 Amanda K. Navine
Amanda K. Navine Tom Denton
Tom Denton Matthew J. Weldy
Matthew J. Weldy Patrick J. Hart
Patrick J. Hart
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Bird Sci. , 24 April 2024
Sec. Bird Conservation and Management
Volume 3 - 2024 | https://doi.org/10.3389/fbirs.2024.1380636
This article is part of the Research Topic Computational Bioacoustics and Automated Recognition of Bird Vocalizations: New Tools, Applications and Methods for Bird Monitoring View all 6 articles
Passive acoustic monitoring (PAM) studies generate thousands of hours of audio, which may be used to monitor specific animal populations, conduct broad biodiversity surveys, detect threats such as poachers, and more. Machine learning classifiers for species identification are increasingly being used to process the vast amount of audio generated by bioacoustic surveys, expediting analysis and increasing the utility of PAM as a management tool. In common practice, a threshold is applied to classifier output scores, and scores above the threshold are aggregated into a detection count. The choice of threshold produces biased counts of vocalizations, which are subject to false positive/negative rates that may vary across subsets of the dataset. In this work, we advocate for directly estimating call density: The proportion of detection windows containing the target vocalization, regardless of classifier score. We propose a validation scheme for estimating call density in a body of data and obtain, through Bayesian reasoning, probability distributions of confidence scores for both the positive and negative classes. We use these distributions to predict site-level call densities, which may be subject to distribution shifts (when the defining characteristics of the data distribution change). These methods may be applied to the outputs of any binary detection classifier operating on fixed-size audio input windows. We test our proposed methods on a real-world study of Hawaiian birds and provide simulation results leveraging existing fully annotated datasets, demonstrating robustness to variations in call density and classifier model quality.
Slowing the alarming pace of global biodiversity loss will require the development of tools and protocols for effective wildlife population monitoring and management (Butchart et al., 2010). Understanding population responses to threats and conservation actions is critical in developing successful conservation strategies (Nichols and Williams, 2006). Passive acoustic monitoring (PAM) using automated recording units is a non-invasive and cost-effective approach to collecting data on sound-producing species, including those with cryptic behaviors or in difficult-to-survey habitats (Sugai et al., 2019). However, PAM can generate large quantities of acoustic data, necessitating machine and deep learning algorithms to detect species of interest semi-automatically (Tuia et al., 2022). These computational tools present a promising opportunity, but inferring accurate biological and ecological significance from the results remains a challenge (Gibb et al., 2018).
In many applications, a classifier score threshold is selected, and classifier outputs are reduced to binary detections (Knight et al., 2017; Cole et al., 2022), which creates false positives and false negatives that need to be accounted for in downstream work (Miller and Grant, 2015; Chambert et al., 2018; Clement et al., 2022). Counts of these detections are a tempting proxy for activity levels, but the ambiguity introduced by mis-detections makes such interpretation difficult. As a result, binary detection counts are often further aggregated to binary indicators of detection-nondetection by validating high-scoring examples. This approach can mitigate the risk of false positives, but at the risk of higher false negative rates (Knight et al., 2017).
However, the underlying call density P(⊕), the proportion of detection windows containing the target vocalization, is a compelling target. When greater than zero, call density is an occupancy indicator. After establishing occupancy (P(⊕) > 0), changes in call density may also indicate changes in abundance, behavior, population health, site turnover, or disturbance, which are difficult to capture using a binary detection–nondetection framework.
The detection rate is the proportion of a classifier’s output scores (z) which are greater than the threshold (t), and can be written as a probability P(z > t). The detection rate is related to the underlying call density P(⊕) by the law of total probability:
This simple relationship highlights an important challenge of using threshold-based detection counts as proxies for call density. P(z > t) is only equal to P(⊕) when both (no false positives) and P(z > t|⊕) = 1 (no false negatives), which can only occur with perfect classifiers that are hard to produce. Consequently, we expect detections to over-count (due to false positives) and under-count (due to false negatives) in an unknown ratio. In Figure 1, we demonstrate a comparison between threshold detection rates and ground-truth call density using synthetic data; the optimal threshold for balancing false positives and negatives depends heavily on the true and, unfortunately, unknown call density we aim to quantify.
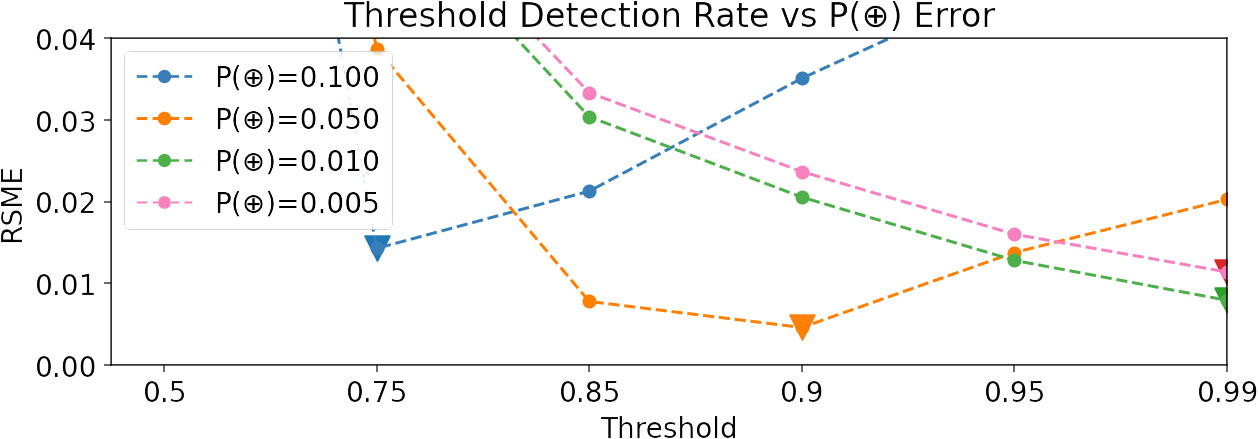
Figure 1 Root mean squared error (RMSE) between detection rates at six different thresholds and true call density P(⊕), using synthetic data and a model with 0.9 ROC-AUC. Notice that the optimal threshold (depicted by a triangle) depends on P(⊕), which may vary across sites.
As we examine different subsets of the data, such as spatiotemporal slices, we expect the detection rate P(z > t) to vary. Equation 1 demonstrates that the detection rate may vary because of changes in call density (which we hope to capture), but also in response to changes in the false-positive and false-negative rates. For example, a territorial species may use readily identifiable vocalizations near a nest but change call type or rate further away from its territory (Reid et al., 2022), and this behavior might shift further depending on the season (Odum and Kuenzler, 1955). This would manifest as a change in site-specific Ps(z > t|⊕), independent of any change in actual call density (where the subscript s represents the choice of site). Likewise, the presence or absence of another species with a similar call can manifest as a change in site-specific , again independent of the call rate of the target species. These examples characterize what is known as a distribution shift. Distribution shifts are ubiquitous and underlie many difficulties in using detection counts. In bioacoustics, previous work has shown that thresholds selected on one dataset targeting a particular false-positive rate will not apply to new datasets because of distribution shifts (Knight and Bayne, 2018), but shifts can easily manifest in subsets of datasets as well.
In this work, we begin developing a “threshold-free” bioacoustic analysis framework that directly estimates call density P(⊕). With the threshold discarded, Equation 1 becomes a statement about the full distribution of classifier scores:
We propose a validation scheme, using a fixed amount of human validation effort, to approximate P(⊕) and conduct 4 experiments to evaluate it. Using a logarithmic binning scheme, we convert the continuous classifier scores to discrete sets and validate within each bin. Logarithmic binning focuses validation effort on higher-scoring examples, which is helpful when the classifier has decent quality and the prevalence of the target species is low. The validation process additionally allows us to obtain a bootstrap estimate of the distribution over possible values of P(⊕) and the construction of confidence intervals. We also obtain estimates of the conditional distributions P(z|⊕) and , describing the range of classifier scores produced in positive and negative examples. This also yields estimates of the reverse conditionals P(⊕|z), , describing the probability of a true-positive given a particular classifier score. The full process is summarized in Figure 2.
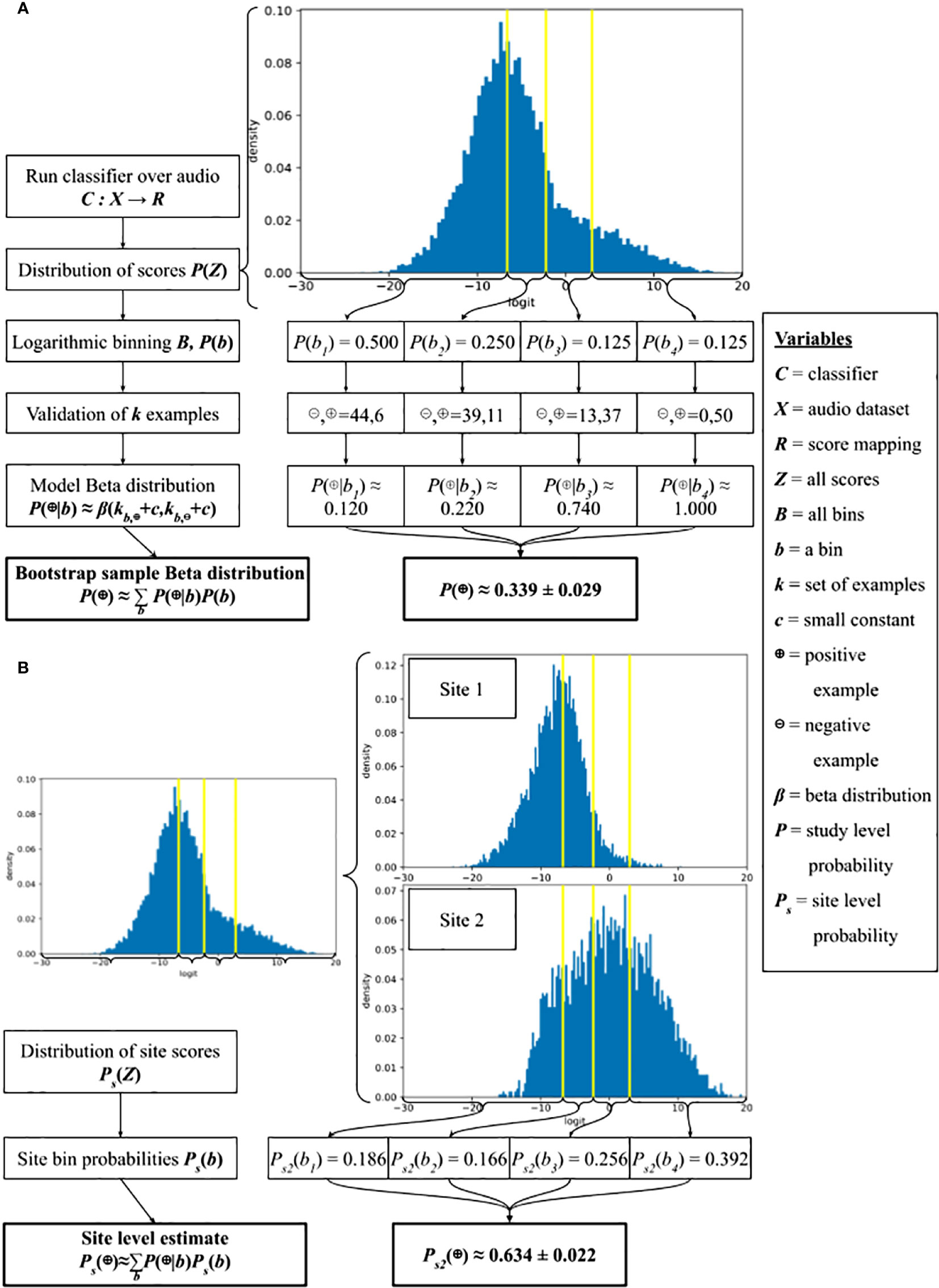
Figure 2 A schematic of our direct call density estimation method at (A) the study-level using our validation scheme and (B) the site- or covariate-level using computational Strategy 1.
We investigate the coverage and error in the estimated probability distributions using a combination of synthetic data and simulated validations on a fully annotated dataset. We explore the impact of the validation parameters on coverage and error, as well as the impact of model quality and ground-truth call density. Of particular note, we demonstrate that the estimates produced by our validation procedure are only lightly coupled with classifier quality: We can obtain reasonable estimates (with good confidence intervals) even with moderately good classifiers, reducing the inherent need for a ‘perfect’ classifier. Finally, we examine 3 strategies for how one might use the estimated distributions produced by validation in generalized settings: For example, to estimate call density for a subset of the data, such as at a particular site s, Ps(⊕). We conduct an experiment to assess the relative effectiveness of the 3 strategies. Computing these distributions allows us to estimate ecological parameters directly and provides a foundation for understanding and addressing the underappreciated problem of distribution shifts. We emphasize that these techniques can be applied to any acoustic classifier on fixed time-windows, including those trained on nonvocal bioacoustic signals such as woodpecker drumming, or abiotic signals such as gunfire.
We used three data sources for the experiments in this paper: synthetic data, a fully-annotated dataset from Pennsylvania, and a collection of PAM recordings from the Hawaiian Islands. The first two data sources were used for simulating the validation scheme and testing its coverage and error rates, as described in Sections 3.2.3 and 3.2.4. The Hawaiian data was used to study the effects of distributional shifts in estimating site-level call rates using study-level validation in Section 3.3.1.
We first assessed the validation procedure using synthetic data, where model quality and label density were controlled parameters. The synthetic dataset consists of pairs where is the ground-truth label, and zi corresponds to a model confidence score, and i indicates a particular example.
We may produce a ‘perfect’ model by setting ; this combination of labels and scores has an area under the receiver-operator characteristic curve score (ROC-AUC) 1.0. We can produce an all-noise model by choosing a random score for each label. We draw the random scores from a unit Gaussian with mean 0.5. The noise model will have an ROC-AUC near 0.5.
Using these extremes we can interpolate between perfect scores and a set of noisy scores to create a model of arbitrary quality. Given a noise ratio r between 0 and 1, we set . After producing the scores using a given noise ratio, we can then measure the ROC-AUC of the model. Empirically, we find that the ROC-AUC decreases roughly linearly from 0.98 to 0.60 as the noise ratio varies between 0.25 and 0.75. A noise ratio of r = 0.37 yields a model with approximately 0.9 ROC-AUC, which we use as a default value.
We may freely vary the label density by changing the proportion of positive and negative labels. We can also vary the noise level to produce an arbitrary model quality. Note that ROC-AUC is not biased by label ratio (unlike many other metrics) (van Merriënboer et al., 2024).
The Powdermill dataset consists of 6.41 hours of fully-annotated dawn chorus recordings of Eastern North American birds collected at Powdermill Nature Reserve, Rector, PA (Chronister et al., 2021). The data comprise 16,052 annotations from 48 species. The annotations allow us to compute a ground-truth call density for each species, which can be used to test the validation procedure, as described in Section 3.2.4. This dataset has particularly high label quality, as multiple expert reviewers labeled each segment, but is relatively small.
We obtain scores for each 5 second audio window in the dataset using the Google Perch bird vocalization classifier (https://tfhub.dev/google/bird-vocalization-classifier/4). The classifier has an EfficientNet-b1 convolutional architecture, and is trained on over 10k species appearing on Xeno-Canto (Ghani et al., 2023). The robust annotations allow us to exactly compute the model’s ROC-AUC for each species. The model achieves a macro-averaged ROC-AUC score of 0.83 on the Powdermill dataset, as reported in the published model card.
The Hawaiian dataset consists of 17.52 hours of audio collected using Song Meters (models 2, 4, or Mini, Wildlife Acoustics Inc., Maynard, MA) in 16-bit.wav format at a sampling rate of 44.1 kHz and default gain from five sites on Hawai‘i Island: Hakalau, Hāmākua, Mauna Kea, Mauna Loa, and Pu’u Lā‘au. These recordings were compiled from past research projects and were annotated by members of the Listening Observatory for Hawaiian Ecosystems at the University of Hawai‘i at Hilo. Using Raven Pro software (Cornell Lab of Ornithology, Ithaca, NY), annotators were asked to create a selection box that captured both time and frequency around every bird call they could either acoustically or visually recognize, ignoring those that were unidentifiable at a spectrogram window size of 700 points. Annotators were allowed to combine multiple consecutive calls of the same species into one bounding box label if pauses between calls were shorter than 0.5 seconds. Recordings were then split into 5 second segments (the length of audio segments assessed by the classifier) and the number of segments that contained an annotated vocalization were tallied for each species in order to determine annotation densities P(⊕).
The majority of recordings were collected at Hakalau Forest National Wildlife Refuge on the eastern slope of Mauna Kea, totaling 11.25 hours. Hakalau is one of the largest (13,240 ha) intact, disease-free, native wet forests in the Hawaiian archipelago (United States Fish and Wildlife Service, 2010), and as such it is widely viewed as having the most intact and stable forest bird community remaining in Hawai‘i. Hakalau provides habitat for eleven native Hawaiian bird species (including five federally listed endangered species), as well as many introduced bird species (Kendall et al., 2023). The next largest contribution of data came from the high-elevation dry forests of Pu’u Lā’au on the southwest slope of Mauna Kea with 5.2 hours of audio. Pu’u Lā’au is within Ka’ohe Game Management Area, a mixed management area open to the public for activities such as hiking and hunting, and a site with ongoing native vegetation restoration efforts intended to preserve and restore habitat for the few remaining native bird species that live there. The remaining recordings were collected in high-elevation open habitat on the southern slopes of Mauna Loa (0.55 hours), similar habitat on the eastern slopes near the summit of Mauna Kea (0.17 hours), and at a low-elevation site in Hāmākua (0.25 hours), an anthropogenically degraded habitat. The recording locations on Mauna Loa and Mauna Kea are potential nesting sites for native endangered seabirds that build burrows in lava flow crevices (Day et al., 2003; Antaky et al., 2019). The Hāmākua site has low potential to harbor native bird species, but is densely populated by introduced bird species, and was included to assess how well our computational per-site analysis would handle absent species in an acoustically active environment.
Within this dataset we focused on three birds native to Hawai‘i Island, one species of least conservation concern, the Hawai‘i ‘Amakihi (Chlorodrepanis virens), one vulnerable species, the ‘Ōma‘o (Myadestes obscurus), and one federally listed endangered species, the ‘Ua‘u (Pterodroma sandwichensis) (Dataset International Union for Conservation of Nature, 2024). Since the introduction of avian malaria, Hawai‘i ‘Amakihi have become uncommon below 500 m (Scott et al., 1986), however they are one of only two Hawaiian honeycreeper species of least conservation concern. On Hawai‘i they reach the highest densities above 1,500 m in the subalpine native forests of Pu‘u Lā‘au The ‘Ōma’o is an endemic thrush species that inhabits montane mesic and wet forests on the windward side of Hawai‘i Island. ‘Ōma’o are thought to be one of the more sedentary forest birds, with high site fidelity, spending the majority of their time within a 2 ha core zone (Netoskie et al., 2023), and are therefore likely to be picked up frequently on a stationary recorder. The ‘Ua‘u, also known as the Hawaiian Petrel, only nests in the Hawaiian Islands where they are threatened by introduced predators (Raine et al., 2020). ‘Ua’u dig nesting burrows on high-elevation volcanic slopes, which they mainly only visit at night, meaning they rarely share acoustic space with non-seabird species (Troy et al., 2016).
Let X = {x} be a large collection of audio examples, and suppose we have a trained classifier mapping audio examples to confidence scores for the target class. While it is not required in what follows that the confidence scores be on the logit scale, we will refer to these scores as logits, and denote these logits with the variable z. Let P(⊕) = P(x ∈ ⊕) denote the probability that x is contained in the positive set for the classifier’s target class, and let . Likewise, we will refer to distributions such as P(⊕|z), the probability that an example is in the positive class given the logit predicted by the classifier.
We may use the law of total probability to expand P(z) over P(⊕):
Or we may expand over :
We may also convert the continuous logit scores into discrete outputs by binning logits into a set of B bins, {b}. We will use b to refer to a generic bin, but will use biwhen explicit indexing is needed. In this case, the bin probabilities P(b) expand over P(⊕):
Or we may expand P(⊕) over bins:
Because of the assumed large volume of data and low cost of running the classifier, the overall distribution P(z) can be easily approximated with high accuracy. We will now describe an efficient method to estimate the distributions with a fixed amount of human validation work, which in turn yields estimates of .
We sort the examples into B logarithmic quantile bins according to their logit scores, such that the lowest scoring 50% of X are assigned to b1, the next lowest scoring 25% are assigned to b2, and so on, with the last bin gathering all remaining examples. With this scheme, the probability that any given x falls into each bin is known (i.e., P(x ∈ b1) = 0.50, P(x ∈ b2) = 0.25, P(x ∈ b3) = 0.125, etc.).
A set of k random examples are selected from within each bin for human evaluation. Each example is labeled as positive, negative, or unsure, so that for each bin b we obtain counts .
The amount of human validation work required to produce these counts is fixed, given a choice of the number of bins B and the number of examples to evaluate from each bin k.
We will now demonstrate how to use the validation outputs to estimate P(⊕), P(⊕|b), and P(b|⊕) (Figure 2A).
We model each bin with a beta distribution , where c is a small constant, representing an uninformative prior for the Beta distribution. and can be zero so the constant c is added to meet parametric constraints of the Beta distribution. Note that the when the total is reduced, increasing the variance of the Beta distribution.
We know P(b) precisely from the logarithmic binning design. Then, using the law of total probability:
and
Because P(⊕) is modeled as a weighted sum of Beta distributions, we can compute its expected value as the weighted sum of the expected values of the per-bin Beta distributions.
We obtain a bootstrap distribution for P(⊕) by sampling the per-bin Beta distributions repeatedly and applying Equation 2. We define a 90% confidence interval for P(⊕) using the 5th and 95th quantiles of the bootstrap distribution.
The ROC-AUC metric is a useful threshold-free indicator of model quality. In addition to its eponymous interpretation as the area under the receiver-operator characteristic curve, it also has a straightforward probabilistic interpretation, as the probability that a uniformly-chosen positive example is ranked higher than a uniformly-chosen negative example (van Merriënboer et al., 2024).
Our proposed validation scheme produces estimates of . One can use these to estimate the model's ROC-AUC on the target data by summing the probability that a positive example is chosen from a higher bin than a negative example, and assuming a 50% probability that the positive example is ranked higher when they come from the same bin:
Our validation procedure responds to effectively five parameters, which can be categorized in three types: First, the Beta distribution prior is a general hyper-parameter. Second, we have user parameters: the number of bins and the number of validations per bin, which determine the total human effort required, and impact the quality of estimates. Finally, we have extrinsic parameters, out of control of the user: The actual prevalence of the target signal in the dataset and the quality of the classifier.
To measure the coverage of our estimate of P(⊕), we checked whether the ground-truth density was within the 90% confidence interval of the bootstrap distribution for P(⊕) around 90% of the time, measured over a large number of trials. We found a value of Beta prior which provides good coverage for both synthetic and fully annotated data, across a wide range of ground-truth densities.
We measured the precision of the validation estimate by tracking the root mean squared error (RMSE) of the expected value of P(⊕) over a large number of trials. We examined the response in error to choice of binning strategy (uniform or logarithmic), changes in the number of bins, number of validated observations per bin, and model quality.
Computing the coverage and precision of validation requires access to the ground-truth density, which we had for both the synthetic data and Powdermill fully-annotated data.
To assess the ability of our validation procedure to reliably estimate P(⊕), we leveraged the fully-annotated Powdermill dataset and a pre-trained bird species classifier. For this experiment, we simulated the entire validation process by leveraging the existing human annotations. For each example we selected for validation, we checked whether the example overlapped a human annotation, and said it was a positive example if there was any overlap. We computed the expected value of P(⊕) from the validation data, as described above, and measured the RMSE from the ground-truth value. We obtained a ground-truth value PGT(⊕) from the annotations by counting the proportion of segments which overlapped annotations for the target species. Finally, we checked whether PGT(⊕) landed in the 90% confidence interval produced by the bootstrap estimate.
It is common for a PAM project to span many microphones, placed at various sites. We refer to any geotemporal subset of the observations X as a site Xs. Likewise, we may have a covariate V and can refer to a subset selected by covariate value v as Xv.
When restricting from the study-level set of observations to a site or covariate subset, we expect to observe distribution shifts: In fact, observing and explaining such distribution shifts is a major reason to engage in bioacoustic monitoring in the first place. Let us consider these distribution shifts in the context of Equation 2 (Figure 2B), and compare to the situation when using a threshold-based binary classification scheme.
We are likely most interested in measuring the change in Ps(⊕) between sites and by comparison to the study-level P(⊕). Thanks to copious observations, we can observe any changes in Ps(z) easily, which we expect will correspond to changes in the relative abundance or activity of the target species. And indeed, our equations tell us that this Ps(z) decomposes as:
While any of the three distributions on the right-hand side of this equation might shift, it is Ps(⊕) which we wish to isolate. All of Ps(⊕), Ps(z|⊕), and are unknown, which means that we need to introduce either new assumptions or additional data to estimate Ps(⊕). We can obtain estimates for Ps(⊕) in a few different ways.
Strategy 0: First, we can add more data. Applying our validation procedure on data from each site will certainly yield per-site estimates of Ps(⊕), though we expect that this validation will be onerous if the number of sites and/or target species is high.
Alternatively, we can substitute in study-level estimates of the component distributions to allow us to isolate Ps(⊕).
Strategy 1: We might assume that Ps(⊕|z) = P(⊕|z) to leverage knowledge gained from validation at the study-level. Then we have:
Or, using our logarithmic binning:
This is very straightforward to compute, but the distribution shift between P(⊕|z) and Ps(⊕|z) may be problematic. Notice that Ps(⊕|z) ∝ Ps(z|⊕)Ps(⊕), and thus depends vitally on the parameter we want to estimate. In particular, if the site is unoccupied by the target species, then Ps(⊕) = 0, so that Ps(⊕|b) = 0 as well.
This strategy is analogous to the application of a binary classifier to a new subset of the data: counting threshold detections typically assumes that the true-positive rate with respect to a given threshold is fixed as we look at different subsets of data.
Strategy 2: Another approach is to assume that Ps(b|⊕) = P(b|⊕): The distribution of logits for positive examples is roughly the same across sites. This seems a far more reasonable assumption: The vocalizations of the target species, wherever it is present, are similar. However, it turns out that this is not enough to solve directly for an estimate of Ps(⊕).
To obtain our estimate, we utilize the decomposition over binned logits, additionally substituting the study-level distribution :
We obtain a distribution over logit bins for any value q ∈ [0,1], specifying an arbitrary mixture of the positive and negative logit distributions:
Then for any choice of q, we may compute the KL-Divergence KL(Ps(b)||Qq(b)), which is the cost of substituting Qq(b) for the ground-truth distribution Ps(b). We then set:
The downside of this strategy is that we are vulnerable to shifts in both the positive and negative distributions, relative to the study-level.
Strategy 3: Because Strategies 1 and 2 use quite separate heuristics for obtaining estimates of P(⊕), they can be combined as an ensemble estimate by taking their geometric mean.
In Section 4.3, we compare all four strategies (per-site validation, substitution of Ps(⊕|b), substitution of Ps(b|⊕), and ensemble estimation) on the Hawaiian PAM data.
Finally, we used real-world PAM deployment data from Hawai‘i to compare varying approaches to estimating site-level densities. We compared the results of site-specific validation to substitution of study-level distributions P(⊕|z) or P(z|⊕).
Feature embeddings were extracted from the recordings using the pre-trained Google Perch model. We then trained a linear classifier over the pre-computed embeddings using examples from 7 native bird species, and 6 common non-native bird species, with variable numbers of training samples (Table 1), following the procedure in Ghani et al. (2023). None of the training examples were sourced from the PAM recordings used in this study. The classifier was then run over the embedded PAM data and a logit score was generated for each 5 second segment within the dataset for each of the three study species.
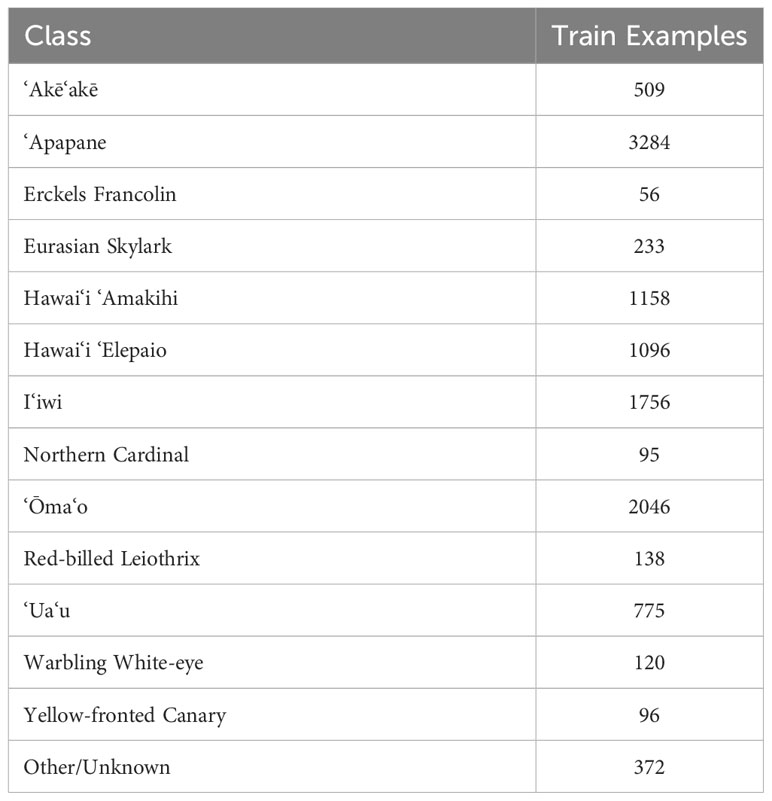
Table 1 Hawaiian classifier training data.
We then applied the validation scheme, using 4 bins and 50 examples per bin for Hawai‘i ‘Amakihi and ‘Ōma‘o for a total of 200 examples for each species. Because of their low density at the study-level, 200 examples per bin were validated for ‘Ua‘u for a total of 800 examples. Using Equation 7 P(⊕) was estimated for each species.
Site-level estimates Ps(⊕) were then computationally estimated for each study species using the methods described above in Section 3.3. Manual site-level validation was then performed for Hawai‘i ‘Amakihi for both the Hakalau and Pu’u Lā‘au datasets to generate validated site-level estimates Psv(⊕). All manual validations were performed by an acoustic specialist trained for Hawaiian bird species (AKN).
In all, we performed the following experiments.
Most experiments verify the proposed validation process, and are named Experiments V1 through V4. In Experiment V1, we verify good coverage with Beta prior parameter 0.1, using both synthetic and Powdermill data (Figure 3). In Experiment V2, we compare the precision of estimates of P(⊕) on synthetic data using uniform or logarithmic binning (Figure 4. In Experiment V3, we check the quality of human validation estimates of P(⊕) on Hawaiian data (Figure 5). In Experiment V4, we demonstrate the impact of varying the number of bins or number of observations on precision of validation estimates (Figure 6).
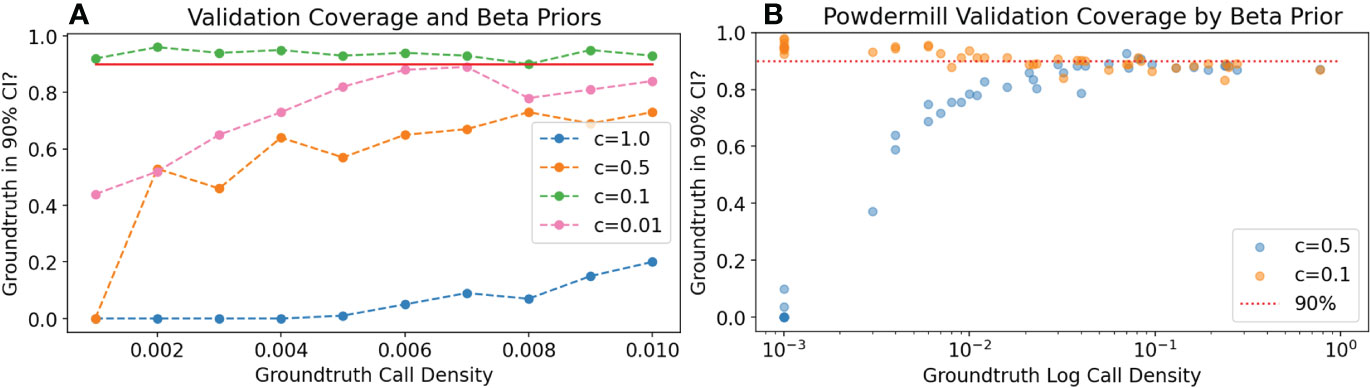
Figure 3 Experiment V1: For different uninformative Beta distribution priors c, measure how often the ground-truth prediction of P(⊕) is in the predicted 90% confidence interval (coverage). The value c = 0.1 has better coverage at low call density to the Jeffrey’s prior or the uniform prior, both on synthetic data (A) and in Powdermill validation simulations (B). In the Powdermill plot, each point corresponds to a different species; model ROC-AUC varies widely by species. All experiments use 4 bins and 50 observations per bin, and 50 experiments were run for each data point appearing in the figure.
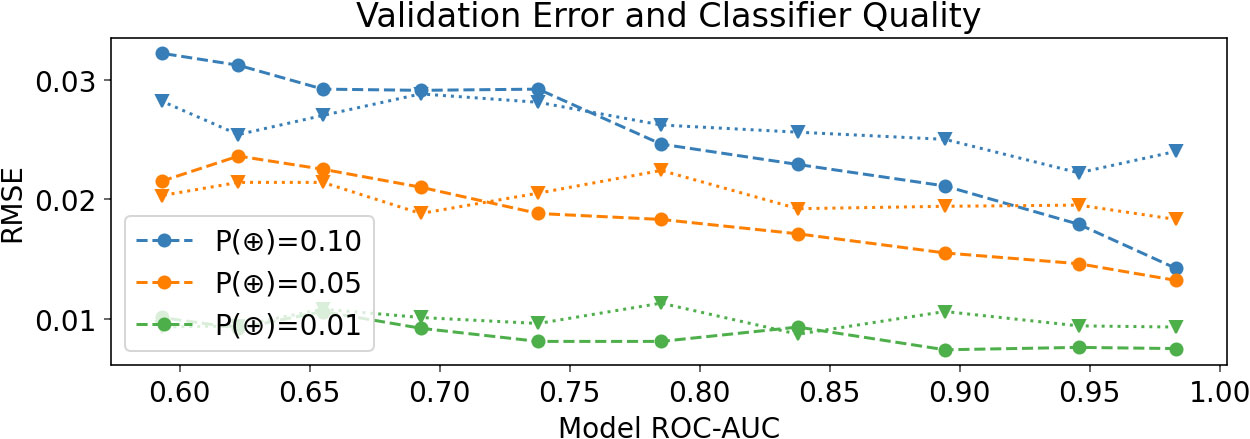
Figure 4 Experiment V2: Root mean squared error (RMSE) of the predicted P(⊕) in synthetic data, demonstrating that error steadily decreases as model quality improves (as one would expect), and that above 0.75 ROC-AUC logarithmic binning gives lower error above 0.75 ROC-AUC. RSME’s are means over 50 trials. Dashed lines report results with logarithmic binning, and dotted lines report results with standard, evenly spaced bins.
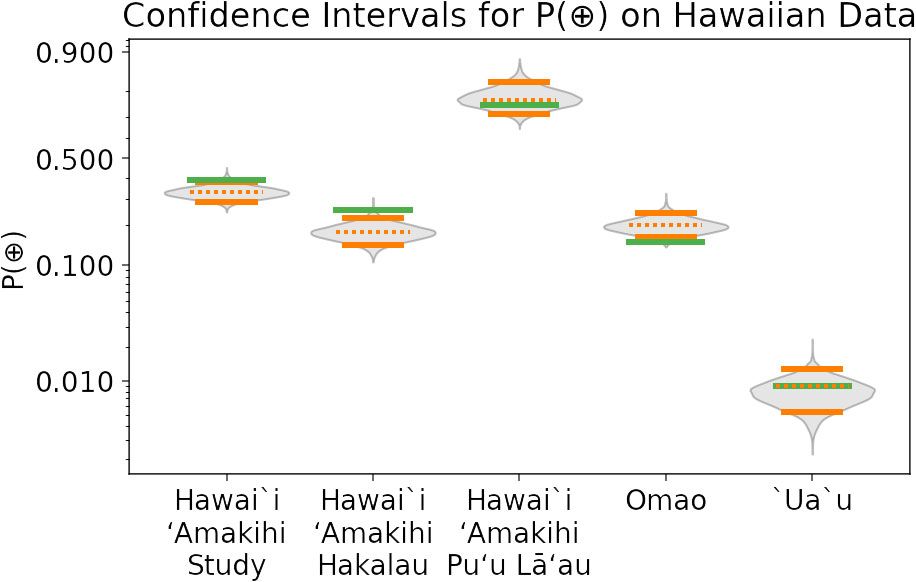
Figure 5 Experiment V3: Confidence intervals for estimated P(⊕) on Hawaiian PAM data, obtained using the full validation procedure. Results are provided for study-wide validations for three species (Hawai‘i ‘Amakihi, ʻŌmaʻo, and ‘Ua‘u), as well as for two site-specific ‘Amakihi validations (which are subsets of the study-level data for ‘Amakihi). Green lines are the annotation density, which approximate ground-truth. Solid orange lines give bounds of the 90% confidence interval, and dotted orange lines give the expected value of P(⊕) based on the validation procedure. The distributions of bootstrap-sampled P(⊕) values are in grey. Note that there is only a 59% chance that all five annotation density values would fall inside accurate 90% CIs.
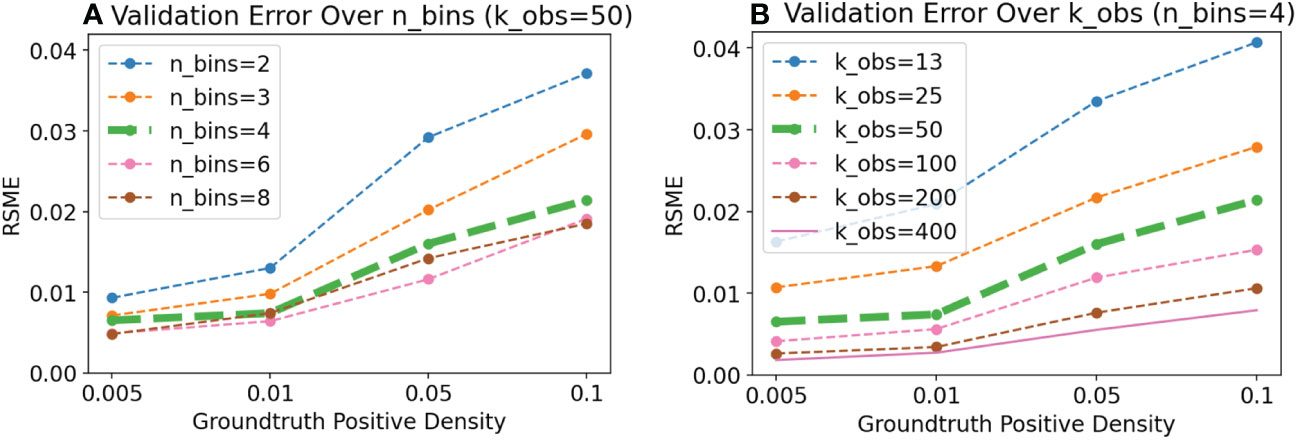
Figure 6 Experiment V4: The two user parameters for validation are the number of bins (nbins) and the number of validation examples per bin (kobs). Here we demonstrate, using the synthetic data harness, variation in the precision of P(⊕) as we vary the number of bins (A) and observations per bin (B). Adding more data (more bins, or more observations) generally leads to lower root mean squared error (RMSE). For this simulated classifier with 0.9 ROC-AUC, error saturates at 4–6 bins, but decreases steadily as more observations per bin are added.
The final Experiment S5 compares strategies for estimating site-level distributions from study-level validation work using human validation of the Hawaiian data (Tables 2, 3).

Table 2 Experiment S5: Annotation density (Ann) and site-level predictions of P(⊕) via validation (Val), substitution of study-level P(⊕|b) (Strat 1) and substitution of study-level P(b|⊕) (Strat 2), and the geometric mean of Strategies 1 and 2 (Strat 3).
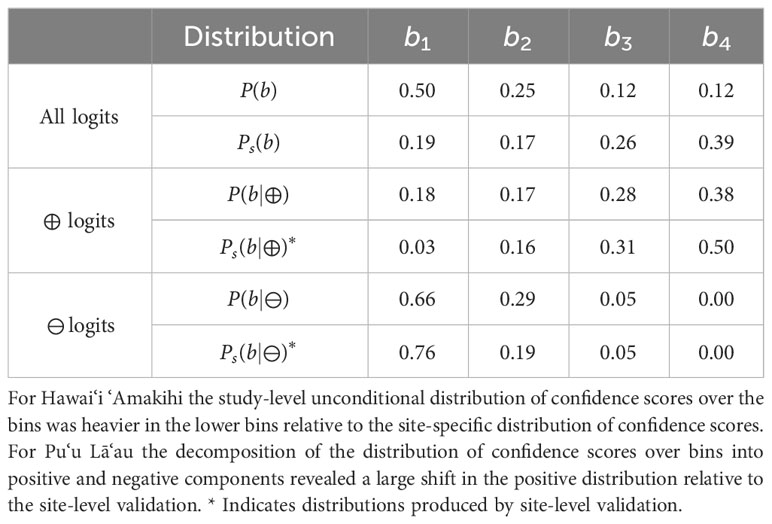
Table 3 Distribution shifts between study-level estimates for Hawai‘i ‘Amakihi and site-level distributions at Pu‘u Lā’au.
We first investigated the coverage of the predicted P(⊕). We found that coverage was typically good when the ground-truth density P(⊕) was above 0.1, and depended on the choice of Beta distribution prior at lower densities. As shown in Figure 3, we had good coverage at low density with the prior c = 0.1. For the synthetic data, we used the default noise value corresponding to a classifier with ROC-AUC 0.9. For the Powdermill data, classifier quality varied widely by species, demonstrating good coverage with the 0.1 prior regardless of classifier quality. We fixed c = 0.1 in all subsequent experiments.
We examine the relationship between classifier quality and RMSE of the predicted P(⊕) on synthetic data, varying the classifier quality between 0.58 and 0.98, and at three different ground-truth densities (Figure 4). We found that improving classifier quality generally decreased the RMSE. We also compared our logarithmic binning scheme to a uniform binning approach, and found that logarithmic binning generally gave a lower RMSE once the classifier ROC-AUC was greater than 0.75. Note that we would expect no improvement for classifiers with ROC-AUC 0.5, since the higher logits are equally likely to be positive or negative examples.
We examined the change in density prediction error on synthetic data as we varied the number of bins and number of observations per bin (Figure 6). In the logarithmic binning scheme, increasing the number of bins only splits observations at the top end of the logit distribution: For high quality classifiers, the highest bins may already be purely positive, so that increasing the number of bins adds no new information. Thus, we observed that eventually there was no improvement in error as more bins were added.
On the other hand, increasing the number of observations per bin steadily decreased the prediction error, as we would expect: The per-bin Beta distributions become narrower and more precise, which translates into more precise predictions of P(⊕).
Thus, we found that for a reasonably good classifier, four bins is likely sufficient, and additional effort is better spent by increasing the number of observations per bin, rather than further increasing the number of bins.
Manual annotation performed by the Listening Observatory for Hawaiian Ecosystems found Hawai‘i ‘Amakihi were present at Hakalau with an annotation density of 0.241 and were the most acoustically active passerine species at Pu’u Lā‘au with an annotation density of 0.748, for an overall study-level annotation density of 0.380. ‘Ōma‘o were only present at Hakalau where their site-level annotation density was 0.240 resulting in a density of 0.155 at the study-level. ‘Ua‘u vocalizations were present at both Mauna Kea and Mauna Loa, with annotation densities of 0.192 and 0.256, respectively, though because there were few recordings from these locations, their study-level annotation density was only 0.009. None of these species were present at the Hāmākua site.
The results of all strategies for cross-site prediction, as well as call densities produced by manual validation (Figure 5), are provided in Table 2. No validation was performed on sites known to be unoccupied.
Overall, Strategy 1 struggled when a site was unoccupied: Weight in low bins is still assigned to the target species, as expected. On the other hand, Strategy 2 generally predicted non-occupied sites correctly: no weight in the high bins implies that there is no contribution from the target species.
Meanwhile, we found that Strategy 2 often overestimated call density when a site was occupied. Examining the actual study- and site-level distributions, we found cases (such as the Hawai‘i ‘Amakihi at Pu’u Lā’au, detailed in Table 3, and the ‘Ua’u at Mauna Kea) where the study-level P(b|⊕) was extremely similar to the site-level Ps(b). In such cases, Strategy 2 selects a Ps(⊕) very close to 1.
Strategy 3 did a surprisingly good job of balancing the strengths and weaknesses of Strategies 1 and 2. Particularly in the case of unoccupied sites, Strategy 2 often correctly predicted Ps(⊕) = 0, so that the geometric mean was zero. And, at least in this study, we found that for occupied sites Strategy 1 tended to underestimate while Strategy 2 overestimated, leading to improved estimates in the geometric mean.
Our method for directly estimating call densities in bioacoustic data from machine learning classifier outputs yielded promising results and could advance the field of PAM by expediting analysis and providing a framework for formal ecological hypothesis testing. This approach is less dependent on highly performant and consistent classifiers because it utilizes the entire distribution of model outputs to estimate study-level and site-specific distributions, which makes it less reliant on consistent decision boundaries around arbitrary threshold levels. We also found the distributions over logarithmic bins helpful in identifying and describing distribution shifts, a pervasive but underappreciated problem in bioacoustic analyses.
Both the simulated data and Powdermill validation simulations offer ground-truth values on which we tested the quality of our validation scheme. We found that a single choice of Beta prior gives strong coverage across a wide variety of ground-truth densities and classifier qualities. The Powdermill validation simulations build confidence by including a scenario with real data distributions and a wide variety of call densities and classifier qualities.
While we found that error decreased with increasing model quality, we also found that adding additional validation effort reduced error. This provides a path to improvement for practitioners with access to a pre-trained classifier without further machine learning effort.
From the Hawaiian PAM dataset, our method produced study-level call density estimates with 90% confidence intervals that contained the manual annotation densities obtained by trained technicians for Hawai‘i ‘Amakihi and ‘Ua‘u but produced a slight overestimate for ‘Ōma‘o. Site-level validations (Strategy 0) similarly achieved estimates close to annotation density values, as would be expected with additional user effort. The manual annotation procedure was not explicitly designed for this study, and some errors may have been introduced in our derivation of annotation densities. For instance, individual vocalizations may have been split into separate 5-second segments. If either portion of the split call was too short to be identified, it would be counted as a negative during validation but marked as a positive annotation for both segments.
This PAM dataset also represents a high level of heterogeneity between sites, ranging from the acoustically active Hakalau to the windswept Mauna Loa, which is nearly devoid of any species vocalizations. This inherent heterogeneity in acoustic characteristics led us to expect the large distribution shifts observed in our analysis. Each of our focal species revealed strengths and challenges to our computational strategies for estimating call densities at the site-level via extrapolation from the study-level distributions of P(⊕) and , and Ps(b).
Not only were Hawai‘i ‘Amakihi at much lower densities at Hakalau than Pu‘u Lā‘au, Pu‘u Lā‘au also has less competition for acoustic space, and therefore the distributions of were significantly different for ‘amakihi at these two sites. Because of this, differing computational strategies performed best for predicting call densities each site. At Pu‘u Lā‘au, where the distribution of Ps(b) closely tracked P(b|⊕), Strategy 3 outperformed the others, balancing out the underestimate from Strategy 1 and overestimate from Strategy 2. However, at Hakalau, where Ps(⊕|z) tracked the study-level P(⊕|z) Strategy 1 made the closest estimate. It is worth noting that all strategies showed distinctly higher acoustic activity levels at Pu‘u Lā‘au, the more active site.
Table 3 shows the exact distribution shifts at Pu‘u Lā‘au Shifts in the negative logits and positive logits Ps(b|⊕) almost exactly canceled out, making Ps(b) closely resemble P(b|⊕), leading to over-prediction in Strategy 2. The distribution shifts in Table 3 are also interesting to consider from a threshold-detection perspective. If the boundary between b3 and b4 were used as a threshold, we would see a significantly increased true positive rate at Pu‘u Lā‘au If one only counted detections at the site-level assuming the same true positive rate as at the study-level, one would infer a too-high estimate of activity change.
Leveraging knowledge about species-habitat associations and vocalization behavior to inform the stratification process of the validation procedure may improve the call density estimates. For example, we could validate the logit distributions across stratified covariates and leverage site-specific covariate values to develop conditional site-level distribution estimates. We hope to explore such approaches in later work.
When a classifier was trained solely on ‘Ōma‘o, a large portion of logits fell into the higher-level bins at Mauna Kea and Mauna Loa (data not shown). This may be because both ‘Ōma‘o and ‘Ua‘u, as well as another seabird species present at these sites, often use low-frequency vocalizations. While our validation protocol yielded similar study-level estimates to those obtained using a classifier trained on all species in Table 1, the site-specific call density 90% confidence intervals did not encompass 0 at sites containing seabird vocalizations. Adding non-class training examples from acoustically similar species shifted ‘Ōma‘o logits out of those top bins and yielded the estimates shown in Table 2.
This emphasized three things: First, our proposed validation procedure lessens our dependency on developing high-performance classifiers, as reliable study-level estimates can be made even when only one species is included in the model. Second, including acoustically similar species can boost model performance, shifting a large portion of the positive examples into the top bins, which subsequently increases the precision of call density estimates by lowering RMSE and improving site-level estimation. Last, observing a strong shift from study-level distributions may indicate when modifications to study design or additional validation efforts are necessary for robust site-level estimates.
The ‘Ua‘u was the only species for which Strategy 2 (and thus Strategy 3) incorrectly predicted presence in unoccupied sites. At the study-level, ‘Ua‘u has a very low overall prevalence. With four bins of 200 examples each, all validated observations of the ‘Ua‘u were obtained in the top bin. Additionally, nearly all logits at Mauna Kea (97.5%), and to a lesser extent at Mauna Loa (79.9%), landed in the top bin. We believe that the heavy wind on the otherwise quiet mountain tops was a useful discriminative feature for the target class (a nocturnal petrel), leading to relatively high logits for all examples at these sites and from other sites containing wind with few vocalizations. However, the classifier still ranks windy examples with the target species higher than windy examples without the target species. In essence, all of the interesting site-level variation is subsumed in the top bin.
This problem could be addressed in a few ways. First, adding more bins at the top should split the positive-windy examples from the negative-windy examples. Second, the study-level validations could be restricted to the mountain environments (Mauna Kea and Mauna Loa), so the windy logits are distributed more evenly over the bins. We would also expect less extreme shifts between the study-level and site-level logit distributions, bolstering the substitution assumptions in Strategies 1 and 2. Finally, the too-broad highest bin suggests a role for a continuous distribution estimate (such as a Kernel Density Estimate) instead of a binned estimate. We leave exploring these options further for later work.
Ecological inference increasingly relies on predictive modeling, especially with the widespread adoption of sensor-based sampling methods that rely on computational algorithms. A key challenge lies in navigating sets of predictions and making informed decisions amidst uncertainty. Classification is a decision process (Spiegelhalter, 1986) that requires disentangling predictive modeling from decision-making under uncertainty (Steyerberg et al., 2010; Resin, 2023). However, threshold-based approaches often conflate these steps, limiting flexibility and potentially leading to sub-optimal decisions (in this case, classifications). Our work takes an important step forward by considering sets of probabilities and surfacing relevant parameters for optimizable utility functions based on available resources, such as lab capacity. Our findings demonstrated that performance increased with more reviewed audio clips, indicating that biacoustic programs can leverage this structured, data-driven approach to allocate their resources adaptively.
The protocol we have proposed here for directly assessing call densities in bioacoustic data has significant applications in the field of avian conservation. Our approach’s relatively low time cost facilitates analysis of PAM data within actionable timeframes, which can boost the utility of monitoring in informing wildlife management decisions (Nichols and Williams, 2006; Gibb et al., 2018). For example, the State of Hawai‘i Department of Land and Natural Resources and U.S. Fish and Wildlife Service are currently taking actions to mitigate avian malaria mortality in forest birds native to Hawai‘i (Warner, 1968) by suppressing the population of its mosquito vector (Culex quinquefasciatus) (Hawai‘i Department of Land and Natural Resources et al., 2023). For malaria-sensitive species, changes in juvenile call densities, a reasonable indicator of fledgling survival, estimated using our approach could be used to assess the efficacy of mosquito control efforts. Further, our methods could provide a standardized approach for analyzing past PAM data to establish historical baselines and assess changes to biodiversity over time with fine spatiotemporal resolution.
While the work described here has great potential, it serves as a preliminary tool, and we foresee multiple potential routes to improvement. First and foremost, future work should focus on improving covariate-level call density estimates. One potential way to do so may be to validate samples along strata or gradients relevant to the ecological or detection process of interest (e.g., along an elevational gradient) instead of validating to bins of the study-level distribution. This would mitigate the distribution shift issues encountered in our study. In addition to distribution shifts along environmental or temporal gradients, shifts in vocalization behavior could also lead to domain shifts. Future work could investigate the effect of separating species-level classifiers into call-type classifiers (i.e., separate classes for ‘songs,’ ‘contact calls,’ ‘begging’), which could improve classifier score calibration at the study-level and thereby improve covariate-level call density estimates. Call-type classifiers would have the additional benefit of aiding in modeling behavior and ecology.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: Zenodo.org, ID: 10581530, https://doi.org/10.5281/zenodo.10581530. Ecological Society of America Data Paper, esajournals.onlinelibrary.wiley.com, https://doi.org/10.1002/ecy.3329.
AN: Writing – review & editing, Writing – original draft, Visualization, Validation, Methodology, Investigation, Funding acquisition, Formal analysis, Data curation, Conceptualization. TD: Writing – review & editing, Writing – original draft, Visualization, Validation, Supervision, Software, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. MW: Writing – review & editing, Writing – original draft, Methodology, Conceptualization. PH: Writing – review & editing, Resources, Project administration, Funding acquisition.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was partially funded by a grant awarded to PH and AN by the United States Geological Survey FY23 National and Regional Climate Adaptation Science Center Program (#G23AC00641).
We want to thank the members of the Listening Observatory for Hawaiian Ecosystems who assisted in the manual annotation of recordings, including Noah Hunt, Saxony Charlot, Nikolai Braedt, and, in particular, lab manager Ann Tanimoto-Johnson. Lauren Harrell in Google Research provided helpful feedback throughout this work. Members of the Google Perch team (Bart van Merriënboer, Jenny Hamer, Vincent Dumoulin, Eleni Triantafillou, Rob Laber) contributed to creating the Perch embedding model and active learning methods used to produce the classifiers used in this paper.
Author TD is employed by Google.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Antaky C. C., Galase N. K., Price M. R. (2019). Nesting ecology in the Hawaiian population of an endangered seabird, the Band-rumped Storm-Petrel (Oceanodroma castro). Wilson J. Ornithol. 131, 402–406. doi: 10.1676/18-123
Butchart S. H. M., Walpole M., Collen B., van Strien A., Scharlemann J. P. W., Almond R. E. A., et al. (2010). Global biodiversity: Indicators of recent declines. Science 328, 1164–1168. doi: 10.1126/science.1187512
Chambert T., Waddle J. H., Miller D. A. W., Walls S. C., Nichols J. D. (2018). A new framework for analysing automated acoustic species detection data: Occupancy estimation and optimization of recordings post-processing. Methods Ecol. Evol. 9, 560–570. doi: 10.1111/2041-210X.12910
Chronister L. M., Rhinehart T. A., Place A., Kitzes J. (2021). An annotated set of audio recordings of Eastern North American birds containing. Ecology 102, e03329. doi: 10.1002/ecy.3329
Clement M. J., Royle J. A., Mixan R. J. (2022). Estimating occupancy from autonomous recording unit data in the presence of misclassifications and detection heterogeneity. Methods Ecol. Evol. 13, 1719–1729. doi: 10.1111/2041-210X.13895
Cole J. S., Michel N. L., Emerson S. A., Siegel R. B. (2022). Automated bird sound classifications of long-duration recordings produce occupancy model outputs similar to manually annotated data. Ornithol. Appl. 124, duac003. doi: 10.1093/ornithapp/duac003
Dataset International Union for Conservation of Nature (2024) (The IUCN Red List of Threatened Species).
Day R. H., Cooper B. A., Blaha R. J. (2003). Movement patterns of Hawaiian Petrels and Newell’s Shearwaters on the island of Hawai‘i. Pacific Sci. 57, 147–159. doi: 10.1353/psc.2003.0013
Ghani B., Denton T., Kahl S., Klinck H. (2023). Global birdsong embeddings enable superior transfer learning for bioacoustic classification. Sci. Rep. 13, 22876. doi: 10.1038/s41598-023-49989-z
Gibb R., Browning E., Glover-Kapfer P., Jones K. E. (2018). Emerging opportunities and challenges for passive acoustics in ecological assessment and monitoring. Methods Ecol. Evol. 10, 169–185. doi: 10.1111/2041-210X.13101
Hawai‘i Department of Land and Natural Resources, Division of Forestry and Wildlife, U.S. Fish and Wildlife Service, Pacific Islands Fish and Wildlife Office, SWCA Environmental Consultants (2023). Environmental Assessment for use of Wolbachia-based Incompatible Insect Technique for the suppression of nonnative southern house mosquito populations on Kaua‘i, Tech. rep., Honolulu, HI: Hawai‘i Department of Land and Natural Resources, Division of Forestry and Wildlife; U.S. Fish and Wildlife Service, Pacific Islands Fish and Wildlife Office; SWCA Environmental Consultants.
Kendall S. J., Rounds R. A., Camp R. J., Genz A. S., Cady T., Ball D. L. (2023). Forest bird populations at the Big Island National Wildlife Refuge Complex, Hawai‘i. J. Fish Wildlife Manage. 14, 1–23. doi: 10.3996/JFWM-22-035
Knight E. C., Bayne E. M. (2018). Classification threshold and training data affect the quality and utility of focal species data processed with automated audio-recognition software. Bioacoustics 28, 539–554. doi: 10.1080/09524622.2018.1503971
Knight E., Hannah K., Foley G., Scott C., Brigham R., Bayne E. (2017). Recommendations for acoustic recognizer performance assessment with application to five common automated signal recognition programs. Avian Conserv. Ecol. 12. doi: 10.5751/ACE-01114-120214
Miller D. A. W., Grant E. H. C. (2015). Estimating occupancy dynamics for large-scale monitoring networks: Amphibian breeding occupancy across protected areas in the northeast United States. Ecol. Evol. 5, 4735–4746. doi: 10.1002/ece3.1679
Netoskie E. C., Paxton K. L., Paxton E. H., Asner G. P., Hart P. J. (2023). Linking vocal behaviours to habitat structure to create behavioural landscapes. Anim. Behav. 201, 1–11. doi: 10.1016/j.anbehav.2023.04.006
Nichols J. D., Williams B. K. (2006). Monitoring for conservation. Trends Ecol. Evol. 21, 668–673. doi: 10.1016/j.tree.2006.08.007
Odum E. P., Kuenzler E. J. (1955). Measurement of territory and home range size in birds. Auk 72, 128–137. doi: 10.2307/4081419
Raine A. F., Driskill S., Vynne M., Harvey D., Pias K. (2020). Managing the effects of introduced predators on Hawaiian endangered seabirds. J. Wildlife Manage. 84, 425–435. doi: 10.1002/jwmg.21824
Reid D. S., Wood C. M., Whitmore S. A., Berigan W. J., Kramer H. A., Kryshak N. F., et al. (2022). Breeding status shapes territoriality and vocalization patterns in spotted owls. J. Avian Biol. 2022, e02952. doi: 10.1111/jav.02952
Resin J. (2023). From classification accuracy to proper scoring rules: Elicitability of probabilistic top list predictions. J. Mach. Learn. Res. 24, 1–21. Available at: https://jmlr.org/papers/v24/23-0106.html.
Scott J., Mountainspring S., Ramsey F., Kepler C. (1986). Forest bird communities of the Hawaiian islands: Their dynamics, ecology, and conservation. Stud. Avian Biol.9, 1–431.
Spiegelhalter D. J. (1986). Probabilistic prediction in patient management and clinical trials. Stat Med. 5, 421–433. doi: 10.1002/sim.4780050506
Steyerberg E. W., Vickers A. J., Cook N. R., Gerds T., Gonen M., Obuchowski N., et al. (2010). Assessing the performance of prediction models: A framework for traditional and novel measures. Epidemiol. (Cambridge Mass.) 21, 128–138. doi: 10.1097/EDE.0b013e3181c30fb2
Sugai L. S. M., Silva T. S. F., Ribeiro J. W., Llusia D. (2019). Terrestrial passive acoustic monitoring: Review and perspectives. BioScience 69, 15–25. doi: 10.1093/biosci/biy147
Troy J. R., Holmes N. D., Joyce T., Behnke J. H., Green M. C. (2016). Characteristics associated with Newell’s Shearwater (Puffinus newelli) and Hawaiian Petrel (Pterodroma sandwichensis) Burrows on Kauai, Hawaii, USA. Waterbirds 39, 199–204. doi: 10.1675/063.039.0211
Tuia D., Kellenberger B., Beery S., Costelloe B. R., Zuffi S., Risse B., et al. (2022). Perspectives in machine learning for wildlife conservation. Nat. Commun. 13, 792. doi: 10.1038/s41467-022-27980-y
United States Fish and Wildlife Service (2010). Hakalau Forest National Wildlife Refuge: comprehensive conservation plan. (Hilo, Hawai‘i: Honolulu, Hawai‘i: Tech. rep., U.S. Fish and Wildlife Service, Big Island National Wildlife Refuge Complex; U.S. Fish and Wildlife Service, Pacific Islands Planning Team).
van Merriënboer B., Hamer J., Dumoulin V., Triantafillou E., Denton T. (2024). Birds, bats and beyond: Evaluating generalization in bioacoustics models. arXiv preprint.
Keywords: bioacoustics, machine learning, wildlife monitoring, Bayesian modeling, predictive reasoning
Citation: Navine AK, Denton T, Weldy MJ and Hart PJ (2024) All thresholds barred: direct estimation of call density in bioacoustic data. Front. Bird Sci. 3:1380636. doi: 10.3389/fbirs.2024.1380636
Received: 01 February 2024; Accepted: 01 April 2024;
Published: 24 April 2024.
Edited by:
Cristian Pérez-Granados, University of Alicante, SpainReviewed by:
Tyler A. Hallman, Bangor University, United KingdomCopyright © 2024 Navine, Denton, Weldy and Hart. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Amanda K. Navine, bmF2aW5lQGhhd2FpaS5lZHU=
†These authors share first authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.