
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Cardiovasc. Med. , 19 July 2022
Sec. Atherosclerosis and Vascular Medicine
Volume 9 - 2022 | https://doi.org/10.3389/fcvm.2022.933803
This article is part of the Research Topic Artificial Intelligence Applied to Coronary Artery Diseases: From pathophysiology to precision medicine View all 5 articles
 Juntae Kim1†Su Yeon Lee1†Byung Hee Cha2Wonseop Lee2JiWung Ryu1
Juntae Kim1†Su Yeon Lee1†Byung Hee Cha2Wonseop Lee2JiWung Ryu1 Young Hak Chung1Dongmin Kim1Seong-Hoon Lim1Tae Soo Kang1Byoung-Eun Park1
Young Hak Chung1Dongmin Kim1Seong-Hoon Lim1Tae Soo Kang1Byoung-Eun Park1 Myung-Yong Lee1
Myung-Yong Lee1 Sungsoo Cho3*
Sungsoo Cho3*Background: In patients with suspected obstructive coronary artery disease (CAD), evaluation using a pre-test probability model is the key element for diagnosis; however, its accuracy is controversial. This study aimed to develop machine learning (ML) models using clinically relevant biomarkers to predict the presence of stable obstructive CAD and to compare ML models with an established pre-test probability of CAD models.
Methods: Eight machine learning models for prediction of obstructive CAD were trained on a cohort of 1,312 patients [randomly split into the training (80%) and internal validation sets (20%)]. Twelve clinical and blood biomarker features assessed on admission were used to inform the models. We compared the best-performing ML model and established the pre-test probability of CAD (updated Diamond-Forrester and CAD consortium) models.
Results: The CatBoost algorithm model showed the best performance (area under the receiver operating characteristics, AUROC, 0.796, and 95% confidence interval, CI, 0.740–0.853; Matthews correlation coefficient, MCC, 0.448) compared to the seven other algorithms. The CatBoost algorithm model improved risk prediction compared with the CAD consortium clinical model (AUROC 0.727; 95% CI 0.664–0.789; MCC 0.313). The accuracy of the ML model was 74.6%. Age, sex, hypertension, high-sensitivity cardiac troponin T, hemoglobin A1c, triglyceride, and high-density lipoprotein cholesterol levels contributed most to obstructive CAD prediction.
Conclusion: The ML models using clinically relevant biomarkers provided high accuracy for stable obstructive CAD prediction. In real-world practice, employing such an approach could improve discrimination of patients with suspected obstructive CAD and help select appropriate non-invasive testing for ischemia.
Estimating the probability of coronary artery disease (CAD) in patients with stable angina or anginal equivalent symptoms is a frequent challenge. The current guidelines recommend estimation of the pre-test probability of CAD scores to guide decisions on whether diagnostic testing could be deferred or performed, and whether the initial test should be non-invasive or invasive (1). However, recent studies have shown that the performance of the traditional pre-test probability of CAD models is limited in estimation of obstructive CAD (2, 3). Moreover, the pre-test probability of CAD models does not reflect the current regulatory status of risk factors such as hypertension, diabetes mellitus (DM), and dyslipidemia.
Machine learning (ML) involves the application of artificial intelligence (AI) that uses computer algorithms to identify patterns in large datasets with a multitude of variables to capture high-dimensional, non-linear relationships among clinical features. Data-driven techniques based on ML can improve the performance of risk predictions by exploiting large data repositories to identify novel risk predictors agnostically and more complex interactions between them. However, only few studies have been conducted on stable obstructive CAD using ML of clinical risk factors and blood biomarkers commonly used in clinical practice. Therefore, we aimed to develop ML models using these features to predict stable obstructive CAD and determine the ranking of the features’ predictive contribution. We also compared the ML models with the established pre-test probability of CAD models to evaluate whether there were significant improvements in discrimination.
We included a cohort of 4,906 patients who visited the outpatient department for angina or anginal equivalent symptoms and underwent invasive coronary angiography at Dankook University Hospital between August 2014 and January 2016. Obstructive CAD was defined as any stenosis 70% or greater in the epicardial coronary artery, 50% or greater in the left main coronary artery, or both. Non-obstructive CAD was defined as a stenosis 20% or greater but less than 70% in any other epicardial coronary artery, or a coronary artery stenosis 20% or greater but less than 50% in the left main coronary artery, as recorded by physicians in the catheterization report. No apparent CAD was defined as all coronary stenoses less than 20% or luminal irregularities. The case group was defined as having obstructive CAD, and the control group was defined as having no apparent CAD. When creating ML models, the inclusion criteria were patients who were diagnosed with chronic stable coronary syndrome after visiting the outpatient department with angina or anginal equivalent symptoms; the exclusion criteria were patients who were diagnosed with acute myocardial infarction (AMI) based on the fifth universal definition of myocardial infarction, had non-obstructive moderate CAD (20–70% stenosis), and previously underwent percutaneous coronary intervention (PCI).
Finally, 1,312 patients (case group = 861, control group = 451) were selected for the analysis. A subset of the dataset was randomly selected to train the risk-prediction algorithms, and the remaining dataset was used for validation (Figure 1). This study was approved by the Institutional Review Board of the Dankook University Hospital (2018-09-014).
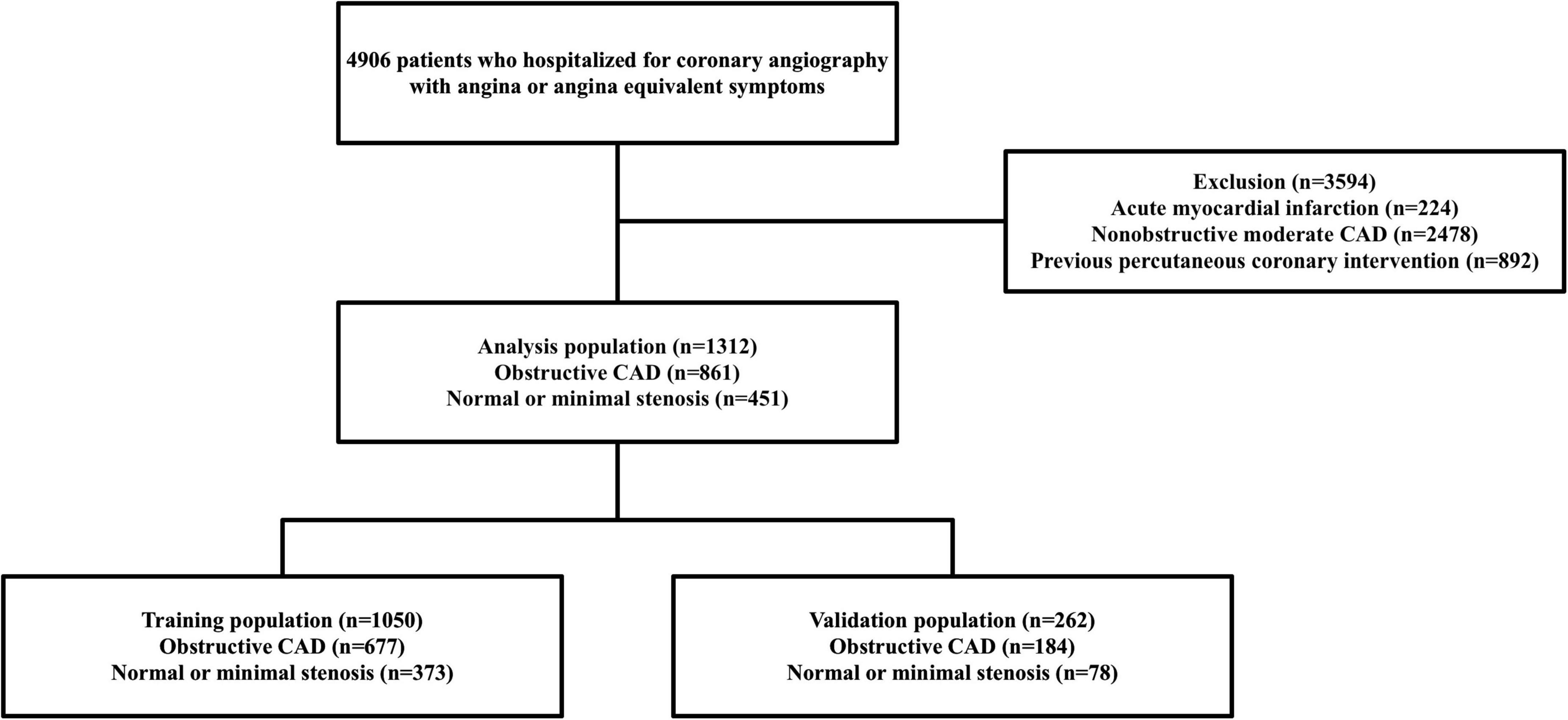
Figure 1. Flowchart of the study population and process. CAD, coronary artery disease.
Baseline information was collected from patients with suspected CAD admitted for invasive coronary angiography, including demographics, cardiovascular risk factors [hypertension, DM, dyslipidemia, chronic kidney disease (CKD), and smoking status], and biomarkers [hemoglobin A1c (HbA1c), creatinine clearance, high-sensitivity cardiac troponin T (troponin T), and lipid profile]. These parameters were also used in the established pre-test probability scores for analysis.
Eight supervised ML algorithms were selected: CatBoost (4), Extreme gradient (XG) boost (5), gradient boost (6), Light Gradient Boosting Machine (lightGBM) (7), MultiLayer Perceptron (MLP) (8), support vector machine with a linear kernel (SVM) (9), Random forest (10), and K-nearest neighbor (11). Each ML model was implemented using Python 3.8.2, with the following packages: xgboost for extreme gradient boost, catboost for CatBoost, lightgbm for lightGBM, pytorch for MultiLayer Perceptron, and scikit-learn for the other ML algorithms. For the MLP and SVM algorithms, categorical features were represented by one-hot encoding. Hyperparameters were tuned using the Bayesian hyperparameter tuning library optuna with fivefold cross-validation on the training population (Supplementary Table 1). To interpret the ML prediction models, we used SHapley Additive exPlanations (SHAP). The SHAP value assesses the impact of each variable by representing the change in log odds when a variable is hidden from the model (12). The MissForest algorithm was used for imputation of missing values in the ML models, except for boosting algorithms (13).
The study population was randomly split into the training (80%; case group = 677, control group 373) and validation (20%; case group = 184, control group = 78) sets. To control the overfitting caused by an imbalanced dataset, the bootstrap resampling method was applied, obtaining equal proportions of numbers in each group of the training population (10 bootstrap samples: case group = 373, control group = 373). To evaluate feature importance, we estimated the SHAP values of 48 available variables in the CatBoost model (Supplementary Figure 1). Twelve variables for obstructive CAD were selected in the final prediction models based on the recursive feature elimination and visual inspection of a SHAP-dependence plot.
The Revised Diamond-Forrester score (2), CAD consortium basic, and CAD consortium clinical (14) were calculated to compare model performance. The models were compared with ML-based models by the area under the receiver operating characteristics (AUROC) using the DeLong method (15) and Matthews correlation coefficient (MCC) (16). The MCC is a useful metric for evaluating binary classification, especially for imbalanced datasets. Continuous variables were expressed as mean ± standard deviation (SD) or median (interquartile range) and were compared by Student’s t-tests or Wilcoxon rank-sum tests. Categorical variables were expressed as proportions and compared by χ2 test. A two-sided p-value < 0.05 was considered significant for all the analyses.
Table 1 presents the baseline characteristics of the development and validation datasets. The mean age of the 1,312 patients was 63 ± 11.8 years, and 59.4% were men. The CAD group was significantly older, had higher systolic blood pressure, and more frequent hypertension, DM, and dyslipidemia than the no CAD group. Moreover, the CAD group had higher levels of HbA1c, troponin T, and triglycerides than the no CAD group. In contrast, creatinine clearance and high-density lipoprotein (HDL) cholesterol levels were significantly lower in the case group.
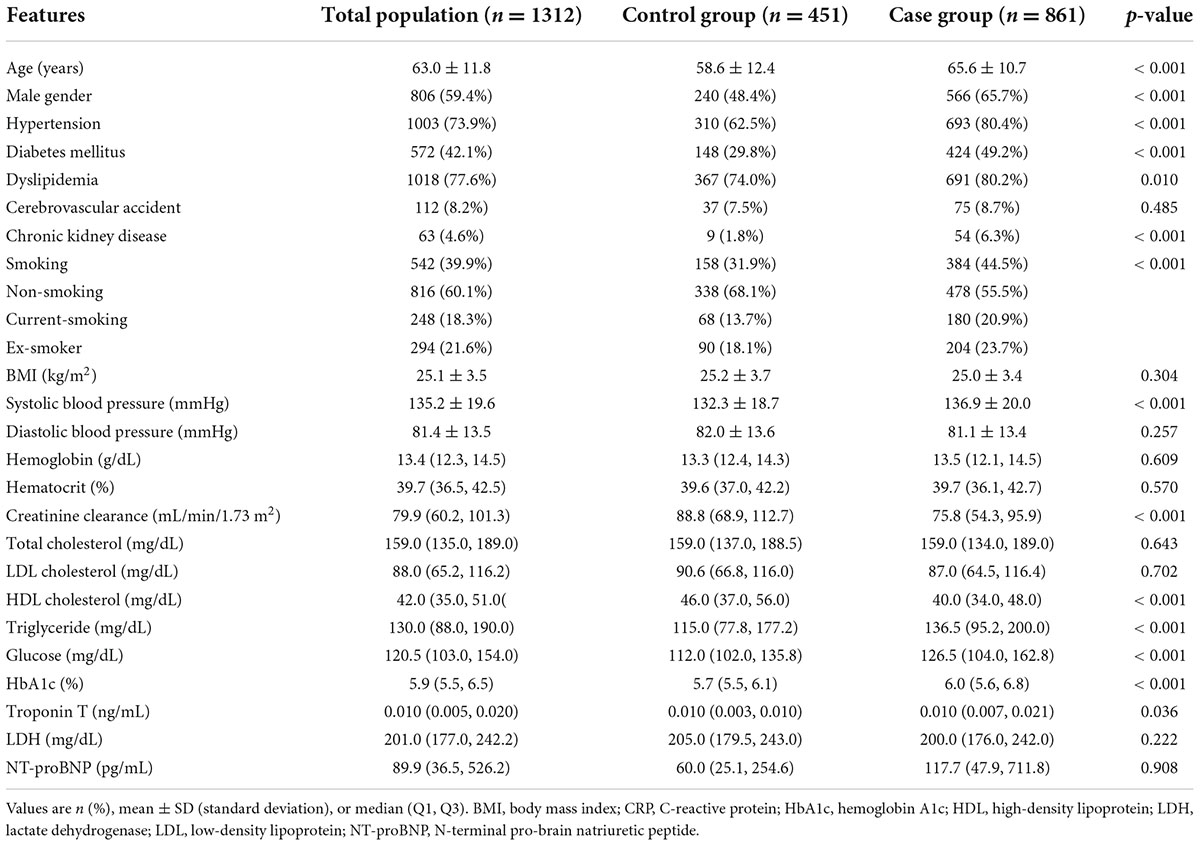
Table 1. Baseline characteristics.
Using 12 potential variables, prediction models for stable obstructive CAD were developed with eight ML algorithms. Among the eight ML-based models, the highest predictive performance was observed for CatBoost (AUROC 0.796; 95% CI 0.74–0.853; MCC 0.448), performing similarly to XGboost (AUROC 0.796; 95% CI 0.74–0.852; MCC 0.399) and lightGBM (AUROC 0.789; 95% CI 0.732–0.846; MCC 0.403), slightly better than random forest (AUROC 0.742; 95% CI 0.679–0.805; MCC 0.413), gradient boost (AUROC 0.732; 95% CI 0.667–0.796; MCC 0.371), Multilayer Perceptron (AUROC 0.728; 95% CI 0.663–0.792; MCC 0.379), and support vector machine (AUROC 0.721; 95% CI 0.657–0.786; MCC 0.373), and significantly better than the K-nearest neighbor model (AUROC = 0.704; 95% CI 0.638–0.77; MCC 0.313) in the independent validation set (Figure 2A). The CatBoost model also performed significantly better than the established pre-test probability of CAD scores, the CAD consortium clinical model (AUROC 0.727; 95% CI 0.664–0.789; MCC 0.313) and Diamond-Forrester score (AUROC 0.687; 95% CI 0.621–0.753; MCC 0.271) (Figure 2B). The AUROC, MCC, accuracy, sensitivity, specificity, positive predictive value, negative predictive value, and F1 of all the risk prediction models are presented in Table 2.
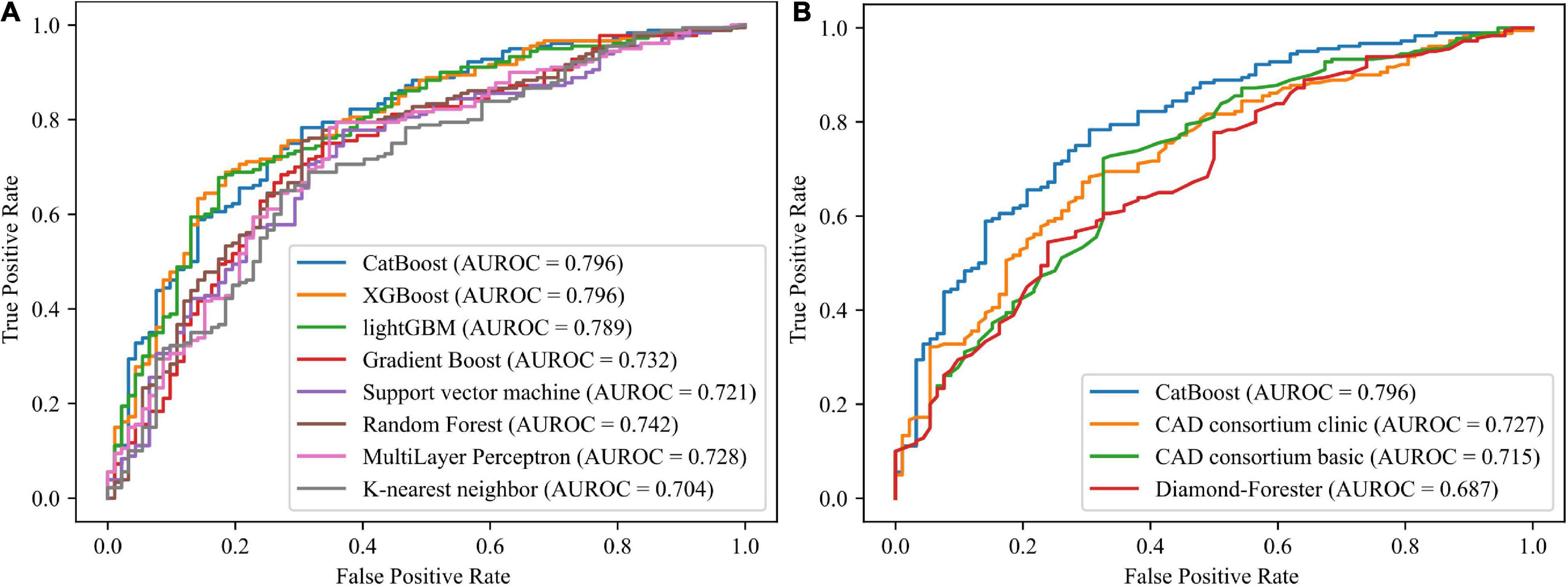
Figure 2. Receiver operating characteristic curves for the machine learning models and established pre-test probability of CAD models. (A) Comparing the eight machine learning models. (B) Comparing the CatBoost model and the established pre-test probability of CAD models. AUROC, area under the receiver operating characteristics; CAD, coronary artery disease; GBM, gradient boosting machine; XG, extreme gradient.
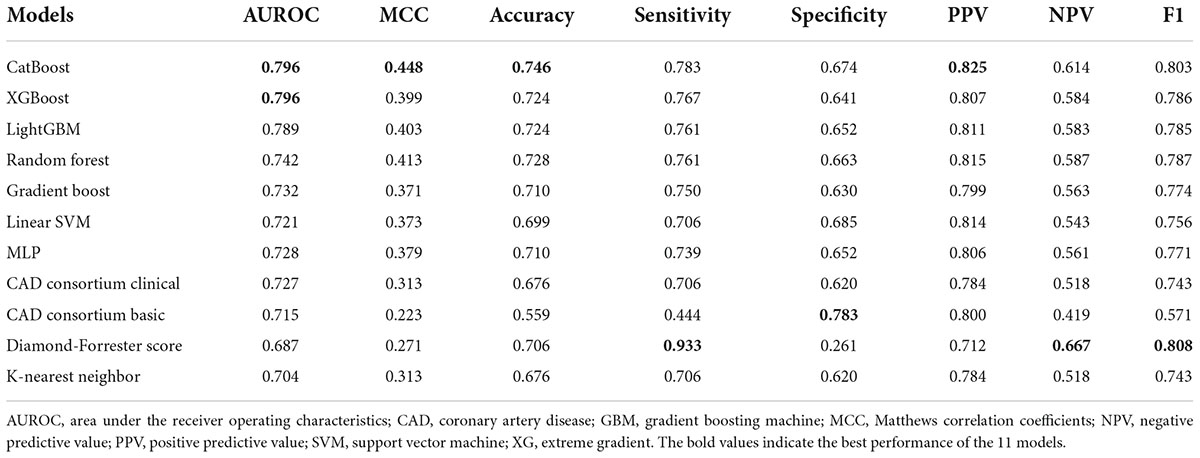
Table 2. Comparison of performance between risk prediction models.
The 12 potential variables for stable obstructive CAD prediction were ranked using SHAP values. Age, sex, hypertension, troponin T, HbA1c, triglycerides, and HDL cholesterol were important features in our study (Figure 3A). To identify features that influenced the prediction model, we constructed a SHAP summary plot of CatBoost. The plot shows how the variable values are related to the SHAP values in the training dataset. Higher SHAP values were associated with higher CAD probability (Figure 3B). The SHAP-dependence plot (Figure 4) can also be used to understand how a single feature affects the output of the CatBoost prediction model. The y-axis values indicate the SHAP values of the features, and the values of features for the x-axis were in the SHAP-dependence plot. In the plot, we visualized how the influence of a feature changed as its values varied. SHAP values exceeding zero for specific features represent increased risk of CAD.
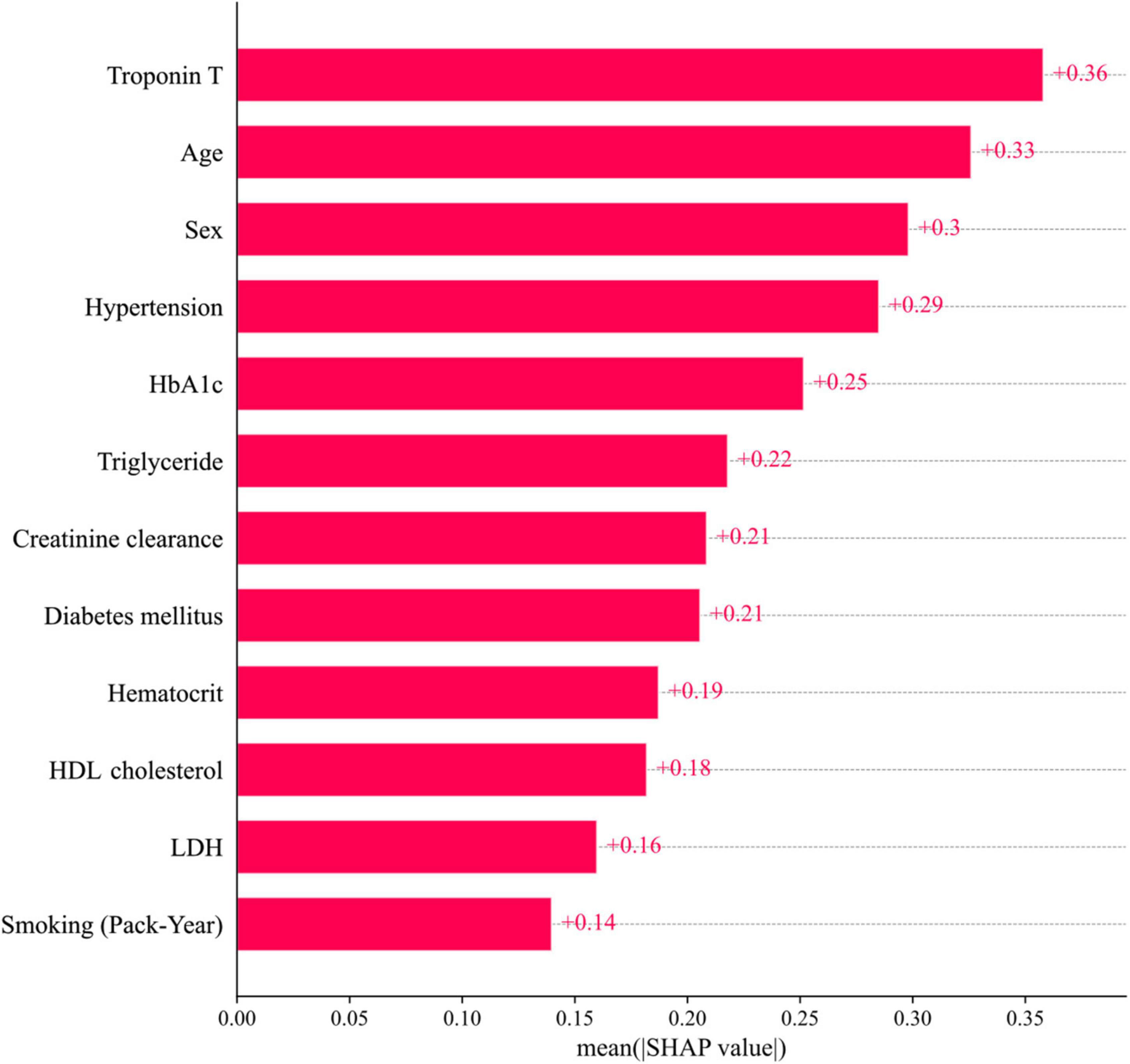
Figure 3. Feature importance ranking. (A) Mean SHAP value of features. (B) Impact on CatBoost model output of SHAP value. HbA1c, hemoglobin A1c; HDL, high-density lipoprotein; LDH, lactate dehydrogenase; SHAP, SHapley Additive exPlanations; Troponin T, high-sensitivity cardiac troponin T.
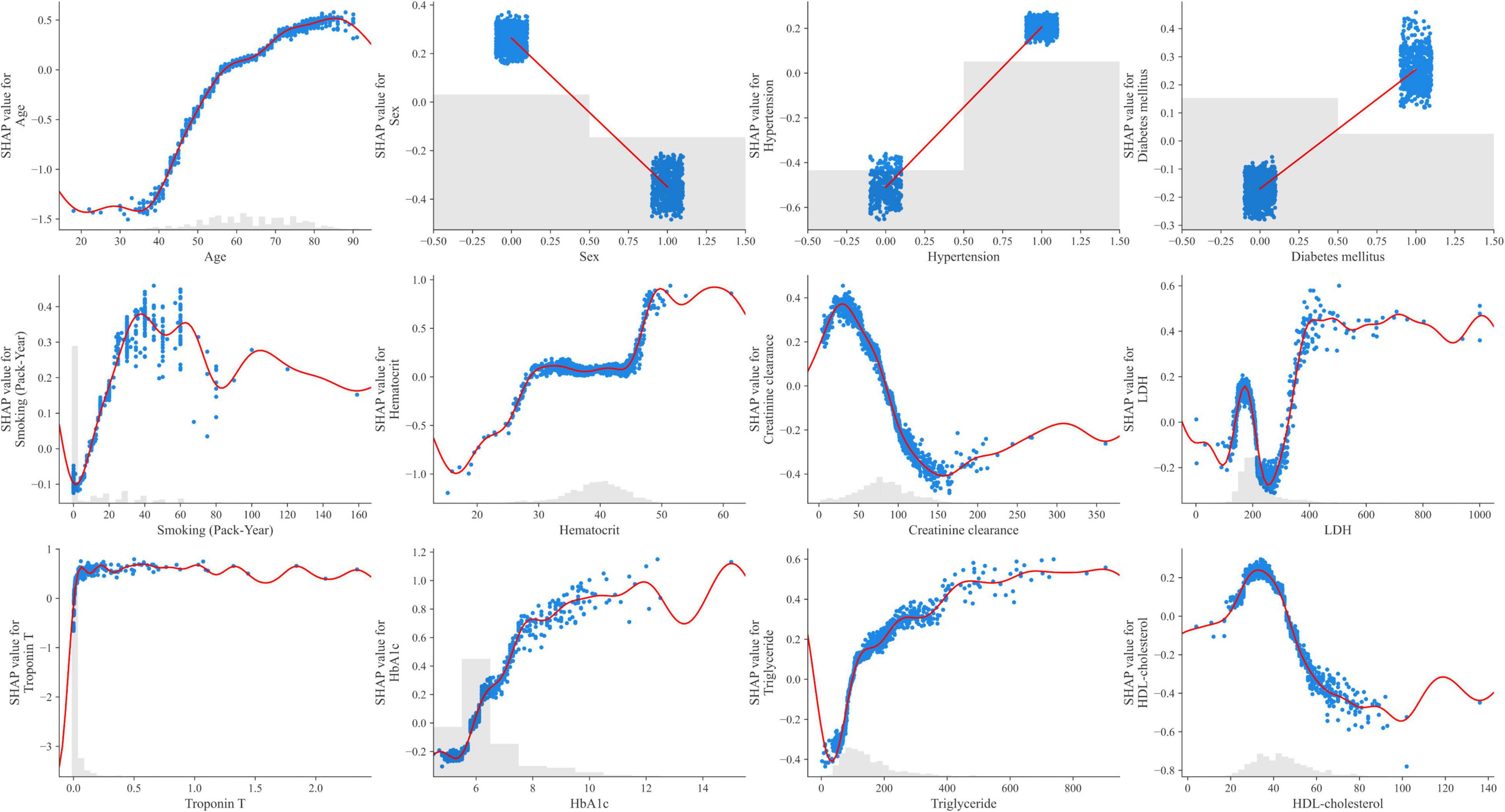
Figure 4. SHAP dependence plots of the CatBoost model. HbA1c, hemoglobin A1c; HDL, high-density lipoprotein; LDH, lactate dehydrogenase; SHAP, SHapley Additive exPlanations; Troponin T, high-sensitivity cardiac troponin T.
The main findings of our analysis were as follows: (1) the ML-based model (CatBoost), using clinically relevant biomarkers, exhibited a more accurate prediction of stable obstructive CAD than the established pre-test probability models, (2) using a novel ML-based model, we identified important features for the diagnosis of obstructive CAD.
Accurate prediction of obstructive stable CAD still represents an unmet need. Current guidelines recommend assessing the probability of obstructive CAD from clinical risk factors and, according to this pre-test, probability refers to non-invasive testing, invasive coronary angiography, or no further assessment (1). However, the diagnostic performance of established pre-test probability models is limited in the estimation of obstructive CAD in contemporary cohorts. Previous data have shown that the current model overestimates the probability of obstructive CAD in unselected patients (17). Another study demonstrated that the updated 2019 ESC guideline pre-test probability recommendations tended to underestimate slightly the disease in the SCOT-Heart trial cohort (18).
As the ML algorithm has been recently used for the diagnosis and prognosis of coronary artery disease, its predictive ability has improved significantly compared with established pre-test and prediction models. In the CREATION cohort study, the ML model provided better accuracy and discrimination than the existing traditional model. Using the ML method instead of established pre-test probability models (modified Diamond-Forrester and CAD consortium score) would imply a correct change in diagnostic strategy in 22.2% of the patients (19). From the CONFIRM registry, it has been shown that an ML model combining clinical features and coronary artery calcium score can accurately estimate the pre-test probability of CAD (20). Also, recent studies have attempted to diagnose stable CAD using multiple biomarkers, but there are limitations regarding difficulties in direct clinical practice application (21).
Only few studies have been conducted on stable obstructive CAD prediction by incorporating multiple biomarkers into the ML algorithm. The ML-based model could be more accurate and account for subtleties in data that are overlooked by linear assumption. In this study, the SHAP value was found to affect obstructive CAD prediction in the following order: troponin T, HbA1c, triglyceride, creatinine clearance, and HDL cholesterol. This means that the SHAP values of HbA1c, HDL cholesterol, triglyceride, and creatinine clearance, which reflect the current state of the disease, were higher than the SHAP values of DM, dyslipidemia, and CKD. Therefore, it may be more helpful in predicting the disease. In our study, even if troponin T was very finely detected within the normal range, it contributed to the prediction of obstructive CAD. Previous studies have reported that elevated levels of troponin T are associated with increased coronary artery plaque volume, structural heart disease, and cardiovascular events (22, 23). Therefore, an ML-based model that incorporates these variables could be more accurate in predicting the disease. Moreover, laboratory data and multiple biomarkers can be directly sampled in an outpatient clinic, and results can be easily obtained; therefore, it is expected that ML algorithms developed based on these data can serve as a pre-test probability model in real-world practice.
The application of the new pre-test probabilities has important consequences in selecting appropriate diagnostic testing. ML-based models may be helpful in clinical decisions when non-invasive diagnostic tests are not available. Furthermore, AI-based integrated analysis of all data, including non-invasive diagnostic tests, will contribute significantly to patients’ precise diagnosis.
This study had several limitations. First, this was a retrospective single-center analysis and thus susceptible to data selection and measurement biases. Second, our ML-based models were not externally validated. Our models were independently divided into training and validation sets to limit overfitting to some extent. In the future, we should conduct a performance test using completely separated test data, which are not used for model development. Third, some values were missing from the data. Missing values could be handled in the boosting algorithm model as the “not available” category. Still, our results were consistent with those obtained with or without missing data imputation (Supplementary Table 2). In the future, detailed and complete hospital-level patient data with minimal missing values will be needed. Fourth, our study did not compare the ML-based model with other non-invasive diagnostic tests. Further randomized control trials comparing the AI-based prediction model and the existing non-invasive stress test are needed to clarify performance power.
In conclusion, we developed and validated a new prediction model for stable obstructive CAD using ML algorithms. Our ML-based model predicted the probability of obstructive CAD more accurately than the existing pre-test probability of CAD scores. It would be useful to predict the risk of CAD, and helpful to select appropriate non-invasive testing for ischemia.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by the Institutional Review Board of Dankook University Hospital. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
JK, SL, and SC designed the study. JR and YC assisted in data acquisition and interpretation. BC and WL performed the statistical analyses. DK, S-HL, B-EP, and M-YL contributed to the discussion. JK and TK drafted the manuscript. SL and SC revised the manuscript. All authors read and approved the final version of the manuscript.
This research was supported by the Chung-Ang University Research Grants in 2022.
BC and WL were employed by CNAI.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcvm.2022.933803/full#supplementary-material
AI, artificial intelligence; AMI, acute myocardial infarction; AUROC, area under the receiver operating characteristics; CAD, coronary artery disease; CI, confidence interval; CKD, chronic kidney disease; DM, diabetes mellitus; HbA1c, hemoglobin A1c; HDL, high-density lipoprotein; lightGBM, Light Gradient Boosting Machine; MCC, Matthews correlation coefficient; ML, machine learning; MLP, MulitLayer Perceptron; PCI, percutaneous coronary intervention; SD, standard deviation; SHAP, SHapley Additive exPlanations; SVM, support vector machine; Troponin T, high-sensitivity cardiac troponin T; XG, Extreme gradient.
1. Knuuti J, Wijns W, Saraste A, Capodanno D, Barbato E, Funck-Brentano C, et al. 2019 ESC Guidelines for the diagnosis and management of chronic coronary syndromes. Eur Heart J. (2020) 41:407–77.
2. Genders TS, Steyerberg EW, Alkadhi H, Leschka S, Desbiolles L, Nieman K, et al. A clinical prediction rule for the diagnosis of coronary artery disease: validation, updating, and extension. Eur Heart J. (2011) 32:1316–30. doi: 10.1093/eurheartj/ehr014
3. Baskaran L, Danad I, Gransar H, Hartaigh BO, Schulman-Marcus J, Lin FY, et al. A comparison of the updated diamond-forrester, CAD consortium, and confirm history-based risk scores for predicting obstructive coronary artery disease in patients with stable chest pain: the SCOT-HEART coronary CTA cohort. JACC Cardiovasc Imaging. (2019) 12(Pt 2):1392–400. doi: 10.1016/j.jcmg.2018.02.020
4. Prokhorenkova L, Gusev G, Vorobev A, Dorogush AV, Gulin A. CatBoost: unbiased boosting with categorical features. Adv Neural Inform Process Syst. (2018) 31:6638–6648.
5. Chen T, Guestrin C editors. Xgboost: a scalable tree boosting system. Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining. New York, NY: ACM (2016). doi: 10.1145/2939672.2939785
6. Friedman JH. Greedy function approximation: a gradient boosting machine. Ann Stat. (2001) 29:1189–232. doi: 10.1214/aos/1013203451
7. Ke G, Meng Q, Finley T, Wang T, Chen W, Ma W, et al. Lightgbm: a highly efficient gradient boosting decision tree. Adv Neural Inform Process Syst. (2017) 30:3146–54. doi: 10.1016/j.envres.2020.110363
8. Murtagh F. Multilayer perceptrons for classification and regression. Neurocomputing. (1991) 2:183–97. doi: 10.1016/0925-2312(91)90023-5
9. Hearst MA, Dumais ST, Osuna E, Platt J, Scholkopf B. Support vector machines. IEEE Intell Syst Their Appl. (1998) 13:18–28. doi: 10.1109/5254.708428
10. Cutler A, Cutler DR, Stevens JR. Random forests. In: Zhang C, Ma Y editors. Ensemble Machine Learning. Berlin: Springer (2012). p. 157–75. doi: 10.1007/978-1-4419-9326-7_5
11. Cover T, Hart P. Nearest neighbor pattern classification. IEEE Trans Inform Theory. (1967) 13:21–7. doi: 10.1109/TIT.1967.1053964
12. Lundberg SM, Lee S-I editors. A unified approach to interpreting model predictions. Proceedings of the 31st International Conference on Neural Information Processing Systems. New York, NY: ACM (2017).
13. Stekhoven DJ, Bühlmann P. MissForest—non-parametric missing value imputation for mixed-type data. Bioinformatics. (2012) 28:112–8. doi: 10.1093/bioinformatics/btr597
14. Genders TS, Steyerberg EW, Hunink MG, Nieman K, Galema TW, Mollet NR, et al. Prediction model to estimate presence of coronary artery disease: retrospective pooled analysis of existing cohorts. BMJ (Clinical research ed). (2012) 344:e3485. doi: 10.1136/bmj.e3485
15. DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. (1988) 44:837–45. doi: 10.2307/2531595
16. Chicco D, Jurman G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genomics. (2020) 21:6. doi: 10.1186/s12864-019-6413-7
17. Reeh J, Therming CB, Heitmann M, Højberg S, Sørum C, Bech J, et al. Prediction of obstructive coronary artery disease and prognosis in patients with suspected stable angina. Eur Heart J. (2019) 40:1426–35. doi: 10.1093/eurheartj/ehy806
18. Bing R, Singh T, Dweck MR, Mills NL, Williams MC, Adamson PD, et al. Validation of European Society of Cardiology pre-test probabilities for obstructive coronary artery disease in suspected stable angina. Eur Heart J Qual Care Clin Outcomes. (2020) 6:293–300. doi: 10.1093/ehjqcco/qcaa006
19. Hou ZH, Lu B, Li ZN, An YQ, Gao Y, Yin WH, et al. Machine learning for pretest probability of obstructive coronary stenosis in symptomatic patients. JACC Cardiovasc Imaging. (2019) 12:2584–6. doi: 10.1016/j.jcmg.2019.07.030
20. Al’Aref SJ, Maliakal G, Singh G, van Rosendael AR, Ma X, Xu Z, et al. Machine learning of clinical variables and coronary artery calcium scoring for the prediction of obstructive coronary artery disease on coronary computed tomography angiography: analysis from the CONFIRM registry. Eur Heart J. (2020) 41:359–67. doi: 10.1093/eurheartj/ehz565
21. Schnabel RB, Schulz A, Messow CM, Lubos E, Wild PS, Zeller T, et al. Multiple marker approach to risk stratification in patients with stable coronary artery disease. Eur Heart J. (2010) 31:3024–31. doi: 10.1093/eurheartj/ehq322
22. De Lemos JA, Drazner MH, Omland T, Ayers CR, Khera A, Rohatgi A, et al. Association of troponin T detected with a highly sensitive assay and cardiac structure and mortality risk in the general population. JAMA. (2010) 304:2503–12. doi: 10.1001/jama.2010.1768
23. Oemrawsingh RM, Cheng JM, García-García HM, Kardys I, van Schaik RH, Regar E, et al. High-sensitivity troponin T in relation to coronary plaque characteristics in patients with stable coronary artery disease; results of the ATHEROREMO-IVUS study. Atherosclerosis. (2016) 247:135–41. doi: 10.1016/j.atherosclerosis.2016.02.012
Keywords: machine learning, artificial intelligence, coronary artery disease, stable angina pectoris, personalized medicine
Citation: Kim J, Lee SY, Cha BH, Lee W, Ryu J, Chung YH, Kim D, Lim S-H, Kang TS, Park B-E, Lee M-Y and Cho S (2022) Machine learning models of clinically relevant biomarkers for the prediction of stable obstructive coronary artery disease. Front. Cardiovasc. Med. 9:933803. doi: 10.3389/fcvm.2022.933803
Received: 01 May 2022; Accepted: 23 June 2022;
Published: 19 July 2022.
Edited by:
Joan T. Matamalas, Brigham and Women’s Hospital and Harvard Medical School, United StatesReviewed by:
Aisha Gohar, Humanitas Research Hospital, ItalyCopyright © 2022 Kim, Lee, Cha, Lee, Ryu, Chung, Kim, Lim, Kang, Park, Lee and Cho. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sungsoo Cho, ZHJzc2Nob0BnbWFpbC5jb20=
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.