 Jia He
Jia He Maggie X. Cheng
Maggie X. Cheng- Department of Applied Mathematics, Illinois Institute of Technology, Chicago, IL, United States
In machine learning, we often face the situation where the event we are interested in has very few data points buried in a massive amount of data. This is typical in network monitoring, where data are streamed from sensing or measuring units continuously but most data are not for events. With imbalanced datasets, the classifiers tend to be biased in favor of the main class. Rare event detection has received much attention in machine learning, and yet it is still a challenging problem. In this paper, we propose a remedy for the standing problem. Weighting and sampling are two fundamental approaches to address the problem. We focus on the weighting method in this paper. We first propose a boosting-style algorithm to compute class weights, which is proved to have excellent theoretical property. Then we propose an adaptive algorithm, which is suitable for real-time applications. The adaptive nature of the two algorithms allows a controlled tradeoff between true positive rate and false positive rate and avoids excessive weight on the rare class, which leads to poor performance on the main class. Experiments on power grid data and some public datasets show that the proposed algorithms outperform the existing weighting and boosting methods, and that their superiority is more noticeable with noisy data.
1 Introduction
In this paper, we study the problem of learning with an imbalanced dataset. In classification, this is also called rare events problem, in which there are thousands of times fewer yes cases than no cases. The yes cases are called events. Usually the events are what we are interested in, which may have very few occurrences while the nonevent cases are abundant. This is typical in network monitoring applications, where data representing events are only a tiny portion of the entire dataset. For instance, we may have a fault or anomaly observed in 1 month’s worth of data while all other observations are nonevents. Using machine learning approach forevent detection and identification would require training a machine learning algorithm with these data, but the scarce representation of events in the dataset makes learning the rare event difficult.
It has been reported in the statistics literature that rare events are difficult to predict [see King and Zeng (2001) and others]. In Weiss (2004), it is pointed out that with imbalanced datasets, the learning algorithms are biased in favor of the class priors. The statistical procedure to predict the event, such as Logistic Regression, often underestimates the probability of the rare events. Such procedures will have a high overall prediction accuracy mainly due to the correct predictions on the large number of nonevent cases, but the recall metrics, defined as the fraction of true positives that have been successfully predicted, is extremely low. Such performance does not serve the purpose of event detection, since what we are interested in is the event. For event detection in a networked system, having a missed detection on important events has more detrimental effect than having a false alarm. Oftentimes we are willing to improve the detection rate even if it will generate more false positives. However, using the standard classifiers, the cost associated with misclassification on either class has the same contribution in the cost function.
To address the problem, we need to give more importance to the rare class in the cost function. This can be done either by directly changing the number of examples in each class in the training set, i.e., by sampling (Cahyana et al., 2019), or by changing the weights of the classes, which also changes the distribution of the classes. A review article (Li and Mao, 2014) provided an in-depth study of data sampling strategies and weight-modification strategies from the Bayesian classification point of view. In addition, the number of classes is also not limited to two classes. It can be extended to multiple-classes (Tanha et al., 2020).
Sampling has the merit of simplicity but it also has limitations. First, there are two forms of rarity as pointed out in Weiss (2004): absolute rarity and relative rarity. While relative rarity can be corrected by under-sampling the main class, absolute rarity can only resort to oversampling the rare class. However there is an issue with this approach—in case there are outliers in the data, the oversampled outliers will ruin the prediction performance. Moreover, under-sampling may also cause loss of information. It is necessary to consider an alternative way to address the rarity issue.
In this paper, we focus on weighting methods. Unlike the previous weighting methods that use the population information or the relative rarity in the sample to decide the weights, we develop algorithms to compute the weights during the training process. The weighting algorithms can work with any classifier. In this paper, we use Logistic Regression, Random Forest, and Support Vector Machine to demonstrate its effectiveness. The proposed algorithms have the advantages of not relying on unknown population information, and being able to improve the prediction performance of the rare class with a controllable tradeoff with the main class. Most importantly, this is the best approach to deal with absolute rarity, which poses great challenges to other methods.
In practice, a user does not have to choose between a weighting method and a sampling method. An ensemble approach that combines sampling techniques and weighting techniques can achieve the best of the two worlds. For instance, (Guo and Viktor, 2004) combines generating synthetic data and boosting procedures to improve the predictive accuracies of both the majority and minority classes. An improvement on the weighing method also contributes to the ensemble techniques.
The rest of the paper is organized as follows: in Section 2, we cover the preliminaries for classification with imbalanced dataset; in Section 3, we propose two weighting algorithms, DiffBoost, and AdaClassWeight. They can address both forms of rarity by adaptively adding weights and combining weighting with boosting; and subsequently in Section 4, we explain how to train a classifier under the computed weights; in Section 5, we provide performance results for the proposed algorithm, along with comparison with related methods; and in Section 6, we conclude the paper with outlook for future work.
2 Classification With Imbalanced Datasets
Among many others (Japkowicz et al., 1995; Liu et al., 2006; Ertekin et al., 2007), using weights is a fundamental approach to address the data imbalance problem in classification. We focus on the use of class weights in this paper, in which we add class weights to the loss function, making it more expensive to have a classification error in the rare class. This is done by assigning the rare class a larger weight and the main class a smaller weight. Weighting is also considered a type of cost-sensitive learning method (Pazzani et al., 1994). In cost-sensitive learning, the cost associated with misclassifying a rare class outweighs the cost of correctly classifying the main class. In King and Zeng (2001), weights are decided based on sample distribution in the population: the rare class weight
Similar to the class-weighted methods, there are previous work that use individual weights in the classification algorithms. We briefly review some existing work that are developed based on the idea of introducing a cost for each individual example. The weight update rule was first introduced in AdaBoost (Freund and Schapire, 1995) to force the classifier to be biased towards the minority class.
Given the number of iterations T, and training data
where αt is a weight update parameter that needs to be computed in each iteration. Zt is normalization factor defined as
Based on the weight update rule of AdaBoost, later works AdaC1, AdaC2, and AdaC3 from Sun et al. (2007), CSB1 and CSB2 from Ting (2000), and Adacost from Fan et al. (1999) were developed by associating a cost Ci ≥ 0 with individual examples in Eq. 1. Examples from the minority class are associated with larger costs than those from the majority class.
• AdaC1 modifies Eq. 1 by introducing Ci inside the exponent,
• AdaC2 adds a cost Ci outside the exponent of Eq. 1,
• AdaC3 can be considered as a combination of AdaC1 and AdaC2, in which Ci is included both inside and outside the exponent,
• AdaCost also uses a cost inside the exponent of Eq. 1, however, instead of directly using cost item Ci, it defines a cost adjustment function
where
All the aforementioned methods involve using a cost. A common drawback of them is that one must manually determine the “optimal” cost, which is predetermined. Arbitrarily selected costs can result in poor classification performance as shown in Section 5. However, there is no better algorithm than exhaustive search to decide the costs. This motivates an algorithm that computes the weights solely from the data and does not depend on any hyper-parameter.
3 The Proposed Weighting Methods
Throughout this paper, we assume the rare class is the positive class. Let N+ be the number of examples in the rare class, and N− the number of examples in the main class, and N+ ≪ N−. The class weights are denoted as w+ for the rare class and w− for the main class.
Through numerous tests, it is observed that what makes it difficult to learn from an imbalanced dataset is not the relative ratio of the rare class to the main class, rather it is the small number of examples in the rare class. In other words, the absolute rarity matters much more than the relative rarity. This is especially true for Logistic Regression, as the logistic model is often estimated by using maximum likelihood estimation and inherently has the “small-sample bias” issue (King and Zeng, 2001). The simple ratio-based algorithm that uses w+/w− = N−/N+ will only use the ratio information regardless of the sample size and is deemed unable to find the optimal weights. For a dataset with (N+, N−) = (200, 2000), a weight ratio of w+/w− = 10 gives too much weight to the rare class, leading to overfitting the rare class; and for a dataset with (N+, N−) = (2, 10), using a weight ratio of w+/w− = 5 is not enough.
We use two experiments on the Spam data to demonstrate the effect of the absolute rarity. In the first experiment, the training set has a total of 2,200 examples, with
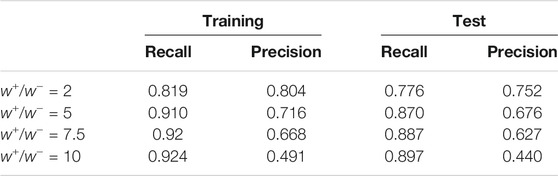
TABLE 1. Spam Data. The number of examples in the training set is
For the second experiment, the training set has a total of 12 examples, with
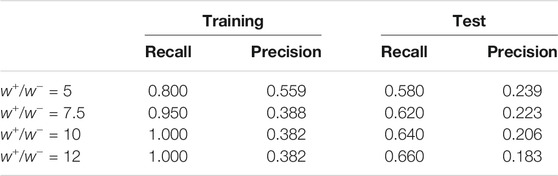
TABLE 2. Spam Data. The number of examples in the training set is
The experiments verified that it is the number of examples in the rare class that determines the error. Therefore, it is necessary to look beyond the ratio and develop an algorithm to find the class weights. We present two algorithms, Differentiated Boosting (DiffBoost) and Adaptive Class Weights (AdaClassWeight).
3.1 A Boosting Style Weighting Method: DiffBoost
We define two index sets I+ = {i: yi = 1}, and I− = {i: yi = − 1}. We use + to denote the rare class and − to denote the main class. In the algorithm DiffBoost, we compute the weights iteratively under an overarching boosting framework.
Algorithm 1. DiffBoost.

The classifier ht maps an element in the feature space χ to a label.
Although the algorithm seems to operate symmetrically on both the rare class and the main class, it actually boosts the performance of the rare class more than the main class. This is due to the fact that N+ ≪ N−, and therefore Dt(i) takes larger values for i ∈ I+ than for i ∈ I−. Initially, the main class is doing well due to the large number of examples, so we have ϵ+ > ϵ− after the first iteration, and then w+ becomes larger than w−. The algorithm starts to behave in favor of the rare class.
This boosting algorithm has the property that as the iteration number T increases, the training error for the rare class monotonically decreases. We outline the proof in the following. The training error of the rare class is given by
Theorem 1.
The proof of Theorem 1 is straightforward from Lemma 1 and Lemma 2.
Lemma 1. The training error of the rare class has the following bound:
Proof. Let
Next, we show that the training error of the rare class is bounded from above by
Recall that H(xi) = sign(f(xi)).
• If yi and f(xi) have the same sign, then
• If yi and f(xi) have different signs,
Combining both cases, we have
(a) is due to that
Lemma 2.
Proof.
Plugging in
• When
• When
Therefore
The following analysis shows that
• The applicable scenario for the weighting algorithm is when data is extremely imbalanced and the rare class has very few data points. Under this condition, it is reasonable to assume that the initial weighted class error
• When
• When
Since the upper bound of
Figure 1 shows the upper bound of the training error and the actual training error vs the iteration number by using DiffBoost. Three algorithms, Logistic Regression (LR), Random Forest (RF) and Support Vector Machine (SVM) are tested on two datasets. The Spam dataset is from UCI machine learning repository (Dua and Graff, 2017). The simulated data are generated using a function. We generate a total of 1,832 examples with three predictors X1, X2 and X3. Each predictor variable follows a Gaussian distribution, X1 ∼ N(0, 1), X2 ∼ N(1, 2) and X3 ∼ N(−2, 1.5). The target function is
The theory and simulation both show that DiffBoost has excellent converging property. However, it still has one issue—ittakes as many iterations to predict a new response as it takes to train the classifier. This problem is inherent to the boosting style algorithms. AdaBoost (Freund and Schapire, 1997) has the same issue. The parameters learned from each iteration as well as αt must be saved, as the final prediction
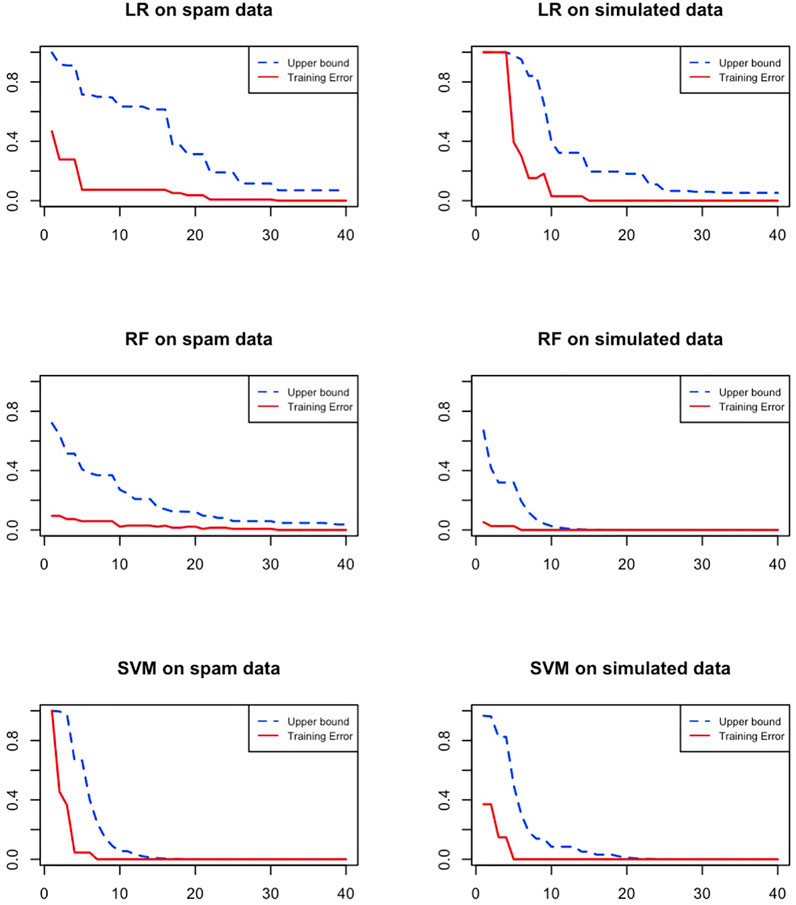
FIGURE 1. The convergence of the DiffBoost algorithm. Training error of the rare class asymptotically converges to zero as its upper bound decreases monotonically.
3.2 Adaptively Computing Class Weights
Algorithm 2. AdaClassWeight.

The algorithm, called AdaClassWeight, starts with an unweighted classifier and adaptively increases the weight of the rare class until a stopping criterion is met. Unlike the DiffBoost algorithm, the AdaClassWeight algorithm only uses the parameters of the classifier learned in the final iteration to make a new prediction. DiffBoost would require all the learned parameters in the past T iterations in order to make a new prediction. AdaClassWeight also differs from DiffBoost in the way that the class error rates
Remark. For the implementation of AdaClassWeight and DiffBoost, we can inject a stopping criterion during the iteration to avoid unnecessary large number of iterations. We can stop whenever the desired error rate for the rare class has been achieved, i.e., we can stop when
4 Incorporating Class Weights Into Classification Algorithms
We show how the class weights w+ and w− computed from DiffBoost and AdaClassWeight are used with Logistic Regression, Random Forest, and Support Vector Machine.
4.1 Weighted Logistic Regression
Logistic Regression models are usually fit by the maximum likelihood method (Cox, 1958; Hastie et al., 2009). The log-likelihood for N observations is given by:
where L is the log-likelihood function, β is the vector of parameters, which is estimated by maximizing the log likelihood, and pi is the probability of the i-th example being in the rare class. To assign a class weight to each class, we modify L(β) as follows:
where w+ and w− are class weights assigned to the positive class and the negative class, respectively.
4.2 Weighted Random Forest
Random Forest uses decision trees as building blocks (Breiman, 2001). At each split, a predictor xj and its corresponding cut point are chosen to minimize the misclassification error, which in practice is replaced by the Gini index (Hastie et al., 2009).
where ni is the number of training observations of class i in the node under consideration.
To incorporate class weights into Random Forest, the weighted Gini index is given as follows:
where wi is the weight for class i, and i ∈ {1, 2}.
4.3 Weighted Support Vector Machine
Support vector classifier is a maximum-margin classifier. The classification problem can be expressed as the following optimization problem (Hastie et al., 2009):
where yi is the i-th observation, and f(xi) is the classification result for the i-th data point xi. The classifier f() is a function of parameters β and β0. Let ϕ(xi) be the transformed feature vector for xi, then f(xi) = βTϕ(xi) + β0. Function ϕ() can be the identity function for linear classification problems. The parameters β and β0 are estimated by solving the optimization problem in (11). Since both yi and f(xi) take values in {−1, +1}, yif(xi) = − 1 only when there is a classification error. Classification error is penalized by using the same weight w on both the positive class and the negative class. To incorporate class weights into SVM, we assign different weights to different classes as follows (Veropoulos et al., 1999; Batuwita et al., 2013):
where w+ and w− are weights applied to the positive class and the negative class, respectively. Chang and Lin (2011) used a different formulation for the optimization problem, but the two formulations are equivalent. The equivalence of the two formulations can be found in Hastie et al. (2009).
5 Experiments
Through experiments on real datasets, we show the excellent performance of the proposed algorithms, and compare them with other algorithms: AdaBoost (Freund and Schapire, 1997), a simple weighting method that uses the ratio of positive cases and negative cases in the sample to compute weights, i.e.,
5.1 Testing Error
Training classifiers under differentiated weights significantly reduces the training error of the rare class. Will this also translate to a reduced error on the testing data? In this experiment we test if reducing training error on the rare class leads to overfitting, which means we will get an increased testing error. Figure 2 shows an overall trend of decreasing for both testing error and training error, so the improvement on training error on the rare class is also an improvement on the testing error. The algorithms start with an unweighted algorithm (w+ = w− = 1 at initialization), and then through iterations as the training error decreases, the testing error also decreases. Results in Figure 2 are obtained from running Logistic Regression on the IEEE 39-bus dataset and the Spam dataset. Other classifiers show similar results.
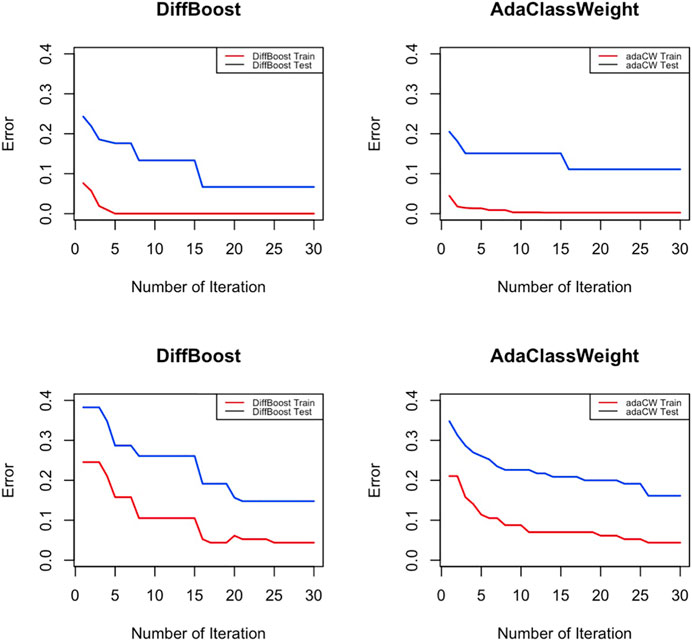
FIGURE 2. Testing error of the rare class decreases along with training error. In the top row, IEEE 39-bus power system data is used; In the bottom row, Spam data is used.
Comparison with other methods on testing error are shown in Table 3. We consider three classifiers: LR, RF, and SVM. When we train a weak classifier under weights, LR can take both individual weights and class weights, but RF and SVM can only take class weights. Since AdaBoost produces one weight per example and does not give class weights, we can only obtain results for AdaBoost when using LR as the weak classifier. This experiment demonstrates that DiffBoost and AdaClassWeight both outperform existing methods in improving the rare class performance. The improvement for SVM is the most significant as the error rate is improved from 0.674 to 0.025.
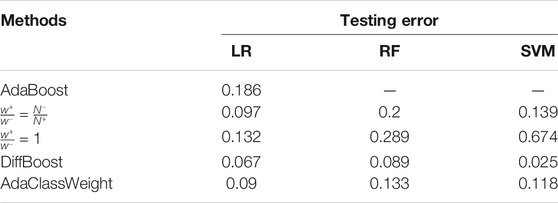
TABLE 3. Testing error
5.2 Receiver Operating Characteristic
It is reasonable to expect that the weighting algorithm will improve the prediction accuracy of the rare class at the expense of the main class. In this experiment, we will find out how much tradeoff exists between the rare class and the main class. We evaluate the performance of DiffBoost and AdaClassWeight in terms of the true positive rate and the false positive rate, and we compare them with 1) the simple weighting algorithm that uses the ratio to decide weight, i.e.,
The ROC curve is the plot of true positive rate versus false positive rate for different cut-off points of a parameter. If increased true positive rate is at the cost of the increased false positive rate, the curve would go along the 45° line (the gray line in Figure 3). Otherwise, if the false positive rate does not go up proportionally, it would stay above the 45° line. On the ROC plot, the area under the curve is used to compare algorithms. The one with the largest area under the curve is considered the best.
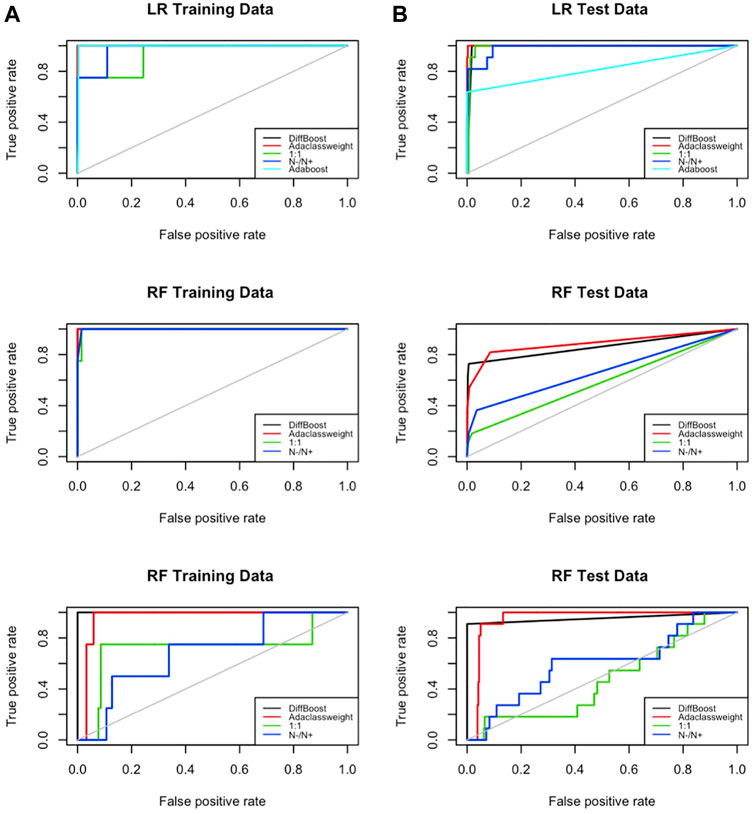
FIGURE 3. ROC on training data and testing data. Tests are done on the IEEE 39-bus power system data. DiffBoost and AdaClass Weight both have a larger area under the curve than other algorithms.
Results from using IEEE 39-bus system data (Figure 3) show that the areas under the curves for the two proposed algorithms are the two largest compared to all other algorithms. This means the false positive rate did not go up proportionally. This is because there are a large number of examples in the main class, and adding appropriate weight on the rare class does not affect the performance of the main class too much.
5.3 Sensitivity to Noise
We care about sensitivity to noise because added weight will also amplify noise if noise happens to be on the rare class. In this section we test if the weighting algorithms DiffBoost and AdaClassWeight are sensitive to noise. We test the algorithms on the IEEE 39-bus dataset and present the results from using Logistic Regression. Results from using the other two classifiers are similar.
Noise is added into data as class noise, i.e., we flip a certain percentage of labels in each class. We define the percentage of flipped labels as the noise level, which takes values in (0, 1, 2, 5, 10, 15%). The results show that DiffBoost and AdaClassWeight can perform better than the ratio-based weighting algorithm, better than the AdaBoost algorithm, and much better than the unweighted algorithm (see Figure 4). The superiority of the two proposed algorithms is more evidenced as the noise level increases. Although the performance of DiffBoost and AdaClassWeight is also impacted by noise, the impact is smaller than other algorithms since the performance drop is not very steep.
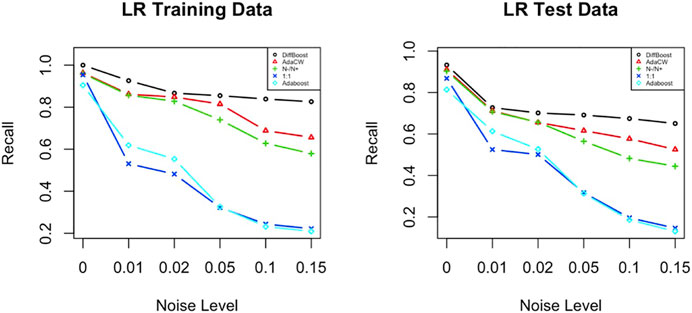
FIGURE 4. Sensitivity to noise for both training data and testing data. Test is done on the IEEE 39-bus power system data. While all algorithms are impacted by noise, the proposed algorithms perform better.
5.4 Comparison With the Boosting Algorithms
The boosting algorithms AdaC1, AdaC2, AdaC3, and Adacost mentioned in Section 2 are developed from AdaBoost and all have similar ROC curves as AdaBoost (see Figure 3). Next we show another aspect of these algorithms: all methods require a preset cost Ci, ∀i, and the classification performance is extremely sensitive to this hyper-parameter. We use the Spam data to demonstrate. The Spam data has a total of 4,597 examples with 2,785 non-spam emails and 1,812 spam emails. We randomly select 1,506 examples from the original dataset. The ratio between non-spam examples and spam examples is 12 : 1, and 50–50% split is used for training and test within each class.
To see the effects of different cost settings on classifiers, we compare the results of Adacost, AdaC1, AdaC2, and AdaC3 based on different cost ratios C+: C−, and report the results on the test data (see Table 4). First of all, the highest recalls of the four algorithms occur at very different locations even for the same dataset. This indicates it is not a simple task to assign cost ratios. In Table 4 the highest recall is highlighted for each algorithm and the precision under the same cost ratio is also reported. Although these recalls are very impressive, the precisions are extremely low. If an algorithm simply predicts all cases as the rare class, it can achieve recall 1.0, but the precision is close to zero. This is observed with these boosting algorithms. In comparison, AdaClassWeight has the highest precision while achieving a high recall. It is also observed that the sum of recall and precision is the highest by the two proposed algorithms.

TABLE 4. Spam data. From left to right: the recall on test data under various cost ratios, the precision corresponding to the highest recall, training time, and test time.
The proposed algorithms also outperform the boosting algorithms in algorithm complexity. For the boosting algorithms, the cost ratio is a hyper-parameter. The optimal value for the hyper-parameter is obtained by a grid search. In the experiment, we performed a grid search for the cost ratio C+/C− ∈ (Pazzani et al., 1994; King and Zeng, 2001) with step size 0.5. The training time would be much longer had we used a finer grid. In comparison, the proposed algorithms adaptively find the weights without a preset hyper-parameter. DiffBoost and AdaClassWeight terminate after T iterations, or before T iterations if a desired tradeoff between the positive class and the negative class have been found, so the algorithms are bounded to T iterations. The proposed algorithms have lower complexity as shown in Table 4.
6 Conclusion and Outlook
We have studied the problem of classifying rare events in imbalanced datasets, in which the rare class examples are significantly fewer than the main class examples. We focused on designing weighting algorithms to compute class weights during the training phase. DiffBoost and AdaClassWeight are general weighting algorithms and can be used in junction with any classifier. It has been tested with Logistic Regression, Random Forest, and Support Vector Machine, and has been applied to several datasets. The experimental results show that they improve the prediction accuracy of the rare class with a controlled tradeoff in the main class. The ROC curves of the proposed algorithms have larger “area under the curve” than the simple ratio-based algorithm, the original unweighted algorithm, and the AdaBoost algorithm as well as other boosting algorithms based on AdaBoost. It also has the advantage of being able to focus on the rare class, giving it a much higher accuracy in case we need to prioritize the rare class, with a controllable tradeoff. Multiclass classification for more than two classes using differential class weights is an easy extension from this work, which will be addressed in the future work.
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/jhe58/Identification-of-Rare-Events-from-Imbalanced-Datasets.
Author Contributions
JH and MC designed the algorithms and performed analysis. JH implemented the algorithms and conducted the experiments. MC provided overall guidance and supervision for problem setup, research methods, and reporting. All authors contributed to the article and approved the submitted version.
Funding
The authors gratefully acknowledge the support of NSF awards 1854077, 1936873, and 2027725. Any opinions, findings, and conclusion or recommendations expressed in this material are those of the authors and do not necessarily reflect the view of the NSF, or the US government.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Batuwita, R., and Palade, V. (2013). “Class Imbalance Learning Methods for Support Vector Machines,” in Imbalanced Learning: Foundations, Algorithms, and Applications. Editors H. He, and Y. Ma (IEEE), 83–99. doi:10.1002/9781118646106.ch5
Cahyana, N., Khomsah, S., and Aribowo, A. S. (2019). “Improving Imbalanced Dataset Classification Using Oversampling and Gradient Boosting,” in 2019 5th International Conference on Science in Information Technology (ICSITech) (IEEE), 217–222. doi:10.1109/icsitech46713.2019.8987499
Chang, C.-C., and Lin, C.-J. (2011). Libsvm. ACM Trans. Intell. Syst. Technol. 2, 1–27. doi:10.1145/1961189.1961199
Cox, D. R. (1958). The Regression Analysis of Binary Sequences. J. R. Stat. Soc. Ser. B Methodol. 20, 215–232. doi:10.1111/j.2517-6161.1958.tb00292.x
Ertekin, S., Huang, J., and Giles, C. (2007). “Active Learning for Class Imbalance Problem,” in Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval-SIGIR’07, 823–824. doi:10.1145/1277741.1277927
Fan, W., Stolfo, S. J., Zhang, J., and Chan, P. K. (1999). Adacost: Misclassification Cost-Sensitive Boosting. ICML 99, 97–105.
Freund, Y., and Schapire, R. E. (1997). A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 55, 119–139. doi:10.1006/jcss.1997.1504
Freund, Y., and Schapire, R. E. (1995). “A Desicion-Theoretic Generalization of On-Line Learning and an Application to Boosting,” in European Conference on Computational Learning Theory (Springer), 23–37. doi:10.1007/3-540-59119-2_166
Guo, H., and Viktor, H. L. (2004). Learning from Imbalanced Data Sets with Boosting and Data Generation. SIGKDD Explor. Newsl. 6, 30–39. doi:10.1145/1007730.1007736
Hastie, T., Tibshirani, R., and Friedman, J. H. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer Series in Statistics. 2nd Edition. Springer.
Japkowicz, N., Myers, C., and Gluck, M. (1995). “A novelty Detection Approach to Classification,” in Proceedings of the 14th International Joint Conference on Artificial Intelligence - Volume 1-IJCAI’95, 518–523.
King, G., and Zeng, L. (2001). Logistic Regression in Rare Events Data. Polit. Anal. 9, 137–163. doi:10.1093/oxfordjournals.pan.a004868
Li, Q., and Mao, Y. (2014). A Review of Boosting Methods for Imbalanced Data Classification. Pattern Anal. Applic. 17, 679–693. doi:10.1007/s10044-014-0392-8
Liu, Y., An, A., and Huang, X. (2006). “Boosting Prediction Accuracy on Imbalanced Datasets with Svm Ensembles,” in Advances in Knowledge Discovery and Data Mining. Editors W. K. Ng, M. Kitsuregawa, J. Li, and K. Chang (Berlin, Heidelberg: Springer Berlin Heidelberg), 107–118. doi:10.1007/11731139_15
Pazzani, M., Merz, C., Murphy, P., Ali, K., Hume, T., and Brunk, C. (1994). “Reducing Misclassification Costs,” in Proceedings of the Eleventh International Conference on International Conference on Machine Learning-ICML’94, 217–225. doi:10.1016/b978-1-55860-335-6.50034-9
Sun, Y., Kamel, M. S., Wong, A. K. C., and Wang, Y. (2007). Cost-sensitive Boosting for Classification of Imbalanced Data. Pattern Recognition 40, 3358–3378. doi:10.1016/j.patcog.2007.04.009
Tanha, J., Abdi, Y., Samadi, N., Razzaghi, N., and Asadpour, M. (2020). Boosting Methods for Multi-Class Imbalanced Data Classification: an Experimental Review. J. Big Data 7, 1–47. doi:10.1186/s40537-020-00349-y
Ting, K. M. (2000). “A Comparative Study of Cost-Sensitive Boosting Algorithms,” in Proceedings of the 17th International Conference on Machine Learning (Citeseer), 983–990.
Veropoulos, K., Campbell, C., and Cristianini, N. (1999). “Controlling the Sensitivity of Support Vector Machines,” in Proceedings of the International Joint Conference on AI, 55–60.
Keywords: imbalanced dataset, bias, classification, machine learning, rare event
Citation: He J and Cheng MX (2021) Weighting Methods for Rare Event Identification From Imbalanced Datasets. Front. Big Data 4:715320. doi: 10.3389/fdata.2021.715320
Received: 26 May 2021; Accepted: 04 November 2021;
Published: 23 December 2021.
Edited by:
Fan Jiang, University of Northern British Columbia Canada, CanadaReviewed by:
Hideitsu Hino, Institute of Statistical Mathematics (ISM), JapanCarson Leung, University of Manitoba, Canada
Copyright © 2021 He and Cheng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Maggie X. Cheng, bWFnZ2llLmNoZW5nQGlpdC5lZHU=