Abstract
The term “multimodality” incorporates visible gestures as part of language, a goal first put forward by Adam Kendon, and this idea revolutionized the scope of linguistic inquiry. But here I show that the term “multimodality” itself is rife with ambiguity, sometimes referring to different physical channels of transmission (auditory vs. visual), and sometimes referring to the integration of linguistic structures with more imagistic, less conventionalized expressions (see David McNeill's work), regardless of the physical channel. In sign languages, both modes are conveyed in a single, visual channel, revealed here in the signing of actors in a sign language theatre. In spoken languages, contrary to expectations raised by defining “modality” in terms of the physical channel, we see that the channel of transmission is orthogonal to linguistic and gestural modes of expression: Some visual signals are part and parcel of linguistic structure, while some auditory (intonational) signals have characteristics of the gestural mode. In this empirical, qualitative study, I adopt the term “mode” to refer solely to specific characteristics of communicative expression, and not to the physical channel. “Multimodal” refers to the coexistence of linguistic and gestural modes, regardless of the physical channel of transmission—straightforwardly encompassing the two natural language systems, spoken and signed.
1 Introduction
Ever since the groundbreaking work of Kendon (1980, 2004) and McNeill (1992), researchers have increasingly paid attention to the gestural side of language, and there is now a very large body of literature about what is termed “multimodality” (see the extensive handbook of Müller et al., 2013, Müller et al., 2014). Because most linguistic organization in spoken languages is in the vocal/auditory channel and most gestural information is in the visual channel, researchers often assume that the types of expression involved can be distinguished by the physical channel. At the same time, since speech and gesture are closely integrated, other researchers hold that they must be considered part of the same phenomenon (Kendon, 2004; Fricke, 2013; Goldin-Meadow and Brentari, 2017). But this dichotomy of views has led to confusion in establishing a unified definition of modality.
Sign languages are characterized by all the traditionally defined levels of linguistic structure—phonology, morphology, syntax, prosody, and semantics (Sandler and Lillo-Martin, 2006; Pfau et al., 2012). But if the physical channel were the determining factor for separating the gestural from the linguistic, sign language would be an anomaly. In sign languages, the vocal-auditory channel is not available, and the linguistic signal itself is conveyed primarily by the hands, the head, and parts of the face, and perceived by the eyes. There should be no “modality” left for gesture and no multimodality in sign language. Yet we know and will show here that signers do gesture (Emmorey, 1999; Sandler, 2009).
In a research paradigm called The Grammar of the Body,1 my colleagues and I were able to associate linguistic structures with precise articulations of face, hands, and body in established and emerging sign languages, demonstrating how visible bodily articulations alone can convey bona fide linguistic structure (Sandler, 2012a; Sandler, 2018), described in Section 2. We will see in Section 3 that the same physical apparatus in sign languages conveys expressions that are gesturally organized as well, and we adopt the term ‘mode’ to refer to either linguistic or gestural forms. By this distinction, identifying both the linguistic mode and the gestural mode in sign language becomes straightforward, so that all natural human languages, spoken or signed, are properly described as multimodal.2 Here, to avoid confusion, I refer to spoken and signed languages as two kinds of language, rather than using the term “modalities.”
This paper deals only with one family of gestures—iconic gestures. Iconicity means that the signal, whether auditory or visual, resembles its meaning. An example of an iconic co-speech visual gesture is shown in Figure 1. As background, Table 1 shows the properties that distinguish iconic gestures from linguistic expressions (essentially, words), based on McNeill (1992), and further discussed in Section 1.1.
FIGURE 1
TABLE 1
| Linguistic mode | Gestural mode |
|---|---|
| Meaningless and meaningful levels (duality of patterning) | Global/holistic |
| Arbitrary | Imagistic/iconic |
| Combinatorial with respect to other elements of the same kind | Noncombinatorial with respect to other elements of the same kind |
| Conventionalized | Idiosyncratic, context-sensitive |
| Discrete | Gradient |
Dichotomy between the linguistic and the gestural, after McNeil (1992).
In his seminal book, McNeill (1992) distinguished gestural from linguistic form, asserting that together they comprise language. McNeill proposed that there are several kinds of gestures, among them, iconic gestures, which describe visual properties or locations, constituting the focus here; beats, which emphasize the rhythm of speech; metaphoric gestures, which abstractly represent concepts or topics in a discourse; and deictics, which point to or establish the location of a referent. Citing the temporal coordination of gesture and speech prosody (see also Brown and Prieto, 2017 for a recent, detailed analysis), McNeill’s treatment proposes that gestural and linguistic form together make ‘language’, distinguishing between “the linguistic” and “language”—a seemingly blurry distinction, but one that I see as essentially correct, precisely because all natural language communication has linguistic and gestural modes of expression, and, although the two can be distinguished, the dividing line is not always clear (see Okrent 2002). Section 1.1 elaborates the characteristics that distinguish the linguistic and the gestural modes in Table 1.
1.1 Linguistic and Gestural Modes
Gestural and linguistic organization comprise two modes of expression common to both spoken and signed languages, and not defined in terms of the physical channel of transmission. The following introduction to properties of gestural vs. linguistic modes, suggested by McNeill (1992) and represented in Table 1, includes certain amendments, that are motivated by the present exploration, as explained throughout this paper.
1.1.1 Duality of Patterning Versus Global
Spoken language morphemes and words are characterized by a meaningless phonological level and a meaningful level, a distinction described in terms of secondary articulation by Martinet (1960), and called duality of patterning by Hockett (1960). Iconic gestures are globally organized—an iconic gesture looks like what it means as a whole, without a list of internal meaningless elements that recombine in a systematic, rule-governed way that characterizes duality of patterning. In sign languages, signs are formed by a finite list of meaningless primitives, like spoken words, and substituting one for another can create new words (Stokoe, 1960). Another criterion for duality of patterning is that the primitive elements can be altered by systematic rules, referring only to the form but without reference to meaning (Sandler, 2012b). The important insight here is that there are systematically organized meaningless and meaningful levels in the linguistic structuring of spoken words and of signs in sign languages. This contrasts with iconic gestures, like the one shown in Figure 1A, in which there is neither a level of finite, meaningless building blocks, nor systematic rules referring to them. The gesture could be made in many different ways and still convey the image of a plank falling. Signs, like spoken words, have duality of patterning; gestures are globally structured.
1.1.2 Arbitrary Versus Imagistic
The forms of spoken language words typically have an arbitrary relationship with their meaning (de Saussure et al., 1959), while iconic gestures are imagistic; they create visual impressions to enhance meaning (see Figure 1A). While signs themselves, akin to spoken words, can also be imagistic or iconic, there are still many differences in degree and type of iconicity between the two kinds of language (see e.g., Sandler, 2009, Perniss et al., 2010, Downing and Stiebels, 2012, Dingemanse et al., 2015, Lepic et al., 2016, and Dingemanse et al., 2020 for more detail). The signs of sign languages have much more iconicity than words in spoken languages do, making the distinction between iconic and arbitrary more nuanced (see Sections 2–4), but the distinction between arbitrary and iconic is still relevant for distinguishing linguistic from iconic gestural form. Signs are “globally” iconic more often than spoken words (see for example Figure 2), and sublexical units, which behave phonologically like meaningless elements, can themselves be interpreted as meaning-bearing, as we will see in Section 2. Section 4 shows how the underlying iconicity in the building blocks of signs can be invoked in artistic expression.
FIGURE 2
1.1.3 Combinatorial/Non-combinatorial Relations
Morphemes and words typically combine with other units of the same type to form larger constituents with predictable meanings (see Werning et al., 2012 (eds) on compositionality). Gestures coincide with constituents of the linguistic signal but do not enter into combinatorial relations with each other. For McNeill, the term combinatorialty is restricted to linear, syntactic combinations and relations; that is, the claim is that sequences of gestures are not combined with each other according to their own rules, which seems correct. While gestural elements can have internal and simultaneous combinatoriality (Calbris, 1990; Fricke, 2014), they do not enter into sequential combinations with each other, without linking independently to linguistic structures. The picture is made more interesting by the observation shown in Section 5.3, that gestures can appear sequentially before or after words (Schlenker, 2019), playing a semantic (linguistic) role. Yet gestures do not seem to combine in any rule-governed way with each other. The intent of the bifurcation in Table 1 between combinatorial and non-combinatorial, then, is sequential combinatoriality of elements of the same kind: linguistic elements are sequentially combinatorial with one another; gestures are not.
1.1.4 Conventionalized Versus Idiosyncratic
Linguistic elements are conventionalized within a community in terms of meaning and distribution. But the same gesture can have different meanings (within and across individuals), depending on the linguistic context, and the choice and meaning of iconic gestural elements also vary within and across individuals. This idiosyncrasy implies context-sensitivity, since the intended meaning of the iconic image can only be interpreted according to context (See Figure 9 below).
1.1.5 Discrete Versus Gradient
Put simply, this distinction means that linguistic elements tend to be underlyingly discrete in the senese that their form does not vary systematically in tandem with gradient degrees of emphasis or meaning.3 Contrarily, any gradient variation in the production of iconic gestures is interpreted analogically to real world form or action. So, in English, adjectives such as big or heavy do not change their form systematically to represent degree of size or heaviness, nor is the form of verbs such as climb or run altered to represent degrees of difficulty or speed.4 The complex word rewind means “to wind again,” and one does not reduplicate the prefix to signal how many times this winding takes place. There is no *rerererewind indicating winding four times. Similarly, enlarge means to make bigger, and the form of the word does not analogically represent the resulting size. We will see in Section 5.3 that this property is only partly definitive in distinguishing the linguistic mode from the gestural.
By these criteria, I will briefly exemplify linguistic structure in the phonology and intonation of sign languages in Section 2, mainly using Israeli Sign Language (ISL) as the example. Section 3 demonstrates gestural elements in sign languages. Section 3.2 demonstrates that, in addition to linguistic roles, the mouth is abundantly used for iconic gesture across sign languages. In so-called classifier constructions, which are hybrids of linguistic and gestural modes, discussed in Section 3.3, the hands combine the linguistic mode with the gestural. Since all of the same articulators used for gesture are also used for strictly linguistically organized material in sign language, dividing the material according to physical channel of transmission clearly does not capture the facts.
Redefining “multimodal” as comprised of gestural and linguistic modes, and divorcing it from the physical channel of transmission, allows for the interaction between the two types of organization that we find in both signed and spoken languages. An informative consequence of the distinction is this: If the gestural and the linguistic are two modes of language, and if they can naturally coexist in the same physical channel as they do in sign languages, this leads to the expectation that there will some interaction between the two in natural communication, and indeed there is. Section 4 provides examples of interaction between linguistic and gestural modes from theatrical and poetic signing in the Ebisu Sign Language Theatre Laboratory. We will see there that signals that have made their way into the linguistic phonological structure still remain available for spontaneous gesture. So, sign languages cross the line between linguistic and gestural modes in one and the same visually perceived system, and they sometimes cross back, making the division a little less crisp than might have been thought. I will argue that this is a theoretically desirable consequence.
Turning to spoken language, here we assume traditional background in linguistic structure, and we will not delve into it here. We also know well that spoken languages exploit visual signals for gesture. But likening “modality” to the physical channel of transmission does not work for spoken language either. The modes of language and their physical instantiation criss-cross in spoken languages. The distinctions and their interactions can be seen schematically in Table 2.
TABLE 2
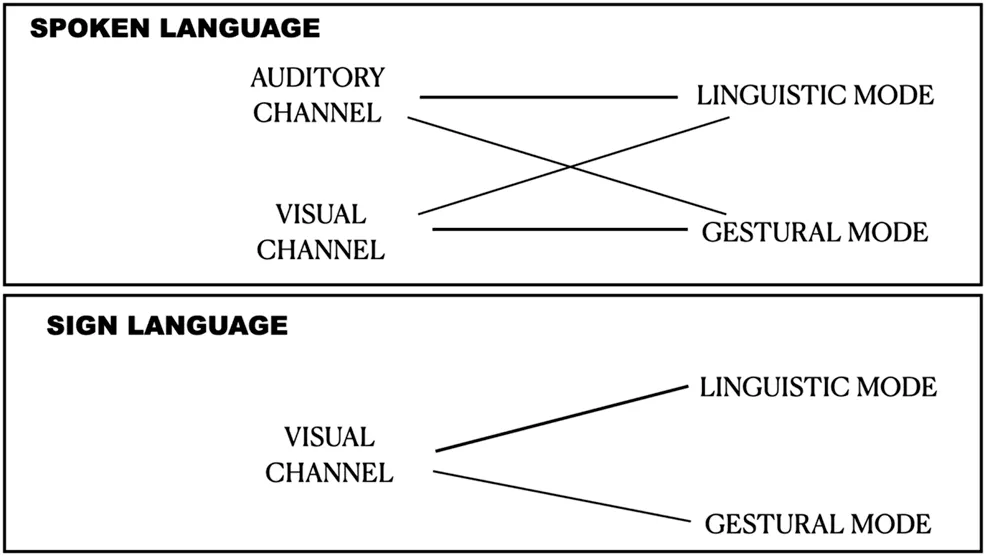 |
The relations between channel and mode in spoken language and in sign language.
Section 5 reviews evidence that spoken languages, like sign languages, exploit visual signals as part of the linguistic mode, but that they also exploit auditory signals for gesture. In other words, there is evidence that spoken languages, primarily transmitted in the auditory channel, also use visual signals in the linguistically organized system, particularly at the levels of reference (Fricke, 2013; Landau, 2016), and semantics (Schlenker, 2018; Schlenker, 2019; Ebert et al., 2020). At the same time, the auditory channel can exploit the gestural mode, specifically, in intonation and information structure (Bolinger, 1983; Ladd, 1996; Swerts and Krahmer, 2008; Prieto, 2015). Once again, we see that the division between the linguistic and the gestural has to do with characteristics of the modes of expression, and not with the channel of transmission. We conclude in Section 6 that spoken and signed languages are not different language “modalities,” but rather two different kinds of language, each multimodal, each exploiting the linguistic and the gestural modes in its own way. This analysis points to a flexible and dynamic model of human language.
1.2 Excluded Topics
Four topics that sometimes figure in gesture and sign language studies will not be dealt with in the present analysis, in the interest of economy. These are: emblems, a gesture-sign “continuum,” pantomime/constructed action, and silent gesture. Here I briefly describe each, to delimit the goals of this study.
1.2.1 Emblems
Kendon, McNeill, and other gesture researchers have dealt with emblems (see also Efron, 1941; Kendon, 1988, Kendon, 2004, and Müller, 2019), such as OK, VICTORY, TIME-UP, BE-QUIET. Emblems are sometimes claimed to be closest to signs of sign language, and, according to Kendon, closest to words, precisely because they are conventionalized, unlike other gestures. But by familiar definitions, emblems seem to be the opposite of words. As Kendon also explains, emblems are whole speech acts. However, this is a function which individual words rarely bear, and therefore it seems to contradict the idea that emblems are closest to words. Emblems have no syntactic or other grammatical category, but rather stand for whole propositions; they cannot undergo inflection or derivation; and they do not enter into hierarchical or sequential relations with other gestures or words. Unlike signs, prototypical emblems are rarely iconic of objects and actions in the world. In fact, unlike iconic and deictic gestures, emblems very rarely become signs, though they can be used as conventional gestures, not only by speakers but by signers as well (Emmorey, 1999; van Loon et al., 2014). Emblems, at least the most prototypical sort, then, are not like other gestures, not like words, and not like signs. Instead, they could be described as a kind of communication game, that takes felicitous advantage of visual, cognitive and cultural affordances that we share. As such, they should certainly be considered in any typology of gesture, but they are not relevant for the present discussion.
1.2.2 A Gesture-Sign Continuum
Nor do I deal with a so-called continuum between gesture and sign (see Müller 2018 for a recent cogent exploration of continua). Although some signs may have gestural roots, the details of earliest signs are more like those of words than of gestures, right from the get-go. In the first-generation signer of Al-Sayyid Bedouin Sign Language that we studied, we found conventionalized signs (still used in the community) as well as pantomimic enactments of events, and we were able to distinguish the two on the basis of criteria in Table 1, even at this earliest stage of sign language emergence (Sandler, 2012b). I am unable to speculate about a single coherent continuum from gestures to words/signs, and I leave that issue outside the scope of this paper.
1.2.3 Pantomime
I also wish to exclude for the most part a system called pantomime (which overlaps with enactment, constructed action, and mimesis), in which signers in some way act out events with part or all of the body (touched on briefly in Section 5.3). I define pantomime as a system in which each part of the body typically represents itself: the hands are the hands, the face is the face, and the body is the body of whoever is being enacted. I refer the reader to Sandler (2009), Sandler (2012b), Cormier et al. (2015), and Stamp and Sandler (2021), among many other sources, for more information about these systems. Pantomime is not irrelevant to the topic of multimodality. In fact, the existence of pantomime rescues the term multi-modal in the sense argued for here, by adding the pantomime mode to the linguistic and gestural modes. We leave exploration of this mode in the paradigm suggested here to future research.
Finally, so-called silent gesture—a research paradigm in which hearing people convey a message through gesture alone—is excluded, as it is not a typical natural form of expression. None of these topics are included in the present analysis. Here, the focus is primarily on linguistic structure and on iconic gesture that commonly comprise both speaking and signing.
2 The Linguistic Mode in Sign Language
Sign languages are typically thought of as conveyed by the hands, and this is accurate at the level of the word. As central as the word is, there are other crucial levels of structure, such as syntax, prosody (including intonation), and the discourse level. At these levels, other parts of the body are recruited for explicitly linguistic purposes (Sandler, 2018). For example, prosodic constituents are separated by different positions of the head and articulations of the face (Nespor and Sandler, 1999), and conventionalized intonational patterns are conveyed by facial articulators (Baker-Shenk, 1983; Nespor and Sandler, 1999; Sandler, 1999; Coerts, 1992; Dachkovsky and Sandler, 2009; Kimmelman et al., 2020). Discourse continuity is maintained by the nondominant hand (Liddell, 2003; Sandler, 2012a; Sandler, 2018), and, since discourse units such as topics and comments are also prosodically marked, they involve the face, head, and torso articulators. Some researchers argue that facial expressions are explicitly syntactic and not intonational (Liddell, 1980; Wilbur and Patchke, 1999; Neidle et al., 2000; Cecchetto et al., 2009), while others argue for the intonational analysis (Nespor and Sandler, 1999; Sandler and Lillo-Martin, 2006; Sandler, 2010; Sandler et al., 2021). In either case, these facial articulations are conventionalized and represent linguistic structure—they do not have the qualities of either gesture or pantomime. For our purposes here, and for comparison with gesture in spoken language, the discussion is limited to the phonology of manual signs and to facial expressions.5
Willliam Stokoe’s (1960) pioneering work showed that American Sign Language (ASL) signs are comprised of contrastive formational elements, so that ASL manifests duality of patterning, as noted above. This breakthrough set the ball rolling, and many researchers on other sign languages followed suit, admitting sign languages to the family of natural human languages. Many signs are iconically motivated (e.g, Perniss et al., 2010, Perniss et al., 2020), proportionately unlike most words in contemporary spoken languages, but they are typically not transparent. That is, sign naïve observers usually cannot guess their meaning (Klima and Bellugi, 1979; Thompson et al., 2020). Also, iconicity can only help children acquire signs if they understand the iconicity (for example that milk comes from milking cows). This understanding can require more world knowledge than small children usually have, nor is it completely clear the extent to which adult signers are conscious of iconic foundations, suggesting that the iconic motivation is only part of linguistic competence. The lexicons of different sign languages are mostly different from each other, suggesting a degree of arbitrariness in selecting the motivation for signs in each language. At the same time, there is a significantly greater overlap in similarity of lexical items across sign languages than across spoken languages (Guerra Currie et al., 2002, Meier et al., 2002). These observations make sign language lexicons fall somewhere in between iconic and arbitrary.
Interestingly, the sublexical building blocks of hand configuration, location, and movement, which productively create minimal pairs and are thus described as meaningless, are often iconically motivated themselves. For example, the location of a sign is often iconically motivated, literally or metaphorically (Fernald and Napoli, 2000; van der Kooij, 2002). The sign LEARN (Figure 2A) in Israeli Sign Language (ISL) metaphorically extends the iconic notion of putting something somewhere—in this case, putting knowledge in the head.6 The signs EAT and LEARN in Figures 2A,B are a minimal pair distinguished by Location features. Their contrastive function shows that the features defining “mouth” and “temple,” respectively, function phonologically. But these features are not arbitrary; they are iconically motivated. Many signs involving mental processes are signed at the temple Location Setting—[head, high, ipsilateral], like LEARN (Figure 2B), THINK (Figure 2C), and DREAM (Figure 2D). Many signs involving the mouth (like SPEAK, TELL, TASTE, EAT) are signed at the same Location ([low, mid, head] in the feature taxonomy of (Sandler, 1989). Similarly, the handshape of many signs that involve gripping something and/or putting something somewhere are iconically motivated, signed with the same “closed B” handshape (EAT, PUT, MOVE, and metaphorically for LEARN). We can call the result “dual duality of patterning,” a level of structure with both meaningless and meaningful properties (Sandler, 2018).
Two-handedness (comprising about half the signs in any lexicon) can also be motivated. Comparing four unrelated sign languages, Lepic et al. (2016) found that signs conveying concepts such as interaction, location, dimension, and composition are significantly more likely to be two-handed in any sign language than chance would predict. Östling et al. (2018) show that two-handedness and body Location are both iconically motivated in 131 different sign languages.
Good examples of interaction as a motivation for two-handedness are the signs meaning NEGOTIATE/DISCUSS in two sign languages: Israeli Sign Language (ISL) and Al-Sayyid Bedouin Sign Language (ABSL), shown in Figure 3. Both the signs and aspects of sublexical motivations are different, showing the relative arbitrariness in selecting iconic elements in any given sign language. For example, in ISL the handshape of NEGOTIATE/DISCUSS represents a line of communication in other signs as well, while in ABSL the handshape of NEGOTIATE/DISCUSS commonly represents a person. But both signs are two-handed, motivated by interaction, and both involve alternating repeated movement, iconically (and metaphorically) representing the back and forth nature of the concept, NEGOTIATE/DISCUSS.
FIGURE 3
As in any language, sublexical elements of signs can’t combine any which way, but are subject to constraints. There are constraints on the form and action of the two hands in two-handed signs (Battison, 1978), one of them requiring the two moving hands in Figure 2 to be symmetrical in shape and movement. These constraints are relaxed in classifier constructions, which are partly gestural, as we will see in Section 4.
Signs, then, are linguistically organized in terms of contrastive sublexical elements as well as systematic constraints on their combination. More evidence for duality of patterning comes from phonological processes such as assimilation and truncation, whose conditions and effects are form- and not meaning-based (Liddell and Johnson, 1986; Sandler, 1989; van der Hulst, 1993; Brentari, 1998; Sandler, 2010; Sandler, 2012b; Fenlon et al., 2016). For example, lexicalized compounds in ISL and in ASL often truncate to monosyllables (Sandler, 1999), with the handshape of the second member of the compound spreading to replace the handshape of the first (Liddell and Johnson, 1986; Sandler, 1987, Sandler, 1989, Sandler, 2017). These systematic processes are based solely on form and can even distort or mask the iconic motivation of the signs. An example is the ISL compound SICK from the signs FEVER and TEA, shown in Figure 4. Similar examples are found in American Sign Language (Klima and Bellugi, 1979; Sandler, 1987, Sandler, 1989).
FIGURE 4
All established sign languages are characterized by linguistic facial expressions, akin to linguistic intonation in spoken languages (Nespor and Sandler, 1999; Sandler and Lillo-Martin, 2006; Sandler, 2010; Ormell and Crasborn, 2012, Hermann and Pendzich, 2014; Sandler et al., 2021). Though some of the facial expressions are common among speakers as well (see Section 5.2), they are not mandatory or rule governed when accompanying speech as they are in sign languages (Janzen, 1999; Janzen and Shaffer, 2002). In a sign language only, there is a finite list of conventionalized linguistic facial expressions (Dachkovsky and Sandler, 2009, Dachkovsky et al., 2013; Pfau and Quer, 2010; Hermann and Steinbach, 2013).7 In spoken languages, some researchers propose that intonation is compositional (e.g., Pierrehumbert and Hirschberg, 1990; Hayes and Lahiri, 1991), with meaningful High and Low, accented and unaccented components following one another sequentially to convey different meanings.8 In sign languages, intonational elements are also compositional, but since they are conveyed by independent facial articulators, they can cooccur simultaneously (Nespor and Sandler, 1999; Sandler and Lillo-Martin, 2006; Dachkovsky and Sandler, 2009). Figure 5 shows ISL linguistic facial expressions: brow raise for polar questions (‘Do you want to go to the movies?’), squint for shared information (‘the movie that we saw together last week’), and a combination of the two for a polar question about shared information (‘Do you want to see the move that we saw together again?’).
FIGURE 5
It is quite possible that some of the linguistic facial expressions described above share properties with gestures used by speakers. There is evidence that iconic signs which may have shared properties with iconic gestures can become more arbitrary over time, obeying phonological constraints (Frishberg, 1975). My colleagues and I also found that phonologization emerges gradually from less conventionalized and less discrete signs in a young sign language such as ABSL (Sandler et al., 2011). Use of the conventionalized upper face expressions for linguistic intonation derives from more general enhanced perception of prosodic prominence on the upper face (Swerts and Krahmer, 2008). What is important is that, in established, contemporary sign languages like ISL (itself only about 90–100 years old, Meir and Sandler, 2008), every articulation of the hands and the upper face described above represents conventionalized, systematic, linguistically organized form.
Turning to the lower face, Liddell (1980) first showed that American Sign language includes linguistic actions of the lower face that are conventionalized as adverbial or adjectival modifications, and the same is true of Israeli and other sign languages. In Israeli Sign Language, for example, the same open-mouth configuration consistently means “protracted action” (“for a long time”), as we see in three different ISL signers’ renditions of the same event in the Canary Row cartoon, when the cat falls through the air holding the canary, shown in Figure 6.
FIGURE 6
We now turn to the gestural mode sign languages.
3 The Gestural Mode in Sign Languages
According to the definition of gestural organization in Table 1, signers of established sign languages incorporate gestures into their linguistically structured language.9Emmorey (1999) shows that ASL signers incorporate conventionalized emblem-like gestures from the broader community into their signed discourse, such as gestures meaning “well,” “shh,” and the like. More useful for defining the modes of language are the iconic gestures that signers employ that are not borrowed from conventionalized emblems. These include affective facial expressions, iconic mouth gestures, and the gestural part of hybrid classifier constructions. We turn to each, below.
3.1 Affect in Sign Language
Signers incorporate emotional and attitudinal facial gestures, like those shown in Figure 7, as hearing speakers do (e.g., Baker-Shenk 1983; Dachkovsky and Sandler, 2009; Hermann and Pendzich, 2014; Kimmelman et al., 2020).10 These expressions are usually idiosyncratic, context sensitive, and gradient in terms of the intensity of the emotion or attitude expressed, and belong to the gestural mode. They are similar to affective facial expressions used by speakers, and can also be compared to paralinguistic intonation, described in Section 5.1.
FIGURE 7
3.2 Iconic Mouth Gestures
Relevant for any discussion of human language is the fact that the mouth is a salient articulator, whether for speech or for other functions. The mouth is important. In sign languages, which do not use the mouth for auditory speech, the mouth is constantly active, conveying a range of different functions, among them, linguistic adverbial and adjectival modification (Liddell, 1980), exemplified in Figure 6 above, mimicry and enactment (Cormier et al., 2008; Stamp and Sandler, 2021), and intermittent mouthing of borrowed spoken words in some societies (see Boyes Braem and Sutton-Spence, 2001; Lewin and Schembri, 2013; Johnston et al., 2015). As for affective mouth actions, we have only to look at emojis to intuitively detect the various roles of the mouth in conveying attitudes and emotions. And even in speech, in which the mouth transmits words auditorily, the action of the mouth is visually salient, playing a role in speech perception (McGurk and McDonald, 1976). But the clearest sign language parallels with iconic manual gestures in spoken language are iconic mouth gestures, which are rampant in sign languages (Sandler, 2009).
The shape and action of the mouth often accompanies signing, to represent physical properties, such as the size and shape of an object, its weight or volume, or the vibrations it creates. In a study of ISL retellings by three signers of the animated cartoon Canary Row, we found that the signers often gestured with their mouths in iconic, idiosyncratic, and context sensitive ways (Sandler, 2009). One signer’s retelling of part of the cartoon is shown in Figure 8.
FIGURE 8
The analysis goes on to show that different mouth gestures are indiosyncratic and context-sensitive, unlike linguistic signals. For example, signers use the same mouth gestures for different objects or actions. Figure 9 shows two identical facial gestures with two different interpretations.
FIGURE 9
Gestures are also gradient. In spoken language, linguistic elements are typically discrete, i.e., their form does not vary analogically with their meaning. But gestures are inherently gradient. For example, a signer displayed one puffed cheek for the bowling ball and two puffed cheeks for the cat’s body after swallowing the ball, shown in Figure 10.
FIGURE 10
Mouth gestures are not sequentially combinatorial; instead, they are linked to the combinations of manually signed phrases and sentences, just as iconic co-speech gestures coincide with combinatorially organized words, and are not organized with respect to each other.
Other sign languages—I venture to say all sign languages—also make use of mouth gestures. Figures 11A,B show mouth gestures in American and Russian sign languages. In Figure 11C we see a second generation signer in an emerging sign language in the Bedouin village of Al-Sayyid producing a mouth gesture to indicate the friction of water spraying from a sprinkler.
FIGURE 11
3.3 Hybrid Classifier Constructions
Such mouth gestures often accompany a particular kind of construction in sign languages, constructions which themselves are partly gestural: classifier constructions (Supalla, 1986; Emmorey, 2003; Zwitzerlood, 2012). In these forms, the conventionalized and lexicalized handshapes alone represent classes of entities, such as humans, small animals, or vehicles; or the size and shape of objects, such as flat, curved, or cylindrical. These classifier handshapes are conventionalized and lexicalized. But the location and movement, elements which are linguistically specified in regular lexical signs, behave gesturally in these hybrid classifier constructions (Schembri, 2003). As argued extensively in papers in Emmorey (2003), motions and locations in classifier constructions are idiosyncratic, imagistic (iconic), gradient, and noncompositional in the sense that their distribution and cooccurrence with other parts of the construction are not specified or systematic.
Handshapes are different. The same lexically specified handshape classifier can persist across several events, leading Sandler and Lillo-Martin (2006) to propose that they combine post-lexically with iconic gestural components of location and movement. Just as gestures tend to occur with expressive mimetics in languages like Japanese (Kita, 1997), mouth gestures tend to occur with classifier constructions in sign languages. In Figures 8A–C, for example, the handshapes are classifiers for a cylindrical object (the drainpipe), and a small animal (the cat). The spatial locations and relations and the movement path are gestural: they are gradient and analogical to the action of the cat in relation to the pipe in the cartoon, as we can see by comparing Figure 8A in which the cat is entering the pipe, Figure 8B, in which the hand (manifesting a small animal classifier) and mouth (manifesting a gesture) move in a zig-zag shape that the cat traverses in the pipe joint, and Figure 8C, where the cat is climbing up higher inside the pipe. Gestures in sign languages, then, are produced in the same visual channel as linguistically organized structure, but they manifest the characteristics of gestural organization, and therefore belong to the gestural mode.
4 Linguistic and Gestural Modes in the Ebisu Sign Language Theatre
As is often the case in artistic use of language, formational elements bubble to the surface. For example, poetic meter and rhyme reveal rhythmic properties and prosodic structure of a spoken language, such as onsets and rhymes as syllable constituents. Properties like these are extracted from language for artistic use, and sometimes even distorted, but in parallel they remain intact in the linguistic structure of the language. The Ebisu Sign Language Theatre Laboratory, formed in 2014,11 offers an opportunity for analysis of sign language components via art. If gestural and linguistic organization are the two relevant modes, and if they can coexist in the same physical channel (see Table 2), then we should expect the barrier to interaction between the two to be easily traversed. Three examples will suffice to show the interaction between linguistic and gestural modes in sign language, in the Ebisu theatre. Crossing the lines in this way is not restricted to sign languages; Section 5 shows criss-crossing of modes in spoken language.
The modus operandi of the Ebisu theatre director Atay Citron is improvisational, ultimately arriving at fully staged performances for deaf and hearing audiences alike, without interpreting (Sandler et al. in press). In an exercise designed to repeat and explore a sign, actress Nurit Shalom took the lexical sign LEARN (see Figure 2B), and altered it by gesturally selecting sublexical elements such as two-handedness (a kind of reduplication indicating large dimensions or intensity, Kouwenberg and LaCharité, 2015). In the basic sign, LEARN, in Figure 12A, the signer adopts an affective (gestural) facial expression conveying “wariness.” The body posture with head averted in Figure 12B replaces the linguistic temple location of the lexical sign to gesturally convey “too much to take in,” The gesture in Figure 12C indicating “large” has a different handshape and orientation than the lexical sign LARGE, and, unlike the lexical sign, which is located in neutral space in front of the signer, the gesture is located above the head, the lexical location of the sign LEARN, and the metaphorical seat of knowledge in lexical signs as those shown in Figure 2. “Too-large-quantity for the head” in Figure 12C, then, is a gesture, based on the sign LARGE. The puffed cheek mouth gesture enhances the meaning of a huge quantity. Note that this mouth gesture is similar to that indicating a round bowling ball in Figures 8, 10D, showing the idiosyncrasy and context-sensitivity of gestural organization.
FIGURE 12
The second example demonstrates more mouth gestures in performance, shown in Figure 13. In telling the biblical story of Genesis, actor Alon Zino indicates that the earth was void with a closed flat hand gesture, interpreted as the barren surface of the earth, and a mouth gesture of sucked in cheeks—emptiness. He then raises flat, spread, open hands, indicating the rising surface of the water, accompanied by puffed cheeks, here conveying massiveness. The hands exploit the gestural mode as well, suggesting an empty surface (Figure 13A) and a rising and spreading mass (Figure 13B). The handshapes are not among the list of linguistic classifiers, instead manifesting iconic gestures. We have seen in Figures 8D, 10A,B, 12C that the puffed cheeks gesture can have many different meanings in different contexts. The sucked cheeks gesture appears in a different sign language, Russian Sign Language, indicating “very tall,” in Figure 11B above.
FIGURE 13
In an original poem, actor Golan Zino manipulates the lexical sign BROKEN, normally signed in neutral space in front of the signer as shown in Figure 14A. He adopts a different location iconically—the ear (Belsitzman, 2017). The expression conveys hearing people’s distorted impression of deaf people as broken-ear people Figure 14B. We saw that the Location can be iconic across the lexicon, for example, the head (temple) representing mental processes, linguistically in Figure 2, and gesturally in Figure 12C. Here, the actor summons this underlying iconic property, giving the ear location iconic meaning, to confront the audience with a provocative image.
FIGURE 14
We have established that puffed and sucked cheeks function as gestures in ISL and other sign languages. These articulations can also be part of linguistic structure. Figure 15 shows two lexical signs in ISL, FAT and THIN, each with obligatory mouth shapes as lexical features of the signs. Given that many signs are iconic and indicate their meanings directly, lexically specified mouth actions of this kind, also iconic, might belong to what Woll terms “echo phonology,” in which the mouth enhances the picture portrayed by the hands, possibly providing an evolutionary link to speech (Woll, 2001). These mouth articulations, then, function both as idiosyncratic gestures (e.g, Figures 8, 10, 12, 13) and as conventionalized lexical features (as in Figure 15). The point is that, since there is no physical barrier between linguistic and gestural modes, some expressions can belong to either mode. An example from spoken language is the use of high tone to linguistically mark polar questions or paralinguistically (I would say “gesturally”) to express emotions like happiness or surprise. We return to spoken language in Section 5.
FIGURE 15
The types of iconicity we have seen in Ebisu involve retrieving and isolating iconic elements from signs and other expressions, and artistically exploiting gestures found in expressive signing as well. Sections 3, 4 show that the difference between the linguistic and gestural modes come to the fore as organizational principles, not defined by physical channel. Interaction is not surprising, then, and the same element can cross the line between modes. On this view, we should expect this to happen in spoken language as well—and, as schematized in Table 2, and expanded below—it does.
5 Crossing the Channel in Spoken Language: Gestural Elements in the Voice and Linguistic Elements on the Hands and Face
Libraries are filled with treatments of the linguistic structure of spoken language, and there is no need to review it here. Analyses of spoken language auditory linguistic structure with accompanying visual hand gestures have also been abundantly covered in the literature. I consider here only contradictions to the common but confusing assumption that spoken language occurs only in the auditory “modality”, and that gesture occurs only in the visual “modality”. To show that this dichotomy is misconceived, the focus in this section is specifically on gesture that is heard, and linguistic form that is seen, in spoken language.
5.1 Gesture in the Voice in Spoken Language
Let’s begin with intonation. It is well known that linguistic intonation is an important component of linguistic structure. Grammaticalized, linguistic intonation reflects information structure (Halliday, 1967; Gussenhoven, 2004) and can be represented abstractly with only two tones, High and Low, accented or unaccented, which combine to create contours, and which aggregate sequentially with phrasal tones at phrase boundaries (Pierrehumbert, 1980; Beckman and Pierrehumbert, 1986; Ladd, 1996; Shattuck-Hufnagel and Turk, 1996), although the phonetic instantiation of these phonemic patterns might vary widely (Prietro, 2015). This system is presumably linguistically organized and transmitted in the same physical channel as the rest of spoken language.
From an evolutionary point of view, intonation has iconic origins. Recall that iconicity means that the signal, whether auditory or visual, resembles its meaning. Regarding the origin of high and low pitch, Ohala (1983) reasoned that high pitch is associated with smallness (like sounds emitted by small animals with small vocal tracts) and low pitch with large size (commensurate with the vocal and resonance apparatus of larger animals). According to Gussenhoven (2004), this Frequency Code is one of three biological codes, which evolved into linguistically organized intonation over time. The others are the Effort Code, evolving into focus marking, and the Production Code, which accounts for high pitch at the beginning of utterances, and lowering toward the end. All three can be considered iconic reflections of their biological origins, in the sense that the signal sounds like what it means. The grammaticalization of these codes, then, is iconically related to their biological foundations, and accounts for linguistic intonational universals.
Intonation can also be paralinguistic (Ladd, 1996; Prieto, 2015), typically reflecting attitudes or emotions, and exhibiting more gradience in form and idiosyncracy in distribution than linguistically organized intonation. To the extent that paralinguistic intonation is holistic, idiosyncratic, sequentially noncombinatoric, and gradient, it could well be considered part of the gestural mode—and that is precisely what Dwight Bolinger argued in a brilliant exploration as long ago as 1983. Bolinger also provided many examples in which intonation combines simultaneously with face and body gestures, resulting in different interpretations of the linguistic signal. Such combinations suggest that the two—paralinguistic intonation and visible gesture—are of the same natural class, which he calls a “gestural complex.”
One example in Bolinger is a question like, “Does he need it?”, which has different interpretations, depending on the intonational and visual gestural signals. The string can be conveyed with rising intonation, typical of English linguistic polar questions, or with falling intonation across the question, introducing gestural idiosyncrasy. Each can be accompanied by various concomitant visual gestures of the face and hands. Some of these are: eyebrows raised or lowered, mouth open or closed at the end, hands outflared with palms up, and more, each imbuing the different intonational patterns of the question with different nuances of meaning and different expectations of the addressee. For example, with rising intonation, eye contact, brows raised, mouth left open, palms up, and head shake, the speaker is in an argumentative and rhetorical mood, and the addressee is expected to answer “Does he need it?” by saying “No.” Bolinger proposes that easier agreement (an answer of “yes”) by the addressee is sought with falling intonation (despite the polar question) and different facial and manual cues. These fine-tuned but important distinctions accompanying linguistic material are among the communicative advantages of the gestural mode.
In fact, prosody can iconically represent the speed of an event by a fast or slow rate of speech, and intonational pitches can also be analogically iconic, so that high pitch cooccurs with descriptions of objects going up and low pitch for objects going down (Perlman et al., 2015).
It is well known that we gesture while we talk on the telephone, even though the gestures cannot be seen by the interlocutor (Bavelas et al., 2008). This indicates that gesture might be critical for the speaker, but implies that the auditory signal alone coneys the linguistic information to the hearer. However, once facial gestures are included as part of the gestural mode, it becomes clear that we can also hear gestures. Bolinger points out that we can hear not only linguistic intonation, which alters the fundamental frequency (basic vocal cord pitch), but we also hear formant frequency differences (reflecting different configurations of the vocal tract), which characterize emotional/paralinguistic intonation and affect vowel sounds. A simple thought experiment confirms that we can tell when the person on the other end of a phone call is amused (smiling, lip corners up). This is because facial gestures including upturned lip corners, jaw lowering, and many others change the configuration of the vocal tract, altering formant frequencies, and can therefore be perceived auditorily. In accord with Bolinger, we affirm that some kinds of intonation in the vocal channel belong to the gestural mode.
5.2 Linguistic Structure on the Face in Spoken Language
Like intonation, facial expressions in hearing speakers can also be seen as iconic from the point of view of evolution. For example, raised eyebrows widen the eye aperture, to perceive more information, evolving to iconically characterize emotional surprise, as well as linguistic polar questions, and focus (see Darwin, 1872; Fridlund, 2014). It is well known that visual gestures complement the linguistic signal, and in fact Janzen (1999), and Janzen and Shaffer (2002) argue that linguistic facial expression in sign language grammaticalized from this more general gestural system. But it is also possible to consider certain visual signals in spoken languages to be part of linguistic structure itself. In a series of papers, Swerts and Krahmer conducted several studies on prosody, investigating auditory and visual cues to polar questions, focus, as well as constituent boundaries. They found that there are consistent visual cues to all of these, typically accompanying the auditory cues. For example, high tones are typically accompanied by brow raise in polar questions, and participants more accurately identify polar questions that are characterized by both than by high tone alone (Swerts and Krahmer, 2008). Identification of questions with brow raise alone without high tone is less successful, suggesting that visible brow raise participates in the linguistic system, but together with auditory intonation. At the pragmatic level, facial expression can also distinguish polite from impolite utterances with the same intonational pattern (Brown and Prieto, 2017).
Though visual, such expressions are part of the spoken language linguistic mode to the extent that they manifest cues to information structure, and they also function as part of the gestural mode, in accord with Bolinger’s gestural complex idea as well as McNeill’s dichotomy, crossing the line between the linguistic and the gestural in a single channel.
5.3 Linguistic Structure on the Hands in Spoken Language
We usually think of visual gestures as cooccurring with speech and enhancing the verbal message in some way. But in recent years, researchers have noticed that visually transmitted gestures can actually represent linguistic structure directly. For example, Fricke (2013) shows that deictic gestures replace or further modify verbal reference and are thus part of the linguistic signal. Ebert et al. (2020) show that German ‘so’ transforms a manual action from gestural to linguistic. Proof of this is the fact that gestures accompanying ‘so’ become at-issue and thus linguistic information (as defined in Potts, 2005), as in Example 1, and, as such, can felicitously be qualified or negated, as in Example 2.
Examples 1 and 2Examples are adapted from Ebert et al. (2020).
Schenkler (2018, 2019) develops the notion of iconic semantics, and distinguishes pro-speech gestures from co-speech gestures and post-speech gestures. Pro-speech gestures precede and fully replace spoken words, and post-speech gestures occur after the relevant spoken expression. Crucially, Schlenker shows that the pro-speech gestures he analyzes are not simply imagistic versions of linguistic utterances (like many co-speech gestures) but are actually part of their semantics.
In his detailed exploration of “gestural semantics,” Schlenker (2019) deals with several types of inferences, among them, presuppositions. In Example 3, the pro‐speech gesture presupposes that Robin was not in a shooting position. In Example 4, the gesture presupposes that the lightbulb is in the ceiling.
Examples 3 and 4Examples are from Schlenker (2018).
These gestures are actually a type of enactment—“acting out” an event with the body,12 but they participate in the semantics of the sentence. Schlenker adds an additional nuance to the discussion, namely, that such iconic gestures belong to “a rich inferential typology” (Schlenker, 2019: 780). Though gestural, they are part and parcel of semantic (and thus linguistic) structure and knowledge. They cross the boundary between linguistic and gestural modes, and between the two physical channels.
Schlenker’s exposition indicates that gestures that are part of the linguistic (semantic) typology observe only two of McNeill’s linguistic criteria: they are sequentially combined with words, and they are to some extent conventionally and not idiosyncratically interpreted (how many ways can you unscrew a lightbulb?). But they are imagistic/iconic, and potentially gradient—important properties of gestural and not linguistic organization. This ambivalence is not counterevidence to the approach I take here, but is rather proof of the idea that linguistic and gestural modes are not tied to the physical channel of transmission. This very fact makes their distribution in language more versatile: the same physical system can organize itself linguistically or gesturally—or both. Human language is expressive and flexible, encompassing both linguistic and gestural modes, and our species fully exploits the exigencies of our bodies in shaping it—in both types of natural language, spoken and signed.
6 Consequences and Conclusion
The goal of linguistic theory is to capture generalizations about language that significantly advance our understanding of the phenomenon. A major advance in our understanding that has taken place over the past 60 years is the inclusion of visual expression in our thinking about language, facilitated by the use of video and especially by inclusion of sign languages in the data about natural language. The field of gesture studies arose in part because of these advances, and it became increasingly clear that there is more to language than the auditory signal.
With this advance came the notion of “multimodality” to describe human language, but the term is ambiguous, meaning either more than one physical transmission system or more than one type of expression or organization. In spoken languages, the most straightforward (but superficial) interpretation of multimodality places gestural material in the visual channel. However, this definition is misleading. Gesture in the auditory channel, such as paralinguistic intonation (Section 5.1), would be a counterexample to the definition.
Since sign languages are conveyed in only one physical channel, the visual channel, they are the ideal test case for determining the most explanatory definition of multimodality. If “modality” refers to the physical transmission system, sign languages by definition cannot be multimodal, since they are conveyed in only one physical channel, the corporeal-visual. Yet, as Section 3 shows, they do incorporate gesture.
By adopting the term “mode” as a particular type of expression, these problems disappear. We are able to show once again that sign languages are not anomalous but rather conform to universal generalizations about language. The message is that all language includes both linguistic and gestural modes. By following this paradigm, the essential differences between spoken and signed languages are revealed, which is equally important for our understanding of human language. Sign languages are more iconic than spoken languages, a natural and productive consequence of the corporeal/visual channel, and by focusing on the mode of expression rather than the physical channel we can see how this iconicity pervades both the linguistic mode and the gestural mode of these languages (Sections 2, 3). Similarly, removing the physical barrier between the linguistic and the gestural in spoken language gives us the freedom to identify auditory gesture in paralinguistic intonation (Section 5)—it is no longer a freak accident.
The hybrid forms in both types of language are perhaps the most convincing consequence of the definition of mode offered here, and the paradigm that it generates. In sign languages, classifier constructions are comprised of linguistic, lexical classificatory handshapes, which combine with locations and movements that are gestural in terms of their organization (Section 3.2). Certain mouth expressions can double as lexically specified and gesturally organized as well (Sections 3.1, 4). Meaningful sublexical components (such as locations, Section 2) can surface in gestural contexts (Section 4). In spoken languages, forms that are gestural according to most of the criteria in Table 1 participate actively in the formal semantics (Section 5.3).
While the approach to mode vs. modality offered here unifies spoken and signed languages in some ways, it also captures their essential differences, structured by the physical channels of transmission. The physical transmission system is not irrelevant or unimportant. It is not a mere secondary “externalization” of inherent structural organization in the brain (contra Chomsky, 2007). Instead, defining linguistic and gestural modes in each language type now makes it abundantly clear how the physical transmission system contributes to the form of each mode of expression in each type of language. The resulting model of language is dynamic, flexible, and extraordinarily creative.
Statements
Data availability statement
The submission relies on and extrapolates from previously published material, online dictionaries, and our Haifa lab materials. Requests for further information should be directed to WS, wsandler@research.haifa.ac.il.
Ethics statement
The studies involving human participants were reviewed and approved by the University of Haifa and the European Research Council. The participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article. Images from the ISL sign language dictionary (Figures 2, 15) are open access and do not require permission.
Author contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Acknowledgments
This research was supported in part by grants from the Israel Science Foundation 5433/04, the US-Israel Binational Science Foundation 2000-372, the National Institute on Deafness and other Communication Disorders of the National Institutes of Health R01-DC6473, and the European Research Council 340140. Unless otherwise indicated, all images are the property of the Sign Language Research Lab, University of Haifa, or online open access material. Thank you to reviewers for very helpful comments.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1.^More information about this approach and findings can be found on the website: https://gramby.haifa.ac.il/
2.^While the term “multimodal” implies more than two modes, here I deal with the two primary modes—linguistic and gestural. In Section 1.1, I suggest that an additional mode is pantomime/enactment, defined and distinguished from other modes there, but not further explored in this article.
3.^Paralinguistic intonation (Ladd, 1996) can indeed reflect degree, but again, such devices are paralinguistic and are indeed better described as gestural and not linguistic (see Section 5 here).
4.^Such iconic signals as speed of speech representing the speed of an activity have the characteristics of gesture; see Section 5.
5.^For analysis of linguistic expression by different parts of the whole body, see Sandler (2018); and for exhaustive background on sign language linguistics, see the chapters in Pfau et al. (2012).
6.^Taub’s (2001) book describes how metaphor is incorporated into iconic signs in ASL. But sign language iconicity has a constraining effect as well. If the intended metaphor does not correspond to those aspects of an object or event that are ionically represented in a literal sign, the metaphor is blocked (Meir, 2010).
7.^Different sign languages can activate different muscles to convey linguistic facial expressions with similar meanings (Dachkovsky et al., 2013).
8.^The terms “combinatorial” and “compositional” have different definitions (see de Boer et al., 2012), but are used somewhat interchangeably here, for simplicity. In compositional expressions, each component must bear meaning or grammatical function. Combinatoriality is neutral with respect to meaning.
9.^The term “established sign language” is used here to mean sign languages that have been established within a community and are used for a range of social functions. Emerging sign languages are in the process of becoming established and are not addressed in this section.
10.^In Section 5.1 below, the idea that vocal intonation can be iconic is motivated.
11.^The Eibsu theatre was supported by Advanced Grant 340140 from the European Research Council. Ebisu is the name of a Japanese Shinto god of good fortune, who is deaf.
12.^Thank you to Karen Emmorey for pointing this out.
References
1
HermannA.SteinbachM. (Editors) (2013). Nonmanuals in Sign Languages (Amsterdam: Benjamins).
2
AronoffM.MeirI.PaddenC.SandlerW. (2003). “Classifier Complexes and Morphology in Two Sign Languages,” in Perspectives on Classifier Constructions in Sign Languages. Editor EmmoreyK. (Mahwah, NJ: Erlbaum), 53–84.
3
Baker-ShenkC. (1983). A Micro-Analysis of Nonmanual Components of Questions in American Sign LanguageUniversity of California Pro-Quest Dissertations Publishing.
4
BattisonR. (1978). Lexical Borrowing in American Sign Language. Silver Spring, Maryland: Linstok Press.
5
BavelasJ.GerwingJ.SuttonC.PrevostD. (2008). Gesturing on the Telephone: Independent Effects of Dialogue and Visibility. J. Mem. Lang.58, 495–520. 10.1016/j.jml.2007.02.004
6
BeckmanM. E.PierrehumbertJ. B. (1986). Intonational Structure in Japanese and English. Phonol. Yearb.3, 255–309. 10.1017/S095267570000066X
7
BellugiU.KlimaE. S. (1979). Language: Perspectives from Another Modality. Ciba Found. Sympbrain Mind69, 99–117. 10.1002/9780470720523.ch6
8
BelsitzmanG. (2017). “The Ebisu Tool Kits: Realizing the Potential of the Expressive Body,” in Paper Presented at the GRAMBY Workshop (Haifa: University of Haifa).
9
BolingerD. (1983). Intonation and Gesture. Am. Speech58, 156–174. 10.2307/455326
10
Boyes BraemP.Sutton-SpenceR. (2001). The Hands Are the Head of the Mouth: The Mouth as Articulator in Sign Languages. Hamburg: Signum Press.
11
BrentariD. (1998). A Prosodic Model of Sign Language Phonology. Cambridge MA: MIT Press.
12
BrownL.PrietoP. (2017). “(Im)politeness: Prosody and Gesture,” in The Palgrave Handbook of (Im)politeness. Editors CulpeperJ.HaughM.KádárD. (London: Macmilan), 357–379. 10.1057/978-1-137-37508-7_14
13
CalbrisG. (1990). The Semiotics of French Gestures. Bloomington, IN: Indiana University Press.
14
Carlo CecchettoC.Carlo GeraciC.Sandro ZucchiS. (2009). Another Way to Mark Syntactic Dependencies: The Case for Right-Peripheral Specifiers in Sign Languages. Language85, 278–320. 10.1353/lan.0.0114
15
CavicchioF.DachkovskyS.LeemorL.Shamay-TsooryS.SandlerW. (2018). Compositionality in the Language of Emotion. PLoS One13, e0201970. 10.1371/journal.pone.0201970
16
ChomskyN. (2007). Of Minds and Language. Biolinguistics1, 9–27.
17
MüllerC.CienkiA.FrickeE.LadewigS. H.McNeillD.BressemJ. (Editors) (2014). Body – Language – Communication: An International Handbook on Multimodality in Human Interaction, Vol. 2 (Berlin: de Gruyter).
18
MüllerC.CienkiA.FrickeE.LadewigS. H.McNeillD.TeßendorfS. (Editors) (2013). Body Language Communication: An International Handbook on Multimodality in Human Interaction, Vol. 1 (Berlin: de Gruyter).
19
CoertsJ. (1992). Nonmanual Grammatical Markers: An Analysis of Interrogatives, Negations, and Topicalisations in Sign Language of the Netherlands. Amsterdam: University of Amsterdam. Doctoral dissertation.
20
CormierK.SmithS.Sevcikova-SehyrZ. (2015). Rethinking Constructed Action. Sign Lang. Linguistics18, 167–204. 10.1075/sll.18.2.01cor
21
DachkovskyS.SandlerW. (2009). Visual Intonation in the Prosody of a Sign Language. Lang. Speech52 (2-3), 287–314. 10.1177/0023830909103175
22
DachkovskyS. (2017). Grammaticalization of Intonation in Israeli Sign Language. Haifa, IL: Doctoral dissertation, University of Haifa.
23
DachkovskyS.HealyC.SandlerW. (2013). Visual Intonation in Two Sign Languages. Phonology30 (2), 211–252. 10.1017/s0952675713000122
24
DarwinC. (1872). On the Expression of the Emotions in Man and Animals. London: John Murray.
25
de BoerB.SandlerW.KirbyS. (2012). New Perspectives on Duality of Patterning: Introduction to the Special Issue. Lang. Cogn.4 (4), 251–259. 10.1515/langcog-2012-0014
26
De SaussureF.BallyC.SechehayeA.BaskinW. (1959). Course in General Linguistics. NY: McGraw Hill Book Company.
27
DingemanseM.BlasiD. E.LupyanG.ChristiansenM. H.MonaghanP. (2015). Arbitrariness, Iconicity, and Systematicity in Language. Trends Cogn. Sci.19, 603–615. 10.1016/j.tics.2015.07.013
28
DingemanseM.PerlmanM.PernissP. (2020). Construals of Iconicity: Experimental Approaches to Form-Meaning Resemblances in Language. Lang. Cogn.12, 1–14. 10.1017/langcog.2019.48
29
DowningL.StiebelsB. (2012). “Iconicty,” in The Morphology and Phonology of Exponence. Editor TrommerJ. (Oxford: Oxford University Press), 379–426.
30
EbertC.EbertC.HörnigR. (2020). “Demonstratives as Dimension Shifters,” Proceedings of Sinn und Bedeutung. Editors FrankeM.KompaN.LiuM.MuellerJ. L.SchwabJ. (Berlin: Osnabruck University, Humboldt University of Berlin) 24, 161–178.
31
EfronD. (1941). Gesture and Environment. New York, NY: King’s Crown Press.
32
EmmoreyK. (1999). “Do signers Gesture?,” in Gesture, Speech, and Sign. Editors MessingL. S.CampbellR. (Oxford: Oxford University Press), 133–158. 10.1093/acprof:oso/9780198524519.003.0008
33
Estev-GilbertN.PrietoP. (2013). Prosodic Structure Shapes the Temporal Realization of Intonation and Manual Gesture Movements. J. Speech, Lang. Hearing Res.3, 850–864.
34
FenlonJ.CormierK.BrentariD. (2016). “The Phonology of Sign Languages,” in Routledge Handbook of Phonological Theory. Editors HannahsS. J.BoschA. (NY: Routledge).
35
FernaldT. B.NapoliD. J. (2000). Exploitation of Morphological Possibilities in Signed Languages. SL&L3, 3–58. 10.1075/sll.3.1.03fer
36
ForthcomingSandlerW.AronoffM.PaddenC. (). “Language Emergence: The Case of Sign Language,” in Oxford Handbook of Deaf Studies, Language, and Education (Oxford University Press). Special issue of Languages.
37
FrickeE. (2014). “136. Deixis, Gesture, and Embodiment from a Linguistic point of View,” in Body Language Communication (HSK 38.2): An International Handbook on Multimodality in Human Interaction, Volume 2. Editors MüllerC.CienkiA.FrickeE.LadewigS. H.McNeillD.BressemJ. (Berlin/Boston: Walter de Gruyter GmbH), 1803–1823. 10.1515/9783110302028.1803
38
FrickeE. (2013). “46. Towards a Unified Grammar of Gesture and Speech: A Multimodal Approach,” in Body Language Communication (HSK 38.2): An International Handbook on Multimodality in Human Interaction, Volume 1. Editors MüllerC.CienkiA.FrickeE.LadewigS. H.McNeillD.BressemJ. (Berlin/Boston: Walter de Gruyter GmbH), 733–754. 10.1515/9783110261318.733
39
FridlundA. (2014). Human Facial Expression: An Evolutionary View. San Diego: Academic Press.
40
FrishbergN. (1975). Arbitrariness and Iconicity: Historical Change in American Sign Language. Language51, 696–719. 10.2307/412894
41
Goldin-MeadowS.BrentariD. (2017). Gesture, Sign, and Language: The Coming of Age of Sign Language and Gesture Studies. Behav. Brain Sci.40, e46–82. 10.1017/S0140525X15001247
42
Guerra CurrieA.-M. P.MeierR. P.WaltersK. (2002). A Crosslinguistic Examination of the Lexicons of Four Signed Languages. In MeierR.CormierK.Quinto-PozosD. (Editors), 224–236.
43
GussenhovenC. (2004). The Phonology of Tone and Intonation. Cambridge: Cambridge University Press. 10.1017/CBO978051161.6983
44
HallidayM. (1967). Intonation and Grammar in British English. The Hague: Mouton.
45
HayesB.LahiriA. (1991). Bengali Intonational Phonology. Nat. Lang. Linguist Theor.9, 47–96. 10.1007/bf00133326
46
HermannA.PendzichN-K. (2014). “Nonmanual Gestures in Sign Languages,” in Body Language Communication (HSK 38.2): An International Handbook on Multimodality in Human Interaction, Volume 2. Editors MüllerC.CienkiA.FrickeE.LadewigS. H.McNeillD.BressemJ. (Berlin/Boston: Walter de Gruyter GmbH), 2149–2162.
47
HockettC. F. (1960). The Origin of Speech. Sci. Am.203, 89–96. 10.1038/scientificamerican0960-88
48
JanzenT. (1999). The Grammaticization of Topics in American Sign Language. Stud. Lang.23 (2), 21–306. 10.1075/sl.23.2.03jan
49
JanzenT.ShafferB. (2002). “Gesture as the Substrate in the Process of ASL Grammaticization,” in Gesture as the Substrate in the Process of ASL Grammaticization. Editors MeierR. P.CormierK.Quinto-PozosD. (Cambridge: Cambridge University Press), 199–223. 10.1017/cbo9780511486777.010
50
JohnstonT.van RoekelJ.SchembriA. (2015). On the Conventionalization of Mouth Actions in Australian Sign Language. Lang. Speech59, 3–42. 10.1177/0023830915569334
51
EmmoreyK. (Editor) (2003). Perspectives in Classifier Constructions in Sign Languages (Mahwah, NJ: Lawrernce Erlbaum Associates). 10.4324/9781410607447
52
KendonA. (1988). “How Gestures Can Become like Words,” in Crosscultural Perspectives in Nonverbal Communication. Editor PoyatosF. (Toronto, CJ:: Hogrefe), 131–141.
53
KendonA. (1980). Gesticulation and Speech: Two Aspects of the Process of Utterance. Berlin: De Gruyter Mouton.
54
KendonA. (2004). Gesture: Visible Action as Utterance. Cambridge: Cambridge University Press. 10.1017/CBO9780511807572
55
KimmelmanV.ImashevA.MukushevM.SandygulovaA. (2020). Eyebrow Position in Grammatical and Emotional Expressions in Kazakh-Russian Sign Language: A Quantitative Study. PLOS ONE15 (6), e0233731. 10.1371/journal.pone.0233731
56
KitaS. (1997). Two-dimensional Semantic Analysis of Japanese Mimetics. Linguistics35, 379–415. 10.1515/ling.1997.35.2.379
57
KlimaE.BellugiU. (1979). The Signs of Language. Cambridge, MA: Harvard University Press.
58
KouwenbergS.LaCharitéD. (2015). Arbitrariness and Iconicity in Total Reduplication. Sl39, 971–991. 10.1075/sl.39.4.03kou
59
LaddD. R. (1996). Intonational Phonology. Cambridge, UK: Cambridge University Press.
60
LadewigS. (2011). Syntactic and Semantic Integration of Gestures into Speech: Structural, Cognitive, and Conceptual Aspects. Frankfurt (Oder): European University Viadrina. PhD diss.
61
LandauI. (2016). Speech Act Control: An Unrecognized Type. Jerusalem, IL: Paper presented at the Israel Association for Theoretical Linguistics Meeting.
62
LepicR.BörstellC.BelsitzmanG.SandlerW. (2016). Taking Meaning in Hand. SL&L19, 37–81. 10.1075/sll.19.1.02lep
63
LewinD.SchembriA. C. (2013). “Mouth Gestures in British Sign Language,” in Nonmanuals in Sign Language. Editors HermannA.SteinbachM. (Amsterdam: Benjamins), 91–110. 10.1075/bct.53.06lew
64
LiddellS. K. (1980). American Sign Language Syntax. The Hague: Mouton de Gruyter.
65
LiddellS. K. (2003). Grammar, Gesture and Meaning in American Sign Language. New York: Cambridge University Press.
66
LiddellS. K.JohnsonR. E. (1986). American Sign Language Compound Formation Processes, Lexicalization, and Phonological Remnants. Nat. Lang. Linguist Theor.4 (4), 445–513. 10.1007/bf00134470
67
MartinetA. (1960). Éléments de Linguistique Générale. Paris: Armand Colin.
68
McGurkH.MacDonaldJ. (1976). Hearing Lips and Seeing Voices. Nature264, 746–748. 10.1038/264746a0
69
McNeillD. (1992). Hand and Mind: What Gestures Reveal about Thought. Chicago, IL: University of Chicago press.
70
MeierR.CormierK.Quinto-PozosD. (Editors). (2002). Modality and Structure in Signed and Spoken Languages.Cambridge, UK: Cambridge University. Press. 10.1017/cbo9780511486777.011
71
MeierR. P.MaukC. E.CheekA.MorelandC. J. (2008). The Form of Children's Early Signs: Iconic or Motoric Determinants?Lang. Learn. Dev.4, 63–98. 10.1080/15475440701377618
72
MeirI.AronoffM.SandlerW.PaddenC. (2010). “Sign Languages and Compounding,” in Compounding. Editors ScaliseS.VogelI. (Amsterdam: John Benjamins), 573–595. 10.1075/cilt.311.23mei
73
MeirI.SandlerW. (2021). “Conventionalization and Variation in Language Emergence: the Case of Two Young Sign Languages in Israel,” in Linguistic Contact, Continuity, and Change in the Genesis of Modern Hebrew. Editors DoronE.Rappaport HovavM.ReshefY.TaubeM. (Amsterdam: Benjamins), 337–363.
74
MeirI.SandlerW. (2008). Language in Space: A Window into Israeli Sign Language. Mahwah, NJ: Lawrence Erlbaum.
75
MeirI. (2010). Iconicity and Metaphor: Constraints on Metaphorical Extension of Iconic Forms. Language86 (4), 865–896. 10.1353/lan.2010.0044
76
MüllerC. (2019). “Gesture And Sign: Cataclysmic Break Or Dynamic Relation?,” in Visual Language. Editors SandlerW.GullbergM.PaddenC. (Lausanne: Frontiers media), 29–48.
77
NeidleC.KeglJ.BahanB.MaclaughlinD. (2000). The Syntax of American Sign Language: Functional Categories and Hierarchical Structure. Boston: The MIT Press.
78
NesporM.SandlerW. (1999). Prosodic Phonology in Israeli Sign Language. Lang. Speech42 (2&3), 143–176. 10.1177/00238309990420020201
79
OhalaJ. J. (1983). Cross-language Use of Pitch: An Ethological View. Phonetica40, 1–18. 10.1159/000261678
80
OkrentA. (2002). A Modality-Free Notion of Gesture and how it can Help us with the Morpheme vs. Gesture Question in Sign Language Linguistics (or at Least Give us Some Criteria to Work with). In MeierR.CormierK.Quinto-PozosD. (Editors), 175–198.
81
OrmelE.CrasbornO. (2012). Prosodic Correlates of Sentences in Signed Languages: A Literature Review and Suggestions for New Types of Studies. Sign Lang. Stud.12, 279–315. 10.1353/sls.2011.0019
82
ÖstlingR.BörstellC.CourtauxS. (2018). Visual Iconicity across Sign Languages: Large-Scale Automated Video Analysis of Iconic Articulators and Locations. Front. Psychol.9, 725. 10.3389/fpsyg.2018.00725
83
PerlmanM.ClarkN.Johansson FalckM. (2015). Iconic Prosody in story reading. Cogn. Sci.39, 1348–1368. 10.1111/cogs.12190
84
PernissP.ThompsonR. L.ViglioccoG. (2010). Iconicity as a General Property of Language: Evidence from Spoken and Signed Languages. Front. Psychol.1, 227. 10.3389/fpsyg.2010.00227l
85
PernissP. (2018). Why We Should Study Multimodal Language. Front. Psychol.9, 1109. 10.3389/fpsyg.2018.01109
86
PernissP.FischerO.LjungbergC. (2020). Operationalizing Iconicity. Amsterdam: John Benjamins.
87
PfauR.QuerJ. (2010). “Nonmanuals: Their Grammatical and Prosodic Roles,” in Sign Languages. Editor BrentariD. (Cambridge UK: Cambridge University Press), 381–402.
88
PfauR.SteinbachM.WollB. (2012). .Sign Language: An International Handbook. Berlin: Walter de Gruyter. 10.1515/9783110261325Sign Language
89
PierrehumbertJ.HirschbergJ. (1990). “The Meaning of Intonational Contours in the Interpretation of Discourse,” in Intentions in Communication. Editors CohenP. R.MorganJ.PollackM. E. (Cambridge MA: MIT Press), 271–311.
90
PierrehumbertJ. (1980). The Phonetics and Phonology of English Intonation. Boston: Massachusetts Institute of Technology. PhD Dissertation.
91
PottsC. (2005). The Logic of Conventional Implicatures. Oxford: Oxford University Press.
92
PrietoP. (2015). Intonational Meaning. Wires Cogn. Sci.6, 371–381. 10.1002/wcs.1352
93
SandlerW. (1987). “Assimilation and Feature Hierarchy in American Sign Language,” in Papers from the Chicago Linguistic Society, Parasession on Autosegmental and Metrical Phonology (Chicago: Chicago Linguistic Society), 266–278.
94
SandlerW.CitronA.BelsitzmanG.BarN. (in press). “Sign Language and Deaf Culture in Performances of the Ebisu Deaf Theatre,” in Deaf and Hard of Hearing: Multidisciplinary Perspectives. Editors CinamonG.MostT. (Tel Aviv-Yafo: Mofat Press). (in Hebrew).
95
SandlerW. (1999). “Cliticization and Prosodic Words in a Sign Language,” in Studies on the Phonological Word (Current Studies in Linguistic Theory). Editors HallT.KleinhenzU. (Amsterdam: Benjamins), 223–255.
96
SandlerW.Lillo-MartinD.DachkovskyS.Müller de QuadrosR. (2021). “Sign Language Prosody,” in The Oxford Handbook of Language Prosody. Editors GussenhovenC.ChenA. (Oxford UK: Oxford University Press), 104–122. 10.1093/oxfordhb/9780198832232.013.44
97
SandlerW.Lillo-MartinD. (2006). Sign Language and Linguistic Universals. Cambridge: Cambridge University Press. 10.1017/CBO978113916.3910
98
SandlerW. (1989). Phonological Representation of the Sign: Linearity and Nonlinearity in American Sign Language. Dordrecht: Foris.
99
SandlerW.AronoffM.MeirI.PaddenC. (2011). The Gradual Emergence of Phonological Form in a New Language. Nat. Lang. Linguist Theor.29, 503–543. 10.1007/s11049-011-9128-2
100
SandlerW. (2012a). Dedicated Gestures and the Emergence of Sign Language. Gest12, 265–307. 10.1075/gest.12.3.01san
101
SandlerW. (2010). Prosody and Syntax in Sign Languages. Trans. Philological Soc.108, 298–328. 10.1111/j.1467-968X.2010.01242.x
102
SandlerW. (2009). Symbiotic Symbolization by Hand and Mouth in Sign Language. Semiotica2009, 241–275. 10.1515/semi.2009.035
103
SandlerW. (2018). The Body as Evidence for the Nature of Language. Front. Psychol.9. 10.3389/fpsyg.2018.01782
104
SandlerW. (2017). The challenge of Sign Language Phonology. Annu. Rev. Linguist.3, 43–63. 10.1146/annurev-linguistics-011516-034122
105
SandlerW. (2012b). The Phonological Organization of Sign Languages. Lang. Linguistic Compass, 1–21.
106
SchembriA. (2003). “Rethinking “Classifiers” in Sign Languages,” in Perspectives on Classifier Constructions in Sign Languages. Editor EmmoreyK. (New York: Psychology Press), 3–34.
107
SchlenkerP. (2019). Gestural Semantics. Nat. Lang. Linguist Theor.37, 735–784. 10.1007/s11049-018-9414-3
108
SchlenkerP. (2018). Gesture Projection and Cosuppositions. Linguist Philos.41, 295–365. 10.1007/s10988-017-9225-8
109
Shattuck-HufnagelS.TurkA. E. (1996). A Prosody Tutorial for Investigators of Auditory Sentence Processing. J. Psycholinguist Res.25, 193–247. 10.1007/bf01708572
110
StampR.SandlerW. (2021). The Emergence of Referential Shift Devices in Three Young Sign Languages. Lingua257, 103070. 10.1016/j.lingua.2021.103070
111
StokoeW. C. (1960). Sign Language Structure. Silver Spring, MD: Linstock Press.
112
SuppallaT. (1986). “The Classifier System in American Sign Language,” in Noun Classes and Categorization. Editor CraigC. G. (Amsterdam: Benjamins), 181–216. 10.1075/tsl.7.13sup
113
SwertsM.KrahmerE. (2008). Facial Expression and Prosodic Prominence: Effects of Modality and Facial Area. J. Phonetics36, 219–238. 10.1016/j.wocn.2007.05.001
114
TaubS. (2001). Language from the Body: Iconicity and Metaphor in American Sign Language. Cambridge: Cambridge University Press. 10.1017/CBO9780511509629
115
ThompsonB.PerlmanM.LupyanG.Sevcikova SehyrZ.EmmoreyK.EmmoreyK. (2020). A Data-Driven Approach to the Semantics of Iconicity in American Sign Language and English. Lang. Cogn.12, 182–202. 10.1017/langcog.2019.52
116
van der HulstH. (1993). Units in the Analysis of Signs. Phonology10, 209–241. 10.1017/S095267570000004X
117
van der KooijE. (2002). “Phonological Categories in Sign Language of the Netherlands,” in The Role of Phonetic Implementation and Iconicity (Utrecht: LOT). PhD Dissertation.
118
van LoonE.PfauR.SteinbachM. (20142014). “169. The Grammaticalization of Gestures in Sign Languages,” in Body Language Communication (HSK 38.2). Editors MüllerC.CienkiA.FrickeE.LadewigS. H.McNeillD.BressemJ. (Berlin/Boston: Walter de Gruyter GmbH), 2133–2149. 10.1515/9783110302028.2133
119
WerningM.WolframH.EdouardsM. (2012). The Oxford Handbook of Compositionality. Oxford: Oxford University Press.
120
WilburR. B.PatschkeC. (1999). Syntactic Correlates of Brow Raise in ASL. Sign Lang. Linguistics, 2, 3–41. 10.1075/sll.2.1.03wil
121
WollB. (2001). “The Sign that Dares to Speak its Name: Echo Phonology in British Sign Language (BSL),” in The Hands Are the Head of the Mouth : The Mouth as Articulator in Sign Languages. Editors Boyes-BraemP.Sutton-SpenceR. (Hamburg: Signum), 87–98.
122
ZwitzerloodI. (2012). “Classifiers,” in Sign Language - an International Handbook. Editors PfauR.SteinbachM.WollB. (De Gruyter Mouton), 158–185.
Summary
Keywords
multimodality, modality, sign language, gesture, mode
Citation
Sandler W (2022) Redefining Multimodality. Front. Commun. 6:758993. doi: 10.3389/fcomm.2021.758993
Received
15 August 2021
Accepted
29 November 2021
Published
12 May 2022
Volume
6 - 2021
Edited by
Adam Schembri, University of Birmingham, United Kingdom
Reviewed by
Marianna Marcella Bolognesi, University of Bologna, Italy
Karen Emmorey, San Diego State University, United States
Updates
Copyright
© 2022 Sandler.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wendy Sandler, wsandler@research.haifa.ac.il
This article was submitted to Language Sciences, a section of the journal Frontiers in Communication
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.