 Lei Zheng
Lei Zheng Nico Marek
Nico Marek Natalia Melnik
Natalia Melnik Stefan Pollmann
Stefan Pollmann
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Cognit. , 10 May 2024
Sec. Learning and Cognitive Development
Volume 3 - 2024 | https://doi.org/10.3389/fcogn.2024.1403749
This article is part of the Research Topic Guidance of Search by Long-Term and Working Memory View all 7 articles
Contextual cueing leads to improved efficiency in visual search resulting from the extraction of spatial regularities in repeated visual stimuli. Previous research has demonstrated the independent contributions of global configuration and spatial position to contextual cueing. The present study aimed to investigate whether learned spatial configuration or individual locations would elicit fixation patterns resembling those observed in the original displays. We found that search guidance based on either local or global spatial context, by combining distractor locations from two learned displays or rotating displays, kept not only search time facilitation intact, in agreement with previous studies, but also enabled search with less fixations and more direct scan paths to the target. Fixation distribution maps of recombined or rotated displays were more similar to the original displays than random new displays. However, for rotated displays this was only true when the rotation angle was taken into account. Overall, this shows an astonishingly flexible use of the oculomotor system for search in incompletely repeated displays.
Contextual cueing is a phenomenon characterized by the extraction of spatial regularities from repeated visual stimulus patterns, leading to enhanced efficiency of visual search. Numerous studies have consistently demonstrated the facilitation effect associated with contextual cueing, wherein participants exhibit faster search times for displays with repeated configurations (Goujon et al., 2015; Jiang and Sisk, 2019; Jiang et al., 2019; Sisk et al., 2019). Notably, previous studies have highlighted the independent contribution of spatial position and global configuration to contextual cueing (Jiang and Wagner, 2004; Zheng and Pollmann, 2019). This was achieved by the design of two types of displays: the first type of display recombined distractors from two learned configurations with the same target location, thereby preserving individual target-distractor relations but destroying the global spatial configuration of distractors. The second type of display was obtained by changing display size (Jiang and Wagner, 2004) or rotating the entire display around its center (Zheng and Pollmann, 2019), thereby preserving the spatial configuration but changing all distractor locations. Contextual cueing was observed in both types of displays, which suggests that both the spatial position of individual items and the overall arrangement of the display contribute to guiding attention and facilitating efficient search processes.
However, these studies only analyzed search times, as a summary measure of the underlying processes. Thus, although the search time benefits for recombined and rotated (or enlarged) displays demonstrated that search was more efficient in these partially repeated displays, they yielded no further information about the underlying processes. One way to learn more about these processes is to measure eye movements.
Contextual cueing not only leads to reduced search times for repeated displays but also to fewer fixations and more efficient fixation patterns (Peterson and Kramer, 2001; Tseng and Li, 2004; Brockmole and Henderson, 2006; Manginelli and Pollmann, 2009). However, in these previous studies, eye movement data were recorded in fully repeated displays. In contrast, in the present study, we explored eye movements in rotated displays—that selectively contained only the previously learned spatial configuration of items but not the learned item locations—or in recombined displays—in which all distractor locations were predictive of the target location, but the overall configuration of distractor locations was not.
There is evidence that both the individual spatial target-distractor relations and the overall spatial configuration contribute to contextual cueing. On the one hand, it was observed that repeating only distractor locations in the vicinity of the target led to search facilitation of about the same magnitude as repeating all locations of a display (Olson and Chun, 2002; Brady and Chun, 2007). On the other hand, in the same studies, effects of global context on contextual cueing were observed, e.g., the search facilitation due to contextual cueing was lost if all distractor locations in the target quadrant were preserved, but the quadrants of a display were shuffled (Brady and Chun, 2007, Exp. 4). Thus, the evidence gained from search times suggests that both the local distractor position and the global target-distractor configuration of a display are vital information sources that help predict the target location.
Here, we asked if the pattern of eye movements made during search in a recombined or rotated display would be similar to the original display that was encountered during the—incidental—learning phase of the experiment. Regarding the recombined displays, the question was, would the eye movement pattern for searching a display in which 100% of distractor locations were predictive of the target, but 50% each stemmed from two different trained displays, thus destroying the overall target-distractor configuration, still be more similar to the eye movement pattern in the original display(s), compared to an eye movement pattern recorded during viewing a new display? Regarding the rotated displays, we asked if a display that is repeated but rotated by 45° elicits a fixation pattern that is similar to the one elicited by the original display, but likewise rotated by 45°. Alternatively, it might be assumed that a rotation angle of 45° is sufficiently small that the fixation pattern from the original display need not be rotated, perhaps using larger attentional foci (indicated by fewer fixations and larger saccade amplitudes) for an efficient search.
It may be argued that higher similarity of fixation patterns for a trained display and its recombined or rotated versions, rather than a new display, is trivial, because it may simply be achieved by fixating the display items one by one. However, fixation patterns are typically not identical when a scene is repeatedly presented. Rather, the number of fixations tends to be reduced for repeated presentations (Smith et al., 2006; Damiano and Walther, 2019). We expected the same here, a fixation pattern that is similar—though perhaps rotated—to the fixation pattern during initial presentation, but reduced in the number of fixations and with a more efficient scan path, yielding a reduced search time.
Twenty-four young adults (13 females and 11 males) with an average age of 23.7 years participated in the experiment, having self-reported normal or corrected-to-normal vision, and provided written informed consent for taking part in this study. Data from two participants were excluded because of unexpected program crashes, resulting in a final sample size of twenty-two participants. After they completed the experiment, participants were compensated with an 8-euro payment or a 1-h study credit.
Participants were individually tested in a sound-attenuated chamber, to ensure minimal external distractions. During the experiment, participants viewed a computer screen from a fixed distance of 57 cm by using a chin rest. Stimuli were presented on a screen with a resolution of 1,920 × 1,080 pixels and a refresh rate of 60 Hz.
The PsychoPy software was used to generate stimuli, control the timing of experimental events, and record participants' responses. Eye movements were recorded with an EyeLink 1000 desktop mount eye-tracking system (SR Research, Missisauga, Ontario, Canada), with 1,000 Hz temporal resolution.
The displays consisted of an arrangement of eleven white items (one T-shaped target and ten L-shaped distractors) that were presented against a black background (Figure 1). The target T was rotated by 90° to the left or right and the distractors were rotated by 0°, 90°, 180°, or 270°. Each letter's orientation was randomly determined for each trial. To increase the search difficulty, there was an offset (seven pixels) of the line junction of the distractor Ls, making the distractors more similar to the target T (Jiang and Chun, 2001).
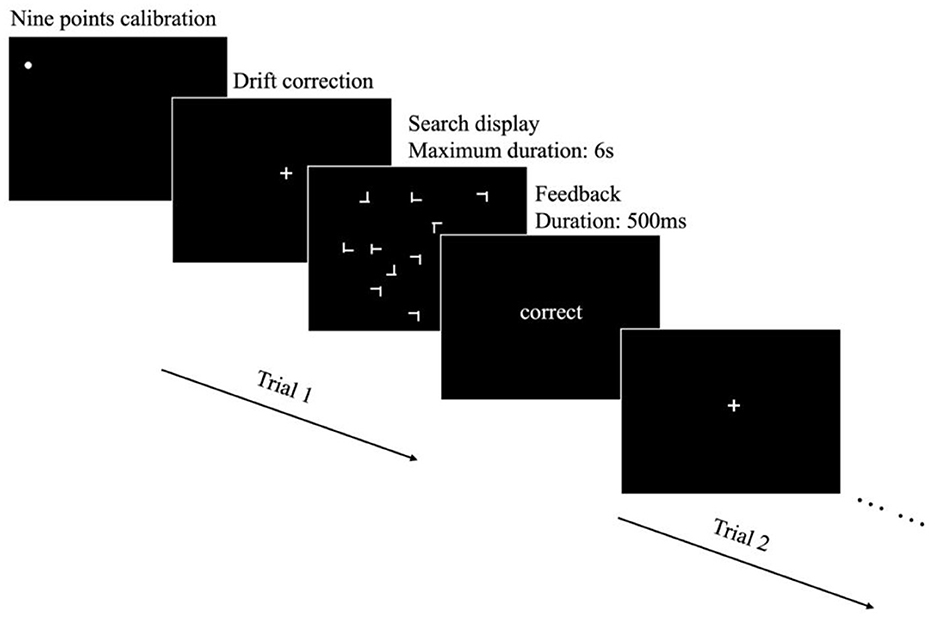
Figure 1. The procedure employed in the present experiment. Prior to the start of each block, a nine-point calibration was conducted to ensure the accuracy of the eye-tracking system. Throughout the block, ongoing calibration checks were performed and adjustments were made when necessary to maintain optimal tracking accuracy. Each trial began with a white fixation cross at the center of the screen, serving as an initial point of visual focus for participants. Following this, a search display was presented, where participants were required to indicate the target's rotation by pressing respective buttons. The search display remained visible until either the button was pressed or a maximum duration of 6 s had elapsed. At the end of each trial, feedback was presented for 500 ms.
The eye tracker was calibrated with the standard nine-point calibration procedure at the start of each block. Throughout the block, recalibration was performed as required to account for any potential measurement errors or variability arising from subtle shifts in pupil position across different trials.
Each trial began with a drift correction procedure to check whether the calibration model is still accurate. Following successful drift correction, participants were presented with the search display, during which they were allowed to freely move their eyes. The task was to identify the orientation of the T target (either rotated to left or rotated to right) by pressing the corresponding left or right key on a keyboard. The search display remained visible until the participants responded, or until a maximum duration of 6 s had elapsed. Participants were given feedback after each response. This feedback provided participants with information regarding the accuracy of their responses in the preceding trial, allowing for real-time performance evaluation. The experimental procedure is illustrated in Figure 1.
The experiment consisted of a learning phase and a transfer phase. The learning phase consisted of 20 blocks of 12 trials (240 trials in total), and the transfer phase consisted of four blocks of 48 trials (192 trials in total). To mitigate participant fatigue and allow for periodic breaks, every set of 48 trials (four blocks in the learning phase, and one block in the transfer phase) was followed by a rest period of 10 s. The whole experiment took about 50 min to complete.
During the learning phase, 12 displays were repeatedly presented over 20 blocks. The positioning of the items in the experiment followed a specific arrangement of four concentric circles with radii of 2.04°, 3.99°, 6.28°, and 8.76°. Within each circle, there were eight equidistant possible item locations. To ensure that the target was not readily detectable at display onset, target locations were chosen only on the three outer circles.
The displays were generated individually for each participant, with the following procedure. Six target positions were randomly chosen on each of the three outer circles. Next, the second target position, following a 45-degree shift, was selected for each target. Overall, for six initial target locations, six rotated target locations were selected. By employing this design, this selection of target positions allowed for the systematic exchange of two target locations in the rotated condition of the transfer phase while maintaining a consistent probability distribution of the target location.
Each target position was paired with two sets of distractors in different positions. Specifically, for each target position, 20 distractor positions were randomly selected from the pool of items. These selected distractor positions were then randomly divided into two sets of ten positions. Each set of ten positions was matched with the target to form a display configuration. In this way, a total of twelve displays (six target locations × two sets of distractor locations) were generated and presented in random order in each block.
The transfer phase consisted of four blocks. Each block consisted of 12 displays encompassing four randomly interleaved configuration types: Fully Repeated, Recombined, Rotated, and New, following the design of the prior study by Zheng and Pollmann (2019). Fully Repeated displays were identical to those presented during the learning phase. This configuration served as a baseline for evaluating the retention and transfer of learned spatial associations. In the Recombined displays, the six target locations were consistent with those of the Fully Repeated displays. However, one half of the distractors each was selected randomly from each of the two distractor sets that were initially paired with the same target location in the learning phase (Figure 2A). To create the Rotated displays, half of the Fully Repeated displays were rotated 45° clockwise, while the other half was rotated 45° counterclockwise. As the polar angle between the two target positions on each circle was 45°, the target location probabilities of the six target locations were kept constant by this manipulation (Figure 2B). Finally, New displays contained again the same six target locations as the other display types, but each target location was paired with two sets of randomly selected distractor locations. To keep learning of repeated and new displays comparable during the transfer phase, New displays were also repeated across transfer blocks.
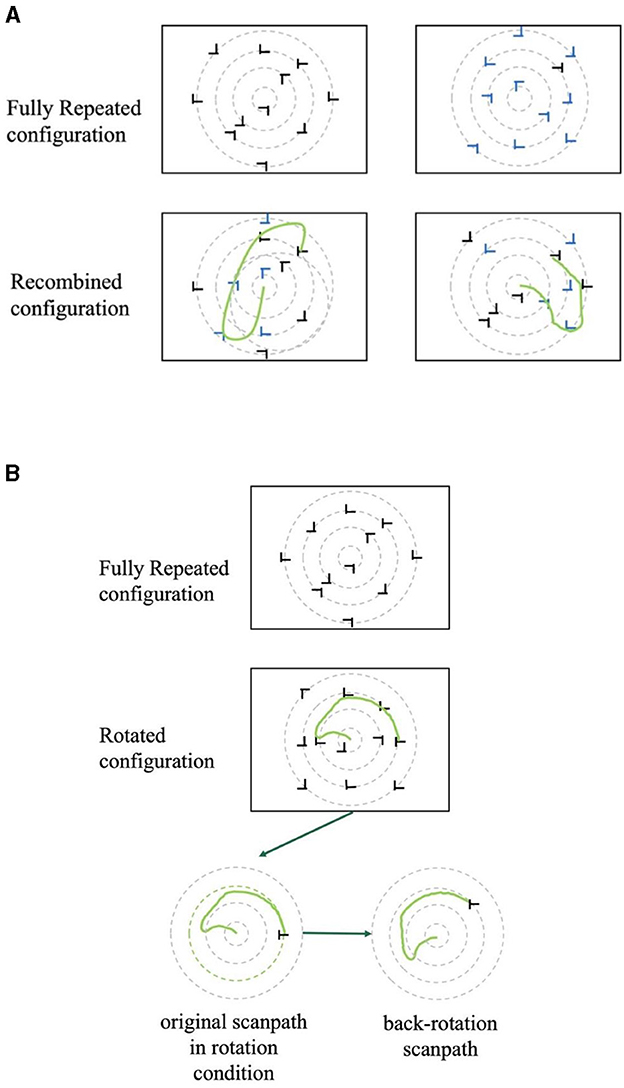
Figure 2. (A) Examples of two recombined displays with the same target location but different (symbolized by black and blue) distractors. In the actual experiment, all distractors were black. The hand-drawn green lines represent possible eye movement trajectories. (B) An example of a fixation pattern in a rotated display and its back-rotated version in the transfer phase.
Our main focus was the analysis of search times, defined as the time from display onset to the response. However, we also analyzed the rate of incorrect responses to rule out speed-accuracy trade-offs. To this end, we conducted one-way analyses of variance to analyze the proportion of trials in which participants either provided incorrect responses or failed to respond within the designated time frame (6 s). Incorrect and slow response trials were excluded from the dataset for search time analyses.
To assess whether the reduction in search time reached a plateau toward the end of the learning phase, indicating that most of the learning had occurred and little additional learning was expected in the transfer phase, a Bayesian ANOVA was conducted on blocks 16–20.
During the transfer phase, we further explored the influence of different configurations on search performance. To analyze the proportion of incorrect trials, we conducted one-way analyses of variance, with the configuration considered as fixed factor. Regarding the analysis of search time, since the main effect across blocks was of particular interest, we performed a repeated measures ANOVA, using search time as dependent variable, and block and configuration as within-subject factors. If the main or interaction effect was significant, we utilized post-hoc tests to investigate specific contrasts.
Equality of search times across the partially and fully repeated conditions was assessed by calculating Bayes factors for the Fully Repeated, Recombined, and Rotated configurations.
We also conducted an examination of fundamental oculomotor metrics, specifically focusing on the number of fixations, saccade amplitude (average per participant), and scan pattern ratio [SPR, calculated by dividing the sum of saccade amplitudes by the straight-line distance from the scene center (initial fixation) to the target location; Brockmole and Henderson, 2006]. Employing a repeated-measures analysis of variance (ANOVA) with the configurations and blocks as main factor, we aimed to ascertain potential dissimilarities in these indicators within distinct configurations and across distinct time blocks. Subsequent paired-sample t-tests were conducted to further elucidate the significance of specific pairwise comparisons.
For each trial, the spatial distribution of the eye movement data was plotted as an FDM with the same limits as the original presentation screen (1,920 × 1,080 pixel). To correct for possible inaccuracies during recording, each FDM was spatially smoothed using a Gaussian filter with sigma of 30. All FDM were saved for visual inspection, transformed into greyscale matrices using the Open Computer Vision Library and subsequently vectorized with Numpy (Harris et al., 2020). Pairwise correlation distances (1 – correlation) were calculated between all vectors. Correlation distance coefficients were then transformed into Pearson coefficients. In order to achieve an approximately normal distribution, Fisher's z-transformation was applied. Figure 3 illustrates representative examples of relatively similar and dissimilar fixation density maps.
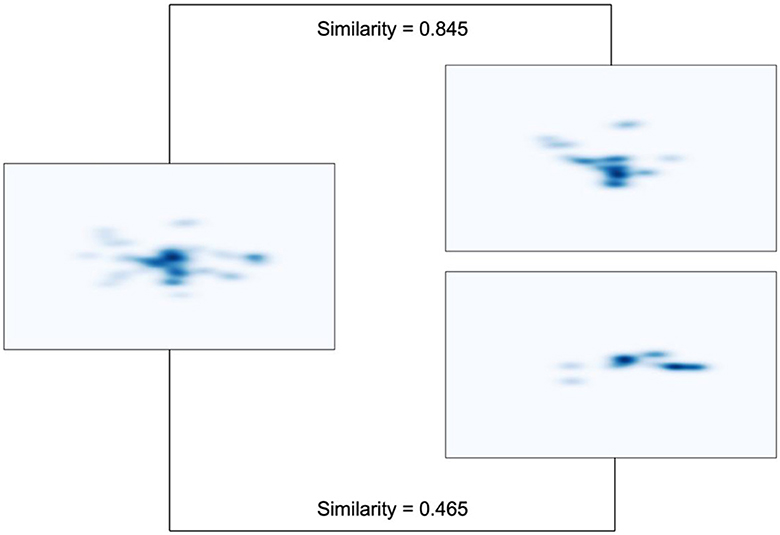
Figure 3. Representative examples of fixation density maps with varying degrees of similarity. The map on the left shares a higher similarity with the one on the top right (0.845), while it exhibits lower similarity with the one on the bottom right (0.465). These examples are taken from three displays belonging to one participant. The three displays share the same target location but are from different conditions: fully repeated condition (left), back-rotated condition (top right), and new condition (bottom right).
The similarity in FDM was assessed using paired t-tests, comparing fully repeated with the other two partially repeated conditions. In addition, we tested the hypothesis that participants were able to mentally rotate a learned display configuration to adapt it to a rotated display. In this case, the fixation pattern may also be rotated to adapt to the display rotation. Consequently, a back-rotated version of the fixation pattern should fit the fixation pattern of the same displays fully repeated (i.e., unrotated) version better than the fixation pattern before back-rotation. The back-rotated condition was created by rotating the fixations from the rotated displays in the direction opposite to display rotation by 45 degrees, as depicted in Figure 2B. Overall, this FDM analysis involved comparisons between fully repeated and recombined displays, rotated and back-rotated displays, as well as fully repeated and back-rotated displays.
The participants exhibited high performance, with error (including slow response) trials rate of only 2.88% throughout the learning phase. The rate of error including slow response trials decreased as the experiment progressed (Figure 4), confirmed by a significant block main effect in a one-way analysis of variance [F(19, 420) = 2.798, p < 0.001, = 0.112].
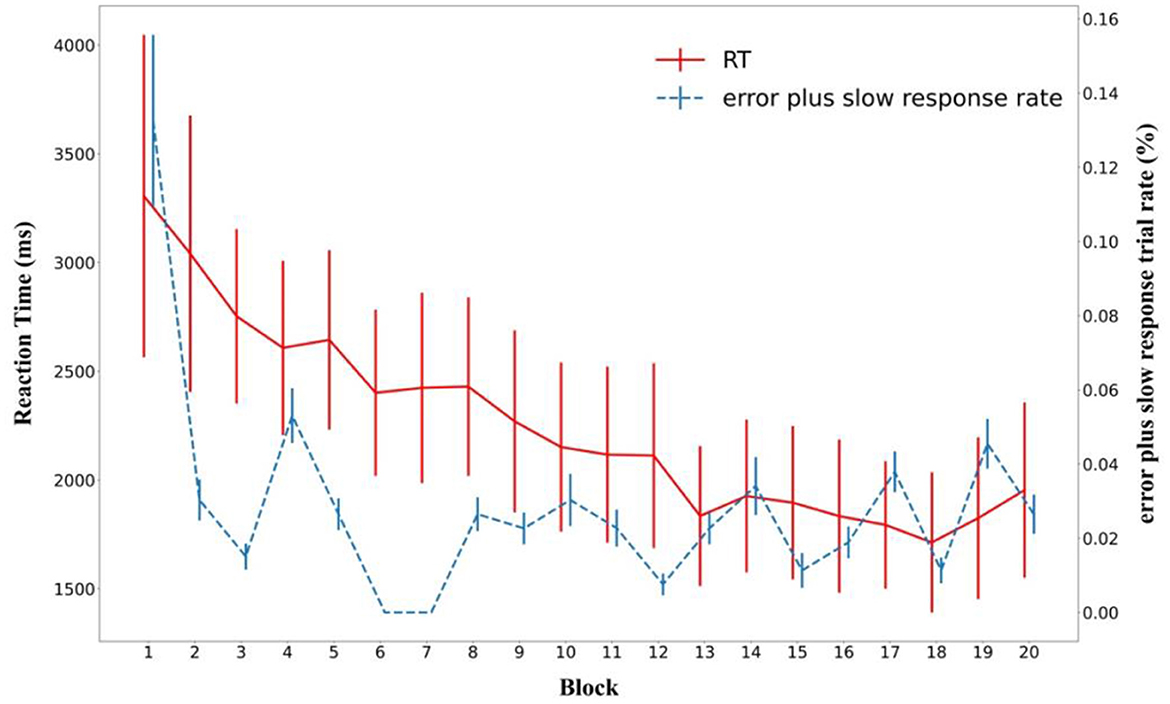
Figure 4. Mean search time and rate of incorrect plus timeout (slow) responses during the learning phase across blocks. Error bars represent standard errors of the mean.
Importantly, search times exhibited a significant decrease over the course of the experiment as well (Figure 4). A one-way ANOVA showed a main effect of Block [F(19, 420) = 6.052, p < 0.001, = 0.215].
However, Figure 4 suggests that search times plateaued toward the end of the learning phase. This was strongly supported by a Bayesian ANOVA over the last five blocks (BF01 = 18.7).
In the transfer phase, the error (including slow response) trials trial rate was measured across four conditions, namely Fully Repeated, Recombined, Rotated, and New. The incorrect response rates in each condition were low overall (3.21% for Fully Repeated, 3.23% for Recombined, 3.79% for Rotated, and 5.11% for New) and a one-way ANOVA did not yield a significant main effect of condition [F(3, 84) = 1.056, p = 0.372].
The repeated measures ANOVA with the configuration and block as factors revealed significant main effects of Configuration [F(3, 63) = 7.875, p < 0.001, = 0.273] and Block [F(3, 63) = 4.925, p = 0.004, = 0.190] with search times decreasing over blocks. The interaction between Configuration and Block was not significant [F(9, 189) = 0.292, p = 0.976, = 0.014].
The post-hoc analysis showed that the search times in the New configuration were significantly higher than in the Fully Repeated configuration [t(21) = 4.509, p < 0.001, d = 0.376], the Recombined configuration [t(21) = 3.827, p = 0.002, d = 0.319], and the Rotated configuration [t(21) = 2.764, p = 0.045, d = 0.231], indicative of contextual cueing in the three (partially) repeated configurations. No other comparisons yielded significant results (Figure 5).
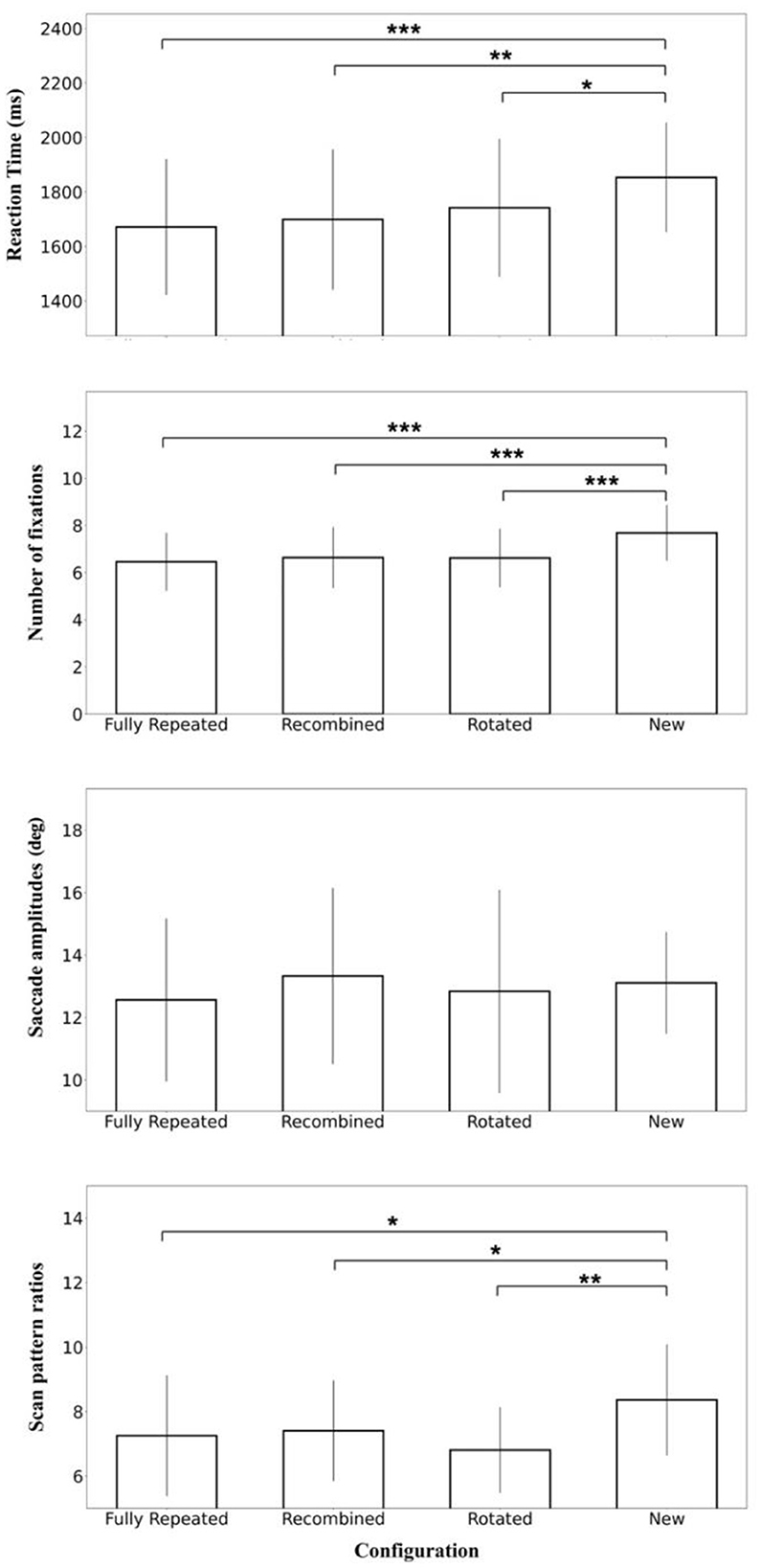
Figure 5. Mean search time, the number of fixations, saccade amplitudes, and scan pattern ratios in the four configurations (fully repeated, recombined, rotated, and new) of the transfer phase. Error bars represent standard errors of the mean. Significance levels are denoted by asterisks, with *p < 0.05; **p < 0.01, ***p < 0.001.
To test for equality of search times between the repeated conditions, Bayes factors were calculated for the Fully Repeated, Recombined, and Rotated configurations. The Bayes factor (BF01) of 1.996 between Recombined and Rotated and 1.081 between Fully Repeated and Rotated yielded anecdotal evidence for equality. Additionally, the Bayes factor of 3.574 between Fully Repeated and Recombined yielded substantial evidence for equality (Wetzels et al., 2011).
The repeated measures ANOVA with the configuration and block as main effect on the number of fixations revealed significant main effects of Configuration [F(3, 63) = 17.903, p < 0.001, = 0.460] and Block [F(3, 63) = 3.284, p = 0.026, = 0.135] with fewer fixations over blocks. The interaction between Configuration and Block was not significant [F(9, 189) = 1.229, p = 0.279, = 0.055].
The post-hoc analysis showed that the number of fixations in the new configuration was significantly higher than in the fully repeated configuration [t(21) = 5.516, p < 0.001, d = 1.176], the recombined configuration [t(21) = 5.534, p < 0.001, d = 1.180], and the rotated configuration [t(21) = 6.060, p < 0.001, d = 1.292]. No other comparisons yielded significant results (Figure 5).
The repeated measures ANOVA on saccade amplitude did not indicate significant main effects of configuration [F(3, 63) = 0.513, p = 0.675, = 0.024] or block [F(3, 63) = 1.543, p = 0.212, = 0.068]. The interaction between configuration and block [F(9, 189) = 0.340, p = 0.960, = 0.010] was also not significant (Figure 5).
The repeated measures ANOVA on scan pattern ratios revealed a significant main effect of configuration [F(3, 63) = 4.397, p = 0.007, = 0.173]. The main effect of block [F(3, 63) = 2.160, p = 0.102, = 0.093] and the interaction between Configuration and Block were not significant [F(9, 189) = 1.606, p = 0.116, = 0.071].
The post-hoc analysis showed that the scan pattern ratios in the new configuration were significantly higher than in the fully repeated configuration [t(21) = 1.835, p = 0.040, d = 0.391], the recombined configuration [t(21) = 2.199, p = 0.020, d = 0.469], and the rotated configuration [t(21) = 3.025, p = 0.003, d = 0.645]. No other comparisons yielded significant results (Figure 5).
We compared FDMs to analyze the similarity of the spatial fixation distribution between conditions. Figure 6 shows the similarity matrix of 12 displays and five conditions.
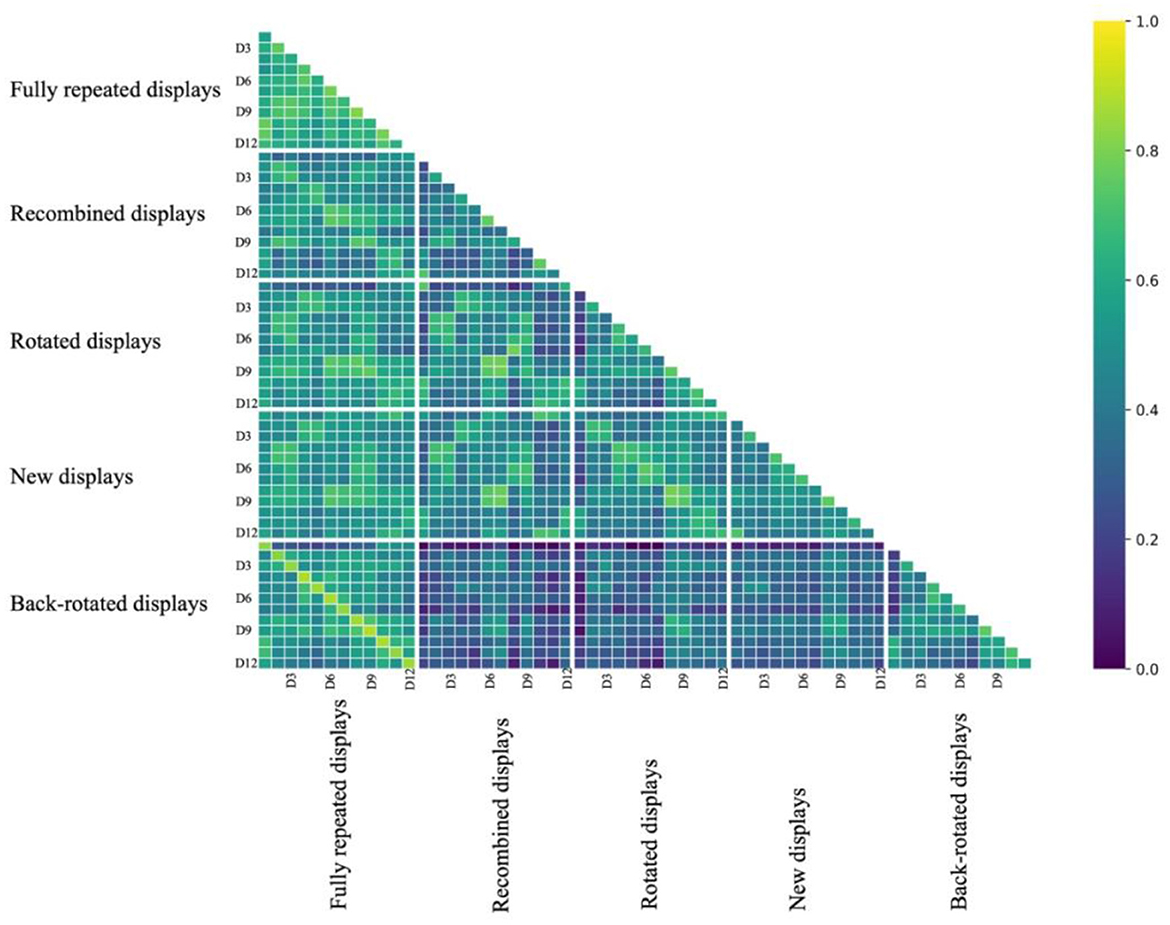
Figure 6. The figure depicts the similarity matrix of 12 displays across five conditions, with distinctive white lines marking the boundaries between different conditions. In the horizontal and vertical axes, “D” represents “display”. Each correlation coefficient in the matrix was converted back from the distance correlation (1–r) and then transformed using the Fisher Z-transformation.
What can be seen in the matrix is that similarity was high in the lines parallel to the main diagonal, indicating that displays sharing the same target location and parts of the distractor locations (i.e., fully repeated and recombined displays) had more similar FDMs than displays not sharing these locations. This was most obvious for the similarity of back-rotated FDMs and fully repeated FDMs, where an individual display and its back-rotated version shared the target and all distractor locations.
In particular, we expected recombined displays to elicit FDMs similar to those of the fully repeated displays they received one half of the distractors from. Consequently, we anticipated that the FDMs of the fully repeated displays were more similar to the FDMs of the respective recombined displays than to those of the new displays sharing the same distractor location. This was confirmed by a t-test comparison, indicating the similarity between repeated and recombined displays was higher than that between the fully repeated and new displays [t(21) = 6.276, p < 0.001, d = 1.338].
We further expected that a rotated display would prompt FDM similar to those of the original display, albeit rotated by the angle of display rotation. Thus, we expected the back-rotated FDMs to be more similar to the FDM for the fully repeated presentation of the same display than the rotated FDM. A t-test comparison revealed that the similarity between repeated and back-rotated displays was higher than that between the repeated and rotated displays [t(21) = 15.490, p < 0.001, d = 3.302].
In addition, in order to confirm that the similarity of back-rotated FDMs of rotated displays and the FDMs of fully repeated displays are not just driven by shared (though rotated) target location, they should be more similar to fully repeated displays than new displays with the same target location. Again, this was confirmed through a t-test, revealing that the similarity between repeated and back-rotated displays was higher than that between the repeated and new displays [t(21) = 10.200, p < 0.001, d = 2.175].
The results of paired t-tests are visually presented in Figure 7, with specific values detailed earlier in the text.
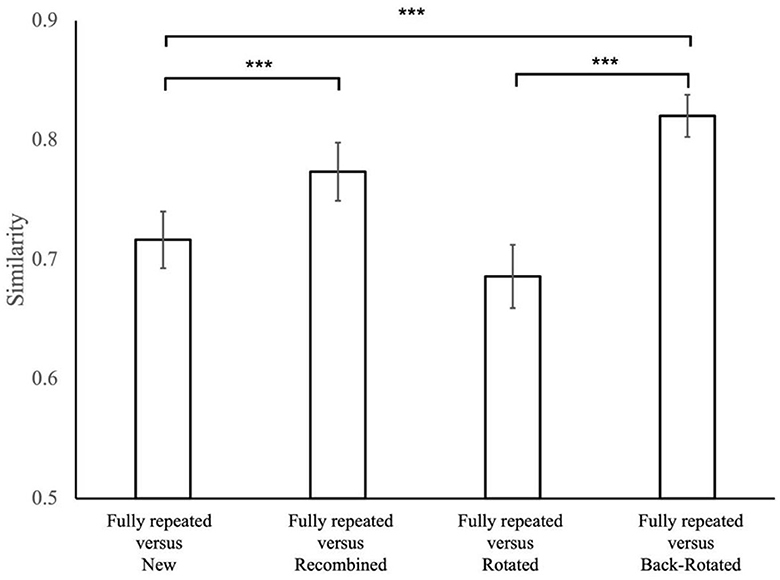
Figure 7. The similarity values for condition comparisons in the present study. Error bars represent standard errors of the mean. The significance level in result of t-tests is denoted by asterisks, with ***p < 0.001.
Looking at the similarity matrix (Figure 6), it appears that fixation patterns between different fully repeated displays are more similar than between different new displays. This is puzzling because using learnt distractor configurations for search guidance might be expected to lead to more distinct fixation patterns for repeated displays. Recently, however, it has been proposed that the search time benefits of repeated displays in the contextual cueing paradigm come about not (only) due to search guidance enabled by the learnt configurations of individual displays, but by a common search path that is optimized for all repeatedly presented displays (Seitz et al., 2023). This common scanpath hypothesis predicts that search paths—and consequently fixation patterns—of different repeated displays should be more similar than between different new displays. We indeed found that the similarity of fixation patterns was significantly higher between different fully repeated displays than between different new displays [tone − sided (21) = 14.667, p < 0.001, d = 3.127]. Thus, the fixation patterns might support the “common scanpath” hypothesis. However, the similarity of fixation patterns between rotated displays were not significantly higher than between new displays, {rotated: [ttwo − sided (21) = −1.843, p = 0.079]}, and, the similarity between recombined displays was significantly lower than between new displays [ttwo − sided (21) = −4.081, p < 0.001, d = −0.870].
Search in repeated displays can not only lead to reduced search times, but also to more efficient scan paths during visual search (Peterson and Kramer, 2001; Tseng and Li, 2004; Brockmole and Henderson, 2006; Manginelli and Pollmann, 2009). Here, we investigated if that is also the case if only partial spatial constellations are repeated in recombined displays or the display is rotated. We found that recombined displays, containing repeated target and distractor positions, but lacking a repeated global configuration, were searched with less fixations and an improved scan pattern ratio than new displays. Furthermore, spatial fixation heat maps in these displays were more similar to those of fully repeated displays than to novel displays.
Likewise, search in rotated displays, in which the global configuration was preserved, but local target and distractor positions were changed, were also searched with less fixations and an improved scan pattern ratio. Spatial fixation heatmaps showed that this was achieved by rotating the fixation pattern along with the display rotation.
Visual search benefits from repeated spatial patterns, even if they are incomplete. For instance, previous work had already shown that repetition of three items out of a previously learned display were sufficient to elicit a search advantage, as an indicator of contextual cueing (Song and Jiang, 2005; Bergmann and Schubö, 2021). Likewise, displays that conserved only spatial relations between individual distractor and target locations by recombining distractor locations from two learned displays with the same target location on the one hand or only global target-distractor configurations on the other hand (by magnification or rotation) elicited contextual cueing (Jiang and Wagner, 2004; Zheng and Pollmann, 2019). The reduced search times found in the latter studies, indicating the use of learned spatial relations for efficient search guidance, were replicated in the present study. In addition, analysis of eye movements showed that the increased search efficiency in both recombined and rotated displays was achieved by making fewer fixations that led more straightforward to the target—indicated by improved scan pattern ratio. This extends previous reports of more efficient eye movement patterns in fully repeated displays (Peterson and Kramer, 2001; Tseng and Li, 2004; Brockmole and Henderson, 2006; Manginelli and Pollmann, 2009) to displays that repeat only local or global spatial context. Note that all four conditions—fully repeated, recombined, rotated, and new—shared the same target locations, so that differences in search efficiency between these conditions cannot be due to target location probability cueing (Geng and Behrmann, 2005; Jiang et al., 2013; Golan and Lamy, 2023).
Fixation heatmaps of recombined displays were more similar to those of fully repeated displays than those of new displays. It might be argued that this is trivial, because recombined and fully repeated displays share half of the distractor locations, whereas fully repeated and new displays share only a few randomly drawn distractor locations, if any. Although fixation need not fall on items, but rather on points that allow to judge item relations important for the task at hand, the partially joint structure may well explain the similarity of fixation heatmaps for fully repeated and recombined displays. However, in combination with the reduced number of fixations and the improved scan pattern ratio, the similarity of fixation heatmaps for recombined and fully repeated displays shows that during search of recombined displays, participants do not just follow the items on the screen, but extract useful information from the previously encountered spatial target-distractor relations to guide search efficiently. Importantly, however, the spatial relation of individual distractors and the target appears to be only useful for contextual cueing if no random distractors lie in between repeated target-distractor pairs (Olson and Chun, 2002).
Concerning the rotated displays, analysis of fixation heatmaps yielded important information that would not have been available by investigating fixation counts and scan pattern ratios alone. We found that the spatial fixation heatmaps of rotated displays were comparably dissimilar to the fixation heatmaps of the identical, but unrotated (fully repeated) displays as new displays. However, when we back-rotated the heatmaps of the rotated displays, they became significantly more similar to the non-rotated displays than the new displays, indicating that our participants appeared to rotate their learned scan patterns to efficiently search in rotated displays.
Unexpectedly, we found that fixation patterns were more similar between different fully repeated displays than between different new displays. If fixations patterns followed incidentally learnt display configurations, one might expect the opposite, namely distinctive fixation patterns for individual repeated displays. Recently, an alternative explanation has been proposed to account for the search time advantage of repeated displays. Seitz et al. (2023) proposed that a common search path is learned that is optimal for all repeated displays, rather than different search paths for individual displays. Our finding of increased fixation pattern similarity between fully repeated displays may support this assumption. However, fixation pattern similarity was not increased between recombined displays or rotated displays. Thus, the search time reductions observed for these displays could not be explained by the concept of a common search path. It seems likely that if learning a common search path contributes to the contextual cueing effect, it may not be the only contributing mechanism. As this was a post-hoc finding, it should be regarded with caution. However, we find it intriguing enough to warrant further research.
Neither for rotated nor recombined displays did we observe altered saccade amplitudes. Increased saccade amplitudes, together with a reduced number of fixations, might have been a sign of a search with an enlarged focus of attention (Geringswald and Pollmann, 2015). This might have been a way to capture the global configuration in altered displays. In contrast, a reduced focus of attention might have been a possible reaction to the conserved spatial relations of individual target-distractor locations in the absence of a preserved global configuration. However, as noted, we observed no indication of such adjustments. Note, that fully repeated, recombined and rotated displays were presented in random sequence, so that a deliberate advance selection of an attentional focus size to focus on more global or local spatial contexts would have been impossible.
We did not see significant differences in the search times to fully repeated, recombined or rotated displays. However, we do not know if a 50% repetition of distractor locations in the recombined displays and a 45-degree rotation of the configuration in the rotated displays equate to the same degree of disruption of the global configuration and individual locations. A more nuanced exploration of these aspects could contribute to a comprehensive understanding of the observed phenomena and guide future research in this domain.
In summary, we found that eliminating either local or global spatial context from repeated search displays kept not only search time facilitation intact, but was also accompanied by less fixations and a more direct scan path to the target. Fixation distribution maps of recombined or rotated displays were more similar to the original displays than random new displays. However, for rotated displays this was only true when the rotation angle was taken into account. Overall, this shows an astonishingly flexible use of the oculomotor system for search in incompletely repeated displays.
The data are available at https://osf.io/k6hxb/.
The studies involving humans were approved by Ethics Board of the Medical Faculty of the Otto-von-Guericke University, Magdeburg. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
LZ: Formal analysis, Investigation, Writing – original draft. NMa: Formal analysis, Writing – review & editing. NMe: Writing – review & editing. SP: Supervision, Writing – review & editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the China Scholarship Council No. 201808120093 and by DFG-grant PO548/18-1.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Bergmann, N., and Schubö, A. (2021). Local and global context repetitions in contextual cueing. J. Vis. 21, 9–9. doi: 10.1167/jov.21.10.9
Brady, T. F., and Chun, M. M. (2007). Spatial constraints on learning in visual search: modeling contextual cuing. J. Exp. Psychol. 33:798. doi: 10.1037/0096-1523.33.4.798
Brockmole, J. R., and Henderson, J. M. (2006). Recognition and attention guidance during contextual cueing in real-world scenes: evidence from eye movements. Q. J. Exp. Psychol. 59, 1177–1187. doi: 10.1080/17470210600665996
Damiano, C., and Walther, D. B. (2019). Distinct roles of eye movements during memory encoding and retrieval. Cognition 184, 119–129. doi: 10.1016/j.cognition.2018.12.014
Geng, J. J., and Behrmann, M. (2005). Spatial probability as an attentional cue in visual search. Percept. Psychophys. 67, 1252–1268. doi: 10.3758/BF03193557
Geringswald, F., and Pollmann, S. (2015). Central and peripheral vision loss differentially affects contextual cueing in visual search. J. Exp. Psychol. 41:1485. doi: 10.1037/xlm0000117
Golan, A., and Lamy, D. (2023). Attentional guidance by target-location probability cueing is largely inflexible, long-lasting, and distinct from inter-trial priming. J. Exp. Psychol. 50, 244–265. doi: 10.1037/xlm0001220
Goujon, A., Didierjean, A., and Thorpe, S. (2015). Investigating implicit statistical learning mechanisms through contextual cueing. Trends Cogn. Sci. 19, 524–533. doi: 10.1016/j.tics.2015.07.009
Harris, C. R., Millman, K. J., Van Der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., et al. (2020). Array programming with NumPy. Nature 585, 357–362. doi: 10.1038/s41586-020-2649-2
Jiang, Y., and Chun, M. M. (2001). Selective attention modulates implicit learning. Q. J. Exp. Psychol. Sect. A 54, 1105–1124. doi: 10.1080/713756001
Jiang, Y., and Wagner, L. C. (2004). What is learned in spatial contextual cuing—configuration or individual locations? Percept. Psychophys. 66, 454–463. doi: 10.3758/BF03194893
Jiang, Y. V., and Sisk, C. A. (2019). “Contextual cueing,” in Spatial Learning and Attention Guidance, Neuromethods, Vol. 151, ed. S. Pollmann (New York, NY: Humana).
Jiang, Y. V., Sisk, C. A., and Toh, Y. N. (2019). Implicit guidance of attention in contextual cueing: neuropsychological and developmental evidence. Neurosci. Biobehav. Rev. 105, 115–125. doi: 10.1016/j.neubiorev.2019.07.002
Jiang, Y. V., Swallow, K. M., Rosenbaum, G. M., and Herzig, C. (2013). Rapid acquisition but slow extinction of an attentional bias in space. J. Exp. Psychol. 39, 87–99. doi: 10.1037/a0027611
Manginelli, A. A., and Pollmann, S. (2009). Misleading contextual cues: how do they affect visual search? Psychol. Res. 73, 212–221. doi: 10.1007/s00426-008-0211-1
Olson, I. R., and Chun, M. M. (2002). Perceptual constraints on implicit learning of spatial context. Vis. Cogn. 9, 273–302. doi: 10.1080/13506280042000162
Peterson, M. S., and Kramer, A. F. (2001). Attentional guidance of the eyes by contextual information and abrupt onsets. Percept. Psychophys. 63, 1239–1249. doi: 10.3758/BF03194537
Seitz, W., Zinchenko, A., Müller, H. J., and Geyer, T. (2023). Contextual cueing of visual search reflects the acquisition of an optimal, one-for-all oculomotor scanning strategy. Commun. Psychol. 1:20. doi: 10.1038/s44271-023-00019-8
Sisk, C. A., Remington, R. W., and Jiang, Y. V. (2019). Mechanisms of contextual cueing: a tutorial review. Attent. Percept. Psychophys. 81, 2571–2589. doi: 10.3758/s13414-019-01832-2
Smith, C., Hopkins, R. O., and Squire, L. R. (2006). Experience-dependent eye movements, awareness, and hippocampus-dependent memory. J. Neurosci. 26, 11304–11312. doi: 10.1523/JNEUROSCI.3071-06.2006
Song, J. H., and Jiang, Y. (2005). Connecting the past with the present: how do humans match an incoming visual display with visual memory? J. Vis. 5, 322–330. doi: 10.1167/5.4.4
Tseng, Y. C., and Li, C. S. R. (2004). Oculomotor correlates of context-guided learning in visual search. Percept. Psychophys. 66, 1363–1378. doi: 10.3758/BF03195004
Wetzels, R., Matzke, D., Lee, M. D., Rouder, J. N., Iverson, G. J., and Wagenmakers, E. J. (2011). Statistical evidence in experimental psychology: an empirical comparison using 855 t tests. Perspect. Psychol. Sci. 6, 291–298. doi: 10.1177/1745691611406923
Keywords: contextual cueing, oculomotor system, spatial location, attention, visual search, mental rotation, global vision, local vision
Citation: Zheng L, Marek N, Melnik N and Pollmann S (2024) Contextual cueing—Eye movements in rotated and recombined displays. Front. Cognit. 3:1403749. doi: 10.3389/fcogn.2024.1403749
Received: 19 March 2024; Accepted: 22 April 2024;
Published: 10 May 2024.
Edited by:
Sebastian Martin Frank, University of Regensburg, GermanyReviewed by:
Mark W. Greenlee, University of Regensburg, GermanyCopyright © 2024 Zheng, Marek, Melnik and Pollmann. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Lei Zheng, emhlbmdsZWktdGpudUBmb3htYWlsLmNvbQ==; Stefan Pollmann, c3RlZmFuLnBvbGxtYW5uQG92Z3UuZGU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.