 Jiong Zhang
Jiong Zhang Dengfeng Sha1,3†
Dengfeng Sha1,3† Yuhui Ma
Yuhui Ma Xiayu Xu
Xiayu Xu Quanyong Yi
Quanyong Yi Yitian Zhao
Yitian Zhao
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Cell Dev. Biol. , 05 May 2023
Sec. Molecular and Cellular Pathology
Volume 11 - 2023 | https://doi.org/10.3389/fcell.2023.1181305
This article is part of the Research Topic Artificial Intelligence Applications in Chronic Ocular Diseases View all 31 articles
Background: Ultra-Wide-Field (UWF) fundus imaging is an essential diagnostic tool for identifying ophthalmologic diseases, as it captures detailed retinal structures within a wider field of view (FOV). However, the presence of eyelashes along the edge of the eyelids can cast shadows and obscure the view of fundus imaging, which hinders reliable interpretation and subsequent screening of fundus diseases. Despite its limitations, there are currently no effective methods or datasets available for removing eyelash artifacts from UWF fundus images. This research aims to develop an effective approach for eyelash artifact removal and thus improve the visual quality of UWF fundus images for accurate analysis and diagnosis.
Methods: To address this issue, we first constructed two UWF fundus datasets: the paired synthetic eyelashes (PSE) dataset and the unpaired real eyelashes (uPRE) dataset. Then we proposed a deep learning architecture called Joint Conditional Generative Adversarial Networks (JcGAN) to remove eyelash artifacts from UWF fundus images. JcGAN employs a shared generator with two discriminators for joint learning of both real and synthetic eyelash artifacts. Furthermore, we designed a background refinement module that refines background information and is trained with the generator in an end-to-end manner.
Results: Experimental results on both PSE and uPRE datasets demonstrate the superiority of the proposed JcGAN over several state-of-the-art deep learning approaches. Compared with the best existing method, JcGAN improves PSNR and SSIM by 4.82% and 0.23%, respectively. In addition, we also verified that eyelash artifact removal via JcGAN could significantly improve vessel segmentation performance in UWF fundus images. Assessment via vessel segmentation illustrates that the sensitivity, Dice coefficient and area under curve (AUC) of ResU-Net have respectively increased by 3.64%, 1.54%, and 1.43% after eyelash artifact removal using JcGAN.
Conclusion: The proposed JcGAN effectively removes eyelash artifacts in UWF images, resulting in improved visibility of retinal vessels. Our method can facilitate better processing and analysis of retinal vessels and has the potential to improve diagnostic outcomes.
Ultra-Wide-Field (UWF) fundus images are a new type of retinal colour fundus image with ultra wide angle characteristics, which can cover 200° Patel et al. (2020) of the retinal fundus in a single image. It has significant advantages over conventional colour fundus images in screening and detecting retina-related diseases such as diabetic retinopathy. However, the imaging characteristics of UWF fundus images often lead to problems with eyelash artefacts in UWF fundus images. As shown in Figure 1, eyelash artefacts obscure the site of the lesion and some of the blood vessels, making it difficult to clearly distinguish key information. In the diagnosis of clinical disease, eyelash artefacts are a serious problem in terms of image quality and pose a significant diagnostic challenge to physicians Kornberg et al. (2016); Ajlan et al. (2020).
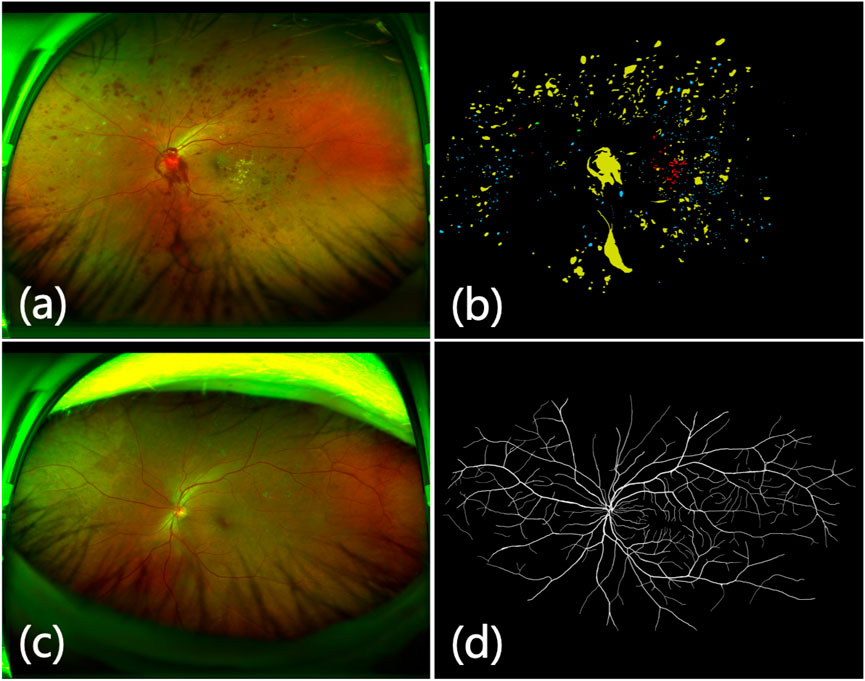
FIGURE 1. Detailed illustration of eyelash artifacts obscuring lesions and blood vessels. (A) The eyelash artifact obscures the lesion information. (B) Ground truth of the lesion in (A). (C) The eyelash artifact obscures the vessel information. (D) Ground truth of the vessel in (C)
To reduce the effect of eyelash artifacts, some physical methods are often applied to the UWF imaging acquisition. These methods include manually pulling up the eyelid, retracting eyelashes via cotton bud Cheng et al. (2008), holding down eyelashes via disposable eyelid speculum (EzSpec) Inoue et al. (2013) and expanding eyelids with the eyelid clamper Ozawa et al. (2020), etc. Although these methods can reduce the appearance of eyelash artifacts to a certain extent, they are not able to completely solve the problem of eyelash artifacts, and these methods bring new challenges during surgical inspections Inoue et al. (2013). Therefore, eyelash artifact has always plagued doctors as a problem with the interpretation of UWF images. In recent years, researchers have found that eyelash artifact is a serious interference problem in the study of UWF images such as lesion detection and blood vessel segmentation Yoo et al. (2020); Li et al. (2020, 2019), as shown in Figure 1. Given the adverse effects of eyelash artifacts on both clinical diagnosis and computer vision tasks, it is necessary to develop an automatic and effective method for removing eyelash artifacts from UWF images.
To the best of our knowledge, there is no automatic algorithm that has been proposed for eyelash artifact removal of UWF images. The main reason is that it is difficult to obtain corresponding image pairs eyelashes/eyelashes-free, and super-sized images are very important for model design and training strategy is no small challenge. At present, the task of removing shadow occlusion Fan et al. (2019) in natural image processing is similar to the task of removing eyelash artifacts in UWF images, both of which are dedicated to removing occlusion artifacts and recovering occluded information Chen et al. (2021). However, compared with natural images, it is more difficult to remove eyelash artifacts in UWF images Matsui et al. (2019). For example, the features of eyelash artifacts are complex and diverse, with large differences, and the structures of blood vessels and lesions are relatively small. Hence, the difficulties of fully automatic UWF image eyelash removal methods: On the one hand, relying on an image acquisition process like natural images, it is impossible to obtain paired UWF images (i.e., images with eyelashes and corresponding eyelash-free labels) for supervised learning. On the other hand, eyelash artifacts in UWF images are usually highly complex and diverse, which makes it difficult to preserve some fine structures such as blood vessels/lesions in the eyelash artifact area for further analysis. Most of the UWF images currently available contain eyelashes, only a small part contains no eyelashes at all and a few contain few eyelashes, and there are no matching image pairs of eyelashes/eyelashes-free at all. Secondly, when designing the model, it is necessary to take into account the removal of eyelashes and the recovery of the information occluded by the eyelashes Mackenzie et al. (2007), and what method to use for training large-size images is also a problem that needs to be considered.
In response to the problems raised above, this paper proposes a Joint Conditional Generative Adversarial Network (JcGAN) to remove eyelash artifacts from UWF images and constructs to two UWF image datasets: synthetic eyelashes (SEL) and real eyelashes (REL). The joint conditional generative adversarial network (See Figure 2) adopts the combination of conditional adversarial network and adversarial network and uses two sets of data sets as input to train the same generator, which not only trains the generator to remove synthetic eyelashes but also trains the generator to remove real eyelashes ability. Connect a background refinement module after the generator to ensure background integrity.
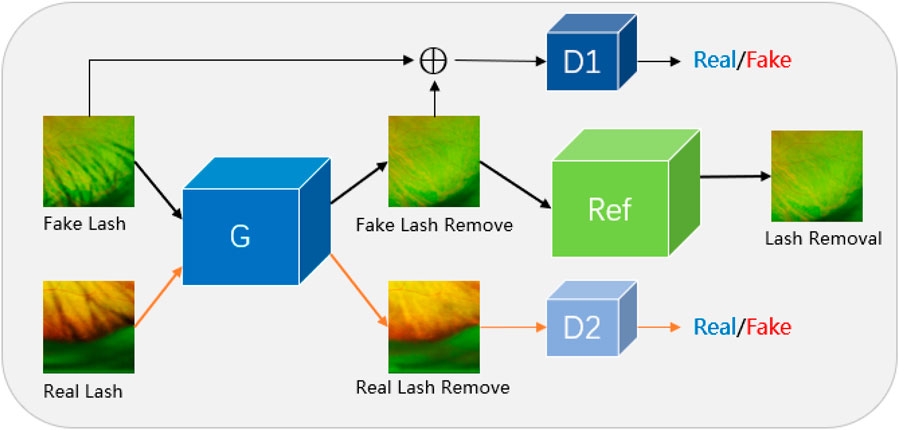
FIGURE 2. We propose Joint Conditional Generative Adversarial Networks (JcGAN) for eyelash artifact removal from UWF images. The network includes a generator G, two discriminators D1 and D2 and a background refinement module called Ref. The generator G and the discriminator D1 form a conditional generative adversarial network that takes the synthetic eyelashes (SEL) dataset as input. The generator G and the discriminator D2 form a generative adversarial network that takes the real eyelashes (REL) dataset as input.
The proposed method extends considerably our previous work Sha et al. (2022), which was trained only on the paired samples with synthetic eyelash artifacts generated from the proposed Eyelash Growing Model. In this work, we first extended our synthetic dataset in a manner contrary to Eyelash Growing Model, where paired samples were obtained by manually erasing eyelash artifacts from real UWF images. Secondly, we have collected an unpaired dataset, which consists of real UWF images with and without eyelash artifacts. In order to fully utilize the unpaired samples and thus further enhance the generalization performance on real UWF images with eyelash artifacts, we have also improved the architecture by introducing one additional discriminator into the generative adversarial network, which shares the generator with the original one. Different from the original discriminator, the additional discriminator aims at distinguishing between real samples without eyelash artifacts and the ones generated from real samples with eyelash artifacts. To this end, the additional discriminator could constrain the generator to improve the performance of eyelash artifact removal on the real UWF images. Overall, the contributions of our work can be summarized as follows:
• For the first time in the UWF fundus imaging field, we construct two datasets for eyelash artifact removal, which respectively consist of paired images with/without synthetic eyelash artifacts and unpaired images with/without real eyelash artifacts.
• We develop a deep learning architecture called Joint conditional Generative Adversarial Networks (JcGAN), which adopts one shared generator with two discriminators for jointly removing real and synthetic eyelash artifacts and utilizes a background refinement module to refine background information.
• We apply the proposed JcGAN on the datasets for eyelash artifact removal. Both quantitative and qualitative results demonstrate the superiority of the proposed JcGAN in eliminating eyelash artifacts and its performance gains to the vessel segmentation task.
Generative Adversarial Network (GAN) was first proposed by Ian Goodfellow Goodfellow et al. (2014). It is a framework for estimating generative models through an adversarial process, including a generative model G that captures data distribution and a discriminant model D that estimates the probability that samples come from training data rather than G-generated data. The training goal of generative model G is to generate images similar to the target domain to greatly increase the error probability of discriminant model D, while the training goal of discriminant model D is to greatly reduce the probability of discriminatory errors. A minimax game process is the so-called generative confrontation. The generative adversarial model is only a mapping from the source domain to the target domain, and cannot specify a fixed target, which is caused by the lack of target guidance. Conditional generative adversarial network (CGAN) Mirza and Osindero (2014) is to add prior conditions to both the generator and the discriminator based on the generative adversarial network, so that a conditional model is formed into the guidance of additional conditions. This extra condition is diverse, it can be class labels or other patterns of data, guided by the extra condition, we can generate a fixed single target for the generator.
Since the availability of UWF images, the range of fundus examinations has been greatly improved and the efficiency of fundus screening has been increased, providing an efficient method of screening for a wide range of eye diseases. However, the existence of eyelash artifacts has increased the difficulty of automatic UWF image examination. At present, methods of removing eyelash artifacts from UWF images are limited to physical avoidance methods of the shooting process. Inoue et al. (2013) have invented a disposable eyelid mirror (EzSpec), a flexible translucent speculum that keeps the eye open to misalignment and covers a wider eyelash area, but the use process requires topical anesthesia, which is expensive and not universal. Ozawa et al. (2020) invented an eyelid clamp to circumvent the problem of eyelash artifacts during UWF images to capture. It is a face-worn tool that keeps the eyes open by applying pressure in the eyelid area, but the avoidance effect of eyelash artifacts is not obvious. In addition, there are some small ways to avoid eyelashes in the process of taking UWF images, such as using tape to stick eyelashes, using cotton swabs to converge eyelashes, or pulling up eyelashes directly by hand, etc. However, these methods The effect of avoiding eyelashes is not obvious, and it is not easy to operate and control. Therefore, the problem of eyelash artifacts in UWF images has always been a disturbing factor of UWF images.
The problem of eyelash artifact occlusion in UWF images is similar to the problem of shadow removal of natural images. However, the automatic algorithm for eyelash artifact removal of UWF images has not been studied before, while the automatic removal algorithms for the task of natural image shadow removal have been extensively explored. In general, image shadow removal algorithms can be divided into traditional methods and deep learning based methods. The traditional methods were developed based on image gradient Finlayson et al. (2005); Gryka et al. (2015), lighting information Yang et al. (2012); Zhang et al. (2015), and region attributes Guo et al. (2012). Deep learning based methods mainly include supervised learning models Zhang et al. (2019); Liu et al. (2020) and unsupervised learning models Hu et al. (2019b).
Previous methods remove shadows by modeling the image as a combination of shadow and shadow-free components Arbel and Hel-Or (2010); Finlayson et al. (2009, 2002), or by shifting colors from shadow-free to shadow regions Shor and Lischinski (2008); Wu and Tang (2005); Xiao et al. (2013). Due to the limitations of the underlying models in those methods, they are usually unable to handle shadows in complex real-world scenes Khan et al. (2015). Following that, researchers explored statistical modeling methods to discover and remove shadows using features such as intensity Gong and Cosker (2014), color Guo et al. (2012), texture Khan et al. (2014), and gradient Finlayson et al. (2005); Gryka et al. (2015). However, these handcrafted features are hard to represent the complex features of shadows. Therefore, Khan et al. (2015) propose a method of using a convolutional neural network (CNN) to detect shadows and then using a Bayesian model to remove shadows. Qu et al. (2017) develop three sub-networks to extract features of multiple views separately, and embedded all sub-networks into a complete framework for shadow removal. Wang et al. (2018) used one conditional generative adversarial network (CGAN) to detect shadows and another CGAN to remove shadows. Hu et al. (2019a) explore orientation-aware spatial context methods to detect and remove shadows. However, these methods are trained in paired images, which are limited by paired datasets. To get rid of the dependence on paired data, Hu et al. (2019b) propose a Mask Shadow GAN framework based on Cycle GAN Zhu et al. (2017), which utilizes unpaired data to learn the mapping from unshadowed domains to shadowed domains and vice versa Of course. Later Liu et al. (2021) develop the LG Shadow Net framework to improve the Mask Shadow GAN Hu et al. (2019b) by introducing a brightness-guided strategy that uses the learned brightness features to guide the learning of shadow removal.
To the best of our knowledge, there is no research using deep learning methods for eyelash artifact removal of UWF images. Also, there is no publicly available dataset on eyelash artifacts in UWF images. This paper constructs two new datasets of eyelash artifacts in UWF images. The first is the paired synthetic eyelashes (PSE) dataset and the second are the unpaired real eyelashes (uPRE) dataset. Table 1 presents the details of the two datasets. All data used in this paper were collected from the affiliated Ningbo Eye Hospital of Wenzhou Medical University and Ningbo People’s Hospital at Ningbo, China. The acquisition device was an Optos fundus camera (Optos PLC, Dunfermline, Scotland). Prior to examination, written informed consents were obtained from subjects in accordance to the tenets of Declaration of Helsinki. The PSE dataset consists of 7025 pairs of eyelash and eyelash-free images with a size of 1024 × 1024, where the eyelashes are from the eyelash growing model Sha et al. (2022). We used 5975 pairs of images as the training set and 1050 pairs of images as the test set. The uPRE dataset includes 3687 each of eyelash images and eyelash-free images with a size of 1024 × 1024, where the eyelashes are from the patients themselves. We used 3037 pairs of images as the training set and 650 pairs of images as the test set.
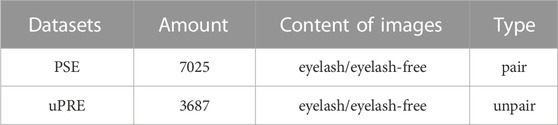
TABLE 1. Details of the two datasets PSE and uPRE.
In practice, it is difficult to obtain paired eyelash/eyelash-free UWF images by controlling the eyelash variables during image acquisition, as is in the case of ISTD Wang et al. (2018). Previously, we proposed an eyelash growing model in the DelashNet Sha et al. (2022) method to solve the above problem. Since the lash removal performance can be easily affected by the reliability of the eyelash growing model, we additionally set up more realistic data pairs into the training set to better guide the model. To this end, we respectively adopted forward and reverse synthesis methods to generate the pairwise dataset for eyelash artifact removal. For the forward synthesis method, the eyelash growing model was developed to simulate eyelash features and generate synthetic eyelashes, followed by a fusion procedure to combine eyelash-free UWF images. For the reverse synthesis method, Photoshop is used to manually erase eyelash artifacts from UWF images and thus generate eyelash-free images. The forward synthesis method fails to simulate the complicated characteristics of eyelash artifacts, thus hinders the model’s capability of identifying and eliminating real eyelash artifacts. Conversely, the reverse synthesis method preserves the authenticity of the eyelash artifacts, but this process may distort the background. The paired data generated in the above two ways construct the Paired Synthetic Eyelashes (PSE) Dataset in this work.
A UWF image contains both eyelash information and eyelash-free information. Therefore, UWF image patches with eyelashes and without eyelashes can be separately obtained by cropping the entire image. We cropped the large size (3900 × 3072) UWF images into several small-size patches for training. The cropped patch size is also an important issue that needs to be considered. If the size is too small, less global information can be preserved. While if the size is too large, it will be impossible to achieve high computational efficiency. Therefore, we finally use patch size of 1024 × 1024 for data training. Although the data with eyelashes and without eyelashes are not completely matched, the construction basis of this real data set is still of great significance to our follow-up model design.
In this section, we introduce the proposed architecture called JcGAN, for eyelash artifact removal in UWF fundus images. The overall framework of JcGAN is illustrated in Figure 3. It adopts one shared generator with two discriminators and learns to translate those images with eyelash artifacts into artifact-free ones via adversarial training jointly with paired and unpaired samples. JcGAN also introduce an additional background refinement module into an end-to-end process, in order to further restore background information obscured by eyelash artifacts.
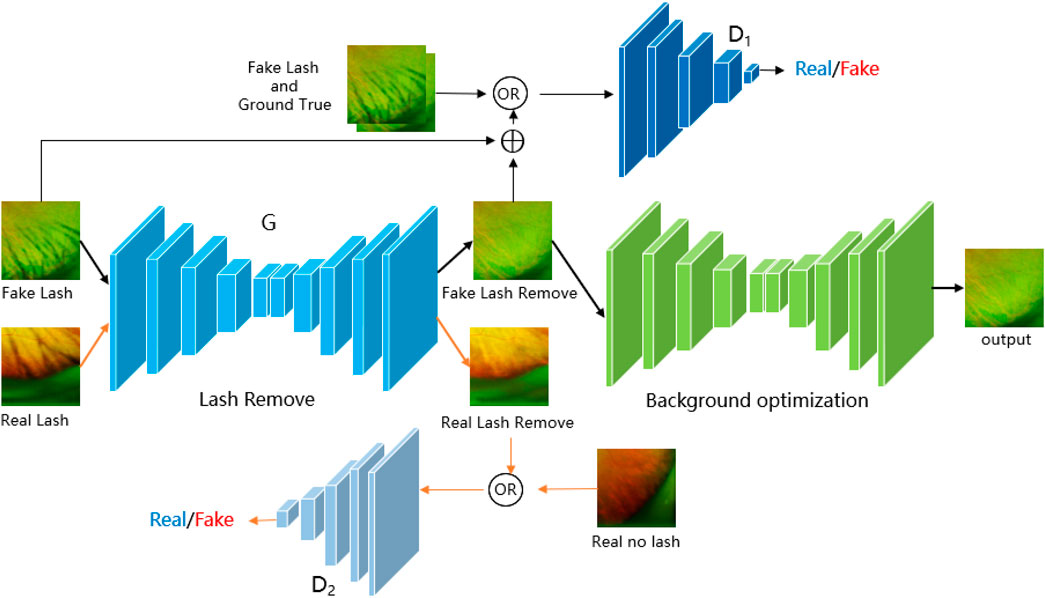
FIGURE 3. Illustration of the architecture of our proposed JcGAN-Net.
Our JcGAN consists of two generative adversarial networks with one shared generator G and an addtional background refinement module (BRM), as shown in Figure 3. The generator G tries to generate the corresponding artifact-free image from the input image with synthetic or real eyelash artifacts, and the discriminator D1 (D2) attempts to distinguish between real artifact-free images and the ones generated from synthetic (real) samples. In order to further restore background details covered by eyelash artifacts, the background refinement module (BRM) is applied to refine the generated results from the generator G via end-to-end training.
Both the generator G and background refinement module (BRM) adopts the same U-shape structure, which contains eight encoder-decoder layers with symmetric skip connections Ronneberger et al. (2015). All encoder layers employ 4 × 4 convolution with stride 2 followed by Batch Normalization (BN) and Leaky ReLU, except the last encoder layer with ReLU instead and no BN. For the first seven decoder layers, we utilize 4 × 4 transposed convolution with stride 2 followed by BN and ReLU. The last decoder layer also removes BN and outputs the final result through Tanh function.
For both discriminators D1 and D2, we construct a network with five 4 × 4 convolutional layers, where stride is set to 2 in the first three layers and 1 in the last two layers. BN is used in the 2nd-4th layers. All layers introduce Leaky ReLU except the last layer. Finally, the discriminator network outputs a confidence map via Sigmoid function, where each pixel represents the probability that the corresponding local region of the input image is identified as coming from a real artifact-free sample.
In order to effectively constrain the proposed JcGAN, we employ the joint adversarial training strategy to optimize the architecture end-to-end based on both paired and unpaired samples. Finally, we construct the loss function including conditional adversarial loss, unconditional adversarial loss and refinement loss.
• Conditional adversarial loss For a synthetic pair of corruption/artifact-free samples (xp/yp), the generator G takes xp and random noise vector z as input and attempts to produce the fake result (denoted as G (z, xp)) which is close to yp as possible, while the discriminator D1 attempts to classify between the real pair (xp, yp) and the fake pair (xp, G (z, xp)). Through the competition between G and D1, JcGAN can learn the mapping from corruption images to the corresponding artifact-free ones. Thus the conditional adversarial loss
In addition, we also introduce L1 distance to further minimize the discrepancy between the generated image G (z, xp) and the real artifact-free image yp:
• Unconditional adversarial loss For unpaired corruption/artifact-free samples (xu/yu), the generator G also takes xu as input and attempts to produce the fake result (denoted as G (z, xu)), while the discriminator D2 attempts to identify whether one given image is real or fake artifact-free image. The competition between G and D2 could promote the perceptual quality of generated images from G. Therefore, the unconditional adversarial loss
• Refinement loss In order to constrain background refinement module (denoted as R) to produce refined artifact-free results more precisely, we adopt L1 distance as refinement loss:
Finally, the total loss function of the proposed JcGAN is defined as:
where λ1 and λ2 represent the weighted parameters of L1 distance and refinement loss.
In this section, we describe the experimental setups, including the evaluation metrics, data ablation, module ablation and comparative experiments.
The proposed JcGAN was implemented with PyTorch library, and the experiments were conducted on two NVIDIA GPUs (Tesla V100 with 32 GB). All training images were resized to 1024 × 1024, and a random horizontal flipping was applied for data augmentation. Adam optimization was applied to train the model, with epochs of 200, the initial learning rate of 0.0002 and batch size of 15. The weighted parameters in the final objective function were experimentally set as: λ1 = 100 and λ2 = 10.
We verify the synthesic data and real data separately. For synthesic paired data, the traditional image enhancement Maini and Aggarwal (2010) evaluation criteria are used to calculate PSNR and SSIM Hore and Ziou (2010):
• Peak Signal to Noise Ratio (PSNR);
where MSE Sara et al. (2019) is the mean squared error between the original image and the processed image.
• Structural Similarity (SSIM);
where μx is the mean of x, μy is the mean of y, δx is the variance of x, δy is the variance of y, and δxy is the covariance of x and y.
• Equivalent numbers of looks (ENL) Vespe and Greidanus (2012);
where μ is the mean of the local area of the image, δ is the variance of the local area of the image. ENL is commonly used to measure the speckle suppression of different SAR/OCT image filters. When the ENL value is bigger, it indicates the image is smoothed well.
• Resunet was used to train a vessel segmentation network, which was indirectly validated by the effect on vessel segmentation performance before and after eyelash artifact removal.
As mentioned above, two datasets including PSE and uPRE are used for evaluation. The PSE dataset consists of two parts, PSE part 1 (PSE1) from the eyelash growing model and PSE part 2 (PSE2) from manual erasure. PSE1 is characterized by the fact that the synthetic eyelashes can only approximate the key information of the real eyelashes to some extent, but cannot completely model the real eyelashes. PSE2 is used to compensate PSE1 by including paired eyelash information from realstic UWF images. To verify the effectiveness of the two data generation approaches, we conduct the data ablation experiments as follows. We designed three experiments to verify the performance of the three dataset combinations respectively. (i) The combination of PSE1 dataset and uPRE dataset. (ii) The combination of PSE2 dataset and uPRE dataset. (iii) The combination of PSE dataset and uPRE dataset.
We used the data of the above three combinations to train three models. For each model, we also tested the three sets of data: PSE1, PSE2 and PSE. Therefore, in the experiment of data ablation, we have completed a total of 3 × 3 data testing. Table 2 shows the values of the PSNR and SSIM of the 3 × 3 groups. The results show that the training method using the third data combination achieves the best results. The results show that the model trained on the PSE + uPRE data achieves the best results. First of all, the PSE1 does not simulate all the information of real eyelashes. Adding the PSE2 reduce the effects of lacking of synthetic eyelashes. Second, the ground truth from PSE2 data has limitations with inaccurate backgrounds. Adding accurate ground truth from the PSE1 can compensate this issue in the PSE2. At the same time, we use the uPRE dataset to verify the effects of the three models. As shown in Figure 4, the ENL results of the real data have been improved to a certain extent.
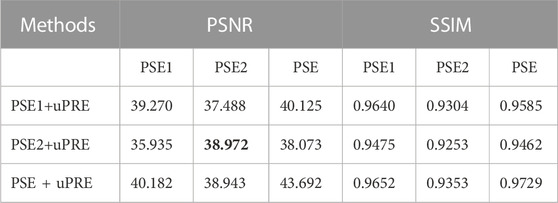
TABLE 2. The values of the PSNR and SSIM tests of our 3×3 groups.
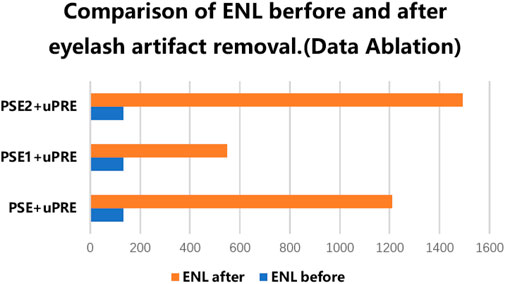
FIGURE 4. Comparison of ENL before and after the real eyelash artifact removal, where the blue bar represents the ENL value of the eyelash artifact area before eyelash artifact removal, and the orange bar represents the ENL value of the same area after eyelash artifact removal.
As shown in Figure 4, all three different data resulted in improved ENL after eyelash removal, among which the combination of PSE2+uPRE achieved the largest improvement, and the combination of PSE + uPRE achieved the second rank. For the test results of synthetic eyelashes data, the combination of PSE + uPRE achieved the best results, which met our expectations. While for the test results of the real eyelash data, the combination of PSE + uPRE has not achieved the best results in the test of real eyelash data. We know that ENL only calculates the local area of eyelash artifact. Therefore, in order to fully verify the performance of these three sets of data, it is necessary to compare them in a larger area.
Figure 5 shows the test results on three sets of training data. From the figure, we can see that the results of the PSE + uPRE training data are significantly better than the results of the other two groups. It removes most of the artifacts and preserves the background much better. Thus, we take the PSE1+PSE2 data as the final PSE dataset.
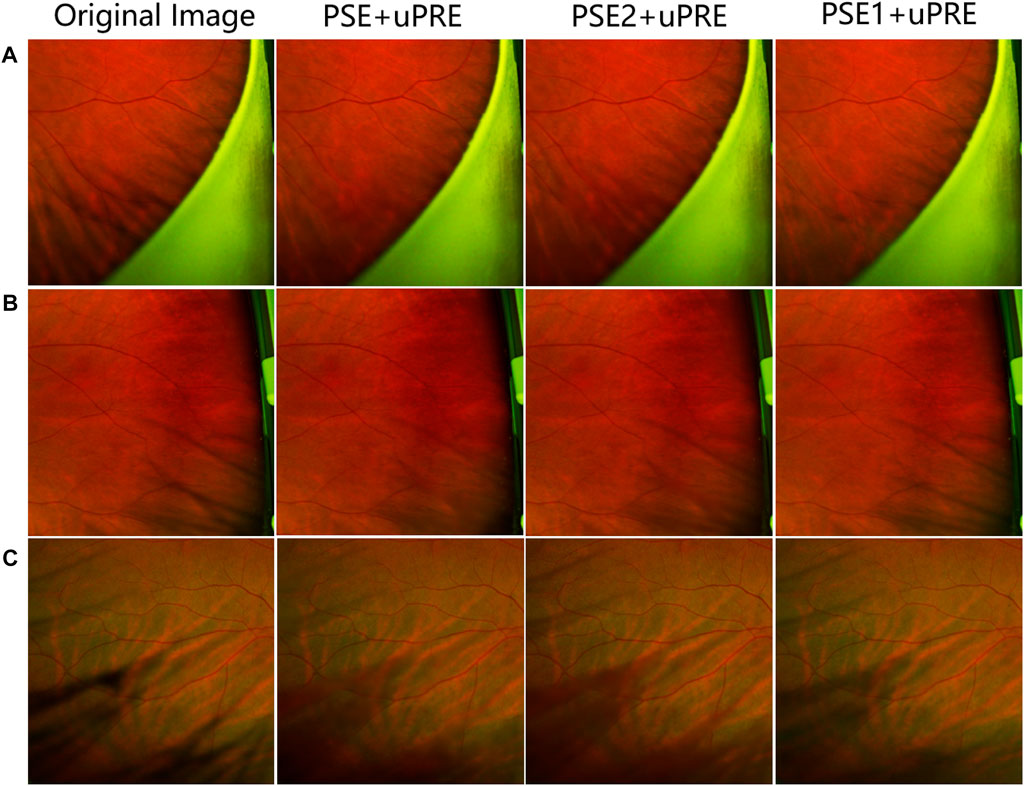
FIGURE 5. Visual representation of a data ablation experiment.(A–C) represent three different pictures, the first column shows the original picture, the second column shows the test results of PSE + uPRE training, and the third column shows the test results of PSE2 + uPRE training, the fourth column shows the test results of the PSE1 + uPRE training.
The JcGAN proposed in this paper includes three sub-nets: a conditional generative adversarial Mirza and Osindero (2014) sub-net (cGAN-sub) composed of generator G and discriminator D1, a generative adversarial Goodfellow et al. (2014) sub-net (GAN-sub) composed of generator G and discriminator D2, and a background refinement sub-net (Ref-sub). To verify the contributions of each sub-net to the overall JcGAN network, we design module ablation experiments as follows.
According to the combination of different sub-net, we conduct a total of four module ablation experiments. 1) The conditional generative adversarial sub-net (cGAN-sub) is used as the baseline of the JcGAN network framework. Hence, we first design experiments to train the conditional generative adversarial sub-net to verify the effectiveness of the baseline module. 2) Based on the conditional generative adversarial sub-net (cGAN-sub), we separately add the background refinement sub-net (Ref-sub) to verify the utility of the background refinement sub-net on model performance. 3) Based on the conditional generative adversarial sub-net (cGAN-sub), we separately add the generative adversarial sub-net (GAN-sub) to verify the utility of the generative adversarial sub-net on model performance. 4) Finally, we add a generative adversarial sub-net (GAN-sub) and a background refinement sub-net (Ref-sub) on the baseline, i.e., our complete JcGAN network framework, to verify the effectiveness of all sub-networks.
After completing the above four experiments, we use the PSE dataset and the uPRE dataset to verify the results respectively. Table 3 shows the PSNR and SSIM values on the PSE dataset.
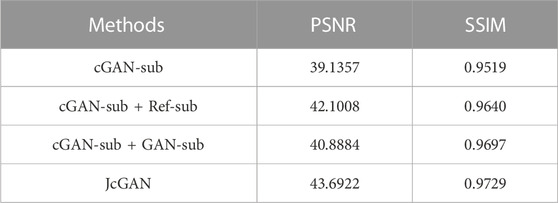
TABLE 3. The values of PSNR and SSIM tested on the PSE dataset for the module ablation experiments.
It is obvious from Table 3 that our method achieves competitive performance on the PSE dataset. The baseline of our model (cGAN-sub) has achieved significant breakthroughs in PSNR and SSIM values. The value of PSNR is as high as 39.1357, which is due to the high resolution Takahashi et al. (2019) of UWF images. Initially, we design Ref-sub as a background refinement sub-network in the overall framework of JcGAN, in order to ensure that the background occluded Audet and Cooperstock (2007) by eyelash artifacts can be fully recovered while eyelash artifacts are removed. Now, after adding Ref-sub on the basis of cGAN-sub, the values of PSNR and SSIM are further improved, which shows that Ref-sub plays an active role. After verifying the effectiveness of cGAN-sub and Ref-sub, we further verify the effectiveness of GAN-sub. Adding GAN-sub on the basis of cGAN-sub means that the joint idea of our JcGAN network is applied. The two datasets train the same generator alternatively so that this generator has the ability to remove synthetic eyelashes and real eyelashes. As shown in the results, our joint strategy achieve competitive performance on the PSE dataset. Finally, the test results of the JcGAN network also show that each sub-network in our whole framework plays an active role, and combining the three sub-networks can produce the best results.
After being evaluated on the PSE Dataset, we also validate our method on the uPRE dataset. We used the local area of eyelash artifact removal to calculate the ENL value. Figure 6 shows the ENL values of the eyelash occluded area before and after eyelash artifact removal.
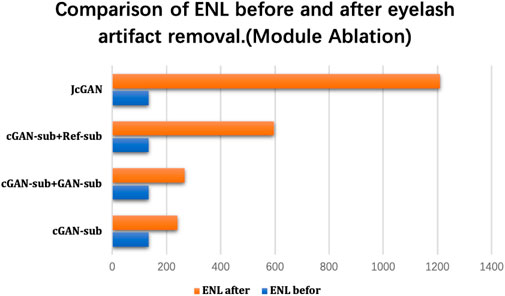
FIGURE 6. Comparison of ENL before and after the real eyelash artifact removal, where the blue bar represents the ENL value of the eyelash artifact area before eyelash artifact removal, and the orange bar represents the ENL value of the same area after eyelash artifact removal.
As shown in Figure 6, the combination of different sub-networks improves the value of ENL. In particular, the addition of the Ref-sub subnet has greatly improved the value of ENL. This shows that our Ref-sub sub-network effectively recovers the background of the eyelash artifact part. The JcGAN network framework improves the value of ENL the most, which also strongly proves that our joint strategy is also successful in the artifact removal of real eyelashes.
To verify the effectiveness of our method, we selected several methods similar to ours for comparative experiments. Currently, no deep learning method has been proposed for artifact removal in ultra-widefield fundus images. Therefore, we selectively choose several classical GAN network related methods Pix2Pix Isola et al. (2017) and cycleGAN Zhu et al. (2017) and some natural image shadow removal methods ST-CGAN Wang et al. (2018) and Mask-ShadowGAN Hu et al. (2019b) as comparison methods in our analysis. We trained the above methods sequentially and tested each method using PSE dataset and uPRE dataset, as shown in Table 4.
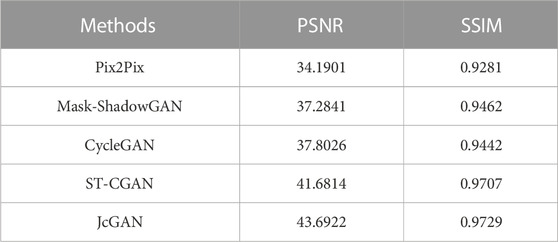
TABLE 4. The values of PSNR and SSIM tested on the PSE Dataset for the comparative experiments.
The results show that our method achieves remarkable performance on the PSE Dataset. Our proposed JcGAN method achieves a high PSNR value of 43.6922 and a SSIM value of 0.9729, the highest among all methods. Compared with the best existing method, JcGAN improves PSNR and SSIM by 4.82% and 0.23%, respectively. At the same time, we compare the visual effects of the PSE Dataset test, and our method also achieves the best results, as shown in Figure 7. From Figure 7 we can see that our method achieves the best results in both eyelash artifact removal and background restoration. Compared with our method, none of the other methods completely remove eyelash artifacts. Among them, ST-CGAN has problems in the process of background recovery, which leads to information loss in the test image. Similarly, we perform the results validation of different methods on the uPRE dataset. We calculated the position ENL value of the local area of the eyelash artifact removal part for different methods. A comparison of ENL value results for different methods on the uPRE Dataset is shown in Figure 8. From Figure 8, we can see that our method JcGAN achieves the largest improvement in ENL value, which shows that our method restores the smooth background in the region removed for eyelash artifacts. Figure 9 shows a visual comparison of the results of different methods on the REL dataset.
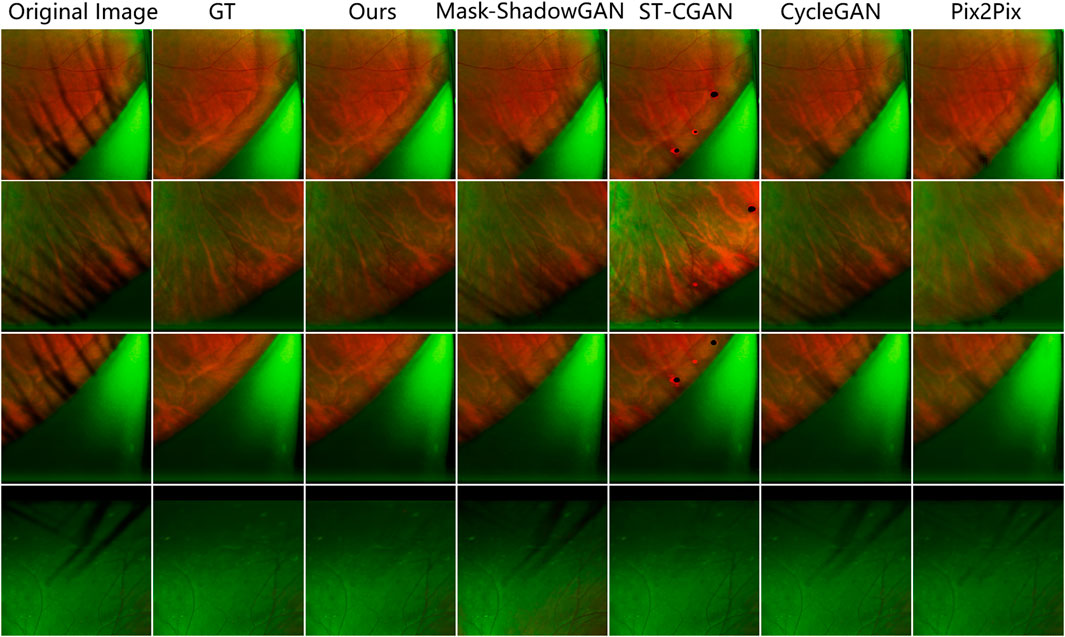
FIGURE 7. Comparison of the results of different methods on the PSE Dataset. Our method removes the most eyelash artifacts and restores the most realistic background information.
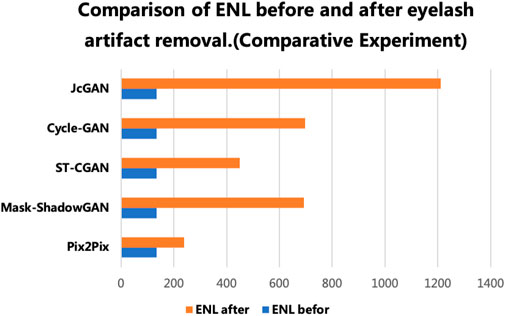
FIGURE 8. Comparison of ENL before and after the real eyelash artifact removal, where the blue bar represents the ENL value of the eyelash artifact area before eyelash artifact removal, and the orange bar represents the ENL value of the same area after eyelash artifact removal.
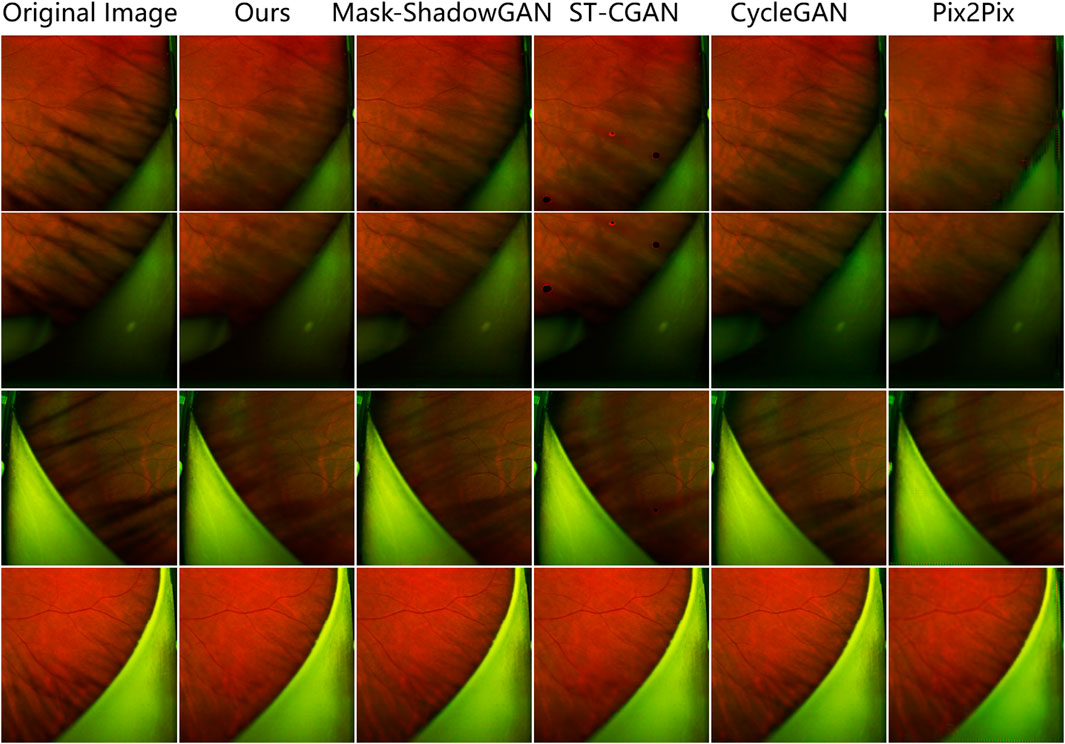
FIGURE 9. Comparison of the results of different methods on the uPRE Dataset. Our method removes the most eyelash artifacts and restores the most realistic background information.
To verify that our proposed eyelash artifact removal algorithm can promote better processing and analysis of retinal vessels, a dedicated experiment for vessel segmentation in UWF images is performed. The corresponding segmentation results are shown in Figure 10, and sensitivity (SEN), Dice and area under curve (AUC) are shown in Table 5. ResU-Net Diakogiannis et al. (2020) is adopted as the segmentation network. 406 eyelash-free images are used to train ResU-Net. For the trained segmentation model, the original image with eyelashes and the image processed by JcGAN are used for testing respectively. Assessment via vessel segmentation illustrates that the SEN, Dice and AUC of ResU-Net have respectively increased by 3.64%, 1.54%, and 1.43% after eyelash artifact removal using JcGAN, as shown in Table 5. As shown in Figure 10; Table 5, the eyelash-removed images have better performance on the vessel segmentation task than the original images. The images processed by our JcGAN network successfully solved the problem that eyelashes were incorrectly segmented as blood vessels, and improved the overall segmentation performance.
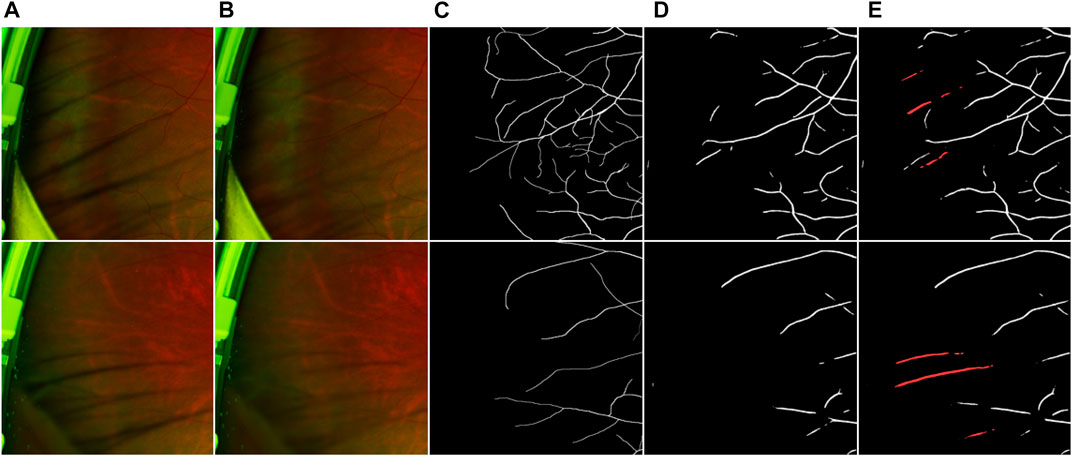
FIGURE 10. Vessel segmentation results. (A) Original image (B) Eyelash Removal image (C) Ground truth (D) The segmentation result of eyelash removal image (E) The segmentation result of original image. The red in (E) represents the wrong segmentation of eyelashes as blood vessels.
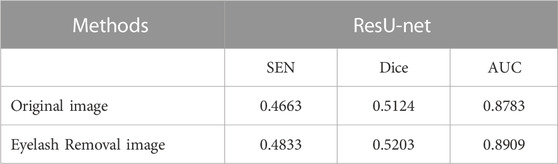
TABLE 5. The results of the eyelashes removal image and the original image on the blood vessel segmentation index.
Artifacts caused by eyelash occlusions hinder high-quality inspection on retinopathy at wide range in UWF fundus images. In this work, we tackle the issue of eyelash artifacts existing in UWF fundus images with deep learning technique for the first time. We firstly collect UWF fundus images and construct two eyelash datasets called paired synthetic eyelashes (PSE) and unpaired real eyelashes (uPRE) respectively. Based on the two datasets, we have proposed a deep learning approach called Joint conditional Generative Adversarial Networks (JcGAN) to eliminate eyelash artifacts in UWF fundus images. The proposed JcGAN could jointly learn the mapping from images with real or synthetic eyelash artifacts to artifact-free ones via two generative adversarial networks with a shared generator. In addition, a background refinement module is trained with the generator in an end-to-end manner to further recover the detailed information of regions corrupted by eyelash artifacts. The experimental results on both PSE and uPRE dataset show that our eyelash artifact removal approach have achieved the best performance. Compared with other deep learning methods, our JcGAN can remove eyelash artifacts more effectively and achieve higher visual effect. Furthermore, JcGAN can significantly facilitate vessel segmentation in UWF fundus images due to the improved visibility of vessels obscured by eyelash artifacts. In the future, we will consider exploring a more appropriate method to construct paired synthetic eyelash samples and introducing prior knowledge of eyelash artifacts into the deep learning model. Furthermore, we will apply our approach to lesion segmentation tasks (e.g., identifying hemorrhages and exudates) as a preprocessing procedure to verify the effectiveness of eyelash artifact removal.
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by the Ethics committee of Cixi Institute of Biomedical Engineering, Ningbo Institute of Materials Technology and Engineering, Chinese Academy of Sciences. The patients/participants provided their written informed consent to participate in this study.
JZ: conceptualization, supervison, writing-original draft, project administration, writing-review and editing; DS: writing-original draft, investigation, validation; YM: methodology, visualization, writing-review and editing; DZ: investigation, writing-review and editing; TT: formal analysis, writing-review and editing; XX: methodology, writing-review and editing; QY: resources, data curation, conceptualization, writing-review and editing; YZ: supervison, project administration, formal analysis, writing-review and editing.
This work was supported in part by the National Natural Science Foundation Program of China under Grants (62103398 and 61906181), in part by the Zhejiang Provincial Natural Science Foundation (LQ23F010002, LZ23F010002, LR22F020008, LZ19F010001, and LQ21F010007), in part by the Ningbo Natural Science Foundation (2022J143, 20221JCGY010608), in part by the Youth Innovation Promotion Association CAS (2021298), the Research Startup Fund of Ningbo University of Technology (2022KQ29), and in part by 2025 S&T Megaprojects (2019B10033, 2019B10061, and 2021Z054).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ajlan, R. S., Barnard, L. R., and Mainster, M. A. (2020). Nonconfocal ultra-widefield scanning laser ophthalmoscopy: Polarization artifacts and diabetic macular edema, 40. Philadelphia, Pa: Retina, 1374.
Arbel, E., and Hel-Or, H. (2010). Shadow removal using intensity surfaces and texture anchor points. IEEE Trans. pattern analysis Mach. Intell. 33, 1202–1216. doi:10.1109/TPAMI.2010.157
Audet, S., and Cooperstock, J. R. (2007). Shadow removal in front projection environments using object tracking. In 2007 IEEE conference on computer vision and pattern recognition, IEEE, 1–8.
Chen, Z., Long, C., Zhang, L., and Xiao, C. (2021). “Canet: A context-aware network for shadow removal,” in Proceedings of the IEEE/CVF international conference on computer vision, 4743–4752.
Cheng, S. C., Yap, M. K., Goldschmidt, E., Swann, P. G., Ng, L. H., and Lam, C. S. (2008). Use of the optomap with lid retraction and its sensitivity and specificity. Clin. Exp. Optometry 91, 373–378. doi:10.1111/j.1444-0938.2007.00231.x
Diakogiannis, F. I., Waldner, F., Caccetta, P., and Wu, C. (2020). Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogrammetry Remote Sens. 162, 94–114. doi:10.1016/j.isprsjprs.2020.01.013
Fan, H., Han, M., and Li, J. (2019). Image shadow removal using end-to-end deep convolutional neural networks. Appl. Sci. 9, 1009. doi:10.3390/app9051009
Finlayson, G. D., Drew, M. S., and Lu, C. (2009). Entropy minimization for shadow removal. Int. J. Comput. Vis. 85, 35–57. doi:10.1007/s11263-009-0243-z
Finlayson, G. D., Hordley, S. D., and Drew, M. S. (2002). “Removing shadows from images,” in European conference on computer vision (Springer), 823–836.
Finlayson, G. D., Hordley, S. D., Lu, C., and Drew, M. S. (2005). On the removal of shadows from images. IEEE Trans. pattern analysis Mach. Intell. 28, 59–68. doi:10.1109/TPAMI.2006.18
Gong, H., and Cosker, D. (2014). “Interactive shadow removal and ground truth for variable scene categories,” in Bmvc (Nottingham, UK: BMVA Press), 1–11.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). Generative adversarial nets. Adv. neural Inf. Process. Syst. 27.
Gryka, M., Terry, M., and Brostow, G. J. (2015). Learning to remove soft shadows. ACM Trans. Graph. (TOG) 34, 1–15. doi:10.1145/2732407
Guo, R., Dai, Q., and Hoiem, D. (2012). Paired regions for shadow detection and removal. IEEE Trans. pattern analysis Mach. Intell. 35, 2956–2967. doi:10.1109/TPAMI.2012.214
Hore, A., and Ziou, D. (2010). “Image quality metrics: Psnr vs. ssim,” in 2010 20th international conference on pattern recognition (IEEE), 2366–2369.
Hu, X., Fu, C.-W., Zhu, L., Qin, J., and Heng, P.-A. (2019a). Direction-aware spatial context features for shadow detection and removal. IEEE Trans. pattern analysis Mach. Intell. 42, 2795–2808. doi:10.1109/TPAMI.2019.2919616
Hu, X., Jiang, Y., Fu, C.-W., and Heng, P.-A. (2019b). “Mask-shadowgan: Learning to remove shadows from unpaired data,” in Proceedings of the IEEE/CVF international conference on computer vision, 2472–2481.
Inoue, M., Yanagawa, A., Yamane, S., Arakawa, A., Kawai, Y., and Kadonosono, K. (2013). Wide-field fundus imaging using the optos optomap and a disposable eyelid speculum. JAMA Ophthalmol. 131, 226. doi:10.1001/jamaophthalmol.2013.750
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2017). “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 1125–1134.
Khan, S. H., Bennamoun, M., Sohel, F., and Togneri, R. (2014). “Automatic feature learning for robust shadow detection,” in 2014 IEEE conference on computer vision and pattern recognition (IEEE), 1939–1946.
Khan, S. H., Bennamoun, M., Sohel, F., and Togneri, R. (2015). Automatic shadow detection and removal from a single image. IEEE Trans. pattern analysis Mach. Intell. 38, 431–446. doi:10.1109/TPAMI.2015.2462355
Kornberg, D. L., Klufas, M. A., Yannuzzi, N. A., Orlin, A., D’Amico, D. J., and Kiss, S. (2016). “Clinical utility of ultra-widefield imaging with the optos optomap compared with indirect ophthalmoscopy in the setting of non-traumatic rhegmatogenous retinal detachment,” in Seminars in ophthalmology (Taylor & Francis), 31, 505–512.
Li, Z., Guo, C., Nie, D., Lin, D., Zhu, Y., Chen, C., et al. (2019). A deep learning system for identifying lattice degeneration and retinal breaks using ultra-widefield fundus images. Ann. Transl. Med. 7, 618. doi:10.21037/atm.2019.11.28
Li, Z., Guo, C., Nie, D., Lin, D., Zhu, Y., Chen, C., et al. (2020). Development and evaluation of a deep learning system for screening retinal hemorrhage based on ultra-widefield fundus images. Transl. Vis. Sci. Technol. 9, 3. doi:10.1167/tvst.9.2.3
Liu, D., Long, C., Zhang, H., Yu, H., Dong, X., and Xiao, C. (2020). “Arshadowgan: Shadow generative adversarial network for augmented reality in single light scenes,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 8139–8148.
Liu, Z., Yin, H., Mi, Y., Pu, M., and Wang, S. (2021). Shadow removal by a lightness-guided network with training on unpaired data. IEEE Trans. Image Process. 30, 1853–1865. doi:10.1109/TIP.2020.3048677
Mackenzie, P. J., Russell, M., Ma, P. E., Isbister, C. M., and Maberley, D. A. (2007). Sensitivity and specificity of the optos optomap for detecting peripheral retinal lesions. Retina 27, 1119–1124. doi:10.1097/IAE.0b013e3180592b5c
Maini, R., and Aggarwal, H. (2010). A comprehensive review of image enhancement techniques. arXiv preprint arXiv:1003.4053.
Matsui, Y., Ichio, A., Sugawara, A., Uchiyama, E., Suimon, H., Matsubara, H., et al. (2019). “Comparisons of effective fields of two ultra-widefield ophthalmoscopes, optos 200tx and clarus 500,” in BioMed research international 2019.
Mirza, M., and Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.
Ozawa, N., Mori, K., Katada, Y., Tsubota, K., and Kurihara, T. (2020). Efficacy of the newly invented eyelid clamper in ultra-widefield fundus imaging. Life 10, 323. doi:10.3390/life10120323
Patel, S. N., Shi, A., Wibbelsman, T. D., and Klufas, M. A. (2020). Ultra-widefield retinal imaging: An update on recent advances. Ther. Adv. Ophthalmol. 12, 2515841419899495. doi:10.1177/2515841419899495
Qu, L., Tian, J., He, S., Tang, Y., and Lau, R. W. (2017). “Deshadownet: A multi-context embedding deep network for shadow removal,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 4067–4075.
Ronneberger, O., Fischer, P., and Brox, T. (2015). “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention (Springer), 234–241.
Sara, U., Akter, M., and Uddin, M. S. (2019). Image quality assessment through fsim, ssim, mse and psnr—A comparative study. J. Comput. Commun. 7, 8–18. doi:10.4236/jcc.2019.73002
Sha, D., Ma, Y., Zhang, D., Zhang, J., and Zhao, Y. (2022). “Delashnet: A deep network for eyelash artifact removal in ultra-wide-field fundus images,” in Proceedings of the 5th international conference on control and computer vision, 107–112.
Shor, Y., and Lischinski, D. (2008). “The shadow meets the mask: Pyramid-based shadow removal,” in Computer graphics forum (Wiley Online Library), 27, 577–586.
Takahashi, H., Tanaka, N., Shinohara, K., Yokoi, T., Yoshida, T., Uramoto, K., et al. (2019). Ultra-widefield optical coherence tomographic imaging of posterior vitreous in eyes with high myopia. Am. J. Ophthalmol. 206, 102–112. doi:10.1016/j.ajo.2019.03.011
Vespe, M., and Greidanus, H. (2012). Sar image quality assessment and indicators for vessel and oil spill detection. IEEE Trans. Geoscience Remote Sens. 50, 4726–4734. doi:10.1109/tgrs.2012.2190293
Wang, J., Li, X., and Yang, J. (2018). “Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 1788–1797.
Wu, T.-P., and Tang, C.-K. (2005). A bayesian approach for shadow extraction from a single image. In Tenth IEEE Int. Conf. Comput. Vis. (ICCV’05) Volume 1 (IEEE), vol. 1, 480–487.
Xiao, C., She, R., Xiao, D., and Ma, K.-L. (2013)., 32. Wiley Online Library, 207–218.Fast shadow removal using adaptive multi-scale illumination transferComput. Graph. Forum
Yang, Q., Tan, K.-H., and Ahuja, N. (2012). Shadow removal using bilateral filtering. IEEE Trans. Image Process. 21, 4361–4368. doi:10.1109/TIP.2012.2208976
Yoo, T. K., Ryu, I. H., Kim, J. K., Lee, I. S., Kim, J. S., Kim, H. K., et al. (2020). Deep learning can generate traditional retinal fundus photographs using ultra-widefield images via generative adversarial networks. Comput. Methods Programs Biomed. 197, 105761. doi:10.1016/j.cmpb.2020.105761
Zhang, L., Zhang, Q., and Xiao, C. (2015). Shadow remover: Image shadow removal based on illumination recovering optimization. IEEE Trans. Image Process. 24, 4623–4636. doi:10.1109/TIP.2015.2465159
Zhang, S., Liang, R., and Wang, M. (2019). Shadowgan: Shadow synthesis for virtual objects with conditional adversarial networks. Comput. Vis. Media 5, 105–115. doi:10.1007/s41095-019-0136-1
Keywords: retina, ultra-wide-field fundus images, artifact removal, conditional GAN, vessel segmentation
Citation: Zhang J, Sha D, Ma Y, Zhang D, Tan T, Xu X, Yi Q and Zhao Y (2023) Joint conditional generative adversarial networks for eyelash artifact removal in ultra-wide-field fundus images. Front. Cell Dev. Biol. 11:1181305. doi: 10.3389/fcell.2023.1181305
Received: 07 March 2023; Accepted: 24 April 2023;
Published: 05 May 2023.
Edited by:
Weihua Yang, Jinan University, ChinaReviewed by:
Xiaodan Sui, Shandong Normal University, ChinaCopyright © 2023 Zhang, Sha, Ma, Zhang, Tan, Xu, Yi and Zhao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Quanyong Yi, cXVhbnlvbmdfX3lpQDE2My5jb20=; Yitian Zhao, eWl0aWFuLnpoYW9AbmltdGUuYWMuY24=
†These authors have contributed equally to this work and share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.