
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Earth Sci. , 06 November 2020
Sec. Solid Earth Geophysics
Volume 8 - 2020 | https://doi.org/10.3389/feart.2020.585317
This article is part of the Research Topic Achievements and New Frontiers in Research Oriented to Earthquake Forecasting View all 28 articles
 Valeri Gitis
Valeri Gitis Alexander Derendyaev*
Alexander Derendyaev*An approach for the systematic forecasting of earthquake magnitudes is considered. To solve this problem, we use the minimum area of alarm method. Testing the approach for Kamchatka and the Aegean Region shows a satisfactory quality of the forecast of earthquakes and their magnitudes.
Field observations show that before a strong earthquake, anomalous phenomena are observed in a number of natural processes: seismic regime, earth surface deformations, fluid chemistry, groundwater level, seismic wave travel times, electric and geomagnetic fields, etc. Usually, these precursors are detected locally near the source of a future earthquake (Mogi, 1979; Kanamori, 1981; Sobolev, 1993; Sobolev and Ponomarev, 2003). At the same time, it is known that with an increase in the energy of the expected earthquake, the epicenter distance to the area of the manifestation of precursors increases and can be more than 1,000 km (Dobrovolsky et al., 1979; Guomin and Zhaocheng, 1992). This introduces additional uncertainty in the estimation of the location of the expected earthquake.
Many aspects of earthquake prediction have been studied, including rock failure and earthquake precursor phenomena, mathematical models for earthquake prediction, machine learning methods, and earthquake prediction testing algorithms (Sobolev, 1993; Kossobokov, 1997; Sobolev and Ponomarev, 2003; Zavyalov, 2006; Rhoades, 2007; Marzocchi and Zechar, 2011; Amei et al., 2012; Keilis-Borok and Soloviev, 2013; Rhoades, 2013; Shebalin et al., 2014). At the same time, a number of works state that earthquakes cannot be predicted (Geller et al., 1997; Koronovsky and Naimark, 2009; Gufeld et al., 2015).
An earthquake forecast is an estimate of the location, time, and magnitude of an earthquake. Usually, forecasts involve estimating the spatial zone and the time interval in which an earthquake with a magnitude above a certain threshold is expected. Such a spatio‐temporal region is often called an alarm zone, which is regularly built with a constant step in a systematic earthquake prediction. The forecast is successful if the epicenter of the target earthquake falls into the alarm zone.
Here, we consider the issue of earthquake magnitude prediction. Most studies have addressed the problem of predicting earthquake magnitudes for a limited area. A few successful studies are presented in Panakkat and Adeli (2007), Adeli and Panakkat (2009), and Asim et al. (2017). The authors solved the problem of predicting the maximum magnitude of a seismic event in a preselected location. For example, in the first two studies, the maximum magnitude per month was predicted in the Southern California region and in the 200 km zone surrounding San Francisco. The input data were eight time series calculated from catalogs of earthquakes that occurred in the forecast area. For training, neural network methods were used. Training was carried out for the interval 1950–1990, and the 1991–2005 interval was used for testing. In Alexandridis et al. (2013), neural network methods were also used to estimate inter-event times between significant seismic events. The examples studied are from across California.
In our case, the forecast problem is solved not for the time series geographically localized at one point but the area presented by the spatio‐temporal grid fields. The forecast for a particular geographical object can be considered a special case. Here, it is possible to use the time series of parameters tuned to the local place of the forecast, such as foreshock precursors of earthquakes (Boore, 2001), energy precursors (Wyss et al., 1990; Bufe and Varnes, 1993; Vallianatos and Chatzopoulos, 2018), precursors tuned to the frequency of strong earthquakes in a given area (Kagan and Jackson, 1991), and others. In our case, the forecast is not based on time series but on spatial and spatio‐temporal grid fields. Fields of forecast features and training parameters cannot be configured to detect the process preceding a strong earthquake in a single predetermined geographical object. They should be universal for the entire area under analysis. Further, it is desirable that the grid fields used for the forecast contain patterns of anomalous behavior of seismic and geodynamic processes that are characteristic of the analyzed region and preceded by strong earthquakes.
We briefly consider the method of the minimum area of alarm and two ways to apply it to predict earthquake magnitudes in Section 2. In Section 3.1, we report the test results obtained to predict earthquakes and their magnitudes for Kamchatka and the Aegean Region. Testing was carried out on the GIS web-based platform for earthquake prediction (https://distcomp.ru/geo/prognosis/) and on the multifunctional web-GIS GeoTime 3 (http://geo.iitp.ru/GT3/).
We have developed the method of the minimum area of alarm for the systematic forecast of strong earthquakes with a magnitude above a certain threshold (Gitis and Derendyaev, 2018; Gitis and Derendyaev, 2019). The system of systematic earthquake prediction regularly with a step
We assume that strong earthquakes are preceded by anomalous manifestations, which can be represented in the grid spatio‐temporal fields of features. consisting of the spatio‐temporal fields of features,
The fields
During training, the algorithm detects target events. An event is detected if its epicenter falls into the alarm area during the training interval. A target earthquake is predicted at the step
In a systematic forecast of earthquake magnitude, it is necessary to indicate the area in which the target event is expected and to evaluate its magnitude. We consider two ways to complete each forecast step
The solution to the problem of earthquake prediction is required for both approaches. Our method of the minimum area of alarm is trained to detect abnormal target objects from a sample consisting of labeled abnormal objects and a mixture consisting of unlabeled abnormal and normal objects. The data model contains two assumptions that allow us to introduce a measure of the abnormality of the analyzed objects.
(1) Abnormality condition: in feature space, the target earthquakes are preceded by vectors (earthquake precursors) for which the values of some components (the values of some feature fields) are unlikely and close to the maximum (or minimum). To simplify the explanation, we assume that the precursors refer only to the maximal values of the fields of features.
(2) Monotonicity condition: feature space vectors that are component-wise larger (or smaller) than the earthquake precursor vector can also be precursors of similar target events.
For training, the earthquake prediction algorithm requires determining the precursor for each target event. Let the event q be preceded by a precursor
The forecast quality is determined by two indicators: 1) the probability of prediction U, equal to the fraction of correctly forecast target events
In classification problems, the decision rule is found by minimizing the function of losses from target detection errors and false alarms. The training algorithm is optimal if it calculates an alarm area with the volume
The algorithm for constructing the forecast field is nonparametric. It consists of two steps: (I) generating a training sample set
Consider the first version of the algorithm.
(1) Generate a training sample set
(2) Calculate the alarm field
a. Assign to the nodes of the grid of the alarm field
b. Replace the value of 1 of the field
The calculated field
Testing simulates the operation mode of the forecast. As in the forecast, it is performed with a constant step
A comparison of the success of regular and random forecasts cannot properly account for the heterogeneity of the spatial distribution of seismicity in the field of analysis. If the area where the target earthquakes occur is small, compared to the analysis area, then a trivial solution is possible because for a large area of analysis L, the announcement of a constant alarm in a relatively small area can lead to a high probability of a forecast with a small level of the alarm volume V. To avoid a trivial solution, the probability of a regular forecast is compared to that of a forecast based on stationary spatial data. The most common method is to compare the number of predicted earthquakes detected during a regular forecast with the number of events expected in the same place in the spatio‐temporal alarm zones, which is estimated from a catalog of earthquakes with an interval of 20–30 years before testing (Molchan, 1997; Kossobokov et al., 1999).
The spatial heterogeneity of the seismic process can be controlled not only by the epicenters of earthquakes in a relatively short period but also by, for example, a spatial field of seismic activity or a field of maximum magnitudes Mmax of expected earthquakes (Bune and Gorshkov, 1980). Therefore, we use a different method for assessing the quality of the analysis area (Gitis and Derendyaev, 2018; Gitis and Derendyaev, 2019): for the same volume of alarm, we compare the probabilities of detecting target events obtained using the spatial field of the earthquake epicenter density and the fields of features selected for the regular forecast.
Our systematic earthquake prediction technology is universal with respect to input data types. All data types, including point fields, time series, and linear, polygonal, and raster fields, are converted to grid spatial and spatio‐temporal fields. This provides versatility to the system for incoming data types. In this work, only forecasting methods were tested. For this, we used the most famous characteristics of earthquake catalogs:
•
•
•
•
•
•
•
The estimation of 3D fields of
There were two objectives for the tests: to verify the possibility of 1) predicting earthquake magnitudes using a linear approximation of the dependence of earthquake magnitudes on the fields of features in relatively large intervals of magnitudes and 2) using the method of the minimum area of alarm for the prediction of earthquakes in small magnitude intervals.
Tests were performed in Kamchatka and the Aegean Region.
Initial data for Kamchatka contain the earthquake catalog of Kamchatka Branch, Geophysical Survey, Russian Academy of Sciences, for April 4, 1986–May 20, 2019, with the magnitudes
Initial data for the Aegean Region contain the earthquake catalog of the International Seismological Center (2020) (accessed June 11, 2020) for May 27, 1983–September 13, 2019, with the magnitudes
The fields of features and the parameters of the algorithm were selected when testing the forecast of earthquakes with the magnitudes
The fields of features
The fields of features
Alarm zone maps are computed at each test step. The number of such maps for each of the selected regions is from 70 to 90. Alarm maps for three regions can be seen on a demo site (https://distcomp.ru/geo/prognosis/). The prediction accuracy for test data is determined by the value of the alarm area
Forecast maps for earthquakes with magnitudes
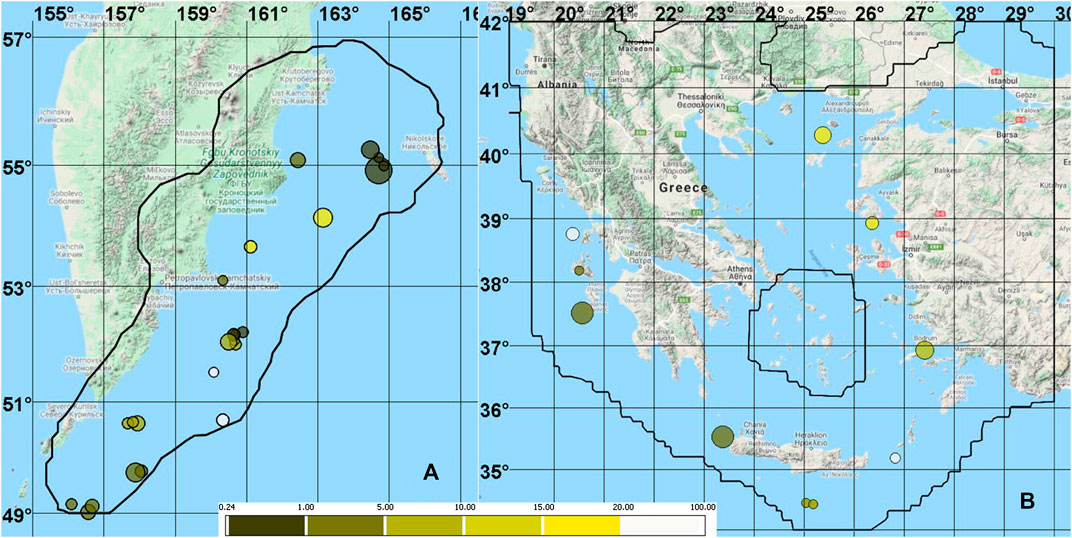
FIGURE 1. The maps of epicenters of the target earthquakes in the test sample color-coded with respect to the volume of alarm required for its successful prediction: (A) 24 magnitude
Consider the results of testing the forecast of earthquakes in large magnitude intervals. For Kamchatka, the intervals
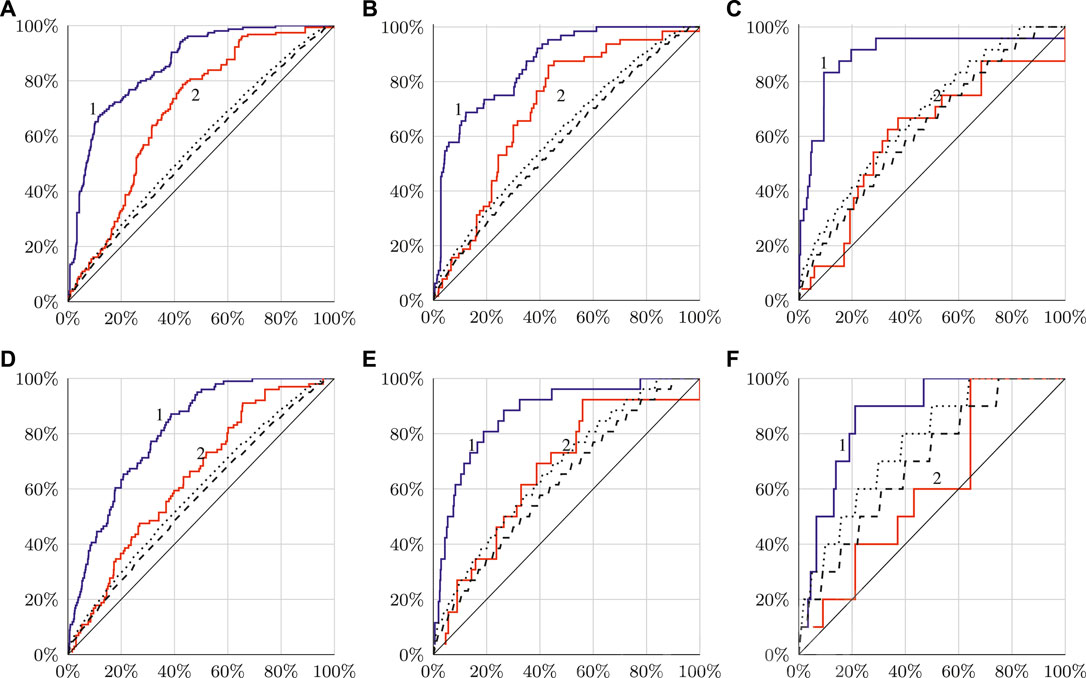
FIGURE 2. Graphs of dependencies
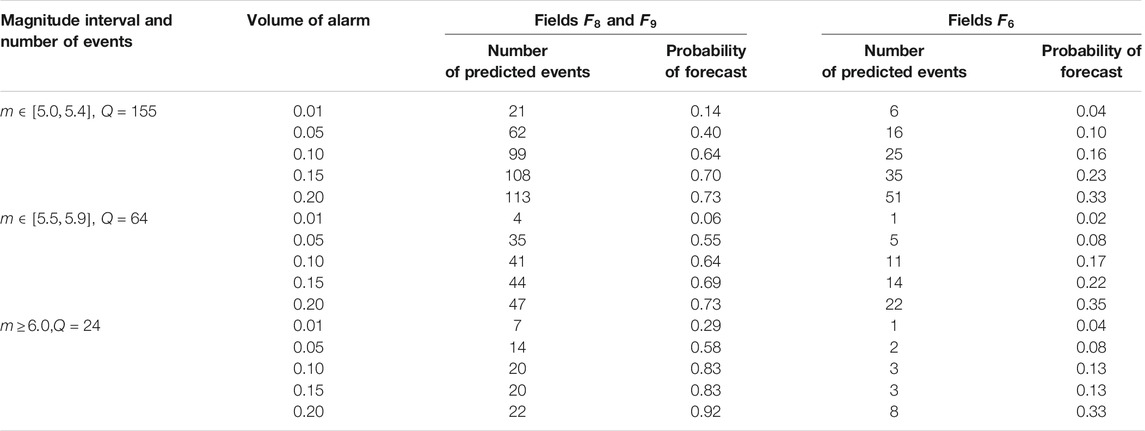
TABLE 1. Kamchatka: probabilities of forecasting the earthquakes in magnitude intervals
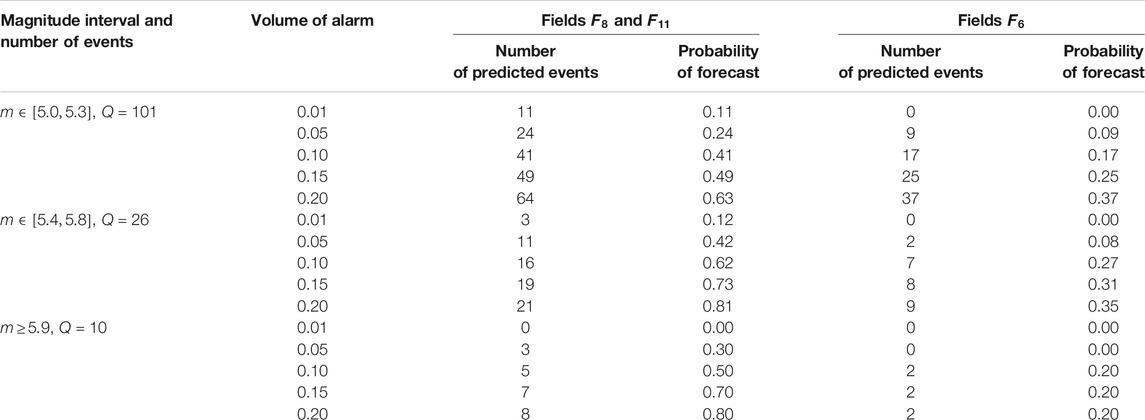
TABLE 2. The Aegean Region: probabilities of forecasting the earthquakes in the magnitude intervals
According to Molchan (2003) and Kossobokov (2006), we also provide two lines: the dotted one corresponds to the confidence levels of 95% and the dashed one corresponds to 99%. They are used to denote “significant” and “very significant” deviation from random guessing, denoted with a diagonal line.
Alarm zones in each region are limited to
The results of testing the forecast of earthquake magnitudes in large intervals of magnitudes are presented in Tables 3, 4. For the forecast, the dependence of the earthquake magnitudes on the values of the feature fields is approximated by the linear function. The forecast results are calculated only for those earthquakes whose epicenters are in the alarm zone. It can be seen that in each interval, the standard error of approximation of the dependence of the earthquake magnitudes on the values of the feature fields practically coincides with the standard deviation of the magnitudes of the target earthquakes. There are two possible reasons for the poor approximation: the magnitude of the earthquake is independent of the values of the selected feature fields or this dependence is non‐linear.

TABLE 3. Results of forecasting the earthquake magnitudes for Kamchatka.

TABLE 4. Results of forecasting the earthquake magnitudes for the Aegean Region.
Tables 5, 6 present the results of earthquake prediction in small magnitude intervals. The following intervals of magnitudes were chosen: for Kamchatka, the intervals are

TABLE 5. Kamchatka: probabilities of earthquake forecasts for the magnitude intervals
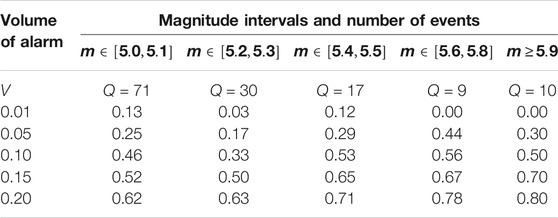
TABLE 6. The Aegean Region: probabilities of earthquake forecasts for the magnitude intervals
The test results presented in Tables 1, 2, 5, 6 indicate that the fields of features and parameters of our training algorithm, selected for the forecast of strong earthquakes with magnitudes
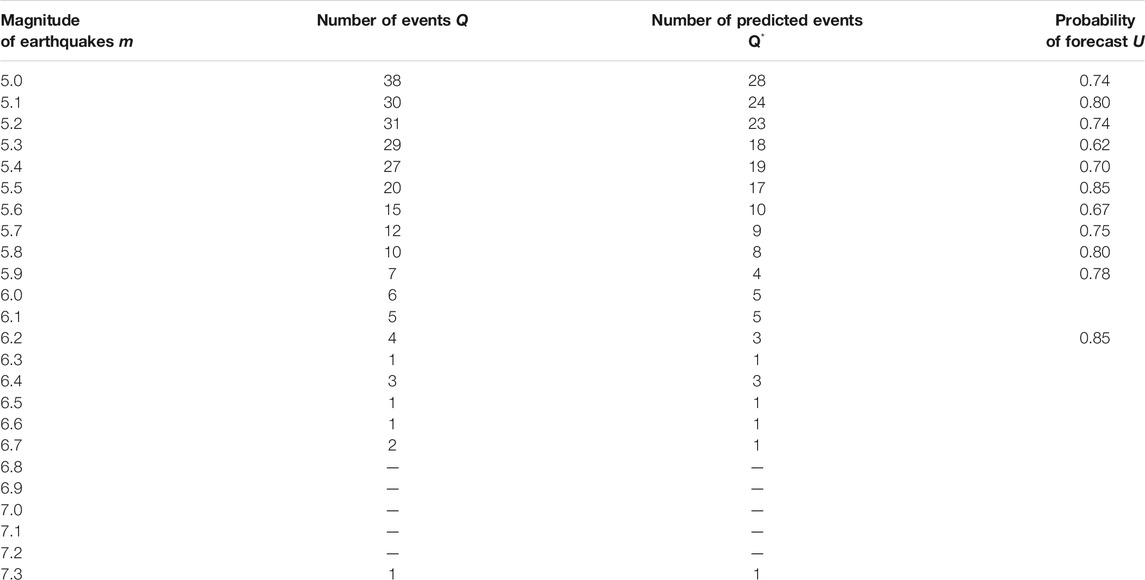
TABLE 7. Kamchatka: probabilities of earthquake forecasts for the magnitudes
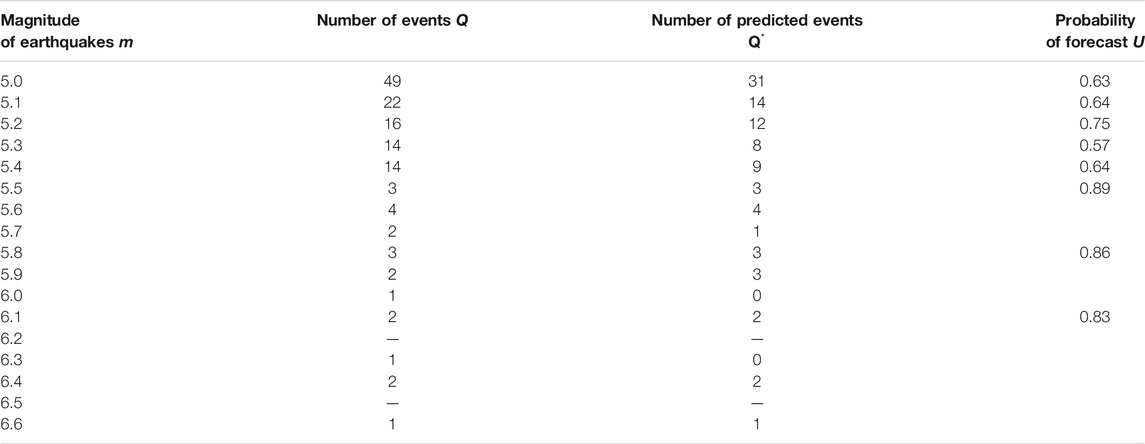
TABLE 8. The Aegean Region: probabilities of earthquake forecasts for the magnitudes
Some disciplines study complex processes and their relationships with simpler instrumentally measured properties. The purpose of one of these tasks is to predict the critical states of the process by the values of the properties. To do this, first, the connections of the process with each property are investigated separately to determine the values of the properties wherein the process does not pass into critical states. For example, in medicine for healthy people, the norms of indicators of functional diagnostics are established. In earthquake prediction for each localized area, the seismic regime parameters’ long-term average values are taken as the norm. It can be assumed that the greater the deviation from the norm, the greater or equal (but not less) the deviation of the process from the normal state to the critical one, given that everything else is equal. This means that the value of the deviation from the norm is a monotonic non‐decreasing function of the feature values.
The formulation of the method of minimum area of alarm is discussed as follows. Consider a set of objects. An object is described by a set of properties denoted in numerical form (a vector of features). The values of properties of the objects that are close to the highest possible value have a low probability. Among the set of objects, there are abnormal objects. They differ from other objects so that the values of some of their properties are close to the maximum possible value. Let there be a training sample from anomalous objects (precedents). It seems natural to classify an object as anomalous if its vector is greater or equal to one of the vectors corresponding to a precedent. However, the description of the object properties can be incomplete and some precedents lack properties that are close to the maximum values. For such precedents, the number of objects classified as anomalous by them can be vast and the objects themselves are very likely to be erroneously classified as abnormal. The task is to allocate the largest number of precedents for a given number of objects classified by them as anomalous.
The idea of the algorithm of the minimum area of alarm is described as follows. In the first step, the algorithm builds for each precedent a set of objects classified by it as abnormal. Next, for a given number
Earthquake magnitude forecasts can be made in two ways: first, by systematically calculating the alarm area of expected earthquakes with an interval
Figure 2 shows the
Our tests show that a linear approximation of the dependence of earthquake magnitudes on the values of feature fields does not provide satisfactory results. The use of the method of the minimum area of alarm for predicting earthquakes belonging to small intervals of magnitudes has been successful enough to predict earthquake magnitudes.
When forecasting earthquakes with large magnitudes, sometimes difficulties arise because of the small number of target events that can be used for training. Testing shows that the method of the minimum area of alarm provides a better result of the forecast of strong earthquakes than the stationary forecast for the case in which the training set of the target earthquakes with large magnitudes is supplemented by earthquakes with smaller magnitudes.
Testing of the application of the method of the minimum area of alarm was carried out according to the fields
The original contributions presented in the study are publicly available. These data can be found here: http://www.isc.ac.uk/iscbulletin/search/ for Aegean Region Centre (2020) (accessed June 11, 2020) and http://sdis.emsd.ru/info/earthquakes/catalogue.php for Kamchatka.
VG and AD contributed to conception and design of the study. AD wrote the software. VG and AD made the analyses. VG wrote the first draft of the manuscript. VG and AD reviewed and edited the manuscript. All authors contributed to the manuscript revision and read and approved the submitted version.
This research was funded by the Russian Foundation for Basic Research (grant number 20-07-00445).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Adeli, H., and Panakkat, A. (2009). A probabilistic neural network for earthquake magnitude prediction. Neural Netw. 22, 1018–1024. doi:10.1016/j.neunet.2009.05.003
Alexandridis, A., Chondrodima, E., Efthimiou, E., Papadakis, G., Vallianatos, F., and Triantis, D. (2013). Large earthquake occurrence estimation based on radial basis function neural networks. IEEE Trans. Geosci. Rem. Sens. 52, 5443–5453. doi:10.1109/TGRS.2013.2288979
Amei, A., Fu, W., and Ho, C.-H. (2012). Time series analysis for predicting the occurrences of large scale earthquakes. Int. J. Appl. 2, 64. Available at: http://www.ijastnet.com/journal/index/313 or https://www.ijastnet.com/journals/Vol_2_No_7_August_2012/8.pdf.
Asim, K. M., Martínez-Álvarez, F., Basit, A., and Iqbal, T. (2017). Earthquake magnitude prediction in Hindukush region using machine learning techniques. Nat. Hazards 85, 471–486. doi:10.1007/s11069-016-2579-3
Bishop, C. M. (2006). “Machine learning and pattern recognition,” in Information science and statistics. Heidelberg: Springer.
Boore, D. M. (2001). Comparisons of ground motions from the 1999 chi-chi earthquake with empirical predictions largely based on data from California. Bull. Seismol. Soc. Am. 91, 1212–1217.
Bradley, A. P. (1997). The use of the area under the roc curve in the evaluation of machine learning algorithms. Pattern Recognit. 30, 1145–1159. doi:10.1016/s0031-3203(96)00142-2
Bufe, C. G., and Varnes, D. J. (1993). Predictive modeling of the seismic cycle of the greater san francisco bay region. J. Geophys. Res. 98, 9871–9883. doi:10.1029/93jb00357
Dobrovolsky, I. P., Zubkov, S. I., and Miachkin, V. I. (1979). Estimation of the size of earthquake preparation zones. Pure Appl. Geophys. 117, 1025–1044. doi:10.1007/bf00876083
Geller, R. J., Jackson, D. D., Kagan, Y. Y., and Mulargia, F. (1997). Earthquakes cannot be predicted. Science 275, 1616. doi:10.1126/science.275.5306.1616
Gitis, V. G., and Derendyaev, A. B. (2018). “Web-based gis platform for automatic prediction of earthquakes,” in International conference on computational science and its applications, Melbourne, United States, July 2–5, 2018, 268–283.
Gitis, V. G., and Derendyaev, A. B. (2019). Machine learning methods for seismic hazards forecast. Geosciences 9, 308. doi:10.3390/geosciences9070308
Gitis, V., Derendyaev, A., and Saltykov, V. (2015). “Gis platform for monitoring and analysis of seismic activity fields (in Russian),” in Problems of complex geophysical monitoring of the Russian far east. Proceedings of the fifth scientific and technical conference, Petropavlovsk-Kamchatsky, October 1–7, 2017, Vol. 27, 47–50.
Gitis, V. G., Derendyaev, A. B., and Petrov, K. N. (2020a). Analysis of the impact of removal of aftershocks from catalogs on the effectiveness of systematic earthquake prediction. J. Commun. Technol. Electron. 65, 756–762. doi:10.1134/s106422692006011x
Gitis, V. G., Derendyaev, A. B., and Petrov, K. N. (2020b). A method of abnormal geological zone identification. Information processes 20, 79–94. Available at: http://www.jip.ru/2020/79-94-2020.htm or http://www.jip.ru/2020/79-94-2020.pdf.
Gufeld, I. L., Matveeva, M. I., and Novoselov, O. N. (2015). Why we cannot predict strong earthquakes in the earth’s crust. Geodyn. Tectonophys. 2, 378–415.
Guomin, Z., and Zhaocheng, Z. (1992). The study of multidisciplinary earthquake prediction in China. J. Earthq. Prediction Res. 1, 71–85.
International Seismological Centre (2020). On-line Bulletin. Available at: http://www.isc.ac.uk/iscbulletin/search/ (Accessed June 11, 2020).
Kagan, Y. Y., and Jackson, D. D. (1991). Long-term earthquake clustering. Geophys. J. Int. 104, 117–134. doi:10.1111/j.1365-246x.1991.tb02498.x
Kanamori, H. (1981). “The nature of seismicity patterns before large earthquakes,” in Earthquake prediction. Editors D. W. Simpson, and P. G. Richards (Washington, DC: American Geophysical Union), 1–19.
Keilis-Borok, V., and Soloviev, A. A. (2013). Nonlinear dynamics of the lithosphere and earthquake prediction. Berlin, Germany: Springer.
Khan, S. S., and Madden, M. G. (2009). “A survey of recent trends in one class classification,” in Irish conference on artificial intelligence and cognitive science. New York, NY: Springer, 188–197.
Koronovsky, N. V., and Naimark, A. A. (2009). Earthquake prediction: is it a practicable scientific perspective or a challenge to science? Moscow Univ. Geol. Bull. 64, 10–20. doi:10.3103/s0145875209010025
Kossobokov, V. (1997). “User manual for m8,” in Algorithms for earthquake statistics and prediction. Editor J. H. Healy, V. I. Keilis-Borok, and W. H. K. Lee, Vol. 6, 167–222.
Kossobokov, V. G. (2006). Testing earthquake prediction methods: the west pacific short-term forecast of earthquakes with magnitude mwhrv
Kossobokov, V. G., Romashkova, L. L., Keilis-Borok, V. I., and Healy, J. H. (1999). Testing earthquake prediction algorithms: statistically significant advance prediction of the largest earthquakes in the Circum-Pacific, 1992-1997. Phys. Earth Planet. Inter. 111, 187–196. doi:10.1016/s0031-9201(98)00159-9
Kotsiantis, S. B., Zaharakis, I., and Pintelas, P. (2007). “Supervised machine learning: a review of classification techniques,” in Emerging artificial intelligence applications in computer engineering. Amsterdam, Netherlands: IOS Press, 160, 3–24.
Marzocchi, W., and Zechar, J. D. (2011). Earthquake forecasting and earthquake prediction: different approaches for obtaining the best model. Seismol Res. Lett. 82, 442–448. doi:10.1785/gssrl.82.3.442
Mjachkin, V., Brace, W., Sobolev, G., and Dieterich, J. (1975). “Two models for earthquake forerunners,” in Earthquake prediction and rock mechanics. New York, NY: Springer, 169–181.
Mogi, K. (1979). Two kinds of seismic gaps. Pure Appl. Geophy. 117, 1172–1186. doi:10.1007/bf00876213
Molchan, G., and Romashkova, L. (2010). Earthquake prediction analysis based on empirical seismic rate: the M8 algorithm. Geophys. J. Int. 183, 1525–1537. doi:10.1111/j.1365-246x.2010.04810.x
Molchan, G. (2003). “Earthquake prediction strategies: a theoretical analysis,” in Nonlinear dynamics of the lithosphere and earthquake prediction. New York, NY: Springer, 209–237.
Molchan, G. M. (1997). Earthquake prediction as a decision-making problem. Pure Appl. Geophy. 149, 233–247. doi:10.1007/bf00945169
Panakkat, A., and Adeli, H. (2007). Neural network models for earthquake magnitude prediction using multiple seismicity indicators. Int. J. Neural Syst. 17, 13–33. doi:10.1142/s0129065707000890
Rhoades, D. A. (2007). Application of the eepas model to forecasting earthquakes of moderate magnitude in southern California. Seismol Res. Lett. 78, 110–115. doi:10.1785/gssrl.78.1.110
Rhoades, D. A. (2013). Mixture models for improved earthquake forecasting with short-to-medium time horizons. Bull. Seismol. Soc. Am. 103, 2203–2215. doi:10.1785/0120120233
Shebalin, P. N., Narteau, C., Zechar, J. D., and Holschneider, M. (2014). Combining earthquake forecasts using differential probability gains. Earth Planets Space 66, 37. doi:10.1186/1880-5981-66-37
Vallianatos, F., and Chatzopoulos, G. (2018). A complexity view into the physics of the accelerating seismic release hypothesis: theoretical principles. Entropy 20, 754. doi:10.3390/e20100754
Wyss, M., Bodin, P., and Habermann, R. E. (1990). Seismic quiescence at parkfield: an independent indication of an imminent earthquake. Nature 345, 426–428. doi:10.1038/345426a0
Keywords: machine learning, one class classification, earthquake forecasting, method of the minimum area of alarm, earthquake magnitude prediction
Citation: Gitis V and Derendyaev A (2020) The Method of the Minimum Area of Alarm for Earthquake Magnitude Prediction. Front. Earth Sci. 11:585317. doi: 10.3389/feart.2020.585317
Received: 20 July 2020; Accepted: 28 September 2020;
Published: 06 November 2020.
Edited by:
Giovanni Martinelli, National Institute of Geophysics and Volcanology, ItalyReviewed by:
Filippos Vallianatos, Technological Educational Institute of Crete, GreeceCopyright © 2020 Gitis and Derendyaev. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alexander Derendyaev, d2ludHNhQGdtYWlsLmNvbQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.