 Nozomi Tanaka
Nozomi Tanaka
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Commun. , 15 April 2022
Sec. Psychology of Language
Volume 7 - 2022 | https://doi.org/10.3389/fcomm.2022.827336
Word order, case marking, and animacy are cues used to convey and comprehend argument roles in transitive events. Japanese, however, is characterized by flexible word order, null arguments, and case-marker omission. This study analyzes corpus data of interviews between native Japanese speakers and L1-English and L1-Korean learners to examine these characteristics in both input to learners and learners' own production. The relative importance of the three cues is estimated based on their distributional properties using the competition model framework. The findings indicate that animacy was the strongest cue for the native speakers and, when at least one NP was elided, for the learners. However, when both subject and object were present, learners adhered to SOV word order. Case marking was reliable when present but was so frequently omitted that it was not a useful cue, contra previous reports. L1 and proficiency effects are also discussed.
For transitive events to be described and understood, the roles of the actors in the events must be identifiable. The syntactic and semantic cues most useful for this purpose vary crosslinguistically. In English, word order is very useful for identifying a subject; but in Japanese and Korean, case marking is more useful (Bates and MacWhinney, 1989; Ito et al., 1993). Preferred cues may also vary among different populations: Children and second language (L2) learners have been reported to rely on different cues than adult native speakers.
This study uses corpus data to investigate how learners and native speakers of Japanese use cues to express transitive relations. Japanese is known for flexible word order and frequent use of null arguments. Furthermore, although case markers are important for assigning subject and object roles, they are also often omitted. The study analyzes the distributional properties of word-order, case-marking, and animacy cues in spoken interactions between native speakers and Japanese learners with different first language (L1) backgrounds, using the competition model framework (Bates and MacWhinney, 1989).
The following sections provide background on the competition model (Section The Competition Model) and on Japanese (Section Cues in Japanese); present the study's research questions (Section The Current Study) and methodology (Section Methods); describe (Section Results) and discuss the results (Section Discussion); and conclude the study by considering its implications and limitations (Section Conclusions).
Bates and MacWhinney's (1989) competition model proposes a functional and emergentist approach that provides a comprehensive account for language processing and acquisition. In this framework, language acquisition is a distribution-driven process of acquiring the mapping between functional levels (i.e., meanings and intentions) and formal levels (i.e., surface forms at the level of lexicon, morphology, syntax, or prosody). Cues help establish these form-function mappings, and cues for the identification of agent subject include word order, case marking, agreement, and animacy. These cues have different strengths (i.e., informational values), which vary depending on language. For example, word order is the strongest (i.e., most important) cue in English, case is the strongest cue in Dutch, German, and Japanese, and subject-verb agreement is the strongest in Italian and French (Bates and MacWhinney, 1989). Consequently, all language learners need to learn the language-specific ranking of cue strengths.
A major predictor of cue strength is cue validity, which has two aspects: overall validity and conflict validity (McDonald, 1986, 1989; Bates and MacWhinney, 1989). Overall cue validity indicates how informative the cue is in signaling its underlying function and can be calculated as the product of the cue's availability and reliability. See Figure 1 for the relationship among the subparts of cue validity.
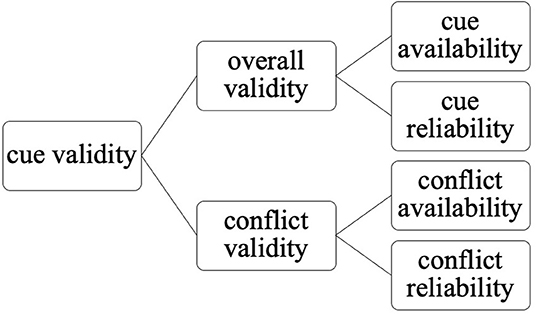
Figure 1. Relationship among cue validity components based on Bates and MacWhinney (1989) and McDonald (1989).
Cue availability measures how frequently a certain cue occurs in the data and is calculated as the number of cases in which a cue is available, divided by the total number of cases. Some cues must be contrastive to provide meaningful information. For example, when a clause has two animate NPs as in (1), it is not possible to assign the agent role solely based on animacy. The boy and the girl are equally likely to be the agent on this basis alone; thus, the animacy cue is unavailable in (1).
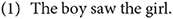
On the other hand, if one NP is animate and the other inanimate, as in (2), the contrast in animacy is a potentially helpful cue in identifying the agent, and thus the animacy cue is available.
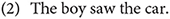
An available cue, however, does not always signal the intended function. Cue reliability indicates how often the cue leads to a correct interpretation when it is available and is calculated as the number of cases in which a cue is reliable, divided by the number of cases in which the cue is available. In (2), for instance, the subject is animate and the object is inanimate, following the typical, highly expected pattern for a transitive event. In such a case, the animacy cue is considered reliable. In (3), however, reliance on the animacy cue alone would result in a misinterpretation, as the agent is inanimate and the patient is animate. The animacy cue in (3) is therefore not reliable.
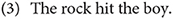
Conflict validity refers to the likelihood of a cue winning out in situations in which co-present cues signal different interpretations and is calculated as the number of competition situations in which the cue leads to a correct interpretation, divided by the number of competition situations. In other words, it is a cue's reliability in a conflict situation. In (3), word order points to the interpretation that the first NP the rock is the subject. However, the animacy information suggests otherwise: The animate noun the boy is more likely to be the agent than the inanimate noun the rock, and therefore more likely to be the subject, if the sentence is interpreted solely based on animacy. In English, the interpretation based on word order is preferred to the interpretation based on animacy, winning out in this conflict situation.
While cue validity remains a main predictor of cue strength, cue reliability (Sokolov, 1988; MacWhinney, 2005) and conflict validity (McDonald, 1986, 1987; McDonald and Heilenman, 1991) have been proposed as better predictors of cue strength for older children and adult native speakers. According to McDonald (1986, 1987), conflicting cues can lead to misinterpretation, which would be detected based on feedback from the environment and would change cue weights. In this learning-on-error model, the cue strengths thus shift incrementally from overall validity to conflict validity. Conflict validity also helps explain how infrequent phenomena can aid acquisition and processing.
Using these concepts, the competition model provides a comprehensive framework to capture the interplay of these cues across languages and across populations, including L2 learners. Three key findings on L2 learning are highlighted below based on Sasaki and MacWhinney (2006).
First, leaners, at least initially, transfer their L1 processing strategies. For example, if the learners' L1 relies heavily on word order to encode transitive sentences, then this strategy is carried over to their L2. This is shown in several studies that investigated L2 acquisition of Japanese, in which word order is not the most important cue, by L1 speakers of English, in which word order is the highest in the cue ranking. Kilborn and Ito (1989) conducted a sentence interpretation task with L1-English learners of Japanese to investigate the roles of word order and animacy. They showed that L1-English learners, even at the advanced proficiency level, chose the first noun of NNV sentences as the agent 88% of the time, when native Japanese speakers only did so 77% of the time. This is particularly interesting because in NVN sentences, which has a greater resemblance to English word order, both the advanced learners and the native speakers chose the first noun as the subject less frequently−67% of the time. These findings led Kilborn and Ito (1989) to conclude that learners did not transfer the specific SVO schema from English, but instead transferred the strategy of relying on word order, which they referred to as “meta-word-order” (p. 282). Sasaki (1994) observed the same trend in some of the L1-English learners in his study, though his results point toward heavier reliance on animacy than word order, as discussed below. Koda (1993) added another wrinkle to the discussion of L1 influence, in a study comparing L1-Chinese, L1-English, and L1-Korean learners of Japanese. She demonstrated that the L1-Chinese and L1-English learners relied on word order, but that the L1-Korean learners relied on case markers. These findings support the suggestion that learners transfer their processing strategy from their L1: L1-Chinese and L1-English learners, whose L1s do not mark case, transferred the word order strategy, but the L1-Korean learners transferred their reliance on case markers from their case-marking L1. L1 influence might also manifest as the underutilization of the important cue in the target language due to the equivalent cue's absence or weakness in one's L1. Rounds and Kanagy (1998) found that case marking was the weakest cue for L1-English child learners of Japanese in an immersion school in the US; they were able to use case marking to some extent but showed difficulty interpreting sentences based on case marking when the subject and object were both animate. In Mitsugi and Macwhinney (2016), L1-English learners of Japanese demonstrated good knowledge of case marking in an offline task but could not use the knowledge in an online processing task.
While learners are expected to show L1 influence, they may also resort to common strategies across different L1s. One of such strategies is to rely on animacy. Lexical semantic properties such as animacy have been proposed to play an important role in L2 learning (Gass, 1987; Sasaki, 1991; Sasaki and MacWhinney, 2006), and some suggest that it is a universal preference to rely on lexical semantics (e.g., Gass, 1987 on L1-Italian learners of English; Sasaki, 1994 on L1-English learners of Japanese). However, this preference is not reported for every L1-L2 pairing (e.g., McDonald, 1987 on L1-Dutch learners of English and L1-English learners of Dutch). A narrower view is that the transfer of such a universal preference only happens if the cue mappings in L1 and L2 have little in common and the transfer of other cues is blocked (MacWhinney, 1987; Shirai, 1992; Sasaki, 1994). For example, between English and Japanese, lexical semantics is the most straightforward cue to transfer, since English and Japanese do not share case-marking systems or canonical word order.
Another possible learner strategy is to rely on the canonical word-order schema. As described above, L1-English learners' use of the word order strategy can be argued in terms of L1 influence. However, Koda's (1993) findings on L1-Chinese learners of Japanese is curious, as they showed the same degree of reliance on word order as L1-English learners, despite word order not being the strongest cue in Chinese. Thus, there is a possibility that learners, regardless of their L1s, may rely on the canonical word-order schema. It could also be due to the property of the input: Sasaki (1994) and Sasaki and MacWhinney (2006) speculated that the canonical SOV order might be more frequent in the input given to learners (instructors' speech, textbooks, etc.) than in native-native interactions, although they did not test this idea.
Lastly, the cue strengths will be adjusted to match the native speakers of the target language over time (MacWhinney, 2005). One of the possible correlates is proficiency (e.g., McDonald and Heilenman, 1991; Sasaki, 1994; Pham and Ebert, 2016; Zhao and Fan, 2021). For example, Sasaki (1994) found that L1-English learners come to rely more on case markers as their proficiency improves. That said, Kilborn and Ito (1989) found that even advanced L1-English learners of Japanese transfer the strategy of reliance on word order, the strongest cue in their L1.
While most work in the competition model framework has used data from sentence interpretation experiments, the model addresses both comprehension and production (Bates and Devescovi, 1989; Zhao and Fan, 2021). In addition, calculating cue validity in corpora can offer a more precise picture of the relative importance of cues, which should be informative for experimenters (Bates and MacWhinney, 1989). McDonald (1987), McDonald and Heilenman (1991), Kempe and MacWhinney (1998), Chan et al. (2009), Tanaka and Shirai (2014), and Zhao and Fan (2021), for example, have used corpus data to estimate cue strengths. The current study follows these studies by using the competition model framework to analyze learner corpus data.
The flexible word order and frequent omission of case marking in Japanese have inspired many studies within and outside the competition model framework. This section presents basic information about the distributional properties of Japanese word order, case marking, and animacy, while reviewing relevant previous studies on L1 and L2 acquisition.
Japanese is a head-final language known for its flexible word order. Although subject-object-verb (SOV), as in (4), is widely accepted as its canonical word order, the OSV order shown in (5), often referred to as scrambling (e.g., Miyagawa, 1997),1 is frequent.


The motivation for scrambling has been a matter of discussion, but some of the proposed motivations include moving NPs to the focus position (e.g., Miyagawa, 1997), putting given information before new information (e.g., Kuno, 1973; Ferreira and Yoshita, 2003), facilitating comprehension (e.g., Yamashita, 2002), and moving long (or heavy) NPs earlier in the sentence (i.e., long-before-short preference; Yamashita and Chang, 2001; Yamashita, 2002, a.o.).
In addition, Japanese allows postposing, which leads to other non-canonical word-order patterns such as OVS and SVO, as shown in (6) and (7), respectively.


Postposing is used to repair, clarify, elaborate, or emphasize the predicate it precedes (Ono and Suzuki, 1992), although it has been suggested some post posed patterns are “routinized” or “grammaticalized” (Ono and Suzuki, 1992).
Table 1 summarizes previous studies' reports of percentages of canonical and non-canonical word-order patterns in Japanese. As seen in Table 1, non-canonical word order in Japanese is not uncommon, and is particularly frequent in naturalistic oral production. This means that word order might not be useful information for agent identification in Japanese, unlike in English, in which word order is rigid (Bates and MacWhinney, 1989). In fact, Ito et al. (1993) ranked word order as the least important cue in Japanese. (But word order might be an important cue in the absence of case markers, as Hinds, 1982 noted.)

Table 1. Previous findings on the frequency of non-canonical word-order sentences in Japanese: raw tokens and proportions (%) of all two-NP sentences in the data.
In addition to flexible word order, Japanese allows null arguments, at the subject position (8), the object position (9), or both (10).

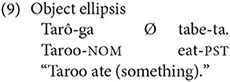

Null arguments give rise to SV and OV sentences, and Sasaki (1994) suggested that such sentences have a role in determining cue strengths in Japanese by serving as counterevidence to the canonical word-order schema. In addition, VS and VO sentences (with postposing) are also possible, further increasing the possible word-order variation in Japanese.
Table 2 presents a summary of subject and object omission rates reported in previous studies. Clearly, both null subjects and null objects are frequent in Japanese. The subject is more likely to be elided, which is expected as subjects tend to be human and often refer to the speaker or the hearer (Fry, 2003).
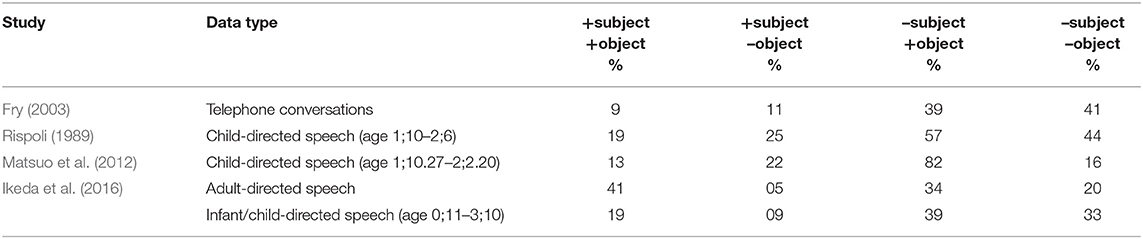
Table 2. Previous findings of subject and object omission rates in Japanese (+subject/object indicates an overt subject/object and –subject/object indicates a null subject/object).
Japanese marks case on NPs. In (4–7), the subject NP is marked with the nominative marker -ga and the direct object NP is marked with the accusative marker -o. There are other markers that do not indicate transitive relations, such as topic marker -wa, dative marker -ni, genitive marker -no, and focus marker -mo “also.” Of these, the topic marker -wa and focus marker -mo and can replace the nominative or accusative markers.
Ito et al. (1993) argued that case marking provides the most important cue for adult native speakers of Japanese, based on its reliability in sentence interpretation experiments. In addition, they found that among the case markers they investigated, the accusative marker -o was the strongest, the nominative marker -ga was the second strongest, and the topic marker -wa was the weakest cues for agent identification. Ito et al. (1993) argued that this is because -ga is used to mark objects in some contexts, including with potential and desiderative forms of the verbs, and to mark the passive subject.
While case marking is the most important cue, Japanese speakers do not rely solely on it (Ito et al., 1993). In fact, it is well-known that Japanese case markers are frequently omitted in adult colloquial speech (e.g., Hinds, 1982; Ito et al., 1993; Fry, 2003). There are multiple factors that influence the omission rate of case markers, including utterance length, sentence type, information structure, and sociolinguistic factors such as gender and dialects (Fry, 2003). Of relevance here are the case markers' interactions with word order and with animacy. Hinds (1982) report that case markers are likely used to indicate grammatical relationship when the sentence involves scrambling or postposing. In addition, the accusative marker -o is less likely to be omitted when it is animate and definite (Minashima, 2001; Fry, 2003) or less implausible object (Kurumada and Jaeger, 2015).
Table 3 summarizes the omission rate of the nominative marker -ga and the accusative marker -o found in previous studies. While the numbers vary across studies, it is clear that omission of case marking is common in Japanese. In general, it is very rare for a transitive clause to be a fully case-marked SOV sentence. In addition to the numbers included in Table 3, Matsuo et al. (2012) reported that when both subject and object are overt in child-directed speech (16.5% of the total utterances), 1.3% had both nominative and accusative markers, 0.3% had one or the other, and 11% had neither. In another study, Ono et al. (2020) reported that among sentences with two NPs in adult conversations, 6% had both nominative and accusative markers, 32% had one or the other, and 62% had no marker or had another marker that did not indicate grammatical relations (e.g., topic marker -wa, focus marker -mo).
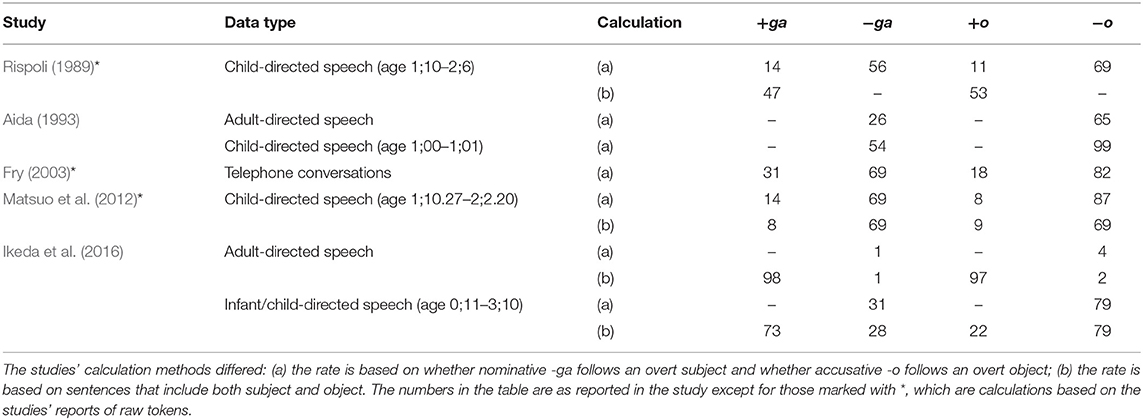
Table 3. Previous findings of overt and omitted case marker rates (%) in Japanese (+ga/o indicates the presence of the nominative/accusative markers and −ga/o indicates the omission of the nominative/accusative markers).
Thus, while case markers are a highly reliable cue in comprehension experiments with adult native Japanese speakers, they are not always present to guide interpretation or acquisition, and their absence/presence is influenced by other factors such as word order and animacy.
Animacy is a lexical semantic property in Japanese as in most other languages. It is not usually morphologically marked and does not assign the agent role through grammar, but instead points to the most likely agent based on world knowledge. Tanaka and Shirai (2014) showed that 93.3% of child-directed speech and 94.7% of children's speech followed this pattern in Japanese. Ono et al. (2020) also showed that 93% of sentences with two NPs involved a human subject. This is not specific to Japanese. Universally, transitive subjects/agents are typically animate and direct objects/patients are typically inanimate (e.g., Comrie, 1979). Nevertheless, the relative strength of animacy and other cues differs among languages. For example, in Dutch, it is the least important cue after case marking and word order, while in Mandarin Chinese, it is the most important cue (Bates and MacWhinney, 1989). In Japanese, animacy is the second strongest cue after case marking according to Ito et al. (1993), and the strongest in child-directed speech according to Tanaka and Shirai (2014).
As described in pervious sections, Japanese native speakers' speech is characterized by flexible word order, frequent null arguments, and high rates of case-marker omission. It is not clear whether such characteristics are also observed in the input learners of Japanese receive, although previous studies offer enough reasons to suspect that this might be the case.
Rounds and Kanagy (1998) reported that in immersion school classrooms, only 2% of the input given to the L1-English child learners of Japanese (from kindergarteners to seventh graders) by native Japanese teachers consisted of fully case-marked SOV sentences (20% were SV sentences marked with the nominative marker -ga or the topic marker -wa, and 5% were OV sentences marked with the accusative marker -o). This study did not report the breakdown of the remaining 83%, but it is implied that the rest did not follow the canonical word order or case marking.
Takeuchi (2014) analyzed the subject expressions (and therefore did not consider the omission of the object or the accusative marker) in three L2 Japanese textbooks (Oka et al., 2009; Banno et al., 2011a,b) and reported that subject omission rates were 37.5%, 53.7%, and 47.9%, respectively2, and that the nominative marker -ga was frequently omitted.
If these characteristics are indeed evident in the input, we do not know what information is available in the input to help learners learn transitivity in Japanese. In addition, it is not clear how learners themselves express transitive relations in their own speech, or whether L1 or proficiency, which have been shown to affect learners' comprehension of transitive expressions, would also affect their production. The current study addresses these gaps by analyzing learner corpus data using the competition model framework.
This study uses learner corpus data to investigate cue strengths in oral interactions between native speakers and learners of Japanese. It adapts methods proposed by McDonald (1989), McDonald and Heilenman (1991), Kempe and MacWhinney (1998), Chan et al. (2009), and Tanaka and Shirai (2014) to estimate cue strengths in native speakers' and learner's speech. The findings complement previous works on sentence interpretation in the following ways.
First, analyzing the native speakers' speech in such interactions will shed light on the characteristics of Japanese input received by learners, which has been largely absent in previous studies, with the exception of Rounds and Kanagy (1998) and Takeuchi (2014).
Second, by analyzing spontaneous production by learners, the study demonstrates how learners themselves use the cues of word order, case marking, and animacy to express transitive relations, extending the prior work within the framework of the competition model that has focused on comprehension. As far as I know, the recent study by Zhao and Fan (2021) was the first to investigate both the input and production in L2 learning (they used written production data while the current study used oral production data), and as they suggested, “[l]anguage production is perhaps the area that has the most urgent need for more empirical data” (p. 4).
Third, this study also addresses the role of null arguments and how they affect relative cue strengths. Previous research has usually limited its analysis to sentences with an overt subject and object, and Ito et al. (1993) proposed the following ranking based on comprehension experiments on such sentences: case marking (accusative > nominative) > animacy > SOV.
In order to address the question of L1 influence raised by previous studies, this study compares L1-English and L1-Korean groups. The two groups were selected because English's dissimilarity and Korean's similarity to Japanese make the two an ideal pair to demonstrate L1 influence. As mentioned in Section The Competition Model, English relies heavily on word order. While it has case marking, its use is very limited (e.g., nominative, accusative, and genitive pronouns they, them, their) and verbal agreement is also limited to subject-verb agreement in present tense (3rd person singular -s). Bates and MacWhinney (1989) suggested the following ranking for English: SVO > VOS, OSV > animacy, agreement > stress, topic. Korean, on the other hand, is similar to Japanese in many ways (Ito et al., 1993): its canonical word order is SOV and it has similar case markers as Japanese, including nominative marker -i/ga, accusative marker -eul/reul, and topic marker -eun/neun. Much like in Japanese, the nominative marker is the strongest cue for agent identification, followed by the accusative marker. In addition, Korean, like Japanese, also allows flexible word order, null arguments, and omission of case markers. In terms of cue ranking, it is very similar to Japanese, although they rank word order higher than animacy: case marking (accusative > nominative) > word order > animacy (Ito et al., 1993).
In addition, the samples in this study represents both learner groups at different proficiency levels, providing an opportunity to address proficiency effects. The information of Japanese Computerized Adaptive Test (J-CAT; Imai et al., 2013) scores available for each learner in the corpus made it possible to use an objective measure of proficiency rather than relying on self-evaluation or using other indicators such as length of learning, and to treat it as a continuous variable rather than using proficiency categories, unlike what is typically done in previous studies.3
Two research questions (RQs), each with two subquestions, are addressed:
1. How are word order, case marking, and animacy used in the Japanese native speakers' speech when they interact with learners?
a. What are the relative cue strengths in sentences with an overt subject and object?
b. What are the relative cue strengths when null arguments are taken into consideration?
2. How are word order, case marking, and animacy used in the learners' speech?
a. Do the relative cue strengths differ from the native speakers with and without null arguments?
b. Do the cue strengths differ depending on the learners' L1 and proficiency?
For native speakers, I predict that when only the sentences with an overt subject and object are considered (RQ 1a), the cue ranking would mirror the previous experimental studies. But when null arguments are taken into consideration (RQ 1b), word order cues and case marking cues would be much weaker and animacy would be the strongest cue, following Tanaka and Shirai (2014).
For learners, there are multiple different scenarios. In the first scenario, learners would have a very similar cue ranking as the native speakers (RQ 2a). Assuming that the native speakers' speech analyzed in this study is representative of the input learners receive, this means that learners' cue strengths mirror what is present in the input, free of L1 influence or learner strategies. As previous studies in Section The Competition Model indicate, this is expected later (i.e., more advanced levels of proficiency) in the development. However, due to the range of proficiency attested the data (Section Data Source), it is more likely that learners would behave differently from native speakers, based on the previous studies. In the second scenario, learners would transfer their L1 strategies, much like in Koda's (1993) study. As a result, the L1-English and L1-Korean learners would rank the cues differently: the case-marking cue would be the strongest for L1-Korean learners and the word-order cue would be the strongest for L1-English learners (RQ 2b). In the third scenario, both learner groups would show a common strategy: based on previous studies, I predict this common strategy to manifest either as reliance on animacy or reliance on word order (RQ 2b). If both groups rely on animacy, it will corroborate previous proposals that the reliance on lexical semantics is a universal strategy (or that, at the very least, it is a common strategy used across the two L1 groups in this study). If both groups rely on word order, it will show that the reliance on word order may not be limited to learners whose L1 relies on word order. A comparison with the native speakers' data would provide further insight as to whether this is due to the input properties, as suggested by Sasaki (1994) and Sasaki and MacWhinney (2006). It is also possible that the cue ranking is influenced by the combination of L1 influence and learner strategies, which is the fourth scenario. For example, the strongest cue may be determined by L1 influence and others by learner strategy, or vice versa. Or L1-Korean learners may transfer their reliance of case marking, while L1-English learners may resort to relying on animacy due to the little similarity between cues in English and those of Japanese, as shown in Sasaki (1994). And finally, learners with higher proficiency are predicted to show less L1 influence and/or rely less on learner strategy (RQ 2b).
The data were retrieved from the International Corpus of Japanese as a Second Language (I-JAS, Sakoda et al., 2016). I-JAS is the largest Japanese learner corpus currently available and contains spoken and written data from over a thousand learners with 12 different L1 backgrounds across different learning contexts (classroom vs. naturalistic, foreign language vs. second language).
I-JAS offers spoken data from interview, role-play, storytelling, and picture-description tasks, as well as written data from composition and story-writing tasks. This study employs the interview task data because (i) it is spoken rather than written; (ii) it involves bi-directional communication (in contrast to the storytelling or picture description tasks) and provides rich data from both native speakers (interviewers) and learners (interviewees); and (iii) the task was long (approximately 30 minutes), which also makes the resulting data richer than that from shorter tasks (e.g., role-playing). The interviews also produced somewhat natural and spontaneous conversation, even though it was semi-structured with a predetermined set of topics.
This study presents data from the two subcorpora that were complete at the time of analysis in 2017: the EAU subcorpus data come from an L1-English group studying Japanese as a foreign language (JFL) in a classroom setting in Australia, and the KKD subcorpus come from an L1-Korean group studying JFL in a classroom setting in Korea. The EAU-I data set contained interviews with 23 learners (16 female), whose proficiency levels ranged from Basic to Intermediate based on the J-CAT total scores (range: 106–257; mean: 190; SD: 40.1) and the KKD-I data set contained interviews with 47 learners (22 female), whose proficiency ranged from Beginner to Near Native (range: 92–352; mean: 247; SD: 65.9).4 All but two (one in each subcorpus) learners were students.
Using the I-JAS search application, all instances of independent verbs within EAU-I and KKD-I were searched and results were exported as a CSV file along with auxiliary information about the subcorpora and participants. Supplementary Material contains the specific steps taken to extract data. In addition, the full data set containing transcriptions and audio recordings was downloaded to supplement the subsequent analyses. The data were then manually coded for verb types to select only simple transitives. The inclusion criteria for transitive verbs were: (i) verbs that canonically appear with an accusative NP marked with -o, and (ii) ill-formed verbs with an intended transitive meaning that appear with an accusative NP marked with -o. Examples of the instances of these verbs5 are in (11) and (12).


Transitive verbs marked for voice [e.g., passive -(rar)eru, causative -saseru] (13) or mood [e.g., abilitative -(rar)eru, desiderative -tai] (14), which require different case-marking patterns, the presence of additional verbal morphology, or a change in valency, were excluded.


In addition, transitive verbs in relative clauses were excluded, as the structure is qualitatively different. Also excluded were cases of repetition (of one's self or the interlocutor), recast, and uptake, as they would inflate the frequency of the same pattern6. In the case of self-correction, the final formulation was kept, following MacWhinney (2000). Finally, 17 tokens (0.56%) for which animacy could not be determined were excluded from the analysis. As a result, the final dataset consisted of 1,369 tokens of transitive verbs from native speakers in both subcorpora, 565 tokens from the EAU, and 1,081 tokens from the KDD.
The following subsections report the distribution of word-order, case-marking, and animacy patterns by group based on total tokens. As shown below, flexible word order, null arguments, and omission of case marking were found to be prevalent in both the native speakers' speech and learners' speech. For this reason, the availability, reliability, and overall validity of each cue will be analyzed in two ways: The first set of analyses focused on 7% of the total tokens which had an overt subject and object. While such analyses would offer only a partial picture, they would make the findings comparable with those of previous experimental work. The second set of analyses evaluates cue strengths based on all analyzed sentences, including sentences with null arguments, in order to get a full picture of what learners do in the absence of some cues7. I will consider the comparison among groups for each cue, as well as the ranking of cues within each participant group (Section Cue Ranking in Each Group).
The data below were fitted into a binomial logistic mixed-effects model using the lmerTest package (Kuznetsova et al., 2017) in R Version 4.1.1. For each cue, both learner groups were compared to the native speaker group by modeling validity, treated as a binary categorical variable (valid, i.e., available and reliable: 1, unavailable or unreliable: 0), as a function of group (native speakers, L1-English learners, L1-Korean learners). The random effect structure included by-sample varying intercept. It is important to point out that proficiency was not factored into the model because native speakers did not have proficiency scores. This means that the model represents the average behavior of each of the three groups. For this reason, a second model was constructed for a subset analysis of the two learner groups to investigate L1 and proficiency effects, estimating the validity of each cue as a function of L1 as a categorical predictor, proficiency scores (JCAT) as a continuous predictor, and the interaction of the two. The reporting below focuses on statistically significant effects.
Table 4 shows the distribution of word-order patterns attested in the production of native speakers and learners.

Table 4. Word-order patterns by language group.
When both subject and object were present, the most common pattern was the canonical word order SOV for all groups (native speakers: 3.73%, L1-English learners: 8.85%, L1-Korean learners: 8.05%). The rate of non-canonical word order was 1.39% (OSV: 1.17%, SVO: 0.22%) for native speakers, 0.53% (OSV: 0.35%, OVS: 0.18%) for L1-English learners, and 1.29% (OSV: 0.83%, SVO: 0.46%) for L1-Korean learners. While non-canonical word order seems less frequent in L1-English learners than in L1-Korean learners, the analyses in Section Evaluation of the Availability, Reliability, and Validity of Word-Order Cue in Sentences With an Overt Subject and Object and in Section Evaluation of the Availability, Reliability, and Validity of Word-Order Cue in All Sentences reveal that L1-English learners and L1-Korean learners are similar to each other in the use of their word-order cues.
Null subjects were very frequent in both native speakers' and learners' speech. Native speakers produced OV sentences 62.53% of the time and VO sentences 1.02% of the time, making the subject omission rate 63.55%, in line with previous studies. Null subjects were similarly high in learners' speech, at 64.25% (all OV) for L1-English learners, and 63.00% (OV: 61.98%, VO: 1.02%) for L1-Korean learners. Null objects were less frequent, at 4.89% (all SV) for native speakers, 2.48% (SV: 2.30%, VS: 0.18%) for L1-English learners, and 5.83% (all SV) for L1-Korean learners. These results are in line with those of previous studies. It was also very common for all groups to elide both the subject and object (native speakers: 26.44%, L1-English learners: 23.89%, L1-Korean learners: 21.83%).
Below, I present the analysis of the word-order cue based on tokens with an overt subject and object (Section Evaluation of the Availability, Reliability, and Validity of Word-Order Cue in Sentences With an Overt Subject and Object) and the analysis of the word-order cues based on all sentences (Section Evaluation of the Availability, Reliability, and Validity of Word-Order Cue in All Sentences).
For the word-order cue, the validity of the canonical word order SOV was calculated. This cue was considered available in all NNV sentences (SOV and OSV), and thus the availability was calculated as the ratio of NNV sentences to all sentences with an overt subject and object. The cue was considered reliable when it was SOV and unreliable when it was OSV. The reliability was calculated as the ratio of SOV sentences to all NNV sentences. Table 5 presents the summary of the word order cue.
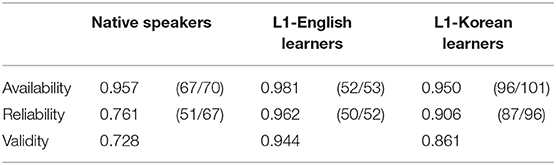
Table 5. Availability, reliability, and validity of the word-order cue (SOV) in sentences with an overt subject and object.
The availability was 0.957 for native speakers, 0.981 for L1-English learners, and 0.950 for L1-Korean learners, which means that sentences with an overt subject and object followed the NNV schema more than 90% of the time for all groups. The reliability was 0.761 for native speakers, 0.962 for L1-English learners, and 0.906 for L1-Korean learners. This means that more than 90% of NNV tokens were SOV in learners' production, but only 76% were in native speakers' production. As a result, the validity was 0.728 for native speakers, 0.944 for L1-English learners, and 0.861 for L1-Korean learners.
The results from the first model comparing all three groups indicated that the validity was significantly higher for L1-English learners (logit coefficient: +1.84, SE = 0.67, z = 2.75, p = 0.006) and L1-Korean learners (logit coefficient: +0.82, SE = 0.42, z = 1.97, p = 0.05) than for native speakers. This means that both learner groups were more likely to rely on the canonical SOV schema to express transitivity than native speakers, suggesting a possibility that learners, regardless of L1, might rely on the canonical word order.
The results from the second model conducting a subset analysis of the learner groups showed there was no evidence that learners used the word-order cue differently depending on their L1 or proficiency.
In addition to the evaluation of the SOV cue, which followed the same criteria described in the previous section (Section Evaluation of the Availability, Reliability, and Validity of Word-Order Cue in Sentences With an Overt Subject and Object), the SO cue (a subject precedes an object), the SX cue (the first NP is the subject), and the OV cue (the preverbal NP is the object) were also evaluated to investigate the influence of the partial frame, as suggested by Sasaki (1994), Kempe and MacWhinney (1998), and Chan et al. (2009).
The SO cue was considered available when the tokens included both subject and object, and not available in sentences with null arguments. The cue was reliable when the subject preceded the object (i.e., SOV, SVO, and VSO).
The SX cue was considered available in all tokens with at least one NP, and not available in verb-only sentences. The cue was reliable when the first or only NP was the subject, regardless of its position relative to the verb (i.e., SOV, SVO, SV, and VS).
The OV cue was considered available in all sentences in which the preverbal slot was filled with an NP (i.e., SOV, OSV, SVO, OVS, SV, and OV). The cue was reliable when the preverbal NP was the object (i.e., SOV, OVS, and OV). Table 6 presents the summary of all four word-order cues.
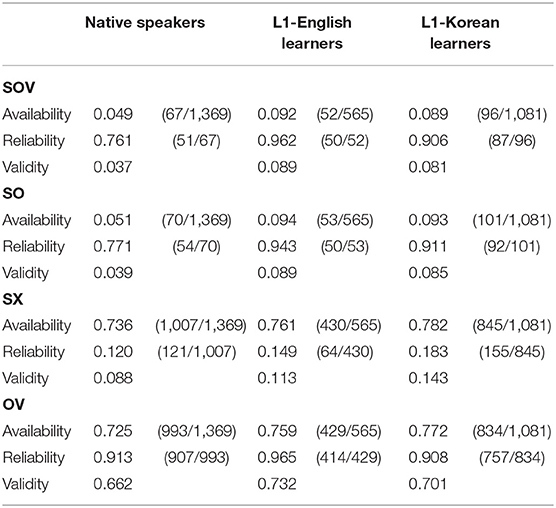
Table 6. Availability, reliability, and validity of word-order cues in all sentences.
In contrast to the results in the previous section (Section Evaluation of the Availability, Reliability, and Validity of Word-Order Cue in Sentences With an Overt Subject and Object), the SOV cue had very low cue validity for all groups (native speakers: 0.037, L1-English learners: 0.089, L1-Korean learners: 0.081). This finding confirms that an otherwise useful cue cannot be used to interpret sentences with null arguments. The validity of SO (native speakers: 0.039, L1-English learners: 0.089, L1-Korean learners: 0.085) and SX (native speakers: 0.088, L1-English learners: 0.113, L1-Korean learners: 0.143) cues was also very low.
The OV cue, on the other hand, was a useful cue, with validity of 0.662 for native speakers, 0.732 for L1-English learners, and 0.701 for L1-Korean learners. The availability was 0.725 for native speakers, 0.759 for L1-English learners, and 0.772 for L1-Korean learners, meaning that the preverbal slot was filled with an NP more than 70% of the time. The reliability was 0.913 for native speakers, 0.965 for L1-English learners, and 0.908 for L1-Korean learners, suggesting that a preverbal NP was most likely an object. Thus, with the absence of the SOV cue, the partial frame of OV can be used to identify the object.
The first model showed that, compared to native speakers, the validity was higher in L1-English learners' SOV (logit coefficient: +0.95, SE = 0.23, z = 4.09, p < 0.0001), SO (logit coefficient: +0.89, SE = 0.23, z = 3.93, p < 0.0001), and OV (logit coefficient: +0.33, SE = 0.14, z = 2.37, p = 0.02) cues, as well as in L1-Korean learners' SOV (logit coefficient: +0.80, SE = 0.20, z = 3.98, p < 0.0001), SO (logit coefficient: +0.81, SE = 0.19, z = 4.16, p < 0.0001), and SX (logit coefficient: +0.54, SE = 0.15, z = 3.54, p = 0.0003) cues. Overall, learners are more likely to rely on word-order cues than native speakers, echoing the results in the previous section (Section Evaluation of the Availability, Reliability, and Validity of Word-Order Cue in Sentences With an Overt Subject and Object).
The second model showed that proficiency was a significant predictor for the validity of the OV cue (logit coefficient: +0.005, SE = 0.002, z = 2.09, p = 0.04), meaning that the validity of the OV cue was higher for learners with higher proficiency.
Therefore, while SOV cue was both highly available and reliable when sentences have an overt subject and object, it was not very useful in the big picture, where null arguments were included in the analysis. Instead, the OV cue was useful for all groups, showing that the partial frame of preverbal object can be used to express transitive relations in the absence of subjects. The OV cue had higher validity in learners with higher proficiency, suggesting that the more advanced learners are, the more they utilize this partial frame. Regardless of which word-order cue was useful, however, learners in general tended to rely more on word-order cues than native speakers, much like with the SOV cue in the previous section (Section Evaluation of the Availability, Reliability, and Validity of Word-Order Cue in Sentences With an Overt Subject and Object).
For the analysis of case marking, the nominative case marker -ga and the accusative case marker -o were coded, whether they appeared with the subject NP or the object NP. If NPs appeared with other case markers like genitive -no or dative -ni, or with other types of particles/postpositions (e.g., topic marker -wa, comitative -to, focus marker -mo), which do not mark transitive relations, they were coded as “other.” The case marking was coded as “null” when an NP appeared with no case marker. Table 7 shows the distribution of case-marking patterns attested in the production of native speakers and learners.
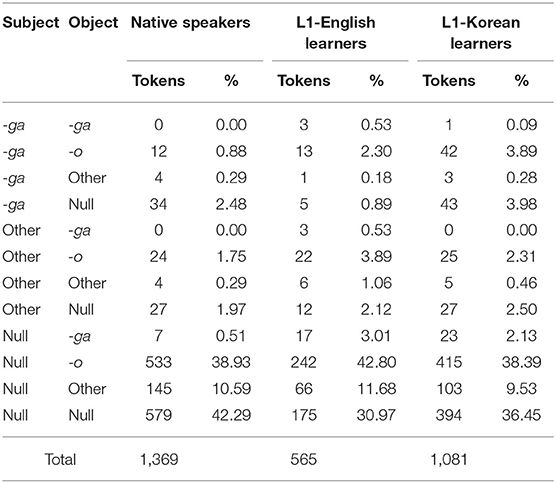
Table 7. Case-marking patterns by language group.
As reported in previous studies, it was not very common for both the subject and object to be case marked. In the two most frequent patterns for all groups, neither the subject nor the object was case-marked or only the object was case-marked; these two patterns constituted 81.22% of the data for native speakers (object only: 38.93%, neither: 42.29%), 73.81% for L1-English learners (object only: 42.80%, neither: 30.97%), and 74.84% for Korean learners (object only: 38.39%, neither: 36.45%).
Although the topic marker -wa was not included in the analysis, topic and subject NPs often coincided (native speakers: 2.34%, L1-English learners: 6.55%, L1-Korean learners: 3.79%). This pattern was less frequent than nominative-marked subject NP for native speakers (3.65%) and L1-Korean learners (8.23%), but more frequent for L1-English learners (3.89%). Ito et al.'s (1993) comprehension experiment also found the topic marker -wa to be a stronger cue than the nominative marker -ga for agent assignment for L1-English learners, while -ga was consistently a stronger cue for agent identification for native Japanese speakers. (Native Korean speakers also used the nominative marker -i/ga as a stronger cue for agent identification than the topic marker -eul/reul.) In addition, Takeuchi (2014) found that -wa marking was used more often than -ga in teacher talk, which may cause the delay in the emergence of -ga marking in learners. While this study focuses on the nominative marker -ga and the accusative marker -o, the role of the topic marker -wa in learning transitivity in Japanese is an important question that needs to be addressed in future research.
Below, I present the analysis of the case-marking cue based on tokens with an overt subject and object (Section Evaluation of the Availability, Reliability, and Validity of Case-Marking Cue in Sentences With an Overt Subject and Object) and based on all sentences (Section Evaluation of the Availability, Reliability, and Validity of Case-Marking Cue in All Sentences).
The availability, reliability, and validity for nominative cue, accusative cue, and both combined were estimated. The nominative cue was considered available when an NP was followed by the nominative marker -ga and was the only nominative-marked NP in the sentence. When the nominative marker -ga appears twice, it does not help establish grammatical relations; therefore, in such cases, the cue was considered unavailable. The availability was thus calculated as the ratio of cases in which -ga marked only one NP to all sentences. The nominative cue was considered reliable when the nominative marker -ga marked the subject. The reliability was therefore calculated as the ratio of cases in which -ga marked the subject to all cases in which ga-marking appeared only once. The availability and reliability of the accusative cue was evaluated in the same way. For both nominative and accusative combined, the case-marking cue was considered available when either the nominative or the accusative cue was available, and reliable when either the nominative or the accusative cue was reliable. Table 8 presents the summary of case-marking cues.
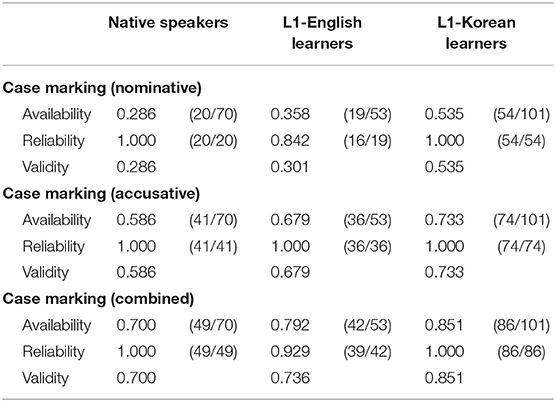
Table 8. Availability, reliability, and validity of case-marking cues in sentences with an overt subject and object.
The availability of the nominative cue was 0.286 for native speakers, 0.358 for L1-English learners, and 0.535 for L1-Korean learners. While the nominative cue was always reliable for native speakers and L1-Korean learners, its reliability was 0.842 for L1-English learners. The overall validity was 0.286 for native speakers, 0.301 for L1-English learners, and 0.535 for L1-Korean learners.
The availability of the accusative cue was 0.586 for native speakers, 0.679 for L1-English learners, and 0.733 for L1-Korean learners. This cue was 100% reliable for all groups, meaning the availability, and validity had the same value.
As indicated in Section Data Extraction, the analysis included only transitive verbs for which the NP-ga NP-o frame is typical. The subject NP was therefore usually an agent or a source, and never occurred with -o, resulting in high reliability of -o. On the other hand, L1-English learners sometimes used -ga to mark the object NP, resulting in lower reliability of -ga.
Combining both, the availability of the case-marking cue was 0.700 for native speakers, 0.792 for L1-English learners, and 0.851 for L1-Korean learners. This means that in all groups, either or both of the case markers was used at least 70% of the time in sentences with an overt subject and object. The reliability was very high, at 1.000 for native speakers and L1-Korean learners and 0.929 for L1-English learners.
The results from the first model showed that the L1-Korean learners had significantly higher validity for all the case-marking cues than native speakers (nominative: logit coefficient: +1.07, SE = 0.34, z = 3.12, p = 0.002; accusative: logit coefficient: +0.66, SE = 0.33, z = 2.00, p = 0.05; combined: logit coefficient: +0.90, SE = 0.38, z = 2.35, p = 0.02). Because the reliability of these cues was 100% for both native speakers and L1-Korean learners, this suggests that L1-Korean learners were less likely to omit case markers than native speakers, adhering to the canonical use of case markers.
The results from the second model did not show any significant effect of L1 or proficiency. Contrary to what we would predict, there was no discernable evidence of transfer in L1-Korean learners despite the similarity in the case marking system between Japanese and Korean.
The evaluation of case-marking cues in all sentences followed the same criteria as the previous section (Section Evaluation of the Availability, Reliability, and Validity of Case-Marking Cue in Sentences With an Overt Subject and Object). Table 9 presents the summary of case-marking cues.
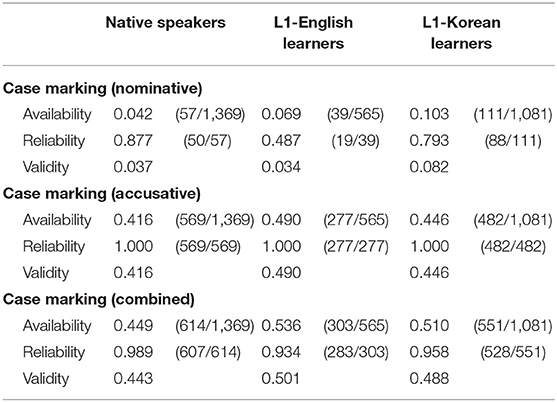
Table 9. Availability, reliability, and validity of case-marking cues in all sentences.
In all cues, the validity was lower here than in the previous section (Section Evaluation of the Availability, Reliability, and Validity of Case-Marking Cue in Sentences With an Overt Subject and Object). The validity of the nominative cue was particularly low (native speakers: 0.037, L1-English learners: 0.034, L1-Korean learners: 0.082). While the validity was similar between L1-English learners and native speakers, there was a qualitative difference: For L1-English learners, the nominative cue showed lower reliability (0.487) than for native speakers (0.877), suggesting that the former used the nominative marker for non-subjects more frequently.
The validity of the accusative cue was 0.416 for native speakers, 0.490 for L1-English learners, and 0.446 for L1-Korean learners. The reliability was 1.000 for all groups, suggesting that the accusative marker was always used to mark the direct object.
The validity of the combined case-marking cue was 0.443 for the native speakers, 0.501 for L1-English learners, and 0.488 for L1-Korean learners. The reliability was over 90% for all groups (native speakers: 0.989; L1-English learners: 0.934, L1-Korean learners: 0.958), suggesting that the validity largely reflects availability.
The first model showed that the nominative cue had significantly higher validity in L1-Koreran learners than in native speakers (logit coefficient: +0.87, SE = 0.21, z = 4.22, p < 0.001). The accusative cue had significantly higher validity in L1-English learners than in native speakers (logit coefficient: +0.35, SE = 0.16, z = 2.14, p = 0.03). Much like in the previous section (Section Evaluation of the Availability, Reliability, and Validity of Case-Marking Cue in Sentences With an Overt Subject and Object), the second model showed no L1 or proficiency effects.
Overall, the results were similar to when the analyses were limited to sentences without null arguments. While the availability and validity of the case-marking cues were noticeably lower when all sentences were considered, reliability remained high for all case-marking cues.
The animacy of the NPs was coded as animate (A) or inanimate (I). The animacy of null arguments was retrieved from the context. Table 10 reports the animacy patterns attested in the data.
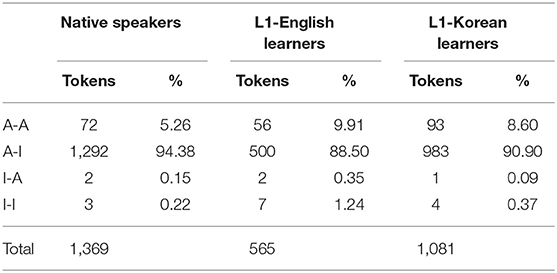
Table 10. Animacy patterns by language group.
The large majority of all groups' transitive utterances contained an animate subject and an inanimate object (A–I; Native speakers: 94.38%, L1-English learners: 88.50%, L1-Korean learners: 90.90%). Animate-animate (A-A) tokens constituted <10% of the data in all groups (Native speakers: 5.26%, L1-English learners: 9.91%, L1-Korean learners: 8.60%), and inanimate subjects (I–A, I–I) were very rare.
Below, I present the analysis of the animacy cue based on tokens with an overt subject and object (Section Evaluation of the Availability, Reliability, and Validity of Animacy Cue in Sentences With an Overt Subject and Object) and based on all sentences (Section Evaluation of the Availability, Reliability, and Validity of Animacy Cue in All Sentences).
The animacy cue was coded as available when there was an animacy contrast (i.e., one animate NP and one inanimate NP, e.g., A-I, I-A). The cue was not available if both NPs had the same animacy status (e.g., A-A, I-I). The availability was therefore calculated as the ratio of A-I and I-A sentences to all utterances. Because animacy usually signals the agent and inanimacy is usually associated with a patient, the cue was considered reliable in A-I sentences but not in I-A sentences. The reliability was therefore calculated as the ratio of A-I sentences to A-I and I-A sentences. Table 11 presents the summary of the animacy cue.
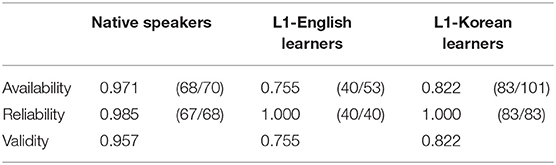
Table 11. Availability, reliability, and validity of word-order, case-marking, and animacy cues in sentences with an overt subject and object.
The availability was 0.971 for native speakers, 0.755 for L1-English learners, and 0.822 for L1-Korean learners. This means that native speakers almost always used the animacy contrast, while learners did so less frequently. When the animacy cue was available, however, it was always reliable for learners (1.000), and the reliability was 0.985 for native speakers. This means that when an animacy contrast was present, it was almost always the prototypical pattern of an animate subject and an inanimate object.
The first model indicated that the validity of the animacy cue was significantly lower for both L1-English learners (logit coefficient: −1.98, SE = 0.67, z = −2.96, p = 0.003) and L1-Korean learners (logit coefficient: −1.58, SE = 0.65, z = −2.45, p = 0.01) than for native speakers. Because the reliability was always 100% for the learners, this means that learners were more likely to use A-A or I-I sentences than native speakers.
The second model indicated that the animacy cue had significantly higher validity for L1-Korean learners than for L1-English learners (logit coefficient: +4.19, SE = 2.01, z = 2.09, p = 0.04).
The evaluation of the animacy cue in all sentences followed the same criteria as the previous section (Section Evaluation of the Availability, Reliability, and Validity of Animacy Cue in Sentences With an Overt Subject and Object). Table 12 presents the summary.
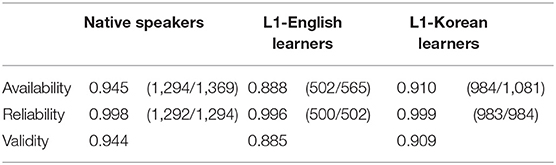
Table 12. Availability, reliability, and validity of cues in all sentences.
The validity was 0.944 for native speakers, 0.885 for L1-English learners, and 0.909 for L1-Korean learners. While the reliability was not 100%, the learners' availability and validity were higher than in the previous section (Section Evaluation of the Availability, Reliability, and Validity of Animacy Cue in Sentences With an Overt Subject and Object).
The first model showed that the validity was significantly lower for L1-English learners (logit coefficient: −0.48, SE = 0.17, z = −2.90, p < 0.003) and L1-Korean learners (logit coefficient: −0.88, SE = 0.21, z = −4.20, p < 0.001) than for native speakers, much like in the previous section (Section Evaluation of the Availability, Reliability, and Validity of Case-Marking Cue in Sentences With an Overt Subject and Object). Thus, learners were less likely to utilize the animacy cue than native speakers even with null arguments.
The second model showed that the animacy cue had significantly higher validity for L1-Korean learners than for L1-English learners (logit coefficient: +2.13, SE = 0.85, z = 2.51, p = 0.01). However, the interaction of L1 and proficiency was also significant (logit coefficient: −0.008, SE = 0.004, SE = −2.021, p = 0.04), indicating different trends for L1-English learners and L1-Korean learners. Figure 2 shows the validity of the animacy cue (calculated for individual participants)8 as a function of JCAT scores with logistic regression fit; the lines represent the predicted validity. The line for L1-English learners is shorter than that for L1-Korean learners as no L1-English learner had JCAT scores higher than 257. If L1-English learners rely more on animacy at higher proficiency levels, they may be adjusting the relative cue strengths to match those of Japanese as their proficiency increases. However, this speculation cannot be tested with the current data because the corpus did not include advanced L1-English learner data. L1-Korean learners, on the other hand, relied less on animacy at higher proficiency levels. It is possible they rely more on lexical semantics at lower proficiency levels, which could be confirmed with longitudinal data (as opposed to the current cross-sectional data).
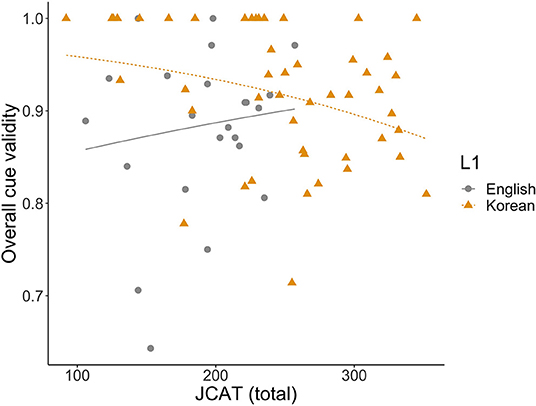
Figure 2. Overall cue validity (calculated for individual participants) of animacy as a function of JCAT scores with logistic regression fit; the lines represent the predicted validity for JCAT scores 106–257 for L1-English learners (solid line) and 92–352 for L1-Korean learners (dotted line).
In sum, much like in the previous section (Section Evaluation of the Availability, Reliability, and Validity of Animacy Cue in Sentences With an Overt Subject and Object), the animacy cue was highly available and reliable for all groups, but both learner groups had lower validity than native speakers, with L1-Korean learners having higher validity than L1-English learners. That said, this section offered a more nuanced picture that two groups followed a different trend—L1-English learners relied more on animacy at higher proficiency, while L1-Korean learners relied less.
Lastly, the ranking of the cues within each group was analyzed. Figure 3 summarizes the overall validity and reliability of cues in sentences with an overt subject and object (Figures 3A,B, respectively) and in all sentences (Figures 3C,D, respectively).
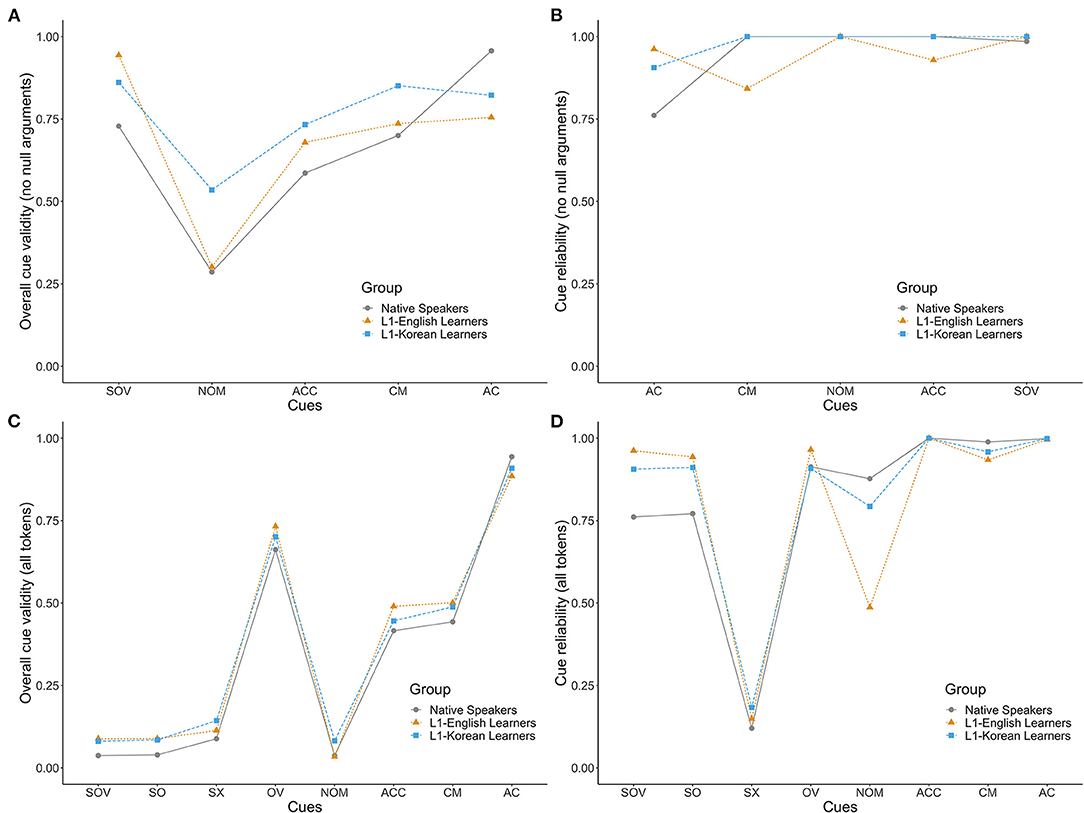
Figure 3. Overall validity and reliability of cues (SOV, canonical word order; SO, subject-object; SX, subject-first; OV, preverbal object; NOM, nominative; ACC, accusative; CM, case marking, combined; AC, animacy) in sentences with an overt subject and object [(A,B), respectively] and in all sentences [(C,D), respectively].
Let us first consider the overall validity as the primary indication of cue strengths. When only the sentences with an overt subject and object were considered, the cue ranking for each group based on overall validity was the following:
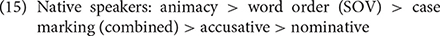
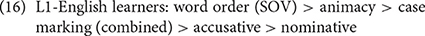
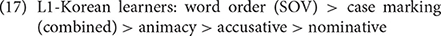
Three points are noteworthy. First, native speakers ranked the animacy cue as the strongest and case-marking cues as the weakest, contradicting previous studies. Second, word order was the strongest cue for both learner groups. This means that learners, regardless of their L1, used a common strategy of relying on word order. While Sasaki (1994) and Sasaki and MacWhinney (2006) suggested this may be due to input properties, this was not supported as word order was not the strongest cue for native speakers. Third, the second most important cue differed between L1-English and L1-Korean learners: it was the case marking (combined) cue for the L1-Korean learners and the animacy cue for the L1-English learners. This is possible evidence of L1 influence, where L1-Korean learners, but not L1-English learners, treated case markers as an important cue due to their L1 background. Therefore, this ranking seems to fit the fourth scenario in Section The Current Study, where the strongest cue is determined by a common learner strategy, and the order of the secondary cues are influenced by L1.
When all sentences, including those with null arguments, were considered, the cue ranking for each group based on overall validity was as follows:


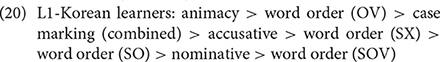
Overall, all groups followed a similar ranking when all sentences were considered, with the same ordering for the five strongest cues, matching the first scenario in Section The Current Study. The inclusion of null arguments in the analysis did not change the picture for the native speakers (except for the addition of word-order cues), but it changed the rankings for learners: Animacy was the strongest cue like the native speakers. This shows that, while learners used a common learner strategy to rely on the canonical word order when both the subject and object were present, they were able to use the same kind of information as native speakers when arguments were elided. The fact that animacy was also the most important cue for native speakers suggest that the reliance on animacy itself may not be a learner strategy. These findings would not have been apparent without investigating all utterances including those with null arguments, which constituted 93% of the data.
Yet another finding is that the preverbal object (OV) cue was the strongest among the different word-order cues for all groups. While the validity of the OV cue was higher for learners than for native speakers (Section Evaluation of the Availability, Reliability, and Validity of Word-Order Cue in All Sentences), showing again that learners rely more on word order than native speakers, the rankings in (18)–(20) show that relative importance of the OV cue did not differ among the groups.
Case marking was not the strongest cue in any group contrary to previous findings. The different rankings observed by this and previous studies may also be due to the task difference (production vs. comprehension) or the fact that the native speakers were talking to non-native speakers and were perhaps using “foreigner talk” in this study's data. That said, as stated above, the reliability of the case marking—particularly the accusative cue—was high for all groups. When the cue ranking was based on cue reliability, the rankings in sentences with an overt subject and object were as follows:
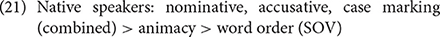
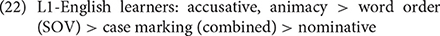

When all sentences were analyzed, the cue ranking based on cue reliability for each group was the following:



The native speakers' ranking in (21) is similar to the ranking proposed based on Ito et al.'s (1993) comprehension experiments (accusative > nominative > animacy > SOV), supporting the claim that reliability is a better predictor of cue strength for native adult speakers (Sokolov, 1988; MacWhinney, 2005). The reliability-based ranking changes slightly in (24), but accusative case marking is still ranked the highest, followed by animacy.
The ranking of case marking, especially accusative marking, in learners were also higher when reliability was considered instead of the overall validity. This shows that while case marking had low validity, its importance was clear through reliability ranking.
In sum, case marking was one of the most reliable cues in native speakers' speech, and this was mirrored in learners' speech, matching the first scenario in Section The Current Study. While this study was not designed to demonstrate the direct relationship between input properties and production or to demonstrate the actual learning process, the results corroborate Zhao and Fan (2021), who showed using statistical modeling that the cue reliability in the input was a reliable predictor of L2 learning.
That said, animacy persisted as an important cue, occupying two highest positions in all groups whether the ranking is based on reliability and validity9. The fact that this was true for native speakers and not just for learners suggest that the reliance on animacy is not necessarily a learner strategy, but that it is one of the most important cues in Japanese that learners can learn to use.
Detailed analyses of interactions between native speakers and learners in a Japanese learner corpus found non-canonical word order, null arguments, and case-marking omission to be frequent in both native speakers' and learners' speech, underscoring the importance of estimating cues in two different ways: one based on sentences with an overt subject and object, as done in previous experimental studies, and the other based on all sentences including those with null arguments. This was done for both native speakers and learners, addressing the research questions repeated below.
1. How are word order, case marking, and animacy used in the Japanese native speakers' speech when they interact with learners?
a. What are the relative cue strengths in sentences with an overt subject and object?
b. What are the relative cue strengths when null arguments are taken into consideration?
2. How are word order, case marking, and animacy used in the learners' speech?
a. Do the relative cue strengths differ from the native speakers in sentences with and without null arguments?
b. Do the cue strengths differ depending on the learners' L1 and proficiency?
The first research question asked how word order, case marking, and animacy are used in native speakers' speech when they interact with learners. Contrary to the prediction in Section The Current Study, the native speakers' cue ranking based on overall validity were similar whether null arguments were included in the analysis or not: Animacy was the most important, word order was the second most important, and case marking was the least important. A difference was only apparent in the importance of the different types of word-order cue. Due to the frequent null arguments, particularly null subjects, the SOV cue or any cue using the position of the subject had little importance, while the OV (preverbal object) cue was important.
Case-marking cues consistently ranked below animacy and word order for the native Japanese speakers based on overall validity. The different findings of this and previous studies may come from the task difference (production vs. comprehension), the nature of the data (spontaneous vs. elicited), or from the fact that the native speakers in the current study were talking to non-native speakers, thus representing foreigner talk. But case marking ranked among the highest based on cue reliability. This follows Sokolov (1988) in that adults' cue strengths follow cue reliability more closely.
The second question asked how the three cues of word order, case marking, and animacy are used in learners' speech. Unlike native speakers, the word-order cue was the most important cue in both learner groups in sentences with an overt subject and object. In addition, both learner groups showed significantly higher validity of the word-order cue than native speakers, due to their reliance on the SOV schema (i.e., high word-order cue reliability). This reliance on word order was previously reported for L1-English learners (Kilborn and Ito, 1989) as evidence of L1 influence, but the fact that the L1-Korean learners used the same strategy supports Sasaki and MacWhinney's (2006) suggestion that learners of Japanese, regardless of L1, may rigidify the SOV schema. One possible explanation for this strategy, as Sasaki (1994) speculated, is that word-order cues are more reliable in the input learners receive than in authentic speech. While the current results do not refute this account, the reliability of the SOV cue in native speakers' speech (0.761) was not very different in this study than what has been previously reported for canonical sentences in native-speaker interactions. This points to the possibility that the word-order strategy seen among learners does not stem from the influence of their L1 or the input they receive.
Both learner groups showed significantly lower validity of the animacy cue than native speakers, resulting from their lower reliance on the animacy contrast (animacy cue availability). This might lead to the conclusion that animacy was not important information for learners, but the picture changed when null arguments were taken into consideration.
Unlike native speakers, who showed similar rankings in sentences with and without null arguments, the whole ranking changed for learners when all data were included in the analysis (19, 20). It is important to note that they had a similar cue ranking as the native speakers, with the differences only apparent in the ranking of the three weakest cues, such as SO, SOV, and nominative cues. This means that, when all sentences, rather than only those with an overt subject and object, were considered, learners behaved much like native speakers.
One of the most important observations is that the animacy cue was ranked highest in all groups when sentences with null arguments were taken into consideration. This cue was both highly available (i.e., widespread use of an animacy contrast and rare use of subject and object with the same animacy value) and reliable (i.e., subjects were animate and objects inanimate). This prototypical animacy configuration was utilized as a strong cue not just by native speakers but also by learners (although to a lesser extent). This finding suggests that previous comprehension experiments focusing on the interpretation of sentences with an overt subject and object did not provide a full picture of how transitive relations in languages with frequent null arguments such as Japanese are expressed, and that the importance of animacy has been previously underestimated.
The OV cue was the most important among different word-order cues when null arguments were taken into consideration. While it was ranked lower than the animacy cue, learners' reliance on word order was still evident: Both learner groups showed higher validity than native speakers for the OV cue (and all other word-order cues), although it was the second most important cue after the animacy cue for all groups.
Like native speakers, learners also showed very high reliability of case marking and ranked the case-marking cue high when the ranking was based on cue reliability. This suggests that learners can come to use case marking reliably when case markers have low overall validity due to frequent omission. It is possible that despite the low overall validity of this cue, its high reliability contributes to learning. Further research, however, should analyze actual classroom discourse and consider the role of instruction to fully address this question.
In the first set of analyses that included only sentences with an overt subject and object, there were no proficiency effects, and L1 difference was only evidence in the animacy cue: the validity of the animacy cue was higher for L1-Korean learners than for L1-English learners in the subset analysis.
While there were no statistically significant L1 effects for case marking, it is noteworthy that L1-English learners and L1-Korean learners ranked the case-marking cue differently. L1-Korean learners ranked the combined case-marking cue as the second most important cue after the word-order cue, but L1-English learners ranked it below animacy and word order (and so did native speakers). This difference can be attributed to L1 backgrounds of learners, because Korean uses a similar case marking with Japanese and the case-marking cue was found to be the most important cue in previous experimental work on Korean.
In the second of analyses that included all sentences, the ranking of the cues was similar between two learner groups, but proficiency effects appeared with the OV cue: The validity of the OV cue was higher for higher proficiency learners, suggesting that learners with higher proficiency are more likely to use this partial frame to express transitive relations.
There was an effect of L1 as well as the interaction of L1 and proficiency for the animacy cue. Its validity was higher for the L1-Korean learners as a group than for the L1-English learners as a group, but the two groups showed opposite trends by proficiency. That is, the animacy cue's validity was higher for L1-English learners with higher proficiency and lower for L1-Korean learners with higher proficiency. Because the L1-English learners' proficiency range was narrower than that of the L1-Korean learners in this study, the extent of these trends is unclear. Nevertheless, given that the animacy cue ranked low in English and higher in Korean, it is possible that L1-English learners adjust relative cue strengths to match the norms of the target language as they gain proficiency, and that L1-Korean learners start out with a heavier reliance on lexical semantics that diminishes as they gain higher proficiency. However, it is also important to remember that, as groups, the L1-English and L1-Korean learners were more like each other, in showing lower validity for the animacy cue, than either group was to the native speakers.
In this study, I showed that both the overall validity and the ranking of the cues change when sentences with null arguments are included in the analysis. Previous experimental work in the competition model framework—both on native Japanese speakers and learners—tested sentences in which case markers were omitted but have not tested sentences with null arguments. This study highlights the necessity to take null arguments into consideration when the cue strengths are estimated in Japanese and other null-argument languages.
This study also showed a different cue ranking for Japanese, even when the type of sentences analyzed were comparable to previous experimental study. I suggested that this can be attributed to task difference (production vs. comprehension) or the nature of the data (spontaneous vs. elicited). A potential study that can be designed to test this possibility would estimate cue strengths based on elicited production, a type of data currently largely missing in the competition model literature, as also proposed by Zhao and Fan (2021).
If it is indeed true that cue strengths in spontaneous production and comprehension experiment can lead to different estimation, this also means that we need to revisit the predictions generated in this study regarding L1 influence, as they were based on pervious comprehension experiments on English and Korean. It would be desirable to conduct a similar type of corpus analysis on English and Korean spontaneous speech in order to predict more accurately how and whether their spontaneous use of L1 cues would influence their L2 spontaneous speech.
The current study analyzed oral interactions between native speakers and learners of Japanese in a learner corpus and found the frequent occurrence of flexible word order, null arguments, and case-marker omission in both native speakers' and learners' speech.
Drawing on the competition model, the study examined how cues of word order, case marking, and animacy are used in native speakers' and learners' speech, as well as looking for L1 and proficiency differences. To my knowledge, this study is among the first to apply the competition model framework to offer a comprehensive picture of input to learners as well as learners' production in any target language, the other being Zhao and Fan (2021).
One set of analyses examined a subset of sentences with an overt subject and object to make the findings comparable to previous competition model research; a second set of analyses examined all sentences to consider the role of null arguments in Japanese. These analyses demonstrated that null arguments influence the relative importance of cues, particularly in analyzing learners' speech, suggesting the importance of taking ellipsis into consideration when examining the role of cues in a null-argument language like Japanese.
Importantly, however, animacy was consistently the strongest cue based on overall validity in native Japanese speakers' speech, and it was also the strongest cue for learners when null arguments were taken into consideration. These findings suggest that future research should look closely into the question of whether reliance on lexical semantics is a learner strategy or reflects the characteristics of the input they receive. Whichever may be the case, this study's findings suggest that both native speakers and learners use the prototypical animacy configuration (animate subject and inanimate object) as a strong cue for expressing transitivity, and that doing so is necessary in a null-argument language like Japanese.
L1-English and L1-Korean groups were similar in their reliance on word order: They produced SOV word order most of the time when they expressed both subject and object overtly and the validity of the word-order cues were consistently higher in both learner groups than in native speakers, which suggests that rigidifying word order is a strategy used by learners regardless of L1 (unless null arguments make such a cue useless). They were also similar in that their validity of the animacy cue was lower than native speakers, although the validity was significantly higher for L1-Korean learners than for L1-English learners. Case marking was ranked as the second strongest cue for L1-Korean learners and the weakest cue for L1-English learners, suggesting L1 influence, as Korean, but not English, has a similar case-marking system as Japanese.
The only proficiency effects observed were in the validity of the OV and animacy cues. The validity of the OV cue was stronger at higher proficiency levels. L1-English and L1-Korean groups showed different trends in regard to the animacy cue, but this observation is limited as the two groups' proficiency ranges differed. Future research should compare L1 groups with similar L2 proficiency levels.
Lastly, case marking ranked low among the cues, contra previous comprehension experiment results, although all groups' production showed very high reliability of the case-marking cues, with the exception of L1-English learners' use of the nominative -ga. Hence, how learners are able to learn case marking when its cue validity is low is still an open question—although explicit instruction on case marking is provided in a typical high school or college Japanese language classroom. Further research is needed on actual classroom discourse, the role of input, and the role of instruction.
Publicly available datasets were analyzed in this study. This data can be found here: http://lsaj.ninjal.ac.jp/.
NT conceived the presented idea, analyzed and interpreted the data, and drafted the manuscript.
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
I thank Brian MacWhinney, Yasuhiro Shirai, and Marta Velnic for their valuable input on the manuscript; two reviewers for their helpful comments on an earlier version of the manuscript; and Laurie Durand for her editorial support. I also gratefully acknowledge the feedback I received at Indiana University's Second Language Studies colloquium, National Institute for Japanese Language and Linguistics's I-JAS Kansei Kinen Sinpoziumu [A symposium commemorating the completion of I-JAS], and a symposium titled CHILDES, TalkBank, Competition, Emergentism: Honoring the Impact of Brian MacWhinney on Language Research.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2022.827336/full#supplementary-material
1. ^List of abbreviations: ACC, accusative; CL, classifier; COP, copula; FILL, filler; GEN, genitive; GER, gerundive; HON, honorific; NOM, nominative; NPST, non-past; PASS, passive; PL, plural; PST, past; TOP, topic marker.
2. ^Takeuchi (2014) reported raw token numbers for Banno et al.'s two textbooks (Banno et al., 2011a,b), which I recalculated as percentages (53.7 and 47.9%, respectively).
3. ^I-JAS also reports the scores from the Simple Performance Oriented Test (SPOT; Ford-Niwa et al., 1994). While these two tests' scores have been found to be highly correlated with each other, Hirotani et al. (2017) found J-CAT total scores to be correlated more strongly with oral proficiency than SPOT scores.
4. ^Proficiency levels were taken from https://www.j-cat2.org/html/ja/pages/interpret.html, where total scores between 0 and 100 would be classified as Beginner, and the minimum cut-off for each subsequent levels were 100 for Basic, 150 for Basic-High, 200 for Pre-Intermediate, 250 for Intermediate, 275 for Intermediate-High, 300 for Pre-Advanced, 325 for Advanced, and 350 for Near Native. The website also offers Common European Framework of Reference (CEFR) and Japanese-Language Proficiency Test (JLPT) equivalents of these levels, and the minimum cut-off of J-CAT total scores for CEFR levels were 175 for A2, 225 for B1, 275 for B2, and 325 for C1.
5. ^The correct pronunciation of the word was zenbu “all” bur pronounced as zyenbu by the speaker. The Japanese examples (11–14) were Romanized based on the transcriptions in Japanese orthography and do not represent phonetic transcription.
6. ^The exclusion of repetition is not unproblematic. First, learners repeat selectively. Further, and more importantly, this exclusion disregards the possibility of a frequency effect from repetition on the learners' language development. The routine practice of excluding repetition in both L1 and L2 acquisition research raises methodological questions that need to be addressed in future research.
7. ^While conflict validity was also analyzed, the results are not included in this paper upon the recommendation of a reviewer as there was too little data. The scarcity of conflict situations in natural interactions underscores the importance of an experimental study to measure conflict validity.
8. ^The validity was calculated as the number of tokens available and reliable for an individual participant divided by all tokens analyzed for the participant.
9. ^When cue coalition (multiple cues supporting the same interpretation) was analyzed, the most frequent pattern was the use of animacy as the sole reliable cue (when both the word-order cue and case-marking cue was unavailable or unreliable) (Native speakers: 702 tokens, 51.3%; L1-English learners: 237 tokens, 41.9%, L1-Korean learners: 496 tokens, 45.9%), but the second most frequent pattern was the combination of the reliable animacy cue and the reliable case-marking cue (when the word-order cue was unavailable or unreliable) (Native speakers: 542 tokens, 39.6%; L1-English learners: 226 tokens, 40.0%, L1-Korean learners: 416 tokens, 38.5%). Case marking was seldom used as the sole reliable cue and was usually used in a redundant context. Therefore, animacy was still the most important cue, but case marking was a strong supportive cue in the absence of a reliable word order cue.
Aida, M. (1993). Omission of postpositions in Japanese mothers' speech to one-year-old children. Sophia Linguist. 33, 313–331.
Banno, E., Ohno, Y., Sakane, Y., and Shinagawa, C. (2011a). Genki I: An Integrated Course in Elementary Japanese. Tokyo: Japan Times.
Banno, E., Ohno, Y., Sakane, Y., and Shinagawa, C. (2011b). Genki II: An Integrated Course in Elementary Japanese. Tokyo: Japan Times.
Bates, E., and Devescovi, A. (1989). “Crosslinguistic studies of sentence production,” in The Crosslinguistic Study of Sentence Processing, eds B. MacWhinney and E. Bates (Cambridge: Cambridge University Press), 225–253.
Bates, E., and MacWhinney, B. (1989). “Functionalism and the competition model,” in The Crosslinguistic Study of Sentence Processing, eds B. MacWhinney and E. Bates (Cambridge: Cambridge University Press), 3–73.
Chan, A., Lieven, E., and Tomasello, M. (2009). Children's understanding of the agent-patient relations in the transitive construction: cross-linguistic comparisons between Cantonese, German, and English. Cogn. Linguist. 20, 267–300. doi: 10.1515/COGL.2009.015
Comrie, B. (1979). Definite and animate direct objects: A natural class. Linguistica Silesiana 3, 13–21. doi: 10.5281/zenodo.3862697
Ferreira, V. S., and Yoshita, H. (2003). Given-new ordering effects on the production of scrambled sentences in Japanese. J. Psycholinguist. Res. 32, 669–692. doi: 10.1023/A:1026146332132
Ford-Niwa, J., Kobayashi, N., and Yamamoto, H. (1994). Nihongo nôryoku kan'i siken (SPOT) ni okeru onsei têpu no yakuwari ni kansuru kenkyû [Development of a Simple Performance Oriented Test (SPOT): a study of the tape listening factor]. J. Jpn. Lang. Educ. Methods 1, 18–19. doi: 10.19022/jlem.1.3_18
Fry, J. (2003). Ellipsis and Wa-Marking in Japanese Conversation. New York, NY: Routledge. doi: 10.4324/9780203484036
Gass, S. (1987). The resolution of conflicts among competing systems: a bidirectional perspective. Appl. Psycholinguist. 8, 329–350. doi: 10.1017/S0142716400000369
Hinds, J. (1982). Case marking in Japanese. Linguistics 20, 541–557. doi: 10.1515/ling.1982.20.7-8.541
Hirotani, M., Matsumoto, K., and Fukada, A. (2017). The validity of general L2 proficiency tests as oral proficiency measures: a Japanese learner corpus based study. Jpn Lang Literat. 51, 243–270. Available online at: https://www.jstor.org/stable/44508416
Ikeda, A., Kobayashi, T., and Itakura, S. (2016). Nihongo bogo wasya no tainyûyôzi hatuwa ni okeru kakuzyosi syôryaku [Omission of case markers in child-directed speech by Japanese-speaking caretakers]. Cognit. Stud. 23, 8–21.
Imai, S., Kuroda, F., Honda, A., Akagi, Y., Nakasono, H., and Ito, S. (2013). J-CAT (Japanese Computerized Adaptive Test) no un'yo [Operation of J-CAT (Japanese Computerized Adaptive Test)]. J. Jpn. Lang. Educ. Methods 20, 30–31. doi: 10.19022/jlem.20.1_30
Ito, T., Tahara, T., and Park, W. (1993). Bun no rikai ni hatasu zyosi no hataraki: Nihongo to kankokugo o tyûsin ni [The role of particles in sentence comprehension: Focusing on Japanese and Korean]. Tokyo: Kazama Shobo.
Kempe, V., and MacWhinney, B. (1998). The acquisition of case-marking by adult learners of Russian and German. Stud. Sec. Lang. Acquisit. 20, 543–587. doi: 10.1017/S0272263198004045
Kilborn, K., and Ito, T. (1989). “Sentence processing strategies in adult bilinguals,” in The Crosslinguistic Study of Sentence Processing, eds B. MacWhinney and E. Bates (Cambridge: Cambridge University Press), 257–291.
Koda, K. (1993). Transferred L1 strategies and L2 syntactic structure in L2 sentence comprehension. Modern Lang. J. 77, 490–500. doi: 10.1111/j.1540-4781.1993.tb01997.x
Kurumada, C., and Jaeger, T. F. (2015). Communicative efficiency in language production: optional case-marking in Japanese. J. Mem. Lang. 83, 152–178. doi: 10.1016/j.jml.2015.03.003
Kuznetsova, A., Brockhoff, P. B., and Christensen, R. H. B. (2017). lmerTest package: tests in linear mixed effects models. J. Stat. Softw. 82, 1–26. doi: 10.18637/jss.v082.i13
MacWhinney, B. (1987). Applying the competition model to bilingualism. Appl. Psycholinguist. 8, 315–327. doi: 10.1017/S0142716400000357
MacWhinney, B. (2000). The CHILDES Project: Tools for Analyzing Talk, 3rd Edn. Mahwah, NJ: Lawrence Erlbaum.
MacWhinney, B. (2005). “A unified model of language acquisition,” in Handbook of Bilingualism: Psycholinguistic Approaches, eds J. Kroll and A. de Groot (Cambridge: Oxford University Press), 49–67.
Matsuo, A., Kita, S., Shinya, Y., Wood, G. C., and Naigles, L. (2012). Japanese two-year-olds use morphosyntax to learn novel verb meanings. J. Child Lang. 39, 637–663. doi: 10.1017/S0305000911000213
McDonald, J. L. (1986). The development of sentence comprehension strategies in English and Dutch. J. Exp. Child Psychol. 41, 317–335. doi: 10.1016/0022-0965(86)90043-3
McDonald, J. L. (1987). Assigning linguistic roles: the influence of conflicting cues. J. Mem. Lang. 26, 100–117. doi: 10.1016/0749-596X(87)90065-9
McDonald, J. L. (1989). “The acquisition of cue-category mappings,” in The Cross-Linguistic Study of Sentence Processing, eds B. MacWhinney and E. Bates (Cambridge: Cambridge University Press), 375–396.
McDonald, J. L., and Heilenman, K. (1991). Determinants of cue strength in adult first and second language speakers of French. Appl. Psycholinguist. 12, 313–348. doi: 10.1017/S0142716400009255
Minashima, H. (2001). On the deletion of accusative case markers in Japanese. Stud. Linguist. 55, 176–191. doi: 10.1111/1467-9582.00078
Mitsugi, S., and Macwhinney, B. (2016). The use of case marking for predictive processing in second language Japanese. Bilingual. Lang. Cognit. 19, 19–35. doi: 10.1017/S1366728914000881
Oka, M., Tsutsui, M., Kondo, J., Emori, S., Hanai, Y., and Ishikawa, S. (2009). Tobira: Gateway to Advanced Japanese. Tokyo: Kuroshio.
Ono, T., Sadler, M., and Daiju, S. (2020). “Nihongo kaiwa ni okeru “kihonteki” tadôsisetu: Genzituteki tôgoron no kôtiku wo mezasite [Basic transitive clauses in Japanese conversation],” in Ninti gengogaku to danwa kinô gengogaku no yûkiteki setten [Cognitive linguistics and discourse-functional linguistics], eds T. Nakayama and N. Otani (Tokyo: Hitsuji Shobo), 165–182.
Ono, T., and Suzuki, R. (1992). Word order variability in Japanese conversation: motivations and grammaticization. Text Interdisc. J. Study Disc. 12, 429–446. doi: 10.1515/text.1.1992.12.3.429
Pham, G., and Ebert, K. D. (2016). A longitudinal analysis of sentence interpretation in bilingual children. Appl. Psycholingusit. 37, 461–485. doi: 10.1017/S0142716415000077
Rispoli, M. (1989). Encounters with Japanese verbs: caregiver sentences and the categorization of transitive and intransitive action verbs. First Lang. 9, 57–80. doi: 10.1177/014272378900902506
Rounds, P. L., and Kanagy, R. (1998). Acquiring linguistic cues to identify agent. Stud. Sec. Lang. Acquisit. 20, 509–542. doi: 10.1017/S0272263198004033
Sakoda, K., Konishi, M., Sasaki, A., Suga, W., and Hosoi, Y. (2016). Tagengo bogo no nihongo gakusyûsya ôdan kûpasu [International Corpus of Japanese as a Second Language]. NINJAL Project Rev. 6, 93–110. doi: 10.15084/00000831
Sasaki, Y. (1991). English and Japanese interlanguage comprehension strategies: an analysis based on the competition model. Appl. Psycholinguist. 12, 47–73. doi: 10.1017/S0142716400009371
Sasaki, Y. (1994). Paths of processing strategy transfers in learning Japanese and English as foreign languages: a competition model approach. Stud. Sec. Lang. Acquisit. 16, 43–72. doi: 10.1017/S0272263100012584
Sasaki, Y., and MacWhinney, B. (2006). “The competition model,” in The Handbook of East Asian Psycholinguistics: Japanese, Vol. 2, eds M. Nakayama, R. Mazuka, and Y. Shirai (Cambridge: Cambridge University Press), 307–314. doi: 10.1017/CBO9780511758652.044
Shirai, Y. (1992). Conditions on transfer: A connectionist approach. Issues Appl. Linguist. 3, 91–120. doi: 10.5070/L431005153
Sokolov, J. L. (1988). Cue validity in Hebrew sentence comprehension. J. Child Lang. 15, 129–155. doi: 10.1017/S0305000900012095
Takeuchi, M. (2014). Subject referential expressions and encoding of referential status in L2 narrative discourse by L1-English learners of Japanese (Doctoral dissertation). Indiana University, Bloomington, IN, United States.
Tanaka, N., and Shirai, Y. (2014). “L1 acquisition of Japanese transitive verbs: how do children acquire grammar in the absence of clear evidence?” in Japanese/Korean Linguistics, Vol. 21, eds S. Nam, H. Ko, and J. Jun (Stanford, CA: CSLI), 281–295.
Yamashita, H. (2002). Scrambled sentences in Japanese: linguistic properties and motivations for production. Text Interdisc. J. Study Disc. 22, 597–633. doi: 10.1515/text.2002.023
Yamashita, H., and Chang, F. (2001). “Long before short” preference in the production of a head-final language. Cognition 81, 45–55. doi: 10.1016/S0010-0277(01)00121-4
Keywords: Japanese, competition model, animacy, word order, case marker, learner corpus
Citation: Tanaka N (2022) Estimating Cue Strengths in Oral Production in a Japanese Learner Corpus. Front. Commun. 7:827336. doi: 10.3389/fcomm.2022.827336
Received: 01 December 2021; Accepted: 07 March 2022;
Published: 15 April 2022.
Edited by:
Juan Carlos Valle-Lisboa, Universidad de la República, UruguayReviewed by:
Brian MacWhinney, Carnegie Mellon University, United StatesCopyright © 2022 Tanaka. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Nozomi Tanaka, dGFuYWthbkBpdS5lZHU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.