 Gertraud Fenk-Oczlon
Gertraud Fenk-Oczlon Jürgen Pilz
Jürgen Pilz
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
BRIEF RESEARCH REPORT article
Front. Commun., 15 April 2021
Sec. Psychology of Language
Volume 6 - 2021 | https://doi.org/10.3389/fcomm.2021.626032
This article is part of the Research TopicMotivations for Research on Linguistic Complexity: Methodology, Theory and IdeologyView all 11 articles
Starting from a view on language as a complex, hierarchically organized system composed of many parts that have many interactions, this paper investigates statistical relationships between the linguistic variables “phoneme inventory size,” “syllable size,” “length of words,” “length of clauses,” and the nonlinguistic variable “population size.” By analyzing parallel textual material of 61 languages (18 language families) we found strong positive correlations between phoneme inventory size, mean number of phonemes per syllable, and mean number of monosyllables. We observed significant negative correlations between phoneme inventory size and the mean length of words and the mean length of clauses, measured as number of syllables. We then correlated the linguistic complexity data with estimated speaker population sizes and could reveal that languages with more speakers tend to have more phonemes per syllable, shorter words in number of syllables, a higher number of monosyllabic words, and a higher number of words per clause. Moreover, we reproduce the results of former studies that found a positive correlation between population size and phoneme inventory size for our language sample. The findings are discussed in light of previous research and within the framework of Systemic Typology. We propose that syllable complexity is a key factor in the correlations identified in this study, and that Zipf's law of Abbreviation explains the associations between “word length,” “syllable complexity,” “phoneme inventory size,” and the extralinguistic variable “population size.”
Language can be viewed as a complex, dynamic, and hierarchically organized system “made up of a large number of parts that have many interaction” (Simon, 1962, p. 468). The present work investigates interactions between the linguistic components “phoneme inventory size,” “syllable complexity,” “length of words,” “length of clauses,” and the extra-linguistic factor “population size.”
The idea to deal with linguistic complexity and particularly with interactions among linguistic components was motivated by an unexpected finding of an earlier study (Fenk-Oczlon, 1983). This study originally tested the hypothesis that language has adapted to memory limitations and that the number of syllables per simple clause (encoding one proposition) will cross-linguistically vary within the range of Miller's magical number seven plus or minus two. We demonstrated that the 28 languages investigated indeed used on average 6.43 syllables to express a matched set of propositions, but the individual languages showed a considerable variation in the number of syllables, ranging from 5.1 syllables in Dutch up to 10.2 in Japanese. We then assumed that syllable complexity might be the decisive factor for this variation and found a highly significant inverse relationship between the length of clauses in number of syllables and the length of syllables in number of phonemes. “The more syllables per clause, the fewer phonemes per syllable” (Fenk-Oczlon and Fenk, 1985). This was a cross-linguistic confirmation of Menzerath's law' (1954) “the bigger the whole, the smaller its parts.” Further empirical studies (Fenk and Fenk-Oczlon, 1993; Fenk-Oczlon and Fenk, 1999, 2005, 2010) revealed additional cross-linguistic relationships between linguistic variables, such as “The more syllables per word, the fewer phonemes per syllable,” The more syllables per clause, the more syllables per word,” “The more phonemes per syllable, the fewer morphological cases.” The present work adds “phoneme inventory size” and “population size” to the set of variables to investigate complexity relationships within the language system and between the number of speakers a language has.
Phoneme inventory size and its relationships with linguistic and nonlinguistic variables remains a matter of debate. The literature about cross-linguistic associations between phoneme inventory size and other linguistic components starts with a paper by Nettle (1995) who reports for a sample of 10 languages an inverse relationship between phoneme inventory size and the average length of a word. Nettle (1998) could repeat this finding for 12 West-African languages and Wichmann et al. (2011) for a sample of more than 3,000 languages averaged over families and macro-areas. Moran and Blasi (2014) likewise replicated a negative correlation between number of segments and word length and demonstrated, moreover, that this inverse relationship shows particularly with the number of vowels. As to syllable complexity measured as number of phonemes Maddieson (2006), Fenk-Oczlon and Fenk (2008) and Easterday (2019) report a positive correlation between inventory size and syllable complexity. Concerning the relationship between phoneme inventory size and the nonlinguistic variable population size, the finding of Hay and Bauer (2007) that languages with more speakers tend to have larger phoneme inventories attracted a lot of interest and has been the subject of extensive debate. Atkinson (2011) and Wichmann et al. (2011) could replicate Hay and Bauer's finding, but Donohue and Nichols (2011) and Moran et al. (2012) could not find such a correlation.
The goals of this paper are: (1) to examine whether the above mentioned negative correlations between phoneme inventory size and word length and the positive correlation between syllable size and phoneme inventory also show when analyzing textual material. All previous studies used single uninflected words for their correlations—Nettle 50 random dictionary entries, Wichmann et al. a 40-item subset of the Swadesh list—or statistical descriptions of the permitted syllable structures in the respective languages (Maddieson, 2006; Fenk-Oczlon and Fenk, 2008). But the length of uninflected words in dictionaries or word lists, or the permitted maximum syllable complexity in individual languages do not reflect word length or syllable size in actual language use or textual material (cf. Maddieson, 2009). Nettle (1998, p. 241) also recognizes the problem of using uninflected lexical stems for comparing word length across languages and argues that “the cross-linguistic distribution of word token lengths in actual texts is heavily affected by the morphological typology of different languages, and so would require a much more complex model than that presented here.” (2) To investigate whether phoneme inventory size correlates negatively with clause length in number of syllables and in number of words. (3) To examine whether our data about syllable complexity, word, and clause length correlate with population size. (4) To test whether Hay and Bauer's positive correlation between phoneme inventory size and population size can be replicated for our sample of 61 languages.
Information about phoneme inventory sizes was mostly obtained from UPSID (Maddieson and Precoda, n.d.) and/or the PHOIBLE database (Moran and McCloy, 2019). Speaker population size data are taken from Amano et al. (2014) who estimated speaker population size on information from the Ethnologue, 16th edition.
The parallel textual material used for our analysis consists of 22 simple declarative sentences encoding one proposition and using basic vocabulary. It was originally constructed to test the hypothesis that language has adapted to short-term memory constraints (Fenk-Oczlon, 1983). Such simple declarative sentences seem to be universal also from a syntactic perspective and are well-suited for large-scale cross-linguistic comparisons because the number of possible translations can be kept to a minimum. The advantage of the matched set of 22 sentences is, moreover, that they not only refer to the same semantic unit, i.e., a proposition but also exhibit the same syntactic structure. This allows to calculate the number of syllables and the number of words per clause or declarative sentence across languages. Examples for the test sentences are: The sun is shining. Blood is red. My brother is a hunter (A complete list of the 22 sentences with their translations into 28 languages is presented in Fenk-Oczlon, 1983). The 22 sentences consist of 96 words and 127 syllables in the English version—for comparison the fable “The North Wind and the Sun” often used for cross-linguistic analyses and phonetic illustrations has 113 words and 137 syllables in the English version.
Native speakers of 61 languages from 18 language families and from all continents were asked to translate the 22 sentences into their mother tongue. Most of our informants were students, many of them linguists we met at international conferences. The basic requirement was a good knowledge of either English or German in order to be able to translate the test sentences into their mother tongue.
The 61 languages are as follows (family name in bold, language names with ISO 639-3 code):
Athabaskan-Eyak-Tlingit [Navajo (NAV)] Atlantic-Congo [Bafut (BFD), Ewondo (EWO), Lamnso (LNS), Kirundi (RUN), Yoruba (YOR)] Austronesian [Batak (BYA), Cham (CJA), Chuukese (CHK), Hawaiian (HAW), Javanese (JAV), Kadazan (DTB), Kemak (KEM), Malagasy (BHR), Malay (MEO), Mambae (MGM), Minangkabau (MIN), Nias (NIA), Roviana (RUG), Tagalog (TGL) Austroasiatic [Vietnamese (VIE)] Basque [Basque (EUS)] Chiquitano [Chiquitano (CAX)] Dravidian [Telugu (TEL)] Indo-European [Albanian (SQI), Armenian (XCL), Bulgarian (BUL), Czech (CES), Croatian (HLV), Dutch (NLD), English (ENG), French (FRA), German (DEU), Greek (ELL), Hindi (HIN), Icelandic (ISL), Italian (ITA), Latvian (LAV), Macedonian (MKD), Norwegian (NOR), Panjabi (PAN), Persian (PER), Polish (POL), Portuguese (POR), Romanian (RON), Russian (RUS), Slovenian (SLV), Spanish (SPA), Tajik (TGK)] Japonic [Japanese (JPN)] Kartvelian [Georgian (GEO)] Koreanic [Korean (KOR)], Mande [Bambara (BAM)] Sino-Tibetan [Mandarin Chinese (CMN)] Tai-Kadai [Thai (THA)] Turkic [Turkish (TUR)] Uralic [Estonian (EKK), Finnish (FIN), Hungarian (HUN)] Uto-Aztecan [Hopi (HOP)] Western Daly [Maranunggu (ZMR)].
The native speakers were instructed to read their translations in normal speech and to count the number of syllables (which is, apart from determining the borders of the syllables, no problem for the informants). The written translations, or their transcriptions, enables a counting of the number of words per clause. The number of phonemes per syllable was determined by ourselves, assisted by the native speakers and by grammars of the respective languages.
We then calculated the mean numbers of phonemes per syllable, syllables per word, phonemes per word, monosyllables (function words and content words), monosyllabic content words, syllables per clause, and words per clause in these texts and correlated the data with the size of the language's phoneme inventories (number of consonants and vowels, number of vowels) found in UPSID and/or the PHOIBLE database. All these variables were correlated, moreover, with the estimated population sizes taken from Amano et al. (2014).
We used Pearson's product-moment correlation tests to examine linear relationships between our variables; the use of Spearman and Kendall correlations, respectively, showed similar results and are therefore omitted. Population size data were log-transformed to test the positive nonlinear (monotone increasing) relationship between population size and number of phonemes per syllable and between population size, phoneme inventory size and vowel inventory. The (pairwise) statistical tests were corrected for the multiple comparisons, using a Benjamini-Hochberg type correction. Moreover, a multivariate analysis of the data was performed to study interdependencies between the variables beyond pairwise relationships.
The results of a multivariate analysis between the linguistic variables phoneme inventory size, vowel inventory, phonemes per syllable, syllables per word, phonemes per word, monosyllables, monosyllabic content words, syllables per clause, words per clause, and the nonlinguistic variable population size are presented in Figures 1, 2 and Table 1.
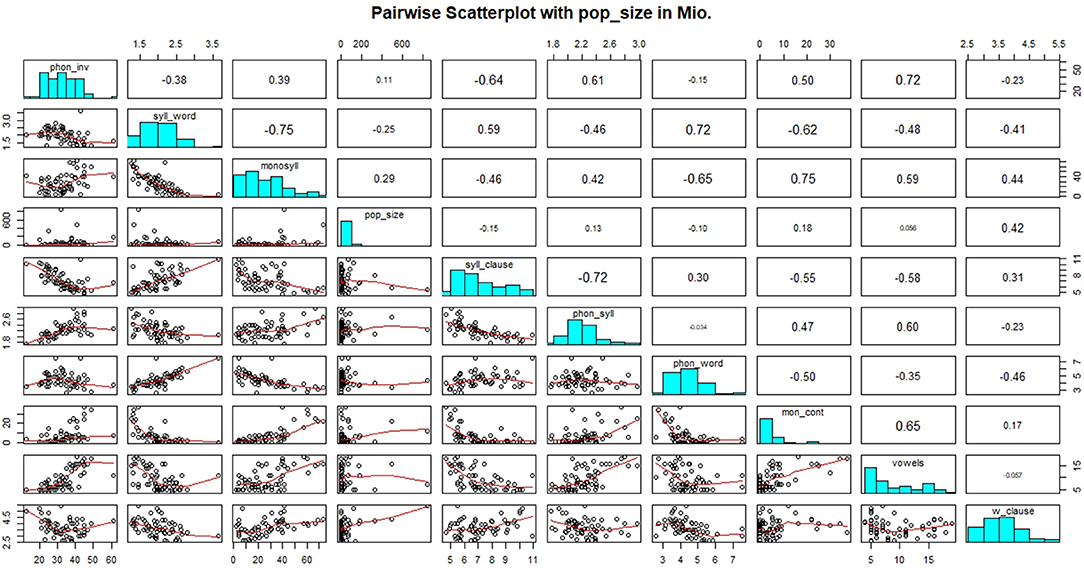
Figure 1. Pairwise scatterplot with population size.
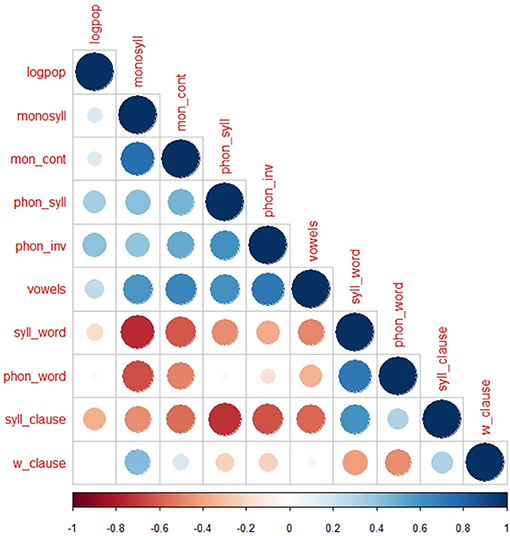
Figure 2. Correlation matrix between the linguistic variables and log of population sizes.
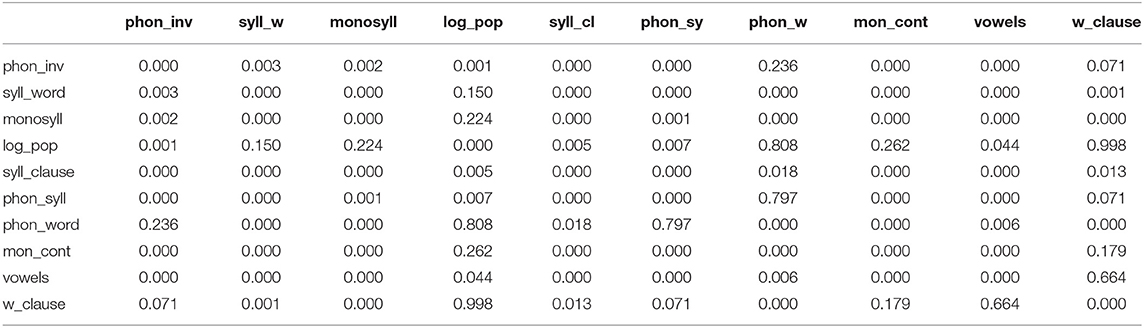
Table 1. p-values of the correlations between the linguistic variables and log population size.
In the lower panel of Figure 1, the red curves are visualizing the smoothed (pairwise) relationships between the variables of our data set, the main diagonal shows their histograms und the upper panel indicates their correlations (character size scales with the absolute values). Figure 2 displays the correlations between the different variables and Table 1 shows the p-values of the correlations between the linguistic variables and log population size.
The p-values of the correlations between population size (instead of log_pop) and the linguistic variables words per clause, monosyllables, syllables per word are as follows:
• words per clause (t = 3.5178, df = 59, p = 0.0008444),
• monosyllables (t = 2.3586, df = 59, p = 0.02168),
• syllables per word (t = −1.9782, df = 59, p = 0.05259).
A generalized linear model analysis and a graphic of the multivariate structural dependencies between the linguistic variables and log_pop are provided in the Supplemental Material. It shows that the variables with positive regression coefficients “log_pop,” “phon_ inv,” “phon_syll,” “phon_word,” and “vowels” form a group pointing into the same direction. In the same vein, “syll_word,” “syll_clause,” and “w_clause” form a group of variables with negative regression coefficients pointing into the opposite direction. In the same vein, “syll_word,” “syll_clause,” and “w_clause” form a group of variables with negative regression coefficients pointing into the opposite direction. It demonstrates, moreover, that syllable complexity (in number of phonemes) is a key factor in this relationship.
As our results demonstrate, a highly significant positive correlation between syllable complexity and inventory size shows also in textual material. Languages with more phonemes tend to have more phonemes per syllable. This is to be expected on purely combinatorial grounds. A high syllable complexity can only be achieved by a rather large number of initial and final consonant clusters. Although languages show different degrees of freedom in the combinatorial possibilities of consonants, those having a larger inventory of consonants will incline to larger consonant clusters and therefore to complex syllables.
Concerning the inverse relationship between word length and phoneme inventory size, we found that only word length measured as number of syllables is significantly negatively correlated with inventory size. The inverse relationship between phoneme inventory size and word length measured as number of phonemes reported by Nettle (1995, 1998); Wichmann et al. (2011) shows only a small and non-significant negative correlation in our textual material. This rather unexpected result might be explained by Menzerath's law (Menzerath, 1954) and its cross-linguistic version (Fenk-Oczlon and Fenk, 1985), i.e., “The more syllables per word, the fewer phonemes per syllable.” The rationale: Languages with long words (in number of syllables) tend to have simple syllable structures. Simple syllable structures on the other hand are associated with small phoneme inventories as we could demonstrate. Therefore, the inverse relationship between word length and phoneme inventory size should be more pronounced with words measured as number of syllables than with words measured as number of phonemes. One might argue that the significant inverse relationship between phoneme inventory size and word length measured as number of phonemes found by Nettle and Wichmann et al. predominately applies to rather short or monosyllabic words. Nettle uses uninflected lexical stems for his calculations which (per se) tend to be shorter than inflected words having case suffixes, etc., and the 40-item subset of the Swadesh list used by Wichmann et al. consists, at least in the English version, of 36 monosyllables.
But a high mean number of monosyllables correlates according to our calculations even positively with phoneme inventory size. This correlation shows particularly between monosyllabic content words and the number of vowels. As concerns phoneme inventory size and clause length, we found a significant inverse relationship between phoneme inventory size and clause length in number of syllables. Languages with smaller phoneme inventories tend to use a higher number of syllables per clause for conveying a proposition. A significant negative correlation shows also between the number of vowels and the number of syllables per clause.
Our analyses reveal new relationships between language structure and language population size. Significant positive correlations show between population size and mean number of monosyllables and mean number of words per clause and an almost significant negative correlation shows between population size and mean number of syllables per word. Significant positive correlations are found between the log of populations sizes and the mean number of phonemes per syllable and vowel inventory. Moreover, Hay and Bauer's (2007) finding of a positive relationship between log of population sizes and phoneme inventory sizes could be replicated in our (albeit smaller) language sample and using a different statistical method.
To summarize: Languages with more speakers tend to have:
• more phonemes per syllable
• a higher number of monosyllabic words
• shorter words in number of syllables
• a higher number of words per clause
• a higher number of vowels
• larger phoneme inventories.
As concerns the positive correlation between population size and phoneme inventory size, Hay and Bauer (2007) did not suggest any explanation. Bybee (2011, p.149) likewise argued “that no explanation is available for why population size should correlate positively with phoneme inventory size.” Wichmann et al. (2011) hypothesized that word length might play a mediating role in this relationship. We also assume that the association between population size and phoneme inventory size could be explained via word length, but we will in further consequence focus on syllable complexity as the key factor in this relationship. But then the question remains.
A possible explanation for an inverse relationship between word length and population size is provided by Zipf ‘s Law of Abbreviation (Zipf, 1949) stating that the size of a word is inversely related to its usage frequency, i.e., more frequently used words tend to be shorter. It is plausible to assume that the greater the number of speakers using a language, the greater the chance that individual words are used more frequently. As words are used more frequently, they become less accented, they begin to undergo erosion and reduction processes such as the weakening or deletion of vowels, consonants or whole syllables. The reductive sound changes result in shorter words, and in more complex syllable structures, e.g., the loss of final segments as in gas-tir vs. guest hor-na vs. horn (examples from Lehmann, 1978) in the history of English led to shorter words in number of syllables and to more complex syllable structures. Phonological reduction processes might also be responsible for the “loss of inflectional morphology in favor of ‘analytic’ periphrastic constructions” (Bentz et al., 2014). The loss of grammatical markers as a result of frequent use could also—at least partly—explain Lupyan and Dale's (2010) finding of an inverse relationship between morphological simplicity (fewer cases, etc.) and population size, or Bentz and Winter (2013) results showing an inverse relationship between number of morphological cases and proportion of L2 speakers. As the speaker population size of languages increases, the usage of word forms increases as well, which in turn leads to shorter words and to the loss of case suffixes, person markers, etc. Moreover, once words are shortened, they are in the sense of Reali et al. (2018) “Easy to diffuse” in large populations.
In the previous section, we presented arguments for why languages with many speakers should tend to have short words and complex syllable structures. Our empirical results clearly confirm these assumptions: large speaker populations tend to have many monosyllabic words, short words in number of syllables, and complex syllable structures. Syllable complexity in turn correlates highly positively with phoneme inventory size. Therefore, population size should correlate positively with phoneme inventory size.
An obvious answer might be: because they tend to have short words and isolating morphology. In a previous study (Fenk-Oczlon and Fenk, 1999), we found a significant negative correlation between word length in number of syllables and number of words per clause in 34 languages: the more words per clause, the fewer syllables per word. A correlation between the number of words per clause and syllable complexity turned out to be highly significant. In the 1999 paper, we linked these findings with notions of morphological typology and argued that a high number of short words per clause indicates a low degree of synthesis and a tendency to analytical/isolating morphology. We further reasoned that isolating/analytic languages are not only characterized by a lower degree of synthesis but also by more complex syllable structures than fusional or agglutinative languages. The present study could demonstrate that population size correlates positively with “more words per clause” and with “more complex syllables in number of phonemes,” which indicates that large populations tend to have isolating morphology. This dovetails nicely with Lupyan and Dale's (2010, p.3) findings that languages with more speakers “are more likely to be classified by typologists as isolating languages.”
To conclude: The mutually dependent relationships found between language-internal complexity relations and the nonlinguistic factor population size suggest a systemic view of language variation. According to Systemic Typology (Fenk-Oczlon and Fenk, 1995, 1999, 2004) each language goes through self-organizing processes optimizing the interaction between its (phonological, morphological, and syntactical) subsystems and the interaction with its “natural” environment, e.g., the cognitive or the social-communicative environment. Table 2 displays some of the mutual relationships found in the current paper together with results of previous studies.
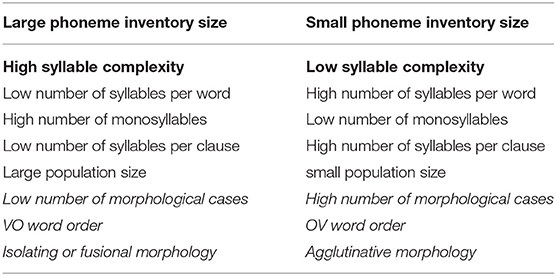
Table 2. Relationships between phoneme inventory size, linguistic structures, and population size (results of previous studies in italics).
Although phoneme inventory size interacts with all the components presented in Table 2, it does it in a rather indirect way, via syllable complexity. Syllable complexity in number of phonemes seems to play a key role in these interactions. It correlates, first of all, highly positively with phoneme inventory size—which is to be expected on purely combinatorial grounds. Furthermore, it correlates negatively with the number of syllables per word and per clause. And as we could show on basis of our parallel textual material, a significant inverse relationship between phoneme inventory size and word length was only found for word length defined as number of syllables and not as number of phonemes, as reported in previous research. We explained this discrepancy by referring to Menzerath's law. Moreover, as previous studies have shown, syllable complexity is also inversely related with the number of morphological cases (Fenk-Oczlon and Fenk, 2005), and significantly associated with the non-metric variable word order: Languages with VO word order tend to have more complex syllables structures than languages with OV order (Fenk-Oczlon and Fenk, 1999). And last but not least, syllable complexity might explain, via word length, the highly debated positive correlation between population size and phoneme inventory size. The rationale: Large speaker population tend to have short words, short words tend to have complex syllables in number of phonemes, and complex syllable structures correlate highly positively with phoneme inventory size.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
GF-O researched the ideas presented and drafted the paper. JP did the statistical analyses. Both authors edited the article.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We thank the reviewers for their insightful comments and helpful suggestions.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2021.626032/full#supplementary-material
Amano, T., Sandel, B., Eager, H., Bulteau, E., Svenning, J.-C., Dalsgaard, B., et al. (2014). Global distribution and drivers of language extinction risk. Proc. R. Soc. B Biol. Sci. 281:20141574. doi: 10.1098/rspb.2014.1574
Atkinson, Q. D. (2011). Phonemic diversity supports a serial founder effect model of language expansion from Africa. Science 332, 346–349. doi: 10.1126/science.1199295
Bentz, C., Kiela, D., Hill, F., and Buttery, P. (2014). Zipf's law and the grammar of languages: a quantitative study of Old and Modern English parallel texts. Corpus Linguist. Lingust. Theory 12, 175–211. doi: 10.1515/cllt-2014-0009
Bentz, C., and Winter, B. (2013). Languages with more second language learners tend to lose nominal case. Lang. Dyn. Change 3, 1–27. doi: 10.1163/22105832-13030105
Bybee, J. (2011). How plausible is the hypothesis that population size and dispersal are related to phoneme inventory size? Introducing and commenting on a debate. Linguist. Typology 15, 147–153. doi: 10.1515/lity.2011.009
Donohue, M., and Nichols, J. (2011). Does phoneme inventory size correlate with population size? Linguist. Typol. 15, 161–170 doi: 10.1515/lity.2011.011
Easterday, S. (2019). Highly Complex Syllable Structure: A Typological and Diachronic Study (Studies in Laboratory Phonology 9). Berlin: Language Science Press.
Fenk, A., and Fenk-Oczlon, G. (1993). “Menzerath's Law and the constant flow of linguistic information,” in: Contributions to Quantitative Linguistics, eds. R. Köhler and B. Rieger (Dordrecht: Kluwer Academic Publishers), 11–31.
Fenk-Oczlon, G. (1983). Bedeutungseinheiten und Sprachliche Segmentierung. Eine Sprachvergleichende Untersuchung Über Kognitive Determinanten der Kernsatzlänge. Tübingen: Narr.
Fenk-Oczlon, G., and Fenk, A. (1985). “The mean length of propositions is 7 plus minus 2 syllables - but the position of languages within this range is not accidental,” in Cognition, Information Processing, and Motivation, ed. G. d'Ydevalle (North Holland: Elsevier Science Publishers B.V.), 355–359.
Fenk-Oczlon, G., and Fenk, A. (1995). Selbstorganisation und natürliche Typologie. Sprachtypol. Universalienforschung 48, 223–238. doi: 10.1524/stuf.1995.48.3.223
Fenk-Oczlon, G., and Fenk, A. (1999). Cognition, quantitative linguistics, and systemic typology. Linguist. Typol. 3, 151–177. doi: 10.1515/lity.1999.3.2.151
Fenk-Oczlon, G., and Fenk, A. (2004). “Systemic typology and crosslinguistic regularities,” in Text Processing and Cognitive Technologies, eds V. Solovyev and V. Polyakov (Moscow: MISA), 229–234.
Fenk-Oczlon, G., and Fenk, A. (2005). “Crosslinguistic correlations between size of syllables, number of cases, and adposition order,” in Sprache und Natürlichkeit. Gedenkband für Willi Mayerthaler, eds. G. Fenk-Oczlon and C. Winkler (Tübingen: Narr), 75–86.
Fenk-Oczlon, G., and Fenk, A. (2008). “Complexity trade-offs between the subsystems of language,” in Language Complexity: Typology, Contact, Change, eds. M. Miestamo, K. Sinnemäki and F. Karlsson (Amsterdam; Philadelphia: John Benjamins), 43–65.
Fenk-Oczlon, G., and Fenk, A. (2010). “Measuring basic tempo across languages and some implications for speech rhythm,” Proceedings of the 11th Annual Conference of the International Speech Communication Association (INTERSPEECH 2010) (Makuhari), 1537–1540.
Hay, J., and Bauer, L. (2007). Phoneme inventory size and population size. Language 83, 388–400. doi: 10.1353/lan.2007.0071
Lehmann, W., (ed.). (1978). “English: a characteristic SVO Language,” in Syntactic Typology (Sussex: The Harvester Press), 169–222.
Lupyan, G., and Dale, R. (2010). Language structure is partly determined by social structure. PLoS One 5:e8559. doi: 10.1371/journal.pone.0008559
Maddieson, I. (2006). Correlating phonological complexity: data and validation. Linguist. Typol. 10, 106–123. doi: 10.1515/LINGTY.2006.017
Maddieson, I. (2009). Monosyllables and Syllabic Complexity. Abstract, Festival of languages, Monosyllables: From Phonology to Typology, University of Bremen.
Maddieson I. Precoda K. (n.d.). UCLA Phonological Segment Inventory Database. Electronic database. University of California, Los Angeles. Available online at: http://web.phonetik.uni-frankfurt.de/upsid.html
Moran, S., and Blasi, D. (2014). “Cross-linguistic comparison of complexity measures in phonological systems,” in Measuring Grammatical Complexity, eds F. J. Newmeyer and L. B. Preston (Oxford: Oxford University Press), 217–240.
Moran, S., and McCloy, D., (eds.),. (2019). PHOIBLE Online. Jena: Max Planck Institute for the Science of Human History. Leipzig: Max Planck Institute for Evolutionary Anthropology. Available online at: https://phoible.org
Moran, S., McCloy, D., and Wright, R. (2012). Revisiting population size vs phoneme inventory size. Language 88, 877–893. doi: 10.1353/lan.2012.0087
Nettle, D. (1995). Segmental inventory size, word length, and communicative efficiency. Linguistics 33, 359–367.
Nettle, D. (1998). Coevolution of phonology and the lexicon in twelve languages of West Africa. J. Quant. Linguist. 5, 240–245. doi: 10.1080/09296179808590132
Reali, F., Chater, N., and Christiansen, H. (2018): Simpler grammar, larger vocabulary: how population size affects language. Proc. R. Soc. B. 285:20172586 doi: 10.1098/rspb.2017.2586
Wichmann, S., Rama, T., and Holman, E. W. (2011), Phonological diversity, word length, population sizes across languages: the ASJP evidence. Linguist. Typol. 15, 177–197. doi: 10.1515/lity.2011.013
Keywords: cross-linguistic correlations, parallel texts, phoneme inventory size, syllable complexity, word length, clause length, population size, Zipf's law of abbreviation
Citation: Fenk-Oczlon G and Pilz J (2021) Linguistic Complexity: Relationships Between Phoneme Inventory Size, Syllable Complexity, Word and Clause Length, and Population Size. Front. Commun. 6:626032. doi: 10.3389/fcomm.2021.626032
Received: 04 November 2020; Accepted: 22 March 2021;
Published: 15 April 2021.
Edited by:
Kilu Von Prince, Heinrich Heine University of Düsseldorf, GermanyReviewed by:
Tiago Pimentel, University of Cambridge, United KingdomCopyright © 2021 Fenk-Oczlon and Pilz. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gertraud Fenk-Oczlon, Z2VydHJhdWQuZmVua0BhYXUuYXQ=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.