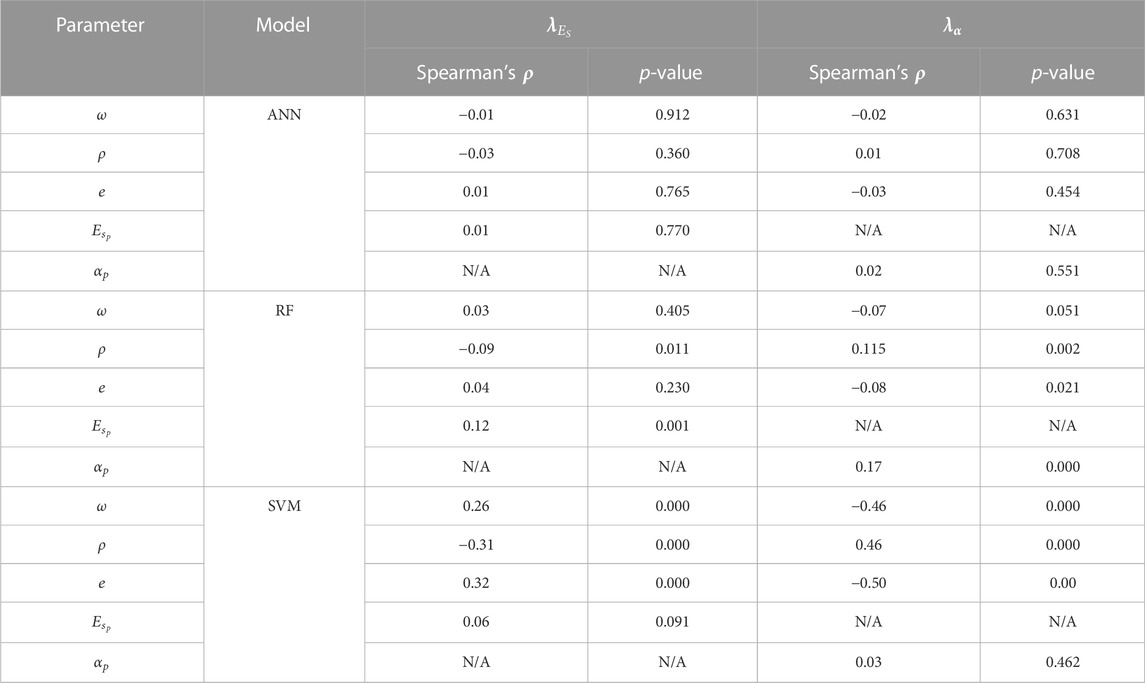
TABLE 3. Summary of results of Spearman’s rank correlation tests between biases and input parameters or predicted compressibility parameters.
5 Characterization of bias distributions
Aside from mean bias and bias COV, characterization of the probability distributions of variables is also common in geotechnical analysis (Guo et al., 2021). In this study, the probability distribution of the bias is an important input parameter in reliability-based geotechnical design; thus, this also required characterization. Figure 10 shows the cumulative distributions of all model biases. The Kolmogorov–Smirnov (K–S) normality test was applied to the logarithms of each model bias, i.e., ln
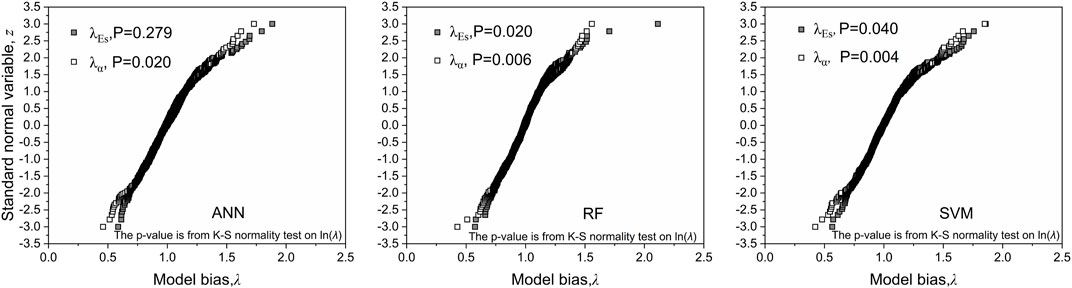
FIGURE 10. Cumulative distributions and K–S normality test results for the biases of the three ML models.
For the five cases that did not follow any common distribution, a fit-to-tail technique was used to linearly approximate the tail distribution of
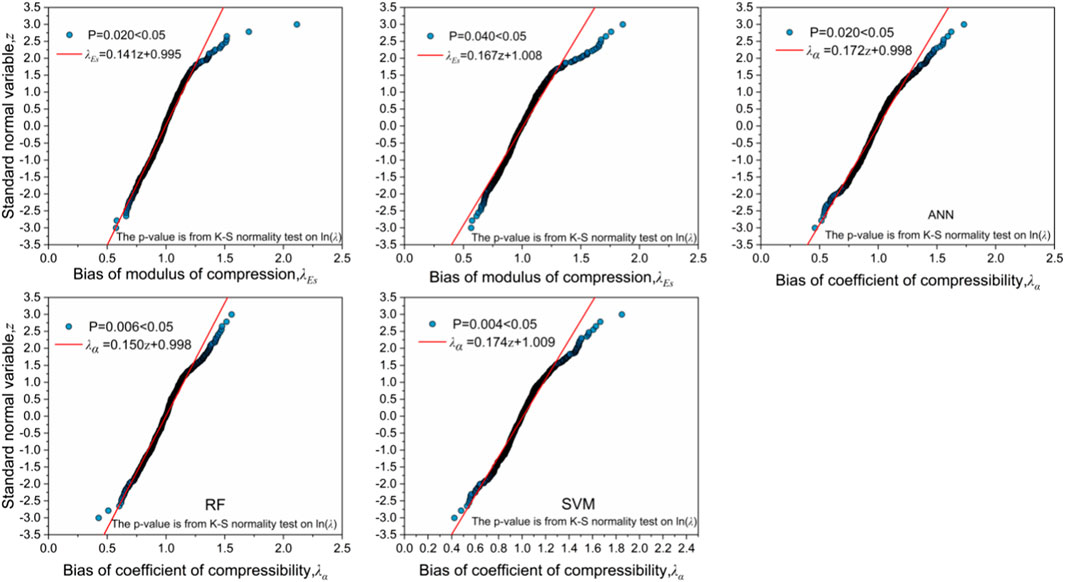
FIGURE 11. Fit-to-tail technique applied to the tail distributions of five model biases.
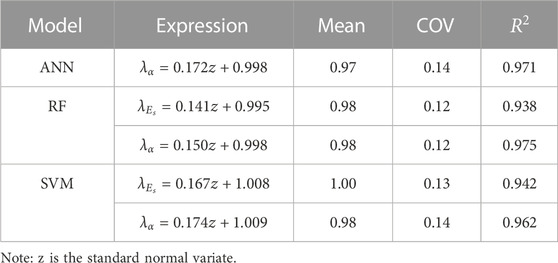
TABLE 4. Expressions and bias statistics for the ANN, RF, and SVM models using the fit-to-tail technique.
6 Conclusion
In this study, three machine learning techniques (i.e., an artificial neural network (ANN), a random forest (RF) model, and a support vector machine (SVM) model) were developed for mapping of the compression parameters of soft soils in the Greater Bay Area of China. The inputs were water content, soil density, and void ratio. The outputs were the modulus of compression and the coefficient of compressibility, which are usually obtained from laboratory consolidation tests. The accuracies of the three machine learning models developed were evaluated and compared using model bias statistics. The models were accurate on average, with low dispersion in prediction accuracy. The bias mean was essentially 1.00 in all cases, and the bias COVs were around 15%. The biases of each of the three models followed multi-order Gaussian distributions, with the exception of
Data availability statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Author contributions
Conceptualization, HL and PL; methodology, PL; validation, JW; formal analysis, HL; investigation, HL and JW; writing—preparation of original draft, HL; writing—review and editing, PL; supervision, PL; funding acquisition, HL and PL.
Funding
This research was funded by the State Key Laboratory of Building Safety and Built Environment Open Foundation (grant no. BSBE 2021-03), the National Natural Science Foundation of China (52008408), the Guangdong Basic and Applied Basic Research Foundation (2021A1515012088), and the Science and Technology Program of Guangzhou, China (202102021017).
Conflict of interest
Author JW was employed by Guangdong Wisdom Cloud Engineering Science and Technology Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Acharyya, R. (2019). Finite element investigation and ANN-based prediction of the bearing capacity of strip footings resting on sloping ground. Int. J. Geo-Engineering 10 (5). 0100, doi:10.1186/s40703-019-0100-z
Amiri, K. E., Emami, H., Mosaddeghi, M. R., and Astaraei, A. R. (2018). Estimation of unsaturated shear strength parameters using easily-available soil properties. Soil Tillage Res. 184, 118–127. doi:10.1016/j.still.2018.07.006
Arditi, D., and Pulket, T. (2010). Predicting the outcome of construction litigation using an integrated artificial intelligence model. J. Comput. Civ. Eng. 24 (1), 73–80. doi:10.1061/(asce)0887-3801(2010)24:1(73)
Bo, M. W., Lwin, T., and Choa, V. (2018). Application of specialized in-situ tests in changi east reclamation and ground improvement projects. Geotechnical Res. 6 (1), 1–50. doi:10.1680/jgere.18.00033
Cao, Z., and Wang, Y. (2013). Bayesian approach for probabilistic site characterization using cone penetration tests. J. Geotechnical Geoenvironmental Eng. 139 (2), 267–276. doi:10.1061/(asce)gt.1943-5606.0000765
Cao, Z-J., Zheng, S., Li, D-Q., and Phoon, K-K. (2019). Bayesian identification of soil stratigraphy based on soil behaviour type index. Can. Geotechnical J. 56 (4), 570–586. doi:10.1139/CGJ-2017-0714
Çelik, S., and Tan, Ö. (2005). Determination of preconsolidation pressure with artificial neural network. Civ. Eng. Environ. Syst. 22 (4), 217–231. doi:10.1080/10286600500383923
Chen, J., Vissinga, M., Shen, Y., Hu, S., Beal, E., and Newlin, J. (2021). Machine learning-based digital integration of geotechnical and ultrahigh-frequency geophysical data for offshore site characterizations. J. Geotechnical Geoenvironmental Eng. 147 (12), 04021160. doi:10.1061/(ASCE)GT.1943-5606.0002702
Ching, J., and Phoon, K. K. (2014). Correlations among some clay parameters - the multivariate distribution. Can. Geotechnical J. 51 (6), 686–704. doi:10.1139/cgj-2013-0353
Ching, J., and Schweckendiek, T. (2021) State-of-the-art review of inherent variability and uncertainty in geotechnical properties and models.ISSMGE Tech. Comm. 304, 56, doi:10.53243/R0001
Das, S. K., Samui, P., Khan, S. Z., and Sivakugan, N. (2011). Machine learning techniques applied to prediction of residual strength of clay. Open Geosci. 3 (4), 449–461. doi:10.2478/s13533-011-0043-1
Demuth Howard, B., Beale Mark, H., De Jess, O., and Hagan Martin, T. (2014). Neural network design. Boston, MA: PWS Publishing Co.
Drucker, H., Burges Chris, J. C., Kaufman, L., Chris, J. C., Kaufman, B. L., Smola, A., et al. (1997). Support vector regression machines. Adv. Neural Inf. Process. Syst. 28 (7), 779–784.
Efron, B., and Hastie, T. (2016). Computer age statistical inference 5. Cambridge, United Kingdom: Cambridge University Press.
Goh, C. A. T., Wong, K. S., and Broms, B. B. (1995). Estimation of lateral wall movements in braced excavations using neural networks. Can. Geotechnical J. 32 (6), 1059–1064. doi:10.1139/t95-103
Guo, C., Guo, P., Zhao, L., Lin, P., and Wang, F. (2021). A weibull-based damage model for shear softening behaviours of soil-structure interfaces. Geotechnical Res. 8 (4), 1–10. doi:10.1680/JGERE.20.00043
Holtz, R. D., Kovacs, W. D., and Sheahan, T. C. (2010). An introduction to geotechnical engineering. 2nd Ed. Upper Saddle River:NJ: PEARSON.
Hou, Y., Li, Q., Zhang, C., Lu, G., Ye, Z., Chen, Y., et al. (2021). The state-of-the-art review on applications of intrusive Sensing,Image processing Techniques,and machine learning methods in pavement monitoring and analysis. Engineering 7 (6), 845–856. doi:10.1016/j.eng.2020.07.030
Hu, H., and Lin, P. (2019). Analysis of resistance factors for LRFD of soil nail pullout limit state using default FHWA load and resistance models. Mar. Georesources Geotechnol. 38, 332–348. doi:10.1080/1064119x.2019.1571540
Jin, Y., Giovanna, B., and Paolo, G. (2018). A bayesian definition of 'most probable' parameters. Geotechnical Res. 5 (3), 130–142. doi:10.1680/jgere.18.00027
Kanungo, D. P., Sharma, S., and Pain, A. (2014). Artificial Neural Network (ANN) and Regression Tree (CART) applications for the indirect estimation of unsaturated soil shear strength parameters. Front. Earth Sci. 8 (3), 439–456. doi:10.1007/s11707-014-0416-0
Kardani, N., Zhou, A., Nazem, M., and Shen, S-L. (2021). Improved prediction of slope stability using a hybrid stacking ensemble method based on finite element analysis and field data. J. Rock Mech. Geotechnical Eng. 13 (1), 188–201. doi:10.1016/j.jrmge.2020.05.011
Kim, Y.-S., and Kim, B.-T. (2006). Use of artificial neural networks in the predictionof liquefaction resistance of sands. J. Geotechnical Geoenviron Ment. Eng. 132 (11), 1502–1504. doi:10.1061/(asce)1090-0241(2006)132:11(1502)
Kiran, S., Lal, B., and Tripathy, S. (2016). Shear strength prediction of soil based on probabilistic neural network. Indian J. Sci. Technol. 9. 99188, doi:10.17485/ijst/2016/v9i41/99188
Koppula, S. D. (1981). Statistical estimation of compression index. Geotechnical Test. J. 4 (2), 68. doi:10.1520/gtj10768j
Krishnan, N. M. A., Mangalathu, S., Smedskjaer, M. M., Tandia, A., Burton, H., and Bauchy, M. (2018). Predicting the dissolution kinetics of silicate glasses using machine learning. J. Non-Crystalline Solids 487, 37–45. doi:10.1016/j.jnoncrysol.2018.02.023
Liaw, A., and Wiener, M. (2002). Classification and regression by random Forest. R. news 2 (3), 18–22.
Lim, Y. X., Tan, S. A., and Phoon, K-K. (2020). Friction angle and overconsolidation ratio of soft clays from cone penetration test. Eng. Geol. 274, 105730. doi:10.1016/j.enggeo.2020.105730
Lin, P., Chen, X., Jiang, M., Song, X., Xu, M., and Huang, S. (2022). Mapping shear strength and compressibility of soft soils with artificial neural networks. Eng. Geol. 300, 106585. doi:10.1016/j.enggeo.2022.106585
Liu, H., Liu, H., Xiao, Y., Chen, Q., Gao, Y., and Peng, J. (2018). Nonlinear elastic model incorporating temperature effects. Geotechnical Res. 5 (1), 22–30. doi:10.1680/jgere.17.00015
Lunne, T., Berre, T., Andersen, K. H., Strandvik, S., and Sjursen, M. (2006). Effects of sample disturbance and consolidation procedures on measured shear strength of soft marine Norwegian clays. Can. Geotechnical J. 43 (7), 726–750. doi:10.1139/t06-040
Makasis, N., Narsilio, G. A., and Bidarmaghz, A. (2018). A machine learning approach to energy pile design. Comput. Geotechnics 97, 189–203. doi:10.1016/j.compgeo.2018.01.011
Mangalathu, S., and Jeon, J-S. (2018). Classification of failure mode and prediction of shear strength for reinforced concrete beam-column joints using machine learning techniques. Eng. Struct. 160, 85–94. doi:10.1016/j.engstruct.2018.01.008
Mcgann, C. R., Bradley, B. A., Taylor, M. L., Wotherspoon, L. M., and Cubrinovski, M. (2015). Development of an empirical correlation for predicting shear wave velocity of Christchurch soils from cone penetration test data. Soil Dyn. Earthq. Eng. 75, 66–75. doi:10.1016/j.soildyn.2015.03.023
Meng, J., Mattsson, H., and Laue, J. (2021). Three dimensional slope stability predictions using artificial neural networks. Int. J. Numer. Anal. Methods Geomechanics 45, 1988–2000. doi:10.1002/nag.3252
Moayedi, H., Mosallanezhad, M., Asa, R., Jusoh, W., and Muazu, M. A. (2019). A systematic review and meta-analysis of artificial neural network application in geotechnical engineering: Theory and applications. Neural Comput. Appl. 32, 495–518. doi:10.1007/s00521-019-04109-9
Motaghedi, H., and Eslami, A. (2014). Analytical approach for determination of soil shear strength parameters from CPT and CPTu data. Arabian J. Sci. Eng. 39 (6), 4363–4376. doi:10.1007/s13369-014-1022-x
Müller, K. R., Smola, A. J., Bf, G. R., Schlkopf, B., and Vapnik, V. (1997). “Predicting time series with support vector machines,” in Proceedings of the 7th International Conference on Artificial Neural Networks, Berlin, Heidelberg, October 8 - 10, 1997.
Naghibi, S. A., Ahmadi, S., and Daneshi, A. (2017) Application of support vector machine, random forest, and genetic algorithm optimized random forest models in groundwater potential mapping. WATER Resour. MANAG., 31(9): 2761–2775. doi:10.1007/s11269-017-1660-3
Najjar, Y. M., and Huang, C. (2007). Simulating the stress–strain behavior of Georgia kaolin via recurrent neuronet approach. Comput. Geotechnics 34 (5), 346–361. doi:10.1016/j.compgeo.2007.06.006
Orense, R. P., Mirjafari, Y., and Suemasa, N. (2018). Screw driving sounding: A new test for field characterisation. Geotechnical Res. 6 (1), 28–38. doi:10.1680/jgere.18.00024
Pan, Q., and Dias, D. (2017). An efficient reliability method combining adaptive Support Vector Machine and Monte Carlo Simulation. Struct. Saf. 67, 85–95. doi:10.1016/j.strusafe.2017.04.006
Park, H. I., and Lee, S. L. (2011). Evaluation of the compression index of soils using an artificial neural network. Comput. Geotechnics 38 (4), 472–481. doi:10.1016/j.compgeo.2011.02.011
Pham, B. T., Nguyen, M. D., Ly, H. B., Pham, T. A., and Bui, G. L. (2019a). “Development of artificial neural networks for prediction of compression coefficient of soft soil,” in CIGOS 2019, innovation for sustainable infrastructure. Editors C. Ha-Minh, D. Dao, F. Benboudjema, S. Derrible, D. Huynh, and A. Tang (Singapore: Lecture Notes in Civil Engineering).
Pham, B. T., Nguyen, M. D., Dao, D. V., Prakash, I., Ly, H-B., Le, T-T., et al. (2019b). Development of artificial intelligence models for the prediction of Compression Coefficient of soil: An application of Monte Carlo sensitivity analysis. Sci. Total Environ. 679, 172–184. doi:10.1016/j.scitotenv.2019.05.061
Pham, B. T., Son, L. H., Hoang Tuan, A, Manh, N. D., and Dieu, T. B. (2018). Prediction of shear strength of soft soil using machine learning methods. Catena 166, 181–191. doi:10.1016/j.catena.2018.04.004
Phoon, K-K., and Kulhawy, F. H. (1999). Characterization of geotechnical variability. Can. Geotechnical J. 36 (4), 612–624. doi:10.1139/t99-038
Phoon, K-K., and Tang, C. (2019).Characterisation of geotechnical model uncertainty, Georisk: Assess. Manag. Risk Eng. Syst. Geohazards, 13, 101–130. doi:10.1080/17499518.2019.1585545
Rafiq, M. Y., Bugmann, G., and Easterbrook, D. J. (2001). Neural network design for engineering applications. Comput. Struct. 79 (17), 1541–1552. doi:10.1016/s0045-7949(01)00039-6
Sadegh, E. M., Abbaspour, M., Abbasianjahromi, H., and Mariani, S. (2021). Machine learning-based prediction of the seismic bearing capacity of a shallow strip footing over a void in heterogeneous soils. Algorithms 14 (10), 288. doi:10.3390/a14100288
Samui, P., Sitharam, T. G., and Kurup, P. U. (2008). OCR prediction using support vector machine based on piezocone data. J. Geotechnical Geoenvironmental Eng. 134: 894–898. doi:10.1061/(asce)1090-0241(2008)134:6(894
Schneider, J. A., Randolph, M. F., Mayne, P. W., and Ramsey, N. R. (2008). Analysis of factors influencing soil classification using normalized piezocone tip resistance and pore pressure parameters. J. Geotechnical Geoenvironmental Eng. 134 (11), 1569–1586. doi:10.1061/(asce)1090-0241(2008)134:11(1569)(ASCE)1090-0241
Scholkopf, B., and Smola, A. J. (2018). Learning with kernels: Support vector machines, regularization, optimization, and beyond: Adaptive computation and machine learning series. Massachusetts, United States: The Mit Press.
Scholkopf, B., Sung, K-K., Burges, C. J. C., Girosi, F., Niyogi, P., Poggio, T., et al. (1997). Comparing support vector machines with Gaussian kernels to radial basis function classifiers. IEEE Trans. Signal Process. 45 (11), 2758–2765. doi:10.1109/78.650102
Shahin Mohamed, A. (2016). State-of-the-art review of some artificial intelligence applications in pile foundations. Geosci. Front. 7 (1), 33–44. doi:10.1016/j.gsf.2014.10.002
Smola, A. J., and Schölkopf, B. (2004). A tutorial on support vector regression. Statistics Comput. 14 (3), 199–222. doi:10.1023/b:stco.0000035301.49549.88
Wang, B., Hou, H., and Zhu, Z. (2021). Transparency and applications of transparentsoil: A review. Geotechnical Res. 8, 130–138. doi:10.1680/jgere.21.00016
Yan, W. M., Yuen, K-V., and Yoon, G. L. (2009). Bayesian probabilistic approach for the correlations of compression index for marine clays. J. Geotechnical Geoenvironmental Eng. 135 (12), 1932–1940. doi:10.1061/(ASCE)GT.1943-5606.0000157
Yoon, G. L., Kim, B. T., and Jeon, S. S. (2004). Empirical correlations of compression index for marine clay from regression analysis. Can. Geotechnical J. 41 (6), 1213–1221. doi:10.1139/t04-057
Zabielska, -A., and Katarzyna, S. (2018). One-dimensional compression and swelling of compacted fly ash. Geotechnical Res. 5 (2), 96–105. doi:10.1680/jgere.17.00017
Zhang, D. M., Zhang, J. Z., Huang, H. W., Qi, C. C., and Chang, C. Y. (2020a). Machine learning-based prediction of soil compression modulus with application of 1D settlement. J. Zhejiang University-SCIENCE A 21 (6), 430–444. doi:10.1631/jzus.a1900515
Zhang, J., Hu, J., Li, X., and Li, J. (2020b). Bayesian network based machine learning for design of pile foundations. Automation Constr. 118, 103295. doi:10.1016/j.autcon.2020.103295
Zhang, L., Shi, B., Zhu, H., Yu, X. B., Han, H., and Fan, X. (2021). PSO-SVM-based deep displacement prediction of Majiagou landslide considering the deformation hysteresis effect. Landslides 18 (1), 179–193. doi:10.1007/s10346-020-01426-2
Zhang, L., Shi, B., Zhu, H., Yu, X., and Wei, G. (2020c). A machine learning method for inclinometer lateral deflection calculation based on distributed strain sensing technology. Bull. Eng. Geol. Environ. 79 (7), 3383–3401. doi:10.1007/s10064-020-01749-3
Zhang, R., Wu, C., Goh, A. T. C., and Wang, L. (2020d). Assessment of basal heave stability for braced excavations in anisotropic clay using extreme gradient boosting and random forest regression. Undergr. Space 7, 233–241. doi:10.1016/j.undsp.2020.03.001
Zhang, W., Li, Y., Wu, C., Li, H., Goh, A. T. C., and Liu, H. (2020f). Prediction of lining response for twin tunnels constructed in anisotropic clay using machine learning techniques. Undergr. Space 6, 353–363. doi:10.1016/j.undsp.2020.02.007
Zhang, W., Wu, C., Zhong, H., Li, Y., and Wang, L. (2021). Prediction of undrained shear strength using extreme gradient boosting and random forest based on Bayesian optimization. Geosci. Front. 12 (01), 469–477. doi:10.1016/j.gsf.2020.03.007
Zhang, W., Xiao, R., Shi, B., Zhu, H., and Sun, Y. (2019). Forecasting slope deformation field using correlated grey model updated with time correction factor and background value optimization. Eng. Geol. 260, 105215. doi:10.1016/j.enggeo.2019.105215
Zhang, W., Zhang, R., Wu, C., Goh, A. T. C., Lacasse, S., Liu, Z., et al. (2020e). State-of-the-art review of soft computing applications in underground excavations. Geosci. Front. 11 (4), 1095–1106. doi:10.1016/j.gsf.2019.12.003
Zhang, W., and Ching, J. (2021). Big data and machine learning in geoscience and geoengineering: Introduction. Geosci. Front., 12, 327–329. doi:10.1016/j.gsf.2020.05.006
Keywords: artificial neural network, random forest, support vector machine, soft soil, model uncertainty, compression indices
Citation: Liu H, Lin P and Wang J (2023) Machine learning approaches to estimation of the compressibility of soft soils. Front. Earth Sci. 11:1147825. doi: 10.3389/feart.2023.1147825
Received: 19 January 2023; Accepted: 03 March 2023;
Published: 24 March 2023.
Edited by:
Binbin Yang, Xuchang University, ChinaCopyright © 2023 Liu, Lin and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Peiyuan Lin, bGlucHkyM0BtYWlsLnN5c3UuZWR1LmNu