 Furkan Luleci
Furkan Luleci F. Necati Catbas
F. Necati Catbas Onur Avci
Onur Avci- 1Department of Civil, Environmental, and Construction Engineering, University of Central Florida, Orlando, FL, United States
- 2Department of Civil, Construction, and Environmental Engineering, Iowa State University, Ames, IA, United States
Structural Health Monitoring (SHM) has been continuously benefiting from the advancements in the field of data science. Various types of Artificial Intelligence (AI) methods have been utilized to assess and evaluate civil structures. In AI, Machine Learning (ML) and Deep Learning (DL) algorithms require plenty of datasets to train; particularly, the more data DL models are trained with, the better output it yields. Yet, in SHM applications, collecting data from civil structures through sensors is expensive and obtaining useful data (damage associated data) is challenging. In this paper, one-dimensional (1-D) Wasserstein loss Deep Convolutional Generative Adversarial Networks using Gradient Penalty (1-D WDCGAN-GP) is utilized to generate damage-associated vibration datasets that are similar to the input. For the purpose of vibration-based damage diagnostics, a 1-D Deep Convolutional Neural Network (1-D DCNN) is built, trained, and tested on both real and generated datasets. The classification results from the 1-D DCNN on both datasets resulted in being very similar to each other. The presented work in this paper shows that, for the cases of insufficient data in DL or ML-based damage diagnostics, 1-D WDCGAN-GP can successfully generate data for the model to be trained on.
Introduction
During the operational life of civil structures, different types of damages can shorten the remaining useful life of the structures. This is particularly important in today’s world, where catastrophic events are increasing, and they are projected to be frequent in the future. In addition, most civil structures that were built decades ago have already started losing their functionality and capacity. This is especially true for the US, where recent studies show the substandard conditions of existing civil structures. Therefore, it is essential to diagnose the structural damages and subsequently prognose the remaining useful life and, based on that, implement an effective health management plan to improve the life cycle of the structure. Hence, with correct maintenance action items derived from the health management plan, the structural lifetime can be extended, costly structural failures can be avoided, and, more importantly, human lives can be saved.
Brief Review on Structural Damage Diagnostics
In the field of Structural Health Monitoring (SHM), the common practice to assess an existing civil structure is to collect operational data using sensors such as accelerometers, potentiometers, strain gauges, fiber optic sensors, or load cells. Damage identification is performed by monitoring the changes in structural properties like stiffness, mass, and damping in an attempt to detect and locate structural defects such as cracks, delamination, spalling, corrosion, and bolt loosening. In vibration-based applications, acceleration data are predominantly used because it has advantages such as being easy to use and being efficient in data processing (Catbas and Aktan, 2002; Catbas et al., 2006; Das et al., 2016).
Vibration-based structural damage diagnostics can be executed in two ways: 1) local methods where Non-Destructive Testing (NDT) and some camera sensing techniques (IR, DIC, RGB, etc.) are involved, and 2) vibration-based (global) methods where the collected vibration data are analyzed parametrically (using a physical model like FEA software or non-physical model like system identification algorithms to estimate the structure’s physical parameters) or nonparametrically (using statistical approaches on the raw vibration data to find the features and then classify or detect the anomalies in it) (Catbas and Malekzadeh, 2016; Avci et al., 2021). In addition, using advanced computer vision techniques, SHM can be conducted at local and global levels, and then, damage diagnostics can be performed (Dong et al., 2021).
With the goal of diagnosing structural damages in the civil structures, several studies are presented in the SHM field by Krishnan Nair and Kiremidjian (2007), Gul and Catbas (2008), Yin et al. (2009), Gul and Catbas (2011), and Silva et al. (2016). The abovementioned studies are parametrically and nonparametrically conducted vibration-based structural damage diagnostic works. One of the common details in those studies is that the amount of collected data is not influential on the success of the proposed algorithms, unlike the Machine Learning (ML) and Deep Learning (DL) algorithms where they require plenty of data input—particularly, DL algorithms yield exceptionally sound results on as much data as possible (Alom et al., 2019).
With the emergence of ML and DL algorithms, they have been used in SHM due to their high performance on feature extraction, classification, regression, and clustering techniques. Several ML methods including parametric and nonparametric vibration-based damage diagnostic studies are introduced. The Artificial Neural Network (ANN) is observed to be the most used algorithm in an ensemble or integrated with different algorithms, followed by Support Vector Machine (SVM). Some of them are those in the works of Lee et al. (2005), Lee and Kim (2007), González and Zapico (2008), Cury and Crémona (2012), Gul et al. (2014), Bandara et al. (2014), Abdeljaber and Avci (2016), Ghiasi et al. (2016), and Santos et al.(2016). Furthermore, it is essential to note that, apart from parametric-based methods where they rely on system identification techniques to extract the structural parameters, using an ML model for nonparametric-based damage diagnostic requires the usage of feature extraction from the raw data (Catbas and Malekzadeh, 2016) such as Principal Component Analysis or Autoregressive. Thus, this causes computational complexity and time, along with other limitations (Avci et al., 2021). The DL algorithms can learn to extract useful features from the raw data and train on them to make accurate predictions. In short, with a correctly built model and proper training, DL models can show superior performance over ML models. In the civil SHM field, there are few studies, including vibration-based unsupervised DL—mostly Autoencoders (Pathirage et al., 2018; Shang et al., 2021; Rastin et al., 2021), and few supervised DL—mostly Convolutional Neural Networks (Abdeljaber et al., 2017, 2018; Eren, 2017; Avci et al., 2017; Yu et al., 2019).
Motivation and Objective
In civil SHM, data collection is a challenging and expensive task such as getting permission from authorities to install costly and laborious SHM systems, setting up communication networks between sensors and data acquisition systems, requesting traffic closures, and having skilled experts on the field. In addition, obtaining valuable data containing damage-associated features is not always very easy. This is one of the previously mentioned SHM challenges. Considering that only a few civil structures have permanent SHM systems in the world, it is also challenging to know about the damage state of the remaining structures. As such, data scarcity is a challenge in civil SHM. One solution is oversampling the dataset by increasing the copy of the existing dataset. However, this solution does not teach the Artificial Intelligence (AI) models to learn the variation in the damage-associated data but teaches only the provided one to the model and may lead to overfitting. Building an FEA model and analyzing the structure under similar damage scenarios then producing displacement, stress, or acceleration data are another solution to tackle the data scarcity challenge. Yet, this methodology can be inaccurate and possibly unreliable compared to real data from particularly complex structures. In addition, it is implausible that observed damages can be reflected correctly in a model along with accumulated numerical FEA errors (Gardner and Barthorpe, 2019).
As the focus shifted toward ML and DL models for the damage diagnostics of civil structures, the aforementioned data scarcity problem hinders the usage of these algorithms because they require large datasets. The study presented in this paper employs Generative Adversarial Networks (GANs) to generate valuable data to be further used by a Deep Convolutional Neural Network (DCNN) model to perform nonparametric damage diagnostics on the existing data of a steel laboratory structure. Specifically, the presented study investigates vibration-based damage detection with scarce data, where GANs can generate data for the ML or DL model to be trained on and then perform damage identification. The proposed methodology in this paper will pave the way for more AI-based SHM procedures to be performed when the data are scarce.
Background on the GAN
Goodfellow et al. (2014) introduced a novel framework containing two separate networks: (i) a generative model that captures the given random data distribution,
The methodology is used successfully on image-based applications. Yet, training GANs might be the most challenging among the other DL networks. For instance, they are very hard to converge due to finding a unique solution to Nash equilibrium where the optimization process is looking to find a balance between two sides instead of a minimum. GANs often experience large oscillation in loss values of generator and discriminator during the training, making it harder to reach convergence. Another issue is the mode collapse where the generator part produces the same outputs due to learning a feature in the data that can be used to trick the discriminator easily. In addition, intuitively, GANs suffer from the discriminator being powerful over the generator, which causes the generator training to fail due to vanishing gradients; thus, the discriminator does not provide sufficient information for the generator to learn (Goodfellow, 2017; Salimans et al., 2016). There are several “hacks” introduced to alleviate these drawbacks in the DL community and some of them are used in this study as well as discussed in the following sections. Radford et al. (2016) proposed using the DCNN in GANs after their adoption in computer vision applications. In their study, they noticed that, in the training process, DCNN helped the GAN to learn significantly. Yet, Arjovsky et al. (2017) introduced a GAN that uses Wasserstein distance as a loss function (WGAN), which improves the training of GAN. In their network, instead of using a discriminator that estimates the probability of the generated images as being real or fake, they used a critic which scores the output’s realness or fakeness of a given image. Fundamentally, WGAN seeks a minimization of the distance between the generated and the training data distribution. WGAN showed considerable benefits to training the GAN, such as being more stable and less sensitive to the parameters and model architecture; loss functions are more meaningful as they directly relate to the quality of generated images. Gulrajani et al. (2017) proposed using a penalization of the gradient during the training of the critic due to using weight clipping on the critic, which enforces the Lipschitz constraint and therefore lowers the learning capacity of the model. They named the model Wasserstein Generative Adversarial Networks with Gradient Penalty (WGAN-GP). The authors showed that the proposed method performed better than WGAN and provided more stable training.
GANs are primarily used in the computer vision field which processes two-dimensional (2-D) data. In addition, there are some studies in different disciplines that attempted to use GANs for one-dimensional (1-D) data generation and reconstruction for different purposes (Truong and Yanushkevich, 2019; Kuo et al., 2020; Luo et al., 2020; Wulan et al., 2020; Sabir et al., 2021; Wang et al., 2021). In the SHM field of non-civil structures, some studies of GAN-based 1-D data generation, reconstruction, and then training an ML classifier are introduced (Gao et al., 2019; Shao et al., 2019; Guo et al., 2020; Zhang et al., 2021). Few studies are introduced in the SHM field of civil structures related to using GAN for 1-D data reconstruction (Zhang et al., 2018; Fan et al., 2021; Jiang et al., 2021). However, no study investigated the usage of WGAN and WGAN-GP extensively to address the data scarcity problem for civil structures and test the generated synthetic data samples on a DCNN model for damage diagnostics on the raw vibration data. The provided methodology will enable the researchers and professionals to generate the needed data samples to train the DL model to be used for vibration-based damage diagnostics.
Methodology
The authors of this study used WGAN-GP that is built on a DCNN, which is named WDCGAN-GP. Because the data used in this study is 1-D, all the convolution operations are executed 1-D both for WDCGAN-GP and DCNN. Thus, in short, 1-D WDCGAN-GP is utilized to generate a synthetic dataset and 1-D DCNN to perform nonparametric damage identification. For simplicity, in the rest of the paper, 1-D WDCGAN-GP and 1-D DCNN is referred to as ℳ1 and ℳ2, respectively. The workflow followed in this study can be summarized in this order: 1) data preprocessing for ℳ1, 2) building the ℳ1, 3) training and fine-tuning the ℳ1, 4) evaluation and interpretation of results from the ℳ1, 5) data preprocessing for the ℳ2, 6) building the ℳ2, 7) training and fine-tuning the ℳ2, 8) testing the ℳ2, and 9) evaluation and interpretation of the results from the ℳ2. The dataset, technical notations, and workflow are explained in the following paragraphs.
The vibration dataset is obtained from the study conducted by Abdeljaber et al. (2017) on a steel laboratory frame (Figure 1) where a total of 30 accelerometers were installed at each 30 joints and a modal shaker excitation is applied on the structure. Respectively, 30 different damaged and one undamaged scenarios are created at 30 joints separately by loosening the bolts of the connections between filler beams and girders. Then, they collected 256 s of vibration data at a sampling rate of 1,024 Hz with a total sample of 262,144 for each damaged case (a total of 30 cases). The tensor notation used in this paper is

FIGURE 1. Steel frame grand simulator structure (Abdeljaber et al., 2017).
Figure 2 represents the workflow of this study where tensors
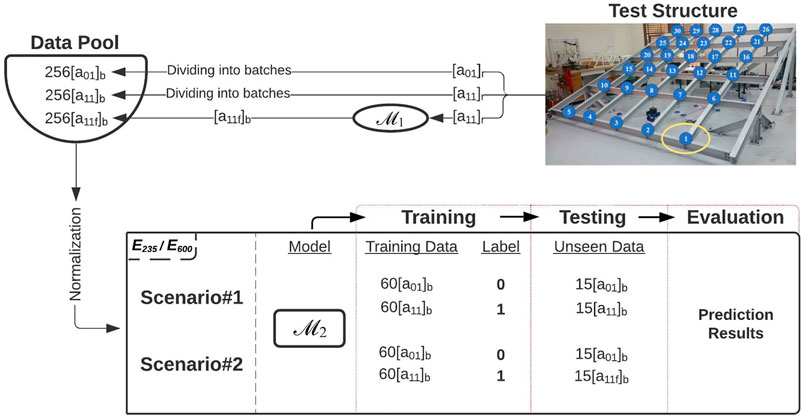
FIGURE 2. The workflow.
ℳ1–Data Preprocessing
The common practice for DL models before training is to make datasets in the same scale for the model to learn and predict more efficiently. In addition, during the front and back propagation through the network where the dot product of weights is calculated, normalization would help the model by putting the datasets on the same scale to alleviate the impact of spike values; thus, it helps the model to yield more accurate results and less computation time. Otherwise, the spikes would have a huge impact on the weight propagation that can result in extreme values, which lowers the model quality in training. In addition, the ℳ1 model consists of batch and instance normalization layers that normalize the data batches during the training. Considering that the dataset does not contain large spikes, the model is tried with both normalized and raw training input, and it is observed that results are not distinctly different. In fact, it is believed that the model captures the spatial-temporal features better when it receives the raw vibration dataset. Hence, normalization is not implemented before the training.
ℳ1–Architecture
After several trials of different model architectures, the one used in this study is shown in Figure 3. First, the generator receives the dimensional noise tensor (z) and passes it through five 1-D transpose convolutions, in which the first layer is

FIGURE 3. 1-D WDCGAN-GP (ℳ1) architecture.
ℳ1–Training and Fine-Tuning
As mentioned, GANs are arguably the most difficult DL models to train among other DL models. Therefore, it requires considerable effort to fine-tune. Although the model used in this study, 1-D WDCGAN-GP, is one of the most robust GAN models in the literature, few approaches have been taken during the fine-tuning after many trials with different hyperparameters. First, using one layer of dropout with 70% in the critic was found beneficial in training. Thus, the capacity of the critic reduces and balances the equilibrium between two adversarial networks and avoids the overfitting problem. Next, a decaying random Gaussian noise is added to the training input to decrease the learning rate of the critic. The learning rate of
ℳ1–Evaluation and Interpretation of Results
Evaluation of the GAN models can be categorized as qualitative and quantitative evaluation, where the former is based on visual evaluation, and the latter is based on numerical evaluation. The most used form of evaluation of GANs used in the DL field is visually comparing the generator’s output with the training data, which are primarily images. Yet, this qualitative approach might not be an easy or efficient way for 1-D data as it suffers from some limitations, such as a limited number of generated output can be viewed by an observer in limited time or observed subjectively by different observers. In addition, unlike the other DL models, GANs lack objective function that makes it challenging to evaluate the performance of the model. That is why there are several methods to assess the model’s performance with no consensus in the DL field yet as to which quantitative measure is the most effective. The study from Borji (2018) investigated the evaluation methods of GANs, and readers are directed to that reference. Recently, the Fréchet Inception Distance (FID) score has been introduced (Heusel et al., 2017) and has become the most used quantitative evaluation method for GANs as several studies proved its effectiveness against other methods such as Inception Score (IS). The FID score is introduced as an improvement over the IS, which lacks capturing the similarity of real input to the produced output. Particularly, the FID has shown remarkably consistent results when compared with a qualitative evaluation of the GAN outputs. The FID formula is based on a statistical formulation, which is provided in Eq. 1.
where
where
During the training of both cases, E235 and E600, the critic and generator losses and FID scores are plotted to monitor the learning process of the model. The critic losses are converging near zero. The generator losses are first increasing as the one that is superior, the critic, rejecting outputs of the generator because the critic has more knowledge on the real data domain. However, after the generator starts learning the gradients and producing more real-looking datasets, it is seen to be returning to its first loss value, which is expected for WGAN-GPs (Figure 4, Generator Loss–tagged plots). The FID calculations are made between the batches,
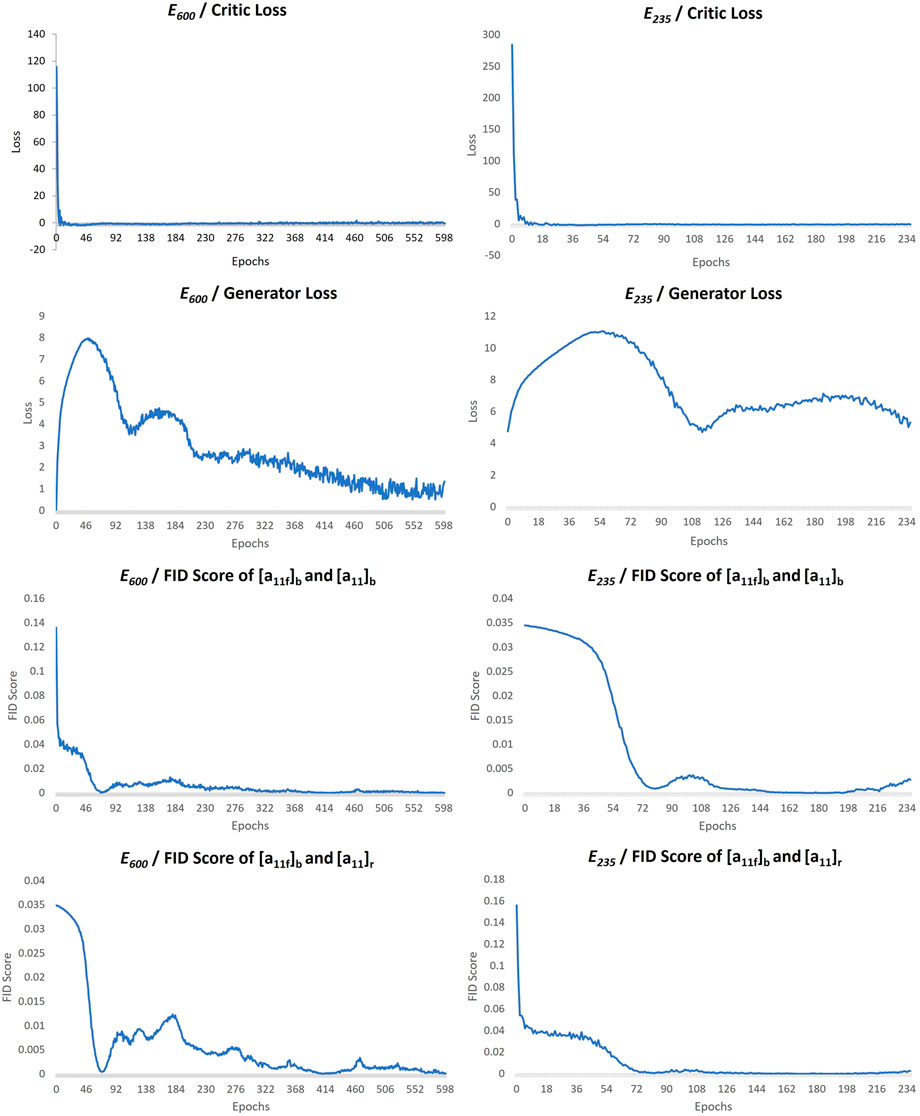
FIGURE 4. Training plots of GAN for cases E235 and E600.
To ensure that
Moreover, the trained ℳ1 model is used to generate 256
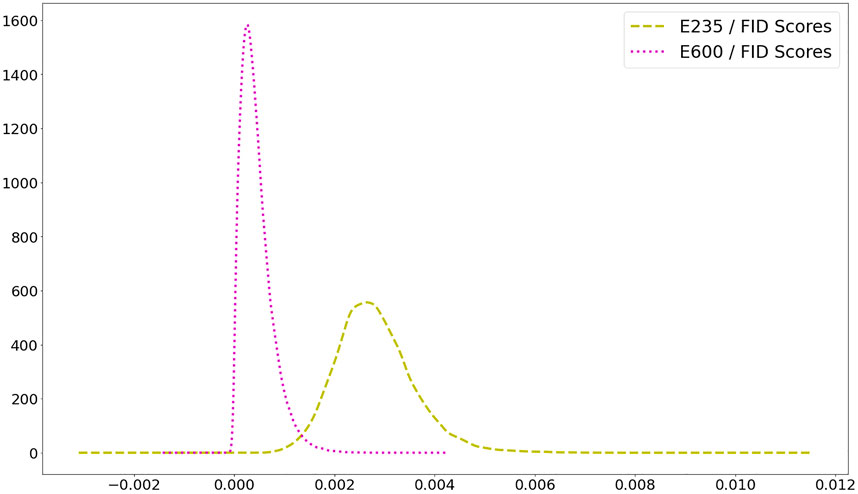
FIGURE 5. The plot of Probability Density Functions of FID scores for E235 and E600.
Next, the creativity and diversity measures are investigated for both cases, E235 and E600. First, the SSIM between the
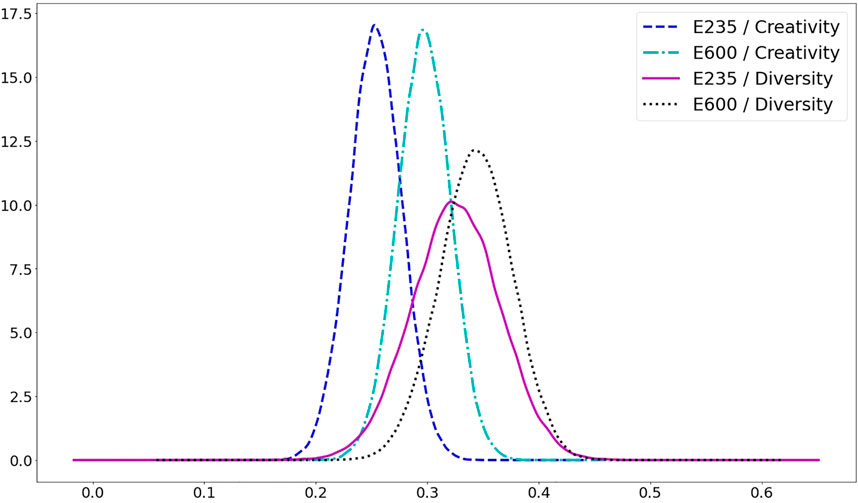
FIGURE 6. The plot of Probability Density Functions of Creativity and Diversity measures for cases E235 and E600.
As the last step of the quantitative evaluation of the results, the box plots are used for both cases, E235 and E600, separately. For that, one with the lowest and one with the highest FID scores from the created real and generated tensors are found, and the tensors are selected. Then, the found real and generated tensors,
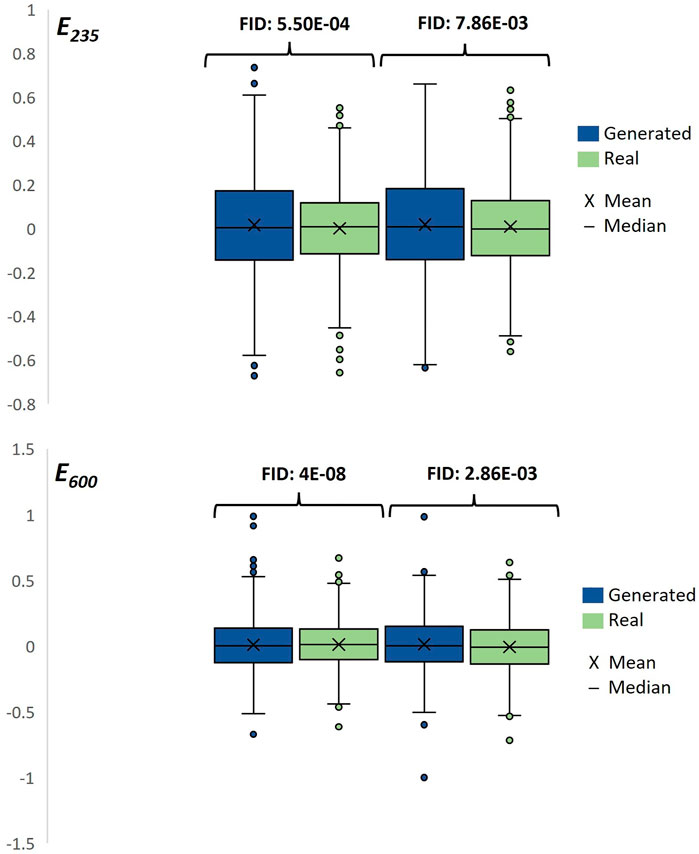
FIGURE 7. Box plots of the tensors for cases E235 and E600 with lowest and highest FID values.
To conduct a qualitative evaluation, which is the most preferred and effective method for evaluating the image data (yet it suffers from its limitations as previously mentioned), the same vibration tensor pairs that were used in Figure 7 are plotted in Figures 8 and9. Although it is not trivial to judge the similarity between the tensors as doing it on the 2-D image data, there is a good consistency between each tensor pair.
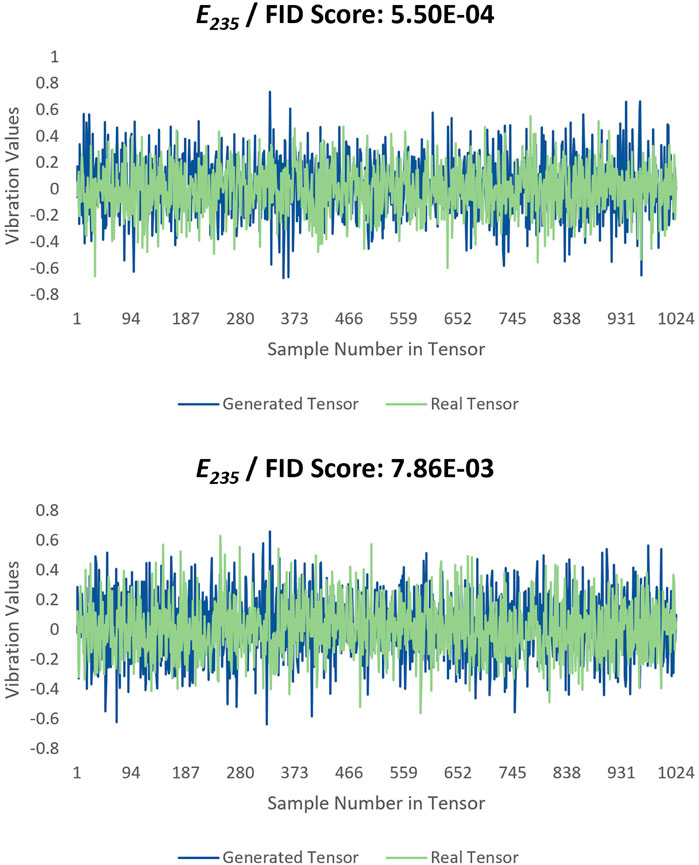
FIGURE 8. Plotted tensor pairs for case E235 with lowest and highest FID values.
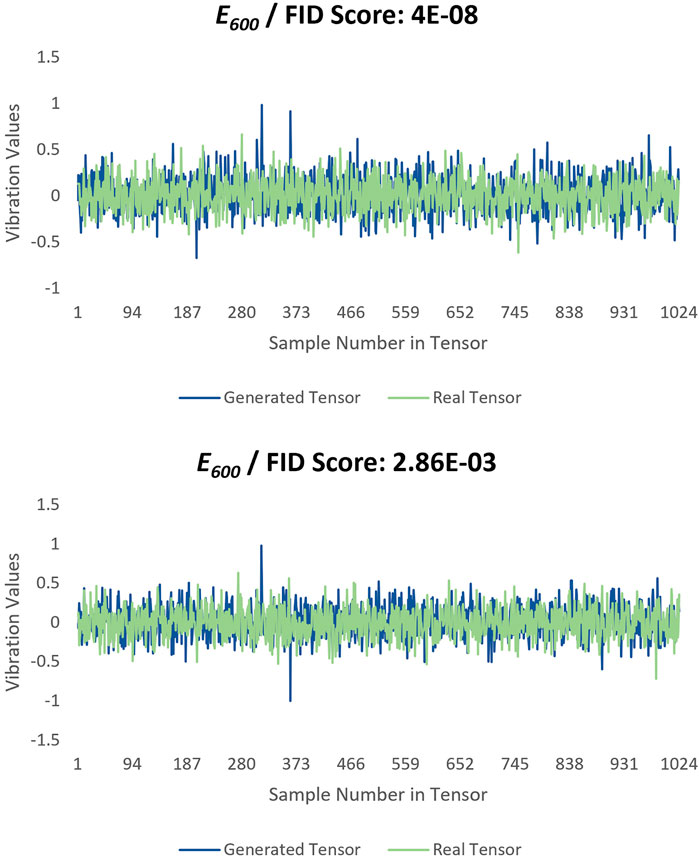
FIGURE 9. Plotted tensor pairs for case E600 with lowest and highest FID values.
ℳ2–Data Processing
Unlike the procedure in the ℳ1—Data Processing section, the tensors from the data pool,
ℳ2–Architecture
The architecture used in ℳ2 is the same architecture that is used in ℳ1’s critic network. In addition, as there was no activation function used at the end of the last layer in critic in the ℳ1 process (only realness or fakeness scores were used in critic), the sigmoid function is used in the ℳ2 phase, which results in prediction score in a range of 0–1 where 0 is labeled as undamaged and 1 as damaged in this work. Last, no dropout is used because there is no use of it for the purpose of a simple detection procedure.
ℳ2—Training and Fine-Tuning
Like in the procedure of ℳ1, the parameters are chosen for ℳ2 after many trials. For cases E235 and E600 and Scenario#1 and Scenario#2, the used learning rate, batch size, and number of the epoch are
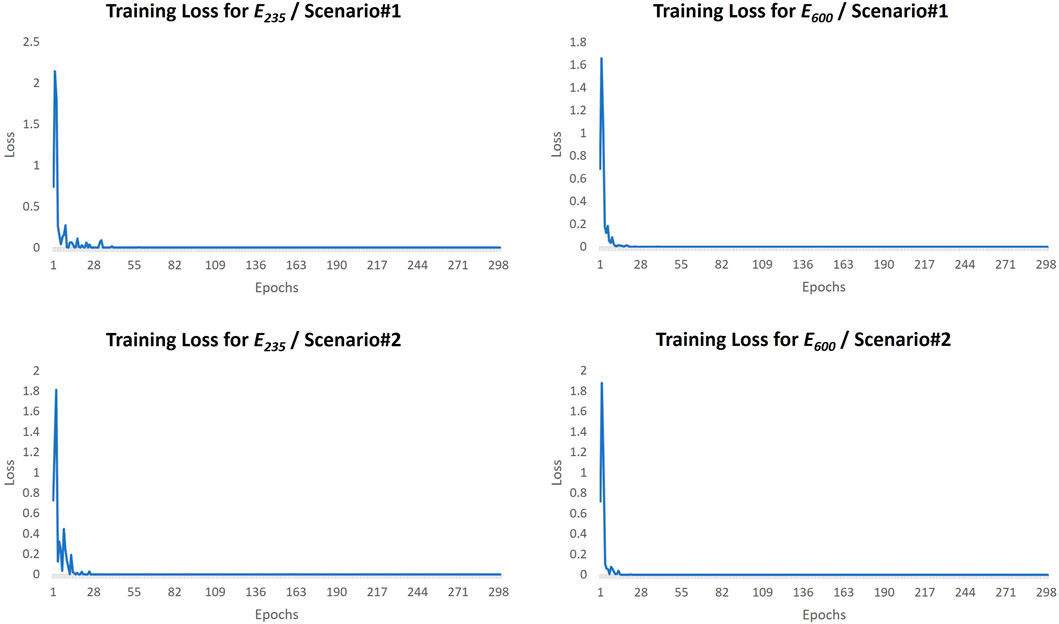
FIGURE 10. Training plots of DCNN (ℳ2) of each scenario for cases E235 and E600.
ℳ2–Evaluation and Interpretation of Results
It is seen in the Figure 10 that, during the training of the ℳ2 model, the training loss functions are converged to zero in each scenario for both cases; in other words, the model learned the data effectively. Yet, the critical part is in testing the model, that is, its performance on unseen data. For evaluating the results, one regression and one classification metric are used. The classification metrics such as Classification Accuracy (CA), which is the ratio of total correct predictions over total predictions, cannot be sufficient when an in-depth evaluation of the model’s performance is needed. Because classification converts the prediction score into the closest label (0 or 1) based on the assumed threshold value, it might not reflect a good accuracy. For instance, a prediction score of 0.48 is converted into 0 (undamaged) if the assumed value of 0.49 as the threshold is used for classification. This might not reflect the real performance of the model because that prediction score of 0.48 might be a result of 48% of damage (as a quantification of the damage such as 48% of bolt loosened) in the system or might be a lot higher or lower and classifying it as label 0 can be a faulty prediction. A ROC and AUC curve can be employed to look for the optimum threshold value that gives the desired classification results for damage detection. Yet, this is not in the scope of this study, and there are not many classification samples in the testing data; therefore, it is not necessary to check for all different thresholds. Thus, the threshold in this study is defined as 0.49 for the CA. Moreover, it is possible for DL-based structural damage diagnostics that the probability of the tensor being undamaged or damaged can also mean the quantification result of the tensor whether it is undamaged or damaged. This is another area of investigation for different levels (detection, localization, and quantification) of damage diagnostics using DL models. Along with a CA metric, a regression metric, Mean Absolute Error (MAE). MAE measures the average of all the prediction errors by taking the summation of the absolute values of the predicted values minus the actual values and then dividing it by the total sample in the test. MAE is an excellent metric tool to measure the model’s error on the dataset.
The resulted prediction scores along with the ground truths (correct target value) on the test tensors are bar plotted in Figures 11 and 12 for cases E235 and E600, including each of their scenarios, respectively. At first glance, it is easy to catch the close prediction scores to ground truths, particularly for case E600 where the scores are closer because the ℳ2 is trained more. Likewise, the prediction scores are slightly closer to the ground truths in Scenario#1 in both cases because no synthetic tensor is involved in the process. Yet, more training helped the model to learn more about the data; thus, it could identify the test instances with more accuracy as this is the situation in both scenarios in case E600. In Figure 11, for Scenario#1, ℳ2 is looking very consistent and confident on the test instances as it predicted all of them successfully. For case E600, Scenario#2, where the model is tested on only synthetic damaged and real undamaged instances, has a slightly off prediction score around 0.10 on tensor 8, which might be negligible. Yet, the quantitative results can give better insight into the model’s performance. Hence, the results are reflected on the CA and MAE metrics, as in Figure 13, and it is seen that the CAs are following the same scores, 100% and 97%, for both cases and scenarios, respectively. Considering that the CA results are very high with only one incorrect prediction, which is for undamaged tensor as damaged, the resulting values in this paper can be concluded as excellent. Yet, the criterion to consider a success rate as “excellent” mainly depends on the used application of the model. For example, in damage detection problems, in order for a classification value of the model’s performance to be considered acceptable, it is prominent to know what percentage of the dataset can be ignored for an achievable safety measure. Last, the MAE results are seemingly very low, which implies that ℳ2 has very low error values on the unseen data, and the model can predict the damage-associated instances from the undamaged data successfully.

FIGURE 11. Testing results of DCNN (ℳ2) for case E235.
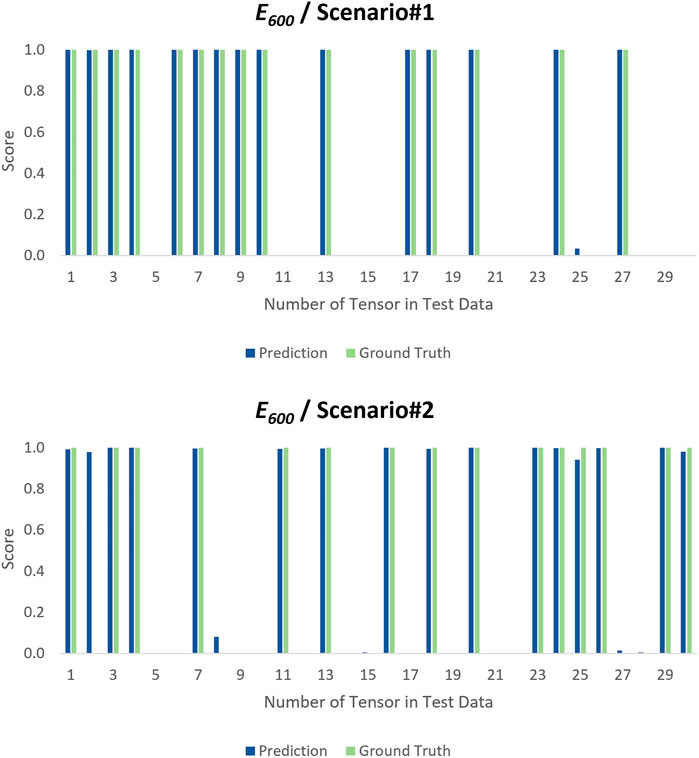
FIGURE 12. Testing results of DCNN (ℳ2) for case E600.
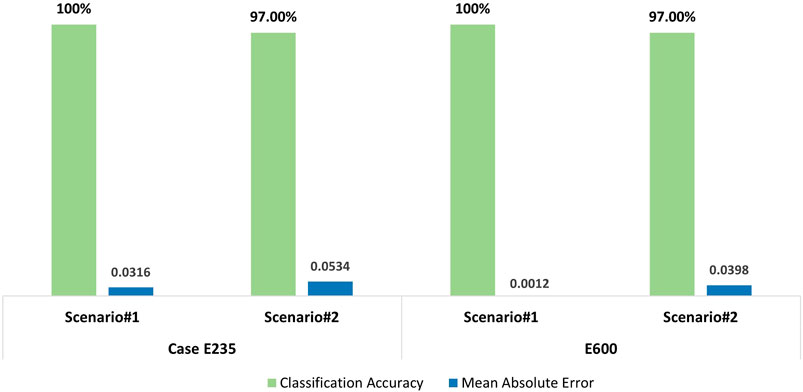
FIGURE 13. Bar plot of Classification Accuracy and Mean Absolute Error of the testing results for cases E235 and E600.
Conclusion
Detecting and locating damage on large civil structures is a challenging task and has been the subject of research for many years. Finding damage-associated vibration data from structures can also be very challenging. Therefore, data scarcity is a setback in civil SHM applications. With the rapid developments in AI, ML, and DL, researchers started to take advantage of such tools for vibration-based structural damage diagnostics and achieved great success. Considering that the DL algorithms perform better with large data, this study used 1-D WGAN-GP to generate synthetic vibration data and validate the produced outputs by employing 1-D DCNN trained on real inputs and tested on a synthetic dataset. The same DCNN model is also tested on a real dataset for benchmarking purposes. The classification results showed that the performance of DCNN on the test data and on the real data is 97% and 100%, respectively, with both scenarios resulting in significantly low model errors. The main conclusions of this study can be listed in bullet points:
• The well-known problem of data scarcity in SHM of civil structures can be tackled by using GANs to generate similar types of datasets. This study showed that GANs could produce a vibration signal that is almost indistinguishable from the real ones, and the generated signals are verified with metrics. Although this study used one of the most advanced GAN methods, the WGAN-GP algorithm, which improves the well-known training problems of GANs, the training is still tedious.
• The study demonstrated that the generated vibration signals are indistinguishable by DCNN. This means that, in a situation where some damage-associated dataset exists for a civil structure, yet the amount of existing dataset is not sufficient for vibration-based damage diagnostics via DL model, and then, the proposed methodology can be used as a solution. As a result, the presented methodology paves the way for more ML- and DL-based models to be utilized for structural damage diagnostics.
• The generated data from GAN is creative and versatile enough that it is not a copy of the input nor a copy of other generated datasets. The analogy is indeed similar to the real structures where dynamic responses for different damage types can contain similar characteristics in the raw data, yet they are not copies of each other. Therefore, when the data are scarce, or a portion of it is missing, GANs can generate additional data similar “enough” to the original data. It also diversifies the input data by adding a somewhat new meaning to the learned variation range of the dataset, which can be used for various damage detection problems for multiple civil structures by adjusting the features in the data used. Hence, it can be used successfully for vibration-based nonparametric damage diagnostics, as demonstrated in this study.
• The presented methodology’s use-case scenario is utilizing a DL model, e.g., 1-D DCNN on a multi-span bridge where only one span has a damaged-associated dataset. To implement damage diagnostics on the raw vibration data using a DL model, the model has to be trained with the already existing data samples, which are undamaged and damaged-associated datasets (undamaged and damaged classes). Yet, it is important to note that the damaged-associated datasets are comparatively very few. This class imbalance in the training dataset of the DL model lowers the model’s performance. In other words, to tackle this data scarcity problem, WGAN-GP can be used to generate the needed data samples to train the DL model efficiently. Thus, the methodology increases the performance of the DL model.
• On the basis of the demonstrated performance herein by GANs on generating vibration data, there is good potential for further use of them in civil SHM applications. More research is needed to generate the damaged dynamic response of structures using the undamaged responses.
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: http://www.structuraldamagedetection.com/benchmark/.
Author Contributions
FC developed the proposal and obtained research funding for the study. FC, OA, and FL contributed to conception and design of the study. FL organized the database and performed the data analysis. FC and OA developed the paper outline, and FL wrote the first draft of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank members of CITRS (Civil Infrastructure Technologies for Resilience and Safety) Research Initiative at the University of Central Florida. The second author would like to acknowledge the support by National Aeronautics and Space Administration (NASA) Award No. 80NSSC20K0326.
References
Abdeljaber, O., and Avci, O. (2016). Nonparametric Structural Damage Detection Algorithm for Ambient Vibration Response: Utilizing Artificial Neural Networks and Self-Organizing Maps. J. Architectural Eng. 22 (2), 04016004. doi:10.1061/(ASCE)AE.1943-5568.0000205
Abdeljaber, O., Avci, O., Kiranyaz, S., Gabbouj, M., and Inman, D. J. (2017). Real-Time Vibration-Based Structural Damage Detection Using One-Dimensional Convolutional Neural Networks. J. Sound Vibr. 388, 154–170. doi:10.1016/j.jsv.2016.10.043
Abdeljaber, O., Avci, O., Kiranyaz, M. S., Boashash, B., Sodano, H., and Inman, D. J. (2018). 1-D CNNs for Structural Damage Detection: Verification on a Structural Health Monitoring Benchmark Data. Neurocomputing 275, 1308–1317. doi:10.1016/j.neucom.2017.09.069
Alom, M. Z., Taha, T. M., Yakopcic, C., Westberg, S., Sidike, P., Nasrin, M. S., et al. (2019). A State-Of-The-Art Survey on Deep Learning Theory and Architectures. Electronics 8 (3), 292. doi:10.3390/electronics8030292
Arjovsky, M., Chintala, S., and Bottou, L. (2017). “Wasserstein GAN,” in Proceedings of the 34th International Conference on Machine Learning. PMLR 70, 214–223.
Avci, O., Abdeljaber, O., Kiranyaz, S., and Inman, D. (2017). Structural Damage Detection in Real Time: Implementation of 1D Convolutional Neural Networks for SHM Applications. Struct. Health Monit. Damage Detect. 7, 49–54. doi:10.1007/978-3-319-54109-9_6
Avci, O., Abdeljaber, O., Kiranyaz, S., Hussein, M., Gabbouj, M., and Inman, D. J. (2021). A Review of Vibration-Based Damage Detection in Civil Structures: From Traditional Methods to Machine Learning and Deep Learning Applications. Mech. Syst. Signal Process. 147, 107077. doi:10.1016/J.YMSSP.2020.107077
Bandara, R. P., Chan, T. H., and Thambiratnam, D. P. (2014). Structural Damage Detection Method Using Frequency Response Functions. Struct. Health Monit. 13 (4), 418–429. doi:10.1177/1475921714522847
Catbas, F. N., and Aktan, A. E. (2002). Condition and Damage Assessment: Issues and Some Promising Indices. J. Struct. Eng. 128 (8), 1026–1036. doi:10.1061/(asce)0733-9445(2002)128:8(1026)
Catbas, F. N., and Malekzadeh, M. (2016). A Machine Learning-Based Algorithm for Processing Massive Data Collected from the Mechanical Components of Movable Bridges. Autom. in Constr. 72, 269–278. doi:10.1016/j.autcon.2016.02.008
Catbas, F. N., Brown, D. L., and Aktan, A. E. (2006). Use of Modal Flexibility for Damage Detection and Condition Assessment: Case Studies and Demonstrations on Large Structures. J. Struct. Eng. 132 (11), 1699–1712. doi:10.1061/(asce)0733-9445(2006)132:11(1699)
Costa, V., Lourenço, N., Correia, J., and Machado, P. (2019). “COEGAN: Evaluating the Coevolution Effect in Generative Adversarial Networks,” in Proceedings of the Genetic and Evolutionary Computation Conference (New York, NY, USA: ACM). doi:10.1061/(asce)0733-9445(2002)128:8(1026)
Cury, A., and Crémona, C. (2012). Pattern Recognition of Structural Behaviors Based on Learning Algorithms and Symbolic Data Concepts. Struct. Control. Health Monit. 19 (2), 161–186. doi:10.1002/stc.412
Das, S., Saha, P., and Patro, S. K. (2016). Vibration-Based Damage Detection Techniques Used for Health Monitoring of Structures: A Review. J. Civil Struct. Health Monit. 6 (3), 477–507. doi:10.1007/s13349-016-0168-5
Dong, C-Z., and Catbas, F. N., (2021). A Review of Computer Vision–Based Structural Health Monitoring at Local and Global Levels. Struct. Health Monit. 20 (2), 692–743. doi:10.1177/1475921720935585
Eren, L. (2017). Bearing Fault Detection by One-Dimensional Convolutional Neural Networks. Math. Probl. Eng. 2017, 1–9. doi:10.1155/2017/8617315
Fan, G., Li, J., Hao, H., and Xin, Y. (2021). Data Driven Structural Dynamic Response Reconstruction Using Segment Based Generative Adversarial Networks. Eng. Struct. 234, 111970. doi:10.1016/j.engstruct.2021.111970
Gao, S., Wang, X., Miao, X., Su, C., and Li, Y. (2019). ASM1D-GAN: An Intelligent Fault Diagnosis Method Based on Assembled 1D Convolutional Neural Network and Generative Adversarial Networks. J. Sign Process. Syst. 91 (10), 1237–1247. doi:10.1007/s11265-019-01463-8
Gardner, P., and Barthorpe, R. J. (2019). “On Current Trends in Forward Model-Driven SHM,” in Structural Health Monitoring (Lancaster, PA: DEStech Publications, Inc.).
Ghiasi, R., Torkzadeh, P., and Noori, M. (2016). A Machine-Learning Approach for Structural Damage Detection Using Least Square Support Vector Machine Based on a New Combinational Kernel Function. Struct. Health Monit. 15 (3), 302–316. doi:10.1177/1475921716639587
González, M. P., and Zapico, J. L. (2008). Seismic Damage Identification in Buildings Using Neural Networks and Modal Data. Comput. Struct. 86 (3–5), 416–426. doi:10.1016/j.compstruc.2007.02.021
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). Generative Adversarial Nets. NIPS
Goodfellow, I. J. (2017). NIPS 2016 Tutorial: Generative Adversarial Networks. ArXiv. abs/1701.00160.
Guan, S., and Loew, M. H. (2020). Measures to Evaluate Generative Adversarial Networks Based on Direct Analysis of Generated Images. ArXiv. abs/2002.12345
Gul, M., and Catbas, F. N. (2008). Ambient Vibration Data Analysis for Structural Identification and Global Condition Assessment. J. Eng. Mech. 134 (8), 650–662. doi:10.1061/(asce)0733-9399(2008)134:8(650)
Gul, M., and Catbas, F. N. (2011). Damage Assessment with Ambient Vibration Data Using a Novel Time Series Analysis Methodology. J. Struct. Eng. 137 (12), 1518–1526. doi:10.1061/(asce)st.1943-541x.0000366
Gul, M., Dumlupinar, T., Hattori, H., and Catbas, F. N. (2014). Structural Monitoring of Movable Bridge Mechanical Components for Maintenance Decision-Making. Struct. Monit. Maintenance J. 1 (3), 249–271. doi:10.12989/smm.2014.1.3.249
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., and Courville, A. (2017). “Improved Training of Wasserstein GANs,” in Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17) (Red Hook, NY: Curran Associates Inc.), 5769–5779.
Guo, Q., Li, Y., Song, Y., Wang, D., and Chen, W. (2020). Intelligent Fault Diagnosis Method Based on Full 1-D Convolutional Generative Adversarial Network. IEEE Trans. Ind. Inf. 16 (3), 2044–2053. doi:10.1109/TII.2019.2934901
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. (2017). “GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium,” in Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17) (Red Hook, NY: Curran Associates Inc.), 6629–6640.
Jiang, H., Wan, C., Yang, K., Ding, Y., and Xue, S. (2021). Continuous Missing Data Imputation with Incomplete Dataset by Generative Adversarial Networks-Based Unsupervised Learning for Long-Term Bridge Health Monitoring. Struct. Health Monit. 4, 147592172110219. doi:10.1177/14759217211021942
Krishnan Nair, K., and Kiremidjian, A. S. (2007). Time Series Based Structural Damage Detection Algorithm Using Gaussian Mixtures Modeling. J. Dynamic Syst. Meas. Control. 129 (3), 285–293. doi:10.1115/1.2718241
Kuo, P.-H., Lin, S.-T., and Hu, J. (2020). DNAE-GAN: Noise-Free Acoustic Signal Generator by Integrating Autoencoder and Generative Adversarial Network. Int. J. Distributed Sens. Networks 16 (5), 155014772092352. doi:10.1177/1550147720923529
Lee, J., and Kim, S. (2007). Structural Damage Detection in the Frequency Domain Using Neural Networks. J. Intell. Mater. Syst. Struct. 18 (8), 785–792. doi:10.1177/1045389X06073640
Lee, J. J., Lee, J. W., Yi, J. H., Yun, C. B., and Jung, H. Y. (2005). Neural Networks-Based Damage Detection for Bridges Considering Errors in Baseline Finite Element Models. J. Sound Vibr. 280 (3–5), 555–578. doi:10.1016/j.jsv.2004.01.003
Luo, T.-j., Fan, Y., Chen, L., Guo, G., and Zhou, C. (2020). EEG Signal Reconstruction Using a Generative Adversarial Network with Wasserstein Distance and Temporal-Spatial-Frequency Loss. Front. Neuroinform. 14, 1–20. doi:10.3389/fninf.2020.00015
Pathirage, C. S. N., Li, J., Li, L., Hao, H., Liu, W., and Ni, P. (2018). Structural Damage Identification Based on Autoencoder Neural Networks and Deep Learning. Eng. Struct. 172, 13–28. doi:10.1016/j.engstruct.2018.05.109
Radford, A., Metz, L., and Chintala, S. (2016). Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks. CoRR. abs/1511.06434
Rastin, Z., Ghodrati Amiri, G., and Darvishan, E. (2021). Unsupervised Structural Damage Detection Technique Based on a Deep Convolutional Autoencoder. Shock Vibr. 2021, 1–11. doi:10.1155/2021/6658575
Sabir, R., Rosato, D., Hartmann, S., and Guhmann, C. (2021). “Signal Generation Using 1d Deep Convolutional Generative Adversarial Networks for Fault Diagnosis of Electrical Machines,” in 2020 25th International Conference on Pattern Recognition (ICPR) (IEEE).
Salimans, T., Goodfellow, I. J., Zaremba, W., Cheung, V., Radford, A., and Chen, X. (2016). Improved Techniques for Training GANs. NIPS
Santos, A., Figueiredo, E., Silva, M. F. M., Sales, C. S., and Costa, J. C. W. A. (2016). Machine Learning Algorithms for Damage Detection: Kernel-Based Approaches. J. Sound Vibr. 363, 584–599. doi:10.1016/j.jsv.2015.11.008
Shang, Z., Sun, L., Xia, Y., and Zhang, W. (2021). Vibration-Based Damage Detection for Bridges by Deep Convolutional Denoising Autoencoder. Struct. Health Monit. 20 (4), 147592172094283. doi:10.1177/1475921720942836
Shao, S., Wang, P., and Yan, R. (2019). Generative Adversarial Networks for Data Augmentation in Machine Fault Diagnosis. Comput. Industry 106, 85–93. doi:10.1016/j.compind.2019.01.001
Silva, M., Santos, A., Figueiredo, E., Santos, R., Sales, C., and Costa, J. C. W. A. (2016). A Novel Unsupervised Approach Based on a Genetic Algorithm for Structural Damage Detection in Bridges. Eng. Appl. Artif. Intell. 52, 168–180. doi:10.1016/j.engappai.2016.03.002
Truong, T., and Yanushkevich, S. (2019). “Generative Adversarial Network for Radar Signal Synthesis,” in 2019 International Joint Conference on Neural Networks (IJCNN) (IEEE).
Wang, Z., Bovik, A. C., Sheikh, H. R., and Simoncelli, E. P. (2004). Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 13 (4), 600–612. doi:10.1109/TIP.2003.819861
Wang, T., Trugman, D., and Lin, Y. (2021). SeismoGen: Seismic Waveform Synthesis Using GAN with Application to Seismic Data Augmentation. J. Geophys. Res. Solid Earth 126 (4), e2020JB020077. doi:10.1029/2020JB020077
Wulan, N., Wang, W., Sun, P., Wang, K., Xia, Y., and Zhang, H. (2020). Generating Electrocardiogram Signals by Deep Learning. Neurocomputing 404, 122–136. doi:10.1016/j.neucom.2020.04.076
Yin, T., Lam, H. F., Chow, H. M., and Zhu, H. P. (2009). Dynamic Reduction-Based Structural Damage Detection of Transmission Tower Utilizing Ambient Vibration Data. Eng. Struct. 31 (9), 2009–2019. doi:10.1016/j.engstruct.2009.03.004
Yu, Y., Wang, C., Gu, X., and Li, J. (2019). A Novel Deep Learning-Based Method for Damage Identification of Smart Building Structures. Struct. Health Monit. 18 (1), 143–163. doi:10.1177/1475921718804132
Zhang, C., Kuppannagari, S. R., Kannan, R., and Prasanna, V. K. (2018). “Generative Adversarial Network for Synthetic Time Series Data Generation in Smart Grids,” in IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm) (IEEE). doi:10.1109/smartgridcomm.2018.8587464
Zhang, X., Qin, Y., Yuen, C., Jayasinghe, L., and Liu, X. (2021). Time-Series Regeneration with Convolutional Recurrent Generative Adversarial Network for Remaining Useful Life Estimation.
Nomenclature
E235 Case where the GAN trained for 235 epochs
E600 Case where the GAN trained for 600 epochs
ℳ1 Used 1-D WDCGAN-GP model in the paper
ℳ2 Used 1-D DCNN model in the paper
Keywords: 1-D Generative Adversarial Networks (1-D Gan), Deep Convolutional Generative Adversarial Networks (DCGAN), Wasserstein Generative Adversarial Networks with Gradient Penalty (WGAN-GP), Structural Health Monitoring (SHM), Structural Damage Detection, 1-D Deep Convolutional Neural Networks (1-D DCNN)
Citation: Luleci F, Catbas FN and Avci O (2022) Generative Adversarial Networks for Data Generation in Structural Health Monitoring. Front. Built Environ. 8:816644. doi: 10.3389/fbuil.2022.816644
Received: 16 November 2021; Accepted: 07 January 2022;
Published: 11 February 2022.
Edited by:
Yves Reuland, ETH Zürich, SwitzerlandReviewed by:
David Lattanzi, George Mason University, United StatesSai G.S. Pai, ETH Centre, Singapore
Copyright © 2022 Luleci, Catbas and Avci. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: F. Necati Catbas, Y2F0YmFzQHVjZi5lZHU=