 Sebastian Jäger
Sebastian Jäger Arndt Allhorn
Arndt Allhorn Felix Bießmann
Felix Bießmann- Beuth University of Applied Sciences, Berlin, Germany
With the increasing importance and complexity of data pipelines, data quality became one of the key challenges in modern software applications. The importance of data quality has been recognized beyond the field of data engineering and database management systems (DBMSs). Also, for machine learning (ML) applications, high data quality standards are crucial to ensure robust predictive performance and responsible usage of automated decision making. One of the most frequent data quality problems is missing values. Incomplete datasets can break data pipelines and can have a devastating impact on downstream ML applications when not detected. While statisticians and, more recently, ML researchers have introduced a variety of approaches to impute missing values, comprehensive benchmarks comparing classical and modern imputation approaches under fair and realistic conditions are underrepresented. Here, we aim to fill this gap. We conduct a comprehensive suite of experiments on a large number of datasets with heterogeneous data and realistic missingness conditions, comparing both novel deep learning approaches and classical ML imputation methods when either only test or train and test data are affected by missing data. Each imputation method is evaluated regarding the imputation quality and the impact imputation has on a downstream ML task. Our results provide valuable insights into the performance of a variety of imputation methods under realistic conditions. We hope that our results help researchers and engineers to guide their data preprocessing method selection for automated data quality improvement.
1 Introduction
In recent years, complex data pipelines have become a central component of many software systems. It has been widely recognized that monitoring and improving data quality in these modern software applications is an important challenge at the intersection of database management systems (DBMSs) and machine learning (ML) (Schelter et al., 2018a; Abedjan et al., 2018). A substantial part of the engineering efforts required for maintaining large-scale production systems is dedicated to data quality, especially when ML components are involved (Sculley et al., 2015; Böse et al., 2017).
Poor data quality can quickly break software applications and cause application downtimes, often leading to significant economic costs. Moreover, poor data quality can foster unfair automated decisions, which marginalize minorities or have other negative societal impacts (Stoyanovich et al., 2020; Yang et al., 2020; Bender et al., 2021). For this reason, many researchers started investigating to what extent monitoring of data quality can be automated (Abedjan et al., 2016; Baylor et al., 2017; Schelter et al., 2018b; Rukat et al., 2020). While some aspects of such monitoring, such as the consistency of data types, are easy to automate, others, such as semantic correctness1, are still the subject of active research (Biessmann et al., 2021). However, even if automatic monitoring tools, such as those proposed in the work of Schelter et al. (2017), would be used, a central challenge remains: How can we automatically fix the detected data quality issues?
One of the most frequent data quality problems is missing values (Kumar et al., 2017). Reasons for incomplete data are manifold: data might be accidentally not recorded, lost through application or transmission errors, intentionally not filled in by users, or result from data integration errors. Throughout the past few decades, researchers from different communities have been contributing to an increasingly large arsenal of methods to impute missing values. Statisticians laid the theoretical foundations for missing value imputation (Rubin, 1976) by describing different missingness patterns (more details are given in Section 3.2). Statistical approaches have been proposed to handle missing values (Schafer and Graham, 2002). Simple strategies include dropping incomplete observations or replacing missing values with constant mathematically valid values. While this might be a reasonable solution to ensure robust functioning of data pipelines, such approaches often reduce the amount of available data for downstream tasks and, depending on the missingness pattern, might also bias downstream applications (Stoyanovich et al., 2020; Yang et al., 2020) and, thus, further decrease data quality (Little and Rubin, 2002; Schafer and Graham, 2002).
Another line of imputation research in the statistics community focuses on multiple imputation (MI) (Rubin, 1987). In MI, one replaces missing values with multiple predictions from an imputation model. Those
More recently, also ML approaches have increasingly been used for imputation. Popular methods include k-nearest neighbors (k-NNs) (Batista and Monard, 2003), matrix factorization (Troyanskaya et al., 2001; Koren et al., 2009; Mazumder et al., 2010), random-forest–based approaches (Stekhoven and Bühlmann, 2012), discriminative deep learning methods (Biessmann et al., 2018), and generative deep learning methods (Shang et al., 2017; Yoon et al., 2018; Li et al., 2019; Nazábal et al., 2020; Qiu et al., 2020).
Most imputation studies provide solid experimental evidence that the respective proposed method in the application setting investigated outperforms other competitors’ baselines. Yet, it remains hard to assess which imputation method consistently performs best in a large spectrum of application scenarios and datasets under realistic missingness conditions. In particular, most benchmarks do not systematically report and compare both imputation quality and the impact of the imputation on downstream ML applications with baselines in a wide range of situations.
In this article, we aim at filling this gap. We benchmark a representative set of imputation methods on a large number of datasets under realistic missingness conditions with respect to imputation quality and the impact on the predictive performance of downstream ML models. For our experiments, we use 69 fully observed datasets from OpenML (Vanschoren et al., 2013) with numeric and categorical columns. Each dataset is associated with a downstream ML task (binary classification, multiclass classification, and regression). We run experiments by artificially introducing varying fractions of missing values of the three missingness patterns (MCAR, MAR, and MNAR, see also Section 3). We then measure both the imputation performance and impact on downstream performance in two application scenarios: 1) missing values in the test data; i.e., we train on complete data and corrupt (and impute) only test data and 2) both training and test data have missing values; i.e., we train and test on corrupted data.
The rest of this article is structured as follows. In Section 2, we review the related work on imputation benchmarking efforts and continue in Section 3 with an overview of the missingness conditions and imputation methods investigated in this study. A detailed description of our benchmark suite and its implementation follows in Section 4. The results of our experiments are described and visualized in Section 5. We then highlight the key findings in Section 6 and, finally, draw our conclusions in Section 7.
2 Related Work
The body of literature that is related to our work consists of two types of studies. Some focus on presenting new or improved imputation methods and compare them with existing and baseline approaches in broader settings, similar to benchmark papers (Bertsimas et al., 2017; Zhang et al., 2018). Others are benchmark studies and compare imputation strategies (Poulos and Valle, 2018; Jadhav et al., 2019; Woznica and Biecek, 2020). However, both have in common that they often focus on specific aspects or use cases and do not aim at an extensive comparison.
Poulos and Valle (2018) compared the downstream task performance on two binary classification datasets (
Similarly, Jadhav et al. (2019) compare seven imputation methods (random, median, k-NN, predictive mean matching, Bayesian linear regression, linear regression, and non-Bayesian) without optimizing their hyperparameters based on five small and numeric datasets (max. 1,030 observations). The authors discuss different missingness patterns but do not state which one they used in their experiments. However, they measured the methods’ imputation performance for
Woznica and Biecek (2020) evaluate and compare seven imputation methods (random, mean, softImpute, miss-Forest, VIM kknn, VIM hotdeck, and MICE) combined with five classification models regarding their predictive performance. Therefore, they use 13 binary classification datasets with missing values in at least one column, which is why they do not know the data’s missingness pattern. The amount of missing values ranges between
The following two articles differ from others because they aim to compare the proposed method against the existing approaches. Zhang et al. (2018) implement an iterative expectation-maximization (EM) algorithm that learns and optimizes a latent representation of the data distribution, parameterized by a deep neural network, to perform the imputation. They use ten classification and three regression task datasets and 11 imputation baselines (zero, mean, median, MICE, miss-Forest, softImpute, k-NN, PCA, autoencoder, denoising autoencoder, and residual autoencoder) for comparison. The authors conducted both evaluations, imputation and downstream task performance, with
To the best of our knowledge, Bertsimas et al. (2017) gave the largest and most extensive comparison, although they focused on introducing an imputation algorithm and presented its improvements. The proposed algorithm cross validates the choice of the best imputation method out of k-NN, SVM, or tree-based imputation methods, where the hyperparameters are also cross validated. The authors then benchmarked their approach on 84 classification and regression tasks against five imputation methods: mean, predictive mean matching, Bayesian PCA, k-NN, and iterative k-NN. They measured the imputation and downstream task performance on
We summarize the abovementioned articles and related benchmarks in Table 1. Most benchmarks use broad missingness fractions but lack realistic missingness conditions or a large number of heterogeneous datasets. Furthermore, no article systematically compares the imputation quality and impact on downstream tasks for imputation methods trained on complete and incomplete data. Studies presenting novel imputation methods based on deep learning often lack a comprehensive comparison with classical methods under realistic conditions, with few exceptions (Zhang et al., 2018). To summarize the contributions of our work, we complement existing research by providing a broad and comprehensive benchmark imputation method with respect to the following dimensions:
1) Number and heterogeneity of datasets:
We use 69 datasets with numeric and categorical columns
2) Varying downstream tasks:
We use 21 regression, 31 binary classification, and 17 multiclass classification tasks
3) Realistic missingness patterns and the amount of missing values:
We use MCAR, MAR, and MNAR missingness patterns and
4) Imputation methods and optimized hyperparameters:
We use six imputation methods that range from simple baselines to modern deep generative models
5) Evaluation on imputation performance and impact on downstream task performance:
We systematically compare the imputation methods based on their imputation performance and how they impact the performance of a downstream model
6) Training on complete and incomplete data:
We simulate and compare the performance when imputation models can learn from complete and incomplete data
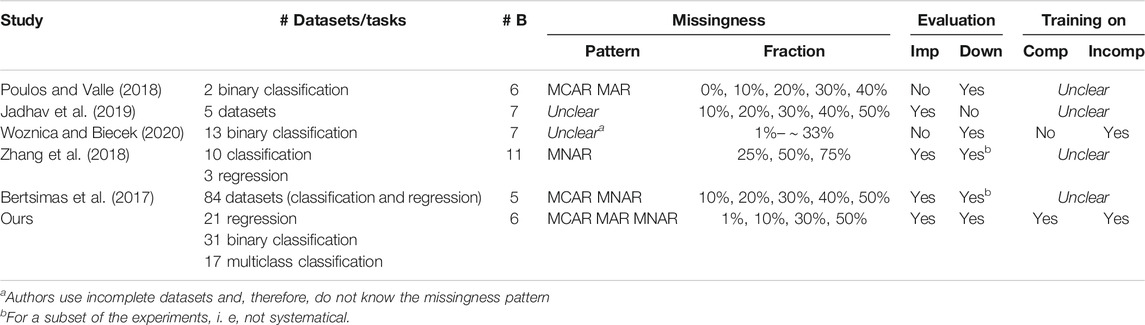
TABLE 1. An overview of related benchmarks. In contrast to our benchmark, all other studies focus on specific aspects such as downstream tasks or missingness conditions. Most importantly, no paper systematically compares imputation methods trained on complete and incomplete datasets. Abbreviations: the symbol # stands for the number, B means baselines, Imp means imputation quality, Down means impact on the downstream task, Comp means complete data, Incomp means incomplete data.
3 Methods
One of the main goals of this work is to provide a comprehensive evaluation of missing value imputation methods under realistic conditions. In particular, we focus on two aspects: 1) a broad suite of real-world datasets and tasks and 2) realistic missingness patterns. The following sections describe the datasets and missingness patterns we considered and the data preprocessing steps. Then follows a detailed description of the compared imputation methods, the used hyperparameter optimization strategies, and metrics for evaluation.
3.1 Datasets
We focus on a comprehensive evaluation with several numeric datasets and tasks (regression, binary classification, and multiclass classification). The OpenML database (Vanschoren et al., 2013) contains thousands of datasets and provides an API. The Python package scikit-learn (Pedregosa et al., 2011) can use this API to download datasets and create well-formatted DataFrames that encode the data properly.
We filter available datasets as follows. To calculate the imputation performance, we need ground truth datasets without missing values. Moreover, especially deep learning models need sufficient data to learn their task properly. However, because we plan to run many experiments, the datasets must not be too big to keep training times feasible. For this reason, we choose datasets without missing values that contain 5 to 25 features and 3.000 to 100.000 observations. We then removed duplicated, corrupted, and Sparse ARFF2 formatted datasets.
The resulting 69 datasets are composed of 21 regression, 31 binary classification, and 17 multiclass classification datasets. The supplementary material contains a detailed list of all datasets and further information, such as OpenML ID, name, and the number of observations and features.
3.2 Missingness Patterns
Most research on missing value imputation considers three different types of missingness patterns:
• Missing completely at random (MCAR, see Table 2): Values are discarded independently of any other values
• Missing at random (MAR, see Table 3): Values in column c are discarded depending on values in another column
• Missing not at random (MNAR, see Table 4) Values in column c are discarded depending on their value in c

TABLE 2. Applying the MCAR condition to column height discards five out of ten values independent of the height values.
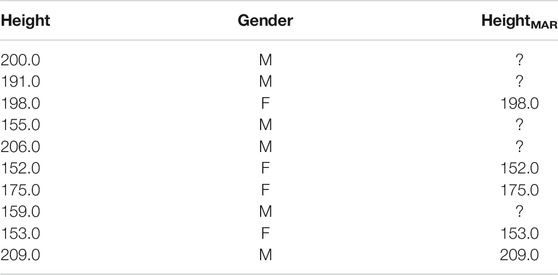
TABLE 3. In the MAR condition, height values are discarded dependent on values in another column, here gender. All discarded height values correspond to rows in which gender was male.

TABLE 4. In the MNAR condition, height values are discarded dependent on the actual height values. All discarded values correspond to small height values.
The missingness pattern most often used in the literature on missing value imputation is MCAR. Here, the missing values are chosen independently at random. Usually, the implementations of this condition draw a random number from a uniform distribution and discard a value if that random number was below the desired missingness ratio. Few studies report results on the more challenging conditions MAR and MNAR. We here aim for realistic modeling of these missingness patterns inspired by observations in large-scale real-world datasets as investigated in the work of Biessmann et al. (2018). We use an implementation proposed in the work of Schelter et al. (2020) and Schelter et al. (2021), which selects two random percentiles of the values in a column, one for the lower and the other for the upper bound of the value range considered. In the MAR condition, we discard values if values in a random other column fall in that percentile. In the MNAR condition, we discard values in a column if the values themselves fall in that random percentile range.
3.3 Data Preprocessing
Data preprocessing is often an essential part of ML pipelines to achieve good results (Sculley et al., 2015). In our experiments, we apply the following three preprocessing steps for all the imputation methods:
• Encode categorical columns: Categories are transformed into a numerical representation, which is defined on the training set and equally applied to the test set
• Replace missing values: To avoid the imputation model from failing
• Normalize the data: The columns are rescaled to the same range, which is defined on the training set and equally applied to the test set
However, the concrete techniques for discriminative imputation, as described in Section 3.4.1, Section 3.4.2, Section 3.4.3, and Section 3.4.4, and generative approaches, as described in Section 3.4.5, are different.
For discriminative imputation approaches, we substitute missing values with their column-wise mean/mode value, one-hot encode categorical columns, and normalize the data to zero mean and unit variance. For generative imputation approaches, we need to preserve the number of columns. For this reason, we encode the categories of categorical columns as values from 0 to
3.4 Imputation Methods
In this section, we describe our six different imputation methods. The overall goal of an imputation method is to train a model on a dataset
3.4.1 Mean/Mode Imputation
As a simple imputation baseline, we use the column-wise mean for numerical or mode, i.e., the most frequent value, for categorical columns to fill missing values.
3.4.2 K-NN Imputation
A popular ML imputation baseline is k-NN imputation, also known as Hot-Deck imputation (Batista and Monard, 2003). For our implementation thereof, we use scikit-learn’s KNeighborsClassifier for categorical to-be-imputed columns and KNeighborsRegressor for numerical columns, respectively.
3.4.3 Random Forest Imputation
Similarl to the k-NN imputation approach, as described in Section 3.4.2, we implement the random forest imputation method using scikit-learn’s RandomForestClassifier and RandomForestRegressor.
3.4.4 Discriminative Deep Learning Imputation
In recent years, the popularity of deep-learning–based models has increased substantially. Consequently, also the application of deep learning methods for imputation has become more popular. A query on Google Scholar for deep learning imputation shows that the number of publications increased from 2,110 publications in 2010 to 10,100 publications in 2020, an increase of over 470%, while the number of publications found for the term imputation alone actually slightly decreased from 41,700 in 2010 to 40,700 in 2020. For example, Biessmann et al. (2018) show that simple deep learning models can achieve good imputation results. To represent a range of possible DL-based imputation models, we decide to optimize the model’s architecture. For this reason, we use the AutoML3 library autokeras (Jin et al., 2019) to implement the discriminative deep learning imputation method. For categorical columns, we use autokeras’ StructuredDataClassifier and for numerical columns StructuredDataRegressor. Both the classes take care of properly encoding the data themselves and optimizing the model’s architecture and hyperparameters. We use
3.4.5 Generative Deep Learning Imputation
All of the abovementioned approaches essentially follow the ideas known in the statistics literature as fully conditional specification (FCS) (van Buuren, 2018): a discriminative model is trained on all but one column as features and the remaining column as the target variable. A well-known FCS method is multiple imputation with chained equations (MICE) (Little and Rubin, 2002). FCS has the advantage to be applicable to any supervised learning method, but it has the decisive disadvantage that, for each to-be-imputed column, a new model has to be trained. Generative approaches are different in that they train just one model for an entire table. All matrix-factorization–based approaches, such as those in the work of Troyanskaya et al. (2001); Koren et al. (2009); Mazumder et al. (2010), can be thought of as examples of generative models for imputation. We do not consider those linear generative models here as they have been shown to be outperformed by the mentioned methods and focus on deep learning variants of generative models only.
Generative deep learning methods can be broadly categorized into two classes: variational autoencoders (VAEs) (Kingma and Welling, 2014)4 and generative adversarial networks (GANs) (Goodfellow et al., 2014). In the following, we shortly highlight some representative imputation methods based on either of these two and describe the implementation used in our experiments.
3.4.5.1 Variational Autoencoder Imputation
VAEs learn to encode their input into a distribution over the latent space and decode by sampling from this distribution (Kingma and Welling, 2014). Imputation methods based on this type of generative model include those in the work of Nazábal et al. (2020); Qiu et al. (2020); and Ma et al. (2020). Rather than comparing all the existing implementations, we focus on the original VAE imputation method for the sake of comparability with other approaches. To find the best model architecture, i.e., the number of hidden layers and their sizes, we follow the approach proposed by Camino et al. (2019). We optimized using zero, one, or two hidden layer(s) for the encoder and decoder and fixed their sizes relative to the input dimension, i.e., the table’s number of columns. If existing, the encoder’s first hidden layer has
3.4.5.2 Generative Adversarial Network Imputation
GANs consist of two parts—a generator and a discriminator (Goodfellow et al., 2014). In an adversarial process, the generator learns to generate samples that are as close as possible to the data distribution, and the discriminator learns to distinguish whether an example is true or generated. Imputation approaches based on GANs include those in the work of Yoon et al. (2018); Shang et al. (2017); and Li et al. (2019). Here, we employ one of the most popular approaches of GAN-based imputation, Generative Adversarial Imputation Nets (GAIN) (Yoon et al., 2018). GAIN adapts the original GAN architecture as follows. The generator’s input is the concatenation of the input data and a binary matrix that represents the missing values. The discriminator learns to reconstruct the mask matrix. Its input is the concatenation of the generator’s output and a hint matrix, which reveals partial information about the missingness of the original data. The computation of the hint matrix incorporates the introduced hyperparameter
3.5 Hyperparameter Optimization
Optimizing and cross validating hyperparameters are crucial to gain insights into a model’s performance, robustness, and training time. Therefore, we choose for each imputation model the, as we find, most important hyperparameters and optimize them using cross-validated grid-search. For the k-NN and random forest imputation methods, we use 5-fold cross validation, whereas we only 3-fold cross validate VAE and GAIN to reduce the overall training time. Table 5 gives an overview of all the imputation approaches and their hyperparameters we optimize, and the number of combinations. We do not define hyperparameter grids for mean/mode and DL imputation, as the former is parameterless and the latter is optimized by autokeras.

TABLE 5. An overview of all imputation methods and their hyperparameters we optimized. Mean/mode imputation does not have any hyperparameters, and Discriminative DL is optimized using autokeras, which is why we do not explicitly define a hyperparameter grid.
3.6 Evaluation Metrics
To evaluate our experiments, we use two metrics: root mean square error (
where N is the number of observations,
where i is the class index, C is the number of classes, and the definition of
where
Imputing categorical columns can be seen as a classification task. Accordingly, we measure performance in this case and for downstream classification tasks by the
4 Implementation and Experiments
In this section, we describe our benchmark suite in detail and its implementation.
As described in Section 3.4, we define a framework that provides for each of the six implemented imputation approaches a common API with the methods fit and transform. Fit trains the imputation model on given data while cross-validating a set of hyperparameters, and transform allows imputing missing values of the to-be-imputed column the imputation model is trained on. For our implementation, we use tensorflow version 2.4.1, scikit-learn version 0.24.1, and autokeras version 1.0.12.
The Python package jenga5 (Schelter et al., 2021) provides two features we use to implement our experiments. First, it implements the mechanisms to discard values for the missingness patterns MCAR, MAR, and MNAR, as described in Section 3.2. Second, it provides a wrapper for OpenML datasets, creates an
4.1 Experimental Settings
Our experimental settings are listed in Table 6. Each experiment is executed three times, and the average performance metrics are reported.

TABLE 6. Overview of our experimental settings. We focus on covering an extensive range of the dimensions described in Section 2. In total, there are
For each of the datasets, we sample one to-be-imputed column upfront, which remains static throughout our experiments.
We split the experiments into four parts. In Experiment 1, we compare imputation approaches with respect to their imputation quality (Section 4.1.1), and in Experiment 2, we compare imputation methods with respect to the impact on downstream tasks (Section 4.1.2). Both experiments are repeated in two application scenarios: Scenario 1 (with complete training data, see Section 4.1.3) and Scenario 2 (with incomplete training data, see Section 4.1.4).
4.1.1 Experiment 1: Imputation Quality
With this experiment, we aim to reveal how accurately the imputation methods can impute the original values. With the help of jenga, we spread the desired number of missing values across all the columns of the test set. For a certain missingness pattern and fraction, e.g.,
Since this work focuses on point estimates of imputed values, the assessment of the inherent uncertainty of imputed values is beyond the scope of this evaluation. We are aware of this limitation and use a second experiment to avoid relying on these single-value summaries. Explanations and other directions to overcome those limitations are, e.g., provided by Wang et al. (2021).
4.1.2 Experiment 2: Impact on the Downstream Task
In Experiment 2, we evaluate the impact of the different imputation approaches on numerous downstream ML tasks. For discriminative models, it is necessary to train one imputation model for each column with missing values. This fact, combined with our large number of experimental conditions (see Table 6), results in vast computational costs. To reduce those, while covering all relevant experimental conditions, we decided to discard values only in the test sets’ to-be-imputed column.
To summarize, the entire experimental procedure is as follows:
1) We train the baseline model of the downstream ML task on the training set and report its
2) After discarding values in the to-be-imputed column, we again use the trained baseline model and calculate its score on the incomplete test set, hence the name
3) We then impute the missing values of the test set and, once more, using the trained baseline model, calculate the
4) Finally, we report the impact on the downstream task’s performance as the percent change of the imputation over the incomplete data relative to the baseline performance on fully observed test data:
4.1.3 Scenario 1: Training on Complete Data
ML researchers commonly use complete (or fully observed) data to train, tune, and validate their ML applications. This is a reasonable assumption as the quality of the training data can be controlled better than that of the test data when the model is deployed in production. For instance, one can use crowdsourced tasks to collect all necessary features in the training data or use sampling schemes that ensure complete and representative training data. In this scenario, one can easily train an imputation model on complete data and use it to impute missing values in the test data before it is fed into the downstream ML model. We use Scenario 1 to simulate such situations and run both experiments, as described in Section 4.1.1 and Section 4.1.2.
4.1.4 Scenario 2: Training on Incomplete
Another common scenario is that not only the test data but also the training data have missing values. Thus, the imputation and downstream ML model has to be trained on incomplete training data. Also, in this scenario, we should expect missing values in the test data, which have to be imputed before applying the downstream ML model. To evaluate this application scenario, we adapt Experiment 1 and Experiment 2 slightly.
We first introduce missing values in the training and test set and then train the baseline and imputation models based on these incomplete data. The calculation of the imputation quality (Experiment 1, Section 4.1.1) remains the same. However, to calculate the impact on the downstream task, we lack the availability of the
5 Results
In this section, we describe and visualize the results of our experiments. For the visualization, we choose to use box plots for all four experiments/scenarios. These allow us to get a decent impression of the distribution of the results based on quantiles. In contrast, the confidence bands of line charts would overlap too much to derive meaningful interpretations. The vertical split represents the increasing difficulty for the missingness patterns: MCAR, MAR, and MNAR. To show different effects of imputing categorical or numerical columns, we further split the plots horizontally. Because we randomly sample on target column for each dataset, there are about
5.1 Experiment 1: Imputation Quality
In this experiment, we evaluate the imputation performance of each method when training on complete data. As described above, our goal was to provide a broad overview of the imputation methods’ performance on various datasets. Using randomly sampled to-be-imputed columns on heterogeneous data leads to a wide range of values for their evaluation metric (
5.1.1 Scenario 1: Training on Complete Data
Figure 1 presents the imputation results when training on complete data. In about
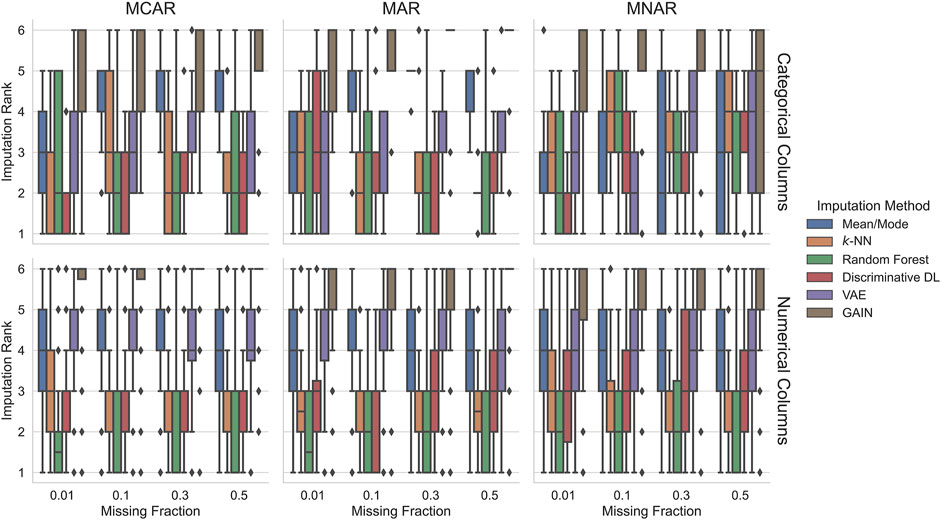
FIGURE 1. Imputation ranks of the imputation methods trained on complete data. Ranks are computed for each experimental condition characterized by the dataset, missingness pattern, and missingness ratio. Since we compare six imputation methods, the possible imputation ranks range between 1 and 6. In most conditions, random forest, k-NN, and discriminative DL perform best. Generative deep learning methods tend to perform worst. In the most challenging MNAR condition, mean/mode imputation achieves competitive results.
When imputing categorical columns, there is no clear best method. However, in many settings, the discriminative DL approach achieves in
When imputing numerical columns, the differences are more pronounced. Random forest is the only method that achieves one of the first three ranks in
To summarize, simple imputation methods, such as k-NN and random forest, often perform best, closely followed by the discriminative DL approach. However, for imputing categorical columns with MNAR missing values, mean/mode imputation often performs well, especially for high fractions of missing values. The generative approaches get middle ranks (VAE) or range on the worst ranks (GAIN).
5.1.2 Scenario 2: Training on Incomplete Data
Figure 2 shows the imputation performance in Scenario 2, i.e., when training on incomplete data. Imputing categorical columns with increasing difficulty, the ranks of mean/mode imputation improve. From MCAR
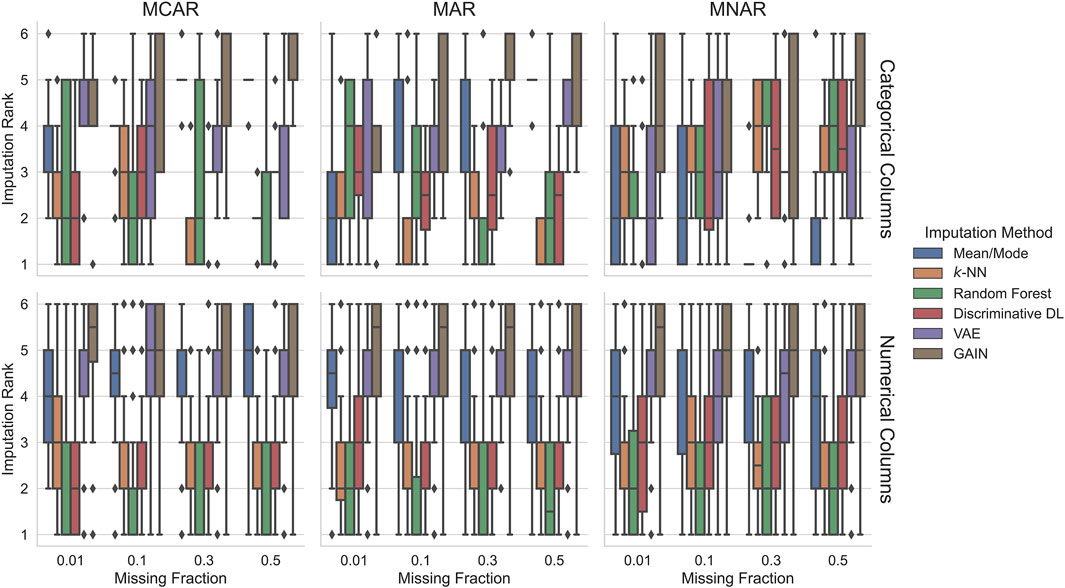
FIGURE 2. Imputation ranks of the imputation methods trained on incomplete data. Ranks are computed for each experimental condition characterized by the dataset, missingness pattern, and missingness ratio. Since we compare six imputation methods, the possible imputation ranks range between 1 and 6. Similar to the training on fully observed data random forest, k-NN and discriminative DL perform better than generative deep learning methods in most settings. In the MNAR conditions, the imputation quality of all the imputation approaches degrades in favor of mean/mode that outperforms the other for
Similar to the fully observed training case (Section 5.1.1), imputation on numerical columns yields a clearer ranking than for categorical missing values. The imputation methods k-NN and random forest rank best with a tendency of random forest to outperform k-NN, where random forest’s variance is higher. The discriminative DL approach yields a very similar performance to the k-NN for the MCAR and MAR settings. In the more challenging MNAR setting, it ranks slightly worse. For MCAR, mean/mode imputation ranks in almost all settings in
Overall, Scenario 1 (Figure 1) and Scenario 2 (Figure 2) results for numerical columns are very similar. GAIN has become better in Scenario 2, although it still ranks worst. For categorical columns, generally, the ranks show higher variance. Most imputation methods worsen when the experimental settings’ difficulty is higher, especially for MNAR, except for mean/mode, which ranks better for MNAR. This effect is even explicit when training on incomplete data. Generally, using methods such as k-NN or random forest achieves best results in most settings and cases.
5.2 Experiment 2: Impact on the Downstream Task
In this experiment, we evaluate the imputation method’s impact on the downstream performance in two scenarios: the imputation model was trained on complete and incomplete data. As described in Section 4.1.2, this time, we discard only values in the dataset’s randomly sampled target column.
5.2.1 Scenario 1: Training on Complete Data
Since training GAIN failed in about
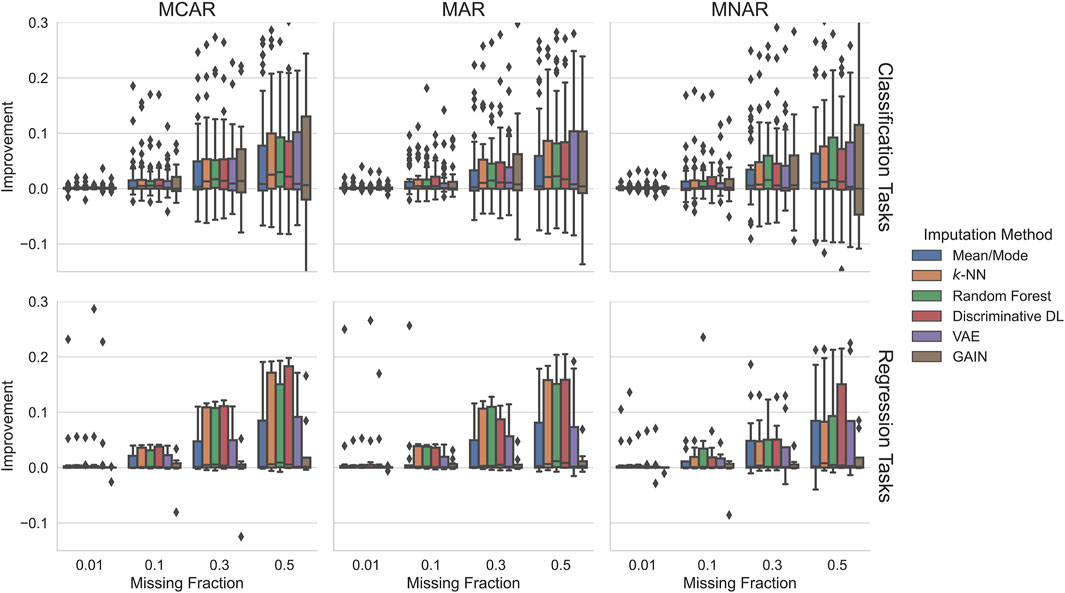
FIGURE 3. Does imputation on incomplete test data improve predictive performance of a downstream ML model? We plot the improvement of the downstream ML model after imputation with imputation models trained on fully observed data. The downstream performance is compared to the performance obtained on incomplete test data, normalized by the ML model performance on fully observed test data. Overall, the classical ML methods and discriminative DL perform best achieving relative improvements of up to 10% and more relative to fully observed test data.
In all cases, using imputation approaches increases the downstream performance in
For regression tasks, all imputation methods on all settings degrade the performance in less than
For classification tasks, few imputation methods in some settings show degrading performance in slightly more than
All in all, independent of the experimental settings, random forest performs in
5.2.2 Scenario 2: Training on Incomplete Data
Figure 4 illustrates the impact imputation has on the downstream task. We show how many percent the predictive performance of a downstream ML model improves compared to incomplete test data. This metric is labeled Improvement and represented on the plots’ y-axis. Here, the different scaling must be taken into account, i.e., the relative improvements are considerably smaller compared to the first scenario. One reason for this is the different basis for calculating the relative values (see Sections 4.1.2 and Sections 4.1.4).
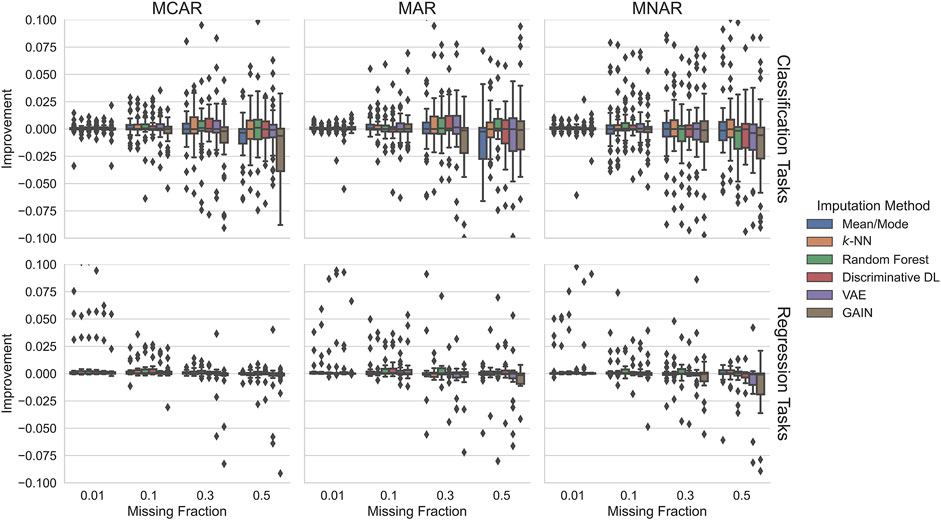
FIGURE 4. Impact on the downstream task of the six imputation methods trained on incomplete data. In regression tasks, no considerable improvements are achieved. In some cases, imputation worsened the downstream ML model. In classification tasks, in contrast, we observe slightly positive effects in some settings, but negative effects predominate in the harder settings.
The potential improvements when the imputation methods are trained on incomplete data are marginal. In all settings, there are hardly any improvements greater than
For classification tasks with up to
For regression tasks, there are hardly any potential improvements over
To summarize, for up to
5.3 Computational Complexity
Our results demonstrate that simple ML methods are often on par with modern deep learning methods. An important question in this context is how the various methods compare in terms of their computational complexity: if methods yield similar predictive performance, it is preferable to use those alternatives with the least computational effort. To measure the training and inference time, we use a subset of our experiments: all datasets, missingness fractions, and imputation methods (shown in Table 6) with MCAR pattern. We first train the imputation method on complete data, then discard the values of the given missingness fraction in the training set, and impute those missing values. The wall-clock run time is measured in seconds when calling our framework’s fit and transform methods (see Section 4 for details), which means that the training duration incorporates hyperparameter optimization (see Section 3.5 for details).
Because training and inference time depends heavily on the dataset’s size, directly averaging all experiments for the imputation methods leads to very similar mean but extremely high standard deviation values. For this reason, we first compute the mean duration and the standard deviation relative to its mean separately for training and inference for the imputation methods on each dataset. Second, we average those values for each imputation method and present them in Table 7. Using this approach helps to average overall experiments and, at the same time, gives indicators for the training and inference durations, as well as their variance.

TABLE 7. Training and inference duration for each imputation method in seconds. We use the wall-clock run time to measure the durations for training, including hyperparameter optimization and inference for all datasets with MCAR missingness pattern and all fractions shown in Table 6. Because training and inference durations depend heavily on the dataset size, we first calculate the durations’ mean and relative standard deviation for each imputation method on every dataset. Second, we average those mean durations and relative standard deviations for the imputation methods and present them as Mean duration and Rel. SD separately for Training and Inference.
As expected, if the imputation model’s complexity increases, their training duration increases too, most of the time by multiple factors. There are two exceptions: discriminative DL and VAE, and an explanation for this could be their number of hyperparameter combinations optimized during training. VAE optimizes only three, GAIN 16 and discriminative DL 50 combinations, representing their training durations order.
Similarly, the inference time increases with the model’s complexity. The differences are clear but not as high as for the training durations. Higher inference standard deviations, e.g., for k-NN and random forest (and discriminative DL), indicate that the best hyperparameters found strongly vary with the experimental settings and influence the model’s computational complexity for inference. One reason for the discriminative DL’s and GAIN’s high training standard deviations could be the usage of early stopping and, at the same time, indicate that it is important to try a huge number of hyperparameters to achieve good results. For mean/mode, the high standard deviation is likely an artifact of the very small training duration. Changes in milliseconds for computations are common and represent a large change relative to the mean/mode imputation’s mean duration.
To summarize, the increasing complexity of the imputation methods is represented in their training and inference duration. For training more complex models, this is supported by a higher variance of training time, indicating the necessity to try a wide range of hyperparameters. On the other hand, once found, the hyperparameters for generative models influence the inference time less than for k-NN or random forest, whose prediction times depend heavily on the hyperparameters.
6 Discussion
We investigated the performance of classical and modern imputation approaches on a large number of heterogeneous datasets under realistic conditions. In the following, we highlight some of the key findings.
6.1 Simpler Imputation Methods Yield Competitive Results
When evaluating imputation quality, our results demonstrate that simple supervised learning methods achieve competitive results and, in many cases, outperform modern generative deep-learning–based approaches. In particular, in the MCAR and MAR settings, we see in Figures 1, 2 that k-NN, random forest, and the discriminative DL approach are, for at least
This finding is in line with the work of Poulos and Valle (2018); Jadhav et al. (2019); and Bertsimas et al. (2017). In these previous studies, the authors report that k-NN imputation is the best choice in most situations. However, Jadhav et al. (2019) and Bertsimas et al. (2017) did not incorporate a random forest imputation method. Other comparisons show a slight advantage of discriminative deep learning methods over random forests (Biessmann et al., 2019), but these experiments were conducted on a much smaller selection of datasets.
For categorical columns (see Figures 1, 2, upper row) in the more challenging imputation settings MAR or MNAR with large missingness fractions, the mean/mode imputation tends to achieve better ranks. This effect can be attributed to the fact that the sets of observed categorical values often have small cardinality. Especially for skewed distributions, using the most frequent value to substitute missing values is a good approximation of the ground truth. If the training data contains a large fraction of missing values, the underlying dependencies exploited by learning algorithms are difficult to capture. For this reason, mean/mode scores for higher MNAR missing values in
Since GAIN failed in about
All in all, using random forest, discriminate DL, or k-NN is a good choice in most experimental settings and promises the best imputation quality. However, incorporating the model’s training and inference time, presented in Table 7, shows that the discriminative DL approach is substantially slower for training and inference than the other two methods. This is because we used the expensive default model optimization of AutoKeras. Exploring fewer hyperparameters could decrease its imputation performance drastically. The training duration’s high variance indicates that trying a large number of hyperparameters is necessary for good performance because early stopping would finish the training if the model converges. k-NN’s standard deviation for inference is in contrast to random forest’s very high standard deviation. This is expected as the inference time grows exponentially with the number of training data points. We conclude that given the similar performance of k-NN and random forests when the training dataset is large, random forests (or similar methods) should be preferred over naive k-NN implementations. Alternatively, one might use appropriate speedups for the nearest-neighbor search, such as
To summarize, the best performing imputation approach is random forest. It not only ranks best in most experimental settings but also shows a good balance of training, including optimizing hyperparameters and inference time that is not influenced by the training set size. However, when coping with datasets that miss
6.2 Substantial Downstream Improvements When the Imputation Method Was Trained on Complete Data
Our results show that imputation can have a substantial positive impact on predictive performance in downstream ML tasks. We observe improvements in the downstream task of 10–20% in more than 75% of our experiments. This holds for most imputation methods; we did not observe a clear advantage for an imputation method overall. Taking into account the considerable differences in wall-clock run time, our results indicate that also when choosing an imputation method that is both fast and improves downstream predictive performance random forests would be the preferred imputation method.
The positive impact of imputation on downstream performance is most pronounced when the imputation methods were trained on fully observed data. When imputation methods were trained on incomplete data, the positive impact of imputing missing values in the test data was substantially lower, sometimes even negative. While this might seem a disadvantage, we emphasize that, in many application use cases, we can ensure that the training data be fully observed, for instance, by acquiring more data before training the imputation and the downstream ML model.
6.3 Limitations
Because one of the main goals of this study is a comprehensive comparison of imputation methods on a large number of datasets and missingness conditions, we made some decisions that limit our results.
First, we focus on point estimates of imputed values rather than multiple imputations because it is 1) easier to handle in automated pipelines and 2) can be considered a more relevant scenario in real-world applications of imputation methods. Thus, we do not consider the inherent uncertainty of the imputation process. We decided to measure and compare the impact imputation methods have on the downstream performance instead of using an evaluation framework that explicitly evaluates the uncertainties, e.g., proposed by Wang et al. (2021). However, comparing imputation methods with respect to the calibration of their uncertainty estimates is an important topic for future research and could be conducted with the same experimental protocol that we developed for our point estimate comparisons.
Second, the used datasets consist of a maximum of 25 features and
Third, to measure the imputation impact on the downstream performance, we discarded and imputed values in only a single column. Therefore, the impact depends heavily on the chosen column’s importance (e.g., see the work of Schelter et al. (2021)). Generally, the impact when using an imputation model could vary when multiple columns are affected by missing values.
7 Conclusion
In this study, we developed an experimental protocol and conducted a comprehensive benchmark for imputation methods comparing classical and modern approaches on a large number of datasets under realistic missingness conditions with respect to the imputation quality and the impact on the predictive performance of a downstream ML model. We also evaluated how the results changed when the imputation and downstream model were trained on incomplete data.
Our results can be summarized in two main findings. First, we demonstrate that imputation helps to increase the downstream predictive performance substantially regardless of the missingness conditions. When training data are fully observed, our results demonstrate that, in more than 75% of our experiments, imputation leads to improvements in downstream ML model predictive performance between
Second, we find that, in almost all experiments, random-forest–based imputation achieves the best imputation quality and the best improvements on the downstream predictive performance. This finding is in line with previous imputation benchmark research in more constrained experimental conditions (see also Section 2). Yet, some aspects of these results appear at odds with some recent work on deep learning methods. While we are aware of the limitations of our experiments (see also Section 6.3), we are convinced that the experimental protocols developed in this study can help to test imputation methods better and ultimately help to stress test these methods under realistic conditions in large unified benchmarks with heterogeneous datasets (Sculley et al., 2018; Bender et al., 2021).
Data Availability Statement
Publicly available datasets were analyzed in this study. These data can be found here: https://www.openml.org.
Author Contributions
SJ and FB contributed to the conception and design of the study. SJ implemented the benchmark suit framework and most imputation methods. AA contributed the VAE implementation. All authors wrote sections of the manuscript and contributed to its revision and read and approved the submitted version.
Funding
This research was supported by the, Zentraler Forschungs- und Innovationsfonds (FIF) of Berliner (formerly Beuth) Hochschule für Technik and the Federal Ministry for the Environment, Nature Conservation and Nuclear Safety based on a decision of the German Bundestag.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fdata.2021.693674/full#supplementary-material
Footnotes
1A great example from life sciences is given in the work of Ziemann et al. (2016).
2Attribute-relation file format.
3“Automated machine learning (AutoML) (…) automatically set [the model’s] hyperparameters to optimize performance,” Hutter and Frank (2019).
4We focus on probabilistic autoencoders here as there are more imputation methods available for VAEs.
5Software package “to study the effects of common data corruptions (e.g., missing values and broken character encodings) on the prediction quality of ML models.” Source: https://github.com/schelterlabs/jenga
References
Abedjan, Z., Chu, X., Deng, D., Fernandez, R. C., Ilyas, I. F., Ouzzani, M., et al. (2016). Detecting Data Errors. Proc. VLDB Endow. 9, 993–1004. doi:10.14778/2994509.2994518
Abedjan, Z., Golab, L., Naumann, F., and Papenbrock, T. (2018). Data Profiling. Synth. Lectures Data Manag. 10, 1–154. doi:10.2200/s00878ed1v01y201810dtm052
Batista, G. E. A. P. A., and Monard, M. C. (2003). An Analysis of Four Missing Data Treatment Methods for Supervised Learning. Appl. Artif. Intelligence 17, 519–533. doi:10.1080/713827181
Baylor, D., Breck, E., Cheng, H.-T., Fiedel, N., Foo, C. Y., Haque, Z., Haykal, S., Ispir, M., Jain, V., Koc, L., Koo, C. Y., Lew, L., Mewald, C., Modi, A. N., Polyzotis, N., Ramesh, S., Roy, S., Whang, S. E., Wicke, M., Wilkiewicz, J., Zhang, X., and Zinkevich, M. (2017). “Tfx,” in Proc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., New York, NY, USA (Association for Computing Machinery), 1387–1395. Part F1296. doi:10.1145/3097983.3098021
Bender, E. M., Gebru, T., Mcmillan-Major, A., Shmitchell, S., and Shmitchell, S.-G. (2021). “On the Dangers of Stochastic Parrots,” in FAccT '21: 2021 ACM Conference on Fairness, Accountability, and Transparency, Canada (Association for Computing Machinery), 610–623. doi:10.1145/3442188.3445922
Bertsimas, D., Pawlowski, C., and Zhuo, Y. D. (2017). From Predictive Methods to Missing Data Imputation: An Optimization Approach. J. Mach. Learn. Res. 18 (196), 1–39.
Biessmann, F., Golebiowski, J., Rukat, T., Lange, D., and Schmidt, P. (2021). “Automated Data Validation in Machine Learning Systems,” in Bulletin of the IEEE Computer Society Technical Committee on Data Engineering.
Biessmann, F., Rukat, T., Schmidt, P., Naidu, P., Schelter, S., Taptunov, A., et al. (2019). Datawig: Missing Value Imputation for Tables. J. Machine Learn. Res. 20, 1–6.
Biessmann, F., Salinas, D., Schelter, S., Schmidt, P., and Lange, D. (2018). “"Deep" Learning for Missing Value Imputationin Tables with Non-numerical Data,” . in Int. Conf. Inf. Knowl. Manag. Proc, Torino Italy (ACM Press), 2017–2026. doi:10.1145/3269206.3272005
Böse, J.-H., Flunkert, V., Gasthaus, J., Januschowski, T., Lange, D., Salinas, D., et al. (2017). Probabilistic Demand Forecasting at Scale. Proc. VLDB Endow. 10, 1694–1705. doi:10.14778/3137765.3137775
Camino, R., Hammerschmidt, C. A., and State, R. (2019). Improving Missing Data Imputation with Deep Generative Models. ArXiv abs/1902, 10666.
F. Hutter, and Frank (2019). Automated Machine Learning - Methods, Systems, Challenges (Cham, Switzerland: The Springer Series on Challenges in Machine Learning (Springer). doi:10.1007/978-3-030-05318-5
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). “Generative Adversarial Nets,”. Advances in Neural Information Processing Systems. Editors Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Q. Weinberger (Montréal, Canada: Curran Associates, Inc.), 27, 2672–2680.
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. (2017). “Gans Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 2017. Editors I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, and R. Garnett, 6626–6637.
Jadhav, A., Pramod, D., and Ramanathan, K. (2019). Comparison of Performance of Data Imputation Methods for Numeric Dataset. Appl. Artif. Intelligence 33, 913–933. doi:10.1080/08839514.2019.1637138
Jin, H., Song, Q., and Hu, X. (2019). “Auto-keras: An Efficient Neural Architecture Search System,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage AK USA (ACM), 1946–1956.
Kingma, D. P., and Welling, M. (2014). “Auto-encoding Variational Bayes,” in 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014. Editors Y. Bengio, and Y. LeCun Conference Track Proceedings.
Koren, Y., Bell, R., and Volinsky, C. (2009). Matrix Factorization Techniques for Recommender Systems. Computer 42, 30–37. doi:10.1109/MC.2009.263
Kumar, A., Boehm, M., and Yang, J. (2017). “Data Management in Machine Learning,” in Proc. ACM SIGMOD Int. Conf. Manag. Data Part, Chicago Illinois USA (Association for Computing Machinery), 1717–1722. F1277. doi:10.1145/3035918.3054775
Li, S. C., Jiang, B., and Marlin, B. M. (2019). “Misgan: Learning from Incomplete Data with Generative Adversarial Networks,” in 7th International Conference on Learning Representations, ICLR 2019, May 6-9, 2019 (New Orleans, LA, USA. (OpenReview.net).
Little, R. J. A., and Rubin, D. B. (2002). Statistical Analysis with Missing Data. 2nd Edition. Hoboken: John Wiley & Sons.
Ma, C., Tschiatschek, S., Turner, R. E., Hernández-Lobato, J. M., and Zhang, C. (2020). “VAEM: a Deep Generative Model for Heterogeneous Mixed Type Data,” in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, December 6-12, 2020. Editors H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin (NeurIPS, 2020). virtual.
Mazumder, R., Hastie, T., and Tibshirani, R. (2010). Spectral Regularization Algorithms for Learning Large Incomplete Matrices. J. Mach. Learn. Res. 11, 2287–2322.
Miyato, T., Kataoka, T., Koyama, M., and Yoshida, Y. (2018). “Spectral Normalization for Generative Adversarial Networks,” in 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018. Conference Track Proceedings (OpenReview.net).
Nazábal, A., Olmos, P. M., Ghahramani, Z., and Valera, I. (2020). Handling Incomplete Heterogeneous Data Using Vaes. Pattern Recognition 107, 107501. doi:10.1016/j.patcog.2020.107501
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 12, 2825–2830.
Poulos, J., and Valle, R. (2018). Missing Data Imputation for Supervised Learning. Appl. Artif. Intelligence 32, 186–196. doi:10.1080/08839514.2018.1448143
Qiu, Y. L., Zheng, H., and Gevaert, O. (2020). Genomic Data Imputation with Variational Auto-Encoders. GigaScience 9, 1–12. doi:10.1093/gigascience/giaa082
Rubin, D. B. (1976). Inference and Missing Data. Biometrika 63, 581–592. doi:10.1093/biomet/63.3.581
Rukat, T., Lange, D., Schelter, S., and Biessmann, F. (2020). “Towards Automated Data Quality Management for Machine Learning,” in ML Ops Work. Conf. Mach. Learn. Syst., 1–3.
Salimans, T., Goodfellow, I. J., Zaremba, W., Cheung, V., Radford, A., and Chen, X. (2016). “Improved Techniques for Training gans,” in Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, December 5-10, 2016. Editors D. D. Lee, M. Sugiyama, U. von Luxburg, I. Guyon, and R. Garnett, 2226–2234.
Schafer, J. L., and Graham, J. W. (2002). Missing Data: Our View of the State of the Art. Psychol. Methods 7, 147–177. doi:10.1037/1082-989x.7.2.147
Schelter, S., Biessmann, F., Januschowski, T., Salinas, D., Seufert, S., and Szarvas, G. (2018a). On Challenges in Machine Learning Model Management. IEEE Data Eng. Bull. 41 (4), 5–15. http://sites.computer.org/debull/A18dec/p5.pdf
Schelter, S., Böse, J.-H., Kirschnick, J., Klein, T., and Seufert, S. (2017). Automatically Tracking Metadata and Provenance of Machine Learning Experiments. Mach. Learn. Syst. Work. NIPS, 1–8.
Schelter, S., Lange, D., Schmidt, P., Celikel, M., Biessmann, F., and Grafberger, A. (2018b). Automating Large-Scale Data Quality Verification. Proc. VLDB Endow. 11, 1781–1794. doi:10.14778/3229863.3229867
Schelter, S., Rukat, T., and Biessmann, F. (2021). “JENGA - A Framework to Study the Impact of Data Errors on the Predictions of Machine Learning Models,” in Proceedings of the 24th International Conference on Extending Database Technology, EDBT 2021, Nicosia, Cyprus, March 23 - 26, 2021. Editors Y. Velegrakis, D. Zeinalipour-Yazti, P. K. Chrysanthis, and F. Guerra (OpenProceedings.org), 529–534. doi:10.5441/002/edbt.2021.63
Schelter, S., Rukat, T., and Biessmann, F. (2020). “Learning to Validate the Predictions of Black Box Classifiers on Unseen Data,” in Proc. 2020 ACM SIGMOD Int. Conf. Manag. Data (New York, NY, USA: ACM)), 1289–1299. doi:10.1145/3318464.3380604
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., et al. (2015). Hidden Technical Debt in Machine Learning Systems. Adv. Neural Inf. Process. Syst. 2, 2503–2511. 2015-Janua.
Sculley, D., Snoek, J., Wiltschko, A. B., and Rahimi, A. (2018). “Winner’s Curse? on Pace, Progress, and Empirical Rigor,” in ICLR Workshops.
Shang, C., Palmer, A., Sun, J., Chen, K.-S., Lu, J., and Bi, J. (20172017). “VIGAN: Missing View Imputation with Generative Adversarial Networks,” in 2017 IEEE International Conference on Big Data, BigData 2017, Boston, MA, USA. Editors J. Nie, Z. Obradovic, T. Suzumura, R. Ghosh, R. Nambiar, C. Wang, H. Zang, R. Baeza-Yates, X. Hu, J. Kepner, A. Cuzzocrea, J. Tang, and M. Toyoda (IEEE Computer Society), 766–775. doi:10.1109/BigData.2017.8257992
Stekhoven, D. J., and Bühlmann, P. (2012). MissForest--non-parametric Missing Value Imputation for Mixed-type Data. Bioinformatics 28, 112–118. doi:10.1093/bioinformatics/btr597
Stoyanovich, J., Howe, B., and Jagadish, H. V. (2020). Responsible Data Management. Proc. VLDB Endow. 13, 3474–3488. doi:10.14778/3415478.3415570
Troyanskaya, O., Cantor, M., Sherlock, G., Brown, P., Hastie, T., Tibshirani, R., et al. (2001). Missing Value Estimation Methods for DNA Microarrays. Bioinformatics 17, 520–525. doi:10.1093/bioinformatics/17.6.520
Vanschoren, J., van Rijn, J. N., Bischl, B., and Torgo, L. (2014). OpenML. SIGKDD Explor. Newsl. 15, 49–60. doi:10.1145/2641190.2641198
Wang, Z., Akande, O., Poulos, J., and Li, F. (2021). Are Deep Learning Models superior for Missing Data Imputation in Large Surveys? Evidence from an Empirical Comparison. CoRR abs/2103.09316.
Woznica, K., and Biecek, P. (2020). Does Imputation Matter? Benchmark for Predictive Models. CoRR abs/2007.02837.
Yang, K., Huang, B., and Schelter, S. (2020). Fairness-Aware Instrumentation of Preprocessing Pipelines for Machine Learning. doi:10.1145/3398730.3399194
Yin, P., Neubig, G., Yih, W.-t., and Riedel, S. (2020). “Tabert: Pretraining for Joint Understanding of Textual and Tabular Data,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, July 5-10, 2020. Editors D. Jurafsky, J. Chai, N. Schluter, and J. R. Tetreault (Association for Computational Linguistics), 8413–8426. Online. doi:10.18653/v1/2020.acl-main.745
Yoon, J., Jordon, J., and van der Schaar, M. (2018). “GAIN: Missing Data Imputation Using Generative Adversarial Nets,” in Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018. Editors J. G. Dy, and A. Krause (vol. 80 of Proceedings of Machine Learning Research), 5675–5684.
Zhang, H., Xie, P., and Xing, E. P. (2018). Missing Value Imputation Based on Deep Generative Models. CoRR abs/1808.01684.
Keywords: data quality, data cleaning, imputation, missing data, benchmark, MCAR, MNAR, MAR
Citation: Jäger S, Allhorn A and Bießmann F (2021) A Benchmark for Data Imputation Methods. Front. Big Data 4:693674. doi: 10.3389/fdata.2021.693674
Received: 11 April 2021; Accepted: 15 June 2021;
Published: 08 July 2021.
Edited by:
Jinsung Yoon, Google, United StatesReviewed by:
Jason Poulos, Duke University, United StatesQi Chen, Victoria University of Wellington, New Zealand
Copyright © 2021 Jäger, Allhorn and Bießmann. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sebastian Jäger, c2ViYXN0aWFuLmphZWdlckBiZXV0aC1ob2Noc2NodWxlLmRl