 Niaz Muhammad Shahani
Niaz Muhammad Shahani Xigui Zheng
Xigui Zheng Cancan Liu1,2
Cancan Liu1,2 Fawad Ul Hassan
Fawad Ul Hassan
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Earth Sci. , 26 October 2021
Sec. Geohazards and Georisks
Volume 9 - 2021 | https://doi.org/10.3389/feart.2021.761990
This article is part of the Research Topic Advances in Modeling, Assessment, and Prevention of Geotechnical and Geological Disasters View all 44 articles
Young’s modulus (E) is essential for predicting the behavior of materials under stress and plays an important role in the stability of surface and subsurface structures. E has a wide range of applications in mining, geology, civil engineering, etc.; for example, coal and metal mines, tunnels, foundations, slopes, bridges, buildings, drilling, etc. This study developed a novel machine learning regression model, namely an extreme gradient boosting (XGBoost) to predict the influences of four inputs such as uniaxial compressive strength in MPa; density in g/cm3; p-wave velocity (Vp) in m/s; and s-wave velocity in m/s on two outputs, namely static Young’s modulus (Es) in GPa; and dynamic Young’s modulus (Ed) in GPa. Using a series of basic statistical analysis tools, the accompanying strengths of each input and each output were systematically examined to classify the most prevailing and significant input parameters. Then, two other models i.e., multiple linear regression (MLR) and artificial neural network (ANN) were employed to predict Es and Ed. Next, multiple linear regression and ANN were compared with XGBoost. The original dataset was allocated as 70% for the training stage and 30% for the testing stage for each model. To improve the performance of the developed models, an iterative 10-fold cross-validation method was used. Therefore, based on the results XGBoost model has revealed the best performance with high accuracy (Es: correlation coefficient (R2) = 0.998; Ed: R2 = 0.999 in the training stage; Es: R2 = 0.997; Ed: R2 = 0.999 in the testing stage), root mean square error (RMSE) (Es: RMSE = 0.0652; Ed: RMSE = 0.0062 in the training stage; Es: RMSE = 0.071; Ed: RMSE = 0.027 in the testing stage), RMSE-standard deviation ratio (RSR) index value (Es: RSR = 0.00238; Ed: RSR = 0.00023 in the training stage; Es: RSR = 0.00304; Ed: RSR = 0.001 in the testing stage) and variance accounts for (VAF) (Es: VAF = 99.71; Ed: VAF = 99.99 in the training stage; Es: VAF = 99.83; Ed: VAF = 99.94 in the testing stage) compared to the other developed models in this study. Using a novel machine learning approach, this study was able to deliver substitute elucidations for predicting Es and Ed parameters with suitable accuracy and runtime.
Young’s modulus (E) is important for predicting the behavior of materials under load and plays a key part in the stability of surface and subsurface structures. E has a broad application in mining, geology, civil engineering, etc., i.e., coal and metal mines, tunnels, foundations, slopes, bridges, buildings, drilling, etc. Computation of accurate rock deformation properties, especially E is essential to the design of any rock engineering or rock mechanics project. Several researchers have studied the deformation and behavior of various types of rocks (Zhao et al., 2017; Rahimi and Nygaard, 2018; Davarpanah et al., 2019; Xiong et al., 2019). Generally, there are two common techniques, static and dynamic, employed to measure E. Static Young’s modulus (Es) is generally acquired as the digression of the stress-strain curve at 50% of the maximum strength of the rock core sample. The dynamic Young’s modulus (Ed) can be determined if the density of the rock along with the velocities of compressional and shear waves is known. In rock engineering, the variation between Es and Ed has been broadly investigated (Brotons et al., 2016). Normally, the value of Ed is slightly greater than the Es studied by various researchers (Zhang, 2006; Kolesnikov, 2009). The ratio between Ed and Es was calculated to range between 1 and 20 (Wang, 2000).
Typically, there are two common techniques, such as destructive and non-destructive, to estimate the strength and deformation of rocks. According to the recommended standards of the International Society of Rock Mechanics (ISRM) and the American Society for Testing Materials (ASTM), the use of destructive testing in the laboratory to directly estimate E is complex, time-consuming and expensive process. At the same time, sample preparation is quite difficult in the case of fragile, internally damaged, thin and highly foliated rocks (Jing et al., 2020). Thus, attention must be paid to the indirect evaluation of E through the use of rock index tests. Many researchers have established prediction models to overcome these shortcomings by employing soft computing methods such as artificial neural network (ANN), multiple regression analysis (MRA) and other novel machine learning approaches (Lindquist et al., 1994; Singh and Dubey, 2000; Tiryaki, 2008; OzcelikBayram et al., 2013; Abdi et al., 2018; Teymen and Mengüç, 2020; Cao et al., 2021; Yang et al., 2020; Duan et al., 2020). Waqas et al. used linear and nonlinear regression, regularization and ANFIS (using neuro-fuzzy inference system) to predict the Ed of sedimentary rocks (Waqas and Ahmed, 2020). Abidi et al. proposed the ANN and MRA (linear) methods for predictive modeling of E using input variables like porosity in %; dry density (γd) in g/cm3; P-wave velocity (Vp) in km/s; and water absorption (Ab) in %. The results indicated that the ANN model outperformed the MRA (Abdi et al., 2018). Davarpanah et al. developed linear and nonlinear relationships between static and dynamic deformation parameters of various rocks and found strong correlations between them (Davarpanah et al., 2020). Aboutaleb et al. conducted non-destructive experiments with SRA (simple regression analysis), MRA, ANN and SVR (support vector regression) and found that ANN and SVR models were more accurate in predicting Ed (Aboutaleb et al., 2018). Mahmoud et al. predicted the Es of sandstone using an ANN network with 409 data events in the training phase and 183 data events in the testing phase. The developed ANN model predicted Es with a high correlation coefficient (R2 = 0.999) and minimum mean absolute percentage error (AAPE = 0.98%) (Mahmoud et al., 2019). Elkatatny developed an ANN network for predicting Ed from the drilling parameters. The study showed encouraging results (Elkatatny, 2021). Elkatatny et al. was first to correlate Es prediction results from different models such as ANN, ANFIS and SVM. The established correlations improved the accuracy of the estimated Es (Elkatatny et al., 2019). Cao et al. employed the novel approach of supervised machine learning, namely an extreme gradient boosting (XGBoost) combined with the firefly algorithm (FA) to predict E. The results showed that the proposed approach is suitable for predicting E.
Based on the above literature and to the best of author’s knowledge, XGBoost machine learning method has rarely been used, especially in combination with ANN and MLR, for predictive modeling of E of rocks. Due to limitations of the conventional predictive methods, the prediction of E with machine learning approaches plays a key role in determining the accuracy of the corresponding data of tests performed in the laboratory. In this novel study, XGBoost is developed for predicting Es and Ed using four input parameters, i.e., uniaxial compressive strength (UCS) in MPa; density in g/cm3; p-wave velocity (Vp) in m/s; and s-wave velocity (Vs) in m/s, complimented with ANN and MLR. Then, the original dataset of 64 data points is split as 70% for the training stage and 30% for the testing stage. To improve the performance of the machine learning model, an iterative 10-fold cross-validation method is used.
Several multivariate parameters of intact sedimentary rocks (marlstone, sandstone, and limestone) are already reported (Moradian and Behnia, 2009) to have been used as inputs to predict the static Young’s modulus (Es) and dynamic Young’s modulus (Ed), which include uniaxial compressive strength (UCS) in MPa; density in g/cm3; p-wave velocity (Vp) in m/s; and s-wave velocity (Vs) in m/s. There were a total of 64 events with no missing data. Table 1 shows the original dataset and statistical distribution in this study.
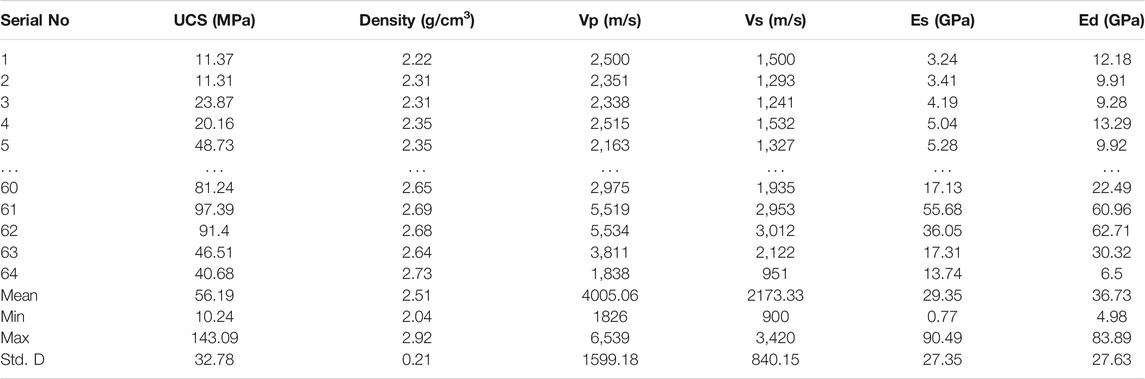
TABLE 1. Original dataset with statistical distribution in this study.
In this study, to visualize the original dataset of E, the seaborn module in Python was used. Figures 1A,B illustrate a pairwise scatter of the kernel density estimation (KDE). The purpose of building a KDE pairwise plot is to examine the association between any two influencing parameters in the original dataset. Based on Figures 1A,B, all the input parameters have a moderate to strong positive correlation with both Es and Ed. Next, Figures 2A,B highlight the diagonal correlations between the input and output parameters. The seaborn module in Python was used for diagonal correlation heatmaps to develop the correlation coefficients of multiple inputs with Es and Ed. Correlation coefficient values are specified in the light red to dark red color for Es and light purple to dark purple for Ed. According to Figures 2A,B, the overall correlation coefficients between the input and output parameters are relatively high. Therefore, all parameters were incorporated to improve the accuracy of the final probabilistic prediction framework in the Es and Ed circumstance. Figure 3 depicts the flow chart of the study.
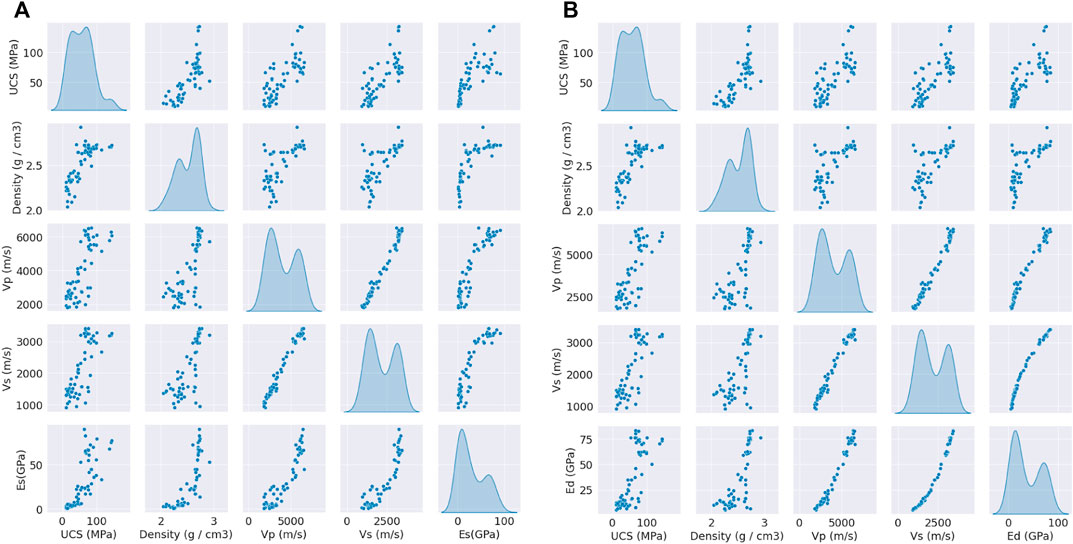
FIGURE 1. Pairwise relationship of input parameters and outputs (A) Es and (B) Ed in the dataset.
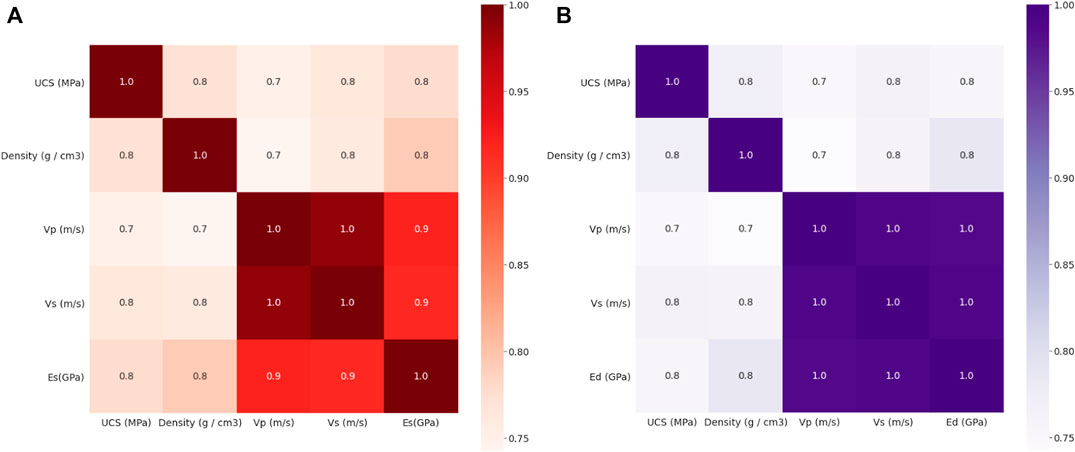
FIGURE 2. Correlation plot of input parameters and outputs (A) Es and (B) Ed in the dataset.
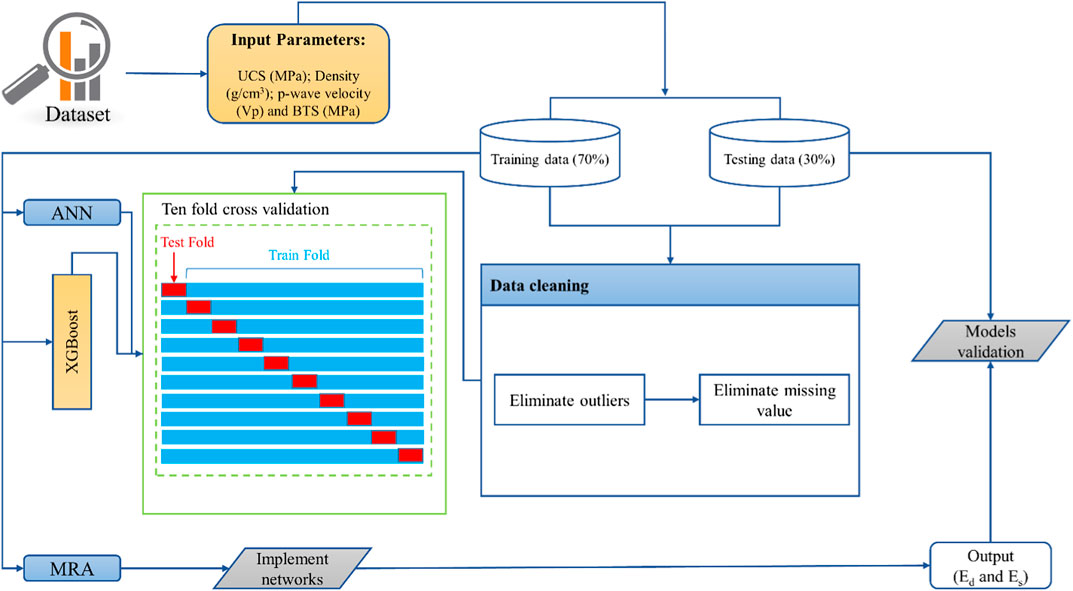
FIGURE 3. Flow chart of the study.
Multiple regression analysis (MRA) can be classified into linear and nonlinear regression. However, this study has implemented the multiple linear regression (MLR) as a result of multiple variables using SPSS (version 23). MLR is a numerical method that uses multiple descriptive parameters to estimate the output of a reporting parameter. The MLR method is used to obtain the best-fit relationship between the parameters. Generally, MLR can be employed to establish the association between independent (input) and dependent (output) parameters. In this study, the MLR technique was used to predict Es and Ed, respectively. The MLR relationship between the inputs and output can usually be expressed by Eq. 1.
where, D depicts the output parameter,
Based on the consequences of MLR, Es and Ed are predicted by the established linear expressions as shown in Eqs 2, 3.
where,
Artificial neural network (ANN) is among many supervised machine learning methods and has found wide application in a variety of fields. An ANN consists of three components, i.e., input layers, hidden layers, and an output layer. The structure of ANN and the choice of hidden layers and neurons play a crucial part in ascertaining its performance (Chester, 1990). The feedforward back-propagation (FFBP) neural network, a multilayer perceptron network, was used owing to its simple process and wide applicability. Back-propagation (BP) is one of the most efficient and commonly employed learning algorithms in multi-layer networks (Cevik et al., 2011; Hajihassani et al., 2014). Each network must contain sufficient neurons depending on the application of ANN. Neurons of a given layer are connected to the neurons of the subsequent consecutive layer with every connection having a certain weightage (Atkinson and Tatnall, 1997). Equation 4 is employed to estimate the approximate number of neurons in the hidden layer (
where, N1 denote the total number of inputs.
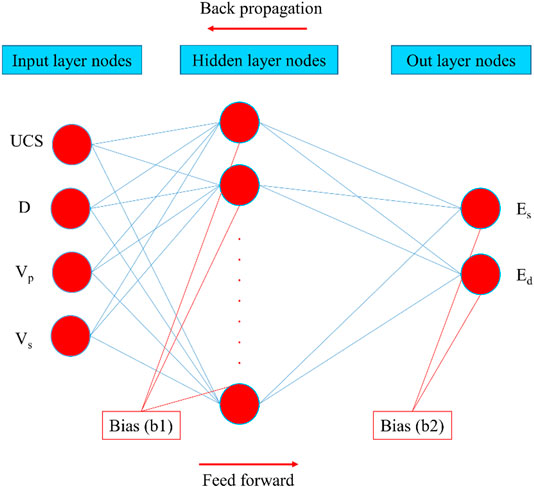
FIGURE 4. Basic architecture of ANN network.
In order to build the net input n, the weighted input
This study used a sigmoid transfer function in the hidden layer and a linear output function in the output layer. To achieve the number of neurons in the hidden layer, this study used some provisions, since there is no specific approach to providing the desired results. In addition, fifty epochs were used for training the ANN network and the least error of validation is considered as a stop to avoid overfitting.
The extreme gradient boosting (XGBoost) algorithm was created by Chen and Guestrin (Chen and Guestrin, 2016). Being an effective tree-based ensemble learning algorithm, it is considered a powerful tool among data science researchers. XGBoost is based on gradient boosting architecture (Friedman, 2001), which uses various complement functions to estimate the results using Eq. 6.
where,
According to Eq. 3 in the kth stage, the kth estimator is connected to the model and the prediction of the kth
whereas
where, Z denotes the quantity of leaf nodes,
where, G denotes the gain parameters,
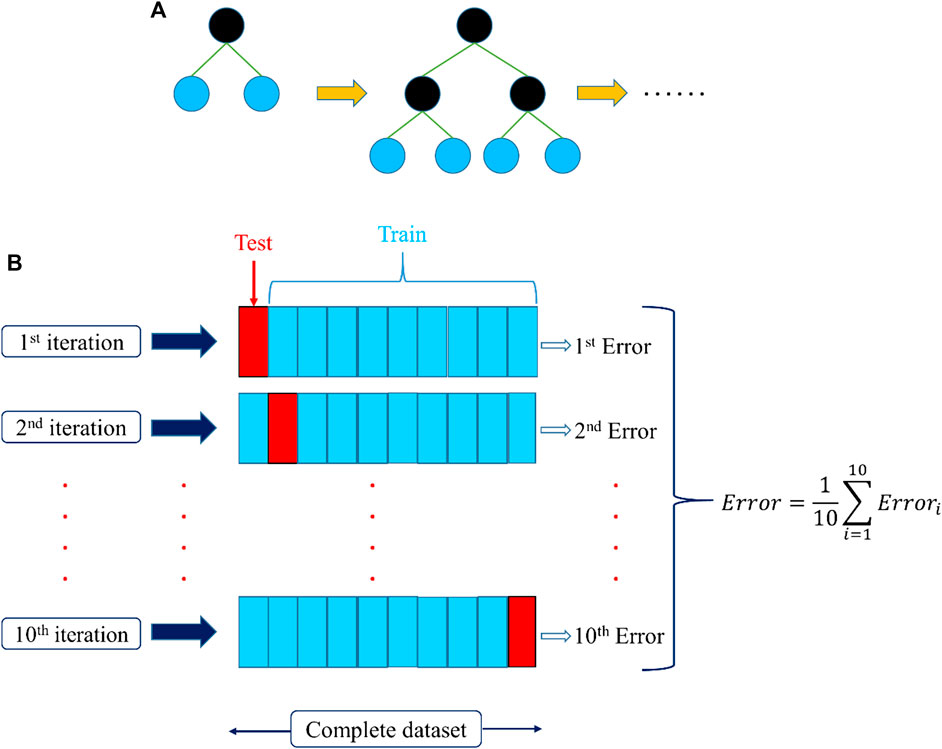
FIGURE 5. (A) Basic structure of the level-wise XGBoost tree model. (B) Grid search cross validation.
The grid search method is used for the adjustment of hyperparameters (Bergstra and Bengio, 2012). The technique approves a search in an identified range of hyperparameters and defines the desired results leading to the best outcomes of the assessment criteria, i.e., R2, MAE, MSE and RMSE. GridSearchCV() has been carried out in scikit-learn Python programing language to process this strategy. This method simply calculates the score of CV for all hyperparameters integrated with a particular reach. In this study, a 10-fold iterated arbitrary arrangement practice was incorporated in the CV command as specified in Figure 5B. GridSearchCV() allows not only to compute the desired hyperparameters, but also to evaluate the metric values to their desired outcomes. This study used all the remaining features of the Python programing language by default to perform Grid Search CV.
Typically, the performance of a model must be estimated when approaching the steadiness of a prediction framework, using an extensive range of performance criteria to select a highly accurate model. Therefore, this study proposes a unique performance criterion as follows:
The correlation coefficient (R2) is the key to the execution of the regression survey. The computation of R2 can be expressed by Eq. 10.
Mean square error (MSE) is the mean of the square of all errors and is one of the important metrics for evaluating the performance of the corresponding models. The computation of MSE can be expressed by Eq. 11.
Root mean square error (RMSE) is the square root of the mean of the square of all errors and is measured as significant metric for mathematical predictions. The computation of RMSE can be expressed by Eq. 12.
Root Mean Square Error Standard Deviation Ratio (RSR) is employed in this study for the comparison of significant models, which can be executed to predict Es and Ed. RSR plays an important role as a valuable metric for testing analytical models. The computation of RSR can be expressed by Eq. 13.
Variance accounts for (VAF) is also considered as one of the important metrics for evaluating the overall performance of the model. Higher the VAF value, the greater will be the performance of the model. The computation of VAF can be expressed by Eq. 14.
where,

TABLE 2. Performance ranking and the corresponding RSR index values.
In this study, a novel machine learning regression XGBoost model was developed and compared with two other models, namely MLR and ANN, to confirm the accuracy of predicting Es and Ed. To avoid overfitting of these models, the original dataset was partitioned into 70% for the training stage and 30% for the testing stage of 64 events. The ANN and XGBoost models are trained on training data and then validated by testing data. The 50 epochs were used for training the ANN model and the least error of validation is considered as a stop to avoid overfitting. According to Eq. 4, a total of nine neurons are selected in the hidden layer, which is connected to four input neurons and two output neurons, as shown in Figure 4. In this study, an XGBoost model with the default features of the XGBoost module was executed, i.e., M = 50 estimators, the regularization properties of γ = 0, λ = 1, and a learning rate of η = 0.3. Moreover, a 10-fold iterated arbitrary arrangement practice was incorporated to substantiate the models.
The original and predicted output values were then arranged and represented in scattered plots in order to ease the performance and correlation analysis of the developed models. The input parameters are UCS (MPa); Density (g/cm3); Vp (m/s); and Vs (m/s). The predicted output parameters are Es and Ed. The final output was evaluated by using performance criteria such as R2, RMSE and VAF, and the developed models were compared to estimate the appropriate model with higher accuracy of prediction results in this study.
Figures 6A,B to Figures 7A,B depict the scatter plots of the predictions of the proposed models (a) MLR, (b) ANN and (c) XGBoost for Es and Ed versus the original data in the training and testing stages, respectively. The prediction performance accuracy of the proposed models is (a) MRA (Es: R2 = 0.928; Ed: R2 = 0.981 in the training stage, and; Es: R2 = 0.717; Ed: R2 = 0.985 in the testing stage), (b) ANN (Es: R2 = 0.958; Ed: R2 = 0.998 in the training stage; and Es: R2 = 0.849; Ed: R2 = 0.998 in the testing stage) and (c) XGBoost (Es: R2 = 0.998; Ed: R2 = 0.999 in the training stage, and; Es: R2 = 0.997; Ed: R2 = 0.999 in the testing stage).
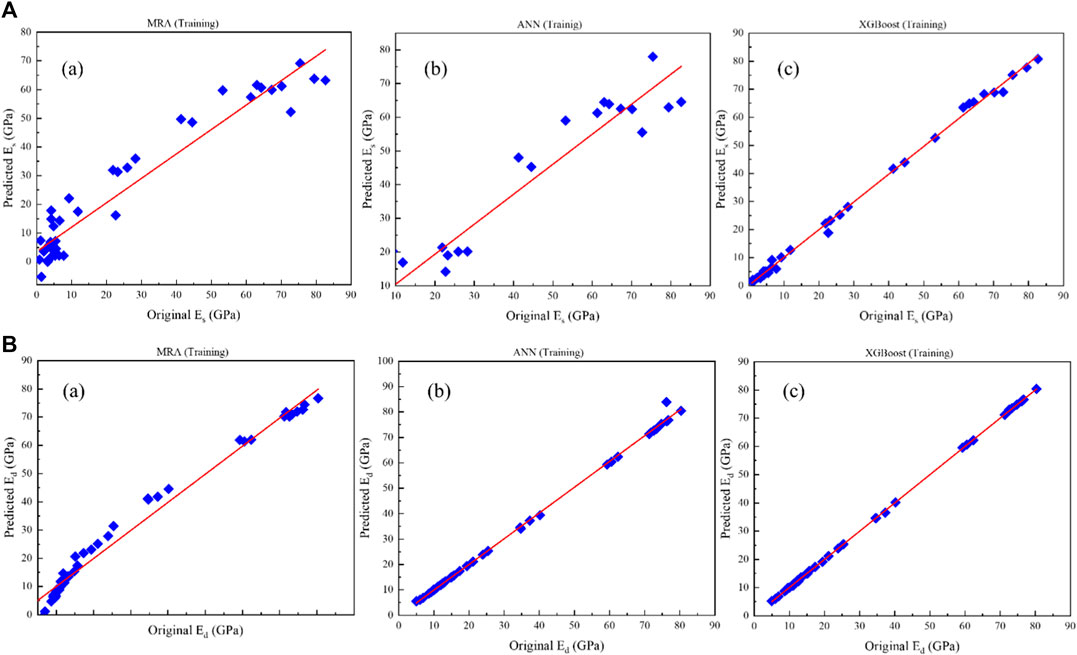
FIGURE 6. Results of (A) Es and (B) Ed prediction against original data in the training stage: (a) MLR, (b) ANN, and (c) XGBoost.
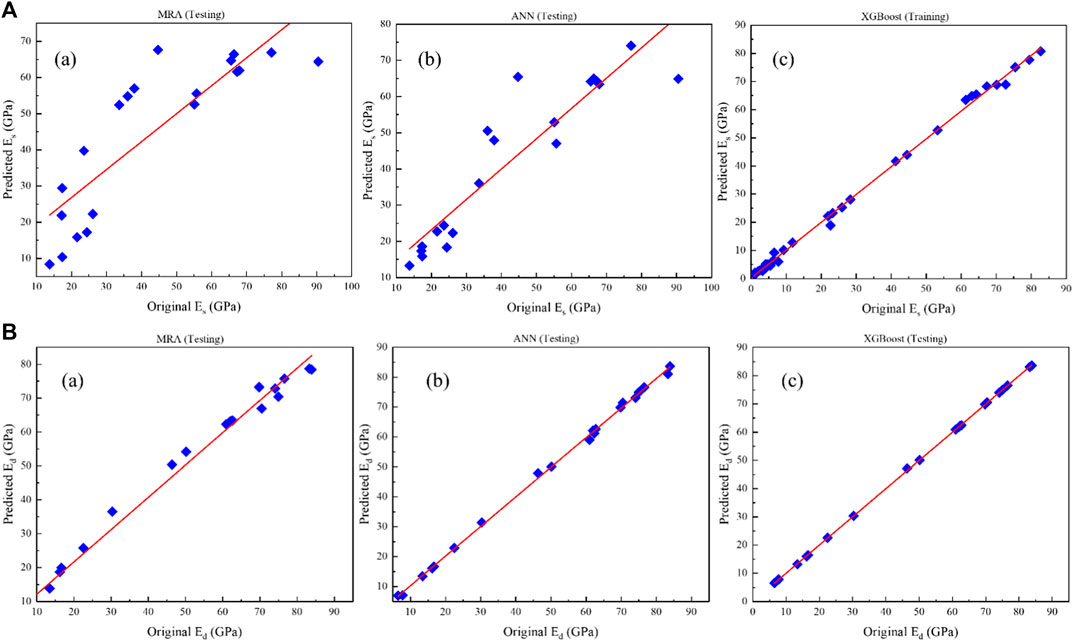
FIGURE 7. Results of (A) Es and (B) Ed prediction against original data in the testing stage: (a) MLR, (b) ANN, and (c) XGBoost.
Simultaneously, to comprehend the good visualization of the predicted values aggregated with the original data of Es and Ed, Figures 8A,B demonstrate the performance of MLR, ANN and XGBoost models in the training stage, respectively. Figures 9A,B demonstrate the performance of MLR, ANN and XGBoost models in the testing stage for (a) Es and (b) Ed, respectively.
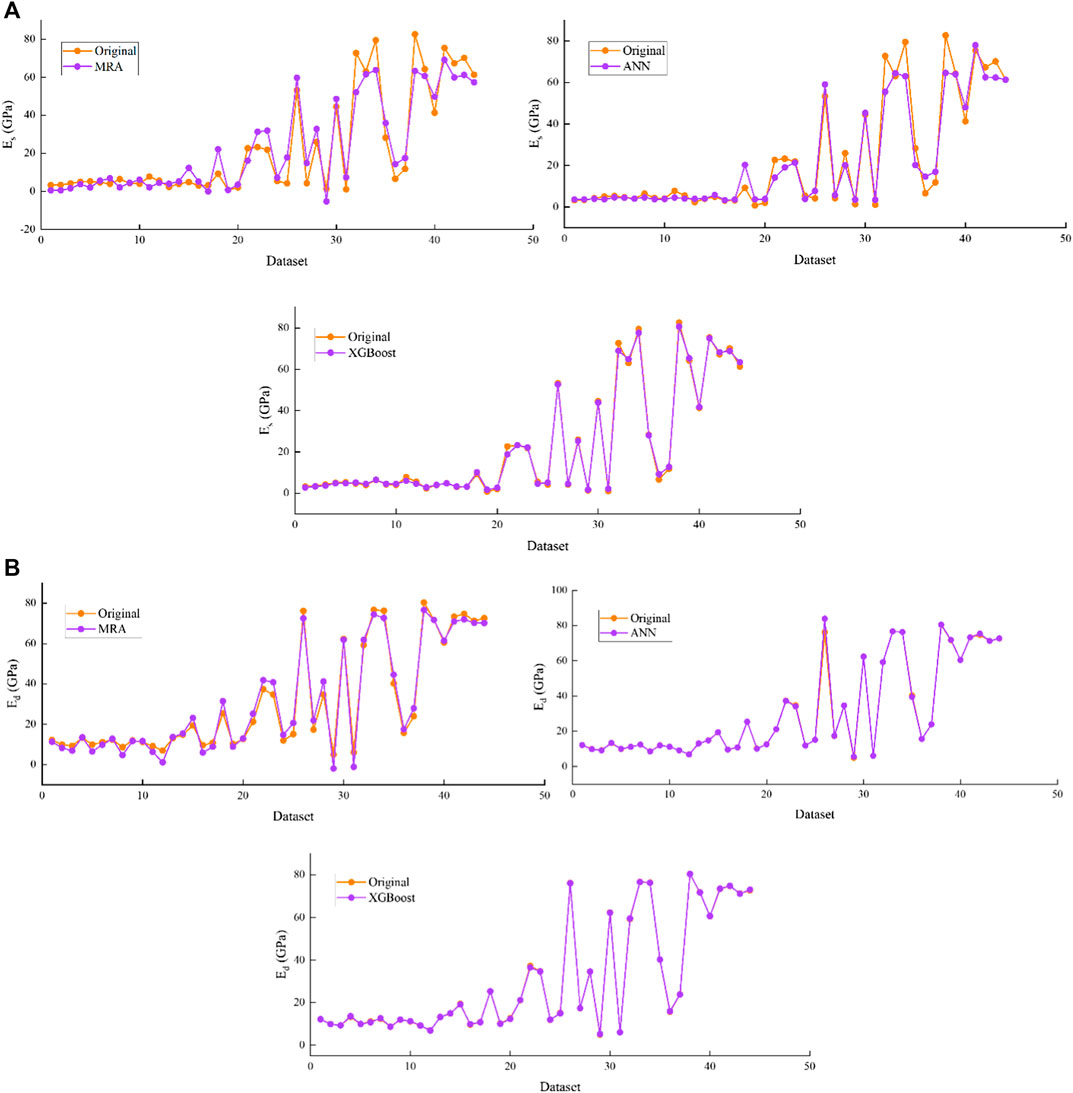
FIGURE 8. Demonstration of predicted against original data of proposed models in the training stage for (A) Es and (B) Ed.
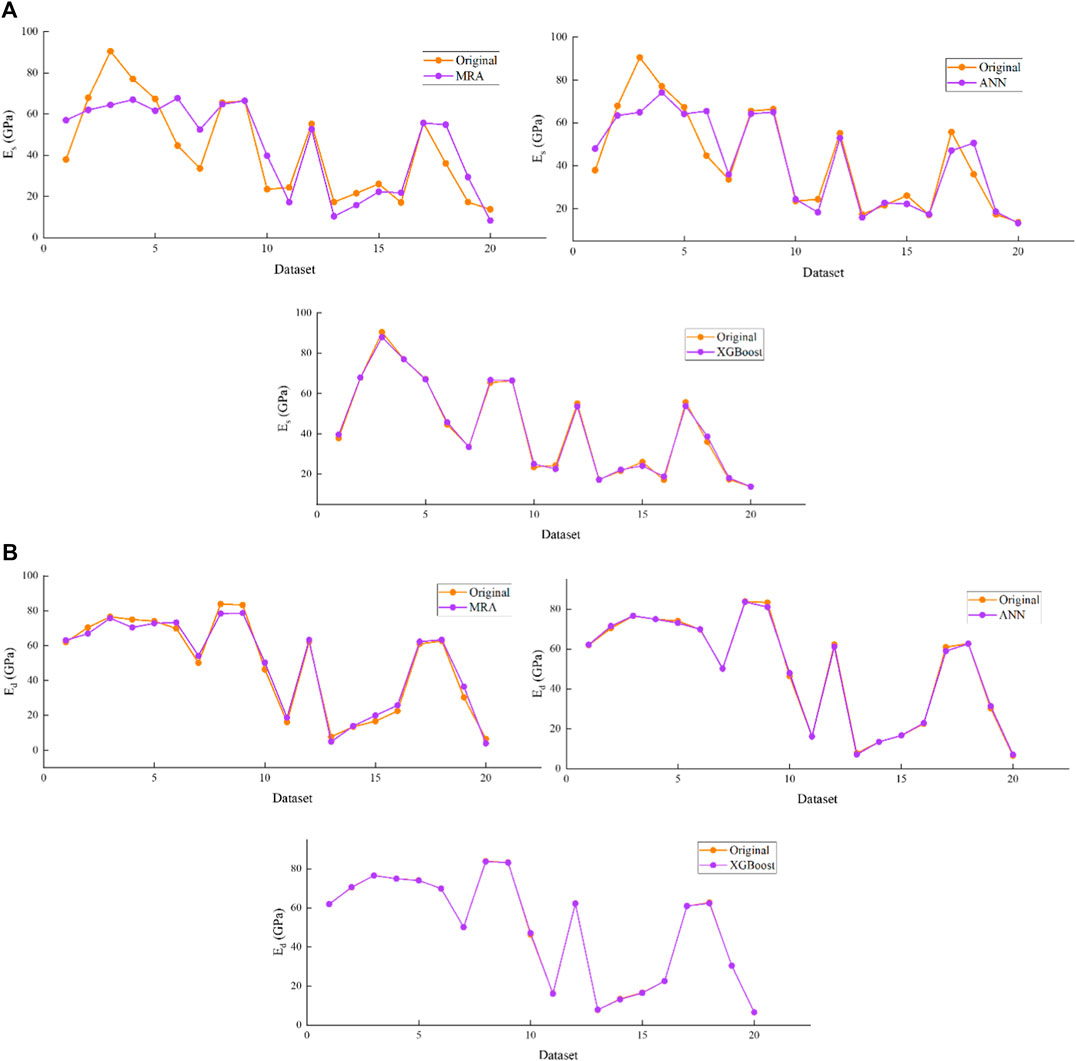
FIGURE 9. Demonstration of predicted against original data of proposed models in the testing stage for (A) Es and (B) Ed.
Figures 10A,B demonstrates the variation of the relative error of the proposed models, i.e., MLR, ANN, and XGBoost, for the prediction of Es and Ed and the original data in (a) training stage and (b) testing stage, respectively. The prediction performance of the proposed models for variation in relative mean square error (MSE) is (a) MLR (Es: MSE = 0.095; Ed: MSE = 0.00014 in the training stage, and; Es: MSE = 2.617; Ed: MSE = 0.079 in the testing stage), (b) ANN (Es: MSE = 1.009; Ed: MSE = 0.030 in the training stage, and; Es: MSE = 0.278; Ed: MSE = 0.079 in the testing stage) and (c) XGBoost (Es: MSE = 0.0043; Ed: MSE = 0.00003 in the training stage, and; Es: MSE = 0.0051; Ed: MSE = 0.0007 in the testing stage).
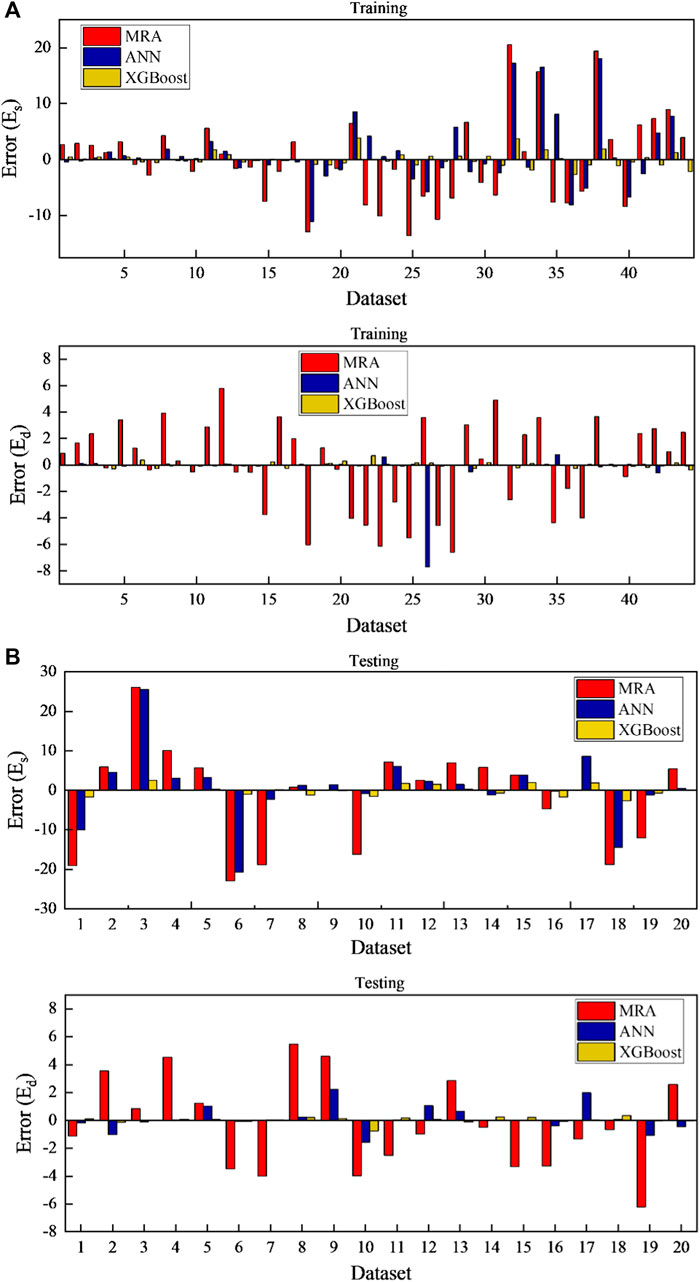
FIGURE 10. Change of relative error between predicted and original data of proposed models in the (A) training stage and (B) testing stage for Es and Ed.
Table 3 shows the performance criterion of the MRA, ANN and XGBoost determined using Eq. 10–14. Figure 11 depicts the comparative Taylor diagrams of the proposed models MRA, ANN and XGBoost in the (a) training stage and (b) testing stage for Es and Ed to further estimate the performance of the models more extensively. The standard deviation values associated with one another by the circular lines are shown as horizontal and vertical coordinates in the diagrams. Two performance metrics, one is the R2 value, indicated by the blue radial lines from the starting of the coordinates, and the other is the RMSE value, specified by the green circular line. Observed values were used as the base model with zero errors, i.e., RMSE = 0 in the diagrams, the maximum R2 = 1, and the computed standard deviations. Next, the R2, RMSE and standard deviation of the other models were compared with the observed values. A best model is one with highest degree of similarity to observed data model. As shown in Figure 11, the XGBoost model has been able to approach the observed data and outperformed the MRA and ANN models in both the training and testing phases.

TABLE 3. Performance criterion of the MRA, ANN, and XGBoost.
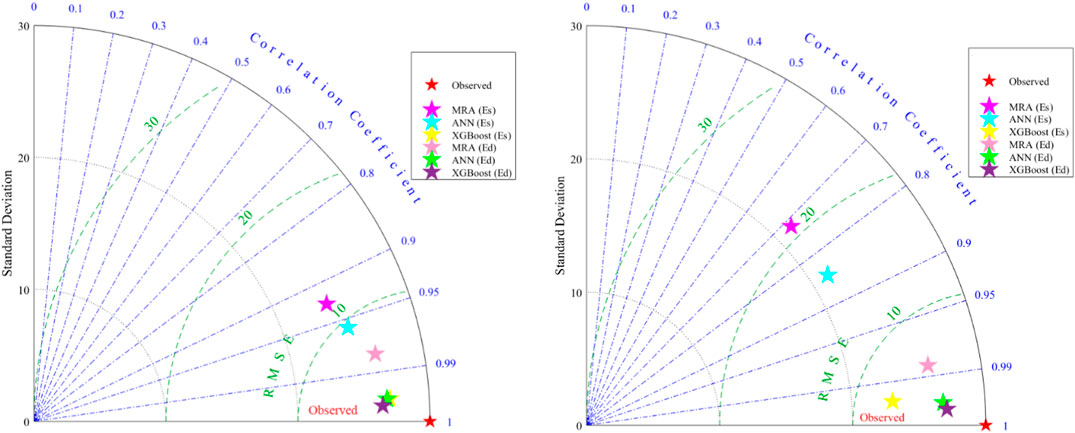
FIGURE 11. The comparative Taylor diagrams of the proposed models MRA, ANN, and XGBoost in the (A) training stage and (B) testing stage for Es and Ed.
Moreover, according to Table 3 and the results in Figure 11, the XGBoost model has revealed the best performance with high accuracy (Es: R2 = 0.998; Ed: R2 = 0.999 in the training stage, and; Es: R2 = 0.997; Ed: R2 = 0.999 in the testing stage), RMSE (Es: RMSE = 0.0652; Ed: RMSE = 0.0062 in the training stage, and; Es: RMSE = 0.071; Ed: RMSE = 0.027 in the testing stage), RSR index value (Es: RSR = 0.00238; Ed: RSR = 0.00023 in the training stage, and; Es: RSR = 0.00304; Ed: RSR = 0.001 in the testing stage) and VAF (Es: VAF = 99.71; Ed: VAF = 99.99 in the training stage, and; Es: VAF = 99.83; Ed: VAF = 99.94 in the testing stage) compared to the other developed models in this study.
Therefore, XGBoost is an applicable machine learning regression model that can be applied to accurately predict the Es and Ed.
Young’s modulus (E) plays an important role in the stability of surface and subsurface structures. Therefore, an accurate estimation of E is mandatory. This study developed a novel machine learning XGBoost regression model with four input parameters, i.e., UCS (MPa), density (g/cm3), Vp (m/s) and Vs (m/s) for predicting Es (GPa) and Ed (GPa). In addition, the MRA and ANN models were included to compare their results with the proposed model. To avoid overfitting of these models, the original dataset was partitioned into 70% for the training stage and 30% for the testing stage of 64 data points. The study concludes that the proposed XGBoost regression model performed more accurately than the other studied models in predicting Es and Ed. Employing a novel machine learning approach, this study was able to provide substitute elucidations to predict Es and Ed parameters with appropriate accuracy and runtime. Future work can be extended using various datasets to further confirm the reliability of the proposed model.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
NS: Conceptualization, Methodology, Writing Original Draft, and Run Code. XZ: Project Supervisor, Funding, and Review and Editing. CL: Run Code and Visualization. FH: Review and Editing. PL: Data Curation and Run Code.
This research was supported by the Science and Technology Innovation Project of Guizhou Province (Qiankehe Platform Talent (2019) 5620 to XZ). No additional external funding was received for this study.
XZ was employed by Guizhou Guineng Investment Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Abdi, Y., Garavand, A. T., and Sahamieh, R. Z. (2018). Prediction of Strength Parameters of Sedimentary Rocks Using Artificial Neural Networks and Regression Analysis. Arabian J. Geosci. 11 (19), 1–11. doi:10.1007/s12517-018-3929-0
Aboutaleb, S., Behnia, M., Bagherpour, R., and Bluekian, B. (2018). Using Non-destructive Tests for Estimating Uniaxial Compressive Strength and Static Young's Modulus of Carbonate Rocks via Some Modeling Techniques. Bull. Eng. Geol. Environ. 77 (4), 1717–1728. doi:10.1007/s10064-017-1043-2
Atkinson, P. M., and Tatnall, A. R. L. (1997). Introduction Neural Networks in Remote Sensing. Int. J. Remote Sensing 18 (4), 699–709. doi:10.1080/014311697218700
Bergstra, J., and Bengio, Y. (2012). Random Search for Hyper-Parameter Optimization. J. Machine Learn. Res. 13 (2), 281–305. doi:10.1016/j.chemolab.2011.12.002
Brotons, V., Tomás, R., Ivorra, S., Grediaga, A., Martínez-Martínez, J., Benavente, D., et al. (2016). Improved Correlation between the Static and Dynamic Elastic Modulus of Different Types of Rocks. Mater. Struct. 49 (8), 3021–3037. doi:10.1617/s11527-015-0702-7
Cao, J., Gao, J., Rad, H. N., Mohammed, A. S., Hasanipanah, M., and Zhou, J. (2021). A Novel Systematic and Evolved Approach Based on XGBoost-Firefly Algorithm to Predict Young’s Modulus and Unconfined Compressive Strength of Rock. Eng. Comput. doi:10.1007/s00366-020-01241-2 Published online
Cevik, A., Sezer, E. A., Cabalar, A. F., and Gokceoglu, C. (2011). Modeling of the Uniaxial Compressive Strength of Some clay-bearing Rocks Using Neural Network. Appl. Soft Comput. 11 (2), 2587–2594. doi:10.1016/j.asoc.2010.10.008
Chen, T., and Guestrin, C. (2016). “Xgboost: A Scalable Tree Boosting System,” in Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, August 13–17, 2016, 785–794.
Chester, D. L. (1990). “Why Two Hidden Layers Are Better Than One,” in Proceeding of IJCNN (Washington, DC), 1, 265–268.
Davarpanah, M., Somodi, G., Kovács, L., and Vásárhelyi, B. (2019). Complex Analysis of Uniaxial Compressive Tests of the Mórágy Granitic Rock Formation (Hungary). Stud. Geotechn. et Mech. 41 (1), 21. doi:10.2478/sgem-2019-0010
Davarpanah, S. M., Ván, P., and Vásárhelyi, B. (2020). Investigation of the Relationship between Dynamic and Static Deformation Moduli of Rocks. Geomech. Geophys. Geo-Energy Geo-Res. 6 (1), 1–14. doi:10.1007/s40948-020-00155-z
Duan, J., Asteris, P. G., Nguyen, H., Bui, X. N., and Moayedi, H. (2020). A Novel Artificial Intelligence Technique to Predict Compressive Strength of Recycled Aggregate concrete Using ICA-XGBoost Model. Eng. Comput. 37, 1–18. doi:10.1007/s00366-020-01003-0
Elkatatny, S. (2021). Real-Time Prediction of the Dynamic Young’s Modulus from the Drilling Parameters Using the Artificial Neural Networks. Arabian J. Sci. Eng.. doi:10.1007/s13369-021-05465-2 Published online
Elkatatny, S., Tariq, Z., Mahmoud, M., Abdulraheem, A., and Mohamed, I. (2019). An Integrated Approach for Estimating Static Young's Modulus Using Artificial Intelligence Tools. Neural Comput. Applic. 31 (8), 4123–4135. doi:10.1007/s00521-018-3344-1
Friedman, J. H. (2001). Greedy Function Approximation: a Gradient Boosting Machine. Ann. Stat., 1189–1232. doi:10.1214/aos/1013203451
Hajihassani, M., Jahed Armaghani, D., Sohaei, H., Tonnizam Mohamad, E., and Marto, A. (2014). Prediction of Airblast-Overpressure Induced by Blasting Using a Hybrid Artificial Neural Network and Particle Swarm Optimization. Appl. Acoust. 80, 57–67. doi:10.1016/j.apacoust.2014.01.005
Jing, H., Rad, H. N., Hasanipanah, M., Armaghani, D. J., and Qasem, S. N. (2020). Design and Implementation of a New Tuned Hybrid Intelligent Model to Predict the Uniaxial Compressive Strength of the Rock Using SFS-ANFIS. Eng. Comput. 37, 1–18. doi:10.1007/s00366-020-00977-1
Kolesnikov, Y. I. (2009). Dispersion Effect of Velocities on the Evaluation of Material Elasticity. J. Min. Sci. 45 (4), 347–354. doi:10.1007/s10913-009-0043-4
Lindquist, E. S., and Goodman, R. E. (1994). “Strength and Deformation Properties of a Physical Model Melange,” in Proceedings of the 1st North American Rock Mechanics Symposium. Editors P. P. Nelson, and SE. Laubach (Rotterdam: Balkema).
Mahmoud, A. A., Elkatatny, S., Ali, A., and Moussa, T. (2019). Estimation of Static Young's Modulus for Sandstone Formation Using Artificial Neural Networks. Energies 12 (11), 2125. doi:10.3390/en12112125
Moradian, Z. A., and Behnia, M. (2009). Predicting the Uniaxial Compressive Strength and Static Young's Modulus of Intact Sedimentary Rocks Using the Ultrasonic Test. Int. J. Geomech. 9 (1), 14–19. doi:10.1061/(asce)1532-3641(2009)9:1(14)
OzcelikBayram, Y. F., Bayram, F., and Yasitli, N. E. (2013). Prediction of Engineering Properties of Rocks from Microscopic Data. Arab J. Geosci. 6, 3651–3668. doi:10.1007/s12517-012-0625-3
Rahimi, R., and Nygaard, R. (2018). Effect of Rock Strength Variation on the Estimated Borehole Breakout Using Shear Failure Criteria. Geomech. Geophys. Geo-Energ. Geo-Resour. 4 (4), 369–382. doi:10.1007/s40948-018-0093-7
Singh, T. N., and Dubey, R. K. (2000). A Study of Transmission Velocity of Primary Wave (P-Wave) in Coal Measures sandstone. J. Scientific Ind. Res. 59, 482–486. doi:10.1361/105497100770340147
Teymen, A., and Mengüç, E. C. (2020). Comparative Evaluation of Different Statistical Tools for the Prediction of Uniaxial Compressive Strength of Rocks. Int. J. Mining Sci. Techn. 30 (6), 785–797. doi:10.1016/j.ijmst.2020.06.008
Tiryaki, B. (2008). Predicting Intact Rock Strength for Mechanical Excavation Using Multivariate Statistics, Artificial Neural Networks, and Regression Trees. Eng. Geol. 99, 51–60. doi:10.1016/j.enggeo.2008.02.003
Wang, Z. (2000). Dynamic versus Static Elastic Properties of Reservoir Rocks. Seismic Acoust. Velocities Res. Rocks 3, 531–539.
Waqas, U., and Ahmed, M. F. (2020). Prediction Modeling for the Estimation of Dynamic Elastic Young's Modulus of Thermally Treated Sedimentary Rocks Using Linear-Nonlinear Regression Analysis, Regularization, and ANFIS. Rock Mech. Rock Eng. 53 (12), 5411–5428. doi:10.1007/s00603-020-02219-8
Xiong, L. X., Xu, Z. Y., Li, T. B., and Zhang, Y. (2019). Bonded-particle Discrete Element Modeling of Mechanical Behaviors of Interlayered Rock Mass under Loading and Unloading Conditions. Geomech. Geophys. Geo-Energ. Geo-Resour. 5 (1), 1–16. doi:10.1007/s40948-018-0090-x
Yang, F., Li, Z., Wang, Q., Jiang, B., Yan, B., Zhang, P., et al. (2020). Cluster-formula-embedded Machine Learning for Design of Multicomponent β-Ti Alloys with Low Young’s Modulus. npj Comput. Mater. 6 (1), 1–11. doi:10.1038/s41524-020-00372-w
Keywords: dynamic Young’s modulus, k-fold crosses validation, machine learning, predictive modeling, static Young’s modulus, XGBoost
Citation: Shahani NM, Zheng X, Liu C, Hassan FU and Li P (2021) Developing an XGBoost Regression Model for Predicting Young’s Modulus of Intact Sedimentary Rocks for the Stability of Surface and Subsurface Structures. Front. Earth Sci. 9:761990. doi: 10.3389/feart.2021.761990
Received: 20 August 2021; Accepted: 12 October 2021;
Published: 26 October 2021.
Edited by:
Zetian Zhang, Sichuan University, ChinaReviewed by:
Harsha Vardhan, National Institute of Technology, IndiaCopyright © 2021 Shahani, Zheng, Liu, Hassan and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xigui Zheng, Y3VtdF9ja3p4Z0AxMjYuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.