 Muzhe Guo
Muzhe Guo Long Nguyen
Long Nguyen Hongfei Du
Hongfei Du Fang Jin
Fang Jin
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Big Data , 28 April 2022
Sec. Medicine and Public Health
Volume 5 - 2022 | https://doi.org/10.3389/fdata.2022.801998
This article is part of the Research Topic Implementation of AI and Machine Learning Technologies in Medicine View all 21 articles
Coronavirus disease 2019 (COVID-19) is known as a contagious disease and caused an overwhelming of hospital resources worldwide. Therefore, deciding on hospitalizing COVID-19 patients or quarantining them at home becomes a crucial solution to manage an extremely big number of patients in a short time. This paper proposes a model which combines Long-short Term Memory (LSTM) and Deep Neural Network (DNN) to early and accurately classify disease stages of the patients to address the problem at a low cost. In this model, the LSTM component will exploit temporal features while the DNN component extracts attributed features to enhance the model's classification performance. Our experimental results demonstrate that the proposed model achieves substantially better prediction accuracy than existing state-of-art methods. Moreover, we explore the importance of different vital indicators to help patients and doctors identify the critical factors at different COVID-19 stages. Finally, we create case studies demonstrating the differences between severe and mild patients and show the signs of recovery from COVID-19 disease by extracting shape patterns based on temporal features of patients. In summary, by identifying the disease stages, this research will help patients understand their current disease situation. Furthermore, it will also help doctors to provide patients with an immediate treatment plan remotely that addresses their specific disease stages, thus optimizing their usage of limited medical resources.
Coronavirus disease 2019 (COVID-19), which is caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), manifests as a wide range of symptoms, including fever, cough, fatigue, breathing difficulties, loss of smell and taste, and pneumonia1. It spreads rapidly from infected people to others through close contact or small exhaled droplets. The pandemic is now causing havoc in countries around the world, with more than 282 million cases and around 5.41 million deaths, as of late December 2021 reported by WHO (2021). This deluge of patients is overwhelming hospitals everywhere, especially in some developing countries where vaccines are not sufficient, and it is difficult to cope with the need to conduct extensive disease testing programs and treat huge numbers of patients in a very short period. It is therefore vital for medical staff to be able to identify patients COVID-19 disease stages before making the decision to hospitalize them. Severe patients need to be hospitalized quickly and receive a higher priority in dedicated treatment, while patients with milder symptoms might only need to self-quarantine at home. Fast and reliable techniques to detect and identify the disease stages are thus the focus of active research by scientists and medical technologists.
Vaira et al. found that anosmia and ageusia associated with fever (>37.5°C) are common onset symptoms that can be an early signal of a COVID-19 infection (discussed by Heerfordt and Heerfordt, 2020; Ortiz-Martínez et al., 2020; Vaira et al., 2020; Walker et al., 2020), therefore, investigated the use of Google Trends to study the loss of smell and smoking cessation and predicted COVID-19 incidence. Wang et al. (2020) built a deep convolutional neural network model to detect COVID-19 from chest X-ray images. Most of the existing work focused on early disease detection, but few works were proposed to identify the disease stages and develop useful insights for patients who must quarantine at home. We therefore propose to explore the problem of disease stage identification, because this will help doctors decide the most appropriate treatment plans for patients at each stage, allowing them to optimize their usage of scarce resources when the hospital is under pressure. Besides, since our work would help create a low-cost, efficient self-monitor solution that can be used by everyone, it is beneficial, especially for people who are quarantined at home.
Interestingly, there have been some huge improvements in wearable technologies over the last few years, with a number of wearable devices being widely introduced that enhance our everyday life. For example, smartwatches such as Fitbit2 are helping us to track our sleep patterns and daily activities, encouraging us to maintain a healthier lifestyle. Smart Shirt is another example of this trend that is beginning to play an important role in our information infrastructure, supporting healthcare systems for monitoring vital signs efficiently and cost-effectively with the universal interface of clothing (Park and Jayaraman, 2003). The possibilities are seemingly unlimited: chip-integrated sensors are being used to monitor a number of physical medicine applications (Bonato, 2005). Sensors have already been developed specifically for COVID-19 applications, including an automatic sanitizer tunnel that detects a human being using an ultrasonic sensor from a distance of 1.5 feet and disinfects him/her using a sanitizer spray (Pandya et al., 2020). Quer et al. (2020) used wearable sensors to differentiate COVID-19 positive vs. negative cases in symptomatic individuals, pointing out that wearable devices are easy to access for most people. The fast development of wearable technologies makes it possible to be utilized to identify COVID-19 disease stages. However, existing studies are all either (i) mainly limited to the detection of COVID-19, with no attempt to identify the stages of the disease; (ii) not designed to analyze variations in the associated factors per COVID-19 stage; or (iii) unable to provide a comprehensive view of the disease for layman readers. Therefore, we seized this opportunity to investigate data-driven approaches to COVID-19 through wearable technologies in an attempt to bridge this gap. This paper introduces a wide-ranging set of data-driven approaches to identify infected patients' stages using wearable technologies. Specifically, this work aims to accurately and early infer from wearable data obtained from sensing devices attached to COVID-19 patients whether the COVID-19 patients are in mild, moderate, severe, or recovery stages in an earlier stage. We achieved this by introducing a model that utilizes a Long-short Term Memory (LSTM) network and a Deep Neural Network (DNN) to aggregate and jointly exploit temporal stream data from wearable devices and attribute stream from characteristics of patients. It is worth mentioning that our comprehensive experimental evaluation shows the improved performance achieved by our model compared to existing machine learning (ML) classification methods, which can only use one of the data streams. By identifying these patients in earlier stages, medical professionals will be able to take swift action if the patient requires early hospitalization or if it is safe for them to continue to self-quarantine at home. In addition, we also compare the lifestyles between severe and mild patients, allowing us to investigate and evaluate factors that impact the recovery of the patients. Specifically, the work aims to address the following three research questions (RQs):
• RQ1: Can we build an accurate ML model to predict COVID-19 stages and identify whether a patient will progress to a more severe stage in an earlier stage?
• RQ2: Which set of factors are associated with the severity of a patients symptoms? What can we learn from these factors in association with COVID-19 stages?
• RQ3: What signs signify recovery or deterioration in COVID-19 patients?
Overall, three novel contributions are made in this research:
1. We develop a classification model with uncertainty quantification to identify the major COVID-19 disease stages. Our model is able to recognize patients' disease stages in a timely manner because we utilize data from the wearable device, which is more responsive to disease stages than the subject's senses.
2. Our work provides useful insights into the progression of COVID-19 disease and vital indicators at each stage. The research input is from a data source (a wearable device like a smartwatch) that everyone can access and use on their own. Our approach is data-driven and can mitigate human bias substantially.
3. We investigate factors associated with COVID-19 severity and recovery. We also create case studies (1) demonstrating the differences between severe and mild patients and (2) showing the signs of recovery from COVID-19 disease using a shape-based pattern extraction model.
The rest of this paper is organized as follows. Section 2 reviews the related work. Section 3 discusses our methodology, including an overview of the data preparation, stage identification model, feature importance, and pattern extraction model. Section 4 shows our evaluation and experimental results. Section 5 presents some limitation in our study. Finally, we offer conclusions in Section 6.
Here, we survey recent related studies on battling the COVID-19 crisis. These studies fall into two broad scientific areas: machine learning (ML) and remote monitoring utilizing the Internet of Things (IoT).
ML Research: Researchers have attempted different methods to battle COVID-19. Assaf et al. developed a model that used white blood cell count, time from symptoms to admission, oxygen saturation, and blood lymphocyte count to predict if a patient is at high risk for COVID-19. Their prediction model can be useful for efficient triage and in-hospital allocation, better prioritization of medical resources, and improving overall management (Assaf et al., 2020). Ahamad et al. (2020) developed a model that applies ML algorithms to reveal potential COVID-19 patients by analyzing their age, gender, fever, and history of travel. By extracting 11 blood indices through a random forest algorithm, Wu et al. (2020) built an assistant discrimination tool that can identify suspected patients using their blood test results. Barstugan et al. (2020) and Elaziz et al. (2020) choose to use image-based diagnosis (CT images) building Support Vector Machine and K-Nearest Neighbors algorithms for predicting suspected COVID-19 infection.
Remote monitoring research: However, these studies' data sources, such as CT images or blood test results, would often need to be collected by trained professionals. With COVID-19 patients number rising, we see a shortage of medical resources worldwide and make clinic visits bear more risk as suspected patients gather for examination. Therefore, many people prefer to use the Internet of Things (IoT) to diagnose COVID-19 to avoid the risk of infection. Singh et al. demonstrated that IoT implementation could help infected patients with COVID-19 identify symptoms rapidly and greatly reduce healthcare costs (Singh et al., 2020). Islam et al. (2020) suggested that wearable devices could provide real-time remote monitoring and contact tracing features, which can be used to improve healthcare systems' current management schemes. For example, Maghdid et al. (2020) designed an artificial intelligence-enabled framework that analyzes signals from a smartphone's sensor signal. It helped to diagnose the severity of pneumonia to predict the COVID-19 infection.
Most prior works were focusing on the early prediction or detection of COVID-19 infection. As the epidemic escalates dramatically every day, we want to further conserve healthcare resources by identifying different stages of COVID-19 patients. For example, diagnosed early and moderate stage patients could adopt self-quarantine treatment in time, saving valuable resources that can then be utilized by patients with severe COVID-19 stage.
We used an open dataset provided by Welltory 3 The dataset comprises multivariate data records from 186 COVID-19 patients experiencing different stages. The data includes variables such as heart rate, sleeping patterns, daily activities, heart rate variability (HRV), blood pressure, patient demographics (age, gender, country, etc.), environmental information, and other patient facts (smoking, alcohol, other background diseases, etc.). We focus on the HRV information measured using wearable devices. HRV is also popular in many clinical and investigational research such as diabetes (Benichou et al., 2018), brain emotion, stress, anxiety (Goessl et al., 2017; Mather and Thayer, 2018), or cardiology related (Sessa et al., 2018). Table 1 provides detailed descriptions of HRV specific features, where rr_data (intervals in milliseconds between consecutive heartbeats) is a sequence data with a length of 100. In addition, we also selected ordered categorical variables with values from 1 to 6 recording the intensity of seven common COVID-19 symptoms that were in the HRV survey dataset: breath, confusion, cough, fatigue, fever, pain, and bluish. We believe these variables can better assist in the task of prediction, but we only focus on the other HRV variables for the subsequent analysis.
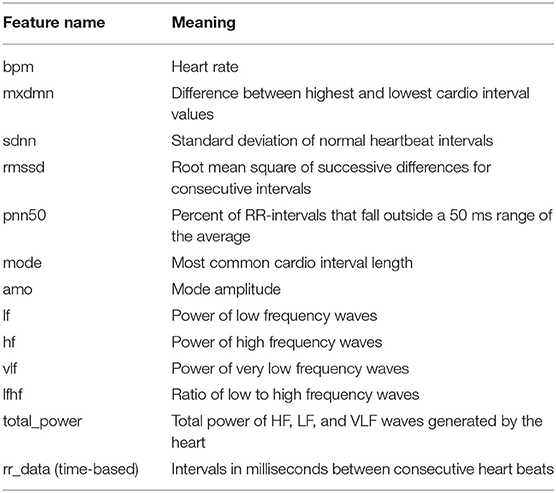
Table 1. List of features specific to heart rate variability (HRV).
Since each patient may be recorded multiple times, the stage of disease may be different from one recording period to the next. For example, some patients who were mild patients at the beginning of the record may become severe patients a week later. So, in the task of predicting the stage of disease, we remove the user code and predict the disease status for each record. All patients have a total of 1,480 complete records. Each record will be associated with a label by a survey from Welltory, identifying the corresponding patient's current stage. Figure 1 summarizes the number of stages per disease stage category.
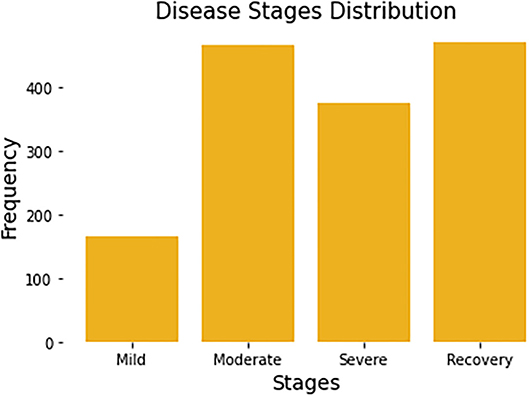
Figure 1. Distribution of four disease stages. Each patient may span multiple disease stages due to the progression of the disease.
To make the most of the information in the data, we enrich our feature set based on temporal and statistical properties. First, for the variable time series, intervals in milliseconds between consecutive heartbeats (represented by rr), we computed a variety of statistics for this sequence, such as its variance (rr_var), skewness (rr_skew), kurtosis (rr_kurt), maximum (rr_max), minimum (rr_min), median (rr_median), mean (rr_mean), interquartile range (rr_iqr), etc. These features are popular and widely used in many research such as heart rate analysis (Bolanos et al., 2006) or brain waves recognition (Campisi and La Rocca, 2014). Besides, we divide each day into four periods and further create four one-hot variables: morning, day, evening, and night. That is, if a row of data for a patient is recorded in the morning, then the variable morning for this record is 1, while the other three variables are all 0. Another variable we created is called day_after_test (days a.t.), and its value depends on the number of days each patient has been infected with COVID-19.
In addition, we obtain two new temporal sequence data using the transformation of rr_data. Suppose the original heartbeat interval is RR = {x1, x2, ..., xT}, we transform this time series by computing lag difference (DI) and the absolute deviation from the mean (DM), in order to remove temporal dependency and to eliminate the trend and seasonality of the time series. Mathematically, the two newly constructed time-series are as follows:
where T = 100 and is the mean of the original rr sequence. To make these three sequences (RR, DI, and DM) have the same length 100, we add the average of the last three numbers of the DI sequence at the end of the DI sequence. All the features we expanded are listed in Table 2. Thus, we end up with a total of 32 attribute features and 3 temporal features for the task of predicting disease stages.
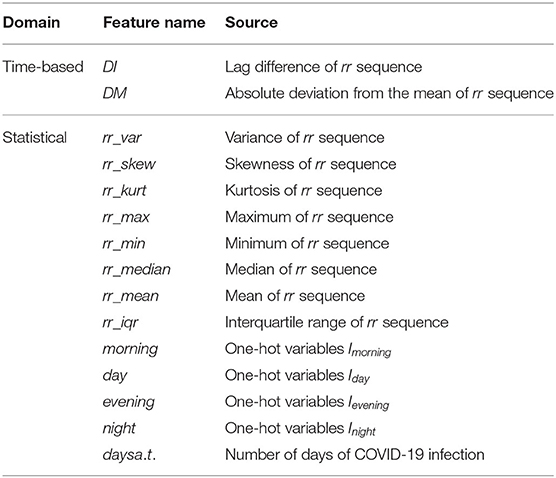
Table 2. List of self-generated features (time-based and statistical features).
There are some missing values in the dataset. It is either due to the network issues when the data is collected or the users choose not to answer some survey questions for any reason. To fill out the missing values, we used MissForest (Stekhoven and Bühlmann, 2012), a non-parametric iterative imputation technique based on the Random Forest algorithm which is proved capable of handling missing values of different data types. Additionally, we normalized the data to avoid scales influencing between features. Let min{Xi, 1:N} and max{Xi, 1:N} are the minimum and maximum values of the attribute feature Xi for all N samples. The min-max normalization values of feature Xi is computed as follows:
Where N = 1, 480 is the sample size.
Similarly, for the temporal sequence features, we use min-max normalization to normalize the data for all samples at each time point. Let min{Xk, t, 1:N} and max{Xk, t, 1:N} are the minimum and maximum values of the temporal feature Xk for all N samples at time t. The min-max normalization values of feature Xk is computed as:
Where N = 1,480 is the sample size and T = 100 is the length of the temporal sequence.
We formulate the problem of identifying disease stages as a multi-class classification problem. From a feature matrix X of a patient, we need to build a classifier f that classifies whether the patient is in Mild, Moderate, Severe, or Recovery stage.
In this task, our classification model utilizes two data streams described in Section 3.1: temporal stream and attribute stream. A temporal stream has temporal characteristics or sequential order. The temporal streams can be real-time, so if our model is embedded in wearable devices in the future, it will be very helpful for early-stage detection. The attribute stream has no temporal characteristics such as demographic information, patient's background disease, etc. Formally, assume that the dataset of size N is defined as = {(Xi, Yi), i = 1, ..., N}, where Yi is the class label and , represents the i-th sample of the combination of the temporal stream (denoted as Xt) and attribute stream (denoted as Xa). The developed classification model f parameterized by θ will classify disease stages based on input streams as the following equation:
where H1 and H2 are latent feature extractors, which are two types of neural networks in our model, Φ is an aggregation function that fuses the latent features from with attribute stream data Xa.
As mentioned earlier, the two input streams of the model are the temporal stream and the attribute stream. The LSTM network is suitable for temporal stream since it is a type of recurrent neural network (RNN) and addresses the problems of vanishing and exploding gradient in general RNNs. Hochreiter (1998). Therefore, in Equation (4), we choose H1 as an LSTM based network to learn latent features from the temporal stream Xt. For the attribute stream Xa, after combining them with the outputs of the LSTM based network, we use H2, a network of multiple fully-connected layers (DNN), to extract their latent features for the final disease stage classification. The DNN is chosen to force the network to explore all the possible relationships of both attribute streams and temporal streams. This is also an approach to combining DNN with LSTM to obtain a novel end-to-end neural network.
Figure 2 shows the overall model which composes of two subnetworks, LSTM and DNN. The two subnetworks are merged to predict the final disease stages. Suppose each patient has D input sequences with a common time length T. An LSTM passes forward over the entire temporal data sequences. We use the hidden size H = 1 in the LSTM, so later we can use an affine layer to map the hidden outputs to one-dimensional data of the same dimensional size as the attribute data. The LSTM unit is composed of a cell state ct, a so-called memory cell, a hidden state ht, an input gate i, a forget gate f, an output gate o, and an input modulation gate g. They are called gates because they control the flow through the LSTM. The four gates will be computed at each time step for cell and hidden state updates. The following is the outline formula of LSTM:
where σ and tanh are the sigmoid function and tanh function, respectively. W is the weight matrix. ct, ht, and xt are the cell state, hidden state, and temporal input at time step t, respectively. ⊙ represents element-wise multiplication.
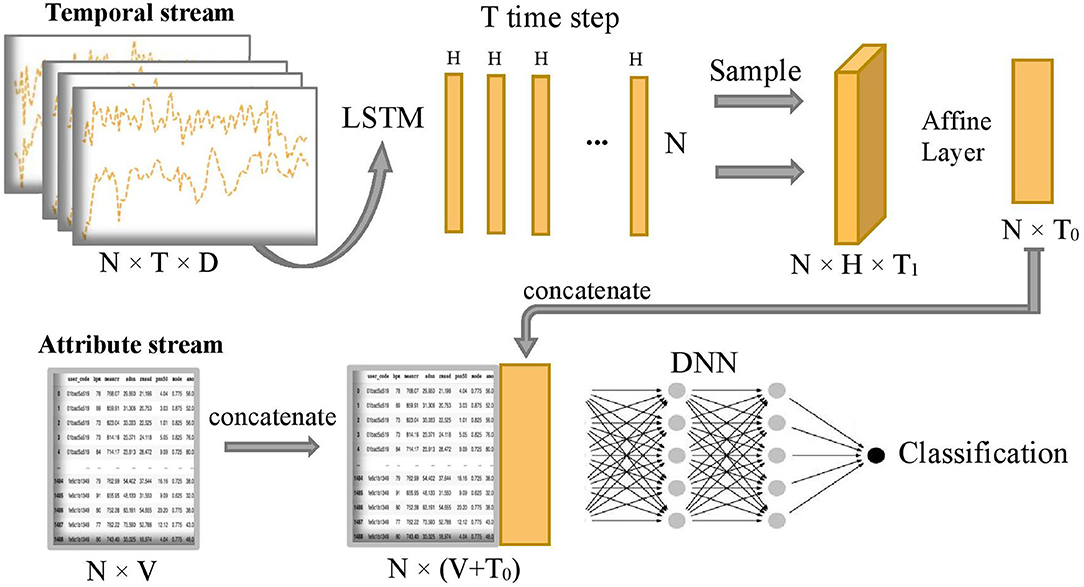
Figure 2. Overview of COVID-19 stage classification model, where N=1,480 represents the sample size, T=100 represents the common length of temporal sequence, D=3 represents the number of temporal sequences, H=1 represents the size of hidden state output by LSTM, T1=20 represents sampling size of the T hidden states, T0=5 represents the final projected size of temporal features in the time dimension, and V=32 represents the number of attribute features.
After running the forward of the LSTM network, T hidden state outputs, {h1, h2, ..., hT}, are returned and evenly sampled with a 20% probability to enhance generalization capability and avoid overfitting, that is, we uniformly sample T1 hidden states from the T hidden states and T1 = 1/5 T. Next, the combined hidden states are flattened to the temporal latent features thanks to the subsequent Affine layer to concatenate with the attribute stream. The temporal latent features have a final projected size T0 = 5, which is equivalent to putting the temporal latent features into 5 additional latent attribute features. Let's define as the final 5 latent features of the temporal stream and xa as the sample values for the original attribute stream Xa. The concatenation of these two streams is defined as follows:
where ⊕ is the concatenation operator. Then, the concatenated stream hc is fed into a deep neuron network H2 which consists of five fully connected layers with number of neurons 1,024, 1,024, 2,048, 1,024, and 1,024, respectively. The output of the model is the predicted probability of being in each disease stage for each sample. Finally, the predicted classification of disease stages y is obtained by the following:
The network uses Leaky ReLU activation function and dropout rate of 30% to enhance the robustness of the model and reduce the computational cost. The learning rate is set to 0.001 and the batch size is set to be the same as the sample size. We use the Adam optimizer, gradient descent algorithm, and softmax cross-entropy loss function to optimize the network.
We perform resampling from our existing samples to quantify the built predictive model's uncertainty. This method is also known as Bootstrap, published by Bradley Efron in Efron (1979). We employ the Bootstrap method because 1) it is invariant under re-parametrization; 2) it does not require the population distribution assumption; 3) it is driven by repeated resampling of data and does not depend on theoretical calculation; 4) it can provide the point estimation and assess the accuracy of the estimation when the traditional statistical method fails.
We present details of the uncertainty quantification algorithm in Algorithm 1. Overall, the intuition of the algorithm is to create new samples, then obtain the prediction output. This process is repeated many times to result in a distribution of output which helps to quantify the model's uncertainty. In order to generate new samples, bootstrapping technique which was introduced by Efron (1979) is utilized. Here, we summarize its workflow in Figure 3:
• Treat the original sample as if it were the population.
• Draw from the sample, at random with replacement, for B times (B is the number of bootstraps).
Given the value of confidence interval (C.I) α%, we will retrain our model from the newly generated samples, perform classification, and obtain a α% confidence interval of the predicted outcomes.

Algorithm 1 Bootstrap method to construct 95% C.I. (Confidence Interval)
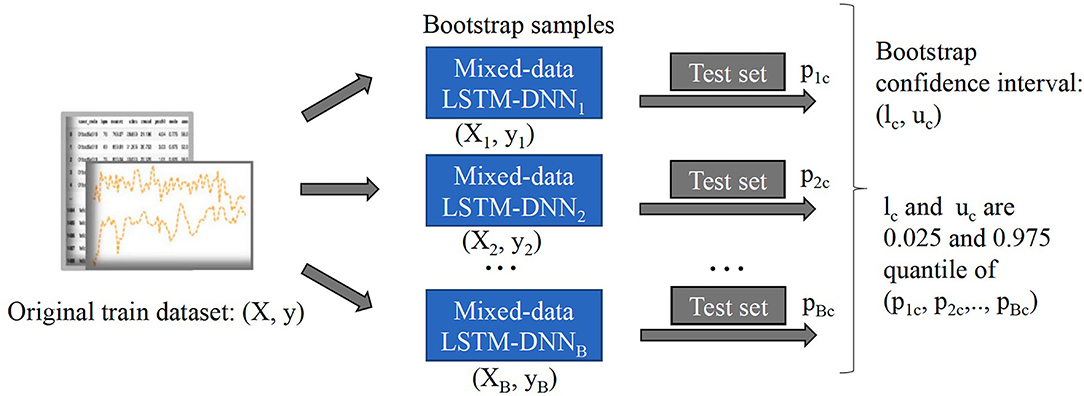
Figure 3. Workflow of bootstrap method to construct 95% confidence intervals.
To verify the effectiveness and advantages of our proposed approach, we compare the classification results on the test dataset with several classical ML and deep learning models using a five-fold cross-validation approach. The baseline models are as follows:
1. Logistic regression (Logit): a multinomial logistic regression model was used to predict the probabilities of different outcomes for our multi-class problem (Kwak and Clayton-Matthews, 2002).
2. Support vector machine (SVM) (Chang and Lin, 2011): various types of kernels were tried and the kernel with the best result was finally chosen.
3. Attribute-based K-nearest neighbors (KNN) (Peterson, 2009): various number of the k nearest neighbors were tried and the k with the best result was finally chosen.
4. Long short-term memory: a popular extension of artificial recurrent neural network (RNN) architecture. It was first introduced by Hochreiter and Schmidhuber (1997).
5. Deep Neural Network: it consists of five fully connected layers with a number of neurons 1,024, 1,024, 2,048, 1,024, and 1,024 respectively, and with the same activation function, dropout rate, learning rate, batch size, optimizer, algorithm, and loss function as our model.
For comparison metrics, we use standard metrics such as accuracy, precision, recall, f1-score, and multi-class AUC (area under ROC curve) to compare the performance of the models. It is worth noting that the inputs to these traditional models above can only be one of the data types and they cannot directly utilize both temporal data and attribute data jointly, so our model is expected to perform better than these models.
To measure the importance of features, we perform the permutation feature importance algorithm on all the temporal and attribute features in turn to break the relationship between the feature and the true outcome. The permutation feature importance algorithm is described in Algorithm 2. This algorithm is based on our proposed classification model f. The general idea is that if a feature is essential for a stage, then shuffling or removing its values increases the model error for that stage because in this case, the model relied on the feature for the prediction. On the other hand, a feature is unimportant for a stage if shuffling or removing its values leaves the model error for that stage unchanged because, in this case, the model ignored the feature for the prediction (Fisher et al., 2019). Therefore, we can rank the losses of the built models after removing one variable at a time to select the most influential features. This approach is applied in Section 4.2 to uncover factors associated with different COVID-19 disease stages.

Algorithm 2 Permutation feature importance
In the classification of time series, a subsequence is called Shapelets (Ye and Keogh, 2009) if it maximally represents a class in some sense. Grabocka et al. (2014) introduced an implementable method to learn time-series shapelets. In one of our case studies 4.4, we try to find shapelets from HRV data that can differentiate between unrecovered patients and recovered patients. For signs of recovery, the patterns are two groups of shapelets that can linearly separate the recovered from unrecovered patients. Suppose xi, i = 1, 2, …, N is the i − th original time series data of length T, and sk, k = 1, 2, …, K is one of the proposed shapelets with length l. It is easy to know that in a time series, there are exactly T − l + 1 segments as long as the starting index of the sliding window is incremented by one. The distance between xi and sk is defined as follows:
where xi, t:t+l is the subsequence of xi from time t to time t + l. Since, in our study, the classification task is binary (recovery and unrecovered). Let us define the target variable, i.e., the patient's recovery status Yi, i = 1, 2, …, N:
Then, the predicted status of the i − th patient is as follows:
where Wk, k = 0, 1, …, K, are the weights of learning, representing the classification hyperplane. By minimizing the logistic loss function with weight regularization terms, we can learn both the optimal shapelet and the optimal linear hyperplane. The loss function is shown in Equation (11):
where
and σ is the sigmoid function.
In the optimization process, a stochastic gradient descent (SGD) approach is adopted. Note that because SGD needs all the functions to be differentiable, an approximation of the minimum function (8) is used. This function is called the Soft Minimum function (Grabocka et al., 2014) and is shown in Equation (13).
where
By applying the above method to the patient's HRV time series data, we aim to find a sequence pattern that can show signs of patient recovery to the greatest extent possible. Our results are shown in Section 4.4.
We randomly split up the data prior to modeling so that all models can use the same data splits. Each time, the models are trained on 4-folds (80% of the data) and tested on 1-fold (20% of the data). These 5-folds take turns being the test dataset to ensure that each sample can be classified. We perform a comprehensive comparison of model classification results. We add up the confusion matrices of the five experiments to obtain the total confusion matrix, which is therefore based on the result of all samples, as shown in Figure 4. For the five evaluation metrics, accuracy, precision, recall, f1-score, and multi-class AUC, we use the average results of the five experiments as the final evaluation results, which are listed in Table 3.
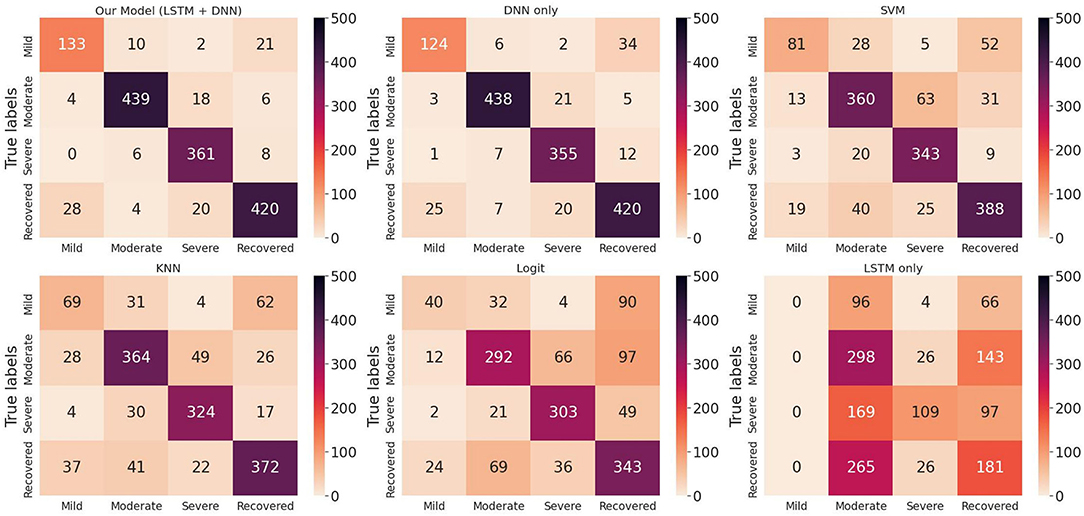
Figure 4. Total confusion matrix for COVID-19 disease stage classification based on 5-fold cross-validation.
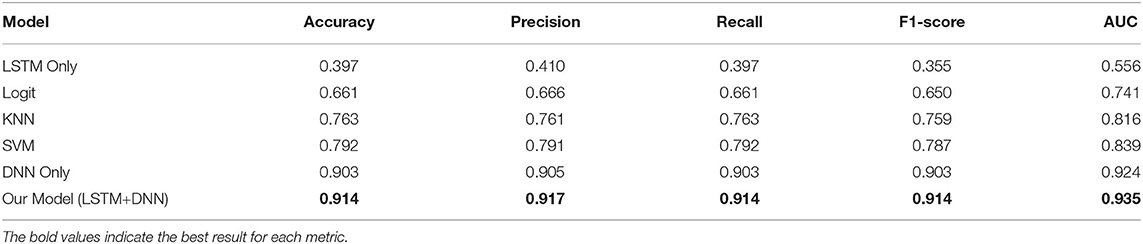
Table 3. Infected stage classification results of models based on 5-fold cross-validation.
On the one hand, we can see the improvement in classifications of our proposed model from the confusion matrix. Our model has less misclassification of disease stages compared to other models. On the other hand, the detailed results in Table 3 also show the advantages of our model. To be specific, the three models Logit, KNN, and SVM are comparable, having accuracy scores of about 0.66 to 0.79 and AUC of about 0.74 to 0.84. The LSTM model gives poor results due to the fact that it only uses temporal data. DNN model is the second-best model with an accuracy score of 0.903 and AUC of 0.924. Our proposed method has the highest scores under all five metrics, with an accuracy score of 0.914 and AUC of 0.935.
Figure 5 are box plots that present uncertainty quantification of the disease stage predictions of our proposed model for some randomly selected patients (Patient 151, 110, 29, and 182). The narrow box plot indicates the narrow 95% C.I., which presents low uncertainty in the prediction. We observe that for patient 29, all the C.I.s are quite narrow, while for all other patients, the C.I.s for certain stages are wider, which shows high prediction uncertainty. Even though there is high uncertainty in the prediction of certain disease stages, the 95% CI for each stage classification has shown that the probability of the classified stage (final prediction on each patient) always has a higher probability value than other stages. It means that our predictive model successfully identifies the disease stages with the performance results provided in Table 1.
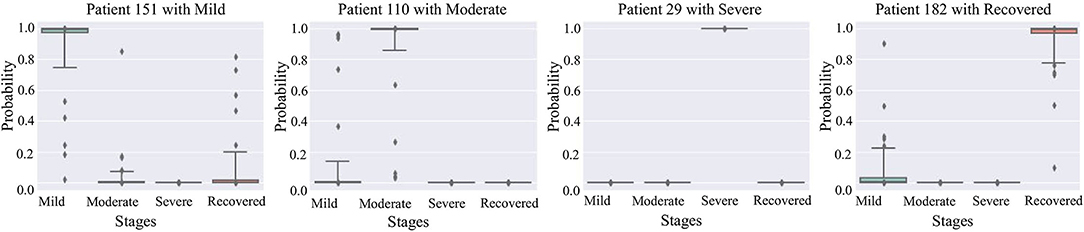
Figure 5. 95% confidence interval of the prediction probabilities for the current stage of COVID-19 patients.
In this section, we focus our analysis on features from wearable data instead of other factors which have been discussed through news channels such as background diseases or body symptoms. We use a random permutation of values shown in Algorithm 2 to calculate feature importance values for each feature based on the ratio of the model's errors between permutations. After obtaining the importance values, these values are rescaled to the range [0–1] to make them comparable. The results are shown in Figure 6. For each stage, the important features are ranked from high to low. The high importance feature means that prediction performance is highly dependent on this feature.
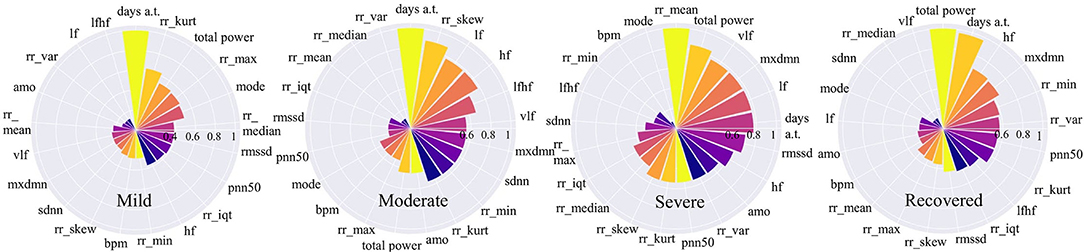
Figure 6. Feature importance for COVID-19 stages. The higher the value is, the more important the feature is.
Figure 6 shows that for mild and moderate stages, the number of days from onset symptoms (days a.t.) is the most important since it ranks top among all variables. It means for mild and moderate patients, HRV variables have not yet shown very obvious characteristics, while the number of sick days can best determine the patients at this stage. This phenomenon is more reliable for mild patients since the number of sick days is far more important than the second-ranked variable. This result can be explained that in the early days of COVID-19 infection, most people have mild symptoms. For severe patients, the number of sick days is no longer important, the average time between each heartbeat, rr_mean, occupies the most important position, even though it is very unimportant in other stages. It indicates that the rr_mean of severe patients is very different from those patients in other stages. In other words, if the condition of a patient gets worse, it will be most clearly reflected by rr_mean. For recovery patients, the total power of waves generated by the heart (total_power) and the number of sick days (days a.t.) are important variables. This shows that, on the one hand, it takes a certain number of days for patients to recover; on the other hand, a significant change in the total power of the waves generated by the heart is most indicative of the recovery phase.
If we focus on different frequency wave power generated by the heart (high-frequency: hf, low-frequency: lf, very-low-frequency: vlf), we can also find something valuable. In the mild stage, no such variables are important. However, in moderate stage, the importance of all the three along with the ratio of low to high frequency waves (lfhf) rank relatively high. Therefore, compared to the patients in the mild stage, the wave power of each frequency of patients in the moderate stage has changed obviously. Besides, for severe patients, the frequency waves that are most different from other stages are low-frequency waves (vlf, lf). While for recovered patients, the frequency wave that is most different from other stages is a high-frequency wave (hf).
Since heart rate variability (HRV) is popular in many healthcare-related research, we chose to explore it to compare daily patterns of severe patients vs. mild patients. The variables for comparison are the average time between each heartbeat (rr_mean), the percent of RR-intervals that fall outside a 50 ms range of the average (pnn50), and the total power of high-frequency waves, low-frequency waves, and very-low-frequency waves generated by the heart (total_power). All the data is normalized with the min-max technique to make them comparable. In addition, we choose data from 5 days before the onset of symptoms to 16 days after the onset of symptoms to show the difference between different stages in the most critical time. We use polynomial regression to do curve fitting and trending analysis separately. At the same time, 95% confidence intervals of fitted curves are shaded. We can find something interesting in the results shown in Figure 7.

Figure 7. Comparison of mild vs. severe patients based on three variables: Total power, Mean RR, and PNN50.
We noticed that the highest value of the total_power curve and its confidence interval did not exceed 0.3. This range of total_power is relatively narrow since we have scaled all the data to the unit interval. It indicates that for people who have COVID-19 symptoms, whether he or she is in the mild stage or the severe stage, the total power of waves generated by the heart is lower approximately a few days before and 2 weeks after the onset. For these three comparative variables, rr_mean, pnn50, and total_power, their curves have a similar pattern. In general, after the symptom onset date, all three variables of severe patients are higher than those of mild patients. The higher value of average time between each heartbeat of severe patients means that their average heart rate is slower than that of mild patients. Furthermore, severe patients usually have higher pnn50. In other words, for severe patients, the outlier heartbeats, heartbeats whose intervals are farther apart from the average interval, occupy a larger proportion. It reveals that the heart rhythm of severe patients is more irregular than that of mild patients. Besides, compared to mild patients, heart-generated wave power of severe patients is stronger.
Following the time dimension, we can also find the different development of the above variables during the illness of mild and severe patients. Curves of patients in severe stage show a trend of increasing after decreasing. The curve of patients in mild stage also decreases at the beginning, while gradually stabilized after the curve rose and then again has a decreasing trend at about 12 to 14 days. This may be because the immune regulation of mild patients does not allow them to rise endlessly, which may also be a feature of gradual recovery. We can also see that after about 13 days, the 95% CI of the curves of both severe and mild patients are relatively narrow, which gives us more confidence to believe that severe and mild patients have indeed evolved in two directions.
In this case study, we try to find the most discriminate patterns that classify best the recovered stage and other stages. These patterns will signify the sign of recovery instead of the progressing disease. In addition, HRV data for the evening hours is used for analysis to avoid the influences of daytime activities of patients. We use the HRV sequence variables, which are the interval between consecutive heartbeats(RR), its lag difference sequence(DI), and its sequence of absolute deviation from the mean(DM) to extract the patterns. The methods for creating DM and DI can be found in Section 3.1.2. All three time series are normalized and combined to explore the discriminate patterns of recovery signs (See Section 3.4).
Figure 8 presents the extracted patterns that best discriminate the sign of recovery (top two subplots) and sample patterns from the patients (bottom four subplots). First, the heartbeat interval data RR (in red) shows a decreasing trend for recovery cases than an increasing trend for other stages. Second, the heartbeat interval differencing data DI (in yellow) shows a sine-shaped pattern in the recovered group while it is a concave-parabola shape for unrecovered samples. Last, the absolute deviation from the mean data DM (in blue) shows a gradually decreasing trend in the recovered stage compared to a convex parabola shape in unrecovered situations. We can conclude a frequent change from these shapelets and an inconsistency of the COVID-19 patients. On the other hand, it shows an overall decreasing trend of the HRV data for the recovered patients in the evening. The subplots of the four patients show portions highlighted by different colors representing different time series. These portions are the ones that are closely similar (having short Dynamic Time Warping (DTW) (Sakoe and Chiba, 1978) distance in latent space) to the extracted shapelets and contribute to identifying signs of recovery.
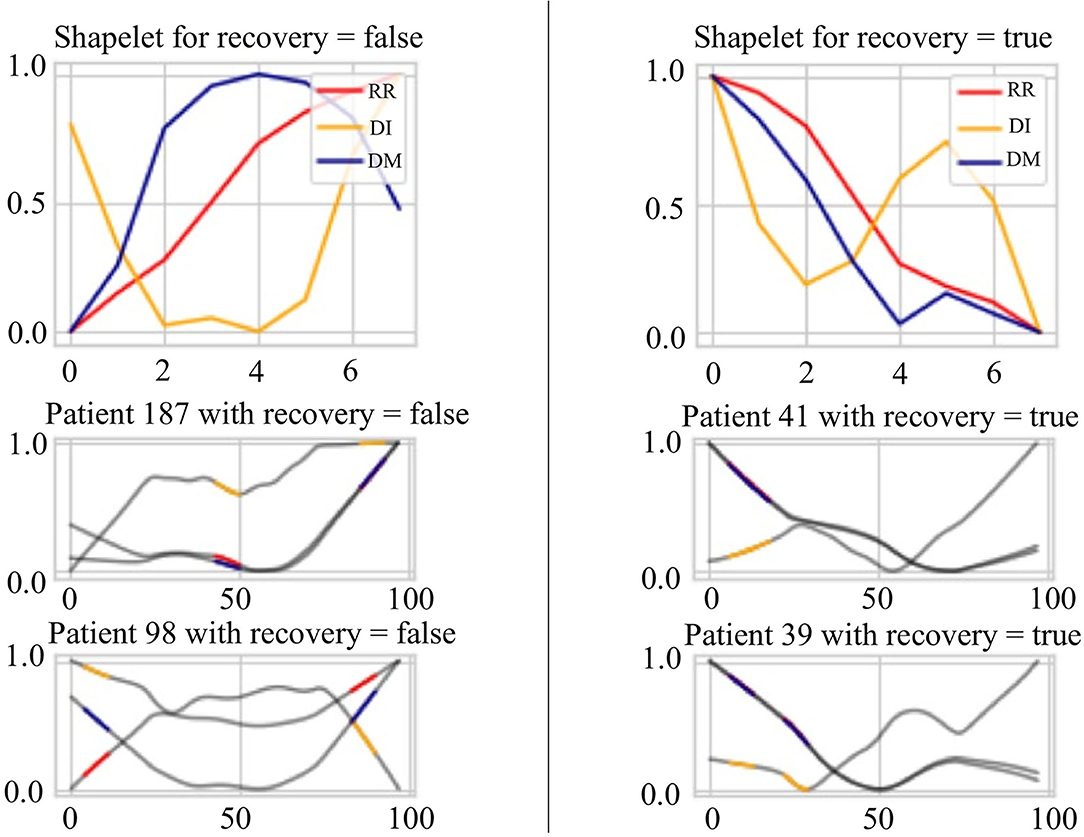
Figure 8. Signs of recovery. The left and right columns present time series shapelets that differentiate between unrecovered patients and recovered patients, respectively. The red shapelet (RR) is the original heartbeat interval. The yellow shapelet (DI) is the differencing transformation of the heartbeat interval. The blue shapelet (DM) is the deviation of the heartbeat interval from the mean value.
There are a few limitations in our study coming from the selected dataset. The number of patients in the study is 186, and they are not randomly selected. So, they are not representative of the entire population. However, this situation usually happens in healthcare data science research since it is time-consuming and expensive to obtain full data from a large population for the initial study. In addition, the uncertainty quantification of the model is down with the assumption that the set of observations is from an independent and identically distributed population. Moreover, some of the recorded data like coughing, having diabetic disease, etc., are self-reported, which have their own limitation. Self-reported information may not be accurate, depending on how honest the patients were when they did the survey.
In this work, we propose a novel predictive model to categorize COVID-19 patients into multiple stages (mild, moderate, severe, and recovered), using a wearable device dataset. Our predictive model exploits temporal stream data and attribute stream data simultaneously for disease stage classification and is able to identify severe patients in an earlier stage even if the symptoms seem to be “mild” or “moderate.” In addition, we apply bootstrap methods to perform uncertainty quantification for the predictive model, and the experimental results demonstrate our predictive model's higher classification accuracy than other existing baseline approaches. Furthermore, we investigate each feature's importance to uncover its association with COVID-19 using a model-agnostic approach. Lastly, we investigate two cases in detail: 1) the first one is used to illustrate the comparisons between mild patients and severe patients. 2) the second one is used to analyze the signs of recovery. We observe that there are fluctuating HRV patterns in severe patients, but a more stable pattern and a clear trend in mild patients or recovering patients.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
MG contributed to the model design and performed experiments. LN contributed to the experimental design and wrote the first draft of the manuscript. HD contributed to the model performance evaluation. FJ was responsible for the overall supervision and experiment design. All authors contributed to manuscript revision and provided critical feedback and helped shape the research.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ahamad, M. M., Aktar, S., Rashed-Al-Mahfuz, M., Uddin, S., Li, P., Xu, H., et al. (2020). A machine learning model to identify early stage symptoms of sars-cov-2 infected patients. Expert Syst. Appl. 160, 113661. doi: 10.1016/j.eswa.2020.113661
Assaf, D., Gutman, Y., Neuman, Y., Segal, G., Amit, S., Gefen-Halevi, S., et al. (2020). Utilization of machine-learning models to accurately predict the risk for critical covid-19. Intern. Emerg. Med. 15, 1435–1443. doi: 10.1007/s11739-020-02475-0
Barstugan, M., Ozkaya, U., and Ozturk, S. (2020). Coronavirus (covid-19) classification using ct images by machine learning methods. arXiv preprint arXiv:2003.09424.
Benichou, T., Pereira, B., Mermillod, M., Tauveron, I., Pfabigan, D., Maqdasy, S., et al. (2018). Heart rate variability in type 2 diabetes mellitus: a systematic review and meta-analysis. PLoS ONE 13, e0195166. doi: 10.1371/journal.pone.0195166
Bolanos, M., Nazeran, H., and Haltiwanger, E. (2006). Comparison of heart rate variability signal features derived from electrocardiography and photoplethysmography in healthy individuals. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2006, 4289–4294. doi: 10.1109/IEMBS.2006.260607
Bonato, P. (2005). Advances in wearable technology and applications in physical medicine and Rehabilitation. J. Neuro Eng. Rehabil. 2, 2. doi: 10.1186/1743-0003-2-2
Campisi, P., and La Rocca, D. (2014). Brain waves for automatic biometric-based user recognition. IEEE Trans. Inf. Forensics Security 9, 782–800. doi: 10.1109/TIFS.2014.2308640
Chang, C.-C., and Lin, C.-J. (2011). Libsvm: a library for support vector machines. ACM Trans. Intell. Syst. Technol. 2, 1–27. doi: 10.1145/1961189.1961199
Efron, B. (1979). Bootstrap methods: another look at the jackknife. Ann. Stat. 7, 1–26. doi: 10.1214/aos/1176344552
Elaziz, M. A., Hosny, K. M., Salah, A., Darwish, M. M., Lu, S., and Sahlol, A. T. (2020). New machine learning method for image-based diagnosis of covid-19. PLoS ONE 15, e0235187. doi: 10.1371/journal.pone.0235187
Fisher, A., Rudin, C., and Dominici, F. (2019). All models are wrong, but many are useful: learning a variable's importance by studying an entire class of prediction models simultaneously. J. Mach. Learn. Res. 20, 1–81. Available online at: https://arxiv.org/abs/1801.01489
Goessl, V. C., Curtiss, J. E., and Hofmann, S. G. (2017). The effect of heart rate variability biofeedback training on stress and anxiety: a meta-analysis. Psychol. Med. 47, 2578. doi: 10.1017/S0033291717001003
Grabocka, J., Schilling, N., Wistuba, M., and Schmidt-Thieme, L. (2014). “Learning time-series shapelets,” in Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (Hildesheim: ACM), 392–401.
Heerfordt, C., and Heerfordt, I. (2020). Has there been an increased interest in smoking cessation during the first months of the covid-19 pandemic? a google trends study. Public Health 183, 6. doi: 10.1016/j.puhe.2020.04.012
Hochreiter, S. (1998). Recurrent neural net learning and vanishing gradient. Int. J. Uncertainity Fuzziness Knowl. Based Syst. 6, 107–116. doi: 10.1142/S0218488598000094
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi: 10.1162/neco.1997.9.8.1735
Islam, M. M., Mahmud, S., Muhammad, L. J., Islam, M. R., Nooruddin, S., Ayonet, S. I., et al. (2020). Wearable technology to assist the patients infected with novel coronavirus (covid-19). SN Comput. Sci. 1, 1–9. doi: 10.1007/s42979-020-00335-4
Kwak, C., and Clayton-Matthews, A. (2002). Multinomial logistic regression. Nurs Res. 51, 404–410. doi: 10.1097/00006199-200211000-00009
Maghdid, H. S., Ghafoor, K. Z., Sadiq, A. S., Curran, K., Rawat, D. B., and Rabie, K. (2020). A novel ai-enabled framework to diagnose coronavirus covid 19 using smartphone embedded sensors: design study. arXiv preprint arXiv:2003.07434. doi: 10.1109/IRI49571.2020.00033
Mather, M., and Thayer, J. F. (2018). How heart rate variability affects emotion regulation brain networks. Curr. Opin. Behav. Sci. 19, 98–104. doi: 10.1016/j.cobeha.2017.12.017
Ortiz-Martínez, Y., Garcia-Robledo, J. E., Vsquez-Castaeda, D. L., Bonilla-Aldana, D. K., and Rodriguez-Morales, A. J. (2020). Can google®trends predict covid-19 incidence and help preparedness? the situation in colombia. Travel Med. Infect. Dis. 37:101703. doi: 10.1016/j.tmaid.2020.101703
Pandya, S., Sur, A., and Kotecha, K. (2020). Smart epidemic tunnel: Iot-based sensor-fusion assistive technology for covid-19 disinfection. Int. J. Pervasive Comput. Commun. doi: 10.1108/IJPCC-07-2020-0091. [Epub ahead of print].
Park, S., and Jayaraman, S. (2003). Enhancing the quality of life through wearable technology. IEEE Eng. Med. Biol. Mag. 22, 41–48. doi: 10.1109/MEMB.2003.1213625
Quer, G., Radin, J. M., Gadaleta, M., Baca-Motes, K., Ariniello, L., Ramos, E., et al. (2020). Wearable sensor data and self-reported symptoms for covid-19 detection. Nat. Med. 27, 73–77. doi: 10.1038/s41591-020-1123-x
Sakoe, H., and Chiba, S. (1978). Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. 26, 43–49. doi: 10.1109/TASSP.1978.1163055
Sessa, F., Anna, V., Messina, G., Cibelli, G., Monda, V., Marsala, G., et al. (2018). Heart rate variability as predictive factor for sudden cardiac death. Aging 10, 166. doi: 10.18632/aging.101386
Singh, R. P., Javaid, M., Haleem, A., and Suman, R. (2020). Internet of things (iot) applications to fight against covid-19 pandemic. Diabetes Metab. Syndr. 14, :521–524. doi: 10.1016/j.dsx.2020.04.041
Stekhoven, D. J., and Bühlmann, P. (2012). Missforest non-parametric missing value imputation for mixed-type data. Bioinformatics 28, 112–118. doi: 10.1093/bioinformatics/btr597
Vaira, L. A., Salzano, G., Deiana, G., and De Riu, G. (2020). Anosmia and ageusia: common findings in covid-19 patients. Laryngoscope 30, 1787. doi: 10.1002/lary.28692
Walker, A., Hopkins, C., and Surda, P. (2020). “The use of google trends to investigate the loss of smell related searches during covid-19 outbreak,” in International Forum of Allergy and Rhinology. (London: Wiley Online Library).
Wang, L., Lin, Z. Q., and Wong, A. (2020). Covid-net: a tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images. Sci. Rep. 10, 1–12. doi: 10.1038/s41598-020-76550-z
Wu, J., Zhang, P., Zhang, L., Meng, W., Li, J., Tong, C., et al. (2020). Rapid and accurate identification of covid-19 infection through machine learning based on clinical available blood test results. medRxiv. doi: 10.1101/2020.04.02.20051136
Keywords: COVID-19, wearable data, neural networks, uncertainty quantification, pattern extraction
Citation: Guo M, Nguyen L, Du H and Jin F (2022) When Patients Recover From COVID-19: Data-Driven Insights From Wearable Technologies. Front. Big Data 5:801998. doi: 10.3389/fdata.2022.801998
Received: 26 October 2021; Accepted: 28 March 2022;
Published: 28 April 2022.
Edited by:
Raghvendra Mall, St. Jude Children's Research Hospital, United StatesReviewed by:
Aniruddha Adiga, University of Virginia, United StatesCopyright © 2022 Guo, Nguyen, Du and Jin. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fang Jin, ZmFuZ2ppbkBnd3UuZWR1
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.