 Ian Maddieson
Ian Maddieson- Department of Linguistics, University of New Mexico, Albuquerque, NM, United States
The phonetic patterns of human spoken languages have been claimed to be in part shaped by environmental conditions in the locales where they are spoken. This follows predictions of the Acoustic Adaptation Hypothesis, previously mainly applied to the study of bird song, which proposes that differential transmission conditions in different environments explain some of the frequency and temporal variation between and within species' songs. Prior discussion of the relevance of the Acoustic Adaptation Hypothesis to human language has related such characteristics as the total size of the consonant inventory and the complexity of the permitted maximum syllable structure, rather than patterns in continuous speech, to environmental variables. Thus the relative frequency with which more complex structures occur is not taken into account. This study looks at brief samples of spoken material from 100 languages, dividing the speech into sonorous and obstruent time fractions. The percentage of sonorous material is the sonority score. This score correlates quite strongly with mean annual temperature in the area where the languages are spoken, with higher temperatures going together with higher sonority scores. The role of tree cover and annual precipitation, found to be important in earlier work, is not found to be significant in this data. This result may be explained if absorption and scattering are more important than reflection. Atmospheric absorption is greater at higher temperatures and peaks at higher frequencies with increasing temperature. Small-scale local perturbations (eddies) in the atmosphere created by high air temperatures also degrade the high-frequency spectral characteristics that are critical to distinguishing between obstruent consonants, leading to reduction in contrasts between them, and fewer clusters containing obstruent strings.
Background
Any communication system using an acoustic channel is inevitably subject to filtering and masking effects which modify the faithfulness of the transmission of a signal. Once any acoustic signal is emitted from its source its characteristics will be modified by a wide variety of factors before it reaches any recipient. When considering sounds transmitted through open air, the temperature and density of the air, the nature of the ground surface below and the presence of obstacles and their surface characteristics are among the various factors that impact both the spectral and temporal characteristics of a signal (Harris, 1966, 1967; Aylor, 1972; Marten and Marler, 1977; Marten et al., 1977; Piercy et al., 1977; Wiley and Richards, 1978; Richards and Wiley, 1980; Martens and Michelsen, 1981; Bass et al., 1984; Martens, 1992; Attenborough et al., 1995, 2011; Embleton, 1996; Sutherland and Daigle, 1998; Wilson et al., 1999; Salomons, 2001; Naguib, 2003; Albert, 2004).
Moreover, the presence of any competing sounds in the environment can affect a hearer's perception of the properties of a signal. Sound is generated by wind, rainfall, flowing water, birds, insects and other creatures, among other sources. Environmental sounds of this kind can selectively mask some characteristics of an acoustic signal in natural settings (Winkler, 2001; Slabbekoorn, 2004a,b; Brumm and Slabbekoorn, 2005).
While a good deal of the research on outdoor sound propagation has been directed to addressing practical issues relevant to humans, such as the mitigation of vehicle or aircraft noise (Salomons, 2001) or the calculation of the source of weapons fire (Beck et al., 2011), a considerable amount of work has also been devoted to the potential effects of both filtering and masking on the design of biological acoustical communication systems. Several basic principles have been put forward (Bradbury and Vehrencamp, 1988; Hauser, 1996; Römer, 2001; Ryan and Kime, 2002). The Acoustic Niche Hypothesis (Krause, 1987, 1993; Farina et al., 2011) proposes that different species tend to avoid competition for the same frequency band and time window, which reduces the impact of masking. Related to this proposition, several studies have shown that song birds in urban areas seem to be raising the pitch of their songs in response to the pervasive presence of lower-frequency human-generated machine noise (Slabbekoorn and Peet, 2003; Wood and Yezerinac, 2006) and Slabbekoorn and Smith (2002) suggest that little greenbul (Andropadus virens) populations adapt their songs to lessen interference from ambient noise. The Acoustic Adaptation Hypothesis (AAH) proposes that the acoustic communications of biological organisms are in part shaped by the transmission characteristics of the environment in which they are employed. There seems a broad consensus that the evidence for this is particularly clear with respect to bird song, the AAH having been particularly studied in this context (e.g., Chappuis, 1971; Morton, 1975; Seddon, 2005; Boncoraglio and Saino, 2007). This research has indicated that such factors as the typical density of vegetation in a species' habitat correlate with both spectral and temporal properties of bird songs. In the spectral domain, Boncoraglio and Saino's (2007) meta-analysis of multiple studies found that “Maximum, minimum, [and] peak frequency and frequency range [are] found to be significantly lower in closed compared with open habitats”. The temporal structure of bird songs also correlates with habitat: for example, Badyaev and Leaf (1997) found that among a group of warblers “species occupying closed habitats avoided the use of rapidly modulated signals and had song structures that minimized reverberation.” It is not so apparent that mammals and anurans typically display any such effect (Waser and Brown, 1986; Daniel and Blumstein, 1988; Ey and Fischer, 2009; Peters et al., 2009; Peters and Peters, 2010). This difference seems likely to be due to the fact that bird song is often much more structured, sequentially complex and varied in pitch than the calls of many mammals and anurans, and so has more features that could be disrupted in poor transmission conditions.
The overall thrust of the AAH is that in environments that are generally hostile to the faithful transmission of acoustic signals the nature of those signals will tend to become simpler in form. Importantly, since many of the factors that modify signals selectively impede transmission of higher frequencies more than of lower ones, components of a signal that involve higher frequencies are the most likely to be simplified (e.g., Dabelsteen et al., 1993; Nemeth et al., 2001). It has been suggested that the AAH may also apply to human languages (Maddieson, 2012; Coupé, 2015; Maddieson and Coupé, 2015; Coupé and Maddieson, 2016). Suggestions that non-linguistic factors have relevance to language structure have a long history, but until recently the importance of the environmental transmission characteristics had not received much attention (but see Munroe et al., 1996, 2009; Munroe and Silander, 1999; Fought et al., 2004 on a connection between climate and language structure). Maddieson and Coupé (2015) found that both the number of consonants in a phonological inventory and the complexity of syllable onsets and codas are significantly correlated with mean annual temperature and precipitation as well as maximum tree cover in the areas where the languages are spoken. These factors are, naturally enough, correlated, as vegetation requires sun and water to thrive. For this reason a principal components analysis was performed to reduce the number of variables. Consonant inventory size and syllable complexity were also combined into a consonant-heaviness index. There is a highly significant relationship (R2 = 0.196, p < 0.0001) between Principal Component 1 and the consonant-heaviness scores in a sample of 663 languages from the LAPSyD database (Maddieson et al., 2013) used by Maddieson and Coupé. Higher levels of consonant-heaviness broadly coincide with lower temperature, precipitation and tree cover (as well as with higher altitude and greater rugosity). This result is consistent with what is known about the effects of the environmental factors mentioned earlier. Consonants, especially obstruents, are more critically dependent on high frequency spectral components for their identification, and more complex syllable margins also lead to more rapid alternations of amplitude and spectral pattern. Hence it plausible that these properties would tend to be simplified where faithfulness of transmission is reduced.
However, this result was based on looking at the overall size of a consonant inventory and the maximal permitted length of syllable onsets and codas. Languages might have large inventories of obstruents and permit complex syllables but make only extremely rare use of these possibilities in the stream of speech. This paper presents a follow-up which examines if the proportion of obstruency vs. sonority in the speech stream in languages also correlates with environmental factors. Short spoken texts are compared using a sample of 100 + languages. The hypothesis under investigation is that in environments which impede faithful transmission, especially of higher frequencies, languages will favor a higher proportion of sonority. This will over time tend to differentiate the lexical forms of the words in languages spoken in environments which favor fidelity of transmission from those spoken in areas that impede faithful transmission of spectral and temporal complexity.
Materials
The texts used in this study are drawn from the recordings available from the Global Recordings Network (GRN), an evangelical Christian organization that provides recordings of didactic religious materials intended to be used to spread a particular sort of Christian faith via recordings made in the native languages of the target audiences. These recordings provide a very useful sample of a wide variety of languages in a relatively standard format. Many of the texts are re-tellings of stories from the Bible, both from Old and New Testament books. They usually involve a single speaker speaking at a moderately rapid rate, but some include more than one voice. More of the speakers are male than female. At some points sound effects and music may be also included, and some have accidental background noise or are of low quality, but a great many of the recordings are clear and have a very good signal to noise ratio. Most of the recordings in this collection are available for download in mp3 format, which sacrifices some fidelity to the quality of the original but is quite satisfactory for the present purposes, provided the original recording was done under good conditions.
There are some drawbacks to using these recordings, especially in that no details concerning the speakers are known. Some inferences concerning age and gender can be made based on the voices heard, but it is not known, for example, what other languages a given speaker may speak in addition to the target language, how much they use that language, or at what age they learned it. It is also evident that some of the recordings have been edited, particularly by truncating the signal at the onset and end of utterances. The nature of the subject matter also leads to a relatively high number of non-indigenous proper names of persons and places being used, e.g., Noah, Jesus, Adam. However, if there are “foreign accent” effects or other factors that make the recording a less than ideal exemplar of the language, these are considered as introducing statistical noise that would make it harder to confirm the hypothesis.
Each recording sample was divided into essentially sonorant and obstruent portions, as well as non-speech interludes. Sonorant and obstruent classifications were based on an auditory identification of the nature of the segments, coupled with close inspection of shape and amplitude changes in the waveform and of the spectral pattern. Files were examined using Praat (Boersma and Weenink, 2017). Vowels, voiced nasals, voiced central and lateral approximants and voiced rhotics were classed as sonorant. All stops, fricatives, and affricates as well as voiceless segments of other types are classed as obstruent. Bursts and any aspiration or affrication following a stop release as well as any preaspiration are included in the obstruent duration. The stop portion of a prenasalized stop or nasal + stop sequence was counted as obstruent, no matter how short, and the nasal portion as sonorant. As in any exercise to divide a continuous speech stream into discrete segments there are difficulties. The most acute issues concern deliminating onset and offset of segments at the margins of utterances. In most cases the articulatory onset of an utterance-initial stop is not apparent in the acoustic record, but since the hypothesis concerns the lexical shape of items an imputed articulation onset is assigned about 70 ms before a visible acoustic signature such as a burst; less if pre-voicing is apparent before the consonant release. At pre-pausal boundaries there is often an extended duration in which speech fades off into non-speech, often with devoicing, especially when the final segment is vocalic, although glottal constriction may also occur in such positions. Decisions as to the end of utterances were mainly based on where the auditory impression of a specific segment identity was lost. On occasion, it was difficult to decide if there was final devoicing or glottalization of a vowel or the syllable was closed by a final /h/ or /ʔ/ segment. Again, if such decisions are made in error, this is likely to weaken the probability of the hypothesis being confirmed.
A short extract from the recording used for the Aleut language is shown in Figure 1 to illustrate the procedure. The waveform and spectrogram (0–7 KHz) of a short (1.7 s) fragment are shown with two annotation tiers. The second of these shows the division into the obstruent (o), sonorant (s) and non-speech (n) intervals used to calculate the sonority score. The first tier shows a segmental transcription created for this exemplary figure based on the auditory identification of the segments heard. Segmental transcriptions were not regularly made; this annotation tier was normally only used to mark such things as a change of speaker or the presence of background noise or music. In this example, two issues in particular might be noted. The nasal in the sequence /ana/ in the middle of the sample appears to be pre-stopped, although this is not at all auditorily apparent. Since this is not a regular phenomenon in Aleut, unlike in, say, Eastern Arrernte, the prestopping is not considered as creating an obstruent interval. Secondly, the final /a/ is heavily glottalized and its end is indeterminate, although the auditory presence of an /a/ segment is indisputable. The end-point chosen for this vowel is a compromise between minimal and maximal options.
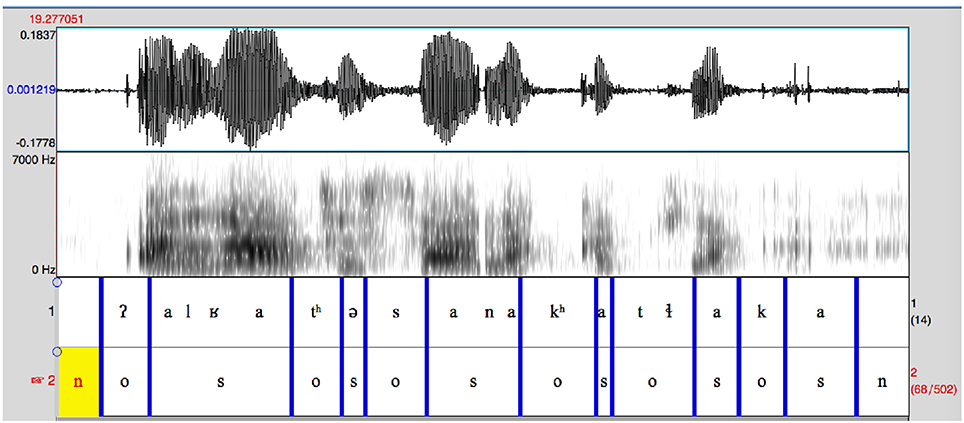
Figure 1. Short extract from Aleut GRN recording.
For each of the language samples the durations of speech fragments in obstruent and sonorant categories were summed, and the percentage of the total speech duration that was sonorant calculated. The speech samples are quite brief, consisting on average of about 1 min of actual speech (mean 66.12 s, s.d. 14.1). The mean sonority score across the samples is 65.52% (s.d. 9.02), although the range is wide, from 89.64 to 41.15%). Scores were calculated for 103 languages, but note that three of the languages whose data is included in Figure 2 below, Towa, Guarani and Southern Qiang, are not included in subsequent analyses as they could not be matched with reliable climatic and ecological data.
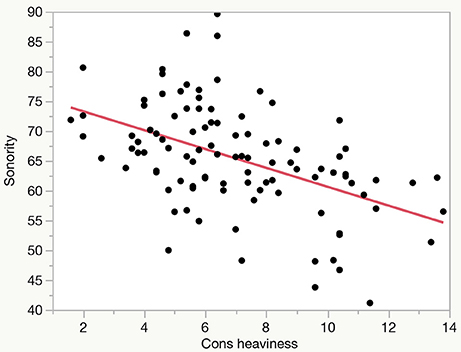
Figure 2. Plot of “consonant heaviness” vs. sonority score for 103 languages.
The sonority scores obtained for the language sample used correlate quite well with the consonant heaviness index for the same languages in Maddieson and Coupé (2015), as shown in Figure 2. This correlation is highly significant (R2 = 0.232, p < 0.0001), which indicates that the static measures of size of consonant inventory and syllable complexity predict a good part of the variance in sonority in continuous spoken language samples.
The sample of languages analyzed in the present study was selected to include a diverse range of representatives from different geographical areas and language families, and to sample the full range of values on Principal Component 1 from the Maddieson and Coupé (2015) study. Languages spoken over smaller geographical areas were preferred to ones spoken over larger areas since climatic and environmental measures are more uniform over smaller areas. Because a somewhat limited number of the recordings targeted were of usable quality, a more carefully structured sample could not be constructed. The list of languages used is included in Appendix 1 in Supplementary Material.
For each language an estimate of the area where it is spoken was taken from the World Language Mapping System, a collaboration between Global Mapping International (2016) and SIL International which generates the language maps used in The Ethnologue (Simons and Fennig, 2017). This procedure requires forcing an alignment between languages as identified in The Ethnologue and those recognized by the Global Recordings Network. Inevitably, there are some discrepancies in this match, as well as with languages as represented by the descriptions included in LAPSyD. For each language area the mean values were computed for Percent Tree Cover and Elevation from values reported in 15-s bins by the Geospatial Information Authority of Japan (http://www.gsi.go.jp/kankyochiri/gm_global_e.html). Mean Temperature data in 5 s bins is from the Climate Research Unit of the University of East Anglia (available at http://www.ipcc-data.org/observ/clim/get_30yr_means.html, see New et al., 1999 for methodology) and covers the period 1961–1990. Other ecological and climatic data was obtained from the International Steering Committee for Global Mapping (http://www.iscgm.org) (disbanded in March 2017) and the UN Food and Agriculture Organization's Sustainable Development Department.
Results
The salient result of this research is that the proportion of a speech sample that is sonorant in a sample of 100 languages is significantly correlated with mean annual temperature, but to a small or negligible extent with the other factors that were found to be related to consonant-heaviness in Maddieson and Coupé (2015). The significance values of simple correlations with single factors are shown in Table 1.

Table 1. Correlations between sonority score and climatic and environmental factors.
When these factors are entered together into a stepwise multiple correlation analysis only temperature is retained as making a significant contribution (R2 = 0.242, p < 0.0001, after elimination of the other variables). In other words, although rugosity and elevation considered individually appear as significantly correlated with sonority in Table 1, this relationship disappears when factors are considered jointly—no doubt because of the well-known relationship between temperature and elevation and the fact that elevation and rugosity (roughness of terrain) are highly correlated with each other.
The linear relationship between sonority score and mean annual temperature (shown on a normalized scale reflecting deviations from global mean) for the 100 language sample is plotted in Figure 3.
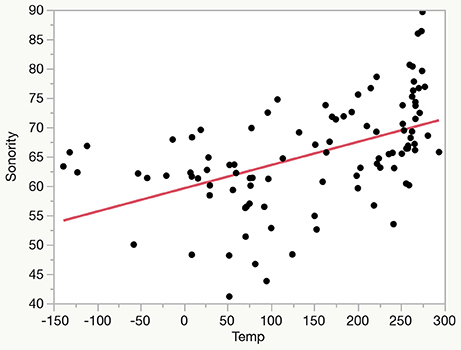
Figure 3. Plot of sonority score vs. temperature for 100 languages.
As seen in Figure 3 there are notable deviations from the general trend, and the present data is probably best regarded as still exploratory in nature. A set of speech samples of longer duration from a larger sample of languages would represent a better test of the robustness of this relationship, and more nuanced temperature data might also be informative. However, there is a strong suggestion that languages habitually spoken in parts of the world that are hotter are more likely to have a more sonorous structure than languages spoken in cooler climates.
A standard objection to claims of any external influence on language structure is that the differences said to be associated with the external influence are simply inherited differences from ancestor states. That is, they can be explained by membership in different language families. In the present case, this is difficult to refute. The 100 language sample used includes languages from 49 different highest-level family classifications. When these 49 family affiliations are included as individual predictors of sonority, it is not surprising that the overwhelming majority of the variance can be associated with individual family affiliation since there are so many parameters present in the statistical model. However the effect of temperature remains significant (p = 0.0203) when language family is included as a random effect in a mixed-effects model. But related languages tend to be spoken in contiguous areas, and are therefore more likely to be spoken under somewhat similar environmental conditions. This can be seen in Figure 4 which plots sonority and temperature for the 7 families from which 5 or more languages are included in the sample. The left panel shows that languages from the same family tend to have somewhat similar sonority scores, with, for example, Altaic and Indo-European below the average and Australian, Niger-Congo and Trans-New Guinea above. The right panel plots the mean annual temperature for the same languages. A similar pattern emerges, with Altaic and Indo-European below the average and Australian, Niger-Congo and Trans-New Guinea above. Austronesian and Sino-Tibetan straddle the means. In this subset of data, sonority and temperature values are quite highly correlated, R2 = 0.4097. While inherited aspects of the segment inventories and syllabic structures undoubtedly account for some of the similarity in sonority scores within families, it cannot be argued that mean temperature is a heritable linguistic trait. Thus perhaps the question should be to what extent might within-family similarities themselves be accounted for (at least in part) by environmental conditions.
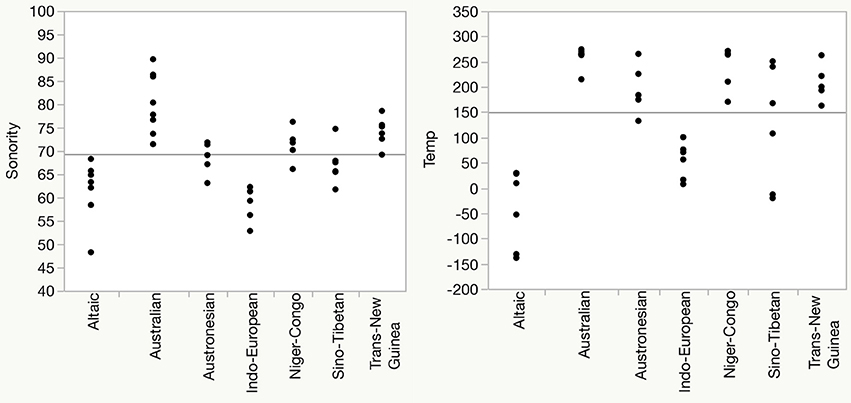
Figure 4. Sonority scores (Left) and normalized mean annual temperature (relative to global mean), (Right) for languages in families with 5 or more languages in the sample.
Discussion
Why would higher average temperature lead to the use of more sonorous sounds? There are various factors at play. First is the fact that atmospheric absorption increases at higher temperatures and it peaks at higher frequencies as the temperature increases (Harris, 1966). This will perturb the fidelity of transmission of frequencies higher in the speech range more than those in a lower range. In addition there is the impact of the turbulence in the air that is associated with higher temperature. Under some conditions heat-induced air turbulence can be seen by the naked eye as a disturbance to the visualization of objects at a distance (though bending of light rays also contributes to this visual effect). Studying the effects of atmospheric turbulence is problematical, since by its very nature turbulence is random, and moreover these effects can never be isolated in practice from other effects, such as ground reflectivity and atmospheric absorption. However, Daigle et al. (1986, p. 622) do suggest that under the experimental outdoor conditions they studied “the dominant mechanism responsible for the measured sound-pressure levels at high frequencies is scattering by atmospheric turbulence” and that these higher frequencies could be attenuated by as much as 20 dB from the source strength (cf Daigle et al., 1983). Ingård (1953) also reported strong attenuation of higher frequencies due to wind turbulence based on earlier studies. Turbulence also disrupts the temporal pattern of acoustic signals, particularly disrupting the integrity of rapidly changing signals. Selective effects of absorption and turbulence on higher frequencies naturally cause more problems for the faithful identification of speech components whose recognition depends on these higher frequencies, perhaps most especially for the burst spectra of consonants and the noise of sibilant fricatives. Sonorants on the other hand are more typically identifiable from lower-frequency elements, and have more slowly-changing temporal structure, and hence are less distorted by these factors.
In addition to these effects refraction due to temperature gradients may also play a role. Under normal daytime conditions, there is a negative temperature gradient in the atmosphere—air nearer the ground is warmer than that higher up (e.g., Fowells, 1948). This causes an upward refraction of sound waves since the speed of sound is higher in warmer air (e.g., Lamancusa, 2010). Further, in general the temperature gradient (“lapse rate”) is greater when ground temperature is higher, for example closer to the tropics (Mokhov and Aperov, 2006). The consequence of this is that overall sound energy is decreased more with distance. The normal daytime temperature gradient therefore generally diminishes the strength of a close-to-ground signal and degrades its perceptibility, but the more so the higher the temperature is, rendering accurate signal recognition more difficult.
As for the process by which such environmental effects shape the structure of languages, this is probably best regarded as a case where the role of the listener is paramount (Ohala, 1981, 2012). If the transmission conditions make it difficult to distinguish between different consonants, and different clusters of consonants, then the templates for given lexical items will likely converge on fewer distinct forms, because with sufficient exposure to tokens degraded during transmission a listener no longer considers them distinct. Over time, this will tend to restructure the phonological shape of words toward having smaller consonant inventories and simpler syllable structures. Naturally, this process is more likely to shape linguistic structure where speakers spend significant time outdoors. The period of human history during which a settled agricultural lifestyle was the predominant economic model—well after the “Neolithic Revolution” (Childe, 1936; Diamond and Bellwood, 2003) but before the Industrial Revolution had run its course—seems the most favorable time-frame within which the process would have impacted the shape of languages. In many cases a simple agricultural economy involves long hours of outdoor labor, tending crops and animals. In 1996 Munroe et al. (Munroe et al., 1996; cf Ember and Ember, 1999) had suggested that more outdoor time was linked to simpler syllable structure, but did not link this in an explanatory way to environmental conditions. This paper presents a reasoned argument to support their speculation.
This paper also argues that acoustic adaptation occurs between different groups of the same species, in this case speakers of different human languages, whereas the majority of work on the AAH has examined between-species differences. However within-species effects are not unique. A number of studies of bird species that live in varied habitats have reported that their song patterns vary according to their environment in a similar way to that found across species. Hunter and Krebs (1979) examined songs of great tit (parus major) populations in widely dispersed sites from Morocco and Iran to Spain, Norway and the U. K. and found that birds inhabiting denser forest environments had songs with a lower maximum frequency, narrower frequency range and fewer notes per phrase than birds inhabiting more open woodland or hedgerows. Nicholls and Goldizen (2006) studied satin bowerbird (Ptilonorhynchus violaceus) populations along the east coast of Queensland, Australia, and found significant effects of variation in local habitat on song structure: “Lower frequencies and less frequency modulation were utilized in denser habitats such as rainforest, and higher frequencies and more frequency modulation were used in the more open eucalypt dominated habitats.” Within-species effects have also been reported, inter alia, by Wasserman (1979), Anderson and Connor (1985), and Tubaro and Segura (1994). These studies, like most studies addressing the AAH, have emphasized the physical characteristics of the environment, such as the vegetation, rather than looking at climatic factors. It would be interesting to see if adding analysis of factors such as temperature and precipitation would add to the insights derived by looking primarily at the characteristics of local vegetation types in accounting for these differences. Note that global relative mean temperature patterns are likely to be more stable over recent time than tree cover, which is strongly affected by human activity as well as climatic change.
The finding that the design of acoustic communication systems within species appears to be shaped by environmental factors indicates that these influences operate over at least a shorter time-span than the interval between “speciation events” (Mayr, 1942), but this is, of course, a highly variable and imprecise datum. On the other hand, the phonological structure of human languages is highly malleable and individual languages can change their systems in the span of a single generation (e.g., Jacewicz et al., 2011). So environmental transmission factors affecting language structures, like other triggers of language change, probably do not require a long time span to operate. However, once entrenched, the consequences of such effects may persist for a long time.
Author Contributions
The author confirms being the sole contributor of this work and approved it for publication.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The author gratefully acknowledges the assistance of Christophe Coupé in calculating the mean temperature values and other ecological variables used in this study.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2018.00028/full#supplementary-material
References
Albert, D. G. (2004). Past Research on Sound Propagation Through Forests. Hanover NH: US Army Corps of Engineers, Cold Regions Research and Engineering Laboratory.
Anderson, M. E., and Connor, R. N. (1985). Northern Cardinal song in three forest habitats in Eastern Texas. Wilson Bull. 97, 436–449.
Attenborough, K., Bashir, I., and Taherzadeh, S. (2011). Outdoor ground impedance models. J. Acoust. Soc. Am. 129, 2806–2819. doi: 10.1121/1.3569740
Attenborough, K., Taherzadeh, S., Bass, H. E., Di, X., Raspet, R., Becker, G. R., et al. (1995). Benchmark cases for outdoor sound propagation models. J. Acoust. Soc. Am. 97, 173–191. doi: 10.1121/1.412302
Aylor, D. (1972). Noise reduction by vegetation and ground. J. Acoust. Soc. Am. 51, 197–205. doi: 10.1121/1.1912830
Badyaev, A. V., and Leaf, E. S. (1997). Habitat associations of song characteristics in Phylloscopus and Hippolais warblers. Auk 114, 40–46. doi: 10.2307/4089063
Bass, H. E., Sutherland, L. C., and Piercy, J. (1984). “Absorption of sound by the atmosphere,” in Physical Acoustics: Principles and Methods, Vol. 17, eds W. P. Mason and R. N. Thurston (New York, NY: Academic Press), 145–232.
Beck, S. D., Nakasone, H., and Marr, K. W. (2011). Variations in recorded acoustic gunshot waveforms generated by small firearms. J. Acoust. Soc. Am. 129, 1748–1759 doi: 10.1121/1.3557045
Boersma, P., and Weenink, D. (2017). Praat: Doing Phonetics by Computer. Available online at: http://www.fon.hum.uva.nl/praat/
Boncoraglio, G., and Saino, N. (2007). Habitat structure and the evolution of bird song: a meta-analysis of the evidence for the acoustic adaptation hypothesis. Funct. Ecol. 21, 134–142. doi: 10.1111/j.1365-2435.2006.01207.x
Bradbury, J. W., and Vehrencamp, S. L. (1988). Principles of Animal Communication. Sunderland: Sinauer.
Brumm, H., and Slabbekoorn, H. (2005). Acoustic communication in noise. Adv. Study Behav. 35, 151–209. doi: 10.1016/S0065-3454(05)35004-2
Chappuis, C. (1971). Un exemple de l'influence du milieu sur les emissions vocales des oiseaux: l'evolution des chants en foret equitoriale. Terre et Vie 25, 183–202.
Coupé, C. (2015). “Testing the acoustic adaptation hypothesis with GIS and spatial regression models,” in Causality in the Language Sciences Meeting, Max Planck Institute for Evolutionary Anthropology (Leipzig).
Coupé, C., and Maddieson, I. (2016). “Quelle adaptation acoustique pour les langues du monde?” in Actes du 13ème Congrès Français d'Acoustique (Le Mans).
Dabelsteen, T., Larsen, O. N., and Pedersen, S. B. (1993). Habitat-induced degradation of sound signals: quantifying the effects of communication sounds and bird location on blur ratio, excess attenuation, and signal-to-noise ratio in blackbird song. J. Acoust. Soc. Am. 93, 2206–2220. doi: 10.1121/1.406682
Daigle, G. A., Embleton, T. F. W., and Piercy, J. E. (1986). Propagation of sound in the presence of gradients and turbulence near the ground. Acoust. Soc. Am. 79, 613–627. doi: 10.1121/1.393451
Daigle, G. A., Piercy, J. E., and Embleton, T. F. W. (1983). Line-of-sight propagation through atmospheric turbulence near the ground. J. Acoust. Soc. Am. 74, 1505–1513. doi: 10.1121/1.390152
Daniel, J. C., and Blumstein, D. T. (1988). A test of the acoustic adaptation hypothesis in four species of marmots. Anim. Behav. 56, 1517–1528. doi: 10.1006/anbe.1998.0929
Diamond, J., and Bellwood, P. (2003). Farmers and their languages: the first expansions. Science 300, 597–603. doi: 10.1126/science.1078208
Ember, M., and Ember, C. R. (1999). Cross-language predictors of consonant-vowel syllables. Am. Anthropol. 101, 730–742. doi: 10.1525/aa.1999.101.4.730
Embleton, T. F. W. (1996). Tutorial on sound propagation outdoors. J. Acoust. Soc. Am. 100, 31–48. doi: 10.1121/1.415879
Ey, E., and Fischer, J. (2009). The “Acoustic Adaptation Hypothesis” — a review of the evidence from birds, anurans and mammals. Bioacoustics 19, 1–2. doi: 10.1080/09524622.2009.9753613
Farina, A., Lattanzi, E., Malavasi, R., Pieretti, N., and Piccioli, L. (2011). Avian soundscapes and cognitive landscapes: theory, application and ecological perspectives. Landsc. Ecol. 26, 1257–1267. doi: 10.1007/s10980-011-9617-z
Fought, J. G., Munroe, R. L., Fought, C. R., and Good, E. M. (2004). Sonority and climate in a world sample of languages. Cross Cult. Res. 38, 27–51. doi: 10.1177/1069397103259439
Fowells, H. A. (1948). The Temperature Gradient in a Forest. California Forest and Range Experiment Station, Forest Service, U.S. Department of Agriculture. Available online at: https://www.fs.fed.us/psw/publications/cfres/cfres_1948_fowells001.pdf
Global Mapping International (2016). World Language Mapping System, Version 17. Available online at: http://www.worldgeodatasets.com/files/9313/0400/5767/WGDS_WLMS.pdf
Harris, C. M. (1966). Absorption of sound in air versus humidity and temperature. J. Acoust. Soc. Am. 40, 148–159. doi: 10.1121/1.1910031
Harris, C. M. (1967). Absorption of Sound in Air Versus Humidity and Temperature. Washington, DC: National Aeronautics and Space Administration.
Hunter, M. L., and Krebs, J. R. (1979). Geographical variation in the song of the Great Tit (Parus major) in relation to ecological factors. J. Anim. Ecol. 48, 759–785. doi: 10.2307/4194
Ingård, U. (1953). A review of the influence of meteorological conditions on sound propagation. J. Acoust. Soc. Am. 25, 405–411. doi: 10.1121/1.1907055
Jacewicz, E., Fox, R. A., and Salmons, J. (2011). Vowel change across three age groups of speakers in three regional varieties of American English. J. Phonol. 39, 683–693. doi: 10.1016/j.wocn.2011.07.003
Krause, B. (1987). Bioacoustics, habitat ambience in ecological balance. Whole Earth Rev. 57, 14–18.
Krause, B. (1993). The niche hypothesis: a hidden symphony of animal sounds, the origins of musical expression and the health of habitats. Explor. J. 71, 156–160.
Lamancusa, J. S. (2010) Outdoor Sound Propagation. State College, PA: State University. Available online at: http://www.mne.psu.edu/lamancusa/me458/10_osp.pdf (Accessed March 30, 2018).
Maddieson, I. (2012). On the origin and distribution of complexity in phonological structure. Grenoble: Journées d'Études de la Parole. Available online at: http://aclweb.org/anthology/F/F12/F12-4004.pdf
Maddieson, I., and Coupé, C. (2015). “Human language diversity and the acoustic adaptation hypothesis,” in Proceedings of Meetings on Acoustics, (Jacksonville, FL).
Maddieson, I., Flavier, S., Marsico, E., Coupé, C., and Pellegrino, F. (2013). “LAPSyD: Lyon-albuquerque phonological systems database,” in Proceedings of Interspeech 2013 (Lyon).
Marten, K., and Marler, P. (1977). Sound transmission and its significance for animal vocalization. I. Temperate habitats. Behav. Ecol. Sociobiol. 2, 271–290. doi: 10.1007/BF00299740
Marten, K., Quine, D., and Marler, P. (1977). Sound transmission and its significance for animal vocalization.II. Tropical forest habitats. Behav. Ecol. Sociobiol. 2, 291–302. doi: 10.1007/BF00299741
Martens, M. J. M. (1992). “Sound propagation in the natural environment, animal acoustic communication and possible impact for pollination,” in Sexual Plant Reproduction, eds M. Cresti, and A. Tiezzi (Berlin: Springer), 225–232.
Martens, M. J. M., and Michelsen, A. (1981). Absorption of acoustic energy by plant leaves. J. Acoust. Soc. Am. 69, 303–306. doi: 10.1121/1.385313
Mayr, E. (1942). Systematics and the Origin of Species from the Viewpoint of a Zoologist. New York, NY: Columbia University Press.
Mokhov, I. I., and Aperov, M. G. (2006). Tropospheric lapse rate and its relation to surface temperature from reanalysis data. Izvest. Atmosph. Oceanic Phys. 42, 430–438. doi: 10.1134/S0001433806040037
Morton, E. S. (1975). Ecological sources of selection on avian sounds. Am. Nat. 109, 17–34. doi: 10.1086/282971
Munroe, R. L., Fought, J. G., and Macaulay, R. K. S. (2009). Warm climates and sonority classes: not simply more vowels and fewer consonants. Cross Cult. Res. 43, 123–133. doi: 10.1177/1069397109331485
Munroe, R. L., Munroe, R. H., and Winters, S. (1996). Cross-cultural correlates of the consonant-vowel syllable. Cross Cult. Res. 30, 60–83. doi: 10.1177/106939719603000103
Munroe, R. L., and Silander, M. (1999). Climate and the consonant-vowel (CV) syllable: replication within language families. Cross Cult. Res. 33, 43–62. doi: 10.1177/106939719903300104
Naguib, M. (2003). Reverberation of rapid and slow trills: implications for signal adaptations to long-range communication. J. Acoust. Soc. Am. 113, 1749–1756. doi: 10.1121/1.1539050
Nemeth, E., Winkler, H., and Dabelsteen, T. (2001). Differential degradation of antbird songs in a neotropical rainforest: adaptation to perch height? J. Acoust. Soc. Am. 110, 3263–3274. doi: 10.1121/1.1420385
New, M., Hulme, M., and Jones, P. (1999). Representing twentieth-century space–time climate variability. Part I: Development of a 1961–90 mean monthly terrestrial climatology. J. Clim. 12, 829–856. doi: 10.1175/1520-0442(1999)012<0829:RTCSTC>2.0.CO;2
Nicholls, J. A., and Goldizen, A. W. (2006). Habitat type and density influence vocal signal design in satin bowerbirds. J. Anim. Ecol. 75, 549–558. doi: 10.1111/j.1365-2656.2006.01075.x
Ohala, J. J. (1981). “The listener as a source of sound change,” in Papers from the Parasession on Language and Behavior (Chicago: Chicago Linguistic Society), 178–203.
Ohala, J. J. (2012). “The listener as a source of sound change: an update,” in The Initiation of Sound Change: Perception, Production, and Social Factors, eds M. J. Solé, and D. Recasens (Amsterdam: John Benjamins), 21–36.
Peters, G., Baum, L., Peters, M. K., and Tonkin-Leyhausen, B. (2009). Spectral characteristics of intense mew calls in cat species of the genus Felis (Mammalia: Carnivora: Felidae). J. Ethol. 27, 221–237. doi: 10.1007/s10164-008-0107-y
Peters, G., and Peters, M. K. (2010). Long-distance call evolution in the Felidae: effects of body weight, habitat, and phylogeny. Biol. J. Linnean Soc. 101, 487–500. doi: 10.1111/j.1095-8312.2010.01520.x
Piercy, J. E., Embleton, T. F., and Suthorland, L. G. (1977). Review of noise propagation in the atmosphere. J. Acoust. Soc. Am. 61, 1403–1418. doi: 10.1121/1.381455
Richards, D. G., and Wiley, R. H. (1980). Reverberations and amplitude fluctuations in the propagation of sound in a forest: implications for animal communication. Am. Nat. 115, 381–399. doi: 10.1086/283568
Römer, H. (2001). “Ecological constraints for sound communication: from grasshoppers to elephants,” in Ecology of Sensing, eds F. G. Barth, and A. Schmid (Berlin: Springer), 59–78.
Ryan, M. J., and Kime, N. M. (2002). “Selection on long-distance acoustic signals,” in Acoustic Communication, eds A. M. Simons, A. N. Popper, and R. R. Fay (New York, NY: Springer), 225–274.
Seddon, N. (2005). Ecological adaptation and species recognition drives vocal evolution in neotropical suboscine birds. Evolution 59, 200–215. doi: 10.1111/j.0014-3820.2005.tb00906.x
Simons, G. F., and Fennig, C. D. (eds). (2017). Ethnologue, Languages of the World, 20th Edn. Dallas, TX: SIL International. Available online at http://www.ethnologue.com (requires subscription).
Slabbekoorn, H., and Peet, M. (2003). Birds sing at higher pitch in urban noise. Nature 424:267. doi: 10.1038/424267a
Slabbekoorn, H. (2004a). Habitat-dependent ambient noise: consistent spectral profiles in two African forest types. J. Acoust. Soc. Am. 116, 3727–3733. doi: 10.1121/1.1811121
Slabbekoorn, H. (2004b). “Singing in the wild: the ecology of birdsong,” in Nature's Music: The Science of Birdsong, eds P. Marker, and H. W. Slabbekoorn (Amsterdam: Academic Press), 178–205.
Slabbekoorn, H., and Smith, T. B. (2002). Habitat-dependent song divergence in the Little Greenbul: an analysis of environmental selection pressures on acoustic signals. Evolution 56, 1849–1858. doi: 10.1111/j.0014-3820.2002.tb00199.x
Sutherland, L. C., and Daigle, G. A. (1998). “Atmospheric sound propagation,” in Handbook of Acoustics, ed M. J. Crocker (New York, NY: John Wiley, and Sons), 305–329.
Tubaro, P. L., and Segura, E. T. (1994). Dialect differences in the song of zonotrichia capensis in the southern pampas: a test of the Acoustic Adaptation Hypothesis. Condor 96, 1084–1088. doi: 10.2307/1369117
Waser, P. M., and Brown, C. H. (1986). Habitat acoustics and primate communication. Am. J. Primatol. 10:135–154. doi: 10.1002/ajp.1350100205
Wasserman, F. E. (1979). The relationship between habitat and song in the White-throated Sparrow. Condor 81, 424–426. doi: 10.2307/1366974
Wiley, R. H., and Richards, D. G. (1978). Physical constraints on acoustic communication in the atmosphere: implications for the evolution of animal vocalizations. Behav. Ecol. Sociobiol. 3, 69–94. doi: 10.1007/BF00300047
Wilson, D. K., Brasseur, J. G., and Gilbert, K. E. (1999). Acoustic scattering and the spectrum of atmospheric turbulence. J. Acoust. Soc. Am. 105, 30–34. doi: 10.1121/1.424594
Winkler, H. (2001). “The ecology of avian acoustic signals,” in Ecology of Sensing, eds F. G. Barth and A. Schmid (Berlin: Springer), 79–104.
Keywords: acoustic adaptation hypothesis, language and environment, sonority, running speech, temperature
Citation: Maddieson I (2018) Language Adapts to Environment: Sonority and Temperature. Front. Commun. 3:28. doi: 10.3389/fcomm.2018.00028
Received: 06 October 2017; Accepted: 12 June 2018;
Published: 24 July 2018.
Edited by:
Steven Moran, Universität Zürich, SwitzerlandReviewed by:
Anouschka Foltz, Bangor University, United KingdomCristiano Broccias, Università di Genova, Italy
Copyright © 2018 Maddieson. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ian Maddieson, ianm@berkeley.edu