 Anna Ranaudo1*
Anna Ranaudo1* Ugo Cosentino1
Ugo Cosentino1 Claudio Greco1
Claudio Greco1 Giorgio Moro2
Giorgio Moro2 Alessandro Bonardi1
Alessandro Bonardi1 Alessandro Maiocchi3
Alessandro Maiocchi3 Elisabetta Moroni4
Elisabetta Moroni4- 1Department of Earth and Environmental Sciences, University of Milano-Bicocca, Milan, Italy
- 2Department of Biotechnology and Biosciences, University of Milano-Bicocca, Milan, Italy
- 3Bracco SpA, Milan, Italy
- 4Institute of Chemical Sciences and Technologies “G. Natta”, National Research Council of Italy, SCITEC-CNR, Milan, Italy
Affitins constitute a class of small proteins belonging to Sul7d family, which, in microorganisms such as Sulfolobus acidocaldarius, bind DNA preventing its denaturation. Thanks to their stability and small size (60–66 residues in length) they have been considered as ideal candidates for engineering and have been used for more than 10 years now, for different applications. The individuation of a mutant able to recognize a specific target does not imply the knowledge of the binding geometry between the two proteins. However, its identification is of undoubted importance but not always experimentally accessible. For this reason, computational approaches such as protein-protein docking can be helpful for an initial structural characterization of the complex. This method, which produces tens of putative binding geometries ordered according to a binding score, needs to be followed by a further reranking procedure for finding the most plausible one. In the present paper, we use the server ClusPro for generating docking models of affitins with different protein partners whose experimental structures are available in the Protein Data Bank. Then, we apply two protocols for reranking the docking models. The first one investigates their stability by means of Molecular Dynamics simulations; the second one, instead, compares the docking models with the interacting residues predicted by the Matrix of Local Coupling Energies method. Results show that the more efficient way to deal with the reranking problem is to consider the information given by the two protocols together, i.e. employing a consensus approach.
Introduction
Affitins are 7-kDa proteins engineered from the naturally occurring DNA-binding protein family termed Sul7d (Kalichuk et al., 2016). Proteins of this family, such as Sac7d and Sso7d, are expressed respectively by extremophile organisms Sulfolobus acidocaldarius and Sulfolobus solfataricus, and act to prevent DNA denaturation thanks to their stability in a broad range of temperature (up to 100°C) and pH (from 0 up to 12). The general topology of Sac7d is that of the OB-fold family. Its tertiary structure consists of a five-stranded incomplete ß-barrel (β1 = residues 3-8, β2 = 11–16, β3 = 20–26, β4 = 29–36, β5 = 39–46), capped at the opening by a three-turn C-terminal α-helix (residues 53–63). The triple-stranded ß-sheet (β3-β4-β5) has been identified as the DNA binding surface (Figure 1) (Robinson et al., 1998).
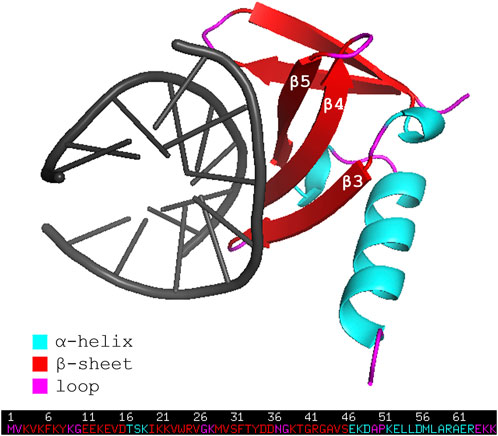
FIGURE 1. Representation of the wild-type affitin Sac7d bound to DNA duplex d(GTAATTTAC)2 (PDB code: 1AZQ). Affitin residues are colored following the secondary structure assignment, as shown in the legend. DNA is shown in black.
Notably, this region can be engineered in order to obtain a binding specificity also towards protein targets (Mouratou et al., 2007; Krehenbrink et al., 2008; Correa et al., 2014; Béhar et al., 2016; Goux et al., 2017; Kauke et al., 2017; Mukherjee et al., 2020; Zajc et al., 2020).
Modulating the binding affinity of affitins towards specific targets can be particularly useful in the perspective of employing affitins as antibody mimetics. Briefly, antibody mimetics are alternative to the antibodies and have been conceptualized with the idea of overcoming the drawbacks that the latter present, such as low stabilities, resulting in a more complicate production, slow and inefficient tissues penetration and slow clearance from the body (Vazquez-Lombardi et al., 2015).
Affitins, being small and highly stable proteins, have thus been considered as potential antibody mimetics. In fact, their small dimensions favor an efficient tissue penetration and their high stability make them ideal scaffolds for engineering and easy to be produced.
Among the examples found in literature, the work by Goux et al. reports on the development of a molecular probe for targeting the Epidermal Growth-Factor Receptor (EGFR). This probe is constituted of an affitin (Nanofitin B10) which has been engineered in such a way to recognize the pharmacological target epidermal growth-factor receptor (EGFR) and to exhibit a unique cysteine moiety at its C-terminus. The latter is used for a fast and site-specific radiolabeling procedure necessary for the Positron Emission Tomography (PET) (Goux et al., 2017).
Affitins engineering is usually accomplished by generating large libraries of mutants, which are subsequently screened for their affinity for the selected protein target. However, once the desired mutant is obtained, no structural information about the affitin-protein complex is readily available. In such a contest, as far as computational approaches are concerned, molecular docking can be considered for an initial structural characterization.
To date, no docking program can always identify a correct solution, especially in the context of the protein-protein interactions; instead, docking results consist of a ranking of the best putative binding poses, according to the docking-score function. These require a post-docking processing, in the attempt of identifying the correct binding geometry through the analysis, scoring and, if need be, reranking of the docking models. The post-docking step can be based on energy-, knowledge-, consensus-, and evolution-based algorithms and includes, for example, the contact analysis, the prediction of the interface, the flexible refinement of the model and the energy minimization of the latter (Vangone et al., 2017).
In the perspective of using affitins as targeting scaffolds, our work focuses on the validation of the docking poses obtained for different affitin-partner complexes available in the Protein Data Bank (PDB) through two procedures described hereafter. The aim is to develop a robust protocol for the initial prediction of the most probable binding geometry between a specific target and a new engineered affitin.
Two post-docking strategies are considered in the present paper: the first one involves the investigation of the stability of docked complexes through Molecular Dynamics (MD) simulations and evaluation of CAPRI, DockQ, and other structural and energetic parameters (Jandova et al., 2021); the second one is the cross-checking between the docking models and the interaction sites predicted through the Matrix of Local Coupling Energies (MLCE) method, based on the individuation of low-intensity energetic interaction networks in the isolated protein structure (Scarabelli et al., 2010).
This paper is organized as follows. The first part presents the results of docking between seven affitins with as many protein partners whose binding experimental structures are available in the PDB. The reliability of the ranking of the docking poses is then checked by means of MD simulations and MLCE approach. Finally, we show how the coupled use of such two methods can improve the identification of the correct docking models.
Methods
Selection and preparation of protein structures
Protein structures were selected by doing a sequence similarity (threshold 60%) search in PDB, starting from the sequence of the wild-type affitin (PDB code: 1AZQ), which resulted in 55 entries. For our study, we selected the seven complexes made up by engineered affitins and protein partners. When available, structures of the proteins partners in the complexes were superimposed to the respective unbound forms, to check whether a significant change in their fold occurred upon binding. As this is not the case, we hold that bound structures of these proteins can be used for rigid docking calculations. All protein structures retrieved from the PDB were prepared using the tool Protein Preparation Wizard included in the Schrödinger package (Sastry et al., 2013; Schrödinger Release 2022-2, 2021). The protocol consists of: 1) elimination of water molecules and counterions, if present; 2) addition of hydrogens; 3) rebuilding of possibly missing side chains and loops with Prime (Jacobson et al., 2002, 2004); 4) optimization of hydrogen bonding network, using PROPKA for the assignment of protonation states at neutral pH; 5) minimization of hydrogen atoms.
Affitins—Partners docking
Protein-protein docking calculations have been carried out using the web server ClusPro (Kozakov et al., 2013, 2017; Vajda et al., 2017; Desta et al., 2020). The structures of affitins and their partners were uploaded as “ligand” and “receptor”, respectively.
We evaluated the performance of the four available scoring schemes (“balanced”, “electrostatic-favored”, “hydrophobic-favored” and “van der Waals + electrostatics”) using as a measure of the capability of identifying the experimental assembly a parameter (crystal_RMSD from now on) describing the distance of the docking model from the crystallographic structure. crystal_RMSD was calculated by: 1) fitting the Cα atoms of the “receptor” (the bigger protein) of the docking models on the same atoms of the crystallographic structure; 2) calculating the RMSD of the Cα atoms of the “ligand” (the smaller protein) of the docking models with respect to the crystallographic structure. We considered as “Native” docking poses having crystal_RMSD ≤0.5 nm, while docking poses with crystal_RMSD >0.5 nm were considered as “Non-Native”.
The reranking of the first ten docking poses based on the crystal_RMSD parameter highlights that, for these complexes, the “balanced” scoring scheme performs better than the others (Supplementary Table S1), therefore we chose to use only this one for subsequent studies.
Docking poses reranking by MD simulations
Among the methods available for the reranking of docking binding poses, the protocol proposed by Jandova et al. was applied. Briefly, it consists in performing MD simulations of the docking poses and monitoring parameters that describe their stability along the simulation time, thus allowing to discriminate among stable poses, i.e. probably Native, and not stable ones, probably Non-Native.
For each complex listed in Table 1, we carried out MD simulations of the crystal structure, of the two poses with the lowest crystal_RMSD values and of the two poses with the highest ones. We labeled the pose with the lowest crystal_RMSD value as A, and the one with the second lowest value as B. C and D are the labels for the poses having the second highest and the first highest crystal_RMSD values, respectively.

TABLE 1. Affitin-Protein complexes analysed.
All MD simulations have been performed with Gromacs, release 2020.6 (Abraham et al., 2015) and visualized with Virtual Molecular Dynamics (Humphrey et al., 1996). The united atom Gromos 53A6 force field (Oostenbrink et al., 2004) has been used together with the SPC water model. Proteins have been centered in cubic or dodecahedral boxes, keeping a 1 nm minimum distance from the edges, and solvated with water molecules. Chloride and sodium ions have been added for maintaining the electroneutrality. Periodic Boundary Conditions (PBC) have been applied in the three dimensions. The systems have been minimized with steepest descent and conjugate gradient algorithms until a convergence criterium of 100 kJ mol−1 nm−1 was reached. Atoms motion equations have been integrated with leap-frog algorithm every 2 fs. A 1.4 nm cut-off was applied to van der Waals and electrostatics interactions, beyond whom the latter have been treated with PME (Darden et al., 1993). The set-up of equilibration and production runs followed reference (Jandova et al., 2021). After minimization, initial velocities have been generated from a Maxwell distribution at 50 K with a random seed. Then, systems have been progressively heated up (50, 150, 300 K) while the heavy atoms were positionally restrained with decreasing force constants (1000, 100, 10 kJ mol−1 nm−2). Production runs have been performed in NPT ensemble at 1 bar and 300 K. Proteins and solvent have been coupled to two velocity-rescaling thermostats (Berendsen et al., 1984; Bussi et al., 2007) every 0.1 ps and to a Berendsen barostat every 1 ps. All bonds have been constrained with LINCS (Hess et al., 1997). Analyses were performed every 500 ps. Two replicas (100 ns each) were carried out for the crystal structures and for each docking pose considered. The total simulation time for each complex sums up to 1 μs.
The CAPRI parameters (Méndez et al., 2003) interface-RMSD (i-RMSD), ligand-RMSD (L-RMSD), and the fraction of native contacts (Fnat) are widely used for the quantification of the quality of a docking model. They are defined and calculated for all simulated systems as follows: 1) i-RMSD. Interface residues are as those having at least one atom within 10 Å of an atom of the other protein. The RMSD of the backbone of these residues is then calculated during the MD simulation after the fitting on the backbone of the same residues in the reference structure, i.e. in the docking model; 2) L-RMSD. The RMSD of the backbone atoms (N,Cα,C,O) of the ligand (the smaller of the two proteins) is calculated during the MD simulation after the superimposition of the same atoms of the receptor (the larger protein) on the reference structure; 3) Fnat. Pairs of residues on different sides of the interface were considered to be in contact if any of their atoms were within 5 Å. Fnat is calculated as the number of native (correct) residue–residue contacts during the MD simulation divided by the number of contacts in the reference structure. DockQ parameter (Basu and Wallner, 2016), describing the overall quality of the model, was calculated too. It ranges from 0 to 1: if DockQ ≥0.80 the model is a high quality one, if 0.80 > DockQ ≥0.49 the model quality is medium, acceptable if 0.49 > DockQ ≥0.23 and incorrect if DockQ <0.23. We also monitored the buried surface area (BSA), the number of hydrogen bonds (HB) and the protein-protein interaction energy (EPP).
Principal Component Analysis (PCA) was performed on the correlation matrix of Spearman coefficients of average values of the CAPRI parameters and of relative standard deviations (rSD) of BSA, HB and EPP. The analysis was conducted on the whole trajectories (production run).
Docking poses reranking by MLCE
MLCE method was used for identifying areas on the partners of the affitins prone to an interaction (from now on, patches). This approach combines the analysis of a given protein’s energetic properties with that of its structural determinants, to identify protein areas that are prone to interact with potential partners.
MLCE is based on the hypothesis that some residues stabilize the protein folding, while others establish interactions with partners. The analysis of the interaction energy that each residue establishes with all other residues of the protein accounts for these different roles: residues which strongly interact with the rest of the protein are related to the stabilization of the folding core, while the recognition sites may have weaker pair interactions, as in this way they can easily undergo conformational changes which can make the protein able to recognize and bind a partner. More specifically, the analysis of the interaction energies of all the amino acids in a protein consists in calculating for each residue the non-bonded part of the potential energy (van der Waals, electrostatic interactions, solvent effects) via a MM/GBSA calculation. The resulting symmetric
For the calculations, REBELOT program, version 1.3.2 (https://github.com/colombolab/MLCE), was used in cluster mode. Calculations were performed on centrotypes of clusters which cover at least 90% of the conformation variability sampled during three independent MD simulations (100 ns each). Patches were predicted on the centrotype of the most populated cluster considering the top 15% or top 10% of spatially contiguous residue pairs with the lowest-energy interactions. Then, they were compared with residues interacting with the affitins in the crystallographic structures and in the docking poses.
Results
PDB codes of complexes of affitins and protein partners considered in the present work are listed in Table 1, together with the name of their partner. The chains selected for docking calculations are listed in Supplementary Table S2).
Affitins—Partners docking
Docking between affitins and their partners was performed with the “balanced” scoring scheme in ClusPro (Kozakov et al., 2017; Vajda et al., 2017), as explained in the Methods section. For all the complexes considered, one or more Native poses among the first ten have been identified. In particular, for complexes 4CJ0, 4CJ1, 6QBA, and 5UFE, two Native poses are found (crystal_RMSD ≤0.5), while the pose with the second lowest crystal_RMSD value are Non-Native for complexes 4CJ2, 5ZAU and 5UFQ.
Calculation of the crystal_RMSD highlights that the ranking coming from the docking score function is often partially wrong, as shown in Table 2 which presents the reranking of the first ten docking poses (labelled in the docking server from 0 (best) to 9 (worst)) based on the crystal_RMSD values. These values are listed in Supplementary Table S1.
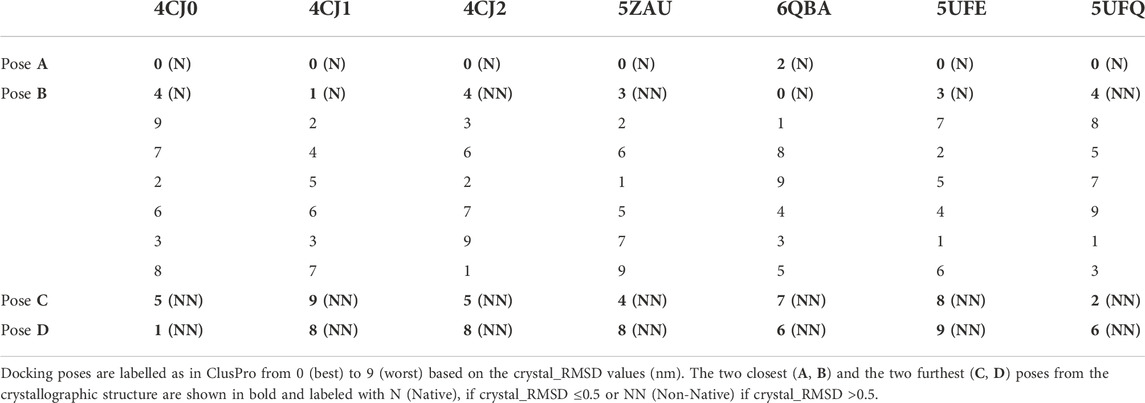
TABLE 2. Reranking of the first ten docking poses.
Indeed, for all complexes, but 6QBA, the best docking pose found by the server is also the closest to the crystallographic structure; however, the ranking of the other poses does not correlate with their crystal_RMSD values. Hence, in a realistic case where the crystallographic structure of the complex is not available, a post-docking step aiming at evaluating the actual quality of the docking poses is necessary. Thus, we applied the two protocols described in the Methods section, in order to verify if they can be used to correctly identify the best models of the complexes.
Docking poses reranking by MD simulations
MD simulations of complexes 4CJ0, 4CJ1, 4CJ2, 5ZAU, 6QBA, 5UFE and 5UFQ were carried out for the crystal structures and for the four docking poses A, B, C, and D, the first two poses being the ones closest to the crystallographic structures, whereas the second two are the poses that are furthest from their experimental counterparts (see also Methods section). Superimposition of the crystallographic structures and the docking poses are shown in Supplementary Figure S1.
The average values of three parameters i-RMSD, L-RMSD and Fnat were calculated from MD trajectories every 500 ps and the DockQ values have been evaluated (see Methods section). Table 3 reports the average values and standard deviations of DockQ from the two replicas of each system, obtained for the crystallographic structure of the complex and for poses A (Native for all the complexes), B (Native for all the complexes but 4CJ2, 5ZAU and 5UFQ), C and D (the latter two Non-Native).
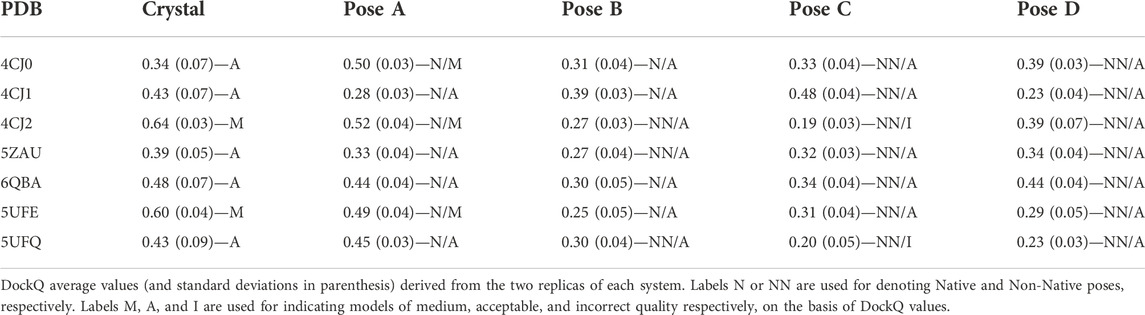
TABLE 3. DockQ values and quality of the models.
As described in the Methods section, the quality of a model is defined as high/medium/acceptable/incorrect if the DockQ value is ≥0.80/≥ 0.49/≥ 0.23/< 0.23 (Basu and Wallner, 2016). It has to be remarked that none of the simulations performed on the crystallographic structure led to DockQ values equal or higher than 0.80, indicating a high quality of the model, and only two out of seven (4CJ2 and 5UFE) fall in the medium-quality area. For this reason, the discussion of the results obtained will not focus on the DockQ absolute values; rather, we will analyze the capability of DockQ parameter to correlate with the crystal_RMSD.
For what concerns poses A, three out of seven (4CJ0, 4CJ2 and 5UFE) are classified as medium quality ones. All of them are very close to the crystallographic structure of the complex (see crystal_RMSD values in Supplementary Table S1 and Supplementary Figure S1), so one could expect similar DockQ values between poses A and the corresponding crystallographic structures. Interestingly, in the case of 4CJ0, the value obtained for the crystallographic structure is lower, whereas it is slightly higher for the other two. For the other four complexes (4CJ1, 5ZAU, 6QBA and 5UFQ) DockQ values of the poses A fall in the acceptable quality range, with 4CJ1 being close to be classified as an incorrect model despite its optimal superimposition with the crystallographic structure (crystal_RMSD = 0.13). On the other hand, many DockQ values falling in the acceptable range were found for the poses C and D, even though they are Non-Native poses. The lowest DockQ values were obtained for Non-Native poses (C or D) only for three out of four complexes (pose D for 4CJ1, and C for 4CJ2 and 5UFQ). As for the other complexes, low DockQ values correspond to poses B, with some of them being good models (see crystal_RMSD values in Supplementary Table S1 and Supplementary Figure S1). In conclusion, DockQ can identify only four out of seven poses A.
Thus, we decided to analyze other structural and energetic parameters related to the protein-protein interface. In particular, we considered the buried surface area (BSA), the number of hydrogen bonds (HB) and the protein-protein interaction energy (EPP). Our focus was addressed to their relative Standard Deviations (rSD), rather than on average values, as the former directly reflects the docking pose changes during the MD simulations.
To get more insights on the capability of these parameters (or a linear combination of these parameters) in determining the quality of the models, Principal Component Analysis (PCA) was performed on the correlation matrix of Spearman coefficients of CAPRI parameters (average values) and of BSA, HB and EPP (rSD). The analysis was conducted on the parameters extracted from the whole trajectory (production run) and led to first two principal components (PCs) describing almost the 85% of the whole data set variability. The overlay of loadings and scores plots (biplot) obtained from the PCA is shown in Figure 2.
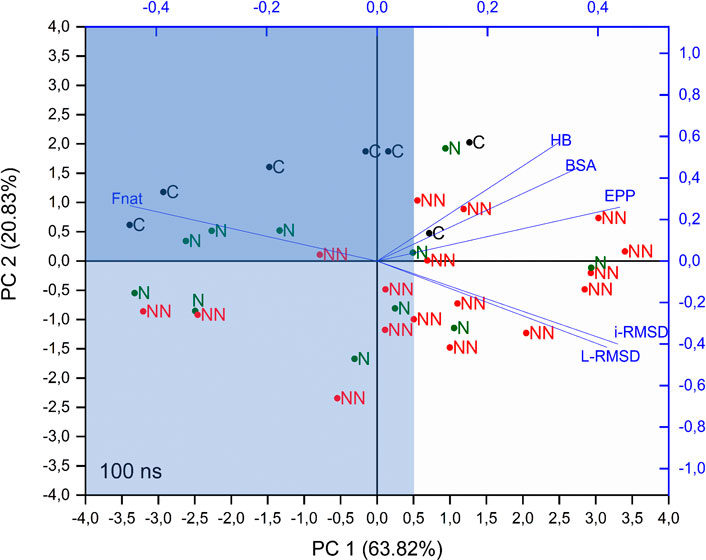
FIGURE 2. PCA biplot of considered parameters. PCA was performed on the correlation matrix of Spearman coefficients of CAPRI parameters (average values) and BSA, HB and EPP (rSD), calculated on the whole trajectory. C, N, and NN labels indicate crystallographic structures, Native and Non-Native poses respectively.
This analysis shows that i-RMSD, L-RMSD and Fnat are highly correlated, with Fnat pointing in the opposite direction: as expected, a high value of the latter is related to low values of i-RMSD and L-RMSD (see loadings of PC1 and PC2 in Supplementary Table S3). HB, BSA and EPP are highly correlated among each other and almost orthogonal to the CAPRI parameters, thus indicating the lack of direct relation with them. Concerning the components of each object (labeled in Figure 2 as C, N, NN for crystallographic structure, Native and Non-Native poses respectively), i.e. their position in the plane defined by PC1 and PC2, the analysis shows that: 1) PC1 is partially able to discriminate the poses: more than 70% of Cs and Ns fall at values of PC1 < 0.5 (light blue area in Figure 2), while 65% of NNs are above this value; 2) along PC2 a clear distinction is visible only for Cs, with all of them placed at PC2 > 0, while Ns and NNs are almost equally scattered. The intersection between areas defined by PC1 < 0.5 and PC2 > 0 is shown in dark blue in Figure 2.
Summing up, the PCA analysis can discriminate around 70% of Native and Non-Native poses, representing a useful tool to determine the quality of a docking pose in a realistic scenario, where the crystallographic structure of the complex is not available.
Docking poses reranking by MLCE
MLCE was used for identifying patches on the partners of the affitins. It must be stressed that this method predicts protein area that can be recognized by a potential binding partner, meaning that in our case not all the predicted areas are regions which actually bind affitins. For the partner that binds the affitin in the complex 6QBA, a large patch involving all the interacting residues is found (Supplementary Figure S2A). For five out of the seven complexes analyzed (4CJ0, 4CJ1, 4CJ2 and 5ZAU), there is a partial overlay between patches predicted by MLCE and residues interacting with the affitins, as observed in the crystallographic structures (Supplementary Figure S2B), while the prediction for complexes 5UFE and 5UFQ does not include residues interacting with the affitins (Supplementary Figure S2C).
As in most the cases MLCE is able to identify the protein zone corresponding to the interacting residues, in principle it can be used as a tool for reranking docking poses. To this end, we decided to rank the poses based on the number of residues of the affitins interacting with residues belonging to patches identified on the other protein. In case the experimental structure is not available, all the patches should be considered.
As shown in Supplementary Table S4, for three out of the seven complexes (4CJ1, 5UFE, and 5UFQ), the highest number of affitins residues interacting with a patch is found for docking poses C or D, which are Non-Native. For complexes 5ZAU and 6QBA, this number is the same for two poses (A and C for the former, A and B for the latter). Only for complexes 4CJ0 and 4CJ2, affitins of pose A have the highest number of interacting residues with a patch. In other words, two (plus two doubtful cases) poses A can be identified based on MLCE analysis. These results indicates that a decision on the quality of a docking model cannot be based on this parameter only but, at the same time, it can be useful if coupled to another one, as shown in the following.
Consensus approach DockQ—MLCE
In the present work, we used two different approaches to identify the correct binding mode of two interacting proteins, among the ones predicted through docking calculations. The first one is related to parameters that account for the stability of the binding pose, while the other is based on the prediction of the possible interacting residues of one of the two partners, through the analysis of the energetic and structural-dynamical properties of this protein.
In the sections above we showed that these methods, if applied individually, can lead to some misleading results, as they are not always able to identify the native binding mode among the predicted docking poses. Concerning DockQ, four poses A were identified as the best ones; in addition, for 6QBA, model A could not be distinguished from D. Considering instead MLCE results, only two poses A were identified, plus two doubtful cases in which poses A could not be distinguished from B or C.
However, since both methods show general good capabilities in discriminating the quality of the docking poses, and they rely on totally different assumptions, we apply a consensus approach which combine these two procedures into a single, more powerful method to identify the native conformation of complexes predicted through docking calculations.
In Table 4 we report, for each complex and each pose, the DockQ values and the number of residues of the affitins interacting with a patch.
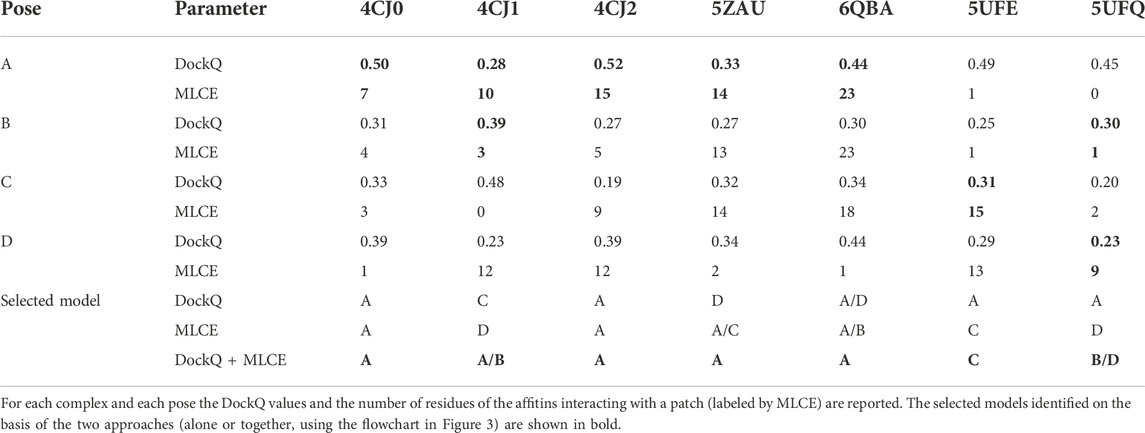
TABLE 4. Selection of the models on the basis of DockQ and MLCE results.
For evaluating both parameters at the same time, we adopted the following criteria for each complex: 1) select the pose presenting the highest values of both parameters (4CJ0-A and 4CJ2-A); 2) if the previous point does not apply, exclude the poses characterized by one best- and one worst-scoring parameter at the same time (4CJ1-C, 4CJ1-D, 5ZAU-D, 6QBA-D, 5UFE-A, 5UFQ-A); 3) select the pose presenting the highest values of both parameters, i.e. repeat the first step (5ZAU-A, 6QBA-A, 5UFE-C); 4) if the previous point does not apply, select the poses presenting the highest value of each parameter, respectively (4CJ1-A and 4CJ1-B, 5UFQ-B and 5UFQ-D). Following this procedure, we identified unique poses in five cases: only for 4CJ1 and 5UFQ identification was not possible. This protocol is also described in a flowchart (Figure 3).
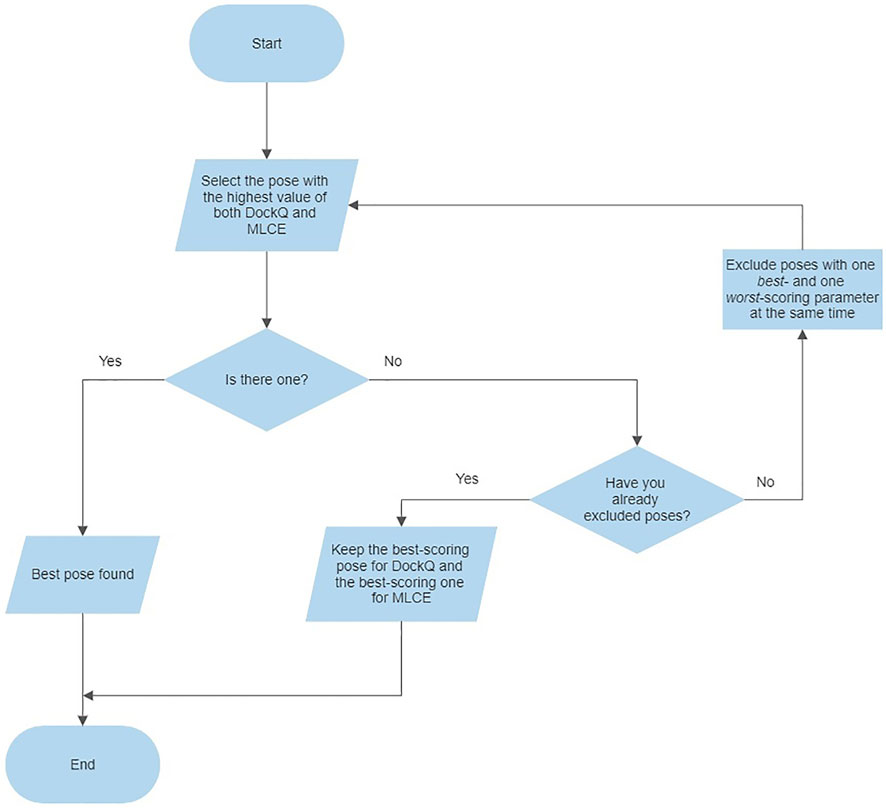
FIGURE 3. Flowchart describing the consensus approach protocol.
Considering that 4CJ1-A and 4CJ1-B are very similar, the combination of the two approaches allowed us to identify five correct models (four poses A, and one pose A/B), significantly improving the prediction obtained applying the two approaches individually.
Discussion
In the present paper, we focused on the reliability of docking and post-docking procedures in predicting the binding geometries between affitins and several protein partners, by testing them on PDB-available complexes.
ClusPro proved to be a suitable docking approach for identifying putative binding geometries of complexes containing affitins. In fact, for all the seven complexes considered (4CJ0, 4CJ1, 4CJ2, 5ZAU, 6QBA, 5UFE, 5UFQ), at least one docking pose among the first ten well overlapping to the crystallographic structure was obtained, with crystal_RMSD values ranging from 0.13 to 0.28 nm. However, as it is known, the predicted binding modes obtained by the docking algorithm and the ranking, could be far from reality. Hence, we applied a method based on the monitoring, during MD simulations, of CAPRI parameters and the global parameter DockQ, in order to identify discriminants among Native and Non-Native poses. The idea at the basis of such an approach is that Native poses should be more stable during the MD simulations, i.e. the mutual arrangement of the two proteins should not change significantly. On the contrary, Non-Native models should undergo larger conformational changes, driving the two proteins away from the initial spatial arrangement. The results obtained showed that only three of the simulations performed on poses A (4CJ0, 4CJ2 and 5UFE) led to medium-quality (≥0.49) DockQ values. The remaining ones are acceptable, with two of them (4CJ1 and 5ZAU) characterized by values close to the incorrect range. Moreover, for some of the complexes (4CJ1, 6QBA), the obtained DockQ values for Native poses were sometimes too similar or even lower than the ones obtained for Non-Native poses. Summing up, DockQ was able to identify four out of seven poses A. Thus, we decided to look for other parameters, descriptive of the protein-protein interface, able to correctly rerank the poses. Among them, our attention was addressed to the number of hydrogen bonds between the two partners (HB), the buried surface area (BSA) and the protein-protein interaction energy (EPP). Principal component analysis (PCA) was performed on the correlation matrix of the Spearman coefficients of CAPRI parameters (average values) and of BSA, HB and EPP (rSD). The analysis was conducted on the whole trajectory (production run) and allowed us to observe that the first principal component is able to discriminate around 70% of Native and Non-Native poses. Concerning MLCE, the method showed to be an adequate tool for the prediction of the interacting residues in most cases. Thus, it was used for the reranking of docking poses, considering the number of residues of the affitins interacting with the patches identified on their partners. However, only two poses A, plus two doubtful cases, were identified. We thus decided to evaluate the quality of the docked poses by combining the results obtained through DockQ and MLCE methods, i.e. to employ a consensus approach. In this way, five out of seven correct models were detected.
Conclusion
Affitins are small and highly stable proteins, features that make them easily engineerable. This results in them being ideal candidates for the development of molecular probes, entities that, through the specific recognition of a biomarker, are nowadays largely employed for the diagnosis of serious diseases such as tumor pathologies. Thanks to their structural stability, affitins-partners interactions can be studied by means of a simple protocol, as it is the one described in this paper. The protocol consists in the employment of ClusPro, a freely available server for protein-protein docking, which, treating the partners as rigid bodies, supplies the potential binding modes of the selected affitins and their partners.
The evaluation of the quality of the docking models is then addressed with two totally distinct approaches. The modeling of the full structural flexibility of the complex is introduced with MD simulations, in order to evaluate, at high atomic resolution, the structural details of the interface regions. Several parameters, including the CAPRI ones and the DockQ, are monitored and overall analyzed with PCA for quantifying the stability of docking models.
A totally different approach, the MLCE, is used in parallel to identify putative binding patches on the surfaces of the proteins. Docking models are reranked on the basis of the match with MLCE results.
DockQ and MLCE, if considered alone, are not fully able to discriminate among the docking poses. However, applying a consensus approach involving both the methods significantly improves the capability of identifying the correct binding mode among the predicted docking models.
Our work thus demonstrates that the combination of the MLCE method, which is completely unbiased, as it is based on the protein’s energetic properties and differs from the algorithm used by ClusPro to determine the potential binding surfaces, together with the dynamic evaluation of the stability of the predicted binding poses obtained with a rigid docking approach, is a fast and effective method to quickly discriminate correct from incorrect predictions generated by initial-stage docking and leads to better quality outcomes.
The overall approach we present here may represent an effective tool for evaluating a large number of affitins, and for selecting and designing new ones that are specific and selective for a target of interest.
We finally highlight that the presented protocol does not aim to be suitable for all protein-protein complexes. However, while applied to the case of affitins and known protein partners, no information about the characteristics of these specific complexes has been used to define it. In principle, the protocol can be transferable to other systems with similar characteristics, specifically, to those ones where no significant conformational rearrangement upon binding occurs.
Data availability statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Acknowledgments
MD simulations and analysis were carried out on high-performance computing resources provided by CINECA as part of the agreement with the University of Milano-Bicocca. Prof. Ivano Eberini (University of Milan) is gratefully acknowledged for providing the access to the Maestro Suite (Schrödinger Inc.) for the setup of the systems to be submitted to MD simulations. Alessia Crespi is acknowledged for running and patiently analyzing a large part of the simulations. Marina Lasagni is also gratefully acknowledged for the essential help with PCA analysis.
Conflict of interest
Author AM is employed by Bracco S.p.A.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fchem.2022.1074249/full#supplementary-material
References
Abraham, M. J., Murtola, T., Schulz, R., Páll, S., Smith, J. C., Hess, B., et al. (2015). Gromacs: High performance molecular simulations through multi-level parallelism from laptops to supercomputers. SoftwareX 1–2, 19–25. doi:10.1016/j.softx.2015.06.001
Basu, S., and Wallner, B. (2016). DockQ: A quality measure for protein-protein docking models. PLoS One 11, e0161879–9. doi:10.1371/journal.pone.0161879
Béhar, G., Renodon-Cornière, A., Mouratou, B., and Pecorari, F. (2016). Affitins as robust tailored reagents for affinity chromatography purification of antibodies and non-immunoglobulin proteins. J. Chromatogr. A 1441, 44–51. doi:10.1016/j.chroma.2016.02.068
Berendsen, H. J. C., Postma, J. P. M., Van Gunsteren, W. F., Dinola, A., and Haak, J. R. (1984). Molecular dynamics with coupling to an external bath. J. Chem. Phys. 81, 3684–3690. doi:10.1063/1.448118
Bergamaschi, G., Fassi, E. M. A., Romanato, A., D’Annessa, I., Odinolfi, M. T., Brambilla, D., et al. (2019). Computational analysis of dengue virus envelope protein (E) reveals an epitope with flavivirus immuno- diagnostic potential in peptide microarrays. Int. J. Mol. Sci. 20 (8), 1921. doi:10.3390/ijms20081921
Bussi, G., Donadio, D., and Parrinello, M. (2007). Canonical sampling through velocity rescaling. J. Chem. Phys. 126, 014101. doi:10.1063/1.2408420
Correa, A., Pacheco, S., Mechaly, A. E., Obal, G., Béhar, G., Mouratou, B., et al. (2014). Potent and specific inhibition of glycosidases by small artificial binding proteins (Affitins). PLoS One 9, e97438. doi:10.1371/journal.pone.0097438
Darden, T., York, D., and Pedersen, L. (1993). Particle mesh Ewald: An N·log(N) method for Ewald sums in large systems. J. Chem. Phys. 98, 10089–10092. doi:10.1063/1.464397
Desta, I. T., Porter, K. A., Xia, B., Kozakov, D., and Vajda, S. (2020). Performance and its limits in rigid body protein-protein docking. Structure 28, 1071–1081.e3. e3. doi:10.1016/j.str.2020.06.006
Genoni, A., Morra, G., and Colombo, G. (2012). Identification of domains in protein structures from the analysis of intramolecular interactions. J. Phys. Chem. B 116, 3331–3343. doi:10.1021/jp210568a
Gourlay, L. J., Thomas, R. J., Peri, C., Conchillo-Sole, O., Ferrer-Navarro, M., Nithichanon, A., et al. (2015). From crystal structure to in silico epitope discovery in the Burkholderia pseudomallei flagellar hook-associated protein FlgK. FEBS J. 282, 1319–1333. doi:10.1111/febs.13223
Goux, M., Becker, G., Gorré, H., Dammicco, S., Desselle, A., Egrise, D., et al. (2017). Nanofitin as a new molecular-imaging agent for the diagnosis of epidermal growth factor receptor over-expressing tumors. Bioconjug. Chem. 28, 2361–2371. doi:10.1021/acs.bioconjchem.7b00374
Hess, B., Bekker, H., Berendsen, H. J. C., and Fraaije, J. G. E. M. (1997). Lincs: A linear constraint solver for molecular simulations. J. Comput. Chem. 18, 1463–1472. doi:10.1002/(sici)1096-987x(199709)18:12<1463::aid-jcc4>3.0.co;2-h
Humphrey, W., Dalke, A., and Schulten, K. (1996). Vmd - visual molecular dynamics. J. Mol. Graph. 14, 33–38. doi:10.1016/0263-7855(96)00018-5
Jacobson, M. P., Friesner, R. A., Xiang, Z., and Honig, B. (2002). On the role of the crystal environment in determining protein side-chain conformations. J. Mol. Biol. 320 (3), 597–608. doi:10.1016/s0022-2836(02)00470-9
Jacobson, M. P., Pincus, D. L., Rapp, C. S., Day, T. J., Honig, B., Shaw, D. E., et al. (2004). A hierarchical approach to all-atom protein loop prediction. Proteins. 55 (2), 351–367. doi:10.1002/prot.10613
Jandova, Z., Vargiu, A. V., and Bonvin, A. M. J. J. (2021). Native or non-native protein–protein docking models? Molecular dynamics to the rescue. J. Chem. Theory Comput. 17, 5944–5954. doi:10.1021/acs.jctc.1c00336
Kalichuk, V., Béhar, G., Renodon-Cornière, A., Danovski, G., Obal, G., Barbet, J., et al. (2016). The archaeal “7 kDa DNA-binding” proteins: Extended characterization of an old gifted family. Sci. Rep. 6, 37274–37310. doi:10.1038/srep37274
Kauke, M. J., Traxlmayr, M. W., Parker, J. A., Kiefer, J. D., Knihtila, R., McGee, J., et al. (2017). An engineered protein antagonist of K-Ras/B-Raf interaction. Sci. Rep. 7, 5831–5839. doi:10.1038/s41598-017-05889-7
Kozakov, D., Beglov, D., Bohnuud, T., Mottarella, S. E., Xia, B., Hall, D. R., et al. (2013). How good is automated protein docking? Proteins. 81, 2159–2166. doi:10.1002/prot.24403
Kozakov, D., Hall, D. R., Xia, B., Porter, K. A., Padhorny, D., Yueh, C., et al. (2017). The ClusPro web server for protein–protein docking. Nat. Protoc. 12, 255–278. doi:10.1038/nprot.2016.169
Krehenbrink, M., Chami, M., Guilvout, I., Alzari, P. M., Pécorari, F., and Pugsley, A. P. (2008). Artificial binding proteins (affitins) as probes for conformational changes in secretin PulD. J. Mol. Biol. 383, 1058–1068. doi:10.1016/j.jmb.2008.09.016
Marchetti, F., Capelli, R., Rizzato, F., Laio, A., and Colombo, G. (2019). The subtle trade-off between evolutionary and energetic constraints in protein-protein interactions. J. Phys. Chem. Lett. 10, 1489–1497. doi:10.1021/acs.jpclett.9b00191
Méndez, R., Leplae, R., De Maria, L., and Wodak, S. J. (2003). Assessment of blind predictions of protein-protein interactions: Current status of docking methods. Proteins. 52, 51–67. doi:10.1002/prot.10393
Morra, G., and Colombo, G. (2008). Relationship between energy distribution and fold stability: Insights from molecular dynamics simulations of native and mutant proteins. Proteins. 72, 660–672. doi:10.1002/prot.21963
Mouratou, B., Schaeffer, F., Guilvout, I., Tello-Manigne, D., Pugsley, A. P., Alzari, P. M., et al. (2007). Remodeling a DNA-binding protein as a specific in vivo inhibitor of bacterial secretin PulD. Proc. Natl. Acad. Sci. U. S. A. 104, 17983–17988. doi:10.1073/pnas.0702963104
Mukherjee, A., Singh, R., Udayan, S., Biswas, S., Reddy, P. P., Manmadhan, S., et al. (2020). A fyn biosensor reveals pulsatile, spatially localized kinase activity and signaling crosstalk in live mammalian cells. Elife 9, 505711–e50648. doi:10.7554/eLife.50571
Oostenbrink, C., Villa, A., Mark, A. E., and Van Gunsteren, W. F. (2004). A biomolecular force field based on the free enthalpy of hydration and solvation: The GROMOS force-field parameter sets 53A5 and 53A6. J. Comput. Chem. 25, 1656–1676. doi:10.1002/jcc.20090
Peri, C., Gagni, P., Combi, F., Gori, A., Chiari, M., Longhi, R., et al. (2013). Rational epitope design for protein targeting. ACS Chem. Biol. 8 (2), 397–404. doi:10.1021/cb300487u
Robinson, H., Gao, Y.-G., McCrary, B. S., Edmondson, S. P., Shriver, J. W., and Wang, A. H.-J. (1998). The hyperthermophile chromosomal protein Sac7d sharply kinks DNA. Nature 392, 202–205. doi:10.1038/32455
Sastry, G. M., Adzhigirey, M., Day, T., Annabhimoju, R., and Sherman, W. (2013). Protein and ligand preparation: Parameters, protocols, and influence on virtual screening enrichments. J. Comput. Aided. Mol. Des. 27 (3), 221–234. doi:10.1007/s10822-013-9644-8
Scarabelli, G., Morra, G., and Colombo, G. (2010). Predicting interaction sites from the energetics of isolated proteins: A new approach to epitope mapping. Biophys. J. 98, 1966–1975. doi:10.1016/j.bpj.2010.01.014
Schrödinger Release 2022-2 (2021). Protein preparation wizard; epik, schrödinger, LLC, New York, NY, 2021; impact, schrödinger, LLC, New York, NY; Prime. New York, NY: Schrödinger, LLC.
Serapian, S. A., Marchetti, F., Triveri, A., Morra, G., Meli, M., Moroni, E., et al. (2020). The answer lies in the energy: How simple atomistic molecular dynamics simulations may hold the key to epitope prediction on the fully glycosylated SARS-CoV-2 spike protein. J. Phys. Chem. Lett. 11, 8084–8093. doi:10.1021/acs.jpclett.0c02341
Sola, L., Gagni, P., D’Annessa, I., Capelli, R., Bertino, C., Romanato, A., et al. (2018). Enhancing antibody serodiagnosis using a controlled peptide coimmobilization strategy. ACS Infect. Dis. 4 (6), 998–1006. doi:10.1021/acsinfecdis.8b00014
Tiana, G., Simona, F., De Mori, G. M., Broglia, R. A., and Colombo, G. (2004). Understanding the determinants of stability and folding of small globular proteins from their energetics. Protein Sci. 13 (1), 113–124. doi:10.1110/ps.03223804
Vajda, S., Yueh, C., Beglov, D., Bohnuud, T., Mottarella, S. E., Xia, B., et al. (2017). New additions to the ClusPro server motivated by CAPRI. Proteins. 85, 435–444. doi:10.1002/prot.25219
Vangone, A., Oliva, R., Cavallo, L., and Bonvin, A. M. J. J. (2017). “Prediction of biomolecular complexes,” in From protein structure to function with bioinformatics. Editor D. J. Rigden (Springer), 265–292.
Vazquez-Lombardi, R., Phan, T. G., Zimmermann, C., Lowe, D., Jermutus, L., and Christ, D. (2015). Challenges and opportunities for non-antibody scaffold drugs. Drug Discov. Today 20, 1271–1283. doi:10.1016/j.drudis.2015.09.004
Keywords: protein-protein interaction, molecular docking, affitins, DockQ, matrix of local coupling energies, consensus approach, diagnostic probes, antibody mimetics
Citation: Ranaudo A, Cosentino U, Greco C, Moro G, Bonardi A, Maiocchi A and Moroni E (2022) Evaluation of docking procedures reliability in affitins-partners interactions. Front. Chem. 10:1074249. doi: 10.3389/fchem.2022.1074249
Received: 19 October 2022; Accepted: 17 November 2022;
Published: 01 December 2022.
Edited by:
Weicheng Hu, Huaiyin Normal University, ChinaReviewed by:
Hongwei Cheng, Xiamen University, ChinaLucia Sessa, University of Salerno, Italy
Crtomir Podlipnik, University of Ljubljana, Slovenia
Copyright © 2022 Ranaudo, Cosentino, Greco, Moro, Bonardi, Maiocchi and Moroni. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Anna Ranaudo, YW5uYS5yYW5hdWRvQHVuaW1pYi5pdA==