 Muhammad Ifte Islam
Muhammad Ifte Islam Farhan Tanvir
Farhan Tanvir Ginger Johnson
Ginger Johnson Esra Akbas
Esra Akbas Mehmet Emin Aktas
Mehmet Emin Aktas
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Big Data , 26 January 2021
Sec. Data Mining and Management
Volume 3 - 2020 | https://doi.org/10.3389/fdata.2020.608043
This article is part of the Research Topic Representation Learning for Graph Mining and Generation View all 4 articles
Network embedding that encodes structural information of graphs into a low-dimensional vector space has been proven to be essential for network analysis applications, including node classification and community detection. Although recent methods show promising performance for various applications, graph embedding still has some challenges; either the huge size of graphs may hinder a direct application of the existing network embedding method to them, or they suffer compromises in accuracy from locality and noise. In this paper, we propose a novel Network Embedding method, NECL, to generate embedding more efficiently or effectively. Our goal is to answer the following two questions: 1) Does the network Compression significantly boost Learning? 2) Does network compression improve the quality of the representation? For these goals, first, we propose a novel graph compression method based on the neighborhood similarity that compresses the input graph to a smaller graph with incorporating local proximity of its vertices into super-nodes; second, we employ the compressed graph for network embedding instead of the original large graph to bring down the embedding cost and also to capture the global structure of the original graph; third, we refine the embeddings from the compressed graph to the original graph. NECL is a general meta-strategy that improves the efficiency and effectiveness of many state-of-the-art graph embedding algorithms based on node proximity, including DeepWalk, Node2vec, and LINE. Extensive experiments validate the efficiency and effectiveness of our method, which decreases embedding time and improves classification accuracy as evaluated on single and multi-label classification tasks with large real-world graphs.
Networks are effectively used to represent relationships and dependence among data. Node classification, community detection, and link prediction are some of the applications of network analysis in many different areas such as social networks and biological networks. On the other hand, there are some challenges in network analysis, such as high computational complexity, low parallelizability, and inapplicability of machine learning methods (Cui et al., 2018). Recently, network embedding as representation learning from graph has become popular for many problems in network analysis (Hamilton et al., 2017; Zhang et al., 2017; Cai et al., 2018; Cui et al., 2018; Goyal and Ferrara, 2018). Network embedding is defined as encoding structural information of graphs into a low-dimensional vector space on their connections (Perozzi et al., 2014). By preserving structure information of the network, nodes with links will be close to each other in vector space. While desirable network embedding methods for real-world networks should preserve the local proximity between vertices and the global structure of the graph, it should also be scalable for large networks (Tang et al., 2015).
While early methods, which consider the network embedding as a dimensionality reduction (Belkin and Niyogi, 2001), are effective on small graphs, the major concern of them is that time complexity is at least quadratic in the number of graph vertices. Therefore, it is not possible to apply them on large-scale networks with billions of vertices (Zhang et al., 2017; Cai et al., 2018; Cui et al., 2018). In recent years, more scalable methods that use matrix factorization or neural networks have been proposed with transforming the network embedding problem into an optimization problem (Tang et al., 2015). DeepWalk (Perozzi et al., 2014) is the pioneering work that uses the idea of word representation learning (Mikolov et al., 2013a; Mikolov et al., 2013b) for network embedding. They preserve network structures or local neighborhood proximity with path sampling using short random walks (Perozzi et al., 2014; Grover and Leskovec, 2016). With path sampling, network embedding is converted to word embedding with considers random walk as a sequence of words. Therefore, it is expected that vertices in a similar neighborhood get similar paths and hence similar representations.
Although recent methods show promising performance for various applications, graph embedding still has some challenges. First of all, many of these methods are still computationally expensive and need a large amount of memory, so they are not scalable to large graphs (scalability problem). Secondly, these approaches attempt to address the non-convex optimization goal using stochastic gradient descent, hence optimization on the co-occurrence probability of the vertices can easily get stuck at a bad local minima as the result of poor initialization (initialization problem). This may cause generating dissimilar representations for vertices within the same or similar neighborhood set. Also, many of these methods use local information with short random walks during the embedding by ignoring the global structure in the graph.
These challenges have motivated researchers to use graph compression (summarization) algorithm that reduces the complexity and size of large graphs. The aim of graph compression is to create a smaller supergraph from a massive graph such that the crucial information of the original graph will be maintained in the supergraph. Vertices with similar characteristics are grouped and represented by super-nodes. Approximations with compressing are used to solve original problems more efficiently, such as all-pairs shortest paths, search engine storage, and retrieval (Adler and Mitzenmacher, 2001; Suel and Yuan, 2001). Using an approximation of the original graph not only makes a complex problem simpler but also makes a good initialization to solve the problem. It has been proved successful in various graph theory problems (Gilbert and Levchenko, 2004). For the scalability problem, embedding on the coarsest graph is more efficient and needs far less memory that makes existing embedding methods applicable to large graphs. For the initialization problem, grouping vertices with similar characteristics in a compressed graph solves the problem of getting different representations for them.
HARP (Chen et al., 2018b) addresses the initialization problem by hierarchically compressing the graph by combining nodes into super-nodes randomly. Thus, it produces effective, low-level representation of nodes though multi-level learning. However, random edge compressing may put dissimilar nodes into the same super-node making their representation similar. Also, multi-level compressing and learning result in significant compression and embedding cost, hence HARP fails to address the scalability problem.
In this paper, we use graph compression to address these two problems and also the limitations of HARP. More precisely, we study graph compression for the Network Embedding problem to answer these two questions:
Does the Network Compression Significantly Boost Learning?
Does the Network Compression Improve the Quality of the Representation?
Our main goal is to obtain more efficient and more effective network embedding models as answers to these questions. For this goal, we present an extension of our first method, NECL, that is a general meta-strategy for network embedding. We propose a proximity-based graph compression method that compresses the input graph to a smaller graph with incorporating the neighborhood similarity of its vertices into super-nodes. NECL compresses the graph by merging vertices with similar neighbors into super-nodes instead of random edge merging, as HARP does. NECL employs the embedding of the compressed graph to obtain the embedding of the original graph. This brings down the embedding cost and captures the global structure of the original graph without losing locality kept in the super-nodes. In addition to reducing the graph’s size for embedding, we get less pairwise relationships from random walks on a smaller set of super-nodes, which generates less diverse training data for the embedding part. All these facts improve efficiency while maintaining similar or better effectiveness comparing to the baseline methods. We then project the embedding of super-nodes to the original nodes.
In NECL, we primarily focus on improving the efficiency of embedding methods, so we do not employ refinement. As a result, we may lose some local information of the nodes because of merging. To overcome this problem, in this paper, we go beyond our original NECL by introducing an embedding refinement method NECL-RF. Our second method, NECL-RF, uses the compressed graph’s projected embedding to initialize the representation for the original graph embedding. Refining these initial representations aids in learning the original graph’s embedding. This provides global information of the graph into learning and also solves the different initialization problem of similar vertices, hence increases the effectiveness. Since the compressed graph is quite small compared to the original graph, the learning time will not increase significantly. Hence similar efficiency is maintained compared to the baseline methods. Moreover, we provide a richer set of experiments to evaluate NECL and NECL-RF. While in the earlier version, we only use DeepWalk and Node2vec as baseline methods for representation learning and combine them with NECL as a general meta-strategy. In this paper, we add one more baseline method, LINE, and present the results of all with NECL and NECL-RF.
Example1. In Figure 1, we present the effectiveness of our compressing and embedding model,NECL, on the well-known Les Miserables network. This undirected network contains co-occurrences of characters in Victor Hugo’s novel ‘Les Miserables’. A node represents a character and an edge between two nodes shows that these two characters appeared in the same chapter of the book. While the original network has 77 vertices and 254 edges, the compressed network has 33 vertices and 64 edges. As we see in the figure, the compressed network preserves the local structure of vertices in super-nodes without losing the global structure of the graphs. It is expected that nodes close in a graph should also be close in the embedding space. For example, in Figure 1A neighborhood sets of the vertices
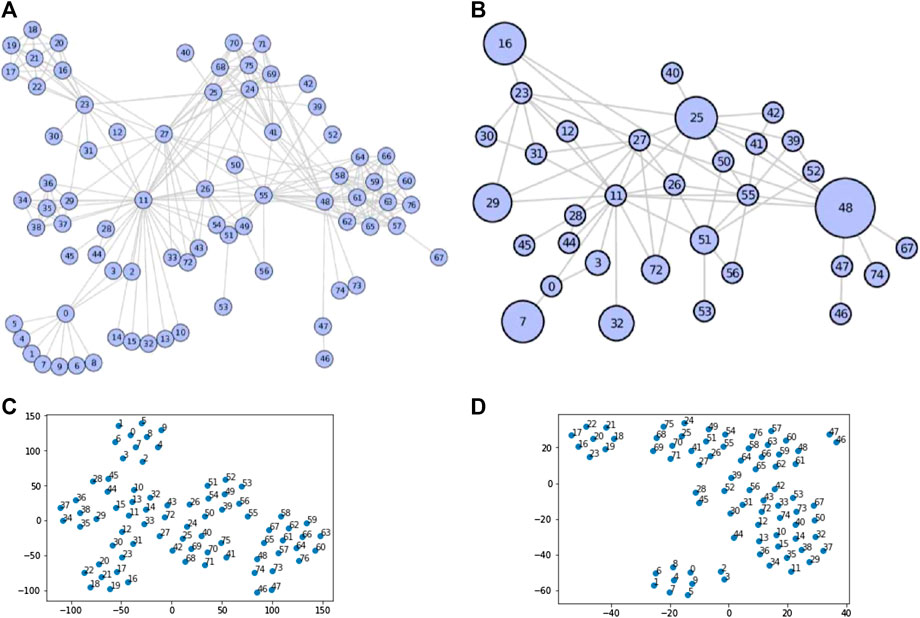
FIGURE 1. Example of graph compressing on Les Miserables network (Original Network (A), Compressed Network (B), Embedding of Original Network (C) and Embedding of Compressed Network (D)).
We summarize our contributions as follows.
• New proximity-based graph compressing method: Based on the observation that vertices with similar neighborhood sets get similar random walks and eventually similar representation, we merge these vertices into super-nodes to get a smaller compressed graph that preserves the proximity of nodes in the original large graph.
• Efficient embedding without losing effectiveness: We do random walks and embedding on the compressed graph, which is much smaller than the original graph, efficiently. This method has similar effectiveness with baseline methods by preserving the global and local structure of the graph in the compressed graph.
• Effective embedding without decreasing efficiency: We use the embedding obtained from the compressed graph as initial vectors for the original graph embedding. This combines the global and local structure of the graph and improves the effectiveness. Embedding of a small compressed graph does not take much time with respect to original graph embedding, so it will not increase the embedding time significantly.
• Generalizable: NECL is a general meta-strategy that can be used to improve the efficiency and effectiveness of many state-of-the-art graph embedding methods. We report the results for DeepWalk Node2vec and LINE.
• The paper is structured as follows. In Section 2, we give the necessary background for our method. and also provide related work. In Section 3, we introduce our neighborhood similarity-based graph compression model by explaining our similarity measure and two different embedding methods that use the compressed graph. In Section 4, we present our experimental results and compare them with the baseline methods. Our final remarks are reported in Section 5.
In this section, we discuss related works in the area of network embedding. We give some details of pioneer works in network embedding focusing on DeepWalk. We also explain random walk based sampling methods and multi-level network embedding approaches here.
Network embedding plays a significant role in network data analysis, and it has received huge research attention in recent years. Previous researchers consider the graph embedding as a dimensionality reduction (Chen et al., 2018a), such as PCA (Wold et al., 1987) that captures linear structural information and LE (locally linear embeddings) (Roweis and Saul, 2000) that preserves the global structure of non-linear manifolds. While these methods are effective on small graphs, scalability is the major concern with them being applied to large-scale networks with billions of vertices, since the time complexity of these methods is at least quadratic in the number of graph vertices (Zhang et al., 2017; Wang et al., 2018). On the other hand, recent approaches in graph representation learning focus on the scalable methods that use matrix factorization (Qiu et al., 2018; Sun et al., 2019) or neural networks (Tang et al., 2015; Cao et al., 2016; Tsitsulin et al., 2018; Ying et al., 2018). Many of these aim to preserve the first and second-order proximity as a local neighborhood with path sampling using short random walks such as DeepWalk and Node2vec (Hamilton et al., 2017; Cai et al., 2018; Cui et al., 2018; Goyal and Ferrara, 2018). Some recent studies aim to preserve higher-order proximity (Ou et al., 2016; Chen et al., 2018b). In addition to these, some recent works integrate contents to learn better representations (Akbas and Zhao, 2019). While some studies use network embedding on node and graph classification (Perozzi et al., 2014; Niepert et al., 2016; Chen et al., 2018b), some others use it on graph clustering (Cao et al., 2015; Akbas and Zhao, 2019; Akbas and Zhao, 2017).
DeepWalk (Perozzi et al., 2014) is the pioneering work that uses the idea of word representation learning in (Mikolov et al., 2013a; Mikolov et al., 2013b) for network embedding. While vertices in a graph are considered as words, neighbors are considered as their context in natural language. A graph is represented as a set of random walk paths sampled from it. The learning process leverages the co-occurrence probability of the vertices that appear within a window in a sampled path. The Skip-gram model is trained on the random walks to learn the node representation (Mikolov et al., 2013a; Mikolov et al., 2013b). We give the formal definition of network embedding as follows.
Definition 1 (Network embedding). Network embedding is a mapping
Here d is a parameter specifying the number of dimensions of our node representation. For every source node
There is an assumption that the conditional independence of vertices will ignore the vertex ordering in the neighborhood sampling to make the optimization problem tractable. Therefore, the likelihood is factorized by assuming that the likelihood of observing a neighborhood node is independent of observing any other neighborhood node given the representation of the source
The conditional likelihood of every source-neighborhood node pair is modeled as a softmax unit parametrized by a dot product of their features.
It is too expensive to compute the summation over all vertices for large networks, so we approximate it using negative sampling (Mikolov et al., 2013b). We optimize Equation 1 using stochastic gradient ascent over the model parameters defining the embedding ϕ.
The neighborhoods
The co-occurrence probability of node pairs depends on the transition probabilities of vertices. Considering a graph G, we define adjacency matrix A that is symmetric for undirected graphs. For an unweighted graph, we have
Optimization of a non-convex function in these methods could easily get stuck at a bad local minima as the result of poor initialization. Moreover, while preserving local proximities of vertices in a network, they may not preserve the global structure of the network. As a solution to these issues, a multi-level graph representation learning paradigm has been proposed (Chen et al., 2018b; Ayan Kumar Bhowmick and Meneni, 2020; Liang et al., 2018; Chenhui Deng and Zhao, 2020). HARP, is proposed in (Chen et al., 2018b) as a graph preprocessing step to get better initialization vectors. In this approach, related vertices in the network are hierarchically combined into super-nodes at varying levels of coarseness. After learning the embedding of the coarsened network with a state-of-the-art graph embedding method, the learned embedding is used as an initial value for the next level. The initialization with the embedding of the coarsened network improves the performance of the state-of-the-art methods. One of the limitations of this method is that multi-level compressing and learning results in significant compression and embedding cost. Random edge compressing may put dissimilar nodes into the same super-node that makes their representation similar.
As a more efficient solution, MILE (Liang et al., 2018) performs multi-level network embedding on large graphs using graph coarsening and refining techniques. It compresses the graph repeatedly based on Structural Equivalence Matching (SEM) and Normalized Heavy Edge Matching (NHEM). After learning the embedding of the compressed graph, they refine it efficiently through a novel graph convolution neural network to get the embedding of the original graph. This way, it receives embedding for large scale graphs in an efficient and effective way. More recently, GraphZoom (Chenhui Deng and Zhao, 2020) proposes a multi-level spectral approach to enhange both the quality and scalability. It performs graph fusion to generate a new graph that effectively encodes the topology of the original graph and the node attribute information. Then they apply spectral clustering methods to merge the nodes into super-nodes with the aim of retaining the first few eigenvectors of the graph Laplacian matrix. Finally, after getting the embedding of the compressed graph, they refine it by applying projection on it to get the original graph embedding. LouvainNE (Ayan Kumar Bhowmick and Meneni, 2020) applies the Louvain clustering algorithm recursively to partition the original graph into multiple subgraphs and construct a Hierarchy partition of the graph, which is represented as a tree. Then they generate different meta-graph from the tree and apply the baseline method i.e., DeepWalk Node2vec. After getting the embedding from different meta-graph, they combine these embeddings to find the final embedding. They use a parameter to regulate the weights of different embedding for combining.
Our approach differs from these by applying similarity-based compressing to preserve the local information. Also, all of these approaches apply hierarchical compressing that may take more time, but we apply single level compressing and use it to get the original graph embedding. NECL uses the graph coarsening to capture the local structure of the network without a hierarchical manner to improve the efficiency of the random walk based state-of-the-art methods.
While a desirable network embedding method for real-world networks should preserve the local proximity between vertices and the global structure of the graph, it should also be scalable for large networks. This section presents our novel network embedding models, NECL and NECL-RF, which satisfy these requirements. We extend the idea of the graph compressing layout to network representation learning methods. After giving some preliminary information, we explain our proximity-based compression method and how we combine compression with network embedding.
In this paper, we consider an undirected, connected, simple graph
Definition 2 (Compressed graph). A compressed graph of a given graph
The critical problem for graph compressing with preserving local structures of the graph is to identify vertices that have similar neighborhoods accurately, so they are more likely to have similar representation. In this section, we discuss how to select vertices to merge into super-nodes.
The motivation of our method is that if two vertices have many common neighbors, many embedding algorithms that preserve local neighborhood information will give similar representations to them. This comes from our following observation that if two vertices,
For example, in the toy graph in Figure 2, the neighbor sets of the nodes a and b are the same. Hence, their transition probabilities to the other neighbor vertices are also the same, i.e.,
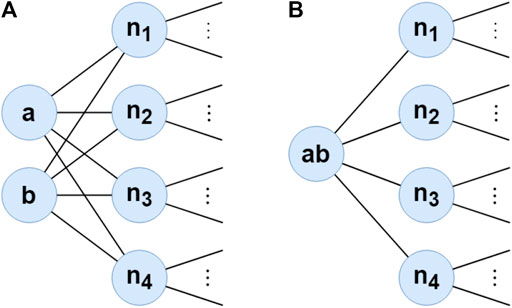
FIGURE 2. Example of graph compressing. (a,b) are merged into super-node ab connected to the neighbors of both (a,b).
Furthermore, compressing may change the transition probability of neighbors of compressed vertices since the number of their neighbor decrease. As a result, the transition probability of each neighbor changes. For example, in the toy graph in Figure 2A, while the transition probability from
In a real-world graph, it is not expected to have too many vertices sharing exactly same neighborhood. However, for many graph mining problems, such as node classification and graph clustering, if two vertices share many common neighbors, they are expected to be in the same class or cluster, although their neighbor sets are not completely the same. Hence, we expect to have similar feature vectors for the vertices in the same class/cluster after embedding. From these observations, we can also apply the same merge operation on these vertices. Following the same idea in the example above, if neighbors of two vertices are similar (but not exactly the same), we can merge them into a super-node and learn one representation for all. While we can project this super-node embedding to original vertices and use the same representation for both, we can also update them in the refinement phase to embed the difference of them into their representation.
In this section, we define our graph compressing algorithm formally.
For a given graph G, if a set of vertices
Theorem 1. Let T be the 1-step transition probability matrix of vertices V in a graph G and let
Proof. The cosine similarity between
By definition of T, we have
and
Hence, if we plug in these into Equation 1, we get
Therefore,
This finalizes the proof.
From Theorem 1, we see that the similarity of transition probabilities from two vertices to other vertices depends on the similarity of their neighbors. Therefore, for the compressing, we define the neighborhood similarity between two vertices as follows.
Definition 3 (Neighborhood similarity) Given a graph G, the neighborhood similarity between two vertices
In order to normalize the effect of high degree vertices, we divide the number of common neighbors by degree of vertices. The neighborhood similarity is between 0 and 1, where it is 0 when two vertices have no common neighbor and one when both have the same neighbors. According to the neighbor similarity, we merge vertices whose similarity value is higher than a given threshold value.
The neighborhood similarity-based graph compressing algorithm is given in Algorithm 1. It is clear that the vertices with a nonzero neighborhood similarity are 2-step neighbors. Therefore, we do not need to compute the similarity between all pairs of vertices. Instead, we just need to compute the similarity between vertices and their neighbors’ neighbors. For each node

Algorithm 1. Graph Compressing (G, λ).
Our NECL framework is adaptive with any embedding method which preserves the neighborhood proximity of nodes, i.e., DeepWalk, Node2vec, and LINE. We get the embedding for the original graph in two ways.
Our main goal in this section is to improve the efficiency of the embedding problem while maintaining similar effectiveness with the baseline methods. For this goal, instead of embedding the original graph, we embed the compressed graph and employ this embedding for the original graph embedding.
We first start compressing the graph for a given similarity threshold, as explained in the previous section. Then we learn the embedding of super-nodes in the compressed graph. Next, we assign the representation of each super-node in the compressed graph as the representation of the corresponding vertices in each super-node and obtain the embedding of the original graph. Since the size of the compressed graph is much smaller than the original graph, the embedding will be more efficient. The details of our algorithm for network embedding on a compressed graph is given in Algorithm 2.

Algorithm 2. NECL: Network Embedding on Compressed Graph.
In the algorithm, after getting the weighted compressed graph S (line 1), we obtain the representation of super-nodes
Our main goal in this section is to improve the effectiveness of the embedding problem while still maintaining similar efficiency with the baseline methods. For this goal, we employ the embedding of the compressed graph as initialization to the original graph embedding and refine it.
When we compress a graph using the neighborhood similarity score, we can easily capture the global structure of the original graph. On a large original graph, the random walk may get stuck in a local neighborhood. As a result, the embedding method may not capture the global structure of the original graph. However, when we do the random walk on the compressed graph, it visits the globally similar neighbors nodes. Hence, we can capture the global proximity of the nodes. That is why, in this method, we first embed the compressed graph for a given similarity threshold to encode the original graph’s global structure in the representation as in Section 3.2.1. Then, for the embedding of the original graph, instead of starting with randomly initialized representations, which happens in the original embedding methods such as DeepWalk and Node2vec, we start with the representations obtained from the compressed graph. In the case of random representations, for example, two similar nodes are likely to have two very different and distanced representations, hence the optimization process may not provide an accurate representation and this may decrease the quality or it may take a longer time to make them similar. However, initializing the representation using the compressed graph embedding provides global structure information as an initial knowledge to the embedding. The original graph embedding updates this initial embedding with local information that may be lost with compressing. Therefore, final embeddings have better quality with integrating local and global information in one representation. In Algorithm 2, the original graph embedding is obtained in line eight by refining the compressed graph embedding given as the initial representation.
We do our experimental studies to compare our methods with different models in terms of efficiency and effectiveness. We evaluate the quality of embeddings through challenging multi-class and multi-label classification tasks on four popular real-world graph datasets. First, in Section 4.1, we present our model’s performance based on different parameters. Then, we compare the results of our models with the results of HARP.
Datasets: We consider four real-world graphs1, which have been widely adopted in the network embedding studies. Two of them are single-label, which are Wiki and Citeseer, and two of them are multi-label datasets, which are DBLP and BlogCatalog (BlogC). In single-label datasets, each node in the datasets has a single-label from multi-class values. In multi-label datasets, a node can belong to more than one class.
Baseline methods: To demonstrate that our methods can work with different graph embedding methods, we use three popular graph embedding methods, namely DeepWalk, Node2vec and LINE, as the baseline methods in our model. We combine each baseline method with our methods and compare their performance. We give a brief explanation of the baseline methods in Section 2. We named our first method as NECL, which uses a compressed graph embedding as the original graph embedding, and the second method as NECL-RF, which uses the compressed graph embedding as the initial vector for original graph embedding and refine it with the original graph.
Parameter Settings: For DeepWalk, Node2vec, NECL(DW), NECL(N2V), NECL-RF(DW) and NECL-RF(N2V), we set the following parameters: the number of random walks γ, walk length t, window size w for the Skip-gram model and representation size d. The parameter setting for all models is
Classification We present our results and compare them with the baseline methods and also HARP in single-label and multi-label classification tasks. For the single classification task, the multi-class SVM is employed as the classifier, which uses the one-vs-rest scheme. For the multi-label classification task, we train a one-vs-rest logistic regression model with
For the evaluation, after getting embeddings for nodes in the graph, we use these embeddings as the features of the nodes. Then, we train a classifier using these features. To train the classifier, we randomly sample a certain portion of labeled vertices from the graph and use the rest of the vertices as the test data. To have a detailed comparison of methods, we vary our training ratio from
We repeat the classification tasks ten times to ensure the reliability of our experiment and report the average macro
We present our results in Tables 1, 2. For the similarity threshold

TABLE 1. Performance comparisons of NECL with baseline methods (BL).

TABLE 2. Compression ratio with the similarity threshold
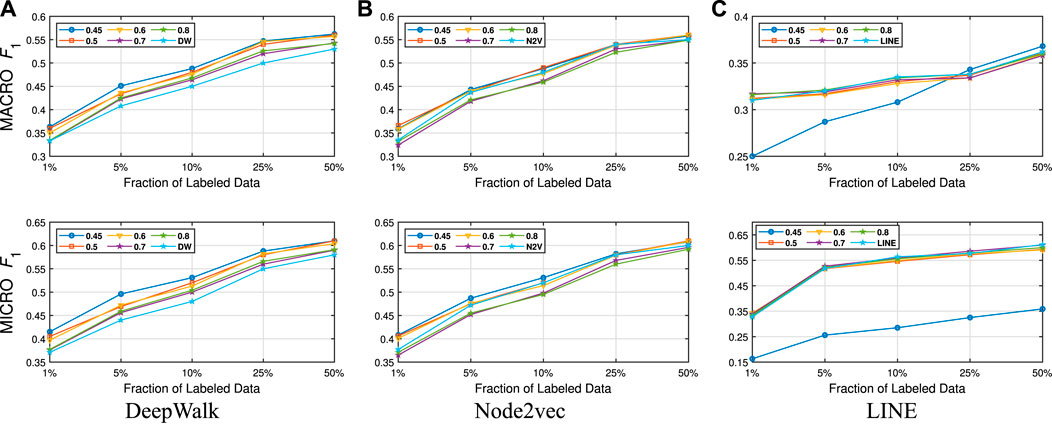
FIGURE 3. Detailed classification results on Citeseer.
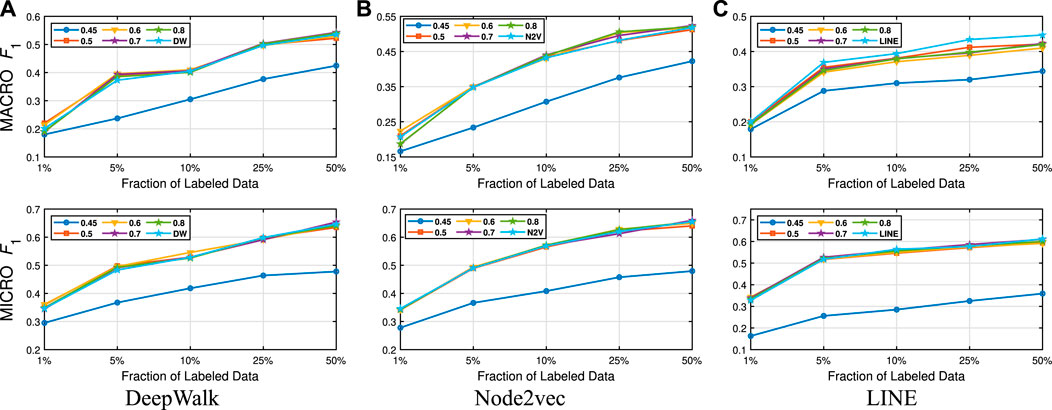
FIGURE 4. Detailed classification results on Wiki.
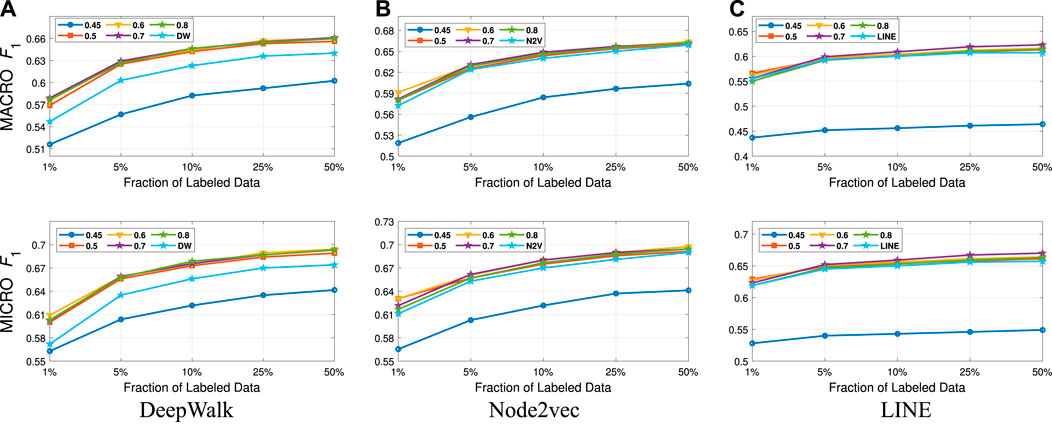
FIGURE 5. Detailed classification results on DBLP.
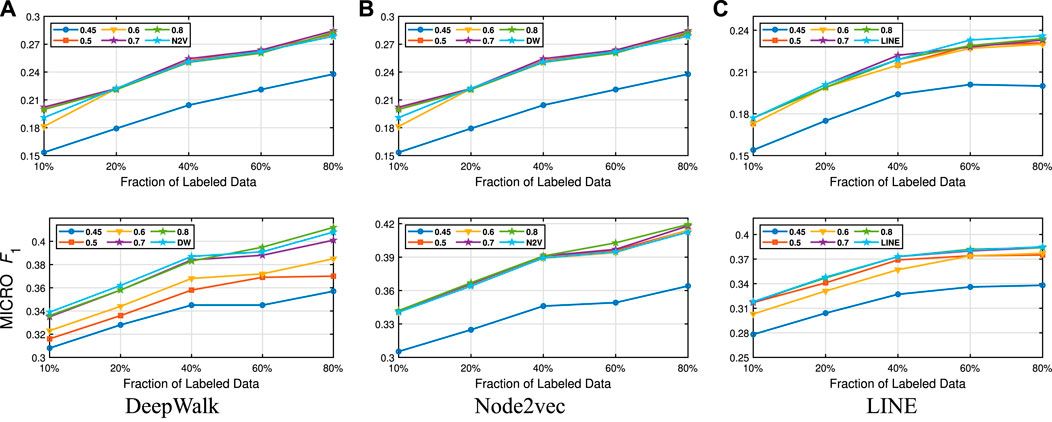
FIGURE 6. Detailed classification results on BlogCatalog.
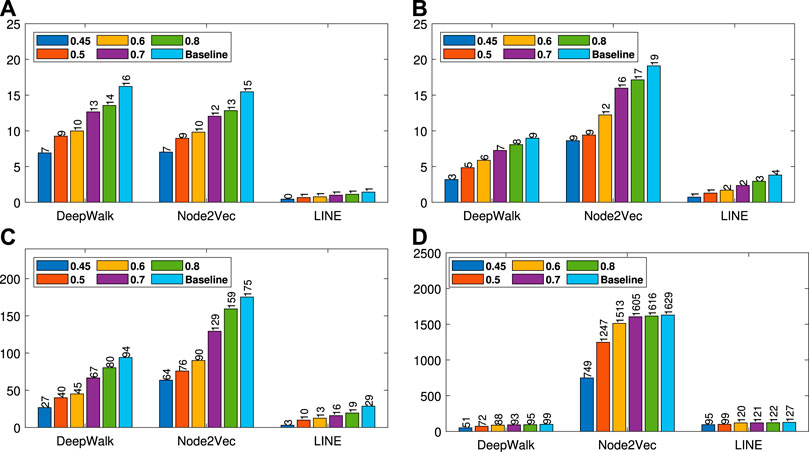
FIGURE 7. Run time analyses for different similarity threshold values λ (Citeseer (A), Wiki (B), DBLP (C) and BlogCatalog (D)).
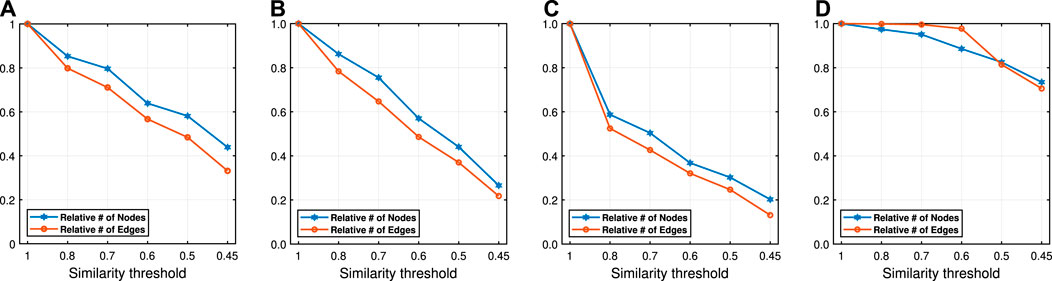
FIGURE 8. The ratio of vertices/edges of the compressed graphs to that of the original graphs. (Citeseer (A), Wiki (B), DBLP (C) and BlogCatalog (D)).
Gain on baseline methods: For all datasets, we present macro
For DBLP, gains of embedding time are much higher than other datasets. On the other hand, for BlogCatalog, gains of embedding times are less with respect to other datasets. As we see from the Tables 1, 2, the gain of embedding time depends on the compression ratio of the number of edges and vertices. With compression, the number of vertices and edges for DBLP decrease from 27,199 to 8,824 (70%) and from 13,3664 to 32,984 (75%), respectively. Therefore, embedding becomes more efficient with better or same accuracy. For BlogCatalog, the compression ratio is lower than the others, around 18%; therefore, the time gain is also lower. The reason for this is that, in DBLP, vertices have many common neighbors, so the neighborhood similarity is higher and this results in more compression. On the other hand, in BlogCatalog, vertices have less common neighbors and so a lower similarity, and this results in less compression. We can conclude that while the gain in the effectiveness of our method depends on the baseline method, the gain in efficiency of our method depends on the characteristics of the dataset.
Detailed Analyses: We compare the performance of NECL framework for different similarity threshold values λ that results in different compression ratios with the performance of the baseline methods. Macro
In addition to the macro
From these detailed analyses, we observe that smaller λ results in smaller compressed graph. As a result, embedding becomes more efficient. However, for
In this section, we evaluate the effectiveness of our NECL-RF method and compare the results with NECL, HARP, and baseline methods. From the analysis of NECL, we can see that
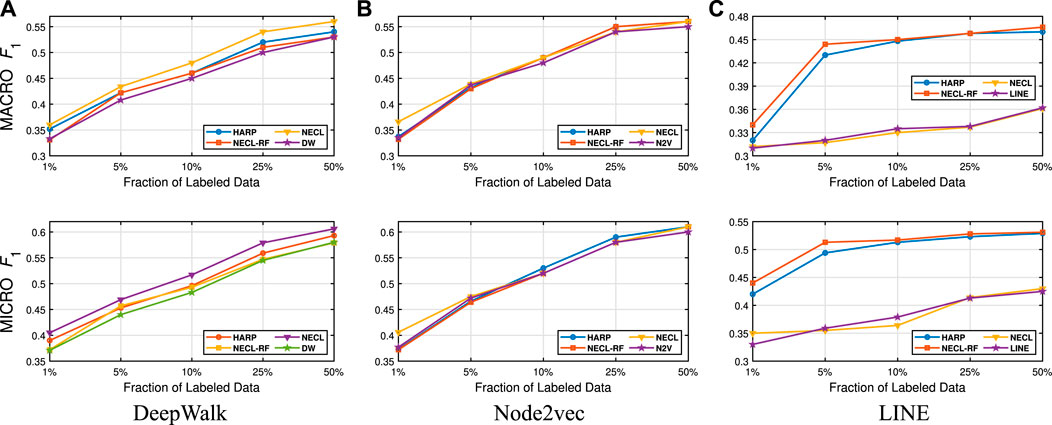
FIGURE 9. Detailed comparisons of classification results on Citeseer
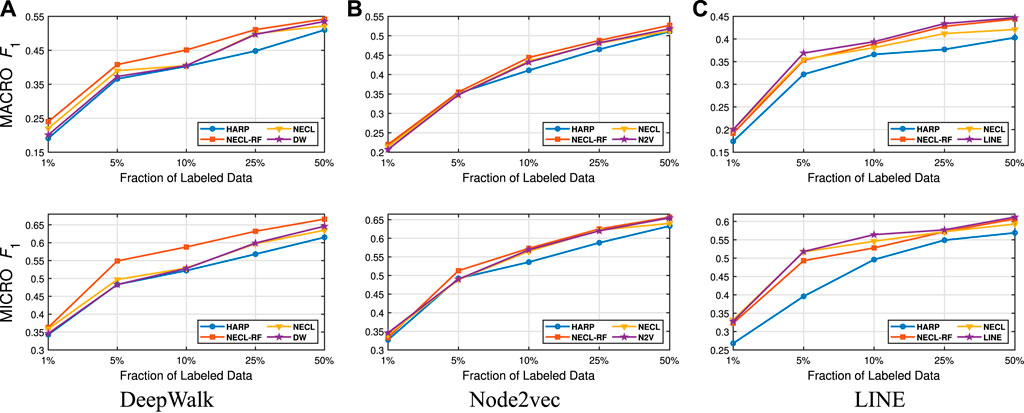
FIGURE 10. Detailed comparisons of classification results on Wiki.
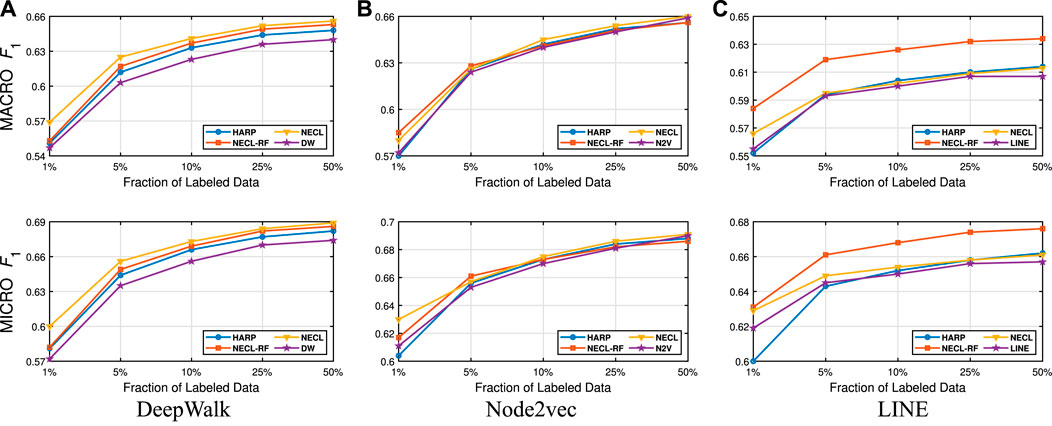
FIGURE 11. Detailed comparisons of classification results on DBLP.
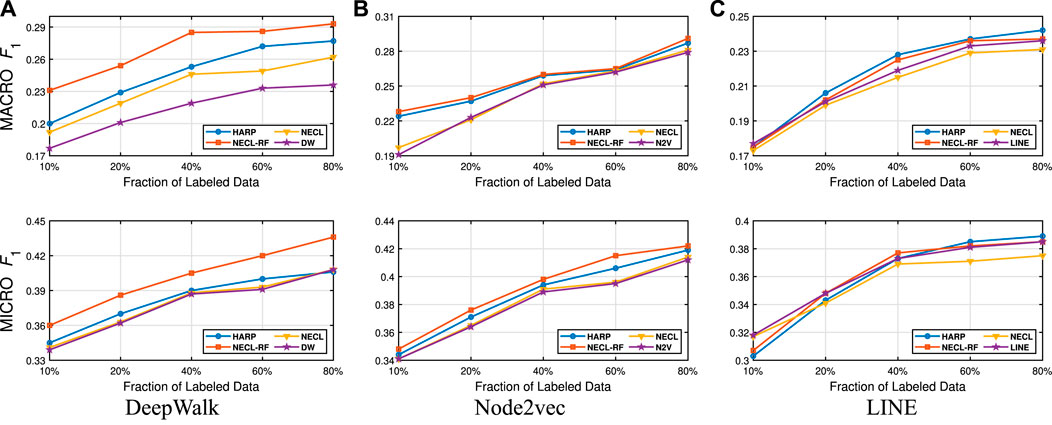
FIGURE 12. Detailed comparisons of classification results on BlogCatalog.
In Table 3, we see that NECL or NECL-RF gives the highest macro
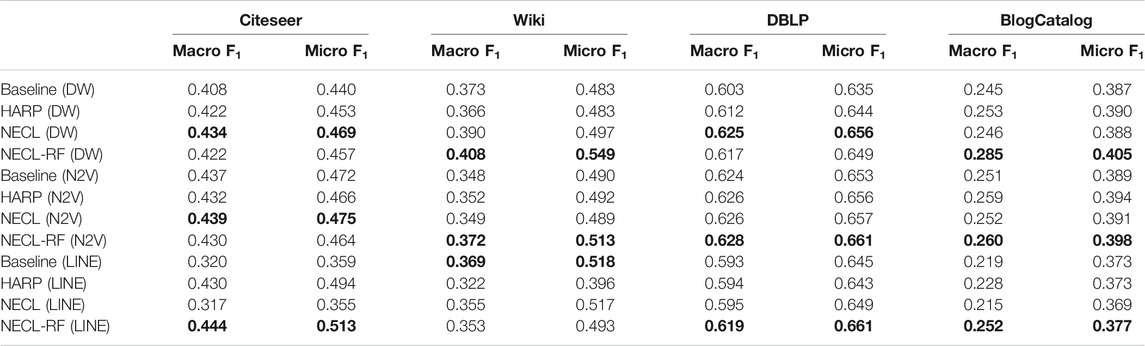
TABLE 3. Performance comparisons of all methods.
While HARP has higher accuracy than baseline methods, it does multiple levels of iteration of graph coarsening and representation learning, so it increases the time complexity. On the other hand, we do iteration only one level in NECL-RF. Embedding time for NECL-RF is the total of embedding time for the original graph and compressed graph. As we see in the previous section, the compressed graph is much smaller than an original graph, so the learning time for the compressed graph is significantly less compare to the baseline method. Hence, complexity does not increase significantly as in HARP. As a result, we get similar or better effectiveness than HARP with less time complexity.
Detailed comparisons between all methods using different portions of labeled vertices as training data are presented in Figures 9–12. In most cases, we see that in most of the cases, NECL and NECL-RF give the highest accuracy compared to other models or give better results than the baseline models. We observe that, for some datasets, refinement decreases the accuracy of NECL. The reason for this decrease might be that, for some classification tasks, learning a global structure with compressed data, which also includes a local structure in the super-nodes, would be enough. So when we relearn and update the embedding of the compressed graph, it might add noise to the features. As a result, it deteriorates the accuracy of the classification task. Also, as we see from the figures, our method has a better improvement on DeepWalk. The reason is that while Node2vec and LINE may learn higher-order proximity, regular random walk in DeepWalk may not capture higher-order proximity, so it loses the global information. It also depends on the datasets.
We present a novel method for network embedding that preserves the local and global structure of the network. To capture the global structure and accelerate the efficiency of state-of-the-art methods, we introduce a neighborhood similarity-based graph compression method. We combine the vertices with common neighbors into super-node. Then we apply network representation learning on the compressed graph so that we can reduce the run time and also capture the global structure. As a first method, we project the embedding of super-nodes to original nodes without refinement. In the second part, we relearn the representation of the network with assigning the super-nodes embedding to its’ original vertices as initial features and update this using the baseline method. In this way, we combine the local structure with the global structure of the network. While the first method provides efficiency with learning on the small compressed graph, the second method provides effectiveness with incorporating global information into embedding with the compressed graph. NECL and NECL-RF are a general meta-strategies that can be used to improve the efficiency and effectiveness of many state-of-the-art graph embedding method. We use three popular state-of-the-art network embedding methods DeepWalk, Node2vec, and LINE as a baseline. Experimental results on various real-world graph show the effectiveness and efficiency of our methods on challenging multi-label and multi-class classification tasks for all these three baseline methods.
The future work of our NECL and NECL-RF could be using different refinement methods of graph embedding. We can apply different neural network models without relearning the whole network to refine the embedding which we get from the compressed graph. Another extension could be done by using different clustering methods or similarity measurements to compressed the graph and use other baseline methods.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding authors.
Conceived and designed the experiments: MI and EA Performed the experiments: MI , GJ, and EA. Analyzed the data: MI, GJ, EA, FT, and MA. Wrote the paper: MI, FT, GJ, EA, and MA.
This work was partially done by the author Ginger Johnson while she attended the Big Data Analytics REU program at Oklahoma State University supported by the National Science Foundation under Grant No. 1659645.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The content of this manuscript has been presented in part at the Big Data conference (Akbas and Aktas, 2019a). Earlier version of this manuscript has been released as a pre-print at Arxiv (Akbas and Aktas, 2019b).
Adler, M., and Mitzenmacher, M. (2001). “Towards compressing web graphs,” in Proceedings of data compression conference Snowbird, UT, USA, March 27-29, 2001 (DCC: IEEE), 203–212.
Akbas, E., and Zhao, P. (2017). “Attributed graph clustering: an attribute-aware graph embedding approach,” in Proceedings of the 2017 IEEE/ACM international conference on advances in social networks analysis and mining, Sydney, Australia, July, 2017, 305–308.
Akbas, E., and Aktas, M. E. (2019a). “Network embedding: on compression and learning,” in IEEE international conference on Big data (Big data), Los Angeles, CA, USA, December 9-12, 2019, 4763–4772.
Akbas, E., and Aktas, M. E. (2019b). Network embedding: on compression and learning. arXiv preprint arXiv:1907.02811
Akbas, E., and Zhao, P. (2019). “Graph clustering based on attribute-aware graph embedding,” in From security to community detection in social networking platforms (Springer International Publishing), 109–131.
Ayan Kumar Bhowmick, M. D., and Meneni, K. (2020). “Louvainne: hierarchical louvain method for high quality and scalable network embedding,” in WSDM, Houston, Texas, USA, February 4-6, 2020.
Belkin, M., and Niyogi, P. (2001). “Laplacian eigenmaps and spectral techniques for embedding and clustering,” in Proceedings of the 14th international conference on neural information processing systems: natural and synthetic, NIPS’01, Vancouver, British Columbia, Canada, Dec 3‐8, 2001, 585–591.
Cai, H., Zheng, V. W., and Chang, K. C.-C. (2018). A comprehensive survey of graph embedding: problems, techniques, and applications. IEEE Trans. Knowl. Data Eng. 30, 1616–1637. doi:10.1109/tkde.2018.2807452
Cao, S., Lu, W., and Xu, Q. (2015). “Grarep: learning graph representations with global structural information,” in Proceedings of the CIKM’15, Melbourne Australia, October, 2015, 891–900.
Cao, S., Lu, W., and Xu, Q. (2016). “Deep neural networks for learning graph representations,” in Thirtieth AAAI conference on artificial intelligence, Phoenix, Arizona, USA, February 12-17, 2016.
Chen, H., Perozzi, B., Al-Rfou, R., and Skiena, S. (2018a). A tutorial on network embeddings. arXiv preprint arXiv:1808.02590
Chen, H., Perozzi, B., Hu, Y., and Skiena, S. (2018b). “Harp: hierarchical representation learning for networks,” in Thirty-second AAAI Conference on artificial intelligence New Orleans, Louisiana, USA, February 2 -7, 2018.
Chenhui Deng, Y. W. Z. Z. Z. F., and Zhao, Z. (2020). “Graphzoom: a multi-level spectral approach for accurate and scalable graph embedding,” in ICLR 2020, Addis Ababa ETHIOPIA, Apr 26- 1st May.
Cui, P., Wang, X., Pei, J., and Zhu, W. (2018). “A survey on network embedding,” in IEEE transactions on knowledge and data engineering.
Fan, R.-E., Chang, K.-W., Hsieh, C.-J., Wang, X.-R., and Lin, C.-J. (2008). Liblinear: a library for large linear classification. J. Mach. Learn. Res. 9, 1871–1874. doi:10.1145/1390681.1442794
Gilbert, A. C., and Levchenko, K. (2004). “Compressing network graphs,” in Proceedings of the LinkKDD workshop at the KDD’10, 124, Washington DC, USA, July, 2010.
Goyal, P., and Ferrara, E. (2018). Graph embedding techniques, applications, and performance: a survey. Knowl. Base Syst. 151, 78–94. doi:10.1016/j.knosys.2018.03.022
Grover, A., and Leskovec, J. (2016). “node2vec: scalable feature learning for networks,” in KDD proceedings of the 22nd ACM SIGKDD (San Francisco, CA, USA:ACM), 855–864.
Hamilton, W. L., Ying, R., and Leskovec, J. (2017). Representation learning on graphs: methods and applications. arXiv preprint arXiv:1709.05584
Liang, J., Gurukar, S., and Parthasarathy, S. (2018). Mile: a multi-level framework for scalable graph embedding. arXiv preprint arXiv:1802.09612
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013a). “Efficient estimation of word representations in vector space,” in Proceedings of workshop at ICLR, Scottsdale, Arizona, May 2-4.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and Dean, J. (2013b). “Distributed representations of words and phrases and their compositionality,” in Advances in neural information processing systems, CA, USA, December 5-10, 2013, 3111–3119.
Niepert, M., Ahmed, M., and Kutzkov, K. (2016). “Learning convolutional neural networks for graphs,” in Proceedings of the ICML’16, New York, USA, June 19-24, 2016, 2014–2023.
Ou, M., Cui, P., Pei, J., Zhang, Z., and Zhu, W. (2016). “Asymmetric transitivity preserving graph embedding,” in Proceedings of the KDD’16 (New York, NY, USA: ACM), 1105–1114.
Perozzi, B., Al-Rfou, R., and Skiena, S. (2014). “Deepwalk: online learning of social representations,” in Proceedings of the SIGKDD’14 (New York city, New york, USA: ACM), 701–710.
Qiu, J., Dong, Y., Ma, H., Li, J., Wang, K., and Tang, J. (2018). “Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec,” in Proceedings of the WSDM’18, Los Angeles, California, USA, Feb 5-9, 2018, 459–467.
Roweis, S. T., and Saul, L. K. (2000). Nonlinear dimensionality reduction by locally linear embedding. Science 290, 2323–2326. doi:10.1126/science.290.5500.2323
Suel, T., and Yuan, J. (2001). “Compressing the graph structure of the web,” in Proceedings of the data compression conference, Snowbird, UT, USA, March 27-29, 2001, 213–222.
Sun, J., Bandyopadhyay, B., Bashizade, A., Liang, J., Sadayappan, P., and Parthasarathy, S. (2019). “Atp: directed graph embedding with asymmetric transitivity preservation. Proc. AAAI Conf. Artif. Intell. 33, 265–272. doi:10.1609/aaai.v33i01.3301265
Tang, J., Qu, M., Wang, M., Zhang, M., Yan, J., and Mei, Q. (2015). “Line: large-scale information network embedding,” in Proceedings of the WWW’15, Florence, Italy, May 18-22, 2015, 1067–1077.
Tsitsulin, A., Mottin, D., Karras, P., and Müller, E. (2018). “Verse: versatile graph embeddings from similarity measures,” in Proceedings of the WWW’18, Lyon, France, April 23, 2018, 539–548.
Wang, H., Wang, J., Wang, J., Zhao, M., Zhang, W., Zhang, F., et al. (2018). “Graphgan: graph representation learning with generative adversarial nets,” in Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, Louisiana, February 2-7, 2018.
Wold, S., Esbensen, K., and Geladi, P. (1987). Principal component analysis. Chemometr. Intell. Lab. Syst. 2, 37–52
Ying, R., You, J., Morris, C., Ren, X., Hamilton, W. L., and Leskovec, J. (2018). “Hierarchical graph representation learning with differentiable pooling,” in Proceedings of the NIPS’18, Montrèal, CANADA, Jan 2-8, 2018, 4805–4815.
Keywords: network embedding, graph representation learning, graph compression, graph classification, node similarity
Citation: Islam MI, Tanvir F, Johnson G, Akbas E and Aktas ME (2021) Proximity-Based Compression for Network Embedding. Front. Big Data 3:608043. doi: 10.3389/fdata.2020.608043
Received: 18 September 2020; Accepted: 07 December 2020;
Published: 26 January 2021.
Edited by:
B. Aditya Prakash, Georgia Institute of Technology, United StatesReviewed by:
Remy Cazabet, Université de Lyon, FranceCopyright © 2021 Islam, Tanvir, Johnson, Akbas and Aktas. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Muhammad Ifte Islam, aWZ0ZS5pc2xhbUBva3N0YXRlLmVkdQ==; Esra Akbas, ZWFrYmFzQG9rc3RhdGUuZWR1
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.