 Jangwon Lee1
Jangwon Lee1 Jesus Flores-Cerrillo
Jesus Flores-Cerrillo Jin Wang
Jin Wang Q. Peter He
Q. Peter He
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Chem. Eng. , 18 November 2022
Sec. Computational Methods in Chemical Engineering
Volume 4 - 2022 | https://doi.org/10.3389/fceng.2022.1064221
This article is part of the Research Topic Editors’ Showcase: Computational Methods in Chemical Engineering View all 8 articles
Pressure swing adsorption (PSA) is a widely used technology to separate a gas product from impurities in a variety of fields. Due to the complexity of PSA operations, process and instrument faults can occur at different parts and/or steps of the process. Thus, effective process monitoring is critical for ensuring efficient and safe operations of PSA systems. However, multi-bed PSA processes present several major challenges to process monitoring. First, a PSA process is operated in a periodic or cyclic fashion and never reaches a steady state; Second, the duration of different operation cycles is dynamically controlled in response to various disturbances, which results in a wide range of normal operation trajectories. Third, there is limited data for process monitoring, and bed pressure is usually the only measured variable for process monitoring. These key characteristics of the PSA operation make process monitoring, especially early fault detection, significantly more challenging than that for a continuous process operated at a steady state. To address these challenges, we propose a feature-based statistical process monitoring (SPM) framework for PSA processes, namely feature space monitoring (FSM). Through feature engineering and feature selection, we show that FSM can naturally handle the key challenges in PSA process monitoring and achieve early detection of subtle faults from a wide range of normal operating conditions. The performance of FSM is compared to the conventional SPM methods using both simulated and real faults from an industrial PSA process. The results demonstrate FSM’s superior performance in fault detection and fault diagnosis compared to the traditional SPM methods. In particular, the robust monitoring performance from FSM is achieved without any data preprocessing, trajectory alignment or synchronization required by the conventional SPM methods.
The synthetic zeolites developed by Union Carbide in the 1950s enabled the development of the pressure swing adsorption (PSA) processes. The first industrial application of PSA went on stream in 1966 at a Union Carbide production facility. Since then, PSA has been widely used to separate a gas product from impurities in various fields, from traditional bulk gas separation and drying, to CO2 sequestration, trace contaminant removal, and many others. A good review of the historical development of PSA technology can be found in Elseviers et al. (2015). With ever-increasing product capacity and carefully designed operations, modern multi-bed PSA systems can take full advantage of the feed pressure to optimize performance and recover more product gases. For multi-bed PSA systems, adsorber vessels are connected by a complex pipe network with literally hundreds of valves to automatically switch the gas flows among the beds, which results in an intrinsically transient, cyclic, highly nonlinear, and complex dynamic process. As industrial adsorbents are usually highly efficient and stable, major production disruptions are most often caused by valve-related problems, such as internal leakage or stiction. If a potential valve problem could be detected in real-time while still in its early stage, corresponding actions can be scheduled as an online maintenance event, which can be conducted without the downtime and in coordination with other process and business considerations. In other words, if a fault can be detected early, the problem can be addressed with minimum disruption before it escalates to a highly costly emergency shutdown. Clearly, successful early fault detection and diagnosis can greatly improve the PSA process throughput, product quality, and economic performance. In addition, such a process monitoring system can serve as a remote monitoring and early warning system for unattended or autonomous PSA operations.
The intrinsically transient and cyclic operation of PSA processes renders most available fault detection and diagnosis solutions ineffective. Despite the importance and potential impact of PSA process monitoring, research in this area has been scarce. Pan et al. (2004) proposed a monitoring approach for continuous processes with periodic characteristics by identifying a stochastic state space model that captures the statistical behavior of changes occurring from one period to another. This approach was validated using a wastewater treatment process (WWTP). While there are similarities between WWTP and PSA processes, there are also major differences. Most notably, for the activated sludge process, which is the central part of a WWTP, there is a strong cycle-to-cycle dynamics due to the continuous growth of the microorganisms, which provides a “linkage” from cycle to cycle. In comparison, for PSA processes, the cycle-to-cycle dynamics is almost non-existent due to the absence of such a linkage between cycles. In addition, the activated sludge process is a natural periodic process with a somewhat constant cycle time driven by the diurnal temperature and light changes. As a result, obtaining the same number of measurements from each period can be easily achieved, which is required by the state space modeling approach. In contrast, PSA is an engineered periodic process, with cycle time dynamically controlled in response to many disturbances that affect a PSA operation, including varying customer demands, operation schedule adjustment based on electricity pricing to minimize cost, and/or raw material feed composition variations. As a result, the cycle time is frequently and often significantly adjusted, which does not satisfy the condition that each cycle contains the same number of measurements as required by the state space approach proposed in Pan et al. (2004). In addition, the state space inferential prediction proposed by Pan et al. requires quality-relevant process output, which we do not have in this study. Recently, Wang et al. (2017) proposed a geometric framework for the monitoring and fault detection of periodic processes. The fault detection is based on the “centroids of the centroids” of the training/normal cycles and a corresponding confidence region defined based on them. The proposed approach was applied to a simulated two-bed PSA process and showed superior performance compared to the conventional dynamic PCA (DPCA) and multi-way PCA (MPCA) methods. For the simulated PSA process, 26 variables were used for process monitoring, including feed flow rates, pressures, and concentrations in and across both beds. However, in industrial PSA processes, most of these variables are not measured, especially the concentrations in and across the beds. In fact, for almost all PSA plants, pressure is the only process variable constantly monitored. In this case, the method proposed by Wang et al. (2017) is not applicable as there is no centroid for a single variable. Another proposed method for monitoring industrial PSA processes is a US patent (Arslan et al., 2014). This method first applied a moving window discrete Fourier transform (DFT) to convert process data (i.e., bed pressure profiles) into frequency spectra; next, a number of “relevant” peaks were identified from the frequency spectra; and finally the logarithm of the amplitude ratio of peak
To develop a process monitoring solution that is suitable for PSA and other cyclic industrial processes, we present a different approach based on the feature space monitoring (FSM) framework we developed recently (He and Wang, 2018). Instead of monitoring the original pressure profile of a PSA process, we first conduct feature engineering, where statistical and shape/morphological features are computed based on the pressure profile to capture the characteristics of each step of the operation cycle. Next, these features are grouped by cycles and monitored by a linear or nonlinear MSPM method for fault detection and diagnosis. Through feature engineering and selection, we not only can readily address the unique challenges associated with cyclic processes, such as the unequal duration for different cycles/steps, but also could detect subtle changes early from a wide range of normal cycle durations. The rest of the paper is organized as follows. Section 2 discusses the key characteristics of the industrial PSA process and the challenges posed to the conventional MSPM methods by these characteristics. Section 3 briefly reviews statistics pattern analysis (SPA), which is the predecessor and a special case of FSM. Section 4 introduces the proposed FSM method for PSA processes. Section 5 presents several case studies, including simulated and real faults in an industrial PSA process, to demonstrate the performance of the proposed method, which is compared to those of the conventional MPCA-based methods. Finally, Section 6 discusses the results and draws some conclusions.
In this section, we discuss the unique characteristics of PSA processes and how these characteristics pose challenges to process monitoring.
PSA processes are operated on repeated cycles of adsorption and regeneration. As shown in Figure 1, the bed pressure is raised during the adsorption step and the impurities are adsorbed by the adsorbent, providing the high-purity product gas. During the regeneration step, the bed pressure is lowered and the impurities are cleaned or purged from the adsorbent, allowing the adsorption-regeneration cycle to be repeated. Therefore, a PSA process is a continuous process but never operates at any single steady state. Instead, it repeats a sequence of operation steps over and over. This is usually termed a cyclic steady-state process, where cycles are very similar to each other, and a whole cycle is considered a “steady-state”.
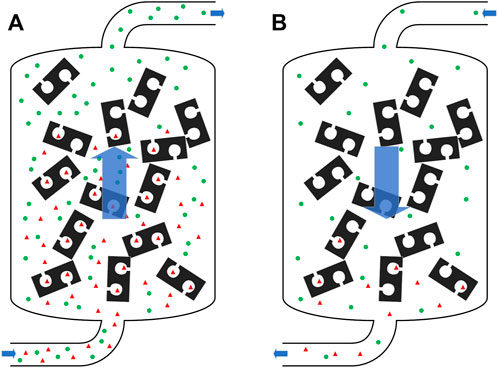
FIGURE 1. Schematic illustration of the major steps involved in a PSA process (A) Adsorption (B) Regeneration.
To take full advantage of the feed pressure and to recover more product gas, multi-bed multi-step PSA systems have been widely applied in industrial applications. In terms of process monitoring, the bed pressure is always measured and is often the only variable constantly measured for PSA processes. The industrial data utilized in this work were collected from one of Linde’s 12-bed 15-step PSA systems. Figure 2 shows two common ways to visualize pressure trajectories in a multi-bed PSA process. Due to the sensitivity of the process’s actual operation and production data, all axis tick labels in this and other figures are omitted when real operation data are used. Figure 2A shows time-series pressure profiles of multiple beds (only three out of twelve beds are shown here to reduce clutter). This type of pressure time-series plot is useful for visualizing and observing between-bed variations. However, only severe faults that significantly deviate from the nominal trajectory can be detected by the naked eyes using this type of plot; in addition, it becomes very cluttered and difficult to read if all beds were plotted on the same figure. Another way to visualize the pressure profile within a bed over multiple cycles is to overlay cycles based on the start of each cycle, as illustrated in Figure 2B. This type of plot can be used to visualize within-bed variations. However, due to the variable duration of cycles, again, only severe faults that show significant deviations from the normal operation can be detected directly by the naked eyes from this type of plot.
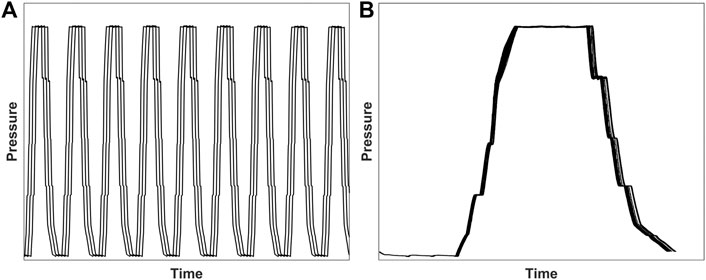
FIGURE 2. Visualization of pressure trajectories in a multi-bed PSA process (A) A sample time-series pressure profiles of three beds in a multi-bed PSA process (B) Overlaid pressure profiles of a single bed over multiple cycles, which illustrates the variable durations from different cycles.
In terms of process monitoring, PSA processes share more similarities with batch processes than with continuous processes. For example, PSA and batch processes can both have variable batch/cycle duration and step durations; they are often dynamic transient processes and do not have a steady state. The variable nature of the PSA cycle duration is demonstrated in Figure 3A, which plots the durations of different cycles from one PSA bed. For the PSA process studied in this work, each cycle consists of 15 steps, as illustrated in Figure 2. For the step durations, about half of the steps follow similar trends as the cycle duration, while the remaining steps have relatively constant durations. Figure 3B plots the variable step duration of the adsorption step across different cycles, and Figure 3C plots the relatively constant step duration of an equalization step across different cycles. For the PSA process studied in this work, the cycle duration is in the order of tens of minutes and the step durations vary from seconds to minutes.
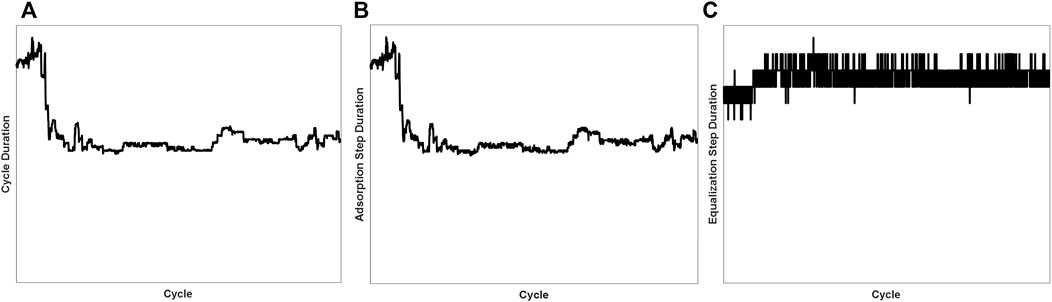
FIGURE 3. Illustrations of the variable cycle and step durations (A) Cycle durations vary significantly from cycle to cycle (B) Durations of the adsorption step follow a similar trend as the cycle durations (C) durations of the equalization steps are close to constant.
Several observations can be made from these plots. First, the cycles are asynchronous across different beds; for the same bed, the cycles do not exactly overlap with each other either. Second, despite the overall highly nonlinear behavior for each cycle, the pressure profile for each individual step is usually much simpler and can be approximated by a simple linear or polynomial function. Finally, not only the cycle durations but also the step durations vary from cycle to cycle. It is important to note that the variations in cycle/step duration is not caused by unmeasured normal process variations, instead, it is a result of deliberate control of cycle and step durations to ensure product quality in response to dynamic scheduling and/or measured disturbances such as demand change and weather conditions. In addition, these characteristics are not unique to PSA processes but are rather common to other cyclic steady-state processes, such as heat exchanger networks under fouling with cleaning-in-place (CIP) operations (Georgiadis and Papageorgiou, 2000), and catalytic conversion processes where the catalyst undergoes periodic deactivation and activation (Jain and Grossmann, 1998).
As discussed above, normal PSA operations cover a wide range of pressure trajectories, due to the dynamically controlled step/cycle durations in response to external disturbances. It is clearly a highly challenging task to detect a subtle fault early from a wide range of normal cycle/step durations with the bed pressure as the only monitored variable. In addition, the characteristics of the PSA processes (and cyclic steady-state processes in general), including asynchronous trajectories, variable cycle/step durations, and nonlinear dynamics, present significant challenges to process monitoring. These challenges cannot be effectively addressed by commonly used multivariate statistical monitoring (MSPM) methods, including both conventional MSPM methods such as MPCA, trilinear decomposition (TLD), and parallel factor analysis (PARAFAC) (Wise et al., 1999), and more recent methods such as multi-way independent component analysis (MICA) (Yoo et al., 2004) and kernel PCA (KPCA) (Choi et al., 2005). These methods assume that the normal process data follow the same distribution and require the construction of a two-dimensional (2-D) data matrix (for data unfolding approaches) or a 3-D data array (for multi-way approaches). In other words, they require synchronization of all steps within a cycle to achieve equal step and cycle durations. Trajectory synchronization can be done through different ways, including simple cut, interpolation, dynamic time warping (DTW), etc. However, these preprocessing steps have their drawbacks, including trajectory distortion, information loss, etc (He and Wang, 2007; He and Wang, 2018). In particular, synchronization is undesirable for PSA processes because the step durations are dynamically controlled and may contain important information on the state of the process operation. Artificially changing the step/cycle durations may distort the contained information and negatively affect the fault detection and diagnosis performance.
In this work, built upon our work in batch process monitoring that can naturally handle variable batch/step durations, we develop an FSM approach for PSA processes. We show that a balance between sensitivity and robustness of the FSM approach can be achieved through feature engineering and selection, which enables early detection of subtle faults with very low false alarm rate.
In traditional MSPM approaches for process monitoring, such as PCA and PLS-based approaches, it is inexplicitly assumed that normal process data (or scores in principal component subspace) follow a multivariate Gaussian distribution. However, this assumption is usually not satisfied in industrial applications, especially for batch processes whose data are often highly non-Gaussian. Statistics pattern analysis (SPA) was proposed to address the non-Gaussian process data commonly seen in industrial processes. In SPA, various statistics of process variables, instead of process variables themselves, are modeled for process monitoring. A statistics pattern (SP) is a collection of various statistics calculated using process data, which captures the characteristics of individual variables (e.g., mean and variance), the interactions among different variables (e.g., covariance), the dynamics (e.g., auto-, cross-correlations), as well as process nonlinearity and process data non-Gaussianity (e.g., skewness, kurtosis, and other higher-order statistics or HOS). SPA has been implemented for both continuous and batch process monitoring. For continuous processes, SPs corresponding to different time periods are computed using a moving window approach. For batch processes, the SP for each batch (or each step in a batch) is computed using all measurements from the batch (or step). In this way, the variable batch/step duration can be naturally handled without any data preprocessing.
For process monitoring, SPA assumes that the SPs of normal operations follow a similar pattern (i.e., normal pattern), while the SPs of abnormal or faulty operations must show some deviation from the normal pattern. A multivariate statistical model can be developed for the normal SPs, which enables the determination of a boundary for normal operation or threshold for fault detection. The implementation of SPA can be simplified by assuming that the normal SPs follow a multivariate Gaussian distribution. Although this assumption appears to be the same as the traditional MSPM methods, it is important to note that this assumption (i.e., normal SPs follow a Gaussian distribution) is usually satisfied to a much better degree for SPs than for the measured process variables themselves. As different statistics are the averages of different functions of the variable measurements in a window/batch/step, the distribution of SPs is asymptotically Gaussian. This argument is supported by the central limit theorem (CLT) under weak dependencies, which relaxes the requirement on the independency among different random variables (Dedecker and Rio, 2008). It was further shown that the CLT applies to sums of bounded random variables generated from stationary dynamic systems (Pène, 2005), which applies to different statistics computed using measurements collected from stable processes. The assumption was also validated in (He and Wang, 2011) for batch process monitoring. With this simplification, the characteristics of normal SPs can be captured by the covariance structure of SPs, similar to PCA, and a threshold can be defined (e.g., based on Hotelling’s T2 or squared prediction error (SPE)). The test SPs can then be projected onto the model and the obtained metric such as T2 or SPE is compared to the threshold for fault detection. More details on batch-based SPA can be found in He and Wang (2011). Since the introduction of SPA, several variations and extensions of SPA have been reported in the literature for process monitoring (He and Xu, 2016; Yang et al., 2018; Zhang et al., 2018; Zhou and Gu, 2019).
As PSA and other cyclic continuous processes share many similarities with batch processes, we expect SPA for batch monitoring can be extended to monitor PSA processes. However, major differences between PSA and regular batch processes must be considered. For the PSA process studied here, the bed pressure is the only measured variable, therefore only univariate statistics can be calculated for process monitoring. In addition, one major challenge for PSA monitoring is that although under tight process control, the normal PSA operation has a wide distribution of step/cycle durations in response to disturbances such as customer demand and scheduling based on electricity pricing. Therefore, normal PSA operation data exhibit a wide distribution of normal cycle trajectory, which makes the detection, not to mention early detection, of abnormal cycles highly challenging. To address this challenge, we explore the power of feature engineering to achieve both sensitivity and robustness in the monitoring performance, as well as minimal data preprocessing for easy practical implementation. Once a fault is detected, it is desirable to identify in which step the fault has occurred, so that the corresponding valves, bed and/or pipeline can be identified for further examination. The proposed fault detection and diagnosis framework is termed feature space monitoring or FSM. There are three steps involved in the proposed FSM framework: 1) feature engineering and selection; 2) fault detection; and 3) fault diagnosis. They are discussed in the following sections.
As shown in Figure 2, although a complete cycle of a PSA process is highly nonlinear, each step is much simpler and can be described by a simple linear or polynomial model. Therefore, in this work, we compute different features for each step separately. In addition to univariate statistics, we explore morphological features to better capture the characteristics of pressure profile in each step of the process. To handle the irregularities in industrial data, for each characteristic we consider multiple features that may exhibit different level of sensitivity to outliers. For example, to assess the dispersion of pressure measurement during a processing step, we compare features that use the mean of the pressure measurements as the reference with others that use the median as the reference. Based on the observation of the pressure profiles and discussions with process engineers, totally 12 features (as defined in the remaining section), both statistical and morphological, are examined in this work to determine if they would provide adequate process monitoring. All features are calculated for each step using raw pressure measurements without any preprocessing such as synchronization, centering, scaling or normalization.
In this work, we use a vector
1. Mean (
2. Standard deviation (
3. Skewness (
4. Kurtosis (
5. Coefficient of variation (
6. Interquartile range (
where
7. Quartile coefficient of dispersion (
8. Mean absolute deviation (
9. Median absolute deviation (
10. Slope (
11. Slope of linear regression line (
12. Mean absolute error (
For the steps with relatively flat pressure profiles (e.g., adsorption, hold and purge steps), we first estimate the global mean of step
where
For the steps with sloped pressure profiles (e.g., equalization, provide purge, blowdown or evacuation, and pressurization steps), the predicted pressure measurements,
Finally, for each cycle, we have all the above-described features combined.
where
After the extracted features are concatenated into a row vector for each cycle following Eq. 15, the features from multiple cycles are concatenated into a matrix as the following.
In this way, a training feature matrix
It is worth noting that the statistical and morphological features are extracted for each step of each cycle based on the raw training data without any preprocessing, without synchronization, scaling, normalization nor alignment. Since the features are calculated using all measurements from each step of the cycle, they are all scalars regardless of the step/cycle durations. Therefore, FSM naturally handles unequal step/cycle durations and asynchronous step/cycle trajectories. In addition, the structure shown in Eq. 15 has the flexibility of allowing different number of features for different steps. In addition, cycle-based features can be conveniently added in a similar fashion.
Feature selection has been widely studied in supervised learning where it has been shown that including irrelevant and noisy features increases model complexity and can degrade model prediction performance (Lindgren et al., 1994; Andersen and Bro, 2010; Wang et al., 2015; Lee et al., 2020). Feature selection also has other benefits including reducing computational cost, improving interpretability of the model, etc. Since MSPM method based on PCA is a dimension reduction technique that is capable of handling collinearity in the process data, it may appear that feature selection is redundant and unnecessary. However, as shown in Ghosh et al. (2014), feature selection can have a significant impact on the monitoring performance of PCA-based MSPM. Specifically, experiments were conducted to show that including irrelevant and noisy features in a PCA-based MSPM model can degrade process monitoring performance (Ghosh et al., 2014).
In general, variable selection is more challenging for process monitoring as it is an unsupervised learning. Specifically, in process monitoring available data for model training are predominantly normal data. Even if fault data were available, they do not represent all possible fault scenarios. Therefore, for process monitoring, it is reasonable to assume that only normal operations data are available for feature selection, as features that are sensitive for detecting one type of fault may not be sensitive for detecting other (potentially unseen) faults. In this work we propose a new feature selection method for process monitoring that utilizes normal operation data only. We assume the true relevant features that are important for process monitoring should capture the key characteristics of the normal operation; consequently, if the true relevant features were used for process monitoring, the monitoring performance would be insensitive to the subsets of the training data used for model building. In other words, features extracted from a set of normal operation data (e.g., the training data) should show (highly) similar behavior as those extracted from another independent set of normal data (e.g., the validation data). In this work, we use false alarm rate (FAR) and false alarm magnitude (FAM) to quantify the difference between the training and validation performance, where FAM is defined as the difference between the monitoring statistic (e.g., T2 or SPE) of the false alarm sample and the threshold of that statistic. In this work, 10-fold cross-validation is conducted using normal operation data to select features that result in similar FAR and FAM in the validation data, and feature selection is conducted through exhaustive search. A more systematic approach is under investigation. In the end, the following four features were selected: mean (
After feature selection, a multivariate statistical model can be developed to extract the patterns of normal cycles by examining the correlations among all features. This model enables the determination of a boundary or threshold for process monitoring. In this work, we assume that under normal operations, the features form a multivariate normal distribution. Since all features are the averages of some functions of multiple measurements in a step/cycle, their distributions are asymptotically Gaussian (Pène, 2005). Similar to He and Wang (2011), here we choose PCA to capture the directions of maximum covariances among all the features. Other SPM methods, such as independent component analysis (ICA), can be applied as well.
Because the features in FSM are usually different types, it is reasonable to scale the training feature matrix
where
PCA based fault detection is well established for monitoring multivariate processes at steady state, where Hotelling’s T2 can be employed for monitoring variations in the PCS while SPE or Q statistic can be employed for monitoring variations in the RS. By monitoring features of individual cycles, we can straightforwardly extend PCA for monitoring cyclic processes which are inherently non-steady state. Similar to PCA-based monitoring of a continuous process, T2 can capture faults that shift away from the normal operation region without violating the covariance among measured/monitored process variables. These faults are usually large operational changes such as a change of feedstock or raw material. On the other hand, SPE are sensitive to the process faults that violate the collinear relationships among the monitored features. The control limits of T2 and SPE can be defined theoretically based on the Gaussian assumption of the features. They can also be determined empirically, e.g., by kernel density estimation (KDE). The latter is used in this work.
By design, PSA processes are tightly controlled to operate in a targeted optimal region. Therefore, we expect there are few process changes that could violate the threshold in PCS and are detectable by T2. In addition, as multiple features included in the FS are closely related to each other, such as the same features from different steps, there could be significant collinearities among features. Therefore, we expect SPE to be sensitive to the process faults with small magnitude but violating the collinearities among features, and enable early detection of potentially catastrophic faults. As shown in Section 5.2, both the traditional multi-way PCA (MPCA) and the proposed FSM detected the faults largely through SPE, as expected.
Once a fault is detected by SPE statistic, the contribution plot can be used for fault diagnosis. In this work, we propose a hierarchical fault diagnosis using SPE to first determine in which step the fault occurred based on the step-wise contribution plot, then postulate what type of fault occurred based on the feature-wise contribution plot.
At the step level (i.e., step-wise diagnosis), SPE statistic is broken down by step:
where
In this section, we use an industrial PSA case study to demonstrate the performance of the proposed FSM method, and compare it to the traditional MPCA method. Note that the method proposed by Wang et al. (2017) is not applicable because pressure measurements are the only available measurements for process monitoring in this study. The patented method by Arslan et al. (2014) cannot be implemented either, because there are no details as how the peaks are defined or classified as “relevant”, and the criteria used for peak selection and control limits determination are unknown. The state space modeling approach by Pan et al. (2004) is not applicable due to the absence of cycle-to-cycle dynamics of the PSA processes and the lack of quality-relevant measurement for the PSA process studied in this work. Because MPCA requires that each step across all cycles has the same duration, two different data preprocessing techniques are studied: one with simple cut denoted as MPCASC and the other with dynamic time warping (DTW) denoted as MPCADTW. For MPCASC, the shortest step durations across all cycles are used as the reference while the last few measurements of any cycle with longer step duration are simply removed to match the shortest, which resulted in 438 variables for the whole cycle. For MPCADTW, the number of variables after unfolding is 705. The significant difference in the number of variables for MPCASC and MPCADTW reflects the significant variation of step durations across different cycles. For FSM, four features are used for each of the 15 steps, which resulted in 60 variables. To ensure that enough number of samples are available for all methods, 2,070 cycles under normal operations are used as the training set, which is about three times the number of variables for MPCADTW. The first 1,449 cycles (70% of 2,070 cycles) are used for model training and the remaining 621 cycles for model validation.
Six fault scenarios of a PSA process are studied in this work, which are listed in Table 1. The first four are simulated faults while the last two are from real industrial data. For the simulated faults, similar faulty process behaviours have been observed in actual operations. They are reproduced based on historical plots of those faults because the historical data are no longer available. All faults are related to valve malfunctions. For example, an internally leaky valve could result in higher or lower pressure in one vessel depending on whether the vessel serves as a pressure provider or receiver, such as the fault scenarios 1, 3 and 5. A sticky valve could result in higher pressure variation, such as the fault scenario 2, sudden pressure increase or drop, such as the fault scenario 4, or a non-smooth (e.g., zig-zag) pressure profile, such as the fault scenario 6. As discussed in the Introduction section, due to frequent open and close operations of valves, it has been found that the process faults are most often caused by valve-related problems. For each fault scenario, totally 16 cycles are used as the test set and among which 3 (deliberately arranged as cycle 4, 9 and 14 for better comparison across all scenarios) are faulty cycles. In these cases, the simulated faults are introduced by modifying a normal cycle randomly selected from the industrial data set. The pressure trajectories of the test set for fault scenarios 1 (simulated fault) and 5 (real fault) are shown in Figure 4.

TABLE 1. Fault scenarios studied in this work.
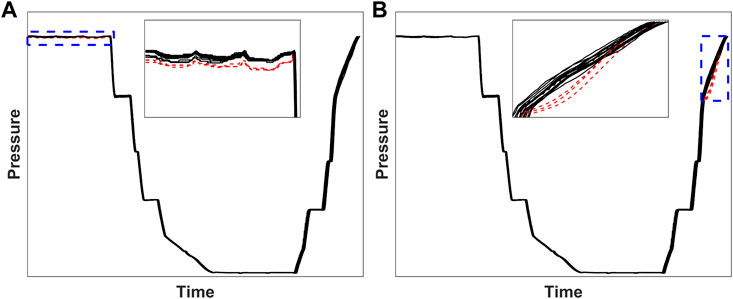
FIGURE 4. Pressure trajectories of the selected test sets (A) Fault scenario 1 (B) Fault scenario 5. Normal cycles are plotted in black while faulty cycles are in red. The steps in which the fault occurred are marked by blue dashed-line rectangles and shown in the zoom-in views.
For all fault detection methods, the number of principal component (PCs) is selected to cover 90% of the variance of their corresponding full feature space. The control limits on Hoteling’s T2 and squared prediction error (SPE) are calculated empirically based on the kernel density estimation of the corresponding statistics (i.e., T2 or SPE) of the training dataset at confidence level 99%. The number of PCs and other information discussed above are listed in Table 2.
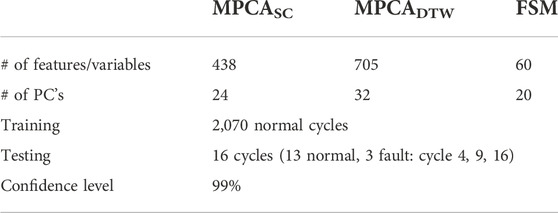
TABLE 2. Training, testing datasets and model parameters.
By considering faults detected in both residual subspace using SPE and principal subspace using T2, the overall fault detection results are shown in Table 3. Specifically, the table lists faulty cycles detected by either SPE, or T2, or both. The fault detection rate (FDR) and false alarm rate (FAR) of each method are also summarized in Table 3. These results show that FSM detects all faulty cycles under all fault scenarios without generating false alarms. In comparison, MPCASC has missed detection under fault scenario 1, while MPCADTW has missed detection under fault scenario 5. In addition, both MPCASC and MPCADTW have false alarms. More details of the fault detection results by T2 and SPE are shown in Table 4. It can be seen that SPE statistic in general is more effective in detecting faults, although it also generates false alarms in the cases of MPCASC and MPCADTW. In comparison, T2 does not generate false alarms for all methods. However, it misses several faults in MPCASC and performs even worse in MPCADTW. Overall, FSM performs robustly with both T2 and SPE and is significantly better than MPCASC and MPCADTW.
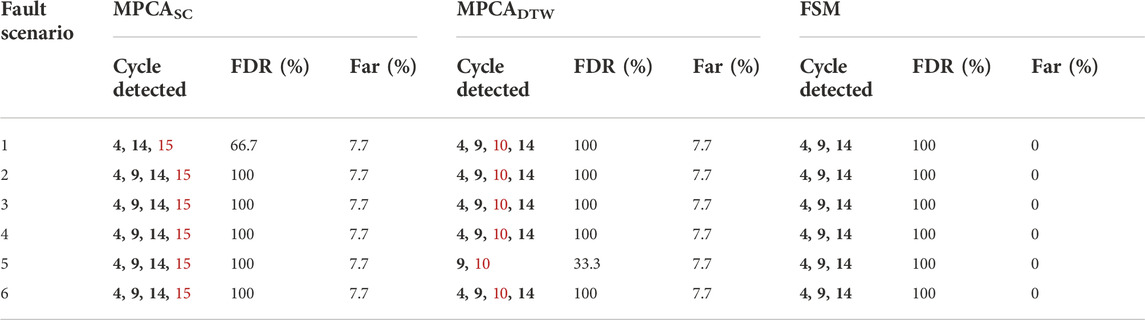
TABLE 3. Fault detection results (true faulty cycles: 4, 9 & 14; FDR: fault detection rate; FAR: false alarm rate). Correctly detected cycles are in bold black. Incorrectly detected cycles are in red.
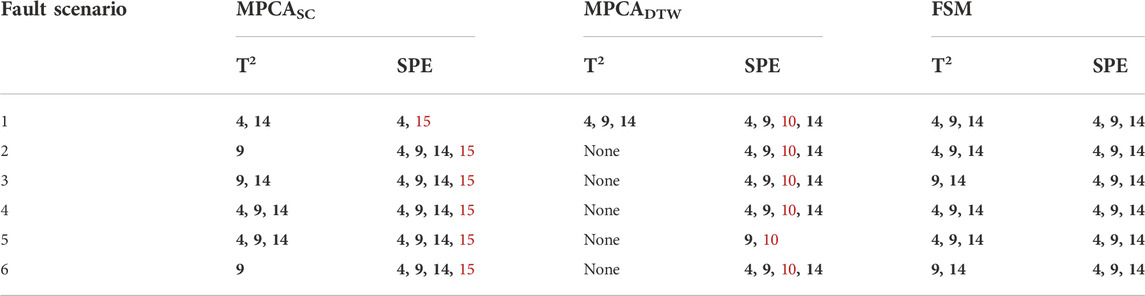
TABLE 4. Details of the fault detection results by T2 and SPE. Correctly detected cycles are in bold black. Incorrectly detected cycles are in red.
To provide additional details on the performance of different methods, we visualized some fault detection results. Due to limited space, only the detection results of fault scenarios one and five in the residual subspace (i.e., using SPE statistic) are visualized in Figures 5, 6 and discussed in detail below. Figure 5 shows that for fault scenario 1, MPCASC has difficulty in detecting Fault 1: missing two out of three faulty cycles. MPCADCW detects all three faulty cycles but also generates a false alarm. Only FSM detects all three faulty cycles without generating false alarms. Figure 6 shows that for fault scenario 5, MPCASC detects all three faulty cycles while generating a false alarm. MPCADCW failed to detect two out of three faulty cycles while generating a false alarm. Again, only FSM successfully detects all faulty cycles without generating false alarms. It is worth noting that FSM results in linear models, which have low risk of overfitting. This is demonstrated in Figure 5C and Figure 6C where the normal test samples have similar SPE values as those of the normal training samples.
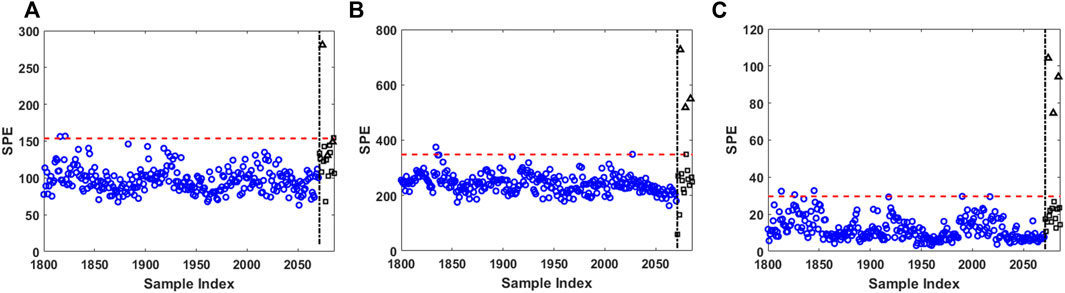
FIGURE 5. Fault scenario 1: fault detection in residual subspace (SPE) from (A) MPCASC (B) MPCADTW and (C) FSM. Blue circles are normal training cycles; black squares are normal testing cycles; black triangles are faulty testing cycles; horizontal red dashed lines are fault detection thresholds; vertical black dash-dotted lines separate training from testing.
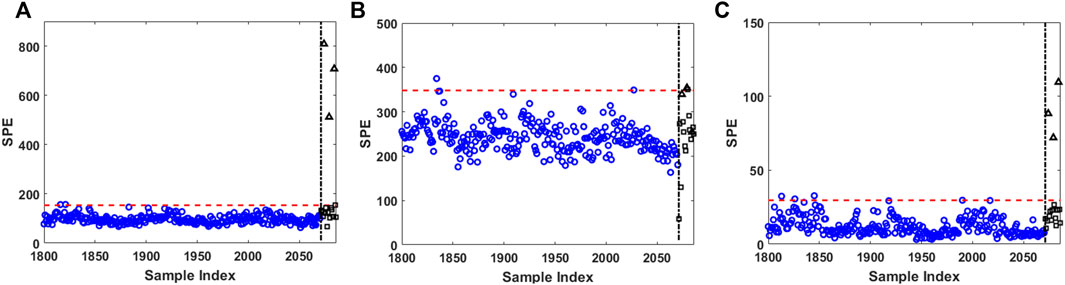
FIGURE 6. Fault scenario 5: fault detection in residual subspace (SPE) from (A) MPCASC (B) MPCADTW and (C) FSM. Blue circles are normal training cycles; black squares are normal testing cycles; black triangles are faulty testing cycles; horizontal red dashed lines are fault detection thresholds; vertical black dash-dotted lines separate training from testing.
We further investigated the false alarms (i.e., cycle 10 for MPCASC and cycle 15 for MPCADTW) to understand why those two cycles generate false alarms. Figure 7 plots the trajectory of all test cycles for the fault scenario 5. All true faulty cycles are plotted in red dashed lines, and all normal test cycles are plotted in black solid lines—except cycle 10 in the cyan dash-dotted line, and cycle 15 in the green dotted line. As described in Table 1, the pressure profiles of the faulty cycles do not follow the normal cycle pressure trajectory during the re-pressurization step (highlighted in the blue dashed-line box). It can be seen that cycles 10 and 15 both behave normally during the re-pressurization step. However, if we zoom in to visualize the pressure profile in other steps (e.g., the insert in Figure 7, which is the zoom-in view of the adsorption step), it can be seen that cycles 10 and 15 are at the lower boundary of all normal cycles, suggesting that the MPCA based approaches may be more sensitive to mean shift. Although the mean shift in this case is within the normal operation range, the cumulative effect (i.e., the persistent small shift that lasts for a period of time) would likely be captured by MPCA as a fault.
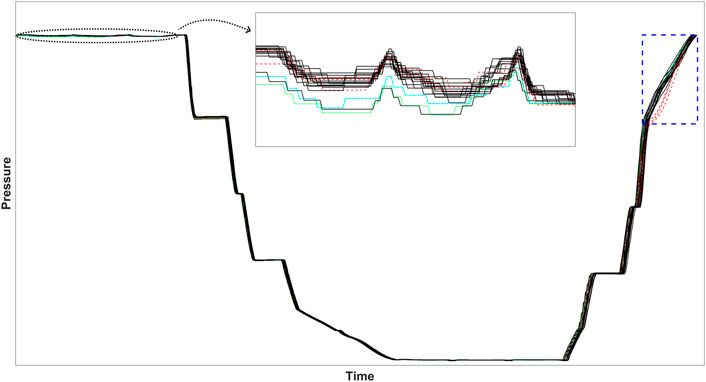
FIGURE 7. The false alarm cycles 10 (in cyan) and 15 (in green) behave normally during the re-pressurization step in which the true fault occurred (highlighted in the blue dashed-line rectangle with faulty cycles plotted as red dashed lines). The zoom-in view of the adsorption step indicates that cycles 10 and 15 are at the lower, but normal, boundary of all cycles.
The normal samples (i.e., cycles) in the test data are industrial data collected from the same PSA process and used for all the fault scenarios. For each faulty cycle, the fault occurred during different steps for different fault scenarios as defined in Table 1. As a result, the false alarms for a specific method across different fault scenarios are the same (e.g., cycle 15 for MPCASC and cycle 10 for MPCADTW) since they are the same normal cycles used in all fault scenarios. Clearly, the value of FAR in Table 1 would be affected by the normal cycles included in the test data. In this study, the normal testing samples were selected randomly to avoid any potential bias.
Further investigation is conducted to understand the reason for MPCADCW’s failure in detecting true faulty cycles under fault scenario 5 (a real fault), for which only one out of three faulty cycles is detected. Since MPCASC is able to detect all faulty cycles, we suspect that the failure is related to data preprocessing by DTW. Therefore, we plot the original pressure profiles of the 16 test cycles, which are shown in Figure 8A and compare them to the pressure profiles after DTW as shown in Figure 8B. A zoom-in view of the faulty step is included for both figures. The comparison clearly indicates that the irregular discrepancies of the faulty cycles shown in the original pressure profiles diminished after trajectory synchronization by DTW. This case suggests that DTW could cause severe information loss or distortion, which in turns affects the fault detection performance. This is consistent with our previous findings that data manipulations during preprocessing, including DTW, could cause information loss or distortion and should be avoided if possible (He and Wang, 2011). This example further raises the alarm that the widely used DTW for batch trajectory warping or alignment in process monitoring applications could potentially be a problematic practice that may lead to missed detections of process faults.
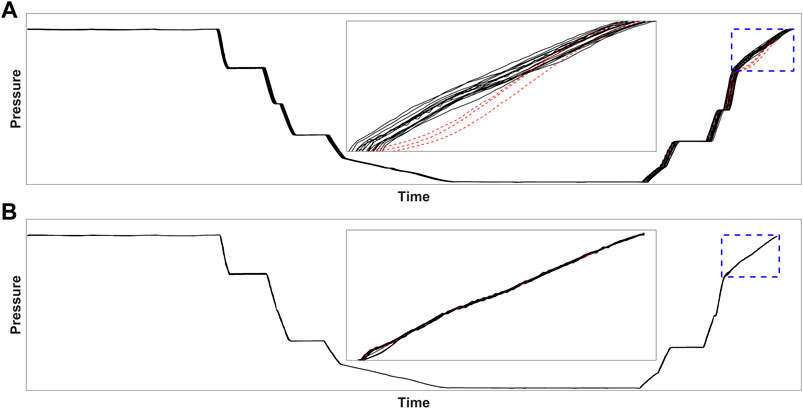
FIGURE 8. Comparison between the pressure profiles of (A) the original 16 test cycles and (B) the test cycles after DTW. The normal testing cycles are plotted in black solid lines while the faulty testing cycles are plotted in red dashed lined. The irregular discrepancies among cycles shown in the original profiles (highlighted in the blue dashed-line rectangles and the zoom-in views) have diminished after DTW, indicating that DTW causes significant information loss or distortion.
After fault detection, fault diagnosis is performed for the detected faulty cycles. For FSM, the procedure outlined in Sec. 4 is followed to construct step-wise and feature-wise contribution plots. For MPCASC and MPCADTW, since pressure is the only measured process variable, only step-wise contribution plot is applicable. Again, we use fault scenarios 1 and 5 as examples. For fault scenario 1, test cycle four is used for illustration as the fault is detected by all methods. For the same reason, test cycle nine is used for fault scenario 5. Figures 9A–C show the step-wise contribution plots for fault diagnosis of test cycle four in fault scenario 1. From Table 1, we know that this is a fault occurring during the adsorption step (i.e., step 1), and the faulty cycles have lower pressure than normal cycles. Figure 9 shows that MPCASC incorrectly attributes this fault to step 10, while MPCADTW and FSM correctly identify the faulty step, with FSM providing the strongest conviction. For FSM, once the faulty step is identified, the faulty step contribution is further broken down to the feature level following the procedure outlined in Sec. 4, as shown in Figure 9D. In this figure, MAE and the mean (
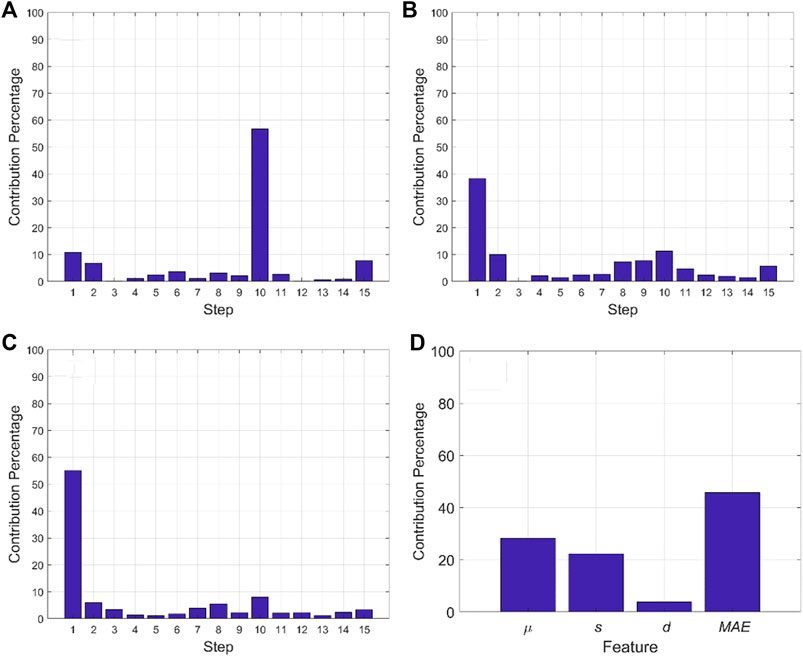
FIGURE 9. Step-wise fault diagnosis for cycle four of fault scenario 1 (A) MPCASC (B) MPCADTW, and (C) FSM, and (D) feature-wise fault diagnosis from FSM. MPCASC wrongly attributes the fault to step 10, while both MPCADTW and FSM correctly attribute the fault to step 1. FSM also shows the clearest diagnosis among all methods. FSM can also further drill down the fault to the feature level where the mean (
The fault diagnosis for cycle nine of fault scenario five is conducted similarly and the results are shown in Figure 10. Here the true fault is a deviation of the pressure profile from the normal trajectories during the last step of the cycle. In this care, both MPCASC and FSM correctly identify the faulty step, while MPCADTW misidentifies the step 10 as the faulty step. FSM also shows the clearest diagnosis among all methods. Feature-wise diagnosis from FSM identifies MAE and the standard deviation (s) as the most significant contributors to the fault, indicating that there could be an increased variation in pressure profile during the last step of the faulty cycle. The misdiagnosis of this fault by MPCADTW can be at least partially attributed to the pressure profile distortion during the DTW preprocessing step as discussed earlier and illustrated in Figure 8.
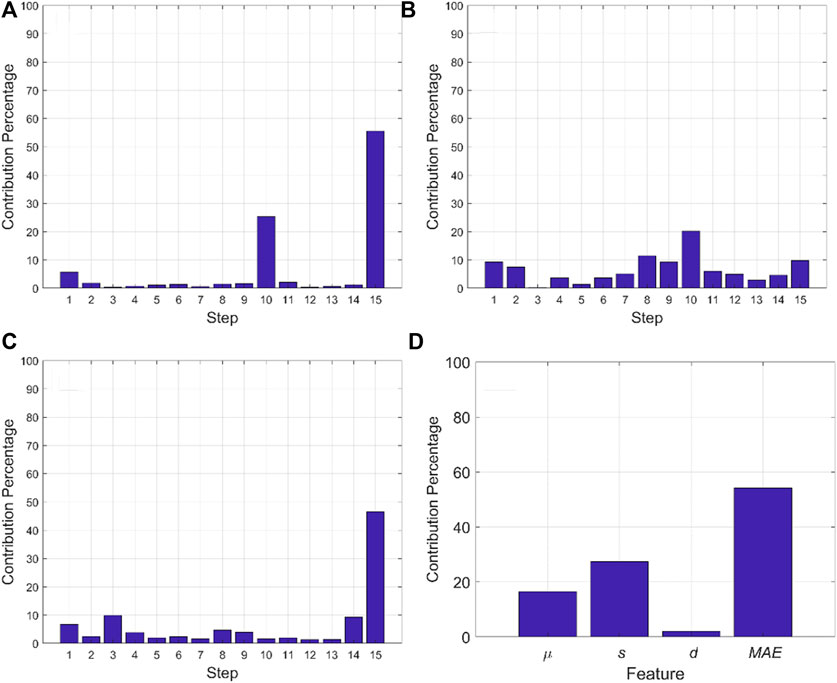
FIGURE 10. Step-wise fault diagnosis for cycle nine of fault scenario 5 (A) MPCASC (B) MPCADTW, and (C) FSM, and (D) feature-wise fault diagnosis from FSM. Both MPCASC and FSM correctly attribute the fault to the last step of the cycle, while MPCADTW wrongly attributes the fault to step 10. FSM also shows the clearest diagnosis among all methods. FSM can also further drill down the fault to the feature level where the standard deviation and MAE are identified as the most significant contributor to the fault, correctly indicating that there is an increased variation in pressure profile during the last step of the faulty cycles.
The overall fault diagnosis results are shown in Table 5. It can be seen that FSM correctly diagnoses all fault scenarios (i.e., correctly identifies all faulty steps). MPCASC has two misdiagnoses (fault scenarios three and 6) and one inconsistent diagnosis from T2 and SPE (fault scenario 1). MPCADTW has two misdiagnoses (fault scenarios five and 6). In addition, FSM provides meaningful diagnoses at the feature level for all fault scenarios.
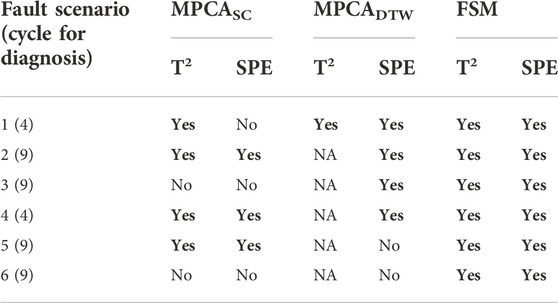
TABLE 5. Details of the fault diagnosis results by T2 and SPE. One faulty cycle detected by all methods is selected for each fault scenario. If the faulty step is correctly identified, it is marked as “Yes”, otherwise marked as “No”. If the faulty cycle is not detected as a fault, its diagnosis is marked as “NA".
In this work, we present a simple yet effective fault detection and diagnosis method, namely feature space monitoring or FSM, for PSA and other cyclic/periodic processes. Different from the conventional MSPM methods, FSM characterizes the normal operation cycle behavior with various statistical and shape/morphological features for each step. FSM naturally handles the challenges in monitoring cyclic processes without any preprocessing steps, which include variable cycle/step duration, wide range of normal cycle/step trajectories, and/or limited measurements—for PSA, bed pressure is often the only measured variable for process monitoring. To be able to detect subtle faults from a wide range of normal cycle trajectories, FSM relies on feature engineering and selection to balance the robustness and sensitivity of the fault detection performance. Finally, through a hierarchical fault diagnosis framework, once a fault is detected, the proposed FSM approach first identifies the step where the fault occurred using a step-wise contribution plot, then postulates the type of fault based on a feature-wise contribution plot.
Using an industrial case study, we demonstrate that FSM outperforms MPCA with simple cut (MPCASC) or dynamic time warping (MPCADTW) in six fault scenarios. Specifically, FSM successfully detected all three faulty cycles in every fault scenario without generating false alarms. In comparison, both MPCASC and MPCADTW had missed detections in some fault scenarios, and both had false alarms in all fault scenarios. In addition, the hierarchical fault diagnosis framework based on FSM correctly identified the faulty steps under all scenarios studied in this work. In comparison, MPCASC and MPCADTW based contribution plots all had misdiagnosis under some fault scenarios. Finally, FSM provides the feature-wise diagnosis capability, which enables a plant engineer to further determine the nature of a fault, such as whether it is a simple mean shift or an increase in variation or a complex fault of both. These fault detection and diagnosis results demonstrate that the FSM-based linear models have a low risk of overfitting and are easy to interpret.
The proposed FSM framework can be applied to other periodic or cyclic processes. In terms of implementation, what FSM features to be included has a big impact on the fault detection and diagnosis performance. In general, the features that should be included for process monitoring depend on the process behavior, and the domain knowledge plays an important role. In addition, depending on the noise level of the process data, it may be necessary to evaluate different versions of the same features that have different degrees of sensitivity to extreme points or outliers. There is usually a trade-off between robustness and sensitivity of the monitoring performance. In this work, the list of features we evaluated were generated based on PSA process behavior and discussions with process engineers. In addition, we proposed an approach to select the relevant features using normal process data only. The variable selection for unsupervised learning was achieved based on the assumption that the truly relevant features should provide consistent monitoring performance, regardless of the training data used. In this work, feature selection was done through a manual search. It is desirable to have a systematic and automated approach for feature engineering and feature selection, which is the area that we are currently working on.
Finally, this work suggested that the widely used DTW for batch trajectory warping or alignment in process monitoring applications could potentially be a problematic practice that may lead to missed fault detections. Specifically, this work demonstrated that DTW could cause severe batch/cycle trajectory distortion, which in turns negatively affected the fault detection performance. Therefore, data preprocessing in process monitoring, including DTW, should be avoided if possible, or conducted with caution and verification if unavoidable.
The datasets presented in this article are not readily available because the sensitivity of the actual operation and production data. Requests to access the datasets should be directed to qhe@auburn.edu.
QH and JW conceived the idea and secured the funding. JL implemented and improved the methodology, conducted data analysis, generated majority of the results, and participated in the manuscript revision; QH supervised and conducted data analysis; QH and JW wrote the initial draft and revised the manuscript; AK and JF provided PSA process knowledge and the process data, critiqued the methodology, reviewed the results, and participated in the manuscript revision. All authors read and approved the final manuscript.
This research is supported by the US National Science Foundation under grant CBET #1805950.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Andersen, C. M., and Bro, R. (2010). Variable selection in regression---a tutorial. J. Chemom. 24 (11–12), 728–737. doi:10.1002/cem.1360
Arslan, E., Neogi, D., Li, X. J., and Misra, P. (2014). Apparatus and methods to monitor and control cyclic process units in a steady plant environment. Washington, DC: U.S. Patent and Trademark Office. U.S. Patent 8,882,883.
Choi, S. W., Lee, C., Lee, J. M., Park, J. H., and Lee, I. B. (2005). Fault detection and identification of nonlinear processes based on kernel PCA. Chemom. Intelligent Laboratory Syst. 75 (1), 55–67. doi:10.1016/j.chemolab.2004.05.001
Dedecker, J., and Rio, E. (2008). On mean central limit theorems for stationary sequences. Ann. Inst. H. Poincare Probab. Stat. 44 (4), 693–726. doi:10.1214/07-aihp117
Elseviers, W., Hassett, P. F., Navarre, J.-L., and Whysall, M. (2015). 50 Years of PSA technology for H2 purification. Des Plaines, IL: Honeywell UOP.
Georgiadis, M. C., and Papageorgiou, L. G. (2000). Optimal energy and cleaning management in heat exchanger networks under fouling. Chem. Eng. Res. Des. 78 (2), 168–179. doi:10.1205/026387600527194
Ghosh, K., Ramteke, M., and Srinivasan, R. (2014). Optimal variable selection for effective statistical process monitoring. Comput. Chem. Eng. 60, 260–276. doi:10.1016/j.compchemeng.2013.09.014
He, F., and Xu, J. (2016). A novel process monitoring and fault detection approach based on statistics locality preserving projections. J. Process Control 37, 46–57. doi:10.1016/j.jprocont.2015.11.004
He, Q. P., and Wang, J. (2007). Fault detection using the k-nearest neighbor rule for semiconductor manufacturing processes. IEEE Trans. Semicond. Manufact. 20 (4), 345–354. doi:10.1109/tsm.2007.907607
He, Q. P., and Wang, J. (2011). Statistics pattern analysis: A new process monitoring framework and its application to semiconductor batch processes. AIChE J. 57 (1), 107–121. doi:10.1002/aic.12247
He, Q. P., and Wang, J. (2018). Statistics pattern analysis: A statistical process monitoring tool for smart manufacturing. Comput. Aided Chem. Eng. 44, 2071–2076. doi:10.1016/B978-0-444-64241-7.50340-2
Hong, H., Jiang, C., Peng, X., and Zhong, W. (2020). Concurrent monitoring strategy for static and dynamic deviations based on selective ensemble learning using slow feature analysis. Ind. Eng. Chem. Res. 59 (10), 4620–4635. doi:10.1021/acs.iecr.9b05547
Jain, V., and Grossmann, I. E. (1998). Cyclic scheduling of continuous parallel-process units with decaying performance. AIChE J. 44 (7), 1623–1636. doi:10.1002/aic.690440714
Lee, J., Flores-Cerrillo, J., Wang, J., and He, Q. P. (2020). Consistency-enhanced evolution for variable selection can identify key chemical information from spectroscopic data. Ind. Eng. Chem. Res. 59 (8), 3446–3457. doi:10.1021/acs.iecr.9b06049
Lindgren, F., Geladi, P., Rännar, S., and Wold, S. (1994). Interactive variable selection (IVS) for PLS. Part 1: Theory and algorithms. J. Chemom. 8 (5), 349–363. doi:10.1002/cem.1180080505
Pan, Y., Yoo, C., Lee, J. H., and Lee, I.-B. (2004). Process monitoring for continuous process with periodic characteristics. J. Chemom. 18 (2), 69–75. doi:10.1002/cem.848
Pène, F. (2005). Rate of convergence in the multidimensional central limit theorem for stationary processes. Application to the Knudsen gas and to the Sinai billiard. Ann. Appl. Probab. 15 (4), 2331–2392. doi:10.1214/105051605000000476
Shang, C., Yang, F., Gao, X., Huang, X., Suykens, J. A. K., and Huang, D. (2015). Concurrent monitoring of operating condition deviations and process dynamics anomalies with slow feature analysis. AIChE J. 61 (11), 3666–3682. doi:10.1002/aic.14888
Wang, J., and He, Q. P. (2010). Multivariate statistical process monitoring based on statistics pattern analysis. Ind. Eng. Chem. Res. 49 (17), 7858–7869. doi:10.1021/ie901911p
Wang, K., Chang, P., and Meng, F. (2021). “Monitoring of wastewater treatment process based on slow feature analysis variational autoencoder,” in 2021 IEEE 10th Data Driven Control and Learning Systems Conference (DDCLS), Suzhou, China, 14-16 May 2021, 495–502.
Wang, R., Edgar, T. F., and Baldea, M. (2017). A geometric framework for monitoring and fault detection for periodic processes. AIChE J. 63 (7), 2719–2730. doi:10.1002/aic.15638
Wang, Z., He, Q. P., and Wang, J. (2015). Comparison of variable selection methods for PLS-based soft sensor modeling. J. Process Control 26, 56–72. doi:10.1016/j.jprocont.2015.01.003
Wise, B. M., Gallagher, N. B., Butler, S. W., White, D. D., and Barna, G. G. (1999). A comparison of principal component analysis, multiway principal component analysis, trilinear decomposition and parallel factor analysis for fault detection in a semiconductor etch process. J. Chemom. 13 (3–4), 379–396. doi:10.1002/(sici)1099-128x(199905/08)13:3/4<379::aid-cem556>3.0.co;2-n
Yang, J., Lv, Z., Shi, H., and Tan, S. (2018). Performance monitoring method based on balanced partial least square and Statistics Pattern Analysis. ISA Trans. 81, 121–131. doi:10.1016/j.isatra.2018.07.038
Yoo, C. K., Lee, J.-M., Vanrolleghem, P. A., and Lee, I.-B. (2004). On-line monitoring of batch processes using multiway independent component analysis. Chemom. Intelligent Laboratory Syst. 71 (2), 151–163. doi:10.1016/j.chemolab.2004.02.002
Zhang, H., Tian, X., Deng, X., and Cao, Y. (2018). Multiphase batch process with transitions monitoring based on global preserving statistics slow feature analysis. Neurocomputing 293, 64–86. doi:10.1016/j.neucom.2018.02.091
Zhao, C., and Huang, B. (2018). A full-condition monitoring method for nonstationary dynamic chemical processes with cointegration and slow feature analysis. AIChE J. 64 (5), 1662–1681. doi:10.1002/aic.16048
Keywords: pressure swing adsorption (PSA), fault detection, fault diagnosis, statistical process monitoring (SPM), statistics pattern analysis, feature space monitoring
Citation: Lee J, Kumar A, Flores-Cerrillo J, Wang J and He QP (2022) Feature-based statistical process monitoring for pressure swing adsorption processes. Front. Chem. Eng. 4:1064221. doi: 10.3389/fceng.2022.1064221
Received: 08 October 2022; Accepted: 07 November 2022;
Published: 18 November 2022.
Edited by:
Fengqi You, Cornell University, United StatesReviewed by:
Brenno Menezes, Hamad bin Khalifa University, QatarCopyright © 2022 Lee, Kumar, Flores-Cerrillo, Wang and He. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Q. Peter He, cWhlQGF1YnVybi5lZHU=; Jin Wang, d2FuZ0BhdWJ1cm4uZWR1
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.